
Abstract
A predefined-time (PT) tracking adaptive control method is studied for non-affine pure-feedback nonlinear systems, with an emphasis on its practical application in robotic exoskeleton technology. A novel PT neural networks control algorithm is implemented, by leveraging the approximation capabilities of neural networks, backstepping technique, barrier functions and Mean Value Theorem. The neural networks are used to approximate the unknown nonlinearities inherent in the system’s control dynamics, while the adaptive law is meticulously designed based on the PT Lyapunov stability criterion. By Lyapunov PT theory, the developed methodology guarantees the system’s convergence within a pre-established time, therefore offering enhanced performance over conventional fixed-time control methodologies. Simulation results validate the efficacy of this proposed control approach, demonstrating its practical implications for controlling robotic exoskeletons under state constraints, thus validating its potential for real-world applications.
Similar content being viewed by others
Introduction
Neural networks have rapidly emerged as a powerful tool in the field of control systems, revolutionizing the way we approach various control problems. These approximation-based adaptive control have proven to be highly effective in sliding model control1,2,3, optimizing control4,5, adaptive control6,7,8. Among them, the strict-feedback nonlinear system, some effective control strategies have been provided9,10,11. The control of non-affine pure-feedback nonlinear systems subject to state constraints has been a formidable challenge in the field of control engineering12,13,14. Such systems, characterized by non-affine dynamics and a lack of direct input-state relationships, have presented significant hurdles for traditional control techniques. The incorporation of neural networks into control strategies has proven to be a promising approach for approximating the complex, often unknown nonlinearities inherent in these systems. For the non-affine pure-feedback nonlinear systems, MVT can be used to change the complex structure to strict-feedback form15,16, and12 proposed MVT based backstepping control which use intermediate virtual control law instead of intermediate states. In the control process, MVT is an efficient principle in calculus that can be used to transform non-affine systems into affine systems. Transforming the control challenge of a pure-feedback system into a strict feedback framework simplifies the controller design process, markedly reducing the associated control complexity.
In system control application, it is often necessary to take into account the convergence time for close-loop system17. Therefore, finite time stable shows the significant advantage over exponential stable of linear feedback control, which the convergence time tends to infinity18,19,20. Especially for UAVs21 and mechanical systems22, the convergence time of the control process is even more important. The convergence time of finite time stable is heavily dependent on the control parameters and initial condition of the system23, furthermore, when the initial state is not available, fixed-time stable proposed a highly effective way which only dependent on known parameters24,25. The advantage of fixed-time stability is that convergence time is guaranteed bound of setting time, but it cannot be predefined or adjusted. For PT control, the convergence time can be predefined as needed through control parameters26,27,28. The predefined time control makes it easy to design a controller with a desired bound of setting time. The key advantage of PT stability is the flexibility to choose the convergence time through a tuning parameter. Therefore, PT control enables explicitly setting the desired convergence speed when designing the controller29,30,31. Combine predefine-time control and adaptive control, a novel convergence theorem is proposed and a state feedback controller for uncertain nonlinear systems is designed which guarantee all states converge to zero32,33. However, the convergence performance of neural network-based controllers and the satisfaction of state constraints within a predefined time have remained critical issues.
This paper addresses these challenges by introducing a novel control methodology that combines PT control, adaptive neural networks, and backstepping technology to design a controller capable of achieving PT convergence and ensuring that state constraints are strictly adhered to. The integration of PT control enhances the convergence guarantees beyond traditional fixed-time control methods, while the use of adaptive neural networks allows the controller to adapt to the uncertainties and complexities of non-affine pure-feedback nonlinear systems. The state constraints are an essential consideration in many practical applications, where overshooting or violating the limits of system variables can have critical consequences. Therefore, our approach maintains a primary focus on the rigorous enforcement of state constraints.
