
Abstract
Pavement crack serves as a crucial indicator of road condition, directly associated with subsequent pavement deterioration. To address the demand for large-scale real-time pavement damage assessment, this study proposes a lightweight pavement damage detection model based on YOLOv5s (LPDD-YOLO). Initially, a lightweight feature extraction network, FasterNet, is adopted to reduce the number of parameters and computational complexity. Secondly, to mitigate the reduction in accuracy resulting from the usage of lightweight network, the attention-based downsampling module and the neural network cognitive module are introduced. These modules aim to enhance the feature extraction robustness and to eliminate interference from irrelevant features. In addition, considering the significant variation in aspect ratios and diverse morphologies of pavement damages, K-Means clustering and the deformable convolution module are employed. These mechanisms ensure dynamic anchor feature selection and extend the scope of deformation ability, respectively. According to the ablation experiment on a self-built dataset, LPDD-YOLO demonstrates notable improvements in both accuracy and efficiency compared to the original model. Specifically, the mAP increases by 4.1%, and the F1 score rises by 5.3%. Moreover, LPDD-YOLO can obtain a 47.3% reduction in parameters and a 54.4% decrease in GFLOPs. It is noteworthy that LPDD-YOLO achieves real-time and accurate damage detection, with a speed of up to 85 FPS. The effectiveness and superiority of LPDD-YOLO are further substantiated through comparisons with other state-of-the-art algorithms.
Similar content being viewed by others
Introduction
Pavement cracks are crucial indicators of road damage, typically resulting from continuous deterioration caused by natural elements such as rainwater erosion and the cumulative impact of vehicle loads1,2. This deterioration significantly affects road longevity and ensure traffic safety. Hence, transportation agencies across all provinces and cities prioritize timely detection and repair of pavement cracks to maintain high-quality roads. However, traditional crack detection methods primarily rely on manual inspections, which are not only inefficient but also risky and susceptible to inspectors’ subjective judgments3. Recently, some automated inspection methods utilizing advanced tools such as lasers4,5 and radar6,7 have demonstrated promising results. Nevertheless, the widespread adoption of such technologies is hindered by their prohibitive costs and operational complexities, severely limiting their application to specific road segments. Consequently, there is an urgent demand in civil engineering to develop more cost-effective and efficient automated crack detection methods to reduce maintenance expenses.
Over the past three decades, researchers have explored automated approaches for pavement damage detection using digital image processing methods such as dynamic thresholding8,9 and edge detection10. For instance, Oliveira et al.11 utilized morphological filters to minimize pixel intensity differences in images, and employed dynamic thresholding to identify dark pixels, thereby achieving preliminary crack recognition and classification. Lim et al.12 proposed a mobile robot equipped with a camera to capture crack images and segmented the cracks using a Laplace Gaussian edge detection algorithm. Despite their capability to achieve precise detection in images with high contrast and continuous damages, these methods often encounter challenges in accurately detecting damages in practical applications due to variations in light intensity, noise, and background interference.
To address the challenges mentioned above, machine learning methods have become increasingly attractive for pavement damage detection13,14. For instance, Yusuke et al.15 proposed a method involving manual feature extraction and utilized support vector machines for crack classification under complex backgrounds. Cheng et al.16 presented a three-threshold pavement crack detection approach employing random forests. In their method, random forests were utilized to predict local crack patches within a structured learning framework, generating crack score maps. By combining morphological operations, they achieved precise crack detection results. Similarly, Yuslena et al.17 utilized gray-level co-occurrence matrices for feature extraction, simplifying the process of crack classification through two-order measurements and achieving precise crack detection. Despite notably improving crack detection accuracy compared to traditional image processing techniques, the involvement of manual subjectivity during feature extraction still constrains both detection speed and accuracy, particularly when applied to large-scale datasets.
In recent years, the rapid advancement of new-generation artificial intelligence technologies, particularly deep learning, has sparked substantial progress in neural networks applications across academia and industry. Convolutional neural networks (CNNs) have demonstrated notably success in diverse fields such as data forecasting18,19 and object detection20,21. Within the specific context of pavement damage detection, the field has witnessed the emergence of two primary categories of techniques: the region-based two-stage detection algorithms, including R-CNN22, Fast R-CNN23, Faster R-CNN24, and U-Net25, as well as the regression-based single-stage detection algorithms, such as Single Shot MultiBox Detector(SSD)26, RetinaNet27, and You Only Look Once(YOLO)28,29,30,31,32 series. These methods have shown considerable promise, with researchers like NaddafSH et al.33 leveraging EfficientDet-D734 for asphalt road damage detection and Hacıefendiobillu et al.35 applying Faster R-CNN to detect concrete pavement cracks. Mandal et al.36 further contributed with their YOLO CSP-Darknet53 network, and achieving notable results in the 2020 IEEE Big Data Challenge.
Despite these significant strides, several research gaps persist in the realm of pavement damage detection. Firstly, the computational demands of current models remain high, necessitating sophisticated hardware that hinders their deployment for real-time, large-scale inspections using portable devices. Secondly, the aspect ratios of pavement cracks vary significantly, and existing models, typically trained on datasets like Pascal VOC37 and COCO38, struggle to adapt to these variations. Lastly, while lightweight models like MobileNet39,40 and ShuffleNet41 have been proposed, they often sacrifice accuracy for efficiency, particularly in complex real-world scenarios with diverse crack morphologies and background noise.
