
Abstract
Sepsis related acute respiratory distress syndrome (ARDS) is a common and serious disease in clinic. Accurate prediction of in-hospital mortality of patients is crucial to optimize treatment and improve prognosis under the new global definition of ARDS. Our study aimed to use machine learning models to develop models that can effectively predict the in-hospital mortality of patients with sepsis related ARDS, calculate the mortality, and to identify related risk factors under the new global definition of ARDS. Based on MIMIC database, our study included 3470 first-time admission records of patients with sepsis related ARDS. After excluding 4 patients under the age of 18, 75 patients with less than 24 h stay in ICU, and 5 cases with missing indicators > 30%, finally 3386 cases were retained. The variance inflation factor (VIF) analysis was used to test the collinearity of the explanatory variables. The data were divided into the training set and the test set according to the ratio of 7:3. Six models, extreme gradient boosting (XGBoost), light gradient boosting (LightGBM), random forest (RF), classification and regression tree (CART), naive bayes (NB) and logistic regression (LR), were designed for training and testing. In the training set, XGBoost (AUROC = 0.951, 95% CI 0.942–0.961), LR (AUROC = 0.835, 95% CI 0.817–0.854), RF (AUROC = 1.0, 95% CI 1.0–1.0), LightGBM (AUROC = 1.0, 95% CI 1.0–1.0), CART (AUROC = 0.831, 95% CI 0.811–0.852), NB (AUROC = 0.793, 95% CI 0.772–0.814). In the test set, XGBoost (AUROC = 0.833, 95% CI 0.804–0.861), LR (AUROC = 0.82695% CI 0.796–0.856), RF (AUROC = 0.846, 95% CI 0.818–0.874), LightGBM (AUROC = 0.827, 95% CI 0.798–0.856), CART (AUROC = 0.753, 95% CI 0.718–0.787), NB (AUROC = 0.799, 95% CI 0.768–0.831). The RF model has the best performance on the test set. Further analyze the feature importance ranking and partial dependence plots of random forest model. Acute physiology and chronic health evaluation III (APACHE III), bicarbonate, anion gap and non-invasive blood pressure systolic were identified as the four most important risk characteristics. In this study, a variety of machine learning models have been successfully constructed to predict the in-hospital mortality of patients with sepsis related ARDS, among which the RF model performs well. Key risk factors identified include APACHE III, bicarbonate, anion gap and non-invasive blood pressure systolic. The identification of these factors helps clinicians to assess patients’ conditions more accurately and develop personalized treatment plans, thereby improving the survival rate and prognosis quality of patients under the new global definition of ARDS.
Similar content being viewed by others

Introduction
Acute respiratory distress syndrome (ARDS) related with Sepsis is a serious challenge in the field of critical care medicine. With its severe illness and poor prognosis, ARDS brings a heavy burden to the medical system and patient families. ARDS is characterized by diffuse alveolar injury and inflammatory response1. Sepsis is one of the common causes of ARDS. Due to a series of complex inflammatory reactions and immune disorders, pulmonary capillary endothelial injury, alveolar epithelial cell injury and protein-rich fluid filling in the alveoli lead to Sepsis, which affects gas exchange and poses a serious threat to patients’ lives2. In recent years, despite certain progress in critical care technologies and treatments, the mortality rate of patients with sepsis related ARDS is still high, especially under the new global definition of ARDS, which may be changing due to more precise identification of patients with milder disease but potentially at risk3. Traditional clinical prediction methods mainly rely on doctors’ experience and limited clinical indicators, such as patients’ age, underlying diseases, vital signs, etc. However, the prognosis of patients diagnosed with ARDS according to the new global definition of ARDS may be different from that of patients diagnosed under the old criteria, which may be related to early intervention, more accurate disease assessment and other factors4.
With the rapid development of medical informatization, the accumulation of medical data has shown an explosive growth, which provides the possibility of using machine learning technology to make more accurate prediction5. As an important branch of artificial intelligence, machine learning can automatically discover patterns and rules from a large number of complex data and build predictive models6. In the medical field, machine learning models have been widely used in disease diagnosis, prognosis prediction, and treatment plan selection7. In the field of cardiovascular diseases, machine learning models can accurately predict the risk of cardiovascular events of patients by analyzing ECG (electrocardiogram), echocardiogram and other data8. In oncology, machine learning models can predict the risk of tumor recurrence and metastasis based on patients’ gene expression data and clinicopathological features9. The application of machine learning to the prediction of in-hospital mortality and risk factor analysis of patients with sepsis related ARDS has many advantages. Machine learning models can integrate various types of data, including clinical symptoms, laboratory test results, imaging data, etc., so as to reflect patients’ conditions more comprehensively10. Machine learning models can deal with nonlinear relationships and complex interactions, and excavate potential rules that are difficult to find with traditional statistical methods11. By constantly optimizing and updating the model, machine learning can adapt to new knowledge and technologies in the medical field to improve the accuracy and timeliness of predictions12. However, there are still some challenges in applying machine learning to the study of sepsis related ARDS. Data quality and integrity is one of the key factors affecting model performance. Medical data may have problems such as missing values, wrong records and inconsistencies, which require effective data cleaning and preprocessing13. In addition, the interpretability of the model is also an important issue. Because the internal mechanism of machine learning model is relatively complex, it is difficult to intuitively understand how the model makes decisions, which may affect doctors’ trust and application of the model results14. In order to solve these problems, researchers need to constantly explore new methods and technologies, improve data quality, enhance the interpretability of models, and ensure the reliability and practicability of models through rigorous verification and evaluation15.
