
Abstract
The Embedded operating system based on STC12C5A MCU is designed to facilitate real-time monitoring and control of the home environment, in order to solve some problems such as low acquisition frequency, poor real-time performance, lack of feedback and adaptation. The Kalman filter and improved k-means algorithm are used to analyze the big data which is processed by BP neural network, and then the most comfortable living environment parameters can be obtained. The independent monitoring mechanism and feedback adjustment are designed to achieve efficient collaboration and stable operation of system hardware and software. The test results show that the system has high acquisition accuracy, fast response speed, good reliability performance, as well as good real-time and adaptive capabilities.
Similar content being viewed by others
Introduction
With the wide application of big data analysis and Internet of Things (IoT), the intelligent home system has been developed rapidly and the internet of everything and intelligent adjustment can be realized. The intelligent systems have been widely used in video surveillance, building safety, electronic examination, security monitoring, environmental measurement, fire warning, and etc1,2,3,4. The monitoring of buildings such as homes and offices is currently a research focus, and many companies have been engaged in research and application in this area, such as Microsoft, Apple Inc., Huawei, Samsung and so on, which have already launched some commercial products now5,6,7,8. The system can be personalized according to the needs of different users to provide the better service and experience, and then the quality and comfort of home life is improved greatly, which has the advantages of energy saving, environmental protection and safety9,10. In addition, it can also realize the connection between home intelligence and city intelligence, furthermore, an important support for the development of smart cities can be provided11,12.
There are still many problems in the intelligent home system on the current. There is a low frequency of data collection, so the information of current environmental changes can’t be transmitted in real time13. There is no support of cloud platform, so the data sharing and remote monitoring can’t be realized14. There is no insufficient space for expansion, so the user’s diverse needs can’t be satisfied15. Meanwhile, it is necessary to deploy multiple sensors and multiple types of sensors in different areas to complete the task of environmental monitoring. If these massive amounts of data need to analyze effectively, the data processing will become complex and the information may be redundant and conflicting, which will make the negative impact on the accuracy and credibility of monitoring results. Therefore, an intelligent home environment monitoring system based on big data technology and improved k-means algorithm is studied in this paper. Most environmental monitoring systems are controlled by the real-time data acquisition, which will lead to the occurrence of delay. The big data monitoring dataset of home environment is used to predict the environmental parameters that the user is accustomed to, and the real-time collected data is combined to achieve the combination of static and dynamic data, thereby the more effective real-time control can be realized. According to user’s living habits, the transformation of home parameters from static to dynamic has been achieved, which can efficiently provide real-time dynamic feedback. Furthermore, this system can also learn user’s lifestyle habits to automatically adjust the home environment based on their behavior patterns, and then, a more personalized and intelligent living experience could be provided.
The Arduino IDE is used to build an embedded real-time operating system to monitor, analyze and regulate the living environmental parameters. The Kalman filter and improved k-means algorithm are applied to analyze, optimize and adjust the collected environmental big data, and then the most comfortable parameters of the habitat environment can be derived. Therefore, the efficient collaboration and stable operation of the system software and hardware is finished. The OneNET cloud platform is used to analyze, store and display the data, and the environmental changes can be remotely controlled through mobile apps or web clients, at the same time, it can be adjusted manually or adaptively. The OneNET cloud platform supports the blocking public access by setting Bucket Policy and ACL, therefore, the public access channel of data can be closed to ensure the data security effectively.
System hardware framework
The system hardware designed in this paper mainly includes STC12C5A microcontroller, sensors, wireless transmission module, Arduino development board, LED display, PC and intelligent furniture. The system schematic diagram is shown in Fig. 1.

System schematic diagram.
The sensors are connected to the microcontroller and used for collecting living environmental parameters, which consist of temperature and humidity sensor, light sensor, PM2.5 sensor, noise sensor and air sensor. The wireless transmission module can upload data to the PC in real time, and send data to the cloud platform, which is used for storing, analyzing, and processing the collected data, and then, the big data processing and intelligent control can be realized. The LED display can display the current living environmental parameters. The Arduino development board controls the operation of the intelligent furniture. The entity of sensor deployment is shown in Fig. 2.

