
Abstract
Deep learning-based image processing methods are commonly used for bridge crack detection. Aiming at the problem of missed detections and false positives caused by light, stains, and dense cracks during detection, this paper proposes a bridge crack detection algorithm based on the improved YOLOv8n model. Firstly, enhancing the model’s feature extraction capabilities by incorporating the global attention mechanism into the Backbone and Neck to gather additional crack characterization information. And optimizing the original feature fusion model through Gam-Concat to enhance the feature fusion effect. Subsequently, in the FPN-PAN structure, replacing the original upsample module with DySample promotes the full fusion of high- and low-resolution feature information, enhancing the detection capability for cracks of different scales. Finally, adding MPDIoU to the Head to optimize the bounding box function loss, enhancing the model’s ability to evaluate the overlap of dense cracks and better reflecting the spatial relationships between the cracks. In ablation and comparison experiments, the improved model achieved increases of 3.02%, 3.39%, 2.26%, and 0.81% in mAP@0.5, mAP@0.5:0.95, precision, and recall, respectively, compared to the original model. And the detection accuracy is significantly higher than other comparative models. It has practical application value in bridge inspection projects.
Similar content being viewed by others
Introduction
Currently, the main bridge detection methods include manual visual inspection, traditional instrument measurement, and traditional image processing1.Traditional measurement methods are highly subjective, have complex and time-consuming processes, lack adaptive learning capabilities, and are susceptible to other factors in complex situations. As deep learning theory and computer technology advance, target detection techniques grounded on deep learning theory are applied in detection2 and segmentation3 tasks in various fields. There are single/dual-stage target detection methods based on R-CNN4, SSD5 and YOLO6, among which the YOLO series of algorithms performs superiorly in terms of detection rate and accuracy and is often applied in daily engineering inspections for identifying the type of disease7 and determining the location of the disease8. And by the way of improving the algorithm model9, the applicability of the target detection algorithm in different scenarios and conditions can be further improved.
Ma et al.10 developed YOLO-MF based on the improved YOLOv3, which calculates the number of cracks by means of the acceleration algorithm and the median flow (MF) algorithm. Liu et al.11 proposed the R-YOLOv5 crack image rotation target detection algorithm, which improves the detection accuracy of concrete bridge crack images with large aspect ratios and clear directional characteristics by introducing angle regression variables and defining new loss functions. Chen et al.12 designed a portable damage detection algorithm called CD-YOLOv8, which runs on the Jetson Xavier NX for real-time detection of bridge images captured by drones. Xu et al.13 proposed the BD-YOLOv8s model, which significantly reduces the impact of factors such as blurriness and artifacts on bridge crack detection by incorporating modules like CARAFE into the model. Zhang et al.14 integrated the CBAM attention mechanism module into the YOLOv8 model to achieve automatic detection of defects such as cracks and water seepage. Li et al.15 incorporated the ConvNeXt V2 model as the backbone network into YOLOv8 and introduced the LSKA mechanism in the SPPF structure, which expanded the receptive field of features, enhanced feature relevance, and further improved crack detection accuracy in various environments. Xiong et al.16 introduced the Asymptotic Feature Pyramid Network (AFPN) to improve feature fusion and overall model performance, enhancing the accuracy of bridge surface crack detection. Li and Liu17 proposed a Multi-Branch Coordinate Attention (MBCA) mechanism, developing a deformable convolution based on MBCA to replace the deep C2F structure in the YOLOv8 architecture, and introduced a global perception module in the coordinate attention mechanism to improve the model’s adaptability to complex feature shapes. Chun, Kikuta et al.18. proposed a new self-training framework using Bayesian neural networks and spatial prior. It is used for unsupervised domain adaptation in crack segmentation and effectively improves the performance of the model after domain adaptation. Deng et al.19 proposed a crack boundary refinement framework (CBRF) for fine segmentation of HR crack images and introduced an active boundary loss in the training process. It addresses the semantic inconsistency of the crack boundary region and improves the safety and practicality of UAV bridge inspection.
Despite significant advancements in the performance of YOLO detection models, there are still some issues in detecting bridge cracks under complex background conditions. The model’s ability to extract key features of cracks is insufficient due to the influence of complex background factors, such as lighting, stains, and dense cracks. Additionally, the model performs poorly in handling dense and overlapping areas of cracks, often overlooking some overlapping and small targets, which leads to missed detections. Therefore, it is necessary to further improve the YOLO model to better adapt to the detection of bridge cracks in complex background conditions.
To address the above issues, this paper proposes a bridge crack detection algorithm based on an improved YOLOv8n model, aiming to enhance the model’s adaptability to complex background conditions, improve the accuracy of crack detection, and reduce the problems of missed detections and false positives. The specific improvements made in this paper are as follows:
-
1.
Incorporating the global attention mechanism20. Improving the performance of deep neural networks by reducing information approximation and amplifying the global interaction representation to enhance the feature recognition and focusing ability of the model.This allows the model to capture global information more comprehensively when processing data, enabling it to identify more targets to be detected. The core design of GaM is to capture feature information through multidimensional interaction and efficient computation so as to enhance the discriminative feature expression. The feature information is captured separately through channel-space dual paths to avoid the loss of information in a single dimension, and then the serial structure is utilized to integrate the channel and spatial attention to enhance the feature expression capability. It has significant advantages in the trade-off between accuracy and speed and is suitable for intensive prediction tasks in resource-constrained scenarios.
-
2.
