
Abstract
Named Entity Recognition for crop diseases and pests (NER-CDP) is significant in agricultural information extraction and offers vital data support for subsequent knowledge services and retrieval. However, existing NER-CDP methods rely heavily on plain text or external features such as radicals and font types and have limited effect on improving word segmentation. In this paper, we propose a multimodal named entity recognition model (CDP-MCNER) based on cross-modal attention to solve the issue of the performance degradation of the NER model caused by potential word segmentation errors. We introduce audio modality information into the field of NER-CDP for the first time and use the pauses in audio sentences to assist Chinese word segmentation. The CDP-MCNER model adopts cross-modal attention as the main architecture to fully integrate the textual and acoustic modalities. Then some data augmentation techniques, such as introducing disturbances in the text encoder, and frequency domain enhancement in the acoustic encoder are used to enhance the diversity of multimodal inputs. To improve the accuracy of the prediction label, the Masked CTC (Connectionist Temporal Classification) Loss is used to further align the multimodal semantic representation. In the experiment studies, we compare with classical text-only models, lexicon-enhanced models, and multimodal models, our model achieves the optimal precision, recall, and F1 score of 91.32%, 93.05%, and 92.18%, respectively. Furthermore, the optimal F1 scores of our method are 81.05% and 79.23% based on the public domain datasets, CNERTA and Ai-SHELL. The experimental results show the effectiveness and generalization of the CDP-MCNER model in the task of NER-CDP.
Similar content being viewed by others


Introduction
Agriculture is a fundamental industry that plays a vital role in supporting national economic construction and development. Various factors such as natural disasters, extreme weather, environmental pollution, and improper field management1 lead to a loss of grain production. Crop diseases and pests have consistently been regarded as the primary causes of crop yield reduction and damage, which pose significant threats to the development of agricultural industrialization and the improvement of agricultural economic benefits. In the current era of information, there is a growing trend of utilizing online data to address agricultural problems. How to deal with large volumes of data and grasp data accuracy have become prominent research directions in fields of agricultural big data2 and natural language processing3. Named Entity Recognition (NER) is vital in exploring knowledge from crop diseases and pests data, it is also a prerequisite for building agricultural knowledge graphs and downstream tasks such as question answering4,5,6. The accuracy of named entity recognition directly affects the quality of downstream tasks, making it an area of considerable value.
NER-CDP (Named Entity Recognition-Chinese Diseases and Pests) aims to identify the boundaries and types of entities with specific meanings in agricultural texts (crops, diseases, drugs, etc.). For example, " (Linquan county is a common place of wheat scab) ". In this passage, the named entity recognition task will extract Chinese entities, "LOCATION:
(Linquan county is a common place of wheat scab) ". In this passage, the named entity recognition task will extract Chinese entities, "LOCATION:  (Linquan county) and Diseases:
(Linquan county) and Diseases:  (wheat scab) ".病 In recent years, some researchers have proposed various methods such as using encoder models with Conditional Random Fields (CRF) or incorporating additional information like lexicons and character-level features7 to conduct the NER-CDP task. Specific examples are shown in Table 1.
(wheat scab) ".病 In recent years, some researchers have proposed various methods such as using encoder models with Conditional Random Fields (CRF) or incorporating additional information like lexicons and character-level features7 to conduct the NER-CDP task. Specific examples are shown in Table 1.
Nevertheless, agricultural entities still face many challenges12 such as polysemy, lengthy entities, rarity, and underutilization of external agricultural dictionaries. Effectively utilizing lexicon and character structure is a crucial strategy to improve text features in Chinese NER. Most existing research for crop diseases and pests NER mainly concentrates on text-only analysis, there is a lack of exploration of integrating information from diverse modalities for Named Entity Recognition.
Compared with the traditional single-modal method, the multimodal named entity recognition method can combine a variety of information to improve the performance of the model13,13. Wu et al.15 split every Chinese character in the text into radicals and utilized CNN to extract radical features. Each Chinese character and its corresponding word in the text are considered as two modalities. A multi-modal Two-stream Cross-Transformer is employed to combine the features of both modalities, effectively enhancing the semantic and boundary information of Chinese words. Meng et al.16 proposed Glyce, a representation method for Chinese characters, which treats them as images and uses the Tianzige-CNN to extract semantic information. The combination of both modalities has consistently outperformed models based solely on lexicon-enhanced text features17. However, the combination of multiple modalities is commonly used in image recognition and growth monitoring in agriculture, but it has not yet been employed in the field of crop diseases and pests knowledge extraction. Currently, named entity recognition tasks within this field still rely on text-based methods, and there has been no exploration of method that combines acoustic and textual modalities.