To address these issues, this paper proposes a novel lightweight pavement damage detection model based on YOLOv5s (LPDD-YOLO). The main contributions and innovations of this study are as follows:
Firstly, the lightweight feature extraction network, FasterNet, is integrated into the LPDD-YOLO framework to reduce the number of parameters and computational complexity, making the model suitable for deployment on portable devices.
Secondly, to enhance the foreground response of road damages in the downsampling stage, the attention-based downsampling module (ADM) is proposed. It utilizes spatial-to-depth convolution and attention mechanism to reduce the loss of spatial information, thereby improving the model’s ability to detect cracks.
Then, inspired by the receptive field block module42 and CSPNet structure43, we design the neural network cognitive module (NNCM) to simulate human cognitive processes. This module enhances the deep features obtained from the lightweight network and effectively addresses the challenges of image distortion and redundant features caused by multi-scale image extraction.
Finally, to improve the capability of detecting cracks with diverse shapes, the deformable convolution module (DCM) is employed. This module mitigates the constraints imposed by fixed geometric structures in CNN building blocks, enabling better adaptation to geometric transformations.
Dataset and performance metrics
To validate and evaluate the proposed model, this study utilizes RDD202244 dataset from the Global Road Damage Detection Competition for training and evaluation. The dataset comprises tens of thousands of multi-category road damage images from six countries: Japan, India, the Czech Republic, Norway, the United States, and China. These images comprehensively cover a wide range of complex road damage scenarios, thereby providing robust support for both the training and testing phases of our model. Given the diversity in damage types, lighting conditions, and pavement characteristics across different regions, this study has narrowed its focus to four specific damage categories: longitudinal cracks (D00), transverse cracks (D10), alligator cracks (D20), and potholes (D40). Examples of each of these damage types are shown in Fig. 1.

Examples of damage: (a) D00: longitudinal crack; (b) D10: transverse crack; (c) D20: alligator crack; (d) D40: potholes.
To ensure the quality and representativeness of the dataset, a set of rigorous selection criteria were employed, encompassing factors such as background complexity, crack distribution patterns (e.g., multiple versus single cracks), crack severity (e.g., coarse versus fine cracks), and the degree of blurriness at the intersections of cracks. Through manual screening based on these criteria, a refined dataset consisting of 4039 high-quality images was adopted for this study. To facilitate efficient model training and evaluation, the dataset was partitioned into training, validation, and testing subsets with an 8:1:1 ratio, ensuring comprehensive validation and evaluation of the model. Detailed information regarding the dataset is provided in Table 1.
In addition, the proposed model is evaluated based on commonly used metrics for object detection networks, including precision (P), recall (R), F1 score (F1), average precision (AP), and mean average precision (mAP). The precision, P, represents the proportion of correctly detected damage instances among all detected damage instances, and the recall, R, represents the proportion of correctly detected damage instances among all damage instances that should have been detected. P and R can be calculated by the following equations:
where TP denotes the number of damage instances with intersection over union (IoU) greater than 0.5 during object classification. FP is the number of damage instances with IoU less than 0.5 during damage classification. FN represents the number of damage instances that are incorrectly classified as background during damage classification.
The F1 score, a comprehensive performance evaluation metric, is calculated as the harmonic mean of P and R, expressed as Eq. 3.
Finally, mAP can be obtained from the average of all APs, which can be calculated as follows.
Proposed model
Baseline
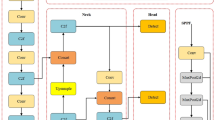
Among commonly used deep learning models, YOLOv5 has attracted significant attention due to its efficiency and accuracy. It can predict the location and classification probability of objects in an image using an end-to-end convolutional neural network. YOLOv5 is available in four versions based on the depth and size of the model. Among them, YOLOv5s is the smallest and fastest model, containing 7.0 million parameters. As depicted in Fig. 2, it consists of the following components: the input, responsible for transmitting data to the model; the backbone, for deep feature extraction; the neck, for aggregating semantic features; and the head, for object classification and localization. To meet the demands of fast and accurate inspection, a lightweight model, YOLOv5s, is selected as the baseline model.

The structure of YOLOv5s network.
Improved FasterNet
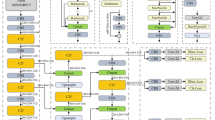
To reduce the computational complexity of the model while maintaining high accuracy in pavement damage detection, we integrated the FasterNet45 lightweight network into the YOLOv5s framework. The FasterNet architecture achieves higher computational efficiency by analyzing the relationship between latency and FLOPs. To further enhance its effectiveness in pavement damage detection, we implemented several targeted architectural modifications. As illustrated in Fig. 3, we first replaced the original embedding module in FasterNet with a DoubleConv module and substituted part of the merging module with the ADM. These modifications not only reduce information loss but also effectively mitigate irrelevant feature interference, boosting feature extraction robustness. The NNCM is subsequently added at the end of the FasterNet network to improve the model’s ability to capture both fine-grained and global features, thereby enabling more precise detection of pavement damages with varying shapes and aspect ratios. Additionally, the width of the FasterNet is suitably reduced to decrease the number of parameters and computational complexity, making the model more suitable for real-time pavement damage detection under limited computational resources.

