
Abstract
Mixed precision quantization represents a sophisticated technique that markedly diminishes a system’s computational and memory demands by reducing the bit width of the model. However, in practical applications, an improper allocation strategy can fail to leverage the advantages of quantization and lead to wasted computational resources and degraded model performance. We propose a bit-width allocation method based on information entropy as a means of mitigating the precision loss caused by quantization. During the forward pass of the model, the entropy value of each layer output is calculated, and a sliding window is employed to smooth these entropy values. By computing a dynamic threshold based on the smoothed average entropy of each layer, we adaptively allocate the bit width for each layer. Furthermore, the threshold and the sliding window size are treated as hyperparameters, which Optuna optimizes. Model accuracy is the constraint, thereby automating the bit-width allocation across layers. Finally, we integrate knowledge distillation, where a larger teacher model guides the training of the quantized model, ensuring high performance despite compression by transferring soft labels and deeper knowledge. Experiments on ResNet20, ResNet32, and ResNet56 architectures show that our method can effectively reduce the bit width of weights and activations to 3.6M/3.6MP while maintaining the accuracy of the model. The maximum accuracy loss of this method on the CIFAR-100 dataset is only 0.6%, and it achieves an accuracy comparable to that of the full-precision model on the CIFAR-10 dataset, fully demonstrating its effectiveness in balancing model compression and performance.
Similar content being viewed by others

Introduction
Modern deep learning models typically contain hundreds of millions or even billions of parameters. For instance, BERT has 340 million parameters1,2, while GPT-3 contains 175 billion parameters. These models require substantial storage and significant computational resources during inference due to complex operations such as matrix multiplications and convolutions, which considerably increase the computational load. However, edge devices are constrained by limited computational power, storage space, and energy, making it a significant challenge to deploy high-performance neural networks on edge devices directly3. Reducing the model’s storage footprint and computational cost has thus become a key issue to address in edge computing scenarios4.
Model quantization5is a prevalent model compression technique that diminishes the storage space and computational complexity of a model. This is achieved by converting high-precision floating-point numbers (e.g., 32-bit) into low-precision integers (e.g., 8-bit, 4-bit, or even lower). While quantization provides significant computational and storage benefits, it also encounters the obstacle of diminished accuracy6. Different layers of a model have varying sensitivities to quantization, and simple fixed-precision quantization methods7 may lead to severe performance degradation in critical layers, thus impacting the overall inference capability of the model. To address this issue, researchers have proposed mixed-precision quantization methods8, which assign different bit widths to different layers to achieve a balance between model performance and resource consumption. Common mixed-precision quantization approaches include automatic bit-width search methods and sensitivity-based bit-width allocation methods. Automatic search methods leverage techniques such as neural architecture search or reinforcement learning to automatically optimize the bit-width configuration for each layer. However, these methods frequently necessitate considerable computational resources and are both intricate and time-consuming. Sensitivity measures the extent to which different layers in a model contribute to a reduction in accuracy during the process of quantization. It can be observed that layers with a higher sensitivity have a greater impact on the overall performance of the model, and thus require a greater bit-width allocation. Conventional sensitivity calculation methods tend to concentrate on localized information, such as alterations in gradients, weights, or activations. This approach, however, tends to neglect the inter-layer dependencies and the overall role of each layer within the network structure. Although these localized metrics can provide some guidance, they are limited in that they are unable to fully capture the complexity of the model as a whole and the global influence of each layer within the network.
To address this issue, a sensitivity metric is needed that takes into account both local features and global information. Information entropy, as a measure of uncertainty and distributional complexity, effectively reflects the complexity of the output at each neural network layer, making it a suitable candidate for this purpose. Entropy not only quantifies the distributional complexity of the output at each layer, capturing local characteristics, but also evaluates the global importance of each layer within the overall network by integrating the entropy values of all layers. Accordingly, the introduction of entropy as a sensitivity metric can provide a logical basis for bit-width allocation during the quantization process, ensuring that the importance of each layer is properly assessed from a global perspective. This paper presents an entropy-based bit-width allocation methodology that calculates the entropy of the output at each layer and makes adjustments to the bit-width allocation based on threshold values. This approach modifies the bit-width according to the actual complexity of the output at each layer, circumventing the limitations of fixed bit-width allocation and better accommodating the specific requirements of different layers. In particular, layers with higher entropy indicate the presence of more complex output features and greater information content, which in turn requires a higher bit-width to ensure the retention of more information. Conversely, layers with lower entropy that produce simpler output features can be assigned lower bit widths to save computational and storage resources. In addition, this work incorporates knowledge distillation, where the quantized model is trained to learn from a high-precision teacher model to improve the accuracy of the quantized model.
This mixed precision quantization method is particularly suitable for scenarios where computational resources and memory are highly constrained, such as deploying deep learning models on edge devices or mobile platforms. By adaptively assigning bit widths to different layers based on their information entropy, our method achieves an efficient balance between compression and performance. It is also well-suited for applications where maintaining high accuracy is critical despite model compression, such as autonomous driving, medical imaging, or real-time video processing. Additionally, the integration of knowledge distillation further enhances its practicality by mitigating accuracy loss, making it a robust choice for tasks requiring both lightweight models and high performance. The main contributions of this work are as follows:
-
A bit-width allocation method based on information entropy is proposed, which dynamically adjusts the bit-width allocation of each layer to improve the performance of the quantization model.
-
We introduce a sliding window technique to calculate and record information entropy, dynamically regulating the window size and threshold range to optimize the bit-width allocation strategy for each layer.
-
Integrating knowledge distillation, the performance and robustness of the quantized model are further enhanced under the guidance of the teacher model.
Related work
Model quantization
Fixed-precision quantization
Among various model compression techniques, quantization has emerged as a key approach in edge computing, largely due to its inherent directness and efficiency. Quantization methods can be broadly classified into two categories based on their precision configuration: fixed-precision quantization and mixed-precision quantization.
Fixed-precision quantization refers to quantizing all model parameters and activations to a uniform precision for a simple and consistent quantisation scheme. However, this approach is difficult to adapt to the importance and data distribution of different layers, which may lead to over-quantization of critical layers or under-quantization of secondary layers, thus affecting model performance. Therefore, researchers are committed to developing optimization techniques that address the issues of parameter quantization, gradient optimization, and error compensation to improve the efficiency and accuracy of fixed-precision quantization.
