
Abstract
The traditional evaluation of compressive strength through repeated experimental works can be resource-intensive, time-consuming, and environmentally taxing. Leveraging advanced machine learning (ML) offers a faster, cheaper, and more sustainable alternative for evaluating and optimizing concrete properties, particularly for materials incorporating industrial wastes and steel fibers. In this research work, a total of 166 records were collected and partitioned into training set (130 records = 80%) and validation set (36 records = 20%) in line with the requirements of data partitioning and sorting for optimal model performance. These data entries represented ten (10) components of the steel fiber reinforced concrete such as C, W, FAg, CAg, PL, SF, FA, Vf, FbL, and FbD, which were applied as the input variables in the model and Cs, which was the target. Advanced machine learning techniques were applied to model the compressive strength (Cs) of the steel fiber reinforced concrete such as “Semi-supervised classifier (Kstar)”, “M5 classifier (M5Rules), “Elastic net classifier (ElasticNet), “Correlated Nystrom Views (XNV)”, and “Decision Table (DT)”. All models were created using 2024 “Weka Data Mining” software version 3.8.6. Also, accuracies of developed models were evaluated by comparing sum of squared error (SSE), mean absolute error (MAE), mean squared error (MSE), root mean squared error (RMSE), Error (%), Accuracy (%) and coefficient of determination (R2), correlation coefficient (R), willmott index (WI), Nash–Sutcliffe efficiency (NSE), Kling–Gupta efficiency (KGE) and symmetric mean absolute percentage error (SMAPE) between predicted and calculated values of the output. At the end, machine learning has been found to be a transformative approach that enhances the efficiency, cost-effectiveness, and sustainability of evaluating compressive strength in industrial wastes-based concrete reinforced with steel fiber. Among the models reviewed, Kstar and DT emerge as the most practical for achieving precise and sustainable results. Their adoption can significantly reduce environmental impacts and promote the sustainable use of industrial by-products in construction. The sensitivity of the input variables on the compressive strength of industrial wastes-based concrete reinforced with steel fiber produced 36% from C, 71% from W, 70% from FAg, 60% from CAg, 34% from PL, 5% from SF, 33% from FA, 67% from Vf, 5% from FbL, and 61% from 61%. Fiber Volume Fraction (Vf) (67%) high sensitivity suggests that steel fiber content greatly impacts crack resistance and tensile strength. Steel Fiber Orientation (61%) indicates the importance of fiber alignment in distributing stresses and enhancing structural integrity.
Similar content being viewed by others

Introduction
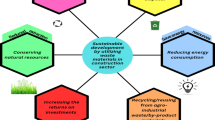
The construction industry is one of the largest consumers of natural resources, and concrete production contributes significantly to CO₂ emissions1. The integration of industrial wastes into concrete addresses environmental concerns while enhancing material performance (see Fig. 1). Below is an overview of how industrial wastes contribute to sustainable concrete construction2. Using industrial wastes in concrete construction offers a viable path toward sustainable development3. It reduces environmental impacts, conserves resources, and improves material properties. Overcoming the challenges of waste variability, processing costs, and regulatory hurdles will require concerted efforts from researchers, policymakers, and industry stakeholders4. As awareness of sustainable practices grows, the integration of industrial wastes in concrete is poised to become a cornerstone of green construction. Using waste materials such as steel fibers in construction and sustainable concrete applications offers significant environmental benefits, including a reduction in carbon footprints5. These benefits stem from repurposing materials that would otherwise contribute to waste accumulation, promoting sustainability, and reducing the demand for virgin resources. Repurposing steel fibers derived from industrial waste or recycled sources minimizes the need for new steel production, which is an energy-intensive process associated with high carbon dioxide emissions6. By integrating waste steel fibers into construction materials like concrete or soil reinforcement, the overall embodied carbon of the project is reduced. This practice also contributes to waste management by diverting steel waste from landfills, where its degradation could take decades. Steel fibers enhance the mechanical properties of materials, such as improving tensile strength, crack resistance, and durability. These enhancements can extend the lifespan of structures, reducing the need for frequent repairs or replacements. As a result, fewer materials and resources are consumed over time, further lowering the environmental impact7. In structural concrete applications, incorporating steel fibers into soil stabilization reduces the reliance on traditional stabilizers like cement or lime, which are associated with significant greenhouse gas emissions during production. This substitution supports sustainable construction goals by lowering overall carbon emissions while maintaining or enhancing the required engineering performance. Using waste steel fibers contributes to a circular economy by reusing materials, conserving natural resources, and reducing the environmental footprint of construction and infrastructure projects.

Schematic illustration of the sustainable use of industrial waste in construction.
The global generation of construction and demolition wastes (CDWs) is rising due to the demolition of obsolete structures, the construction of new edifices and infrastructure, and the expansion of existing buildings to accommodate the increasing population’s demand for livable spaces. Nonetheless, the substantial volume of created construction and demolition wastes (CDWs) was inadequately managed within the circular value chain, resulting in their deposition in pristine landfills or utilization in low-tech applications, such as filler materials in basement building or aggregates in non-structural concrete. Given the annual global generation of 10 billion tons of construction and demolition waste (CDW), there is an urgent necessity to devise innovative, sustainable, and practical solutions to mitigate issues arising from CDW production and to manage its environmental, economic, and social repercussions. Thus, the issues related to CDWs can be addressed, fostering a more habitable environment for individuals. Furthermore, CDWs can be transformed into high-value-added products, yielding economic advantages for nations. Recent research have concentrated on the valorization of construction and demolition wastes (CDWs) to mitigate the environmental impact of the construction industry1. Mansoori et al.2 examined the impact of ceramic waste powder (CWP), micro silica (MS), and steel fiber (SF) on self-compacting mortar. CWP diminished mechanical characteristics by 20% and augmented permeability by 14%. Nevertheless, the incorporation of MS enhanced characteristics by 30%. The incorporation of fibers ranging from 0.5% to 1% enhanced flexural strength, with the enhancement being more pronounced in samples with elevated MS concentration. The adhesion between cement paste and fibers was enhanced by using both micro silica and steel fibers. The substitution of micro silica resulted in a 99% increase in electrical resistance in samples containing 20% ceramic waste powder. Microstructure analyses validated the substantial enhancement in density and homogeneity of hydration products due to the presence of tiny silica particles. Nguyen and Quang3 develop models for predicting the compressive strength and CO2 emissions of geopolymer concrete (GPC) via Gene-expression programming (GEP). The analysis employs 274 data points about GPC strength and CO2 emissions from fly ash (FA) and ground granulated blast furnace slag (GGBFS). The models exhibit elevated correlation coefficients and acceptable errors. The research indicates that augmenting GGBFS content, Na2O content, and NaOH solution molarity, while reducing FA content, FA/GGBFS ratio, and water/binder ratio, can substantially improve GPC strength. The research indicated appropriate contents of FA and GGBFS, alkaline activators, aggregates, and further factors. Moncayo et al.4 assessed cabuya fiber, cultivated in Ecuador, as an acoustic absorption material and presents a machine learning methodology to imitate its characteristics. Eight samples of cabuya fiber were made with thicknesses between 12 mm and 30.6 mm. Sound absorption coefficients were determined utilizing an impedance tube, and a Gaussian regression model was developed for predictive analysis. The findings indicated that the 30.6 mm sample attained peak absorption coefficients of 0.91 at 2 kHz and 0.9 at 5 kHz, with a mean square error of merely 0.0002. These findings offered insights into the utilization of cabuya fiber and sophisticated prediction models to improve building acoustic performance and mitigate environmental effect. Ulucan et al.5 evaluated the efficacy of machine learning regression models in forecasting the early-age compressive strength of concretes derived from recycled concrete aggregates sourced from a structure demolished during the Sivrice-Elazig earthquake on January 24, 2020. The study seeks to ascertain strength with high precision and utility, given the swift construction of new edifices and the expedited completion of projects. Seven traditional machine learning techniques were utilized, focusing on the compressive strength values of early-age concrete at 1 and 3 days. The correlation between experimental findings and anticipated results was examined, and a comprehensive comparison of these advanced regression methods was performed. This study greatly advances sustainable development and circular economy objectives by employing waste resources and accurately assessing the early-age compressive strengths of manufactured concretes. Kiran et al.6 is presently investigated the transformation of ceramic waste into fine aggregates for paver blocks. Evaluations are underway to ascertain the efficacy of these improved blocks. Findings indicate that substituting natural aggregates with as much as 30% ceramic waste markedly enhances compressive strength and rebound outcomes. This research advances the creation of sustainable and cost-effective construction materials, reduces landfill waste, and conserves natural resources. Tijani et al.7 investigated the utilization of agro-industrial by-products, namely sorghum husk ash (SHA) and palm kernel shell (PKS), as substitutes for conventional building materials. The research sought to develop a durable, sustainable, and economically viable pavement construction utilizing a combination of SHA-PKS and natural aggregate. The efficacy of the SHA-PKS based PC was analyzed, and the viability of integrating SHA and PKS was examined. Artificial Neural Network (ANN) models were created to enhance the prediction of porosity and permeability. The results indicated that augmenting the quantities of SHA and PKS resulted in a reduction of PC densities, while simultaneously enhancing porosity and permeability. The combination of SHA-blended PKS-based PC containing 40% PKS and 20% SHA attained the designated metrics for sidewalks and cycle paths, decreasing embodied carbon, embodied energy, and cost by 23%, 20%, and 24%, respectively. Amran and Onaizi8 focused on formulating low-carbon concrete mixtures by substituting 50% of cement with fly ash (FA) and including nano-sized glass powder (4% and 6% of cement weight) as nanomaterial additions. The ideal mixture ratios comprised 10% effective microorganisms and 4–6% nano-sized glass powder additions. The findings indicated a substantial favorable influence on resistance and durability characteristics when substituting 10% of mixing water with effective microorganisms (EMs) broth and integrating nanomaterial additions. This study emphasizes the significance of environmentally sustainable concrete additive technologies in the advancement of advanced concrete types. The research underscores the potential of nanomaterial additions derived from Saudi industrial waste to improve the characteristics of FA-based concrete. Smirnova et al.9 revealed that the compositions of the composites were connected with stress–strain diagrams under bending tension and acoustic emission characteristics. The composites contained polypropylene microfibre at 5%-vol. and 3.5%-vol. concentrations, facilitating workability at low water-to-binder ratios. Deformation diagrams were acquired for all compositions, with acoustic signals reaching their zenith in the strain-softening region. This non-destructive testing technique can be employed to assess constructions utilizing strain-hardening composites.
Research methodology
Collected database and statistical study
An extensive literature search was conducted and a representative data was collected from published research paper10. It has been reported that the steel fiber reinforced concrete was cured under ambient temperature and was not considered as a serious variable in this model10. This was because the concrete material properties dominate the characteristic behavior of the concrete. In the context of advanced machine learning models, the relative contribution of curing temperature may appear negligible if its variability within the dataset is limited or if other variables strongly correlate with compressive strength. In the pre-processing phase, Z-score standardization has been used in this research work to up-score the consistency of variables with different units for optimal performance. The collected 166 records were divided into training set (130 records = 80%) and validation set (36 records = 20%) in line with the requirements of data partitioning and sorting for optimal performance11. Partitioning the dataset into training set (130 records, 80%) and a validation set (36 records, 20%) offers several benefits in line with the requirements of data partitioning and sorting for optimal model performance11. This approach ensures that the model is trained on a majority portion of the dataset, allowing it to learn the underlying patterns and relationships effectively. The separation of a validation set provides an independent dataset to evaluate the model’s generalization capability, ensuring that its performance is not overly optimized for the training data11. The 80/20 split adheres to standard practices in machine learning, balancing sufficient training data to develop a robust model and a meaningful validation set size for accurate performance assessment. This partitioning strategy also helps in detecting potential issues like overfitting, where the model performs well on training data but poorly on unseen data. By using a sorted or stratified approach when partitioning the data, the distribution of key features or target variables can be maintained across both sets, preserving the dataset’s representativeness. This method ensures that the model is exposed to diverse scenarios during training while being tested on a similarly distributed subset of data. The benefits include improved reliability of performance metrics, better insights into model behavior, and the ability to tune hyperparameters effectively, leading to optimal performance and increased confidence in the model’s predictions. The appendix includes the complete dataset, while Table 1 summarizes their statistical characteristics. Finally, Fig. 2 shows the violin distribution for each input and Fig. 3 shows Pearson correlation matrix, histograms, and the relations between variables.