The MIMIC database (Medical Information Mart for Intensive Care) is a large, publicly available medical database containing a wealth of clinical data on intensive care patients. It provides valuable resources for the research on sepsis related ARDS3. Through in-depth mining and analysis of the data of patients with sepsis related ARDS in MIMIC database, we can better understand the characteristics and rules of diseases, and provide valuable references for clinical practice16. Many studies have attempted to use machine learning techniques to predict the prognosis of patients with ARDS. Support Vector Machine (SVM) algorithm was used to build a mortality prediction model for ARDS patients, and good results were achieved17. Another study applied Random Forest algorithm to analyze the clinical data of ARDS patients and found some important prognostic features18. However, most of these studies are limited to specific data sets or algorithms, and there are relatively few studies on patients with sepsis related ARDS.
Our study aimed to use a variety of machine learning models based on MIMIC database, including Extreme Gradient Boosting (XGBoost), Light Gradient Boosting (LightGBM), Random Forest (RF), Classification and Regression Tree (CART), Naive Bayes (NB), logistic regression (LR). A prediction model for in-hospital mortality of patients with sepsis related ARDS was established, and the risk factors affecting the prognosis of patients were analyzed. By comparing the performance of different models, the optimal model is selected to provide more accurate and reliable decision support for clinicians, thereby improving the treatment level and survival rate of patients with sepsis related ARDS.
Methods
Ethical and moral considerations
The MIMIC database included in our study was legitimate, and this study was conducted in strict accordance with the Guidelines for the Development and Reporting of Machine Learning Predictive Models in Biomedical Research. The MIMIC-IV database was approved by the ethics review committees of MIT and Beth Israel Deaconess Medical Center. Because the data in this retrospective study were confidential, informed consent of patients was waived.
Inclusion criteria
Patients were diagnosed with sepsis-related ARDS according to the new global definition of ARDS. The new global definition of ARDS is as follows: ARDS is defined as an acute, diffuse, inflammatory lung injury caused by susceptible risk factors such as pneumonia, non-pulmonary infection, trauma, blood transfusion, burn, aspiration, or shock. This results in increased alveolar capillary permeability and reduced ventilated lung tissue, leading to hypoxemia and bilateral pulmonary edema. The diagnostic criteria include acute onset within two weeks of the inciting factor, the use of high-flow nasal cannula (HFNC) at least 30 L/min, the use of pulse oximetry oxygen saturation to assess oxygenation status, the inclusion of lung ultrasound in imaging examinations, and appropriate revisions for resource-limited areas. Patients have a complete first admission record, ensuring that comprehensive clinical information is available for analysis3,19.
Exclusion criteria
Patients under the age of 18 years were excluded because the physiological and pathological characteristics of minors are significantly different from those of adults and may affect the accuracy and generality of the model20,21. Patients staying in ICU for less than 24 h were excluded. This is because the observation time of such patients is too short, which may not fully reflect the development and prognosis of the disease, thus affecting the reliability of the data and the predictive power of the model. Cases where more than 30% of the indicators were missing were also excluded10. A large number of missing data may lead to incomplete information, affect the training and prediction effect of the model, and then reduce the accuracy and stability of the model.
Model construction and evaluation methods
Data on patients with sepsis-related ARDS who met the inclusion criteria and were not excluded were extracted from the MIMIC database. The data included basic demographic information, clinical symptoms, laboratory test results, treatment measures, etc. After cleaning to remove outliers and errors, multiple imputation was used to handle missing values, filling in data with a missing proportion of less than 30% to ensure data integrity and availability. Standardizing the data made different indexes comparable, which was helpful for model training and optimization8.
Variable selection
In this study, multiple variables were selected to construct machine learning models for predicting the in-hospital mortality of patients with sepsis-related ARDS, including:
-
Clinical variables: Heart rate, blood pressure (systolic, diastolic, and mean non-invasive blood pressure), and respiratory rate, which reflect the cardiovascular and respiratory status of patients.