One optimization approach is parameter quantization. PACT9 introduces a trainable parameter that dynamically adjusts the clipping range of activations. This technique reduces information loss during quantization, allowing the model to preserve accuracy more effectively during inference. Similarly, LQ-Nets10, a learning-based method, incorporates a learning module to optimize the quantization function’s parameters through backpropagation.
Another critical optimization area is gradient quantization, where the goal is to maintain accuracy during backpropagation despite reduced precision. Wang and Kang11 address this by optimizing the gradient quantization strategy through a comprehensive analysis of the distribution characteristics of gradients. This approach ensures that high accuracy is maintained even during 8-bit integer training.
In addition, error compensation techniques are employed to mitigate the information loss caused by quantization. These techniques are especially important in forward propagation, where error compensation is applied12, while quantization is used in backpropagation to preserve gradient precision. Gong et al.13 introduce a bias compensation method that adjusts the quantization parameters of the model to compensate for output errors caused by quantization.
Despite these advancements, fixed-precision quantization’s reliance on a uniform bit-width across all layers limits its flexibility. Different layers in a model can have varying importance and data distributions, and a one-size-fits-all approach may lead to over-quantization in critical layers or under-quantization in less important ones. These issues highlight the need for optimization techniques that can dynamically adjust bit-width allocation across layers, ensuring better model performance and efficiency.
Mixed-precision quantization
Mixed-precision quantization represents a more flexible quantization method that permits the utilization of disparate precision levels within a singular model. By analyzing the characteristics and importance of each layer, the most appropriate bit widths can be allocated. This approach optimizes the utilization of computational and storage resources while maintaining model accuracy14. Mixed-precision quantization can be broadly classified into two main approaches: automatic bit-width search methods and sensitivity-based bit-width allocation approach.
Automatic search is a technique used to optimize parameters and strategies automatically, aiming to find the optimal quantization configuration. The fundamental concept is to utilize search algorithms to automatically explore and adjust the combination of quantization parameters, thereby discovering the optimal quantization strategy. Common automated search and optimization techniques include Neural Architecture Search (NAS), Reinforcement Learning (RL), and Evolutionary Algorithms (EA). In the context of RL, HAQ15 and AutoQ16 represent the bit-width allocation problem as a Markov Decision Process (MDP), using RL to identify the optimal bit-width allocation across network layers. On the other hand, DNAS17 leverages differentiable NAS techniques, transforming the search for quantization strategies into a differentiable optimization problem that can be solved using techniques like gradient descent. SPOS18 employs a uniform sampling strategy to ensure that all potential architectural configurations have an equal opportunity to be evaluated during the search process. While these automated search methods can enhance the efficiency of quantization strategy optimization, they frequently necessitate substantial computational resources. NAS, in particular, typically demands substantial computational resources, with the search process involving the training of hundreds to thousands of models. Even with efficient search algorithms, the search process can take several weeks. For instance, regarding the use of evolutionary algorithms for NAS, the authors of Real et al.19 mentioned that the entire search process utilized 450 GPUs and required several weeks to complete.
The primary focus of sensitivity-based bit-width allocation methods is identifying a criterion to measure the sensitivity of each network layer to quantization. The existing research has explored various sensitivity metrics to evaluate the importance of network layers, including the Hessian matrix, rounding error, scaling factors, and network orthogonality. The Hessian matrix is a frequently utilized methodology for the assessment of network layer sensitivity. In HAWQ20 and HAWQ-v221, the authors proposed using the average Hessian trace as a sensitivity metric to ascertain the significance of layers and employed a Pareto frontier-based approach to facilitate the automatic allocation of bit-widths. The Hessian matrix describes the local second-order properties of the model’s loss function, as it depends on the local values of the parameters, making it less effective at capturing the sensitivity characteristics of the global optimum. In contrast, Kloberdanz and Le22 introduced a method that searches for the optimal bit-width for each layer’s weights based on rounding errors, which can be used as a preprocessing step to enhance the performance of any quantization method. Nevertheless, the current approach to addressing rounding errors is focused on searching for the optimal bit-width for quantized weights, without achieving layer-wise quantization for activations. In LIMPQ23, the scaling factor in the quantizer is used as a crucial metric for differentiating between layers with varying degrees of sensitivity to quantization. However, methods that rely on learning the scaling factor often depend on specific training processes and data, which can result in poor generalization. The orthogonality of the network is employed to ascertain the significance of each layer24, with greater bit-width assigned to layers displaying stronger orthogonality. Nevertheless, the orthogonality-based approach may be highly contingent on the specific network architectures in question.
To overcome the limitations of the above sensitivity metrics, we use information entropy as the standard for bit-width allocation. Information entropy measures the overall uncertainty and information content of each layer’s output, reflecting the layer’s ability to transmit and represent information within the overall network. Unlike approaches that rely solely on local parameters, entropy captures the global sensitivity characteristics of each layer. By analyzing information entropy, it is possible to take into account the quantization requirements of both weights and activations, allowing for a more balanced bit-width allocation. Entropy-based bit-width allocation allows more precise adaptation to the requirements of different layers without relying on complex exploration strategies.
Application of information entropy in deep learning
The concept of information entropy, as postulated by Shannon in information theory25, is predicated on the fundamental tenet that an event’s degree of uncertainty is directly correlated with its informational content. If the probability of an output is evenly distributed across multiple possible outcomes, this indicates a higher degree of uncertainty in the output, which carries more information and results in a higher entropy value. Furthermore, information entropy can also quantify the complexity of the output. The degree of complexity is reflected in the number and diversity of different patterns or features present in the output. In the case of outputs comprising a multitude of intricate patterns and features, such as those observed in image classification tasks, where low-level characteristics such as edges and colors are present alongside high-level attributes like object shapes and categories, the probability distribution tends to be more dispersed. This is indicative of elevated complexity and, consequently, higher entropy.
