
Abstract
The comprehensive benefit evaluation of LID based on multi-criteria decision-making methods faces technical issues such as the uncertainties and vagueness in hybrid information sources, which can affect the overall evaluation results and ranking of alternatives. This study introduces a multi-indicator fuzzy comprehensive benefit evaluation approach for the selection of LID measures, aiming to provide a robust and holistic framework for evaluating their benefits at the community level. The proposed methodology integrates quantitative environmental and economic indicators with qualitative social benefit indicators, combining the use of the Storm Water Management Model (SWMM) and ArcGIS for scenario-based analysis, and the use of hesitant fuzzy language sets and Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) for decision-making. The framework’s novelty lies in the integration of the hesitant fuzzy weighted average algorithm to handle subjective uncertainties in expert judgment and the incorporation of multi-return period scenarios to enhance the robustness of the evaluation. The comprehensive benefits of 26 LID configurations were conducted in Chenglong Road Subdistrict under five rainfall return period scenarios of 5, 10, 20, 50, and 100 years. The results show that LID measures, particularly combinations of sunken green spaces and permeable paving, offer significant reductions in runoff and peak flow, along with improved flood mitigation across multiple return periods. Additionally, this study identifies practical LID implementation priorities for local decision-makers. The relative closeness is influenced by the indicators and non-calibrated parameters. However, it overall does not affect the main trends and key insights derived. The robustness of the proposed approach is reinforced by four key aspects: the impact of the Thiessen polygon method in ArcGIS, the influence of composite runoff coefficient and iterative optimization in SWMM, the effect of hesitant fuzzy linguistic sets and TOPSIS on weight calculation, and the contribution of simulations under different return periods to stability analysis.
Similar content being viewed by others
Introduction
Urbanization, coupled with unpredictable rainfall intensity and frequency, has led cities to encounter numerous environmental challenges that threaten urban sustainability and water management, such as flooding, contaminated stormwater runoff, increased occurrence of extreme weather events, depletion of groundwater resources, and sewage overflows1,2,3,4. Among these impacts, stormwater flooding stands out as a frequent and perilous disaster of global concern among these impacts, as it diminishes urban resilience and has the potential to inflict substantial damage on the economy, environment, infrastructure, and human lives5,6. In 2023, 152 floods (46.63%) and 88 storms (26.99%) ranked as the top two among 326 major natural disasters affecting 117 countries and territories, while the injured population, affected population, and direct economic losses associated with these events were all among the top four highest globally7. In 2023, China experienced a total of 35 regional heavy rainfall events, affecting 52.789 million people with flood disasters, resulting in 309 deaths and missing persons, and causing direct economic losses of up to 244.57 billion yuan8.
As one of stormwater management strategies, low impact development (LID) was coined in the 1990s in the USA, which mitigates the effects of land development on local hydrology and water quality by harnessing natural processes for the storage, retention, infiltration, purification, utilization, and drainage of stormwater9,10. The main LID measures include permeable pavements, green roofs, sunken green spaces, rain gardens, and bioretention basins. The working principle of these measures is to improve the condition of the urban surface, enhance the city’s ability to retain and infiltrate water, thereby effectively collecting and utilizing rainwater resources, and significantly reducing urban surface runoff 11,12,13.
Existing research has extensively explored the environmental benefits of LID. LID effectively reduces surface runoff and peak flow rates by promoting rainwater infiltration, storage, and purification, thereby alleviating the pressure on urban drainage systems14,15,16. Moreover, LID facilities improve water quality by reducing non-point source pollution and protecting receiving water bodies from contamination17. The impact of rain gardens on water quality and quantity was assess with two results: when the area of rain gardens accounted for 2% of the catchment area, the runoff reduction rate ranged from 1.93 to 9.69%; the reduction rate in the number of overloaded pipes ranged from 0 to 11.15%, while the reduction rates for total suspended solids, chemical oxygen demand, total nitrogen, and total phosphorus were 2.36–30.35%, 2.37–30.11%, 2.34–30.08%, and 2.32–31.35%, respectively18. In addition to flood control and water quality enhancement, LID also serves the purposes of water conservation and natural ecosystem protection19.
The implementation of LID brings notable economic benefits. By reducing the construction and operation costs of stormwater management facilities, LID lowers the investment requirements for public infrastructure20. Simultaneously, LID helps mitigate economic losses caused by flood disasters and increases land values, promoting the healthy development of the real estate market21. Besides, LID implementation also yields extensive social benefits. By improving the urban water environment, LID enhances residents’ quality of life and raises public awareness and participation in environmental protection22. Furthermore, LID facilities provide more green spaces for urban residents, contributing to mitigating the urban heat island effect and enhancing the city’s livability23.
Both quantitative and qualitative methods are employed in the benefit evaluation. Quantitatively, studies often employ urban stormwater management models (SWMM) to simulate the impact of LID facilities on runoff reduction, peak flow attenuation, and pollutant removal24. Economic benefits are typically assessed by comparing construction and operation costs with flood damage reductions through full life-cycle cost (LCC) analyses25. Social benefits are gauged using surveys, expert evaluations, or willingness-to-pay (WTP) methods26. Qualitatively, studies explore non-monetized benefits such as enhanced urban ecology, improved quality of life, and community aesthetics using frameworks like the Analytic Hierarchy Process (AHP)27. However, quantitative methods may overlook qualitative nuances, while qualitative approaches can lack objectivity and precision. A comprehensive approach combining both methodologies is thus essential for a holistic evaluation of LID benefits. Therefore, addressing the integration of hybrid information sources is the first objective that this paper aims to resolve.
There are also studies that conduct in-depth research on LID combination schemes. Three LID measures—bioretention basins, infiltration trenches, and permeable pavements—were selected as study subjects to evaluate their runoff control effectiveness15. A case study of a dense residential area in Tehran established a method for designing LID layouts suitable for residential areas. Seven different LID plans were identified, and results indicated that under rainfall events with return periods of 2, 5, and 10 years, runoff reductions ranged from 36.7 to 93.1%, 28.3–78.7%, and 16.3–66.4%, respectively28. In a study in a city in Washington State, USA, the best combination of LID measures, including infiltration trenches, rain barrels, rain gardens, bioretention facilities, and permeable pavements, was determined29. Although the existing studies have provided valuable insights into the effectiveness of various LID measures and their combinations, there is a notable gap in research that focuses on recommending specific LID combination proportions based on a comprehensive evaluation of their benefits under different rainfall return periods.
This paper is organized as follows: In Sect. 2, methodology, a framework for evaluating the comprehensive benefits of LID measures is established. In Sect. 3, Chenglong Road Subdistrict as the study area are tested. In Sect. 4, comparison of the results discussed. In last Sect. 5, summary of key findings and perspectives for future research are outlined.
Methodology
A multi-indicator fuzzy comprehensive benefit evaluation approach for the selection of LID measures is proposed to offer a framework for evaluating the comprehensive benefits of LID measures at the community level in Fig. 1. Random, empirical and fuzzy datasets are obtained through three distinct methods: scenario simulation using SWMM and ArcGIS for environmental and the third economic benefit indicator; industry standards for additional economic indicators; and expert surveys for social benefit indicators. ArcGIS-SWMM is combined for scenario analysis, while HFLS-TOPSIS is created for decision-making.

The proposed framework for evaluating the comprehensive benefits of LID measures at the community level. Environmental benefit evaluation indicators are in the green box, economic benefit evaluation indicators are in the red box, social benefit evaluation indicators are in the blue box. The rectangle represents the calculation flowchart.
Indicator category
The comprehensive benefits of LID initiatives are influenced by various factors. While the majority of existing research predominantly focuses on the environmental benefits of LID measures, particularly their effectiveness in controlling runoff 30, it is essential to adopt a multifaceted approach in developing a comprehensive evaluation system for LID benefits. These benefits encompass social, economic, and environmental dimensions31. A holistic benefit assessment framework for LID measures is constructed by considering environmental, economic, and social advantages when selecting indicators, with reference to relevant studies32,33,34,35.
Considering that standardization is required during the calculation of comprehensive benefits, the evaluation indicators are classified into benefit-type indicators and cost-type indicators. Benefit-type indicators refer to those where a larger value indicates a better status, while cost-type indicators refer to those where a larger value indicates a worse status. The construction and maintenance costs are classified as cost-type indicators, while groundwater replenishment, as well as environmental and social benefits, are categorized as benefit-type indicators.
Environmental benefit
The environmental benefit (\(\:{I}_{1}\)) is especially designed to address the mitigation of urban stormwater flooding through the application of LID strategies during precipitation events. Rainfall runoff can be efficiently managed by utilizing LID techniques that promote infiltration and storage of rainfall. LID measures are integral in infiltrating and storing stormwater, thereby reducing the volume and speed of runoff, which enhances the management of rainwater36. These measures help control stormwater runoff by facilitating infiltration and storage. Vegetation within LID measures also plays a vital role in stormwater retention, which not only delays the peak runoff time but also reduces overflow in drainage pipes, thus alleviating pressure on urban drainage systems37. To assess these benefits, three distinct indicators have been selected based on the simulation results derived from SWMM. These indicators include the total runoff reduction rate (\(\:{I}_{11}\)), the peak runoff reduction rate (\(\:{I}_{12}\)), and the peak delay time (\(\:{I}_{13}\)).
In the study area, the peak runoff reduction rate (\(\:{I}_{11}\)) is defined as the difference in runoff volume between scenarios with and without LID measures (\(\:{R}_{i}-{R}_{0}\)), expressed as a percentage of the runoff volume in the scenario without LID measures (\(\:{R}_{0}\)) for the \(\:{i}_{th}\) rainfall event. The peak reduction rate (\(\:{I}_{12}\)) is calculated as the difference between the peak runoff volumes with and without LID measures (\(\:{P}_{i}-{P}_{0}\)), as a percentage of the peak runoff volume without LID measures (\(\:{P}_{0}\)) for the same rainfall scenario.
