
Abstract
Many people die from suicide, and it is a significant challenge in most societies, which calls for improved assessment procedures. This work presents a risk assessment model and outlines the risk factors for suicidal attempts under conditions of risk uncertainty. This algorithm assesses risk factors entirely using an interval-valued q-rung orthopair fuzzy (ivq-ROF) set information based Sugeno–Weber aggregation operators and EDAS method. Second, it applies Positive Distance from the Average (PDA) and Negative Distance from the Average (NDA) to balance an assessment, normalize various criteria, and rank them into higher order. We proposed ivq-ROF Sugeno–Weber weighted averaging (ivq-ROFSWWA), ivq-ROFS weighted geometric (ivq-ROFSWG) operators and EDAS method for improving the process of aggregation of fuzzy information. In the final type of stage, add up the PDA and NDA scores to determine the critical risk factors. This approach also increases the accuracy of predicting suicide risk, which is a vital asset for mental health researchers and practitioners to build effective intervention and prevention initiatives. Also, the nature of the algorithm renders decisions on compound data interfaces beneficial to numerous public health situations. Its application may include understanding factors that should inform policies that touch on mental health services and enhance the utilization of scarce resources in meeting the growing demand for such services. In conclusion, this study aspires to avoid future suicides due to a solid analytical framework for the research problem.
Similar content being viewed by others


Introduction
Evaluating the risk analysis concerning suicidal attempts, along with the identification of risks under conditions of uncertainty, is significant for planning effective prevention measures. That is the goal of assessment of risk factors: knowing the psychological processes, social relationships, financial state, or environmental conditions that have been discovered to relate to violent behavior or factors that may be known to relate to causes of violence. These factors, therefore, require risk analysis, particularly under conditions of uncertainty, including crisis and mental health difficulties. Understanding these risks allows the development of specific interventions by healthcare professionals as well as governmental and non-government organizations, a decrease in preventable mortality and enhancement of mental health stability in unstable environments. Suicide risk assessment model based on fuzzy mathematics discussed by Xu et al.1. Fuzzy logic detection of medically serious suicide attempt records in major psychiatric disorders utilized by Modai et al.2. The development of a fuzzy logic model-based suicide risk assessment tools used by Ayhan et al.3. Explainable AI for suicide risk assessment using eye activities and head gestures discovered by Liu et al.4.
The crisp set theory concerns the set frontiers, which are specified. Crisp’s theory is clear that an element is either entirely in a set or not at all. There is no other option. Every member of a universal set belongs to a subset or is not part of it, for the elements of a subgroup are exhaustive. Crisp set has a clear definition; hence, the issue of ambiguity on the part of an element to be in or out of the set is eliminated.
Significance of fuzzy sets
A fuzzy set (FS) defines the generalization of the crisp set concept. This element can belong to a specific set to a certain degree, as proposed by Lotfi A. Zadeh5 in 1965. FS theory can be applied well when there is confusion, fuzziness, lack of clarity, or indefiniteness, such as uncertainty. In Zadeh’s concept, the fuzzy set addresses the aspect referred to as the degree of membership, which ranges between 0 and 1. FS theory, there is the function that maps the nonempty set to the closed interval of the real numbers \([0, 1]\), where the number in the interval represents the degree of membership of an element to a set. It is helpful for decision-making, detecting patterns, diagnosing, etc., that is why it is abbreviated as FS.
Another generalization of FS is that put forward. A Zadeh is called an interval-valued fuzzy set (ivFS). The membership degree (MD) inside ivFS is described by an interval, which is a subinterval of \([0, 1]\). It is the same as FS, whereby IvFS is helpful in disciplines such as decision-making and pattern recognition.
Atanassov6, an extension of FS, initiated the concept of IFS. In IFS, there are two functions: the MD and the NMD; they must be in the closed interval 0,1. Several authors have employed IFS to build applications for decision-making, pattern recognition, etc. Interval-valued intuitionistic fuzzy sets have been introduced by Atanassov and Gargov7. In movies, the degrees of membership MD and NMD are defined as intervals of form a, \(b \subseteq [0, 1]\) and the condition holds that \(\sum max {b}_{i}\in \left[0, 1\right]\).
Now interval-valued q-rung orthopair fuzzy set (ivq-ROFS)8 is a mathematical framework which is extended from the q-rung orthopair fuzzy set to deal with uncertainty and vagueness in the decision-making processes. The idea of interval values extended the notions of q-rung orthopair fuzzy sets. Therefore, it becomes more flexible and adaptable for applications with ill-defined and precise numerical values. By adopting interval-based MD and NMD, the resulting approach offers an effective means for the representation and processing of complex data, wherein the concept of such degrees better accommodates the inherent uncertainty in real-world scenarios. ivq-ROFS has applications in the fields of multi-criteria decision-making, resource allocation, and intelligent systems for dealing with challenges in uncertain environments. Interval-valued q-rung orthopair fuzzy sets (ivq-ROFS) are efficiently applied to suicide risk assessment by considering the uncertainties and complexities associated with assessing multiple risk factors. ivq-ROFS models can represent imprecision and incomplete knowledge by using interval values for representing MD and NMD. It is flexible enough to include and integrate diverse criteria of psychological, social, and biological types and allow for overlapping or conflicting factors. Such an approach enables systematic and reliable decision-making. It provides a robust framework for labeling, which is thought to be an intervention for handling the multifaceted problems of suicide risk assessment.
The thought of aggregation operators (AOs) is a fundamental concept in fuzzy set theory for assessing uncertain and fuzzy information. Many mathematicians worked hard to diagnose many AOs, as discussed in references such as Aczel–Alsina Power Aggregation Operators proposed by Khan et al.9, Archimedean aggregation operator by Khan et al.10, Aczel–Alsina power aggregation operators by Khan et al.11, Frank Choquet Bonferroni Mean Operators of Bipolar by Wang et al.12.
Intuitionistic fuzzy sets (IFS) by Atanassov6 have been developed from the basic fuzzy sets where the sum of the membership and non-membership values is between 0 and 1. In contrast, Pythagorean fuzzy sets (PyFS)13 are developed again from IFS but with the sum of the squares of the membership and non-membership values between 0 and 1. In research work by Zhang et al.12, interval-valued Pythagorean fuzzy sets referred to as ivPyFS have been presented. ivPyFS is derived from PyFS, a splendid tool to address the uncertainty or ambiguity inherent to the MCDM problems. Foundations of this set have been investigated in the previous literature. q-rung orthopair fuzzy set (q-ROFS) is one of the other advanced generalizations of fuzzy set theory that can represent uncertainty and imprecision much more flexibly. In q-ROFS, the sum of MD raised to the power q and non-membership degree raised to the power q cannot exceed 1, thereby offering the flexibility of expressing the uncertain situation by ranking in more applications and fields. On this foundation, the interval-valued q-rung orthopair fuzzy set (ivq-ROFS) further develops q-ROFS through interval representation of both MD and NMD. This interval representation covers the broader range of uncertainty, automatically making the ivq-ROFS tool more suitable for solving complex decision-making issues and tasks with higher ambiguity and fuzziness.
Das et al.14 use the idea of a hesitant fuzzy soft set and hesitant bipolar-valued fuzzy soft set used by Das et al.15, weighted hesitant bipolar-valued fuzzy soft set in decision-making by Das et al.16, An innovative fuzzy multi-criteria decision-making by Das et al.17, fuzzy soft group decision-making using weighted average ratings Das et al.18 and in Das et al.19 decision making. Gitinavard et al.20, employed the model to evaluate the risk factor in their studies, An extended multi-attribute group decision approach by Gitinavard et al.21, intuitionistic fuzzy group decision analysis for sustainability risk assessment by Gitinavard et al.22, An extended multi-attribute group decision approach by Gitinavard et al.23 also use the dynamic intuitionistic fuzzy group decision making for the assessment of risk by Gitinavard et al.24. Yin et al.25 used Entropy Weight for Financial Risk Measurement and Analysis to Enhance Energy.
