
Abstract
Domain generalization (DG) addresses the challenge of out-of-distribution (OOD) data; however, the reliance on statistical correlations during model development often introduces shortcut learning problems. Current approaches to mitigating these issues commonly involve the integration of causal inference, formalizing DG problems through a general structural causal model. Nevertheless, ensuring the independence of features when incorporating causal models is often overlooked, leading to spurious causal relationships. In this work, we design three independent feature modules using GAN variants (GAN, WGAN, and WGAN-GP) and select the best-performing WGAN module to integrate into the existing causal model framework, constructing an independent causal relationship learning (ICRL) model. Extensive experiments on widely used datasets demonstrate that our model, with independent causal representations, outperforms the original model in both performance and efficiency, thereby validating the effectiveness of our proposed approach. The code for ICRL can be accessed at: https://github.com/22Shao/ICRL.git.
Similar content being viewed by others

Introduction
Deep neural networks are rapidly approaching or even surpassing human-level performance in object classification1, demonstrating outstanding results across various fields such as complex strategy games, medical image analysis, and cross-lingual text translation2,3,4. However, as real-world tasks become more complex and application scenarios diversify, the limitations of deep neural networks are becoming more apparent. Even minor, imperceptible changes or variations in background, particularly with out-of-distribution (OOD) data, can significantly compromise their predictive accuracy5,6,7. Consequently, domain generalization (DG) has gained attention, aiming to create models capable of generalizing to unseen target domains by utilizing data from different training domains or environments.

The structural causal model (SCM) for domain generalization (DG) is represented, where solid arrows denote causal relationships from parent to child nodes, while dashed arrows indicate statistical dependencies.
Common strategies to enhance DG performance include invariant feature learning, meta-learning, and adversarial training8,9,10. However, these methods do not entirely eliminate the shortcut learning problem, which often arises in deep neural network training. When superficial correlations are removed, predictions tend to become random11,12. To address this, causal representation learning methods with strong assumptions are needed to identify and control confounding factors, reducing spurious correlations and enabling the model to focus on causal features13,14,15,16,17. Causal representation learning frameworks in deep learning typically involve causal variable learning, causal mechanism learning, and causal structure learning. Nonetheless, these models often overlook the control of feature independence, leading to misleading causal relationships18,19,20,21.
This paper proposes a domain generalization learning model based on independent causal relationships. To better illustrate this model, a structural causal model (SCM) is introduced to represent the intrinsic causal mechanisms between data and labels in domain generalization, enhancing the model’s generalization capability, as shown in Fig. 1. Domain-specific information is treated as causal factors, while domain-invariant factors, such as “animal posture” in the cat-dog classification task, are considered non-causal. In contrast, factors unrelated to the category, such as “image style” in cat-dog classification, are regarded as non-causal and typically domain-dependent. Attention is also given to the independence of causal factors, like “background color and brightness” in cat-dog classification. Each raw data point x is composed of a mixture of causal factors S and non-causal factors U, with only the former influencing the label Y, as depicted in Fig. 1. The goal is to disentangle the independent causal factors S from the input x, reconstructing the invariant causal mechanism, which can be achieved through causal intervention \(P(Y \mid do(U), S)\). The do-calculus operator \(do(\cdot )\)22 represents intervention on the variables. However, since causal relationships cannot be fully formalized and complex dependencies exist among variables in real-world data, designing models that ensure factor independence remains a challenging task.

Explanation of the properties of causal factors.
Inspired by statistical independence, we build upon the findings of studies23,24,25,26 to establish a hypothesis where causal factors strictly adhere to independence. For the causal factor S to be considered independent, it must satisfy two properties: (1) S follows a normal distribution; (2) the decomposition of S satisfies uncorrelatedness. As shown in Fig. 2a, a dependency exists between the causal factor S and the non-causal factor U. If this dependency is not removed through independence testing, the effect of U on Y may be erroneously attributed to S, leading to confounding bias. Conversely, Fig. 2b illustrates an ideal causal factor S that meets the independence criteria. Based on this, we propose the Independent Causal Relationship Representation for Domain Generalization (ICRL) algorithm, which enforces the learned representation to satisfy the above properties. We further simulate the decomposition of causal factors across each dimension of the representation, resulting in enhanced generalization capabilities.
In summary, for each input, we first design a Generative Adversarial Network (GAN) capable of fitting a standard normal distribution. This model aligns the factors to follow a normal distribution and eliminates the correlation between S and U, before feeding them into an existing causal representation learning model to uncover causal mechanisms, thereby improving generalization. Our contributions are as follows:
-
1.
We construct a GAN model to ensure factors follow a normal distribution.
-
2.
We develop an ICRL model for domain generalization based on independent causal relationships.
-
3.
Extensive experiments and analysis on widely-used datasets demonstrate the effectiveness and superiority of our method.
Related work
Domain generalization
Domain Generalization (DG) refers to a machine learning approach that enables models to perform well across different domains, even when trained only on data from specific domains, demonstrating strong cross-domain generalization capabilities27. Since the introduction of DG, numerous methods have been developed to explore this concept. These include aligning source domain distributions through invariant representation learning28,29, exposing the model to domain shifts via meta-learning during training30,31, and augmenting data through domain synthesis32.
Additionally, Multi-Task Learning (MTL)33 aids in domain generalization by training multiple tasks simultaneously, allowing the model to share feature representations across tasks, which helps maintain performance across different data distributions. In DG, tasks can be treated as proxies for different domains, and MTL enables the model to identify and extract common features across tasks (or domains), thus improving performance in unseen domains.