The implementation of LID measures can effectively delay the occurrence of the peak runoff. The peak time refers to the moment when the rainfall intensity reaches its maximum during a rainfall event. The peak delay time (\(\:{I}_{13}\)) is defined as the difference between the time at which the peak occurs with LID measures and the time at which the peak occurs without LID measures (\(\:{T}_{{F}_{i}}-{T}_{{F}_{0}}\)), as calculated using the SWMM software simulation.
Economic benefit
The economic benefit (\(\:{I}_{2}\)) is associated with the cost of constructing grey infrastructure to mitigate urban stormwater flooding, in collaboration with the urban drainage network, after the implementation of LID measures38,39. This study reviews the benefits of groundwater replenishment and the cost related to the construction and maintenance of LID measures40. Notably, the technical specifications for sponge city development provide the basis of estimating the construction and maintenance cost of LID measures. Based on this, three economic indicators were selected: construction cost \(\:{I}_{21}\), maintenance cost \(\:{I}_{22}\), and groundwater replenishment benefit \(\:{I}_{23}\).
The construction cost (\(\:{I}_{21}\)) of LID measures is calculated for various combinations using an average cost approach, where the construction cost represents a one-time investment for implementing the LID measures. The formula for this calculation is provided, where \(\:{M}_{i}\) denotes the unit cost of the \(\:{i}_{th}\) LID measure, and \(\:{A}_{i}\) represents the area occupied by the \(\:{i}_{th}\) LID measure in the sub-catchment.
The maintenance cost (\(\:{I}_{22}\)) refers to the expenses required to ensure the continued operation of LID measures after their implementation. This is calculated using the formula where \(\:{m}_{i}\) is the unit cost of the \(\:{i}_{th}\) type of LID measure, and \(\:{A}_{i}\) indicates the area occupied by that measure in the sub-catchment.
The groundwater replenishment benefit (\(\:{I}_{23}\)) is computed as the product of the shadow price of water (\(\:a\)) 38, the volume of rainwater infiltration (\(\:H\)) obtained from SWMM simulations, and the infiltrated surface area (\(\:S\)).
Social benefit
The enhancement of both the natural and human environments as well as the beautification of urban landscapes, constitutes the social benefits of LID interventions. Consistent with previous study41, three qualitative indicators have been selected to assess these social benefits: landscape promotion value (\(\:{I}_{31}\)), continuous demonstration effect (\(\:{I}_{32}\)), and ecological function (\(\:{I}_{33}\)). In addition to their widespread application on urban rooftops to mitigate rainfall runoff, green roofs also enhance the aesthetic appeal of the surrounding areas by filtering and partially purifying pollutants carried by rainwater through the roots of the vegetation42. Following the implementation of LID strategies, residential communities with improved green landscaping can serve as prominent community landmarks, potentially promoting the area at the city, provincial, and even national levels. Sunken green space, as small-scale storage facilities, can both retain rainfall runoff and contribute to the overall aesthetics quality of the landscape. Since all social benefit indicators are qualitative, fuzzy logic may be applied to quantify these benefits following further analysis.
ArcGIS-SWMM scenario modelling
The primary source of the environmental benefit indicators is SWMM. Using ArcGIS, sub-catchment areas are delineated, individual and combined LID measures are configured, and scenario simulations are conducted with SWMM to generate high-quality results. These simulation results produce critical outputs, including total runoff volume, peak runoff volume, peak time, and infiltration volume43.
The first step in the modeling process is the use of ArcGIS for hydrological analysis. After analyzing flow direction, flow rate, and river classification using the original Digital Elevation Model (DEM) maps, watershed outlets are identified. The sub-catchment area is defined by the location of these watershed outlets. The accuracy of sub-basin delineation significantly impacts the precision of the modeling results, and sub-basin delineation serves as the foundation for assessing the environmental benefits of LID interventions44,45,46. Tyson polygon technique is more suitable for modeling stormwater flooding in the study area than manual delineation methods, particularly for constructing urban stormwater models. SWMM simulation parameters consist of both calibrated and non-calibrated variables. Calibrated values can be obtained from SWMM user manual and relevant literature, while non-calibrated parameters can be directly extracted from ArcGIS.
Previous research demonstrates that LID measures effectively mitigate urban stormwater flooding. However, the effectiveness of different LID strategies varies, and the selection of appropriate LID measures should consider the specific characteristics of the study area. Once the LID measures have been selected, the LID module is incorporated into SWMM. Subsequently, simulations are conducted to determine the total runoff volume, peak runoff volume, peak time, and infiltration volume both before and after the implementation of LID measures.
HFLS-TOPSIS comprehensive evaluation
Evaluating problems in uncertain environments is challenging due to the complexities of modeling and addressing uncertainties. To overcome these challenges, we adopt the hesitant fuzzy language sets (HFLS) proposed by Rodriguez in 2012, which quantifies the evaluation information provided by the experts47. This approach enhances the objectivity and scientific rigor of expert assessments. TOPSIS is employed to provide a more thorough evaluation of the decision-making process, as it integrates multiple evaluation indicators while accounting for their respective weights and interrelationships.
Hesitant fuzzy weighted average algorithm
In this study, we apply the hesitant fuzzy weighted average algorithm and the Euclidean distance method to determine the weights of the indicators, thereby maximizing group consensus. A set of seven levels was chosen: extremely unimportant, very unimportant, unimportant, moderately important, important, very important, and extremely important. Each evaluation level corresponds to a numerical value: {0, 0:17, 0:33, 0:5, 0:67, 0:83,1}48. An attitude-neutral scaling technique is applied to normalized the data, ensuring comparability across all data points. Let \(\:{d}^{+}\) and \(\:{d}^{-}\) represent the maximum and minimum values in the evaluation set \(\:{\text{Z}}_{\text{i}}^{\text{n}}\), respectively. The extended value is calculated as \(\:d=\lambda\:{d}^{+}+(1-\lambda\:){d}^{-}\). Since it is assumed that all experts in this study are impartial, \(\:{\uplambda\:}\) is set to \(\:1/2\).
The significance of the indicators influencing the comprehensive benefits of LID procedures was then assessed using expert judgments expressed as \(\:{S}_{n},\:\left(n=\text{1,2},\dots\:,n\right)\) through hesitant fuzzy language. The corresponding values for each of the seven evaluation levels in the hesitant fuzzy language set are expanded and standardized to a common length (\(\:L\)), which is subsequently used to calculate expert weights. In the formula below, \(\:{\text{U}}_{\text{a,i}}\) denotes the hesitant fuzzy number assigned by expert \(\:a\) for indicator \(\:\text{i}\). The calculation process is as follows.
To determine the importance of indicator \(\:{I}_{i}\), the Euclidean distance between experts \(\:a\) and \(\:b\) is calculated using the following formula:
\(\:{W}_{a}\) represents the weight of expert \(\:a\), and \(\:{W}_{a}{U}_{a,i}^{1}\) represents the weighted expert evaluation of the hesitant fuzzy number. Consequently, the following formula calculates the Euclidean distance weighting between the evaluations of experts \(\:a\) and \(\:b\).
From these calculations, the weight optimization model is derived.
Using the hesitant fuzzy weighted average operator approach, indicator weights are established based on the hesitant fuzzy assessments and expert weights provided by the experts 49. The detailed steps are as below.
Step 1. Expand to the same length the hesitation fuzzy evaluation data given by each expert
Step 2. The following formula is used to determine the weighted hesitant fuzzy evaluation values based on the expert weights \(\:{W}_{a}\), which are derived from the expert weight optimization model (10).
Step 3. The parameters of the weighted average algorithm (\(\:{\alpha\:}_{i}\), \(\:{\beta\:}_{i}\), \(\:{\gamma\:}_{i}\)) are computed as follows.
Step 4. Let \(\:{Q}_{i}\) represent the weight value of the \(\:{i}^{th}\) indicator.
TOPSIS evaluation method
Various scenarios emerge when the research region is subjected to the weighting index. In this study, we propose the application of TOPSIS to determine the ideal scenario by integrating the comprehensive benefits of multiple scenarios. The detailed procedures are as follows.
Step 1. The original data matrix \(\:A\), where \(\:k\) represents the number of evaluation items and \(\:i\) represents the \(\:{i}^{th}\) indicator, is created for the comprehensive benefit evaluation of LID measures.
Step 2. Standardize the original data matrices according to the classification of indicator types. For benefit-type indicators, \(\:{B}_{k,i}^{{\prime\:}}\) is calculated using formula (16), while the cost-type indicators, \(\:{B}_{k,i}^{{\prime\:}}\) is calculated using formula (17).
Upon completing the standardization process, the standardized matrix \(\:A^{\prime\:}\) is obtained through formula (18).
Step 3. The weights of the LID measure comprehensive benefit evaluation indicators are used to construct the weighting matrix.
Step 4. In the comprehensive benefit evaluation index of LID measures, identify the positive ideal solution \(\:{C}^{+}\) and the negative ideal solution \(\:{C}^{-}\).
Step 5. Calculate the distance between each evaluation item and both the positive ideal solution \(\:{C}^{+}\) and the negative ideal solution \(\:{C}^{-}\).
Step 6. Calculate the relative closeness of each evaluation object as follows.
Step 7. By comparing the comprehensive benefit evaluation scores \(\:{N}_{k}\) of the LID measures and ranking the programs based on their comprehensive benefit values, the best program is identified.
Testing the proposed methodology
Research area selection
Chengdu, situated in the western Sichuan Basin of southwest China (Fig. 2a), has core functions as “the western economic center, western scientific and technological innovation center, western foreign exchange center, and a national advanced manufacturing base” 50. By the end of 2022, Chengdu’s urbanization rate reached 79.9%, achieving a GDP of nearly 2.1 trillion yuan, and with a resident population density of 1484 people per square kilometer which remarkably surpassed that of Beijing, Tianjin, and Chongqing—three of China’s major municipalities 51. Within the five central urban areas of Chengdu, Jinjiang District, located in the southeast of the city (Fig. 2b), has the smallest total area of 61 km2 and the second largest population density, reached an urbanization rate of 100% for the permanent resident population52.