The improved FasterNet architecture.
Attention-based downsampling module
Most CNN architectures rely on convolution or pooling operations for image downsampling. Although these methods effectively reduce the spatial resolution of feature maps, as illustrated in Fig. 4a,b, both convolution and pooling inevitably result in the loss of some information. This loss can lead to the failure to capture subtle local changes or reduce the model’s sensitivity to high-frequency information, such as edges and textures, which in turn causes ineffective learning and performance degradation. To address this issue, attention mechanisms46,47 are introduced to enhance the foreground response of damage instances, helping to mitigate the information loss that occurs during convolution or pooling downsampling. By focusing on key regions, attention mechanisms can effectively preserve and amplify responses to damaged areas while suppressing background noise, thereby improving the model’s ability to capture features.
However, traditional attention mechanisms do not fully address the aforementioned issue. To comprehensively solve this challenge, we draw inspiration from previous research48,49 and propose a novel downsampling module-ADM. As shown in Fig. 4c, the module consists of three core components designed to tackle the problem of information loss: a space-to-depth (SPD) convolution layer, an attention layer, and a pointwise (PW) convolution layer. Specifically, the input feature map is first downsampled through the SPD convolution layer, where spatial information is transferred to the channel dimension via slicing, ensuring that all original information is preserved. Then, adaptive pooling is applied to assess the importance of different channels and spatial locations, enabling the model to focus on the most crucial features. After that, a PW convolution layer is introduced, utilizing learnable parameters to reduce the number of channels, thereby enhancing the model’s adaptability to deeper convolutions. Through these procedures, the ADM successfully maintains essential positional information and long-range dependencies while simultaneously enhancing the representation of fine-grained features.

The structure of Convolution, Pooling, and Attention-based Downsampling Module.
Neural network cognitive module
Image distortion and redundant feature extraction are inevitable consequences of cropping, scaling, and other operations applied to multi-scale images in YOLO. To address this challenge, the spatial pyramid pooling-fast (SPPF) module is adopted. Although this module enhances the network’s ability to handle multi-scale targets through pooling operations at different scales, it does not fully optimize the distribution of the receptive field. All pooling operations are performed within receptive fields of the same size, and each pooling operation contributes equally to the input. This approach overlooks the effect of receptive field eccentricity, whereas in real cognitive processes, the perceptual importance of different regions varies. Therefore, although SPPF is capable of handling multi-scale image features, it is unable to simulate the human perceptual system’s differentiated emphasis on different regions of information. For this reason, inspired by the RFB module42 and the CSPNet structure43, this paper developed a novel module named NNCM. The NNCM is designed to simulates human cognitive processes, enhancing the deep features obtained from the lightweight network and effective addressing the challenges of image distortion and redundant feature extraction.
In this study, we believe that human cognitive recognition of objects is not a single-stage process but rather involves both the detection of shallow features and the comprehension of detailed object content. Consequently, the CSPNet structure is utilized to simulate the processing of shallow features, and the convolutions with different dilation rates are adopted to mimic the process of comprehending detailed object content in the human neural system. The specific details are as follows: By using a PW convolution to split the input feature map into two halves, shallow and detailed features can be processed in parallel, increasing the efficiency of feature processing. As shown in Fig. 5, the first segment is transmitted directly to the output to simulate the human shallow cognitive process, while the second segment utilizes a 3*3 convolution operation to process the basic features, expanding the receptive field to allow the network to focus on more fine-grained details during feature extraction. Subsequently, the extracted details are further divided into four segments using a PW convolution. Then, dilated convolutions with three different dilation rates are applied to simulate the different eccentricities of the receptive field in the human neural system, assigning varying importance to features from different regions. Following this, the combination of PW convolutions and 3*3 convolutions enhances robustness against small spatial changes and improves the unnatural transition of image features that may arise from using dilated convolutions with different dilation rates during feature fusion. Finally, the two segments are concatenated, and channel correlations are decoupled using a PW convolution to produce the final output. Through these processes, the NNCM achieves competitive performance comparable to networks based on deeper backbones. However, the NNCM is lighter and imposes less demand on the network architecture, making it suitable for integration with various backbone structures.

The structure of NNCM.
Deformable convolution module
A significant challenge in pavement crack detection is effectively handling the diverse geometric linear structure features presented by cracks. Although existing CNNs can adapt to geometric deformations by leveraging diverse data, their internal structures lack mechanisms to adapt to various geometric deformations. This modeling approach, which relies on data diversity to capture geometric deformations, may not generalize well to new tasks involving unknown geometric transformations. This fundamental limitation occurs because convolutional units in neural networks can only sample the input feature maps at fixed positions. Within the same neural network layer, where all activation units share a uniform receptive field size, this approach proves inadequate for higher-level layers that semantically encode spatial positions. To address the challenge posed by varying scales or deformations in object positions,equipping the model with spatial geometric deformation capabilities is crucial for precise crack localization.
