
Abstract
In recent years, the utilization of silicon, rather than graphite, has emerged as a compelling alternative for anode materials in Li-ion batteries, promising higher energy density. However, a significant challenge lies in the degradation of silicon anodes due to volume fluctuations during charge and discharge cycles, resulting in a rapid decline in battery capacity. To tackle this issue, researchers are investigating the integration of self-healing polymers as binding agents in the anode structure through trial-and-error approaches, which is both time-consuming and expensive. Overcoming practical experimentation challenges, this study delves self-healing polymers through machine learning methods as a more practical approach. The role of structural features and functional groups within these polymers in maintaining anode integrity and prolonging battery capacity across multiple charge cycles were explored by utilization of random forest, ridge algorithms, support vector machines, and neural networks. Notably, the neural networks algorithm exhibits superior performance, achieving 96% accuracy for test data. SHAP analysis revealed that ether functional groups, donor and acceptor hydrogen bonds, and dual-interconnected rings have the most positive impact on preserving battery capacity. In this study, we introduce a set of design principles for selecting functional groups aimed at enhancing the self-healing capabilities and prolonging the lifespan of Si-based LIBs. This study has the potential to pave the way for the development of more efficient and enduring Li-ion batteries.
Similar content being viewed by others


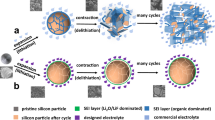
Introduction
The advancement of Li-ion (Li-ion) batteries has been driven by the demand for high-performance energy storage technologies1,2,3,4. As the need intensifies for batteries not only with higher power density but also with enhanced cycle stability5,6, attention has turned to silicon (Si) as a promising candidate.
Silicon boasts a remarkable theoretical capacity of 4200 mAh/g, surpassing conventional graphite anodes by over tenfold (372 mAh/g), positioning it as a viable option for anode materials in Li-ion batteries7. However, Si encounters significant volume expansion (300%) during lithiation and delithiation processes, leading to pulverization, loss of electrical contact, unstable solid electrolyte interface (SEI) formation, and rapid capacity degradation, thus limiting its practical application in industrial Li-ion batteries8,9.
To tackle these challenges, researchers have dedicated significant efforts10, exploring various strategies including nanostructured Si11,12, porous Si13,14, Si-carbon composite materials15,16,17, and innovative structural designs18,19,20,21. While these methods have shown promise in mitigating volume fluctuations and enhancing the electrochemical performance of Si anodes, their widespread adoption is impeded by the substantial costs and intricate synthesis processes involved8. One effective approach to tackle the challenges associated with Si-based anodes is by developing advanced binder materials capable of accommodating the significant mechanical strain induced by Si volume changes22. Binders not only provide structural integrity to the electrode23but also facilitate efficient electron and ion transport within the electrode matrix24,25, aid in the dispersion of active materials26, and promote the development of a stable solid electrolyte interface (SEI) film27,28,29.
To enhance the mechanical integrity and performance of Si-based anodes, incorporating polar functional groups into polymer binders has been explored. These groups can form strong interactions, such as hydrogen bonding and electrostatic attractions, with Si particles, thereby improving structural cohesion. In addition to these interactions, metal–ligand coordination plays a significant role in designing self-healing binders. This dynamic bonding involves reversible interactions between metal ions and ligands, enabling the material to autonomously repair and maintain its mechanical properties under stress30. For instance, elastomers utilizing various metal–ligand bonds have shown excellent self-healing properties due to the full reconstruction of these bonds during the healing process31. A 3D conductive polyaniline binder doped with phytic acid was synthesized and used with silicon nanoparticles, achieving 1137 mA h g⁻¹ after 500 cycles at 1 A g⁻¹. polyaniline enhances structural stability and conductivity, offering insights for commercial high-performance lithium-ion batteries32.
One innovative approach involves the synthesis of a composite binder composed of multi-hydroxyl polyvinyl alcohol (PVA) and electroactive squaric acid (SA). The crosslinking reactions between SA and PVA chains form a robust binder network that stabilizes both the macro and micro-structures of Si electrodes. This composite binder has demonstrated improved initial coulombic efficiency, enhanced rate performance, and prolonged cycling stability in Si anodes33. Molecularly engineered conductive polymer binders, including star-like polyaniline (s-PANi), cross-linked polyaniline (c-PANi), and linear polyaniline (l-PANi) were developed by He et al.34. Among these, s-PANi demonstrated superior performance, delivering a reversible capacity of 1776 mAh g⁻¹ after 100 cycles at 500 mA g⁻¹. This was attributed to its 3D-conjugated conductive network, which better accommodates the large strain induced by cycling compared to cross-linked or linear structures.