Replacing the original upsample module with the DySample module, reducing the spatial dimensions of the feature maps while retaining important spatial information and feature details. Instead of using a fixed interpolation kernel or a static learning kernel, DySample dynamically generates up-sampling kernel parameters based on the content of the input feature map and makes the up-sampling process adaptive to the local structure of the image by predicting the sampling kernel weights at each position through a lightweight network. Efficient up-sampling is realized through the combination of dynamics, multi-scale adaptation, and high efficiency, which better trades off computational efficiency and accuracy, making the YOLO model more efficient and accurate in bridge inspection tasks.
-
3.
Adding MPDIoU loss function into Head optimizes the bounding box function loss and enhances the model’s ability to evaluate box overlap. When dealing with relatively dense cracks, this loss function more accurately reflects the overlap and relative positional relationships between the crack boxes, improving the model’s detection accuracy and robustness. The core mechanism of MPDIoU is to simultaneously optimize the overlap region and the minimum point distance between the predicted and real boxes. The minimum point distance is introduced, and a new metric for comparing bounding box similarity based on the minimum point distance directly minimizes the point distances between the upper left and lower right corners of the predicted bounding box and the real bounding box. And includes all relevant factors considered in existing loss functions, overlapping or non-overlapping regions, centroid distance, width-height deviation, etc., which is better able to deal with the case of overlapping cracks compared to other loss functions.
This paper will conduct research from the following sections: Section “YOLOv8n network architecture” introduces the YOLOv8n network architecture, Section “Methodology” describes methodologies to improve the structure of the model, Section “Experimental results and analysis” presents experiments and result analysis, and Section “Conclusion” provides a summary of this paper.
YOLOv8n network architecture
YOLOv8 is a variant of the YOLO (You Only Look Once) series of models. Compared to previous versions, YOLOv8 has a slight increase in the number of parameters and model complexity, but it features a deeper network structure and more efficient algorithm modules, resulting in significant improvements in detection performance and stability. Although the updated version of the model achieves higher accuracy, its computational load is substantial, and the network structure is overly complex. During the model improvement process, a large number of ablation studies and comparative experiments are required. Additionally, the data volume for bridge crack detection is quite large, and rapid detection is necessary. Therefore, this paper plans to use the YOLOv8 model.
YOLOv8 includes a total of five variants of different network sizes, with the number of parameters increasing from smallest to largest as follows: v8n, v8s, v8m, v8l, and v8x. The main differences among these models lie in the number of parameters, computational complexity, inference speed, etc. All models are based on the core architecture of YOLOv8, utilizing similar designs for the Backbone, Neck, and Head to ensure consistent basic operations in object detection tasks. YOLOv8n is the smallest model in this series, featuring the fewest parameters, low memory usage, and rapid detection speed. It allows for quick experimental validation during model improvements, saving time and computational resources. Additionally, it achieves high detection accuracy, making it well-suited for the needs of this model improvement and bridge crack detection. Therefore, this paper chooses to base its research on the YOLOv8n model.
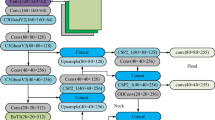
The main structure of YOLOv8n consists of three parts: Backbone, Neck, and Head. The complete network architecture is shown in Fig. 1.

Structure of YOLOv8n.
The Backbone consists of multiple components, including convolutional layers, deconvolutional layers, activation functions, batch normalization, and residual connections. It is primarily responsible for capturing feature information at different scales from the input image. Through operations such as convolution and deconvolution, the Backbone transforms the image information into efficient feature representations, providing input for the Neck. Compared to previous versions, YOLOv8n has eliminated the C3 module in the Backbone and adopted the CSP-based C2F module, resulting in higher computational efficiency and more effective information extraction capabilities.
The Neck mainly includes architectures such as the SPPF pooling layer, Feature Pyramid Network (FPN), and Path Aggregation Network (PAN). It is responsible for fusing and enhancing feature maps extracted at different levels through multiple upsampling and downsampling processes, effectively combining high- and low-resolution feature information.
The Head is responsible for the final object detection and classification tasks, consisting of a detection head and a classification head. The detection head includes a series of convolutional and deconvolutional layers that predict the bounding box regression values for each anchor box and the confidence of object presence. The classification head uses global average pooling to classify each feature map, outputting the probability distribution for each category.
Methodology
Incorporation of the global attention mechanism
In this paper, we incorporate the Global Attention Mechanism21 into the original YOLOv8n model structure, integrating it with the existing C2F module to address the issue of insufficient comprehensive extraction of key features related to cracks under complex background conditions. The global attention mechanism is a technique used to enhance the performance of deep neural networks, consisting of specialized channel and spatial attention sub-modules. By reducing information redundancy and amplifying global interactions, it improves the performance of deep neural networks, enhancing the YOLOv8n model’s ability to recognize and extract features of cracks. This allows the model to process information in images more comprehensively and provides richer feature inputs for multi-scale feature fusion. Additionally, it mitigates the adverse effects of complex background conditions during the detection process, enabling the model to more effectively adjust to the features of crack images, detect more objects, and enhance the accuracy of detection.
The global attention mechanism adopts the same sequential channel-space attention mechanism as CBAM22. After the image features are input, they pass through the channel attention mechanism and the spatial attention mechanism, which interact with each other to jointly extract features, as shown in Fig. 2.

The global attention mechanism.