The advent of machine learning and deep learning has made information entropy emerge as a pivotal instrument for assessing model efficacy and refining algorithms. In training classification models, the cross-entropy loss function26 calculates the discrepancy between the predicted class probabilities and the actual distribution, guiding the optimization of model parameters. In models such as decision trees and random forests, information gain27 is used to select the best feature by measuring the reduction in the uncertainty (information entropy) of the target variable under specific feature conditions. Furthermore, information entropy plays a pivotal role in the information bottleneck method28, wherein the entropy of the intermediate layers is introduced as a constraint, compelling the model to compress the input information to the greatest extent possible while retaining information pertinent to the output. This results in the generation of more compact and generalizable models.
In neural networks, the output of each layer can be conceptualized as a feature representation of the input data processed by that layer. Information entropy plays a crucial role in measuring the complexity and uncertainty of these features. In layers with high entropy, the output features are more complex and include different patterns or combinations of features. This requires the use of higher bit widths to represent these complex features and retain more information accurately. Using a lower bit width can result in the complexity of these features being blurred due to quantization errors. This could lead to a reduction in the expressiveness and accuracy of the model.
Methods
Method overview
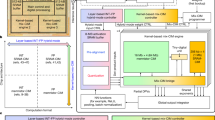
To address the issue of accuracy loss that can occur during model quantization, we propose an entropy-based approach to bit-width allocation. In the forward pass of the model, the output entropy of each layer is calculated to ascertain the relative importance of the different layers in the quantization process. A sliding window is employed to mitigate the impact of random fluctuations in entropy values, which may arise from the inherent randomness of individual calculations. In addition, we use Optuna to dynamically adjust the size of the sliding window and thresholds to ensure the rationality of the bit-width allocation. Once the optimal bit-width allocation strategy is obtained, the model is quantized accordingly, and a pre-trained teacher model is used to guide the training of the quantized model, helping recover the accuracy lost due to quantization. Figure 1 illustrates the proposed entropy-based bit-width allocation framework, which integrates key steps such as entropy calculation, sliding window processing, hyperparameter optimization, and knowledge distillation.
In the entropy calculation module, we demonstrate how to compute the information entropy of each layer during the forward pass. The entropy is calculated based on the output of each layer, and a sliding window is employed to smooth the continuous entropy values, ensuring that the entropy measurement is more stable and accurate. The sliding window averages the entropy values of each layer’s output and continuously updates them. The final averaged entropy values for each layer are aggregated and stored, forming an entropy dataset, which serves as the basis for the subsequent bit-width allocation. In the bit-width allocation section, the process of bit-width allocation and hyperparameter adjustment is illustrated. The 75th and 50th percentiles of the entropy dataset are determined as two thresholds used for bit-width allocation. Based on each layer’s average information entropy, comparisons are made with these two thresholds to assign different bit-widths. By incorporating Optuna for hyperparameter optimization, the entropy thresholds and sliding window size are automatically adjusted, achieving precise bit-width allocation. Once the optimal bit-width allocation strategy is determined, the quantization process is performed. Each layer of the model is quantized according to the assigned bit-width. Due to the reduced precision of weights and activation values during the quantization process, the accuracy of the quantized model may decrease. To alleviate this problem, we introduced a large-scale high-precision model that has been fully trained on the dataset and has good generalization ability as a teacher model to guide the training of the student model (i.e., the quantized model). In the framework of mixed precision quantization, the teacher model, as a high-precision benchmark, can effectively reduce the precision loss during fine-tuning and help ensure that the quantized model can still maintain good performance.

Structure diagram of mixed precision quantization method.
LSQ quantification
Quantization is the process of converting continuous values into discrete values. The most basic quantization method is linear quantization, which maps floating-point numbers to a fixed number of discrete levels. The formula for linear quantization is as follows:
Where x is the input value, \(x_{\min }\) is the minimum value, and s is the scaling factor, defined as:
Here \(x_{\max }\) is the maximum value, and b is the bit-width for quantization. For example, for 8-bit quantization, the range of discrete values consists of 255 values.
This standard quantization method has a significant drawback: the scaling factor is fixed, which means that the quantization precision is the same for all data points and cannot adapt to dynamically changing data distributions. Specifically, when the data distribution is uneven, the fixed step size in dense regions may be too coarse, leading to the loss of important information. To address this issue, the Learned Step Size Quantization (LSQ) algorithm was proposed in29, where the scaling factor is a learnable parameter that can be optimized during training using gradient descent. It allows the model to adaptively adjust the quantization precision during training, minimizing quantization error to the greatest extent possible.
During the forward pass, the step size s is used to quantize the weights or activations. The quantization formula is as follows:
Where q is the quantized value, x is the original floating-point number, s is the quantization step size, and \(q_{\min }\) and \(q_{\max }\) are the lower and upper limits of the quantized values. The clip() function is defined as:
Where x represents the elements of the input values, min is the lower bound, and max is the upper bound. The clip() function contains the values within a given range, truncating any values that exceed the boundaries to the boundary values. Then, the quantized value q(x) is multiplied by the step size s to restore it to the approximate float-point range:
Where \(\hat{x}\) is the float-point approximation after quantization.
During backpropagation, the quantization error is propagated backward, and the step size is updated. The gradient of the step size can be computed using the chain rule as follows:
The LSQ algorithm updates the step size using this gradient descent method. Assuming the loss is L, and the quantized weight or activation is \(\hat{x}\), the gradient update formula for the step size s is as follows:
Where \(x_i\) is the floating-point value and \(q_i\) is the corresponding quantized value, this formula reflects the contribution of each sample to the step size. The update of the step size usually requires a smaller learning rate. To prevent gradient explosion or vanishing, the update to the step size is scaled using a scaling factor, which balances and compensates for the update.
Where \(\alpha\) is the learning rate for the step size, N is the number of quantized values, and g is the gradient of the step size. By applying a clipping operation to the gradient(clip), extreme gradient values are prevented from having an excessively large impact on the step size.
The learning process for the step size fully leverages the backpropagation mechanism, allowing gradient information to be effectively transmitted back to both the original floating-point values and the quantization step size s. This enables the step size to be optimized during training, allowing for better adjustment of quantization error and reducing performance loss.
Information entropy calculation based on sliding window
Information entropy is used to describe the average uncertainly or randomness of information, typically denoted as H(X), X is a random variable. For a discrete random variable with possible values and corresponding probabilities \(P(x_i)\), information entropy is defined as:
Here \(P(x_i)\) is the probability of the value \(x_i\), and n is the number of possible output events. The logarithm is typically taken as the binary logarithm(\(\log _2\)), and the unit is bit.

