
Abstract
RASSF family proteins play crucial roles in mitosis, apoptosis, cell migration, adhesion, and immune functions, primarily acting as tumor suppressors. Their roles in renal clear cell carcinoma (ccRCC) are not fully understood. We analyzed the expression and prognostic significance of RASSF genes in 573 ccRCC samples from TCGA and GEO, identifying two molecular subtypes with distinct characteristics. We developed a RAS score to assess prognosis and molecular status and investigated the key gene C1QL1 through in vitro assays. Four RASSF genes were identified as associated with prognosis and progression in ccRCC. Based on their co-expression, we defined two patient subtypes, one with poorer prognosis. A higher RAS score correlated with advanced disease and worse outcomes but indicated a favorable response to specific inhibitors, supporting personalized treatment strategies. Additionally, VHL mutations may cause abnormal SFMBT1 expression, leading to high C1QL1 levels, which promote tumor progression via the YAP-EMT pathway. Our findings highlight the potential of RASSF-based molecular subtypes and scoring systems in personalizing ccRCC treatment. Understanding C1QL1’s role may facilitate the development of novel therapeutic approaches.
Similar content being viewed by others

Introduction
Clear cell renal cell carcinoma (ccRCC), constituting approximately 70% of all adult renal cell carcinoma (RCC) cases, is the predominant histological subtype1. Characterized by its aggressive and metastatic properties, around 30% of ccRCC patients exhibit distant metastases upon diagnosis2. Although local ccRCC typically undergoes surgical resection, recurrence or metastasis occurs in 30–40% of cases post-surgery3. Conventional chemotherapy and radiotherapy are generally ineffective against ccRCC; however, advanced therapies such as targeted therapy and immunotherapy, particularly involving immune checkpoint inhibitors, have demonstrated substantial success in treating advanced stages4,5. Consequently, developing methods for the early prediction and detection of metastatic potential in ccRCC is crucial for enhancing patient outcomes. Moreover, a deeper understanding of oncological mechanisms, including the role of tumor suppressor proteins like the Ras-association domain family (RASSF), could illuminate new therapeutic strategies.
Despite extensive research in various cancers, the specific roles and mechanisms of RASSF proteins in ccRCC remain elusive. RASSF proteins are crucial tumor suppressors, impacting several cellular functions including apoptosis, cell cycle control, and microtubule stability, crucial for cancer development and progression6. Research indicates that RASSF proteins suppress tumors by modulating the Ras GTPase family, affecting apoptosis and cell proliferation. For instance, RASSF1A promotes apoptosis through MST1 and MST2 kinase pathways and is frequently deactivated in various cancers7,8. Additionally, proteins like RASSF2 and RASSF6 trigger apoptosis and regulate the cell cycle via pathways such as MST1, JNK, and NF-κB9,10.
This study utilized 573 ccRCC samples from the TCGA and GEO databases to investigate the expression of RASSF genes and their prognostic relevance. Through clustering, we identified two distinct molecular subtypes, each exhibiting unique patterns of RASSF expression, clinical characteristics, and molecular markers. We observed notable disparities in survival rates, tumor progression speeds, and therapeutic responses between these subtypes. These insights led to the creation of a RAS scoring system to evaluate and predict individual patient outcomes and therapeutic responses. Additionally, we examined C1QL1, a critical gene in our model, to assess its role in tumor progression and potential as a therapeutic target. The whole research process is shown in Fig. 1.

The work flow diagram of this study.
Materials and methods
Our research complies with all relevant ethical regulations and guidelines. The collection of patient samples has been approved by the Ethics Committee of the Affiliated Hospital of Putian University.
Expression and prognosis of RASSF family in ccRCC
We utilized the BEST website (rookieutopia.com) to retrieve expression data and prognostic impact of RASSF family members in ccRCC11. Data for 534 patients were downloaded from the UCSC XENA platform, comprising TCGA-KIRC datasets. We analyzed the expression of RASSF family members across different clinical stages and their effects.
ccRCC subtype identification based on RASSF association
Expression data for four key RASSF family genes were sourced from the UALCAN platform. The interactions and functions of these genes were further analyzed using GeneMANIA. The “limma” and “sva” R packages were employed to address batch effects, followed by data integration from the UCSC XENA and GEO databases, which included TCGA-KIRC data for 534 patients and GSE29609 data for 39 patients. We conducted cluster analysis on 573 ccRCC patients using the “ConsensusClusterPlus” R package, with PCA confirming k = 2 as the optimal number of subgroups12. Survival analyses were performed using the “survival” and “survminer” R packages.
Molecular characterization of subpopulations
Differentially expressed genes related to prognosis among subgroups were identified using the “limma” package. GeneMANIA was utilized to explore the interactions and functions of these genes. Functional annotations and pathway enrichment analyses were conducted using the MSigDB databases and the “ClusterProfiler” and “GSVA” packages, including GO, KEGG, and GSVA13,14. Additionally, we compared clinical features, transcriptional and metabolic differences between subtypes, and analyzed immune cell infiltration using ssGSEA. The CBNplot tool was employed to examine the relationships between differential genes and pathway enrichment15.
Clinical and molecular characteristics of patients with high and low RAS scores
To develop the RAS score, differential genes between the two subtypes were further filtered. The “forestplot” R package was employed to generate univariate Cox regression charts, and Principal Component Analysis (PCA) was utilized to establish the RAS score. This score categorized patients into high and low groups based on PC1 and PC2, exploring associations with survival outcomes. We examined the relationship between RAS score and clinicopathological features. Gene mutations in the high and low score groups were analyzed using the “Maftools” package16. The “ssGSEA” method assessed the interplay between immune infiltration, RAS score, and the tumor microenvironment. Pathway activities were evaluated using the “GSVA” package, comparing tumor and metabolic pathway activities between the groups. Heat maps of chemokines, immune cells, epigenetic genes, and genes related to glucose and lipid metabolism in each score group were created using the “pheatmap” R package.
Characteristics of chemotherapy, targeted therapy, and immunotherapy in high and low scores
Given the significant clinical and molecular disparities highlighted by the subgroups and scoring systems, we further investigated the relationships between the RAS score and chemotherapy, targeted therapy, and immunotherapy. We analyzed the expression differences in immune checkpoint-related genes between high and low score groups, employing the pRRophetic17 tool to calculate the half-maximal inhibitory concentration (IC50) as a measure of drug response, thereby assessing the effectiveness of chemotherapy and targeted therapies. Additionally, we used data sets from GSE176307 and GSE91061 obtained from the TCIA and GEO databases to evaluate the predictive capacity of the RAS score for immune treatment responses. Statistical comparisons were conducted using Wilcoxon and χ2 tests.
Identification and prognostic analysis of differentially expressed genes between high and low scores
Using the “limma” package, differentially expressed genes between high and low score groups were identified, revealing upregulation in genes such as SAA1, FABP6, and C1QL1. The BEST website (rookieutopia.com) was then used to further analyze the expression, prognosis, and function of these genes in ccRCC. Correlation analyses between C1QL1 expression levels and clinical parameters (age, grade, clinical stage, and TNM stage) in ccRCC patients were performed using chi-square tests via the Sparkle platform (grswsci.top). Additionally, the study conducted via the Sparkle platform (grswsci.top) explored several aspects: the expression of C1QL1 across single cell subsets in ccRCC, the impact of high C1QL1 expression on tumor pathway activation and metabolic processes, the association between C1QL1 expression and diverse immune cell populations within the tumor microenvironment, and the influence of C1QL1 expression on prognosis, as well as the synergistic effects of various immune cells.