-
Laboratory indicators: Oxygen saturation, hemoglobin, glucose, prothrombin time (PT), partial thromboplastin time (PTT), anion gap, bicarbonate, urea nitrogen, chloride, creatinine, magnesium, mean corpuscular hemoglobin (MCH), mean corpuscular hemoglobin concentration (MCHC), phosphoric acid, platelet count, potassium, red blood cell distribution width (RDW), sodium, white blood cell count, partial pressure of carbon dioxide, partial pressure of oxygen, pH value, and calculated total CO2, which reflect the patient’s metabolism, coagulation, kidney function, and acid-base balance.
-
Scoring systems: APACHE III and simplified acute physiology score (SAPS II), which comprehensively assess the severity of the patient’s condition.
-
Demographic characteristics: Basic information such as patient age and body temperature, which helps assess the overall health status and susceptibility to disease.
Our study selects six machine learning models, namely XGBoost, LightGBM, RF, CART, NB, and LR. The preprocessed data were randomly divided into a training set and a test set in a 7:3 ratio. The training set was used for model training and parameter adjustment, including hyperparameter tuning through techniques like cross - validation, while the test set was used to evaluate the model’s generalization ability and prediction performance. Model performance was assessed using metrics such as the area under the curve (AUC), accuracy, recall, and F1 value, with the aim of identifying the best - performing model on the test set.
Statistical analysis
Our research utilized Python (version 3.9.7) and R (version 3.9.7) for data preprocessing, employing multiple interpolation to handle missing values. By establishing a reasonable interpolation model, indices with a missing proportion of less than 30% were filled to retain effective information and data integrity. To ensure the robustness of the regression model, a multicollinearity test was performed on the explanatory variables using the Variance Inflation Factor (VIF). Generally, a VIF value less than 10 indicates no significant multicollinearity among variables22. For the training of the model, cross - validation techniques such as 5 - fold cross - validation were used. In this approach, the training set was further divided into five subsets, with four subsets used for training and the remaining one for validation in each iteration. This process was repeated five times to ensure that each subset was used once for validation. By dividing the training set data into different subsets for training and verification, the model’s hyperparameters were optimized, such as the learning rate, the number and depth of trees in XGBoost, the number of trees in random forest, and the number of feature selection, to enhance the model’s performance and generalization ability. In the evaluation of model performance, the AUC was used to measure the model’s ability to distinguish between positive and negative cases, with values closer to 1 indicating better performance. The accuracy rate was used to measure the overall prediction accuracy of the model, the recall rate to evaluate the model’s ability to recognize positive examples, and the F1 value to balance the prediction performance across different categories by considering both accuracy and recall. To compare the performance differences between different models, paired T-tests and ANOVA were used. If the difference was statistically significant, multiple comparison methods (Bonferroni correction) were further applied to clarify the significant differences between the models. P < 0.05 was considered statistically significant.
Results
Research design
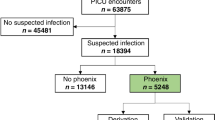
This study is a retrospective analysis based on the MIMIC database to develop an effective machine learning model to accurately predict in-hospital mortality in patients with sepsis related ARDS and to identify key risk factors. Our study included 3470 first-time admission records of patients with sepsis related ARDS using MIMIC database. After excluding 4 patients under 18 years old, 75 patients with less than 24 h stay in ICU, and 5 cases with missing indicators > 30%, 3386 cases were ultimately retained. The dataset was randomly divided into a training set and a test set at a ratio of 7:3. Specifically, the training set consisted of 2370 cases (70% of 3386), and the test set consisted of 1016 cases (30% of 3386). Figure 1.

Flow chart of MIMIC data analysis.
Baseline data analysis
There were 2479 cases in the survival group and 916 cases in the death group. There were no statistically significant differences in gender between the survival group and the death group (P > 0.05), while heart rate, non-invasive blood pressure systolic blood pressure, non-invasive blood pressure diastolic blood pressure, mean non-invasive blood pressure, arterial blood pressure - systolic blood pressure, arterial blood pressure diastolic blood pressure, mean arterial blood pressure, respiratory rate, blood pressure, blood pressure, blood pressure. Oxygen saturation Pulse oxygen saturation determination, hemoglobin, glucose, prothrombin, PTT, anion gap, bicarbonate, urea nitrogen, chlorine, creatinine, magnesium, MCH, MCHC, phosphoric acid, platelet count, PT, RDW, sodium, white blood cells, partial pressure of carbon dioxide, partial pressure of oxygen, pH, calculate total CO2, APACHE III. age and body temperature were significant differences (P < 0.05). (Table 1).
Multicollinearity test and variable selection based on VIF
In this study, a multicollinearity test was performed using the VIF to ensure the robustness of the regression model. Variables with a VIF value less than 10 were retained in the final model. A total of 28 variables were kept, including Gender, Age, Heart rate, Non-invasive blood pressure, SpO2, pCO2 Hemoglobin, Glucose, Prothrombin, PTT, PT, Anion gap, Creatinine, Magnesium, MCH, MCV, Phosphate, Platelet count, pH, Base Excess, APACHE III, and SAPSII. These variables showed low multicollinearity and high statistical independence. Variables with VIF values ≥ 10 were excluded to ensure model stability. The retained variables provide a reliable basis for subsequent regression analysis.
