
Abstract
This study aims to construct a prediction model for the demand for medical and daily care services of the elderly and to explore the factors that affect the demand for medical and daily care services of the elderly. In this study, a questionnaire survey on the demand for medical and daily care services of 1291 elderly was conducted using multi-stage stratified whole cluster random sampling. SPSS21.0 statistical analysis software was used to describe the basic data of the elderly statistically, and univariate analysis was used to screen variables for model construction and binary logistic regression analysis. The acquired dataset has class imbalance, and to handle this issue, Synthetic Minority Over Sampling Technique with TomekLink (SMOTE-TomekLink) was adopted to resample the dataset for class-balancing. To improve computational efficiency, we used three algorithms to develop prediction models, including Random Forest (RF), Gradient Boosting Decision Tree (GBDT), and Light Gradient Boosting Machine (LightGBM) algorithms. The performance of each model was measured, and the performance of the prediction model was obtained using the following performance metrics: accuracy (ACC), recall (R), precision (P), F1-score, and area under the receiver operating characteristic (AUC). The prediction models for the medical and daily care services demand of the elderly were developed and validated using 12 and 13 key features, respectively. The LightGBM algorithm emerged as the superior prediction model for estimating the service needs of the elderly. For the medical service demand prediction model, LightGBM achieved an AUC of 0.910 and F1-score of 0.841. In the daily care services demand prediction model, LightGBM demonstrated an AUC of 0.906 and an F1-score of 0.819. In the LightGBM model, the analysis of feature importance indicates that the number of chronic diseases, education level, and financial sources emerge as the most significant predictors for the demand of healthcare services, encompassing both medical and daily care services. Based on questionnaire information combined with feature selection, unbalanced data processing and machine learning methods, this study constructed a machine learning model for predicting the demand for medical and daily care services for the elderly, and analyzed the influencing factors of the demand for medical and daily care services for the elderly, providing a reference for the construction and verification of future prediction models for the demand for medical and daily care services for the elderly.
Similar content being viewed by others
Introduction
The phenomenon of population aging is a hot topic of concern worldwide. According to the criteria for the division of aging set out in the United Nations’ “Population Ageing and its Socio-Economic Consequences,” China entered an aging society at the beginning of the 20th century. Over the following two decades, China’s aging population increased significantly, and the degree of aging of the population became increasingly prominent. According to China’s seventh census, there are 264.02 million elderly people aged 60 and above, accounting for 18.7% of the total population1. As the population ages, the number of elderly with disabilities, semi-disabilities, and chronic diseases will increase.
These vulnerable populations require not only medical services but also daily care services. Medical services for the elderly refer to those tailored to meet the specific health needs of older adults. This includes, but is not limited to, routine medical check-ups, disease prevention, diagnostic services, treatment of acute and chronic illnesses, rehabilitation services, and end-of-life care. These services are crucial in managing the multiple health challenges that often accompany aging. Daily care services encompass a broader range of support services aimed at maintaining or improving the quality of life for elderly individuals. This includes assistance with activities of daily living (ADLs), such as bathing, dressing, eating, and mobility, as well as social and emotional support to combat loneliness and isolation. Daily care services can be provided in various settings, including the home, community centers, or specialized care facilities. The long-term care system in the United States offers insights into addressing the challenges of eldercare, yet it faces a persistent shortage of care workers due to the growing elderly population. According to the Health Resources and Services Administration, the demand for direct care workers for the elderly is projected to increase by 34%, necessitating an additional 650,000 workers2. Similarly, studies in other developing countries have shown that as the aging population rises, the growing demand for home care services also increases3. In China, the prevalent “4-2-1” family structure in China, where two working adults are responsible for the care of four elderly parents and one child, is straining the traditional model of family-based eldercare. This family structure is becoming increasingly unsustainable4. Furthermore, the high costs and insufficient supply of institutional eldercare, coupled with the elderly’s strong preference for family care, prevent institutional care from becoming the dominant model5,6. China’s demographic landscape is unique in that it is aging before it becomes wealthy, which adds significant pressure to the country’s eldercare security system. In light of these challenges, it is imperative for China to focus on the escalating demand for medical and daily care services among the elderly. This attention is crucial for developing comprehensive and sustainable strategies to support the aging population.