Chengdu features a terrain that gently slopes from northwest to southeast, with an average altitude of 750 m, and experiences a subtropical monsoon climate with abundant rainfall. These natural conditions, combined with rapid urbanization and climate change, have made the city prone to urban floods, which has been a recurring issue in its history, with significant events in 1981, 2011, 2013, and 2020 causing extensive damage and disruptions. Characterized by complex water systems, a narrow downstream outlet section, and inadequate urban drainage infrastructure, Chenglong Road Subdistrict, located in the middle of Jinjiang District (Fig. 2c and d), has become one of the most severely impacted areas during extreme rainfall events53.

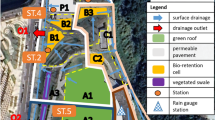
Locations of the tested area. (a) Chengdu in Sichuan Province; (b) Jinjiang District in Chengdu; (c) Chenglong Road Subdistrict in Jinjiang District; (d) Chenglong Road Subdistrict.
In the Chenglong Road Subdistrict, flooding events in 2021 highlighted the vulnerability of low-lying areas and aging storm sewer systems. For example, on August 25, flooding at the intersection of Chenglong Street and Fengxiang Street disrupted pedestrian traffic and affected local businesses (Fig. 3a), while heavy rains on September 14 led to severe waterlogging on Haitang Road (Fig. 3b) under the jurisdiction of Fengshu Community. These incidents underscore the need to assess the flood risks in Chenglong Road Subdistrict and to encourage the implementation of LID measures. Such initiatives would provide a theoretical and practical foundation for urban planners and decision-makers to enhance the resilience of similar communities to urban flooding.

(a) A flooded store on Chenglong Avenue on August 25, 2021; (b) Haitang Road on September 14, 2021, located in Fengshu Community of Chenglong Road Subdistrict.
LID measures configuration
Regarding the land use distribution within the Chenglong Road Subdistrict, we selected the most applicable sunken green space and permeable pavement, and the green roofs suitable for buildings, outlined in the Technical Regulations for Sponge City Planning and Construction Management (Trial Version) of Chengdu 54. Then, 26 configurations were planned, including no LID and 25 combined LID measures as shown in Table 1. 30% was set as the upper limit proportion of LID areas in built-up areas, according to the Chengdu Sponge City Special Planning 2016–203055.
Hybrid information sources and basic datasets
The SWMM model and ArcGIS tool were employed to conduct scenario simulations, providing environmental benefit evaluation indicators for LID initiatives. The economic benefit evaluation indicators were derived from the costs associated with LID measures, as outlined in the Technical Guidelines for Sponge City Construction 56. The social benefit evaluation indicators were assessed through a structured questionnaire, with ratings provided by five experts.
The basic datasets necessary for scenario simulations include digital elevation model (DEM) data, land use type data, and rainfall data. DEM data were obtained from the China Geospatial Data Cloud platform (http://www.gscloud.cn), with a resolution of 30 m, then primarily imported into ArcGIS to utilize hydrologic analysis tools for calculating drainage points, delineating sub-catchments, analyzing areas, and determining slopes and characteristic widths within the study area. The land use data were sourced from the Finer Resolution Observation and Monitoring of Global Land Cover, a series of land use and cover product datasets developed by Tsinghua University in 2017 57. The downloaded dataset is identified as 100E40N.tif. These data were utilized to calculate the areas of buildings, greenery, roads, and undeveloped land within the region, which were then used to determine the impervious and pervious areas of the study area.
Environmental indicator value processing
Hydrological analysis and rainfall data preparation
(1) Sub-catchment delineation.
The hydrological analysis process involved several key steps. Sink filling tool is essential for addressing depressions in the DEM data that could cause runoff interruption at concave points, ensuring that the analysis results are not impacted by missing data. Flow direction tool analyzes the movement of water, determining the direction in which water flows from higher to lower elevations58. Flow accumulation tool calculates the total number of grid cells contributing to water accumulation at each point59. Once the flow accumulation is calculated, the river network classification tool is used to categorize the river network based on flow volume, and the raster river network vectorization tool converts the river network from raster to vector format. Catchment point identification tool identifies the grid cells with the highest flow accumulation, while the watershed tool is used to divide the study area into smaller catchments based on the flow direction and river network data.
The sub-catchment delineation process in this study involved the creation of a Thiessen polygon map. Sub-catchments are typically delineated using either a manual method or a Thiessen polygon method. The manual delineation method is based on the distribution of buildings and roads and is most applicable to smaller areas with regular road networks and simple drainage systems 60. For this study, due to the large size of the research area and the lack of drainage pipe data, the Thiessen polygon method was selected as the most suitable approach. Thiessen polygons divide the study area into regions based on the locations of drainage points, and the resulting sub-catchments are then manually adjusted to ensure accuracy46.
The delineation process began with vectorizing the watershed using the Catchment Polygon Processing tool in the Terrain Preprocessing toolbox, which produced a vectorized catchment map. Next, the Drainage Point Processing tool was used to capture the catchment points, identifying those locations where the flow accumulation was greatest. The result was a drainage point dataset that identified the critical areas where water accumulates. Thiessen polygons were then created using the Thiessen Polygon tool in the Neighborhood Analysis toolbox, which divided the study area based on the locations of the drainage points. Finally, the Clipping tool was used to refine the sub-catchment boundaries and produce the final sub-catchment map. The sub-catchment delineation was manually adjusted after the Thiessen polygon method to ensure that the boundaries were in accordance with the local topography and drainage features. This method allowed for a more accurate and reliable partitioning of the study area into 47 sub-catchments (SUB1-SUB47, Table A1 in Supplementary Material), which were used for further analysis.
(2) Parameter calculation.
The non-calibrated parameters, including area, average slope, characteristic width, and imperviousness rate, were primarily extracted using ArcGIS based on the 47 sub-catchments. The area calculation field was added to the attribute table of the sub-catchments by selecting the double precision type and calculating the area after projecting the sub-catchment vector map using the China_Lambert_Conformal_Conic projection coordinate system. The slope analysis tool was then used to generate the slope map. The characteristic width was calculated by dividing the sub-catchment area by the maximum flow length within the sub-catchment61. The imperviousness rate was calculated by dividing the area of impervious land within each sub-catchment by the total sub-catchment area. The results are presented in Table A1 in Supplementary Material.
Calibration parameters can be categorized into two groups: the runoff routing module, which includes the pipe manning’s coefficient, impervious manning’s coefficient, pervious manning’s coefficient, impervious depression storage, pervious depression storage, and the percentage of impervious area with no depression storage; and the runoff generation module, which encompasses the maximum infiltration rate, minimum infiltration rate, and infiltration decay constant. As empirical parameters, calibration parameters are primarily determined by consulting the SWMM user manual, referencing relevant literature, and considering research findings from similar regions34,42,43,62. These serve as the initial values for the iterative optimization during model calibration.
(3) Design for short-duration intense rainfall.
The study area, as the central area of Chengdu, experiences a high incidence of basin rainstorms and short-duration heavy precipitation, characterized by significant hourly rainfall amounts 63,64. According to the “Comprehensive Plan for Drainage (Rainwater) and Flood Prevention in Central Chengdu”, we comprehensively consider 5, 10, 20, 50, and 100 years as the return periods for rainstorm simulations, covering the low, medium, and high return periods for rainfall mentioned in the upcoming “Technical Standards for Urban Flood Control and Drainage Engineering Design in Sichuan Province” 65. The revised Chengdu’s rainstorm intensity formula in 2015 66 was employed to design short-duration intense rainfall process in 120 min, obtaining rainfall intensity for different recurrence period in Table 2.
where \(\:\text{i}\) is the rainfall intensity (mm/min), \(\:\text{P}\) is the rainfall return period, and \(\:\text{t}\) is the rainfall duration (min).
Chicago rain type was adopted to design the variation of rainfall intensity over time based on the rainfall intensity using Chengdu rainstorm intensity formula. When the rainfall peak coefficient is 0.4, it can effectively characterize the rainfall hyetograph 67. As shown in Fig. 4, the 2-hour designed short-duration intense rainfall for the study area, with a time step of 10 min, exhibit variations of 77.32, 89.15, 101.00, 116.64, and 128.47 mm, corresponding to different storm return periods. These data were then used to derive rainfall time series inputs for the SWMM simulation.

Chicago rain type rainfall process line.
SWMM construction and calibration
Once data related to sub-catchments and rainfall have been acquired, creating the simulation model becomes relatively straightforward. The model was constructed by sequentially drawing sub-catchments, nodes, pipes, outfalls, and rain gauges 68. Before running the model, both calibration and non-calibration parameters must be manually input, followed by a parameter calibration exercise 69. The model is illustrated in Fig. 5.

SWMM model of the study area.
Due to the underdeveloped rainwater drainage monitoring system in China and the lack of observed data during model calibration, this study employs an iterative optimization method based on the composite runoff coefficient for model calibration 70. The specific approach involves using the composite runoff coefficient, determined based on the actual conditions of the study area, as the calibration target. According to the urban drainage design manual and the outdoor drainage design code71, it was initially estimated that the actual composite runoff coefficient falls between 0.5 and 0.7, combined with the impermeability rate of the study area (58%). We used the area proportions of green spaces (runoff coefficient 0.15), rooftops, and pavements (runoff coefficient 0.9) as weighting factors, and calculated a more precise value 0.61 as the target.
Non-calibrated parameters, calibrated parameters, and rainfall data are then input into the SWMM model to obtain the simulated runoff coefficient. The parameter calibration was performed using rainfall data with a 10-year return period, as shown in Table 3. An iterative technique was employed to optimize the model simulation results because of the discrepancy between the runoff coefficients by the model and the real runoff coefficients in the study area. Through an iterative process, the model parameters are continuously optimized to bring the simulated composite runoff coefficient closer to the targeted value.