Mechanism of C1QL1 in promoting ccRCC progression
We utilized the linkedomics platform (http://linkedomics.org/admin.php) to investigate the potential mechanisms by which C1QL1 influences ccRCC progression18. Survival analysis related to the enrichment scores of the Hippo pathway in ccRCC was performed using the PESSA platform (shinyapps.io)19, assessing the correlation between YAP1 expression levels and ccRCC prognosis. Further, the GPSAdb platform was employed to analyze the relationship between C1QL1 and YAP1 in both normal and tumor tissues20. RNA sequencing and enrichment analyses were conducted to delve deeper into C1QL1’s specific mechanisms. The regulatory relationship between SFMBT1 and C1QL1 was explored using data from GSE141577. The UALCAN website was utilized to analyze C1QL1 methylation levels and examine the correlations between its expression, epigenetic gene expression, and m6A expression. Lastly, differences in genomic mutations between high and low expression groups were compared using the BEST website.
RNA sequencing
RNA sequencing analysis was conducted by Shanghai Applied Protein Technology (Shanghai, China). Total RNA was extracted from specimens using TRIzol reagent. The integrity of the RNA was assessed using an Agilent Bioanalyzer 4150, with integrity values ranging from 9.1 to 9.6. Differential expression analysis revealed significant changes in the expression of genes involved in KEGG pathways following C1QL1 knockdown.
Untargeted metabolomics
Untargeted Metabolomics analysis was carried out by Shanghai Applied Protein Technology (Shanghai, China). The culture medium from Caki-2 cells (~ 10⁷ cells per sample) was carefully removed using a pipette. The cells were then washed with PBS pre-warmed to 37 °C, and the PBS was subsequently discarded. To extract metabolites and precipitate proteins, 800 µL of cold methanol/acetonitrile (1:1, v/v) was added to each sample. The resulting mixture was collected into a new centrifuge tube and centrifuged at 14,000 g for 20 min at 4 °C to collect the supernatant. The supernatant was dried using a vacuum centrifuge. For LC-MS analysis, the dried samples were reconstituted in 100 µL of acetonitrile/water (1:1, v/v), centrifuged at 14,000 g for 15 min at 4 °C, and the final supernatant was subjected to injection.
To ensure the stability and repeatability of the instrument, quality control (QC) samples were prepared by pooling 10 µL from each sample. These QC samples were analyzed alongside the experimental samples, being injected at regular intervals (every 4 samples) throughout the analysis sequence.
Chromatin immunoprecipitation and integrated analysis
Raw sequencing data from GSE141577 were first subjected to quality control. Adapter trimming was performed using Trim Galore to remove low-quality bases and adapter sequences. Trimmed reads were aligned to the human reference genome (hg38) using Bowtie2 with high sensitivity settings. Low-quality and improperly paired reads were filtered out using Samtools. The complexity of the sequencing library was estimated using Preseq. PCR duplicates were removed using Picard, and insert size distribution was analyzed. Mitochondrial reads were excluded to focus on nuclear DNA. Peaks were called with MACS2 to identify regions of significant enrichment. Finally, the BAM files were converted to BigWig format using deepTools for visualization in IGV.
ccRCC tissues
Biological specimens of ccRCC patients in the Department of Urology, the Affiliated Hospital of Putian University from March 2019 to December 2023 were collected. Tumor tissues (T) and adjacent non-tumor tissues (P) were collected from patients in Putian University, and the adjacent tissues were resected at least 1 cm from the edge of the tumor. This study was approved by the Ethics committee of the Affiliated Hospital of Putian University, and the ethics approval number was [PYFY(2023036)]. All the patients provided written informed consent. The study was conducted in accordance with the principles of the Declaration of Helsinki. All methods were performed in accordance with relevant guidelines and regulations. “Stratification of C1QL1 expression groups (high vs. low) was performed using archived qPCR data from our earlier study involving clinical specimen analyses21. All functional assays in this work (e.g., glycogen staining, oil red staining, Multiplex immunofluorescence staining) were conducted in vitro on pre-processed patient samples.”
Cell lines and cell culture
Cancer cell lines Caki-2 were obtained from the American Type Culture Collection (ATCC). Cells were maintained in Roswell Park Memorial Institute 1640 medium (RPMI-1640, Gibco), both supplemented with 10% fetal bovine serum and 1% penicillin–streptomycin. Mycoplasma contamination was ruled out for all cell lines, which were incubated at 37 °C in a humidified atmosphere with 5% CO2.
Generation of knockdown cells
The construction of stable knockdown cell lines was performed as previously described and validated in our earlier publication21.
Antibodies and regents
The antibodies used in this study were as follow: C1QL1 (1:2000,#A181419),β-actin (1:5000,#AC026), and HRP-conjugated Rabbit IgG (1:20000, #AS014), YAP1 (1:2000, # A21333),pYAP (1:2000, # AP1436), SPHK1 (1:2000, #A25694) were procured from Abclonal Antibody.For inhibition studies, cells were treated with the SPHK1 inhibitor PF-543 (# S7177, Selleck Chemicals) according to the manufacturer’s instructions.
Western blot
Western blot analysis was performed as previously described and validated in our earlier publication.Cell and tissue proteins were extracted using standard procedures, and protein concentrations were determined using a BCA Protein Assay Kit (Beyotime, Shanghai, China). Equal amounts of protein were loaded onto a 10% precast gel for electrophoresis, and transferred to a PVDF membrane. The membrane was blocked, incubated with primary and secondary antibodies, and protein bands were detected using an Invitrogen iBright FL1500 gel imager. Antibody dilutions and all procedures were performed according to the protocols detailed in our previous work.
Glycogen staining and oil red staining
Glycogen staining was performed using the Leagene Glycogen Staining Kit (Cat# DG0005). Tissue samples were fixed in 10% formalin overnight, stained with Schiff Reagent, and then mounted for microscopy. Detailed steps for dehydration, rehydration, and additional processing were followed according to the kit’s instruction manual. Oil Red O staining was performed using the Beyotime Oil Red O Staining Kit (Cat# C0158M). Tissue samples were fixed in 4% paraformaldehyde for 30 min at room temperature, stained with Oil Red O solution, and then counterstained with hematoxylin. Detailed steps for dehydration, staining, and rinsing were followed according to the kit’s instruction manual.
Multiplex Immunofluorescence staining
Multiplex immunofluorescence staining was conducted using the Servicebio® TSAPLus Fluorescent Four-Label Five-Color Staining Kit (Cat# G1255). Paraffin-embedded tissue sections were processed for antigen retrieval, and endogenous peroxidase activity was quenched using provided reagents. Tissue sections were incubated with primary antibodies overnight at 4 °C, followed by corresponding HRP-conjugated secondary antibodies. Tyramide signal amplification (TSA) was employed for each target using specific fluorophore-labeled tyramides, enhancing signal visibility and separation. The detailed protocol for reagent preparation and sequential antibody application is provided in the kit’s instruction manual to ensure optimal staining results. The following antibodies were used: CD138 (1:1000, #GB115052, Servicebio), CD56 (1:2000, #GB112671, Servicebio), and Vimentin (1:1000, #A19607, Abclonal).