Currently, domestic and foreign studies related to the demand for medical services or daily care services for the elderly are primarily focused on analyzing the current situation and the influencing factors7,8,9. The studies still use traditional logistics regression, and there are fewer studies related to the construction of predictive models using machine learning. Machine learning represents a primary approach to data mining. By constructing machine learning models, complex relationships can be automatically processed, and machine models have demonstrated predictive utility in the medical field10,11,12. Additionally, machine learning models have been extensively utilized in other research domains13,14,15. Currently, there is a lack of studies on the demand for healthcare services despite the prevalence of model prediction studies. Previous studies have demonstrated that the performance of a single weak learner can be enhanced by integrating multiple learners. With the application of large-scale data and the advancement of computers technology, machine learning plays a more pivotal role in health risk assessment. A comparison of several studies revealed that RF (Random Forest), GBDT (Gradient Boosting Decision Tree), and LightGBM (Light Gradient Boosting Machine) exhibited superior prediction performance and broader applicability16,17,18. Therefore, this study selected the three models for the construction of a prediction model for the demand for medical and daily care services for the elderly and evaluation and comparison of the prediction performance of the three models. This was done to identify a more suitable model for predicting the demand for medical and daily care services for the elderly.
Materials and methods
Study design, setting, and participants
In this study, questionnaire surveys were conducted among community-dwelling elderly individuals aged 60 years or older in three cities: Guangzhou, Suzhou, and Qingdao. These cities were selected using a multi-stage stratified whole cluster random sampling method to ensure the representativeness of the sample. First, one county/district was randomly selected in each city jurisdiction. Yuexiu District was selected from Guangzhou City, Kunshan District from Suzhou City, and Jimo District from Qingdao City. Secondly, two streets were randomly selected from each county/district. Finally, four communities were randomly selected from each street. 1,380 questionnaires were distributed, and 1,291 were returned, with an effective recovery rate of 93.6%. This study was ethically reviewed by Zhengzhou University (ZZUIRB2022-07). All participants provided written informed consent. All methods were carried out following the principles of the Declaration of Helsinki.
Measures and variables
The questionnaire survey method is a method to measure the problem under study and collecting information using controlled measurements. This study used a self-designed questionnaire to collect demographic characteristics, family resources, socioeconomic status, lifestyle habits, number of chronic diseases, and demand for healthcare (medical and daily care) services for the elderly living at home in communities.
-
(1)
Demographic characteristics include age and gender.
-
(2)
Socioeconomic status encompasses educational level, financial sources, monthly income, and medical insurance.
-
(3)
Family resources included the following variables: spouse, living style, number of children, and frequency of visits.
-
(4)
Lifestyle habits include smoking, drinking, and sleep time.
-
(5)
Chronic Disease Conditions: This study investigated the types of chronic disease conditions suffered by the elderly, including cerebrovascular diseases, cardiovascular diseases, respiratory diseases, endocrine system and nutritional, metabolic diseases, musculoskeletal diseases, urological diseases, rheumatologic diseases, oncologic diseases, and other diseases. The total number of chronic diseases in older adults was obtained by summing the number of all self-reported diseases in older adults.
In this study, the number of chronic diseases among the elderly was categorized as 0, 1, 2, and ≥ 3 chronic diseases.
The dependent variable in this study was the demand for healthcare services, which encompassed both medical services and daily care services. In this research, medical services referred to individuals willing to receive any of the following: clinical treatment, medical rehabilitation, nursing care, emergency medical assistance, home-based medical care, traditional Chinese medicine services, and preventive health care. Daily care services, referred to individuals open to accepting any of these services: home visits, meal assistance, bathroom assistance, bathing assistance, mobility assistance, emergency response assistance, psychological care, and recreational activities.
In this survey, the utilization of medical and daily care services by the elderly was quantified and categorized based on the number of services required. The demand for medical services among the elderly was categorized based on the number of distinct services required: ‘0’ indicating no demand for medical services, ‘1’ indicating a demand for one type of medical service, ‘2’ indicating a demand for two types of medical services, and ‘≥3’ indicating a demand for three or more types of medical services. Similarly, the demand for daily care services was classified as follows: ‘0’ for no demand, ‘1’ for a demand for one type of daily care service, ‘2’ for a demand for two types of daily care services, and ‘≥3’ for a demand for three or more types of daily care services. For analytical purposes, the frequency of usage of medical services among the elderly participants was categorized into two groups: ‘0’ indicating no demand for medical services, and ‘1’ indicating any demand for medical services. Similarly, the frequency of usage for daily care services was also categorized into two groups: ‘0’ representing no demand for daily care services, and ‘1’indicating any demand for daily care services.
