
Abstract
Data clustering is a fundamental yet challenging task in data science. The minimum sum-of-squares clustering (MSSC) problem aims to partition data points into k clusters to minimize the sum of squared distances between the points and their cluster centers (centroids). Despite being NP-hard, solvers exist that can compute optimal solutions for small to medium-sized datasets. One such solver is SOS-SDP, a branch-and-bound algorithm based on semidefinite programming. We used it to obtain optimal MSSC solutions (optimum clusterings) for various k across multiple datasets with known ground truth clusterings. We evaluated the alignment between the optimum and ground truth clusterings using six extrinsic measures and assessed their quality using three intrinsic measures. The results reveal that the optimum clusterings often differ significantly from the ground truth clusterings. Additionally, the optimum clusterings frequently outperform the ground truth clusterings, according to the intrinsic measures that we used. However, when ground truth clusters are well-separated convex shapes, such as ellipsoids, the optimum and ground truth clusterings closely align.
Similar content being viewed by others

Introduction
Motivation
Data science is strongly related to the progress in multiple sub-fields of mathematics and computer science. Understanding the data and finding hidden relations between data instances or variables are getting more and more important, especially in the era of Big Data and Artificial Intelligence. Grouping the data instances according to their inner similarity is called clustering analysis1, Chapter 10.32,3. A vast amount of literature is devoted to this problem, covering several different aspects. Nevertheless, two important questions always need to be answered: (i) what is the number of groups that we want to cluster the data into? (ii) what is the similarity measure that will be used to compute the similarity of two data points and consequently to define groups of similar data, i.e., the clusters? Usually, these two questions are strongly related, i.e., the number of clusters and the clustering are strongly dependent on the underlying similarity measure.
In some cases, we know in advance the actual number of groups into which the data should be clustered, e.g., based on some domain-specific knowledge. In these cases, the main task is to compute an assignment of the data points into this number of groups, which is also called the k-clustering problem. However, this is a rather rare situation. Usually, the number of clusters has to be determined during the clustering analysis. Some methods, such as the hierarchical clustering methods, determine the number of clusters during the clustering process. Other methods, such as the k-means or the k-median clustering algorithms, require this number as input, and there are many different criteria and techniques that can be used to determine the appropriate number of clusters, e.g., the cross-validation, the “Elbow” method, the gap statistic, the silhouette method, etc., see4,5.
Clustering is often part of exploratory research and, in general, there is not only one good/optimum clustering. The selection of similarity measures, number of groups, and good assignment into clusters are often done iteratively, based on an increasing understanding of the data and partial clustering results. Many algorithms for clustering analysis are known in the literature. Usually, they iteratively define groups of similar data points by following some principles that should hold for good clustering, e.g., cluster homogeneity, cluster completeness, possessing a rag bag cluster, n-invariance, see e.g.,6. In each iteration, they improve the clustering such that the selected criteria are improved. Once there is no more improvement or the maximum number of iterations is reached, the algorithm terminates.
In a very complex situation where there are many criteria and principles for good clustering, and consequently many different algorithms for computing such solutions, usually leading to many different clustering solutions for the same dataset, the question naturally arises as to what is a ground truth, i.e., which groups are most natural, which data points really belong to the same group. Very often such clustering is not known, but for some datasets it is provided by the data provider. If we know the ground truth clustering, we can compare the clustering computed by different algorithms with it. This was the main motivation for us. We focused on an exact mathematical programming formulation of the clustering problem, solved it with available global optimization algorithms, and compared the optimum solution with the ground truth clustering.
The data clustering problem
The data clustering problem can be formulated as follows: given a set of data points \({\mathcal {P}}=\{p_1,p_2,\ldots ,p_n\}\subset \mathbb {R}^m\), the objective is to find the cluster number k and an assignment \(\chi :{\mathcal {P}}\rightarrow \{1,2,\ldots ,k\}\) such that \(\chi (p_i)=\chi (p_j)\) for any pair of (very) data similar points \(p_i\) and \(p_j\) (\(p_i \ne p_j\)). For any k assignment \(\chi\) we can define the i-th cluster, implied by \(\chi\) as \(C_i=\chi ^{-1}(i)\) and the corresponding clustering is \({\mathcal {C}}=\{C_1,\dots , C_k \}\).
Even if we already know the number k, there are still many possibilities for how to measure (high) similarity between the data points and how to compute good clustering \({\mathcal {C}}\). In this paper, we will focus on Euclidean distance measure between the two data points. The closer the points are in the Euclidean distance, the more similar they are. We evaluate each clustering by considering the total sum of squares of distances between the data points and the centroid of the corresponding cluster. This means that: (i) for each cluster we compute its centroid (the vector sum of all data points from this cluster, divided by the cardinality of this cluster). (ii) for each data point we compute the square Euclidean distance between it and the centroid of the cluster to which this data point is assigned. The sum of squares of these distances across all data points is a measure of the quality of the clustering. The smaller it is, the better the clustering.
We can formulate the problem of minimizing the sum of squares of distances as a mathematical optimization problem, where the decision variables represent assignments \(\chi\) and the objective function is the sum of squares of distances. This yields the so-called minimum sum-of-squares clustering (MSSC) problem, formally introduced in “Mathematical programming formulation for MSSCproblem” section. This problem is well-known in the literature7,8 as it arises in a wide range of applications, for example, image segmentation9,10, biology11 and document clustering12. It is an NP-hard problem13,14, which means that there is no polynomial time algorithm to solve it to optimality (unless P=NP). Nevertheless, we can still solve it for small datasets, e.g., by using the exact solver SOS-SDP15. The announcement of this solver was actually the trigger for our research. We decided to solve the MSSC problem to optimality for a number of small datasets for which the ground truth clustering \({\mathcal {C}}_{true}\) and the true number of clusters \(k_{true}\) were known - usually provided by the dataset provider.
Clustering performance can be quantified by a number of metrics. There are mainly two types of metrics to evaluate this performance. To compare different clustering methods, we use intrinsic and extrinsic measures. Extrinsic measures require ground truth labels, while intrinsic measures do not.