The input feature F1 first undergoes processing by the channel attention mechanism, producing an intermediate feature F2 through element-wise multiplication. It is then processed by the spatial attention mechanism, resulting in the output feature F3 through another element-wise multiplication. Given that the input feature map F1 has a size of C × H × W, the intermediate state F2 and the output state F3 can be defined as follows:
The specific structure of the spatial and channel attention modules is shown in Fig. 3a and b. The channel attention module uses a three-dimensional arrangement to preserve three-dimensional information, and then utilizes a two-layer multi-layer perceptron (MLP) to amplify the cross-dimensional channel-space dependencies. The MLP is a codec structure with a reduction ratio, similar to BAM (Bottleneck Attention Module). Subsequently, it performs a reverse permutation operation to return the processed data to its original structure, ensuring that subsequent operations can be carried out correctly. In the spatial attention sub-module, in order to focus on spatial information, spatial information fusion is conducted through two convolutional layers, using the same reduction ratio r as in the channel attention sub-module. At the same time, the pooling operation is removed to further preserve the feature maps.

Channel and spatial attention submodules.
Change the upsampling module
This paper enhances the model’s ability to extract and fuse features of cracks at different scales in images by introducing the dynamic upsampler (DySample23) to replace the original upsample module. This modification facilitates better integration of high- and low-resolution feature information, thereby improving the model’s accuracy in crack detection. By continuously adjusting the sampling strategy, the model can better cope with variations and noise, making it more adaptable to bridge crack detection under complex background conditions and enhancing its robustness.
DySample is designed from the perspective of point sampling, dividing a point into multiple points to achieve clearer edges. The sampling process is conducted by finding the correct semantic clustering for each upsampling point, thus enabling efficient upsampling. The specific structure is illustrated in Fig. 4.

Structure of DySample.
First, given the upsampling ratio factor for the sampling set S and a feature map X of size\(C \times H \times W\), a linear layer with input and output channel sizes of C and\(2{s^2}\), respectively, is employed to generate an offset O of size \(2{s^2} \times H \times W\). Then, the offset is reshaped to the desired size \(2 \times sH \times sW\) using the Pixel-Shuffling method. Finally, the sampling set S is obtained by adding the offset O to the original sampling grid G, expressed as:
However, the initial offset positions shared between upsampled points ignore the positional relationships, and the unconstrained walking range of the offsets can lead to unordered point sampling. Therefore, a static range factor is introduced, which multiplies the output offset O by a static range factor (0.25) after generating the offsets. This precisely meets the theoretical boundary conditions between overlapping and non-overlapping regions, constraining the movement range of the sampling positions locally.
Improved head loss function
The YOLOv8n model has a variety of loss function types, commonly including EIoU24, DIoU25, SIoU26, GIoU27, and WIoU, with the default loss function being CIoU28. In this paper, we optimize the boundary box loss function by incorporating the MPDIoU29 function into the head of the YOLOv8n model to replace the original CIoU function. This enhancement improves the model’s ability to evaluate box overlap in object detection, thereby reducing the issue of missed detections of cracks during bridge crack detection caused by dense and overlapping cracks.
MPDIoU is an improved version of the traditional IoU metric, serving as a novel boundary box similarity comparison metric based on the minimum point distance. It directly minimizes the distance between the top-left and bottom-right points of the predicted and true bounding boxes, enhancing the accuracy and efficiency of bounding box loss regression. MPDIoU incorporates all relevant factors considered in existing loss functions, including overlapping and non-overlapping areas, center point distance, width-height deviation, etc. This enables it to effectively reflect the overlap and spatial relationships between objects, especially in scenarios involving densely packed objects. The calculation diagram of MPDIoU is illustrated in Fig. 5.

MPDIoU calculation diagram.
The specific calculation formula for the MPDIoU loss function is as follows:
\(\left( {x_{1}^{A} ,y_{1}^{A} } \right)\), \(\left( {x_{2}^{A} ,y_{2}^{A} } \right)\) represents the coordinates of the top-left and bottom-right corners of the truth box A, while \(\left( {x_{1}^{B} ,y_{1}^{B} } \right)\), \(\left( {x_{2}^{B} ,y_{2}^{B} } \right)\) represents the coordinates of the top-left and bottom-right corners of the predict box B.
Based on the aforementioned improvement plan, we obtained the final improved YOLOv8n detection model. The structure diagram of the final model is shown in Fig. 6.

Structure of the improved YOLOv8n model.
In the detection process, firstly, multiple Gam attention mechanism layers are added in the backbone part to combine with the C2f module. Through the multi-dimensional information interaction to improve the feature extraction ability of the model under the background of light, stains, etc., to obtain more feature information. After the feature information extraction is completed, the up-sampling kernel parameters are dynamically generated by DySample to better adapt to the complex image structure and realize efficient up-sampling. Subsequently, Gam-Concat is used to fuse the multi-scale feature information of Backbone and Neck to obtain more comprehensive information and improve the detection accuracy. Finally, the crack image is detected by the head, while the MPDIoU bounding box function loss mechanism based on the minimum point distance is utilized for better detection of dense and overlapping cracks.
Experimental results and analysis
Experimental environment configuration and data preparation
Before conducting model experiments, it is necessary to set up the experimental environment and collect and process the experimental images. In this paper, some images of bridge cracks under different conditions were acquired by UAV, and image broadening was performed on some of the images by rotating and cropping. At the same time, a large number of network public bridge crack datasets are acquired for model training, and finally a total of 4029 crack images for model testing are obtained. The images used in this manuscript are from various parts of the bridge structure, including the deck, piers, abutments, and more. All of these images are concrete material images, including cement concrete and asphalt concrete. The collected images were then classified into three sets: training set, validation set, and prediction set, in a ratio of 8:1:1. The cracks were labeled for type and extent using LabelImg, and the labeled images will be used for subsequent model training, validation, and prediction. Some images from the dataset are shown in Fig. 7.

Crack dataset.
