
Abstract
Skin diseases, a significant category in the medical field, have always been challenging to diagnose and have a high misdiagnosis rate. Deep learning for skin disease classification has considerable value in clinical diagnosis and treatment. This study proposes a skin disease classification model based on multi-scale channel attention. The network architecture of the model consists of three main parts: an input module, four processing blocks, and an output module. Firstly, the model has improved the pyramid segmentation attention module to extract multi-scale features of the image entirely. Secondly, the reverse residual structure is used to replace the residual structure in the backbone network, and the attention module is integrated into the reverse residual structure to achieve better multi-scale feature extraction. Finally, the output module consists of an adaptive average pool and a fully connected layer, which convert the aggregated global features into several categories to generate the final output for the classification task. To verify the performance of the proposed model, this study used two commonly used skin disease datasets, ISIC2019 and HAM10000, for validation. The experimental results showed that the accuracy of this study was 77.6\(\%\) on the ISIC2019 skin disease series dataset and 88.2\(\%\) on the HAM10000 skin disease dataset. External validation data was added for evaluation to validate the model further, and the comprehensive evaluation results proved the effectiveness of the proposed model in this paper.
Similar content being viewed by others

Introduction
With the rapid development of artificial intelligence technology, the importance of computer vision as a research branch is becoming increasingly prominent. As a key research direction of computer vision, image classification is receiving unprecedented attention, especially in medicine and health, and is showing great potential. For example, it is particularly crucial in organ recognition1, skin disease differentiation and diagnosis2, Help solve many problems related to the classification of fetal organs3, and other areas.
Problem statement
There are various types of skin diseases with complex pathogenesis, and multiple factors easily influence the diagnostic process. Traditional skin disease diagnosis mainly relies on the doctor’s visual observation and empirical judgment. This method inevitably has limitations such as intense subjectivity, high misdiagnosis rate, and difficulty in promptly capturing changes in the condition when facing certain skin diseases with minor manifestations, similar morphology, or rapid development4. At the same time, although there have been breakthroughs in the previous research on skin disease classification based on traditional machine learning methods, it also faces problems such as cumbersome feature engineering and weak model generalization ability when dealing with complex textures, nonlinear feature associations, and large-scale cases5.
In this context, the breakthrough progress of deep learning algorithms in medical image processing provides new ideas and tools for solving the above-mentioned problems. The outstanding performance of Convolutional Neural Networks (CNNs)6 in large-scale image classification challenges such as ImageNet in recent years further validates their potential and advantages in medical image classification tasks. Therefore, the skin disease classification algorithm based on convolutional neural networks has important research and application value. With its unique convolutional structure and hierarchical feature extraction capability, CNN can automatically extract key features from skin disease images and accurately classify them, overcoming some inherent shortcomings of traditional diagnostic methods. Through deep learning technology, CNN can significantly improve the accuracy and efficiency of skin disease diagnosis and adapt to the constantly growing data volume and disease diversity, effectively promoting the development process of intelligent healthcare. Although many works have improved convolutional neural networks using different methods, many existing works still have the following issues: (1) insufficient feature extraction and low classification accuracy; (2) Low contrast skin lesions, changes in lesion shape, and irregularity can all reduce the performance of accurate feature extraction; (3) The increase in imbalanced skin categories increases the probability of more image categories affecting the predictive performance of other categories; (4) Researchers occasionally combine data from multiple sources to improve prediction accuracy, but this process significantly affects the system’s computation time; (5) Redundant and unrelated features can increase the error rate and testing time during the training and testing process; (6) In the prediction process, melanoma, Akia melanoma, and moles are all mistakenly classified as the same category. For an accurate multi-class classification problem, adding hidden layers to neural networks or other classifiers is always very difficult.
Major contributions
The main innovations and contributions of this study are as follows:
-
(1)
This study proposes a skin disease classification model based on multi-scale channel attention, using convolutional neural networks as the core and advanced attention mechanisms.
-
(2)
This model introduces a pyramid segmentation attention module and improves it by removing the SE module in PSA and introducing an efficient channel attention module ECA that does not reduce dimensionality, reducing the problem of information loss.
-
(3)
This design can better achieve multi-scale feature extraction by replacing the residual structure in the backbone network with an inverted residual structure and integrating the attention module into the inverted residual structure.
-
(4)
To validate the performance of the proposed model, this study conducted an experimental analysis using the ISIC2019 skin disease series dataset and two skin disease datasets, HAM10000. The effectiveness and generalization of the model were verified through ablation experiments.In order to further validate the model, real external validation data was added for evaluation, and the comprehensive evaluation results proved the effectiveness of the proposed model in this paper.
The overall structure of this article is as follows: The second part is related work, which will mainly elaborate on the latest research progress and detailed information of each research; The third part provides a detailed description of the proposed model architecture, including model description, network architecture, and an improved pyramid segmentation attention module; The fourth part is the experimental section, which includes an introduction to the experimental environment, an introduction to the dataset, analysis of evaluation indicators on both datasets and ablation experiments; The last part is a summary and outlook of this article.
Related works
With the development of deep learning, more and more fields are starting to train end-to-end learning based on deep learning models, and any feature extraction is no longer considered an independent processing step. Nasr et al. designed a concise and efficient convolutional neural network model aimed at accurately identifying melanoma7. The study first performed image preprocessing to remove noise and artifacts that may interfere with diagnosis and then inputted the processed images into a pre-trained CNN. The final experimental results showed that the CNN model performed well in classification accuracy, surpassing other comparative classification methods. Melanoma is the most lethal form of skin cancer, and its incidence rate has increased in the past decades. However, with the early detection of this malignant disease, the possibility of extending individual lifespan dramatically increases. Akram et al.8 proposed a skin optimizer that utilizes information theory deep feature fusion and entropy-controlled binary bat optimization for skin injury classification and achieved significant results in evaluation on three well-known dermatoscopy datasets. Bibi et al.9 proposed a deep learning architecture for classifying multiple types of skin cancer and melanoma detection. The proposed architecture consists of four core steps: image preprocessing, feature extraction and fusion, feature selection, and classification. The experimental process selected two datasets, ISIC2018 and ISIC2019, for comparison and achieved good performance. Dillshad et al.10 proposed a system based on optimization-assisted deep learning for accurately identifying multiple skin injuries. The sequential program of the system starts with preprocessing and ends with classification.