A cross-linked polyacrylamide (PAM) binder was developed, forming a 3D polar network via a condensation reaction with citric acid. This binder significantly improved tensile properties and adhesion, enabling the silicon anode to achieve a reversible capacity of 1280 mAh g⁻¹ after 600 cycles at 2.1 A g⁻¹ and 770.9 mAh g⁻¹ after 700 cycles at 4.2 A g⁻¹. The study presents a cost-effective binder engineering strategy that enhances the long-term cycling stability and performance of silicon anodes35. A double-wrapped binder with rigid polyacrylic acid (PAA) inside and elastic bifunctional polyurethane (BFPU) outside was designed to manage stress in silicon anodes. PAA dissipates stress during lithiation, while BFPU buffers residual stress and self-heals microcracks, improving cycling life for high-energy-density batteries36.
Among the various materials, poly (vinylidene fluoride) (PVDF) has long been the conventional binder of choice for Li-ion batteries (LIBs) utilizing carbonaceous anodes, prized for its electrochemical stability, binding capacity, and facilitation of Li-ion transportation. However, its effectiveness wanes when applied to alloy-based anodes due to weak interactions with active materials and the current collector, resulting in electrode instability and significant volume changes37.
In contrast, both natural polymers (e.g., gelatin38, carboxymethyl cellulose (CMC)39, alginate40, pectin41) and synthetic polymers (e.g., poly (acrylic acid) (PAA)42, poly (vinyl alcohol) (PVA)43,44, polyacrylonitrile (PAN))45have demonstrated efficacy in enhancing the cyclability of Si37, Si/C, and Si/Gr composite anodes8,46. However, their one-dimensional configuration limits interaction with the Si surface and fails to adequately restrain swelling in the electrolyte47,48. Branched polysaccharides such as gum arabic49, xanthan gum50, and graft copolymers like NaPAA-gCMC51, PAL-NaPAA52, and PVDF-g-PtBA53 offer additional contact points with active materials for effective stress dissipation. Nevertheless, the absence of interchain connections leads to polymer chain slipping during volume expansion that compromise the electrode long-term stability.
To address these challenges, 3D polymer networks have been engineered, featuring multiple interchain connections that sustain mechanical integrity to withstand cycling-induced stress54,55,56. These network binders, characterized by covalent and noncovalent interactions such as hydrogen bonding and electrostatic interactions, effectively restrict continuous movement of Si particles and introduce a self-healing effect57,58. The self-healing capability not only restores the binder’s original structure but also enhances cell efficacy by re-establishing conduction pathways and mechanical resilience7. The exploration of self-healing properties in binders holds significant promise for advancing battery technologies, particularly in enclosed and intricate systems like energy storage devices.
The design of 3D polymer networks for self-healing binders relies heavily on the presence of specific structural features and functional groups that enable dynamic interactions, such as hydrogen bonding, electrostatic interactions, and covalent bonds. These interactions are critical for maintaining the structural integrity of silicon anodes during charge/discharge cycles and for restoring mechanical properties after damage. For example, functional groups like carbonyl oxygens, ether groups, and hydrogen bond donors/acceptors play a key role in facilitating self-healing by forming reversible bonds that can break and reform under stress. These insights from experimental studies provide a foundation for understanding the mechanisms behind self-healing binders.
However, identifying the optimal binder through experimental design remains a time- and resource-intensive process that is prohibitively expensive. The rapid advancements in artificial intelligence (AI) and machine learning (ML) present a considerable opportunity to revolutionize the design loop of polymeric binders for Si-based anodes. These innovations have the potential to significantly expedite and enhance the binder selection process, thereby improving performance and reducing the need for iterative experimental stages currently required.
This study builds upon previous binder design methodologies by addressing a critical gap in the field: the reliance on costly and time-consuming experimental approaches. While prior researches have explored various binder materials (e.g., natural and synthetic polymers) and their mechanical properties, our approach uniquely targets the identification of key functional groups that enhance self-healing capabilities and capacity retention. We make a synergy between experimental insights and computational predictions by incorporating the structural and functional properties into our computational methods. This allows us to systematically identify the key design principles for high-performance binders, accelerating the discovery of features which positively impact the state of health (SoH) or capacity retention of silicon-based LIBs.
Here, we have developed a ML model to predict the functional groups with the greatest impact on the capacity retention of Si-based Li-ion batteries, leveraging a dataset comprising 80 cross-linked polymer binders extracted from 450 articles detailing experimental tests on binders for LIBs silicon anodes.
Our results revealed that an increase in the number of carbonyl oxygens (excluding carboxyl), secondary amine functional group, and two interconnected rings positively influences the model’s performance. Additionally, a reduction in the number of aromatic nitrogens, and the tertiary amine functional group positively impacts the model. Our research represents the inaugural exploration into this specific area, and has the potential to pave the way for the development of more efficient and enduring Li-ion batteries.