Feature selection and data preprocessing
Data preprocessing involves organizing data before analyzing them and using them to train models19. We preprocessed the dataset to prepare 14 candidate features based on previous studies. Features with a missing percentage of not more than 30% were retained and filled in with mean interpolation. Dataset outliers were addressed by excluding extreme values in the top and bottom 1%. Because the range of different feature values widely varied and some of the used algorithms require standardization of the data to ensure that the variables contribute equitably to the model in subsequent analyses, univariate analysis was used to screen for overall features.
Machine learning algorithms
-
(1)
Random Forest (RF)The RF algorithm was derived from Breiman L20, is a widely used ensemble learning method known for its ease of implementation in both classification and regression tasks. It operates by constructing a collection of decision trees, with the final output being determined by a vote among them (for classification) or an average (for regression). In this study, the following parameters were chosen (partially) for the RF model:
-
①
Number of trees (ntree = 200): We selected 200 trees to balance computational efficiency with model performance, as this number provided adequate accuracy without excessive computation.
-
②
Minimum number of decision tree nodes (nodesize = 1): This parameter is set to 1, allowing the trees to grow until each leaf node contains at least one instance.
-
①
-
(2)
GBDT (Gradient Boosting Decision Tree) GBDT is an iterative algorithm that builds upon the decision tree framework. It sequentially combines weak learners to form a strong predictive model. The parameters for the GBDT model in this study are as follows (partially):
-
①
Learning rate (shrinkage = 0.01): The shrinkage parameter, or learning rate, is set to 0.01 to ensure that each new tree corrects the errors of the previous ones in small increments, which can lead to better convergence and generalization.
-
②
Depth of decision tree (interaction.depth = 3): The interaction depth of the trees is limited to 3 to control the model’s complexity and prevent overfitting, while still allowing the model to capture relevant interactions among features.
-
③
Number of iterative regression trees (n.trees = 1 1000): The model uses 1000 trees to iteratively refine its predictions. This number is chosen to provide sufficient model capacity while remaining computationally feasible.
-
①
-
(3)
LightGBM (Light Gradient Boosting Machine) The LightGBM algorithm was proposed by Ke et al. in 201721, is designed to address the computational inefficiencies of traditional GBDT algorithms. Compared with models such as GBM22 and XGBoost23, LightGBM effectively addresses the issue of slow computation speed and large memory consumption. The parameters for the LightGBM model in this study are (partially):
-
①
Learning rate (1eaming_rate-0 0.125): The learning rate is set to 0.125, which is relatively high and allows for faster convergence during training by making larger updates to the model’s predictions.
-
②
Maximum depth of tree model (max_depth = 5): The maximum depth is set to 5 to prevent the model from becoming too complex, which could lead to overfitting, while still allowing it to capture complex patterns in the data.
-
③
Number of iterations for boosting (n_estimators = 1000): Similar to GBDT, 1000 iterations are used to ensure the model has enough capacity to learn from the data without excessive computational cost.
-
④
Number of leaf nodes in a tree (num_1eaves 31): The default value for num_leaves is set to 31, which determines the complexity of the tree. This value is chosen to balance the model’s ability to fit the training data with the risk of overfitting.
-
①
Model development
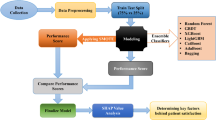
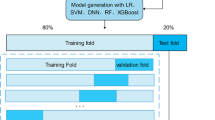
We developed three machine learning models using the filtered features as independent variables and whether an individual has a demand for medical services and a demand for daily care services as dependent variables. Synthetic Minority Over Sampling Technique with TomekLink (SMOTE-TomekLink) was adopted to resample the dataset for class-balancing. The processed dataset was divided into training and test sets in a ratio of 7:3, where the training set was used for model training and the test set was used for model validation. We employed random search to explore different hyperparameter combinations and identify the optimal configuration. A 10-fold cross validation was performed using the training set where one tenth of the training set was used for testing and each part of the remaining nine tenths was used sequentially for training in the training phase for better performance. Confusion matrix is used to evaluate the performance of the model based on ML algorithm. The performance of the model was assessed by calculating the accuracy (ACC), precision (P), recall (R), F1-score, and receiver operating characteristic (ROC) curve and AUC. The development process for the classification prediction models is shown in Fig. 1.