Role of TNM and TCNM
Data aggregation can be carried out more flexibly and realistically relying on the concepts of t-norm and t-conorm. Many mathematicians have proposed many TNM and TCNM operations for diverse fuzzy structures in this regard. For example, Menger first proposed probabilistic metric spaces26. Another topic he discussed concerned the importance of TNM and TCN in FS theory. Furthermore, the way of Einstein TNM and TCNM was discovered by Wang and Liu27; Archimedean TNM and TCNM by Xia et al.28. Liu et al.29 discussed the idea of Hamacher’s fuzzy TCNM and TNM concepts. Deschrijver et al.30 discussed Lukasiewicz TNM and TCNM and proposed the notions of AA sum and AA product, the TNM and TCNM operations, respectively. Frank31, and so forth, discovered the Frank TNM and TCNM.
To handle ambiguous data successfully in the analysis of suicidal risk, the Sugeno–Weber aggregation operators model the non-linear relationships. They can be effectively applied to the modeling of uncertain data. They are based on triangular norms TNM and TCNM, which provide a flexible structure to aggregate criteria in a fuzzy environment. The Sugeno–Weber operators are more flexible, more theoretically consistent, and more efficient than the Dombi, Aczel–Alsina, Frank, Einstein, Archimedean, and other TNMs and TCNMs operational laws. Strategically, it allows for interactions between psychological, social, and environmental risk factors and captures them correctly. Using these operators, our algorithm yields actionable insights to clinicians and policymakers and hence is preferable to real-world risk analysis under uncertainty.
Sugeno32 has introduced a family of nilpotent TNMs, including the asymptotic members, drastic sum, and probabilistic sum. On the other hand, Weber33 defined a family of nilpotent TNM one of which is a variant of product and drastic product that are asymptotic members. Sugeno–Weber TNM and TCNM of Sugeno and Weber are prestigious for their flexibility and accuracy in aggregating under uncertainty. In this regards many scholars proposed multiple MCDM approaches using the Sugeno–Weber operations for examples Yager34 proposed them, and Klement et al.35 provided a comprehensive theoretical foundation for TNM and TCNM. The use of Sugeno–Weber operations combined with Heronian mean operators to Picture FS was carried out by Zhang et al.36. Recently, Hussain and Ullah37 discussed the application of Sugeno–Weber operators in modern decision-making problems to present their flexibility and robustness in depicting the reality of different fuzzy environments and real-world challenges.
Role of the EDAS method for fuzzy information
It is a robust multi-criteria decision making (MCDM) technique that evaluates the alternatives based on distance from the average solution; this is the EDAS (evaluation based on distance from average solution). Being the risk analysis tool, its significance lies in its capability to deal with complex, uncertain, and scenic cases with multiple criteria. With its focus on relative distances instead of absolute ones, EDAS is excellent at dealing with incomplete or noisy data and performing balanced and unbiased evaluations. This offers precise, interpretable results to the stakeholders so that decisions can be made based on that. EDAS offers highly scalable and flexible integration with various advanced techniques, including probabilistic modeling, making it a system choice for systematic decision-making in uncertain environments. In deciding the multicriteria decision-making, an essential component of any decision-making process, the EDAS method Zhang et al.38 plays a vital role because the evaluations systematically balance all the options under the conflicting criterion. The main idea of the EDAS approach is to rank an alternative according to its similarity to an average solution obtained for a particular criterion. This distance is measured in two ways: positive distance from the average (PDA) to express how much an alternative is better than the average and negative distance from the average (NDA) to express how much the average is better than the concerned alternative.
Although positive and negative distances are incorporated into the essential appraisal, EDAS guarantees all other alternatives are examined holistically, and their drawbacks weighed against their merits. Further, to introduce uniformity in the criteria in different units and scales, EDAS incorporates a normalization process. In the stakeholder context, it becomes easy to make decisions when the criteria adopted are organized in various levels of hierarchical importance. The last step in ranking alternatives is weighing each criterion’s total PDA and NDA scores and arriving at the most preferred alternative.
The primary goal of EDAS is to solve problems through decision-making rather than just managing them. It is perfect in trade-off considerations within a given choice. It has a well-defined and standard method of comparing choices without the added dimension of strategy-to-alternative mapping. As a result, EDAS is shown to have the ability to have a relatively simple, diverse, yet effective solution for MCDM by weighing the advantages and disadvantages.
Research gap
While substantial progress has been made in the investigation of suicide in terms of its multicausality, the lack of effective stochastic models of suicidal behavior warrants renewed efforts. Most conventional risk assessment frameworks cannot adequately manage the fuzziness inherent in actual data while simultaneously providing robust predictive modeling results. However, the application of MCDM approaches has been relatively scarce within this line of research.
The risk analysis for suicidal attempts is a complex decision-making process that inevitably requires balancing various psychological, social, and environmental factors. Usually, methods for assessing the risk of suicidality are subjective and susceptible to biases and inconsistencies. In addition, available frameworks are complex to utilize to foretell human behavior and risk variables. In order to overcome these limitations, this paper proposes a novel, objective approach that integrates diffusion-based behavior modeling and an advanced MCDM framework. By alleviating subjectivity in suicide risk assessment under uncertainty, the proposed method is helpful for clinical applications and addressing robust policy questions by providing actionable insights.
In particular, the literature lacks studies using interval-valued q-rung orthopair fuzzy sets (ivq-ROFS) to improve the richness and accuracy of risk evaluations. Moreover, although the EDAS method has been widely used in different decision-making fields, its future in analyzing suicidal risk has not been explored much. Some significant contributions are listed as follows:
-
Propose a new algorithm that integrates ivq-ROFS and EDAS.
-
Develop the Sugeno–Weber AOs for a holistic, fair, and precise evaluation of suicidal risk factors.
-
To investigate the applicability of the proposed theory, we investigate some fundamental axioms of AOs, such as boundedness, monotonicity, and idempotency
-
The detailed MCDM algorithm is provided based on the proposed AOs and EDAS approach.
-
The case study on assessment of risk in a suicidal attempt
-
Present a real-life numerical example of investigating risk analysis and factors affecting suicidal attempts based on the proposed theory.
-
Make a deep comparison with some existing MCDM models.
-
Also, a sensitive analysis to check the variation of the parameter.
-
Filling these gaps, the research will enhance the range of preventive measures and interventions with the ultimate goal of decreasing suicidal attempt rates.
Risk assessment and ivq-ROFS
We quantify risk factors using ivq-ROS to encapsulate the lack of data in Granovetter’s model and the uncertainty and imprecision they embody. Such a process involved the Specialists allotted weigion of ivq-ROFSs to categorise the risk levels into low, medium, and high systematically. Subsequently, ivq-ROF information inference systems were leveraged based on expert knowledge and based on the identified risk factors to elucidate their interrelationships. The meticulous selection of parameters included ivq-ROFS and AOs for handling vagueness and supporting versatility in decision-making. These parameters were chosen because they represented the values in the model with significance to a particular risk domain with sufficient arithmetic efficiency to prevent computational waste.
This is the proposed study’s breakthrough, which combines the EDAS method with Sugeno–Weber t-norm and t-conorm to make the risk assessment more precise. It uses a hybrid approach that results in a more robust evaluation of restaurants by combining distance-based decision-making with advanced fuzzy aggregation techniques. This model will significantly help industries like finance, healthcare, and engineering in uncertainty handling and decision accuracy. Similarly, this approach would improve investment strategies and reduce financial losses. Optimizing risk assessment in manufacturing’s production process could mean savings in operational costs. The study offers economic benefits and better decision-making in risk-sensitive sectors; these advancements have industrial relevance.
Organization of the proposed study
The organization of the proposed work is given as follows: “Preliminaries” section discusses some preliminaries, and “Operations of Sugeno–Weber triangular norm based on ivq-ROFS” section presents the ivq-ROFS based t-norm and t-conorm operational rules. The ivq-ROFS information-based AOs established in “Interval-value Q-rofvs based Sugeno–Weber aggregation operators” and “EDAS method” sections discussed the EDAS method for ivq-ROFS based information and the MCDM algorithm for proposed AOs. The case study is offered in “Case study”” section and the numerical example is solved in “Numerical example” section. The comparison with other present AOs is provided in “Comparative study” section, and the conclusions are discussed in “Conclusion” section. Figure 1 presents the graphical overview of the proposed study.

Flow chart for a case study.
Preliminaries
To substantiate the presumptions of this paper, there is some basic concept of Sugeno–weber triangular norms, \(IvqROFS,\) and some fundamental axioms for this paper have been found. Table 1 shows the details of the mathematical symbol.