Violin distribution for each input.

Correlation, distribution and interpreting chart.
Research program
Five different ML techniques were used to predict the compressive strength of the concrete using the collected database. These techniques are “Semi-supervised classifier (Kstar)”, “M5 classifier (M5Rules), “Elastic net classifier (ElasticNet), “Correlated Nystrom Views (XNV)”, and “Decision Table (DT)”. All models were created using the November 2024 “Weka Data Mining” software version 3.8.6. The following section discusses the results of each model. The accuracies of developed models were evaluated by comparing sum of squared error (SSE), mean absolute error (MAE), mean squared error (MSE), root mean squared error (RMSE), Error %, Accuracy % and coefficient of determination (R2), correlation coefficient (R), willmott index (WI), Nash–Sutcliffe efficiency (NSE), Kling–Gupta efficiency (KGE) and symmetric mean absolute percentage error (SMAPE) between predicted and calculated steel fiber reinforced concrete compressive strength parameters values. The definition of each used measurement is presented in Eqs. 1–11.
where N is the number of entry terms or sample size, yi is the dependent variables, xi is the values independent variables, \(\overline{x }\) is the mean of the independent variables, \({\sigma }_{y}\) and \({\sigma }_{x}\) are the standard deviation of the dependent and independent terms.
Theory of the machine learning techniques
Semi-supervised classifier (Kstar)
The K-Star (K) classifier* known as the “instance-based learner” is a distance-based machine learning algorithm primarily used for classification tasks12. It is a non-parametric instance-based learning method where the classification of an instance depends on a similarity measure derived from training examples. The algorithm can operate in both supervised and semi-supervised learning modes. K-Star does not create an explicit model13,14,15. Instead, it uses stored instances to classify new data points. The unique aspect of K-Star is its use of an entropy-based distance measure rather than conventional Euclidean or Manhattan distances16,17,18,19. The distance is measured by the probability of transforming one instance into another using a series of transformations20,21,22,23. In a semi-supervised setting, the algorithm can leverage both labeled and unlabeled data. Unlabeled data is used to refine the distance measure or infer class probabilities through transductive learning10,11,23. The entropy-based distance metric makes K-Star robust against noise and variations in data. The instance-based semi-supervised classifier, sometimes referred to as Kstar (or K*), classifies data using an entropy-based distance function24. The main concept is to use a probability-based metric to assess how similar two examples are. It is semi-supervised because it may employ both labeled and unlabeled data during training to create a more reliable classifier. Figure 4 shows a general structure of the Kstar approach.

General structure of the Kstar approach (adapted from Birant24).
The transformation probability P(x → y) is defined as the probability of transforming instance x to y. The computation involves all possible transformations.
where Pt represents the probability of each transformation step. The distance between two instances x and y is given by:
The class of the nearest neighbors is used for classification. The most probable class is determined using:
where wi is the weight of neighbor xi and P(xi → x) is the probability of transformation.
M5 classifier (M5Rules)
The M5 classifier, often referred to as M5Rules, is a machine learning method that combines rule-based learning with the principles of regression trees17. It is primarily designed for regression problems but can also handle classification tasks when labels are converted into numeric values. M5Rules generates interpretable rule-based models, making it valuable for domains where understanding model decisions is crucial10,11,20,21,22,23. M5Rules builds on the M5 Model Tree, a regression tree where each leaf node contains a linear regression model instead of a single predicted value. After building the model tree, M5Rules extracts rules by traversing paths from the root to each leaf node19. Each path corresponds to a rule. Redundant rules are pruned, and the model is simplified by merging similar regions, reducing overfitting. While M5Rules is primarily for regression tasks, it can handle classification by transforming categorical labels into numerical values (e.g., one-hot encoding or ordinal transformation). The M5 model tree is the source of the rule-based classifier M5Rules. For predictive modeling, it blends linear regression and decision tree techniques25. Linear regression models are found at the leaf nodes of the decision tree, which divides data according to attributes (Fig. 5).

