
Abstract
Remote sensing (RS) change detection incurs a high cost because of false negatives, which are more costly than false positives. Existing frameworks, struggling to improve the Precision metric to reduce the cost of false positive, still have limitations in focusing on the change of interest, which leads to missed detections and discontinuity issues. This work tackles these issues by enhancing feature learning capabilities and integrating the frequency components of feature information, with a strategy to incrementally boost the Recall value. We propose an enhanced hybrid of CNN and Transformer network (EHCTNet) for effectively mining the change information of interest. Firstly, a dual branch feature extraction module is used to extract the multi-scale features of RS images. Secondly, the frequency component of these features is exploited by a refined module I. Thirdly, an enhanced token mining module based on the Kolmogorov-Arnold Network is utilized to derive semantic information. Finally, the semantic change information’s frequency component, beneficial for final detection, is mined from the refined module II. Extensive experiments validate the effectiveness of EHCTNet in comprehending complex changes of interest. The visualization outcomes show that EHCTNet detects more intact and continuous changed areas and perceives more accurate neighboring distinction than state-of-the-art models.
Similar content being viewed by others
Introduction
Remote sensing (RS) imagery, compared to traditional surveying and mapping data, offers unparalleled advantages such as wide-area coverage, high temporal frequency, fewer constraints on data collection, and rich information content1,2. These characteristics make RS imagery well-suited for studying land use and environmental changes at large scales1,3,4. Depending on the dataset characteristics, change detection tasks can be categorized into various types, including synthetic aperture radar (SAR), multi-spectral, hyper-spectral, very high-resolution, and heterogeneous image change detection5. Among these, very high-resolution imagery has gained prominence due to its ability to capture intricate details of artificial and natural structures. Consequently, methods for change detection in high-resolution RS images are critical for applications such as agricultural surveys, disaster assessment, land cover monitoring, urban expansion studies, and internal urban change analysis.
Despite its significance, change detection in RS imagery remains a challenging problem due to several factors: (1) limited spectral information in very high-resolution images compared to medium-resolution ones6, (2) high spectral variability due to complex artificial materials7,8, (3) information loss caused by occlusions such as clouds and shadows9, and (4) inconsistent object features across images from different platforms, times, or locations8,10,11. These challenges underscore the need for advanced models that can extract high-level semantic change information from bi-temporal images, surpassing traditional feature extraction approaches.
Traditional change detection methods relied heavily on manually crafted features and conventional machine learning techniques12,13,14, which often fail to capture complex spatial and temporal relationships in RS imagery15. Deep learning-based approaches, particularly convolutional neural networks (CNNs) and Transformers, have since emerged as the dominant paradigms, achieving superior performance by automatically learning hierarchical features16,17. While CNNs excel at extracting localized features, they struggle to capture global context due to their limited receptive fields18. In contrast, Transformers offer a global perception capability but often require large datasets to perform optimally, making them less suitable for small-scale datasets19.
To bridge these gaps, hybrid architectures combining CNNs and Transformers have shown great promise in remote sensing change detection8,20. These hybrid methods leverage the local feature extraction capabilities of CNNs and the global context modeling of Transformers to achieve robust representations. However, remote sensing imagery exhibits several unique characteristics, including global scene coverage, multi-scale object representation, complex land cover patterns, solar radiation and atmospheric effects, and geometric distortions caused by terrain variations. These characteristics pose significant challenges for general computer vision methods, which are often designed for natural images with relatively uniform scales and simpler scene structures21,22. Additionally, many current change detection models focus on both changed regions and consistent background information. While consistent background modeling reduces false positives, it risks overshadowing the primary goal of RS change detection: identifying changes critical for applications like disaster response and illegal construction monitoring. These scenarios demand high recall rates to ensure that all significant changes are detected, even at the cost of precision.
In this work, we propose Enhanced Hybrid CNN-Transformer Network (EHCTNet), a novel architecture designed to address the aforementioned challenges by integrating local and global feature extraction with advanced semantic token learning. Our method incorporates spectral and spatial attention mechanisms, hybridizing CNNs and Transformers for superior performance in remote sensing change detection tasks. The main contributions of our work are as follows:
-
We propose a dual-branch hybrid architecture combining CNN and Transformer blocks to effectively integrate local and global features. This approach enhances multi-scale feature representation and significantly improves the accuracy of remote sensing change detection.
-
We design novel modules including a head residual Fast Fourier Transform (HFFT), a Kolmogorov-Arnold Network (KAN)-based channel and spatial attention block (CKSA), and a back residual Fast Fourier Transform (BFFT), which are tailored to sequentially extract first-order features, semantic tokens, and second-order semantic difference information. These modules enhance the model’s ability to capture both subtle and high-level changes, thereby improving the Recall metric and ensuring comprehensive detection.
-
EHCTNet demonstrates robust performance in detecting the change of interest. It maintains the coherence and structural integrity of objects while enhancing the discriminability between adjacent regions. Visualization results further highlight its effectiveness in remote sensing change detection tasks.
Change detection
Remote sensing change detection methods can be broadly classified into two phases: conventional and deep learning-based approaches. Traditional statistical and machine learning techniques, such as image algebra23, principal component analysis (PCA)12,24, clustering25, change vector analysis14, support vector machines (SVM)13, random forests26, and decision trees27, dominate the conventional category11,28. These methods rely on manually designed features, offering interpretability but lacking the capacity to represent complex, high-level object information15. Consequently, their detection capabilities are limited and are generally considered inferior to deep learning approaches28.
Deep learning methods, such as convolutional neural networks (CNNs) and Transformers, have significantly advanced change detection by automatically learning hierarchical features15. These methods can be categorized into single-stream, siamese, and generative adversarial networks (GANs)28. Single-stream models represent image pairs in a common feature space and utilize a single architecture for change detection. For example, Zhan et al. proposed a logarithmic transformation framework for heterogeneous SAR and optical images, achieving comparable statistical distributions between the modalities29. Similarly, sparse autoencoders and capsule neural networks have been utilized to map images into shared feature spaces for improved classification30,31. While single-stream models are computationally efficient, they often fail to fully capture discriminative semantic information, limiting their effectiveness. Siamese networks, on the other hand, utilize two sub-networks to extract features from bi-temporal images, followed by a change detection module. These networks, such as DSMNN-Net32 and FC-Siam family architectures33,34, excel at handling heterogeneous datasets and imaging conditions. Zhao et al. introduced a feature space transformation to align heterogeneous images for change detection35. However, the complexity of these architectures and the large number of parameters can lead to optimization challenges28. GAN-based approaches have recently gained attention for their ability to handle domain adaptation and generate synthetic data. For instance, CycleGANs have been employed to impose cycle-consistency for domain adaptation in SAR-optical change detection36. Despite their potential, GANs suffer from instability during training, which can impact feature representation and model performance28.