Data Augmentation34 is another key technique in DG, increasing data diversity to simulate domain variations, thereby helping the model learn more general features. Common techniques include image rotation, flipping, color perturbation, and more complex synthetic data generation methods.
In contrast to the above methods, our approach tackles the DG problem from the perspective of causal feature independence.This approach focuses on reducing confounding factors by making causal features independent, thereby uncovering the underlying causal mechanisms and demonstrating enhanced generalization performance. In contrast to the recent AMCR method35, which relies on sample diversification and data augmentation but is limited when significant discrepancies exist between the target and source domains, our method leverages causal feature independence to learn more accurate causal features, achieving more efficient cross-domain generalization. Furthermore, compared to the bilevel optimization-based meta-learning framework proposed by Chen et al.36, which aligns features between source domains using traditional statistical methods, our approach removes non-causal factors, preventing reliance on domain-specific noise and mitigating the impact of spurious correlations, thereby exhibiting stronger adaptability in large-scale domain shifts.
Causal mechanisms
Since Judea Pearl introduced the theory of causal inference, it has had a profound impact on modern statistics, artificial intelligence, and machine learning37. Unlike statistical correlations, which rely on data trend consistency to determine relationships, causal relationships reflect the intrinsic characteristics and structures within and between variables. In recent years, various methods based on causal relationships have been proposed to discover invariant causal mechanisms38,39,40 or recover causal features41,42, thereby improving out-of-distribution (OOD) generalization. However, these methods often depend on restrictive assumptions in causal graphs or structural equations. Recent studies have addressed this issue using counterfactual methods to mitigate data distribution shifts, reduce language bias and enhance class balance43,44,45. For example, Deng et al.46 introduced the counterfactual model CounterAL, which improves performance on under-annotated out-of-distribution (OOD) tasks by better generalizing to unseen data through the use of factual and counterfactual samples. However, these approaches typically focus on sample generation and feature synthesis, often overlooking the in-depth modeling of causal mechanisms and factors. To better explore the relationships between causal factors, Fangrui Lv et al.47 introduced an intervention-based Causal Independence Representation Learning (CIRL) method into Domain Generalization (DG). This method explicitly models causal factors using dimensional representations based on theoretical formulations, while relying on more general causal structures without restrictive assumptions.
Our proposed approach is similar to CIRL in its use of intervention-based causal decomposition. However, we reinforce the condition of causal independence during the extraction of causal factors by employing distribution matching techniques to ensure strict independence between factors. In short, our method places greater emphasis on maintaining independence among causal factors.
Statistical independence
Statistical independence describes a lack of any relationship between two events or random variables, meaning that the occurrence or value of one does not affect the occurrence or value of the other48. It is commonly expressed as \(P(A \cap B) = P(A) \cdot P(B)\), where A and B are two events. Since the assumption of independence contributes to building more robust and generalizable models, testing for feature or factor independence is crucial in domain generalization. Common methods for testing independence include the Chi-Square Test49, Spearman and Kendall correlation coefficients50, and Mutual Information51. However, in domain generalization using causal inference, independence testing is often less rigorous. For example, CIRL uses simple correlation tests, which do not fully ensure independence between elements, as statistical uncorrelatedness does not imply independence.
For normally distributed random variables, independence and uncorrelatedness are equivalent. If two random variables X and Y follow a joint normal distribution (i.e., their joint distribution is a bivariate normal distribution), then independence and uncorrelatedness are equivalent. Therefore, our model enhances feature independence by matching the distribution to a normal form after removing correlations, ensuring strict independence between elements.
Methods
In this section, we consider Domain Generalization (DG) from the perspective of independent causal factors, adopting a general structural causal model as shown in Fig. 1. Previous studies have demonstrated47,52,53 that the intrinsic causal mechanisms (formalized as conditional distributions) are identifiable given the causal factors, and mature frameworks exist for learning causal representations based on the properties of these factors. However, since associations between causal factors may lead to misleading outcomes, we aim for complete independence between the factors when they occur. Therefore, we propose learning causal representations based on the properties of independent causal factors, serving as a mimic while retaining strong generalization capabilities.

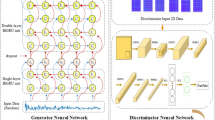
ICRL framework. The causal intervention module generates augmented images by intervening on non-causal factors. Both the original and augmented image representations are fed into the decomposition module, which applies a decomposition loss to enforce separation between causal and non-causal factors. The disentangled factors are then processed by the Independence module to ensure they follow a normal distribution. Finally, the Adversarial Masking module performs an adversarial task between the generator and the masker, ensuring that the learned representations possess sufficient causal information for classification.
Causal independence from the perspective of statistical independence
In statistics, proving the independence of two random variables or events typically relies on the relationship between their joint and marginal distributions. The most common method is the direct calculation approach: first, the joint distribution of random variables X and Y, \(P(X=x, Y=y)\), is computed, followed by the marginal distributions \(P(X=x)\) and \(P(Y=y)\). If the product of the marginal distributions equals the joint distribution, i.e., \(P(X=x, Y = y) = P(X = x) \cdot P(Y=y)\), then X and Y are proven to be independent.
However, in practical causal inference, it is often challenging to accurately obtain the joint distribution, making it difficult to directly determine independence between X and Y. Therefore, we use correlation coefficients to assess the independence of causal factors. If the correlation coefficient is zero and X and Y follow a normal distribution, then they are independent. We assume that X and Y are jointly normally distributed random variables. According to the definition of a bivariate normal distribution, the joint distribution of X and Y is given by:
For the joint normal distribution of X and Y, the joint probability density function (PDF) is:
Here, \(\rho\) represents the correlation coefficient. When X and Y are uncorrelated, \(\text {Cov}(X, Y) = 0\), implying \(\rho = 0\). In this case, the joint PDF simplifies to:
This can be viewed as the product of the PDFs of two independent normal distributions:
where
According to the definition of independence, if the product of the marginal distributions equals the joint distribution, i.e., \(P(X=x, Y=y) = P(X=x) \cdot P(Y=y)\), then X and Y are independent.