We use simplified Chinese in the model, and the dataset mainly comes from agricultural text in China. In crop diseases and pests named entity recognition, entity categories such as “PART (growth cycle)” and “DRUG (Insecticides, fungicides, etc.)” are relatively easy to recognize because they have obvious patterns with characters like “ (period)” and “concentrations such as 10 mol/L”. However, recognizing entity categories like “LOCATION (Planting area or institutional area)” and “ORG (Institution or organization)” are more challenging because they use words flexibly and lack regular patterns. The aforementioned text-based methods rely solely on textual data, and might not effectively accomplish named entity recognition tasks in the absence of critical contextual elements. For instance, without contextual information and prior experience, the phrase “
(period)” and “concentrations such as 10 mol/L”. However, recognizing entity categories like “LOCATION (Planting area or institutional area)” and “ORG (Institution or organization)” are more challenging because they use words flexibly and lack regular patterns. The aforementioned text-based methods rely solely on textual data, and might not effectively accomplish named entity recognition tasks in the absence of critical contextual elements. For instance, without contextual information and prior experience, the phrase “ (average sunshine time and average temperature)” might be mistakenly recognized as two location entities “
(average sunshine time and average temperature)” might be mistakenly recognized as two location entities “ (Rizhao city)” and “
(Rizhao city)” and “ (Heping city)”. Another example is that improper sentence segmentation can lead to the misinterpretation of the phrase "
(Heping city)”. Another example is that improper sentence segmentation can lead to the misinterpretation of the phrase " (Spodoptera exigua/ Embryo) “, resulting in the entity being misclassified as a crop entity “甜菜 (Beet)" rather than a pest entity "
(Spodoptera exigua/ Embryo) “, resulting in the entity being misclassified as a crop entity “甜菜 (Beet)" rather than a pest entity " (Spodoptera exigua)”. Compared with the visual modality, the introduction of the acoustic modality is beneficial for Chinese named entity recognition18. To solve the problem of missing word separators in sentences, it is helpful to identify word boundaries in Chinese text by pausing between adjacent words in Chinese speech. This allows for more accurate extraction of complex agricultural entities associated with crop diseases and pests, including diseases, symptoms, and control measures. Given the current lack of publicly available multimodal NER datasets for this field, a large-scale multimodal dataset called AgMNER (Agricultural Multimodal Named Entity Recognition) is constructed. This dataset is specifically designed for performing multimodal named entity recognition in the field of crop diseases and pests.
(Spodoptera exigua)”. Compared with the visual modality, the introduction of the acoustic modality is beneficial for Chinese named entity recognition18. To solve the problem of missing word separators in sentences, it is helpful to identify word boundaries in Chinese text by pausing between adjacent words in Chinese speech. This allows for more accurate extraction of complex agricultural entities associated with crop diseases and pests, including diseases, symptoms, and control measures. Given the current lack of publicly available multimodal NER datasets for this field, a large-scale multimodal dataset called AgMNER (Agricultural Multimodal Named Entity Recognition) is constructed. This dataset is specifically designed for performing multimodal named entity recognition in the field of crop diseases and pests.
In this study, we integrate acoustic information and text data in the field of agriculture for the first time. To effectively integrate the data of the two modalities, we use the cross-modal attention module as the main architecture of the proposed model. This method can use the sentence pause in the audio to alleviate the problem of improper word segmentation caused by the absence of natural segmentation in Chinese sentences. The main contributions of this paper are as follows:
-
(1)
A multimodal named entity recognition model, CDP-MCNER is proposed, which incorporates speech information into NER-CDP tasks. The input of the model is diversified through data augmentation methods which are implemented by adding disturbance, introducing noise, changing sound speed and pitch, and enhancing the frequency domain. The main component of our model is a multi-layer cross-modal attention module, where the acoustic and text features are interacted and fused. Then, the text representation is enhanced by using the acoustic features and transmitted to the CTC/CRF project for label inference.
-
(2)
A large-scale and high-quality Chinese agricultural multimodal dataset named AgMNER is constructed. This is the first Chinese multimodal dataset in the agricultural field. It contains 10 categories and 68,513 entities.
-
(3)
This paper compares CDP-MCNER with other advanced mainstream models on the constructed AgMNER dataset and the experimental results indicate that CDP-MCNER has better performance. The experimental results obtained from other multimodal datasets also show that the proposed model achieved better generalization and robustness.
Methods
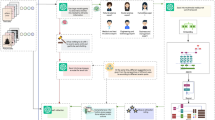
In this paper, we propose a multimodal named entity recognition model (CDP-MCNER), which takes the cross-modal attention module as the main network structure. The CDP-MCNER model consists of four parts: text encoder, acoustic encoder, cross-modal attention module, and CRF/CTC project layer. The overall architecture of the CDP-MCNER model is shown in Fig. 1. This section will introduce the implementation principles of the text encoder, acoustic encoder, cross-modal attention module, and CTC project. The details of CRF can be referred to Huang et al.19.

Overall architecture of CDP-MCNER.
Multimodal encoder
To effectively capture the modality dynamics between textual and acoustic information and facilitate further integration of the two modalities, the text information and audio information are processed by transformer separately.