Statistical methods
In this research, we employed the nonparametric Wilcoxon rank-sum test to evaluate the differences in continuous variables between two groups. To identify differentially expressed genes associated with RASSF subtypes, a Cox regression model was utilized. Kaplan–Meier survival curve analysis was conducted to determine survival differences among various risk groups, with the log-rank test assessing the statistical significance of these differences. All analyses were performed using R software (version 4.3.1), and a bilateral p-value of less than 0.05 was considered statistically significant. Differences between the groups were further analyzed using a two-tailed Student’s t-test, with p-values less than 0.05 denoting significant differences. Data were presented as mean ± standard deviation (mean ± SD). All computational analyses were conducted using GraphPad Prism 9 and Microsoft Excel 2013.
Result
Expression and prognosis of RASSF family in ccRCC
The RASSF family is well-researched across a variety of tumors. In this study, we analyzed the expression of RASSF family members in ccRCC using the BEST website, identifying eight genes with differential expression (Fig. 2A–H). This indicates a significant role for the RASSF family in ccRCC. Subsequently, we examined genes associated with prognosis (Fig. 2I–L) and assessed the expression of these prognostic genes in disease progression (Fig. 2M–P). Additionally, the progression and prognostic implications of specific RASSF genes, namely RASSF1, RASSF2, RASSF4, and RASSF10, were analyzed across various cohorts, including TCGA, GEO, ICGC_EU, and E-mate-1980 (Supplementary Fig. 1). RASSF5 and RASSF7 are highly expressed in tumors, and there are differences in different stages, but they have no effect on the OS of tumors. (Supplementary Fig. 1). Our findings suggest that differences in the expression of RASSF3, RASSF6, RASSF8, and RASSF9 in ccRCC are associated with prognosis and disease progression.

Expression and prognostic significance of the RASSF family in ccRCC. (A–H) Differential expression of RASSF family members in ccRCC. (I–L) Genes from the RASSF family with differential expression and prognostic relevance in ccRCC. (M–P) Genes from the RASSF family associated with disease progression in ccRCC.
Identification of ccRCC subtypes based on RASSF
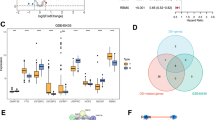
We assessed the roles of four RASSF genes—RASSF3, RASSF6, RASSF8, and RASSF9—as potential risk factors in ccRCC using multivariate regression analysis (Fig. 3A). Given their significant impact on ccRCC, these genes were further analyzed with GeneMANIA to explore interactions with proteins related to oxidative phosphorylation, respiratory chain, ATP metabolism, and mitochondrial function (Fig. 3B). Initially, we identified the top 10 genes positively associated with these key RASSF genes within the TCGA-KIRC dataset, which exhibited notable expression differences in ccRCC (Supplementary Table 1). Subsequently, non-negative matrix factorization (NMF) was employed to determine the subtypes, revealing two distinct clusters (Fig. 3C,D). The distribution of populations within these subtypes was characterized by principal component analysis (PCA) (Fig. 3E), and survival analysis conducted with the Survival package indicated that subtype B was associated with a poorer prognosis (Fig. 3F). Furthermore, we examined the expression of genes defining these subtypes as risk factors (Fig. 3G). Notably, lower expressions of RASSF3, RASSF6, and RASSF9 in subtype B correlated with adverse prognoses, aligning with the trend of decreased expression observed in disease progression within the TCGA-KIRC dataset (Fig. 3H–J).

Identification of ccRCC subtypes based on RASSF correlation. (A) Multifactor regression risk forest map for four genes of the RASSF family in the TCGA-KIRC dataset. (B)Protein interaction network analysis of four genes in the RASSF family. (C, D) Identification of ccRCC subtypes based on RASSF family genes. (E)Population distribution of subtypes A and B of ccRCC identified by PCA analysis. (F)Prognostic curves for subtypes A and B. (G) Analysis of prognostic risk factors for subpopulation building genes. (H–J) Relationship between expression levels of RASSF3, RASSF6, and RASSF9 and prognosis in two subtypes.
Analysis of clinical and molecular characteristics of subpopulations
To elucidate the clinical and molecular distinctions between two patient subgroups, we initially analyzed the expression of key genes (Fig. 4A) and evaluated the differences in epigenetic-related gene expression (Fig. 4B). We observed that subgroup A, which exhibited a more favorable prognosis, had a positive correlation with various protective and epigenetic regulatory factors. Conversely, subgroup B, characterized by a poorer prognosis, demonstrated a strong association with clinical progression (Fig. 4C). Molecularly, the two subgroups exhibited significant differences in tumor pathway enrichment. Notably, subgroup B showed suppressed activities in the HIPPO pathway, Rho GTPase cycle, and FGFR signaling pathway (Fig. 4D). Furthermore, we analyzed metabolic pathway variations and found marked suppression of pathways such as Lysine Degradation, Inositol Phosphate Metabolism, and ADP Ribosylation in subgroup B (Fig. 4E). Additionally, this subgroup displayed distinct differences in the enrichment of key metabolites, including 1-Phosphatidyl-D-myo-inositol, 3’,5’ Cyclic GMP, and Phosphatidate, along with their associated metabolic pathways (Fig. 4F).Furthermore, our investigation into immune cell infiltration revealed a decreased expression of several immunosuppressive cells in subgroup B (Fig. 4G), highlighting profound differences in immune dynamics between the subgroups.

Clinical and molecular characteristics of subpopulations. (A) Expression profiles of key model genes across different subpopulations. (B) Differential expression of epigenetics-related genes among subpopulations. (C) Heatmap analysis illustrating the clinical characteristics of Subgroups A and B. (D) Comparative analysis of tumor pathway enrichment across the two subgroups. (E) Metabolic pathway enrichment comparison between the two patient subgroups. (F) Differential analysis of metabolite enrichment in the subgroups. (G) Variability in immune cell infiltration across Subgroups A and B.
Molecular characterization of subpopulations
Following a comprehensive analysis of the clinical and molecular characteristics of subgroups A and B, we examined prognostic-related differentially expressed genes in these subtypes. We found that most of these genes acted as protective factors (A), with SAA1 and C1QL1 identified as biomarkers indicative of poor prognosis. Subsequent analysis of the protein interaction networks revealed significant relationships with processes such as angiogenesis, amino acid transport, and cell adhesion (B). Moreover, we assessed the expression levels of these differential genes across subpopulations, noting that SAA1 and C1QL1, associated with adverse outcomes, exhibited higher expression levels in both subpopulations (C). Further investigation into the molecular biological processes of these subpopulations showed that these processes are intricately linked to the binding of various hormones, proteins, and kinases, as well as to angiogenesis, inflammation, and cell adhesion (D). Lastly, a detailed analysis of the pathway enrichment of these differential genes highlighted their specific regulatory roles (E–G), particularly emphasizing SAA1’s significant involvement in cell adhesion and inflammatory responses. Additionally, the linkage between C1QL1 and inflammation was reaffirmed by findings from our prior research.

Molecular characterization among subpopulations. (A) Univariate prognostic hazard ratio plot of differentially expressed genes between the two subgroups. (B) protein interaction analysis of differentially expressed genes. (C) expression of differentially expressed genes in the two subgroups. (D) Differentially expressed genes were involved in biological processes. (E) Differential gene enrichment was associated with positive phase regulation of angiogenesis. (F) Correlation between differential gene enrichment and inflammatory response. (G) Correlation between differential gene enrichment and cell adhesion.