Causal factor normalization based on the GAN model
Traditional normalization techniques, such as Box-Cox or logarithmic transformations, often perform poorly when applied to high-dimensional data. In contrast, GAN models excel at handling high-dimensional and complex structured data, enabling them to capture intricate distributions in high-dimensional spaces54. Thus, we designed a GAN model to ensure that the causal factor X follows a normal distribution. For a set of causal factors X and an outcome variable Y, our goal is for the GAN to generate a normalized causal factor \(X'\), such that \(X'\) follows a normal distribution while preserving its causal relationship with Y.
As shown in Fig. 3, the GAN model consists of a generator G that takes a noise vector z as input and produces the causal factor \(X' = G(z)\). The discriminator D is trained to distinguish between the real causal factors X and the generated ones \(X'\). The discriminator’s objective is to output a decision that separates the generated causal factors from the true ones. The overall optimization objective for the GAN is:
To ensure that the generated causal factors \(X'\) follow a normal distribution, we introduce a normalization constraint in the generator’s optimization process. The additional normal distribution loss term is defined as:
where \(\mu\) and \(\sigma\) represent the mean and standard deviation of the normal distribution. Accordingly, the generator’s objective function is modified to:
Here, \(\lambda\) is a regularization coefficient that balances the GAN loss with the normal distribution loss. During optimization, the generator gradually learns to produce causal factors \({\hat{X}} = G(z)\) that approximate the normal distribution \({\mathscr {N}}(\mu , \sigma ^2)\). This means that as the training progresses, the optimization will force the generator to output causal factors that conform to the normal distribution. Additionally, \(\sigma\) serves as a lower bound to ensure the data follows the specified distribution (guaranteed through training the discriminator), making this approach an unbiased estimator that can be further applied to causal inference.
Independent causal representation learning
In this section, we present a representation learning algorithm inspired by the concept of independent causal relationships. Briefly, the algorithm first applies Fourier transform to intervene and separate causal factors, followed by normalization. A designed GAN model is then used to transform the intervened factors into a normal distribution while ensuring zero correlation between them. Finally, a masked attention mechanism is employed to extract causal information from sub-dimensions, allowing for a more effective representation. The overall framework is depicted in Fig. 3.
Causal separation module
The first step is to intervene on the causal factors, separating the causal factor S from the non-causal factor U. In most cases, directly extracting causal factors is challenging due to the complexity of data transformations or non-linear mappings in the causal factor extractor \(g(\cdot )\). Therefore, we leverage the Fourier transform module proposed by Xu55 to capture non-causal factors, as illustrated in Fig. 4.

Fourier transform to separate causal factors.
Based on the characteristics of the Fourier transform: the phase component retains the high-order statistical information of the original signal, while the amplitude component contains classical statistical information56,57. For the input image \(x^0\), its Fourier transform is expressed as:
where \({\mathscr {A}}(x^0)\) and \({\mathscr {P}}(x^0)\) represent the amplitude and phase components, respectively. Using the FFT algorithm, the Fourier transform \({\mathscr {F}}(x^0)\) and its inverse \({\mathscr {F}}^{-1}(x^0)\) can be efficiently computed58. We then perform linear interpolation on the amplitude information between the original image \(x^0\) and a randomly sampled image from any source domain \(\hat{x^0}\):
where \(\lambda \sim U(0, 1)\) controls the degree of perturbation. The perturbed amplitude is combined with the original phase component, and the enhanced image \(\hat{x^0}\) is obtained by applying the inverse Fourier transform:
The representation generator implemented via a CNN model is denoted as \(g(\cdot )\), where \(r = g(\cdot ) \in {\mathbb {R}}^{1 \times N}\), with N being the dimensionality. To maintain the invariance of the causal factor S despite the intervention on U, the optimization of g is performed to enforce consistent representation across the intervention:
where \({\hat{r}}^0_i\) and \({\hat{r}}^a_i\) denote the Z-score normalized i-th column of \(R^0 = \left[ (r^0_1)^T, \ldots , (r^0_B)^T \right] ^T \in {\mathbb {R}}^{B \times N}\) and \(R^a = \left[ (r^a_1)^T, \ldots , (r^a_B)^T \right] ^T\), respectively, \(B \in {\mathbb {Z}}_+\) is the batch size, \(r^0_i = {\hat{g}}(x^0_i)\) and \(r^a_i = {\hat{g}}(x^a_i)\) for \(i \in \{1, \ldots , B\}\). And the COR function measures the correlation between representations before and after intervention, achieving the separation of causal and non-causal factors.
Causal independence module
In the process of ensuring independence of causal factors, we strictly adhere to the definition of independence outlined in Sect. 3.1. Therefore, it is necessary to ensure that any two dimensions of the representation are mutually independent:
We then employ a GAN model to maintain the normal distribution of the factors. To select the most suitable GAN model, we designed and compared three different types: Vanilla GAN59, Wasserstein GAN60, and Wasserstein GAN with Gradient Penalty61. Based on the comparison, the most appropriate GAN model was selected. The loss functions for the three GAN models were defined in Sect. 3.2.