Definition 1
39 The Sugeno–Weber t-norm and t-conorm are defined as follows:
and
where \(\Upsilon_{R} \left( {{\ddot{\mathfrak{K}}}, {\ddot{\mathfrak{A}}}} \right)\) and \({\rm Z}_{R} \left( {{\ddot{\mathfrak{K}}}, {\ddot{\mathfrak{A}}}} \right)\) are expressions of drastic t-norm and t-conorm, respectively. In addition, \(\Upsilon_{S} \left( {{\ddot{\mathfrak{K}}}, {\ddot{\mathfrak{A}}}} \right)\) and \({\rm Z}_{S} \left( {{\ddot{\mathfrak{K}}}, {\ddot{\mathfrak{A}}}} \right)\) is the probabilistic addition of t-norm and t-conorm.
Definition 2
40 An q-ROFS \({\breve{G} }\) is stated:
where \(\mu \left(\varpi \right)\) indicates the MD, \(\varepsilon \varpi\) indicates the NMD. with some realistic restrictions:
\(r\left(\varpi \right)=\sqrt[q]{1- sum\left({\left(\mu \left(\varpi \right)\right)}^{q},{\left(\varepsilon \left(\varpi \right)\right)}^{q}\right)}\), denotes the hesitancy degree of q-ROFS.
Definition 3
8 Consider \(\breve{G}\) to be the set of the universe of discourse, the ivq-ROFS stated as:
where \({\mu }^{l}\left(\varpi \right)\) indicates the lower MD, \({\mu }^{u}\left(\varpi \right)\) indicates the upper MD, \({\varepsilon }^{l}\left(\varpi \right)\) indicates the lower NMD and \({\varepsilon }^{u}\left(\varpi \right)\) indicates the upper NMD.
\(r\left(\varpi \right)=\left[\sqrt[q]{1- sum\left(\begin{array}{c}\left[{\left({\mu }^{l}\left(\varpi \right)\right)}^{q},{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}\right], \\ \left[{\left({\mu }^{u}\left(\varpi \right)\right)}^{q},{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\right]\end{array}\right)}\right]\), represents the hesitancy degree.
Definition 4
41 Let \({\alpha }_{1}\) and \({\alpha }_{2}\) be the two ivq-ROFS, then.
-
\(1.\quad \alpha ^{c} = \left\{ {\begin{array}{*{20}c} { < \varpi ,~\left[ {\left( {\mu ^{l} \left( \varpi \right)} \right)^{q} ,~\left( {\mu ^{u} \left( \varpi \right)} \right)^{q} } \right],} \\ {~\left[ {\left( {\varepsilon ^{l} \left( \varpi \right)} \right)^{q} ,~\left( {\varepsilon ^{u} \left( \varpi \right)} \right)^{q} } \right] > |\varpi \in } \\ \end{array} } \right\}\)
-
\(2. \quad {\alpha }_{1}\oplus {\alpha }_{2}=\left\{\begin{array}{c}<\varpi , \left[\begin{array}{c}\sqrt[q]{\begin{array}{c}{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}+{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}\\ -{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}\end{array}}, \\ \sqrt[q]{\begin{array}{c}{\left({\mu }^{u}\left(\varpi \right)\right)}^{q}+{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\\ -{\left({\mu }^{u}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\end{array}}\end{array}\right],\\ \left[\begin{array}{c}{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q},\\ {\left({\mu }^{u}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\end{array}\right]\\ >\varpi \in \breve{G} , q\ge 2\end{array}\right\}\)
-
\(3.\quad {\alpha }_{1}\otimes {\alpha }_{2}=\left\{\begin{array}{c}\begin{array}{c}<\varpi ,\left[{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}, {\left({\mu }^{u}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\right]\\ \left[\begin{array}{c}\sqrt[q]{\begin{array}{c}{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}+{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}\\ -{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}\end{array}}, \\ \sqrt[q]{\begin{array}{c}{\left({\mu }^{u}\left(\varpi \right)\right)}^{q}+{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\\ -{\left({\mu }^{u}\left(\varpi \right)\right)}^{q}{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\end{array}}\end{array}\right]>\varpi \in \breve{G} \end{array}\\ q\ge 2\end{array}\right\}\)
Definition 5
Consider an ivq-ROFS \(\varphi = \left( {\left[ {\mu^{l} , \mu^{u} } \right], \left[ {\varepsilon^{l} , \varepsilon^{u} } \right]} \right)\) the score function and accuracy function are, respectively, represented as:
If two ivq-ROFVs \({\varphi }_{1}=\left(\left[{\mu }_{1}^{l}, {\mu }_{1}^{u}\right], \left[{\varepsilon }_{1}^{l}, {\varepsilon }_{1}^{u}\right]\right)\) and \({\varphi }_{2}=\left(\left[{\mu }_{2}^{l}, {\mu }_{2}^{u}\right], \left[{\varepsilon }_{2}^{l}, {\varepsilon }_{2}^{u}\right]\right)\), then we have \(\mathcal{S}\left({\varphi }_{1}\right)<\mathcal{S}\left({\varphi }_{2}\right)\) if \({\varphi }_{1}<{\varphi }_{2}\) and \(\mathcal{S}\left({\varphi }_{1}\right)>\mathcal{S}\left({\varphi }_{2}\right)\) if \({\varphi }_{1}>{\varphi }_{2}\). When \(\mathcal{S}\left({\varphi }_{1}\right)=\mathcal{S}\left({\varphi }_{2}\right)\) then \(\mathfrak{A}\left({\varphi }_{1}\right)=\mathfrak{A}\left({\varphi }_{2}\right)\) if \({\varphi }_{1}\approx {\varphi }_{2}\).
Operations of Sugeno–Weber triangular norm based on ivq-ROFS
Based on ivq-ROFS-based information, some necessary operations of Sugeno–weber triangular norms are defined. These aggregation expressions are used very uniquely in the proposed work.
Definition 6
For three ivq-ROFVs,\(\alpha = \left( {\left[ {\mu^{l} , \mu^{u} } \right], \left[ {\varepsilon^{l} , \varepsilon^{u} } \right]} \right)\), \(\alpha_{1} = \left( {\left[ {\mu_{1}^{l} , \mu_{1}^{u} } \right], \left[ {\varepsilon_{1}^{l} , \varepsilon_{1}^{u} } \right]} \right)\), and \(\alpha_{2} = \left( {\left[ {\mu_{2}^{l} , \mu_{2}^{u} } \right], \left[ {\varepsilon_{2}^{l} , \varepsilon_{2}^{u} } \right]} \right)\).Basic operations of the Sugeno–Weber Triangular norm are given as:
-
\((a)\quad \left({\alpha }_{1}\oplus {\alpha }_{2}\right)=\left[\begin{array}{c}\left(\begin{array}{c}\sqrt[q]{{\mu }_{1}^{l}+{\mu }_{2}^{l}-\frac{\upsilon }{1+\upsilon }{\mu }_{1}^{l}{\mu }_{2}^{l}},\\ \sqrt[q]{{\mu }_{1}^{u}+{\mu }_{2}^{u}-\frac{\upsilon }{1+\upsilon }{\mu }_{1}^{u}{\mu }_{2}^{u}}\end{array}\right),\\ \left(\begin{array}{c}\sqrt[q]{\frac{{\varepsilon }_{1}^{l}+{\varepsilon }_{2}^{l}-1+\upsilon {\varepsilon }_{1}^{l}{\varepsilon }_{2}^{l}}{1+\upsilon }}\\ \sqrt[q]{\frac{{\varepsilon }_{1}^{u}+{\varepsilon }_{2}^{u}-1+\upsilon {\varepsilon }_{1}^{u}{\varepsilon }_{2}^{u}}{1+\upsilon }}\end{array}\right)\end{array}\right]\)