Although siamese and GAN-based methods show promise, their complexity and training challenges highlight the need for more efficient and robust solutions.
Hybridization architectures
The hybridization of CNNs and Transformers has emerged as a powerful approach for feature learning in computer vision and RS image semantic understanding19,37,38. While pre-trained CNNs are often used as backbones for feature extraction in change detection8,11,39, their performance can be limited when applied directly to remote sensing tasks. To address this, hybrid architectures integrate CNNs for local feature extraction with Transformers for capturing global relationships21,22.
For example, Zheng et al. proposed L-Former, which employs Transformers in shallow layers and CNNs in deeper layers, achieving competitive results22. However, existing hybrid models often emphasize the importance of capturing consistent background information to reduce false positives in change detection tasks11. Recent works have emphasized focusing on background consistency to improve precision and F1 scores11,40. Recently, diffusion models41,42 have demonstrated exceptional capabilities in generating fine-grained, semantically consistent outputs across various domains, including computer vision and natural language processing. Yet, this shift risks neglecting the primary goal of identifying changed areas, particularly in critical applications such as disaster response and unauthorized construction monitoring, where recall is paramount.
Despite the progress in hybrid models, existing methods lack sophisticated strategies tailored to specific remote sensing scenarios. To bridge this gap, we propose an enhanced hybrid CNN-Transformer network that improves feature learning capability and overall accuracy. By incorporating token mining and refinement modules, our method incrementally enhances recall, ensuring comprehensive and reliable change detection.

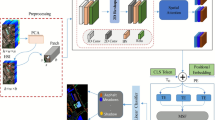
Overall network structure of the EHCTNet (RS images and ground truth data are from LEVIR-CD dataset11).
Related work
Proposed method
The entire architecture of EHCTNet, comprising five modules: (1) the feature extraction module, (2) refined module I, (3) the enhanced token mining based Transformer module, (4) refined module II, and (5) the detection head module, is depicted in Fig. 1. The feature extraction module consists of dual branches hybridization architecture of CNN and Transformer (HCT) designed to capture raw multi-scale features from bi-temporal images. The HCT combines the local feature extraction capabilities of CNNs with Transformers’ global contextual feature learning abilities to significantly enhance the raw feature representation. Refined module I, which follows the feature extraction module, is a frequency attention module designed to refine the frequency details of the raw multi-level features and to generate first-order features. The enhanced token mining based Transformer module adopts the first-order refined features as input to gain semantic information. Refined module II, which is placed in the deeper part of EHCTNet, symmetrically to refined module I, is also a frequency attention module designed to refine the frequency components of the semantic information within the enhanced token mining based Transformer module and to generate second-order semantic difference information. Refined module I primarily aids the model in acquiring refined frequency features for each image, which benefits change detection, and refined module II is utilized for learning high-level semantic difference information from the semantic difference map. Lastly, the detection head is used to generate the change map.
Feature extraction module
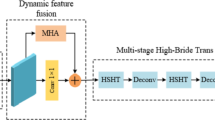
Inspired by the hybridization idea19 and the CMTFNet model3, we construct a dual HCT blocks, named the feature extraction module, to fuse local features with global features. The two branches of the feature extraction module, which share learnable parameters, are identical. Each branch of the feature extraction module is an HCT, and the structure of the HCT is shown in Fig. 2. The encoder part uses ResNet5043 to encode hierarchical features. ResNet50 contains 4 stages. Specifically, it first uses a 7×7 convolution layer and a max-pooling layer reprojecting the input image of size (3 × \(H_0\) × \(W_0\)) into an array of size (64 × \(H_0/4\) × \(W_0/4\)). Then, the first stage employes a ResNet50 block to rescale the array into a feature map (e1: 256 × \(H_0/4\) × \(W_0/4\)). Each of the remaining 3 stages consists of a series of ResNet50 blocks, where each ResNet50 block comprises a 1×1 convolution, a 3×3 convolution, and another 1×1 convolution. In each stage, the ResNet50 block downsamples the feature map from the previous stage by a factor of 2, generating feature maps of resolutions: e2: 512 × \(H_0/8\) × \(W_0/8\), e3: 1024 × \(H_0/16\) × \(W_0/16\), and e4: 2048 × \(H_0/32\) × \(W_0/32\).
In the decoder of HCT, we first use 3×3 convolution to reproject e3 and e4 to \(e3^{\prime }\) and \(e4^{\prime }\) with 512 channels. Then, \(e4^{\prime }\) is fed into Transformer blocks to generate multi-scale global contextual information. That is, \(e4^{\prime }\) is decoded by a Transformer block to get d3 (512×\(H_0/16\)×\(W_0/16\)). Subsequently, we fuse \(e3^{\prime }\) and d3 to get d2 (512 × \(H_0/8\) × \(W_0/8\)). The remaining process is carried out in the same way to obtain d1 (256 × \(H_0/4\) × \(W_0/4\)) and raw multi-scale features (d0: 256 × \(H_0/4\) × \(W_0/4\)).
The encoder part uses ResNet50 to encode hierarchical features, while the decoder part consists of 3 Transformer blocks to decode multi-scale global contextual features. In order to fuse the local hierarchical features with the global contextual features, fusion operations are performed after the first three decoder blocks. The first two fusion operations capture rich local features and global contextual information but lack spatial detail. Therefore, the third fusion is crucial for integrating the spatial features from the first CNN module, such as radiation intensities, edges, corners, and texture. The decoder generates multi-scale global contextual information and gradually restores the feature resolution by fusing the hierarchical features obtained from the CNN module. In addition, a learnable variable is used to weigh the importance of the local features and global contextual information in the fusion process. Thus, the contribution of the two elements to the output is formulated as:
where i is the \(i_{th}\) stage of the encoder and decoder part of the feature extraction module, \(\alpha\) represents the learnable variable, \(e_i\) is the output local features of the encoder part, and \(d_i\) is the output global contextual information of the decoder part.

Illustration of the HCT branch (RS image is from LEVIR-CD dataset11).