Motivated by the above-mentioned issue, in this context, the main objectives of this paper are to develop a systematic control framework that not only ensures PT convergence but also provides robust control performance and guarantees the satisfaction of state constraints for non-affine pure-feedback nonlinear systems. The main contributions are summarized as following.
-
1.
Pure feedback system converted to strict feedback system based on MVT, and unmodeled dynamics approximated by neural networks. Neural networks backstepping control is designed for pure feedback nonlinear systems, and the proposed control strategy guarantees that the PT stable of the systems.
-
2.
Based on PT adjustment function and Lyapunov theory, the close-loop system can be proved PT stable. The proposed the neural networks adaptive law is simple and easy to realize.
-
3.
Compared to traditional exponential stability or practical stability approaches, as well as finite-time and fixed-time stability methods, this technique introduces PT control mechanisms. Notably, it ensures that the tracking error is zero, and the convergence time is a predetermined parameter that remains unaffected by initial conditions.
The rest of the paper consists of the following parts. In Section II, pure feedback non-affine nonlinear system mathematical description of the problem and some basic definitions are presented. In Section III, the PT adaptive neural network control scheme for constrained nonlinear systems is presented. In Section IV, theoretical results are illustrated by simulation examples. In Section V, a conclusion is summarized.
Problem statement and preliminaries
Consider the pure-feedback non-affine nonlinear systems described by the equations as:
where \(x = \left[ {x_{1} ,x_{2} , \ldots ,x_{n} } \right]^{T} \in \Re^{n}\) is the system state, \(u \in \Re\) is controller, \(y \in \Re\) is output, respectively, \(\overline{x}_{i} = \left[ {x_{1} ,x_{2} , \ldots ,x_{i} } \right]^{T} \in \Re^{i}\), \(h_{i} :\Re_{ \ge 0} \times \Re^{n} \times \Re \to \Re\) are nonlinear smooth functions, \(y_{d} \in \Re\) is desired trajectory, and \(d_{i} \left( t \right)\) is the unknown external disturbances, \(i = 1,2, \ldots ,n\).
Assumption 1
Let \(g_{i} \left( {x_{i} ,x_{i + 1} } \right) = \frac{{\partial h_{i} }}{{\partial x_{i + 1} }}\left( {\overline{x}_{i} ,x_{i + 1} } \right),i = 1, \ldots ,n - 1\), \(g_{n} \left( {x,u} \right) = \frac{{\partial h_{n} }}{\partial u}\left( {\overline{x}_{n} ,u} \right)\), the sign of the functions \(g_{i} \left( * \right)\) are available, and there exist positive constants \(\underline {g}_{i}\). Without loss of generality, supposed that \(g_{i} \left( * \right) \ge \underline {g}_{i} > 0\). There exist positive constants \(\overline{d}_{i}^{{}}\) such that \(\left| {d_{i} \left( t \right)} \right| \le \overline{d}_{i}^{{}}\).
Based on MVT12, the nonlinear functions are transformed as
where \(\lambda_{i} \in \left( {0,1} \right)\), \(x_{{\lambda_{i} }} = \lambda_{i} x_{i + 1} + \left( {1 - \lambda_{i} } \right)z_{i + 1}\), \(g_{i} \left( {\overline{x}_{i} ,x_{{\lambda_{i} }} } \right) = \left. {\frac{{\partial h_{i} }}{{\partial x_{i + 1}^{*} }}} \right|_{{x_{i + 1}^{*} = x_{\lambda i} }}\), and make an assumption \(g_{i} \left( {\overline{x}_{i} ,x_{{\lambda_{i} }} } \right) \ge g_{i0} > 0\), and
where \(\lambda_{n} \in \left( {0,1} \right)\), \(x_{{\lambda_{n} }} = \lambda_{n} u\), \(g_{n} \left( {x,x_{{\lambda_{n} }} } \right) = \left. {\frac{{\partial h_{n} }}{{\partial u^{*} }}} \right|_{{u^{*} = x_{\lambda n} }}\), and make an assumption \(g_{n} \left( {x,x_{{\lambda_{n} }} } \right) \ge g_{n0} > 0\), then system can be got as
Definition 1
32: Consider the nonlinear system.