-
\((b)\quad \left({\alpha }_{1}\otimes {\alpha }_{2}\right)=\left[\begin{array}{c}\left(\begin{array}{c}\sqrt[q]{\frac{{\varepsilon }_{1}^{l}+{\varepsilon }_{2}^{l}-1+\upsilon {\varepsilon }_{1}^{l}{\varepsilon }_{2}^{l}}{1+\upsilon }}\\ \sqrt[q]{\frac{{\varepsilon }_{1}^{u}+{\varepsilon }_{2}^{u}-1+\upsilon {\varepsilon }_{1}^{u}{\varepsilon }_{2}^{u}}{1+\upsilon }}\end{array}\right),\\ \left(\begin{array}{c}\sqrt[q]{{\mu }_{1}^{l}+{\mu }_{2}^{l}-\frac{\upsilon }{1+\upsilon }{\mu }_{1}^{l}{\mu }_{2}^{l}},\\ \sqrt[q]{{\mu }_{1}^{u}+{\mu }_{2}^{u}-\frac{\upsilon }{1+\upsilon }{\mu }_{1}^{u}{\mu }_{2}^{u}}\end{array}\right)\end{array}\right]\)
-
\((c)\quad {\alpha }^{\varpi }=\left[\begin{array}{c}\left(\begin{array}{c}\sqrt[q]{\frac{\upsilon }{1+\upsilon }\left(1-{\left(1-{\varepsilon }_{l}^{q}\left(\frac{\upsilon }{1+\upsilon }\right)\right)}^{\varpi }\right)},\\ \sqrt[q]{\frac{\upsilon }{1+\upsilon }\left(1-{\left(1-{\varepsilon }_{u}^{q}\left(\frac{\upsilon }{1+\upsilon }\right)\right)}^{\varpi }\right)}\end{array}\right),\\ \left(\begin{array}{c}\sqrt[q]{\left(\left(1+\upsilon \right){\left(\frac{{\mu }_{l}^{q}+1}{1+\upsilon }\right)}^{\varpi }-1\right)\frac{1}{\varpi } },\\ \sqrt[q]{\left(\left(1+\upsilon \right){\left(\frac{{\mu }_{u}^{q}+1}{1+\upsilon }\right)}^{\varpi }-1\right)\frac{1}{\varpi }}\end{array}\right)\end{array}\right]\)
-
\((d)\quad \varpi \alpha =\left[\begin{array}{c}\left(\begin{array}{c}\sqrt[q]{\left(\left(1+\upsilon \right){\left(\frac{{\varepsilon }_{l}^{q}+1}{1+\upsilon }\right)}^{\varpi }-1\right)\frac{1}{\varpi } },\\ \sqrt[q]{\left(\left(1+\upsilon \right){\left(\frac{{\varepsilon }_{u}^{q}+1}{1+\upsilon }\right)}^{\varpi }-1\right)\frac{1}{\varpi } }\end{array}\right),\\ \left(\begin{array}{c}\sqrt[q]{\frac{\upsilon }{1+\upsilon }\left(1-{\left(1-{\mu }_{l}^{q}\left(\frac{\upsilon }{1+\upsilon }\right)\right)}^{\varpi }\right)}, \\ \sqrt[q]{\frac{\upsilon }{1+\upsilon }\left(1-{\left(1-{\mu }_{u}^{q}\left(\frac{\upsilon }{1+\upsilon }\right)\right)}^{\varpi }\right)}\end{array}\right)\end{array}\right]\)
Example 1
Consider \(\alpha =\left\{\left({0.77,0.49}\right), \left(0.58, 0.72\right)\right\}\), \({{\alpha }}_{1}=\left\{\left({0.69,0.72}\right), \left(0.51, 0.63\right)\right\}\) and \({{\alpha }}_{2}=\left\{\left({0.83,0.56}\right), \left(0.60, 0.73\right)\right\}\) be the three ivq-ROFVs and \(q=3\) \(\upsilon =2\), then
Interval-value Q-rofvs based Sugeno–Weber aggregation operators
Sugeno–weber T-norms are based on operational laws, and this paper expresses the new mathematical approach of ivq-ROFV based information: ivq-ROFSWWA and ivq-ROFSWWG operators.
Definition 7
Let a class of ivq-ROFVs \(\alpha_{\chi } = \left( {\left[ {\mu_{\chi }^{l} , \mu_{\chi }^{u} } \right], \left[ {\varepsilon_{\chi }^{l} , \varepsilon_{\chi }^{u} } \right]} \right), \chi = 1, 2,3, . . . , \kappa\). The iv-ROFSWWA operator is categorized as follows:
Theorem 1
For classes \({\alpha }_{\chi }=\left(\left[{\mu }_{\chi }^{l}, {\mu }_{\chi }^{u}\right], \left[{\varepsilon }_{\chi }^{l}, {\varepsilon }_{\chi }^{u}\right]\right), \chi =1, {2,3}, . . . , \kappa\), the accumulated value of the ivq-ROFSWWA operator is still an ivq-ROFV, then find the following.
Proof
See appendix.
Theorem 2
Assume that the classes ivq-ROFVs \({\alpha }_{\chi }=\left(\left[{\mu }_{\chi }^{l}, {\mu }_{\chi }^{u}\right], \left[{\varepsilon }_{\chi }^{l}, {\varepsilon }_{\chi }^{u}\right]\right), \chi =1, {2,3}, . . . , \kappa\), which implies that \({\alpha }_{\chi }=\alpha\). Then.
Proof
See appendix.
Theorem 3
For any two sets of ivq-ROFVs \({\alpha }_{\chi }=\left(\left[{\mu }_{\chi }^{l}, {\mu }_{\chi }^{u}\right], \left[{\varepsilon }_{\chi }^{l}, {\varepsilon }_{\chi }^{u}\right]\right),\) and \({\alpha }_{\chi }{\prime}=\left(\left[{{\mu }{\prime}}_{\chi }^{l}, {{\mu }{\prime}}_{\chi }^{u}\right], \left[{{\varepsilon }{\prime}}_{\chi }^{l}, {{\varepsilon }{\prime}}_{\chi }^{u}\right]\right), \chi =1, {2,3}, . . . , \kappa\) which implies that \({\alpha }_{\chi }={\alpha }_{\chi }{\prime}\). Then.
Proof
See in appendix.
Theorem 4
For a set of ivq-ROFVs \({\alpha }_{\chi }=\left(\begin{array}{c}\left[{\mu }_{\chi }^{l}, {\mu }_{\chi }^{u}\right], \\ \left[{\varepsilon }_{\chi }^{l}, {\varepsilon }_{\chi }^{u}\right]\end{array}\right), \chi =1, {2,3}, . . . , \kappa .\) If \({\alpha }^{-}=\left({min}\left\{{\mu }_{\chi }\right\},{max}\left\{{\varepsilon }_{\chi }\right\}\right)\) and \({\alpha }^{+}=\left({max}\left\{{\mu }_{\chi }\right\},{min}\left\{{\varepsilon }_{\chi }\right\}\right)\), then.
Proof
See in appendix.
Definition 8
Consider the class of ivq-ROFVs \({\alpha }_{\chi }=\left(\left[{\mu }_{\chi }^{l}, {\mu }_{\chi }^{u}\right], \left[{\varepsilon }_{\chi }^{l}, {\varepsilon }_{\chi }^{u}\right]\right), \chi =1, {2,3}, . . . , \kappa\), the ivq-ROFSWWG operator is expressed as:
Theorem 5
Consider the class of ivq-ROFVs \(\alpha_{\chi } = \left( {\left[ {\mu_{\chi }^{l} , \mu_{\chi }^{u} } \right], \left[ {\varepsilon_{\chi }^{l} , \varepsilon_{\chi }^{u} } \right]} \right), \chi = 1, 2,3, . . . , \kappa\), the ivq-ROFSWWG operator is expressed as:
Proof
See in appendix.
Theorem 6
Consider the class of ivq-ROFVs \({{\alpha }}_{\upchi }=\left(\left[{\upmu }_{\upchi }^{{l}}, {\upmu }_{\upchi }^{{u}}\right], \left[{\upvarepsilon }_{\upchi }^{{l}}, {\upvarepsilon }_{\upchi }^{{u}}\right]\right),\upchi =1,{ 2,3}, . . . ,\upkappa\), which implies that \({{\alpha }}_{\upchi }={\alpha }\). Then.
Proof
See in appendix.
Theorem 7
Consider the set of ivq-ROFVs \({{\alpha }}_{\upchi }=\left(\left[{\upmu }_{\upchi }^{\text{l}}, {\upmu }_{\upchi }^{\text{u}}\right], \left[{\upvarepsilon }_{\upchi }^{\text{l}}, {\upvarepsilon }_{\upchi }^{\text{u}}\right]\right)\) and \(\upalpha _{\chi }^{\prime } = \left( {\left[ {\upmu _{\chi }^{{\prime l}} ,~\upmu _{\chi }^{{\prime u}} } \right],~\left[ {\varepsilon _{\chi }^{{\prime l}} ,\varepsilon _{\chi }^{{\prime u}} } \right]} \right),~\chi = 1,~2,3, \ldots ,~\kappa\). If \(\upalpha _{\chi } \le \upalpha _{\chi }^{\prime}\), then.