M3 model framework (adapted from Khalid et al.26).
Each leaf node uses a regression equation:
where β0 is the intercept, βi are the coefficients, and xi are the input features. The decision tree splits are determined by minimizing the variance in the target variable y:
Elastic net classifier (ElasticNet)
The Elastic Net is a regularization technique that combines L1 (Lasso) and L2 (Ridge) penalties in a linear model. While it is primarily used for regression tasks, it can be adapted for classification by integrating it into logistic regression or other classification frameworks20. Elastic Net is particularly effective when dealing with high-dimensional data (e.g., when the number of features exceeds the number of samples) and when features are correlated. Elastic Net is a linear regression method that combines L1-norm (lasso) and L2-norm (ridge) penalties27. It is particularly useful when features are correlated.
The objective function:
\({\Vert \beta \Vert }_{1}:L1 \,norm\, (lasso\,penalty)\). \({\Vert \beta \Vert }_{2}^{2}:L2\,norm\, (ridge \,penalty)\). \(\lambda\): Regularization parameter. \(\propto\): Mixing parameter (0 \(\le \alpha \le 1)\). Elastic Net uses coordinate descent to optimize the coefficients β.
Correlated Nyström views (XNV)
Correlated Nyström Views (XNV) is a machine learning method designed for tasks like classification and regression, particularly in multi-view learning contexts. Multi-view learning deals with data that comes from multiple representations or “views” of the same entity. XNV combines Nyström approximation (a technique for scaling kernel methods) with mechanisms to correlate and integrate information across these views. Multi-view data refers to datasets where instances have multiple feature sets (e.g., text and image data describing the same entity). XNV leverages correlations between views to improve model performance18,21. The Nyström method is a computational technique to approximate large kernel matrices. This is critical for kernel-based methods when handling large datasets. Instead of computing the full kernel matrix, the Nyström method samples a subset of data points to approximate it efficiently. XNV aligns and correlates the representations learned from different views, ensuring that the model captures complementary information. The combination of Nyström approximation and correlated views makes XNV scalable for large datasets with high-dimensional features in multiple views. XNV employs the Nystrom approximation for kernel approaches to handle large-scale data effectively28. Using linked embeddings, it integrates several data views (such as feature sets). Nystrom Approximation for Kernel Matrix K:
C: Submatrix of K (columns corresponding to sampled points). W: Submatrix of K (intersection of rows and columns of sampled points). \(W^{f}\) Pseudoinverse of W. Correlated Nystrom Views combine the embeddings from different views using a correlation matrix R:
\({Z}_{i}\) Embedding from the i-th view, R: Correlation matrix learned during training. The embeddings Z are fed into a classifier (e.g., SVM or logistic regression).
Decision table (DT)
A Decision Table (DT) is a simple, interpretable rule-based machine learning model used for classification. It organizes decision-making logic into a tabular format, making it easy to visualize, interpret, and validate. In machine learning, DTs are useful for summarizing and predicting outcomes based on input attributes16. Columns in the table represent features or attributes of the dataset. Rows of the table list combinations of attribute conditions. Each row corresponds to an output class or decision, based on the attribute conditions. A decision table is a basic rule-based classifier that uses a table with actions (class labels) and conditions (attributes) to represent knowledge29. Key Equations: Each row in the decision table corresponds to a rule: If \({A}_{1}={v}_{1}\) and \({A}_{2}={v}_{2}\) and … then Class = c. When multiple rows match, the class is determined by majority voting:
where \(\parallel\) is the indicator function.
Sensitivity analysis
Sensitivity analysis evaluates how the variations in input parameters, such as industrial waste materials and steel fiber content, affect the compressive strength of concrete12,13,14,15,16. This process identifies key factors influencing the strength and their relative importance, helping optimize the concrete mix design17,18,19,20. The Hoffman & Gardener method is a sensitivity analysis technique that uses rank correlation between input variables and the output to measure the influence of each input parameter21,22,23. This method is particularly suited for cases where input–output relationships may be nonlinear or nonmonotonic, as it evaluates the sensitivity using nonparametric statistics10,11. A preliminary sensitivity analysis was carried out on the collected database to estimate the impact of each input on the (Y) values. “Single variable per time” technique is used to determine the “Sensitivity Index” (SI) for each input using Hoffman and Gardener30 formula as follows:
Results and discussion
Kstar model
The Kstar model for the prediction of the compressive strength of industrial wastes-based concrete reinforced with steel fiber was executed using the hyper-parameters displayed in Fig. 6. The Kstar utilized hyperparameters such as batchsize of 100, false debug, false doNotCheckCapabilities. False entropicAutoBlend, 20 globalBlend, and 2 numDecimalPlaces. In the context of the K* (Kstar) machine learning algorithm, the hyperparameters mentioned have specific roles that influence the model’s performance and configuration. A batch size of 100 refers to the number of instances processed together in one iteration of the learning process. In the case of K*, this setting might determine the number of data points used during each update of the model, affecting the computational efficiency and the model’s ability to learn from large datasets. The “false debug” setting indicates that debugging information is not output during model training or evaluation. This setting helps in reducing the verbosity of the algorithm’s output, allowing the user to focus on the primary results rather than diagnostic messages. The “false doNotCheckCapabilities” hyperparameter implies that the system checks capabilities or configurations during execution, ensuring that the algorithm runs correctly according to the available computational resources or requirements. The “false entropicAutoBlend” parameter suggests that automatic blending of entropic distance measures is disabled. Entropic blending could be used to adapt the distance metric, but turning this off means the K* algorithm would rely on predefined or static distance calculations without adapting dynamically to the data. The “20 globalBlend” hyperparameter might be setting a blending factor or threshold for how distance measures are combined globally within the model, potentially affecting the model’s flexibility in accommodating varying data distributions. Lastly, the “2 numDecimalPlaces” setting controls the precision of the numerical results, limiting the output to two decimal places. This can be important for simplifying results and ensuring consistency in the model’s performance evaluations. Overall, these hyperparameters help configure the K* algorithm’s behavior, influencing computational efficiency, flexibility, and output precision, depending on the specific requirements of the task and the dataset. The model produced the following performance indices; SSE 301.5, MAE 1.55 MPa, MSE 4.0 MPa, RMSE 2.0 MPa, Error 3.5%, Accuracy 96.5%, R2 0.99, R 0.995, WI 1.0, NSE 0.99, KGE 0.985, and SMAPE 3.14 (see Fig. 7). The Kstar (K*) model’s performance for predicting the compressive strength of industrial waste-based concrete is assessed based on provided performance metrics. The model demonstrates high prediction accuracy and robustness, which has significant implications for sustainable concrete construction. With an accuracy of 96.5% and an error of only 3.5%, the Kstar model is highly reliable for predicting compressive strength. The extremely high R2 (0.99) and R (0.995) indicate that the model captures nearly all the variability in the data. The low RMSE (2.0 MPa) and MAE (1.55 MPa) confirm minimal deviations from actual values, ensuring dependable results. The SMAPE value of 3.14% further substantiates the low prediction error in percentage terms. WI (1.0), NSE (0.99), and KGE (0.985) metrics validate that the model effectively balances correlation, bias, and variance. The SSE of 301.5 reflects a well-tuned model that minimizes cumulative errors across predictions. The precise prediction of compressive strength enables the formulation of efficient concrete mixes, minimizing resource wastage. Enhances the use of industrial wastes like fly ash, slag, and recycled materials by accurately estimating their impact. The model helps avoid overdesign by reliably predicting required compressive strength, reducing unnecessary cement and resource usage. The model enables real-time monitoring and adjustment during concrete production, ensuring consistent quality and performance and encourages the adoption of industrial by-products, reducing environmental impact while maintaining structural integrity. Minimizing errors in strength prediction reduces experimental trials and production costs. The high reliability of predictions promotes the integration of non-conventional materials (e.g., steel fibers, biomedical ash, and plastics) into construction projects. Employ the Kstar model in early design stages for selecting optimal material proportions. Use the model to verify mix designs for various applications, ensuring adaptability to diverse project requirements. Incorporate more variables such as curing conditions, temperature effects, and long-term durability metrics to enhance model versatility. Extend the model’s use from laboratory settings to field applications to evaluate its performance under real-world conditions. Utilize predictive tools like the Kstar model to foster data-driven decision-making in sustainable construction. The Kstar model’s high predictive accuracy and low error metrics make it a powerful tool for optimizing the compressive strength of industrial waste-based concrete reinforced with steel fibers. Its application has the potential to revolutionize sustainable concrete construction by improving resource efficiency, reducing environmental impact, and maintaining structural reliability. Future research and field applications will further validate its effectiveness in promoting sustainable practices in the construction industry.

The considered hyper-parameters of (Kstar) model.