Refined module I
In general, spatial attention mainly focuses on local features of interest. However, frequency domain analysis can capture both high frequency (detail) and low frequency (overall structure) information, which is suitable for multi-scale change detection tasks. In addition, combining spectral layers and multi-head attention enables models to achieve state-of-the-art (SOTA) performance44,45. Therefore, we designed joint modules consisting of refined module I, the enhanced token mining based Transformer module, and refined module II, which follow the feature extraction module. Refined module I yields first-order features that are beneficial for representing detailed information in each raw feature image. In this work, the refined module I mainly consists of a Fast Fourier Transform (FFT) layer, a weighted gating mechanism, and an inverse FFT layer45,46. The FFT transforms the feature map from the physical to the frequency space. The weighted gating mechanism, as a learnable weight parameter within the neural network, can effectively identify the frequency-domain features in the feature map by adjusting its weights through the process of back-propagation during training, thereby determining the significance of each frequency component in the feature representation. The inverse FFT converts the feature map from the frequency domain back to the spatial domain, thereby generating refined frequency features with enhanced detail, referred to as first-order features. Finally, the output of refined module I is passed through a residual connection to retain the characteristics in the raw feature image.
Enhanced token mining based transformer module
The feature extraction module extracts and fuses multi-scale features from bi-temporal RS images in the previous two procedures. Then, we utilize refined module I to obtain the first-order features. In this step, the enhanced token mining based Transformer module is used for the semantic token extraction and semantic information perception. The enhanced token mining based Transformer module consists of two units: the KAN47 based channel and spatial attention (CKSA) block , and the Transformer unit.
KAN can enhance feature representation through its hierarchical structure to model complex nonlinear relationships. It enables tailored activations at the network edge by computing each input channel’s contribution47,48. The applicability and efficacy of KAN have already been tested in computer vision domain49 and RS domain48. We first designed the KAN47 based channel and spatial attention (CKSA) block (Fig. 3) to generate two condense semantic token sets. Max-pooling and average-pooling provide information on distinctive object features, enabling the inference of finer channel-wise attention50. In the channel attention of Fig. 3, max-pooling and average-pooling are employed to compute the channel attention map (\(\mathbb {R}^{1 \times 1 \times C}\)). The flatten operation transforms the 3D array into a 1D array (\(\mathbb {R}^{C}\)). The KAN network is then trained to estimate the attention weights for all channels. Finally, these 1D arrays are reprojected back to \(X_{CKA}\) with shape of \(\mathbb {R}^{1 \times 1 \times C}\). Therefore, the procedure can be defined as:
where MaxPool, AvgPool, KAN and \(\sigma\) represents the max-pooling, average-pooling, KAN and Sigmoid operations in channel attention unit of Fig. 3.
In addition, Spatial attention in CKSA still uses maximum and average pooling, but along the channel axis, to obtain a spatial attention map (\(\mathbb {R}^{1 \times 1 \times C}\)). At the last stage of CKSA, we reproject the channel-spatial attention map into 1D semantic tokens (\(X_{CKSA} \in \mathbb {R}^{C}\)). Semantic tokens, encompassing both spatial structures and channel-wise dependencies, are one of the key components in Siamese change detection network11. Semantic tokens represent high-level concepts of change interest, and their operations are beneficial for interacting with change information in remote sensing change detection tasks8. In the CKSA, the process of converting feature images to tokens can be expressed as:
where Concat represents concatenate the MaxPool output and AvgPool output, \(\sigma ^{\prime }\) is the Softmax operation.
Though these tokens contain rich details of feature image variations, they lack interactive relational semantics among the tokens. Transformer51 can fully exploit high-level global semantic relations in the token space8. Therefore, we incorporate a Transformer block into the subsequent stage of the enhanced token mining based Transformer module. First, the two token sets derived from the CKSA are concatenated to form a token aggregation, which is then fed into the encoder of the Transformer8,11 to capture the global semantic context between these tokens. Since the token aggregation involves concatenating semantic token sets along the second dimension (dim = 1), it can be likened to binding two bundles of token bars together. Therefore, the Transformer encoder can extract the intra-relationships within one set of tokens and the inter-relationships between the two sets of semantic tokens. As a result, the output from the Transformer encoder is enriched with high-level semantic information within the intra-tokens and global semantic information across the inter-tokens.
We divide the high-level semantic context into two sets of context tokens, each with the same dimension as the CKSA tokens. The two sets of context tokens encapsulate condensed semantic context and represent the high-level information regarding the hotspot. Subsequently, Transformer decoder51 is deployed to restore the two sets of context tokens to dual semantic pixel maps in pixel space. The dual-branch pixel maps, rich in high-quality semantic information, enable each pixel within the maps to be represented by the two sets of context tokens. This representation effectively highlights the pixel values of interest in the semantic maps.
The semantic pixel maps effectively reveal semantic hotspots in the feature space. Subsequently, the semantic pixel maps are subtracted from each other to obtain a semantic difference map, which represents the semantic information of change. Subtraction between the semantic pixel maps can result in both positive and negative outcomes. To ensure that all values are non-negative, we convert any negative results to their absolute values, as defined by:
where \(X_{SPFM1}\) and \(X_{SPFM2}\) represent the pixel values of the semantic pixel maps, and \(X_{SUB}\) denotes the pixel value of the semantic difference map generated by taking the absolute of the subtraction.
Refined module II
HFFT of refined module I and BFFT of refined module II are symmetrically positioned at the early and late stages of the EHCTNet model, as illustrated in Fig. 1. Similar to HFFT, BFFT also includes an FFT layer, a weighted gating, an inverse FFT layer, and a residual connection. BFFT is used to refine the semantic difference map and generate the second-order semantic difference map. In this subsection, the semantic difference map is first rescaled to match the dimensions of the original RS images. The BFFT converts the rescaled semantic difference map’s physical space to frequency space, where it portrays the detailed information of the semantic difference map. It then restores this depicted detail information to the physical space, thereby generating second-order semantic difference information in the refined semantic difference map.
Detection head
The second-order semantic difference information in the refined semantic difference map represents the final stage of semantic information. It is directly utilized in the detection head module to discriminate between the changed and background areas. A fully convolutional network is employed in the detection head to generate a change map, which has a dimension of \(\mathbb {R}^{H_{0} \times W_{0} \times 2}\), where \(H_{0}\) and \(W_{0}\) represent the height and width of the original bi-temporal RS images.
Loss function
Currently, most change detection tasks are still binary classification problems. The cross-entropy loss function is one of the most favored methods for minimizing the loss in neural networks and optimizing the network parameters. By definition, the loss function is formally expressed as:
where L is the cross-entropy loss, G represents the ground truth value and P denotes the predicted value.