Proof
See in appendix.
The proposed ivq-ROFSWWG operators also satisfy the essential conditions of AOs, such as boundedness, idempotency, and monotonicity. The proof is simple and can be stated below as Theorems 2, 3, and 4.
EDAS method
In this discussion, it is said that EDAS is very useful for solving daily life problems, and the EDAS method is subdivided into the following steps.
Step 1 Initially, Experts elect the attribute for the selection of the top alternative.
Step 2 Decision experts take a fuzzy decision matrix that contains the alternatives and criteria.
where \(\mathbf{i}\) and \(\mathbf{j}\) denote the alternative and attribute, respectively.
Step 3 The average solution for all alternatives is evaluated by the formula mentioned below.
Step 4 Evaluation of PDA and NDA.
For the evaluation of PDA, use the formula.
For the Evaluation of NDA
Step 5 Evaluate weight for PDA and NDA, as listed.
where \({\boldsymbol{\Upsilon}}_{{\varvec{i}}}\) is a weight of the criteria.
Step 6 Normalization of PDA and NDA. The normalization of values is calculated by the formula given below.
Step 7 Score function.
Score values are calculated by the formula given below.
Step 8 Ranking of Alternatives.
Sorting the alternatives on the base of the highest values of the score function results in the best alternatives.
EDAS method, based on the given algorithm, applied the operators to real-life problems to find the best one. Specialists allotted weight to every attribute.
Proof
Step 1 Initially, to select the best alternative, choose attributes.
-
\({\text{X}}_{1}=\text{Logistic Regression}\)
-
\({\text{X}}_{2}=\text{Random Forest}\)
-
\({\text{X}}_{3}=\text{Neural Networks}\)
-
\({\text{X}}_{4}=\text{Bayesian Networks}\)
-
\({\text{X}}_{5}=\text{Gradient Boosting Algorithms}\)
Step 2. Decision matrix having ivq-ROFS based values. Shown in Table 2.
Step 3. Average solution for all aggregated values.
Step 4. Evaluation of PDA and NDA as listed in Tables 2 and 3.
Step 5. Next, the weight of PDA and NDA is calculated, as shown in Tables 4 and 5.
Step 6 Normalization of \({\Omega }_{ij}\) and \({\lambda }_{ij}\) as shown in Table 6.
Step 7. The score function formula calculates the score values, as shown in Table 7.
Step 8 Arrange all the values of the score function in increasing order. To find the ranking of alternatives.
Table 8 shows the data noticed out of all the possibilities using the EDAS method \({\text{\rm X}}_{1}\) be the best solution for investigating risk analysis and factors affecting suicidal attempts.
Algorithm based on proposed AOs
The following section aims to determine the best solution using the MCDM method. Also, let the group of attribute \(\upupsilon =\left({\upupsilon }_{1}, {\upupsilon }_{2}, {\upupsilon }_{3}\dots ,{\upupsilon }_{n}\right)\) and the alternative set \({\rm X}=\left({\rm X}_{1}, {\rm X}_{2}, {\rm X}_{3},\dots , {\rm X}_{n}\right)\) where the weight vector WV \({\text{\rm E}}_{i}=\left({\rm E}_{1}, {\rm E}_{2},{\rm E}_{3}, . . . , {\rm E}_{n}\right), \sum_{i=1}^{n}{\rm E}_{i}=1\). Data should be taken from specialists in ivq-ROFVs \({\alpha }_{\chi }=\left({\mu }_{\chi }, {\varepsilon }_{\chi }\right)\), must satisfy the term \(0 \le \left(\left[{\left({\mu }^{l}\left(\varpi \right)\right)}^{q}+{\left({\varepsilon }^{l}\left(\varpi \right)\right)}^{q}\right]+\left[{\left({\mu }^{u}\left(\varpi \right)\right)}^{q}+{\left({\varepsilon }^{u}\left(\varpi \right)\right)}^{q}\right]\right)\le 1\). The decision matrix completed by the ivq-ROFV is shown below. The evaluation method of ivq-ROF data can be described according to the following MCDM algorithm that was defined:
Step 1 The decision matrix filled by the specialist’s data has ivq-ROF.
Step 2 The whole data is usually categorized into positive and negative data types. Then, normalize all the data with the same type with the help of the following formula.
Step 3 The data can be aggregated by applying the proposed operators ivq-ROFSWWA and ivq-ROFSWWG.
Step 4 Using the score function, the best option is determined.
Step 5 Ranking of alternatives on the base of highest values.
Step 6 Final result.
Figure 2 presents the graphical representation of the proposed work.

Graphical representation of the proposed study.
Case study
Globally, suicide is considered to be a public health issue and is associated with multiple and varied determinants. Solving this problem is possible only with the use of tools that allow identifying and assessing suicidal behavior, including situations that are far from clear and when data is incomplete and rapidly changing. The paper considers five algorithmic options and assesses them, considering the four primary features to determine the finest approach for searching for the factors connected with suicides. The details of alternatives are given as follows:
-
(1)
Logistic regression: Logistic Regression is an essential basic statistical model for binary classification, which makes it very suitable to evaluate suicidal risk. This model works by establishing a link between different input values and the probability of a suicide attempt with a logistic function. This model is also highly interpretable as coefficients show how much each risk factor contributes, which allows for identifying the most essential components. Besides, Logistic Regression is computationally efficient and has good performance on a small scale. Therefore, Logistic Regression is well-equipped to serve as an initial analysis. However, the prerequisite in the above is that the input variables are assumed to be linearly combined with the natural log of the odds of the outcome and neglect more complex, nonlinear interactions between risk factors. In addition, it suffers from extreme dimensions and does not inherently require uncertainty in features in assessing risk for suicide, among other problems in the analysis of high-dimensional data.
-
(2)
Random forest: Random Forest is an ensemble-based learning method, which, during training, generates several decision trees and ensembles them to boost accuracies and robustness. In particular, it is very well suited to handle the nonlinear relationship and vast dimensions of data, thus making it an excellent instrument to assess the complex risk factors related to suicidal behavior. Another unique feature is they can calculate these feature importance scores, helping to pinpoint which essential risk factors include a history of past attempts at suicide or high use of substances. Random Forest is also robust to overfitting and handles missing data well when you have it in a real-world example of the dataset. Nevertheless, although superior to simpler models such as Logistic Regression in terms of performance, it lacks interpretive power as it is an ensemble. Moreover, Random Forest has no intrinsic probabilistic modeling of probabilistic outcomes, which is key in suicidal risk analysis when data is typically incomplete or ambiguous.
-
(3)
Neural networks: Deep learning models mimic the structure as well as the function of the human brain, and those models are called Neural Networks. These are deeply interconnected layers of many nodes, which are highly effective for tasks requiring processing large datasets with many features because they learn very complex, non-linear representations of the patterns in data. In terms of disrupting complex interactions between psychological, social, and environmental factors related to suicidal risk, Neural Networks can help better describe these than simpler models might. They are at ease, can learn from the data, and do not need explicit feature engineering. Nevertheless, Neural Networks are resource- and highly data-intensive, which may be a limitation in smaller or less complete datasets. The big drawback, however, is their lack of interpretability, which is often referred to as “a black box,” as it is difficult to understand what was added to this output. In clinical settings, this can be a significant barrier to understanding the reasoning behind risk predictions before making a decision.
-
(4)
Bayesian networks: Probabilistic graphical models of variables representing the variables and dependency relationships using directed acyclic graphs defined using the Bayesian Networks. Because they are particularly good at handling uncertainty and probabilistic reasoning, they are especially suited for analyzing suicidal risk, for example, when the data is incomplete or ambiguous. Explicit in Bayesian Networks is how risk factors, depression severity, and the social support they do and do not provide are entwined, and they provide a clear graphical representation of these dependencies. This increases the interpretability as well as gives clinicians insight into how various factors contribute to suicide risk. Bayesian Networks also allow prior knowledge or expert opinions to be included, giving them flexibility in the context. Nevertheless, knowledge or assumption of the network’s structure is required when constructing an accurate Bayesian network, which can be challenging in complex domains such as suicidal behavior. Additionally, they can become computationally expensive for large networks, thereby preventing some applications’ scalability.