Relation between predicted and calculated strength using (Kstar).
M5Rules model
The M5Rules model for the prediction of the compressive strength of industrial wastes-based concrete reinforced with steel fiber was executed using the hyper-parameters displayed in Fig. 8. The M5Rule model utilized hyperparameters such as batchsize of 100, false buildRegressionTree, false debug, 4.0 minNumInstances, false unpruned, false useUnsmoothed, and 4 numDecimalPlaces. In the context of the M5Rules model, the hyperparameters mentioned are key to defining how the model functions and impacts its performance. A batch size of 100 refers to the number of instances used in each training iteration when the model is being updated, influencing the computational efficiency and convergence rate. In this case, a batch size of 100 suggests that the model will process 100 samples at once before updating, which is typically a balance between training speed and stability in learning. The “false buildRegressionTree” hyperparameter indicates that the model will not construct a regression tree, which is typically a key component of M5 decision tree-based models. This suggests that the focus might be on using rule-based techniques or other forms of learning rather than regression tree construction. “False debug” means that debugging output is disabled, reducing the verbosity of the process and ensuring that only essential information is displayed during training, which can help improve the clarity of results when debugging is not necessary. The "4.0 minNumInstances" hyperparameter specifies the minimum number of instances required to consider a node during the learning process. This is a critical threshold that helps prevent overfitting by ensuring that the model does not generate rules or make splits based on too few data points. Setting this value to 4.0 indicates that the model will only generate rules for subsets of data that have at least 4 instances, ensuring that each rule is based on a sufficiently large portion of the data. The “false unpruned” setting means that the model will not use pruning, a technique that typically helps in reducing the complexity of decision trees by cutting back branches that have little predictive power. In this case, disabling pruning might result in a more complex model that could potentially overfit, though it may also capture more nuances in the data. The “false useUnsmoothed” hyperparameter indicates that unsmoothed predictions will not be used. Smoothing often helps reduce the impact of outliers or overly sharp fluctuations in predictions, and turning it off suggests that the model will make direct, unsmoothed predictions based on the rules generated during learning. Finally, the “4 numDecimalPlaces” setting controls the precision of numerical outputs, ensuring that results are reported with four decimal places of precision. This is important for ensuring that the model’s predictions and evaluations are accurate and presented consistently. Together, these hyperparameters guide the structure and behavior of the M5Rules model, influencing its ability to generalize from the data, its complexity, and the precision of its predictions. The model produced the following performance indices; SSE 1362.5, MAE 3.3 MPa, MSE 16.8 MPa, RMSE 4.05 MPa, Error 7.0%, Accuracy 93%, R2 0.965, R 0.98, WI 0.99, NSE 0.96, KGE 0.945, and SMAPE 3.075 (see Figs. 9 and 10). The M5Rules model’s performance metrics for predicting the compressive strength of industrial waste-based concrete demonstrate its predictive capability and potential utility in sustainable construction. Below is a detailed evaluation of the model’s performance indices and implications for practical applications. With an accuracy of 93% and R2 of 0.965, the M5Rules model reliably predicts compressive strength. However, the error metrics (e.g., RMSE of 4.05 MPa and MAE of 3.3 MPa) suggest slightly higher variability compared to other advanced models. SSE (1362.5) and MSE (16.8 MPa) indicate cumulative prediction errors that, while within acceptable limits, could be optimized for better precision. High values for R (0.98), NSE (0.96), and WI (0.99) confirm a strong relationship and agreement between predicted and actual compressive strength values. The KGE (0.945) and SMAPE (3.075%) demonstrate that the model balances correlation, bias, and variability effectively, suitable for practical applications. The model provides reliable predictions, aiding in optimizing mix proportions for industrial waste-based concrete reinforced with steel fibers. The model reduces the need for extensive trial-and-error testing, conserving resources. By accurately predicting compressive strength, the model supports confidence in using waste materials (e.g., fly ash, slag, recycled aggregates), promoting sustainability. Predictions with a 7% error rate allow for effective material usage, reducing the overdesign and costs associated with experimental trials. The M5Rules model’s high accuracy can be leveraged to monitor concrete quality in real-time during production, ensuring adherence to design requirements. The model supports the widespread adoption of waste-based and fiber-reinforced concrete, aligning with sustainable construction goals. The model’s SSE and RMSE values indicate room for improvement in reducing prediction errors, which could further enhance its reliability. Incorporating additional input variables like curing conditions, age of concrete, and environmental factors might improve prediction accuracy. The M5Rules model’s performance metrics are slightly less robust than some other models (e.g., Kstar), suggesting potential benefits from hybrid modeling approaches. Use the M5Rules model for initial mix design and adjustments during production, ensuring efficient resource utilization. Fine-tune the model by training it on larger datasets with diverse mix compositions to improve generalizability. Pair the M5Rules model with optimization algorithms (e.g., genetic algorithms or particle swarm optimization) for enhanced mix design. Test the model’s predictions under real-world conditions to confirm its applicability across various project settings. The M5Rules model demonstrates high reliability and robust predictive capabilities for the compressive strength of industrial waste-based concrete reinforced with steel fibers. While slightly less accurate than some advanced models, it remains a practical tool for sustainable construction. Future refinement and integration into construction workflows can further enhance its utility, promoting environmentally friendly and resource-efficient concrete solutions.

The considered hyper-parameters of (M5Rules) model.

Rules of optimized Cs.

Relation between predicted and calculated strength using (M5Rules).
ElasticNet model
The ElasticNet model for the prediction of the compressive strength of industrial wastes-based concrete reinforced with steel fiber was executed using the hyper-parameters displayed in Fig. 11. The model utilized hyperparameters such as false additionalStats, alpha of 0.001, batchSize of 100, false debug, false doNotCheckCapabilities, elsilon of 1.0E-4, maxIt of 10,000,000, numDecimalPlaces of 2, numInnerFolds of 10, numModels of 100, false sparse, threshold of 1.0E-7, and true use_method2. In the context of the ElasticNet model, the specified hyperparameters play crucial roles in controlling the training process, optimization, and model behavior. The “false additionalStats” setting indicates that no additional statistics will be generated during the model’s execution, which helps keep the output focused on core results and avoids unnecessary computational overhead. The "alpha of 0.001" hyperparameter is a regularization parameter that controls the balance between the L1 (Lasso) and L2 (Ridge) regularization terms in the ElasticNet model. A value of 0.001 indicates a relatively small level of regularization, which means that the model will allow more flexibility in fitting the data but may be more prone to overfitting compared to higher values of alpha. The "batchSize of 100" indicates that the model processes 100 data instances at a time during each iteration of training, balancing computational efficiency and convergence rate. This setting influences how quickly the model updates and learns from the data. The “false debug” setting means that debugging output is not generated, streamlining the process and focusing on the core results. “False doNotCheckCapabilities” suggests that the system checks the algorithm’s capabilities during execution, ensuring that the model runs according to the available computational resources or requirements. The "elsilon of 1.0E-4" refers to a small value used in the optimization process, likely related to tolerance or convergence criteria. This setting helps the algorithm decide when to stop iterating based on how small the changes are between iterations, preventing unnecessary computation. The "maxIt of 10,000,000" sets a very high limit for the maximum number of iterations the optimization algorithm can run. This large value ensures that the algorithm will have sufficient opportunities to converge to an optimal solution, though in practice, the model will likely stop earlier based on other stopping criteria. The "numDecimalPlaces of 2" controls the precision of the model’s output, ensuring that results are rounded to two decimal places for clarity and consistency in reporting. The "numInnerFolds of 10" indicates the number of folds used in cross-validation, helping to assess the model’s performance and generalization ability. Cross-validation with 10 folds is a standard approach to balance bias and variance when evaluating model performance. The "numModels of 100" indicates that 100 separate models will be trained, likely as part of an ensemble learning approach. This can help improve predictive accuracy by averaging the predictions of multiple models to reduce variance and overfitting. The “false sparse” setting indicates that the model will not use sparse data representations, which might be relevant in cases where the data is highly sparse, such as in high-dimensional datasets with many zero values. Here, the model uses a dense representation instead. The "threshold of 1.0E-7" is another small value related to convergence or stopping criteria, indicating the threshold below which the algorithm considers the changes in the model’s parameters to be negligible, thereby stopping further iterations. Finally, the “true use_method2” suggests that a second method or variant of the ElasticNet algorithm is being used, which could involve a different optimization technique or regularization approach. This setting could be designed to enhance the model’s performance under certain conditions or for specific types of datasets. Altogether, these hyperparameters fine-tune the behavior of the ElasticNet model, ensuring it performs well in terms of regularization, computational efficiency, accuracy, and generalization, while also providing flexibility to adapt to different types of data and model configurations. The model produced the following performance indices; SSE 8203, MAE 8.0 MPa, MSE 93.7 MPa, RMSE 9.6 MPa, Error 16.0%, Accuracy 84%, R2 0.785, R 0.885, WI 0.935, NSE 0.78, KGE 0.81, and SMAPE 14.76 (see Fig. 12). The ElasticNet model provides moderate prediction capabilities for compressive strength. While it shows acceptable correlation and agreement metrics, its error and accuracy values indicate room for improvement. Below is a detailed analysis and its implications for sustainable concrete construction. An accuracy of 84% and an R2 value of 0.785 indicate that the model provides reasonable predictions but struggles with precision compared to other models. High SSE (8203), MSE (93.7 MPa), and RMSE (9.6 MPa) highlight significant prediction errors. The correlation coefficient (R = 0.885) and Willmott Index (WI = 0.935) suggest that the model reasonably captures the relationship between input variables and compressive strength. However, the agreement metrics are less robust compared to other advanced models. A high error percentage (16%) and SMAPE (14.76%) emphasize the need for improvement in prediction accuracy and reducing variability. NSE (0.78) and KGE (0.81) demonstrate moderate predictive efficiency, indicating the model is reliable but not optimal for precise predictions. The ElasticNet model can be useful for preliminary mix design evaluations where approximate predictions are sufficient. The model provides a starting point for assessing the influence of input variables like industrial wastes and fiber reinforcement. It supports the use of industrial wastes by providing a predictive framework to estimate their impact on compressive strength, aiding in sustainable construction practices. The relatively high error and variability metrics limit the model’s utility for critical applications requiring precise strength predictions. With refinement and incorporation of additional features, the ElasticNet model can better balance its predictive power with computational efficiency. The model’s higher error metrics (MAE, RMSE, and SMAPE) indicate that it struggles with the complexity of the dataset. Lower accuracy compared to other models like Kstar or M5Rules suggests it is less suitable for applications requiring high precision. Include additional predictors, such as curing conditions, temperature, and long-term durability properties, to enhance model performance. Refine ElasticNet regularization parameters (α and λ) to reduce bias and variance trade-offs. Combine ElasticNet with other algorithms, such as gradient boosting or ensemble methods, for improved predictions. The ElasticNet model demonstrates moderate predictive performance, with strengths in interpretability and usability for preliminary analyses. However, its higher error metrics and lower accuracy make it less suitable for high-precision applications in sustainable concrete construction. Enhancements through feature engineering, hyperparameter tuning, and hybrid modeling could significantly improve its performance, making it more competitive with advanced machine learning models. ElasticNet’s relatively weak performance may indicate challenges in capturing the complexity of the relationships within the dataset, which can be attributed to either overfitting or an under-representation of the intricate interactions between variables. In practical terms, this suggests that the model might be overly tuned to the specific characteristics of the training data, failing to generalize effectively to unseen data. Overfitting occurs when ElasticNet’s balance between L1 and L2 regularization is insufficient to prevent the model from adapting too closely to noise or less meaningful patterns in the training data. Alternatively, the weak performance could highlight a limitation in ElasticNet’s linear structure, which may struggle to represent complex, nonlinear relationships inherent in the dataset. This under-representation could mean that more sophisticated models, such as those capable of capturing nonlinearity (e.g., decision trees, ensemble methods, or neural networks), may be better suited for the problem. From a practical perspective, these observations suggest the need for further investigation into the dataset’s properties, including feature selection, engineering, or transformation to better align with ElasticNet’s strengths. Additionally, it highlights the importance of evaluating alternative modeling approaches that may provide more robust predictions for datasets with complex relationships.