Experiment and analysis
To comprehensively validate the superiority of our proposed EHCTNet model, we have conducted extensive comparisons with SOTA change detection methods on two large-scale, high spatial resolution remote sensing (RS) image datasets, namely, LEVIR-CD52 and DSIFN-CD53.
Datasets
LEVIR-CD52 is a large RS dataset for building change detection. The original dataset derived from Google Earth contains 637 pairs of very high-resolution RS images, each with a size of 1024 × 1024 pixels. The images in the LEVIR-CD dataset were cut into small patches of size 256 × 256 due to the limitations of GPU power8, resulting in 7120, 1024, and 2048 pairs for training, validation, and testing respectively11.
DSIFN-CD53 is a publicly available binary change detection dataset that comprises high-resolution (2m) satellite image pairs from six major Chinese cities: Beijing, Chengdu, Shenzhen, Chongqing, Wuhan, and Xi’an. These image pairs are manually curated from Google Earth and are split into 394 sub-image pairs of 512×512 pixels. Subsequently, these sub-image pairs are augmented to yield 3988 dual-temporal image pairs. The dataset is divided into 3600 training pairs, 340 validation pairs, and 48 testing pairs. This dataset is extensively utilized in the RS change detection domain. Similar to the LEVIR-CD dataset, these 512 × 512 DSIFN-CD image pairs were further sliced into 256 × 256 patches to accommodate the GPU memory constraints, resulting in subsets of 14400 training image pairs, 1360 validation image pairs, and 192 testing image pairs for change detection11.
Evaluation metrics
The standard evaluation indices used in the change detection tasks to assess the performance of approaches include Precision, Recall, Intersection over Union (IoU), and Overall Accuracy (OA)8.
Precision quantifies the proportion of correct positive predictions, defining it as the percentage of correctly predicted positive instances out of all the instances predicted as positive, which is defined as:
where TP and FP represent the number of true and false positives in the confusion matrix computed by comparing the ground truth with the predicted values. When the cost or risk associated with false positives is high (High Cost of False Positives), it is crucial to maximize Precision as much as possible. This is particularly important in medical diagnosis, legal decisions, and financial fraud detection. In this case, a high Precision indicates that the algorithm is less likely to misclassify background information as areas of change.
Recall represents the number of positive predictions made out of all actual positive cases in the dataset, and it quantifies the percentage of actual positives that were correctly identified, which is defined as:
where FN represents the false negative value in the confusion matrix. In contrast to Precision, Recall is more appropriate for cases where the cost of false negatives is high, such as in disease screening, security identification, rare events detection, and change detection. In this case, a high Recall indicates that the model successfully identifies most of the change of interest. In change detection scenarios, it is crucial to achieve a high Recall to ensure that the change of interest is not overlooked, as the occurrence of change is significant and rare.
IoU is commonly used to measure the proportion of overlap between the ground truth and the predicted results, which is expressed as:
The IoU value ranges from 0 to 1, with 1 indicating perfect overlap between the ground truth and the prediction and 0 indicating no overlap. In change detection tasks, we prioritize the changed area over the background. As stated in Formula 9, the IoU score primarily focuses on the area of interest that has changed rather than considering both categories (changed area and background area) equally. Furthermore, after calculating the IoU scores for all regions of interest, it is necessary to compute the average of these scores to obtain the mean Intersection over Union (MIoU), which is defined as:
where i denotes the index of the region of interest, N is the total number of regions of interest.
OA, which stands for Overall Accuracy, represents the percentage of correctly predicted areas out of the total areas in the dataset. It is defined as:
where TN represents true negative. OA calculates an algorithm’s performance across all classes into a single value; however, it does not provide insight into the algorithm’s effectiveness on individual classes, especially in the case of imbalanced datasets.
Historically, the F1-score has been considered a primary evaluation metric in remote sensing change detection tasks due to its consideration of both Precision and Recall. This is reflected in works such as Chen et al.8 and Jiang et al.11, where the F1-score is formulated as follows:
In conclusion, the Recall, F1-score, and IoU metrics are suitable for evaluating the performance of models in change detection tasks. The OA metric is also adopted in this work to understand the overall performance of change detection models across both change and background categories.
Implementation details
EHCTNet is implemented in PyTorch and trained end-to-end on an NVIDIA GeForce RTX 3060 GPU using the stochastic gradient descent (SGD) optimizer and a linear learning rate policy. The initial learning rate is 0.01, the batch size is 8, the weight decay is 0.0005, and the momentum is 0.99, respectively. After each training epoch, a validation process is conducted, and the model with the best performance is saved for evaluation on the test set.
Comparison with state-of-the-art methods
We compared EHCTNet with 11 SOTA methods in this subsection on the LEVIR-CD and DSIFN-CD benchmark datasets. These SOTA methods include FC-EF54, FC-Siam-Di54, FC-Siam-Conc54, DTCDSCN55, IFNet53, SNUNet56, CropLand57, BIT8, VcT11, SMDNet58, GCRNet59. In our study, we selected BIT and VcT as the primary comparison benchmarks due to their distinct contributions to the field of change detection. BIT stands out as a cutting-edge, robust Transformer architecture specifically designed for change detection tasks. Concurrently, VcT is distinguished by its focus on leveraging background information, which recently shows superior performance compared to other methods in the domain11.
Comparisons on LEVIR-CD
The result of the above 11 change detection methods and our EHCTNet on the LEVIR-CD dataset is listed in Table 1. Table 1 shows that the EHCTNet architecture significantly outperforms the other approaches. The Recall and IoU metrics of EHCTNet achieve the best scores among the above 11 methods, demonstrating that EHCTNet can accurately and completely detect changes of interest in bitemporal remote sensing images. In specific, our EHCTNet outperforms BIT by + 3.69\(\%\), + 1.60\(\%\), + 1.37\(\%\), + 0.13\(\%\) on Recall, F1, IoU, and OA, and beats VcT by + 11.38\(\%\), + 4.96\(\%\), + 4.12\(\%\), + 0.39\(\%\), respectively. These improved metrics highlight the effectiveness of the EHCTNet framework in remote sensing image change detection tasks, especially in comparison to BIT and VcT methods that emphasize background information. Furthermore, the Recall metrics indicate that the EHCTNet framework can identify changed areas to the extent practicable, rendering it highly effective for RS image change detection tasks, particularly for datasets such as LEVIR-CD, which can be used as training data sets for the detection of illegal constructions.