where \(x \in \Re^{n}\) is the system state, \(\psi :\Re_{ \ge 0} \times \Re^{n} \to \Re^{n}\) is nonlinear smooth function and satisfied the \(\psi \left( {t,0} \right) = 0\). For any given constant \(T_{p}\), and \(T_{p} > 0\), such the system (5) is asymotically stable, and satisfied \(\lim_{{t \to T_{p}^{ - } }} x\left( t \right) = 0\), \(x\left( t \right) = 0\), \(\forall t \ge T_{p}\), then the equilibrium point \(x\left( t \right) = 0\) is PT stable.
Lemma 1
32: If there were two a continuous functions \(V\left( t \right),\tilde{V}\left( t \right)\) satisfying
where \(V\left( t \right) \ge \tilde{V}\left( t \right) \ge 0\), \(k > 0\), \(\delta\) is constant, \(\mu \left( t \right)\) is PT adjustment function and satisfy
where \(\rho\) is a positive constant or \(+ \infty\), then the \(V\left( t \right)\) is bounded for all \(t \in \left[ {0,T_{p} } \right)\) and \(\lim_{{t \to T_{p}^{ - } }} \tilde{V}\left( t \right) = 0\) (Table 1).
Lemma 2
For \(a,b \in \Re\), and satisfy the \(a > b \ge 0\), the following inequality holds:
Lemma 3
34: For neural networks approximation, the following radial basis function neural networks is used, the neural networks
where the input vector \(Z \in \Xi_{Z} \subset \Re^{n}\), weights vecor \(W = \left[ {W_{1} ,W_{2} , \ldots ,W_{l} } \right] \in \Re^{l}\), the neural networks node number \(l > 1\), \(\Psi \left( Z \right) = \left[ {\Psi_{1} \left( Z \right),\Psi_{2} \left( Z \right), \ldots ,\Psi_{l} \left( Z \right)} \right]^{T}\), and active function is choose as the Gaussian functions, as
where \(\mu_{i} = \left[ {\mu_{i1} ,\mu_{i2} , \ldots ,\mu_{in} } \right]^{T}\) is the center of the respective field and \(\eta\) is the width of the Gaussian function. Any continuous function \(F\left( Z \right):\Re^{m} \to \Re\) can be approximated by RBFNNs for compact set \(\Xi_{Z} \subset \Re^{m}\) as
where \(W^{ * }\) is ideal weight of NNs, \(\Psi \left( Z \right)\) is active function, \(\varepsilon \left( Z \right)\) is approximation error and satisfies \(\left| {\varepsilon \left( Z \right)} \right| < \overline{\varepsilon }\).
