
Abstract
In this paper, a plug and play fuzzy mask extraction module for single image rain streak removal is proposed. Specifically, fuzzy mask maps of the rain data-set are obtained by optimizing the convex combination of several grouping functions; Based on these fuzzy mask maps as ground truth, we develop a deep learning architecture that learns the fuzzy rain map; We then fix the model to obtain a unified network model as a plug and play fuzzy mask extraction module for Single Image Deraining; When we embed a plug and play fuzzy mask extraction module into a deraining deep neural network architecture, it will improve performance due to fusion with the fine guided information of the fuzzy rain mask map. Our method differs from other mask maps as the fuzzy mask ground truth is extracted based on the pixel-level membership of the background and foreground of the image, so the grey similarity and spatial similarity between each pixel and its neighboring pixels of a single rain image can be expressed more elaborately. We provide a unified fuzzy mask module in image rain removal, which can lessen the burden of designing an attention module. The advantage of our proposed method is, as long as our fuzzy mask extraction module is embedded in any encoding and decoding rain removal network, it can obtain additional guided information such as rainy/non-rainy regions and the degree of degraded image, which can be greatly beneficial in rain detection and removal. Comprehensive experiments show that combining the rain removal network with our proposed model not only improves the rain removal effect of the algorithm, but also gives clearer background details of the image. The proposed fuzzy mask learning model is critically beneficial for either rain removal algorithms.
Similar content being viewed by others


Introduction
As a common weather phenomenon, rain would degrade the quality of images captured outdoors and then adversely affect the performance of vision tasks, e.g., object detection2, image recognition3, and segmentation4. Hence, it is necessary to design an effective deraining method for the recovery of clean background images5,6. In this paper, we focus on the problem of single image rain removal, whose objective is to recover the rain-free background of an image degraded by Rain Streaks or Rain Accumulation5,7,8.
Previously, researchers mainly relied on different prior knowledge and physical properties to deal with this deraining task. For example, Kang et al.9 leveraged an image decomposition technology for single-image rain removal. Luo et al.10 built a screen blend model and proposed discriminative sparse codes to accurately separate the rain layer ( only containing rain streaks or drops ) and the derained image layer from the non-linear composition of a rain image. Li et al.11 proposed patch-based priors with Gaussian mixture models to accommodate multiple orientations and scales of the Rain Streaks.
In recent years, deep convolutional network based approaches have received an increasing attention5,12,13,14,15,16. For example, Fu et al.17 developed a deep detail network (DetailNet) to remove Rain Streaks. Some researchers proposed to adopt generative adversarial networks for addressing this task, such as 18,19,20. Wang et al.21,22 explicitly encoded the prior structure of the rain layer and first proposed a deep unfolding rain convolutional network (RCDNet) with clear interpretability. Besides, semi/unsupervised methods were designed23 in order to improve the generalization performance and loosen the requirement of paired training data.
However, most of the existing methods are based on the additive composite model which assumes that Rain Streaks are superimposed onto the clean background image. To simulate more complicated scenarios including Rain Accumulation or rain occlusion, Yang et al.1,24 built a heavy rain model (HRM) and developed HRM-based JORDER and JORDER-E. It is worth noting these works first proposed the conception of the rain-streak regions in HRM and designed a contextualized dilated network module to distinguish rainy and non-rainy regions. Wang et al.25 constructed SPANet, in which an attention module, namely Spatial Attentive Module (SAM), is designed to extract rain mask maps. Zamir et al.26 proposed a multi-stage progressive network (MPRNet) for image restoration, which introduced the attention mechanism in each stage of the network to extract rain mask maps. Li et al.27 constructed a Single Image Deraining network embedding consistency network (ECNet), where a Mask Guided Attention Module (Mask-GAM) is used to learn the rain mask maps.
Despite their promising performances on synthetic or real image deraining, most of these rain-attention-based deraining methods have two major limitations: 1) The degree to which background details are destroyed by rain layers is not well characterized; 2) Most of these designed rain attention modules are jointly trained with the entire deraining network and they generally cannot be easily embedded into other deraining frameworks as a plug-in module.
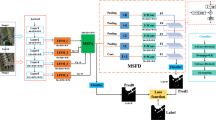
In this paper, we aim to design a universal rain mask extraction module, which can be easily integrated into current rain-attention-based deraining methods for further helping improve their rain removal performance. As shown in Fig. 1 (All data-sets such as, Rain100L,Rain100H, Rain800,etc. used in the paper are openly available at https://github.com/hongwang01), based on the current benchmark dataset with paired rain-clean images, we first introduce a convex combination of the grouping functions to segment rain residue and then obtain the fuzzy mask maps of rain images. Such fuzzy mask maps are extracted on the pixel level, and the gray and spatial similarities between neighboring pixels can be expressed more accurately. It has good flexibility and well characterizes the degree to which background details are destroyed by rain layers. Then by regarding the extracted fuzzy mask maps as the ground truth, we design a deep network, called Resblock+LSTM, for fuzzy mask extraction. Taking the trained Resblock+LSTM as a plug and play Fuzzy Mask extraction module, PnP-FM, and embedding it into current rain-attention-based deraining algorithms, the resulting network can obtain additional guiding information such as rainy/non-rainy regions and the degree blurred by rain, which is beneficial for rain detection and removal.