Before conducting model training, it is necessary to determine the experimental parameters for the model training and to build a virtual environment for the experiment. The specific parameters for the model training are shown in Table 1. The image input size is set to 640, the number of threads is set to 2, the number of training epochs is 300, and the batch size for training is 8, meaning that 8 images are used in each iteration. Mosaic data augmentation is employed, the optimizer used is SGD. And we have set up an early stopping mechanism that will stop the training if there is no improvement in performance after 50 epochs.
The hardware configuration and environmental parameters of the computer used for model training in this paper are shown in Table 2. The operating system is Windows 11, the CPU model is i9-13900KF, and the GPU model is NVIDIA GeForce RTX 4090 with a capacity of 24GB. The Python version used for setting up the virtual environment is 3.8.18, the CUDA version is 11.7, the PyTorch version is 2.4.0, and the TorchVision version is 0.19.0.
After completing the model experiments, this paper uses precision(P), recall(R), mAP@0.5, and mAP@0.5:0.95 as evaluation criteria for the model tests, with mAP@0.5 and mAP@0.5:0.95 being the primary evaluation metrics. The specific calculation formulas and graphical representations for each metric are presented in Eqs. (9), (10), (11), and Fig. 8.

Calculation diagram of evaluation metrics.
In this context, TP represents the number of positive samples predicted as positive, FN represents the number of positive samples predicted as negative, and FP represents the number of negative samples predicted as positive. M represents the total number of categories employed for detection, whereas N indicates the number of images tested. The IoU is the intersection over the union between the ground truth box and the predicted box, where A represents the ground truth box and B represents the predicted box. mAP@0.5 is the mean average precision calculated at an IoU threshold of 0.5, while mAP@0.5:0.95 is the mean average precision calculated at multiple IoU thresholds ranging from 0.5 to 0.95 in increments of 0.05.
Incorporation of attention mechanism
In the YOLO model, both the Backbone and Neck parts contain a certain number of C2F modules, and the effects of adding attention mechanisms at different positions may differ. To determine the specific positions for adding Gam and to verify the detection performance at different addition locations, this paper adds the global attention mechanism to different sections. The specific addition positions in the experiments are as follows: ① Three Gam layers are added after the C2F modules in the Backbone. ② Three Gam layers are added after the C2F modules in the Neck. ③ Three Gam layers are added after the C2F modules in both the Backbone and Neck. We conducted experimental validations after the improvements, and the results are shown in Table 3.
From the experimental results, it can be seen that after adding Gam to both the Backbone and Neck sections, the mAP@0.5 and mAP@0.5:0.95 of Experiment ③ are better than those of Experiment ②. The mAP@0.5 of Experiment ③ is similar to that of Experiment ①, but the mAP@0.5:0.95 is higher, indicating superior detection performance compared to the individual additions. By adding Gam to both sections, the model has more feature extraction layers, resulting in richer crack feature information during feature extraction, feature fusion, and the final detection process. The recall rate of Experiment ③ reached 77.91%, which is significantly higher than that of the other two experiments. This indicates that the model extracted more comprehensive crack information and detected more crack targets in the experiments. Consequently, the model’s detection performance is enhanced, effectively addressing the issues of missed detections caused by factors such as lighting and stains. The difference between mAP@0.5 and mAP@0.5:0.95 lies in their distinct IoU thresholds, representing different levels of localization accuracy. mAP@0.5:0.95 reflects higher-precision localization capabilities and stricter evaluation criteria. The slightly lower mAP@0.5 in trial ③ is attributed to the improved recall and the model’s balance in precise localization. By detecting more previously unrecognized cracks and enhancing high-precision localization ability, the model may exhibit slight fluctuations in mAP@0.5. Given the superior detection performance of the model in Experiment ③, this paper incorporates the Gam attention mechanism layer after the C2F modules in both the Backbone and Neck sections.
After incorporating the global attention mechanism, the feature fusion process in the Backbone and Neck has adopted a new connection method. The original model used the C2F-Concat fusion method, which combined features of different scales collected from the C2F layers in the Backbone with the Neck through feature pyramid networks and path aggregation networks. The new fusion method is the Gam-Concat connection, which discards the C2F module and performs fusion through the Gam layer. To verify the advantages and disadvantages of the two methods, this paper conducted experiments using both C2F-Concat and Gam-Concat fusion methods, and the results are displayed in Table 4.
Experiment 1 used the C2F-Concat fusion method, while Experiment 2 employed the Gam-Concat fusion method. Both methods have the same number of Gam layers. However, the Gam-Concat fusion method performs an additional feature extraction process before each feature fusion compared to the C2F-Concat fusion method, resulting in more comprehensive feature fusion information. The C2F-Concat fusion method lacks processing of the feature fusion layer by the subsequent Gam layer, resulting in relatively weaker feature information. Compared to Experiment 1, Experiment 2 achieved a recall rate improvement of 1.39% and a precision rate improvement of 0.26%, allowing for the detection of more cracks with better precision. Additionally, both mAP@0.5 and mAP@0.5:0.95 results for Experiment 2 are higher than those for Experiment 1. Therefore, this paper adopts the Gam-Concat method for image feature fusion, and the improved feature fusion method is shown in Fig. 9, with the left side representing the structure before improvement and the right side showing the structure after improvement.

Different fusion methods.
Optimizing the loss function
Different loss functions have their own characteristics and advantages. To verify the practicality of the loss function used in this paper for bridge crack detection under complex background conditions, this paper conducted experimental validation using four different loss functions: CIoU, GIoU, SIoU, and MPDIoU. Among them, CIoU is the loss function used in the original model, and the experimental results are shown in Table 5.