-
(5)
Gradient Boosting Algorithms: Gradient Boosting Algorithms, being a robust machine learning technique, is a technique of building models sequentially using decision trees by combining many weak learners. Overall, it’s about enhancing accuracy, as the previous models were rejected due to errors. Gradient Boosting is a potent technique in suicidal risk analysis as it can capture highly complex and non-linear relationships between risk factors (for example, depression severity, social isolation, and availability of resources for people with mental health problems) and the probability of suicide attempt. This can efficiently work with both categorical and numerical data and yields the feature importance scores of the key risk factors. However, the tuning has to be made carefully enough to avoid overfitting, which can be computationally expensive. While it might be less interpretable than simpler models, SHAP can improve its explanatory power and, thus, make it worthwhile for algorithms that should study suicidal risk in uncertainty.
The details of attributes are given as follows:
-
(1)
Accuracy of risk assessment: The term accuracy of risk assessment means that the algorithm can be able to detect people who are at high risk of suicidal attempts. This attribute is vital within the context of your research because of the enormous consequences of even minor prediction errors. This guarantees high accuracy so that it can be reasonably sure not only to identify those at higher risk of suicide but also to do so with certainty around differences in depression severity, social isolation, and access to mental health resources. Real-world scenarios involve noisy, incomplete, and uncertain data, and the algorithm must handle this very well to reach this. By integrating probabilistic reasoning and systematic evaluation of risk factors, diffusion-based behavior modeling and advanced Multi-Criteria Decision Making (MCDM) can improve accuracy. To allow for actionable insights to clinicians and policymakers, providing them the ability to know about future risks and to intervene promptly and effectively, it is critical for our understanding of risk to exist in all practical accuracy.
-
(2)
Practical applicability: The practical applicability involves the ability of the algorithm to be used in practical implementation matters in the real-world context, for instance, in clinical practices, community mental health intervention, or even in emergency services. This characteristic emphasizes your research and the need for the algorithm to be user-friendly, scalable, and adaptable for different populations and settings. Moreover, the algorithm’s applicability is practical in that it requires computational efficiency, ease of integration, and the capacity to process real-time data. The algorithm can also be formulated such that it can meet end users’ requirements (i.e., mental health professionals) with high performance and reliability by integrating interpretable models (e.g., Logistic Regression, fed in feature importance from Gradient Boosting) and a robust framework to address uncertainty.
-
(3)
Adaptability to uncertainty: The algorithm is adaptable to uncertainty since there is no certitude when it comes to analyzing suicidal risk. Data are incomplete, subject to self-report and risk factors change. Your algorithm is told to effectively model and quantify this uncertainty in order to get reliable risk assessments. Probabilistic data can be handled with techniques such as Bayesian Networks and Monte Carlo simulations, which can run a number of different scenarios. Moreover, diffusion models help the algorithm simulate variability in behavioral patterns over time. This algorithm can help make more robust and realistic predictions about risk, and this information can be used when making decisions in an environment that is not certain.
-
(4)
Interpretability: Interpretability refers to the capability of the algorithm to provide clear and understandable insights into the prediction outcomes and related decision-making processes. In the domain of suicidal risk assessment, interpretability is critical as clinicians and policymakers need to understand.
-
i.
Why did the algorithm label some individuals as being at high risk?
-
ii.
What are the predominant contributors to such risk? Interpretability is inherent in Logistic Regression and Random Forest models; the coefficient in Logistic Regression models and their feature importance scores in Random Forest models. On the other hand, for more complex models, Neural Networks, or Gradient Boosting, to name a few, SHAP (Shapley Additive explanations) or similar techniques are needed to understand the predictions made. As such, a high level of interpretability guarantees that the algorithm’s outputs are trustworthy outputs that can be acted upon, improving communications and making decisions with stakeholders based on facts.
-
i.
Numerical example
Let us consider the set of alternatives and attributes in the shape of the decision matrix presented in Table 9. Where the considered alternatives \({\text{\rm X}}_{i} \left(i=1, 2, 3, 4, 5\right)\) and \({\upsilon }_{1} \left(1, 2, 3, 4\right)\) is known as a set of attributes presented column-wise. The procedure for evaluating the best alternative is given as follows:
Step 1 The decision matrix filled by the specialist’s data has ivq-ROFS based information.
Step 2 Given data is in positive type, normalization of the matrix is not required.
Step 3 By applying our proposed Aggregation operators to the information in Table 9 and results in Table 10, which is given as.
Step 4 Applying the score function for the optimal solution, shown in Table 11:
According to ivq-ROFSWWA and ivq-ROFSWWG operators, the outcome represents the light blue for the operator outcome and the light red shown in Fig. 3.

Graphical view of score function.
Step 5 Ranking.
Table 12 shows that applying both ivq-ROFSWWA \({\rm X}_{1}\) is the best option, and the ivq-ROFSWWG operator \({\text{\rm X}}_{4}\) be the best for investigating risk analysis and factors affecting suicidal attempts.
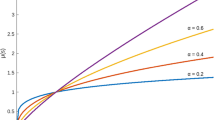
Sensitive analysis
The developed model consists of a parameter also; thus, the developed approach becomes flexible. In the following, we have observed the ranking of the alternatives based on different values. The ranking obtained is shown in Tables 13 and 14.
The results remain consistent across different parameter values. We manipulated the parameter values within the range of 3 to 15. We also consistently obtained an identical ranking of the alternatives. Thus, we can infer that the parameter value may be picked solely by those who decide based on their liking. The graphical representation of the ranking of the alternatives as obtained at several parameter values is shown in Fig. 4 as well as Fig. 5, respectively.

Variation of parameter for ivq-ROFSWWA.

Variation of parameter for ivq-ROFSWWG.
The graphical representation of ivq-ROFSWWA is given in Fig. 4. When we change the value of the parameter in ivq-ROFSWWA, values slightly change, but the ranking of alternatives remains unchanged.
The graphical representation of ivq-ROFSWWG is given in Fig. 5. When we change the value of the parameter in ivq-ROFSWWG from 3 to 15, values slightly change, but the ranking of alternatives remains unchanged.
Comparative study
In this section, we evaluate the introduced aggregation operator’s efficiency and accuracy in utilizing real-life cases of suicidal risk factors. The derived aggregation operators based on interval-valued q-rung orthopair fuzzy sets give experts more confidence in decision-making. To ensure the credibility of our proposed aggregation operators, the results have been compared to other methods developed by different authors. In particular, we employed the properties of interval-valued q-rung orthopair fuzzy weighted averaging (ivq-ROFWA) and interval-valued q-rung orthopair fuzzy weighted geometric (iv-ROFWG) described by Joshi et al.8 and interval-valued q-rung orthopair fuzzy exponential weighted averaging (ivq-ROFEWA) and interval-valued q-rung orthopair fuzzy exponential weighted geometric (ivq-ROFEWG) discussed by Garg42. However, in the case of interval-valued intuitionistic fuzzy Einstein weighted averaging (iv-IFEWA) and interval-valued intuitionistic fuzzy weighted Einstein geometric (iv-IFEWG) AOs for multicriteria decision-making methods stated in Wang and Liu43 also compare with the existing operators which are defined by Gitinavard et al.44 the values were more significant and could not be aggregated. The proposed operator was better than others, drastically escalating extraneous data’s effects, as shown in Table 15. This method can ensure that the experienced staff pick the most appropriate one that will bring the best results for them.
Table 15 shows the comparative study of the proposed approach with the other existing operators. As a result of ranking, \({\text{\rm X}}_{1}\) is the best alternative while using the ivq-ROFSWWA, and Χ4 is the best alternative by using the ivq-ROFSWWG. In a comparative study, many existing operators fail to provide the results. The reason behind this scenario is the limitations of that operator. Likewise, the operator used by Gitinavard et al.44, Fan et al.45, and Wang and Liu46 failed to provide the results. Still, the proposed study is based on the interval-valued q-rung orthopair fuzzy, in which we deal with the lower MD, NMD, and also upper MD, NMD. The existing AOs are unable to evaluate the data like the proposed AOs. Figure 6 presents the graphical overview of the comparative study.

Graphical view of comparative analysis.