Clinical characteristics of patients with high and low scores
In our detailed analysis of the clinical and molecular characteristics of subgroups A and B, we recognized the heterogeneity among ccRCC patients and noted that these subgroups alone might not adequately reflect individual differences. Consequently, we developed a quantifiable assessment tool named the RAS score to evaluate the RAS pattern in each patient. This scoring system enabled us to categorize patients into high-score and low-score groups. We then established a personalized scoring system based on differentially expressed genes related to prognosis, and extensively analyzed the clinical and molecular characteristics of patients within these scoring categories. In terms of clinicopathological features, a significantly higher proportion of patients in the high-score group exhibited poorer stages, TNM staging, grades, and overall survival (OS) compared to those in the low-score group (Fig. 6A–F). This outcome indicates that the RAS score possesses specific sensitivity and specificity for personalized assessment, suggesting that patients with high scores generally experience poorer prognoses.

Clinical characteristics of patients with high and low scores. The proportions of each clinical factor and score are shown on the right. Changes in clinical factors and scores are depicted on the left. (A) The relationship between high and low score patients and progression of different pathological stages. (B) Relationship between patients with high or low scores and different pathological grades. (C) Relationship between high and low score patients and tumor size. (D) Relationship between high and low score patients and lymph node metastasis. (E) Relationship between high and low score patients and distant metastasis. (F) Relationship between patients with high or low scores and prognosis. (G) Relationship between high-score patients and genomic mutations. (H) Relationship between patients with low score and genomic mutations. (I) The differences in gene mutations between the high and low score groups. (J) The differences in gene mutations between the high and low score groups. (K) Immune cell infiltration in different score groups. (L) Enrichment pathway analysis of high-low ranking groups. (M) metabolic pathway analysis was enriched in high and low score groups.
Additionally, we compared the somatic mutation rates of significantly mutated genes (SMGs) across the scoring groups and observed that mutations in TTN (15% vs. 11%), MTOR (8% vs. 5%), and SETD2 (9% vs. 7%) were more prevalent in the high-score group (Fig. 6G). Conversely, VHL (28% vs. 30%) and PBRM1 (12% vs. 22%) showed higher mutation rates in the low-score group (Fig. 6H). We further examined the expression of differentially expressed genes between the high and low score groups (Fig. 6I) and identified that many of these genes are intricately linked to tumor cell adhesion and invasion capabilities, such as MYH7, MKL2, MET, CTNNA2, CDH11, and COL1A2.
To delve deeper into the molecular characteristics of patients categorized by our scoring system, we commenced by analyzing the expression levels of various chemokines across the high-score and low-score groups. We found that most chemokines were expressed at higher levels in the low-score group (Fig. 6J). Subsequently, we investigated the association between the scores and immune-cell infiltration, observing reduced immune-cell infiltration in the high-score group (Fig. 6K). We also examined differences in the activation of tumor-related and metabolic pathways between the two groups. Notably, pathways involved in key biological processes such as glycolysis, fatty acid metabolism, endoplasmic reticulum stress, and MTORC1 were more activated in the high-score group (Fig. 6L). In terms of metabolic pathways, the high-score group exhibited significant enrichment in pathways such as fatty acid elongation, tryptophan metabolism, the citric acid cycle (TCA cycle), and arginine biosynthesis (Fig. 6M). Moreover, we conducted a detailed analysis comparing the expression of genes associated with glycolysis, fatty acid metabolism, and epigenetics between the high and low score groups (Supplementary Fig. 2A–D). This analysis highlighted distinctive molecular features related to glucose and lipid metabolism and epigenetics in patients from the high and low score groups.
Differential response to treatment: a scoring system-based analysis of chemotherapy, targeted therapy, and immunotherapy
After a comprehensive analysis of the clinical and molecular characteristics of patients in different scoring groups, we observed significant disparities in treatment responses. Patients in the high-score group generally exhibited a poorer prognosis (Fig. 7A) and demonstrated low responsiveness to commonly used chemotherapy agents such as cisplatin and gemcitabine (Fig. 7B–D). This suggests that these chemotherapy drugs may not be suitable for patients with high scores and poor prognosis. Furthermore, when assessing the sensitivity of these patients to common first- and second-line therapies, it was found that high-score patients showed limited sensitivity to antiangiogenic agents like sorafenib and acitinib, thus advising against their use for this group (Fig. 7E–F). Conversely, these patients responded well to mTOR inhibitors (Fig. 7G–H).

Characteristics of chemotherapy, targeted therapy, and immunotherapy in high and low scores. (A) Survival curve of patients with high and low scores. (B–D) Response to cisplatin, gemcitabine, and pazotinib in patients with high scores. (E–F) Treatment sensitivity of patients with high scores to sorafenib and axitinib. (G–H) Response to mTOR in patients with high scores. (I–L) Expression of common immunoassays LAG3, PDCD1, CTLA4, and CD274 in patients with high scores. (M–N) Relationship between high CTLAT4 and PDL1 expression and IPS in patients with high score. (O–R) Differences in PD1 immunotherapy response in patients with high scores.
Regarding immunotherapy, our analysis of immune checkpoint expression based on scoring revealed higher expressions of LAG3, PDCD1, and CTLA4, and lower expression of CD274 in the high-score group (Fig. 7I–L). In a targeted treatment cohort, individuals with high CTLA4 expression among high-scoring patients showed better prognoses, while no significant prognostic difference was noted among patients with high expressions of both CTLA4 and PDL1, indicating that immunotherapy targeting CTLA4 might yield better outcomes for high-score patients (Fig. 7M,N). Additionally, in the immunotherapy cohort, patients with high PD1 expression in the high-score group exhibited a poorer response to treatment (Fig. 7O–R). Overall, although patients with high scores generally have a worse prognosis, they may benefit more from treatments targeting CTLA4 and mTOR. These findings underscore the RAS score’s significant role in predicting treatment responses and patient prognosis, establishing it as an effective predictive biomarker.
Impact of C1QL1 expression on tumor progression and prognosis in ccRCC: insights from RAS score analysis and multi-omics data
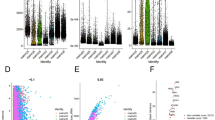
Upon analyzing the association between C1QL1 expression and tumor progression, we observed significant differences in gene expression among patients with varying RAS scores, particularly between the A and B subgroups. Notably, genes such as SAA1, FABP6, and C1QL1 exhibited significantly increased expression in tumors (Fig. 8A). High expression of SAA1 and FABP6 is linked to poor prognosis (Supplementary Fig. 3A-G, 3 J-P). Specifically, SAA1 is primarily associated with angiogenesis, inflammation, and immune responses (Supplementary Fig. 3H,I), while FABP6 correlates significantly with kidney development, ribosome synthesis, and various metabolic pathways (Supplementary Fig. 3Q–R).