In the experiments, the mAP@0.5 and mAP@0.5:0.95 of the CIoU function reached 81.64% and 63.44%, respectively. According to the experimental results, except for the relatively poor performance of the SIoU function, both GIoU and MPDIoU showed some improvements, with MPDIoU yielding the best results, increasing mAP@0.5 and mAP@0.5:0.95 by 0.81% and 0.1%, respectively. The SIoU function considers the scale and shape information of the boxes in its calculations, but it encounters issues when dealing with some extreme-shaped boxes and fails to effectively reflect the actual overlap between cracks, resulting in poor performance in the experiments. GIoU introduces an additional distance term to consider the distance between boxes, but its relatively simple handling does not fully capture the relative positional relationships between boxes. Additionally, GIoU does not account for the scale differences between the boxes, potentially leading to misjudgments when addressing cracks with significant size differences. It also shows poor robustness when the IoU is low, resulting in a lower mAP@0.5 compared to the CIoU function, although its mAP@0.5:0.95 is higher. MPDIoU combines multiple pieces of information (such as position, scale, and shape), allowing for a more comprehensive assessment of box overlap and reflecting the relative spatial relationships between cracks, thereby enhancing detection accuracy. In the experiments, MPDIoU had a precision that was 1.51% higher than the CIoU function. This shows that it is good at lowering false positives caused by dense cracks. Moreover, MPDIoU demonstrated better robustness when dealing with boxes of different shapes and scales, with both mAP@0.5 and mAP@0.5:0.95 outperforming other loss functions. Therefore, this paper adopts MPDIoU for the optimization of the bounding box loss function.
Ablation experiment
Once the model improvements were complete, this paper designed ablation experiments for each improvement point to validate their impact on the bridge crack detection performance. The specific experimental conditions and results are shown in Table 6.
In this study, experiment ① is the detection test of the original YOLOv8n model; experiments ②, ③, ④, and ⑤ are model tests with a single improvement, with the improvement points being MPDIoU, Gam, and DySample, respectively. Experiment ⑥ is the final detection model test that incorporates all the improvement points. According to the results shown in the Table above, the original YOLOv8n model was first tested, and the results of experiment ① showed that the recall reached 76.3%, precision reached 85.74%, and mAP@0.5 and mAP@0.5:0.95 reached 81.64% and 63.44%, respectively. Upon analyzing the experiment results, we discovered that complex factors like stains and lighting caused certain missed detections and false positives in the model during the detection process. Additionally, it was prone to false negatives in images with dense cracks. As shown in Fig. 10.

Original model detection results. In the figure, column (a) is the original image of the crack and column (b) is the original model detection result.
As shown in the red part of Fig. 10, there are influencing factors such as cement and folds in cracks 1 and 2. The model’s ability to identify disturbances in this area is insufficient, leading to their incorrect detection as cracks. And in some images, the cracks are relatively dense and exhibit overlapping situations. The original model’s ability to determine overlapping boxes is inadequate, resulting in missed detections of some cracks, as shown in crack 3. In crack 4, due to insufficient lighting and a dark image, the model is unable to adequately extract crack information from the image, leading to the judgment that there are no cracks present and resulting in a missed detection.
In the subsequent four individual experiments, Experiment ③ incorporated the Gam attention mechanism into the Backbone and Neck, resulting in improvements of 0.98% and 1.50% in mAP@0.5 and mAP@0.5:0.95, respectively, compared to the original model. Experiment ④ utilized DySample to modify the model’s upsampling module, leading to increases of 1.03% and 0.83% in mAP@0.5 and mAP@0.5:0.95, respectively, compared to the original model. During the experiments, the model’s feature extraction capability and detection accuracy in complex background environments improved, with the recall and precision of the improved experiments shown in Fig. 11.

Precision and recall curves.
Figure 11a shows the recall curves of the original model in Experiment ① and the improved experiments ③ and ④, while Fig. 11b illustrates the precision curves. Due to the early stopping mechanism, experiment iterations may be different. The improved experiments ③ and ④ have higher precision and recall values than the original model. The final precision and recall reached 86.17%, 77.91%, and 87.52%, 77.11%, respectively, which are increases of 0.43%, 1.61%, and 1.78%, 0.81% compared to the old model. Incorporating the Gam attention mechanism into Experiment ③ made it possible for more feature extraction layers to gather information about crack features. This led to a more complete set of feature information, which let the model find more cracks to be detected. The significant increase in recall indicates that the inclusion of Gam enabled the model to detect more cracks that the original model missed, effectively reducing missed detections caused by factors such as lighting and stains. The richness of key feature information also indirectly strengthened the feature fusion stage and the final detection process, leading to an improvement in overall detection accuracy. After adding the DySample upsampling module to Experiment ④, the model demonstrated stronger feature extraction and fusion capabilities for targets of different scales, facilitating the full integration of high- and low-resolution feature information, allowing the model to achieve higher detection precision. During the experiments, the model’s precision saw a significant increase, with precision improving by 1.78%, indicating that DySample effectively reduced false positives caused by complex background conditions during the detection process.
Experiment ② improved the head loss function using MPDIoU, optimizing the bounding box function loss. The metrics such as precision, recall, and mAP showed significant improvements. The bounding box function loss of the original model and the improved model during the training process is illustrated in Fig. 12, where the thin line represents the original model from Experiment ①, and the thick line indicates the improved Experiment ②.

Bounding box function loss.
