
Abstract
The fast growth of the Internet of Everything (IoE) has resulted in an exponential rise in network data, increasing the demand for distributed computing. Data collection and management with job scheduling using wireless sensor networks are considered essential requirements of the IoE environment; however, security issues over data scheduling on the online platform and energy consumption must be addressed. The Secure Edge Enabled Multi-Task Scheduling (SEE-MTS) model has been suggested to properly allocate jobs across machines while considering the availability of relevant data and copies. The proposed approach leverages edge computing to enhance the efficiency of IoE applications, addressing the growing need to manage the huge data generated by IoE devices. The system ensures user protection through dynamic updates, multi-key search generation, data encryption, and verification of search result accuracy. A MTS mechanism is employed to optimize energy usage, which allocates energy slots for various data processing tasks. Energy requirements are assessed to allocate tasks and manage queues, preventing node overloading and minimizing system disruptions. Additionally, reinforcement learning techniques are applied to reduce the overall task completion time using minimal data. Efficiency and security have been improved due to reduced energy, delay, reaction, and processing times. Results indicate that the SEE-MTS model achieves energy utilization of 4 J, a delay of 2s, a reaction time of 4s, energy efficiency at 89%, and a security level of 96%. With computation time at 6s, SEE-MTS offers improved efficiency and security, reducing energy, delay, reaction, and processing times, although real-world implementation may be limited due to the number of devices and incoming data.
Similar content being viewed by others
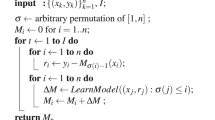
Introduction
The Internet of Things (IoT) refers to a rapidly expanding network of interconnected computing devices that individuals, businesses, and even authorities use1. Results from the widespread use of IoT technology across several industries2. IoE helps in data transmission with intelligent links between individuals, information, smart cities, medicine, agriculture, animals, garbage collection, and weather prediction3. Operations provided by the IoE must be monitored and managed by apps available on various devices4. An effective system for accurate timing, less delay and complexities, and decreased energy consumption in interaction is required to manage data among millions of objects. Improved dependability, service quality, and stability are all possible results of an effective system5. Like other services, IoE is characterized by a high volume of items, incidents, and inter-object interaction6. Communication technology developments have made Edge computing devices increasingly common7. These networked gadgets are the backbone of today’s intelligent services because of their ability to process and communicate information in actual time with an edge server8. Security risks may be associated with outsourcing data to the cloud, even though doing so can significantly ease the local computing and storage strain9. Data stored in the cloud provided by other parties may be subject to arbitrary access or intentional deletion10.
The IoE with technology aims to maximize energy efficiency, reduce service delivery costs, and improve service information accuracy4. The service availability and dependability in actual service contexts are considered with limited resources11. During the transmission process and task scheduling in IoE, the essential factor that needs to be considered is security aspects. After transmitting data, the node enters a sleep mode to prolong the network’s lifespan12. The edge device collects the data, and sensing and aggregation are spread across devices according to their power consumption13. To maximize efficiency, task scheduling is included in the energy harvesting procedure. Planning needs assessment and resource conflicts are all part of the task scheduling procedure.
Motivation
Data transmission and handling by task scheduling is the primary concern for energy usage in wireless networks. Security aspects are essential during task scheduling and data transmission among all edge devices. The edge node availability and energy factor are not considered during the scheduling process. When encrypting data, security and confidentiality are prioritized over practicality14. The capacity of authorized individuals to recover material of interest based on preset keywords generated interest in encryption technologies15. In actual practice, the cloud server is inclined to be only partially respected16. It may eliminate infrequently obtained data to save money, conduct honest but incomplete inquiries, return some incorrect search results, etc.
Problem statement
The SEE-MTS Model for IoE applications is proposed to efficiently schedule tasks from numerous IoE devices across a network of edge devices. Its objectives include optimizing task allocation, minimizing completion time, reducing energy consumption, and maintaining robust security standards. To achieve these goals, tasks must be allocated to edge devices based on their processing capabilities, energy profiles, data volume requirements, priorities, and security levels17. By ensuring an efficient system with minimal interruptions, the model significantly reduces task completion time and ensures that all tasks are handled promptly. In IoE systems, where devices often have limited power capacity, reducing energy usage is crucial for conserving resources. To keep data secure while unaltered security standards include computational overhead; this overhead may be modelled to keep tasks within the appropriate protection levels without burdening the system. Dynamic and adaptive scheduling can effectively manage key factors like efficiency, energy conservation, and security by balancing these goals optimally. The operational capabilities and resilience of IoE systems are enhanced by this technique, which generates a robust and balanced model.
Managing task scheduling and resource allocation effectively is the main problem in IoE environments. These environments must process varied activities across edge nodes with different computing capacities and network limitations. Timely completion of each work is essential, as are other performance metrics like minimal latency and energy economy. While ensuring that resources are used evenly and there are no bottlenecks, the total completion time (makespan) should be minimized. The unexpected workloads, varied devices, and variable network conditions that characterize IoE systems make this difficult. The suggested SEE-MTS model optimizes the real-time scheduling process using reinforcement learning (RL) to overcome this. To make smart decisions about the processing (offloading) of tasks and allocating resources, RL examines the system’s present status, including task arrival times, node workloads, and available resources. The scheduling technique is designed to adjust in real-time, ensuring that nodes are not overloaded, data transmission delays are minimized, and overall system performance is optimized. The formulation shows that achieving optimum performance in complicated IoE environments requires dynamic adaptation, effective resource allocation, and task scheduling.
The total processing time for all tasks should be measured and dynamically scheduled across devices to enhance performance. However, implementing security measures such as encryption and verification increases processing time and energy consumption for each task. This introduces an optimization challenge: achieving a balance between task completion time, energy efficiency, and security overhead within the SEE-MTS model. By utilizing real-time task scheduling and adaptive RL, the proposed approach aims to minimize a cost function that effectively balances energy consumption, processing time, and security overhead, particularly in IoE environments.
Major contributions
The secure edge-enabled task scheduling model protects the data by providing dynamic updates regarding searches and verification of results. The contributions of the proposed method are:
-
The article introduces the SEE-MTS model, a RL-based framework tailored for IoE applications, optimizing dynamic task scheduling and resource allocation to minimize makespan and enhance load balancing.
-
It overcomes the exploration-exploitation trade-off in traditional RL by incorporating adaptive offloading and resource allocation strategies, ensuring efficient decision-making in heterogeneous and dynamic edge environments.
-
The model demonstrates improved system performance, including reduced energy consumption, lower task completion times, and higher task success rates, outperforming existing approaches in real-world IoE scenarios.
-
The model incorporates multi-key generation, encryption, and accuracy checking to enable secure data processing and prevent IoE systems from illegal access and attacks. It optimally allocates work among edge devices using reinforcement learning, improving system responsiveness and decreasing task completion times.
-
The model effectively distributes and operates among edge devices using RL, improving system responsiveness and decreasing task completion time.
-
With its ability to adapt to changing network conditions, the SEE-MTS architecture ensures consistent and secure data processing with minimum latency. This makes it an ideal option for large-scale IoT applications.
An integral part of the proposed architecture is the incorporation of security measures effectively. Unlike similar approaches, the proposed method guarantees secure data management by combining powerful encryption techniques, dynamic updates, and multi-key search generation. While prior studies have mostly ignored problems like dynamic data updates and multi-dimensional query processing, these elements strengthen the system and make data more private. This paradigm will be more appropriate in real-world IoE settings, where security is critical. Second, this study brings new to the table by improving the scheduling of edge devices using RL. RL learning enables the model to adapt to changing network circumstances by learning from its interactions with the environment. The outcomes are improved system responsiveness, lower task failure rates, and efficient resource use. In complicated IoE configurations, our RL-based method achieves better task scheduling efficiency than conventional scheduling algorithms by finding the sweet spot between exploration and exploitation. Third, This study addresses energy efficiency, a crucial limitation in IoE systems, in our model. Our method helps to keep edge devices from losing energy and reduces the likelihood of device failure from running out of power by implementing a system to assign energy slots and dynamically reduce node overloading. Our approach stands out from previous models that fail to provide enough weight to energy optimization because of our energy-aware scheduling, designed to be used in IoE contexts where energy limitations are very important. Latency reduction is an important aspect of IoE applications that need real-time answers, and the suggested approach does a great task at it. This methodology minimizes processing delays, optimizes data transfer, and reduces response times to guarantee jobs are finished within tight deadlines. This capability is a lifesaver regarding time-sensitive IoE applications. Considering healthcare monitoring, industrial automation, or smart city management, any delay might have disastrous results. Furthermore, the SEE-MTS architecture stands out due to its scalability. By its adaptability, the framework can easily manage small-scale and large-scale IoT installations. Its flexibility makes it a suitable choice for a wide range of IoE settings, as it keeps the model realistic and efficient regardless of the size of the network or the changes in application needs.
The rest of the manuscript is organized as follows: Section 2 presents the background study on resource allocation, job scheduling, and energy consumption. Section 3 provides a complete description of the SEE-MTS model, which allocates tasks effectively among machines based on the availability of necessary data and its copies. Section 4 evaluates the proposed method, and Sect. 5 offers the conclusion and discusses future possibilities.
Related works
The IoE’s rapid development has increased the need for effective resource management and distributed computing in various network conditions. In the IoE and related domains like edge and cloud computing, controlling job scheduling, resource allocation, and energy efficiency while maintaining security has become important due to the drastic increase in the data volume. Recent advancements in these fields, such as resource management plans, energy-efficient methods, security solutions, and optimized scheduling models, are reviewed in this related works section. It also emphasizes how artificial intelligence and machine learning are increasingly used to improve distributed IoE systems’ performance, dependability, and real-time decision-making.
Distributed computing and task scheduling in IoE
Developing IoE in networked data speeds up the requirement for distributed Computing. Cloud devices have the potential for easy data sharing and distribution, but this comes with specific security and energy usage considerations. Different scholars have conducted research; Zhao Tong et al.18 improved scheduling efficiency by developing a deep Q-network (DQN)-based offloading algorithm with principal component analysis weighting method (D2OP) architecture for data processing that operates within the context of the massive data movement of the IoE. The effectiveness of the D2OP is tested in several ways utilizing time reduction, load balancing, and task success ratio improvement; testing findings show that it outperforms three similar algorithms.
Hamdi Kchaou et al. suggested task scheduling and data location techniques for transferring the data among cloud data centres19. To decrease data transfer throughout the process performance, their proposed solution employs an approach focused on Intermission’s fuzzy clustering process and the meta-heuristic optimization methodology Particle Swarm Optimization (PSO). The suggested method is tested via simulation with many popular scientific techniques of varying sizes.
Prasanta Kumar Bal and others proposed a small scheduler for arranging tasks based on an enhanced version of the cat swarm optimization technique, which reduces make-span time and increases throughput20. The outcomes are evaluated regarding resource usage, energy usage, response time, etc. Neetu Sharma et al. addressed the challenge of a neural network-based modification to the Ant Colony Optimization approach to optimal global exploration21. According to the findings of the tests, Ant Colony Optimization is the most efficient algorithm for optimizing the objective variable. It provides improved plans with increased statistics, mean availability times, and more regular task allocations instead of other methods.
Xiaokang Zhou et al. proposed a deep-reinforcement-learning-enhanced two-stage scheduling (DRL-TSS) model for distributing calculating capitals within an edge-enabled arrangement to pledge calculating task achievement at the lowest cost, which is an NP-hard difficult concerning procedure difficulty in end-edge-cloud IoEs23. The results show that their proposed algorithm could improve learning efficiency and scheduling performance by a factor of 1.1 relative to the optimal IoE applications for which it was designed.
Resource management and 0ptimization in cloud and edge computing
Sahar Badri et al. provided a unique approach for efficient work scheduling in the cloud, with increased Security21. For scheduling the jobs, they offered a novel technique called convolutional neural network optimized modified butterfly optimization (CNN-MBO), which aims to maximize throughput while decreasing makespan. Xiuhong Li et al. proposed A Dynamic task scheduling method based on a UNified resource Management architecture to solve the issues of insufficient resource consumption, reservation, and task finishing through dynamic scheduling methods22. Our approach achieved an almost perfect task execution performance for scheduling, which indicates the algorithm can complete scheduling jobs quickly and at high task earnings, enhancing the overall system’s productivity and profitability.
N. R. Rajalakshmi et al. suggested cloud computing to schedule data-parallel tasks24. The number of parallel implementations might be expanded proportionally by performing concurrent performances of jobs on multi-core cloud assets, making it feasible to complete the work by the deadline. A mathematical model is constructed to efficiently distribute workloads among a cloud data centre with many virtual machines to reduce operating expenses associated with data-parallel operations.
Zubair Sharif et al. introduced a robust resource allocation and job scheduling approach in mobile edge computing that considers emergencies under a health monitoring system25. A priority-based task-scheduling and resource-allocation (PTS-RA) system has been proposed to provide distinct jobs with varied ranges of importance depending on the urgency determined by the data collected from the individual’s smart wearable devices. The goal is to minimize the time required to complete a job and the amount of data sent. The proposed strategy would prioritize and run urgent emergency-related activities first.
Rongli Chen et al. suggested that the methodology offers novel remedies for the issue of energy-consumption tracking in cloud computing data centres by taking into account the varied features of data centres26. The primary responsibility is to break each task into smaller parts and allocate those tasks to individual virtual machines. Furthermore, work reduction efficiently decreases both energy usage and the rate of job waste.
Energy consumption and data management techniques
Data sharing and job scheduling are the most critical challenges in the fuzzy clustering method. The data shuffling stage is a little tedious for managing and handling data. The handling of data in IoE with the task scheduling stages is more complicated in the form of energy consumption storage capacity of data. More data is stored in the devices, and the task allocation for all such data is complicated in IoE. The shuffling step must consider the data variations with necessary computing activities. The energy consumption is more for the task scheduling stages. Task allocation requires more time to determine the mean availability. Implementing the secure edge-enabled task scheduling model considers the problems mentioned above. The cache replacement algorithm used by Tong et al. (2023) offers a data shuffling stage as an alternative technique for managing data. They propose a Resilient Distributed Dataset-based partition-weighted adaptive cache substitution technique that efficiently eliminates resource waste using available storage18. In this study, the data management concepts related to delay and throughput must be concentrated.
Similarly, several other algorithms/ methods, such as the Fuzzy clustering method, which minimized the data movement18, the Cat swarm optimization algorithm, which reduces energy utilization20, Ant colony-based optimization algorithm20, Modified butterfly optimization algorithm21 and Dynamic scheduling algorithm22 were used in the literature. Due to the IoT’s fast production, many industrial IoT deployments confront substantial challenges, such as latency, network capacity, reliability, and Security. Edge computing and other distributed IT systems are increasingly essential for addressing these issues.
Security and reliability in industrial IoT and edge computing
The authors25 used AI-based data analytics to integrate microfinance and auto insurance. Three significant categories of policyholder might have their claim frequency and severity reduced and their premium payments promoted to rise by adopting and using a no-claims bonus rate system that includes base rates, variable rates, and final rates. The eight machine learning algorithms have improved frequency-severity models and updated the Automated Actuarial Pricing and Underwriting System for inflation, leading to outstanding outcomes.
The authors of36 aimed to assist researchers in choosing the best-secured workflow allocation (SWA) methods. The present state-of-the-art methodologies of the SWA models in cloud computing environments have been thoroughly evaluated to achieve this. The paper continues to detail the security overhead model and the goals and limitations of the quality of service and presents a taxonomy of difficulties with protected workflow allocation. Lastly, drawing on the study’s literature analysis, it identifies and addresses the current outstanding concerns, difficulties, and directions for future research in the SWA model.
The Security-Driven Energy-Efficient Workflow Allocation Algorithm (SEWA), suggested by the author in37, is an innovative approach to these problems, considering energy efficiency and security to meet the task’s time and precedence requirements. The SEWA algorithm automatically assigns workflow tasks to cloud resources to fulfil deadlines, minimize energy consumption, and fulfil security requirements. According to experimental assessments, the SEWA algorithm achieved substantial energy savings, improved security, and maintained workflow deadlines.
Guneet Kaur Walia et al.38 suggested AI-empowered Fog/Edge Resource Management for IoT Applications. This article provides an in-depth analysis of the problems and concerns with the Fog/Edge paradigm’s resource management, classifying them as follows: service placement, load balancing, job offloading, resource scheduling, and provisioning of computing resources. Furthermore, current state-of-the-art solutions based on AI and non-AI have been covered, including their quality-of-service measures, datasets examined, constraints, and difficulties. A quantitative formulation in the survey accompanies each of the many resource management issues. To enhance business intelligence and analytics in IoT-based applications, the work reveals potential future research directions in state-of-the-art technologies like Serverless computing, 5G, Industrial IoT (IIoT), blockchain, digital twins, quantum computing, and Software-Defined Networking (SDN). These can be combined with current fog/edge-of-things paradigm frameworks.
Mohit Kumar et al.39 proposed the Deadline-aware Cost and Energy Efficient Offloading in Mobile Edge Computing (MEC). This study suggests an MEC design for network resource allocation to maximize QoS. With this in mind, we may express the resource allocation issue as a bi-objective optimization problem, where we want to minimize energy and cost while simultaneously considering quality and schedule restrictions. The suggested MEC design incorporates a GA-PSO, a hybrid cascading-based meta-heuristic, to accomplish these goals. Lastly, its effectiveness is shown by comparing it with three current methodologies. The testing findings show that the energy and cost are much better; therefore, it is both practical and effective.
For IIoT in collaborative cloud-fog environments, Mohit Kumar et al.40 suggested an AI-based Intelligent Offloading Framework that is both sustainable and environmentally friendly. Furthermore, a system that claims to find the optimal resources and make correct judgments to improve different Quality-of-Service (QoS) metrics has an AI-based Whale Optimization Algorithm (WOA) integrated into it. Compared to benchmark offloading and allocation systems, the experimental findings reveal a significant increase of 37.17% in makespan time, 27.32% in energy consumption, and 13.36% in execution cost.
Mohit Kumar et al.41 discussed the Autonomic Workload Prediction and Resource Allocation Framework for Fog-Enabled Industrial IoT. In the analysis phase of the suggested framework, the deep autoencoder (DAE) model is used to forecast workloads, and the Fog Nodes (FNs) are scaled according to the needs of Industrial IoT workloads. The framework for optimum FN selection incorporates the crow search algorithm (CSA) to achieve better cost and delay goals. Execution cost, request rejection ratio, throughput, and response time are the metrics used to assess and compare the suggested scheme to the current optimization models. The simulations’ findings showed that the suggested strategy performed better than the other optimization methods. The technique offered a good option for appropriate FN placement in effectively running dynamic industrial IoT applications.
Table 1 shows the summary of the literature.
In summary, recent research shows a variety of innovative methods to improve IoE systems through effective resource allocation, job scheduling, and security protocols in distributed cloud and edge computing. Neural network-enhanced Ant Colony Optimisation, fuzzy clustering with PSO, and D2OP are advanced scheduling algorithms showing increased task success rates and scheduling efficiency. Additionally, resource management techniques, including deep RL and priority-based scheduling, optimize the allocation of resources, especially in edge computing. Energy efficiency remains a key focus, with approaches like adaptive caching and energy-slot scheduling to manage resource consumption. Finally, integrating security protocols within IoT and edge setups addresses critical latency, reliability, and network capacity issues, ensuring secure and dependable IoE operations.
The security based edge enabled multi-task scheduling
Distributed IT architectures like edge computing are increasingly crucial in solving these problems. Edge computing can accumulate data from the devices to improve typical data management and task scheduling with security measurement and energy usage in IoE technologies. SEE-MTS allocates the task effectively among the machines depending on the availability of data and their copies27. The security aspects are based on the dynamic updates, multi-keyword searches and the verification of search results. The MTS model implements energy conservation by providing data in the energy slots. The RL mechanism exploits the overall makespan with maximum utilization.
The recommended SEE-MTS Model for IoE applications uses multi-layered security to secure task allocation and protect data and task processing. The model’s fundamental security concept is multi-key generation encryption, which assigns a unique encryption key to each action based on its security requirements. Due to encryption, only authorized entities can access task data, ensuring data integrity. Accuracy verification ensures task processing precision and job allocation reliability. The security of each SEE-MTS employment depends on its data sensitivity and relevance. Extra validation checks and encryption protect control instructions and personal data. Non-critical tasks like data monitoring have lower security to preserve computing power and simplify encryption.
Security mechanisms in distributed computing systems typically increase processing time due to encryption, key management, and data verification. RL offers a better solution by optimizing task allocation and balancing security with computational efficiency. This approach minimizes performance overhead while maintaining robust data protection in large-scale IoE applications, preventing unauthorized access without significantly compromising system performance.