After optimization using the iterative method, the results from the 6th optimization were adopted as the model parameters. The model was then used to simulate rainfall events with return periods of 5, 10, 20, 50, and 100 years, yielding five simulated composite runoff coefficients of 0.575, 0.607, 0.622, 0.654, and 0.671, respectively. It can be observed that the composite runoff coefficient increases as rainfall intensity increases. In order to determine whether the dispersion between the simulated composite runoff coefficients and the targeted runoff coefficients is within an acceptable standard range, the coefficient of variation method was used to test the degree of dispersion 72. The results of the dispersion calculation are shown in Table 4. The formula for calculating the coefficient of variation is as follows.
where \(\:{\text{C}}_{\text{v}}\left({\Psi}\right)\) denotes the coefficient of variation; ΔΨ represents the difference between simulated composite runoff coefficient and targeted composite runoff coefficient; \(\:\stackrel{\text{-}}{\Psi}\) indicates the average of simulated composite runoff coefficients.
As shown in Table 4, for the designed rainfall process with return periods of 5, 10, 20, 50, and 100 years, the coefficients of variation between the simulated and targeted composite runoff coefficients are all less than 10% 73. This indicates that the SWMM constructed based on the iterative optimization calibrated parameters, non-calibrated parameters, and rainfall data, provides results within an acceptable range, and the model is suitable for continued simulation and analysis.
Results for scenarios without LID measures (F0)
The study area without LID measures (configuration F0) was simulated using SWMM to determine the total runoff volume, peak runoff volume, and peak time for each return period. Figure 6 presents the simulation results for various design rainfall scenarios, ranging from a 5-year to a 100-year return period, without LID measures. The total runoff volume increases from 46.24 mm to 88.01 mm, peak runoff volume rises from 260.6 m³/s to 480.43 m³/s, and the peak time decreases from 58 min to 49 min. As the rainfall intensity increases, both the total and peak runoff volumes increase, and the peak time occurs earlier.

Environmental indicator results for the five return periods without LID measures.
Results for scenarios with LID measures (F1-F25)
The simulation results for the total runoff reduction rate, peak runoff reduction rate, and peak delay time for the study area under the five rainfall return periods (5, 10, 20, 50, and 100 years) across 25 LID configurations are present in Figs. 7, 8 and 9. The total runoff reduction rate of the combined LID configuration was significantly higher than that of the individual LID measures. Furthermore, the runoff control effectiveness of the combination of three LID measures was superior across the 5-year, 10-year, 20-year, and 50-year rainfall return periods. However, for the 100-year rainfall return period, the runoff control effect of the combination of two LID measures was comparable to that of the three-LID combination configuration.

Total runoff reduction rate (I11) for 25 configurations under five return periods.
In the individual LID deployment scenarios, the total runoff reduction effect was ranked as follows: permeable paving > green roof > sunken green space for rainfall events of with return periods of 5, 10, and 20 years; whereas for the design rainfall with return periods of 50 and 100 years, the runoff reduction effect followed the order: permeable paving > sunken green space > green roof. Among the two-LID combination configuration, F16 exhibited the highest total runoff reduction rate (70.65%) for the 5-year return period, while F6 had the lowest reduction rate (57.45%). Similarly, F10, F10, F4, and F7 had the highest total runoff reductions for the 10-, 20-, 50-, and 100-year rainfall return periods, respectively, with F7 demonstrating the lowest reductions for all of these return periods. In the three-LID combination scenarios, the best runoff control was achieved by F25, and the worst by F20, for the 5-year, 10-year, and 20-year return periods. For the 50-year and 100-year return periods, F20 provided the best runoff control, while F24 performed the worst.

Peak runoff reduction rate (I12) for 25 configurations under five return periods.
The peak runoff reduction rate was found to be inversely related to the duration of the return period. Specifically, a lower peak runoff reduction rate was observed as the rainfall returns period increased. Significant differences in peak runoff reduction rates were observed between the single and two-LID measure configurations under the same rainfall return period, whereas the three-LID measure configurations showed no substantial differences in peak runoff reduction rates. For the individual LID measures, the peak runoff reduction effects for each LID measure are as follows: sunken green space > green roof > permeable paving for the 5-year return period; green roof > sunken green space > permeable paving for the 10-year return period; and green roof > permeable paving > sunken green space for the 20-year, 50-year, and 100-year rainfall return periods. Among the two-LID combination configurations, F12 achieved the highest peak runoff reduction for the 5-year, 10-year, and 20-year rainfall return periods, while F9 exhibited the lowest reduction. For the 50-year rainfall return period, F17 showed the highest peak runoff reduction, whereas for the 100-year rainfall return period, F6 had the highest peak runoff reduction and F16 showed the lowest reduction.

Peak occurrence delay times (I13) for 25 configurations under five return periods.
The peak delay time effect for the single LID measure was ranked as follows: sunken green space > green roof > permeable paving for the 5-year rainfall return period. However, for the remaining four return period, the order was reversed to green roof > permeable paving > sunken green space. For the 5-year rainfall return period, successful two-LID combination configurations included F6, F7, F12, F13, and F17. For the other four rainfall return periods, the best-performing two-LID combination configurations were F12, F11, F5, and F16, in that order. It can be inferred that for a 30% deployment of green roof, the peak runoff reduction rate ranges from 19.50 to 61.61%, the peak delay time is between 2 and 4 min, and the total runoff reduction rate varies from 20.25 to 43.94%. With 30% permeable paving, the peak runoff reduction rate ranges from 11.54 to 53.11%, the peak delay time is between 1 and 3 min, and the total runoff reduction rate spans from 25.69 to 48.09%. When 30% of the sunken green space is used, the total runoff reduction rate ranges from 20.81 to 39.84%, the peak runoff reduction rate varies from 10.05% to 65.75, and the peak delay time ranges from 1 to 5 min. In the two-LID combination configurations, the total runoff reduction rate ranges from 35.88 to 70.65%, the peak runoff reduction rate varies from 19.24 to 73.25%, and the peak delay time ranges from 2 to 6 min. For the three-LID configurations, the total runoff reduction rate varies from 51.84 to 69.98%, the peak runoff reduction rate spans from 30.77 to 72.51%, and the peak delay time ranges from 3 to 5 min. These results suggest that LID measures can effectively delay the peak time while reducing both the total and peak runoff volumes.
Comprehensive benefit evaluation and configuration ranking
Social and economic indicator values
Five experts in municipal construction, sponge city development, and university research were invited to assess the ecological function, continuous demonstration effect, and social benefits of LID measures using a specially designed questionnaire. The assessment results were then converted into corresponding scores to quantify the social benefit of LID measures. For individual LID measures, the average evaluation score from five experts was used. For combined LID configurations, scores were assigned based on the proportional contribution of each LID measure.
Referenced from the Technical Guidelines for Sponge City Construction 57 and relevant literature 74, more conservative values for the construction and maintenance costs was selected. The construction costs were set 200 RMB/m2 for permeable paving, 130 RMB/m2 for green roofs, and 45 RMB/m2 for sunken green spaces. The maintenance costs were 5 RMB/m2 for permeable paving, 8.5 RMB/m2 for green roofs, and 4 RMB/m2 for sunken green spaces. For different combinations of LID measures, the costs were calculated based on the proportion of each LID measure. The groundwater replenishment benefit was calculated according to formula (6).
The indicator values under the scenario of 5-year return period are summarized in Table 5. The remaining rainfall return period index data can be found in Table A2-A6 in Supplementary material.
Calculation of indicator weights
The importance of indicators within the comprehensive benefit evaluation system was assessed, resulting in the hesitation fuzzy language values. These fuzzy evaluation data were then processed to calculate the indicator weights, which were used to establish a weighting matrix using the attitude-neutral scaling technique (Table A7 in Supplementary material). The weights of the five experts were calculated afterward as \(\:{\text{W}}_{\text{a}}\)= {0.174846327,0.180785331,0.208478203,0.229490253,0.206399887}. The indicator weights were calculated with the hesitant fuzzy weighted average method in Table 6.
TOPSIS evaluation and ranking results
The comprehensive benefits for 26 configurations under five rainfall return period scenarios of 5, 10, 20, 50, and 100 years was computed using the TOPSIS evaluation method following the steps in Sect. 2.3.2, which led to the identification of the optimal configuration. For example, the standardized matrix \(\:A^{\prime}\) was obtained after standardizing the original matrix \(\:A\) of indicator values under the 5-year return period.
Construct the weighted matrix \(\:V\) using the weights of the comprehensive benefit evaluation indicators for LID measures obtained in Sect. 5.2.