The considered hyper-parameters of (ElasticNet) model.

Relation between predicted and calculated strength using (ElasticNet).
XNV model
The XNV model for the prediction of the compressive strength of industrial wastes-based concrete reinforced with steel fiber was executed using the hyper-parameters displayed in Fig. 13. The XNV model utilized hyperparameters such as 0.01 regularization parameter gamma, sample size for Nystroem method of 100, RBFKernel-C 250,007–G 0.01 kernel function, false doNotApplyStandardization, batchSize of 100, false debug, false doNotCheckCapabilities, 2 numDecimalPlaces, and seed of 1. The XNV model utilizes several hyperparameters that influence its performance and how it processes data. The "0.01 regularization parameter gamma" refers to a setting that controls the regularization strength in the model, particularly in kernel-based methods like Support Vector Machines (SVM). A value of 0.01 suggests a relatively weak regularization, allowing the model more flexibility to fit the training data, though it could also be more prone to overfitting. The "sample size for Nystroem method of 100" indicates the number of samples used in the Nystroem approximation technique. This method is often applied to kernel methods, such as SVM, to approximate the kernel matrix more efficiently, especially in large datasets. A sample size of 100 means the method will use 100 data points to approximate the kernel function, balancing accuracy and computational efficiency. The "RBFKernel-C 250,007–G 0.01 kernel function" specifies the use of a Radial Basis Function (RBF) kernel in combination with specific hyperparameters for the kernel. "C 250,007" refers to the regularization parameter for the RBF kernel, controlling the trade-off between maximizing the margin and minimizing classification errors. A value of 250,007 is quite large, suggesting a stronger emphasis on reducing classification errors. The "–G 0.01" specifies the gamma parameter for the RBF kernel, with 0.01 being a small value, indicating that the model will consider a wider range of data points in its decision boundary, which can impact the smoothness of the decision function. The “false doNotApplyStandardization” setting means that data standardization, such as scaling features to have zero mean and unit variance, will be applied, which is crucial for models that rely on distance metrics or kernel functions, ensuring that all features are treated equally. The "batchSize of 100" refers to the number of samples the model processes together during each iteration of training, influencing both computational efficiency and convergence speed. A batch size of 100 strikes a balance between processing time and model learning efficiency. The “false debug” setting indicates that debugging information will not be output during the training process, focusing on the core results instead of diagnostic messages. “False doNotCheckCapabilities” suggests that the model checks the system’s capabilities to ensure proper execution, preventing potential compatibility issues during model training. The “2 numDecimalPlaces” hyperparameter controls the precision of numerical results, ensuring that the model’s predictions and evaluations are reported with two decimal places for clarity and consistency. Finally, the "seed of 1" specifies a fixed seed value for random number generation, ensuring that the results are reproducible across different runs of the model. This is particularly useful for experiments, enabling comparison between results under the same conditions. In general, these hyperparameters control various aspects of the XNV model, including regularization, kernel function configuration, sample size for approximation methods, data processing techniques, and output precision, helping to ensure efficient, accurate, and consistent performance. The model produced the following performance indices; SSE 3883.5, MAE 4.95 MPa, MSE 46.9 MPa, RMSE 6.75 MPa, Error 11.0%, Accuracy 89%, R2 0.895, R 0.945, WI 0.97, NSE 0.895, KGE 0.895, and SMAPE 9.375 (Fig. 14). The XNV (Correlated Nyström Views) model demonstrates strong performance in predicting the compressive strength of industrial waste-based concrete reinforced with steel fiber. While not as precise as some advanced models, its balance of accuracy and error metrics makes it a viable tool for sustainable construction. Below is an in-depth analysis. Accuracy of 89% and R2 of 0.895 demonstrate strong predictive capabilities for practical use in sustainable construction. Metrics like WI (0.97) and NSE (0.895) show consistent agreement and efficiency in predictions. Error metrics such as RMSE (6.75 MPa) and SMAPE (9.375%) indicate some variability in predictions, though they remain within acceptable limits for practical use. An 11% error rate suggests minor over- or under-estimation in predictions. A high correlation coefficient (R = 0.945) confirms a strong relationship between the input variables and compressive strength. The KGE (0.895) highlights the model’s ability to balance correlation, bias, and variability effectively. The XNV model’s strong predictive capabilities can help optimize the proportions of industrial waste materials in concrete mixes, reducing dependency on traditional materials like cement and natural aggregates. Reliable predictions of compressive strength build confidence in using waste materials such as fly ash, slag, and recycled aggregates, promoting sustainability in construction. By minimizing the need for extensive physical testing, the model saves costs and time during the mix design phase, especially for waste-based concrete. The model can be used in production settings for quality assurance, ensuring that concrete mixes consistently meet design strength requirements. The model supports sustainable construction practices by enabling precise design of concrete mixes with reduced environmental footprints. While strong, the error metrics (MAE, RMSE) suggest some variability, which could be improved for applications requiring high precision. Predictions may vary under different environmental conditions or mix designs not represented in the training dataset. Include more diverse data points, such as mixes with varying curing conditions and ages, to enhance model generalizability. Combine XNV with other machine learning models like XGBoost or ensemble techniques for improved accuracy. Integrate additional features, such as temperature, curing time, and concrete age, to improve model precision. The XNV model demonstrates robust predictive performance for compressive strength of industrial waste-based concrete reinforced with steel fibers. Its high accuracy, strong correlation, and moderate error levels make it a reliable tool for sustainable construction applications. While it may not outperform advanced models like Kstar or M5Rules in precision, it offers a balanced approach that is computationally efficient and practical for real-world use. Further refinement through dataset expansion, feature engineering, and hybrid modeling can enhance its performance, ensuring greater utility in optimizing concrete mixes for sustainable construction.