The performance of machine learning models on training sets
In the training set, we evaluated six machine learning models designed. The AUROC of the XGBoost model reached 0.951 (95% CI 0.942–0.961), showing very good differentiation ability. This suggests that the XGBoost model performs well in predicting in-hospital mortality based on training data and can more accurately identify patients who are likely to have a poor prognosis. The AUROC of LR model was 0.835 (95% CI 0.817–0.854), which was not as prominent as the XGBoost model, but still had certain predictive power and could distinguish patients with different prognoses to a certain extent. The RF model has an AUROC of 1.0 (95% CI 1.0–1.0), which shows almost perfect differentiation in the training set. However, it is important to note that this overfitting in the training set may affect its ability to generalize on new data (i.e. the test set). The AUROC of LightGBM model is 1.0 (95% CI 1.0–1.0), which is similar to the performance of the random forest model in the training set, and has high prediction accuracy, but also faces the risk of possible overfitting. The AUROC of CART model is 0.831, (95%CI 0.811–0.852), which is relatively stable and can provide certain reference value for prediction. The AUROC of the NB model was 0.793 (95% CI 0.772–0.814), which was relatively weak among the six models, but still had a certain ability to distinguish the prognosis of patients to a certain extent. (Table 2 and Fig. 2).

ROC curves, DCA, and calibration curves of prediction models. (A) Machine learning models on training sets. (B) Machine learning models on test sets. (C) DCA curve. (D) calibration curve). AUROC area under the receiver operating characteristic curve, ROC receiver operating characteristic, DCA decision curve analysis; NB naive bayes, CART cassification and regression tree, LightGBM light gradient boosting machine, LR logistic regression, RF random forest, XGBoost extreme gradient boosting.
The performance of machine learning models on test sets
In the test set, the AUROC of XGBoost model is 0.833 (95%CI 0.804–0.861), which still maintains a good prediction performance, indicating that it can generalize well in the face of new data, and has certain practical application value. The AUROC of LR model is 0.826 (95%CI 0.796–0.856), which is close to the performance of XGBoost model, indicating that LR model can also provide relatively reliable prediction on new data. The RF model had an AUROC of 0.846 (95% CI 0.818–0.874) and performed best in the test set. This indicates that RF model can more accurately predict the in-hospital mortality of patients with sepsis related ARDS when processing new and unseen data, and has strong generalization ability and stability. The AUROC of LightGBM model is 0.827 (95%CI 0.798–0.856), which has good performance and is close to the random forest model, and has certain practical application potential. The CART model, with an AUROC of 0.753 (95% CI 0.718–0.787), performs relatively poorly in the test set and may require further optimization or parameter adjustment to improve its performance. The AUROC of NB model was 0.799 (95% CI 0.768–0.831), and its performance in the test set was in the middle level, with certain predictive power. Based on the analysis of the results of the test set, it can be seen that the random forest model has the best performance in predicting the in-hospital mortality of patients with sepsis related ARDS, which provides a more reliable basis for clinical decision-making. (Table 3 and Fig. 2).
Feature importance ranking and risk feature determination of random forest model
Our study further analyzed the random forest model with the best performance in the test set, and identified the four most important risk features through feature importance ranking and Partial dependence plots (Figs. 3, 4). Shapley additive explanation (SHAP) is commonly used in sepsis related studies to explain the extent to which individual features in a machine learning model for predicting sepsis contribute to the model’s output. Based on mean SHAP and SHAP values, our study found that this feature of APACHE III is considered to have important predictive value in random forest models. It may be related to the physiology of the patient, the severity of the disease or other factors closely related to the prognosis. The change of Bicarbonate level may reflect the acid-base balance of patients, which is important for predicting hospital mortality. Abnormal bicarbonate levels may indicate a metabolic disorder in the patient, which may affect prognosis. The abnormal Anion gap may be related to electrolyte imbalance and metabolic acidosis in patients, and thus become one of the important factors affecting hospital mortality. Non-invasive blood pressure systolic reflects the state of the patient’s cardiovascular function. Unstable or abnormal systolic blood pressure may be associated with organ hypoperfusion and cardiovascular complications, which increase the risk of hospital death.

Feature-ranking plots (A) and summary plots (B) of the RF model.

Partial dependence plots of the RF model. (A) APACHE III. (B) Bicarbonate. (C) Anion gap. (D) Non-invasive blood pressure systolic.