Therefore, a new module named DCM is designed by integrating the deformable convolution50 into the YOLOv5 neck network. The limitations of conventional convolutional layers, which use fixed geometric structures (e.g., square or rectangular grids) to sample input features, are intended to be addressed by this module. These fixed structures struggle to adapt to the irregular shapes and varying aspect ratios of pavement cracks, leading to inadequate feature extraction. By enabling dynamic adjustment of sampling positions according to the input features, the DCM introduces flexibility into the convolution process. This adaptability increases the model’s capacity to accurately detect cracks by better capturing their geometric variations.
As depicted in Fig. 6, the DCM operates as follows: The input features are initially split into two segments using a PW convolution. One segment remains unchanged, preserving the original feature information. The other segment is modified by applying a combination of a PW convolution and a 3*3 deformable convolution. The deformable convolution introduces offsets to the sampling positions, allowing the model to adaptively adjust the receptive field based on the input features. These offsets are learned during training, enabling the model to focus on the most relevant regions of the input feature map. These two segments are finally concatenated, and another PW convolution is used to decouple the channel correlations, further enhancing the model’s capability to adapt to the significant variations in aspect ratios and shapes of road damages.

The structure of DCM.
LPDD-YOLO
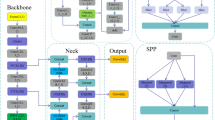
In summary, to address the challenge of pavement crack detection with limited computational resources on portable devices while maintaining high accuracy, this paper proposes a novel model, LPDD-YOLO, built upon the YOLOv5s framework, as shown in Fig. 7. Initially, the K-Means algorithm is employed for clustering and adaptive initialization of anchor boxes on the training dataset. Subsequently, FasterNet, a lightweight network, is introduced to reduce the model’s parameter count and computational complexity. Then, to further enhance feature extraction and mitigate the interference of irrelevant features, several modules, including DoubleConv, ADM, and NNCM, are incorporated into the backbone network. Finally, the DCM module is integrated into the neck of the model to enable geometric deformation capabilities, improving its adaptability to spatial transformations. Through these innovative design choices, LPDD-YOLO achieves an optimal balance between computational efficiency and detection performance, making it well-suited for real-time pavement damage detection applications.

The structure of proposed LPDD-YOLO network.
Experiments and discussion
Platform construction and model training
The model was developed and evaluated on a laptop with Windows 11 Home version operating system, equipped with an Intel i7-12650H 2.3GHz CPU, 32GB of RAM, and an NVIDIA RTX3050 GPU. Python was used as the primary development language, with PyTorch chosen as the deep learning framework. During the training process, after extensive literature review51,52,53,54,55 and experimental research, we adjusted the input image size to 640*640 pixels, set the batch size to 16, and defined the training duration to 150 epochs. To optimize the training process, we selected the SGD optimizer and configured its key parameters as follows: lr = 0.01, lrf = 0.01, momentum = 0.937, and weight_decay = 0.0005. Finally, to ensure smooth training initiation, we implemented a warm-up strategy during the first three phases. Subsequently, a cosine learning rate decay strategy was employed to gradually decrease the learning rate, ensuring stable gradient descent throughout the entire training process.
Ablation experiments
Through ablation experiments, the effects of different improvement techniques on detection results were systematically evaluated. Based on YOLOv5s, the model introduced with the lightweight feature extraction network FasterNet is referred to as LPDD-YOLO-a. Adding ADM to LPDD-YOLO-a yields LPDD-YOLO-b. LPDD-YOLO-c is obtained by incorporating NNCM into LPDD-YOLO-b, and LPDD-YOLO-d is developed by adding DCM to LPDD-YOLO-c. The first embedding module in LPDD-YOLO-d is then replaced with DoubleConv to produce LPDD-YOLO-e. Finally, LPDD-YOLO is achieved by applying the K-Means algorithm to update the initial anchor boxes in LPDD-YOLO-e. The performance in terms of parameter count, computational complexity, F1 score, mAP, and detection speed (FPS) for different combinations of backbone and neck configurations are shown in Table 2.
As shown in Table 2, although LPDD-YOLO-a’s mAP decreased by 8.7% and its F1 score decreased by 6.8% compared to YOLOv5s, it achieved a significant reduction in the number of parameters by 4.72 million (a 67.2% decrease) and a reduction in computational complexity by 10.7 GFLOPs (a 67.7% decrease). These indicate that, despite some trade-offs in performance metrics, LPDD-YOLO-a provides more advantages for practical applications that require real-time processing and high device performance.
Further comparison between LPDD-YOLO-b and LPDD-YOLO-a shows that replacing the last two merging modules with ADM in the FasterNet feature extraction network resulted in a 6.1% increase in mAP and a 4.3% improvement in the F1 score. These indicate that the ADM module enhances the model’s perceptual ability during the downsampling process, optimizing the CNNs performance in crack detection. It is worthy to mention that downsampling frequently results in the loss of spatial information in the image, making it challenging to identify small features like cracks. By slicing and adaptively selecting features, the ADM module effectively mitigates this information loss. This improves the overall detection performance by better preserving small crack features, even at lower resolutions. Additionally, compared to LPDD-YOLO-a, the computational complexity increased by just 1.7 GFLOPs, while the parameter count of LPDD-YOLO-b grew by only 1.34 million. This demonstrates that the ADM module successfully balances maintaining computational efficiency with improving accuracy.