Moreover, the author proposed a superior optimization method using machine learning classifiers to classify the top features in the fused feature vector and evaluated the proposed framework using the publicly available dataset HAM10000, achieving significant results. Srinivasu et al.11 proposed a model for classifying skin diseases using MobileNet V2 and Long Short Term Memory (LSTM) based on deep learning. The model effectively maintains state information for accurate prediction and can work on lightweight computing devices. Subsequently, Nirupama et al.12 proposed a novel skin disease classification model utilizing advanced deep learning techniques, which combines MobileNet-V2 backbone, Squeeze and Excitation (SE) blocks, Spatial Pyramid Pooling (ASPP), and channel attention mechanism. The model was trained on four different datasets, such as the PH2 dataset, HAM10000 dataset, DermNet dataset, and Skin Cancer ISIC dataset, and the results showed superior classification performance. Demyanov et al. trained a five-layer CNN to achieve the classification of skin disease images, which improved the average classification accuracy on the ISIC dataset13. Esteva et al. used 129450 clinical images containing 2032 skin diseases to train the Inception-v3 model. This is the first time many clinical images have been used to train CNN for skin disease classification, which is a milestone14. The results of this study show that using convolutional neural networks for skin disease classification can achieve diagnostic levels comparable to dermatologists. Brinker et al. trained CNN using the HAM10000 dataset and compared the performance of the algorithm with that of dermatologists. This is the first time that CNN has achieved classification performance comparable to professional dermatologists without clinical image training15. Subsequently, the emergence of classic networks such as VGGNet16, GoogleNet17, and ResNet18 provided new options for research on deep learning-based skin disease classification algorithms.
Although many works have achieved excellent performance on various experimental datasets using deep learning models, most deep learning models require a large amount of labeled data for training, and obtaining many labeled medical images takes much work. Lopez et al. used VGGNet for skin lesion classification and demonstrated the effectiveness of transfer learning in this task19. Han et al. used a pre-trained ResNet-152 model and fine-tuned 19398 images from multiple skin disease datasets to classify clinical images of 12 skin diseases20. Haenssle et al. used a pre-trained Inception V4 network for skin disease classification and also achieved good results21.
In recent years, attention mechanisms and adversarial training have been used to design skin disease classification algorithms, and good results have been achieved. To solve the problems caused by data limitations and data imbalance in the classification process, Qin et al. proposed a style-based Generative Adversarial Network (GAN) for generating high-quality skin disease images. Then, they added these artificially synthesized images to the training set of the pre-trained ResNet-50 model, which improved the model’s classification performance22. Pedro et al. evaluated the effectiveness of the attention and self-attention modules in skin disease classification based on the ResNet architecture. They demonstrated that the attention mechanism can obtain more detailed information about the target to be focused on, effectively improving classification performance23. Panda et al. conducted a comparative study on skin injury classification using transfer learning methods on different deep learning models, further demonstrating the value of transfer learning for network training24. Jang et al. proposed a method using multi-plane and multi-slice Transformers, demonstrating the feasibility of effectively combining CNN and Transformer for 3D medical images25. Cheng et al. proposed a group attention block stacked in ResNet style to capture feature dependencies in channels and space. ResGANet improves the feature representation ability of CNN, enhances classification accuracy on multiple skin lesion datasets, and demonstrates good generalization ability26. Table 1 is a summary of classic models.
Proposed architecture
This study adopts the idea of combining convolutional neural networks with attention mechanisms to classify skin diseases. To fully utilize the advantages of convolutional neural networks, attention mechanisms are introduced to better extract complex feature representations of skin disease images.
General description
This article’s proposed models enhance the attention mechanism and the overall network architecture. For the attention module, the study builds on the Pyramid Split Attention (PSA)27 module and incorporates Efficient Channel Attention (ECA)28 to improve the extraction of multi-scale features. Regarding network structure, the research utilizes ResNet as its backbone, refining the traditional residual network’s bottleneck design and implementing inverted residuals to minimize information loss, enabling more effective feature extraction.
The network’s architecture is organized into three main components: input modules, four processing blocks, and output modules. In the input module, the design begins with a 7 \(\times\) 7 convolutional layer, succeeded by a 3 \(\times\) 3 max pooling layer. This configuration leverages a larger receptive field, facilitating the model’s ability to capture multi-scale information and the intrinsic relationships among adjacent features.
The four processing blocks constitute the network’s core, comprising 3, 4, 6, and 3 bottleneck structures. The first three blocks utilize standard bottleneck structures, while the middle block substitutes the typical 3\(\times\)3 convolutional layer with a pyramid segmentation attention module. In the final block, an inverted residual bottleneck structure is employed. This begins with a 1\(\times\)1 convolution to expand the channels in the input feature map, followed by the pyramid segmentation attention module to extract multi-scale feature representations in a high-dimensional space. The process concludes with another 1\(\times\)1 convolution to map the residuals and reduce the dimensionality to the original input size.
The output module consists of adaptive average pooling and fully connected layers, which transform the aggregated global features into several categories, yielding the final output for the classification task. Figure 1 illustrates the overall network structure.

Network architecture diagram: (a) Representing the detailed structural diagram of Inverted Residuals Bottleneck, (b) represents the detailed structural diagram of Bottleneck.