The initial vector representation of the input text “甜菜夜蛾胚胎发育的时间 (Embryonic development time of Spodoptera exigua)……” after applying BERT pre-training is represented as \(E = [E1, E2, E3, \ldots , \;En].\) Each character-level embedding consists of three vectors: the token embedding which representing the meaning of the word, the Segment embedding which is used to distinguish different sentences, and the Position embedding which encodes the position of the word in the sequence. During the pre-training process, 15% of the vocabulary in each sequence is randomly masked. The entire sequence is processed by a bidirectional transformer encoder. Only the masked words are predicted. The loss value and gradient value of the word vector of the sample generated by the current BERT model are input to calculate the generated disturbance \(\gamma\). The disturbance \(\gamma = [\gamma 1,\;\gamma 2,\;\gamma 3,\; \ldots ,\;\gamma n]\) is added to the trained word embeddings \(T = [T1,\;T2,\;T3,\; \ldots ,\;Tn]\) to generate adversarial samples. The word embeddings \(T = [T1, \;T2, \;T3,\; \ldots ,\; Tn]\) and the disturbance \(\gamma = [\gamma 1, \;\gamma 2, \;\gamma 3,\; \ldots , \;\gamma n]\) are then inputted together into the cross-modal attention module. The adversarial training process can be formally represented as the following equation:
where \({\gamma }_{adv}\) represents the computed perturbation; \(\Omega\) is the perturbation space; \(L\) denotes the loss function; \(\theta\) represents the internal model parameters; \(x\) denotes the input; \(y\) denotes the output; \(D\) represents the sample space; \(E\) represents the empirical risk. The inner part of the equation maximizes the loss function, while the outer part minimizes the empirical risk. In this study, The direction of the perturbation is aligned with the direction of increasing loss. After calculating the forward loss, the gradient is calculated by using backpropagation. Once the gradient of the embedding is obtained, \({\gamma }_{adv}\) is calculated by using Eq. (1) and the gradient. In Eq. (2), \(g\) represents the gradient, and \(||g|{|}_{2}\) refers to the L2 norm of the gradient. L2 normalization preserves the direction of the gradient, which is then accumulated with the original embedding sample to obtain the adversarial sample. Based on the new adversarial samples, the new loss is calculated. We performed backpropagation to obtain the gradients of the adversarial samples. Finally, we restore the modified embeddings to their original states and update the model parameters using the obtained gradients. These steps ensure that the direction of gradient ascent is optimal.
The acoustic modality encoder in this paper can be roughly divided into four parts: a speech preprocessing layer, a two-dimensional convolutional layer, a data augmentation layer, and a transformer-based encoder. Since the neural network cannot directly use audio as input, we make a feature extraction of audio data. To obtain clear speech features20, Mel filters are utilized to analyze the sound signal and separate the frequency characteristics of the speech signal. In this process, the speech signal is segmented into frames by Mel filters. Each frame undergoes a Short-Time Fourier transform21 to compute the power spectrum and filter bank results22. Then, downsampling is performed using a two-dimensional convolutional layer. For the speech signal \(Y=({y}_{1},{y}_{2},{y}_{3},\dots ,{y}_{n}),\) where \({y}_{j}\) represents the j-th waveform frame, it undergoes two two-dimensional convolutions. The first convolution has an input channel of “1” and an output channel of 3 × 3 dimension23. The second convolutional input channel and output channel are both of 3 × 3 dimension. Then the time dimension T and feature dimension dim of the input features are halved. Then the time dimension is moved to position 1, and the last two dimensions are fused and restored to the input dimension via a linear transformation. To increase the diversity of samples, the data augmentation techniques are used to enrich the language dataset of this project with a proportion of 10%. We introduce the noise to the audio and vary the amplitude of the speech signal by any pitch change within 10% around the frequency axis. Additionally, the speed of the speech is varied by randomly shifting the signal along the time axis. We also incorporate positional encoding features while encoding word vectors. The encoding equation used for this purpose is as follows:
where \(t\) represents a position in a given input sentence, \({\overrightarrow{p}}_{t}\in {R}^{d}\) is the positional encoding corresponding to position \(t,\) and \(d\) is the dimension of positional encoding. \(f:N\to {R}^{d}\) is a function that generates the output vector \({\overrightarrow{p}}_{t},\) it is observed that the frequencies of the trigonometric functions decrease along the vector dimension. Thus, the function \(f\) forms a geometric series in terms of wavelength, ranging from \(2\pi\) to \(10000\cdot 2\pi.\) Finally, the processed acoustic features are inputted into a transformer-based encoder, which consists of 6 identical stacked layers24. The transformer encoder consists of a self-attention layer and a feed-forward neural network, which can automatically learn the relationships and semantic information from the input features and generate more expressive representations. It utilizes a self-attention mechanism to capture long-range dependencies and sequence information, thereby effectively modeling and encoding speech signals. To enable multimodal interaction in the next step, this study inputs both textual representations and acoustic representations into the cross-modal attention module.
Cross-modal attention module
Conventional transformers are limited in capturing contextual features of the acoustic modality in conjunction with textual features due to the different time sequence lengths of each modality. Sentence pauses in speech audio can guide Chinese word segmentation and improve its accuracy. To achieve this, this paper proposes integrating acoustic modality features with textual modality features by Cross-modal attention module. This module allows one modality to receive information from the other, enhancing the overall performance. In the transfer of acoustic modality to textual modality, this study keeps all dimensions of the Cross-modal attention module fixed at \(d\). The Cross-modal transformer is formed by multiple layers of Cross-modal Attention Modules, as depicted in Fig. 2.