Calculation of information entropy
For a given layer, the output values can be collected through multiple forward passes. The probability distribution of these output values is calculated, giving the probabilities \(P(x_i)\). Using Eq. 9 the contribution of each possible output value to the entropy is computed. The contributions of all output values are then summed, and the negative of this sum gives the total information entropy H(X). The traditional method of calculating information entropy provides a global measure of the overall output, which is effective for static or infrequently changing data. However, during neural network training, the output features change over time, making static entropy calculations inadequate in capturing these dynamics. To address this issue, we use a sliding window to calculate the output entropy of each layer. Unlike traditional sliding window operations, we adopt an averaging-based smoothing approach. Specifically, when the sliding window is full, the entropy values within the window are averaged, and the window is then cleared and refilled with new data. This method combines the characteristics of window smoothing and data reset, using the average value to smooth the output entropy of each layer and reduce noise. The detailed design process is shown in Algorithm 1:
In this method, a sliding window is initially configured. As the model performs forward propagation, hook functions are used to capture the output data of each layer, and the entropy of the current output is calculated in accordance with Eq. 9. The calculated entropy values are sequentially added to the sliding window. In the event that the window is not yet full, the recently computed entropy value is directly added; once the window is full, the average of all entropy values within the window is calculated to reflect the overall characteristics of recent output data. The window is then cleared, and the computed average is reinserted as the first value in the window. New entropy values continue to be smoothly added to the window until it fills again. During this process, the averaging step is repeated each time the sliding window is filled and refilled. This process continues until all data is processed. Finally, the remaining entropy values in the sliding window are averaged, and this average is used as the entropy value for the layer’s output, which is further utilized for bit-width allocation decisions.
Figure 2 shows a concrete example of using sliding window smoothing to calculate entropy values. For simplicity, we assume that the window size is 5 and that the sequence of entropy values for a given layer is, in order: [2.416, 2.551, 1.621, 2.093, 3.158, 2.307, 5.315, 1.532]

Example calculations for a sliding window.

Information entropy calculation.
Figure 3a,b respectively show the comparison between the traditional entropy calculation method and the sliding window entropy calculation method in different layers of the ResNet20 model. Specifically, the experiment records the output entropy of each layer during multiple forward passes and processes these entropy values using two different approaches. Figure 3a illustrates the raw entropy values for each layer across multiple forward passes, where most layers exhibit significant fluctuations due to the influence of input data characteristics and model parameters. In such cases, the analysis of entropy might be affected by extreme values, leading to inaccuracies in the final entropy calculation. Figure 3b presents the entropy values after applying the sliding window smoothing method during the same forward passes. Compared to Fig. 3a, the entropy curves are significantly smoother, with reduced fluctuations, and the overall trend of entropy values is more stable. By using the sliding window to smooth the entropy values, the random noise in individual entropy calculations is effectively reduced. This method not only provides a more stable measure of entropy, accurately reflecting the complexity and information content of the output in each layer but also improves the precision of bit-width adjustments during quantization, helping to maintain the performance of the quantized model.
Dynamic threshold setting
The distribution of input data may change over time or between tasks. For example, if a model processes different types of data (such as images or text), the internal activation states and the complexity of feature extraction may also vary. A dynamic threshold allows the model to adapt its response to changes in the data in real-time, allowing it to handle different data distributions more effectively.
A percentile is a statistical measure that is used to describe the relative position of a specific value within a dataset, calculated based on the dataset itself, thus reflecting the actual distribution of the data. Compared to a fixed threshold, using percentiles to set thresholds ensures that they are closely aligned with the distribution characteristics of the current dataset, avoiding the issue of a fixed threshold being unsuitable for different datasets. Since the distribution of entropy values can vary across datasets and network layers, dynamically setting the threshold using percentiles allows for adaptive adjustments based on the entropy distribution in each layer. This ensures greater flexibility and adaptability while preventing extreme entropy values from having an excessive impact on the threshold setting. As a result, the bit-width allocation strategy can more reasonably match the needs of each network layer, enhancing accuracy and stability during quantization. Percentiles are determined by sorting a set of data and finding the value that corresponds to a particular percentage position. The position of a percentile can be calculated using the following formula:
Where n is the number of data points in the dataset, p represents the percentile to be calculated(e.g., 75 for the 75th percentile), and P is the position of the percentile within the dataset. If the calculated position P is an integer, the percentile corresponds to the \(P-th\) data point in the sorted dataset. If P is not an integer, interpolation is used by taking the two closest data points and performing linear interpolation to estimate the percentile value.
In this method, the entropy of each layer is calculated, collected, and stored to form an entropy dataset. With each iteration, this dataset is updated with newly computed entropy values. Threshold 1 is set as the 75th percentile of the entropy dataset, while Threshold 2 is set as the 50th percentile. The 50th percentile provides a robust baseline, resistant to the influence of outliers, whereas the 75th percentile highlights data points that are significantly above the average level, balancing detection rate and false positive rate. It should be noted that the adjustment of thresholds is not a fixed process, but rather a dynamic one.
Given that the entropy values of the model layers may change with each iteration, it follows that the entropy dataset also changes accordingly. The thresholds are updated by recalculating the percentiles of the entropy dataset. If the overall entropy dataset increases in the current iteration, the thresholds will also increase. Based on the calculated thresholds, bit-width allocation for each layer is adjusted. If the bit-width list 2, 4, 6 is selected, the bit-width allocation strategy is as follows:
-
If the layer’s average entropy is higher than Threshold 1, the maximum bit-width of 6 is assigned.
-
If the layer’s average entropy is between Threshold 1 and Threshold 2, a bit-width of 4 is assigned.
-
If the layer’s average entropy is lower than Threshold 2, the minimum bit-width of 2 is assigned.
Figure 4 illustrates the entropy distribution and corresponding bit-width allocation for the last 10 layers of the ResNet20 model during the forward pass. The average entropy of each layer falls within the range of 5.5 to 7.0, which reflects the varying complexity of information representation across the layers. Layers with entropy values exceeding the specified Threshold 1 (i.e., those above the 75th percentile) are indicative of greater information content and thus are assigned a bit-width of 6. Layers with entropy values between Threshold 1 and Threshold 2 (between the 50th and 75th percentiles) are assigned a bit-width of 4. Finally, layers with entropy values lower than Threshold 2 (below the 50th percentile) are allocated the minimum bit-width of 2, as these layers have lower information complexity and thus can operate with reduced bit-width.