Network architecture
In ResNet, the traditional bottleneck structure design effectively optimizes residual connections to reduce the number of model parameters and computational costs. This structure typically consists of three consecutive convolutional layers: first, 1\(\times\)1 convolution is used for dimensionality reduction, then 3\(\times\)3 convolution is used to extract features, and finally, 1\(\times\)1 convolution is used for dimensionality enhancement, thereby mapping low-dimensional features back to the original input channel count. However, this design of first reducing dimensions and then increasing dimensions has the following limitations:
-
(1)
Information loss: Initial dimensionality reduction may result in some important information being compressed and discarded, as well as incredibly sparse and critical information in high-dimensional spaces that may not be effectively preserved due to dimensionality reduction.
-
(2)
Feature expression ability: Due to the significant compression of the channel first, it may limit the network’s ability to learn complex features, especially when capturing rich multi-scale or deep-level features.
This study introduces the inverted residual structure based on the traditional bottleneck structure to improve the network backbone. The inverted residual bottleneck structure is an improved solution to the traditional bottleneck structure. Its design concept first increases the dimensionality and then reduces it. This structure first increases the number of channels through a 1\(\times\)1 convolution to expand the feature dimension, then extracts features, and finally performs dimensionality reduction through another 1\(\times\)1 convolution to restore the original number of channels. In the model proposed in this study, each inverted residual bottleneck structure is first upscaled using a 1\(\times\)1 convolution. An improved PSA module is used, and another 1\(\times\)1 convolution is used for dimensionality reduction. This operation enables the model to extract multi-scale features in high-dimensional space, improving the network’s performance in skin disease classification tasks. The inverted residual bottleneck structure of the model is shown in Fig. 2.

Inverted residual bottleneck structure diagram: (a) Represents the original structure, (b) represents the improved detailed module.
The advantage of the inverted residual bottleneck structure is maintaining information integrity. By first increasing the dimensionality, feature learning can be performed in a higher dimensional space, avoiding potential information loss caused by direct dimensionality reduction and helping to improve the network’s expressive power. In addition, unlike classical methods such as SENet and CBAM, the network proposed in this study integrates attention blocks into residual structures. In contrast, most classical methods only embed attention blocks into residual or entire networks.
Improved pyramid attention segmentation module
In deep learning models, classical attention mechanisms are crucial in enhancing the network’s ability to recognize and leverage features effectively. The fundamental approach of common channel attention mechanisms involves representing the original input through channel features and facilitating cross-channel interactions to derive channel weights. Consequently, recent research efforts have concentrated on refining channel feature representation and improving cross-channel interaction methods to amplify the performance benefits of attention mechanisms in various models. One of the most prevalent channel attention methods is the Squeeze and Excitation Networks (SENet)29, which learns the significance of feature channels through global average pooling and fully connected layers. In this approach, each feature channel is assigned a weight based on its importance, enabling the neural network to prioritize specific proper feature channels pertinent to the task at hand. However, a notable limitation of SENet is its inadequate consideration of spatial information, which can lead to suboptimal performance in tasks where spatial relationships are critical.
To address this shortcoming, modules like the Bottleneck Attention Module (BAM) and the Convolutional Block Attention Module (CBAM) have been developed30. These modules enrich attention information by integrating spatial and channel attention, incorporating max pooling to enhance channel feature representation. Additionally, the Style-based Recalibration Module (SRM) further refines channel feature representation by concatenating the outcomes of average pooling and standard deviation pooling31. Despite these advancements, common attention mechanisms still exhibit several limitations: Neglect of Multi-Scale Information and Weak Long-Term Dependency.
These limitations highlight the need for more sophisticated attention mechanisms that can effectively address multi-scale information and long-term dependencies, thereby enhancing the overall performance of deep learning models. Based on the above issues, this study improved the pyramid segmentation attention module, which can effectively extract multi-scale information from skin disease images and establish longer-distance inter-channel correlations. The PSA module is mainly implemented through two steps, namely channel feature representation and feature recalibration.
-
(1)
Channel feature representation The core technology for multi-scale feature extraction is the use of Squeeze Pyramid Concat (SPC)27, which can segment channels and extract multi-scale features from each segmented channel feature map. For the input feature map X, the feature map X is first divided into S parts to represent \(\left[ X_{0}, X_{1}, \ldots X_{S-1}\right]\), with each segmented part having a channel count of \(C^{\prime }=C / S\). This segmentation operation allows the network to process channels in parallel at multiple scales. Extract spatial information of feature maps of different scales from each set of channel feature maps divided by the SPC module, that is, use convolution kernels of different sizes for each part to obtain receptive fields of different scales and extract information of different scales. The increase in the size of the convolution kernel will lead to an increase in computational complexity. In order to control the computational cost, a grouped convolution strategy is introduced, which means that each part of the partition is grouped and convolved separately. The schematic diagram of multi-scale feature extraction is shown in Fig. 3.
The size of each convolution kernel is determined by, and the size of the group is adaptively selected according to the size of the convolution kernel, as shown in formula (1).
$$\begin{aligned} K_{i}=2 \times (i+1)+1, G_{i}=2^{\frac{K_{i}-1}{2}}, F_{i} \in R^{c \times H \times W} \end{aligned}$$(1)Therefore, the specific calculation method for multi-scale features is shown in formula (2).
$$\begin{aligned} F_{i}=\operatorname {Conv}\left( K_{i} \times K_{i}, G_{i}\right) \left( X_{i}\right) , i=0,1,2 \ldots , S-1 \end{aligned}$$(2)After extracting features through convolution kernels of different sizes, they are concatenated on the channel to obtain a multi-scale fused feature map, as shown in formula (3).
$$\begin{aligned} F=\operatorname {Cat}\left( \left[ F_{0}, F_{1}, \ldots F_{s-1}\right] \right) \end{aligned}$$(3)The original squeezing pyramid structure in the PSA module divides the number of input channels into 4 groups, that is S=4, the convolution kernel size of each group increases \(k=3,5,7,9,\) sequentially, and each group is further grouped for convolution. Especially, at that time, the default number of groups was 1. According to the above formula, determine the specific number of groups \(G=1,4,8,6\).