Flowchart of the proposed plug and play fuzzy mask extraction (PnP-FM) framework. Stage 1: We first construct the fuzzy mask benchmark datasets where the fuzzy mask ground truth of each image is obtained by our proposed fuzzy mask extractor. Stage 2: A PnP-FM is designed. Taking the extracted fuzzy mask maps in Stage 1 as the ground truth, Resblock+LSTM module is trained on the above fuzzy mask benchmark datasets to learn mask map for any rain image, and then the trained Resblock+LSTM is regarded as PnP universal tool. Stage 3: PnP-FM is integrated into a deraining algorithm for further performance improvement.
The main contributions of this paper are as follows:
-
1.
We propose a fuzzy mask extraction method by optimizing a convex combination of the grouping functions and constructing the corresponding fuzzy mask benchmark datasets where fuzzy mask maps can more finely portray the degree to which image details are damaged by rain.
-
2.
We design a unified fuzzy mask learning network Resblock+LSTM based on the built fuzzy mask benchmark datasets, which is taken as a universal plug and play fuzzy mask extraction module, called PnP-FM. One advantage of the proposed PnP-FM is that it is convenient for researchers to integrate it to their deraining models and reduces the burden of designing a specific rain-attention module. Another advantage is that it can locate the rainy/no-rainy region more accurately, and can emphasize how much the Rain Streaks blur the background.
-
3.
As seen from Fig. 1, Our proposed PnP-FM can be regarded as a universal rain-attention-submodule to be easily embedded into a deep neural network framework for single image rain removal. Extensive experiments comprehensively substantiate that the introduction of the proposed PnP-FM can finely help the existing methods extract the rain mask and gain better rain removal performance (see Fig. 2 and Section Experiments)
The rest of our paper is organized as follows. In the 2nd Section , we review the related work. In the third Section , we propose an algorithm to extract fuzzy mask benchmark, and in the forth Section we present a plug and play fuzzy mask extraction network module. Extensive experiments are conducted in the fifth Section . The sixth Section concludes this paper.

Column 1 shows the original images with (a) rain streak and (d) rain accumulation; Column 2 shows the corresponding derained results by JORDER-E1; Column 3 shows the derained results after integrating the proposed PnP-FM into JORDER-E.
Related work
Single image rain removal
The aim of single image rain removal is to estimate the rain-free background layer (clean image, without rain streak and rain drop ) of an image degraded by Rain Streaks and rain accumulation 28. Before 2017, the typical methods are model-based approaches (or non-deep learning approach). For example, Kang et al.29 leveraged image decomposition technology for single image rain removal; Luo et al.30 built screen blend model and proposed discriminative sparse codes to accurately separate of non-linear layers. Li et al.31 proposed patch-based priors with Gaussian mixture models to accommodate multiple orientations and scales of the Rain Streaks.
Deep convolutional network was first proposed for single image rain removal32 in 2017. Since then, data-driven approaches (or deep learning approaches) have received an increasing attention33,34,35,36,37. For example, Fu et al.18,19 attempted to remove Rain Streaks via a deep detail network (DetailNet); Generative adversarial network was used to reduce the domain gaps between the generated results and real clean images in38,39,40; Semi/unsupervised methods were employed by41 to improve the generality and scalability by learning directly from real rain data. Unfortunately, the above-mentioned methods are not good at capturing fine-grained detail signals and the diversified appearances of real Rain Streaks.
Further work has been developed to overcome these difficulties. Yang et al.24,42 built a heavy rain model (HRM) and developed algorithm JORDER and JORDER-E. It is worth noting that HRM added a binary map to provide rain streak locations, while a contextualized dilated network module is designed to extract regional contextual information. Incidentally, this is the first such work to add an attention module to deraining deep network. Wang et al.43 constructed a paired rain image benchmark data-set and proposed spatial attentive network (SPANet). To better extract additional information from local region to global space, an attention module SAM is designed to extract the location information in four directions (up, down, left and right). These works achieve excellent performance on synthetic or real images, particularly on heavy rain images. Furthermore, their attention modules are trained by using a binary mask map as the benchmark, which is simply a threshold segmentation for the residual between the rain image and the clean background image with threshold equals 0.