Bit width allocation of some layers of ResNet20.
The dynamic adjustment mechanism allows for the thresholds to be modified in accordance with the prevailing circumstances of the model and the input data, thus avoiding the potential information loss that may occur due to improper bit-width allocation caused by fixed thresholds.
Hyperparameter optimization
In deep learning, parameters refer to the weights and biases learned from the training data, whereas hyperparameters are variables that must be manually set before training, such as learning rate, batch size, thresholds, and sliding window size. Hyperparameters determine the training process and performance of the model and cannot be automatically learned from the data. Different models and datasets often require different hyperparameter configurations, and there are complex interactions between these hyperparameters. Manually tuning them is time-consuming and prone to error. To address this issue, we utilize the Optuna tool to automatically search for the optimal hyperparameter configurations using methods such as Bayesian optimization, reducing the workload of manual tuning. During the search process, Optuna experiments with different combinations of hyperparameters, ensuring the effectiveness and adaptability of the bit-width allocation strategy. In this work, the hyperparameters to be optimized include thresholds and the size of the sliding window.
Threshold optimization
The initial approach involved the establishment of fixed percentiles as the basis for the thresholds. However, it should be noted that different models and tasks exhibit a range of characteristics, and the feature complexity and distribution of different datasets can vary. Consequently, the 75th percentile may not invariably represent the optimal high threshold in experiments. By using Optuna for threshold optimization, we define the search range for each threshold within the search space and then dynamically sample combinations of these thresholds using Bayesian optimization. The current combinations of thresholds are evaluated against the performance of the model, and the sampling strategy is continuously adjusted to balance the exploration of new regions with the optimization of the existing best solutions. After several iterations, Optuna gradually converges toward the optimal threshold settings, ultimately identifying the most suitable threshold combinations for the task and dataset. These thresholds are then used to allocate appropriate bit-width to different layers, thereby minimizing quantization errors to an absolute minimum.
Sliding window size
We use a sliding window to smooth and update the information entropy of each layer in the model. The size of the sliding window determines the upper limit of entropy values recorded for each layer. A larger window can smooth out more historical data, effectively reducing noise, but it may introduce a delay in updating the entropy, potentially affecting the real-time accuracy of the entropy values. In contrast, a smaller window can respond more quickly to changes in entropy, but with fewer data points recorded, it is more susceptible to short-term fluctuations, leading to instability in the entropy values. To address this, we use the Optuna tool, which treats the sliding window size as a hyperparameter to be optimized. Within a given search space, Bayesian optimization dynamically samples different window sizes, runs multiple experiments, and continuously adjusts and optimizes the window size based on model performance. After several iterations, Optuna can identify the optimal window size within the search space, ensuring that entropy calculations can effectively smooth out noise while maintaining real-time accuracy and responsiveness.
By using Optuna to automatically adjust the sliding window size and threshold range, with model accuracy as a constraint, the optimal hyperparameter settings and bit-width allocation strategy can be identified in a relatively short time, accelerating the model optimization process.
Knowledge distillation
Following the quantization process, the model is configured to use a lower bit width, which serves to reduce the numerical range of weights and activations. This in turn reduces the representational capacity of the model, resulting in some loss of accuracy. To mitigate this, we incorporate knowledge distillation, using the guidance of a larger teacher model to fine-tune the quantized model, thereby reducing the errors introduced by quantization.
Knowledge distillation30, proposed by Hinton and colleagues, is a model compression method based on transfer learning. It transfers the knowledge from a larger, more complex model (often referred to as the “teacher model”) to a smaller, simpler model (called the “student model”). During the distillation process, the teacher model provides not only hard labels (one-hot labels) as supervisory signals but also soft labels, namely its output probability distribution for each class. The capture of fine-grained output information captures the relationships between classes, helping the student model learn richer feature representations and thereby improving its generalization ability.
In classification tasks, the most commonly used loss function is the cross-entropy loss function, which measures the difference between the predicted probability distribution and the actual label distribution. For a classification task with C classes, given a sample x with a true label y, and the predicted probability distribution \(p(y \mid x)\) by the model, the cross-entropy loss function is formulated as:
Where \(y_i\) is the one-hot encoding of the actual label (if the sample belongs to class i, then \(y_i=1\), otherwise \(y_i=0\)), and \(p(y_i \mid x)\) is the predicted probability that the model assigns the sample to class i.
We aim for the quantized model to learn the predicted probability distribution of the teacher model, and this can be achieved using a loss function based on Kullback-Leibler (KL) divergence. KL divergence measures the difference between two probability distributions. For the predicted probability distribution of the student model \(q(y \mid x)\) and the predicted probability distribution of the teacher model \(p(y \mid x)\), the KL divergence is defined as:
The KL-based loss function(i.e., the knowledge distillation loss function) can be expressed as:
During the distillation process, the student model not only learns from the soft labels provided by the teacher model but also from the real labels. Therefore, the total loss function is composed of two parts: the cross-entropy loss from the real labels and the distillation loss from the teacher model. The total loss function can be expressed as:
The introduction of the distillation loss encourages the student model’s output to align closely with that of the teacher model. This implies that the student model not only learns from the real labels but also mimics the probability distribution of the teacher model’s output. Since the teacher model’s output contains more information about inter-class relationships and class similarities, this enables the student model to maintain high performance even after quantization.
Bit width allocation algorithm description
We propose an entropy-based bit-width allocation method, with the core tenet of measuring the importance of each layer by calculating the output entropy. The thresholds are adjusted on a dynamic basis in accordance with the entropy values, thereby facilitating the allocation of bit-width across the various layers of the model.