The considered hyper-parameters of (XNV) model.

Relation between predicted and calculated strength using (XNV).
DT model
The XNV model for the prediction of the compressive strength of industrial wastes-based concrete reinforced with steel fiber was executed using the hyper-parameters displayed in Fig. 15. The DT model utilized hyperparameters such as batchSize of 100, crossVal of 2, false debug, true displayRules, false doNotCheckCapabilities, discrete and numeric classes of evaluationMeasure, numDecimaPlaces of 2, and false useBk. The Decision Tree (DT) model utilizes several hyperparameters that influence how it learns from the data and evaluates its performance. The "batchSize of 100" indicates that the model processes 100 instances at a time during each iteration of training. This setting can impact the convergence speed and computational efficiency of the model. A batch size of 100 suggests a balanced approach to ensure the model learns efficiently without consuming too many resources. The "crossVal of 2" refers to the use of twofold cross-validation, a technique used to assess the model’s generalization ability. In this case, the dataset is split into two subsets, with the model being trained on one subset and validated on the other. This process is repeated, and the results are averaged to estimate the model’s performance. The choice of twofold cross-validation indicates a relatively quick evaluation, though it may not be as robust as higher k-fold values (e.g., 5 or 10). The “false debug” setting means that no debugging information will be output during the model’s execution, keeping the focus on the primary results. This reduces unnecessary verbosity, making the output cleaner and more concise. The “true displayRules” hyperparameter indicates that the model will display the decision rules learned during training. This setting is helpful for interpreting how the model makes predictions, as decision trees typically produce human-readable rules based on feature splits. The “false doNotCheckCapabilities” setting means that the model will check the available system capabilities to ensure proper execution. This helps prevent issues related to incompatible configurations or missing resources during the model’s training process. The "discrete and numeric classes of evaluationMeasure" suggests that the model is evaluating performance using both discrete and numeric classes of output. This implies that the model may handle both categorical and continuous outcomes, depending on the nature of the dataset and the target variable. The "numDecimalPlaces of 2" setting controls the precision of the numerical output, limiting the results to two decimal places. This is particularly useful for presenting model performance metrics and results in a concise and readable format. Finally, the “false useBk” hyperparameter indicates that the model will not use a backpropagation algorithm, which is typically associated with neural networks. This is in line with the nature of decision trees, which do not rely on backpropagation but instead make decisions based on splitting rules derived from the data. In general, these hyperparameters define how the DT model processes data, evaluates its performance, and presents its results. They influence aspects such as training efficiency, model interpretability, cross-validation strategy, and output precision, which together ensure that the model is both effective and transparent in its decision-making process. The model produced the following performance indices; SSE 704.5, MAE 2.35 MPa, MSE 33.35 MPa, RMSE 2.7 MPa, Error 4.5%, Accuracy 95.5%, R2 0.98, R 0.99, WI 1.00, NSE 0.98, KGE 0.985, and SMAPE 4.145 (see Figs. 16 and 17). The Decision Table (DT) model demonstrates exceptional predictive performance, with high accuracy, low error metrics, and strong agreement indices. Its balanced efficiency and simplicity make it a valuable tool for the sustainable construction industry. Below is a detailed analysis and its implications. Accuracy of 95.5% and an R2 value of 0.98 highlight the DT model’s robustness for compressive strength prediction. Low SSE (704.5), MSE (33.35 MPa), and RMSE (2.7 MPa) reflect minimal prediction errors. The correlation coefficient (R = 0.99) and Willmott Index (WI = 1.00) demonstrate perfect alignment between observed and predicted values. NSE (0.98) and KGE (0.985) further confirm the model’s efficiency and reliability. Metrics like MAE (2.35 MPa) and SMAPE (4.145%) indicate precise predictions, making the model suitable for detailed mix design and analysis. The DT model’s high accuracy supports precise optimization of industrial waste materials in concrete mixes, improving structural performance and sustainability. Reliable predictions foster confidence in using industrial by-products (e.g., fly ash, slag) and steel fibers, contributing to waste reduction and resource conservation. The model minimizes reliance on extensive experimental testing, saving time and resources in mix design processes. By accurately predicting compressive strength, the DT model enables the efficient use of alternative materials, aligning with global sustainability initiatives in construction. For quality assurance purposes, the model ensures consistent performance of concrete mixes, facilitating better quality control during production and application. While the DT model performs exceptionally well, its rule-based structure may limit adaptability to highly complex or non-linear datasets and may not account for interactions between variables as effectively as more advanced machine learning models. Introduce additional input variables, such as temperature, humidity, and curing conditions, to improve predictive scope. Combine DT with ensemble methods like Random Forest or Gradient Boosting for enhanced flexibility and robustness. The DT model demonstrates excellent predictive performance for the compressive strength of industrial wastes-based concrete reinforced with steel fiber. Its high accuracy, low error metrics, and perfect agreement indices make it a reliable and practical tool for sustainable concrete construction. By supporting the optimized use of industrial waste materials, the model contributes to reducing environmental impacts and promoting sustainable practices in the construction industry.

The considered hyper-parameters of (DT) model.

Optimized CS based on ranges of the influential inputs.

Relation between predicted and calculated strength using (DT).
Overall, in Table 2 and Fig. 18 is a comparison of the models based on their performance metrics and reliability for practical applications. In terms of accuracy, Kstar has the highest accuracy (96.5%) and lowest error (3.5%), making it the most precise model. DT closely follows with an accuracy of 95.5% and an error of 4.5%, showing excellent predictive capability. M5Rules achieves a balance of accuracy (93%) with moderate error (7.0%). XNV and ElasticNet have lower accuracies and higher errors, indicating they are less reliable for precise applications. In terms of efficiency, Kstar and DT exhibit near-perfect efficiency metrics (NSE and KGE close to 1.0), making them the most reliable. M5Rules performs well but lags slightly behind in terms of efficiency. ElasticNet shows the lowest efficiency metrics, reflecting significant room for improvement. In terms of the error metrics, Kstar achieves the lowest RMSE (2.0 MPa), indicating minimal prediction deviations. DT also has a very low RMSE (2.7 MPa), ensuring high reliability for practical use. ElasticNet has the highest RMSE (9.6 MPa), making it the least precise. The Kstar model is the most reliable for predicting the compressive strength of industrial wastes-based concrete reinforced with steel fiber, given its superior performance metrics with highest accuracy (96.5%), lowest error (3.5%) and RMSE (2.0 MPa), near-perfect correlation (R2 = 0.99, R = 0.995), and exceptional agreement metrics (WI = 1.0, NSE = 0.99, KGE = 0.985). However, the Decision Table (DT) model is also highly reliable and offers excellent performance with slightly lower computational complexity. It may be preferred for applications requiring simpler implementation while still maintaining high accuracy (95.5%) and low error (4.5%). On the models recommendation for sustainable construction, use Kstar for critical applications requiring the highest precision in predicting compressive strength, such as structural design optimization or compliance with stringent standards and this agrees with reported works31,32,33,34. Secondly, use DT for cost-effective and simpler implementations without significant loss in prediction accuracy. This is particularly beneficial for routine quality control and standardization in construction projects. It can shown that this research models especially the Kstar, DT, and M5Rule with R2 of 0.99, 0.98, and 0.965 respectively exhibit more decisive and reliable performances with both error and efficiency indices over a previously published model with SVR Adaboost presented as a best model of that work with R2 of 0.9610. The present work went further to explore other performance indices such as the NSE, WI, KGE, and SMAPE, which present a far more reliable predictions than what has presented in previous works10.