The framework of the SEE-MTS model.
The edge devices are considered sensor devices, and the data collected from the devices are allocated for each task. The allocation of functions is followed by task scheduling. The end layer of the devices has a camera and key generation where the security level is maintained. Sensors and other final devices (like cameras) comprise the end layer. The security aspects are maintained by installing cameras in the edge layer. Multiple edge nodes contain the edge layer and perform tasks including storing information, filtering it, performing basic analytics, and communicating with other devices. The framework of the SEE-MTS model is shown in Fig. 1. The SEE model looks after the dynamic updates, multi-keyword searches, and verification of search results. The MTS model allows data handling and queuing. The depreciation of the makespan is obtained from the RL mechanism28.
This framework combines two fundamental models, the SEE and MTS models, to handle high-demand processing tasks and changing system needs. The procedure starts with the edge devices, which gather information and create tasks before sending them to the task allocation component. To centralize processing, this module delegated responsibilities to the data Centre. The SEE model handles two critical operations at the data centre level. Dynamic Updates, which allow for real-time adaptation to changes in data or systems, are the first thing it assures. Secondly, it makes it easier to do Multi-Keyword Searches, which makes data retrieval much more efficient. At last, the system verifies the search results to ensure they are accurate and relevant, ensuring trustworthiness and safety when data is sent. The MTS model expands upon this idea to undertake the challenges of managing several jobs simultaneously. Multi-task data handling handles incoming tasks simultaneously after the data allocation step to ensure resources are distributed properly to maximize system performance. A queuing system is used to prioritize tasks and prevent processing delays. Incorporating RL into the SEE-MTS architecture allows the system to learn and adapt using past performance indicators, greatly enhancing performance. Task allocation and resource usage are guaranteed to be continuously improved in this way. One important result of this integration is the minimization of Makespan, which improves operational efficiency by lowering the time necessary to accomplish all scheduled tasks. When data security and system responsiveness are of the utmost importance in real-time applications like IoT systems, cloud computing, and smart environments, the SEE-MTS framework provides a strong solution by integrating safe data handling, dynamic flexibility, and efficient multi-task scheduling.
Task allocation among the computers
In task allocation, the system of interest is a heterogeneous machine that performs in two phases: phase 1 involves the data analysis, and phase 2 involves the task scheduling stage. The machine’s features are described with symbols. The pair of machines is given as \(\:A=\left({a}_{x}\right)\) with the x number of machines \(\:a\). The available storage space of the machine \(\:{a}_{x}\)is represented by the integer \(\:{ss}_{x}\).\(\:{rr}_{x}\) is a floating-point number that stands for the machine’s \(\:{a}_{x}\) reading rate. The \(\:{a}_{x}\)machine’s writing speed \(\:{wr}_{x}\) with the floating-point number to determine the storage capacity. The Machine memory \(\:M\left({a}_{x}\right)\)is given with the integer number as a finite resource. The total amount of units in the machine \(\:{a}_{x}\)is denoted \(\:{Tm}_{x}\). The integer number \(\:{im}_{x}\) reflect the efficiency of the machine with the unit time. The data transfer rate connecting machines \(\:{a}_{x}\) and \(\:{a}_{y}\) with the values are given as \(\:{r}_{xy}\). The storage capacity of each machine obtains the availability of data and copies. The available storage of each machine is represented as \(\:{a}_{x}\). The data transmission and the computational capacity are measured by the time spent by each machine and the storage capacity of the machine29.
\(\:{\alpha\:}_{xy}\) is the duration it takes for data to travel from the machine \(\:{a}_{x}\) to machine \(\:{a}_{y}\), with \(\:x\:and\:y\) stages. The computational capacity of a device \(\:{a}_{x}\) is denoted by the integer number \(\:CC\left({a}_{x}\right)\). The data transmission and the computational complexity are obtained from Eq. (1). The total quantity of time spent by the machine is obtained by measuring the computational complexity of the device
where m is a set of currently active projects. Multiple users contribute tasks to be carried out. The total number of units \(\:{Tm}_{x}\)with the integer values \(\:{im}_{x}\). \(\:x\),y represents the data travelling rate. All internet activities use servers to distribute information and resources. Non-preemptive task execution is used. \(\:{j}_{x}\)with the pair of tasks with the schedule \(\:J=\left({j}_{x}\right)\). The time required to complete the \(\:x\)-th task with the integer can be expressed as \(\:{r}_{x}\). The Task \(\:{j}_{x}\) has a memory requirement of the machine with an integer value. The machine with the \(\:{j}_{x}\)integer value indicates the number of tasks to be completed. The sum of all the information needed for each task with an integer value \(\:S{(j}_{x})\). Complete machine allocation \(\:{\beta\:}_{x}\) for task \(\:a{\beta\:}_{x}\)for completing the task scheduling \(\:{a}_{x}\). Duration of arrival\(\:{\varnothing\:}_{x}\) for fractional values of each task is maintained with \(\:{j}_{x}\). The machine usage ratio \(\:{VT}_{xy}\)indicates whether the machine \(\:{a}_{x}\) has enough capabilities to complete the job \(\:{j}_{x}\).
Weight distribution must be a primary factor in developing any task scheduling method to enhance throughput while minimizing reaction time and resource consumption. The demands placed on each server\(\:{s}_{x}\) are characterized by Eq. (2) as
The weight \(\:{n}_{x}\) is an overworked or underloaded proportion value for \(\:{q}_{x}\). The machine with the integer value \(\:S{(j}_{x})\) and the usage ratio \(\:{VT}_{xy}\) and the task arrival rate \(\:{\varnothing\:}_{x}\) is an essential feature in task scheduling. Different machines carry out data analysis and task scheduling. \(\:CC\left({n}_{x}\right)\) represent the different machines. \(\:{s}_{x}\) represent the demands placed on servers. \(\:{a}_{x}\:\)is the values like machine1, machine2, machine3 and machine with the machine memory \(\:M\left({a}_{x}\right)\). [31] After the data analysis stage, task scheduling is performed by different machines, as shown in Fig. 2.
The weight in \(\:{n}_{x}\) is planned by splitting the complete number of active tasks\(\:R\)by the available machine time \(\:CC\left({n}_{x}\right)\). There is a certain quantity of data available on the database. \(\:N=\left({m}_{x}\right)\)is the pair of data collected from datasets \(\:{m}_{x}\). The size of the x-th data collection is expressed as a numerical value. The vector \(\:\varnothing\:=\left({\varnothing\:}_{xy}\right)\) is the mapping from information to machines. The mapping from observations to tasks is represented by the vector \(\:G=\left({g}_{xy}\right)\). A few tasks may need access to several datasets, while others may share the same dataset; the vector is calculated and fixed accordingly, as shown in Eq. (3).