Main results
The tracking control of nonlinear system (1) is investigated by employing backstepping technology in conjunction with an adaptive neural network PT control. For strict-feedback affine system (4), combine backstepping control and PT control to design constraint control procedure. Define PT adjustment function
In the first step, define the tracking error
based on system (4), we have
Choose NNs to approximate the nonlinear system \(f_{1}\), \(Z_{1} = \left[ {x_{1} ,z_{2} } \right] \in \Omega_{1} \subset \Re^{2}\) and satisfy the \(\Omega_{1}\) is compact set
Choose a Lyapunov candidate functional as
where \(\tilde{\theta }_{1} = \hat{\theta }_{1} - \theta_{1}\), and \(\hat{\theta }_{1} \left( 0 \right) > 0\), \(\hat{\theta }_{1}\) is estimation of \(\theta_{1} = \left\| {W_{1}^{*} } \right\|^{2}\), take the time derivative (16) along the trajectory of (14), then we have
Based on NNs approximation, we have
Choose the NNs adaptive law as
Based on inequations
design the virtual control
where \(k_{1} > 0\), then
The \(i\) th step \(2 \le i \le n - 1\), consider the tracking error state
then the system can be get
Choose NNs to approximate the nonlinear system \(f_{i} \left( {\overline{x}_{i} ,z_{i + 1} } \right) - \dot{\alpha }_{i - 1}\),\(Z_{i} = \left[ {\overline{x}_{i} ,y_{d} , \ldots y_{d}^{{\left( {i - 1} \right)}} ,z_{i + 1} ,\hat{\theta }_{1} , \ldots \hat{\theta }_{i - 1} ,\mu , \ldots \mu^{{\left( {i - 1} \right)}} } \right]^{T} \in \Omega_{i} \subset \Re^{4i - 2}\) and satisfy the \(\Omega_{i}\) is compact set
Choose a Lyapunov functional candidate as
where \(\tilde{\theta }_{i} = \hat{\theta }_{i} - \theta_{i}\), and \(\hat{\theta }_{i} > 0\), \(\hat{\theta }_{i}\) is estimation of \(\theta_{i} = \left\| {W_{i}^{*} } \right\|^{2}\), take the time derivative (27) along the trajectory of (25), then we have
Based on NNs approximation, we have
Choose the NNs adaptive law as
Based on inequations
design the virtual control
where \(k_{i} > 0\), then
The nth step, consider the tracking error state
then the system can be get
Choose NNs to approximate the nonlinear system \(f_{n} - \dot{\alpha }_{n - 1}\),\(Z_{n} = \left[ {\overline{x}_{n} ,y_{d} , \ldots y_{d}^{{\left( {n - 1} \right)}} ,\hat{\theta }_{1} , \ldots \hat{\theta }_{n - 1} ,\mu , \ldots \mu^{{\left( {n - 1} \right)}} } \right]^{T} \in \Omega_{n} \subset \Re^{4n - 3}\), and satisfy the \(\Omega_{n}\) is compact set
Choose a Lyapunov functional candidate as
where \(\tilde{\theta }_{n} = \hat{\theta }_{n} - \theta_{n}\), and \(\hat{\theta }_{n} > 0\), \(\hat{\theta }_{n}\) is estimations of \(\left\| {W_{n}^{*} } \right\|^{2}\), take the time derivative (38) along the trajectory of (36), then we have
Based on NNs approximation, we have
Choose the NNs adaptive law as
based on inequations
design the virtual control
where \(k_{n} > 0\), then
Remark 1
The control signal (44) contain several terms, parameter \(k_{n} > 0\) is designed constant, \(a_{n} > 0\) is positive constant, state \(z_{n}\) is bounded based on Lyapunov theory. Based on Lyapunov candidate functional, \(\frac{1}{{k_{{b_{n} }}^{2} - z_{n}^{2} }}\) is bounded. To realize the PT control, the \(\mu \left( t \right)\) is bounded, therefore, the control signal is bounded.
Theorem 1
Consider the pure-feedback nonlinear system (1), based on MVT system can be changed into strict feedback affine system (4), adaptive neural network PT actual controller (44) is designed with virtual control law (22), (33) and adaptive law (19), (30), (41) for neural networks. The proposed control scheme confirms that closed-loop system is PT stable, and all states of error systems remain within the state constrained interval. The convergence time \(T\) is predefined by control parameter and independent of the initial parameters.
Proof
Choose the following Lyapunov candidate functional as:
Based on inequations as
based on
and
then we have
where
□
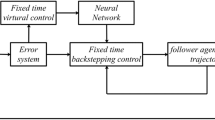
The adaptive neural networks PT backstepping control structure is shown in Fig. 1.

Overall block diagram of PT control process.
Remark 2
The programming, following the PT-adaptive control algorithm outlined in Eqs. (22), (33) and (44), along with the program block diagram illustrated in Fig. 1, can be summarized as follows:
-
Step 1: Calculate the error between the system’s output and the ideal output.