Single image raindrop removal
The aim of the single image raindrop removal is to recover a clear background image which is damaged by raindrops adhered to a glass window or camera lens. There have been some limited works in this direction using data-driven deep neural network methods. Qian et al.39 proposed an attention generative adversarial network, where they combined Resblock with LSTM (long short term memory) in an attention module to locate raindrops, and further guided the contextual auto-encoder to remove raindrops. Quan et al.44 designed two attention modules in a convolutional neural network, where one module is used to locate raindrop edges and another to locate raindrop regions from channel, and then the information from the two modules is integrated to guide the subsequent network to remove the raindrop. Shao et al.45 proposed a selective skip connection GAN (SSCGAN) combining the selective skip connection and self-attention mechanism. During training, the selective skip connection model (SSCM) extracts raindrop binary masks, conversely, they use self-attention blocks (SABs) to push the generator network to correct the raindrops binary masks. To express various blurring degrees and resolutions of raindrop image, Shao et al.46 keep digging intrinsic prior of a raindrop image, and proposed a soft mask with the value in [-1,1] indicating the blurring level of the raindrops on the background and construct an uncertainty guided multi-scale attention network (UMAN).
Despite their good performances, binary mask maps have limitations because they only reflect whether a raindrop exists or not at certain location, but cannot provide information regarding the size and the thickness of the raindrop, and how much the raindrops blur the background pixels. Similarly, although soft masks proposed later can explore positive effects of the blur degree attribute of raindrops on the task of raindrop removal, they cannot distinguish the pixel information of background and rain as they only perform normalization processing for the rain residual. However, information on locations and blurring levels provides strong prior knowledge to guide the removal task of rain streak, rain accumulation, and raindrop removal.
Toward this end, in this paper we propose a fuzzy mask module, which can extract such information as location, size, and blurring level of the rain streak, Rain Accumulation and raindrops on the background, and this in turn will guide the subsequent network to recover a rain image.
Grouping function
The representation and aggregation of membership degrees (preferences or support degrees) of the objects have been widely studied in the literature by means of t-norms and t-conorms47. Bustince et al. introduced overlap functions48 and grouping functions49 to study the relationship between objects from two classes. Overlap functions measure the degree in which an object is simultaneously supported by both classes (overlap), while grouping functions measure the degree in which the object is supported by the combination of the two classes (grouping).
Jurio et al.50 investigated in depth properties of overlap and grouping functions, and applied a convex combination property of several grouping functions to segment a grey-scale image by a thresholding technique. Due to the grouping function being defined on the membership degrees of each pixel belonging to the target and the background, the gray similarity and spatial similarity between each pixel and its neighboring pixels are expressed by the weighted value method. This turns out to be beneficial to extract information regarding rain size, rain thickness, and so on.
Motivated by Jurio et al.50, we will apply grouping functions to threshold segmentation for the rain residual and obtain the fuzzy mask benchmark. The fuzzy mask extraction method will be introduced in detail in the next section.
Fuzzy mask benchmark
The convex combination of grouping functions is a new grouping function and provide a consensus between different grouping functions. In 50, A.Jurio et al. combine several grouping functions to segment a greyscale image by a thresholding technique and achieve fine segmentation effect. Inspired by this, we attempt to differentiate the degree of the image was damaged by rain by optimizing the convex combination of grouping functions. Similar to the study done in 50, we present fuzzy mask extracting algorithm of a rain image and obtain fuzzy mask bench mark from Rain100L, Rain100H, Rain800, Raindrop in this section.
Fuzzy mask extracting algorithm
To extract a fuzzy mask map for any residual R between a rain image O and corresponding clean background B, just as, \(R=O-B\). first, We convert these RGB three-channel image R to gray-scale image. We start from a membership degree (preference or support degree) of the residual R to each one of the classes including rain layer and background. For this, we built two fuzzy sets \(Q_{R_{t}}\) and \(Q_{B_{t}}\) from restricted equivalence functions REF (please refer to 51) with the following membership functions, for every grey level \(q = 0, 1,..., L \pmb {-} 1\):
where \({m_R}(t)\) and \({m_B}(t)\) represent the gray average value of the rain pixels and the gray average value of the background pixels for every fixed grey level t , respectively, and their calculation formula is as follows:
where h(q) represents the number of pixels whose gray value is equal to q.

Fuzzy mask extraction algorithm.
After obtaining the fuzzy sets of rain layer and background layer, the ultimate goal is to separate the rain layer from the background . Follow50, the following four grouping functions are obtained associated with the fuzzy sets of rain layer and background:
Then to obtain a consensus between all the methods, the convex combination of the four grouping functions is calculated by the Eq. (9).
where \(w_{1},...,w_{4}\) are non-negative weights and satisfy \(\sum \limits _{i = 1}^4 {{w_i}} = 1\).
The convex combination of the four grouping functions based on every pixel is a new grouping function, now we calculate the weighted sum of these convex combination grouping functions according to the pixel statistical distribution by the Eq. (10).
Traverse all grayscale values t in the rain image, we will obtain the best threshold \(t^{*}\) while the greatest sum of grouping functions is obtained. At this time, the rain layer in the rain image can be best separated from the background. Just as follows:
We let
And then let M through CV2.imwrite, we obtain a three-channel tensor is our fuzzy mask map, which is note as FM.