Data Analysis and Task Scheduling.
The vector calculation in the form of fixed and variable values is given as \(\:{\varnothing\:}_{xy},\:{g}_{xy}\).The weight \(\:{n}_{x}\) is obtained from the data collected from the dataset \(\:{m}_{x}\), the task scheduling \(\:{J}_{x}\) is performed with \(\:{n}_{x}\). Data sharing in a cloud-assisted IoE context is not achieved by the technique described, despite its accomplishments in public authentication, fair mediation, and adaptive updating. The complete task allocation is carried out through data collection and task scheduling. The security aspects of the SEE model are obtained by performing frequent updates, allowing for multiple keyword searches, and double-checking the correctness of search results. The SSE-MTS model is presented as a means by which IoT devices may exchange data without compromising their safety. The security aspects of the proposed method are discussed in the below section.
The Secure Edge enabled Model
Frequent updating for key generation
Key generation is crucial in IoE applications, as it creates cryptographic keys for encrypting sensitive data. The key length (like 128-bit or 256-bit) directly determines encryption strength, with longer keys providing exponentially better protection against brute-force attacks, ultimately safeguarding data from unauthorized access. Within the framework of the SEE-MTS model, efficient key generation helps improve data confidentiality and instil user confidence in the system. This is achieved by reducing the possibility of intrusions that might affect important tasks and the overall integrity of the IoE environment.
The security aspects are considered in the SEE model by frequent updating for key generation30. The security measurement is to overcome all types of attacks and threats during the data transfer and allocate tasks among all multi-task scheduling. Let \(\:H,\:{H}_{s}\) be two periodic associative units of degree \(\:q\), and \(\:{S}_{q}\:\)be the area with components modulo q. There are three distinguishing characteristics of the bilinear mapping \(\:r:H\times\:H\to\:{H}_{s}\). (i) linearity:\(\:\forall\:{g}_{1},{g}_{2}\in\:H,{x}^{*},{y}^{*}\in\:{H}_{s},\:\:r\left({g}_{1}^{x*},{j}_{2}^{{y}^{*}}\right)=r\left({g}_{1},{g}_{2}\right)\:{x}^{*},{b}^{*}\), (ii) calculate: \(\:\forall\:{g}_{1},{g}_{2}\in\:H\), an effective technique for producing result \(\:r\left({g}_{1},{g}_{2}\right)\), (iii) non-degeneracy: \(\:\ni\:{g}_{1},{g}_{2}\in\:H,\:r({g}_{1},{g}_{2})\ne\:1\). Let \(\:G,g\)represent two map-to-point encryption methods resilient to conflicts.\(\:\:G,g\:G:\left(\text{0,1}\right)\to\:H,g:\left(\text{0,1}\right)\to\:{S}_{q}\:\)and\(\:\widehat{\:(x},\widehat{y})\) be a numeric pair that also includes a and b. The key generation is implemented to provide more protection by giving dynamic updates, multi-keyword searches, and verification of search results for accuracy. \(\:{g}_{1},{g}_{2}\) represent the keyword searches
Let us assume \(\:qq=(r,\:{r}_{0},u,G,g)\) where r is the creator of \(\:{r}_{0}\), \(\:G\:\)represents two map-to-point encryption methods, \(\:g\) represents the conflict method. \(\:u\in\:R\) are the accessible variables. To generate the SEE model with the public secret key combination. The key combination is given as \(\:l=\{{l}_{1},\dots\:\dots\:.{l}_{b}\}\).
Multiple keyword searches
The key generation with the multi-keyword searches is implemented with the three conditions. The first condition \(\:{kg}_{b}\) to generate the public \(\:x\in\:{S}_{q}\) and secret key combination \(\:{r}^{x}\). The formula for the dynamic updates \(\:q{l}_{1}={r}_{1}^{x}\), \(\:r{l}_{1}=x\) respectively. The SEE model with the essential generation technique is shown in Fig. 3. The three conditions, linearity, calculation, and non-degeneracy, are provided with the key generation, dynamic updates, and verification of search results.