Dataset and machine learning models
Dataset
For this study, we systematically reviewed 450 articles detailing experimental tests on binders for silicon anodes in LIBs. From this pool, 160 articles reporting on the utilization of cross-linked binders were identified, considering their superior intrinsic performance. Among these, a subset of 80 binders was selected based on the feasibility of rendering their chemical structures using the KingDraw program. To ensure the robustness of our models, we used a standard train-test split along with cross-validation to divide our data for training, validation, and testing. The structures generated by the KingDraw program were saved in .mol chemical format and subsequently converted to Simplified Molecular-Input Line-Entry System (SMILES) chemical format using the OpenBabel platform. SMILES notation is a concise line notation method for representing chemical species using short ASCII strings. It offers a clear depiction of molecular structures based on established chemical rules. In the realm of machine learning, SMILES format is widely employed for constructing datasets, storing molecules, predicting molecular properties, designing drugs, and other chemical tasks. Its standardized structure facilitates analysis using machine learning algorithms, contributing to advancements in chemical research and applications.
Fingerprints
To evaluate polymer performance, we calculated the ratio of capacity after one hundred cycles to the initial cycle’s capacity, expressed as a percentage, which served as the target measure. The RDKit library, tailored for chemical computations, facilitated the computation of properties for each polymer. Initially considering 114 properties from the SCBDD site, we retained 73 after filtering out features with zero or undefined values, focusing on characteristics such as functional groups and molar weight.
Alternatively, we employed a method that bypassed the use of the RDKit library for feature extraction. In this approach, we utilized the KingDraw program to obtain .mol outputs, which were then processed through the OpenBabel site to convert them into SMILES format. The SMILES representations were subsequently inputted into the SCBDD site for calculations, with feature extraction performed using the RDKit library. It is noteworthy that while the outcomes of this alternative method aligned with those of the initially mentioned approach, the latter stood out for its efficiency in terms of time.
Machine-learning models
In the realm of supervised learning, two distinct approaches were explored: regression and classification. Regression models, cornerstone in predictive analytics, aim to establish relationships between independent and dependent variables, enabling quantitative predictions. For regression analysis, we employed random forest, ridge algorithms, and neural networks. These models play a crucial role in identifying patterns within datasets and predicting numerical outcomes, especially when dealing with a relatively high number of features compared to the available data.
In contrast, for classification analysis, we utilized random forest algorithms, support vector machines, and neural networks to categorize data into distinct classes, providing a framework for sorting and labeling information. These algorithms were chosen for their ability to handle the complexity introduced by the relatively high number of features.
Results and discussion
Regression models performance and validation
In the Random Forest algorithm for regression, after fitting the data with the StandardScaler function and utilizing 5-fold cross-validation with 100 estimators, the results obtained were as follows: Mean Train R-squared: 0.83 and Mean Test R-squared: −0.07. To improve upon these results, a simpler method of data division (Train-Test-Split) was employed, allocating 20% of the data for testing. This approach yielded relatively better results compared to the previous state, with Train R-squared reaching 0.82 and Test R-squared achieving 0.22. Furthermore, we tried to analyze feature importance and optimize hyperparameters (e.g., the number of trees, maximum depth, and minimum samples per leaf) but the model’s performance on the test data remained suboptimal, highlighting the need for further refinement. Random forest, while powerful, requires large datasets to perform well. Here, the relatively small dataset and relatively high-dimensional feature set may cause issues to identify meaningful patterns.
In the Ridge algorithm, combined with feature selection, the data were scaled using the RobustScaler algorithm, and 20% of the data were designated for testing. Subsequently, the SelectKbest command was utilized to identify 25 important features, which were then processed within the Ridge algorithm. The outcomes revealed a Mean Train R-squared of 0.10 and a Mean Test R-squared of 0.00. Ridge regression is likely struggling because it assumes a linear relationship, which might not fit the data well if there are non-linearities or interactions between features.
Moving on to the Neural network algorithm, the data were scaled using the RobustScaler algorithm, followed by division into 15-fold cross-validation sets for training and testing. A five-layer forward neural networks algorithm with the tanh activation function was employed. The results indicated a training R-squared of 0.88 and a testing R-squared of about 0.84. Figure 1 illustrates the changes in the loss function with respect to the number of epochs executed by the algorithm. The fluctuations observed in Fig. 1 could be attributed to various factors such as local gradients, learning rate, the number of nodes, the depth of the neural networks implemented, and the limited amount of training data in each category. Nonetheless, given the overall decreasing trend depicted in the graph, the efficiency and accuracy of the model are affirmed.

Loss function changes of train and test sets according to the number of times the program is executed (epochs) for the regression neural network algorithm.
Grounded in game theory, SHAP values were calculated to assign importance to each feature, with positive values indicating a positive impact on the prediction and negative values signifying a negative impact. The magnitude of these values quantifies the strength of the respective effects59,60.
According to Fig. 2 obtained from SHAP analysis, an increase in the following features positively influences the model’s performance: number of carbonyl oxygens (excluding carboxyl), secondary amine functional group, two interconnected rings, methoxy and ester functional groups, carboxylic acid (including unsaturated carboxylic acids), number of carbonyl oxygens, and number of benzene and aromatic rings. Additionally, a reduction in rotatable bonds, the number of unsaturated and saturated carbo rings, the number of radical electrons, the number of aromatic nitrogens, and the tertiary amine functional group also positively impacts the model.

The effect of features on the model performance using SHAP analysis on regression neural network algorithm.