Since this detection is a single-object detection, we only improved the bounding box loss function, which led to nearly identical classification losses for both experiments. As shown in the regression curve, the improvement of the loss function led to significant optimization of the bounding box loss in the early stages of the experiment, resulting in an initial loss value significantly lower than the original model. Additionally, the optimization rate was faster, achieving high accuracy after only a few iterations, and the final value was also smaller, far superior to the original model. A smaller bounding box loss value indicates that the model with the improved loss function predicts bounding boxes that are closer to the real situation. Furthermore, compared to the original model, mAP@0.5 and mAP@0.5:0.95 increased by 0.81% and 0.1%, respectively. The experimental results indicate that when the loss function is improved, the model has better bounding box loss and more accurate bounding box predictions. This effectively addressing the problem of missed detections caused by dense cracks, as shown by the cracks in Fig. 12.
Ablation experiment ⑥ is the final improved model that integrates all the improvement points, combining the advantages of MPDIoU, Gam, and DySample. The final detection results of the experiment show a significant improvement, with the detection metrics recall, precision, mAP@0.5, and mAP@0.5–90 reaching 77.11%, 88.00%, 84.66%, and 66.83%, respectively. Compared to the original model, these metrics improved by 0.81%, 2.26%, 3.02%, and 3.39%. The F1-Score values of tests ③ and ⑤ were also calculated to be 0.8183 and 0.8220, respectively, so the results of test ⑤ were better than test ③. The three improvement points presented in this paper have a significant optimization effect on the YOLOv8n model, thereby enhancing its performance and its ability to detect bridge cracks in complex backgrounds. They effectively address the issues of false positives and missed detections caused by lighting, stains, and dense cracks in the original model. The experimental results of the final detection model are shown in Fig. 13.

Results of the improved model.
In the figure, column (a) shows the original images of untreated cracks, column (b) presents the detection outcomes of the initial model, and column (c) displays the detection results of the improved model proposed in this paper. From the final detection results, some issues present in the original model have been resolved to a certain extent, as indicated by the yellow areas in the figure:
The improved model demonstrates a stronger ability to identify cracks in complex backgrounds, effectively reducing the model’s false detections caused by stains and other distracting backgrounds, such as wrinkles. Additionally, even in conditions with insufficient lighting and less distinct crack features, the model maintains excellent detection capability, as shown in cracks 1, 2, and 5.
For images with densely packed cracks, the improved model exhibits a stronger ability to overlap bounding boxes and has a superior bounding box function loss. This allows for better recognition of dense targets and overlapping boxes, tackling the original model’s issues with overlooked and erroneous detections in areas with concentrated cracks, thereby enhancing the model’s robustness, as illustrated by cracks 3 and 4.
The improved model also provides more accurate detection of cracks. As shown in crack 6, in comparison to the original model, the modified model’s determination of crack areas aligns more closely with the actual crack locations, while confidence in detecting cracks has increased by 0.11.
Combining the various experimental indicators, the improved model proposed in this paper has a very great improvement compared with the original model. The misdetection and false positives of the original model have been solved to a large extent, effectively overcoming the influence of complex background conditions and reducing the occurrence of misdetection and false positives. Although the model performance has been improved to a certain extent, there is still room for progress in the future research process. Research can be conducted in the direction of lightweight design to suit the deployment of multiple devices or to further enhance the accuracy of detection by fusion with multimodal perception.
Comparison experiment
We conducted a comparison between the improved YOLOv8n model and other algorithms, using the same dataset and experimental environment configuration conditions, to verify its applicability and superiority. The particular experimental setup and outcomes are presented in Table 7.
This paper compares several commonly used YOLO models with the improved model proposed herein. Experiments 1 to 5 involve existing YOLO models, where experiments 1 and 2 utilize the earlier v5s and v6s models. The performance and complexity of the s models are higher than those of the same generation n models. Since this paper is based on the improved YOLOv8n model, it is not directly comparable to earlier versions of n models; therefore, comparisons are made with the better-performing s models. Some of the comparative experiments additionally incorporated enhancements to the baseline models, with the objective of augmenting the performance of the comparison models and bolstering their credibility. Experiments 3 and 4 are also based on improvements to the YOLOv8n model. In experiment 3, YOLOv8-odconv30 employs a more novel dynamic convolution algorithm that replaces the original convolution layers. This makes it easier to extract feature information at different sizes in images and helps the model focus on important features even when the background is complicated. In experiment 4, YOLOv8-Gost incorporates lightweight modules such as Gostconv31 and C3Gost32 into the YOLOv8n model to improve model performance, reduce model complexity and parameter count, and enhance detection accuracy and efficiency. Experiment 5 is conducted on the next-generation YOLOv9c33 detection model, which significantly outperforms YOLOv8n in terms of performance and size. Verifying the extent of improvement in the execution of the improved model by comparing it with a better-performing model. Experiment 6 represents the improved model in this study. The specific outcomes of the comparative experiments are presented in Table 7. The mAP@0.5 and mAP@0.5:0.95 curves for the comparative experiments are illustrated in Fig. 14.

Comparison experiment results.
Comprehensive analysis of the chart data: The improved model presented in this research has a reduced number of parameters and diminished complexity. Although there is a certain increase in the number of parameters compared to the lightweight models in experiments 3 and 4, it is still much smaller than that of the next-generation YOLOv9c model in experiment 5. Compared to the s models in experiments 1 and 2, the enhanced model presented in this research is also simpler and has a lower computational load.