(1) Vanilla GAN
In the context of Vanilla GANs, the loss functions for the generator and discriminator can be expressed as follows:
The objective of a GAN is for the generator to produce a distribution that closely resembles the distribution of real data. The discriminator’s role is to differentiate between real and generated data. The loss function is defined as:
where \(z\) represents the input noise to the generator, typically sampled from a normal distribution.
(2) Wasserstein GAN
The core idea of Wasserstein GAN (WGAN) is to use the Wasserstein distance to measure the discrepancy between the generated data distribution and the true data distribution. This approach enhances training stability and addresses the gradient vanishing problem commonly encountered in Vanilla GANs. The loss function is defined as follows:
In WGAN, the discriminator is referred to as the “critic” because it outputs a score rather than a probability.
(3) Wasserstein GAN with Gradient Penalty
WGAN-GP improves upon WGAN by incorporating a gradient penalty term to ensure a closer approximation of the Wasserstein distance between the generated distribution and the real distribution. The loss function is defined as follows:
where \({\hat{r}}\) is a sample obtained through interpolation between the real data distribution and the generated data distribution.
To ensure that the loss conforms to a normal distribution, we apply a normal distribution loss directly to the output of the generator. This can be achieved by minimizing the proximity of the generator’s output mean and standard deviation to the desired values, as well as ensuring the difference aligns with a unit variance.
Ultimately, the loss function can be expressed as a combination of the GAN loss and the normal distribution loss:
where \({\mathscr {L}}_{\text {GAN}}\) represents the loss function of any of the aforementioned GAN models, and \(\beta\) is a hyperparameter used to balance the two components of the loss. This formulation effectively combines the normal distribution loss with the losses from the three types of GAN models.
After achieving complete independence of the features, we conduct a feature analysis. Based on previous literature, we introduce a causal decomposition loss function \({\mathscr {L}}_{\text {Fac}}\), expressed as:
For the same dimensions of \(R^0\) and \(R^a\), the objective is to maximize their correlation; for different dimensions, the goal is to minimize the correlation.
Adversarial encoding module
In multiple source domains, while using monitoring labels y, we cannot guarantee that every dimension of the learned representations corresponds to causal factors for the classification \(X \rightarrow Y\). Specifically, there may exist lower-dimensional representations that carry causal information with minimal correlation. Therefore, dimensions with higher correlation require reinforcement to enhance their impact. With the assistance of our independent causal model, the dimensions should also be joint, allowing us to select sub-dimensions that contain diverse new causal information not found in the remaining dimensions, thereby enriching the overall representation. Consequently, we utilize a specially designed adversarial encoding module. By constructing a mask based on a neural network, we represent the learning responsibility of each dimension with \(w'\) and define \(\epsilon \in (0, 1)\) to indicate which dimensions are optimal while the rest are considered inferior:
Here, we sample from a mask close to a value of 1 for kN, utilizing the commonly used differentiable GumbelSoftmax technique62. By multiplying the learned mask with the obtained masks \(h_1\) and \(1-m\), we can obtain the respective masks for the dimensional values. These masks are then input into two different classifiers, \(h_1\) and \(h_2\). The loss functions for the optimal and suboptimal representations are defined as follows:
We optimize the mask by minimizing \({\mathscr {L}}^{\sup }_{\text {cls}}\) and maximizing \({\mathscr {L}}^{\inf }_{\text {cls}}\), while also minimizing the overall loss to generate the models and classifiers \(h_1\) and \(h_2\).
In summary, our objective is:
Experiments
Datasets
In practical applications, numerous challenges arise in the recognition of various digits and objects. To demonstrate that our improved model effectively enhances recognition accuracy of identical items across different environments, we evaluate it on two publicly available datasets: Digits-DG63 and PACS64. The Digits-DG dataset includes four subsets-MNIST65, MNIST-M66, SVHN67, and SYN65-which feature variations in font styles, backgrounds, and stroke colors. For each domain, we randomly select 300 images per class, splitting the data into 80% for training and 20% for validation. For object recognition, we use the PACS dataset, which encompasses four distinct domains: Art-Painting, Cartoon, Photo, and Sketch. These domains contain seven categories: dog, elephant, giraffe, guitar, house, horse, and person. To ensure a fair comparison with baseline models, we adhere to the original train-validation splits provided by53 when testing the model on this dataset.
Implementation details
Following the commonly used leave-one-domain-out protocol64, we designate one domain as the unseen target domain for evaluation while training on the remaining domains. Based on previous experimental findings, for Digits-DG, all images are resized to 32\(\times\)32, and the network is trained from scratch using mini-batch SGD with a batch size of 128, momentum of 0.9, and weight decay of 5e-4 for 50 epochs. The learning rate is reduced by a factor of 0.1 every 20 epochs. For PACS, all images are resized to 224\(\times\)224. The network is trained from scratch for 50 epochs using mini-batch SGD with a batch size of 16, momentum of 0.9, and weight decay of 5e-4, with the learning rate decaying by a factor of 0.1 at 80% of the total epochs. The hyperparameters \(\kappa\) and \(\tau\) are selected based on the results from the source domain validation set, as the target domain is not accessible during training. Specifically, we set \(\kappa = 60\%\) for Digits-DG and PACS, and \(\kappa = 80\%\) for Office-Home. The \(\tau\) value is set to 2 for Digits-DG and 5 for the other datasets. All results are reported as the average accuracy over three independent runs.