More details of extracting fuzzy masks FM are described in Algorithm 1.
Fuzzy mask bench mark data set
Till now, The major developments in the mask map extracting approach are driven by the following ideas: Qian et al.39 proposed a binary Mask map, the binary Mask map is obtained by segmented by a fixed threshold \(T=30\). Yang et al.24 and Wang et al43 using a binary mask map for rain steak,which is computed by thresholding the difference between the rain image and clean image a fixed threshold \(T=0\), called \(res-mask\) by us in this paper. To describe the degree of ambiguity of the rain relative to the background, Shao et al. 46 proposed a soft mask map, which is obtained by normalized the difference between the rain image and clean image. However, hard mask map or called binary mask map lost a lot of information because the fixed threshold is not inelastic. The soft mask extracting method does not do the separation process from the background, so a lot of background texture details are left, which will lead to a smooth phenomenon in the recovered image. Therefore, the idea of fuzzy membership function was introduced to characterize the degree of an image degraded by rain in this paper, and fuzzy mask map algorithm is proposed by the flexibly threshold value to distinguish the damage degree.
Rain100L, Rain100H, Rain800, Raindrop are representative datasets used to train supervised data-driven deep learning methods for rain removal or raindrop removal. Rain100L include ... with one type of rain streak, Rain100H include .... with five different directions Rain Streaks, Rain800 include many heavy rain Rain accumulationimages with the different kinds of rain streak, which is leveraged to train the methods which address heavy rain or rain accumulation, Raindrop is the real pair of raindrop images collected semi-automatically. It is the only publicly available raindrop dataset. Most supervised algorithms for raindrop removal use this dataset to train models. To compare between our proposed method with others, we calculate all the mask maps for the four representative datasets by above mentioned methods, As show in Fig. 3, the \(res-mask\) method misjudge some no rain region for rain region on Rain100L and Rain100H, but the \(res-mask\) method misjudge almost whole rain image for rain region on Rain800 and Raindrop. The binary mask map extracting method work better than former, which inverse misjudge some rain region for no rain region. The soft mask map and fuzzy mask map eatracting methods can extract more detailed rain information and work effectively both rain streak and raindrop, but soft mask map always show some background information left. Summarize above, our proposed method in this paper extract mask map for not only rain streak images but also raindrop images, which locate the rain region more accurately, and describe the degree of the rain tensity more precisely. The rain image dataset with fuzzy mask map information is called a fuzzy mask bench mark dataset. In the project, we construct four fuzzy mask bench mark datasets associated to Rain100L, Rain100H, Rain800, and Raindrop.

The rain mask maps extracted using residual, binary, soft, fuzzy mask extracting algorithms from Rain100L50, Rain100H50, Rain800, and Raindrop39. The first column are the original rain images. The second column are the extracted residual mask maps. The third column are extracted binary mask maps. The forth column are the extracted soft mask maps. The last column are extracted fuzzy mask maps which is proposed in this paper. From top to bottom are the corresponding operations on Rain100L, Rain100H, Rain800, and Raindrop.
A plug and play fuzzy mask module
In the paper, we use PSNR and SSIM as metrics to evaluate the quality of the mask map and the recovered image. The PSNR and SSIM is caculated by the formulas:
where X represent the image to be evaluated,Y represent the reference image,H and W represent the height and width of the image,respectively.\(u_X\) and \(u_Y\) represent the mean of images X and Y,respectively.\(\sigma _X\) and \(\sigma _Y\) represent the standard deviation of images X and Y,respectively.\(C_1\),\(C_2\) and \(C_3\) are constants.
Our aim is to provide a plug and play network module to learn the fuzzy mask map accurately for all rain images, we train all basic network modules and few modules39,52,53,54 that was devoted to extract rain mask map based on the fuzzy mask bench mark datasets. We choose a module with a small weight scale and high performance as a plug and play fuzzy mask extracting module and fix it. Some basic modules such as ImageNet, GoogleNet, AlexNet, \(UNet\text{- }3\), \(UNet \text{- }5\), ResNet, and \(ResBlock+ LSTM\) are trained the fuzzy mask bench mark datasets from Rain100L, Rain100H, Rain800, and Raindrop, respectively, Using the PyTorch framework on a PC with a E5-2650 v4 2.20GHz CPU and a Tesla P40 GPU. We adopt the MSE (mean square error)loss function as follows:
where the O is the original rain image and the FM is the fuzzy mask benchmark of the rain image. f is to learn the function by the related basic network module.
We adopt the Adam optimizer with batchsize of 16 to optimize the network modules, which learning rate \(\eta\) is initialized at 0.005 and delay \(\eta\) by \(\frac{1}{10}\) after 30K iterations. We train these networks for 40K iterations. Fig. 4 show four overviews, such as \(UNet\text{- }5\), \(UNet \text{- }3\), ResNet, and \(ResBlock\text{+ }LSTM\) , respectively. When an rain image is inputted into the corresponding module, output is the rain mask map and we let the output is as close as possible to the fuzzy mask map ground truth, and the final output just is fuzzy mask map by optimizing the \(L_{FM}\).