Comparing the accuracies of the developed models using Taylor charts.
Sensitivity analysis results
A sensitivity index of 1.0 indicates complete sensitivity, a sensitivity index less than 0.01 indicates that the model is insensitive to changes in the parameter. Figure 19 shows the sensitivity analysis with respect to CS. The sensitivity of the input variables on the compressive strength of industrial wastes-based concrete reinforced with steel fiber produced 36% from C, 71% from W, 70% from FAg, 60% from CAg, 34% from PL, 5% from SF, 33% from FA, 67% from Vf, 5% from FbL, and 61% from 61%. The analysis involves evaluating the influence of various input variables on the compressive strength of concrete made from industrial waste and reinforced with steel fibers. Sensitivity indices, derived from the contribution percentages provided, highlight the impact of each variable. Water (W) (71%) is most influential variable, indicating water significantly affects workability, hydration, and strength development. Fine Aggregates (FAg) (70%) plays a crucial role in packing density and bonding within the concrete matrix. Fiber Volume Fraction (Vf) (67%) high sensitivity suggests that steel fiber content greatly impacts crack resistance and tensile strength. Steel Fiber Orientation (61%) indicates the importance of fiber alignment in distributing stresses and enhancing structural integrity. Coarse Aggregates (CAg) (60%) contributes to compressive strength by providing bulk and resistance to deformation. Cement (C) (36%), while important, its influence is less dominant compared to other components like water and aggregates. Plastic Waste (PL) (34%) has moderate impact, likely due to its effect on density and mechanical properties. Fly Ash (FA) (33%) contributes to pozzolanic reactions but has limited direct impact on immediate strength compared to aggregates or water. Steel Fibers (SF) (5%): The volume fraction (Vf) is more impactful than fiber material itself. Fiber Length (FbL) (5%) suggests length variations have minimal effect compared to orientation and volume. The impact on design, production, and optimization is optimizing the water-to-cement ratio and selecting high-quality aggregates are critical for achieving desired compressive strength35. Secondly, focus on fiber volume and alignment to enhance crack resistance and ductility36. Moderate contributions from fly ash and plastic waste suggest potential for further optimization to balance sustainability and performance31,37. High sensitivity of water and aggregates demands strict control during mixing to ensure uniform quality. Proper mixing techniques are essential to achieve uniform distribution and desired orientation of fibers. Adjust proportions of water, aggregates, and fibers to achieve optimal compressive strength while minimizing material costs. Maximize the use of industrial wastes like fly ash and plastic waste without compromising structural integrity31,32,33,36. Use advanced dispersion methods or fiber alignment tools to optimize the role of steel fibers. Focus on precise control of water content, aggregate properties, and fiber volume during design and production34,37. Optimize the use of plastic waste and fly ash to enhance sustainability without sacrificing performance. Explore innovative treatments for steel fibers and alternative fiber lengths to improve their contributions. In structural applications, incorporating steel fibers into soil stabilization can reduce the reliance on traditional stabilizers like cement or lime, which are associated with significant greenhouse gas emissions during production. This substitution helps in achieving sustainable construction goals by lowering overall carbon emissions while maintaining or enhancing the required engineering performance. Overall, using waste steel fibers contributes to a circular economy by reusing materials, conserving natural resources, and reducing the environmental footprint of construction and infrastructure projects.