Entity of sensor deployment.
As the perception layer, sensors obtain the home environment data, which can be sent to the gateway by RF modules. As the network layer, PC is used to analyze and process the database by improved k-means algorithm. As the application layer, the OneNET cloud platform is responsible for storing and managing data, furthermore, the user can check the result and control the furniture through different apps and terminals. The overall workflow of the system is shown in Fig. 3.

Internal workflow of the system.
The data are collected and uploaded to the MQTT server at intervals of seconds, and then transferred to the MySQL database as JSON format. This database provides user with real-time data query functionality, including data from all indoor environments. The data table is shown in Fig. 4, which can be queried in PHPMyAdmin backend database.

Backend database.
Data acquisition and analysis
Data filtering
Data acquisition and signal processing is an important part in the intelligent home environment system, which needs to process and convert the raw data collected by the sensors for subsequent data analysis and control16. In this paper, the Kalman filter method based on recursive operation is used to improve the accuracy and stability of the collected data by dynamically predicting and correcting the raw signals collected by the sensors, and the specific processing steps are as follows.
Condition prediction
where x(n|n-1) is the state prediction value, F is the state transfer matrix, x(n-1|n-1) is the state value at the previous moment, B is the input matrix, and u(n) is the control quantity.
Error prediction
where P(n|n-1) is the error covariance prediction, P(n-1|n-1) is the prediction of the previous moment, and Q is the process noise covariance matrix.
Kalman gain calculation
where K(n) is the Kalman gain, H is the observation matrix, and R is the observation noise covariance matrix.
Status correction
where x(n|n) is the state correction value and z(n) is the observed value.
Error correction
where P(n|n) is the error covariance correction value and I is the unit matrix.
The Kalman filter can estimate the next state by using the system state equation and the current state. If the prior estimates are used to improve the error covariance and state matrix, the Kalman gain and the estimated values of state variables can be adjusted with the changes of information at different times. According to the characteristics of original data collected from various sensors and their application requirements, Kalman filter is carried out through a series of parameter adjustments and calibrations17,18,19. When the filtering is achieved, the reliability and stability of environmental monitoring data can be improved. The comparison of the error values between Kalman filter and traditional least mean square filter is shown in Fig. 5, which can be seen that the mean error of Kalman filter can be reduced by more than 50%.

Error comparisons between Kalman filter and traditional least mean square filter.
Improved k-means cluster analysis
The DBSCAN is a clustering algorithm based on density, while the k-means is based on distance20. Compared to others, the k-means is simple and efficient, which can be applied to analyze the situation with large dataset21. The improved k-means algorithm inherits these advantages, what is the research needs to analyzed exactly. Meanwhile, some problems can be solved, such as easily trapping in local optima and difficulty in discovering non convex clusters. Therefore, the improved k-means algorithm is designed for analysis in the paper.
The data need to upload cloud platform, which is the key functions of the intelligent home environment system, so that remote access and management of data can be realized, at the same time, it can support large-scale processing and analysis of data22. Due to the huge volume of big data for environmental monitoring and the low density of data value, cluster analysis can be used to divide the data samples into a number of disjoint clusters, which are used to group the data according to the characteristic attributes23. The k-means algorithm can divide the data into k clusters, and the data points in each cluster are closest to the cluster center. The position of the cluster center is continuously adjusted until the center of the clusters is no longer moving, so that the data can be classify and cluster the data points for better analysis and processing15. The formula for the clustering center is
where ci denotes the clustering center, n denotes the number of data points in the cluster, and xi denotes the coordinates of the data points.