V=\(\left[\begin{array}{ccccccccc}\text{0.0146}&\:\text{0.0498}&\:\text{0.0377}&\:\text{0.0000}&\:\text{0.0910}&\:\text{0.0006}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0295}&\:\text{0.0000}&\:\text{0.0000}&\:\text{0.0569}&\:\text{0.0000}&\:\text{0.0381}&\:\text{0.0000}&\:\text{0.0000}&\:\text{0.0000}\\\:\text{0.0000}&\:\text{0.0741}&\:\text{0.0753}&\:\text{0.1260}&\:\text{0.1170}&\:\text{0.0297}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0927}&\:\text{0.0714}&\:\text{0.0377}&\:\text{0.0474}&\:\text{0.0152}&\:\text{0.0612}&\:\text{0.0147}&\:\text{0.0200}&\:\text{0.0197}\\\:\text{0.1012}&\:\text{0.0941}&\:\text{0.0377}&\:\text{0.0095}&\:\text{0.0758}&\:\text{0.0438}&\:\text{0.0733}&\:\text{0.1000}&\:\text{0.0983}\\\:\text{0.0629}&\:\text{0.1175}&\:\text{0.1130}&\:\text{0.1050}&\:\text{0.1127}&\:\text{0.0009}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0768}&\:\text{0.1035}&\:\text{0.1130}&\:\text{0.0210}&\:\text{0.0953}&\:\text{0.0015}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0692}&\:\text{0.1038}&\:\text{0.0753}&\:\text{0.1145}&\:\text{0.0975}&\:\text{0.0727}&\:\text{0.0733}&\:\text{0.1000}&\:\text{0.0983}\\\:\text{0.0748}&\:\text{0.0692}&\:\text{0.0377}&\:\text{0.0684}&\:\text{0.0195}&\:\text{0.0900}&\:\text{0.0147}&\:\text{0.0200}&\:\text{0.0197}\\\:\text{0.1049}&\:\text{0.0823}&\:\text{0.0753}&\:\text{0.0379}&\:\text{0.0303}&\:\text{0.0578}&\:\text{0.0293}&\:\text{0.0400}&\:\text{0.0393}\\\:\text{0.1081}&\:\text{0.0962}&\:\text{0.0753}&\:\text{0.0190}&\:\text{0.0607}&\:\text{0.0492}&\:\text{0.0587}&\:\text{0.0800}&\:\text{0.0787}\\\:\text{0.0751}&\:\text{0.1180}&\:\text{0.1130}&\:\text{0.0840}&\:\text{0.1083}&\:\text{0.0017}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0809}&\:\text{0.1110}&\:\text{0.1130}&\:\text{0.0420}&\:\text{0.0997}&\:\text{0.0020}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0740}&\:\text{0.0971}&\:\text{0.0753}&\:\text{0.1030}&\:\text{0.0780}&\:\text{0.0781}&\:\text{0.0587}&\:\text{0.0800}&\:\text{0.0787}\\\:\text{0.0771}&\:\text{0.0797}&\:\text{0.0753}&\:\text{0.0799}&\:\text{0.0390}&\:\text{0.0864}&\:\text{0.0293}&\:\text{0.0400}&\:\text{0.0393}\\\:\text{0.1100}&\:\text{0.0922}&\:\text{0.0377}&\:\text{0.0285}&\:\text{0.0455}&\:\text{0.0538}&\:\text{0.0440}&\:\text{0.0600}&\:\text{0.0590}\\\:\text{0.0810}&\:\text{0.1175}&\:\text{0.1130}&\:\text{0.0915}&\:\text{0.0585}&\:\text{0.0000}&\:\text{0.0880}&\:\text{0.1200}&\:\text{0.1180}\\\:\text{0.0764}&\:\text{0.0890}&\:\text{0.0753}&\:\text{0.0630}&\:\text{0.1040}&\:\text{0.0827}&\:\text{0.0440}&\:\text{0.0600}&\:\text{0.0590}\\\:\text{0.1049}&\:\text{0.1123}&\:\text{0.0753}&\:\text{0.0610}&\:\text{0.0693}&\:\text{0.0411}&\:\text{0.0587}&\:\text{0.0800}&\:\text{0.0787}\\\:\text{0.1023}&\:\text{0.1122}&\:\text{0.0753}&\:\text{0.0820}&\:\text{0.0737}&\:\text{0.0461}&\:\text{0.0587}&\:\text{0.0800}&\:\text{0.0787}\\\:\text{0.1033}&\:\text{0.1108}&\:\text{0.0753}&\:\text{0.0705}&\:\text{0.0542}&\:\text{0.0471}&\:\text{0.0440}&\:\text{0.0600}&\:\text{0.0590}\\\:\text{0.1038}&\:\text{0.1136}&\:\text{0.0753}&\:\text{0.0725}&\:\text{0.0888}&\:\text{0.0473}&\:\text{0.0733}&\:\text{0.1000}&\:\text{0.0983}\\\:\text{0.1060}&\:\text{0.1109}&\:\text{0.0753}&\:\text{0.0495}&\:\text{0.0498}&\:\text{0.0493}&\:\text{0.0440}&\:\text{0.0600}&\:\text{0.0590}\\\:\text{0.1065}&\:\text{0.1137}&\:\text{0.0753}&\:\text{0.0515}&\:\text{0.0845}&\:\text{0.0496}&\:\text{0.0733}&\:\text{0.1000}&\:\text{0.0983}\\\:\text{0.1076}&\:\text{0.1124}&\:\text{0.0753}&\:\text{0.0400}&\:\text{0.0650}&\:\text{0.0506}&\:\text{0.0587}&\:\text{0.0800}&\:\text{0.0787}\end{array}\right]\)
Subsequently, the positive ideal solution \(\:{C}^{+}\) and the negative ideal solution \(\:{C}^{-}\) of the weighted normalized matrix were determined. The Euclidean distances from each solution to the positive ideal solution and the negative ideal solution were calculated, as well as the relative closeness \(\:{\text{N}}_{\text{k}}\) (i.e., comprehensive benefit value). Similarly, the relative closeness of each solution under rainfall return periods of 10, 20, 50, and 100 years using the above method were obtained in Table 7.
Results and discussion
Robustness of the proposed approach
The robustness of the integrated approach, which combines ArcGIS-SWMM and HFLS-TOPSIS, is essential to ensuring the stability, reliability, and accuracy of the methodology across diverse hydrological conditions and decision-making scenarios. This robustness is reinforced by four key aspects that contribute to the overall reliability of the proposed approach.
(1) Impact of the Thiessen polygon method on hydrological processing in ArcGIS. The adoption of the Thiessen polygon method for delineating sub-catchments in ArcGIS plays a critical role in enhancing the robustness of the hydrological processing in our approach. By subdividing the study area into smaller, more homogeneous units, this method ensures a more accurate representation of spatial variations in rainfall and other hydrological parameters. This, in turn, minimizes errors associated with the over-generalization or simplification of catchment characteristics. Specifically, the Thiessen polygon method enables a precise representation of hydrological variability, which significantly contributes to the accuracy of the subsequent hydrological simulations in SWMM 75. Furthermore, this approach increases the adaptability of the model to various catchment sizes and spatial configurations, making it applicable to a wide range of urban stormwater management applications 76.
(2) Influence of composite runoff coefficient and iterative optimization in SWMM. The robustness of the SWMM modeling component is further strengthened by incorporating a comprehensive runoff coefficient, combined with an iterative optimization process for model parameter calibration. The runoff coefficient accounts for diverse land use, soil, and surface conditions, which are essential for accurately simulating runoff generation processes. When combined with iterative optimization, this coefficient enables more precise calibration of model parameters by minimizing discrepancies between simulated and observed data77. Moreover, the use of the coefficient of variation (CV) as a validation metric ensures that the model’s parameters are finely tuned to reflect observed runoff behavior across different conditions, thereby enhancing its accuracy and robustness. This iterative optimization not only improves the model’s predictive capabilities but also ensures stability under varying hydrological scenarios, reducing the risk of overfitting 78,79.
(3) Effect of hesitant fuzzy linguistic sets and TOPSIS on weight calculation and ranking. The integration of hesitant fuzzy linguistic sets (HFLS) and the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) significantly enhances the robustness of the decision-making process. HFLS allows for a more flexible and accurate representation of decision-makers’ preferences and uncertainties, which is particularly valuable when dealing with complex systems that involve subjective judgments 80. By incorporating multiple linguistic terms and their associated degrees of hesitancy, HFLS addresses the inherent vagueness and uncertainty present in decision-making processes. This flexibility is particularly advantageous in multi-criteria decision analysis (MCDA) for urban stormwater management, where uncertainties in parameter selection and weighting can significantly impact the outcomes. Additionally, the use of TOPSIS ensures that alternatives are ranked systematically based on their overall performance relative to ideal and negative-ideal solutions, thus providing a transparent and robust evaluation method for decision-making 81. The combination of HFLS and TOPSIS mitigates subjective biases, enhancing the credibility of the decision-making process and ensuring that the final ranking of alternatives is both reliable and consistent.
(4) Contribution of simulations under different return periods to stability analysis. Simulations across multiple return periods (e.g., 2-year, 5-year, 10-year, 25-year, and 100-year) add a critical layer of robustness to the study. By evaluating the model’s performance under a range of hydrological conditions, we can assess its stability and reliability across different rainfall intensities and frequencies. This analysis provides a comprehensive evaluation of the model’s robustness under extreme weather events, which are crucial in urban stormwater management 82. It also helps identify potential weaknesses in the model’s performance and assesses its applicability under varying return periods, which is essential for designing resilient urban stormwater systems. This sensitivity analysis ensures that the model’s predictions remain reliable and consistent, even under extreme or atypical hydrological scenarios, thereby further enhancing the overall robustness of the proposed methodology.
Flood control effects and indicator sensitivity analysis
The effectiveness of LID measures in controlling flooding is assessed based on three key environmental indicators: total runoff reduction rate (\(\:{I}_{11}\)), peak runoff reduction rate (\(\:{I}_{12}\)), and peak delay time (\(\:{I}_{13}\)). Compared to simulations without LID measures, the implementation of LID interventions leads to reductions in total runoff volume ranging from 20.25 to 70.65%, peak runoff reductions of 10.05–73.25%, and peak delay times of 1 to 6 min. The results reveal that LID measures significantly mitigate urban stormwater flooding by reducing both the total runoff volume and peak flow rates, while also providing moderate delays in the peak runoff occurrence 14.
Further analysis shows that the combined application of multiple LID measures is more effective than individual interventions 15. For single LID measures, total runoff reduction rates range from 20.25 to 48.09%, peak runoff reduction rates vary from 10.05 to 65.75%, and peak delay times range from 1 to 5 min. Among individual measures, permeable paving demonstrates the highest performance in runoff reduction, while green roofs excel in peak runoff reduction. When combining two LID measures, the total runoff reduction rate increases to between 35.88% and 70.65%, the peak runoff reduction rate ranges from 19.24 to 73.25%, and peak delay times extend from 2 to 6 min. For combinations of three LID measures, total runoff reductions range from 51.84 to 69.98%, peak runoff reductions from 30.77 to 72.51%, and peak delays from 2.5 to 5 min.