The structure of fuzzy mask extraction network.
Figure 5 from top to bottom show the fuzzy mask maps that learned from fuzzy mask bench mark datasets from Rain100L, Rain100H, Rain800, and Raindrop using four different network modules mentioned above respectively. We have an intuitively result of rain streak fuzzy mask maps, just as, \(ResBlock\text{+ }LSTM\) learns a more accurate rain streak position information and the blur degree of the rain streak related to the background. For the extraction of raindrop fuzzy mask map, the \(UNet \text{- }5\) locate the raindrop more accurately. Tabs.1 also supports above conclusion. For example, about the rain streak fuzzy mask map extracting, \(ResBlock\text{+ }LSTM\) shows the best performance, which outperforms the second network by two points on the Rain100L dataset, and outperforms the second network by almost one point on the Rain100H and Rain800 datasets. About the rain drop fuzzy mask map extracting, \(UNet\text{- }5\) shows the best performance, which outperforms the second network by almost two points on the Raindrop dataset.
As show in Fig. 5 and Table 1, we show a qualitative and quantitative comparison of the four network modules that rank the top four in performance. According to the experiments, \(UNet\text{- }5\) outperforms the others quantitatively and qualitatively for extracting raindrop fuzzy mask map, and \(ReBlock\text{+ }LSTM\) outperforms the others quantitatively and qualitatively for extracting raindrop fuzzy mask map. Therefore we choose the \(UNet\text{- }5\) after trained as a fixed plug and play raindrop fuzzy mask extracting module. Similar to this, \(ReBlock\text{+ }LSTM\) is fixed as a plug and play rain streak fuzzy mask extracting module.

Fuzzy mask extracted by different networks. The first row is the result of Rain100L, the second row is the result of Rain100H, the third row is the result of Rain800, the forth row is the result of Raindrop. From left to right are the fuzzy mask map of the corresponding datasets extracted by different networks.
Experiments
To evaluate our plug and play fuzzy mask module convenience, effectiveness, and efficiency, we construct comprehensive experiments. We change the network framework with an attention module for rain removal tasks by replacing its attention module with our fixed modules, which shows the convenience of plug and play modules being used. Comparing the deraining effect of the paired algorithms ( original framework and its variant) on the synthetic rain map and the real rain map, whether qualitatively or quantitatively, the performance of the variant is improved; thus, the fact confirms that our trained module is an effective attention extracting module. We provide a trained fixed attention mechanism network module, any algorithm using our fuzzy mask module must short training time because saving the time of training attention module naturally. More importantly, the network model we use to extract fuzzy mask map is simple and small scale, so the testing time become also small, and we also give the testing time comparison (please see Table 2), in other words, our proposed algorithm is confirmed the efficiency.
Experiment content and Settings
In this section We introduce the five pairs methods to be compared and corresponding experiment settings. We construct the fairness experimental setup for every pair method by maintaining original experiment setting, so the experimental setup for each pair of methods is slightly different. Details are as follows.
As show in Fig. 6 , the first pair methods are \(JORDER-E\) and \(JORDER-E+FM\), in where,the original network uses ContextualizedDilatedNetwork to extract the rain image features and then passes through a convolution layer to get the mask corresponding to the rain image, We replace ContextualizedDilatedNetwork with \(Resblock+LSTM\), and input the original rain image into \(Resblock+LSTM\) to get the fuzzy mask corresponding to the rain image directly. In the experiment, we set the batch size to 8, the input crop size to 64 and the number of training epochs to 200. The second pair methods are SPANet and \(SPANet+FM\), in where,the original network uses the mask extract from SAM(SpatialAttentionModule) to guide the SARB(Spatialattentionresidualblocks) module to gradually derain, We replace SAM(SpatialAttentionModule) with \(Resblock+LSTM\), and input the fuzzy mask extracted by \(Resblock+LSTM\) into SARB(Spatialattentionresidualblocks) to guide it to gradually derain, in the experiment, we set the batch size to 10, the number of training iterations to 40K. The third pair methods are AttentiveGAN and \(AttentiveGAN+FM\), in where,the original network uses \(Resblock+LSTM\) to extract the mask corresponding to the rain image, and sends it to the subsequent UNet cascade with the original image to remove the raindrop, we replace \(Resblock+LSTM\) with \(UNet-5\) to extract the fuzzy mask of the raindrop mask, and then cascade it with the original rain image and send it to the subsequent UNet to complete the rain removal, in the experiment,we set the batch size to 1 and the number of training epochs to 100. The forth pair methods are SSCGAN and \(SSCGAN+FM\), in where,the original network uses multiple GRU modules to extract the mask of the rain image in the UNet skip connection part, and cascade it to the decoding part of UNet to guide the network to remove raindrop, we retain the skip connection structure of UNet, replace multiple GRU modules with \(UNet-5\), extract the fuzzy mask of the rain image, and cascade it with the original rain map features into the decoding part of UNet to guide the network to remove raindrop, in the experiment, we set the batch size to 16 and the number of training iteration 2K. The fifth pair methods are DuRN and \(DuRN+FM\), in where, the original network uses three \(DuRB-S\) modules to extract the rain image mask to guide the subsequent \(DuRB-P\) modules to remove raindrop, we replace the 3 \(DuRB-S\) modules with a \(UNet-5\) module to extract the fuzzy mask corresponding to the rain image, input to the subsequent \(DuRB-P\) module, and guide the network to remove the raindrop, in the experiment, we set the batch size to 24, the input crop size to 256 and the number of training epochs to 4K. Next, for three tasks, such as, rain streak, rain accumulation, rain drop, we show comprehensive experiment result on synthetic rain image and real rain image by qualitative and quantitative evaluation.