Cross modal attention \(C{A}_{i}({{\varvec{X}}}_{\boldsymbol{\alpha }},{{\varvec{Y}}}_{{\varvec{\beta}}})\) between sequences \({{\varvec{X}}}_{\boldsymbol{\alpha }},{{\varvec{Y}}}_{{\varvec{\beta}}}\) from various modalities.
In this study, a multi-head cross-modal attention mechanism is firstly utilized, treating textual modality \(X_{\alpha }\) as Querys and the acoustic modality \(X_{\beta }\) as Keys and Values:
where \(C{A}_{i}\) refers to the i-th head of cross-modal attention, and \(\{ W_{Q\alpha }^{i} ,W_{K\beta }^{i} ,W_{V\beta }^{i} \} \in R^{d/m \times d}\), \(W\prime \in R^{d \times d}\) represents the weight matrices for Querys, Keys, Values, and the multi-head attention, respectively. Equation (4) corresponds to the case when i = 1. Then, the following sub-layers are stacked on top:
where \(LN\) refers to Layer Normalization, \(FEN\) represents Fully Connected Feedforward Networks25. \(Z = [Z1,Z2,Z3, \ldots ,Zn]\) is the output representation of the Cross-modal Transformer. The output from the cross-modal transformers that shares the same target modality are concatenated. Finally, the new representation \(Z\in {R}^{d\times T}\) after interactive fusion is sent to the CRF/CTC project layer for inferring NER labels.
CTC layer
In addition to the aforementioned work, a CRF/CTC project layer is also established on our multimodal model, with a combined loss function of Masked CTC Loss and CRF Loss. In practical training, the phoneme corresponding to each frame is not known, which adds to the difficulty and labor intensity of the training process. To address this, this paper establishes a maximum output length to reduce the difficulty of training. We also introduce a special label called “Blank” in the CTC Loss function. The “Blank” is utilized to represent repeated characters or gaps between two characters in the output sequence26. Building upon this, we no longer process the entire sequence as a single unit. Instead, masking is introduced to handle partially variable data27. For instance, taking “甜菜夜蛾胚胎发育的时间 (Embryonic development time of Spodoptera exigua)” as an example, the phoneme information is no longer in the label format of the original \(s=[\text{t},\text{i},\text{a},\text{n},\text{c}\dots \dots ]\). It follows the Eq. (8):
where \(s{\prime}\) represents the labels for each frame, where irrelevant words like "的时间 (the time of)" are marked as 0. In this case:
where \(y\) represents the input values, \({N}_{\omega }\) denotes the preceding model, \({e}_{s{^{\prime}}_{t}}^{t}\) is the activation of output unit \(s{\prime}\) at time \(t\), which represents the likelihood of the label at time \(t\). \(l\) refers to the set of phoneme sources for the label sequence, \(l{\prime}\) represents the sequence set with the addition of the “Blank” label, and \(\pi\) denotes a path of length \(t\) composed of elements from \(l\). The probability of a path is calculated as the product of the probabilities of each observed label at each time step, with the sequence length being \(t\) and the probabilities being multiplied \(t\) times. This step assumes that the network outputs are conditionally independent at different time steps. In Masked CTC Loss, a mask vector \(U\) of the same length is regarded as the input sequence, where the elements can be 0 or 1 (1 represents valid, 0 represents invalid). Masked CTC Loss utilizes the mask vector in the calculation of CTC Loss, during which the loss function ignores the results from invalid positions and refrains from including them in the loss calculation. This ensures that only the results at valid positions will affect the computation of the loss function.
In the next step, a simplification operation is used on the output sequence to merge consecutive identical characters or Blank labels into single characters or a single Blank label. Then, all Blank labels are removed from the merged output sequence to obtain the final predicted sequence. Finally, this layer compares the predicted sequence with the corresponding label sequence and calculates the difference between them. During this process, the calculation of CTC loss involves all possible alignments and the loss value is obtained by summing in different ways. This alignment task is combined with the labeling task:
where \(\lambda\) is a hyperparameter.
Experiments and analysis
Datasets
To our knowledge, there is currently no publicly available multi-modal dataset that combines texts and speech for the NER-CDP task. This paper follows the format of the AISHELL-NER speech dataset28 and develops our dataset for crop diseases and pests. This section will discuss the process of building a dataset, introduce the statistics of the dataset, and compare AgMNER with other datasets in this field.
Entity division and corpus annotation
To ensure the comprehensiveness of the corpus, scraping techniques were used to extract semi-structured and unstructured data from the China Pesticide Information Website and the China Crop Germplasm Information Website. A total of 20,141 text sentences were obtained after removing and cleaning the irrelevant noise information, such as navigation and advertisements.