The PSA module utilizes the SE module to extract channel feature representations from feature maps of different scales, capturing the importance of each feature in the channel dimension and obtaining channel attention vectors at different scales, as shown in formula (4). The entire multi-scale channel attention weight vector is shown in formula (5).
$$\begin{aligned} & Z_{i}=S E\left( F_{i}\right) , i=0,1,2, \ldots , S-1 \end{aligned}$$(4)$$\begin{aligned} & Z=Z_{0} \oplus Z_{1} \oplus \ldots \oplus Z_{s-1} \end{aligned}$$(5)Subsequently, the Softmax function was used to recalibrate the weights of channel attention information, thereby constructing a long-term channel attention dependency relationship and effectively promoting the interaction between channel attention information of different scales. The calculation formula for this step is shown in formula (6).
$$\begin{aligned} A_{i}=\operatorname {Softmax}\left( Z_{i}\right) =\frac{\exp \left( Z_{i}\right) }{\sum _{i-0}^{s-1} \exp \left( Z_{i}\right) } \end{aligned}$$(6) -
(2)
Feature recalibration Subsequently, the corresponding scale feature map is multiplied with the attention vector that undergoes weight recalibration to obtain the multi-scale channel attention weighted feature map. After concatenation, a feature map containing richer multi-scale information is obtained. The specific calculation formula for this step is shown in formula (7)and formula (8):
$$\begin{aligned} & Y_{i}=F_{i} \otimes A_{i}, i=1,2,3 \ldots S-1 \end{aligned}$$(7)$$\begin{aligned} & \text{ Out } =\operatorname {Cat}\left( \left[ Y_{0}, Y_{1}, \ldots , Y_{s-1}\right] \right) \end{aligned}$$(8)The pyramid attention segmentation module extracts multi-scale information and models long-term dependencies across channels through a series of operations, greatly improving the feature extraction performance of the attention mechanism. PSA uses the SE module to extract information from feature maps of different scales, but the dimensionality reduction operation of the fully connected layer in the SE module may cause potential information loss issues. Therefore, this study removes the SE module from PSA and introduces an efficient channel attention module ECA that does not reduce dimensionality.

Schematic diagram of multi-scale feature extraction,The left side of the figure represents segmented feature extraction, while the right side performs feature concatenation32.
ECA has demonstrated the importance of avoiding dimensionality reduction in channel attention through experiments. In response to the shortcomings of SE module in cross channel interaction, a 1x1 convolutional layer is directly applied after the global average pooling layer to capture cross channel interaction, removing the fully connected layer, reducing computational complexity and improving efficiency. The ECA module structure is shown in Fig. 4.

ECA33 overall structure diagram (1×1 convolutional layer is directly applied after the global average pooling layer to capture cross channel interaction).

Improved PSA overall structure diagram(replaces the SE module in the original PSA block with the ECA module).
In ECA, the size of the convolution kernel adapts to changes through a function, as shown in formula (9). This design allows for more thorough cross channel interaction in layers with a larger number of channels.

Schematic diagram of improved multi-scale feature extraction(Replace the ordinary grouped convolution in the original PSA with depthwise separable convolution (DWConv)).
Therefore, the introduction of ECA module effectively achieves cross channel interaction while avoiding potential information loss caused by dimension reduction. Moreover, the ECA module can achieve better results with only a few parameters involved, which is also its advantage compared to the SE module.
This study replaces the SE module in the original PSA block with the ECA module, inserts it before Softmax, and uses the multi-scale features extracted by the SPC module as input to further extract the importance of each feature in the channel dimension of the multi-scale feature map, obtaining channel attention vectors at different scales. This improvement can better achieve cross channel interaction, avoid information loss caused by dimensionality reduction, and may have a positive impact on establishing long-term channel attention dependence for subsequent Softmax operations. Therefore, the improved PSA module obtains channel attention vectors at different scales as shown in formula (10).
In order to reduce the number of parameters in the model, this study used a relatively lightweight convolution operation method called Depthwise Separable Convolution (DWConv) instead of the ordinary grouped convolution in the original PSA, which to some extent reduced the number of parameters and lowered the computational cost. Therefore, the specific calculation method for the multi-scale features of the improved PSA module is shown in formula (11).
The schematic diagram of the improved multi-scale feature extraction operation is shown in Fig. 6.
This study modified the pyramid attention segmentation module, which to some extent avoids information loss, has better cross channel interaction ability, and has fewer parameters. The improved pyramid attention segmentation module is shown in Fig. 5.
Experiment
Experimental environment
This experiment achieves the task of skin disease image classification by training a convolutional neural network constructed based on the PyTorch framework. The experimental equipment configuration includes a 30GB hard drive, a remote server running Ubuntu 18.04 operating system, and an NVIDIA V100 GPU graphics card aimed at improving training and evaluation efficiency. Table 2 shows the specific experimental environment settings. The experimental environment configuration of this study meets the computing resource conditions required for the operation of the algorithm model.
Data preprocessing and model training parameters
In this section, a detailed explanation was provided on the data preprocessing and model parameters of the research model.
-
(1)
In terms of dataset preprocessing: transforms. Resize (256) adjusts the shortest edge of the image to 256 pixels while keeping the aspect ratio unchanged. Standardize the image by normalizing the pixel values of each channel to a distribution with a mean of 0 and a standard deviation of 1. Mean values: [0.485, 0.456, 0.406] correspond to the three channels of RGB. Standard deviation: [0.229, 0.224, 0.225] corresponds to the three channels of RGB.