-
Step 2: Design the virtual control based on the neural networks.
-
Step 3: Formulate PT adaptive laws to facilitate the training of neural network weights.
-
Step 4: Utilize backstepping control to determine the control variables.
In Fig. 1, for pure-feedback nonlinear system, backstepping technique constituted control flow, as a recursive control design technique that involves stabilizing a part of the system at a time, starting from the system output and working backward through the system input. Neural network is used to approximate the unknown nonlinear functions of the system, and adaptive law is constructed to learn the system’s behavior from system input and output data. Virtual control laws are designed based on PT adjustment function and neural network in each step of backstepping control. Then the controller is constructed in the last step of backstepping control.
Simulation examples
This section provides two illustrative examples to demonstrate the effectiveness of the proposed PT control scheme.
Mathematical example
The nonaffine pure-feedback nonlinear dynamics is
The ideal output is \(y_{d} = \sin \left( t \right)\), and design the state of the error system
Choose virtual control
where \(k_{1} = 5\), and virtual control is
where \(k_{2} = 5\) and \(k_{3} = 5\) controller have the following form:
The active function is Gaussian function as \(\Psi \left( Z \right) = \left[ {\psi_{1} ,\psi_{2} , \ldots ,\psi_{5} } \right]\), and \(\psi_{i} \left( x \right) = \exp \left( {\frac{{\left\| {x - c_{i} } \right\|^{2} }}{{2b_{i}^{2} }}} \right)\), \(c_{i} = \left[ {\begin{array}{*{20}c} { - 1} & { - 0.5} & 0 & {0.5} & 1 \\ \end{array} } \right]\), \(b_{i} = 5\).
The select the initial parameters as \(x = \left( {1,0,0} \right)^{T}\), and predefine-time \(T_{p} = 5\).
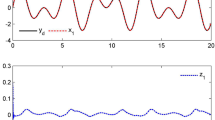
The simulation results are shown in Figs. 2, 3, 4, 5 and 6. The output \(x_{1}\), desired signal \(y_{d}\) and error state \(z_{1}\) are shown in Fig. 2. The state \(x_{2}\), desired virtual signal \(\alpha_{1}\) and error state \(z_{2}\) are shown in Fig. 3. The state \(x_{3}\), desired virtual signal \(\alpha_{2}\) and error state \(z_{3}\) are shown in Fig. 4. From Figs. 2, 3, 4, 5 and 6, the system output is able to track the desired signal in predefine time. All tracking error states are shown in Fig. 5, and trajectories of the controller is shown in Fig. 6.

System state \(x_{1}\), desired signal \(y_{d}\) and error signal \(z_{1}\).

System state \(x_{2}\), virtual signal \(\alpha_{1}\) and error signal \(z_{2}\).

System state \(x_{3}\), virtual signal \(\alpha_{2}\) and error signal \(z_{3}\).

Trajectories of error signals \(z_{1} ,z_{2} ,z_{3}\).

Trajectories of the controller \(u\).
Comparison between the proposed method and fixed-time control in14. In14 the convergence time is guaranteed bound of setting time, but it cannot be predefined or adjusted. In this PT control, the convergence time can be predefined as needed through control parameters.
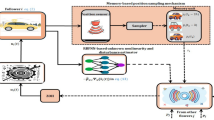
Robotic exoskeleton22
In order to verify the effectiveness of proposed adaptive neural networks PT control in mechanical system, the exoskeleton robot system is proposed in Fig. 7. Robotic exoskeletons have significant theoretical research value and practical application value. Robotic exoskeletons are wearable devices designed to help or enhance the user’s physical abilities. Exoskeletons can provide support for people whose mobility is limited by injury, disability, or aging. They can help these people regain their ability to walk and improve their overall quality of life. In industries such as construction, warehousing and manufacturing, exoskeletons can reduce physical stress on workers, allowing them to lift heavier loads with less effort and reduce the risk of injury. In physical therapy and rehabilitation process, exoskeletons can be used as part of a training regimen to help patients regain strength and motor function after a stroke, spinal cord injury, or other condition that affects movement. Ongoing research is addressing these challenges through innovations such as soft exoskeletons, which provide greater comfort and greater range of motion, as well as the integration of artificial intelligence and smart sensors to improve the responsiveness and usefulness of devices. The future of robotic exoskeletons looks promising, with the potential for a wider range of applications in various fields as the technology advances, becoming more accessible and affordable.