Based on previous studies10, crop diseases and pests entities are classified into 10 categories. In addition to the category of “crop”, “disease” and “pest” are further classifications of crop “diseases and pests”, “drug” refers to the means used for preventing and controlling diseases and pests, “pathogeny” is the root cause of crop diseases, “location” refers to the growing position of crops or the position of a specific organization, “strains”, “growth cycle” and “part” of the crop are also considered, “ organization " represents the institution responsible for certifying or cultivating crops. Table 2 presents the introduction, number, and share of the specific categories, which collectively consist of 68,513 entities.
After completing the categorization, the obtained data was annotated in BIO format using the text-oriented crop diseases and pests named entity annotation system ChineseNERAnno, which was developed by our research team. To ensure the consistency and accuracy of annotation, this software establishes a data dictionary leveraging the SQLite database, which facilitates the achievement of semi-automatic annotation via entity matching. We set up two rounds of labeling processes, involving experts, teachers, and students from the agriculture and forestry sectors as labeling participants. Before the first round of labeling, the labeling training should be conducted to unify the labeling rules and specifications. After marking the first round, our researchers conducted a second round of inspection to ensure consistency and accuracy. Consequently, a corpus of 17,797 Chinese crop diseases and pests named entities is obtained. This portion is used as a text-only dataset, and the annotated data set is divided into the training set, validation set, and test set according to the ratio of 8:1:1.
In this study, we need to build a large-scale multimodal crop diseases and pests dataset. Due to the large amount of data and the high cost of gathering multiple participants for recording, this paper opts to utilize the Microsoft Voice Interface API to convert this text data. Microsoft Voice Interface is a tool that can convert text into voice audio. After converting the text datasets into audio files, we have checked the audio to ensure there are pauses between words and sentences, which are almost indistinguishable from manually recorded speech. To ensure that gender does not become a disturbing factor in experiments, 50% of male and female voices are selected for synthesis in this study. Each audio file name corresponds to the audio identifier in the text, and the order of sentences is randomly shuffled for each voice. This textual part is combined with the synthesized audio files to form the multimodal dataset AGMNER for crop diseases and pests. In the AgMNER, the content of the audio part is consistent with the text part. Table 3 shows some examples of the multimodal dataset AgMNER. The speech waveform in the table is the sound wave image of this example.
Evaluation metrics and experimental settings
Precision (P), Recall (R), and F1-score(F1) were used as evaluation metrics in this experiment. The calculation formulas are shown in (13), (14) and (15), where TP stands for True Positions, FP stands for False Positions, and FN stands for False Negatives.The text part of AgMNER was output in the BIO format as a text-only dataset. For model training, AdamW was used as the optimizer29, with a dropout of 0.5 and a decay rate of 0.01. The maximum sequence length set in this study was 400, and text above this length would be truncated. The maximum audio length was set to 8808. Multimodal named entity recognition requires too many computing resources for computers. When the amount of data is too large or the length of characters is too long in future work, we can use cloud computing services to expand computing resources. The epoch was set to 100. Training, validation, and test sets were randomly divided 8:1:1 from the whole dataset. The training set, validation set, and test set of the text-only dataset were consistent with the contents of the multimodal dataset. Table 4 lists other hyperparameters. “audio-hidden” means “the dimension of the audio encoder”. “n-blocks” means “the number of transformer blocks in the audio encoder”. The experiments were implemented using PyTorch 1.13.1 on a single NVIDIA GeForce GTX 3060ti GPU and 32G RAM.
Comparative experiments
In this experiment, a series of advanced and representative models were selected as the baselines for comparative analysis with the proposed CDP-MCNER, including text-only models, lexicon-enhanced models, and multimodal models.
In the text-only models, the methods of BiLSTM-CRF, BERT-BiLSTM-CRF, and CNN-BiLSTM-CRF were compared with the model proposed in this paper. BERT, a pre-trained model, can generate different vectors for a single word30. The BiLSTM network is composed of two LSTM units in the forward and backward directions, enabling it to capture contextual information from both preceding and following elements simultaneously. This enhances its understanding of dependency relationships within sequential data. The “gate” mechanism31 selectively controls the flow and forgetfulness of information, allowing the BiLSTM to effectively handle long-term dependencies. The method of combining CNN and BiLSTM involves utilizing CNN to calculate character-level representations. These character-level representation vectors are then connected with word embedding vectors to the BiLSTM network32. Finally, the output vectors are passed through the CRF layer to decode the best label sequence. This combination allows for improved utilization of dependency relationships in the data, thereby enhancing the accuracy of NER tasks. However, the text-only models mentioned earlier can not fully utilize words and their sequential information. To address this, this study chose two representative vocabulary-enhanced models: Lattice LSTM and LEMON. Lattice LSTM encodes all potential words in the input character sequence and performs word matching in the lexicon. On the other hand, LEMON introduces a fragment model based on enhanced lexicon memory that enhances the position-relevant features learned from the lexicon. It combines character-level and word-level features to generate improved feature representations for possible candidate names. More details about Lattce-LSTM and LEMON can refer to33,34.