Impact of C1QL1 expression on tumor progression and prognosis in ccRCC: Insights from RAS score analysis and multi-omics data. (A) illustrates the differential gene analysis between patients with high and low RAS scores. (B) explores the relationship between C1QL1 expression and tumor progression. (C) highlights the differential expression of C1QL1 across single-cell subsets of urinary tumors. (D–G) detail expression variations of C1QL1 in different subsets of the KIRC-GSE159115 dataset. (H) shows the correlation between gene expression and pathway levels quantified by TCPA-RPPA sequencing of functional proteins. (I) presents the Pearson correlation of GSVA scores between z-scores of C1QL1 expression level and 14 tumor states.(J) discusses GSEA analysis on hallmark gene sets. (K) Heatmap displaying the differential expression of genes involved in glucose and lipid metabolism between the C1QL1 high and low expression groups. (L) C1QL1 high and low expression and glycogen staining. (M) C1QL1 high and low expression and oil red staining. (N) GSVA relationship analysis C1QL1 expression and metabolism. (O) identifies the maximum values of each spot cell component post-deconvolution of the spatial transcriptome. (P) maps the single-gene spatial transcriptome . (Q) delineates the differential expression of specific genes in malignant, mixed, and normal regions. (R) analyzes the Spearman correlation between gene expression and microenvironmental components at single-cell resolution. (S–U) Sequentially analyze, respectively, the synergistic effects of C1QL1 expression and the infiltration of plasma cells, NK cells, and cancer-associated fibroblasts (CAFs) on survival outcomes. (V) Multiple immunofluorescence analysis showing low expression of C1QL1 with infiltration of plasma cells, cancer-associated fibroblasts (CAFs), and NK cells.( Fig. 8W) Multiple immunofluorescence analysis showing high expression of C1QL1 with infiltration of plasma cells, CAFs, and NK cells.
Further analysis of C1QL1 expression in ccRCC indicated that its levels are significantly elevated in tumor tissues (Supplementary Fig. 4A) and increase with the progression of TNM stages (Supplementary Fig. 4B–D). Analysis of the GSE22541 dataset also demonstrated high C1QL1 expression in patients with distant metastases (Supplementary Fig. 4E). Moreover, C1QL1 expression correlated with age and sex (Supplementary Fig. 4F,G) and was strongly associated with higher pathological grades and stages (Supplementary Fig. 4H,I). To reduce biases from single-center data, we extended our analysis to include the GSE167573 and E_MATB_1980 datasets, confirming that C1QL1 also exhibits high expression in these cohorts, positively associated with clinical progression (Supplementary Fig. 4J–N). Additionally, a Cox hazard ratio analysis highlighted C1QL1 as a negative prognostic biomarker (Supplementary Fig. 4O,P).
In single-cell data, C1QL1 expression varied significantly across different urinary tumors, particularly exhibiting higher levels in the tumor subgroups of the KIRC_GSE159115 dataset (Fig. 8B–G). Further analyses of TCGA-KIRC proteomic and transcriptomic data showed a positive correlation between C1QL1 expression and common tumor progression phenotypes (Fig. 8H–I). Previous studies have demonstrated that C1QL1 influences the NF-κB signaling pathway and cell cycle progression21. In terms of tumor metabolism, highly expressed C1QL1 activates glycolysis while inhibiting fatty acid metabolism (Fig. 8J). Additionally, we observed differences in the expression of genes related to glycolipid metabolism between groups with high and low levels of C1QL1 (Fig. 8K). We further validated the association of C1QL1 expression with glycolysis and lipid metabolism through Oil Red O and periodic acid–Schiff (PAS) staining (Fig. 8L,M). Moreover, C1QL1 is implicated in various metabolic activities (Fig. 8N). To further validate the results described above, we additionally performed non-targeted sequencing, as shown in Supplementary Fig. 4Q–R.
Regarding immune cell interactions, analysis of GSE175540-GSM5924030_ffpe_c_2 revealed that C1QL1 expression was negatively correlated with the infiltration of B cells, plasma cells, and cancer-associated fibroblasts (CAFs), while showing a positive correlation with NK cells and macrophages (Figs. 8O–R). We also analyzed the effects of C1QL1 on NK cells, plasma cells, and CAFs (Figs. 8S–U) and further validated these findings using tissue multiplex immunofluorescence staining (Fig. 8V–W). In conclusion, C1QL1 plays a crucial role in tumor progression, metabolism, and immunity.
Mechanism of C1QL1 in promoting the progression of ccRCC
Through single-gene enrichment analysis of C1QL1, we discovered that its high expression is significantly associated with the inhibition of the Hippo signaling pathway (Fig. 9A). Further investigations into the expression of the Hippo pathway in ccRCC and its relationship with prognosis revealed that low expression of this pathway correlates with poor prognosis (Fig. 9B). Notably, the low expression of YAP1, a core transcription factor within the Hippo pathway, is also linked to adverse outcomes in ccRCC patients (Fig. 9C). Consequently, we hypothesize that the high expression of C1QL1 may negatively impact prognosis by inhibiting the Hippo pathway. Additionally, our analysis of the correlation between C1QL1 and YAP1 expression in both normal and tumor tissues indicated that in most normal tissues, as well as specifically in kidney tissues, C1QL1 and YAP1 expressions are positively correlated (Fig. 9D–E). However, in various urological tumors, including renal clear cell carcinoma, these genes mostly exhibit a negative correlation (Fig. 9F–G).

Mechanism of C1QL1 in promoting the progression of ccRCC. (A) Enrichment analysis of high-low score differential gene pathways. (B) Prognostic relationship between high and low Hippo pathway expression in ccRCC. (C) Prognostic relationship between YAP1 expression and ccRCC. (D) The relationship between C1QL1 and YAP1 in pan-normal tissues. (E) Relationship between C1QL1 and YAP1 in normal renal tissues. (F) The relationship between C1QL1 and YAP1 in pancarcinoma. (G) Relationship between C1QL1 and YAP1 in ccRCC. (H) Enrichment analysis of C1QL1 knockdown pathway. (I) Differential gene volcano map after SFMBT1 knockdown in GSE141577 data set.(J) CHIP data from GSE141577 showed the binding relationship between SFMBT1 and C1QL1. (K) Correlation between SFMBT1 and C1QL1 expression in ccRCC. (L) Differential expression of C1QL1 methylation in normal and tumor tissues. (M) Relationship Between C1QL1 Expression and Methylation in ccRCC. (N) Expression differences of DNA methylation and acetylation in high and low expression of C1QL1. (O) C1QL1 high and low expression and m6A modifiation-related gene expression differences. (P) Relationship between high and low expression of C1QL1 and different genomic mutations. (Q) Inhibition of C1QL1 expression by PF-543, an SPHK1 inhibitor. (R) Increased YAP1 levels following reduced C1QL1 expression. (S) Schematic illustration of the mechanisms underlying the abnormal high expression of C1QL1 and its roles in promoting tumor progression, metabolism, and immune interactions. Q and R have been cropped, and the original images are shown in Supplementary Material 1.
In addition, our RNA-seq data analysis revealed that high expression of C1QL1 is associated with enrichment in extracellular matrix (ECM)-receptor interactions and focal adhesion. It was also observed that the Hippo signaling pathway plays a significant role in regulating cell-ECM interactions and cell adhesion, suggesting a complex interplay in tumor dynamics (Fig. 9H). To further elucidate the mechanism behind C1QL1’s overexpression in tumors, we conducted a comprehensive analysis of the regulatory effects exerted by transcription factors, DNA methylation, m6A modification, and acetylation on C1QL1. Utilizing the GPSAdb platform (gpsadb.com), our findings suggest that the transcription repressor SFMBT1 might play a pivotal role in the overexpression of C1QL1. Experimental analysis within the GSE141577 dataset corroborated this, showing that reduction of SFMBT1 leads to a significant increase in C1QL1 expression (Fig. 9I).