-
(2)
Model parameter settings: During the model training process, we input an image size of 224 \(\times\) 224, Stride is set to 2, kernel size is set to 7, and the activation function is a linear function nn. linear(). Set the Bachsize to 32, which is a choice based on the dataset’s size. 32 is a common choice for medium-sized datasets. When Epochs is set to 100, and the learning rate is set to 0.0001, the model can achieve good convergence.
Datasets
This study conducted experimental validation on two classic datasets, ISIC201934 and HAM1000035.
ISIC2019
In order to evaluate the performance of the proposed model in real-world scenarios, the experiment used the skin disease dataset from the International Skin Imaging Collaboration (ISIC) for dataset selection. ISIC is an international research collaboration project dedicated to early skin cancer detection and diagnosis; relevant datasets are released annually. The following section briefly introduces the ISIC2019 dataset used in this study.
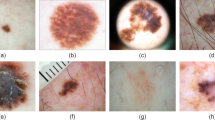
The ISIC2019 Skin Disease Series dataset is used to test the ability of the proposed model to classify different types of skin lesions. It provides 25331 images for training, including eight different types of skin lesions. The specific categories and number of images are as follows: 12875 melanocytic nevi (NV), 4522 melanomas (MEL), 3323 basal cell carcinoma (BCC), 2624 benign keratosis (BKL), 867 actinic keratosis (AKIEC), 253 vascular lesions (VASC), 239 cutaneous fibroadenomas (DF), and 628 squamous cell carcinoma (SCC)30. The ISIC2019 dataset example is shown in Fig. 7.

ISIC2019 dataset sample.

Image visualization with Grad-CAM technique.
Considering the size of the dataset, this experiment will split the dataset into a training set, validation set, and testing set in a ratio of 6:2:2. The dataset parameters are shown in Table 3. The original image size in the dataset is 1024\(\times\)1024 or 600\(\times\)450. In the data preprocessing stage, the image is converted into a data format suitable for model input and standardized. Firstly, randomly adjust and crop the image size to ensure that the output image size is 224 \(\times\) 224. Then, randomly flip the image horizontally for simple data augmentation and convert the image to tensor format. Finally, normalizing the image data is beneficial for model convergence.
HAM10000
In order to further validate the effectiveness of the model, this study also conducted comparative experiments on the Human Against Machine with 10000 Training Images (HAM10000) dataset, which has 10000 training images. The following will briefly introduce the HAM10000 dataset used in this study. The HAM10000 dataset provides 10015 dermatoscopy images with classification labels for training, and 1006 images for validation and testing. The training set of this dataset contains seven different categories, namely 6705 melanocytic nevi (NV), 115 cutaneous fibroids (DF), 1113 melanomas (MEL), 327 photokeratosis (AKIEC), 1099 benign keratosis (BKL), 514 basal cell carcinoma (BCC), and 142 vascular lesions (VASC). The image size in the dataset is 650 \(\times\) 450 pixels.The detailed information is shown in Table 4.
HAM10000 dataset has a serious problem of data imbalance, so this study uses data augmentation to expand the training set, and uses methods such as flipping and shifting to sample and fill in the data distribution. The number of training sets after data augmentation is 52625, which to some extent improves the diversity of training data and the data distribution is relatively balanced.
Grad-CAM is a popular visualization research tool. It is widely used in CNN visualization technology, such as image classification, object detection, and segmentation. It can be used to understand the importance of classification tasks in deep learning methods and to understand which practical features the classification model has learned, providing important assistance for subsequent classification decisions.During the visualization process, Grad-CAM first uses gradient calculation methods to generate feature maps for each category;Secondly, these feature maps are transferred onto the original image and help determine where the decision was made in the image.Due to Grad-CAM’s linear technology, it can be quickly and easily implemented in different neural networks; Finally, Grad-CAM does not use “bounding boxes” to display the position of a specific object in the classification image; instead, it creates a pixel map associated with that object. This approach provides a more accurate, detailed, and high-quality visualization display. Figure 8 shows the image example obtained by applying Grad-CAM technology to skin disease classification images (using the HAM10000 dataset as an example).
Evaluation
In this study, the evaluation indicators commonly used by most researchers were employed36. The evaluation metrics involved in this experiment include Accuracy, Precision, Recall, and Macro-f1.
Experimental results and analysis on the ISIC2019 dataset
This experiment conducted model training on NVIDIA V100 using the ISIC2019 skin disease dataset. On the training parameters, set the initial learning rate to 0.0001, batch size to 32, and epoch value to 100. In order to fully evaluate the performance of the model, in addition to the baseline model ResNet37, this study also used classic models from recent years as comparison models, including EPSANet32, BoTNet38 with multi head self attention module, MobileNet_v339, GhostNet_v240 and MobileViTv3. The line graph of the variation of val accuracy with epoch during model training is shown in Fig. 9.

ISIC2019 dataset sample.
Table 5 shows the performance comparison of the proposed model with the baseline model and five other models on the ISIC2019 dataset. The evaluation indicators are Accuracy, Precision, Recall, and Macrof1, and all four indicators use the Macro average method, which adds up and averages the evaluation indicators of different categories, giving the same weight to all categories. Macro averaging does not bias towards categories with more samples due to differences in the number of samples in each category. It focuses on the performance of each category, and in cases of imbalanced data, this approach can better evaluate classification accuracy.

ISIC2019 dataset sample.

HAM10000 dataset sample.

Comparison of models on the HAM10000 dataset.

Comparison of models on the real validate dataset.