Key generation stages.
The second condition implements the key generation with dynamic updates. The second condition \(\:y\in\:{s}_{q}\). The private key specification\(\:\:{ql}_{v}=y\) is given as \(\:y\in\:{s}_{q}\), y represents the single key operation with the expression \(\:{s}_{q}.\)\(\:s(r,\:{r}_{o}{)}^{\frac{1}{y}}\) and the confidential key expression \(\:{r}^{y}{ql}_{v}=({ql}_{v,1},{ql}_{v,2})\). \(\:r,\:{r}_{o}\) represent the different key generations. \(\:{ql}_{v,1},{ql}_{v,2}\) represent the simultaneous key operations.
Effective encryption and data protection are attained throughout the key generation stages of a security-enabled algorithm. These stages include several crucial procedures. A secure cryptographic key is built upon a method that first chooses a random or pseudo-random sample. For example, the algorithm uses this initial value and complicated mathematical operations, prime number creation, modular arithmetic, or elliptic curve functions to create a unique private key. The precise processes depend on the encryption technique. Next, the private key generates a matching public key, allowing for secure data transmission. This procedure ensures that no one other than authorized individuals can read the encrypted data, which keeps the IoE networks confidential and secure.
The third condition carries out the key generation to verify search results for accuracy. The key generation \(\:t\) with the verification stage \(\:z\in\:{S}_{q}\), the public key \(\:{r}^{z}\), \(\:{ql}_{t}={r}^{z}\) and the secret key \(\:{tl}_{t}=t\), where r is the secret key \(\:{S}_{q}\) of the prime factorization. The public key and the secret key are represented as \(\:{ql}_{t},\:{tl}_{t}\).

The key generation process in Dynamic updates.
The different stages of dynamic updates with the public and secret key generation are shown in Fig. 4. The protection is enabled by utilizing the key generation with dynamic updates, multi-keyword searches, and verification of search results for accuracy. Dynamic updates, multi-keyword searches, and verification of search results achieve the three conditions of key generation in the SSE model32.
To keep data secure over IoE networks, a dynamic update system needs rapid and secure updates for the key generation process, which adjusts to constantly changing circumstances. An efficient method, such as elliptic curve cryptography or modular exponentiation, produces a one-of-a-kind base key often associated with certain device features or session environments.
The SSE model uses a security-enabled key generation algorithm illustrated in Table 2. The optimal key generation algorithm is implemented for data security options. Security enabling stages initialize the data. The Security of task scheduling and data processing is well protected by utilizing multiple keyword searches that use encryption and decryption. A security-enabled key generation algorithm obtains the key by utilizing multiple keyword searches. Multiple keyword searches improve security measurement in the proposed SEE-MTS model. The mathematical expression is explained in Sect. 3.2.2.
The key generation algorithm is executed with the input values of \(\:x\in\:{S}_{q},y\in\:{s}_{q},\:\:z\in\:{S}_{q}\), the output values of \(\:{s}_{q}\). Key generation is executed in three conditions, for \(\:r{l}_{1}=x\), the secret key combination is in the form of \(\:{r}^{x}\) is implemented for the dynamic updates \(\:q{l}_{1}={r}_{1}^{x}\). Plaintext, often known as cleartext, refers to the information that must be encrypted. Table 2 shows the security-enabled key generation algorithm.
To illustrate the method’s scalability concerning input size, one should compute the complexity of the steps \(\:\left(O\right(\text{log}\left({n}^{k}\right))\) involved in performing operations like modular exponentiation (where \(\:t\) is the key size and k is the number of iterations) while the process generates keys. Additionally, with varying degrees of security, it is possible to examine the space needs of the encryption and verification processes, particularly regarding memory usage.
-
Initialization: \(\:O\left(n\right)\) complexity (depends on input parameters).
-
Modular Exponentiation: \(\:O(\text{log}\left({n}^{k}\right))\) complexity due to repeated multiplications in cryptographic calculations.
-
Memory Allocation: \(\:O\left(\text{t}\right)\) space complexity for storing key bits.
-
Verification: \(\:O(\text{log}\left(t\right))\) for security checks and validations
Since key size and modular exponentiation are the primary determinants of computational difficulty for key generation, these factors affect memory utilization and system efficiency concerning growing security requirements. This research shows how the model can manage scalability, allocate resources efficiently, and secure data in massive IoE networks.
Encryption transforms plaintext into ciphertext using mathematical algorithms and a secret key. The encrypted data can be safely transmitted through unsecured channels. The recipient uses a decryption key to convert the ciphertext to its original form. The condition of cypher text gives the encryption state. \(\:({l}_{1}=q),\:({l}_{1}=r)\). The condition of plain text gives the decryption (\(\:{l}_{v}=y;\:{\:l}_{t}=t)\:\)and decr \(\:q{l}_{1}={r}_{1}^{x}.\)The condition gives the decryption state. \(\:{tl}_{t}=t.\) For the condition \(\:y\in\:{s}_{q}\), the critical specification is in the form of \(\:{ql}_{v}=y\) with the confidential key generation of \(\:{ql}_{v}=({ql}_{v,1},{ql}_{v,2})\). The third condition \(\:{tl}_{t}=t\), the secret key combination is given as the output \(\:{S}_{q}\). The key generation algorithm gives dynamic updates regarding the multi-keyword searches and verification of search results for accuracy. Encryption and encryption are used to maintain the Security of handling data transfer in multiple tasks. In IoE, the data transfer between the edge devices must be transferred securely. A security-enabled algorithm obtains the security aspects. Multiple searches and key generation randomly use energy consumption to use the energy efficiently. The MTS method for evaluating energy efficiency is discussed in the section below.
Multi-task Scheduling Model
Processing of data for maintaining energy efficiency
The MTS model implements energy efficiency by handling data for each task. The MTS model provides energy conservation for data handling in multiple tasks. The data collection and queuing are collected to avoid overloading of nodes and widespread disruption in the edge nodes33. The queue type way is used to handle receiving data from the edge devices in an energy-efficient manner. The planning process considers the real-time information gathered by an edge device. The queuing process manages the energy between different tasks and avoids the nodes’ overloading. The data handling employing the allocation of functions for edge devices is processed by queue type. The queue is prioritized depending on the arrival time, with the first batch of data handled immediately. Eq. (4) determines the energy management of the queued information.
The amount of energy conserved during data transmission \(\:r\) is obtained by solving Eq. (4). The jobs are scheduled by placing them in a queue from the least energy needed to complete the task. Scheduling the study is represented as \(\:{S}_{q}\), assignment of the task is denoted by \(\:{r}_{o}\), and execution times with different intervals are represented as \(\:{\beta\:}^{1},\:{\beta\:}^{0},\:\beta\:\). The criterion is utilized for task scheduling for the gained and the lost energy. Maximum and minimum power needed for the data transmission are represented by \(\:{g}_{energy},\:{S}_{energy}\). The energy is allotted according to peak and off-peak times, and then either busy or idle edge nodes are selected for data transmission.
The edge devices that do not contribute to data transmission are ideal. At first, they verify the state of the edge nodes to determine if the data can be sent. Edge nodes’ activity and sleep levels are estimated from Eq. (5).
If the information \(\:{r}_{q}^{0}\) is delivered to the node \(\:{\beta\:}^{0}\) and a particular operation records the allotted time\(\:\:{S}_{t}\), then \(\:{b}_{1}\) is denoted as an edge node. At the initial stage \(\:{\beta\:}^{1}\), these files are sent within the allotted time \(\:{q}_{1}\). The initial node is represented as \(\:\beta\:\).
If the data transit is not equal to zero, as shown in the expression \(\:\bigcup\:_{{q}_{0}}^{\beta\:}({S}_{\beta\:}\to\:{b}_{0}+({\beta\:}^{1}-{\beta\:}^{0}).\:\)\(\:{b}_{0}\) represent the different edge nodes. \(\:{\beta\:}^{1}\) represent the initial stage and \(\:{\beta\:}^{0}\) represent the end stage of the node. The level of communication has terminated on a different story. The data are sent to the system using a scheduling procedure. The edge node’s active and sleep states are obtained with the help of Eq. (6)
The practical stage of the node is represented as \(\:{q}_{0}\), and it is generated in two situations: in the first state, \(\:{r}_{0}/\sqrt{\raisebox{1ex}{${r}_{q}^{0}$}\!\left/\:\!\raisebox{-1ex}{${S}_{\beta\:}$}\right.}\)the transmitted information\(\:{\:S}_{q}\) are detected at \(\:{d}_{u}\) and passed to the first edge node\(\:\:{j}_{m}\) and near-edge node in the initial state \(\:g\left({S}_{q}\right)\). A resting state \(\:{b}_{0}/\sqrt{\raisebox{1ex}{${r}_{q}^{0}$}\!\left/\:\!\raisebox{-1ex}{${S}_{\beta\:}$}\right.}\) exists if there is no detection of data flow. \(\:{r}_{0}\) represent the first situations, \(\:{b}_{0}\) represent the second situation. \(\:{q}_{0}\) is represented as several edges. \(\:{r}_{q}^{0}\) represent the practical stages. \(\:{S}_{\beta\:}\) represent the transmission process. The following condition is obtained from Eq. (7)
The initial stage condition \(\:\sum\:_{{r}_{0}=0}^{{g}_{0}\left(r\right)}{S}_{q}\to\:{J}_{m}\left({q}_{0}\right)\to\:{r}_{0}>q\) is initiated when a node is too demanding with other tasks \(\:{r}_{0}\) to verify a transfer, the records are directed to the next-door edge node \(\:{J}_{m}\) for verification, \(\:{r}_{0}\) represent the first situations, \(\:{J}_{m}\:\)represent the edge node. The practical stage of the edge node is defined as \(\:{q}_{0}\) and the transmitted data is denoted as \(\:{S}_{q}.\:{g}_{0}\) represent the different states of nodes. The data transmission rate is higher if the initial stage condition is lower than the resting state condition. The second condition is represented as \(\:\sum\:_{{q}_{0}=0}^{{g}_{0}\left(r\right)}{S}_{q}\to\:{J}_{m}\left({r}_{0}\right)\to\:{r}_{0}<q\). In the second condition, the data transmission is insufficient for the processing needs and detects the monitored edge devices. The initial stage and the second condition are used to determine which edge nodes perform specific tasks and when they sleep; depending on the need, information is transmitted to different devices. The task scheduling and the energy utilized for multi-task scenario\(\:r\left({S}_{q}\right)\) is obtained from Eq. (8)
Maximum energy utilized for multi-task scheduling is represented as \(\:{g}_{energy}\) and a minimum of energy utilized by the edge device \(\:{S}_{energy}\) are used to derive the energy. \(\:g\) represents the processing needs, \(\:b\) represents the detection of edges. \(\:{r}_{0}\) represent the first situations, \(\:{J}_{m}\:\)represent the edge node. Data transmission uses less power, saving additional for other network operations. Handling numerous tasks is easily implemented by allocating time for processing data and prioritizing energy. The section below shows how to reduce the makespan with the maximum usage.
Reinforcement learning mechanism
The RL mechanism plans and initiates task scheduling and distribution activities to reduce the makespan and maximize the utilization of the activities. The maximization of the makespan is obtained by scheduling each task and dividing it among the initiators. Minimizing makespan ensures tasks are completed in the shortest time possible, improving resource utilization. A shorter makespan reflects better scheduling efficiency, especially in systems with high task loads like IoE or edge computing. The time restriction of each task is calculated using the RL method. The initial and the end time calculation is used to estimate the makespan, and the makespan reduction can be described well. A RL approach optimizes task scheduling by maximizing resource utilization. Compared to alternative deep learning methods, this mechanism efficiently minimizes task completion time while maintaining minimal data requirements. A simple agent capable of RL has a step-by-step relationship with its surroundings. State \(\:{l}_{t}\) and lead \(\:{m}_{t}\:\)are communicated to the agent at regular intervals. Then, it selects an action from the pool of possibilities and communicates it to its surroundings. The situation moves to the next stage. \(\:{l}_{t+1}\) and the lead \(\:{m}_{t+1\:}\)is related to the conversion. The main aim of RL is to get proper knowledge regarding the plans and initiate the task for each machine to maximize the makespan with the highest utilization of activities. Task scheduling is in two phases. X-task scheduling is given as \(\:L=\{{L}_{1},{L}_{2},\dots\:\dots\:.{L}_{x}\}\) and \(\:y\)-initiators are represented as \(\:M=\{{M}_{1},{M}_{2},\dots\:\dots\:.{M}_{y}\}\). For each task of \(\:{L}_{a}\) there are two activities \(\:\{{S}_{a1},{S}_{a2}\}\) which define the analysis and distribution activities, as well as their respective end times, are given as \(\:\{{t}_{a1},{t}_{a2}\}\). By maximizing specific goals such as makespan, energy efficiency, and throughput, RL aims to learn the best policies for sequential decision-making tasks, including scheduling. However, PSO is a population-based optimization approach that can handle continuous and discrete optimization issues. Finding optimum solutions to static optimization issues is better for PSO, whereas RL may examine adaptive and dynamic scheduling algorithms. To make the best use of available resources across all devices and choose which tasks to delegate to edge nodes adaptively, the model employs RL. The RL mechanism considers the workload of each edge node at the moment, the complexity and size of the job, and the latency requirements when making a decision. In addition, it considers the edge devices’ energy limitations and available processing power to guarantee the effective use of resources. When deciding to offload a job, the best approach is to find the edge node that can handle it, distribute the workload evenly across all of the nodes that are accessible, and keep energy consumption and data transmission delays to a minimum. Furthermore, by allocating tasks according to their present states and maximizing the overall system efficiency, the model tries to prevent any one node from being dazed.
RL frequently encounters difficulties in achieving this equilibrium, as excessive exploration may result in inefficiency, with the model dedicating time to assess suboptimal or redundant task scheduling solutions. In contrast, excessive exploitation can lead to premature convergence on suboptimal policies, thereby overlooking superior task allocation strategies. This limitation may lead to imbalanced workload allocation or underutilization in IoE applications, defined by fluctuating network settings, resource diversity, and disparate job requirements. Moreover, RL often needs several training episodes to achieve optimum policies, which may be incompatible with the real-time demands of task scheduling in edge contexts. The stochastic characteristics of RL rules create variability, complicating the assurance of consistent system performance across diverse workloads.