The datasets with a ground truth clustering are actually the classification datasets, where the classification labels are considered as the ground truth label. This idea was elaborated in16, where the authors show that this approach requires careful attention since the class labels are assigned based on the properties of each individual data point, while the clusterings take into account relations between the data. Our paper is aligned with this observation and provides a deeper understanding of this issue.
A ground truth-based comparative study was done in17, where the authors did not solve an exact clustering problem (like MSSC) but rather compared five widely known approximate algorithms for data clustering on seven published micro-array gene expression datasets and one artificial dataset. The performances of these algorithms were assessed with several quantitative performance measures, which are different from the measures that we use in this paper.
In18 the authors introduced a population-based metaheuristic algorithm to solve MSSC approximately, which performs like a multi-start k-means. They demonstrate that this algorithm outperforms all recent state-of-the-art approximate algorithms for MSSC in terms of local minima and the computed clusters are closer to the ground truth compared to the clusters computed by other algorithms, on the artificial Gaussian-mixture datasets.
In6,16,17, the ground truth labels and the extrinsic metrics were used to validate the quality of clusterings and compare different clustering methods. The ground truth labels have shown limitations in many instances for detecting the hidden pattern of the sample and they can produce misleading information when used as true ground labels for measuring the quality of clusterings16.
The clustering problem and its variants remain subject of intensive research. The multi-view clustering problem recently received lot of research attention. It can be formulated as a problem of non-negative matrix factorization of several view matrices with joint consensus matrix19,20,21. This optimization problem is again very hard, so the authors devised their own algorithms, for which they proved a convergence, but not necessarily to a global optimum. The resulting local optima were used to extract multi-view clusterings, and these clusterings were compared with the ground truth labelings using some of the well-known similarity measures, like accuracy and normalized mutual information (NMI). A similar approach was used for complex data clustering22, graph-based subspace clustering23, and representation learning24. In this work, the authors do not use the clusterings based on the global optimum of mathematical programming formulations of the basic problems, as we do in this paper, since they do not compute the global solutions. Actually, they made no attempt to compute the global optima of the mathematical programming formulation of the clustering problem, as we do, probably because these problems are very hard to solve globally.
Our contributions
The main goal of this paper is to solve exactly the MSSC problem on a large list of small or medium size datasets available in the literature for which the true number of clusters \(k_{true}\) and the ground truth clustering \({\mathcal {C}}_{true}\) are known, and to check how the MSSC optimum clustering \({\mathcal {C}}_{MSSC}\), i.e. the clustering that corresponds to an optimum solution of MSSC aligns with the ground truth clustering. More precisely, we
-
solve the mathematical programming formulation of clustering problem MSSC to optimality for values of k with \(|k-k_{true}|\le 2\) for 12 real datasets and for 12 artificial datasets, obtained from https://github.com/deric/clustering-benchmark/tree/master/src/main/resources/datasets, which are small enough and for which the ground truth clustering \({\mathcal {C}}_{true}\) is available. This data is available under the open data standards, together with the optimum solutions, see25;
-
compare the MSSC optimum clusterings \({\mathcal {C}}_{MSSC}\) with the ground truth clusterings \({\mathcal {C}}_{true}\) by computing a number of extrinsic measures: Adjusted Mutual Information (AMI), Adjusted Random Score (ARS), Homogeneity (h), Completeness (c), normalized mutual information (NMI) and Fowlkes-Mallows scores (FMS);
-
additionally evaluate the quality of the optimum MSSC clusterings \({\mathcal {C}}_{MSSC}\) and of the ground truth clusterings \({\mathcal {C}}_{true}\) by computing three intrinsic measures: the Calinski-Harabasz Criterion (CHC), the Davies Bouldin Index (DBI), and the Silhouette Evaluation Score \(S_{score}\);
-
provide a better understanding of why and when the optimum clustering aligns with the ground truth clustering.
Our analysis shows that
-
the optimum clustering (i.e., the optimum solution of MSSC) can be computed if the number of data points times the number of clusters k is approximately below 1000;
-
the optimum clusterings \({\mathcal {C}}_{MSSC}\) usually significantly differ from the ground truth clustering in the following manner: the values of the extrinsic measures are often far below the optimum, which is 1 and would be achieved if the ground truth and the optimum clustering would be the same. Additionally, the values of extrinsic measures, evaluated at \({\mathcal {C}}_{MSSC}\) and corresponding to \(k_{true}\) are rarely optimum, i.e., other k often gives better values of these measures;
-
the ground truth clusterings are usually much worse compared to the optimum clusterings by considering the three intrinsic quality measures;
-
when the ground truth clustering has natural expected geometry, i.e., the clusters have the form of convex sets, e.g., ellipsoids, which are well separated from each other, then the ground truth clustering is very similar to the optimum clustering.
These observations are not unexpected but, to the best of our knowledge, have never been shown so explicitly.
The main innovation of this paper therefore lies in computing the global optimum of the MSSC formulation for the clustering problem and rigorously comparing it to the ground truth clustering provided by domain specialists who supplied the original data. Through a detailed quantitative analysis, we demonstrate that these two clusterings exhibit significant discrepancies, providing robust evidence that, in general, they are far from being similar.
Outline
The rest of the paper is structured as follows. In “Mathematical programming formulation for MSSCproblem” section, we present the SDP relaxation for MSSC problem and explains hows the exact solver SOS-SDP works. “Quality measures” section introduces all the metrics to compare the quality of different clustering and the metrics of all clustering results are presented in “Numerical results” section. “Discussion” section analyzes the numerical results and “Conclusions” section concludes the paper and discusses future work.
Notation
The Euclidean distance between two points \(p,q\in \mathbb {R}^m\) is denoted by \(d_E\) and defined as follows \(d_E(p,q)=\Vert p-q\Vert =\sqrt{\sum _{i}^m (p_i-q_i)^2}\). We use [n] to denote the set of integers \(\{1,\dots ,n\}\). The trace of matrix X is denoted by \(\text {tr}(X)\). The space of symmetric matrices is equipped with the trace inner product, which for any \(X, Y \in {{\mathcal {S}}}^{n}\) is defined as \({\langle X,Y \rangle }:= \text {tr}(XY)\). The associated norm is the Frobenius norm \(\Vert X\Vert _F := \sqrt{\text {tr}(X^2)}=\sqrt{\sum _{ij} x_{ij}^2}\). The cone of symmetric positive semidefinite matrices of order n is denoted by \({{\mathcal {S}}}_+^n :=\{X \in {{\mathcal {S}}}^n\mid X\succeq {\textbf{0}} \}\).