Among the environmental indicators, the total runoff reduction rate (\(\:{I}_{11}\)) and peak runoff reduction rate (\(\:{I}_{12}\)) exhibit high sensitivity. Small changes in these values significantly alter the comprehensive ranking of LID configurations, with higher runoff reduction rates generally resulting in better overall rankings. These indicators are critical for assessing the flood control capabilities of LID measures, as they directly reflect the measures’ ability to reduce runoff and mitigate peak flows 74. On the other hand, peak delay time (\(\:{I}_{13}\)) is less sensitive but still plays a role in areas prone to flash floods, where even a brief delay in peak runoff can provide valuable time for emergency responses.
In terms of economic indicators, construction cost (\(\:{I}_{21}\)) and maintenance cost (\(\:{I}_{22}\)) demonstrate moderate sensitivity. While these cost-related factors are essential for determining the feasibility of large-scale LID implementations, they do not drastically affect the overall ranking unless costs become prohibitively high 83. Groundwater replenishment benefit (\(\:{I}_{23}\)), which reflects the long-term economic benefits of LID measures on groundwater recharge, shows relatively low sensitivity due to its indirect and longer-term nature. However, it remains an important consideration for sustainable water management 84.
Social indicators, including landscape promotion value (\(\:{I}_{31}\)), continuous demonstration effect (\(\:{I}_{32}\)), and ecological function (\(\:{I}_{33}\)), are more challenging to quantify but still contribute significantly to the evaluation process. These indicators show moderate to low sensitivity, as they often rely on subjective assessments and long-term observations. Nevertheless, they can have a substantial impact on public perception and the acceptance of LID measures, especially when the measures enhance aesthetic value, ecological function, and community involvement 84.
Comprehensive benefit analysis under 5 scenarios
Under different rainfall scenarios, the comprehensive benefits of LID measures decrease as the rainfall intensity increases 85. LID measures demonstrate better comprehensive benefits during moderate to low intensity rainfall.
For the individual LID measures, it is evident that when implemented independently, permeable paving yields the lowest comprehensive benefit across all five return periods, while sunken green space provides the highest benefit. This discrepancy can largely be attributed to the higher construction and maintenance costs associated with permeable paving, coupled with its relatively lower landscape promotion value, continuous demonstration effect and ecological function, compared to other LID measures. In contrast, sunken green space generates the highest comprehensive benefit due to its significant reduction in peak runoff and its relatively low construction costs. Furthermore, construction cost emerges as the most influential factor in determining the overall benefit ranking. This finding is consistent with similar studies in the field86, where cost-effectiveness plays a critical role in the prioritization of LID measures for urban stormwater management.
For combinations of two LID measures, the F8 configuration exhibits the highest comprehensive benefit for the 5-year and 10-year return periods, while the F4 configuration shows the lowest benefit. The F8 configuration consists of 5% permeable paving and 25% sunken green space, with the latter effectively reducing peak runoff. Additionally, the sunken green space has lower construction and maintenance costs, with significant advantages in continuous demonstration effect and ecological function. When combined with permeable paving, which performs well in runoff control, the overall results are favorable. Conversely, the F4 configuration, comprising 5% green roofs and 25% permeable paving, ranks lowest, mainly due to the predominant area occupied by permeable paving. For the 20-year, 50-year, and 100-year return periods, the F17 configuration shows the highest comprehensive benefit, while the F4 configuration again ranks the lowest. This outcome is attributed to the higher demand for more extensive green roof areas to control peak runoff at higher return periods.
When combining three LID measures, the F22 configuration consistently provides the highest comprehensive benefit across all five return periods, while the F23 configuration has the lowest. The F22 configuration consists of 10% green roofs, 5% permeable paving, and 15% sunken green space, whereas the F23 configuration includes 10% green roofs, 15% permeable paving, and 5% sunken green space. The F22 configuration benefits from a smaller proportion of permeable paving and is primarily composed of sunken green space, which is associated with lower construction and maintenance costs, as well as higher continuous demonstration effect and ecological function.
Considering 25 configurations, the F8 configuration yields the highest comprehensive benefit for the 5-year and 10-year return periods, while the F22 configuration provides the highest benefit for the 20-year, 50-year, and 100-year return periods. The F2 configuration consistently shows the lowest comprehensive benefit. For lower return periods, where rainfall intensity is smaller, the combination of sunken green space (which has low construction costs) and a smaller area of permeable paving with good overall runoff control produces the best results. For higher return periods, where rainfall intensity increases, the best performance is achieved by replacing part of the sunken green space with green roofs, which are more effective at reducing peak runoff.
Implementation recommendation of LID measures
According to the “Chengdu City 14th Five-Year Water Conservancy Development Plan,” the main urban area of Chengdu is required to enhance its flood prevention and control capacity to withstand a rainstorm with a return period of 50 years. Based on the comprehensive benefits evaluation results presented earlier, the F22 configuration provides the highest comprehensive benefit during the 50-year and 100-year return periods. Therefore, for Chenglong Road Subdistrict in Jinjiang District, it is recommended to adopt the F22 configuration, which consists of 10% green roofs, 5% permeable paving, and 15% sunken green space. This configuration offers lower construction costs while achieving higher total runoff and peak runoff reduction. Additionally, the green roofs and sunken green spaces contribute to improving the urban environment, and the configuration demonstrates a significant continuous effect, making it the most beneficial option.
Furthermore, Chenglong Road Subdistrict consists of nine communities, each exhibiting distinct land use types and building densities. Consequently, the F22 configuration may not be universally applicable across all these communities. Among these, seven communities with higher building densities feature roof areas of approximately 61% in Shuishan, 72% in Guohuai, 71% in Xiangzhang, 52% in Huangjinglou, 59% in Langou, and 63% in Gufeng and Fengshu. These conditions are conducive to the implementation of green roofs. For these areas, a combination of green roofs, permeable paving, and sunken green spaces is recommended. In contrast, Zhuojincheng Community has a roof area of approximately 39%, with the remainder consisting primarily of the Chengdu Xinglinli Soccer Field, a fire equipment factory, and undeveloped land, resulting in fewer buildings. For this community, the F3 configuration, which involves 30% sunken green space, is recommended. This configuration not only aids in alleviating flooding but also offers significant construction cost advantages. In Huaxin Community, the roof area accounts for approximately 47%, with a relatively low building density. Therefore, the adoption of the F8 configuration, which combines permeable paving and sunken green space, is advised.
Conclusion
This study introduces a multi-indicator fuzzy comprehensive benefit evaluation approach for the selection of LID measures, offering a framework for evaluating the comprehensive benefits of LID measures at the community level. This holistic assessment model integrates quantitative indicators for environmental and economic benefits, as well as qualitative indicators for social benefits. Compared with other LID benefit evaluation methods, the use of SWMM in conjunction with ArcGIS for scenario analysis and the application of TOPSIS for decision-making is an innovative combination. The key contributions of this study can be summarized as follows: (1) integration of hesitant fuzzy weighted average algorithm in the experts’ judgments solves the problem of the uncertainty and vagueness from the subjective hesitant information; (2) the integration of scenario-specific evaluation focusing on multiple rainfall return periods adds robustness to the analysis; and (3) derivation of practical LID implementation priorities for local level decision-makers.
25 LID configurations were evaluated under five rainfall return period scenarios of 5, 10, 20, 50, and 100 years in the established model, which provide a balanced representation of common and extreme events. Firstly, the low coefficients of variation across multiple rainfall scenarios (all below 10%) demonstrate that the model based on 47 sub-catchments in Chenglong Road Subdistrict is robust and reliable for further analysis. The environmental benefits indicator simulation results show that LID measures exhibit a certain reduction in total runoff volume and peak flow, and to some extent, delay the peak time, thereby alleviating urban stormwater flooding. The effectiveness of the two combined measures is superior to that of individual measures and the three-measure combination.
This study acknowledges several limitations that should be addressed in future research. First, the drainage network data for Chenglong Road Subdistrict in Jinjiang District, Chengdu, was unavailable due to data constraints. Consequently, network data were derived from ArcGIS-based hydrological analysis, which may introduce certain uncertainties. Additionally, land use data for the study area were sourced from a 2017 dataset from the Tsinghua University Land Use and Cover Products Database, rather than from more recent 2023 data, which could result in discrepancies. Future studies should aim to obtain accurate, up-to-date drainage network and land use data, thereby improving the model’s precision. Second, although this study evaluates the comprehensive benefits of LID measures using a limited set of indicators, future research could expand the evaluation framework by incorporating additional environmental metrics, such as pollutant emissions and greenhouse gas reductions. This would provide a more holistic assessment of LID measure benefits, thus enhancing the understanding of their environmental, economic, and social impacts.
Data availability
Data is provided within the manuscript or supplementary information files.