The k clusters of traditional algorithm must be determined in advance. A certain data is selected as the center of clustering randomly, so it is easy to fall into the local search. Therefore, it is difficult to get the best clusters. The screening results of data clustering centers can be obtained by calculating the regional data aggregation density of each clustering center. The largest cluster area is used as the initial cluster area and counted until the number of selected clusters meets the requirements, and then, the improved k-means algorithm has formed. The initial clusters selected by this algorithm can better reflect the spatial distribution characteristics of the data, thereby the termination of clustering results in local optima can be avoided, which is due to the randomness of initial value selection.
If the samples ci and the other samples of average Euclidean distance are calculated to achieve the k-means in the sample set, in order to improve the clusters and prevent getting stuck in local search. The calculation formula is
where d is the Euclidean distance and xj denotes the rest of the sample.
When more remaining samples exist in the average Euclidean distance of sample ci, it indicates that ci is the clustering center of this sample set, which can make the constraint function converge more easily. Li is set as the distance from each data with a cluster to the cluster center, which can be obtained by calculating the Euclidean distance from different cluster centers as
where pj is the number of samples in the cluster and ci is the clustering center of the i cluster.
It is assumed that the evaluation value V is used to describe the closeness of each data to the clustering center in each cluster. The clustering of the improved k-means algorithm is best when it reaches the minimum value, which is computed as
where cm and cn are the clustering centers of the different clusters.

Clustering performance comparison.
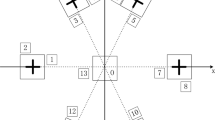
The dataset of environmental temperature is taken as an example to verify the clustering performance between two algorithms. The experimental comparative analysis is conducted on the clustering center selection effect of the article method itself, and the results are shown in Fig. 1. It can be seen from Fig. 6(a) that the multiple cluster centers are arranged in a concentrated manner, which indicates that the method has fallen into local optima during the clustering process24. On the contrary, the clustering centers are evenly distributed without clustering in Fig. 6(b), which can obtain the correct clustering centers and provide guarantees for subsequent abnormal data mining.
Each of the data collected by various sensors is assigned to the cluster of clustering centers, which is closest to ci. The clustering center is calculated based on the data in each cluster, and then, it will redistribute through continuous iteration of the dataset until it is updated to the point, where the clustering center no longer changes. The measurement range, resolution and related information and analysis methods of home environment parameters collected in this paper are shown as Table 1.
The parameters of living environment can be seen, the data takes a relatively high value of the data resolution as the levels of 0.1 °C, 0.1%RH, 1 lx, 1 dB and 0.1% in digital form, so it is convenient for precise analysis by the improved k-means clustering algorithm. The optimal environmental parameters for the living environment can be derived by Kalman filter and improved k-means algorithm, so that the dynamic adjustment and balance of the environmental parameters can be realized by controlling the intelligent furniture through the system.
There are usually significant changes in environmental parameters at different times or functional areas. The big data analysis and data mining of collected environmental parameters are needed in the paper, so the 120 sets of sample data are collected for system performance analysis. The traditional algorithm has the limitation in handling irregular datasets and the weak ability to track real-time environmental information, so the error of missing or abnormal data will appear. On the contrary, the improved algorithm uses density based spatial clustering methods, which not only have higher sensitivity to outliers, but also can intuitively identify the main clusters in the home environment. Therefore, the improved algorithm has the superior adaptive and tracking capabilities, which makes it more advantageous in analyzing user’s preferences for environment parameters, and can effectively reveal user’s favorite living habits.
The error rate refers to the proportion of missing or abnormal data. The error value refers to the cumulative value of missing or abnormal data, which will seriously affect system performance analysis and even cause the system to lose its adaptive adjustment capability. The comparison of accumulated error values for different sets between pre-algorithm and improved algorithm is shown in Fig. 7. It can be seen that the error values of improved algorithm have significantly decreased in both peak and mean values. Comparing with the pre-algorithm, its error rate has been reduced by over 60%. Thereby, the accuracy of the system can be improved greatly, which can provide strong support for subsequent data analysis.

Comparison of errors between pre-algorithm and improved algorithm.