We denote by \({\textbf{e}}_n\) the vector of all ones of length n. In case that the dimension of \({{\textbf{e}}}_n\) is clear from the context, we omit the subscript. The operator \(\text {diag}:\mathbb {R}^{n\times n} \rightarrow \mathbb {R}^n\) maps a square matrix to a vector consisting of its diagonal elements. Its adjoint operator is denoted by \(\text {Diag}:\mathbb {R}^n \rightarrow \mathbb {R}^{n\times n}\). The rank of matrix X is denoted by \(\text {rank}(X)\). The average value of components of vector v is denoted by \(\text {avg}(v)\).
Mathematical programming formulation for MSSC problem
In this paper, we use the formulation of the MSSC problem as a mathematical optimization problem in binary variables, which are subject to linear constraints, and with a non-convex objective function that represents the sum of squares of Euclidean distances between the data points and the centroids of the clusters to which the points correspond.
For given set of data points \({\mathcal {P}}=\{p_1,p_2,\ldots ,p_n\}\subset \mathbb {R}^m\) and given integer k we define k-clustering as an assignment \(\chi :{\mathcal {P}}\rightarrow \{1,2,\ldots ,k\}\). The data points that are mapped to integer \(1\le i\le k\) are called the i-th cluster. The assignment is nontrivial if there is no empty cluster. We can represent each nontrivial assignment \(\chi\) by a matrix \(X\in \{0,1\}^{n\times k}\) such that \(x_{ij}=1\) if and only if \(\chi (p_i)=j\). Therefore, the row-sums of X must be equal to 1 (each data point is assigned to exactly one cluster) and the column-sums of X must be at least one (otherwise the assignment is not nontrivial). Therefore, the minimum sum-of-squares clustering (MSSC) problem for a fixed k can be formulated as a non-linear integer programming problem (Vinod8, Rao7):
where \(c_j\) is the centroid of the j-th cluster and can be substituted as
This formula can be derived by setting the gradient with respect to the variable \(c_j\) of the objective function to zero. We obtain
By expressing the varibble \(c_j\) we get the formula (1).
Peng et al.26 introduced equivalent formulations for (MSSC) by introducing substitution \(Z:=X(X^\top X)^{-1}X^\top\):
where \(W = (W_{ij}) \in {{\mathcal {S}}}^n\) with \(W_{ij} = p_i^\top p_j\). If we know an optimum matrix Z for (2), we can get back the optimum clustering matrix X for (MSSC) by using the fact that \(z_{ij}>0\) if and only if the data vertices \(p_i\) and \(p_j\) are in the same cluster. So we can put \(p_1\) to cluster 1 and the same we do with all \(p_i\) with \(z_{1i}>0\). The first data point that remains unassigned is then put to cluster 2 and the same all data points with \(z_{2i}>0\). This is repeated until all data points are assigned.
MSSC in formulation (2) remains NP-hard. However, this formulation opens new possibilities to solve (MSSC) to optimality. Piccialli et al15 introduced an SDP relaxation for (2) by eliminating the constraint \(\textrm{rank}(Z)=k\), which can be solved to arbitrary precision with state-of-the-art SDP solvers (e.g.,27,28). The SDP relaxation serves as a model to generate lower bounds in the exact methods such as the branch-and-bound algorithm. The SOS-SDP algorithm from15 is an implementation of such branch-and-bound algorithm based on this relaxation, which was additionally significantly strengthened with the following cutting planes:
-
Triangle inequalities, which are based on the observation that if the points i and j are in the same cluster and the points j and h are in the same cluster, then the points i and h must necessarily belong to the same cluster:
$$\begin{aligned} Z_{ij} + Z_{ih} \le Z_{ii} + Z_{jh}, ~\forall i, j, h \in [n],~ i\ne j\ne h. \end{aligned}$$ -
Pair inequalities
$$\begin{aligned} Z_{ij} \le Z_{ii},~Z_{ij} \le Z_{jj},~\forall i, j \in [n],~i \ne j \end{aligned}$$that every feasible solution of (2) satisfies.
-
Clique inequalities
$$\begin{aligned} \sum _{(i,j)\in I\times I,i<j} Z_{ij} \ge \frac{1}{n-k+1},~\forall I \subset [n],~|I| =k+1, \end{aligned}$$enforcing that for any subset I of \(k + 1\) points at least two points have to be in the same cluster.
The branch-and-bound algorithm also demands strong upper bounds for the optimum value, which are usually obtained by computing good feasible solutions, in our case good assignments to clusters. The SOS-SDP algorithm computes these bounds by using the COP k-means algorithm from29, which is a special variant of the well-known k-means heuristics.
Quality measures
Let denote by \({\mathcal {C}}_{true}:=\{C_{true,1},\dots ,C_{true,k} \}\) the clustering with cluster number k, given by the data provider - we call it the ground truth clustering, and \({\mathcal {C}}_{MSSC}=\{C_{MSSC,1},\dots ,C_{MSSC,k} \}\) the exact clustering, i.e., the optimum solution of (MSSC), computed in our case by the SOS-SDP algorithm.
To assess the quality of the computed clusterings, we use both external (extrinsic) and internal (intrinsic) measures).
Using the former, we will compare the computed clusters \({\mathcal {C}}_{MSSC}\) with the ground truth clusters \({\mathcal {C}}_{true}\), while the latter do not require ground truth clustering because for the computed clusters they measure certain criteria such as cluster compactness. There is a long list of possible measures, see for example6, but we restrict ourselves only to those implemented in the Python library scikit-learn (https://scikit-learn.org/stable/modules/clustering.html#clustering-performance-evaluation), which we chose for our computations, see also30. We include the definition for each method and original reference (see Table 1) for each method in this section, but more details can be also found from textbooks such as31,32.