Moreover, comparing LPDD-YOLO-c and LPDD-YOLO-b shows a 2% increase in mAP and a 3% increase in the F1 score. The utilization of the NNCM module is responsible for these achievements. Due to the impact of receptive field eccentricity, traditional CNNs often fail to adequately capture global context information, leading to incomplete feature representation. NNCM simulates the human cognitive process by efficiently integrating local and global features, assigning varying importance to different positions in the feature map. By successfully addressing issues including image distortion and redundant feature extraction, this approach improves the accuracy of crack detection. Notably, the computational complexity of LPDD-YOLO-c remains the same as LPDD-YOLO-b, demonstrating that the NNCM module enhances feature representation without significantly increasing computational costs.
Subsequently, a comparison between LPDD-YOLO-d and LPDD-YOLO-c reveals a 2.5% increase in mAP and a 1% increase in the F1 score. These improvements show that the DCM module effectively alleviates the limitations on the model’s expressiveness imposed by the inherent geometric structure of convolutional kernels. The geometric structure of convolutional kernels in conventional CNNs, such as square or rectangular shapes, frequently falls short of accurately capturing the unstructured features in complex images. In order to solve this issue, the DCM module introduces the concept of dynamic convolution kernels, which enable the convolution operation to adaptively adapt to the content of different images. This dynamic adjustment not only improves the flexibility of feature extraction but also enhances the model’s ability to recognize various types of cracks. In terms of both parameter count and computational complexity, LPDD-YOLO-d shows a slight increase in the number of parameters but a slight reduction in computational complexity, indicating that the DCM module enhances accuracy while maintaining computational efficiency.
Finally, performance is further enhanced by replacing the embedding module of the feature extraction network with the DoubleConv module and updating the initial anchor frames using the K-Means algorithm. The final established model, LPDD-YOLO, demonstrated a 4.1% increase in mAP and a 5.3% increase in the F1 score compared to the original YOLOv5s model. Furthermore, the number of parameters was reduced by 47.3% and the computational complexity decreased by 54.4%. Therefore, it can be concluded that LPDD-YOLO offers an efficient and lightweight detection model for pavement damage detection in complex scenes.
Comparison of different lightweight backbones
In this section, the detection performance of the LPDD-YOLO model is compared with YOLOv5s utilizing various lightweight feature extraction networks. To evaluate performance, models incorporating lightweight backbones such as MobileNetV339, MobileNetV240, ShuffleNetV241, GhostNet56 were trained for 150 epochs on the same training and validation dataset, following consistent training approach. The results are shown in Table 3.
As demonstrated in Table 3, it is noticeable that models integrating MobileNetV3 and MobileNetV2 have fewer parameters and lower computational complexity compared to the original YOLOv5s, while demonstrating slower inference speed. This suggests that although depthwise separable convolutions efficiently reduce the parameter count and computational complexity of the model, they may result in increased memory access costs. Consequently, this poses a problem that lightweight networks may not deliver fast performance. The ShuffleNetV2 network leverages four principles from lightweight network design, achieving faster inference speed due to its optimized structures. Nevertheless, experimental results reveal its accuracy for pavement damage detection is lacking. The GhostNet network, which reduces channel usage for primary feature extraction and increases feature maps through cost-effective linear transformations, achieves higher detection accuracy and speed compared to MobileNetV3, MobileNetV2, and ShuffleNetV2. However, the increased computational complexity due to excessive linear transformation operations severely affects its deployment. In contrast, the proposed LPDD-YOLO, utilizing Im-FasterNet, achieves parameter counts and detection speed comparable to GhostNet. It is worthy to mention that LPDD-YOLO reduces GFLOPs by 0.9 (an 11% decrease) compared to GhostNet and outperforms it by 3.7% in terms of mAP. This highlights the advantages of LPDD-YOLO in resource-limited devices, emphasizing its efficiency and competitive performance in pavement damage detection.
Comparison of different models
In this section, the detection performance of LPDD-YOLO is compared with several state-of-the-art detection models. During the experiments, Faster R-CNN24, SSD26, RetinaNet27, YOLOv3-tiny30, YOLOv7-tiny57, YOLOv5s32, Wang-M-YOLOv552 and Hu-M-YOLOv553 are employed for comparison. The results from these models are listed in Table 4.
As depicted in Table 4, Faster R-CNN, SSD, and RetinaNet exhibit notably slower inference speeds for pavement damage detection compared to models from the YOLO series. In practical engineering applications, detection speed plays a crucial role in the efficiency of pavement damage detection. Hence, YOLO series algorithms are more suitable as benchmark models for such applications.
Furthermore, when comparing YOLOv3-tiny, YOLOv7-tiny, and YOLOv5s, three models with similar parameter counts and computational complexities, it becomes evident that YOLOv5s achieves the highest detection accuracy and competitive inference speed. Through optimization, YOLOv5s not only significantly reduces the number of parameters and computational complexity, but also improves precision, recall, F1 score, and mAP by 7.2%, 3.5%, 5%, and 4.1%, respectively. Despite a slight decrease in FPS, this has negligible impact on real-time detection.