Additionally, analysis of ChIP data from GSE141577 revealed that SFMBT1 may directly bind to the promoter region of C1QL1, potentially facilitating the upregulation of C1QL1 (Fig. 9J). Furthermore, SFMBT1 and C1QL1 exhibit a significant correlation in their expression within ccRCC (Fig. 9K).We also examined the methylation levels of C1QL1 in both tumor and normal tissues and found that hypomethylation of C1QL1 in tumor tissues could be a contributing factor to its elevated expression (Fig. 9L). Further comparisons revealed that high expression of C1QL1 correlates significantly with the reduced expression of DNA methylation-related genes such as DNMT3A and acetylation-related genes including HDAC1, HDAC2, HDAC4, and HDAC5 (Fig. 9M-N). Moreover, abnormalities in m6A modification were also linked to the high expression levels of C1QL1 (Fig. 9O).
Through the analysis of the relationship between genomic mutations and C1QL1 expression, we identified a correlation of high C1QL1 expression with mutations in VHL, SETD2, BAP1, and other related genes (Fig. 9P). Previous research indicates that mutations in VHL lead to diminished SFMBT1 expression, with SPHK1 being the direct target gene22. Consequently, we postulate that VHL mutations may suppress SFMBT1 expression, thereby elevating SPHK1 levels and subsequently increasing C1QL1 expression. To test this regulatory mechanism, we employed SPHK1 inhibitors to investigate the effect of SFMBT1 on C1QL1 expression (Fig. 9Q). Additionally, we utilized cell lines stably transfected in previous studies to examine the regulatory interactions between siC1QL1 and YAP1 (Fig. 9R). Our findings demonstrate that SPHK1 inhibitors suppress C1QL1 expression, while knockdown of C1QL1 promotes YAP1 expression. The mechanism of abnormal C1QL1 expression and its relationship with tumor progression, tumor metabolism and immunity (Fig. 9S).
Discussion
Clear cell renal cell carcinoma (ccRCC) is the most prevalent subtype of renal cell carcinoma. Despite advancements in treatment, significant challenges remain in managing this disease. The introduction of targeted therapies and immunotherapies, particularly those aimed at the immunosuppressive tumor microenvironment (TME), has led to improved clinical outcomes for some patients23,24. However, resistance to immune checkpoint inhibitors (ICIs) is still widespread, resulting in many patients failing to achieve sustained benefits25,26,27. Therefore, it is crucial to investigate new biomarkers and underlying mechanisms to enhance therapeutic development.In this context, the RASSF family has garnered increasing attention due to its important role in various cancer types. Comprising ten members, most of which are recognized as tumor suppressor proteins, RASSF proteins are frequently silenced through promoter methylation, a phenomenon observed across multiple cancers28,29,30. Beyond their tumor suppressor functions, RASSF proteins contribute to essential cellular processes such as microtubule stabilization, regulation of cell division, apoptosis, cell migration and adhesion, as well as the modulation of NF-κB activity and inflammation31,32,33. Despite the extensive and complex roles that RASSF family members play in cancer, their specific contributions to ccRCC remain inadequately defined.
In our study, we first conducted a comprehensive analysis of the expression profiles, prognostic significance, and associations with disease progression of RASSF family members in clear cell renal cell carcinoma (ccRCC). We identified four key genes: RASSF3, RASSF6, RASSF8, and RASSF9. Subsequent analyses revealed that these genes are intricately linked to essential biological processes such as oxidative phosphorylation, metabolism, mitochondrial respiratory chain function, and ATP synthesis—critical components of energy metabolism. This connection is particularly significant given that ccRCC is characterized by abnormal energy metabolism34.Following this, we employed NMF clustering to classify all patients into two RAS subgroups, designated as Cluster A and Cluster B. Comparative analysis of these two subgroups indicated that HAGH, GADD45GIP1, DRAP1, MRPL23, KRTCAP2, and MIF serve not only as prognostic risk factors for ccRCC but also exhibit similar risk characteristics in other cancers35,36,37,38. These findings underscore the crucial role of RASSF family genes in ccRCC and other malignancies, providing new insights for future research into targeted therapies.
In our study, we further analyzed the population characteristics of ccRCC patients divided into two groups, revealing significant multidimensional differences. Notably, patients in Cluster B have a poorer prognosis, which correlates strongly with clinical progression indicators. Molecularly, the two subgroups show distinct differences in tumor pathway enrichment; particularly, Cluster B exhibits inhibition of the HIPPO pathway. Since the activation of the HIPPO pathway is closely associated with various metabolic pathways, we subsequently compared metabolic pathway differences between the subgroups. Our findings indicate that in Cluster B, there is significant inhibition of lysine degradation, inositol phosphate metabolism, and ADP-ribosylation, along with their associated metabolites.
We also evaluated genes associated with prognosis in the two ccRCC subtypes and discovered that while most genes exhibited protective qualities, SAA1 and C1QL1 were indicators of poor prognosis. SAA1 is closely linked to cell adhesion and inflammatory responses, a relationship that was also confirmed in our prior studies21. C1QL1 is similarly associated with inflammation. The primary differences between the subgroups were related to angiogenesis, amino acid transport, and cell adhesion, aligning with the characteristics of ccRCC as a vascular tumor. Additionally, ccRCC is known for its high levels of methylation39. In terms of treatment strategies, we compared the expression of epigenetic-related genes between the subgroups and noted that DNA methyltransferases such as DNMT1, DNMT3A, and DNMT3B were upregulated in Cluster A. Several clinically approved DNMT inhibitors, including Azacitidine and Decitabine, have shown promise in renal cancer studies40,41,42, suggesting their potential suitability for patients in Cluster A who generally have a better prognosis. Overall, our multidimensional comparison deepens the understanding of the distinct characteristics of patient subtypes, providing a solid foundation for future clinical interventions.
However, the heterogeneity between individual patients means that differences observed between subgroups may not accurately reflect every individual’s condition. To address this, we developed a scoring system based on subgroup characteristics, termed the “RAS score”. This personalized scoring system, constructed from genes differentially expressed and associated with prognosis, allows us to delve deeper into the clinical and molecular characteristics, as well as the treatment responses of patients with varying scores. Clinically, patients in the high-score group exhibited a significantly higher incidence of poor prognostic features such as advanced Stage, TNM staging, high grade, and overall survival (OS), underscoring their poor prognosis in comparison to those in the low-score group. Moreover, these patients had higher somatic mutation rates in genes like TTN, MTOR, and SETD, which denote distinct genetic mutation profiles. Molecularly, the high-score group displayed lower chemokine expression and increased infiltration of immunosuppressive cells. Additionally, these patients exhibited activations of crucial metabolic pathways including glycolysis, fatty acid metabolism, endoplasmic reticulum stress, and MTORC1, which are indicative of more pronounced metabolic dysregulation.
In the comparison of treatment responses, patients in the high-score group exhibited poor responses to commonly used chemotherapy drugs such as cisplatin, gemcitabine, and pazopanib. Given that ccRCC is generally resistant to chemotherapy43,44, this finding is particularly significant. Moreover, we assessed the efficacy of first- and second-line treatments in the high-score group, finding these patients showed limited sensitivity to sorafenib and axitinib, yet responded favorably to second-line mTOR inhibitors. Additionally, we evaluated the response to several commonly used immunotherapeutic agents. In the treatment cohort studied, patients with high RAS scores had poorer outcomes with PD-1 immunotherapy but appeared to respond well to CTLA4-targeted immunotherapies. Overall, our study highlights a strong correlation between the RAS score and clinical characteristics, molecular features, and treatment responses, establishing the RAS score as a valuable prognostic marker for patient outcomes.