Classification models performance and validation
In this section, we delve into the outcomes of machine learning classification models. To facilitate analysis, we categorized capacity efficiency values into three groups: “low,” “good,” and “perfect,” representing varying levels of capacity retention after 100 cycles. Specifically, values ranging from 0 to 34.6 were labeled as “low,” those from 34.6 to 69.33 as “good,” and those from 69.33 to 104 as “perfect.” This classification framework aids in comprehending how effectively the models predict capacity efficiency across diverse retention levels. In the Support Vector Machine (SVM) algorithm, the data underwent scaling using the StandardScaler function and was subsequently partitioned using 5-fold cross-validation. The Poly kernel was selected due to its minimal error compared to other available options.
For the SVM, the train accuracy, precision, recall, and F1-score were 0.68, 0.73, 0.68, and 0.64, respectively, while the test metrics were 0.54, 0.59, 0.54, and 0.44, indicating moderate performance but poor generalization. For the Random Forest algorithm, the data was standardized using the StandardScaler command and split using 5-fold cross-validation. The number of estimators was fixed at 5.
The Random Forest model achieved strong training performance (accuracy: 0.91, precision: 0.92, recall: 0.91, F1-score: 0.91) but showed significant overfitting, with test metrics dropping to 0.52, 0.63, 0.52, and 0.51 for accuracy, precision, recall, and F1-score respectively. While the SVM and random forest models achieved low test accuracies (SVM: 0.54, Random Forest: 0.52), they provide valuable insights into the dataset’s complexity and the challenges of predicting binder performance. These baseline results reinforced the need for more sophisticated models, such as neural networks, to effectively handle the high-dimensional and complex nature of the dataset.
In the Neural network algorithm with feature selection, the data was scaled using the StandardScaler and partitioned using 20-fold cross-validation. Subsequently, features were selected using lasso with an alpha value of 0.0003, retaining the top 50 features. The alpha value of 0.0003 was determined through manual experimentation, where we tested a range of alpha values and selected the one that provided the best balance between feature selection and model performance. This value was chosen because it effectively reduced the number of features while maintaining a high level of predictive accuracy. A 3-layer neural network was then constructed, with 150 epochs, a batch size of 2, and a patience of 5. The Neural Network with Lasso feature selection demonstrated excellent performance on both training (accuracy: 0.95, precision: 0.95, recall: 0.95, F1-score: 0.95) and test data (accuracy: 0.90, precision: 0.90, recall: 0.90, F1-score: 0.89), highlighting its superior generalization ability, and high accuracy without overfitting or underfitting.
This model achieves a commendable accuracy of approximately 90% in correctly predicting the data within each group (low, good, perfect). Figure 3 illustrates the cost function of the neural network classification algorithm against the number of epochs. The fluctuations observed in this graph can be attributed to the significant number of parameters involved in the algorithm, as well as the limited amount of test data and the complexity of the model. It is noteworthy that despite these fluctuations, the results obtained with the current parameter values surpass all previous implementations. Thus, these specific parameter values were selected for the algorithm.

Changes in the train and test sets loss function of the neural network classification algorithm along with feature selection according to the number of epochs.
The confusion matrix of this algorithm is depicted in Fig. 4. Furthermore, the absolute impact of important features on each group was explored through SHAP analysis (Fig. 5).

Confusion matrix of neural network algorithm along with feature selection for training and test data.

SHAP analysis and display of the absolute magnitude of the effect of important features on each perfect, good, and low group for the neural network with feature selection.
According to Fig. 5, the carboxylic acid functional group, carbonyl oxygens, ether functional group, average molecular weight, and saturated carbocycles exhibit the greatest absolute effect on the “perfect” group. The Neural Networks algorithm without feature pre-selection underwent the same execution steps as the previous model, with the exception that all features were included in the neural networks. The algorithm was iterated 250 times, with each category having a training data size (category size) of 16. The number of training sessions before adjusting the learning rate was set to 50. The performance metrics demonstrated a Mean Train Accuracy of 0.97 and a Mean Test Accuracy of 0.96.

Changes in the train and test sets loss function of the neural networks algorithm without feature pre-selection across epochs.
The hyperparameters for the neural network, including the number of layers, neurons, epochs, batch size, and patience, were manually chosen based on iterative experimentation and performance evaluation. While we did not employ automated optimization techniques like grid search or Bayesian optimization, the selected configuration (e.g., a five-layer network with the tanh activation function) demonstrated strong performance, achieving a test accuracy of 96%. To prevent overfitting, we relied on techniques such as early stopping (with a patience parameter) and robust data splitting into training and test sets. Although additional regularization methods like dropout or weight decay were not tested in this study, the high-test accuracy and consistent performance across training and test data suggest that the model generalizes well.