Extrinsic measures
The extrinsic methods in general evaluate how two different clusterings match. In our case, we use them to assess how the clustering computed by solving the MSSC to optimum (we call this clustering the optimum clustering and denote it by \({\mathcal {C}}_{MSSC}\)) matches with the ground truth clustering, i.e., the clustering provided by the data provider algorithm (we denote it by \({\mathcal {C}}_{true}\)). We use six measures from the Python scikit-learn package30. For the sake of completeness, we provide here a short description for each of them, based on the well-known literature34,36,37,39,40,41,42.
-
Mutual Information: The mutual information41,42 is also known as the information gain and is computed by
$$\begin{aligned} \begin{aligned}&\textrm{ MI}({\mathcal {C}}_{true},{\mathcal {C}}_{MSSC})\\&\quad =\sum _{C_{true,i} \in {\mathcal {C}}_{true}} \sum _{C_{MSSC,j} \in {\mathcal {C}}_{MSSC}} \frac{|C_{true,i}\cap C_{MSSC,j}|}{(\sum _{C_{true,i} \in {\mathcal {C}}_{true}} |C_{true,i}|)^2 } \log \frac{|C_{true,i} \cap C_{MSSC,j}|}{|C_{true,i}||C_{MSSC,j}|}, \end{aligned} \end{aligned}$$(3)where \(k_{true}\) and \(k_{MSSC}\) are the number of clusters in \({\mathcal {C}}_{true}\) and \({\mathcal {C}}_{MSSC}\), respectively, and \(C_{\cdot ,i}\) is the i-th cluster in the clustering assignment \({\mathcal {C}}_{\cdot }\). The score is nonnegative, and a higher value indicates a higher similarity between the two clusterings.
-
Adjusted Mutual Information (AMI):
The adjusted mutual information score for \({\mathcal {C}}_{true}\) and \({\mathcal {C}}_{MSSC}\) is computed as33
$$\begin{aligned} \textrm{AMI}({\mathcal {C}}_{true}, {\mathcal {C}}_{MSSC}) = \frac{\textrm{MI}({\mathcal {C}}_{true}, {\mathcal {C}}_{MSSC}) - \mathbb {E}[\textrm{ MI}]}{ \text {avg}(H({\mathcal {C}}_{true}), H({\mathcal {C}}_{MSSC})) - \mathbb {E}[\textrm{ MI}]}, \end{aligned}$$where \(\text {avg}(\cdot )\) denotes the arithmetic average and \(H({\mathcal {C}})\) is the entropy of a clustering \({\mathcal {C}}\):
$$\begin{aligned} H({\mathcal {C}}) = \sum _{C_i \in {\mathcal {C}}} -\frac{|C_i|}{\sum _{C_j \in {\mathcal {C}}} |C_j|} \log \frac{|C_i|}{\sum _{C_j \in {\mathcal {C}}} |C_j|}, \end{aligned}$$(4)and \(\mathbb {E}(\textrm{ MI})\) is the expected mutual information between two random clusterings.
The AMI score is between \(-1\) and 1. It is 1 when the compared clusterings are identical.
-
Adjusted Random Score (ARS): ARS34,35 computes the proportion of pairs of data points that are in the same cluster or in a different cluster in both clusterings (in our case: \({\mathcal {C}}_{true}\) and \({\mathcal {C}}_{MSSC}\)) and normalize this proportion by using the expected similarity specified by a random model, usually based on the generalized hypergeometric distribution. It is computed as
$$\begin{aligned} \textrm{ARS} = \frac{\textrm{ RI} - \mathbb {E}[\textrm{ RI}]}{\max (\textrm{ RI}) - \mathbb {E}[\textrm{ RI}]}, \end{aligned}$$where random index \(\textrm{ RI}= \frac{a+b}{\left( {\begin{array}{c}n\\ 2\end{array}}\right) }\) and a and b are the numbers of pairs of elements that are in the same cluster in \({\mathcal {C}}_{true}\) and in the same cluster in \({\mathcal {C}}_{MSSC}\) and the number of pairs of elements that are in different clusters in \({\mathcal {C}}_{true}\) and in different clusters in \({\mathcal {C}}_{MSSC}\), respectively. The value \(\mathbb {E}[\textrm{ RI}]\) is the expected value of \(\textrm{ RI}\) between two random clusterings. The score is between \(-1\) and 1. It is 1 when the compared clusterings are identical.
-
Homogeneity (h), Completeness (c) and V-measure (v)36:
Homogeneity measures how homogeneous the clusters are in \({\mathcal {C}}_{MSSC}\), i.e., whether the data points from the same cluster from \({\mathcal {C}}_{MSSC}\) (mostly) belong to the same cluster in \({\mathcal {C}}_{true}\).
Completeness measures how many similar samples are put together by the clustering algorithm, i.e., if the data points belonging to the same cluster from \({\mathcal {C}}_{true}\) are also in the same cluster in \({\mathcal {C}}_{MSSC}\).
The homogeneity h and completeness c are between 0 and 1 and are defined as
$$\begin{aligned} h= 1- \frac{H({\mathcal {C}}_{true}|{\mathcal {C}}_{MSSC})}{H({\mathcal {C}}_{true})}, ~c= 1- \frac{H({\mathcal {C}}_{true}|{\mathcal {C}}_{MSSC})}{H({\mathcal {C}}_{MSSC})}, \end{aligned}$$where \(H({\mathcal {C}}_1\mid {\mathcal {C}}_{2})\) is the conditional entropy of the clusters in \({\mathcal {C}}_1\) given the clustering prediction \({\mathcal {C}}_2\) (recall, n is the number of data points)
$$\begin{aligned} H({\mathcal {C}}_{1} \mid {\mathcal {C}}_{2})= - \sum _{C_{2,j}\in {\mathcal {C}}_{2}} \sum _{C_{1,i} \in {\mathcal {C}}_{1}} \frac{|C_{2,j}\cap C_{1,i}|}{n} \log \frac{|C_{2,j}\cap C_{1,i}|}{\sum _{C_{1,s} \in {\mathcal {C}}_{1}} |C_{2,j}\cap C_{1,s}|}, \end{aligned}$$(5)and H is entropy, defined above.