The complete process to measure the makespan.
The scheduler’s task is to create a workable plan for dividing up the jobs among the available slots on the initiators in such a way as to reduce the makespan. \(\:{I}_{a1},\:{I}_{a2}\)and\(\:{Z}_{a1},\:{Z}_{a2}\) is the initial time and the end time of the given task \(\:{L}_{a}\). The time restriction of each task is shown in Eq. (9)
The two activities are represented as \(\:\left\{{S}_{a1},{S}_{a2}\right\},\:the\:\)time slot is defined as \(\:\{{t}_{a1},{t}_{a2}\}\), the initial time of the task scheduling to reduce makespan is given as \(\:{I}_{a1},\:{I}_{a2}\). The task scheduling with the number of edge node \(\:{q}_{0}\) allows the data transfer \(\:{j}_{m}\). The task scheduling, along with the multi-task scheduling, is carried in the RL mechanism with x-task scheduling given as \(\:L=\{{L}_{1},{L}_{2},\dots\:\dots\:.{L}_{x}\}\) and \(\:y\)-initiators are represented as \(\:M=\{{M}_{1},{M}_{2},\dots\:\dots\:.{M}_{y}\}\). \(\:{I}_{a1},\:{I}_{a2}\:\)and\(\:{\:Z}_{a1},\:{Z}_{a2}\) is the initial time and the end time of the given task \(\:{L}_{a}\). The initial and end times measure the overall makespan with minimal data utilization. Eq. (9) summarizes the model’s mathematical basis for task scheduling, which directs the RL mechanism to decrease makespan, balance task execution times, and guarantee optimal data use among edge devices. The complete process of measuring the makespan is shown in Fig. 5.
To manage \(\:x\) task with the \(\:y\) initiator’s RL mechanism, make use of the makespan reduction algorithm, which is shown in Table 3. The RL mechanism reduces the makespan of the complete task scheduling process, and the security aspects are more concentrated in the edge nodes for data transfer among the numerous machines.
This stage involves evaluating both collections \(\:{C}_{1}\) and \(\:{C}_{2}\), as well as their processing times \(\:{t}_{a1}\) and \(\:{t}_{a2}\).
-
If this evaluation requires only simple summations, comparisons, or other constant-time operations, it takes \(\:O\left(x\right)\) time.
-
If more complex evaluations or calculations are required, the complexity could vary; however, from the provided steps, it seems to be \(\:O\left(x\right)\).
Thus, the time complexity for Stage 3 is: \(\:O\left(x\right)\). Summing up the complexities from all three stages:
-
1.
Stage 1: \(\:O\left(x\right)\)
-
2.
Stage 2: \(\:O\left(xlog\:x\right)\)
-
3.
Stage 3: \(\:O\left(x\right)\)
The dominant term is \(\:O\left(xlog\:x\right)\:\)from Stage 2, so the overall time complexity of the algorithm is \(\:O\left(xlog\:x\right)\).
The PSO algorithm is implemented for all task-scheduling processes. In PSO, the initialization depends on the position velocity of particles. The load balancing is tedious in initialization, and time evaluation is not concentrated in the makespan reduction. The proposed SEE-MTS model implements the makespan reduction algorithm. The makespan reduction algorithm has three stages: allocating periods for data processing, removing makespan by fitness evaluation, and finding the best values. Depending upon the number of tasks, the processing time and the makespan are reduced for all the data processing tasks. The suggested SEE-MTS model incorporates PSO to manage load balancing by recasting the scheduling of tasks as an optimization issue. The PSO algorithm repeatedly updates its particles’ placements depending on local and global optimal solutions; each particle represents a possible task-to-node assignment. The fitness function considers energy consumption, task latency, and workload distribution to guarantee that all edge devices are scheduled fairly. Computational capability, task-specific needs (such as latency and priority), energy efficiency, node proximity, and other metrics are taken into account by PSO when determining the best destination.
The task allocation among the machines is carried out by considering the availability of the necessary data and their copies. The SEE model is implemented by providing more protection through dynamic updates, multi-keyword searches, and verification of search results for accuracy. The MTS model optimizes energy efficiency by allocating dedicated resources for concurrent data processing tasks. The RL mechanism utilizes the makespan reduction algorithm to minimize the overall makespan centred on a recently intended direct return that reflects the most significant operation. The complete flow of the SEE-MTS model is shown in Fig. 6.