Figure 6 illustrates the changes in the loss function with respect to the number of epochs. To reduce loss fluctuations in the model without feature selection, the following measures were taken: (1) Cross-Validation: A 15-fold cross-validation was implemented to ensure a balanced and robust evaluation of the model performance across different splits of the dataset. (2) EarlyStopping: The use of the EarlyStopping callback monitored validation loss and halted training when no further improvement was detected, helping to avoid overfitting and stabilize loss trends. (3) Robust Scaling: The dataset was scaled using the RobustScaler to mitigate the influence of outliers and improve convergence stability during training. (4) Random Seed Setting: fixed random seeds were applied across libraries (NumPy, TensorFlow, and Random) to ensure consistent and reproducible results. (5) Network Architecture: A balanced architecture with progressively reducing dense layers and the use of the tanh activation function contributed to smoother learning curves.
In comparison to the algorithm with feature selection described earlier, the fluctuations in loss are reduced, and even at its peak, the loss remains relatively small, approximately 0.12, which can be considered negligible. In Fig. 7, the confusion matrix of the neural network algorithm is presented, providing insights into the accuracy of predictions across different groups. For the training data, only one misclassification is observed (a polymer categorized as belonging to the “good” group is incorrectly predicted as a member of the “low” group), while for the test data, all groups are accurately predicted. According to Fig. 8, carbonyl oxygens, saturated carbo rings, ester functional group, average molecular weight, and exact molecular weight exert the greatest absolute effect on the “perfect” group.

Confusion matrix of the neural network algorithm without feature pre-selection.

Impact of some important features on each perfect, good, and low group for the neural network without feature pre-selection according to SHAP analysis.
Here the neural network without feature selection outperformed the version with feature selection, achieving a test accuracy of 0.96 compared to 0.90. This suggests that the full set of features may contain valuable information that is lost during feature selection, even when using methods like Lasso regression. While we attempted various manual refinements to the feature selection process, none resulted in better performance than the model without feature selection. This could indicate that the feature selection criteria need further refinement or that the interactions between features are too complex to be captured by simple selection methods. Alternatively, the NN may inherently handle high-dimensional data more effectively, leveraging all available features to identify subtle patterns that contribute to improved performance.
It is important to note that categorizing the binders into three distinct capacity retention groups (low, good, and perfect) was intended to improve interpretability and allow a more meaningful inspection of binder efficiency. Consequently, some imbalance was introduced unintentionally. We addressed this issue to some extent through careful data splitting and cross-validation, future work may explore techniques such as data augmentation or synthetic data generation to balance the dataset. Despite this, our results demonstrate that the model was still able to achieve high precision and reliable predictions. We recognize that a more balanced dataset could further enhance model performance, and we hope that in future research—either by us or by other researchers—a more comprehensive and balanced dataset will be developed to refine these findings.
Guidelines for designing self-healing binders
Guidelines for design provide valuable insights and heuristics, offering logical approaches to crafting polymers that meet specific property criteria. In this study, we introduce a set of design principles for selecting functional groups aimed at enhancing the self-healing capabilities and prolonging the lifespan of Si-based LIBs. Here, SHAP analysis is employed as a standardized and unbiased method to comprehensively elucidate the influence of each feature on the model’s prediction. Positive and negative feature contributions reveal the factors that most strongly influence binder capacity retention, guiding material scientists in optimizing chemical compositions or cross-linking strategies to enhance performance. According to the results of the algorithms, the presence of polar functional groups (e.g., -OH, -COOH, -(C = O)NH2, and others depicted in Fig. 9) in the polymer is crucial when designing a more efficient binder for Si anodes. These groups exhibit strong interactions with the silanol groups on the Si surface and facilitate the dissolution of the binder in the solvent for streamlined processing. For example, the presence of carbonyl oxygens (excluding carboxyl groups) could lead to strong hydrogen bonds and electrostatic interactions, which enhance the self-healing properties of binders. These interactions help maintain structural integrity during the large volume changes of silicon anodes, preventing pulverization and improving cycle life. Ether groups contribute to the flexibility and elasticity of polymer chains, allowing the binder to accommodate volume changes during charge/discharge cycles. Additionally, ether groups can participate in hydrogen bonding, further enhancing the self-healing capabilities of the binder. Based on these findings, we propose the following design principles for self-healing polymer binders:
-
Incorporate functional groups: Prioritize the inclusion of carbonyl oxygens, ether groups, and hydrogen bond donors/acceptors to enhance self-healing and mechanical properties.
-
Optimize polymer architecture: Design polymers with interconnected rings and balanced rigidity/flexibility to accommodate volume changes and dissipate stress effectively.
-
Leverage polar interactions: Use polar functional groups to improve adhesion, solubility, and electrochemical stability.
These insights not only guide the design of binders for silicon anodes but also provide a framework for developing advanced materials for other energy storage systems.

Structural factors of binders with the most positive effects on the amount of battery capacity retention after 100 cycles compared to the first cycle.
The primary limitation of this study was the relatively small dataset of 80 cross-linked polymer binders. While this dataset was carefully curated from 450 articles, its size may restrict the generalizability of the ML models. A larger and more diverse dataset would improve the robustness of the predictions and enable the models to capture more complex patterns. While our ML model provide valuable insights, the predictions have not yet been validated experimentally. We plan to synthesize and test the top-performing binders predicted by our model to validate their performance experimentally.