Experimental results
The results on the Digits-DG dataset are presented in Table 1, where ICRL outperforms all compared baselines in terms of average accuracy. Notably, ICRL exceeds the performance of domain-invariant representation methods such as CCSA68 and MMD-AAE69 by 8.5% and 8.4%, respectively, highlighting the importance of uncovering the inherent causal mechanisms between data and labels rather than relying on superficial statistical dependencies. Furthermore, we compare ICRL with CIRL47, as both methods utilize similar causal intervention classification and adversarial masking modules. ICRL surpasses CIRL by 0.5%, indicating that enforcing strict mutual independence across the disentangled features of an image further enhances the effectiveness of extracting the intrinsic causal relationships between data and labels. This provides additional validation of the effectiveness of our approach.
The results on the PACS dataset were obtained using three different GAN models based on ResNet-18 and ResNet-50, as shown in Tables 2 and 3, respectively. It can be observed that the WGAN method outperforms both Vanilla GAN and WGAN-GP, achieving significantly better performance by 4.22% on ResNet-18 and 1.45% on ResNet-50. Additionally, when comparing ICRL with CIRL, which does not strictly enforce causal independence, ICRL shows a slight improvement, outperforming CIRL by 1.06% on ResNet-18 and 0.72% on ResNet-50.
Vanilla GAN employs the Jensen-Shannon (JS) divergence to measure the difference between the generator’s distribution and the real distribution. However, in practice, the JS divergence tends to a constant when the two distributions have little overlap, leading to vanishing gradients and preventing the generator from updating effectively, thus making the training unstable or prone to collapse. WGAN addresses this issue by replacing the JS divergence with the Wasserstein distance (Earth Mover’s Distance), which offers smoother gradients when the generator’s distribution approaches the real distribution, thereby mitigating the vanishing gradient problem and stabilizing the training process. As a result, WGAN outperforms Vanilla GAN. Moreover, since the data used to train the Vanilla GAN models in this experiment were randomly sampled from a normal distribution within the range of [− 1,1], and WGAN does not require the complexity of gradient penalties on simple data, it performed better than WGAN-GP. Despite using simple random data to train the Vanilla GAN models, our model still performed slightly better than causal representation models without strict independence enforcement. Overall, this demonstrates the advantage of independent causal features.
Experimental analysis
Ablation study
We analyze the impact of the Causal Intervention (CInt.), Causal Independence (CIid.), and Adversarial Masking (AdvM.) modules within CIRL. Table 4 presents the results of different ICRL variants on the PACS dataset using ResNet-18 as the backbone. By comparing variants 1, 2, and 3, we can observe the varying degrees of influence each component has on the model’s performance. This demonstrates that the degree of independence between causal factors significantly affects overall model performance, while the CInt., CIid., and AdvM. modules are interdependent and equally essential for optimal results.
Visual explanation
To intuitively validate the claim that ICRL representations can model causal factors, we applied the visualization technique from78 to generate attention maps for the last convolutional layer of both the baseline method (DeepAll) and CIRL. The results, shown in Fig. 5, demonstrate that ICRL focuses more on specific regions compared to the baseline, learning representations that are more closely associated with the target class. For instance, in the case of the guitar, the ICRL model places greater emphasis on the guitar body, while CIRL still focuses on the entire guitar (both body and neck), lacking attention to specific parts.

Visualization of the attention maps from the final convolutional layer on the PACS dataset.
Independence of causal representations
To intuitively demonstrate the effectiveness of our causal independence approach, we use \(\Vert C \Vert ^2_F = \Vert \text {diag}(C) \Vert ^2\) as a metric, where smaller values indicate greater independence. Here, C represents the correlation matrix. The results, as shown in Fig. 6, clearly illustrate that on both ResNet-18 and ResNet-50, ICRL achieves better independence throughout the entire training process compared to CIRL, validating the effectiveness of the causal independence module we designed. Additionally, the differences in independence among Vanilla GAN, WGAN, and WGAN-GP can be observed in the figure. Consistent with the model performance, WGAN demonstrates a significantly higher degree of causal independence compared to Vanilla GAN and WGAN-GP. This is because WGAN incorporates the Wasserstein distance to measure the difference between the real and generated distributions, unlike Vanilla GAN, which uses the Jensen-Shannon divergence. The Wasserstein distance prevents the vanishing gradient problem during optimization, leading to more stable training. Consequently, WGAN is better able to approximate a normal distribution, ensuring that each causal factor corresponds to a normal distribution, thus achieving independence among the factors. In contrast, WGAN-GP introduces a gradient penalty to enforce the Lipschitz continuity of the discriminator, which requires constraining the critic’s gradients at each training step. This constraint may affect the model’s parameter updates, especially in simpler tasks where the gradient penalty may excessively restrict the generator’s freedom, leading to an overly cautious training process. In this experiment, as we only need to generate and fit a simple standard normal distribution, such excessive regularization can cause overfitting due to the overly conservative training approach. Therefore, WGAN, which fits causal factors to a normal distribution, yields the best independence results in this experiment, thus enhancing the model’s overall domain generalization ability.

Independence of causal representations evaluated on the PACS dataset with Sketch as the unseen target domain, using ResNet-18.

Sensitivity of CIRL to hyperparameters \(\tau\) and \(\kappa\) evaluated on the PACS dataset with Sketch as the unseen target domain, using ResNet-18.
Parameter sensitivity
Figure 7 illustrates the sensitivity of CIRL to hyperparameters \(\tau\) and \(\kappa\), where \(\tau \in \{2.0, 4.0, 6.0, 8.0, 10.0\}\) and \(\kappa \in \{0.4, 0.5, 0.6, 0.7, 0.8, 0.9\}\). It can be observed that CIRL achieves robust competitive performance with ResNet-18 as the backbone when \(4.0 \le \tau \le 10.0\) and \(0.7 \le \kappa \le 0.9\), further validating the stability of our approach.