Robotic exoskeleton control structure.
The mechanical system is described as
where \(q\) is joint angle. In the first step, define the tracking error \(x_{1} = q - y_{d} ,x_{2} = \dot{q} - \dot{y}_{d}\), where \(y_{d} = \sin \left( t \right)\), then
where \(F\left( {x_{1} ,x_{2} } \right) = - D^{ - 1} \left( {x_{1} } \right)\left( {C\left( {x_{1} ,x_{2} } \right)x_{2} + G\left( {x_{1} } \right) + f} \right),g\left( {x_{1} } \right) = D^{ - 1} \left( {x_{1} } \right)\), based on system (58) and adaptive neural networks PT control theory, the initial condition is choose as \(x_{1} \left( 0 \right) = 1,x_{2} \left( 0 \right) = 0\).
The active function is Gaussian function as \(\Psi \left( Z \right) = \left[ {\psi_{1} ,\psi_{2} , \ldots ,\psi_{5} } \right]\), and \(\psi_{i} \left( x \right) = \exp \left( {\frac{{\left\| {x - c_{i} } \right\|^{2} }}{{2b_{i}^{2} }}} \right)\), \(c_{i} = \left[ {\begin{array}{*{20}c} { - 2} & { - 1} & 0 & 1 & 2 \\ \end{array} } \right]\), \(b_{i} = 5\).
The simulation result is shown in Fig. 8 with compared with the result in6. It can be seen from the figure that output of exoskeleton robot system is tracking desired signal at predesign time \(T = 5\), and the trajectory is smooth, which demonstrates remarkable capabilities in terms of PT convergence and state constraints satisfaction. Figure 9 shows the actual and expected outputs, Fig. 10 shows the joint acceleration, and Fig. 11 is the controller of the system.

System error states under different control method.

System state \(q\) and desired signal \(y_{d}\).

System state \(\dot{q}\).

Trajectories of the controller \(u\).
Conclusions
In this research, a novel PT control methodology for controlling non-affine pure-feedback nonlinear systems with state constraints is presented. By combining adaptive neural networks, backstepping technology, and PT control, the controller demonstrates remarkable capabilities in terms of PT convergence and state constraints satisfaction. The PT neural networks control feature is particularly significant for practical applications where predictable and bounded convergence is crucial. The method utilizes neural networks control to ensure predefined-time stability of all signals within the systems, allowing system outputs to track the desired trajectory accurately within a user-specified time. Theoretical analysis and simulation results have provided evidence of the effectiveness and robustness of the proposed control approach. It offers valuable insights for researchers and engineers working in the field of control systems and further research and practical applications.
Data availability
All data generated or analysed during this study are included in this published article.
References
Yan, H. et al. Event-triggered sliding mode control of switched neural networks with mode-dependent average dwell time. IEEE Trans. Syst. Man Cybern.: Syst. 51(2), 1233–1243 (2021).
Al-Mahasneh, A. J., Anavatti, S. G., Garratt, M. A. & Pratama, M. Stable adaptive controller based on generalized regression neural networks and sliding mode control for a class of nonlinear time-varying systems. IEEE Trans. Syst. Man Cybern.: Syst. 51(4), 2525–2535 (2021).
Dang, S. T., Dinh, X. M., Kim, T. D., Xuan, H. L. & Ha, M.-H. Adaptive backstepping hierarchical sliding mode control for 3-wheeled mobile robots based on RBF neural networks. Electronics 12(11), 2345 (2023).