According to Table 4, the performance analysis of each model on the ISIC2019 dataset is as follows:
-
(1)
Accuracy: Through experimental comparison, the accuracy of the proposed model in this study is 77.6%, while the baseline model ResNet has an accuracy of 75.1%, proving that the accuracy of the model has improved by 2.5% compared to the baseline model. EPSANet applied the PSA module to the ResNet backbone network and achieved an accuracy of 76.4% in this task, proving the effectiveness of the PSA module in improving model performance. EPSANet At the same time, the accuracy of the proposed model in this study has improved by 1.2% compared to EPSANet, proving that the work done in this study is valuable.EPSANet outperforms the state-of-the-art methods MobileNetv3 and GhostNetv2 in various metrics, especially compared to the GhostNetv2 model, with an accuracy increase of 4.6%.
-
(2)
Precision: Through experimental comparison, the proposed model has an Precision of 68.5%, while the baseline model ResNet has an accuracy of 62.2%. The accuracy of the model has increased by 6.3% compared to the baseline model and 1.8% compared to the second best performing EPSANet.
-
(3)
Recall rate: Through experimental testing, the model proposed in this study achieved the best recall rate of 64.2% among all compared models. Compared to the baseline model, the recall rate has increased by 8.7%.
-
(4)
Macrof1: Through experimental testing, the model proposed in this study achieved the best results, with a 0.6% improvement compared to the second best EPSANet and a 7.5% improvement compared to ResNet. The bar chart of the experimental results of each model on the ISIC2019 dataset is shown in Fig. 9.
The comparison bar chart of the indicators of each model on the test set is shown in Fig. 10. By comparing with different models, it can be seen that the model proposed in this study has achieved varying degrees of improvement in accuracy, precision, recall, and Macrof1 compared to the baseline model and EPSANet. BoTNet and MobileViTv3, as classic models in recent years, have achieved good performance in multiple tasks. However, these two models perform poorly in this task, possibly because the lesions in skin disease images are concentrated in the central local position of the image, which makes the task insensitive to the global environment. The self attention mechanism that focuses on capturing global information is not as effective as the convolutional neural network based on multi-scale attention in this task. In addition, the small amount of data and the lack of pre training are also reasons for the poor performance of these two models.
Experimental results and analysis on the HAM10000 dataset
The experiment on the HAM10000 dataset also used the baseline model ResNet as well as the classic models EPSANet, BoTNet, and MobileViTv3 in recent years as comparison models. The experiment was conducted on the NVIDIA V100 with an initial learning rate of 0.0001, a batch2 initial value of 32, and an epoch value of 100. Table 6 shows the performance comparison of the proposed model with the baseline model and five other models on the HAM10000 dataset.The line graph of the variation of valcAccuracy with epoch during model training is shown in Fig. 11.
According to Table 5, the performance analysis of each model on the HAM10000 dataset is as follows:
-
(1)
Accuracy: Through experimental comparison, the model proposed in this study has an accuracy of 88.2% on the HAM10000 dataset, while the baseline model ResNet has an accuracy of 86.7%. This proves that the model has an accuracy improvement of 1.5% compared to the baseline model. EPSANet achieved an accuracy of 87.1% in this dataset, demonstrating that the PSA module can effectively improve the performance of the model. At the same time, the model proposed in this study has an accuracy improvement of 1.1% compared to EPSANet, proving that the work done in this study is valuable.
-
(2)
Precision: Through experimental comparison, the proposed model has an Precision of 83.9% on the HAM10000 dataset, while the baseline model ResNet has an accuracy of 81.3%. The accuracy of the model has increased by 2.6% compared to the baseline model, and by 1.1% compared to the second best performing EPSANet.
-
(3)
Recall rate: Through experimental testing, the model proposed in this study achieved the best recall rate of 79.1% among all compared models. Compared to the baseline model, the recall rate increased by 3.8%.Especially with a 12% increase in recall compared to the state-of-the-art method MobileNet_v3.
-
(4)
Macrof1: Through experimental testing, the model proposed in this study achieved the best results, with a 3.6% improvement compared to the second best EPSANet and a 4.4% improvement compared to the baseline model ResNet.The bar chart of the experimental results of each model on the HAM10000 dataset is shown in Fig. 12.
In summary, the experimental results of the model proposed in this study on the ISIC2019 dataset and HAM10000 dataset show that the model has achieved a certain degree of improvement in multiple performance indicators. Therefore, the skin disease classification algorithm model based on multi-scale channel attention has achieved a certain degree of performance improvement in skin disease classification tasks compared to other classical models, proving this work’s effectiveness. Regarding the computational efficiency of the model, There are problems, such as many parameters and insufficient model weight, which is also an important focus of future research.
External validation results and analysis of this model
To further validate the effectiveness of the model, real data collected from hospitals were used for external verification. The data was sourced from Dermatology Department of Wuxi Second People’s Hospital in Jiangsu Province, China, and the selected images were of high quality and clarity, with detailed medical history information and precise diagnosis. The data included seven major categories: actinic keratosis (AKIEC), melanoma, melanocytic nevi, and basal cell carcinoma.The bar chart of the experimental results of each model on the real validate dataset is shown in Fig. 13.
Among them, the external validation data source and training set type are wholly matched, and multi-center validation is used in the validation process. The validation set comprises local data and validation data from the dataset.The detailed results are shown in Table 7.
According to Table 7, the performance analysis of each model on the real dataset is as follows:
-
(1)
Accuracy: The validation results on real datasets show that the model proposed in this study achieves an accuracy of 77.7%, which is 2.1% higher than EPSANet and better than other advanced models. This further demonstrates the practical value of our model in skin disease classification.
-
(2)
Precision: Unfortunately, in terms of accuracy, the MobileNet-v3 model ranks first, with an accuracy of 76%. The model proposed in this paper has an accuracy of 74.5%, which is 1.5% less than MobileNetv3. We analyze that this is due to a certain gap between the real dataset and the two publicly available datasets used for model training, which will also be a problem we will further address in future research.