Model development process.
SMOTE and TomekLinks for balancing the dataset
The rarity of elderly individuals exhibiting no demand for healthcare services constitutes a low-incidence event, leading to a significant imbalance in the dataset. Imbalanced datasets are a common challenge in machine learning, where the number of samples in one class greatly outnumbers the samples in the other class. In our case, the dataset has a limited number of samples representing elderly people without healthcare needs, which can lead to a biased model that predominantly predicts the majority class.
This imbalance poses a significant challenge during the training and evaluation of classification models, as the model may become biased towards the predominant class, leading to suboptimal performance, especially in terms of the minority class. To address this issue, we employed two resampling techniques: the synthetic minority over-sampling technique (SMOTE)24 and TomekLinks25. SMOTE is an over-sampling strategy designed to increase the number of minority class samples by synthesizing new examples rather than by over-sampling with replacement. TomekLinks, on the other hand, is an under-sampling approach that aims to reduce the number of samples in the majority class by removing instances that are nearest neighbors to samples of the minority class but are misclassified by a simple classifier. The combination of SMOTE and TomekLinks in a sequential manner allows for a more balanced dataset. First, SMOTE is applied to over-sample the minority class, followed by TomekLinks to under-sample the majority class, ensuring that the synthetic samples generated by SMOTE are not immediately removed by the TomekLinks procedure. This two-step approach maintains a diverse set of examples while cleaning the decision boundary, which can lead to a more robust and fair classification model.
Model assessment
The predictive model’s performance was evaluated by calculating a series of performance metrics, including accuracy (ACC), recall (R), precision (P), F1-score, and area under the receiver operating characteristic curve (AUC). The binary confusion matrix had been employed to compute these matrices, Table 1.
Accuracy (ACC) represents the percentage of samples correctly identified by the model out of the total sample size. Recall (R) indicates the percentage of elderly individuals with actual needs correctly identified by the model out of all elderly individuals with actual needs. Precision (P) reflects the percentage of elderly individuals with actual needs among all individuals identified as having needs by the model. The F1-score represents the harmonic mean of precision and recall, balancing the trade-off between the two26. The Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) curve is a measure of the model’s predictive ability. The AUC ranges from [0 ~ 1], with higher values indicating better predictive performance27. An AUC of 0.5 suggests the model has no predictive ability, values between 0.5 and 0.7 indicate low predictive ability, values between 0.7 and 0.9 suggest moderate predictive ability, and values above 0.9 indicate high predictive ability. The calculation formula is as follows:
ACC\(\:=\frac{\text{TP+TN}}{\text{TP+FP+TN+FN}}\)
R=\(\:\frac{\text{TP}}{\text{TP+FN}}\)
P=\(\:\frac{\text{TP}}{\text{FP+TP}}\)
F1 = 2\(\:\times\:\frac{\text{R}\times\text{P}}{\text{R+P}}\)
Precision and recall are critical indicators of the model’s predictive performance. A low precision rate may result in a high number of false reports, while a low recall rate indicates that a significant number of elderly individuals with actual needs are not detected28. Since accuracy, recall, and precision are individual evaluation metrics and may not comprehensively represent the model’s predictive capabilities, the F1-score and AUC values are considered when assessing the predictive performance of the models. In cases where the accuracy, recall, and precision of the three models are comparable, the F1-score and AUC values are taken into account for a more nuanced evaluation. Performance evaluation matrices are computed under the four confusion matrices.
Statistical analysis
This study used SPSS 21.0 statistical analysis software to clean and analyze the data. Counts were expressed as frequencies (percentages), and comparisons between groups were made using the χ2 test. Multicategorical variables were encoded as dummy variables, with significant predictors from univariate tests advancing to feature selection for model building and subsequent binary logistic regression analysis. The significance level was set at α = 0.05. SMOTE-TomekLink resampling, classifier creation, and optimization all took place in R studio 4.1.1 (R Development Core Team). The randomforest, gbm, and lightgbm packages in R studio 4.1.1 (R Development Core Team) were employed to analyze the RF, GBDT, and LightGBM, respectively. Model performance was assessed using AUC, F1-score, Accuracy, Precision, and Recall.