During the forward pass, the output entropy of each layer is calculated as a measure of the layer’s importance. By the pre-established thresholds, the network layers are divided into high-entropy and low-entropy layers, with different bit-widths (e.g., 6-bit, 4-bit, and 2-bit) allocated accordingly. The aforementioned process is shown in Algorithm 2:

Bit width allocation algorithm based on information entropy
The sliding window \('window'\) should be initialized to calculate entropy, and the structure \('layer\_entropy'\) should be created for the storage of entropy values. Next, define two key functions: one for calculating the entropy of each layer’s output (\('calculate\_entropy()'\)), and another for smoothing these entropy values using the sliding window (\('apply\_sliding\_window()'\)). During each training iteration, the forward propagation process should be performed to obtain the output of each layer. Subsequently, the entropy values of these outputs should be calculated and recorded. It is recommended that the sliding window function to smooth the entropy values, thus ensuring stability. Based on the entire set of entropy values, compute the thresholds, and compare each layer’s entropy with the thresholds to assign appropriate bit-widths. Ultimately, Optuna should be used for hyperparameter optimization to achieve the best balance between model performance and quantization bit-width through iterative computation. This will entail adjusting the sliding window size and thresholds and determining the optimal bit-width configuration for each layer. Following the allocation of bit-width, we apply knowledge distillation to address any potential performance deficits resulting from the quantization process. This approach not only markedly reduces the computational and storage overhead of the model but also ensures its continued optimal performance.
Experiment
In this section, we conducted quantization experiments on three models, ResNet20, ResNet32, and ResNet56, using the CIFAR-10 and CIFAR-100 datasets, and compared the accuracy results with mainstream methods such as PACT [3], LSQ [20], and LIMPQ [15]. ResNet110 was selected as the teacher model, with pre-trained models used for initialization. The bit-widths of the first and last layers were kept at 8 bits, and we selected the bit-width list {6, 4, 2}. During the forward pass, we computed the output entropy for each layer and dynamically assigned bit widths based on thresholds. The model was quantized using the optimal bit-width strategy and trained for 60 epochs, with a cosine learning rate scheduler and the SGD optimizer. The initial learning rate was set to 0.1, with a weight decay of 1e-4, and the first 5 epochs were used for a warm-up period.
Evaluation criteria
In this study, we use two metrics, accuracy and compression ratio, to evaluate the performance of different quantization methods. Accuracy is usually used to measure the impact of quantization methods on model performance. Specifically, it refers to the proportion of correctly predicted samples after quantization. For classification problems, accuracy refers to the proportion of correctly classified samples to the total number of samples, and the calculation formula is as follows:
If the model has high accuracy, it means that it correctly identifies the categories of most input samples when predicting. In practical applications, this usually means that the model has strong generalization ability and better performance.
The compression ratio is used to measure the ability of the quantization method to reduce the model storage space and computing overhead. It indicates the degree of reduction in the size of the quantized model relative to the size of the original unquantized model. The higher the compression ratio, the smaller the model is and the more storage and computing resources are saved. The calculation formula is as follows:
The calculation of model storage size refers to the memory space occupied by the model in the computer. It is usually determined by the number of parameters of the model and the number of bits stored for each parameter. The basic formula for calculating the model storage size is:
Implementation of the CIFAR-10 dataset
The CIFAR-10 dataset contains 50,000 training images and 10,000 test images, comprising a total of 10 categories of object images. The baseline refers to the full-precision model, while MP represents the average value for mixed-precision quantization.
Quantization of bit-width and accuracy
The experimental results are presented in Table 1. In comparison to the baseline full-precision model, our method achieves significantly lower bit-width with minimal accuracy loss, thereby increasing the efficiency of model compression. In both the PACT and LSQ methods, the bit-width is fixed at 4 bits. Across the three models, the accuracy of these methods is found to be consistently lower than that of our approach, Of these PACT shows the most noticeable accuracy drop, with an average of nearly 2%. This indicates that the fixed bit-width quantization strategy fails to account for the varying sensitivity of different layers to quantization, which ultimately results in degraded model performance. In our proposed method, the model exhibiting the greatest accuracy loss is ResNet32, yet even then, the accuracy only declines by 0.58%. The remaining two models show almost no difference in accuracy compared to the full-precision model. The experimental results demonstrate that uniform, fixed-precision quantization does not adequately account for the sensitivity of different layers to accuracy, and this “one-size-fits-all” approach can therefore lead to performance degradation. This is especially true for critical layers, where fixed-precision quantization may not be sufficient to preserve the feature representation capabilities of the original model. In contrast, our method dynamically assigns different bit-width to layers based on their sensitivity to quantization. To maintain high accuracy, higher bit-widths are allocated to key layers, while lower bit-widths are assigned to less sensitive layers, further compressing the model.
In comparison to the LIMPQ method, both approaches make use of variable bit-width, but our method is capable of achieving lower bit-width while maintaining a higher level of accuracy. LIMPQ determines the sensitivity of each layer by learning a scaling factor, quantizing the bit-width to 4MP. However, on the ResNet20 model, there is a noticeable drop in accuracy, and the accuracy of all three models is lower than that of our approach. The results indicate that using information entropy to analyze the sensitivity of each layer provides a more accurate assessment, leading to a more reasonable bit-width allocation.
Additionally, we enhanced our method with the incorporation of knowledge distillation (Ours_KD), using a pre-trained ResNet110 as the teacher model to guide the training of the quantized model. The results demonstrate that, compared to the original method, the accuracy of all three models improved. It is noteworthy that the accuracy of ResNet20 and ResNet56 even surpassed that of the full-precision models.
Comparison of training accuracy and loss
Figure 5a,b present a comparative analysis of the training accuracy and loss of the ResNet20 model across four different approaches: LSQ, LIMPQ, our proposed method, and our method with knowledge distillation (Ours_KD). As illustrated, the accuracy curve of our method demonstrates a relatively stable trajectory, ultimately attaining a higher level of accuracy. This is because our method, through precise bit-width allocation based on information entropy, reduces quantization error and retains the essential characteristics of the model, resulting in a more stable training process and faster convergence. In contrast, the accuracy curve of the LSQ method demonstrates considerable and inferior convergence, predominantly due to its fixed low bit-width, which fails to capture critical information in certain layers, resulting in unstable training. The LIMPQ method’s performance is intermediate between the aforementioned approaches, yet its accuracy still exhibits some fluctuations at various stages. This is likely because its approach to learning scaling factors does not fully capture the quantization sensitivity of different layers.