-
(3)
Recall rate:Compared with other classic models, the recall rate of this study reached 59.8%, which is 13.3% higher than the MobileViT_v3 model and 2.8% higher than the EPSANet model.
-
(4)
Macro_f1: Through experimental testing, the model proposed in this study achieved the optimal result value of 64.8%, while the BoTNet value was 50.4%. The model proposed in this study improved by 14.4% compared to BoTNet and also showed significant improvement compared to other advanced models.
Based on the above analysis, it is concluded that the overall performance of this model is good on external validation datasets, but there are still relative errors in certain indicators. This reason is preliminarily considered to be related to the actual data volume and lack of preprocessing, which is also a problem that needs to be addressed in subsequent research.
Ablation experiment
In order to further verify the impact of the improved pyramid segmentation attention module and the selection of inverse residual structure on the classification results, this study demonstrated through ablation experiments that the modifications made to the model have a positive effect on improving the experimental results. In order to reduce the impact of imbalanced data categories on the experiment, the HAM10000 dataset with data augmentation and category supplementation was selected for ablation experiments. In terms of experimental design, this study conducted experiments on the following four situations, and the results of the ablation experiment are shown in Table 8.
-
(1)
The original ResNet network.
-
(2)
Only use PSA+ResNet with improved pyramid segmentation attention module in bottleneck structures.
-
(3)
Only use the inverse residual structure of IR+ResNet in the last three layers.
-
(4)
Simultaneously using an improved pyramid segmentation attention module and an IR+PSA+ResNet with the last three layers of inverted residual structure.
According to the results in Table 8, it can be analyzed that the network with an improved pyramid segmentation attention module added to the ResNet bottleneck structure alone has a certain degree of improvement in accuracy, precision, recall, and Macro_f1 compared to the baseline model ResNet. This is because the attention mechanism can better extract image features, thereby improving the performance of classification tasks. When using the inverted residual structure alone in the last three layers of the network, the four indicators of Accuracy, Precision, Recall, and Macro_f1 also show slight performance improvements. This is because the inverted residual structure can avoid potential information loss during dimensionality reduction and improve the network’s feature expression ability. In order to combine the advantages of both, this study simultaneously used an improved pyramid segmentation attention module and an inverted residual structure, and integrated attention blocks into the inverted residual structure. This design realizes the extraction of multi-scale features in high-dimensional space, which will better leverage the advantages of the inverse residual structure and improve the performance of skin disease classification algorithms. Table 6 shows that the model proposed in this study has achieved improvements in all indicators, and each modification is beneficial for improving the performance of skin disease classification tasks.
Conclusion
This study proposes a skin disease classification model based on multi-scale channel attention. The network architecture of the model consists of three main parts: an input module, four processing blocks, and an output module. Firstly, the model has improved the pyramid segmentation attention module to extract multi-scale features of the image fully; Secondly, the reverse residual structure is used to replace the residual structure in the backbone network, and the attention module is integrated into the reverse residual structure to achieve better multi-scale feature extraction. Finally, the output module consists of an adaptive average pool and a fully connected layer, which convert the aggregated global features into several categories to generate the final output for the classification task. In order to verify the performance of the proposed model, this study used two commonly used skin disease datasets, ISIC2019 and HAM10000, for validation. The experimental results showed that the accuracy of this study was 77.6\(\%\) on the ISIC2019 skin disease series dataset and 88.2\(\%\) on the HAM10000 skin disease dataset.
The limitations of this work are as follows: (1) When extracting multi-scale features in high-dimensional space, the model cannot evaluate whether valuable feature responses have been extracted in each dimension, which may lead to sparsity issues; (2) Although we have reduced the parameter count through depthwise separable convolution to compensate for the increased parameter count caused by this design, the overall parameter count of the model is still relatively large; (3) Due to the lack of a dermatoscopy storage system in the local hospital, there are certain difficulties in collecting real hospital datasets. In the future, classification models based on multi-kernel residual modules and multi-focus attention mechanisms will be designed and trained on multiple universal datasets, and efforts will be made to validate them in real clinical data, providing clinical support for multi-type classification of skin diseases.
Data availability
Due to patient privacy, external validation datasets generated and/or analyzed during this study are not publicly available, but may be obtained from the corresponding authors upon reasonable request. The public dataset can be downloaded on the internet by oneself.
References
Chen, M., Cui, D., Haick, H. & Tang, N. Artificial intelligence-based medical sensors for healthcare system. Adv. Sensor Res. 3, 2300009 (2024).
Groh, M. et al. Deep learning-aided decision support for diagnosis of skin disease across skin tones. Nat. Med. 30, 573–583 (2024).
Rauf, F. et al. Artificial intelligence assisted common maternal fetal planes prediction from ultrasound images based on information fusion of customized convolutional neural networks. Front. Med. 11, 1486995 (2024).
Yadav, R. & Bhat, A. A systematic literature survey on skin disease detection and classification using machine learning and deep learning. Multimed. Tools Appl. 83, 1–32 (2024).
Saleh, N., Hassan, M. A. & Salaheldin, A. M. Skin cancer classification based on an optimized convolutional neural network and multicriteria decision-making. Sci. Rep. 14, 17323 (2024).
Zhao, X. et al. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 57, 99 (2024).
Nasr-Esfahani, E. et al. Melanoma detection by analysis of clinical images using convolutional neural network. In 2016 38th annual international conference of the IEEE engineering in medicine and biology society (EMBC), 1373–1376 (IEEE, 2016).
Akram, T. et al. Dermo-optimizer: Skin lesion classification using information-theoretic deep feature fusion and entropy-controlled binary bat optimization. Int. J. Imaging Syst. Technol. 34, e23172 (2024).