Comparisons on DSIFN-CD
The experimental results of these methods on the DSIFN-CD dataset are shown in Table 2. Our EHCTNet method presents competitive performance on the DSIFN-CD dataset. Specifically, our EHCTNet outperformed BIT on Recall, F1, IoU, and OA by + 15.83\(\%\), + 6.07\(\%\), + 4.51\(\%\), and + 1.19\(\%\), respectively. In addition, the Recall, F1, IoU, and OA metrics of EHCTNet have been improved by + 25.49\(\%\), + 6.80\(\%\), + 4.35\(\%\), and + 0.29\(\%\) respectively, when compared with the VcT method. Especially for the Recall metric, the performance improvement indicates that EHCTNet achieves a significant improvement over VcT, which suggests that our EHCTNet does effectively detect essential and helpful change information from the dual images. Consequently, the EHCTNet method is suitable for changed area detection, such as detecting increments in artificial structures and facilities on the DSIFN-CD dataset.
In addition, while GCRNet achieves competitive metrics on the LEVIR-CD dataset but performs poorly on the DSIFN-CD dataset, SMDNet shows the opposite trend, performing well on DSIFN-CD but less effectively on LEVIR-CD. The performance variability across datasets suggests that GCRNet and SMDNet are not robust enough for different change detection tasks. Our EHCTNet, which mainly focuses on mining semantic change information from bitemporal RS images, exhibits stable and outstanding performance on both the LEVIR-CD and DSIFN-CD datasets. The comparison results in Tables 1, and 2 indicate that our EHCTNet also outperforms the BIT and VcT approaches, which mainly pay close attention to background information. Therefore, the improvement of EHCTNet indicates that the change information of interest is more important than the backgroud information for the remote sensing change detection task. It is worth noting that the Recall metric of EHCTNet substantially outperforms all the above models, illustrating that our EHCTNet is more suitable for the RS image change detection domain. It effectively captures the continuous and intact changes of interest, as demonstrated in Fig. 4.

Illustration of CKSA.

The heatmaps and change results of our EHCTNet are compared with those of two state-of-the-art (SOTA) approaches (BIT8 & VcT11). The baseline means the feature extraction module of our EHCTNet. The yellow rectangle indicates the presence of missed detections, false detections, and incorrect merging of adjacent change areas. RS images and ground truth data are from LEVIR-CD dataset11.
Feature extraction improvement
The HCT is utilized in the feature extraction module of our EHCTNet. We conducted a comparison experiment between the feature extraction module (ResNet 18) of SOTA methods and our HCT on the LEVIR-CD dataset, as shown in Fig. 5. It shows that our HCT significantly outperforms the ResNet commonly used in other SOTA change detection models. In Fig. 5, our feature extraction module has improved Recall, F1, IoU, and OA by + 3.69\(\%\), + 2.2\(\%\), + 1.79\(\%\) and + 0.18\(\%\), respectively.
In addition, another comparison of DSIFN-CD datasets is also experimented within this work, as shown in Fig. 6. Figure 6 shows that the HCT in EHCTNet is also superior to the ResNet 18. Compared to the ResNet 18, our HCT has improved Recall, F1, IoU, and OA by + 8.75\(\%\), + 5.61\(\%\), + 4.05\(\%\) and + 1.29\(\%\), respectively.
Note that the metrics of our hybrid feature extraction module improved significantly, which extracts more detailed image features than those feature extraction modules used in other change detection tasks. Our feature extraction baseline, which is only utilized for extracting image features in the shallow layers of the EHCTNet, even achieved competitive performance compared to other well-designed methods in Tables 1 and 2. The CNN-Transformer hybridization’s competitive performance ensures that the feature extraction module provides more detailed features to perceive high-level change information in subsequent procedures. Consequently, compared with other methods shown in Tables 1 and 2, EHCTNet achieves the highest evaluation metrics. Especially for the LEVIR-CD dataset, which accurately marks the edges of image objects, EHCTNet gains an extremely high IoU score of 90.38\(\%\).
Ablation studies and analysis
Influence of enhanced token mining based transformer module
The feature extraction module extracts image features from dual temporal RS images using the multi-scale feature-extracting capabilities of the CNN and Transformer hybridization. This procedure comprehensively utilized dual images’ spatial, textual, and brightness features. These image features are generally regarded as low-level features. Therefore, we integrate an enhanced token mining based Transformer module into EHCTNet to capture semantic information. The CKSA block is constructed to generate tokens by categorizing features into concepts, resulting in two bundles of tokens. The Transformer encoder exploits the global semantic relationships between tokens to generate semantic information about the area of interest. Subsequently, the Transformer decoder projects this high-level semantic information back into the feature image space to obtain pixel-level, semantic feature maps. The effectiveness of the enhanced token mining based Transformer module is shown in Tables 3 and 4. As can be seen from Table 3, after introducing the enhanced token mining based Transformer module into EHCTNet, the Recall, F1 score, IoU, and OA of the network improved by + 4.61\(\%\), + 2.36\(\%\), + 2.00\(\%\), + 0.21\(\%\), respectively. Table 4 further shows that the Recall, F1, IoU, and OA of the network improved by + 16.93\(\%\), + 4.79\(\%\), + 3.27\(\%\), + 0.45\(\%\) respectively. These improvements demonstrate that the semantic information benefits change detection on the LEVIR and DSIFN datasets.
Role of refined module I
The feature extraction module can only provide raw image features to the enhanced token mining based Transformer module. In order to delve deeper into the frequency information behind the feature images, we develop the refined module I, placing it between the feature extraction module and the enhanced token mining based Transformer module. This module is designed to extract first-order features, such as lines, edges, corners, and other intricate patterns from feature images. By analyzing these localized frequencies, the network gains a more nuanced understanding of the extent and the transitional boundaries of each object feature within the image. Table 3 shows that the refined module I improves the Recall, F1 score, IoU, and OA by + 0.66\(\%,\) + 0.07\(\%\), + 0.06\(\%\), + 0.00\(\%\) on the LEVIR-CD dataset, respectively. While Table 4 indicates that the refined module I improves the Recall, F1 score, IoU, and OA by + 0.28\(\%\), + 0.31\(\%\), + 0.27\(\%\), + 0.12\(\%\) on the DSIFN-CD dataset, respectively. Therefore, these frequency components from the dual feature images provide an additional frequency variation feature to the subsequent modules of the EHCTNet model, which is conducive to the expression of change features.