Efficiency comparison
Table 5 presents the average runtime comparison of three models, each incorporating different GAN variants, on ResNet-18 and ResNet-50. The results show that the average runtime across the four domains follows the order: Vanilla GAN < WGAN < WGAN-GP. Additionally, the ICRL models using Vanilla GAN and WGAN demonstrate shorter average runtimes compared to CIRL. In terms of performance, the ICRL model with WGAN outperforms those with Vanilla GAN and WGAN-GP, making WGAN an ideal choice for handling causal independence within the ICRL framework.
Discussion
This paper introduces ICRL model for domain generalization, with a focus on ensuring the independence of causal features in deep learning models. The experimental results demonstrate that ICRL significantly outperforms several baseline models, including domain-invariant representation methods and CIRL approach. These findings underscore the critical role of independent causal feature representations in improving out-of-distribution generalization.
One of the key contributions of this work is the incorporation of strict independence among causal features, a crucial factor often overlooked in prior domain generalization and causal representation learning methods. By enforcing feature independence through a carefully designed GAN-based approach, our model effectively addresses the issue of spurious correlations that often compromise the generalization ability of machine learning models. This advancement is particularly evident in our comparison with CIRL, where ICRL outperformed the latter by a modest but meaningful margin, particularly in tasks involving complex domain shifts. This suggests that enforcing independence not only aids in capturing more accurate causal features but also enhances the model’s robustness when exposed to previously unseen domains.
Additionally, the use of Wasserstein GAN (WGAN) in the ICRL framework proved to be beneficial, offering superior performance compared to other GAN variants like Vanilla GAN and WGAN-GP. The ability of WGAN to provide more stable gradients during training was pivotal in achieving the desired causal independence in the learned representations, further validating the role of WGAN in domain generalization tasks.
Our model’s strong performance across multiple datasets, including Digits-DG and PACS, provides compelling evidence of its utility in real-world domain generalization scenarios. Notably, ICRL’s ability to generalize across diverse domains-such as handwritten digits, artistic styles, and photos-demonstrates its potential to solve a variety of practical machine learning challenges. Furthermore, the results from our ablation study highlight the importance of each component in the ICRL framework, particularly the Causal Intervention and Causal Independence modules, which work synergistically to achieve enhanced performance.
Despite these strengths, there are still limitations to the current work. While the current framework’s dependence on GAN models for distribution matching introduces computational overhead, which could impact scalability when working with very large datasets or real-time applications. This concern becomes even more significant when applying ICRL to high-dimensional data, where the computational costs of ensuring feature independence may become prohibitively large.
Moreover, while ICRL has demonstrated clear advantages in image-related tasks, its applicability in other domains, such as text classification, presents unique challenges. Text data, being sequential and highly context-dependent, requires more nuanced treatment of causal relationships. For instance, in tasks such as sentiment analysis or topic modeling, the structure of sentences, specific keywords, and the broader context play a critical role in determining the label. However, unlike images, where features can be relatively independent, text data inherently involves complex dependencies among words that may complicate the task of ensuring feature independence. In sentiment analysis, for example, individual words might not have a clear causal influence, but only in specific contexts do they form causal relationships. This makes ensuring causal feature independence while preserving contextual meaning more challenging in text classification tasks than in image tasks.
Furthermore, ICRL uses Generative Adversarial Networks (GANs) to transform features into a normal distribution for distribution matching. While this works well in image-based tasks, text representations-particularly when using word embeddings or other forms of vector representations-do not always conform to a normal distribution. The inherent ambiguity and contextual dependencies in language can complicate the process of ensuring both feature independence and contextual relevance. Consequently, adapting ICRL for optimizing text classification tasks remains a significant direction for future research.
Future work could explore ways to ensure causal feature independence while reducing computational costs. Additionally, extending the current method to handle more complex causal structures in multimodal data, such as text, could further enhance the model’s applicability across a variety of machine learning tasks.
Conclusion
This paper highlights the limitations of previous causal representation learning approaches in handling factor independence. We design a WGAN model to enforce a normal distribution on features. Furthermore, we propose the ICRL framework to learn causal representations, emphasizing the independent causal factors with desirable properties. Comprehensive experiments demonstrate the effectiveness and superiority of ICRL.
Data availability
Data is available at: https://github.com/22Shao/ICRL/tree/main/Dataset. All figures in this article were generated using Python software.
References
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778 (2016).
Agostinelli, F., McAleer, S., Shmakov, A. & Baldi, P. Solving the rubik’s cube with deep reinforcement learning and search. Nat. Mach. Intell. 1, 356–363 (2019).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4, 3–11 (Springer, 2018).
Zhou, Z. Massively multilingual text translation for low-resource languages. arXiv preprint arXiv:2401.16582 (2024).
Zhou, K., Liu, Z., Qiao, Y., Xiang, T. & Loy, C. C. Domain generalization: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 45, 4396–4415 (2022).
Ding, Y. et al. Domain generalization by learning and removing domain-specific features. Adv. Neural. Inf. Process. Syst. 35, 24226–24239 (2022).
Nagarajan, V., Andreassen, A. & Neyshabur, B. Understanding the failure modes of out-of-distribution generalization. arXiv preprint arXiv:2010.15775 (2020).
Jiang, L., Wu, J., Zhao, S. & Li, J. Domain-invariant feature learning with label information integration for cross-domain classification. Neural Comput. Appl. 1–20 (2024).
Khoee, A. G., Yu, Y. & Feldt, R. Domain generalization through meta-learning: a survey. Artif. Intell. Rev. 57, 285 (2024).
Dayal, A. et al. Madg: margin-based adversarial learning for domain generalization. Adv. Neural Inf. Process. Syst. 36 (2024).