This study validated the superiority of multimodal methods over traditional single-modality approaches by comparing the multimodal NER models of MuIT35 and Unified Multimodal Transformer36 with a single-modality NER model. MuIT adopts an end-to-end approach with bidirectional cross-modal attention mechanisms to directly capture the interactions between multimodal sequences at different time steps without the need for explicit data alignment. It potentially adjusts the flow from one modality to another for named entity recognition. The UMT method further incorporates an entity span detection module on top of the multimodal interaction module to guide the final prediction of NER.
Table 5 presents the comparison results, the CDP-MCNER model outperformed all other models in terms of the three evaluation metrics. It achieves a precision of 91.32%, a recall of 93.5%, and an F1 score of 92.18%. The improvement in F1 score over the BERT-BiLSTM-CRF text-only model and the LEMON lexicon-enhanced model is 1.59% and 1.60%, respectively. The experimental results demonstrate that incorporating the acoustic modality can greatly enhance the performance of the named entity recognition model. Furthermore, the CDP-MCNER model achieves a 1.16% improvement in comparison to the optimal multimodal model, BERT-UMT-CRF. This improvement can be attributed to the implementation of data augmentation techniques and alignment using Masked CTC Loss. These methods enhanced the diversity of samples from both text and speech modalities, enabling the extraction of word boundary information from speech for Chinese text. Consequently, these methods positively influenced the performance of the multimodal model that integrates both text and speech.
Generalization study
In order to validate the generalization of the CDP-MCNER model, we chose the public domain corpus CNERTA and Ai-SHELL for experiments. The CNERTA dataset includes five areas: finance, technology, sports, entertainment, and news. The Ai-SHELL dataset belongs to the social domain. The experiment uses the precision, recall, and F1-score as the evaluation metric, and the experimental results are shown in Table 6.
The CDP-MCNER model achieves the optimal F1-score of 81.05% and 79.23% on the two datasets, respectively. The audio parts of CNERTA and Ai-SHELL corpora are artificial recordings, and the sentence pause is more obvious, so the CDP-MCNER model has a great improvement over other models. The experimental results indicate that the CDP-MCNER model performs well on AgMNER datasets and has certain applicability in other fields.
Ablation study
To demonstrate the effectiveness of data augmentation methods in the text modality and the impact of the CTC project layer on the overall model, this study conducted ablation experiments on the AgMNER dataset. For ease of comparison, this study referred to the model without data augmentation methods as Model-I and the model without the CTC project layer as Model-II. The experimental results are shown in Table 7.
Compared to the complete model CDP-MCNER in this study, the F1 scores of the two models decreased by 0.56% and 0.79%, respectively. The experimental results indicate that the adoption of data augmentation methods and the introduction of the CTC project layer help to improve the performance of the models in NER-CDP tasks. The former method enhanced the models’ generalization ability and robustness, while the latter integrated the acoustic modality with the text modality to enhance Chinese word segmentation. Specific details are explained in the following text.
The effect of data augmentation
The percentage of data augmentation samples in this paper was set to 10%. The results in Table 8 indicate that the introduction of perturbations to text, incorporation of noise, the transformation of amplitude and speed of sound in audio, as well as enhancement of the frequency domain can significantly augment the model’s generalization capacity and improve its robustness. This section compares the parameters of these data augmentation methods to validate their efficacy. In the textual encoder, epsilon was a parameter that generated adversarial samples and was used for adversarial training of named entity recognition tasks. We set epsilon with 0.02 as the starting point and gradually increased its value. The result in Fig. 3 demonstrates that the F1-score attains optimal performance when the epsilon value is 0.03. The zoom factor represents the level of introduced white noise. 0.02 is the most suitable parameter for introducing white noise level, and it also achieves the optimal F1-score as depicted in Fig. 4.

The result corresponding to the change of epsilon.

The result corresponding to the change of zoom factor.
In this study, the pitch and speed of sound were changed by rolling around a certain range of the frequency axis. The effectiveness of different ranges is evaluated by implementing a 5% increment. As illustrated in Fig. 5, the F1-scores of 5%, 15%, and 20% exhibit respective decreases of 1.07%, 1.25%, and 2.14% compared to the F1-score of 10%. In this experiment, we also explored other audio data augmentation methods, including data mixing and language modeling. However, these methods complicated the model framework excessively which required much more computing resources, resulting in a decrease in efficiency. The data augmentation methods proposed in this paper effectively solve the domain adaptation problem in the model.

The result of pitch and sound speed changes in various ranges.
The effect of the CTC project
The case of aligning text using Masked CTC Loss is shown in Fig. 6. It uses partial audio of "八月是秋冬菜的播种和育苗季节 (August is the sowing and seedling season of autumn and winter vegetables)" as an example. Figure 7 displays the relationship between timestamps (x-axis) and probability values of the character dictionary (y-axis). At each point in time, a character from the dictionary or a “Blank” is generated. The result at a specific point in time is represented by a one-dimensional matrix with a length equal to the size of the character dictionary. Each element in the matrix represents the probability of a specific Chinese character or a Blank, and the sum of all probabilities is always 1. By referring to the probability trends in Fig. 7 and the probability distribution in Fig. 7, the output example of "-、秋 (autumn)、冬 (winter)、菜 (vegetables)、菜 (vegetables)、-、-"can be obtained. After removing duplicate characters and symbols, the final result of "秋冬菜 (autumn and winter vegetables)" is gained. This CTC alignment method significantly improves the accuracy of multimodal named entity recognition models.