Bibi, S. et al. Msrnet: multiclass skin lesion recognition using additional residual block based fine-tuned deep models information fusion and best feature selection. Diagnostics 13, 3063 (2023).
Dillshad, V. et al. D2lfs2net: Multi-class skin lesion diagnosis using deep learning and variance-controlled marine predator optimisation: An application for precision medicine. CAAI Trans. Intell. Technol. https://doi.org/10.1049/cit2.12267 (2023).
Srinivasu, P. N. et al. Classification of skin disease using deep learning neural networks with mobilenet v2 and lstm. Sensors 21, 2852 (2021).
Nirupama & Virupakshappa. Mobilenet-v2: An enhanced skin disease classification by attention and multi-scale features. J. Imaging Inf. Med. https://doi.org/10.1007/s10278-024-01271-y (2024).
Demyanov, S., Chakravorty, R., Abedini, M., Halpern, A. & Garnavi, R. Classification of dermoscopy patterns using deep convolutional neural networks. In 2016 IEEE 13th International symposium on biomedical imaging (ISBI), 364–368 (IEEE, 2016).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–8 (2017).
Brinker, T. J. et al. A convolutional neural network trained with dermoscopic images performed on par with 145 dermatologists in a clinical melanoma image classification task. Europe. J. Cancer 111, 148–154 (2019).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Szegedy, C. et al. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1–9 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Lopez, A. R., Giro-i Nieto, X., Burdick, J. & Marques, O. Skin lesion classification from dermoscopic images using deep learning techniques. In 2017 13th IASTED international conference on biomedical engineering (BioMed), 49–54 (IEEE, 2017).
Han, S. S. et al. Classification of the clinical images for benign and malignant cutaneous tumors using a deep learning algorithm. J. Invest. Dermatol. 138, 1529–1538 (2018).
Haenssle, H. A. et al. Man against machine: diagnostic performance of a deep learning convolutional neural network for dermoscopic melanoma recognition in comparison to 58 dermatologists. Ann. Oncol. 29, 1836–1842 (2018).
Qin, Z., Liu, Z., Zhu, P. & Xue, Y. A gan-based image synthesis method for skin lesion classification. Comput. Methods Progr. Biomed. 195, 105568 (2020).
Pedro, R. & Oliveira, A. L. Assessing the impact of attention and self-attention mechanisms on the classification of skin lesions. In 2022 International Joint Conference on Neural Networks (IJCNN), 1–8 (IEEE, 2022).
Panda, S., Tiwari, A. S. & Prusty, M. R. Comparative study on different deep learning models for skin lesion classification using transfer learning approach. Int. J. Sci. Res. Publ. 11, 219–232 (2021).
Jang, J. & Hwang, D. M3t: three-dimensional medical image classifier using multi-plane and multi-slice transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 20718–20729 (2022).
Cheng, J. et al. Resganet: Residual group attention network for medical image classification and segmentation. Med. Image Anal. 76, 102313 (2022).
Zhang, H., Zu, K., Lu, J., Zou, Y. & Meng, D. Epsanet: An efficient pyramid split attention block on convolutional neural network. arXiv preprint arXiv:2105.14447 (2021).
Wang, Q. et al. Eca-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11534–11542 (2020).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141 (2018).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), 3–19 (2018).
Lee, H., Kim, H.-E. & Nam, H. Srm: A style-based recalibration module for convolutional neural networks. In Proceedings of the IEEE/CVF International conference on computer vision, 1854–1862 (2019).
Zhang, H., Zu, K., Lu, J., Zou, Y. & Meng, D. Epsanet: An efficient pyramid squeeze attention block on convolutional neural network. In Proceedings of the asian conference on computer vision, 1161–1177 (2022).
Wang, Q. et al. Eca-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11534–11542 (2020).
Hameed, M., Zameer, A. & Raja, M. A. Z. A comprehensive systematic review: Advancements in skin cancer classification and segmentation using the isic dataset. CMES-Comput. Model. Eng. Sci. 140, 2131–2164 (2024).
Adebiyi, A. et al. Accurate skin lesion classification using multimodal learning on the ham10000 dataset. medRxiv 2024–05 (2024).
Opitz, J. A closer look at classification evaluation metrics and a critical reflection of common evaluation practice. Trans. Assoc. Comput. Linguistics 12, 820–836 (2024).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Srinivas, A. et al. Bottleneck transformers for visual recognition (2021). arxiv:2101.11605.
Howard, A. et al. Searching for mobilenetv3 (2019). arxiv:1905.02244.
Tang, Y. et al. Ghostnetv2: Enhance cheap operation with long-range attention (2022). arxiv:2211.12905.
Funding
This work was supported by grants from Sponsored by Natural Science Foundation of Xinjiang Uygur Autonomous Region (grant number:2024D01C299;2022D01C184),and State Key Laboratory of Pathogenesis, Prevention and Treatment of High Incidence Diseases in Central Asia Fund(SKL-HIDCA-2024-BC9);
Author information
Authors and Affiliations
Contributions
Hui Liu and Yibo Dou jointly serve as first authors, with Hui Liu focusing on model design and platform development, while Yibo Dou is responsible for the initial writing of the manuscript and Assist in platform development. Kai Wang, YunMin Zou and Gan Sen provide guidance on real data collection and verification. HuLing Li was dedicated to the task of processing datasets,Gan Sen and Xiangtao Liu reviewed this article. All authors have made indispensable contributions to this article and unanimously acknowledged the final submitted version.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, H., Dou, Y., Wang, K. et al. A skin disease classification model based on multi scale combined efficient channel attention module. Sci Rep 15, 6116 (2025). https://doi.org/10.1038/s41598-025-90418-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-90418-0