To investigate the underlying mechanisms of C1QL1 overexpression in tumors, we comprehensively analyzed the effects of transcription factors, DNA methylation, m6A modification, and acetylation on C1QL1 expression. Our findings indicate that the transcription factor SFMBT1 plays a crucial role in mediating the elevated expression of C1QL1. A reduction in SFMBT1 expression correlates with an increase in C1QL1 expression. We further validated that SPHK1, a direct downstream target of SFMBT1, exerts a regulatory effect on C1QL1.Additionally, we observed that the hypomethylated state of C1QL1 in tumor tissues may contribute to its high expression levels. Notably, increased C1QL1 expression was significantly associated with decreased expression of several key epigenetic regulators, including DNMT3A, HDAC1, HDAC2, HDAC4, and HDAC5. Moreover, abnormalities in m6A modification were closely linked to the upregulation of C1QL1.
Interestingly, our analysis revealed that high C1QL1 levels are associated with mutations in genes such as VHL, SETD2, and BAP1. Previous studies have established that VHL mutations can lead to decreased SFMBT1 expression21. Based on this observation, we hypothesize that VHL mutations may facilitate the upregulation of C1QL1 by downregulating SFMBT1, which subsequently increases the levels of the direct-acting protein SPHK1. This cascade of events may be regulated by changes in DNA methylation status and RNA modifications. Ultimately, these molecular events could contribute to tumor progression through the inhibition of the Hippo signaling pathway.
Admittedly, our study has several limitations. First, while we relied on bioinformatics analysis and utilized multiple data cohorts with large clinical sample sizes to confirm the renal clear cell subtype and construct scoring systems, there remains a lack of external validation through clinical trials. Second, although we have partially verified the relationship between C1QL1 expression and tumor progression, metabolism, and immunity, the specific mechanisms underlying these associations have not been thoroughly elucidated and will require further investigation. Lastly, the design, screening, and diagnosis of C1QL1 as a potential drug target necessitate improvement to provide more robust clinical guidance.
Conclusion
In conclusion, our research provides significant insights into the prognostic variations among RAS subtypes and elucidates the role of C1QL1 in clear cell renal cell carcinoma (ccRCC). The RAS score we established demonstrates a robust capability to predict both prognosis and therapeutic response, while C1QL1 emerges as a promising clinical prognostic marker and a potential therapeutic target. These findings highlight the critical importance of these markers in the development of personalized treatment strategies, which have the potential to substantially enhance patient outcomes.
Data availability
The TCGA-KIRC cohort can be downloaded from TCGA (https://portal.gdc.cancer.gov/) and datasets GSE29609 and GSE141577 are available in the NCBI GEO (https://www.ncbi.nlm.nih.gov/geo/) public repositoriy. For further inquiries, please contact the corresponding author.
References
Jonasch, E., Gao, J. & Rathmell, W. K. Renal cell carcinoma. BMJ 349, g4797. https://doi.org/10.1136/bmj.g4797 (2014).
Sung, H. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71, 209–249. https://doi.org/10.3322/caac.21660 (2021).
Jiang, Z. et al. Utilizing a novel model of PANoptosis-related genes for enhanced prognosis and immune status prediction in kidney renal clear cell carcinoma. Apoptosis 29, 681–692. https://doi.org/10.1007/s10495-023-01932-3 (2024).
Posadas, E. M., Limvorasak, S. & Figlin, R. A. Targeted therapies for renal cell carcinoma. Nat. Rev. Nephrol. 13, 496–511. https://doi.org/10.1038/nrneph.2017.82 (2017).
Davidson, G. et al. Mesenchymal-like tumor cells and myofibroblastic Cancer-Associated fibroblasts are associated with progression and immunotherapy response of clear cell renal cell carcinoma. Cancer Res. 83, 2952–2969. https://doi.org/10.1158/0008-5472.CAN-22-3034 (2023).
Volodko, N., Gordon, M., Salla, M., Ghazaleh, H. A. & Baksh, S. RASSF tumor suppressor gene family: Biological functions and regulation. FEBS Lett. 588, 2671–2684. https://doi.org/10.1016/j.febslet.2014.02.041 (2014).
Song, H., Oh, S., Oh, H. J. & Lim, D. S. Role of the tumor suppressor RASSF2 in regulation of MST1 kinase activity. Biochem. Biophys. Res. Commun. 391, 969–973. https://doi.org/10.1016/j.bbrc.2009.11.175 (2010).
Matallanas, D. et al. RASSF1A elicits apoptosis through an MST2 pathway directing proapoptotic transcription by the p73 tumor suppressor protein. Mol. Cell. 27, 962–975. https://doi.org/10.1016/j.molcel.2007.08.008 (2007).
Oh, H. J. et al. Role of the tumor suppressor RASSF1A in Mst1-mediated apoptosis. Cancer Res. 66, 2562–2569. https://doi.org/10.1158/0008-5472.CAN-05-2951 (2006).
Kudo, T. et al. The RASSF3 candidate tumor suppressor induces apoptosis and G1-S cell-cycle arrest via p53. Cancer Res. 72, 2901–2911. https://doi.org/10.1158/0008-5472.CAN-12-0572 (2012).
Liu, Z. et al. BEST: A web application for comprehensive biomarker exploration on large-scale data in solid tumors. J. Big Data. 10 https://doi.org/10.1186/s40537-023-00844-y (2023).
Wilkerson, M. D. & Hayes, D. N. ConsensusClusterPlus: A class discovery tool with confidence assessments and item tracking. Bioinformatics 26, 1572–1573. https://doi.org/10.1093/bioinformatics/btq170 (2010).
Yu, G., Wang, L. G., Han, Y. & He, Q. Y. ClusterProfiler: An R package for comparing biological themes among gene clusters. OMICS 16, 284–287. https://doi.org/10.1089/omi.2011.0118 (2012).
Kanehisa, M., Furumichi, M., Sato, Y., Matsuura, Y. & Ishiguro-Watanabe, M. KEGG: Biological systems database as a model of the real world. Nucleic Acids Res. 53, D672–d677. https://doi.org/10.1093/nar/gkae909 (2025).
Sato, N., Tamada, Y., Yu, G., Okuno, Y. & CBNplot Bayesian network plots for enrichment analysis. Bioinformatics 38, 2959–2960. https://doi.org/10.1093/bioinformatics/btac175 (2022).
Mayakonda, A., Lin, D. C., Assenov, Y., Plass, C. & Koeffler, H. P. Maftools: Efficient and comprehensive analysis of somatic variants in cancer. Genome Res. 28, 1747–1756. https://doi.org/10.1101/gr.239244.118 (2018).
Geeleher, P., Cox, N. & Huang, R. S. pRRophetic: An R package for prediction of clinical chemotherapeutic response from tumor gene expression levels. PLoS One. 9, e107468. https://doi.org/10.1371/journal.pone.0107468 (2014).
Vasaikar, S. V., Straub, P., Wang, J. & Zhang, B. LinkedOmics: Analyzing multi-omics data within and across 32 cancer types. Nucleic Acids Res. 46, D956–D963. https://doi.org/10.1093/nar/gkx1090 (2018).