Conclusion
Considering that network-structured polymers with covalent bonds exhibit higher bond energies compared to dynamic covalent bonds (such as disulfide bridges, alkoxyamine bonds, Diels–Alder, hydrazine bonds, and boronic ester bonds), as well as non-covalent supramolecular interactions (including hydrogen bonding, host-guest interactions, metal coordination bonds, and electrostatic interactions), it is advisable to prioritize polymers containing non-covalent bonds in their composition to enhance the capacity retention of Si-based LIBs during extended cycles.
In light of the results from the regression neural networks algorithm, which demonstrated superior performance compared to other algorithms, the following considerations are recommended for the design of polymer binders (where applicable) to leverage their self-healing properties for prolonged lifespan and enhanced capacity of LIBs based on Si anodes:
-
Increasing the presence of carbonyl oxygens (excluding carboxylic acid), secondary amine functional groups, two interconnected rings, methoxy functional groups, carboxylic acid (including unsaturated carboxylic acids), the number of carbonyl oxygens, and the number of benzene and aromatic rings.
-
Reducing the number of rotatable bonds, unsaturated and saturated carbocycles, radical electrons, aromatic nitrogen, and tertiary amine functional groups.
Data availability
The full list of 450 articles detailing experimental tests on binders, subset of 80 binders, dataset and codes used during the current study are available in the GitHub repository (https://github.com/samadpour/Self-Healing-Silicon-Based-Anode-in-Li-ion-Batteries).
References
Etacheri, V., Marom, R., Elazari, R., Salitra, G. & Aurbach, D. Challenges in the development of advanced Li-ion batteries: A review. Energy Environ. Sci. 4(9), 3243–3262. https://doi.org/10.1039/c1ee01598b (2011).
Chen, Y. et al. A review of lithium-ion battery safety concerns: the issues, strategies, and testing standards. J. Energy Chem. 59, 83–99. https://doi.org/10.1016/j.jechem.2020.10.017 (2021).
Tarascon, J. M. & Armand, M. Issues and Challenges Facing Rechargeable Lithium Batteries, Nature, vol. 414, pp. 359–367, Dec. (2001). https://doi.org/10.1038/35104644
Dunn, B., Kamath, H. & Tarascon, J. M. Electrical Energy Storage for the Grid: A Battery of Choices, Science (80-.)., vol. 334, no. 6058, pp. 928–935, Nov. (2011). https://doi.org/10.1126/science.1212741
Li, M., Lu, J., Chen, Z. & Amine, K. 30 Years of Lithium-Ion batteries. Adv. Mater. 30, 1–24. https://doi.org/10.1002/adma.201800561 (2018).
Goodenough, J. B. Electrochemical energy storage in a sustainable modern society. Energy Environ. Sci. 7(1), 14–18. https://doi.org/10.1039/c3ee42613k (2014).
Kwon, T., Choi, J. W. & Coskun, A. The emerging era of supramolecular polymeric binders in silicon anodes. Chem. Soc. Rev. 47(6), 2145–2164 (2018).
Feng, K. et al. Silicon-Based anodes for Lithium-Ion batteries: from fundamentals to practical applications. Small 14(8). https://doi.org/10.1002/smll.201702737 (2018).
Watson, H. et al. Silicon-based anode for Lithium-ion batteries: effectiveness of materials synthesis and electrode Preparation Anix. Prostaglandins Leukot. Essent. Fat. Acids. 115, 60–66. https://doi.org/10.1097/JU.0000000000002945 (2016).
Rehman, W. U., Wang, H., Manj, R. Z. A., Luo, W. & Yang, J. When silicon materials Meet natural sources: opportunities and challenges for low-cost lithium storage. Small 17(9), 1904508 (2021).
Liu, Z. et al. Silica-derived hydrophobic colloidal nano-Si for lithium-ion batteries. ACS Nano. 11(6), 6065–6073 (2017).
Park, M. H. et al. Silicon nanotube battery anodes. Nano Lett. 9(11), 3844–3847 (2009).
An, Y. et al. Green, scalable, and controllable fabrication of nanoporous silicon from commercial alloy precursors for high-energy lithium-ion batteries. ACS Nano. 12(5), 4993–5002 (2018).
Vrankovic, D. et al. Highly porous silicon embedded in a ceramic matrix: a stable high-capacity electrode for Li-ion batteries. ACS Nano. 11(11), 11409–11416 (2017).
Huang, Y., Han, X. & Chen, H. Investigation of porous Silicon/Carbon composite as anodes for lithium ion batteries. Journalof Inorg. Mater. 30(4), 351–356 (2015).
Luo, Z., Xiao, Q., Lei, G., Li, Z. & Tang, C. Si nanoparticles/graphene composite membrane for high performance silicon anode in lithium ion batteries. Carbon N Y. 98, 373–380 (2016).