The V-measure v is the weighted harmonic mean between the homogeneity and the completeness:
$$\begin{aligned} v = \frac{(1 + \beta ) \cdot h \cdot c}{\beta \cdot h + c}, \end{aligned}$$(6)where \(\beta \ge 0\). When \(\beta <1\), more weights are attributed to homogeneity; when \(\beta >1\) more weights are attributed to completeness; when \(\beta =1\), the score is also called normalized mutual information (NMI), which we report in tables of “Numerical results” section:
$$\begin{aligned} \textrm{NMI} = \frac{2 \cdot h \cdot c}{ h + c}, \end{aligned}$$(7) -
Fowlkes-Mallows scores (FMS)37: The Fowlkes-Mallows score (FMS) is defined as the geometric mean between pairwise precision and recall, using True Positive (TP), False Positive (FP), and False Negative (FN):
$$\begin{aligned} \textrm{FMS} = \frac{\textrm{TP}}{ \sqrt{(\mathrm {TP + FP}) \cdot (\mathrm {TP + FN})}}, \end{aligned}$$where TP is the number of pairs of points that belong to the same clusters in both \({\mathcal {C}}_{true}\) and \({\mathcal {C}}_{MSSC}\), FP is the number of pairs of points that belong to the same clusters in \({\mathcal {C}}_{true}\) and to different clusters in \({\mathcal {C}}_{MSSC}\), and FN is the number of pairs of points that belongs to the same clusters in \({\mathcal {C}}_{MSSC}\) and to different clusters in \({\mathcal {C}}_{true}\). The score ranges from 0 to 1, and a high value indicates a good similarity between the two clusters.
Intrinsic measures
Available methods in Python:
-
Calinski-Harabasz Criterion (CHC)38, also known as the Variance Ratio Criterion.
The score is defined as the ratio of the between-the-cluster dispersion and the within-the-cluster dispersion. Good clustering has a large variance between the cluster and a small variance within the cluster, hence a large CHC.
-
Davies Bouldin Index (DBI)39, which is defined as follows. Let \(C_{r}, r\in [k]\), be the r-th cluster and \(s_r\) the average Euclidean distance between the data points \(p_i\) from cluster \(C_r\) and the centroid of that cluster, denoted by \(c^r\):
$$\begin{aligned} s_r = \left( \frac{1}{|C_r|}\sum _{i\in C_r} \Vert p_i -c^r\Vert _2^2\right) ^{1/2},\forall r\in [k]. \end{aligned}$$(8)The DBI score is defined as
$$\begin{aligned} \textrm{DBI} = \frac{1}{k}\sum _{i=1}^k\max _{i\ne j \in [k]}\left( \frac{s_i+s_j}{\Vert c^i-c^j\Vert _2}\right) , \end{aligned}$$(9)Therefore, DBI can only have non-negative values, and the smaller the value of DBI, the better the clustering.
-
Silhouette Evaluation Score (\(S_{score}\))40, defined as
$$\begin{aligned} S_{score} = \frac{1}{n}\sum _{i=1}^n\frac{b_i-a_i}{\max \{a_i,b_i\}}, \end{aligned}$$(10)where \(a_i\) is the mean distance between the i-th data point and the other data points of the same cluster. Similarly, \(b_i\) is the mean distance between the i-th data point and all other data points of the nearest cluster. The fraction \(\frac{b_i-a_i}{\max \{a_i,b_i\}}\) thus measures how well the i-th data point is positioned in the cluster to which it is assigned. Thus, the value of \(S_{score}\) is between \(-1\) and 1, and the closer it is to 1, the more appropriate the clustering.
Numerical results
Datasets
As benchmark datasets, we used datasets collected by Tomas Barton and available in GitHub (https://github.com/deric/clustering-benchmark/tree/master/src/main/resources/datasets). These datasets consist of a subset of real data and a subset of artificial data. For all these datasets, the data providers have also provided the so-called ground truth clustering, i.e., the number of clusters and the classification into this number of clusters according to certain similarity criteria. We were not aware of these similarity criteria, probably they cannot be described explicitly, i.e. in the form of a mathematical distance.
From both datasets, we selected only those for which we were capable of solving (MSSC) for the values of \(k\ge 2\) with \(|k-k_{true}|\le 2\). Therefore, we exclude the instances where the number of data points or \(k_{true}\) was too large (i.e., \(n\cdot k_{true}>1000\)). Nevertheless, we tried to solve also few instances with \(n\cdot k_{true}>1000\) and the computing times were huge (more than a week on one computing node with 2x AMD EPYC 7402 24-core processors and 128 GB DDR4-3200 ram), but we managed to solve five such instances: dermatology, ecoli, glass, 3MC, lsun.
The information about the selected datasets is summarized in Tables 2 and 3, where n is the number of data points, m is the number of variables (features), including the categorical variable containing the labels of the ground truth clustering in the data samples, and \(k_{true}\) is the clustering number for the ground truth clustering.
All these datasets are formally numerical, which means that there is no categorical value in any dataset. However, a closer look reveals that some real datasets include also variables that are by their nature categorical, like heart-statlog and zoo, which contain half or even all variables that are categorical by their nature, respectively. We did not take this fact into account. The exact clustering results are included in the GitHub repository, see https://github.com/shudianzhao/GroundTruth_VS_OptimalCluster.
Results on real and artificial datasets
Table 4 and Table 5 contain the names of datasets (column instances) used in the computations, the value k for which (MSSC) was solved, the corresponding optimum values \(d_{SOS\cdot }\) for (MSSC) (note that the rows highlighted in gray contain the feasible values of (MSSC), evaluated at \({\mathcal {C}}_{true}\)). The rest of the columns contain the scores of the extrinsic and the intrinsic measures, described in “Quality measures” section, which were computed for the optimum clusterings \({\mathcal {C}}_{MSSC}\) and for \({\mathcal {C}}_{MSSC}\) (gray rows).
Column \(d_{SOS\cdot }\) show that optimum values of (MSSC) decrease with k, as is expected - more groups enable smaller sum of squares of distances between the data points and the cluster centroids. For each dataset, we can observe that the corresponding value of \(d_{SOS\cdot }\) in the gray rows, i.e., the values of (MSSC) evaluated at \({\mathcal {C}}_{MSSC}\), is usually much higher compared to the optimum value for \(k=k_{true}\). This reveals that the ground truth clusterings \({\mathcal {C}}_{true}\) are often far from the optimum of (MSSC).