Finally, the optimized YOLOv5s(LPDD-YOLO) was compared with two state-of-the-art (SOTA) models, Wang-M-YOLOv5 and Hu-M-YOLOv5. The experimental results demonstrated that LPDD-YOLO exhibited significant advantages in accuracy, F1 score, mAP, and inference speed. Specifically, compared to Wang-M-YOLOv5 and Hu-M-YOLOv5, LPDD-YOLO achieved an 8.7% and 7.6% increase in precision; led by 2.9% and 3.4% in F1 score; showed an improvement of 3.2% and 1.9% in mAP; and outperformed both by 10 and 28 FPS, respectively. These clearly indicate that LPDD-YOLO has achieved a new level of accuracy and efficiency in pavement damage detection. The overall performance comparison outcomes remain unchanged despite Wang-M-YOLOv5’s slight recall advantage.
In summary, LPDD-YOLO model has demonstrated exceptional performance in the field of pavement damage detection, offering a strong technical basis for upcoming pavement maintenance and management.
Comparison of different damage instances
To further validate the robustness of the LPDD-YOLO model, the results for four types of damage instances on the test dataset are presented and compared with the baseline model, YOLOv5s. The experimental results are summarized in Table 5.
The experimental results presented in Table 5 demonstrate varied improvements in the detection capabilities of different damages achieved by LPDD-YOLO. Specifically, longitudinal crack D00, transverse crack D10, and alligator crack D20 all exhibit improvements in both precision and recall. Notably, the precision of D40 improves by more than 10%, however, this improvement is accompanied by a decrease in recall. Additionally, the detection performance for various types of crack damages, as indicated by the mAP, shows varying degrees of improvement. In contrast, the detection results for pothole damage indicate a slight decrease in mAP. This discrepancy may be attributed to an excessive number of PConv layers, leading to insufficient contextual information for detecting pothole damage. Consequently, the feature extraction network may not effectively extract the features of pothole damage and learn from them.

Test results of different damage instances: (a)–(h) YOLOv5s detection results; (i)–(p) LPDD-YOLO detection results.
To further explore the performance of LPDD-YOLO, several instances of the test results are presented. Figure 8a–h demonstrate the damage detection results of the YOLOv5s model, while Fig. 8i–p illustrate the outcomes of the LPDD-YOLO model. It is evident that LPDD-YOLO can identify damages missed by the YOLOv5s model, achieving a higher probability of detection. This indicates that LPDD-YOLO demonstrates superior performance compared to the YOLOv5s model in detecting pavement damages. As a result, LPDD-YOLO exhibits significant potential for effective applications in pavement damage detection tasks.
Damage instance analysis under complex background
Despite the progress made by current mainstream road damage detection algorithms, the LPDD-YOLO model proposed in this paper achieves significant performance enhancements. To comprehensively evaluate the practical application effectiveness of this model in complex background scenarios, several typical samples are selected for analysis. The crack images, as shown in Fig. 9, have a variety of complex background elements, including moving vehicles, dense trees, scattered houses, etc., all of which constitute potential interfering factors. Additionally, some of them face issues of overexposure or shadow coverage.

Damage instance analysis under complex background: the rectangular box represents a correctly detected instance, the elliptical box indicates a missed detection.
Fortunately, it can be seen from Fig. 9a–d that the proposed LPDD-YOLO model can accurately identify road damage instances even in the presence of interfering factors such as vehicles, trees, and houses, demonstrating its strong robustness. However, when the contrast of the sample is poor, as shown in Fig. 9e–h, where strong exposure or large areas of shadow cover occur, the boundary between the damaged area and the background becomes blurred. This undoubtedly increases the difficulty for the model to distinguish between damage and background, potentially leading to missed detection. Nevertheless, it is noteworthy that such scenarios of low contrast are relatively infrequent in real-world road damage detection settings, consequently exerting only a minimal influence on practical road damage detection and maintenance tasks. In summary, although complex background conditions pose certain challenges to high-precision detection, they have no major impact on the overall detection and maintenance performance of LPDD-YOLO.
Conclusion
This paper proposes a novel lightweight model, LPDD-YOLO, based on YOLOv5s for efficient pavement damage detection. The framework of LPDD-YOLO is described in detail, and comprehensive performance testing and validation of this model are conducted. The main contributions and findings can be summarized as follows:
-
(1)
Lightweight and efficient design LPDD-YOLO integrates the lightweight feature extraction network FasterNet, resulting in a 47.3% reduction in parameter count and a 54.4% decrease in computational complexity compared to the original YOLOv5s model. This significant optimization makes LPDD-YOLO highly suitable for deployment on portable devices with limited computing resources, such as drones, mobile robots, and embedded systems. With a real-time detection speed of up to 85 FPS, the model enables efficient large-scale pavement inspection.
-
(2)
Enhanced feature extraction and robustness By introducing the ADM, NNCM, and DCM, LPDD-YOLO successfully addresses the challenges of spatial information loss, image distortion, and geometric variations in pavement cracks. These modules enhance the model’s ability to detect fine-grained cracks and adapt to diverse crack morphologies, resulting in a 4.1% increase in mAP and a 5.3% improvement in the F1 score compared to YOLOv5s.
-
(3)
Practical impact on pavement maintenance The proposed model demonstrates superior performance in detecting various types of pavement damages, including longitudinal cracks, transverse cracks, alligator cracks, and potholes. Its high accuracy and efficiency make it a valuable tool for transportation agencies and infrastructure managers, enabling timely detection and repair of road damages.