Concerning the training loss, our method also demonstrates superior convergence. The loss value decreases rapidly in the early stages of training and eventually stabilizes at a lower level. This is because our method effectively retains critical information in key layers, reducing the information loss caused by quantization. As a result, the model can be optimized more efficiently, leading to better performance throughout the training process.

Accuracy and loss for ResNet20.

Compression ratios for different models on CIFAR-10.
Compression ratio
Figure 6 and Table 1 demonstrate that our method consistently balances accuracy and compression ratio across various models. The method is equally effective when applied to smaller models, such as ResNet20, and larger models, such as ResNet56. It can maintain accuracy close to that of full-precision models, even at high compression ratios. While methods such as PACT and LSQ achieve higher compression ratios, their accuracy is inferior to that of our method when applied to all three models. In particular, PACT suffers a more pronounced decline in accuracy on ResNet20, ResNet32, and ResNet56, with an average reduction of approximately 2%. This suggests that its uniform 4-bit quantization strategy fails to account for the varying quantization needs of different layers, resulting in degraded model performance. Although the LIMPQ method achieves a compression ratio of 12.2x, our method, while achieving similar compression ratios, still maintains higher performance. For instance, on ResNet32 and ResNet56, our method achieves compression ratios of 11.58x and 16.02x, respectively, with accuracy surpassing that of LIMPQ. This demonstrates that our approach achieves a better balance between model compression and performance retention.
Implementation of the CIFAR-100 dataset
The CIFAR-100 dataset contains 50,000 training images and 10,000 test images, with a total of 100 categories. The baseline refers to the full-precision model, while MP represents the average value for mixed-precision quantization.
Quantization of bit-width and accuracy
Table 2 presents the results of quantization experiments on the ResNet20, ResNet32, and ResNet56 models using different quantization methods on the CIFAR-100 dataset. Both the PACT and LSQ methods use fixed-precision quantization, and all three models show significant accuracy drops. In particular, for the ResNet20 model, PACT results in an accuracy drop of nearly 10%, and the other two models also see a drop of about 4%. In comparison, while the LSQ method shows slightly improved accuracy across the three models, it still lags behind our proposed method, where the maximum accuracy loss is only 0.7%. This illustrates that a uniform fixed-bit-width quantization strategy fails to account for the unique characteristics of each layer, neglecting the differences in computational complexity, feature extraction capability, and tolerance to quantization errors, ultimately leading to degraded model performance.
The LIMPQ method also uses a mixed-precision bit-width configuration and shows relatively consistent performance across the three models, with an accuracy drop of around 1%. Nevertheless, our method outperforms LIMPQ in both bit-width configuration and accuracy. This demonstrates that using information entropy as a sensitivity metric more accurately assesses the importance of each model layer, allowing for the most appropriate bit-width allocation. By maintaining higher precision in key layers and applying stronger compression to less sensitive layers, our method achieves better performance.
In the Ours_KD method, we combined quantization with knowledge distillation, using a pre-trained ResNet110 model as the teacher model to direct the training of each quantized student model, further enhancing model performance. It is noteworthy that for ResNet56, the accuracy was slightly superior to that of the baseline full-precision model, demonstrating the ability to maintain, or even improve, accuracy while compressing the model.

Accuracy and loss for ResNet56.
Comparison of training accuracy and loss
Figure 7a,b compare the accuracy and loss curves during training across four methods: LSQ, LIMPQ, Ours, and Ours_KD. It can be observed that the accuracy of the LSQ method fluctuates significantly in the early stages of training, and its training loss remains noticeably higher than the other methods throughout the process, with a relatively slower convergence speed. This is primarily due to the fixed low-bit-width quantization strategy, which leads to larger quantization errors and affects the stability of model training. The LIMPQ method demonstrates performance characteristics that are intermediate between those of LSQ and our proposed method. While it exhibits relatively stable accuracy and loss curves, fluctuations are still evident. This is because its approach of determining bit-width by learning scaling factors does not fully account for the sensitivity of each layer to quantization, which impacts the overall training effectiveness of the model.
In contrast, our method shows a rapid decline in loss during the early stages of training and maintains a lower level throughout the process, demonstrating better convergence and stability, ultimately achieving higher accuracy. The ResNet32 model has a maximum accuracy loss of only 0.6% while the bit width is quantized to 3.6MP. This is because information entropy provides a more accurate measure of the sensitivity of each layer to quantization, thus enabling a more precise allocation of bit width. This results in a reduction in quantization errors and the preservation of the model’s essential feature information, thereby facilitating a more streamlined training process. The incorporation of knowledge distillation into the Ours_KD method serves to further enhance the model’s convergence and accuracy during the training process. The guidance from the teacher model enables the student model to continue learning key features even after quantization, thereby improving its generalization ability.

Compression ratios for different models on CIFAR-100.
Compression ratio
Figure 8 and Table 2 show that our method can achieve a high compression ratio while maintaining almost unchanged model accuracy. In both the PACT and LSQ methods, a uniform 4-bit quantization strategy was used, achieving an 8x compression ratio but resulting in significant accuracy drops. In particular, on the ResNet20 model, PACT and LSQ exhibited a notable decline in accuracy, with drops of approximately 9% and 3%, respectively. In contrast, our method achieved a 15.88x compression ratio with only a 0.7% accuracy drop. This illustrates that a uniform quantization strategy is inadequate for addressing the disparate quantization requirements of different layers. It is unable to make precise adjustments for layers that are particularly susceptible to quantization, resulting in significant information loss in these crucial layers and, consequently, an overall reduction in model accuracy. Compared to the LIMPQ method, our approach achieved a higher compression ratio while maintaining accuracy close to the full-precision model. For instance, on the ResNet56 model, our method achieved a 16x compression ratio with an accuracy as high as 74.56%.