Discussion
Sepsis related ARDS has long been a hot and difficult problem in the field of critical care medicine. In recent years, with the continuous progress of medical technology and the deepening of the understanding of the disease, the management and treatment of ARDS patients have indeed achieved a certain degree of improvement. However, despite the adoption of many new treatment strategies and interventions, the in-hospital mortality of such patients remains high23,24. In predicting the prognosis of ARDS patients, the traditional clinical scoring system has revealed significant limitations. When assessing patients’ disease conditions and predicting prognosis, these systems often fail to comprehensively consider the differences between individuals and the complexity of disease changes25. Most of them are based on some fixed indicators and criteria, which cannot be flexibly adapted to the unique pathophysiological characteristics of each patient26,27. Under the background of the new global definition of ARDS, machine learning technology came into being, bringing new ideas and methods to solve this problem. At present, many studies have tried to apply machine learning to prognosis prediction of ARDS patients. However, the existing research is not perfect, there are still many shortcomings. For example, due to the relatively small sample size of some studies, the reliability of the obtained results is limited to a certain extent28,29. In addition, the data sources of many studies are relatively single and lack of strong support from multi-center and large-scale databases, which may lead to insufficient universality of research results30,31. In addition, the interpretability of many machine learning models is poor, and it is difficult to clearly and intuitively show clinicians how the models make decisions, which undoubtedly increases the doubts and confusion of clinicians in practical application32,33.
Comparison of performance of different machine learning models
The performance comparison of different machine learning models has presented diverse results, which provides valuable insights for us to deeply understand and evaluate the performance of each model in predicting the in-hospital mortality of patients with sepsis related ARDS. In the training set, the XGBoost model showed excellent performance, with an AUROC of 0.951. This excellent value indicates that the XGBoost model can effectively capture and understand complex patterns and features in training data, demonstrating strong learning and fitting capabilities34. It is followed by RF and LightGBM models, both of which have an AUROC of 1.0, which also reflects their excellent fitting effect on training data35. However, this near-perfect training set performance needs to be viewed with caution. Such high performance may suggest a potential risk of overfitting the model. Overfitting means that the model overadapts to specific patterns and noise in the training data, which can lead to poor performance in the face of new, previously unseen data. Therefore, in order to more accurately evaluate the actual predictive power and generalization performance of the model, further validation in the test set is needed. In the test set, the performance of the model has changed. RF model stands out, with an AUROC of 0.846, which indicates that it shows excellent predictive ability in the face of new data, and can accurately identify the in-hospital mortality of patients, fully demonstrating its strong generalization ability and stability36. The AUROC of LightGBM model is 0.827, and the AUROC of XGBoost model is 0.833, which also maintains a good prediction level. The performance of these three groups in the test set is relatively close, which reflects the adaptability to new data and the accuracy of prediction. In comparison, AUROC of logistic regression model is 0.826, and AUROC of NB model is 0.799, which is slightly weaker than the previous models, but still has certain predictive value. To a certain extent, they can provide useful information and reference for prediction tasks37. However, the performance of CART model is relatively poor, with an AUROC of only 0.753. This may mean that the model has deficiencies in structural design or feature selection that require further optimization and improvement, such as adjusting the depth of the tree, node splitting criteria, or re-examining and filtering the input features to improve its predictive performance and accuracy. In comparison with previous studies, there may have been few previous studies that comprehensively compared the performance of multiple machine learning models in predicting in-hospital mortality in patients with septicaemia related ARDS. What is new in this study is the detailed presentation of the performance differences between different models in the training set and the test set. The excellent performance and potential overfitting risk of the XGBoost model in the training set, and the excellent generalization ability of the random forest model in the test set. At the same time, the reasons for the poor performance of CART model and the direction of improvement are clearly pointed out. While previous studies may not have been in-depth or involved in this area, this study provides a more comprehensive and in-depth insight into the application of predictive models in this field.
Risk factors were identified by a random forest model
Through in-depth analysis of the random forest model, we successfully identified four key risk factors: APACHE III, bicarbonate, anion gap, and non-invasive blood pressure systolic. These factors were selected based on their clinical relevance and statistical significance38. APACHE III provides a comprehensive evaluation of the patient’s condition, incorporating a wider range of physiological indicators and factors such as age. Unlike SAPSII, which emphasizes the simplification and rapid assessment of physiological parameters, APACHE III offers a more detailed overview. Including both scores in the model allows for a more comprehensive capture of the patient’s condition characteristics, enhancing the predictive accuracy39,40. Abnormal bicarbonate levels are closely related to acid-base imbalances, which can affect the normal functioning of multiple organs and systems41. Monitoring bicarbonate levels and taking corrective measures in a timely manner is essential for improving patient outcomes. Changes in the anion gap may indicate metabolic disorders, which can weaken the patient’s ability to cope with the disease. Understanding the changing trends of the anion gap helps doctors identify potential metabolic problems early and take targeted treatment measures to reduce their adverse impact on patient survival. Non-invasive blood pressure systolic reflects the cardiovascular function status of patients. Unstable blood pressure, especially systolic blood pressure that is too high or too low, may indicate a problem with the regulation of the cardiovascular system42,43. Real-time monitoring and regulation of blood pressure, and maintaining the stability of cardiovascular function, are crucial for improving patient survival and prognosis44. To ensure the robustness of the model, we conducted a thorough variable selection process. This included univariate analysis, consideration of clinical characteristics, medical mechanisms, demographic features, and behavioral habits. We also performed a VIF analysis to check for multicollinearity and eliminate redundant variables. All variables included in the model had VIF values less than 10, indicating that multicollinearity was not a significant issue. This rigorous selection process ensured that the variables included in the model were independent and provided unique contributions to the prediction.