Results
Participant characteristics
A total of 1,291 elderly individuals were included in this study. Of these, 724 (56.1%) were females and 567 (43.9%) were males. The percentage of elderly individuals requiring medical services is 87.5%, while the percentage requiring daily care services is 70.8%, as shown in Supplementary Material (eTable 1). The univariate analysis of demand for medical care services and demand for daily care services among the elderly showed that factors such as age, educational level, financial sources, monthly income, medical insurance, spouse, living style, number of children, frequency of visits, smoking, sleep time and number of chronic diseases were statistically significant in differentiating between the groups with and without demand for services (P < 0.05). Gender was only statistically significant in differentiating the demand for daily care services among the elderly (P < 0.05). As shown in Table 2.
A comparison of the predictive performance of various models
Table 3 presents the prediction performance of three machine learning models across different service demands. The LightGBM model achieves the highest performance for the medical services demand prediction with AUC of 0.910, F1-score of 0.841, ACC of 0.846, R of 0.870 and P of 0.814. On the other hand, the LightGBM model also achieved the best results for the daily care services demand prediction, recording AUC of 0.906, F1-score of 0.819, ACC of 0.830, R of 0.867 and P of 0.777. Figure 2 presents a comparative visualization of the AUC outcomes for the forecasting models pertaining to the demand for medical services and the demand for daily care services.

ROC curves for demand forecasting models for healthcare services.
Note: A. Comparison of AUC results of medical service demand prediction models.
B. Comparison of AUC results of daily care service demand prediction models.
Importance analysis of the characteristics of each model
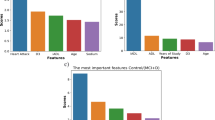
The results of the medical service demand prediction indicated that the top six in the importance ranking of each prediction model were education level, the number of chronic diseases, monthly income and the frequency of visits. The results of the LightGBM model, which had the best prediction performance, demonstrated that number of chronic diseases, education level, and financial source were the most influential factors in determining the demand for medical services among the elderly. As shown in Fig. 3A. The results of the daily care services demand prediction indicated that the top six in the importance ranking of each prediction model were age, the number of chronic diseases, and monthly income. The LightGBM model results demonstrated that the number of chronic diseases, education level, monthly income, and the frequency of visits, had the highest importance in the demand for daily care services for the elderly. As illustrated in Fig. 3B.

Ranking of the importance of each predictive model feature.
Note: A. Ranking of importance of each prediction model in medical service demand prediction.
B. Ranking of importance of each prediction model in daily care service demand prediction.
Discussion
Globally, approximately 10.4% of the healthcare and long-term care needs of individuals aged 65 and older remain unmet, with China facing particularly severe challenges29. As China’s population ages, the increase in the average age has led to a sharp rise in the demand for healthcare services among the elderly. This study found that among a sample of 1291 elderly individuals selected from three cities in China, the demand for medical services reached 87.5%, and the demand for daily care services reached 70.8%, a proportion that is not commonly observed in previous studies30,31, highlighting the importance and urgency of current healthcare service needs. In light of this, the present study sampled 1291 elderly individuals from three cities in China and employed machine learning algorithms for predictive tasks, using univariate analysis methods for feature selection. Three machine learning algorithms were deployed for the predictive tasks, and the elderly medical and daily care services demand prediction models were developed and validated using 12 and 13 important features, respectively, including demographic, social, economic, health, and other parameters.