Geirhos, R. et al. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv preprint arXiv:1811.12231 (2018).
Geirhos, R. et al. Shortcut learning in deep neural networks. Nat. Mach. Intell. 2, 665–673 (2020).
Forney, A. & Mueller, S. Causal inference in ai education: A primer. J. Causal Inf. 10, 141–173 (2022).
Schölkopf, B. et al. Toward causal representation learning. Proc. IEEE 109, 612–634 (2021).
Kuang, K. et al. Causal inference. Engineering 6, 253–263 (2020).
Ling, Z. et al. A light causal feature selection approach to high-dimensional data. IEEE Trans. Knowl. Data Eng. 35, 7639–7650 (2022).
Ling, Z., Yu, K., Zhang, Y., Liu, L. & Li, J. Causal learner: A toolbox for causal structure and markov blanket learning. Pattern Recogn. Lett. 163, 92–95 (2022).
Lagemann, K., Lagemann, C., Taschler, B. & Mukherjee, S. Deep learning of causal structures in high dimensions under data limitations. Nat. Mach. Intell. 5, 1306–1316 (2023).
Guo, S., Tóth, V., Schölkopf, B. & Huszár, F. Causal de finetti: On the identification of invariant causal structure in exchangeable data. Adv. Neural Inf. Process. Syst. 36 (2024).
Müller, J., Schmier, R., Ardizzone, L., Rother, C. & Köthe, U. Learning robust models using the principle of independent causal mechanisms. In DAGM German Conference on Pattern Recognition, 79–110 (Springer, 2021).
Yang, M. et al. Causalvae: Disentangled representation learning via neural structural causal models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9593–9602 (2021).
Pearl, J., Glymour, M. & Jewell, N. P. Causal inference in statistics: A primer. 2016. Internet resource (2016).
Dawid, A. P. Conditional independence in statistical theory. J. R. Stat. Soc. Ser. B Stat Methodol. 41, 1–15 (1979).
Kac, M. Statistical Independence in Probability, Analysis and Number (Courier Dover Publications, 2018).
Neuberg, L. G. Causality: models, reasoning, and inference, by judea pearl, cambridge university press, 2000. Economet. Theor. 19, 675–685 (2003).
Khanna, S., Ansanelli, M. M., Pusey, M. F. & Wolfe, E. Classifying causal structures: Ascertaining when classical correlations are constrained by inequalities. Phys. Rev. Res. 6, 023038 (2024).
Zhou, K., Yang, Y., Qiao, Y. & Xiang, T. Mixstyle neural networks for domain generalization and adaptation. Int. J. Comput. Vision 132, 822–836 (2024).
Zhao, H., Des Combes, R. T., Zhang, K. & Gordon, G. On learning invariant representations for domain adaptation. In International conference on machine learning, 7523–7532 (PMLR, 2019).
Phung, T. et al. On learning domain-invariant representations for transfer learning with multiple sources. Adv. Neural. Inf. Process. Syst. 34, 27720–27733 (2021).
Chen, K., Zhuang, D. & Chang, J. M. Discriminative adversarial domain generalization with meta-learning based cross-domain validation. Neurocomputing 467, 418–426 (2022).
Wang, J. X. Meta-learning in natural and artificial intelligence. Curr. Opin. Behav. Sci. 38, 90–95 (2021).
Liang, X. et al. Task oriented in-domain data augmentation. arXiv preprint arXiv:2406.16694 (2024).
Li, Y., Tian, X., Liu, T. & Tao, D. Multi-task model and feature joint learning. In Twenty-fourth international joint conference on artificial intelligence (2015).
Jackson, P. T., Abarghouei, A. A., Bonner, S., Breckon, T. P. & Obara, B. Style augmentation: data augmentation via style randomization. In CVPR workshops 6, 10–11 (2019).
Mehmood, N. & Barner, K. Augmentation, Mixing, and Consistency Regularization for Domain Generalization. In 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), 1–6 (IEEE, 2024).
Jia, C. & Zhang, Y. Meta-learning the invariant representation for domain generalization. Mach. Learn. 113, 1661–1681 (2024).
Zhang, C., Mohan, K. & Pearl, J. Causal inference under interference and model uncertainty. In Conference on Causal Learning and Reasoning, 371–385 (PMLR, 2023).
Waldner, D. Invariant causal mechanisms. Qual. Multi-Method Res. 14, 28–33 (2016).
Wang, R., Yi, M., Chen, Z. & Zhu, S. Out-of-distribution generalization with causal invariant transformations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 375–385 (2022).
Lu, C., Wu, Y., Hernández-Lobato, J. M. & Schölkopf, B. Invariant causal representation learning for out-of-distribution generalization. In International Conference on Learning Representations (2021).
Guo, X., Yu, K., Liu, L., Cao, F. & Li, J. Causal feature selection with dual correction. IEEE Trans. Neural Netw. Learn. Syst. 35, 938–951 (2022).
Bechavod, Y., Ligett, K., Wu, Z. S. & Ziani, J. Causal feature discovery through strategic modification. arXiv preprint arXiv:2002.070243 (2020).
Dang, Z. et al. Counterfactual generation framework for few-shot learning. IEEE Trans. Circuits Syst. Video Technol. 33, 3747–3758 (2023).
Chen, L., Zheng, Y., Niu, Y., Zhang, H. & Xiao, J. Counterfactual samples synthesizing and training for robust visual question answering. IEEE Trans. Pattern Anal. Mach. Intell. 45, 13218–13234 (2023).