Advantages
This research has significant advantages and value. First of all, by leveraging the extensive MIMIC database, it incorporates a large cohort of sepsis-related ARDS patients, significantly enhancing the reliability and generalizability of the findings. Compared to small-scale studies, large-scale samples can more comprehensively and accurately reflect the true nature and patterns of the disease, reducing potential biases and errors associated with small sample sizes. Secondly, the study employs a multi-model machine learning approach, utilizing models such as XGBoost, LightGBM, RF, CART, NB, and LR. This strategy allows for a comprehensive evaluation of the performance and applicability of different models from multiple perspectives. Through a detailed comparison, the study provides a clearer understanding of the strengths and limitations of each model, facilitating the selection of the most suitable predictive model. Thirdly, a VIF analysis was conducted to ensure that the variables included in the model are independent and free from multicollinearity issues, with all variables having VIF values less than 10. This ensures the robustness of the model. Fourthly, the study identifies key risk factors through the random forest model, providing important insights into the disease progression and prognosis of sepsis-related ARDS patients. These factors offer valuable references for clinical treatment and intervention strategies. Fifthly, the variable selection process is thorough, encompassing univariate analysis, clinical characteristics, medical mechanisms, demographic features, and behavioral habits. These strengths collectively enhance the study’s contribution to the field, providing a robust and reliable predictive model for in-hospital mortality in sepsis-related ARDS patients.
Limitations
This study was retrospective in design and had some limitations. Firstly, the integrity and accuracy of the data may not be satisfactory, with some case records possibly lacking detail and key information potentially missing, which could affect the reliability of the results. Secondly, although multiple imputation methods were used to handle missing values, there may still be information bias. In addition, the performance of the model may be limited by the specific population characteristics and treatment patterns in the database. The patient population in the MIMIC database may have different characteristics from those in other medical environments, so the model needs further validation and adjustment when applied to other settings. Moreover, the difference in AUROC values of the XGBoost model between the training set and the test set indicates the presence of overfitting, highlighting the importance of model validation and the need for larger and more diverse datasets. Future research plans to address these issues by increasing the sample size, exploring different feature selection methods, and model hyperparameter tuning, in order to improve the model’s generalization ability and performance.
Conclusions
We have successfully constructed a variety of machine learning models to predict the in-hospital mortality of patients with sepsis related ARDS, and identified important risk factors. The excellent performance of the random forest model in the test set provides a valuable tool for clinical prediction. However, our study also has certain limitations. In the future, we need to carry out further prospective and multi-center studies, combine more clinical information and biological indicators, and continuously optimize the model to improve the prediction accuracy and clinical application value, and provide more powerful support for improving the prognosis of patients with sepsis related ARDS.
Data availability
The dataset utilized in this study, MIMIC-IV, is publicly accessible and can be obtained from the PhysioNet repository (https://physionet.org/content/mimiciv/). All data generated or analyzed during the current study are included in the published article and are part of the MIMIC-IV dataset.
References
Sinha, P., Meyer, N. J. & Calfee, C. S. Biological phenotyping in sepsis and acute respiratory distress syndrome. Annu. Rev. Med. 74, 457–471 (2023).
Jing, W., Wang, H., Zhan, L. & Yan, W. Extracellular vesicles, new players in sepsis and acute respiratory distress syndrome. Front. Cell. Infect. Microbiol. 12, 853840 (2022).
Qian, F., van den Boom, W. & See, K. C. The new global definition of acute respiratory distress syndrome: insights from the MIMIC-IV database. Intensive Care Med. 50, 608–609 (2024).
Xiao, L. X. et al. Exploring the therapeutic role of early heparin administration in ARDS management: a MIMIC-IV database analysis. J. Intensive Care 12 (1), 9 (2024).
Wong, A. K. I., Cheung, P. C., Kamaleswaran, R., Martin, G. S. & Holder, A. L. Machine learning methods to predict acute respiratory failure and acute respiratory distress syndrome. Front. Big Data 3, 579774 (2020).
Bhattarai, S. et al. Can big data and machine learning improve our understanding of acute respiratory distress syndrome?? Cureus 13, e13529 (2021).