-
(4)
Future work Although LPDD-YOLO shows significant improvements in pavement damage detection, there are still several areas for future research. First, further enhancements can be done to improve the detection of potholes, particularly in low-contrast environments where the model’s performance may be affected. Furthermore, addressing challenges related to noise effects, such as shadows, contamination, and other environmental factors, will be crucial for improving the model’s robustness in complex real-world scenarios. Additionally, exploring the integration of LPDD-YOLO with other sensing technologies, such as LiDAR or thermal imaging, could enhance its capabilities for comprehensive infrastructure monitoring.
In conclusion, LPDD-YOLO represents a significant advancement in lightweight deep learning models for pavement damage detection. Its efficient design, high accuracy, and real-time performance make it a powerful tool for improving pavement maintenance and infrastructure management. Future work will focus on addressing the remaining challenges and expanding the model’s applications to other infrastructure monitoring tasks.
Data availability
The data used to support the findings of this study are available from the corresponding author upon reasonable request.
References
Zhou, L. et al. Uav vision-based crack quantification and visualization of bridges: system design and engineering application. Struct. Health Monit. 14759217241251778 (2024).
Qiu, D., Xiao, M., Wan, S., Qin, C. & Zhu, Z. Pavement crack detection in infrared images using a dcnn and ccl algorithm. IEEE Sens. J. 23, 4548–4555 (2022).
Tian, Y., Chen, C., Sagoe-Crentsil, K., Zhang, J. & Duan, W. Intelligent robotic systems for structural health monitoring: Applications and future trends. Autom. Constr. 139, 104273 (2022).
Jia Yi, T. & Ahmad, A. Quality assessments of unmanned aerial vehicle (uav) and terrestrial laser scanning (tls) methods in road cracks mapping. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 48, 183–193 (2023).
Chastre, C., Neves, J., Ribeiro, D., Neves, M. G. & Faria, P. Advances on Testing and Experimentation in Civil Engineering: Geotechnics (Transportation, Hydraulics and Natural Resources (Springer Nature, 2022).
Xiong, X., Tan, Y., Hu, J., Hong, X. & Tang, J. Evaluation of asphalt pavement internal distresses using three-dimensional ground-penetrating radar. Int. J. Pavement Res. Technol. 1–12 (2024).
Shi, X., Zhang, A., Han, G., Yin, Y. & Chen, W. The design of 3d ground penetrating radar system for bridge inspection. IEEE Sens. J. (2024).
Wilson, A. et al. Recent advances in thermal imaging and its applications using machine learning: A review. IEEE Sens. J. 23, 3395–3407 (2023).
Nguyen, A. et al. Asr crack identification in bridges using deep learning and texture analysis. In Structures 50, 494–507 (Elsevier, 2023).
Xin, C., Wang, C., Xu, Z., Wang, J. & Yan, S. Marker-free fatigue crack detection and localization by integrating the optical flow and information entropy. Struct. Health Monit. 22, 1008–1026 (2023).
Oliveira, H. & Correia, P. L. Automatic road crack segmentation using entropy and image dynamic thresholding. In 2009 17th European Signal Processing Conference, 622–626 (IEEE, 2009).
Lim, R. S., La, H. M. & Sheng, W. A robotic crack inspection and mapping system for bridge deck maintenance. IEEE Trans. Autom. Sci. Eng. 11, 367–378 (2014).
Sabato, A., Dabetwar, S., Kulkarni, N. N. & Fortino, G. Noncontact sensing techniques for ai-aided structural health monitoring: a systematic review. IEEE Sens. J. 23, 4672–4684 (2023).
Hou, Y. et al. Intelligent analysis of subbase strain based on a long-term comprehensive monitoring. Trans. Geotech. 33, 100720 (2022).
Fujita, Y., Shimada, K., Ichihara, M. & Hamamoto, Y. A method based on machine learning using hand-crafted features for crack detection from asphalt pavement surface images. In Thirteenth International Conference on Quality Control by Artificial Vision 2017 10338, 117–124 (SPIE, 2017).
Peng, C. et al. A triple-thresholds pavement crack detection method leveraging random structured forest. Constr. Build. Mater. 263, 120080 (2020).
Sari, Y., Prakoso, P. B. & Baskara, A. R. Application of neural network method for road crack detection. TELKOMNIKA (Telecommun. Comput. Electron. Control) 18, 1962–1967 (2020).
Rangappa, N., Prasad, Y. R. V. & Dubey, S. R. Lednet: Deep learning-based ground sensor data monitoring system. IEEE Sens. J. 22, 842–850 (2021).
Yang, X., Tong, J., Yu, Z. & Tian, Y. Deep learning-based automatic rockfall impact force reconstruction for flexible barrier systems in full-scale tests. Autom. Constr. 165, 105510 (2024).
Song, Y., Xie, Z., Wang, X. & Zou, Y. Ms-yolo: Object detection based on yolov5 optimized fusion millimeter-wave radar and machine vision. IEEE Sens. J. 22, 15435–15447 (2022).