The best scores for each measure, evaluated on optimum clusterings, are highlighted in bold. All the measures we use have different preferences among these clustering results: different measures often achieve their best value for different k.
Moreover, the extrinsic measures rarely achieve the best score for \(k=k_{true}\) (recall, \(k_{true}\) is k in the gray rows) and the ground truth clusterings have scores for the intrinsic measures which significantly differ from the best scores, for both real and artificial data set.
We denote by \(k_{opt}\) the value of k for which the given quality measure reaches its best value. We can observe that \(k_{opt}\) is not necessarily equal to \(k_{true}\). Table 6 summarizes the difference \(|k_{true}-k_{opt}|\) across all real and artificial datasets, for all quality measures. We can see that ARS has \(|k_{true}=k_{opt}|\) for 58.33% of the artificial datasets and FMS has \(|k_{true}=k_{opt}|\) for 50.00% of the real datasets and for \(|k_{true}=k_{opt}|\) for 58.33% of the artificial datasets. All other measures have \(k_{true}\ne k_{opt}\) for more than 50% of the datasets.
Visualizations
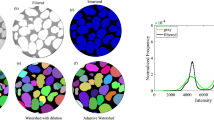
In this subsection, we visualize the ground truth and optimum clusterings for four datasets using principal component analysis (PCA): the iris and the sonar datasets from the real dataset group and the 3-spiral and the gaussians1 datasets from the artificial dataset group. These are shown in Figs. 1, 2, 3, 4, 5, 6, 7, 8. We have chosen these four because they represent extreme cases: For two of them (iris, gaussian1), the ground truth clusters have an ellipsoidal shape and are well separated in the two-dimensional space spanned by the two principal components, whereas for the other two data sets, the ground truth clusters are either highly overlapping (sonar) or have a non-ellipsoidal geometry (3-spiral).
For the iris and gaussian1 datasets, the ground truth and optimum clusterings are very similar, which we can realize by looking at the quality measures for \(k=k_{true}\) in the corresponding tables. For the other two datasets, the quality measures are very poor, which means that the ground truth and the optimum clustering are very different. For the iris and sonar datasets, which have 4 and 60 dimensions, respectively, only the first two principal components are visualized, while the 3-spiral and gaussians1 datasets are two-dimensional, so the visualizations are completely correct. We can see that the ground truth clusters for the iris and the Gaussian1 are in the form of ellipsoids that are well separated, so the optimum and the ground clusterings are very similar. For the other two datasets, the ground truth clusters overlap or have the shape of spirals, and optimum clustering is completely different.

PCA visualization of ground truth clusters for the iris dataset.

PCA visualization of optimum clusters for \(k=k_{true}\) for the iris dataset.

PCA visualization of ground truth clusters for the sonar dataset.

PCA visualization of optimum clusters for \(k=k_{true}\) for the sonar dataset.

Visualization of ground truth clusters for 3-spiral dataset.

Visualization of optimum clusters for \(k=k_{true}\) for 3-spiral dataset.

Visualization of ground truth clusters for gaussians1 dataset.

Visualization of optimum clusters for \(k=k_{true}\) for gaussians1 dataset.
Discussion
The numerical results from Tables 4 and 5 reveal several interesting facts. The main one is that the ground truth clustering usually does not match the optimum MSSC clustering. This has already been observed by other authors16, but our work shows it very clearly.
As first, even detecting \(k_{true}\) is very challenging. We expected that the most popular quality measures for clustering from “Quality measures” section would have the best value for \(k=k_{true}\). This would justify the usual approach where we detect \(k_{true}\) by computing clusterings for different k by using some of the popular heuristic algorithms and then estimate \(k_{true}\) to be the value for which some of the quality measures have the best value.
Table 6 shows that this is wrong. None of the quality measures can be used to detect \(k_{true}\) for MSSC for the great majority of datasets. The FMS has the best value for \(k=k_{true}\) for 50.0% of real datasets and for 58.3% of artificial datasets, while ARS has the best value for \(k=k_{true}\) for 58.3% of artificial datasets. All the other measures achieve the best values for \(k\ne k_{true}\) in more than 50 %. This means that we can not rely on these quality measures to detect \(k_{true}\). Also the optimum value of (MSSC) can not be used to detect \(k_{true}\) since this value is monotonically decreasing with k increasing, as is depicted in the 3rd columns of Tables 4 and 5. It is also interesting that the objective value of (MSSC), which is obtained on the ground truth clustering, is usually far from the optimum value for \(k=k_{true}\), which means that the ground truth clustering is a feasible solution for (MSSC), which is in most cases far from the optimum.
We note that the intrinsic measures need special attention: all of them are related to Euclidean distance, but none of them measures exactly the same thing as we do in the objective function of (MSSC). They compare the within-the-group distances to between-the-group distances in different ways, whereas the objective function of (MSSC) only considers within-the-group distances. This is also a possible reason why these measures usually have the best value at different k, also different from \(k_{true}\).
The only exceptions are the gaussians1 dataset, where the ground truth and the optimum clustering are the same, and the iris dataset, where the ground truth and the optimum clustering are similar but not the same. These clusterings are visualized in Figs. 1, 2 and 7, 8. These figures actually describe the numerical results very well. If the ground truth clusters have the expected geometry, i.e., the clusters have the form of convex sets, ellipsoids, which are well separated from each other, then such ground truth clustering is very similar to optimum clustering. Otherwise, if the clusters have geometrically different shapes, such as 3-spirals, or are overlapping, then the ground truth clustering is far from the optimum clustering, which always enforces the ellipsoidal geometry of the clusters since the Euclidean distance underlies this model.