This investigation evaluated various models for forecasting healthcare services utilization among the elderly and identified LightGBM as the top-performing model, with an AUC of 0.910, F1-score of 0.841. Furthermore, LightGBM exhibited superior predictive capabilities (AUC = 0.906, F1-score = 0.819) when compared to other models in predicting the demand for elderly daily care services. Moreover, all predictive models exhibited high recall and precision, indicating that they can make accurate and efficient decisions regarding healthcare resource allocation and minimize costly risks. Related studies have demonstrated that LightGBM exhibit superior predictive performance in a range of applications2,10,32. For example, a study of environmental factors on the number of days demanded for cardiovascular admissions, which compared six machine learning models (including logistic regression (LR), support vector machine (SVM), ANN, random forest (RF), extreme gradient boosting (XGBoost), and light gradient boosting machine (LightGBM)), showed that LightGBM had the best performance among the integrated learning models2. Within the context of our research, the LightGBM model emerged as the superior predictor, with key variables including chronic diseases, education level, frequency of visit, and financial source emerging as the primary influencers of medical services utilization among the elderly. Concurrently, the model highlighted that the count of chronic diseases, education level, financial resources, monthly income, and frequency of visit were the key factors shaping the demand for daily care services within this demographic group. These findings align with our logistic regression analysis presented in the Supplementary Material, eTable 2. Educational level exerts a significant influence on the demand for medical and daily care services among the elderly, demonstrating a positive correlation. Specifically, elderly individuals with higher levels of education exhibit a stronger demand for medical and daily care services. This finding aligns with the results of Xu X33, suggesting that an elevated level of education is often associated with greater health awareness, attentiveness to personal health status, and a readiness to adopt new health-related concepts. As a result, these individuals tend to have higher expectations and requirements for healthcare services. The number of chronic diseases is a pivotal factor affecting the demand for medical and daily care services. Chronic conditions represent the most significant adverse influence on the quality of life for the elderly, particularly as age-related diseases are predominantly chronic, including cardiovascular and cerebrovascular diseases and diabetes mellitus. This is consistent with previous research identifying chronic diseases as a critical factor in the healthcare services demand among the elderly34. The presence of comorbidities or complications from chronic diseases can impair the elderly’s self-care capabilities35. Studies indicate that those aged 65 and over with chronic diseases often face reduced mobility and physical functioning, leading to an increased demand for medical and daily care services36. Additionally, our logistic regression results suggest that the frequency of visits is a determinant of the demand for medical services and daily care services among the elderly. Research indicates that the frequency of family visits may reflect the level of familial attention and support. Elderly individuals who receive fewer visits might feel insecure and neglected, prompting them to focus more on self-care and health maintenance37. Therefore, it is imperative for healthcare providers and policymakers to consider these factors when designing services aimed at improving the well-being of the elderly population.
Machine learning represents a significant advancement in the field of research, moving beyond the traditional focus on the observation of influencing factors. Instead, it emphasizes the construction of predictive models and the importance ranking of influencing factors. This approach offers valuable insights that can inform the formulation of relevant policies by the government in the context of an aging population. Furthermore, it can enhance the efficiency and cost-effectiveness of management, ultimately leading to more effective services that can alleviate the challenges posed by an aging population. Based on the findings of this study, the following recommendations are made: First, the service demands of vulnerable elderly people who are old, financially disadvantaged, and suffering from illness should be included in the basic elderly care services security system to ensure their basic living. On the one hand, the government has the responsibility to provide this basic security; on the other hand, given the limited payment capacity of vulnerable elderly groups, they cannot obtain necessary medical and daily care services on their own. Secondly, it is necessary to strengthen the construction of the basic medical services system, especially the support for vulnerable elderly groups, and further optimize the medical and daily care subsidy system, expand subsidy coverage, and increase subsidy funds by strengthening the assessment of their needs and capabilities. Finally, it is recommended to combine medical insurance with elderly care services to provide professional medical services for the elderly. In addition, barriers between elderly care and medical insurance should be eliminated to ensure that the elderly can obtain medical and daily care services without worries.
Limitations
This study has some limitations. Firstly, this study is a cross-sectional study, which cannot dynamically reflect the change of data in the time series, and more data are needed subsequently to gain insight into the process and pattern of the demand for medical and daily care services for the elderly at home. Secondly, this study lacks medical clinical indicators of the elderly, which has some limitations in guiding the demand for medical and living services for the elderly. Finally, this study only used three algorithms to construct the prediction model, which does not entirely determine that a particular model is an optimal model, and more related research is still needed to select the most suitable prediction model for this field.
Conclusion
In summary, this study, leveraging questionnaire data in conjunction with feature selection, techniques for addressing imbalanced data, and machine learning methods, has contributed to a deeper understanding of healthcare services utilization among the elderly. Furthermore, it has provided a predictive model that aids in confronting the challenges posed by population aging. The insights garnered from this research can inform the development of more effective and targeted healthcare policies and services, ultimately enhancing the well-being of the elderly population.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
National Bureau of Statistics. Bulletin of the Seventh National Population Census [EB/OR]http://www.stats.gov.cn/
Zallman, L., Finnegan, K. E., Himmelstein, D. U., Touw, S. & Woolhandler, S. Care for America’s elderly and disabled people relies on immigrant labor. Health Aff (Millwood). 38, 919–926. https://doi.org/10.1377/hlthaff.2018.05514 (2019).