Wen, G., Chen, C. L. P. & Ge, S. S. Simplified optimized backstepping control for a class of nonlinear strict-feedback systems with unknown dynamic functions. IEEE Trans. Cybern. 51(9), 4567–4580 (2021).
Wen, G., Chen, C. L. P. & Li, B. Optimized formation control using simplified reinforcement learning for a class of multiagent systems with unknown dynamics. IEEE Trans. Ind. Electron. 67(9), 7879–7888 (2020).
Li, Y., Zhu, Q. & Zhang, J. Distributed adaptive fixed-time neural networks control for nonaffine nonlinear multiagent systems. Sci. Rep. 12(1), 8459 (2022).
Li, Y., Zhang, J., Ye, X. & Chin, C. S. Adaptive fixed-time control of strict-feedback high-order nonlinear systems. Entropy 23(8), 963 (2021).
Li, T. et al. Neural network-based robust bipartite consensus tracking control of multi-agent system with compound uncertainties and actuator faults. Electronics 12(11), 2524 (2023).
Zhang, H., Liu, Y. & Wang, Y. Observer-based finite-time adaptive fuzzy control for nontriangular nonlinear systems with full-state constraints. IEEE Trans. Cybern. 51(3), 1110–1120 (2021).
Liu, Y. H., Su, C. Y., Li, H. & Lu, R. Barrier function-based adaptive control for uncertain strict-feedback systems within predefined neural network approximation sets. IEEE Trans. Neural Netw. Learn. Syst. 31(8), 2942–2954 (2020).
Sun, L., Huang, X. & Song, Y. Distributed event-triggered control of networked strict-feedback systems via intermittent state feedback. IEEE Trans. Autom. Control 68(8), 5142–5149 (2023).
Liu, Y. H. et al. Guaranteeing global stability for neuro-adaptive control of unknown pure-feedback nonaffine systems via barrier functions. IEEE Trans. Neural Netw. Learn. Syst. 34(9), 5869–5881 (2023).
Li, Y., Zhu, Q., Zhang, J. & Deng, Z. Adaptive fixed-time neural networks control for pure-feedback non-affine nonlinear systems with state constraints. Entropy 24(5), 737 (2022).
Li, Y., Zhang, J., Xu, X. & Chin, C. S. Adaptive fixed-time neural network tracking control of nonlinear interconnected systems. Entropy 23(9), 1152 (2021).
Zhou, S. & Song, Y. Neuroadaptive control design for pure-feedback nonlinear systems: A one-step design approach. IEEE Trans. Neural Netw. Learn. Syst. 31(9), 3389–3399 (2020).
Zhang, Y. et al. Global predefined-time adaptive neural network control for disturbed pure-feedback nonlinear systems with zero tracking error. IEEE Trans. Neural Netw. Learn. Syst. 34(9), 6328–6338 (2023).
Ahsan, M., Salah, M. M. & Saeed, A. Adaptive fast-terminal neuro-sliding mode control for robot manipulators with unknown dynamics and disturbances. Electronics 12(18), 3856 (2023).
Cui, R.-H. & Xie, X.-J. Finite-time stabilization of output-constrained stochastic high-order nonlinear systems with high-order and low-order nonlinearities. Automatica 136, 110085 (2022).
He, X., Li, X. & Song, S. Finite-time input-to-state stability of nonlinear impulsive systems. Automatica 135, 109994 (2022).
Kuang, S., Guan, X. & Dong, D. Finite-time stabilization control of quantum systems. Automatica 123, 109327 (2021).
Lin, G., Li, H., Ahn, C. K. & Yao, D. Event-based finite-time neural control for human-in-the-loop UAV attitude systems. IEEE Trans. Neural Netw. Learn. Syst. 34(12), 10387–10397 (2023).