Xu, Y., Zhu, Y., Han, F., Luo, C. & Wang, C. 3D Si/C fiber paper electrodes fabricated using a combined electrospray/electrospinning technique for Li-ion batteries. Adv. Energy Mater. 5(1), 1400753 (2015).
Wang, B. et al. Adaptable silicon–carbon nanocables sandwiched between reduced graphene oxide sheets as lithium ion battery anodes. ACS Nano. 7(2), 1437–1445 (2013).
Sun, C. F. et al. A beaded-string silicon anode. ACS Nano. 7(3), 2717–2724 (2013).
Liu, X. et al. Sandwich nanoarchitecture of Si/reduced graphene oxide bilayer nanomembranes for Li-ion batteries with long cycle life. ACS Nano. 9(2), 1198–1205 (2015).
Xu, Y. et al. Electrospun flexible Si/C@ CNF nonwoven anode for high capacity and durable lithium-ion battery. Compos. Commun. 11, 1–5 (2019).
Chou, S. L., Pan, Y., Wang, J. Z., Liu, H. K. & Dou, S. X. Small things make a big difference: binder effects on the performance of Li and Na batteries. Phys. Chem. Chem. Phys. 16(38), 20347–20359 (2014).
Kwon, T., Choi, J. W. & Coskun, A. Prospect for supramolecular chemistry in high-energy-density rechargeable batteries. Joule 3(3), 662–682 (2019).
Joyce, C., Trahey, L., Bauer, S. A., Dogan, F. & Vaughey, J. T. Metallic copper binders for lithium-ion battery silicon electrodes. J. Electrochem. Soc. 159(6), A909 (2012).
Qin, D. et al. Flexible fluorine containing ionic binders to mitigate the negative impact caused by the drastic volume fluctuation from silicon nano-particles in high capacity anodes of lithium-ion batteries. J. Mater. Chem. A. 3(20), 10928–10934 (2015).
Wenzel, V., Nirschl, H. & Nötzel, D. Challenges in lithium-ion‐battery slurry Preparation and potential of modifying electrode structures by different mixing processes. Energy Technol. 3(7), 692–698 (2015).
Browning, K. L. et al. The Study of the Binder Poly(acrylic acid) and Its Role in Concomitant Solid–Electrolyte Interphase Formation on Si Anodes, ACS Appl. Mater. Interfaces, vol. 12, no. 8, pp. 10018–10030, Feb. (2020). https://doi.org/10.1021/acsami.9b22382
Li, S. et al. A review of rational design and investigation of binders applied in silicon-based anodes for lithium-ion batteries. J. Power Sources. 485, 229331 (2021).
Yang, Y. et al. Towards efficient binders for silicon based lithium-ion battery anodes. Chem. Eng. J. 406, 126807 (2021).
Brassinne, J., Fustin, C. A. & Gohy, J. F. Polymer gels constructed through metal–ligand coordination. J. Inorg. Organomet. Polym Mater. 23, 24–40 (2013).
Das, M., Pal, S. & Naskar, K. Exploring various metal-ligand coordination bond formation in elastomers: mechanical performance and self-healing behavior. Express Polym. Lett. 14(9), 860–880 (2020).
Zhang, C. et al. Conductive polyaniline doped with phytic acid as a binder and conductive additive for a commercial silicon anode with enhanced lithium storage properties. J. Mater. Chem. A. 8(32), 16323–16331 (2020).
Huang, W. et al. An electrochemically transformed multifunctional binder network simultaneously strengthens the interphase stability and mechanical integrity of silicon anodes. Chem. Eng. J. 478, 147314 (2023).
He, X., Han, R., Jiang, P., Chen, Y. & Liu, W. Molecularly engineered conductive polymer binder enables stable lithium storage of Si. Ind. Eng. Chem. Res. 59(7), 2680–2688 (2020).
Liu, Z. K. et al. On-site cross-linking of polyacrylamide to efficiently bind the silicon anode of lithium-ion batteries. ACS Appl. Mater. Interfaces. 15(20), 24416–24426 (2023).
Jiao, X. et al. Highly energy-dissipative, fast self‐healing binder for stable Si anode in lithium‐ion batteries. Adv. Funct. Mater. 31(3), 2005699 (2021).
Nguyen, C. C., Yoon, T., Seo, D. M., Guduru, P. & Lucht, B. L. Systematic investigation of binders for silicon Anodes: interactions of binder with silicon particles and electrolytes and effects of binders on solid electrolyte interphase formation. ACS Appl. Mater. Interfaces. 8, 12211–12220. https://doi.org/10.1021/acsami.6b03357 (May 2016).
Jiang, Y. et al. Electrochemical performance of Si anode modified with carbonized gelatin binder. J. Power Sources. 325, 630–636. https://doi.org/10.1016/j.jpowsour.2016.06.089 (2016).