Yang, H. et al. PESSA: A web tool for pathway enrichment score-based survival analysis in cancer. PLoS Comput. Biol. 20, e1012024. https://doi.org/10.1371/journal.pcbi.1012024 (2024).
Guo, S. et al. GPSAdb: A comprehensive web resource for interactive exploration of genetic perturbation RNA-seq datasets. Nucleic Acids Res. 51, D964–D968. https://doi.org/10.1093/nar/gkac1066 (2023).
Weng, K. Q. et al. Identification of Treg-related prognostic molecular subtypes and individualized characteristics in clear cell renal cell carcinoma through single-cell transcriptomes and bulk RNA sequencing. Int. Immunopharmacol. 130, 111746. https://doi.org/10.1016/j.intimp.2024.111746 (2024).
Liu, X. et al. Genome-wide screening identifies SFMBT1 as an oncogenic driver in cancer with VHL loss. Mol. Cell. 77, 1294–1306e1295. https://doi.org/10.1016/j.molcel.2020.01.009 (2020).
Hsieh, J. J. et al. Renal cell carcinoma. Nat. Rev. Dis. Primers. 3, 17009. https://doi.org/10.1038/nrdp.2017.9 (2017).
Barata, P. C. & Rini, B. I. Treatment of renal cell carcinoma: Current status and future directions. CA Cancer J. Clin. 67, 507–524. https://doi.org/10.3322/caac.21411 (2017).
Capitanio, U. et al. Epidemiology of renal cell carcinoma. Eur. Urol. 75, 74–84. https://doi.org/10.1016/j.eururo.2018.08.036 (2019).
Diaz-Montero, C. M., Rini, B. I. & Finke, J. H. The immunology of renal cell carcinoma. Nat. Rev. Nephrol. 16, 721–735. https://doi.org/10.1038/s41581-020-0316-3 (2020).
Braun, D. A. et al. Beyond conventional immune-checkpoint inhibition - novel immunotherapies for renal cell carcinoma. Nat. Rev. Clin. Oncol. 18, 199–214. https://doi.org/10.1038/s41571-020-00455-z (2021).
Amaar, Y. G. et al. Ras association domain family 1 C protein stimulates human lung cancer cell proliferation. Am. J. Physiol. Lung Cell. Mol. Physiol. 291, L1185–1190. https://doi.org/10.1152/ajplung.00072.2006 (2006).
Fukatsu, A. et al. RASSF3 downregulation increases malignant phenotypes of non-small cell lung cancer. Lung Cancer. 83, 23–29. https://doi.org/10.1016/j.lungcan.2013.10.014 (2014).
Allen, N. P. et al. RASSF6 is a novel member of the RASSF family of tumor suppressors. Oncogene 26, 6203–6211. https://doi.org/10.1038/sj.onc.1210440 (2007).
Hamilton, G., Yee, K. S., Scrace, S. & O’Neill, E. ATM regulates a RASSF1A-dependent DNA damage response. Curr. Biol. 19, 2020–2025. https://doi.org/10.1016/j.cub.2009.10.040 (2009).
Crose, L. E. et al. Alveolar rhabdomyosarcoma-associated PAX3-FOXO1 promotes tumorigenesis via Hippo pathway suppression. J. Clin. Invest. 124, 285–296. https://doi.org/10.1172/JCI67087 (2014).
Park, H. W. et al. Correlation between hypermethylation of the RASSF2A promoter and K-ras/BRAF mutations in microsatellite-stable colorectal cancers. Int. J. Cancer. 120, 7–12. https://doi.org/10.1002/ijc.22276 (2007).
Wettersten, H. I., Aboud, O. A., Lara, P. N. Jr. & Weiss, R. H. Metabolic reprogramming in clear cell renal cell carcinoma. Nat. Rev. Nephrol. 13, 410–419. https://doi.org/10.1038/nrneph.2017.59 (2017).
Scire, A. et al. Glyoxalase 2: Towards a broader view of the second player of the glyoxalase system. Antioxid. (Basel). 11 https://doi.org/10.3390/antiox11112131 (2022).
Nakayama, K., Nakayama, N., Wang, T. L. & Shih Ie, M. NAC-1 controls cell growth and survival by repressing transcription of Gadd45GIP1, a candidate tumor suppressor. Cancer Res. 67, 8058–8064. https://doi.org/10.1158/0008-5472.CAN-07-1357 (2007).
Penticuff, J. C., Woolbright, B. L., Sielecki, T. M., Weir, S. J. & Taylor, J. A. MIF family proteins in genitourinary cancer: Tumorigenic roles and therapeutic potential. Nat. Rev. Urol. 16, 318–328. https://doi.org/10.1038/s41585-019-0171-9 (2019). 3rd.
Huang, M. Y. et al. The DRAP1/DR1 repressor complex increases mTOR activity to promote progression and confer everolimus sensitivity in Triple-Negative breast cancer. Cancer Res. https://doi.org/10.1158/0008-5472.CAN-23-2781 (2024).
Koch, A. et al. Analysis of DNA methylation in cancer: Location revisited. Nat. Rev. Clin. Oncol. 15, 459–466. https://doi.org/10.1038/s41571-018-0004-4 (2018).
Arai, E. et al. Genetic clustering of clear cell renal cell carcinoma based on array-comparative genomic hybridization: Its association with DNA methylation alteration and patient outcome. Clin. Cancer Res. 14, 5531–5539. https://doi.org/10.1158/1078-0432.CCR-08-0443 (2008).
Montero, A. J. et al. Epigenetic inactivation of EGFR by CpG Island hypermethylation in cancer. Cancer Biol. Ther. 5, 1494–1501. https://doi.org/10.4161/cbt.5.11.3299 (2006).
Olino, K., Park, T. & Ahuja, N. Exposing hidden targets: Combining epigenetic and immunotherapy to overcome cancer resistance. Semin Cancer Biol. 65, 114–122. https://doi.org/10.1016/j.semcancer.2020.01.001 (2020).
Li, X. et al. The M6A methyltransferase METTL3: Acting as a tumor suppressor in renal cell carcinoma. Oncotarget 8, 66. https://doi.org/10.18632/oncotarget.17263 (2017).
Bahadoram, S., Davoodi, M., Hassanzadeh, S., Barahman, M. & Mafakher, L. Renal cell carcinoma: An overview of the epidemiology, diagnosis, and treatment. G Ital. Nefrol. 39, 2022 (2022).
Acknowledgements
Data come from TISCH, TCGA database and GEO is appreciated by the author. The authors would like to acknowledge those who volunteered their tissue samples for this project.
Funding
This research was funded by Science and Technology Plan Project of Putian City, China (Project No.: 2023S3F009).
Author information
Authors and Affiliations
Contributions
JYL was responsible for the conceptualization of the study. KQW and QDG handled data curation, while JYL conducted the formal analysis. The investigation was carried out by QDG, and the methodology was developed by JYL. Project administration was managed by XYY and NX. The original draft was prepared by JYL, KQW, and QDG, with NX and XYY contributing to the review and editing of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Informed Consent
Written informed consent has been obtained from the patients to publish this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.




Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, JY., Weng, KQ., Gao, QD. et al. Molecular subtyping of renal clear cell carcinoma based on prognostic RASSF family genes and validation of C1QL1 as a key prognostic marker. Sci Rep 15, 9786 (2025). https://doi.org/10.1038/s41598-025-94978-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-94978-z

{kind=link}
{kind=link}
{kind=link}
{kind=link}