Impact of refined module II
The enhanced token mining based Transformer module generates dual semantic pixel maps. An absolute subtraction of dual semantic maps is performed to generate a semantic-level difference map. Similar to refined module I, refined module II also employs an FFT layer, a weighted gating mechanism, and an inverse FFT layer to extract the frequency components of the semantic difference map. Table 3 shows that refined module II can improve the model’s performance (Recall: + 0.85\(\%\), F1 score: + 0.20\(\%\), IoU: + 0.17\(\%\), OA: + 0.01\(\%\)) on the LEVIR-CD test dataset. Additionally, the combination of refined module I and refined module II (EHCTNet) achieves the best evaluation metrics, demonstrating the effectiveness of refined module I and refined module II on the LEVIR-CD test dataset. Although the DSIFN-CD test dataset is more complex than the LEVIR-CD dataset, refined module II can also perceive the valuable change information, significantly improving the Recall metric by + 0.99\(\%\). Furthermore, the combination of refined module I and refined module II also demonstrates the best performance on the DSIFN-CD dataset, achieving the highest Recall metric (89.01\(\%\)) under the premise of overall high evaluation metrics, as shown in Table 4. The frequency component is added back to the semantic level difference map to enhance additional information that is beneficial for detecting change of interest.
Overall, Refined Module II demonstrates a much stronger performance improvement over Refined Module I on the LEVIR-CD dataset. In contrast, Refined Module I outperforms Refined Module II in enhancing the model performance on the DSIFN-CD dataset. In general, the DSIFN-CD dataset exhibits greater complexity due to its simplified annotations, whereas the LEVIR-CD dataset is characterized by higher annotation precision. This indicates that Refined Module I is more effective in extracting low-level feature changes in complex datasets, while Refined Module II excels at capturing high-level semantic changes in precise datasets. Consequently, the combination of Refined Module I and Refined Module II is crucial for ensuring that EHCTNet achieves the most robust performance on both the LEVIR-CD and DSIFN-CD datasets compared to the other SOTA methods. Tables 3 and 4 show that our EHCTNet architecture can improve the Recall performance by 0.97\(\%\) and 1.26\(\%\) on LEVIR-CD and DSIFN-CD datasets respectively. Our EHCTNet is appropriate for improving the change detection rate in the specific remote sensing change detection tasks.
Visualization
Network visualization
In EHCTNet, several crucial nodes visualize the features and semantic information, including the raw features, first-order features, semantic pixel features, high-level semantic difference features, second-order semantic difference features, and change heatmap. These visualizations demonstrate the processing of dual-temporal images and help to understand the effectiveness of EHCTNet, as illustrated in Fig. 7. The feature extraction module of EHCTNet is used to extract raw features, which contain only low-level features. First-order features, perceived by the HFFT layer, enhance the frequency component of the raw features in the second step. Next, the enhanced token mining based Transformer is employed to learn semantic information of interest related to change. The semantic pixel maps can capture more continuous information of changed areas than the previous two steps, as shown in (d) of Fig. 7. Subsequently, the subtraction operation and BFFT are introduced to generate the high-level semantic difference map and the second-order semantic difference map, respectively. The change representations of the high-level semantic difference map and the second-order semantic difference map are more intact than the semantic pixel maps, as shown in (e) and (f) of Fig. 7. Finally, the change map is obtained by the detection head of EHCTNet, and a compact detection heatmap is shown in (g) of Fig. 7. This indicates that EHCTNet can progressively perceive features and semantic concepts in changed areas.

The improvement of our HCT over ResNet18 on LEVIR-CD dataset.
Visualization comparison to SOTA
We compared four methods: two SOTA methods, our baseline, and our EHCTNet on the LEVIR-CD and DSIFN-CD test datasets, as shown in Fig. 8. The two SOTA methods include BIT and Vct. BIT is typical of comprehensive SOTA methods that focus on the background and change information of dual temporal images. At the same time, VcT, as a SOTA approach, strives to mine the background information to detect changed areas. In Fig. 8, rows (a) and (b) represent scenes of few buildings and dense buildings. Scene (a), which represents the two different light condition images of the same region, shows that both BIT and our baseline can detect the existence of buildings in the given context, but they cannot accurately perceive the unchanged information. While our EHCTNet can perceive that there is no change of interest in this scene. Rows (b) contains some cases of missed detection and lacks the ability to distinguish between neighboring objects, as indicated by the orange rectangle in row (b) for the BIT method. In addition, due to its emphasis on background information, the VcT method exhibits a higher rate of missed detections in change regions, particularly at the image edges in the upper right corner, when compared to the BIT method. This is evident in the results shown in Fig. 8b. Our EHCTNet demonstrates the best performance in addressing the issue of missed detections in change of interest, as shown in the second row and seventh column of Fig. 8.

The improvement of our HCT over ResNet18 on DSIFN-CD dataset.

An example of network visualization (a Bi-temporal input images; b Raw multi-scale feature images; c First-order feature images; d Semantic pixel maps; e Semantic difference map; f Second-order semantic difference map; g Change detection heatmap). RS images are from LEVIR-CD dataset11.

Visualization results of different methods on the LEVIR-CD (a and b) and DSIFN-CD (c and d) test datasets. Different colors are utilized to highlight the performance differences among these methods in change detection tasks: white for true positives, black for true negatives, red for false positives, and green for false negatives. The orange rectangle indicates the presence of missed detections, discontinuity, and incorrect merging of adjacent change areas. RS images and ground truth data are from LEVIR-CD and DSIFN-CD datasets11.
In the DSIFN-CD dataset, the BIT method fails to extract many of the changed regions. While the VcT method outperforms BIT due to its additional clustering module, it still struggles to achieve continuous and complete detection results. In contrast, our EHCTNet demonstrates superior performance in producing continuous and intact detection results compared to the other methods, as shown in Fig. 8c,d.
Generally speaking, continuous and complete detection capability is highly advantageous in remote sensing change detection tasks, particularly in scenarios such as disaster area identification, victim rescue operations, illegal building monitoring, and asset loss assessment. In summary, our EHCTNet excels in prioritizing the detection of change of interest over BIT and VcT, and it can more clearly identify intact and continuously changed areas than the two methods. In summary, it provides more accurate neighboring distinction and edge information detection capability than SOTA methods.