The five pairs methods to be compared. From top to bottom, each row is \(JORDER-E\), SPANet, AttentiveGAN, SSCGAN and DuRN before and after the transformation.
Results and discussion
In this section, we test the performance of some deraining networks (such as SPANet and \(JORDER-E\)) that originally contain attention networks on some synthetic rain streak datasets (including rain accumulation, such as Rain800) and some real rain streak datasets after adding our fuzzy mask module, and qualitatively and quantitatively compared with the original network. We have discussed the removal of raindrops in another article55.
As shown in Fig. 7, the rain removal effects of the original SPANet and the network after adding our fuzzy mask module on different synthetic datasets Rain100L, Rain100H,Rain800, are presented respectively.The first row shows the test results of the network on Rain100L before and after the attention module is replaced. The original SPANet will have excessive rain removal and lose background details. After adding the fuzzy mask module, more complete background details are retained.The second row shows the test results of the network on Rain100H before and after the attention module is replaced.From the figure, we can see that more complete background text details are retained after adding the fuzzy mask module.And the last row shows the test results of the network on Rain800 before and after the attention module is replaced.It is very intuitive to see that adding the fuzzy mask module solves the problem that the original network will retain a lot of rain streak artifacts.In Figs. 8 and 9, we use models trained on different datasets to test the performance of the network before and after replacing the attention module on the real rain streak datasets.From the figure, we can see that after replacing our fuzzy mask module, more details of the rain image background are retained.

The results of SPANet adding Fuzzy Mask and not adding Fuzzy Mask on synthetic datasets.

The results of SPANet adding Fuzzy Mask and not adding Fuzzy Mask on SPA-Data.

The results of SPANet adding Fuzzy Mask and not adding Fuzzy Mask on Real-Data.
As show in Fig. 10, the rain removal effects of the original \(JORDER-E\) and the network after adding our fuzzy mask module on different synthetic datasets Rain100L, Rain100H,Rain800, are presented respectively.The first row shows the test results of the network on Rain100L before and after the attention module is replaced.The original network will have residual Rain Streaks ,after adding our fuzzy mask module, the residual Rain Streaks are removed.The second row shows the test results of the network on Rain100H before and after the attention module is replaced.As can be seen from the figure, the rain removal result of the original network will have redundant artifacts in the sky. After adding our fuzzy mask module, the rain artifacts are removed.And the last row shows the test results of the network on Rain800 before and after the attention module is replaced.The original network may lose some background texture information when removing rain. After adding our fuzzy mask module, more background texture details are restored. Figures 11 and 12, we use models trained on different datasets to test the performance of the network before and after replacing the attention module on the real rain streak datasets.After adding our fuzzy mask module, more residual rain stripes are removed while retaining more background details.
In Tables 3, 4, 5 we have carried out a quantitative analysis of the above experiments. From the data in the table, we can see that after adding our fuzzy mask module, the performance of the network has a certain improvement compared to the original network.

The results of JORDER-E adding Fuzzy Mask and not adding Fuzzy Mask on synthetic datasets.

The results of JORDER-E adding Fuzzy Mask and not adding Fuzzy Mask on SPA-Data.

The results of JORDER-E adding Fuzzy Mask and not adding Fuzzy Mask on Real-Data.
Conclusion
More and more data-driven algorithm design ideas for vision tasks focus on designing various attention modules to extract target masks, and rain removal is no exception. We design a plug and play fuzzy mask extraction module for data-driven deep neural network-based algorithms, which is suitable for various types of rain removal including Rain Streaks, rain accumulation, and raindrops. Our work is different from previous work, such as, the first is that we introduce the idea of fuzzy membership into the model of mask extraction in the paper, which fuzzy degree is suit to describe the objective reality of rain image formation. Whether it is rain streak or raindrop, due to the difference of rain intensity , the degree of damage to the image by rain is different, which is the essential attribute. The second is that we have trained a fixed module to recognize fuzzy masks map, which is a plug and play fuzzy mask module for any rain removal deep neural networks, thus, it is critical beneficial to saves the cost of designing the attention module and shortens the time cost of training the model for researchers. Adding the fuzzy idea directly to the deep neural network to extract the fuzzy mask shortens the preprocessing process, which is the limitation of our proposed algorithm in the paper and the direction of our next work.