Datasets ecoli, zoo, and thy also deserve some attention. For the first two datasets, all extrinsic measures are relatively high (higher compared to the other datasets, above 0.6), but the highest values are obtained for different values of k, also different from \(k_{true}\). For the thy dataset, all extrinsic measures are highest for \(k=k_{true}\), but these values are around 0.5 (for FMF it is 0.8). The intrinsic measures for these three datasets are somewhat convoluted, with their best values obtained for different k, with no apparent pattern. We also reviewed the geometry of the ground truth and the optimal clusters in the space spanned by the two principal components. The figure is not included, but it shows that the ground truth clusters overlap strongly in this two-dimensional space, but the geometry of the points allows for an ellipsoidal shape of clusters. It appears that in the original 8-dimensional space, the ground truth clusters are sufficiently separated from each other so that the optimal clusters are close to them. Moreover, the ground truth clusters are of very different sizes, 5 of them are large (\(\ge 20\)) and three of them are small (\(\le 5\)), and this is probably the reason why the extrinsic measures reach their optimum either for smallest k or for largest k.
In common clustering practice, we do not know ground truth clustering, but we still want to know how good is the clustering we obtained with a clustering algorithm. In such a case, we can rely on the intrinsic measures. Our results show that the choice of the intrinsic measure is crucial. Different measures tend to give very different answers about the quality of the clustering. Thus, before making a choice, we should understand very well what exactly (what kind of similarity) the chosen intrinsic measure measures, and make a choice on that basis.
Our work therefore confirms the conclusions of16 that the datasets with known ground truth, which are usually used as benchmark datasets for classification problems, can be used for benchmarking the clustering algorithms with careful attention, since the class labels are usually assigned based on the properties of each individual data point, probably including additional information not present in the dataset itself, while the clustering algorithms take into account the relationships (similarity) between the data.
Conclusions
In this paper, we considered the mathematical programming formulation of the NP -hard minimum sum-of-squares clustering problem (MSSC) and solved it to optimality for a number of real and artificial datasets for which the ground truth clustering (the clustering created by the data provider) was available and which were of small size (the number of data points times the number of true clusters \(k_{true}\) had to be approximately less than 1000). We solved these instances for the number of clusters k equal or close to the ground truth \(k_{true}\) using the exact solver SOS-SDP15.
For each dataset and each k that we used we compared the optimum clustering (optimum solution of (MSSC)) with the ground truth clustering by using a number of extrinsic and intrinsic measures.
We showed that the ground truth clusterings are usually quite far from the optimum clustering, for all k close to \(k_{true}\), which means that (i) they yield the value of the objective function of (MSSC), which is usually much worse (higher) compared to the optimum value of (MSSC), (ii) the values of intrinsic measures evaluated at the ground truth clustering are usually much worse than the values of the intrinsic measures evaluated at the optimum clustering, (iii) the values of the extrinsic measures which we used to measure the alignment between the ground truth and the optimum clustering showed that they differ a lot. However, if the ground truth clustering has a natural geometry, i.e., if the clusters look like ellipsoids that are well separated from each other, then the ground truth clustering and the optimum clustering are very similar.
We can derive the following main conclusions: (i) The ground truth clusterings were defined by data providers who often used similarity measures that were not based on Euclidean distance or on distances equivalent to this distance. It is likely that the similarity measure used was in fact not a distance (metric) according to the mathematical definition, see e.g.43. They may have even used additional information not included in the variables describing the data points. Therefore, there is most likely no mathematical distance at which the optimal value of (MSSC), where the objective function would be defined using this distance, would have ground truth clustering as the optimum solution. (ii) We should be very careful when comparing the clustering obtained by a particular clustering algorithm with the ground truth clustering. If such an algorithm measures the similarity between data points with a distance equal to the Euclidean distance, such as the famous k-means algorithm, while the ground truth clusters do not have an ellipsoidal geometry, then we cannot expect to obtain a solution that is close to the ground truth clustering. (iii) Determining the most appropriate number of clusters by considering where the values of the extrinsic or intrinsic measures have the best value can also be misleading. Very often these measures give contradictory answers: different measures suggest different k, which very often differ from \(k_{true}\). The situation is somewhat better when the clusters have a natural ellipsoidal geometry. This confirms the great importance of choosing the similarity measure over the data points in data clustering: it should capture the geometry of the underlying data. Clustering should also be evaluated using quality measures that are aligned with the similarity measure used in the calculation.
In our future work, we aim to assess clusterings generated by algorithms that approximately solve (MSSC). These clusterings will be compared against those corresponding to the global optima of (MSSC). Furthermore, we will contrast both sets of clusterings with ground truth clusterings and those produced by well-established heuristic methods, such as k-means, agglomerative hierarchical clustering, and density-based clustering, among others. This comparative analysis may offer insights into the alignment between these different clusterings, as well as provide a deeper understanding of the performance trade-offs incurred when relying on standard heuristic approaches in lieu of (local) optimum clusterings.
Data availibility
The data used for numerical experiments and all the exact clustering results are included in the GitHub repository (https://github.com/shudianzhao/GroundTruth_VS_OptimalCluster) and25.
Change history
31 July 2025
This article has been updated to amend the license information.
References
James, G., Witten, D., Hastie, T. & Tibshirani, R. An introduction to statistical learning. In Springer Texts Statist., vol. 103. https://doi.org/10.1007/978-1-4614-7138-7 (Springer, 2013).
Berkhin, P. A survey of clustering data mining techniques. In Grouping Multidimensional Data, 25–71 (Springer, 2006)
Xu, R. & Wunsch, D. II. Survey of clustering algorithms. IEEE Trans. Neural Netw. 16(3), 645–678 (2005).
Hennig, C. et al. (eds) Handbook of Cluster Analysis (CRC Press, 2015).
Kodinariya, T. M. et al. Review on determining number of cluster in K-means clustering. Int. J. 1(6), 90–95 (2013).
Amigó, E., Gonzalo, J., Artiles, J. & Verdejo, F. A comparison of extrinsic clustering evaluation metrics based on formal constraints. Inf. Retr. J. 12(4), 461–486 (2009).
Rao, M. Cluster analysis and mathematical programming. J. Am. Stat. Assoc. 66(335), 622–626 (1971).
Vinod, H. D. Integer programming and the theory of grouping. J. Am. Stat. Assoc. 64(326), 506–519 (1969).
Dhanachandra, N., Manglem, K. & Chanu, Y. J. Image segmentation using K-means clustering algorithm and subtractive clustering algorithm. Procedia Comput. Sci. 54(1877–0509), 764–771 (2015).
Shi, J. & Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 22(8), 888–905 (2000).