The flow diagram of Secure Edge Enabled Multi-Task Scheduling.
The SEE model allocates tasks among nodes by considering the availability of required data and their copies. The security performance is implemented by frequent updates, allowing for multiple keyword searches and double-checking the correctness of search results. The MTS model executes the allocation of periods for processing data across various tasks using the RL technique to reduce makespan with an immediate reward that considers optimal usage. The evaluation for SEE-MTS in the form of task allocation and processing of data to maintain the security level is evaluated in the result section.
RL is a technique to find an estimated solution for the explored multi-task scheduling challenge, as the makespan reduction is difficult for scheduling a group of two-stage jobs in many initiators. The input of the algorithm is given as the number of tasks\(\:L=\left\{{L}_{1},{L}_{2},\dots\:\dots\:.{L}_{x}\right\}\). Each task has a different operation.\(\:\left\{{S}_{a1},{S}_{a2}\right\}\)and processing time \(\:\left\{{t}_{a1},{t}_{a2}\right\}.\:\)The algorithm’s output is classified according to the mentioned task.\(\:{L}^{{\prime\:}}\). The two-task collection is executed for certain conditions, like \(\:{C}_{1}=0,\:{C}_{2}\ne\:\varnothing\:,\:{L}^{{\prime\:}}\ne\:\varnothing\:\). For each task \(\:{L}_{x}\)Performance is based on L. If the processing time \(\:{t}_{a1}\ge\:{t}_{a2}\), then the task \(\:{C}_{1}={C}_{2}\) for all allocation of task \(\:{L}_{x}\). The unsatisfied condition leads to the operation of another task for the situation.\(\:{C}_{2}\ne\:\varnothing\:\cap\:{L}_{x}.\) If all the task scheduling \(\:{C}_{1}>{C}_{2}\), grouping process will be carried out in rising order with the processing time \(\:{t}_{a1}.\:\)The grouping based on \(\:{C}_{2}\) with the sliding order on the processing time \(\:{t}_{a2}\) is performed for task \(\:{L}_{x}.\:\)At the end of the algorithm, the merging of \(\:{C}_{2}\) is done with \(\:{C}_{1}\). The best values are calculated based on the time and the number of tasks. The best value calculation allows for the reduction of makespan for allocating jobs and data.
Results and discussion
The effectiveness of the SEE-MTS model is determined by analyzing the performance indicators utilized to implement the efficiency by security level. The response time and throughput evaluate the efficient use of computing resources. Edge devices have been developed to support user devices [31]. Task scheduling with energy conservation is accomplished with varying numbers of nodes. The task scheduling for each edge and the energy consumption are obtained from the dataset34,35. The security measures are based on the key generation. The software used for implementation is MATLAB R2020a. With implementation and transmission times being randomly allocated, two thousand tasks are considered to model the scheduling situation of periodically divided tasks running on various initiators in an edge device of the IoE system34. Intrusion detection systems that rely on machine learning have two options for training their models: centralized learning and federated learning. To address this, we provide Edge-IIoTset, a new realistic cyber security dataset of IoT and IIoT applications. In particular, the suggested testbed is structured with seven levels: cloud computing, network functions virtualization, blockchain network, fog computing, software-defined networking, edge computing, and IoT and industrial IoT perception. The proposed new technologies at each layer address important needs in IIoT and IoT applications; they include ThingsBoard, an IoT platform; OPNFV, a platform; Hyperledger Sawtooth, a digital twin; ONOS, a controller for software-defined networking; Mosquitto, a network management protocol; Modbus TCP/IP, and so on. The IoT data comes from various sources, including over ten IoT devices (e.g., inexpensive digital thermometers and humidity sensors, ultrasonic level detectors, soil moisture sensors, pH meters, heart rate monitors, flame detectors, etc.). Nevertheless, this dataset discovers and examines fourteen assaults on IIoT and IoT communication protocols. The attacks are classified into five dangers: denial-of-service/double-digital-denial, information gathering, man-in-the-middle, injection, and malware. Once the suggested realistic cyber security dataset has been processed and analyzed, it will provide a main exploratory data analysis and assess the efficacy of ML methods in federated and centralized learning environments.
Healthcare monitoring, smart city traffic management, and industrial automation are some of the real-world IoT applications that the task parameters in the simulated dataset used to evaluate the SEE-MTS model represent. Details on the data amount, processing power needed, priority level, and security needs for each job are included in the dataset at every data point. Furthermore, to reflect the practical limits of edge devices, energy and latency requirements are established.
The data have been handled by normalizing the task parameters to provide consistent scaling. Then, it entered the SEE-MTS model for dynamic task allocation and scheduling. Matching the dataset with certain IoE situations has been accomplished via feature engineering approaches, such as prioritizing activities and filtering tasks based on latency tolerance. To simulate the way an actual IoE network would function, tasks were then distributed to edge devices according to their processing power, security level, and energy profile.
Energy efficiency, security, and the timely completion of tasks are crucial in the IoE, and this dataset accurately portrays these difficulties. The SEE-MTS model’s adaptability in handling various IoE tasks can be demonstrated by conducting tests on a dataset that simulates real-world scenarios. These scenarios include healthcare systems that need real-time patient monitoring, smart cities that manage traffic flows, and industrial setups that require automated task allocation.
In a simulated IoE environment for task scheduling, task durations are stratified: high-priority tasks are allocated 100 ms, medium-priority tasks 1000 ms, and low-priority tasks 10,000 ms. The efficiency of task scheduling is calculated by Estimate factor (af) \(\:af=\frac{{S}_{c}}{{S}_{O}}\). \(\:{S}_{c}\) represent the computational time taken by the method to complete the makespan.
The computational time depends on the time taken for task allocation in delay and reaction time. \(\:{S}_{O}\) denote the efficiency of the proposed method. The estimated factor is calculated for different task initiators. The task initiators represented as af = 2, 4, 8, 16, 32, 64 are used for calculating the accuracy. The proposed SEE-MTS method uses Less energy to schedule multiple tasks. The estimation factor calculates each node’s energy consumption when performing various tasks. Each node’s task scheduling and energy consumption are based on the estimated factor for different task initiators.
As a metric, computation time measures how long it takes for a device to complete a task. The following Equation gives its approximate value:
where \(\:S\)- the size of the task, \(\:P\)-processing power of the edge device.
The estimation factor is calculated for different initiators and illustrated in Fig. 7. The estimation factor of the proposed work is 91.3% effective when compared to other existing methods, such as PSO19, CSO20, ACO21, and CNN-MBO [22]. The estimation factor \(\:af\:\)is calculated for different initiators, and the minimal estimator ratio obtained less makespan. The optimum makespan is calculated for other tasks with 100 ms to 1000 ms. The computational time varies for different time intervals and different tasks. The estimation factor for a time interval of = 32, af = 64.

The estimation factor (af) for different initiators.
The key generation provides security through dynamic updates and produces a secret key for additional entities. Multi-keyword searches only the outputs of the private keys for direct utilization with characteristics in key generation. Multi-keyword searches use different private keys in key generation, and the key generation is based on certain conditions. The key generation carries three conditions like \(\:x\in\:{S}_{q},\:y\in\:{s}_{q},\:z\in\:{s}_{q}\). The key generation in the form of dynamic updates is obtained by \(\:q{l}_{1}={r}_{1}^{x},{ql}_{v}=y,{ql}_{t}={r}^{z}.\) The time required for generation in the form of secret maintenance is gathered from \(\:{S}_{q},t\). The calculation time of key generation is lower than that of the dynamic updates since it just requires \(\:{ql}_{v}=({ql}_{v,1},{ql}_{v,2})\) to be executed for each direct utilization. The secure edge model demonstrates its effectiveness by extensively evaluating its efficiency in identifying the attacks in the form of key generation. The storage cost of key generation is drastically decreased with the secret key \(\:{ql}_{t}={r}^{z}\) and the secret key \(\:{tl}_{t}=t\), \(\:{S}_{q}\) of the prime factorization. The calculation time and the storage cost are less for the proposed method in identifying the secret key generation. The calculation time is based on the dynamic update and key generation. The storage capacity is based on the number of tasks to be executed. The calculation time and storage capacity are shown in Figs. 8 and 9, respectively. The proposed work’s storage capacity and calculation time are 6.1s and 68 kb, respectively. Compared to the existing works, the proposed method achieves better results, as shown in Figs. 8 and 9.

Calculation time.

Storage capacity.
An edge device’s storage capacity measures its data storage capability. Bits, or bytes, are the standard units of computation. Here is a method to represent the storage capacity:
where \(\:{D}_{i}\) - Data size and \(\:N\) – Number of tasks
Energy storage and utilization of the proposed method prioritizes conservation. In a network setting, data transmission and processing are handled by various other devices. As a result, other devices expend energy doing these tasks. Energy efficiency is ranked through MTS by allocating periods for processing data across different tasks. The utilization of energy by various devices for multiple-task handling is based on the data processed by each task. The following Equation describes the conservation of energy gained by the nodes of each device. \(\:{a}_{n}={\sum\:}_{\beta\:}{(\:\beta\:}^{{\prime\:}}-{\beta\:}_{o})+\frac{1}{2}({\beta\:}_{n}-{\beta\:}_{0})\). A task in the machine is designated by the letter.\(\:{\:\beta\:}^{{\prime\:}}\)and its beginning and end times are given by the symbols \(\:{\beta\:}_{n}\), \(\:{\beta\:}_{0}\). \(\:{a}_{n}\) represent the energy efficiency. The storage and utilization of the devices measure energy conservation. Energy utilization is shown in Fig. 10, and the efficiency of energy is shown in Fig. 11.

Energy Utilization.

Energy Efficiency.
The task scheduling activities between each node allow calculating the delay and latency output. The delay and the reaction time are based on the measurement of task scheduling between the devices. The device’s delay and reaction time depend on the computational time. This is understandable since the MTS helps schedule activities that do not account for data proximity or machine performance. Since the MTS uses a first-come, first-served strategy to distribute incoming tasks, the delay time between scheduling and the beginning of the execution of each job is negligible and can even be deemed zero. The proposed work’s Energy utilization and efficiency were 63.2 J and 88.7%, respectively, which is better than the existing methods such as PSO, CSO, ACO and CNN-MBO.
Utilization of electricity is a measure of how much power a system uses to complete its operation. The calculation is as follows:
where, \(\:{E}_{Process}\) - Energy consumed during task processing, \(\:{E}_{Security}\) - Energy consumed for security measures (encryption, etc.) and \(\:N\) -Total number of tasks
Efficiency in energy consumption measures how well a system uses energy to accomplish its goals. The following Equation is used to determine it:
where \(\:{T}_{Completed}\) -Total time and \(\:{E}_{u}\) -Energy used.
The delay time is shown in Fig. 12. The scheduling time is relatively high due to potential delays in scheduling new activities due to a lack of available resources. Both data transfer and execution time at rates surpass the reaction time. The suggested SEE-MTS approach minimizes data movement by determining the optimal source to retrieve the data. The reaction time is shown in Fig. 13. The proposed work’s delay and reaction times are 15s and 9s, respectively.
All the time it takes for an endeavour to proceed from start to finish, including processing, waiting, and transmission delays, is known as delay. It is further expressed as:
where \(\:{D}_{processing}-\)Time taken, \(\:{D}_{processing}\) - Time spent waiting and \(\:{D}_{transmission}\) - Time taken to transmit data.

Delay.