Accession codes
The data supporting the findings of this study are openly available at https://github.com/mendy-2013/PnP-fuzzy-mask-extractor.
References
Yang, W. H. et al. Joint rain detection and removal from a single image with contextualized deep networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 42, 1377–1393 (2019).
Li, W. Y., Liu, X. Y. & Yuan, Y. X. SIGMA: Semantic-complete graph matching for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5291–5300 (2022).
Kim, M. C., Jain, A. K. & Liu, X. M. AdaFace: Quality adaptive margin for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18750–18759 (2022).
Kim, N., Kim, D. W., Lan, C. L., Zeng, W. J. & Kwak, S. ReSTR: Convolution-free referring image segmentation using Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18145–18154 (2022).
Wang, H., Wu, Y., Li, M., Zhao, Q. & Meng, D. Survey on rain removal from videos or a single image. Science China Information Sciences 65, 1–23 (2022).
Wang, H. et al. Structural residual learning for single image rain removal. Knowledge-Based Systems 213, 106595 (2021).
Wang, H. et al. From rain generation to rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14791–14801 (2021).
Wang, H., Xie, Q., Wu, Y., Zhao, Q. & Meng, D. Single image rain streaks removal: A review and an exploration. International Journal of Machine Learning and Cybernetics 11, 853–872 (2020).
Kang, L. W., Lin, C. W. & Fu, Y. H. Automatic single-image-based rain streaks removal via image decomposition. IEEE Transactions on Image Processing 21, 1742–1755 (2011).
Luo, Y., Xu, Y. & Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, 3397–3405 (2015).
Li, Y., Tan, R. T., Guo, X. J., Lu, J. B. & Brown, M. S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2736–2744 (2016).
Li, X., Wu, J. L., Lin, Z. C., Liu, H. & Zha, H. B. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In Proceedings of the European Conference on Computer Vision, 254–269 (2018).
Zhang, H. & Patel, V. M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 695–704 (2018).
Fan, Z. W., Wu, H. F., Fu, X. Y., Huang, Y. & Ding, X. H. Residual-guide network for single image deraining. In Proceedings of the 26th ACM International Conference on Multimedia, 1751–1759 (2018).
Li, G. B. et al. Non-locally enhanced encoder-decoder network for single image de-raining. In Proceedings of the 26th ACM International Conference on Multimedia, 1056–1064 (2018).
Li, R. T., Cheong, L. F. & Tan, R. T. Single image deraining using scale-aware multi-stage recurrent network. arXiv preprint arXiv:1712.06830 (2017).
Fu, X. Y. et al. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3855–3863 (2017).
Zhang, H., Sindagi, V. & Patel, V. M. Image de-raining using a conditional generative adversarial network. IEEE Transactions on Circuits and Systems for Video Technology 30, 3943–3956 (2019).
Qian, R., Tan, R. T., Yang, W. H., Su, J. J. & Liu, J. Y. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2482–2491 (2018).
Li, R. T., Cheong, L. F. & Tan, R. T. Heavy rain image restoration: Integrating physics model and conditional adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1633–1642 (2019).
Wang, H., Xie, Q., Zhao, Q. & Meng, D. A model-driven deep neural network for single image rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3103–3112 (2020).
Wang, H., Xie, Q., Zhao, Q., Liang, Y. & Meng, D. RCDNet: An interpretable rain convolutional dictionary network for single image deraining. arXiv preprint arXiv:2107.06808 (2021).
Wei, W., Meng, D., Zhao, Q., Xu, Z. & Wu, Y. Semi-supervised transfer learning for image rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3877–3886 (2019).
Yang, W. H. et al. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1357–1366 (2017).
Wang, T. Y. et al. Spatial attentive single-image deraining with a high quality real rain dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12270–12279 (2019).
Zamir, S. W. et al. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14821–14831 (2021).
Li, Y. Z., Monno, Y. & Okutomi, M. Single image deraining network with rain embedding consistency and layered LSTM. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 4060–4069 (2022).
Yang, W., Tan, R. T., Wang, S., Fang, Y. & Liu, J. Single image deraining: From model-based to data-driven and beyond. IEEE (2021).
Kang, L. W., Lin, C. W. & Fu, Y. H. Automatic single-image-based rain streaks removal via image decomposition. IEEE Transactions on Image Processing 21, 1742–1755 (2011).
Yu, L., Yong, X. & Hui, J. Removing rain from a single image via discriminative sparse coding. In 2015 IEEE International Conference on Computer Vision (ICCV) (2015).