Chen, Z., Li, Z. & Chen, C. L. P. Disturbance observer-based fuzzy control of uncertain MIMO mechanical systems with input nonlinearities and its application to robotic exoskeleton. IEEE Trans. Cybern. 47(4), 984–994 (2017).
Tian, B. et al. Multivariable finite time attitude control for quadrotor uav: theory and experimentation. IEEE Trans. Ind. Electron. 65(3), 2567–2577 (2018).
Liu, D., Liu, Z., Chen, C. L. P. & Zhang, Y. Distributed adaptive neural fixed-time tracking control of multiple uncertain mechanical systems with actuation dead zones. IEEE Trans. Syst. Man Cybern.: Syst. 52(6), 3859–3872 (2022).
Zhang, D., Zhu, S., Zhang, H., Si, W. & Zheng, W. X. Fixed-time consensus for multiple mechanical systems with input dead-zone and quantization under directed graphs. IEEE Trans. Netw. Sci. Eng. 10(3), 1525–1536 (2023).
Lv, J., Ju, X., and Wang, C. Neural network-based nonconservative predefined-time backstepping control for uncertain strict-feedback nonlinear systems. IEEE Trans. Neural Netw. Learn. Syst., pp. 1–12 (2023).
Liu, Y., Xia, Z. & Gui, W. Multiobjective distributed optimization via a predefined-time multiagent approach. IEEE Trans. Autom. Control 68(11), 6998–7005 (2023).
Jiménez-Rodríguez, E., Muñoz-Vázquez, A. J., Sánchez-Torres, J. D., Defoort, M. & Loukianov, A. G. A Lyapunov-like characterization of predefined-time stability. IEEE Trans. Autom. Control 65(11), 4922–4927 (2020).
Zhu, Y., Wang, Z., Liang, H., and Ahn, C. K. Neural-network-based predefined-time adaptive consensus in nonlinear multi-agent systems with switching topologies. IEEE Trans. Neural Netw. Learn. Syst. pp. 1–11, 2023.
Xiao, L., Jia, L., Dai, J., Cao, Y., Li, Y., Zhu, Q., Li, J., and Liu, M. Design and analysis of a novel distributed gradient neural network for solving consensus problems in a predefined time. IEEE Trans. Neural Netw. Learn. Syst. pp. 1–10 (2022).
Ferrara, A. & Incremona, G. P. Predefined-time output stabilization with second order sliding mode generation. IEEE Trans. Autom. Control 66(3), 1445–1451 (2021).
Ning, P., Hua, C., Li, K. & Meng, R. Event-triggered control for nonlinear uncertain systems via a prescribed-time approach. IEEE Trans. Automatic Control 68(11), 6975–6981 (2023).
Hua, C., Ning, P. & Li, K. Adaptive prescribed-time control for a class of uncertain nonlinear systems. IEEE Trans. Autom. Control 67(11), 6159–6166 (2022).
Liu, Z., Dong, X., Xue, J., Li, H. & Chen, Y. Adaptive neural control for a class of pure-feedback nonlinear systems via dynamic surface technique. IEEE Trans. Neural Netw. Learn. Syst. 27(9), 1969–1975 (2016).
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62001263.
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.F. and J.Z.; methodology, Y.L.; software, Y.L.; validation, Y.L.; formal analysis, J.Z.; investigation, Y.L.; resources, J.Z.; data curation, Y.F.; writing—original draft preparation, Y.F.; writing—review and editing, Y.L.; visualization, J.Z.; supervision, J.Z.; project administration, Y.L.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fang, Y., Zhang, J. & Li, Y. Neural networks adaptive predefined-time control for pure-feedback nonlinear systems: a case study on robotic exoskeleton systems. Sci Rep 15, 6041 (2025). https://doi.org/10.1038/s41598-025-90002-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-90002-6
Keywords
This article is cited by
-
Appointed time tracking control for marine surface vessels using the novel integral barrier function
Scientific Reports (2025)