Managerial implications
The contribution of the proposed model is to provide critical actionable areas for improvement in suicide risk assessment and prevention strategies, specifically among managers. A data-driven approach to handling uncertainty in risk evaluation can be achieved through the EDAS method, which integrates the Sugeno–Weber t-norm and t-conorm. This allows mental health professionals to get mental health checkups to higher risk people more precisely, therefore allowing timely interventions and ideal resource organization. These insights are helpful to policymakers to develop more effective, evidence-based suicide prevention programs that will improve public health strategies. This approach refines risk classification, decreasing operational inefficiencies and properly targeting and achieving cost-effectiveness of preventive measures, thus enhancing suicide prevention initiative impact.
Some other Managerial implications are discussed as follows: For the construction of a hospital in a pandemic situation. Decision makers collect the data in the form of ivq-ROF; after collecting the data, apply the EDAS method with the Sugeno–Weber t-norm and t-conorm to aggregate the data for the selection of the best alternative based on the highest score values. In the end, the ranking of alternatives.
The same new entrepreneur wishes to invest a big cap in the stock market. At the outset, they have a lot of competing firms, and they are in a complex and perplexing environment in which they have to make decisions. In order to identify the safest and most promising investment option, the suggested MAGM methodology is applied. An interval-valued q-rung orthopair fuzzy value (ivq-ROFV) is the best way to collect pertinent information under the condition of uncertainty and ambiguity by the decision maker. Following this, a finite selection of companies is made as alternatives, where the key attributes in selecting the options are those of safety protocol, public interest, political stability, and financial performance. The ivq-ROFSWWA and ivq-ROFSWWG operators then synthesized the data and ranked it in the end. A well-structured method that helps the decision maker to decide the best of the company for a protected and profitable investment, making a well-informed and dependable choice.
Conclusion
In this study, the work has established an interval-valued q-rung orthopair fuzzy sets (ivq-ROFS) model to analyze and identify the factors influencing suicidal attempts and risks under uncertain conditions. With the help of the ivq-ROFS mechanism, suggested on this basis, we defined a means for more appropriate modeling of uncertainty and vagueness between the suicidal factors or risks. The interval-valued approach enabled more accurate consideration of the grades of belief and credibility because the evaluation base was a fuzzy number.
Including ivq-ROFS in our algorithm helped develop a multidimensional risk approach to determine and prioritize risk factors for interventional action in mental health. The findings suggest that ivq-ROFS could improve the consistency and validity of risk assessments to provide a valuable resource for professionals to identify those at most significant risk and implement prevention strategies wisely. More research studies should be conducted to improve the algorithm or to further extend its use in the overall realm of mental health. However, real-time data and increased utilization of other enhanced techniques in the system could sharpen the prophecy feature of the model, leading to improvements in the lives of persons at risk of undertaking a suicidal attempt.
In the future, we will extend our proposed theory for multiple fuzzy frameworks, such as the complex fuzzy framework proposed by Garg and ur Rehman47, and Khan et al.48 presented the rough fuzzy set-based AOs, and Ahmad et al.49 present the entropy measure for q-rung orthopair fuzzy soft set, and Hussain et al.50 presents T-Spherical Fuzzy Information and Schweizer-Sklar Operations Based Maclaurin Symmetric Mean Operator Nazeer et al.51 present interval-valued t-spherical fuzzy using AA AOs. Some Pythagorean fuzzy set-based AOs for decision-making problems were discussed by Hussain and Pamucar52.
Data availability
Data are however available from the corresponding author upon reasonable request.
References
Xu, Y., Shang, L., Xu, J., Gao, Q. & Chen, D. Suicide risk assessment model based on fuzzy mathematics. In Advanced Data Mining and Applications 595–609 (Springer, 2020). https://doi.org/10.1007/978-3-030-65390-3_45.
Modai, I., Kuperman, J., Goldberg, I., Goldish, M. & Mendel, S. Fuzzy logic detection of medically serious suicide attempt records in major psychiatric disorders. J. Nerv. Ment. Dis. 192(10), 708. https://doi.org/10.1097/01.nmd.0000142020.20038.dd (2004).
Ayhan, F., Üstün, B. & Ergüze, T. T. The development of a fuzzy logic model-based suicide risk assessment tool. J. Neurobehav. Sci. 7(3), 156. https://doi.org/10.4103/jnbs.jnbs_30_20 (2020).
Liu, S. et al. Explainable AI for Suicide Risk Assessment Using Eye Activities and Head Gestures. In Artificial Intelligence in HCI (eds Degen, H. & Ntoa, S.) 161–178 (Springer, 2022). https://doi.org/10.1007/978-3-031-05643-7_11.
Zadeh, L. A. Fuzzy sets. Inf. Control 8(3), 338–353. https://doi.org/10.1016/S0019-9958(65)90241-X (1965).
Atanassov, K. T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 20(1), 87–96. https://doi.org/10.1016/S0165-0114(86)80034-3 (1986).
Atanassov, K. & Gargov, G. Interval valued intuitionistic fuzzy sets. Fuzzy Sets Syst. 31(3), 343–349. https://doi.org/10.1016/0165-0114(89)90205-4 (1989).
Joshi, B. P., Singh, A., Bhatt, P. K. & Vaisla, K. S. Interval valued q-rung orthopair fuzzy sets and their properties. J. Intell. Fuzzy Syst. 35(5), 5225–5230. https://doi.org/10.3233/JIFS-169806 (2018).
Khan, M. R., Ullah, K., Tehreem, Khan, Q. & Awsar, A. Some Aczel-Alsina power aggregation operators based on complex q-rung orthopair fuzzy set and their application in multi-attribute group decision-making. IEEE Access 11, 115110–115125. https://doi.org/10.1109/ACCESS.2023.3324067 (2023).
Khan, M. R., Ullah, K. & Khan, Q. Multi-attribute decision-making using Archimedean aggregation operator in T-spherical fuzzy environment. Rep. Mech. Eng. 4(1), 18. https://doi.org/10.31181/rme20031012023k (2023).
Khan, M. R., Ullah, K., Karamti, H., Khan, Q. & Mahmood, T. Multi-attribute group decision-making based on q-rung orthopair fuzzy Aczel-Alsina power aggregation operators. Eng. Appl. Artif. Intell. 126, 106629. https://doi.org/10.1016/j.engappai.2023.106629 (2023).
Wang, L., Zhang, H. & Wang, J. Frank Choquet Bonferroni mean operators of bipolar neutrosophic sets and their application to multi-criteria decision-making problems. Int. J. Fuzzy Syst. 20(1), 13–28. https://doi.org/10.1007/s40815-017-0373-3 (2018).
Yager, R. R. Properties and applications of Pythagorean fuzzy sets. In Imprecision and Uncertainty in Information Representation and Processing 119–136 (Springer, 2016).
Das, A. K. et al. An efficient water quality evaluation model using weighted hesitant fuzzy soft sets for water pollution rating. In Mechatronics (CRC Press, 2025).
Das, A. K., Gupta, N. & Granados, C. Weighted hesitant bipolar-valued fuzzy soft set in decision-making. Songklanakarin J. Sci. Technol. 45, 681 (2023).
Das, A. K. et al. An innovative fuzzy multi-criteria decision making model for analyzing anthropogenic influences on urban river water quality. Iran. J. Comput. Sci. 8(1), 103–124. https://doi.org/10.1007/s42044-024-00211-x (2025).
Das, A. K. & Granados, C. An advanced approach to fuzzy soft group decision-making using weighted average ratings. SN Comput. Sci. 2(6), 471. https://doi.org/10.1007/s42979-021-00873-5 (2021).
Das, A. K. & Granados, C. A new fuzzy parameterized intuitionistic fuzzy soft multiset theory and group decision-making. J. Curr. Sci. Technol. 12(3), 547 (2022).
Das, A. K. & Granados, C. IFP-intuitionistic multi fuzzy N-soft set and its induced IFP-hesitant N-soft set in decision-making. J. Ambient Intell. Human Comput. 14(8), 10143–10152. https://doi.org/10.1007/s12652-021-03677-w (2023).
Hamzeh, A. M., Mousavi, S. M. & Gitinavard, H. Imprecise earned duration model for time evaluation of construction projects with risk considerations. Autom. Constr. 111, 102993. https://doi.org/10.1016/j.autcon.2019.102993 (2020).