A CTC alignment sample.

The output probability of each character dictionary.
Case study and error analysis
To validate the effect of using speech information for enhancing Chinese word segmentation and improving the accuracy of named entity recognition, this paper provides some examples of our model and the comparative models in Table 8. It was apparent that the BERT-BiLSTM-CRF model incorrectly classified the organization entity "江苏省激素研究所 (Jiangsu Hormone Research Institute)" as both the location entity "江苏省 (Jiangsu province)" and the organization entity "激素研究所 (Hormone Research Institute)". CDP-MCNER regarded the whole as an entity for entity recognition. Similarly, the crop entity "秋冬菜 (autumn and winter vegetables)" was incorrectly recognized as "冬菜 (winter vegetables)". These errors might occur due to the higher frequency of the entity "江苏省 (Jiangsu province)" in the training set and the lack of clear boundaries for the entity "秋冬菜 (autumn and winter vegetables)". Our researchers carefully listened to the corresponding audio clips and found that there was no obvious pause in the audio clips of "江苏省激素研究所 (Jiangsu Hormone Research Institute)" and "秋冬菜 (autumn and winter vegetables)". However, as for the recognition error of a long entity"二芳甲酰基肼类昆虫生长调节剂 (Diaryl formyl hydrazine insect growth regulators)", we listened to the corresponding audio and found that the announcer voluntarily paused between "二芳甲酰基肼类 (Diaryl formyl hydrazides)" and "昆虫生长调节剂 (insect growth regulator)". The results indicate that error recognition can easily occur without speech information auxiliary word segmentation and CTC project alignment. Furthermore, the incorporation of acoustic modality enables the alignment of speech with text, thereby facilitating accurate word boundary identification and enhancing recognition efficacy.
Conclusions
This paper utilized speech information to assist Chinese word segmentation and created AgMNER, the first large-scale Chinese multimodal dataset for crop diseases and pests, comprising 10 categories. CDP-MCNER, a multimodal named entity recognition model for crop diseases and pests, was proposed. The model can interactively fuse textual and acoustic modality information in the cross-modal attention module and utilize data augmentation methods to enhance the sample features of text and speech. Finally, the Masked CTC Loss was employed to further align the refined representations obtained through interactive fusion for accurate prediction. The experimental results demonstrated that the multimodal named entity recognition model, which incorporated both text and speech, outperforms other text-only models and lexicon-enhanced models. Besides, the introduction of data augmentation methods enabled the model to gain a better ability of generalization and robustness, which provided a basis for further research and significance in other domains.
In future work, we will supplement the research on Chinese typology, especially at the syntactic, semantic and morphological levels,and extend the model to multiple language domains such as Korean, Japanese, and English to validate its generalizability more comprehensively. Additionally, we will supplement the dataset and establish a more lightweight model to build the agricultural multimodal knowledge graph to achieve modern smart agriculture.
Data availability
The dataset that support the findings of this study are available on request from the corresponding author upon reasonable request.
References
Guan, L., Zhang, J. & Geng, C. Diagnosis of fruit tree diseases and pests based on agricultural knowledge graph. J. Phys: Conf. Ser. 1865, 42052 (2021).
Jin Ning, Z. C. W. H. Classification technology of agricultural questions based on Bigru_Mulcnn. Trans. Chinese Soc. Agric. Mach., 2020:199–206.
Li, J., Sun, A., Han, J. & Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 34, 50–70 (2020).
Wu, S. et al. Construction of visual knowledge graph of crop diseases and pests based on deep learning. Trans. Chinese Soc. Agric. Eng. 36, 177–185 (2020).
Hao, X., Wang, L., Zhu, H. & Guo, X. Joint agricultural intent detection and slot filling based on enhanced heterogeneous attention mechanism. Comput. Electron. Agric. 207, 107756 (2023).
Zhang, J. et al. Chinese named entity recognition for apple diseases and pests based on character augmentation. Comput. Electron. Agric. 190, 106464 (2021).
Malarkodi, C. S., Lex, E. & Devi, S. L. Named entity recognition for the agricultural domain. Res. Comput. Sci. 117, 121–132 (2016).
Zhang, W. et al. Research on the chinese named-entity–relation-extraction method for crop diseases based on bert. Agronomy. 12, 2130 (2022).
Li, L. et al. Named entity recognition of diseases and insect pests based on multi source information fusion. Trans. Chinese Soc. Agric. Mach. 52, 253–263 (2021).
Guo, X. et al. Chinese agricultural diseases and pests named entity recognition with multi-scale local context features and self-attention mechanism. Comput. Electron. Agric. 179, 105830 (2020).
Zhao, P., Wang, W., Liu, H. & Han, M. Recognition of the agricultural named entities with multifeature fusion based on Albert. IEEE Access. 10, 98936–98943 (2022).