Yue, Z., Wang, T., Sun, Q., Hua, X.-S. & Zhang, H. Counterfactual zero-shot and open-set visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 15404–15414 (2021).
Deng, X. et al. Counterfactual active learning for out-of-distribution generalization. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 11362–11377 (2023).
Lv, F. et al. Causality inspired representation learning for domain generalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8046–8056 (2022).
Nasser, R. Deciding whether there is statistical independence or not?. J. Math. Stat. 3, 151–213 (2007).
Tallarida, R. J., Murray, R. B., Tallarida, R. J. & Murray, R. B. Chi-square test. Manual of pharmacologic calculations: with computer programs 140–142 (1987).
Shi, H., Drton, M., Hallin, M. & Han, F. Center-outward sign-and rank-based quadrant, spearman, and kendall tests for multivariate independence. arXiv preprint arXiv:2111.15567 (2021).
Steuer, R., Kurths, J., Daub, C. O., Weise, J. & Selbig, J. The mutual information: detecting and evaluating dependencies between variables. Bioinformatics 18, S231–S240 (2002).
Brehmer, J., De Haan, P., Lippe, P. & Cohen, T. S. Weakly supervised causal representation learning. Adv. Neural. Inf. Process. Syst. 35, 38319–38331 (2022).
Dang, Z. et al. Disentangled representation learning with transmitted information bottleneck. IEEE Transactions on Circuits and Systems for Video Technology (2024).
Saxena, D. & Cao, J. Generative adversarial networks (gans) challenges, solutions, and future directions. ACM Comput. Surveys (CSUR) 54, 1–42 (2021).
Xu, Q., Zhang, R., Zhang, Y., Wang, Y. & Tian, Q. A fourier-based framework for domain generalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 14383–14392 (2021).
Oppenheim, A. V. & Lim, J. S. The importance of phase in signals. Proc. IEEE 69, 529–541 (1981).
Piotrowski, L. N. & Campbell, F. W. A demonstration of the visual importance and flexibility of spatial-frequency amplitude and phase. Perception 11, 337–346 (1982).
Elliott, D. & Rao, K. Fast fourier transform and convolution algorithms (1982).
Goodfellow, I. et al. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 27 (2014).
Arjovsky, M., Chintala, S. & Bottou, L. Wasserstein gan (2017). arXiv:1701.07875.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V. & Courville, A. C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 30 (2017).
Jang, E., Gu, S. & Poole, B. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144 (2016).
Zhou, K., Yang, Y., Hospedales, T. & Xiang, T. Deep domain-adversarial image generation for domain generalisation. In Proceedings of the AAAI conference on artificial intelligence 34, 13025–13032 (2020).
Li, D., Yang, Y., Song, Y.-Z. & Hospedales, T. M. Deeper, broader and artier domain generalization. In Proceedings of the IEEE international conference on computer vision, 5542–5550 (2017).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Ganin, Y. & Lempitsky, V. Unsupervised domain adaptation by backpropagation. In International conference on machine learning, 1180–1189 (PMLR, 2015).
Netzer, Y. et al. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, vol. 2011, 4 (Granada, 2011).
Motiian, S., Piccirilli, M., Adjeroh, D. A. & Doretto, G. Unified deep supervised domain adaptation and generalization. In Proceedings of the IEEE international conference on computer vision, 5715–5725 (2017).
Li, H., Pan, S. J., Wang, S. & Kot, A. C. Domain generalization with adversarial feature learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 5400–5409 (2018).
Carlucci, F. M., D’Innocente, A., Bucci, S., Caputo, B. & Tommasi, T. Domain generalization by solving jigsaw puzzles. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2229–2238 (2019).
Shankar, S. et al. Generalizing across domains via cross-gradient training. arXiv preprint arXiv:1804.10745 (2018).
Zhou, K., Yang, Y., Hospedales, T. & Xiang, T. Learning to generate novel domains for domain generalization. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVI 16, 561–578 (Springer, 2020).
Balaji, Y., Sankaranarayanan, S. & Chellappa, R. Metareg: Towards domain generalization using meta-regularization. Adv. Neural Inf. Process. Syst. 31 (2018).
Piratla, V., Netrapalli, P. & Sarawagi, S. Efficient domain generalization via common-specific low-rank decomposition. In International conference on machine learning, 7728–7738 (PMLR, 2020).
Dou, Q., Coelho de Castro, D., Kamnitsas, K. & Glocker, B. Domain generalization via model-agnostic learning of semantic features. Adv. Neural Inf. Process. Syst. 32 (2019).
Mahajan, D., Tople, S. & Sharma, A. Domain generalization using causal matching. In International conference on machine learning, 7313–7324 (PMLR, 2021).
Huang, Z., Wang, H., Xing, E. P. & Huang, D. Self-challenging improves cross-domain generalization. In Computer vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, proceedings, part II 16, 124–140 (Springer, 2020).
Selvaraju, R. R. et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, 618–626 (2017).
Acknowledgements
This work was supported in part by the National Social Science Foundation of China under Grant 20BTJ046.
Author information
Authors and Affiliations
Contributions
Conceptualization, L.X.; methodology, L.X. and Y.S; software, Y.S. ; validation, Y.S. ; formal analysis, L.X.; investigation, Y.S.; resources, L.X.; analysed the results, Y.S. ; writing—original draft preparation, L.X., Y.S.; writing—review and editing, L.X.; visualization, Y.S. ; supervision, L.X.; project administration, L.X.; funding acquisition, L.X. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, L., Shao, Y. ICRL: independent causality representation learning for domain generalization. Sci Rep 15, 11771 (2025). https://doi.org/10.1038/s41598-025-96357-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-96357-0