Bridel, J. S., Azaïs, T., Morcrette, M., Tarascon, J. M. & Larcher, D. Key Parameters Governing the Reversibility of Si/Carbon/CMC Electrodes for Li-Ion Batteries, Chem. Mater., vol. 22, no. 3, pp. 1229–1241, Feb. (2010). https://doi.org/10.1021/cm902688w
Kovalenko, I. et al. Oct., A major constituent of brown algae for use in high-capacity Li-ion batteries., Science, vol. 334, no. 6052, pp. 75–79, (2011). https://doi.org/10.1126/science.1209150
Yoon, D. E. et al. Dependency of electrochemical performances of silicon lithium-ion batteries on glycosidic linkages of polysaccharide binders. ACS Appl. Mater. Interfaces. 8(6), 4042–4047 (2016).
Magasinski, A. et al. Nov., Toward Efficient Binders for Li-Ion Battery Si-Based Anodes: Polyacrylic Acid, ACS Appl. Mater. Interfaces, vol. 2, no. 11, pp. 3004–3010, (2010). https://doi.org/10.1021/am100871y
Il Choi, S. et al. Preparation of Si/C anode with PVA nanocomposite for Lithium-ion battery using electrospinning method. Korean Chem. Eng. Res. 56, 139–142 (2018).
Park, H. K., Kong, B. S. & Oh, E. S. Effect of high adhesive Polyvinyl alcohol binder on the anodes of lithium ion batteries. Electrochem. Commun. 13(10), 1051–1053 (2011).
Luo, L. et al. Comprehensive Understanding of high Polar polyacrylonitrile as an effective binder for Li-ion battery nano-Si anodes. ACS Appl. Mater. Interfaces. 8(12), 8154–8161 (2016).
Chen, L., Xie, X., Xie, J., Wang, K. & Yang, J. Binder effect on cycling performance of Silicon/carbon composite anodes for lithium ion batteries. J. Appl. Electrochem. 36, 1099–1104 (2006).
Huang, S. et al. Low addition amount of self-healing ionomer binder for Si/graphite electrodes with enhanced cycling. New. J. Chem. 42(9), 6742–6749 (2018).
Shi, Y., Zhou, X. & Yu, G. Material and structural design of novel binder systems for high-energy, high-power lithium-ion batteries. Acc. Chem. Res. 50(11), 2642–2652 (2017).
Ling, M. et al. Dual-functional gum Arabic binder for silicon anodes in lithium ion batteries. Nano Energy. 12, 178–185 (2015).
Jeong, Y. K. et al. Millipede-inspired structural design principle for high performance polysaccharide binders in silicon anodes. Energy Environ. Sci. 8(4), 1224–1230 (2015).
Wei, L., Chen, C., Hou, Z. & Wei, H. Poly (acrylic acid sodium) grafted carboxymethyl cellulose as a high performance polymer binder for silicon anode in lithium ion batteries. Sci. Rep. 6(1), 19583 (2016).
Luo, C. et al. Novel lignin-derived water-soluble binder for micro silicon anode in lithium-ion batteries. ACS Sustain. Chem. Eng. 6(10), 12621–12629 (2018).
Lee, J. et al. Amphiphilic graft copolymers as a versatile binder for various electrodes of high-performance lithium‐ion batteries. Small 12(23), 3119–3127 (2016).
Chen, D. et al. Self-healing materials for next-generation energy harvesting and storage devices. Adv. Energy Mater. 7(23), 27–31. https://doi.org/10.1002/aenm.201700890 (2017).
Liu, T. et al. Interweaving 3D network binder for high-areal‐capacity Si anode through combined hard and soft polymers. Adv. Energy Mater. 9(3), 1802645 (2019).
Cai, Y. et al. Dual cross-linked fluorinated binder network for high-performance silicon and silicon oxide based anodes in lithium-ion batteries. ACS Appl. Mater. Interfaces. 11(50), 46800–46807 (2019).
Wei, L. & Hou, Z. High performance polymer binders inspired by chemical finishing of textiles for silicon anodes in lithium ion batteries. J. Mater. Chem. A. 5(42), 22156–22162 (2017).
You, R. et al. An environmental friendly cross-linked polysaccharide binder for silicon anode in lithium-ion batteries. Ionics (Kiel). 25, 4109–4118 (2019).
Yang, Z. Y. et al. Structural analysis and identification of false positive hits in luciferase-based assays. J. Chem. Inf. Model. 60(4), 2031–2043 (2020).
Xie, Y. R., Castro, D. C., Bell, S. E., Rubakhin, S. S. & Sweedler, J. V. Single-cell classification using mass spectrometry through interpretable machine learning. Anal. Chem. 92(13), 9338–9347 (2020).
Author information
Authors and Affiliations
Contributions
Mahta Moazzenzadeh and Mahmoud Samadpour conceptualized the study and developed the research framework. Mahta Moazzenzadeh prepared the figures and wrote the first draft of the manuscript. Mahmoud Samadpour revised the manuscript, incorporating feedback and ensuring clarity and coherence. All authors reviewed and approved the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Moazzenzadeh, M., Samadpour, M. Machine learning-driven insights into self-healing silicon-based anodes for high-performance lithium-ion batteries. Sci Rep 15, 11176 (2025). https://doi.org/10.1038/s41598-025-95906-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-95906-x