Li, Y. Rain streak removal using layer priors. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016).
Fu, X., Huang, J., Zeng, D., Yue, H. & Paisley, J. Removing rain from single images via a deep detail network. In IEEE Conference on Computer Vision & Pattern Recognition (2017).
Li, X., Wu, J., Lin, Z., Liu, H. & Zha, H. Recurrent squeeze-and-excitation context aggregation net for single image deraining (Springer, Cham, 2018).
He, Z. & Patel, V. M. Density-aware single image de-raining using a multi-stream dense network. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018).
Fan, Z., Wu, H., Fu, X., Huang, Y. & Ding, X. Residual-guide network for single image deraining. ACM (2018).
Li, G., Xiang, H., Wei, Z., Chang, H. & Liang, L. Non-locally enhanced encoder-decoder network for single image de-raining. In 2018 ACM Multimedia Conference (2018).
Li, R., Cheong, L. F. & Tan, R. T. Single image deraining using scale-aware multi-stage recurrent network. (2017).
Zhang, H., Sindagi, V. & Patel, V. M. Image de-raining using a conditional generative adversarial network. IEEE Transactions on Circuits and Systems for Video Technology (2017).
Qian, R., Tan, R. T., Yang, W., Su, J. & Liu, J. Attentive generative adversarial network for raindrop removal from a single image. (2018).
Li, R., Cheong, L. F. & Tan, R. T. Heavy rain image restoration: Integrating physics model and conditional adversarial learning. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019).
Wei, W., Meng, D., Zhao, Q., Xu, Z. & Wu, Y. Semi-supervised transfer learning for image rain removal. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020).
Wenhan, Y. et al. Joint rain detection and removal from a single image with contextualized deep networks. IEEE transactions on pattern analysis and machine intelligence 2020426, 1377–1393 (2020).
Wang, T. et al. Spatial attentive single-image deraining with a high quality real rain dataset. In IEEE Computer Society Conference on Computer Vision & Pattern Recognition (2019).
Quan, Y., Deng, S., Chen, Y. & Ji, H. Deep learning for seeing through window with raindrops. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019).
Shao, M., Li, L., Wang, H. & Meng, D. Selective generative adversarial network for raindrop removal from a single image. Neurocomputing 426 (2020).
Shao, M. W., Li, L., Meng, D. Y. & Zuo, W. M. Uncertainty guided multi-scale attention network for raindrop removal from a single image. IEEE Transactions on Image Processing PP (2021).
Fodor, J. & Roubens, M. Fuzzy Preference Modelling and Multicriteria Decision Support (Fuzzy Preference Modelling and Multicriteria Decision Support, 1994).
Bustince, H., Fernandez, J., Mesiar, R., Montero, J. & Orduna, R. Overlap functions. Nonlinear Analysis: Theory, Methods & Applications 72, 1488–1499 (2010).
Bustince, H., Pagola, M., Mesiar, R., Hullermeier, E. & Herrera, F. Grouping, overlap, and generalized bientropic functions for fuzzy modeling of pairwise comparisons. IEEE Transactions on Fuzzy Systems 20, 405–415 (2012).
Jurio, A., Bustince, H., Pagola, M., Pradera, A. & Yager, R. R. Some properties of overlap and grouping functions and their application to image thresholding. Fuzzy Sets & Systems 229, 69–90 (2013).
Bustince, H., Barrenechea, E. & Pagola, M. Restricted equivalence functions. Fuzzy Sets and Systems 157, 2333–2346 (2006).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer Assisted Intervention, 234–241 (Springer, 2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. IEEE (2016).
Shi, X. et al. Convolutional lstm network: A machine learning approach for precipitation nowcasting. MIT Press (2015).
Hu, M. & Song, Y. Grouped mask-guided single image removal of raindrops. Journal of Northwestern University (Natural Science Edition) 04, 581–589 (2022).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 12371290) and the Shaanxi Province Key Research, Development Plan, China (No. 2024GX-YBXM-145).
Author information
Authors and Affiliations
Contributions
M.H. conceived and designed the experiments, performed formal analysis, carried out investigations, drafted the original version of the manuscript, participated in the review and editing of the manuscript, and managed resources. Y.S. was involved in software development, result validation, and visualization tasks, and editing the manuscript. S.Zh. developed software, validated results, and created visualizations. Z.X. developed software, validated results, created visualizations. B.J. contributed to reviewing and editing the manuscript, and also supervised the whole project. All authors critically reviewed and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hu, M., Song, Y., Zhang, S. et al. A plug and play fuzzy mask extraction module for single image deraining. Sci Rep 15, 10277 (2025). https://doi.org/10.1038/s41598-025-94643-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-94643-5
This article is cited by
-
SHARK: Single Image Rain Streak Removal Using Harris Corner Loss and R-CBAM Network
Circuits, Systems, and Signal Processing (2025)