McNicholas, B., Madden, M. G. & Laffey, J. G. Machine learning classifier models: the future for acute respiratory distress syndrome phenotyping?? Am. J. Respir. Crit. Care Med. 202, 919–920 (2020).
Wei, S. et al. Machine learning-based prediction model of acute kidney injury in patients with acute respiratory distress syndrome. BMC Pulm. Med. 23 (1), 370 (2023).
Pennati, F. et al. Machine learning predicts lung recruitment in acute respiratory distress syndrome using single lung CT scan. Ann. Intensive Care 13 (1), 60 (2023).
Jiang, Z. et al. Machine learning for the early prediction of acute respiratory distress syndrome (ARDS) in patients with sepsis in the ICU based on clinical data. Heliyon 10, e28143 (2024).
Zeiberg, D. et al. Machine learning for patient risk stratification for acute respiratory distress syndrome. PLoS One 14, e0214465 (2019).
Wang, R., Cai, L., Zhang, J., He, M. & Xu, J. Prediction of acute respiratory distress syndrome in traumatic brain injury patients based on machine learning algorithms. Med. (Kaunas) 59 (1), 171 (2023).
Zhou, Y. et al. Machine learning models for predicting acute kidney injury in patients with sepsis-associated acute respiratory distress syndrome. Shock 59, 352–359 (2023).
Zhan, J., Chen, J., Deng, L., Lu, Y. & Luo, L. Exploring the ferroptosis-related gene lipocalin 2 as a potential biomarker for sepsis-induced acute respiratory distress syndrome based on machine learning. Biochim. Biophys. Acta Mol. Basis Dis. 1870, 167101 (2024).
Maddali, M. V. et al. Validation and utility of ARDS subphenotypes identified by machine-learning models using clinical data: an observational, multicohort, retrospective analysis. Lancet Respir. Med. 10, 367–377 (2022).
Wang, X. et al. Early human albumin administration is associated with reduced mortality in septic shock patients with acute respiratory distress syndrome: A retrospective study from the MIMIC-III database. Front. Physiol. 14, 1142329 (2023).
Yan, Y. et al. Diagnostic value of mechanical power in patients with moderate to severe acute respiratory distress syndrome: an analysis using the data from MIMIC-III]. Zhonghua Wei Zhong Bing Ji Jiu Yi Xue 34, 35–40 (2022).
Dong, D., Wang, Y., Wang, C. & Zong, Y. Effects of transthoracic echocardiography on the prognosis of patients with acute respiratory distress syndrome: a propensity score matched analysis of the MIMIC-III database. BMC Pulm Med. 22, 247 (2022).
Matthay, M. A. et al. A new global definition of acute respiratory distress syndrome. Am. J. Respir. Crit. Care Med. 209, 37–47 (2024).
Constantin, J. M. et al. Personalised mechanical ventilation tailored to lung morphology versus low positive end-expiratory pressure for patients with acute respiratory distress syndrome in France (the LIVE study): a multicentre, single-blind, randomised controlled trial. Lancet Respir. Med. 7, 870–880 (2019).
Lin, J., Gu, C., Sun, Z., Zhang, S. & Nie, S. Machine learning-based model for predicting the occurrence and mortality of nonpulmonary sepsis-associated ARDS. Sci. Rep. 14, 28240 (2024).
T, S. et al. Variant-specific inflation factors for assessing population stratification at the phenotypic variance level. Nat. Commun. 12, (2021).
Xu, C., Zheng, L., Jiang, Y. & Jin, L. A prediction model for predicting the risk of acute respiratory distress syndrome in sepsis patients: a retrospective cohort study. BMC Pulm Med. 23, 78 (2023).
Chaudhuri, D. et al. Focused update: Guidelines on use of corticosteroids in sepsis, acute respiratory distress syndrome, and community-acquired pneumonia. Crit. Care Med. 52, e219–e233 (2024).
Chaudhuri, D. et al. Executive summary: guidelines on use of corticosteroids in critically ill patients with sepsis, acute respiratory distress syndrome, and community-acquired pneumonia focused update 2024. Crit. Care Med. 52, 833–836 (2024).
Al Duhailib, Z., Farooqi, M., Piticaru, J., Alhazzani, W. & Nair, P. The role of eosinophils in sepsis and acute respiratory distress syndrome: a scoping review. Can. J. Anaesth. 68 (5), 715–726 (2021).
Reilly, J. P. et al. Exposure to ambient air pollutants and acute respiratory distress syndrome risk in sepsis. Intensive Care Med. 49, 957–965 (2023).
Qiao, X., Yin, J., Zheng, Z., Li, L. & Feng, X. Endothelial cell dynamics in sepsis-induced acute lung injury and acute respiratory distress syndrome: pathogenesis and therapeutic implications. Cell. Commun. Signal. 22, 241 (2024).