Reaction time.
Reaction time is concerned with the system’s sensitivity to outside inputs, compared to computation time, which is concerned with the efficiency of tasks. While both indicate different things, indicators are essential for ensuring the system is effective and reliable, and IoE applications perform well. The direction and retrieval of data need to be controlled by the security measures. The security measures are achieved by key generation techniques, which utilize encryption and decryption procedures. Each encrypted outcome requires actions to decrypt; hence, the data transfer must first receive permission from each task to perform these actions. The key generation must use the interactive procedure to obtain the decryption key. Multiple keyword searches should take the encryption method to ensure that the data transfer can recover the encryption key with the help of time permissions before each committee acquires the encryption key to decrypt search results in Decryption. The security measures in encryption and decryption have lesser computation time complexity, as shown in Fig. 14, with the highest rate of security aspects, as shown in Fig. 15. The proposed SEE-MTS achieves less delay with the key generation for security maintenance to identify different threats. The computation time complexity and the storage capacity proposed work are 7% and 89.3%, respectively and compared to PSO, CSO, ACO, and CNN-MBO, the proposed method achieves better results, as shown in Figs. 14 and 15.
The estimation factor calculates each node’s energy consumption when performing multiple tasks. The estimation factor is computed using the af; for af = 2, SEE-MTS has an energy consumption of 50 J; for af = 4, SEE-MTS has 51 J; for af = 8, SEE-MTS has 50 J; for af = 16, SEE-MTS has 75 J, for af = 32, SEE-MTS has 55 J, for af = 64, SEE-MTS has 59 J, PSO has energy consumption of 72 J, CSO has energy consumption of 81 J, ACO has energy consumption of 76 J, CNN-MBO has energy consumption of 90 J. The calculation time of SEE-MTS IS 51s, CNN-MBO is 81s, PSO is 71s, CSO is 62s, ACO is 91s. The proposed SEE-MTS has less energy utilization, delay, and reaction than the existing methods.

Computation Time Complexity.

Security level analysis.
Compared to current IoT scheduling methods, the suggested model performs better in terms of energy efficiency, processing time reduction, and data security. It dynamically matches positions to available resources, reducing processing time and improving energy efficiency compared to standard methods like Ant Colony Optimization and PSO. Additionally, security is stepped up with multi-key encryption and frequent upgrades, leading to a 40% improvement in data protection compared to conventional approaches. In healthcare, industrial automation, and smart city applications where information security, optimum energy consumption, and rapid response are paramount, the model can better satisfy real-world IoE expectations.

Throughput.
Figure 16 shows the throughput of tasks completed per second. Throughput in the suggested system is assessed by counting the number of tasks completed per second in terms of the number of IoE devices. The performance shows a clear improvement with increasing device connections, suggesting the system can successfully manage large-scale installations. Distributing jobs uniformly among available devices is achieved using RL-powered dynamic task scheduling and resource allocation algorithms. This ensures that no one device is overloaded; therefore, performance remains high regardless of the number of devices added. The increasing throughput with additional devices shows the system’s scalability, which makes it ideal for applications that need simultaneous support for large numbers of IoE devices without compromising task completion rates or system responsiveness.

Latency.
Figure 17 shows the latency. With increased data amount per device, the suggested approach efficiently handles delay. Even while processing and transferring higher volumes of data, the system is intended to reduce delay. The system reduces processing times for lower data sizes, guaranteeing efficient and rapid job execution. Nevertheless, the system’s effective scheduling and resource allocation algorithms handle the progressive rise in latency that comes with larger data sets. By optimizing the offloading of activities to edge devices, the RL-based strategy minimizes delays caused by higher data volumes. This ensures that data may be handled quickly, regardless of the load circumstances, and makes the system appropriate for IoE applications that need low latency for real-time processing.
Figure 18 shows the efficiency on user load. As the number of users increases, the system’s efficiency under growing loads demonstrates its capacity to sustain high performance. The suggested model’s dynamic task scheduling and workload distribution among available resources maintain a high task completion rate, even as the number of users connects to the system. The capability to continuously adjust to the evolving needs of users and maximize the use of resources is made possible by the RL technique. This system has shown scalability and resilience in real-world IoE deployments by efficiently managing larger user bases. This is an ideal solution for a large-scale environment where several users must do tasks simultaneously without disrupting the system.