References
1. Pörtner, H.O., Roberts, D.C., Adams, H., et al. Climate change 2022: Impacts, adaptation and vulnerability[R]. IPCC. (2022)
2. Misal, H., Hoare, V.H.C., Miles, V. Responding to the climate crisis–taking action on the IPCC 6th Assessment Report[J]. Weather (00431656), 77(4). (2022)
3. Gulshad, K., Szydłowski, M., Mustafa, A. Assessing climate change threats and urbanization impacts on surface runoff in Gdańsk (Poland): insights from remote sensing, machine learning and hydrological modeling[J]. Stochastic Environmental Research and Risk Assessment: 1–18. (2024)
4. Wang, C., Middel, A., Myint, S.W., et al. Assessing local climate zones in arid cities: The case of Phoenix, Arizona and Las Vegas, Nevada[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 141: 59–71. (2018)
5. Herslund, L., Mguni, P. Examining urban water management practices–Challenges and possibilities for transitions to sustainable urban water management in Sub-Saharan cities[J]. Sustainable Cities and Society, 48: 101573. (2019)
6. Mustafa, A., Szydłowski, M., Veysipanah, M., et al. GIS-based hydrodynamic modeling for urban flood mitigation in fast-growing regions: a case study of Erbil, Kurdistan Region of Iraq[J]. Scientific Reports, 13(1): 8935. (2023)
7. UNDRR. 2023 Global natural disaster assessment report. Available online: https://www.preventionweb.net/publication/2023-global-natural-disaster-assessment-report. (accessed on 26 November 2024)
8. Ministry of Emergency Management of the People’s Republic of China. Basic situation of natural disasters in China in 2023. Available online: https://www.mem.gov.cn/xw/yjglbgzdt/202401/t20240120_475697.shtml. (accessed on 26 November 2024) (in Chinese)
9. Lima, CAS., Heck, HAD., Aleska, K., Leidiane, D., Robert, SDS et al. Multicriteria analysis for identification of flood control mechanisms: Application to extreme events in cities of different Brazilian regions [J]. International Journal of disaster risk,71. (2022)
10. Xu, Z., Cheng, T. Theoretical basis of urban water management and sponge city construction: Research progress of urban hydrology. Hydraulic Engineering, 50(1): 53–61. (2019) (in Chinese)
11. Zeng, J., Huang, G., Luo, H., Mai, T., Wu, H. First flush of non-point source pollution and hydrological effects of LID in a Guangzhou. Scientific Reports. 9.(2019)
12. Zhuang, Q., Li, M., Lu, Z. Assessing runoff control of low impact development in Hong Kong’s dense community with reliable SWMM setup and calibration[J]. Journal of environmental management,345. (2023)
13. Hamedami, A., Bazilio, A., Soleimanifar, H., Shipley, H., Giacomoni, M. Improving the treatment performance of low impact development practices-comparison of sand and bioretention soil mixtures using column experiments[J]. Water,13(9). (2021)
14. Li, C., Zhang, Y., Wang, C., Shen, R., Gisen, J. I. A., & Mu, J. Stormwater and flood simulation of sponge city and LID mitigation benefit assessment. Environmental Science and Pollution Research, 30(27), 39493–39509. (2023)
15. Hu, Z., Liu, Z., Peng, S, et al. Simulation of storm water runoff control effect in low impact development (LID). Environmental Engineering, 10(07): 3956–3960. (2016) (in Chinese).
16. Hu, M., Zhang, X., Siu, Y., et al. Flood mitigation by permeable pavements in Chinese sponge city construction[J]. Water, 10(2): 172. (2018)
17. Zha, X., Fang, W., Zhu, W., Wang, S., Mu, Y., Wang, X., & Luo, P. Optimizing the deployment of LID facilities on a campus-scale and assessing the benefits of comprehensive control in sponge city. Journal of Hydrology, 635, 131189. (2024)
18. Li, J., Zhang, B., Li, Y., et al. Simulation of rain garden effects in urbanized area based on Mike Flood[J]. Water, 10(7): 860. (2018)
19. Coffman, L. Low-impact development design strategies: an integrated design approach (Prince George’s County, Maryland) [J]. (2000)
20. Wang, Z., Chui, T. F. M., & Fang, W. Life-cycle cost-benefit analysis of low impact development practices at the hectare scale [J]. Journal of Environmental Management, 239, 435–446. (2019)
21. Chui, T. F. M., Ngai, S. Y., & Ng, S. T. Quantifying the environmental benefits of green roofs: A Hong Kong case study. Urban Forestry & Urban Greening, 20, 295–304. (2016)
22. Xu, H., Yu, L., Wang, Y., & Zhang, H. Co-benefits of stormwater management and microclimate improvement of low impact development facilities in a high-rise residential area. Urban Climate, 55, 101904. (2023)
23. Li, J., & Yu, Y. The impact of urban green space on urban microclimate: a case study of Beijing. Procedia Environmental Sciences, 20, 200–206. (2014)
24. He, L., Li, S., Cui, C. H., et al. Runoff control simulation and comprehensive benefit evaluation of low-impact development strategies in a typical cold climate area[J]. Environmental Research, 206: 112630. (2022)
25. Wu, X., Tang, R., Wang, Y. Evaluating the cost–benefit of LID strategies for urban surface water flooding based on risk management[J]. Natural Hazards: 1–20. (2024)
26. Zhan, W., Chui, T. F. M. Evaluating the life cycle net benefit of low impact development in a city[J]. Urban Forestry & Urban Greening, 20: 295–304. (2016)
27. Li, J., Deng, C., Li, Y., et al. Comprehensive benefit evaluation system for low-impact development of urban stormwater management measures[J]. Water Resources Management, 31: 4745–4758. (2017)
28. Maryam, M., Mehdy, H. S. S., Fakhreddin, B. Integrated approach for low impact development locating in dense residential areas based on sustainable development criteria[J]. Water Science and Technology, 86(6):1590–1612. (2022)
29. Yasir, A., Yonas, D. Identifying cost-effective low-impact development (LID) under climate change: a multi-objective optimization approach[J]. Water, 14(19). (2022)
30. Liu, Y., Cibin, R., Bralts, V., et al. Optimal selection and placement of BMPs and LID practices with a rainfall-runoff model[J]. Environ Model Software, 80: 281–296. (2016) (in Chinese)
31. Li, S. Study on comprehensive benefit evaluation system and application of low impact development measures of sponge city [D]. Tianjin University of Technology. (2022) (in Chinese)
32. Koc, K., Ekmekcioglu, O., Ozger, M. An integrated framework for the comprehensive evaluation of low impact development strategies[J]. Journal of environmental management, 294. (2021)
33. Li, Q., Wang, F., Yu, Y., et al. Comprehensive performance evaluation of LID practices for the sponge city construction: A case study in Guangxi, China[J]. Journal of Environmental Management, 10–20. (2019)
34. Bai, Y., Li, Y., Zhang, R., Zhao, N., Zeng, X. Comprehensive performance evaluation system based on environmental and economic benefits for optimal allocation of LID facilities[J]. Water, MDPI AG, 11(2): 341. (2019)
35. Li, J., Yao, Y., Ma, M., Li, Y., Xia, J., et al. A multi-index evaluation system for identifying the optimal configuration of LID facilities in the newly built and built-up urban areas[J]. Water Resour Manage, 35: 2129–2147. (2021)
36. Kourtis, I., Tsihrintzis, V., Baltas, E. A robust approach for comparing conventional and sustainable flood mitigation measures in urban basins[J]. Journal of environmental Management,269. (2020)
37. Chen, Q., Zou, C., Huang, C., et al. Research on optimal configuration of LID facilities based on multi-objective particle swarm optimization algorithm [J]. China Water Supply and Drainage, 35(19): 126–132. (2019) (in Chinese)
38. Gao, J., Li, J., Li, Y., Xia, J., Lv, P. A distribution optimization method of typical LID facilities for sponge city construction[J]. Ecohydrology & Hydrobiology, 13–22. (2021)
39. Eckart, K., McPhee, Z., Bolisetti, T. Performance and implementation of low impact development – a review. Sci. Total Environ[J]. 607–608, 413–432. (2017)
40. Du, X., Jia, S., Fang, M., Ye, X. Recharge effect of sponge city construction on regional groundwater resources [J] Water Resources Protection, 35 (2): 13–17. (2019)
41. Wang, B. Comprehensive benefit evaluation of low impact development measures based on sponge city construction [D]. Fuzhou University. (2020) (in Chinese)
42. Wu, Y., She, D., Xia, J. Impact of typical LID measures on urban rainfall runoff process [J]. South-to-north Water Diversion and Water Science and Technology, 19(05): 833–842. (2021) (in Chinese)
43. Wang, Y., Li, X., Luo, X. Study on runoff characteristics of low-impact development: a case study of Chongqing Yuelai [J]. Guangdong Water Resources and Hydropower, (11): 56–62. (2021) (in Chinese)
44. Parizi, E., Khojeh, S., Hosseihi, S., Moghadam, Y. Application of unmanned aerial vehicle DEM in flood modeling and comparison with global DEMs: Case study of Atrak River basin, Iran[J]. Journal of environmental management,317. (2022)
45. Zhang, M. Optimization research on drainage network system based on SWMM Model [D]. Harbin Normal University. (2021) (in Chinese)
46. Richter, A., Ng, K., Karimi, N., Wu, P., Kashani, A. Optimization of waste management regions using recursive Thiessen polygons[J]. Journal of Cleaner Production, 234: 85–96. (2019)
47. Rodriguez, R., Martinez, L., Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans Fuzzy Syst. 20(1):109–119. (2012)
48. Torra, V. Hesitant fuzzy sets[J]. International Journal of Intelligent Systems, 25(6): 529–539. (2010)
49. Li, Z., Liang, X., Yin, H. A multi-criteria group decision making method for elevator safety evaluation with hesitant fuzzy judgements [J]. Appl. Comput. Math. 16: 296–312. (2017)
50. The State Council of the People’s Republic of China. The State Council’s Approval of the “Overall Planning of Chengdu’s National Land Space (2021–2035)”. Available online: https://www.gov.cn/zhengce/content/202409/content_6977829.htm. (accessed on 21 November 2024) (in Chinese)
51. Chengdu Municipal Statistics Bureau. Chengdu Statistical Yearbook 2023. Available online: https://cdstats.chengdu.gov.cn/cdstjj/c155010/2023-12/29/content_d2483a7e5a7244e4be2b7886e0563edc.shtml. (accessed on 21 November 2024) (in Chinese)
52. Jinjiang District Statistics Bureau, Chengdu. 2023 Statistical Bulletin on National Economic and Social Development of Jinjiang District, Chengdu. Available online: https://www.cdjinjiang.gov.cn/jjq/c164793/2024-05/10/content_4439d6f7984647bf81c8ffc2be94e51e.shtml. (accessed on 21 November 2024) (in Chinese)