Conclusion
In this work, we proposed EHCTNet, an enhanced hybrid CNN-Transformer framework for remote sensing change detection. EHCTNet consists of five modules: feature extraction, refined modules I and II, an enhanced token mining-based Transformer, and a detection head. It combines CNNs and Transformers to extract multi-scale features, uses a KAN-based attention block to identify valuable tokens, and employs a symmetric FFT structure to refine frequency components of feature images and semantic maps. The detection head predicts changes between bi-temporal images. Results showed that EHCTNet enhances edge detection, improves detection continuity, and achieves higher Recall, identifying more subtle changes than state-of-the-art methods. It effectively captures changes caused by complex reconstructions and solar radiation. Extensive experiments on LEVIR-CD and DSIFN-CD validated its effectiveness, with ablation studies highlighting the contributions of each module. This work focused on single-source data, limiting its application to multi-modal scenarios. Future work will explore mining changes from multi-source remote sensing images to further enhance its versatility and effectiveness.
Data availibility
The LEVIR-CD and DSIFN-CD datasets are openly available at: https://github.com/Event-AHU/VcT_Remote_Sensing_Change_Detection (accessed on 29 January 2024).
References
Kerr, J. T. & Ostrovsky, M. From space to species: Ecological applications for remote sensing. Trends Ecol. Evol. 18, 299–305. https://doi.org/10.1016/S0169-5347(03)00071-5 (2003).
Tian, Y. et al. Advancing application of satellite remote sensing technologies for linking atmospheric and built environment to health. Front. Public Health https://doi.org/10.3389/fpubh.2023.1270033 (2023).
Wu, H., Huang, P., Zhang, M., Tang, W. & Yu, X. Cmtfnet: CNN and multiscale transformer fusion network for remote-sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 61, 1–12. https://doi.org/10.1109/TGRS.2023.3314641 (2023).
Li, Z. et al. Local feature acquisition and global context understanding network for very high-resolution land cover classification. Sci. Rep. 14, 12597 (2024).
Shafique, A., Cao, G., Khan, Z., Asad, M. & Aslam, M. Deep learning-based change detection in remote sensing images: A review. Remote Sens. https://doi.org/10.3390/rs14040871 (2022).
Dalla Mura, M. et al. Challenges and opportunities of multimodality and data fusion in remote sensing. Proc. IEEE 103, 1585–1601. https://doi.org/10.1109/JPROC.2015.2462751 (2015).
Lu, M. et al. Land cover change detection by integrating object-based data blending model of Landsat and Modis. Remote Sens. Environ. 184, 374–386. https://doi.org/10.1016/j.rse.2016.07.028 (2016).
Chen, H., Qi, Z. & Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 60, 1–14. https://doi.org/10.1109/TGRS.2021.3095166 (2022).
Tatar, N., Saadatseresht, M., Arefi, H. & Hadavand, A. A robust object-based shadow detection method for cloud-free high resolution satellite images over urban areas and water bodies. Adv. Space Res. 61, 2787–2800. https://doi.org/10.1016/j.asr.2018.03.011 (2018).
Mercier, G., Moser, G. & Serpico, S. B. Conditional copulas for change detection in heterogeneous remote sensing images. IEEE Trans. Geosci. Remote Sens. 46, 1428–1441. https://doi.org/10.1109/TGRS.2008.916476 (2008).
Jiang, B. et al. VCT: Visual change transformer for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 61, 1–14. https://doi.org/10.1109/TGRS.2023.3327139 (2023).
Richards, J. Thematic mapping from multitemporal image data using the principal components transformation. Remote Sens. Environ. 16, 35–46. https://doi.org/10.1016/0034-4257(84)90025-7 (1984).
Bovolo, F., Bruzzone, L. & Marconcini, M. A novel approach to unsupervised change detection based on a semisupervised SVM and a similarity measure. IEEE Trans. Geosci. Remote Sens. 46, 2070–2082. https://doi.org/10.1109/TGRS.2008.916643 (2008).
Liu, S., Bruzzone, L., Bovolo, F., Zanetti, M. & Du, P. Sequential spectral change vector analysis for iteratively discovering and detecting multiple changes in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 53, 4363–4378. https://doi.org/10.1109/TGRS.2015.2396686 (2015).
Cheng, G. et al. Change detection methods for remote sensing in the last decade: A comprehensive review. Remote Sens. https://doi.org/10.3390/rs16132355 (2024).
Miao, R. et al. Dasunet: A deeply supervised change detection network integrating full-scale features. Sci. Rep. 14, 12464 (2024).
Tang, Y., Cao, Z., Guo, N. & Jiang, M. A Siamese Swin-Unet for image change detection. Sci. Rep. 14, 4577 (2024).
Chen, Y. et al. Mobile-former: Bridging mobilenet and transformer. 2108.05895 (2022).
Khan, A. et al. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 56, 2917–2970. https://doi.org/10.1007/s10462-023-10595-0 (2023).
Shen, F. et al. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv preprint arXiv:2310.06313 (2023).
Peng, Z. et al. Conformer: Local features coupling global representations for recognition and detection. IEEE Trans. Pattern Anal. Mach. Intell. 45, 9454–9468. https://doi.org/10.1109/TPAMI.2023.3243048 (2023).
Zheng, T. et al. L-former: A lightweight transformer for realistic medical image generation and its application to super-resolution. In Medical Imaging 2023: Image Processing (eds Colliot, O. & Išgum, I.) (SPIE, 2023).
Bruzzone, L. & Prieto, D. Automatic analysis of the difference image for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 38, 1171–1182. https://doi.org/10.1109/36.843009 (2000).
Celik, T. Unsupervised change detection in satellite images using principal component analysis and \(k\)-means clustering. IEEE Geosci. Remote Sens. Lett. 6, 772–776. https://doi.org/10.1109/LGRS.2009.2025059 (2009).
Liu, J. et al. Convolutional neural network-based transfer learning for optical aerial images change detection. IEEE Geosci. Remote Sens. Lett. 17, 127–131. https://doi.org/10.1109/LGRS.2019.2916601 (2020).
Seo, D. K., Kim, Y. H., Eo, Y. D., Lee, M. H. & Park, W. Y. Fusion of SAR and multispectral images using random forest regression for change detection. ISPRS Int. J. Geo-Inf. https://doi.org/10.3390/ijgi7100401 (2018).
Im, J. & Jensen, J. R. A change detection model based on neighborhood correlation image analysis and decision tree classification. Remote Sens. Environ. 99, 326–340. https://doi.org/10.1016/j.rse.2005.09.008 (2005).
Chen, J. et al. Change detection with cross-domain remote sensing images: A systematic review. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 17, 11563–11582. https://doi.org/10.1109/JSTARS.2024.3416183 (2024).