Goligher, E. C. et al. Physiology is vital to precision medicine in acute respiratory distress syndrome and sepsis. Am. J. Respir. Crit. Care Med. 206, 14–16 (2022).
Diamond, J. M. Don’t inhale: acute respiratory distress syndrome risk and tobacco exposure in patients with sepsis. Am. J. Respir. Crit. Care Med. 205, 866–867 (2022).
Byrnes, D., Masterson, C. H., Artigas, A., Laffey, J. G. Mesenchymal Stem/Stromal Cells Therapy for Sepsis and Acute Respiratory Distress Syndrome. Semin Respir Crit Care Med. 42(1), 20–39 (2021).
Shi, Y., Wang, L., Yu, S., Ma, X. & Li, X. Risk factors for acute respiratory distress syndrome in sepsis patients: a retrospective study from a tertiary hospital in China. BMC Pulm. Med. 22 (1), 238 (2022).
Zhou, L., Li, S., Tang, T., Yuan, X. & Tan, L. A single-center PICU present status survey of pediatric sepsis-related acute respiratory distress syndrome. Pediatr. Pulmonol. 57, 2003–2011 (2022).
Sinha, P., Churpek, M. M. & Calfee, C. S. Machine learning classifier models can identify acute respiratory distress syndrome phenotypes using readily available clinical data. Am. J. Respir. Crit. Care Med. 202, 996–1004 (2020).
Sjoding, M. W. et al. Deep learning to detect acute respiratory distress syndrome on chest radiographs: a retrospective study with external validation. Lancet Digit. Health 3, e340–e348 (2021).
Lam, C. et al. Multitask Learning With Recurrent Neural Networks for Acute Respiratory Distress Syndrome Prediction Using Only Electronic Health Record Data: Model Development and Validation Study. JMIR Med Inform. 10(6), e36202 (2022).
Bai, Y., Xia, J., Huang, X., Chen, S. & Zhan, Q. Using machine learning for the early prediction of sepsis-associated ARDS in the ICU and identification of clinical phenotypes with differential responses to treatment. Front. Physiol. 13, 1050849 (2022).
Li, Q., Zheng, H. & Chen, B. Identification of macrophage-related genes in sepsis-induced ARDS using bioinformatics and machine learning. Sci. Rep. 13, 9876 (2023).
Janc, J., Janc, J. J., Suchański, M., Fidut, M. & Leśnik, P. Aldosterone levels do not predict 28-day mortality in patients treated for COVID-19 in the intensive care unit. Sci. Rep. 14, 7829 (2024).
Li, X., Tian, Y., Li, S., Wu, H. & Wang, T. Interpretable prediction of 30-day mortality in patients with acute pancreatitis based on machine learning and SHAP. BMC Med. Inf. Decis. Mak. 24, 328 (2024).
Ming, T. et al. Integrated analysis of gene co-expression network and prediction model indicates immune-related roles of the identified biomarkers in sepsis and sepsis-Induced acute respiratory distress syndrome. Front. Immunol. 13, 897390 (2022).
Yoon, S. J. et al. Prediction of postnatal growth failure in very low birth weight infants using a machine learning model. Diagnostics (Basel) 13, 3627 (2023).
Khalilzad, Z., Hasasneh, A. & Tadj, C. Newborn Cry-Based diagnostic system to distinguish between sepsis and respiratory distress syndrome using combined acoustic features. Diagnostics (Basel). 12 (11), 2802 (2022).
Grunwell, J. R. et al. Identification of a pediatric acute hypoxemic respiratory failure signature in peripheral blood leukocytes at 24 hours post-ICU admission with machine learning. Front. Pediatr. 11, 1159473 (2023).
Acknowledgements
This research was funded by Health and Youth Technical Backbone Talent Cultivation Plan of Ningbo (2021QNJSGG-XZW). We thank Dr. Bo Lu for his valuable contributions to the data processing in this study.
Author information
Authors and Affiliations
Contributions
Z.W.X. and X.M.F. conceptualized and designed the project. Z.W.X.and K.Z. conducted the analysis and wrote the manuscript. D.Q.L. conducted the analysis. K.Z. reviewed the draft manuscript. X.M.F. revised the manuscript and supervised this project. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, Z., Zhang, K., Liu, D. et al. Predicting mortality and risk factors of sepsis related ARDS using machine learning models. Sci Rep 15, 13509 (2025). https://doi.org/10.1038/s41598-025-96501-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-96501-w
Keywords
This article is cited by
-
Application of machine learning for the diagnosis and prognosis of sepsis-induced acute respiratory distress syndrome: a systematic review and meta-analysis
BMC Medical Informatics and Decision Making (2026)
-
Predicting 30-day in-hospital mortality in ICU asthma patients: a retrospective machine learning study with external validation
BMC Pulmonary Medicine (2025)