In the final analysis, it can be inferred that the uniform clustering, balanced class size, and good clustering effect can be achieved by the Kalman filter and improved k-means algorithm, which has the advantages of effectively balancing monitoring cost and performance. Meanwhile, this algorithm is easy to implement with the strong interpretability of results, which is suitable for large-scale datasets.
Independent monitoring and feedback regulation
The intelligence should be achieved by the independent monitoring mechanism and feedback regulation, which can adjust the control parameters of intelligent furniture in real time according to the user’s needs and environmental changes. With the algorithm processing, the big data of environmental parameters are uploaded to the cloud platform, which are suitable for user’s living habits. The data is called at regular intervals through the control algorithm and compared with the real-time monitoring data. The difference is used to achieve the adjustment of environmental parameters on time. The process of monitoring and feedback is shown in Fig. 8.
The independent monitoring mechanism can be realized through sensors to monitor the various parameters of living environment in real time, such as temperature, humidity, light, PM2.5, noise and oxygen. According to the monitored data, the intelligent furniture will be automatically controlled and adjusted to meet the occupant’s needs. Take the temperature parameter as an example, the logic of independent monitoring mechanism is as follows.
The feedback adjustment can be achieved through the intelligent control algorithms, and the control parameters of intelligent furniture can be adjusted in real time based on the occupant’s feedback. For example, human infrared sensors can be used to detect human activity, and if the human body is detected to be stationary, the living environmental parameters can be automatically adjusted to maintain comfort. The logic of feedback adjustment is as follows.

Data monitoring and feedback regulation flow.
In short, the control parameters of intelligent furniture can be adjusted in real time based on temperature data and human activity to maintain comfort. The other similar environmental parameters can be designed against the data collected from their corresponding sensors.
System test and performance analysis
System test and data acquisition
In order to ensure the accuracy of the monitoring data, the different types of sensors are used to continuously detect the 6 parameters of temperature, humidity, light, PM2.5, noise and oxygen content at 17:00 to 22:00 every day for a week, which are the main time of user’s spending indoors. The environmental parameters maybe subtle differences in different functional areas within a home environment. For example, a well ventilated bedroom will have a lower temperature than the living room. Therefore, the same sensors are placed in different areas for analysis and their linear relationships should be identified. Since there are many accidental factors and other unexpected or specific situations, the data are collected three times at every specific locations and fixed time points. The time is divided into one minute for each time, and the final detection value is taken as the average of the three collected data in one time period.
The BP neural network function from Matlab toolbox is used as the algorithm library, a simulation software is developed to simulate and evaluate the performance of data fusion technology based on BP neural network in detail25,26. The Kalman filter is used to preprocess the data effectively in order to make the data suitable for subsequent BP neural network model training and to resolve redundancy and conflict27,28,29. And then, the data output of 10 sensors is used to analyzed by Matlab in the home environment, each sensor is targeted at 264 sets of data samples in different states. 184 sets of data are randomly selected as the training sample set, and the remaining 80 sets of data are used as the test and validation sets to evaluate the data fusion effect after training. The linear regression curves of the BP neural network trained by each sensors are shown in Fig. 9.


BP neural network linear regression curve for environmental parameters.
The data collected from the environment are analyzed to derive the relationship between the different parameters and the level of human comfort and health. After 33 steps of learning the neural network, the network converges and the training error value converges to around 0.0007, which can be seen from Fig. 10. The suitable environmental ranges of parameters are shown as Table 1, too high or too low will affect human comfort and health, therefore, the intelligent control system can be adjusted more accurately for the home environment by the independent monitoring and feedback regulation.
When the feature layer data fusion is executing in the BP neural network, it is necessary to extract relevant features from the original data30,31,32. After obtaining the feature vectors of the observation target, the corresponding feature level fusion can be applied to obtain the more comprehensive and consistent description. However, there is a potential risk in the fusion processing, which is due to the data loss or feature extraction errors. Therefore, the number of hidden layers and their corresponding convergence characteristics are very important. If the number is not enough, the training process to fall into local optima will occur. If the number is too much, the calculation time will be very long. From the analysis to the experiments, when the 4 hidden layers are selected, the network can achieve convergence after learning 33 steps to 0.0007, which can ensure the convergence speed of BP neural network and improve its performance indicators.