Ebrahimnejad, S., Naeini, M. A., Gitinavard, H. & Mousavi, S. M. Selection of IT outsourcing services’ activities considering services cost and risks by designing an interval-valued hesitant fuzzy-decision approach. J. Intell. Fuzzy Syst. 32(6), 4081–4093. https://doi.org/10.3233/JIFS-152520 (2017).
Ebrahimnejad, S., Gitinavard, H. & Sohrabvandi, S. A new extended analytical hierarchy process technique with incomplete interval-valued information for risk assessment in IT outsourcing. Int. J. Eng. 30(5), 739–748 (2017).
Mousavi, S. M. & Gitinavard, H. An extended multi-attribute group decision approach for selection of outsourcing services activities for information technology under risks. Int. J. Appl. Decis. Sci. 12(3), 227–241. https://doi.org/10.1504/IJADS.2019.100437 (2019).
Borujeni, M. P., Behzadipour, A. & Gitinavard, H. A dynamic intuitionistic fuzzy group decision analysis for sustainability risk assessment in surface mining operation projects. J. Sustain. Min. 24(1), 15–31. https://doi.org/10.46873/2300-3960.1435 (2025).
Yin, S., Liu, A., Zhang, Y., Wang, Y. & Wang, J. A fuzzy model using entropy weight for financial risk measurement and analysis to enhance energy performance: A case study of new energy vehicle in China. J. Innov. Res. Math. Comput. Sci. 3(1), 22. https://doi.org/10.62270/jirmcs.v3i1.25 (2024).
Menger, K. Statistical metrics. Proc. Natl. Acad. Sci. U S A 28(12), 535–537. https://doi.org/10.1073/pnas.28.12.535 (1942).
Wang, W. & Liu, X. Intuitionistic fuzzy information aggregation using einstein operations. IEEE Trans. Fuzzy Syst. 20(5), 923–938. https://doi.org/10.1109/TFUZZ.2012.2189405 (2012).
Xia, M., Xu, Z. & Zhu, B. Some issues on intuitionistic fuzzy aggregation operators based on Archimedean t-conorm and t-norm. Knowl.-Based Syst. 31, 78–88. https://doi.org/10.1016/j.knosys.2012.02.004 (2012).
Liu, P. Some Hamacher aggregation operators based on the interval-valued intuitionistic fuzzy numbers and their application to group decision making. IEEE Trans. Fuzzy Syst. 22(1), 83–97. https://doi.org/10.1109/TFUZZ.2013.2248736 (2014).
Deschrijver, G., Cornelis, C. & Kerre, E. E. On the representation of intuitionistic fuzzy t-norms and t-conorms. IEEE Trans. Fuzzy Syst. 12(1), 45–61. https://doi.org/10.1109/TFUZZ.2003.822678 (2004).
Frank, M. J. On the simultaneous associativity ofF(x, y) andx+y−F(x, y). Aeq. Math. 19(1), 194–226. https://doi.org/10.1007/BF02189866 (1979).
Sugeno, M. Theory of fuzzy integrals and its applications (Tokyo Institute of Technology, 1974).
Weber, S. A general concept of fuzzy connectives, negations and implications based on t-norms and t-conorms. Fuzzy Sets Syst. 11(1–3), 115–134. https://doi.org/10.1016/S0165-0114(83)80073-6 (1983).
Yager, R. R. On the interpretation of fuzzy if then rules. Appl. Intell. 6(2), 141–151. https://doi.org/10.1007/BF00117814 (1996).
Klement, E. P., Mesiar, R. & Pap, E. Construction of t-norms. In Triangular Norms 53–100 (Springer, 2000). https://doi.org/10.1007/978-94-015-9540-7_3.
Zhang, H., Zhang, R., Huang, H. & Wang, J. Some picture fuzzy Dombi Heronian mean operators with their application to multi-attribute decision-making. Symmetry 10(11), 593. https://doi.org/10.3390/sym10110593 (2018).
Hussain, A. & Ullah, K. An intelligent decision support system for spherical fuzzy Sugeno-Weber aggregation operators and real-life applications. Spectr. Mech. Eng. Oper. Res. 1(1), 177. https://doi.org/10.31181/smeor11202415 (2024).
Zhang, S., Wei, G., Gao, H., Wei, C. & Wei, Y. EDAS method for multiple criteria group decision making with picture fuzzy information and its application to green suppliers selections. Technol. Econ. Dev. Econ. 25(6), 1123–1138 (2019).
Sarkar, A. et al. Sugeno–Weber triangular norm-based aggregation operators under T-spherical fuzzy hypersoft context. Inf. Sci. 645, 119305 (2023).
Farid, H. M. A. & Riaz, M. Some generalized q-rung orthopair fuzzy Einstein interactive geometric aggregation operators with improved operational laws. Int. J. Intell. Syst. 36(12), 7239–7273. https://doi.org/10.1002/int.22587 (2021).
Wang, Y., Hussain, A., Yin, S., Ullah, K. & Božanić, D. Decision-making for solar panel selection using Sugeno-Weber triangular norm-based on q-rung orthopair fuzzy information. Front. Energy Res. 11, 1293623 (2024).
Garg, H. New exponential operation laws and operators for interval-valued q-rung orthopair fuzzy sets in group decision making process. Neural Comput. Appl. 33(20), 13937–13963 (2021).
Liu, P. & Wang, P. Multiple-attribute decision-making based on Archimedean Bonferroni operators of q-Rung orthopair fuzzy numbers. IEEE Trans. Fuzzy Syst. 27(5), 834–848. https://doi.org/10.1109/TFUZZ.2018.2826452 (2019).
Gitinavard, H., Ghaderi, H. & Pishvaee, M. S. Green supplier evaluation in manufacturing systems: A novel interval-valued hesitant fuzzy group outranking approach. Soft. Comput. 22(19), 6441–6460. https://doi.org/10.1007/s00500-017-2697-1 (2018).
Fan, C. et al. A new model of interval-valued intuitionistic fuzzy weighted operators and their application in dynamic fusion target threat assessment. Entropy 24(12), 1825 (2022).
Wang, W. & Liu, X. Interval-valued intuitionistic fuzzy hybrid weighted averaging operator based on Einstein operation and its application to decision making. J. Intell. Fuzzy Syst. 25(2), 279–290 (2013).
Garg, H. & Ur Rehman, U. A group decision-making algorithm to analyses risk evaluation of hepatitis with sine trigonometric laws under bipolar complex fuzzy sets information. J. Innov. Res. Math. Comput. Sci. 3(1), 65–90 (2024).
Khan, M. R., Raza, A. & Khan, Q. Multi-attribute decision-making by using intuitionistic fuzzy rough Aczel-Alsina prioritize aggregation operator. J. Innov. Res. Math. Comput. Sci. 1(2), 96 (2022).
Ahmmad, J. Classification of renewable energy trends by utilizing the novel entropy measures under the environment of q-rung orthopair fuzzy soft sets. J. Innov. Res. Math. Comput. Sci. 2(2), 1. https://doi.org/10.62270/jirmcs.v2i2.19 (2023).
Hussain, M., Hussain, A., Yin, S. & Abid, M. N. T-spherical fuzzy information and Shweizer-Sklar operations based Maclaurin symmetric mean operator and their applications. J. Innov. Res. Math. Comput. Sci. 2(2), 52. https://doi.org/10.62270/jirmcs.v2i2.21 (2023).
Nazeer, M. S., Ullah, K. & Hussain, A. A novel decision-making approach based on interval-valued T-spherical fuzzy information with applications. J. Appl. 1(2), 79–79 (2023).
Hussain, A. & Pamucar, D. Multi-attribute group decision-making based on pythagorean fuzzy rough set and novel Schweizer-Sklar T-norm and T-conorm. J. Innov. Res. Math. Comput. Sci. 1(2), 1 (2022).
Author information
Authors and Affiliations
Contributions
RuiHua Liang and Ni Duan conceived the idea. XueJing Liu and Chuanqin Liu contributed to the validation and investigation of the results. Chuanqin Liu supervised the work. All authors contributed significantly to the main manuscript text.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liang, R., Duan, N., Liu, X. et al. Algorithm for investigating risk analysis and factors affecting suicidal attempts under uncertainty. Sci Rep 15, 15933 (2025). https://doi.org/10.1038/s41598-025-97910-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-97910-7