Jiang, D., Tang, C. & Zhang, A. Cluster analysis for gene expression data: a survey. IEEE Trans. Knowl. Data Eng. 16(11), 1370–1386 (2004).
Mahdavi, M. & Abolhassani, H. Harmony \(k\)-means algorithm for document clustering. Data Min. Knowl. Discov. 18(3), 370–391 (2009).
Mahajan, M., Nimbhorkar, P. & Varadarajan, K. The planar \(k\)-means problem is NP-hard. In Theoretical Computer Science, 442, 13–21 Special Issue on the Workshop on Algorithms and Computation (WALCOM 2009) (2012).
Megiddo, N. & Supowit, K. J. On the complexity of some common geometric location problems. SIAM J. Comput. 13(1), 182–196 (1984).
Piccialli, V., Sudoso, A. M. & Wiegele, A. SOS-SDP: an exact solver for minimum sum-of-squares clustering. INFORMS J. Comput. 34(4), 1841–2382 (2022).
Zhang, T., Zhong, L. & Yuan, B. A critical note on the evaluation of clustering algorithms arXiv:1908.03782 (2019).
Zhu, Y. et al. A ground truth based comparative study on clustering of gene expression data. Front. Biosci. 13(10), 3839–3849 (2008).
Gribel, D. & Vidal, T. HG-means: A scalable hybrid genetic algorithm for minimum sum-of-squares clustering. Pattern Recognit. 88(0031–3203), 569–583 (2019).
Deng, P. et al. Multi-view clustering guided by unconstrained non-negative matrix factorization. Knowl.-Based Syst. 266, 110425 (2023).
Wang, D. et al. A generalized deep learning algorithm based on NMF for multi-view clustering. IEEE Trans. Big Data 9(1), 328–340 (2023).
Wang, D. et al. A multi-view clustering algorithm based on deep semi-NMF. Inf. Fusion 99, 101884 (2023).
Kang, Z., Xie, X., Li, B. & Pan, E. CDC: A simple framework for complex data clustering ArXiv:2403.03670 (2025).
Kang, Z., Lin, Z., Zhu, X. & Xu, W. Structured graph learning for scalable subspace clustering: From single view to multiview. IEEE Trans. Cybern. 52(9), 8976–8986 (2022).
Wang, D., Li, T., Deng, P., Luo, Z., Zhang, P., Liu, K. & Huang, W. Dnsrf: Deep network-based semi-NMF representation framework. ACM Trans. Intell. Syst. Technol. 15(5), (2024).
Zhao, S. et al. GroundTruth_VS_OptimalCluster: Clustering benchmark datasets, v1.0.0. https://doi.org/10.5281/zenodo.14883433 (2025).
Peng, J. & Wei, Y. Approximating \(k\)-means-type clustering via semidefinite programming. SIAM J. Optim. 18(1), 186–205 (2007).
ApS, M. The MOSEK optimization toolbox for MATLAB manual. Version 9.0. http://docs.mosek.com/9.0/toolbox/index.html (2019).
Sun, D., Toh, K. C., Yuan, Y. & Zhao, X. Y. SDPNAL+: A matlab software for semidefinite programming with bound constraints (version 1.0). Optim. Methods Softw. 35(1), 87–115 (2020).
Wagstaff, K., Cardie, C., Rogers, S. & Schrödl, S., et al. Constrained \(k\)-means clustering with background knowledge. In ICML 2001, 1, 577–584 (2001)
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Han, J., Kamber, M. & Pei, J. Data Mining: Concepts and Techniques. The Morgan Kaufmann Series in Data Management Systems. (Elsevier Science, 2011)
Raschka, S. & Mirjalili, V. Python Machine Learning, 3rd ed. (Packt Publishing, 2019)
Vinh, N.X., Epps, J. & Bailey, J. Information theoretic measures for clusterings comparison: Is a correction for chance necessary? In ICML 2009, 1073–1080 (Association for Computing Machinery, 2009)
Hubert, L. & Arabie, P. Comparing partitions. J. Classif. 2(1), 193–218 (1985).
Yeung, K. Y. & Ruzzo, W. L. Details of the adjusted rand index and clustering algorithms, supplement to the paper an empirical study on principal component analysis for clustering gene expression data. Bioinformatics 17(9), 763–774 (2001).
Rosenberg, A. & Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of EMNLP-CoNLL 2007, 410–420 (2007).
Fowlkes, E. B. & Mallows, C. L. A method for comparing two hierarchical clusterings. J. Am. Stat. Assoc. 78(383), 553–569 (1983).
Harabasz, C. T. & Karoński, M. A dendrite method for cluster analysis. Commun. Stat. 3, 1–27 (1974).
Davies, D. L. & Bouldin, D. W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. PAMI–1(2), 224–227 (1979).
Rousseeuw, P. J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987).
Fano, R. M. The Transmission of Information (Massachusetts Institute of Technology, Research Laboratory of Electronics, 1949).
Shannon, C. E. A mathematical theory of communication. ACM SIGMOBILE Mobile Comput. Commun. Rev. 5(1), 3–55 (2001).
Sharma, S. Metric Space. DPH Mathematics Series (Discovery Publishing House, 2006).
Acknowledgements
The research of J.P. was co-funded by the Republic of Slovenia, the Ministry of HE, Science and Innovation, the Slovenian Research and Innovation Agency (ARIS), and the European Union—NextGenerationEU program through the DIGITOP project, and by the Slovenian Research and Innovation Agency (ARIS) through the annual work program of Rudolfovo.
Funding
Open access funding provided by Royal Institute of Technology.
Author information
Authors and Affiliations
Contributions
S.Z have conducted the analysis of numerical results and visualised results Tables 1, 2, 3, 4, 5, 6, and written the measurements section and numerical results in the manuscript. J.P have organised research, provided resources, partially written introduction, discussion and conclusions and proof-read the paper. T.H. conducted numerical results used for further analysis included in Tables 4, 5 and polished the manuscript. L.B. prepared Figs. 1, 2, 3, 4, 5, 6, 7, 8.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bautista, L.A., Hrga, T., Povh, J. et al. Ground truth clustering is not the optimum clustering. Sci Rep 15, 9223 (2025). https://doi.org/10.1038/s41598-025-90865-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-90865-9