Sensitivity analysis.
Conclusions
The research work entitled “evaluating the compressive strength of industrial wastes-based concrete reinforced with steel fiber using advanced machine learning” has been studied applying data collection from literature, sorting and curation methods. A total of 166 records were collected and partitioned into training set (130 records = 80%) and validation set (36 records = 20%) in line with the requirements of data partitioning and sorting for optimal model performance. These data entries represented ten (10) components of the steel fiber reinforced concrete such as C, W, FAg, CAg, PL, SF, FA, Vf, FbL, and FbD, which were applied as the input variables in the model and Cs, which was the target. Advanced machine learning techniques were applied to model the compressive strength (Cs) of the steel fiber reinforced concrete such as “Semi-supervised classifier (Kstar)”, “M5 classifier (M5Rules), “Elastic net classifier (ElasticNet), “Correlated Nystrom Views (XNV)”, and “Decision Table (DT)”. All models were created using 2024 “Weka Data Mining” software version 3.8.6. Also, accuracies of developed models were evaluated by comparing sum of squared error (SSE), mean absolute error (MAE), mean squared error (MSE), root mean squared error (RMSE), Error (%), Accuracy (%) and coefficient of determination (R2), correlation coefficient (R), willmott index (WI), Nash–Sutcliffe efficiency (NSE), Kling–Gupta efficiency (KGE) and symmetric mean absolute percentage error (SMAPE) between predicted and calculated values of the output. At the end of the exercise, the following was concluded;
-
In terms of accuracy, Kstar has the highest accuracy (96.5%) and lowest error (3.5%), making it the most precise model, DT closely follows with an accuracy of 95.5% and an error of 4.5%, showing excellent predictive capability, M5Rules achieves a balance of accuracy (93%) with moderate error (7.0%) and XNV and ElasticNet have lower accuracies and higher errors, indicating they are less reliable for precise applications.
-
In terms of efficiency, Kstar and DT exhibit near-perfect efficiency metrics (NSE and KGE close to 1.0), making them the most reliable, M5Rules performs well but lags slightly behind in terms of efficiency, and ElasticNet shows the lowest efficiency metrics, reflecting significant room for improvement.
-
In terms of the error metrics, Kstar achieves the lowest RMSE (2.0 MPa), indicating minimal prediction deviations. DT also has a very low RMSE (2.7 MPa), ensuring high reliability for practical use. ElasticNet has the highest RMSE (9.6 MPa), making it the least precise.
-
The Kstar model is the most reliable for predicting the compressive strength of industrial wastes-based concrete reinforced with steel fiber, given its superior performance metrics with highest accuracy (96.5%), lowest error (3.5%) and RMSE (2.0 MPa), near-perfect correlation (R2 = 0.99, R = 0.995), and exceptional agreement metrics (WI = 1.0, NSE = 0.99, KGE = 0.985).
-
However, the Decision Table (DT) model is also highly reliable and offers excellent performance with slightly lower computational complexity. It may be preferred for applications requiring simpler implementation while still maintaining high accuracy (95.5%) and low error (4.5%).
-
On the models recommendation for sustainable construction, use Kstar for critical applications requiring the highest precision in predicting compressive strength, such as structural design optimization or compliance with stringent standards.
-
Secondly, use DT for cost-effective and simpler implementations without significant loss in prediction accuracy. This is particularly beneficial for routine quality control and standardization in construction projects.
-
The sensitivity of the input variables on the compressive strength of industrial wastes-based concrete reinforced with steel fiber produced 36% from C, 71% from W, 70% from FAg, 60% from CAg, 34% from PL, 5% from SF, 33% from FA, 67% from Vf, 5% from FbL, and 61% from 61%.
-
Fiber Volume Fraction (Vf) (67%) high sensitivity suggests that steel fiber content greatly impacts crack resistance and tensile strength. Steel Fiber Orientation (61%) indicates the importance of fiber alignment in distributing stresses and enhancing structural integrity.
Data availability
The data supporting this research work will be made available on request from the corresponding author.
References
Ilcan, H. et al. Effect of industrial waste-based precursors on the fresh, hardened and environmental performance of construction and demolition wastes-based geopolymers. Constr. Build. Mater. 394, 132265. https://doi.org/10.1016/j.conbuildmat.2023.132265 (2023).
Mansoori, A., Moein, M. M. & Mohseni, E. Effect of micro silica on fiber-reinforced self-compacting composites containing ceramic waste. J. Compos. Mater. 55, 95–107. https://doi.org/10.1177/0021998320944570 (2020).
Pham, V.-N. & Nguyen, V.-Q. Effects of alkaline activators and other factors on the properties of geopolymer concrete using industrial wastes based on GEP-based models. Eur. J. Environ. Civ. Eng. https://doi.org/10.1080/19648189.2024.2357677 (2024).
Bravo-Moncayo, L., Puyana-Romero, V., Argotti-Gómez, M. & Ciaburro, G. Enhanced environmental sustainability for the acoustic absorption properties of cabuya fiber in building construction using machine learning predictive model. Sustainability https://doi.org/10.3390/su16146204 (2024).
Ulucan, M., Yıldırım, G., Alatas, B. & Alyamaç, K. E. Comparing machine learning regression models for early-age compressive strength prediction of recycled aggregate concrete. Fırat Üniversitesi Mühendislik Bilim. Derg. 36, 563–580 (2024).
Kiran, G. U., Nakkeeran, G., Roy, D. & Alaneme, G. U. Optimization and prediction of paver block properties with ceramic waste as fine aggregate using response surface methodology. Sci. Rep. 14, 23416 (2024).
Tijani, M. A., Ajagbe, W. O. & Agbede, O. A. Recycling sorghum husk and palm kernel shell wastes for pervious concrete production. J. Clean. Prod. 380, 134976. https://doi.org/10.1016/j.jclepro.2022.134976 (2022).
Amran, M. & Onaizi, A. Sustainable admixtures to enhance long-term strength and durability properties of eco-concrete: an innovative use of Saudi agro-industrial by-products. Int. J. Build. Pathol. Adapt. (2024).
Smirnova, O. M., Menendez Pidal, I., Alekseev, A. V., Petrov, D. N. & Popov, M. G. Strain hardening of polypropylene microfiber reinforced composite based on alkali-activated slag matrix. Materials (Basel) https://doi.org/10.3390/ma15041607 (2022).
Li, Y. et al. Compressive strength of steel fiber-reinforced concrete employing supervised machine learning techniques. Materials 15, 4209. https://doi.org/10.3390/ma15124209 (2022).
Ebid, A., Onyelowe, K. C. & Deifalla, A. F. Data utilization and partitioning for machine learning applications in civil engineering. In International Conference on Advanced Technologies for Humanity. In book: Industrial Innovations: New Technologies in Cities’ Digital Infrastructure, Publisher: Springer (2023). https://doi.org/10.1007/978-3-031-70992-0_8
Onyelowe, K. C. et al. Multi-objective optimization of sustainable concrete containing fly ash based on environmental and mechanical considerations. Buildings 12, 948. https://doi.org/10.3390/buildings12070948 (2022).
Onyelowe, K. C. et al. Evaluating the compressive strength of recycled aggregate concrete using novel artificial neural network. Civ. Eng. J. 8(8), 1679–1694. https://doi.org/10.28991/CEJ-2022-08-08-011 (2022).
Onyelowe, K. C. et al. Global warming potential-based life cycle assessment and optimization of the compressive strength of fly ash-silica fume concrete; environmental impact consideration. Front. Built Environ. 8, 992552. https://doi.org/10.3389/fbuil.2022.992552 (2022).
Onyelowe, K. C. et al. Optimization of green concrete containing fly ash and rice husk ash based on hydro-mechanical properties and life cycle assessment considerations. Civ. Eng. J. https://doi.org/10.28991/CEJ-2022-08-12-018 (2022).
Onyelowe, K. C., Gnananandarao, T., Jagan, J., Ahmad, J. & Ebid, A. M. Innovative predictive model for flexural strength of recycled aggregate concrete from multiple datasets. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-022-00558-1 (2022).
Onyelowe, K. C. et al. AI mix design of fly ash admixed concrete based on mechanical and environmental impact considerations. Civ. Eng. J. https://doi.org/10.28991/CEJ-SP2023-09-03 (2023).
Onyelowe, K. C., Ebid, A. M. & Ghadikolaee, M. R. GRG-optimized response surface powered prediction of concrete mix design chart for the optimization of concrete compressive strength based on industrial waste precursor effect. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00827-7 (2023).
Onyelowe, K. C. & Ebid, A. M. The influence of fly ash and blast furnace slag on the compressive strength of high-performance concrete (HPC) for sustainable structures. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00817-9 (2023).
Onyelowe, K. C., Ebid, A. M., Aneke, F. I. & Nwobia, L. I. Different AI predictive models for pavement subgrade stiffness and resilient deformation of geopolymer cement-treated lateritic soil with ordinary cement addition. Int. J. Pavement Res. Technol. https://doi.org/10.1007/s42947-022-00185-8 (2022).
Ebid, A. M., Onyelowe, K. C., Denise, P. N., Kontoni, A. Q. & Gallardo, S. H. Heat and mass transfer in different concrete structures: A study of self-compacting concrete and geopolymer concrete. Int. J. Low-Carbon Technol. 2023(18), 404–411. https://doi.org/10.1093/ijlct/ctad022 (2023).
Onyelowe, K. C., Ebid, A. M. & Hanandeh, S. Advanced machine learning prediction of the unconfined compressive strength of geopolymer cement reconstituted granular sand for road and liner construction applications. Asian J. Civ. Eng. https://doi.org/10.1007/s42107-023-00829-5 (2023).
Al-Kharabsheh, B. N. et al. Basalt fiber reinforced concrete: A compressive review on durability aspects. Materials 16(1), 429. https://doi.org/10.3390/ma16010429 (2023).
Birant, K. U. Semi-supervised k-star (SSS): A machine learning method with a novel holo-training approach. Entropy 25(1), 149. https://doi.org/10.3390/e25010149 (2023).
Ayaz, Y., Kocamaz, A. F. & Karakoç, M. B. Modeling of compressive strength and UPV of high-volume mineral-admixtured concrete using rule-based M5 rule and tree model M5P classifiers. Constr. Build. Mater. 94, 235–240. https://doi.org/10.1016/j.conbuildmat.2015.06.029 (2015).
Khalid, E. G., Jamal, E. K., Isam, S. & Aziz, S. Comparison of M5 model tree and nonlinear autoregressive with eXogenous inputs (NARX) neural network for urban stormwater discharge modelling. MATEC Web Conf. 295, 02002. https://doi.org/10.1051/matecconf/201929502002 (2019).
Meng, K., Gai, Y., Wang, X., Yao, M. & Sun, X. Transfer learning for high-dimensional linear regression via the elastic net. Knowl. Based Syst. 304, 112525. https://doi.org/10.1016/j.knosys.2024.112525 (2024).
Granata, F., Di Nunno, F. & de Marinis, G. Advanced evapotranspiration forecasting in Central Italy: Stacked MLP-RF algorithm and correlated Nystrom views with feature selection strategies. Comput. Electron. Agric. 220, 108887. https://doi.org/10.1016/j.compag.2024.108887 (2024).
Żabiński, K. & Zielosko, B. Decision rules construction: Algorithm based on EAV model. Entropy 23(1), 14. https://doi.org/10.3390/e23010014 (2020).
Hoffman, F. O. & Gardner, R. H. Evaluation of uncertainties in radiological assessment models. Chapter 11 of Radiological Assessment: A textbook on Environmental Dose Analysis. Edited by Till, J. E. and Meyer, H. R. NRC Office of Nuclear Reactor Regulation, Washington, D. C. (1983).
Surya Prakash, R. & Parthasarathi, N. Numerical analysis of FRP retrofitting in RC beam-column exterior joints at high temperatures and predictive modeling using artificial neural networks. J. Struct. Fire Eng. https://doi.org/10.1108/JSFE-05-2024-0012 (2024).
Parthasarathi, N., Prakash, M. & Subhash, V. Enhancing environmental sustainability in concrete buildings with zeolite and reduced graphene oxide additives. Innov. Infrastruct. Solut. 9, 468. https://doi.org/10.1007/s41062-024-01792-z (2024).
Ramana, I. & Parthasarathi, N. Synergistic effects of fly ash and graphene oxide composites at high temperatures and prediction using ANN and RSM approach. Sci. Rep. 15, 1604. https://doi.org/10.1038/s41598-024-83778-6 (2025).
Surya Prakash, R. & Parthasarathi, N. Transient state analysis of rehabilitated RC beams using finite element modelling and prediction using an artificial neural network. Eng. Res. Express 6, 025109. https://doi.org/10.1088/2631-8695/ad46e9 (2024).
Wani, S. R. & Suthar, M. A comparative analysis of the predictive performance of tree-based and artificial neural network approaches for compressive strength of concrete utilising waste. Int. J. Pavement Res. Technol. https://doi.org/10.1007/s42947-024-00454-8 (2024).
Wani, S. R. & Suthar, M. Using soft computing to forecast the strength of concrete utilized with sustainable natural fiber reinforced polymer composites. Asian J. Civ. Eng. 25, 5847–5863. https://doi.org/10.1007/s42107-024-01150-5 (2024).
Wani, S. R. & Suthar, M. Utilizing machine learning approaches within concrete technology offers an intelligent perspective towards sustainability in the construction industry: A comprehensive review. Multisc. Multidiscip. Model. Exp. Des. 8, 1 (2025). https://doi.org/10.1007/s41939-024-00601-5
Acknowledgements
N/A.
Funding
The authors received no external funding for this research work.
Author information
Authors and Affiliations
Contributions
KCO conceptualized the research work, KCO, VK, AME, SH, SMZP, VFNS, ROSM, RFZV, PA, & SA wrote the main manuscript text, KCO & AME prepared figures and SMZP, VFNS, ROSM, & RFZV provided the revisions and replies to reviewers’ comments. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Onyelowe, K.C., Kamchoom, V., Ebid, A.M. et al. Evaluating the strength of industrial wastesbased concrete reinforced with steel fiber using advanced machine learning. Sci Rep 15, 8082 (2025). https://doi.org/10.1038/s41598-025-92194-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-92194-3
Keywords
This article is cited by
-
Optimized machine learning models for predicting ultra-high-performance concrete compressive strength: a hyperopt-based approach
Multiscale and Multidisciplinary Modeling, Experiments and Design (2025)