Convergence line of BP neural network learning.
Parameter optimization and performance analysis
The calculation and optimization of the most suitable environmental parameters for occupants can be modeled by multiple regression analysis, which is implemented by Python’s Scikit-Learn library. The multiple regression model can be expressed as
where Y is the explanatory variable, X1 to Xn are the explanatory variables, β0 to βn are the coefficients, and ε is the error term.
The explanatory variable is the subjective evaluation of environmental comfort by the occupants in the system, while the explanatory variables are the environmental parameters such as temperature, humidity, light, PM2.5, noise and oxygen content. The influence degree of each environmental parameter on comfort and the corresponding coefficients are obtained by performing multiple regression analysis for collecting a certain number of data samples. With the obtainment of regression model, it can be optimized by the genetic algorithm library or optimization algorithm library in Python, in order to search for the most comfortable combination of environmental parameters that are most suitable for occupant’s habitation. The regression model is established as
where comfort is the explained variable, and temperature, humidity, light, PM2.5, noise and oxygen are the explanatory variables.
The intelligent home environment system is designed to find the most livable combination of environmental parameters in this paper. The D-S evidence theory can be used for optimization, in which the value ranges of parameters and each variable can be divided into a certain number of discrete values respectively. The code of improved k-means algorithm can be encapsulated in a black-box model by using Matlab’s Function module, and then, as the original dataset detected by sensors, the clustering center as well as the result after clustering can be obtained. The livable environment quality index (EQI) with integrated temperature, humidity, light, PM2.5, noise and oxygen is obtained after analysis as shown in Fig. 11.

Cluster analysis of environment quality index.
The system’s ability of personalized services can be provided with the user-centric nature, which is reflected in different user’s preferences and requirements for home environment. A partial cluster value datasets are constructed based on the sensor data of different user in different times and areas as Table 2. Therefore, the 9 datasets of user’s sample are utilized as the input layer variables, which are the cluster value output of 5 sensors with 6 parameters in different states.
The fusion results can be seen from Table 3, the recognition rate is the ratio of calculated result and optimal value. When the number of input variables reaches 6, the recognition rate of system fusion has reached over 99%. Furthermore, this system has significant advantages in accuracy.
With the calculation and optimization the most suitable combination of environmental parameters for living can be obtained, thus the optimization and adaptive adjustment of the intelligent home environment system is realized. In addition, a series of test results on the performance of the system are designed in order to facilitate the evaluation and optimization of the performance of the entire intelligent home environment system, including the information of each performance module, sub-module, parameter, parameter standard range, test objectives, test methods and so on. The specific test results are shown in Table 4. It can be seen that the system has excellent response speed and system stability, and the errors are within reasonable limits.
The data from the sensor network is uploaded to the cloud platform server, and then the JSON format data is transmitted to the MySQL database to provide user with real-time query. The App is used as a bridge between user and home system to achieve remote monitoring and control of various environmental parameters remotely. By connecting with the cloud platform, the App can synchronize various data of the home environment in real time, furthermore, the instant and convenient data access and device management services can be provided to the user. The part of display interface is shown in Fig. 12.
It can be seen from Fig. 12 that the 6 parameters in the home environment can be read in real time, meanwhile, the EQI of home and the user’s comfort can be seen too. In addition, the user can also achieve the remote control through the switch button in the interface, and then, the convenience will be realized.

Cloud platform display interface.
Conclusion
An embedded intelligent home environment real-time operating system based on STC12C5A microcontroller is designed, including sensor module, signal acquisition and processing module, embedded system, cloud platform and smart furniture interaction module, which the real-time monitoring and adjustment of living environmental parameters can be realized.