53. Ying, X., Ni, T., Lu, M., Li, Z., Lu, Y et al. Sub-catchment-based urban flood risk assessment with a multi-index fuzzy evaluation approach: a case study of Jinjiang district, China[J]. Geomatics Natural Hazards and Risks,14(1). (2023)
54. Chengdu Urban-Rural Construction Committee. Technical Regulations for Sponge City Planning and Construction Management of Chengdu (Trial Version). Available online: https://www.shgbc.org/Attach/Attaches/201808/201808150515242254.pdf. (accessed on 21 November 2024) (in Chinese)
55. Chengdu Institute of Planning & Design, Chengdu Municipal Engineering Design & Research Institute Co., Ltd. Chengdu Sponge City Special Planning 2016–2030. Available online: https://www.gbwindows.net/download/1933.html. (accessed on 21 November 2024) (in Chinese)
56. Ministry of Housing and Urban-Rural Development of the People’s Republic of China. Technical Guidelines for Sponge City Construction – Low Impact Development Stormwater System Construction (Trial Version). Available online: https://www.mohurd.gov.cn/gongkai/zhengce/zhengcefilelib/201411/20141103_219465.html. (accessed on 21 November 2024) (in Chinese)
57. Gong P, Chen B, Li X, et al. Mapping essential urban land use categories in China (EULUC-China): Preliminary results for 2018[J]. Science Bulletin, 2020, 65(3): 182–187. (2020)
58. Jenson, S., Domingue, J. Extracting topographic structure from digital elevation data for geographic information system analysis[J]. Photogrammetric Engineering and Remote Sensing, 54(11): 1593–1600. (1988)
59. Tarboton, D., Bras, R., Rodriguez–Iturbe I. On the extraction of channel networks from digital elevation data[J]. Hydrological Processes 5: 81–100. (1991)
60. Zhang M. Study on optimization of drainage pipe network system based on SWMM model [D]. Harbin Normal University. (2021) (in Chinese)
61. Li, B. Research on simulation and control of rainstorm waterlogging in M City based on GIS and SWMM [D]. Shenyang Jianzhu University. (2016) (in Chinese)
62. Lu, H., Zou, Y., Sun, J., H, et al. Simulation of waterlogging control effect in Tiexinqiao experimental base based on SWMM [J]. Water Resources Conservation, 36(01): 58–65. (2020) (in Chinese)
63. Liu, X., Chen, Y., Guo, J., et al. Brightness temperature characteristics of short-duration heavy rainfall in the Chengdu–Chongqing railway region in China[J]. Atmosphere, 14(5): 896. (2023)
64. Zhang, T., Wei, W., Qing, P., Wang, X. Liao, W. Statistical analysis of the characteristics of short-time heavy rainfall in Chengdu in July and August [J]. Journal of Chengdu University of Information Technology, 35(3):7. (2020) (in Chinese)
65. Sichuan Provincial Department of Housing and Urban-Rural Development. Notice of the Sichuan Provincial Department of Housing and Urban-Rural Development on Publicly Soliciting Opinions on the Local Technical Standard for Engineering Construction “Technical Standards for Design of Urban Flood Control and Drainage Engineering in Sichuan Province (Draft for Comments)”. Available online: https://jst.sc.gov.cn/scjst/c101428/2023/12/13/7c3c44270f414ad3b5548fff29279d1a.shtml. (accessed on 24 November 2024) (in Chinese)
66. Chengdu Water Authority. The Revised Rainstorm Intensity Formula for Chengdu Central Urban Area Released to the Public. Available online: https://cdwater.chengdu.gov.cn/cdsswj/c173496/2015-05/22/content_190404a5111d45cc9e0d3663eec9aab5.shtml. (accessed on 21 November 2024) (in Chinese)
67. Wang, H., Wu, Z., Hu, C. Analysis of urban rainstorm flood inundation based on GIS and SWMM coupling [J]. Huanghe River, 39(08): 31–35 + 43. (2017) (in Chinese)
68. Hao, X., Li, Y., Liu, S. Comparison of dynamic flow interaction methods between pipe system and overland in urban flood analysis[J]. Scientific Reports. 11(1). (2021)
69. Yang, B., Zhang, T., Li, J., Feng, P., Miao, Y. Optimal designs of LID based on LID experiments and SWMM for a small-scale community in Tianjin, north China[J]. Journal of Environmental Management,334. (2023)
70. Liu, X. Parameter calibration method of urban rainfall runoff model based on runoff coefficient [J]. Water Supply and Drainage, 45(11): 213–217. (2009) (in Chinese)
71. Ministry of Housing and Urban-Rural Development of the People’s Republic of China. Outdoor Drainage Design Code GB50014-2021. Available online: https://www.beijing.gov.cn/zhengce/zhengcefagui/qtwj/202204/W020220412617234058432.pdf. (accessed on 24 November 2024) (in Chinese)
72. United States Environmental Protection Agency. Storm water management model applications manual. Available online: https://nepis.epa.gov/Exe/ZyNET.exe/P100EA7H.TXT?ZyActionD=ZyDocument&Client=EPA&Index=2006+Thru+2010&Docs=&Query=&Time=&EndTime=&SearchMethod=1&TocRestrict=n&Toc=&TocEntry=&QField=&QFieldYear=&QFieldMonth=&QFieldDay=&IntQFieldOp=0&ExtQFieldOp=0&XmlQuery=&File=D%3A%5Czyfiles%5CIndex%20Data%5C06thru10%5CTxt%5C00000032%5CP100EA7H.txt&User=ANONYMOUS&Password=anonymous&SortMethod=h%7C-&MaximumDocuments=1&FuzzyDegree=0&ImageQuality=r75g8/r75g8/x150y150g16/i425&Display=hpfr&DefSeekPage=x&SearchBack=ZyActionL&Back=ZyActionS&BackDesc=Results%20page&MaximumPages=1&ZyEntry=1&SeekPage=x&ZyPURL. (accessed on 25 November 2024)
73. Fu C. Simulation of urban waterlogging of certain district in Handan based on SWMM model [D]. Hebei University of Engineering. (2020) (in Chinese)
74. Li S. Comprehensive benefit evaluation system and application of low impact development measures for sponge cities. Tianjin University of Technology. (2022) (in Chinese)
75. Li, R., Wang, J., Hu, H. Sub-catchment division method and rainstorm waterlogging scenario modeling in north Huangpu district[J]. Water Resources and Power, 37(07): 50–53. (2019)
76. Dong, Z., Bain, D. J., Akcakaya, M., et al. Evaluating the Thiessen polygon approach for efficient parameterization of urban stormwater models[J]. Environmental Science and Pollution Research, 30(11): 30295–30307. (2023)
77. Rossman, L. A. Storm water management model user’s manual[J]. (2010)
78. Vieux, B. E, Vieux, B. E. Distributed hydrologic modeling using GIS[M]. Springer Netherlands. (2001)
79. Yang, J., Gong, Y., Li, X., Chen, L. Applicability of landscape index for assessing performance of low impact development schemes. China Water & Wastewater, 36(9):110–116. (2020)
80. Ying, X., Ni, T., Lu, M., et al. Sub-catchment-based urban flood risk assessment with a multi-index fuzzy evaluation approach: a case study of Jinjiang district, China[J]. Geomatics, Natural Hazards and Risk, 14(1): 2182173. (2023)
81. Tzeng, G. H., Huang, J. J. Multiple attribute decision making: methods and applications[M]. CRC press. (2011)
82. Cardoso, M. A., Almeida, M. C., Brito, R. S., et al. 1D/2D stormwater modelling to support urban flood risk management in estuarine areas: Hazard assessment in the Dafundo case study[J]. Journal of Flood Risk Management, 13(4): e12663. (2020)
83. Zhang, W., Hou, J., Shen, T., et al. An optimal design method for low-impact development (LID) facilities based on the hydrodynamic model and genetic algorithm-assisted decision-making[J]. Water Policy, 25(4): 313–337. (2023)
84. Gao, Y., Chen, J., Wang, D., Zhang, Z., Zhao C. Comprehensive benefits evaluation system and application of low impact development measures in sponge city [J]. Water Resources Protection, 37(3): 13–19. (2021)
85. Yu, Q., Li, N. Research progress of effects of low impact development on rainfall runoff reduction under different rainfall characteristic[J]. Water Resources and Power, 39(08):18–21 + 9. (2021) (in Chinese)
86. Zeng, J., Huang, G., Mai, Y., et al. Optimizing the cost-effectiveness of low impact development (LID) practices using an analytical probabilistic approach[J]. Urban Water Journal, 17(3):1–8. (2020)
Acknowledgements
The authors would like to express their sincere appreciation to the five experts who participated in the survey for their valuable insights and contributions. The authors also greatly appreciate the anonymous referees for their thoughtful and constructive feedback, which significantly improved the quality of this manuscript. Furthermore, the authors would like to thank the editors for their time and assistance throughout the review process.
Funding
This work was supported by the Major Programs of the National Social Science Foundation of China [grant number 22&ZD142, 2022]; the Research Funds for the Central Universities of Sichuan University [grant number 2021sj-pt10, 2021]; the Philosophy and Social Science Research Fund of Chengdu University of Technology [grant number 12400-000002-23QH012, 2023]; and the Chengdu University of Technology 2023 Young and Middle-aged Backbone Teachers Development Funding Program [grant number 10912-JXGG2023-06691, 2023].
Author information
Authors and Affiliations
Contributions
Ting Ni and Xiaohong Zhang wrote and revised the main manuscript text. Peng Leng visualized the result data and prepared Figs. 7, 8 and 9. Conceptualization were performed by Ting Ni and Mark Pelling. Supervision and funding acquisition were performed by Ting Ni and Jiuping Xu. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
The Office of Humanities of Social Sciences, which is in charge of ethical review, at the Chengdu University of Technology, approved this study.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work the authors used [ChatGPT 3.5] in order to [polish the writing to meet the academic style, and improve the spelling, grammar, clarity, concision and overall readability]. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ni, T., Zhang, X., Leng, P. et al. Comprehensive benefits evaluation of low impact development using scenario analysis and fuzzy decision approach. Sci Rep 15, 2227 (2025). https://doi.org/10.1038/s41598-025-85763-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-85763-z
Keywords
This article is cited by
-
Research on the evaluation of undergraduate students’ core competencies in the context of industry–education integration
Scientific Reports (2025)
-
Emergency Response to Urban Flooding: An Assessment of Mitigation Performance and Cost-Effectiveness in Sponge City Construction
Water Resources Management (2025)