Regarding precision and recall, all experiments except experiment 1 show certain improvements when referencing the original YOLOv8n model. Experiment 3 achieved an increase in precision, but the recall rate decreased, indicating that the improvement in precision relied on the reduction in recall. Conversely, in Experiment 4, the recall rate improved, but the precision significantly dropped to only 83.98%. Although the model was able to identify more cracks, it could not perform effective detection. The other experiments maintained a high precision while improving recall, with the data from the improved model in this paper outperforming Experiment 5, leading by 0.4% in precision and 0.05% in recall. Compared to Experiment 2, there are variations in performance. The model in this paper has a higher recall but a slightly lower precision. However, it has a much higher detection accuracy than the model in Experiment 2. This means that the improved model’s predictions are much more accurate and match up better with where the cracks actually are, showing better performance across a range of IoU values. indicating that the model’s predictive outcomes in this paper are far superior to those of Experiment 2 and are more aligned with the actual crack locations, demonstrating better performance across different IoU values. Meanwhile, the F1-Score values of test 2, 4, and 6 were calculated to be 0.8217, 0.8081, and 0.8220, respectively, so the indicators of this paper’s model are better when considered together.
The number of training epochs varies slightly amongst the experiments because of the early stopping mechanism. The final mAP@0.5 and mAP@0.5:0.95 values for all experiments are relatively good, reaching over 80% and 60%, respectively. The improved model in this paper had the best results, coming in at 84.66% and 66.83%. Although the performance improvement rate of the model in the early stages was slow, but after several iterations, both mAP@0.5 and mAP@0.5:0.95 showed significant improvements, surpassing other experimental models and even showing some advantages over the next-generation models.
Finally, experimental comparisons were made with some other types of target detection models and the results are shown in Table 8.
The results show that compared with some earlier models such as Faster R-CNN, SSD, this paper’s model performs better and has a big lead in detection accuracy. Compared to the DETR Transformer, the proposed model achieves a slight lead in both mAP@0.5 and mAP@0.5:0.95, indicating that it can better overcome the influence of complex background conditions across different IoU thresholds, thereby improving the identification and detection of target cracks.
In summary, the experimental results indicate that the improved model performs exceptionally well in detecting bridge cracks under complex backgrounds, being able to identify more targets while maintaining a high precision. Additionally, the model exhibits stronger robustness, maintaining high detection accuracy even at high IoU thresholds, making it more suitable for bridge crack detection tasks in complex backgrounds.
Conclusion
To address the issues of false positives and missed detections in bridge crack detection under complex background conditions, this paper proposes a detection method based on an improved YOLOv8n model. By incorporating the global attention mechanism, the model’s ability to capture global information is improved, allowing it to identify more cracks that need to be detected and resolving the missed detection problems caused by factors such as lighting. The DySample is used to modify the model’s upsampling module, facilitating effective fusion of features at different levels, improving the detection accuracy for cracks of various scales, and reducing false positives caused by stains, wrinkles, and other factors. Additionally, the introduction of MPDIoU improves the head loss function, optimizes the boundary box loss, and enhances the model’s ability to assess box overlap, addressing the missed detection issues caused by overlapping cracks.
We conducted ablation experiments and comparative experiments based on the self-built bridge crack dataset. Compared to the original model, the experimental results of the improved model show an increase of 3.02% in mAP@0.5 and 3.39% in mAP@0.5:0.95. The model is capable of identifying more cracks that need detection while maintaining high detection accuracy across different IoU thresholds. Compared to other YOLO detection models, the detection model presented in this paper is of moderate size, with precision and recall rates superior to the vast majority of models. Furthermore, both mAP@0.5 and mAP@0.5:0.95 are higher than those of other improved models tested, including next-generation detection models. The improved model demonstrates superior performance in bridge crack detection, achieving high accuracy in detection tasks and significantly reducing the issues of false positives and missed detections caused by complex background conditions. It is better suited for bridge crack detection tasks under such conditions, making it practically significant for real-world bridge inspection projects.
Data availability
The datasets utilized in this paper are accessible to the corresponding author with a reasonable requests.
References
Xu, X. & Zhang, X. Crack detection of concrete bridges based digital image. J. Hunan Univ. Nat. Sci. 40, 34–40 (2013).
Hu, D., Yee, T. & Goff, D. Automated crack detection and mapping of Bridge decks using deep learning and drones. J. Civil Struct. Health Monit. 14, 729–743. https://doi.org/10.1007/s13349-023-00750-0 (2024).
Tran, T. S., Nguyen, S. D., Lee, H. J. & Tran, V. P. Advanced crack detection and segmentation on Bridge decks using deep learning. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2023.132839 (2023).
Ren, S., He, K., Girshick, R., Sun, J. & Faster, R-C-N-N. Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149. https://doi.org/10.1109/tpami.2016.2577031 (2017).
Liu, W. et al. SSD: Single shot multibox detector. arxiv https://arxiv.org/abs/1512.02325 (2016).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. arxiv https://arxiv.org/abs/1506.02640 (2016).
Sun, Z. et al. Road surface defect detection algorithm based on YOLOv8. Electronics 13. https://doi.org/10.3390/electronics13122413 (2024).
Li, Z., Kwan, B. H., Tham, M. L., Ng, O. E. & Wang, P. S. P. Abnormal detection of commutator surface defects based on YOLOv8. Int. J. Pattern Recognit. Artif. Intell. https://doi.org/10.1142/s0218001424500137 (2024).
Li, X., Xu, L., Wei, M., Zhang, L. & Zhang, C. An underwater crack detection method based on improved YOLOv8. Ocean Eng. https://doi.org/10.1016/j.oceaneng.2024.119508 (2024).
Ma, D. et al. Automatic detection and counting system for pavement cracks based on PCGAN and YOLO-MF. IEEE Trans. Intell. Transp. Syst. 23, 22166–22178. https://doi.org/10.1109/tits.2022.3161960 (2022).