-
(1)
The Kalman filter and improved k-means algorithm are used to provide more effective accuracy, which are applied to analyze the collected environmental big data to derive the most suitable environmental parameters for the occupants. Comparing with the pre-algorithm, its error rate has been reduced by over 60% in order to improve the system performance. Meanwhile, the system is optimized and adjusted by the multivariate regression, and the efficient collaboration and stable operation of the system hardware and software are realized.
-
(2)
Through the collection experiments and functional tests, the results show that the system can realize the real-time monitoring of home environment and adaptive adjustment of intelligent furniture by the gateway and OneNET cloud platform with the independent monitoring and feedback regulation. Undoubtedly, It has obvious advantages in collection accuracy, response speed and stability, which will promote the theory research and system application levels of intelligent home system.
The excellent functionality and potential value of the system have demonstrated in the paper, but this research is still expanding and deepening in several directions.
-
(1)
Miniaturization and low power design. The size of the device will be reduced further in order to make it easier to deploy. In order to reduce the energy consumption and extend the service life of battery, the algorithm and hardware components will be optimized, and then the low-power processing method and system within 6 V can be designed for long time working.
-
(2)
System security. The redundant and erroneous data can be effectively removed by the sampling filtering and clustering algorithms. The OneNET cloud platform can achieve the encrypted transmission of device data, and then, the communication security can be ensured. The terminal login password will be set and required, when the user want to read data or execute operation remotely.
-
(3)
Multi environment integration. More environmental parameters have been analyzed in this research, which is due to the complexity of home environment. 9 different sensors for data analysis have been equipped in the system at present. Meanwhile, the interfaces have been reserved for easy expansion, and the home environment network can be deployed at a deeper level.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Sahar, G., Abu, B. K., Rahim, S., Khani, N. & Bibi, T. Recent advancement of data-driven models in wireless sensor networks: a survey. Technol 9, 261–262 (2021).
Ullah, I. & Mahmoud, Q. H. Design and development of a deep learning-based model for anomaly detection in IoT networks. IEEE Access. 9, 103906–103926 (2021).
Chiang, L., Chee, K., Teck, K. H., Zheng, K. L. & Yit, Y. L. Jian P. C. A novel and low-cost cloud-enabled IoT integration for sustainable remote intravenous therapy management. Electronics 13, 1801 (2024).
Chiang, L. K. et al. Development and evaluation of an IoT-driven auto-infusion system with advanced monitoring and alarm functionalities. IEEE Int. Symp. Circuits Syst. 1, 1–5 (2024). (2024).
Narwade, S. H., Shinde, P. V., Shinde, N. M., Jadhav, V. V. & Shaikh, S. F. Hydrangea-type bismuth molybdate as a room-temperature smoke and humidity sensor. Sens. Actuat B-Chem. 348, 40–43 (2021).
Karabati, S. & Tan, B. Design and implementation of an open, interoperable automate demand response infrastructure. Lawrence Berkeley Natl. Lab. 12, 537–550 (2021).
Suyang, Z., Zhi, W., Jianing, L. & Xiaopeng, Z. Real-time energy control approach for smart home energy management system. Electr. Pow. Compo. Sys.. 42, 315–326 (2021).
Bochkovskiya, A., Chienyao, W. & Hongyuan, L. YOLOv4: optimal speed and accuracy of object detection. Comput. Vis. Pattern Recog. 17, 198–215 (2020).
Chunzheng, H., Fushuai, M., Zeyu, D. & Wei, D. Smart home environment monitoring system based on microcontroller. J. Phys. Conf. Ser. 2405, 35–41 (2022).
Ting, F. & Yang, Y. Distributed communication protocol in wireless sensor network based on internet of things technology. Wirel. Pers. Commun. 126, 44–45 (2022).
Yahui, H. & Daozhong, L. Multisource data acquisition based on single-chip microcomputer and sensor technology. Open. Comput. Sci. 12, 66–67 (2022).
Fangmin, Y., Yan, Z. & Junchao, Z. IoT technology for intelligent management of energy, equipment and security in smart house. Int. J. Adv. Comput. Sci. Appl. 14, 33–35 (2023).