Conclusion
This paper proposes a novel mixed-precision quantization method that evaluates the contribution of each layer to the final decision by smoothing and calculating the information entropy using a sliding window. The allocation of higher bit-width to layers with high entropy is justified by the greater uncertainty and information richness indicated by these layers. The enhanced preservation and processing of information enabled by these bit-width leads to improved model accuracy. We introduce a dynamic threshold setting mechanism that adjusts the bit-width allocation based on each layer’s entropy. By combining the sliding window with optimization tools and utilizing model accuracy as a constraint, the optimal bit-width allocation strategy is determined through the optimization of thresholds and window size Once the bit-width allocation strategy is determined, we quantize the model accordingly and use a pre-trained teacher model to guide the training of the quantized model to recover any accuracy loss caused by quantization. Experimental results demonstrate that using information entropy to guide bit-width allocation is both feasible and effective, showing advantages over other mainstream methods. In the case of the ResNet20 model, the average bit-width was reduced to 3.6MP by our method, resulting in an accuracy of 91.5%. This represents a mere 0.5% decline in comparison to the full-precision model.
Data availability
The datasets used in this study are publicly available. The CIFAR-10 and CIFAR-100 datasets, which were utilized for training and evaluating the models in this work, can be accessed and downloaded from the CIFAR dataset website. These datasets are widely recognized and used in the field of machine learning and computer vision research. Website: https://www.cs.toronto.edu/~kriz/cifar.html
References
Ansari, A. & Quaff, A. R. Data-driven analysis and predictive modelling of hourly Air Quality Index (AQI) using deep learning techniques: a case study of Azamgarh, India. Theor. Appl. Climatol. 156(1), 74 (2025).
Shelishiyah, R. et al. A hybrid CNN model for classification of motor tasks obtained from hybrid BCI system. Sci. Rep. 15(1), 1–10 (2025).
Islam, A. and Ghose, M. DELTA: Deadline aware energy and latency-optimized task offloading and resource allocation in GPU-enabled, PiM-enabled distributed heterogeneous MEC architecture. J. Syst. Archit. (2025). 103335.
Musa, A. et al. Lightweight deep learning models for edge devices-a survey. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 17, 18–18 (2025).
Nagel, M. et al. A white paper on neural network quantization. arXiv preprint (2021). arXiv:2106.08295.
Yu, C. et al. Improving Quantization-aware Training of Low-Precision Network via Block Replacement on Full-Precision Counterpart. arXiv preprint (2024). arXiv:2412.15846.
Shinde, T., Jain, R., and Sharma, A. K. Lightweight neural networks for speech emotion recognition using layer-wise adaptive quantization. J. Name (2025). X, XX–XX.
Xu, H. et al. Effective and Efficient Mixed Precision Quantization of Speech Foundation Models. arXiv preprint (2025). arXiv:2501.03643.
Choi, J., Wang, Z., Venkataramani, S. et al. Pact: Parameterized clipping activation for quantized neural networks. arXiv preprint (2018). arXiv:1805.06085.
Zhang, D. et al. Lq-nets: Learned quantization for highly accurate and compact deep neural networks. In Proceedings of the European conference on computer vision (ECCV) (2018).
Wang, S. & Kang, Y. Gradient distribution-aware int8 training for neural networks. Neurocomputing 541, 126269 (2023).
Zhou, Q. et al. Octo: INT8 training with loss-aware compensation and backward quantization for tiny on-device learning. In 2021 USENIX Annual Technical Conference (USENIX ATC 21) (2021).
Gong, C., Zheng, H., Hu, M. et al. Minimize quantization output error with bias compensation. arXiv preprint (2024). arXiv:2404.01892.
Fang, Y. et al. Mixed-Precision Quantization: Make the Best Use of Bits Where They Matter Most. arXiv preprint (2024). arXiv:2412.03101.
Wang, K., Liu, Z., Lin, Y. et al. Haq: Hardware-aware automated quantization with mixed precision. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8612–8620 (2019).
Lou, Q. et al. Autoq: Automated kernel-wise neural network quantization. arXiv preprint (2019). arXiv:1902.05690.
Wu, B. et al. Mixed precision quantization of convnets via differentiable neural architecture search. arXiv preprint (2018). arXiv:1812.00090.
Guo, Z. et al. Single path one-shot neural architecture search with uniform sampling. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XVI (Springer International Publishing, 2020).
Real, E. et al. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, 33 (2019).
Dong, Z. et al. Hawq: Hessian aware quantization of neural networks with mixed-precision. In Proceedings of the IEEE/CVF international conference on computer vision (2019).
Dong, Z. et al. Hawq-v2: Hessian aware trace-weighted quantization of neural networks. Adv. Neural. Inf. Process. Syst. 33, 18518–18529 (2020).
Kloberdanz, E. & Le, W. Mixquant: Mixed precision quantization with a bit-width optimization search. arXiv preprint (2023). arXiv:2309.17341.
Tang, C., Ouyang, K., Wang, Z. et al. Mixed-precision neural network quantization via learned layer-wise importance. In European Conference on Computer Vision, 259–275 (Springer Nature Switzerland, 2022).
Ma, Y., Jin, T., Zheng, X. et al. Ompq: Orthogonal mixed precision quantization. In Proceedings of the AAAI Conference on Artificial Intelligence, 37 (2023).
Shannon, C. E. A mathematical theory of communication. Bell Syst. Tech. J. 27(379–423), 623–656 (1948).
Mao, A., Mohri, M. & Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In International Conference on Machine Learning (PMLR, 2023).
Quinlan, J. R. Induction of decision trees. Mach. Learn. 1, 81–106 (1986).
Tishby, N., Pereira, F. C. & Bialek, W. The information bottleneck method. arXiv preprint (2000). arXiv:physics/0004057.
Esser, S. K., McKinstry, J. L., Bablani, D. et al. Learned step size quantization. arXiv preprint (2019). arXiv:1902.08153.
Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. arXiv preprint (2015). arXiv:1503.02531.
Funding
This work was supported by the National key R&D Program of China (2022YFE0107300), and the Key R&D Program of Shandong Province (Soft Science Project) (2023RKY01010).
Author information
Authors and Affiliations
Contributions
Ting Qin conceived the study, developed the methodology, and led the writing of the first draft. Zhao Li commented on the paper. Jiaqi Zhao, Yuting Yan, and Yafei Du provided critical feedback, revised the manuscript, and supervised the review and editing process. All authors contributed to the final version of the manuscript and approved its submission.
Corresponding author
Ethics declarations
Competing interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qin, T., Li, Z., Zhao, J. et al. Mixed precision quantization based on information entropy. Sci Rep 15, 12974 (2025). https://doi.org/10.1038/s41598-025-91684-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-91684-8