Zhan, T., Gong, M., Jiang, X. & Li, S. Log-based transformation feature learning for change detection in heterogeneous images. IEEE Geosci. Remote Sens. Lett. 15, 1352–1356. https://doi.org/10.1109/LGRS.2018.2843385 (2018).
Ma, W. et al. Change detection in remote sensing images based on image mapping and a deep capsule network. Remote Sens. https://doi.org/10.3390/rs11060626 (2019).
Gong, M., Yang, H. & Zhang, P. Feature learning and change feature classification based on deep learning for ternary change detection in SAR images. ISPRS J. Photogramm. Remote. Sens. 129, 212–225. https://doi.org/10.1016/j.isprsjprs.2017.05.001 (2017).
Seydi, S. T., Hasanlou, M. & Chanussot, J. DSMNN-Net: A deep siamese morphological neural network model for burned area mapping using multispectral sentinel-2 and hyperspectral prisma images. Remote Sens. https://doi.org/10.3390/rs13245138 (2021).
Caye Daudt, R., Le Saux, B., Boulch, A. Fully convolutional siamese networks for change detection, in 2018 25th IEEE International Conference on Image Processing (ICIP) 4063–4067. https://doi.org/10.1109/ICIP.2018.8451652 (2018).
Caye Daudt, R., Le Saux, B., Boulch, A. & Gousseau, Y. Multitask learning for large-scale semantic change detection. Comput. Vis. Image Underst. 187, 102783. https://doi.org/10.1016/j.cviu.2019.07.003 (2019).
Zhao, W., Wang, Z., Gong, M. & Liu, J. Discriminative feature learning for unsupervised change detection in heterogeneous images based on a coupled neural network. IEEE Trans. Geosci. Remote Sens. 55, 7066–7080. https://doi.org/10.1109/TGRS.2017.2739800 (2017).
Liu, J. et al. An end-to-end supervised domain adaptation framework for cross-domain change detection. Pattern Recogn. 132, 108960. https://doi.org/10.1016/j.patcog.2022.108960 (2022).
Li, Z., Hu, J., Wu, K., Miao, J. & Wu, J. Adjacent-atrous mechanism for expanding global receptive fields: An end-to-end network for multiattribute scene analysis in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 62, 1–19. https://doi.org/10.1109/TGRS.2024.3422007 (2024).
Li, Z., Hu, J., Wu, K., Miao, J. & Wu, J. Comprehensive attribute difference attention network for remote sensing image semantic understanding. IEEE Trans. Geosci. Remote Sens. 63, 1–16. https://doi.org/10.1109/TGRS.2024.3516501 (2025).
Li, Q., Zhong, R., Du, X. & Du, Y. Transunetcd: A hybrid transformer network for change detection in optical remote-sensing images. IEEE Trans. Geosci. Remote Sens. 60, 1–19. https://doi.org/10.1109/TGRS.2022.3169479 (2022).
Jian, P., Chen, K. & Cheng, W. Gan-based one-class classification for remote-sensing image change detection. IEEE Geosci. Remote Sens. Lett. 19, 1–5. https://doi.org/10.1109/LGRS.2021.3066435 (2022).
Shen, F. et al. Imagdressing-v1: Customizable virtual dressing. arXiv preprint arXiv:2407.12705 (2024).
Shen, F., Tang, J. Imagpose: A unified conditional framework for pose-guided person generation, in The Thirty-Eighth Annual Conference on Neural Information Processing Systems (2024).
He, K., Zhang, X., Ren, S., Sun, J. Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 770–778 (2015).
Patro, B. N., Agneeswaran, V. S. Efficiency 360: Efficient vision transformers. arXiv preprint arXiv:2302.08374 (2023).
Patro, B.N., Namboodiri, V.P., Agneeswaran, V.S. Spectformer: Frequency and attention is what you need in a vision transformer. arXiv preprint arXiv:2304.06446 (2023).
Cooley, J. W. & Tukey, J. W. An algorithm for the machine calculation of complex Fourier series. Math. Comput. 19, 297–301 (1965).
Liu, Z. et al. Kan: Kolmogorov-arnold networks. arXiv preprint arXiv:2404.19756 (2024).
Cambrin, D.R. et al. Kan you see it? Kans and sentinel for effective and explainable crop field segmentation. arXiv preprint arXiv:2408.07040 (2024).
Azam, B., Akhtar, N. Suitability of kans for computer vision: A preliminary investigation. arXiv preprint arXiv:2406.09087 (2024).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. Proc. Eur. Conf. Comput. Vis. (ECCV) 1807, 06521 (2018).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, I (2017).
Chen, H. & Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. https://doi.org/10.3390/rs12101662 (2020).
Zhang, C. et al. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote. Sens. 166, 183–200 (2020).
Daudt, R.C., Le Saux, B., Boulch, A. Fully convolutional siamese networks for change detection, in 2018 25th IEEE International Conference on Image Processing (ICIP) 4063–4067 (IEEE, 2018).
Liu, Y., Pang, C., Zhan, Z., Zhang, X. & Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 18, 811–815 (2020).
Fang, S., Li, K., Shao, J. & Li, Z. Snunet-cd: A densely connected siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 19, 1–5 (2021).
Liu, M., Chai, Z., Deng, H. & Liu, R. A CNN-transformer network with multiscale context aggregation for fine-grained cropland change detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 15, 4297–4306 (2022).
Jia, J., Lee, G., Wang, Z., Zhi, L. & He, Y. Siamese meets diffusion network: SMDNet for enhanced change detection in high-resolution RS imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2401, 09325 (2024).
Zhang, X. et al. Globally-aware continuous-time redistribution learning for RS image change detection. IEEE Trans. Geosci. Remote Sens. 62, 1–15. https://doi.org/10.1109/TGRS.2024.3454055 (2024).
Funding
The research was supported by the Scientific Research Project of Lingnan Normal University (ZL2401, ZL1935), the Ministry of Education of the People’s Republic of China University-Industry Collaborative Education Program (220802313194815).
Author information
Authors and Affiliations
Contributions
Conceptualization, Z.S., H.W. and J.Y.; methodology, J.Y. and H.W.; validation, J.Y.; formal analysis, J.Y. and Z.S.; investigation, Z.S and J.Y.; resource, Z.S. and H.W.; data curation, J.Y.; writing-original draft preparation, J.Y. and H.W.; writing-review and editing, J.Y., H.W. and Z.S. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yang, J., Wan, H. & Shang, Z. Enhanced hybrid CNN and transformer network for remote sensing image change detection. Sci Rep 15, 10161 (2025). https://doi.org/10.1038/s41598-025-94544-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-94544-7