Yan, M. Design of agricultural product cold chain transportation monitoring system based on Internet of Things technology. Proc. Indian Natl. Sci. Acad. 89, 22–24 (2023).
Wang, J. et al. Sensorless control strategy for interior permanent magnet synchronous motors in the full-speed section. Energies 16, 7701 (2023).
Niu, H., Liu, L., Jin, D. & Liu, S. High-tracking-precision sensorless control of PMSM system based on fractional order model reference adaptation. Fractal Fract. 7, 21–28 (2023).
Jia, Q. Research on environment monitoring of network computer rooms in colleges and universities based on the internet of things technology. Wirel. Pers. Commun. 128, 33–34 (2022).
Bin, H., Yahui, Z., Zhize, D., Zixin, Z. & Yannian, Z. Multi-target assignment hunting strategy of UAV swarm based on improved k-means algorithm and shortest time mechanism. J. Northwest. Polytech. Univ. 40, 1297–1301 (2022).
Aldahmashi, J. & Xiandong, M. Real-time energy management in smart homes through deep reinforcement learning. IEEE Access. 12, 433155–443272 (2024).
WenLan, X. & Haoming, H. Design and application of home fire alarm system. J. Phys. Conf. Ser. 1871, 79–84 (2021).
Sun, L., Zhang, J. & Ding, W. Feature reduction for imbalanced data classification using similarity based feature clustering with adaptive weighted K⁃nearest neighbors. Inf. Sci. 2593, 591⁃613 (2022).
Moodi, F. & Saadatfar, H. An improved K⁃means algorithm for big data. JIET Softw. 16, 48⁃59 (2022).
Yousif, S. & Yan, W. Application and evaluation of a K-Medoids-based shape clustering method for an articulated design space. J. Comp. Des. Eng. 8, 935–948 (2021).
Sinaga, K. P. & Yang, M. S. Unsupervised K-means clustering algorithm. IEEE Access. 8, 80716–80727 (2020).
Premkumar, M. et al. Augmented weighted K-means grey wolf optimizer: an enhanced metaheuristic algorithm for data clustering problems. Sci. Rep. 14, 5434 (2024).
Ren, C. et al. Optimal parameters selection for BP neural network based on particle swarm optimization: a case study of wind speed forecasting. Knowl. Based Syst. 56, 226–239 (2014).
Wu, Y. C. & Feng, J. W. Development and application of artificial neural network. Wirel. Pers. Commun. 102, 1645–1656 (2018).
Gao, X. X. et al. Programmable surface plasmonic neural networks for microwave detection and processing. Nat. Electron. 6, 319–328 (2023).
Nakagome, S., Trieu, P. L., He, Y. T., Ravindran, A. S. & Contreras-Vidal, J. L. An empirical comparison of neural networks and machine learning algorithms for EEG gait decoding. Sci. Rep. 10, 4372 (2020).
Boob, D., Dey, S. S. & Lan, G. H. Complexity of training ReLU neural network. Discrete Optim. 44, 100620 (2022).
Shaopeng, Y., Liyuan, D. & Fengyuan, P. Study of Intelligent Fire identication system based on back propagation neural network. Int. J. Comput. Intell. Appl. 3, 2350014 (2023).
Jahani-nasab, M. & Bijarchi, M. A. Enhancing convergence speed with feature enforcing physics-informed neural networks using boundary conditions as prior knowledge. Sci. Rep. 14, 23836 (2024).
Chen, J. et al. Zheng W. F. predict the effect of meteorological factors on haze using BP neural network. Urban Clim. 51, 101630 (2023).
Acknowledgements
This work was supported by Tianjin Research Innovation Project for Postgraduate Students under grant No. 2021KJ085, Tianjin Research Program Project for Higher Education Undergraduate Teaching Quality and Reform under grant No. A231403802.
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, S., Liu, C. & Li, M. Study of intelligent home environment system based on big data and improved k-means algorithm. Sci Rep 15, 5743 (2025). https://doi.org/10.1038/s41598-025-90039-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-90039-7