Zhao, P., Zhao, C., Wu, H. & Wang, W. Recognition of the agricultural named entities with multi-feature fusion based on bert. Trans. Chinese Soc. Agric. Eng. 38, 112–118 (2022).
Zhang, H. et al. Mintrec: A new dataset for multimodal intent recognition. Proceedings of the 30th ACM International Conference on Multimedia, 2022:1688–1697.
Ren, Y. et al. Owner name entity recognition in websites based on multiscale features and multimodal co-attention. Expert Syst. Appl. 224, 120014 (2023).
Wu, S., Song, X. & FENG, Z. Mect: Multi-metadata embedding based cross-transformer for chinese named entity recognition. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers): Association for Computational Linguistics, 2021:1529–1539.
Meng, Y. et al. Glyce: Glyph-Vectors for Chinese Character Representations. Adv. Neural Inform. Process. Syst. 32, (2019).
Guo, X. et al. Cg-aner: Enhanced contextual embeddings and glyph features-based agricultural named entity recognition. Comput. Electron. Agric. 194, 106776 (2022).
Zhang, B., Cai, J., Zhang, H. & Shang, J. Visphone: Chinese named entity recognition model enhanced by visual and phonetic features. Inf. Process. Manage. 60, 103314 (2023).
Huang, Z., Xu, W. & Yu, K. Bidirectional Lstm-Crf Models for Sequence Tagging. arXiv preprint, 2015.
Tiwari, V. Mfcc and its applications in speaker recognition. Int. J. Emerging Technol. 1, 19–22 (2010).
Kwok, H. K. & Jones, D. L. Improved instantaneous frequency estimation using an adaptive short-time fourier transform. IEEE Trans. Signal Process. 48, 2964–2972 (2000).
Ravindran, S., Demirogulu, C. & Anderson, D. V. speech recognition using filter-bank features. The Thrity-Seventh Asilomar Conference on Signals, Systems \& Computers. Pacific Grove, CA, USA: IEEE, 2003:1900–1903.
Dong, L., Xu, S. & Xu, B. Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Calgary, AB, Canada: IEEE, 2018:5884-5888
Vaswani, A. et al. Attention is all you need. Adv. Neural Inform. Process. Syst. 30, (2017).
Bebis, G. & Georgiopoulos, M. Feed-forward neural networks. Ieee. Potentials. 13, 27–31 (1994).
Graves, A., Fernández, S., Gomez, F. & Schmidhuber, J. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. Proceedings of the 23rd International Conference on Machine Learning: ACM, 2006:369–376.
Higuchi, Y., Watanabe, S., Chen, N., Ogawa, T. & Kobayashi, T. Mask Ctc: non-autoregressive end-to-end asr with ctc and mask predict. Arxiv Preprint 2005.08700. (2020).
Chen, B. et al. Aishell-Ner: Named entity recognition from chinese speech. In ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing: IEEE, 2022:8352–8356.
Llugsi, R. E. Y. S. Comparison between adam, adamax and adamw optimizers to implement a weather forecast based on neural networks for the andean city of Quito. IEEE Fifth Ecuador Technical Chapters Meeting: IEEE 2021, 1–6 (2021).
Devlin, J., Chang, M., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. Arxiv Preprint arXiv:1810.04805v2 (2018).
Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. & Dyer, C. Neural architectures for named entity recognition. Arxiv Preprint arXiv:1603.01360v3. (2016).
Ma, X. & Hovy, E. End-to-end sequence labeling via bi-directional Lstm-Cnns-Crf. Arxiv Preprint SOPASVW60032943 (2016).
Zhang, Y. & Yang, J. Chinese ner using lattice Lstm. Arxiv Preprint arXiv:1805.02023v4 (2018).
Zhou, Y., Zheng, X. & Huang, X. Chinese named entity recognition augmented with lexicon memory. Arxiv Preprint arXiv:1912.08282v2. (2019).
Tsai, Y. H. et al. Multimodal transformer for unaligned multimodal language sequences. Proceedings of the Conference. Association for Computational Linguistics. Meeting: NIH Public Access, 2019:6558.
Yu, J., Jiang, J., Yang, L. & Xia, R. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, 2020:3342–3352.
Acknowledgements
This work was supported by the Natural Science Foundation of Shandong Province (grant ZR2022MG070) and the Youth Natural Science Foundation of Shandong Province (grant ZR2023QF016). Thanks to the anonymous reviewers for their insightful comments. We also thank all the help of the teachers and students.
Author information
Authors and Affiliations
Contributions
R.L.: Conceptualization, Software, Data curation, Validation, Writing-original draft. X.G.: Data curation, Visualization. H.Z.: Validation, Software. L.W.: Methodology, Writing—Review & Editing, Supervision.All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Consent for publication
I have read and understood the publication policy, and submit the manuscript in accordance with this policy.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, R., Guo, X., Zhu, H. et al. A text-speech multimodal Chinese named entity recognition model for crop diseases and pests. Sci Rep 15, 5429 (2025). https://doi.org/10.1038/s41598-025-88874-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-88874-9