Phillips, D. R. Ageing in the Asia-Pacific region: issues, policies and future trends. (2000).
Qin, F. J. Model selection and optimization of home-based elderly care services: from the perspective of public product theory. Taxation Econ. 56–61 (2019).
Wang, Z. et al. Effects of individual, family and community factors on the willingness of institutional elder care: A cross-sectional survey of the elderly in China. BMJ Open. 10, e032478. https://doi.org/10.1136/bmjopen-2019-032478 (2020).
Yon, Y., Ramiro-Gonzalez, M., Mikton, C. R., Huber, M. & Sethi, D. The prevalence of elder abuse in institutional settings: A systematic review and meta-analysis. Eur. J. Public. Health. 29, 58–67. https://doi.org/10.1093/eurpub/cky093 (2019).
Qin, Y., Yao, X., Ma, Q., Salvador, J. T. & Pang, L. Needs and influence factors of medical-nursing-pension of disabled elderly. Med. (Baltim). 102, e35189. https://doi.org/10.1097/MD.0000000000035189 (2023).
Chen, S. et al. Unmet needs of activities of daily living among a community-based sample of disabled elderly people in Eastern China: A cross-sectional study. BMC Geriatr. 18, 160. https://doi.org/10.1186/s12877-018-0856-6 (2018).
Phi, P. M., Giang, L. T. & Pham, T. T. H. Unmet needs for care for activities of daily living among older adults with functional disabilities in Vietnam. Front. Public. Health. 11, 1216785. https://doi.org/10.3389/fpubh.2023.1216785 (2023).
Rufo, D. D., Debelee, T. G., Ibenthal, A. & Negera, W. G. Diagnosis of diabetes mellitus using gradient boosting machine (LightGBM). Diagnostics (Basel). https://doi.org/10.3390/diagnostics11091714 (2021).
Seto, H. et al. Gradient boosting decision tree becomes more reliable than logistic regression in predicting probability for diabetes with big data. Sci. Rep. 12, 15889. https://doi.org/10.1038/s41598-022-20149-z (2022).
Xuan, P. et al. Gradient boosting decision Tree-Based method for predicting interactions between target genes and drugs. Front. Genet. 10, 459. https://doi.org/10.3389/fgene.2019.00459 (2019).
Li, Z. & Hu, D. Forecast of the COVID-19 epidemic based on RF-BOA-LightGBM. Healthc. (Basel). https://doi.org/10.3390/healthcare9091172 (2021).
Zhong, J. et al. Robust prediction of hourly PM(2.5) from meteorological data using LightGBM. Natl. Sci. Rev. 8, nwaa307. https://doi.org/10.1093/nsr/nwaa307 (2021).
Utkin, L. V. & Konstantinov, A. V. Attention-based random forest and contamination model. Neural Netw. 154, 346–359. https://doi.org/10.1016/j.neunet.2022.07.029 (2022).
Yin, H. et al. A machine learning model for predicting acute exacerbation of in-home chronic obstructive pulmonary disease patients. Comput. Methods Programs Biomed. 246, 108005. https://doi.org/10.1016/j.cmpb.2023.108005 (2024).
Zhang, X. et al. Improving the prediction performance of leaf water content by coupling multi-source data with machine learning in rice (Oryza sativa L). Plant. Methods. 20, 48. https://doi.org/10.1186/s13007-024-01168-5 (2024).
Xinyang, S. et al. A machine learning radiomics model based on BpMRI to predict bone metastasis in newly diagnosed prostate cancer patients. Magn. Reson. Imaging. 107, 15–23. https://doi.org/10.1016/j.mri.2023.12.009 (2024).
Géron, A. Hands-on Machine Learning With Scikit-Learn, Keras, and TensorFlow (O’Reilly Media, Inc., 2022).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Ke, G. et al. Curran Associates Inc., Long Beach, California, USA,. In Proceedings of the 31st International Conference on Neural Information Processing Systems 3149–3157 (2017).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Chen, T., Guestrin, C. & XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016).