Dong, S. et al. Lightweight multi-scale encoder-decoder network with locally enhanced attention mechanism for concrete crack segmentation. Meas. Sci. Technol. 36, 025021 (2025).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 580–587 (2014).
Girshick, R. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, 1440–1448 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, 234–241 (Springer, 2015).
Liu, W. et al. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, 21–37 (Springer, 2016).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, 2980–2988 (2017).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 779–788 (2016).
Redmon, J. & Farhadi, A. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7263–7271 (2017).
Redmon, J. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Bochkovskiy, A. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Jocher, G. et al. ultralytics/yolov5: v6. 2-yolov5 classification models, apple m1, reproducibility, clearml and deci. ai integrations. Zenodo (2022).
Naddaf-Sh, S., Naddaf-Sh, M.-M., Kashani, A. R. & Zargarzadeh, H. An efficient and scalable deep learning approach for road damage detection. In 2020 IEEE International Conference on Big Data (Big Data), 5602–5608 (IEEE, 2020).
Tan, M., Pang, R. & Le, Q. V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10781–10790 (2020).
Hacıefendioğlu, K. & Başağa, H. B. Concrete road crack detection using deep learning-based faster r-cnn method. Iran. J. Sci. Technol. Trans. Civil Eng. 46, 1621–1633 (2022).
Mandal, V., Mussah, A. R. & Adu-Gyamfi, Y. Deep learning frameworks for pavement distress classification: A comparative analysis. In 2020 IEEE International Conference on Big Data (Big Data), 5577–5583 (IEEE, 2020).
Everingham, M., Van Gool, L., Williams, C. K., Winn, J. & Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vision 88, 303–338 (2010).
Lin, T.-Y. et al. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, 740–755 (Springer, 2014).
Howard, A. et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF international conference on computer vision, 1314–1324 (2019).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4510–4520 (2018).
Ma, N., Zhang, X., Zheng, H.-T. & Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), 116–131 (2018).
Liu, S., Huang, D. et al. Receptive field block net for accurate and fast object detection. In Proceedings of the European conference on computer vision (ECCV), 385–400 (2018).
Wang, C.-Y. et al. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 390–391 (2020).
Arya, D., Maeda, H., Ghosh, S. K., Toshniwal, D. & Sekimoto, Y. Rdd2022: A multi-national image dataset for automatic road damage detection. Geosci. Data J. (2022).
Chen, J. et al. Run, don’t walk: chasing higher flops for faster neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12021–12031 (2023).
Wang, S., Li, Y. & Qiao, S. Alf-yolo: Enhanced yolov8 based on multiscale attention feature fusion for ship detection. Ocean Eng. 308, 118233 (2024).
Zhou, Z., Hu, Y., Yang, X. & Yang, J. Yolo-based marine organism detection using two-terminal attention mechanism and difficult-sample resampling. Appl. Soft Comput. 153, 111291 (2024).
Sunkara, R. & Luo, T. No more strided convolutions or pooling: A new cnn building block for low-resolution images and small objects. In Joint European conference on machine learning and knowledge discovery in databases, 443–459 (Springer, 2022).
Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 13713–13722 (2021).
Dai, J. et al. Deformable convolutional networks. In Proceedings of the IEEE international conference on computer vision, 764–773 (2017).
Xing, J., Liu, Y. & Zhang, G.-Z. Improved yolov5-based uav pavement crack detection. IEEE Sens. J. 23, 15901–15909 (2023).
Wang, S. et al. Measurement of asphalt pavement crack length using yolo v5-bifpn. J. Infrastruct. Syst. 30, 04024005 (2024).
Hu, H. et al. Road surface crack detection method based on improved yolov5 and vehicle-mounted images. Measurement 229, 114443 (2024).
Xu, W., Li, X., Ji, Y., Li, S. & Cui, C. Bd-yolov8s: enhancing bridge defect detection with multidimensional attention and precision reconstruction. Sci. Rep. 14, 18673 (2024).
Wang, J. et al. Road defect detection based on improved yolov8s model. Sci. Rep. 14, 16758 (2024).
Han, K. et al. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 1580–1589 (2020).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7464–7475 (2023).
Acknowledgements
This work is supported by National Natural Science Foundation of China [Nos. 12002066, 12002065], Natural Science Foundation of Hunan Province [Nos. 2024JJ6035, 2024JJ5007], Scientific Research Fund of Hunan Provincial Education Department [No. 24B0299], Changsha Municipal Natural Science Foundation [No. kq2402006], and the Research and Innovation Projects of Postgraduate at Changsha University of Science and Technology [No. GSLGCX23147].
Author information
Authors and Affiliations
Contributions
Y. W, and J.C were primarily responsible for the experimental design and conducted the data analysis. Y.C assisted in these tasks and contributed to the interpretation of results. S. D and J.M offered theoretical guidance throughout the project, ensuring the scientific rigor of the study. X.K was instrumental in manuscript preparation, drafting the initial version and incorporating critical revisions based on feedback. All authors collaboratively reviewed and approved the final manuscript, each contributing uniquely to its content and presentation.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Dong, S., Wang, Y., Cao, J. et al. Advanced lightweight deep learning vision framework for efficient pavement damage identification. Sci Rep 15, 12966 (2025). https://doi.org/10.1038/s41598-025-97132-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-97132-x