Liu, Y. et al. Rotating target detection method of concrete Bridge crack based on YOLO v5. Appl. Sci. https://doi.org/10.3390/app132011118 (2023).
Chen, Q. & Jiang, X. A portable real-time concrete Bridge damage detection system. Measurement. https://doi.org/10.1016/j.measurement.2024.115536 (2025).
Xu, W. Y., Li, X., Ji, Y. C., Li, S. & Cui, C. BD-YOLOv8s: Enhancing Bridge defect detection with multidimensional attention and precision reconstruction. Sci. Rep. https://doi.org/10.1038/s41598-024-69722-8 (2024).
Zhang, C. H. et al. Automated detection and segmentation of tunnel defects and objects using YOLOv8-CM. Tunn. Undergr. Space Technol. https://doi.org/10.1016/j.tust.2024.105857 (2024).
Li, Q. J., Zhang, G. Y. & Yang, P. CL-YOLOv8: Crack detection algorithm for Fair-Faced walls based on deep learning. Appl. Sci. https://doi.org/10.3390/app14209421 (2024).
Xiong, C., Zayed, T., Jiang, X., Alfalah, G. & Abelkader, E. M. A novel model for instance segmentation and quantification of bridge surface cracks-The YOLOv8-AFPN-MPD-IoU. Sensors. https://doi.org/10.3390/s24134288 (2024).
Li, T., Liu, G. & Tan, S. Superficial defect detection for concrete bridges using YOLOv8 with attention mechanism and deformation Convolution. Appl. Sci. https://doi.org/10.3390/app14135497 (2024).
Chun, P. & Kikuta, T. Self-training with bayesian neural networks and Spatial priors for unsupervised domain adaptation in crack segmentation. Comput. Aided Civ. Infrastruct. Eng. 39, 2642–2661. https://doi.org/10.1111/mice.13315 (2024).
Deng, L. et al. Cascade refinement extraction network with active boundary loss for segmentation of concrete cracks from high-resolution images. Autom. Constr. https://doi.org/10.1016/j.autcon.2024.105410 (2024).
Xiong, C., Zayed, T. & Abdelkader, E. M. A novel YOLOv8-GAM-Wise-IoU model for automated detection of Bridge surface cracks. Constr. Build. Mater. https://doi.org/10.1016/j.conbuildmat.2024.135025 (2024).
Liu, H., Li, L., Li, Y., Long, Q. & Chen, Z. A. Hybrid attention mechanism and RepGFPN method for detecting wall cracks in high-altitude cleaning robots. IEEE Photonics J. https://doi.org/10.1109/jphot.2024.3453943 (2024).
Su, H. et al. Research on a U-Net Bridge crack identification and feature-calculation methods based on a CBAM attention mechanism. Buildings. https://doi.org/10.3390/buildings12101561 (2022).
Lin, Z., Yun, B. & Zheng, Y. LD-YOLO: A lightweight dynamic forest fire and smoke detection model with dysample and spatial context awareness module. Forests. https://doi.org/10.3390/f15091630 (2024).
Zhang, Y. F. et al. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 506, 146–157. https://doi.org/10.1016/j.neucom.2022.07.042 (2022).
Zheng, Z. et al. Distance-IoU loss: Faster and better learning for bounding box regression. arxiv https://arxiv.org/abs/1911.08287 (2019).
Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arxiv https://arxiv.org/abs/2205.12740 (2022).
Rezatofighi, H. et al. Generalized intersection over union: A metric and A loss for bounding box regression. arxiv https://arxiv.org/abs/1902.09630 (2019).
Liu, X., Yang, X., Chen, Y. & Zhao, S. Object detection method based on CIoU improved bounding box loss function. Chin. J. Liq. Cryst. Displays 38, 656–665 (2023).
Ma, S. & Xu, Y. MPDIoU: A loss for efficient and accurate bounding box regression. arxiv https://arxiv.org/abs/2307.07662 (2023).
Li, C., Zhou, A. & Yao, A. Omni-dimensional dynamic convolution. arxiv https://arxiv.org/abs/2209.07947 (2022).
Firdiantika, I. M., Lee, S., Bhattacharyya, C., Jang, Y. & Kim, S. EGCY-Net: An ELAN and GhostConv-based YOLO network for stacked packages in logistic systems. Appl. Sci. https://doi.org/10.3390/app14072763 (2024).
Xu, J. et al. Wood surface defects detection based on the improved YOLOv5-C3Ghost with SimAm module. IEEE Access 11, 105281–105287. https://doi.org/10.1109/access.2023.3303890 (2023).
Zou, J. & Wang, H. Steel surface defect detection method based on improved YOLOv9 network. IEEE Access 12, 124160–124170. https://doi.org/10.1109/access.2024.3453931 (2024).
Author information
Authors and Affiliations
Contributions
All authors contributed significantly to this paper. W.X. and H.L. developed the research idea of this paper. H.L. and J.X. collected the experimental data. H.L. and G.L. carried out the experiments and analyzed the results. H.L. wrote the paper. W.X. and Y.J. supervised the revision of the manuscript. H.L. and Z.Z. revised the manuscript. All authors have read and agreed to the publication of this paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, W., Li, H., Li, G. et al. Improved YOLOv8n-based bridge crack detection algorithm under complex background conditions. Sci Rep 15, 13074 (2025). https://doi.org/10.1038/s41598-025-97842-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-97842-2
Keywords
This article is cited by
-
A crack detection model fusing local details and global context for nuclear cladding coating surfaces
Scientific Reports (2025)