Chawla, N. V., Bowyer, K. W., Hall, L. O. & Kegelmeyer, W. P. SMOTE: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357 (2002).
Ivan, T. Two modifications of CNN. IEEE Trans. Syst. Man. Commun. SMC. 6, 769–772 (1976).
Santos, M. S., Abreu, P. H., Garcia-Laencina, P. J., Simao, A. & Carvalho, A. A new cluster-based oversampling method for improving survival prediction of hepatocellular carcinoma patients. J. Biomed. Inform. 58, 49–59. https://doi.org/10.1016/j.jbi.2015.09.012 (2015).
Handelman, G. S. et al. eDoctor: machine learning and the future of medicine. J. Intern. Med. 284, 603–619. https://doi.org/10.1111/joim.12822 (2018).
Ma, H., Xu, C. F., Shen, Z., Yu, C. H. & Li, Y. M. Application of Machine Learning Techniques for Clinical Predictive Modeling: A Cross-Sectional Study on Nonalcoholic Fatty Liver Disease in China. Biomed Res Int https://doi.org/Artn 430437610.1155/2018/4304376 (2018) (2018).
Rahman, M. M. et al. A systematic review and meta-analysis of unmet needs for healthcare and long-term care among older people. Health Econ. Rev. 12, 60. https://doi.org/10.1186/s13561-022-00398-4 (2022).
Feng, T. The health status of China’s elderly and their demand for healthcare services. China Popul. Dev. Stud. 3, 327–342 (2020).
Huang, Y. et al. Demand prediction of medical services in home and community-based services for older adults in China using machine learning. Front. Public. Health. 11, 1142794 (2023).
Dong, J. et al. Machine learning-based intradialytic hypotension prediction of patients undergoing hemodialysis: A multicenter retrospective study. Comput. Methods Programs Biomed. 240, 107698. https://doi.org/10.1016/j.cmpb.2023.107698 (2023).
Xu, X., Li, P. & Ampon-Wireko, S. The willingness and influencing factors to choose institutional elder care among rural elderly: An empirical analysis based on the survey data of Shandong Province. BMC Geriatr. 24, 17. https://doi.org/10.1186/s12877-023-04615-5 (2024).
Xie, F., Shu, Q., Li, J. & Chen, Z. Y. An exploration of status of chronic diseases and its influencing factors of older people in Chinese home care and long-term care facilities: A cross-sectional study. Front. Public. Health. 11, 1321681. https://doi.org/10.3389/fpubh.2023.1321681 (2023).
Albarrati, A. M., Gale, N. S., Munnery, M. M., Cockcroft, J. R. & Shale, D. J. Daily physical activity and related risk factors in COPD. BMC Pulm Med. 20, 60. https://doi.org/10.1186/s12890-020-1097-y (2020).
Ma, R. et al. Physical Multimorbidity and social participation in adult aged 65 years and older from six Low- and Middle-Income countries. J. Gerontol. B Psychol. Sci. Soc. Sci. 76, 1452–1462. https://doi.org/10.1093/geronb/gbab056 (2021).
Zhong, J. et al. Robust prediction of hourly PM2.5 from meteorological data using LightGBM. Natl. Sci. Rev. https://doi.org/10.1093/nsr/nwaa307 (2021).
Funding
This research was funded by Henan Province key research and development and promotion of special projects (scientific and technological research), grant number 212102310814. National Key R&D Program for Active Health and Aging Science and Technology Response Key Special Project, grant number 2020YFC2006100. Annual Project of Henan Provincial Philosophy and Social Science Planning, grant number 2020BSH017.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Guangdong Wang, Leping Wan, Xinle Wang and Yan He. The first draft of the manuscript was written by Guangmei Yang, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, G., Wang, G., Wan, L. et al. Utilizing SMOTE-TomekLink and machine learning to construct a predictive model for elderly medical and daily care services demand. Sci Rep 15, 8446 (2025). https://doi.org/10.1038/s41598-025-92722-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-92722-1
Keywords
This article is cited by
-
Advancements in Machine Learning for Brain Tumor Classification and Diagnosis: A Comprehensive Review of Challenges and Future Directions
Archives of Computational Methods in Engineering (2026)
-
Artificial neural network-driven approaches to improved forecasting of disability care expenditures in an aging Kingdom of Saudi Arabia population
Scientific Reports (2025)