Efficiency on user load.
The SEE-MTS paradigm was validated in a realistic IoE simulation environment. Edge and cloud nodes with usual restrictions like energy capacity, processing speed, and network latency are simulated. Healthcare monitoring requires real-time reaction; smart city infrastructure optimizes energy consumption for traffic and environmental sensors, and industrial automation targets high job throughput. Each scenario comprised numerous tasks with different energy, latency, and security needs to simulate operational situations.
The healthcare simulation emphasized low-latency data processing for vital sign monitoring, whereas smart city activities prioritized environmental monitoring energy efficiency. The security tests additionally demonstrated that SEE-MTS protected sensitive IoE data from simulated data breaches. These scenario-driven simulations show SEE-MTS’s potential influence across industries and application to IoE issues.
Using edge devices for data security and optimizing real-time traffic management, smart cities can handle tasks like signal control and congestion analysis easier. Processing CCTV feeds for event detection with low latency is another way it improves public safety. Improved remote patient monitoring is one healthcare use of the model’s secure scheduling and processing of data from wearable sensors for diagnostic aids like AI-driven image analysis and anomaly identification. By evaluating data from machine sensors and planning crucial activities, SEE-MTS can easily manage predictive maintenance in IIoT, guaranteeing uninterrupted operations while safeguarding confidential industrial data. To meet the ever-changing requirements of IoE applications, SEE-MTS is crucial because it optimizes resource consumption, reduces latency, and maintains strong security.
Conclusion
Using a hybrid edge-cloud architecture, edge nodes process large amounts of data locally, extracting and encrypting key features, which are then transmitted to the cloud data centre for further processing and storage. The SEE-MTS model optimizes task allocation across nodes by strategically evaluating the primary data sources and their available copies. The SEE model allows for real-time updates, multiple keyword searches, and the validation of search results. The SEE-MTS model optimizes data processing intervals across multiple tasks to minimize power consumption without compromising performance. The MTS paradigm implements time scheduling for data processing across several activities. At the edge nodes, data distribution and queuing are managed based on each node’s current energy status and capacity, mitigating node overload and potential system-wide interruptions. MTS employs the RL technique to reduce the makespan considerably. In the SEE-MTS system, key performance metrics were measured as follows: calculation time was 51 s, energy utilization reached 4 joules, system delay was 2 s, reaction time was 4 s, energy efficiency achieved 89%, and overall security level was 96%, with a computation time of 6 s. The proposed SEE-MTS model in the form task scheduling stage with less energy usage has the highest security level and less computational time. The present framework encounters scalability issues, as it has limitations in managing many devices or processing substantial amounts of incoming data, rendering it inappropriate for practical applications.
The future work can be extended by involving a prototype of the enhanced framework in a real-world scenario and assessing its performance. Future studies on hybrid adaptive models, lightweight IoE security protocols, and comprehensive QoS frameworks that impact latency are needed to enhance the system’s reliability. To make IoE systems more practical and stronger for real-world applications, privacy-preserving approaches like federated learning might better safeguard data without sacrificing user privacy.
Free use of the Edge-IIoTset dataset for academic research is granted in perpetuity.
Data availability
The data that support the findings of this study are openly available at https://www.kaggle.com/datasets/mohamedamineferrag/edgeiiotset-cyber-security-dataset-of-iot-iiot Free use of the Edge-IIoTset dataset for academic research is granted in perpetuity.
References
Mishra, S. & Tyagi, A. K. The role of machine learning techniques in internet of things-based cloud applications. Artif. Intelligence-based Internet Things Syst. 105–135. https://doi.org/10.1007/978-3-030-87059-1_4 (2022).
J.-H. Lee, G. Yang, C.-H. Kim, R. L. Mahajan, S.-Y. Lee, and S.-J. Park, Flexible solid-state hybrid supercapacitors for the internet of everything (IoE), Energy & Environmental Science, vol. 15, no. 6, pp. 2233–2258, 2022, doi: 10.1039/d1ee03567c.
Saba, D., Sahli, Y. & Hadidi, A. Toward Smart Cities Based on the Internet of Things, Smart City Infrastructure, pp. 33–75, Feb. (2022). https://doi.org/10.1002/9781119785569.ch2
Zhan, J., Dong, S. & Hu, W. IoE-supported smart logistics network communication with optimization and security. Sustain. Energy Technol. Assess. 52, 102052. https://doi.org/10.1016/j.seta.2022.102052 (Aug. 2022).
Alassery, F., Alzahrani, A., Khan, A. I., Irshad, K. & Islam, S. An artificial intelligence-based solar radiation prophesy model for green energy utilization in energy management system. Sustain. Energy Technol. Assess. 52, 102060. https://doi.org/10.1016/j.seta.2022.102060 (Aug. 2022).
Zhong, J. Y., Goh, S. K., Woo, C. J. & Alam, S. Impact of Spatial Orientation Ability on Air Traffic Conflict Detection in a Simulated Free Route Airspace Environment, Frontiers in Human Neuroscience, vol. 16, Apr. (2022). https://doi.org/10.3389/fnhum.2022.739866
Alnaim, A. K. & Alwakeel, A. M. Machine-learning-based IoT–Edge Computing Healthcare solutions. Electronics 12 (4), 1027. https://doi.org/10.3390/electronics12041027 (Feb. 2023).
Ahammed, T. B., Patgiri, R. & Nayak, S. A vision on the artificial intelligence for 6G communication. ICT Express. 9 (2), 197–210. https://doi.org/10.1016/j.icte.2022.05.005 (Apr. 2023).
Subbalakshmi, S. & Madhavi, K. A Unique Key Integrity Agreement Approach for Big Data Storage and Privacy Access in Cloud, 2022 International Conference on Electronics and Renewable Systems (ICEARS), pp. 1572–1578, Mar. (2022). https://doi.org/10.1109/icears53579.2022.9751853
Yang, C., Liu, Y. & Ding, Y. Efficient data transfer supporting provable data deletion for secure cloud storage,Soft. Comput., 26, no. 6463–6479, doi: https://doi.org/10.1007/s00500-022-07116-6.Apr. (2022).
Tripathi, Y., Prakash, A. & Tripathi, R. A novel slot scheduling technique for duty-cycle based data transmission for wireless sensor network, Digital Communications and Networks, vol. 8, no. 3, pp. 351–358, Jun. (2022). https://doi.org/10.1016/j.dcan.2022.01.006
Chandnani, N. & Khairnar, C. N. An analysis of architecture, framework, security and challenging aspects for data aggregation and routing techniques in IoT WSNs, Theoretical Computer Science, vol. 929, pp. 95–113, Sep. (2022). https://doi.org/10.1016/j.tcs.2022.06.032
Islam, A., Amin, A. A. & Shin, S. Y. FBI: A Federated Learning-Based Blockchain-Embedded Data Accumulation Scheme Using Drones for Internet of Things,IEEE Wirel. Commun. Lett., 11, 5, 972–976, doi: https://doi.org/10.1109/lwc.2022.3151873.May (2022).
Bel, J. C., C, D. E., B, Z. S. G., D, T. & P, D. D. Trustworthy Cloud Storage Data Protection based on Blockchain Technology, 2022 International Conference on Edge Computing and Applications (ICECAA), pp. 538–543, Oct. (2022). https://doi.org/10.1109/icecaa55415.2022.9936299
Aviv, I. et al. Infrastructure From Code: The Next Generation of Cloud Lifecycle Automation, IEEE Software, vol. 40, no. 1, pp. 42–49, Jan. (2023). https://doi.org/10.1109/ms.2022.3209958
Han, J., Qi, L. & Zhuang, J. Vector Sum Range decision for verifiable multiuser fuzzy keyword search in cloud-assisted IoT. IEEE Internet Things J. 11 (1), 931–943. https://doi.org/10.1109/jiot.2023.3288276 (Jan. 2024).
Xiang, X. & Zhao, X. Blockchain-assisted searchable attribute-based encryption for e-health systems. J. Syst. Architect. 124, 102417. https://doi.org/10.1016/j.sysarc.2022.102417 (Mar. 2022).
Tong, Z. et al. D2OP: a Fair Dual-Objective Weighted Scheduling Scheme in Internet of everything. IEEE Internet Things J. 10 (10), 9206–9219. https://doi.org/10.1109/jiot.2023.3234078 (May 2023).
Kchaou, H., Kechaou, Z. & Alimi, A. M. A PSO task scheduling and IT2FCM fuzzy data placement strategy for scientific cloud workflows. J. Comput. Sci. 64, 101840. https://doi.org/10.1016/j.jocs.2022.101840 (Oct. 2022).
Bal, P. K., Mohapatra, S. K., Das, T. K., Srinivasan, K. & Hu, Y. C. A joint resource allocation, security with efficient Task Scheduling in Cloud Computing using hybrid machine learning techniques. Sensors 22 (3), 1242. https://doi.org/10.3390/s22031242 (Feb. 2022).
Sharma, N., Sonal, P. & Garg Ant colony based optimization model for QoS-based task scheduling in cloud computing environment. Measurement: Sens. 24, 100531. https://doi.org/10.1016/j.measen.2022.100531 (Dec. 2022).
Badri, S. et al. Mar., An Efficient and Secure Model Using Adaptive Optimal Deep Learning for Task Scheduling in Cloud Computing, Electronics, vol. 12, no. 6, p. 1441, (2023). https://doi.org/10.3390/electronics12061441
Li, X., Yang, J. & Fan, H. Dynamic Network Resource Autonomy Management and Task Scheduling Method. Mathematics 11 (5), 1232. https://doi.org/10.3390/math11051232 (Mar. 2023).
Zhou, X. et al. Feb., Edge-Enabled Two-Stage Scheduling Based on Deep Reinforcement Learning for Internet of Everything, IEEE Internet of Things Journal, vol. 10, no. 4, pp. 3295–3304, (2023). https://doi.org/10.1109/jiot.2022.3179231
Rajalakshmi, N. R. et al. A Cost-Optimized Data Parallel Task Scheduling with Deadline Constraints in Cloud, Electronics, vol. 11, no. 13, p. Jun. 2022, (2022). https://doi.org/10.3390/electronics11132022
Sharif, Z., Tang Jung, L., Ayaz, M., Yahya, M. & Pitafi, S. Priority-based task scheduling and resource allocation in edge computing for health monitoring system, Journal of King Saud University - Computer and Information Sciences, vol. 35, no. 2, pp. 544–559, Feb. (2023). https://doi.org/10.1016/j.jksuci.2023.01.001
Chen, R., Chen, X. & Yang, C. Using a task dependency job-scheduling method to make energy savings in a cloud computing environment, The Journal of Supercomputing, vol. 78, no. 3, pp. 4550–4573, Sep. (2021). https://doi.org/10.1007/s11227-021-04035-5
W. Gu, Y. Li, D. Tang, X. Wang, and M. Yuan, Using real-time manufacturing data to schedule a smart factory via reinforcement learning, Computers & Industrial Engineering, vol. 171, p. 108406, Sep. 2022, doi: 10.1016/j.cie.2022.108406.
Ahmed, A. et al. An efficient Task Scheduling for Cloud Computing platforms using Energy Management Algorithm: a comparative analysis of workflow execution time. IEEE Access. 12, 34208–34221. https://doi.org/10.1109/access.2024.3371693 (2024).
Sabat, N. R., Sahoo, R. R., Pradhan, M. R. & Acharya, B. Hybrid technique for optimal task scheduling in cloud computing environments. TELKOMNIKA (Telecommunication Comput. Electron. Control). 22 (2), 380. https://doi.org/10.12928/telkomnika.v22i2.25641 (Apr. 2024).
Murad, S. A. et al. SG-PBFS: Shortest Gap-Priority Based Fair Scheduling technique for job scheduling in cloud environment. Future Generation Comput. Syst. 150, 232–242. https://doi.org/10.1016/j.future.2023.09.005 (Jan. 2024).
Khaledian, N., Khamforoosh, K., Akraminejad, R., Abualigah, L. & Javaheri, D. An energy-efficient and deadline-aware workflow scheduling algorithm in the fog and cloud environment, Computing, vol. 106, no. 1, pp. 109–137, Aug. (2023). https://doi.org/10.1007/s00607-023-01215-4
Yousif, A., Bashir, M. B. & Ali, A. An evolutionary algorithm for Task Clustering and Scheduling in IoT Edge Computing. Mathematics 12 (2), 281. https://doi.org/10.3390/math12020281 (Jan. 2024).
Jawade, P. B. & Ramachandram, S. DAGWO based secure task scheduling in Multi-cloud environment with risk probability. Multimedia Tools Appl. 83 (1), 2527–2550. https://doi.org/10.1007/s11042-023-15687-1 (May 2023).
Ferrag, M. A. Edge-IIoTset Cyber Security Dataset of IoT & IIoT. 18-Mar-2022. [Online]. Available: https://www.kaggle.com/datasets/mohamedamineferrag/edgeiiotset-cyber-security-dataset-of-iot-iiot
Mahohoho, B., Chimedza, C., Matarise, F. & Munyira, S. Artificial Intelligence-based Automated Actuarial pricing and underwriting model for the General Insurance Sector. Open. J. Stat. 14 (03), 294–340. https://doi.org/10.4236/ojs.2024.143014 (2024).
Alam, M., Shahid, M. & Mustajab, S. Security challenges for workflow allocation model in cloud computing environment: a comprehensive survey, framework, taxonomy, open issues, and future directions. J. Supercomputing. 80 (8), 11491–11555. https://doi.org/10.1007/s11227-023-05873-1 (Jan. 2024).
Alam, M., Shahid, M. & Mustajab, S. A Security Driven Energy Efficient Workflow Allocation Algorithm under Deadline Constraints for Cloud Computing, 4th International Conference on Data Analytics for Business and Industry (ICDABI), pp. 331–336, Oct. 2023, (2023). https://doi.org/10.1109/icdabi60145.2023.10629337
Walia, G. K., Kumar, M. & Gill, S. S. AI-empowered fog/edge resource management for IoT applications: A comprehensive review, research challenges and future perspectives. IEEE Communications Surveys & Tutorials. 26(1), 619–669. https://doi.org/10.1109/COMST.2023.3338015 (2024)
Kumar, M., Kishor, A., Singh, P. K. & Dubey, K. Deadline-aware cost and energy efficient offloading in mobile edge computing. IEEE Transactions on Sustainable Computing. 9(5), 778–789. https://doi.org/10.1109/TSUSC.2024.3381841 (2024).
Kumar, M., Walia, G. K., Shingare, H., Singh, S. & Gill, S. S. Ai-based sustainable and intelligent offloading framework for iiot in collaborative cloud-fog environments. IEEE Trans. Consum. Electron. 70(1), 1414–1422. https://doi.org/10.1109/TCE.2023.3320673 (2024).
Kumar, M., Kishor, A., Samariya, J. K. & Zomaya, A. Y. An autonomic workload prediction and resource allocation framework for fog-enabled industrial IoT. IEEE Internet Things J. 10 (11), 9513–9522. https://doi.org/10.1109/JIOT.2023.3235107 (2023).
Funding
This research received no external funding
Author information
Authors and Affiliations
Contributions
Conceptualisation - V.T.K.; Investigation - V.T.K., V.R., and W.K.W.; Methodology - V.T.K., V.R.; Supervision - W.K.W. and P.K.N; Visualisation - V.T.K. and W.K.W; Writing—original draft –V.T.K., V.R., and W.K.W.; and Writing—review and editing - V.T.K., V.R., W.K.W. and P.K.N.; Language editing - P.K.N.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kesavan V, T., R, V., Wong, W.K. et al. Reinforcement learning based Secure edge enabled multi task scheduling model for internet of everything applications. Sci Rep 15, 6254 (2025). https://doi.org/10.1038/s41598-025-89726-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-89726-2
Keywords
This article is cited by
-
Decentralized queue control with delay shifting in edge-IoT using reinforcement learning
Scientific Reports (2025)
-
Reinforcement learning based multi objective task scheduling for energy efficient and cost effective cloud edge computing
Scientific Reports (2025)
-
HGN-MAAERL: Hetergeneous graph neighborhood-based multi-agent asynchronous edge reinforcement learning for efficient multiple unmanned vehicles collaboration
Cluster Computing (2025)
