
Abstract
As the core part of battlefield situational awareness, air target intention recognition plays an important role in modern air operations. Aiming at the problems of data scarcity and insufficient temporal feature extraction in the process of air target intention recognition, an air target intention data extension and recognition model based on Deep Learning named IDERDL is proposed, where ID denotes intention data, E denotes data extension, R denotes intention recognition, and DL denotes deep learning. The model mainly consists of two parts: intention data generation and intention recognition. First, the air target intention recognition problem is analyzed in detail, and the air target intention space and feature set are constructed and coded uniformly. Second, the intention data generation model is built based on the denoising diffusion model, and the improved knowledge distillation method is applied to the denoising diffusion model to accelerate the sampling process of the model. Finally, the temporal block based on dilated causal convolution is built to solve the problem of temporal feature extraction. At the same time, the graph attention mechanism is introduced to mine and analyze the relationship between different features. The output of the graph attention mechanism will be channeled to the softmax layer for classification, which ultimately yields the result of target intention recognition at the current moment. The experimental results show that the intention recognition accuracy of the IDERDL model can reach 98.73%, which is better than most of the air target intention recognition methods. The IDERDL model considers the scarcity of intention data for the first time, as well as temporality, which is of great significance for improving tactical intention recognition capabilities.
Similar content being viewed by others
Introduction
With the introduction of new operational concepts such as Decision-Centric Warfare and Joint All-Domain Operation, as well as the development of modern weapons and equipment, the intensity, timeliness, and complexity of confrontation in the air and space domain have increased dramatically. It requires us to be able to quickly acquire and process battlefield information, deduce the enemy target’s operational intention, realize clear and effective battlefield posture assessment, and implement reasonable and favorable decision-making on this basis. Intention recognition is the key to the transition of modern warfare from the information domain to the cognitive domain and is the prerequisite and foundation of battlefield cognition and intelligent decision-making, which is of great significance for commanders to understand the battlefield situation and make reasonable decisions1.
With the further development of battlefield informatization and intelligence in the new situation, the uncertainty and confrontation of the war itself and the deception and concealment of the warring parties have brought great difficulties to the collection of battlefield situational data. At the same time, due to the significant asymmetry in military strength and information advantages among the warring parties, there are significant disparities in battlefield data collection, resulting in a severe scarcity of air target intention data. In particular, the application of AI techniques to intention recognition tasks requires a large amount of data as support. One possible solution to the data scarcity problem is the sample generation technique, which generates more synthetic data based on existing real intention data. Typical sample generation techniques mainly include Generative Adversarial Network (GAN)2, Diffusion Model3, Variational auto-encoder (VAE)4, and so on.
As early as the 1970s, some countries had begun to utilize information systems to assist in intention recognition. With the development of decision support systems, more and more researchers have begun to study the problem of tactical intention recognition of air targets. Existing methods for target intention recognition are mainly based on statistical theory (Evidence theory5,6,7,8, Bayesian networks9,10,11,12,13), cognitive modeling (Template matching14, Expert systems15), and Artificial intelligence16,17,18,19,20,21,22,23,24,25,26. We will briefly introduce the above air target intention recognition methods and compare the advantages and disadvantages of different methods in Section II.
Most of the above studies only rely on the state of the target at a single moment to recognize its tactical intention. In actual combat, the tactical intention of an enemy target usually needs to be reflected by changes in its state over multiple consecutive time periods. At the same time, the scarcity of air target intention data can lead to inadequate model training, affecting its assessment accuracy and applicability.
To address the above problems, this paper proposes an air target intention data extension and recognition model based on Deep Learning named IDERDL, where ID denotes intention data, E denotes data extension, R denotes intention recognition, and DL denotes deep learning. The main contributions of this paper are as follows.
-
(1)
Aiming at the problem of scarcity of original intention data, we constructed an intention data extension model based on the denoising diffusion probability model, adding Gaussian noise to the intent data in the forward process and denoising it in the reverse process to generate airborne target intention data.
-
(2)
Aiming at the problem of long sampling process of Denoising Diffusion Probabilistic Model (DDPM), we apply the improved knowledge distillation method to denoising diffusion model to accelerate the sampling process of the model. The improved knowledge distillation method consists of several teacher models and a student model. The seven teacher models are designed according to the seven operational intentions of the air target, and the loss function during the training process of the teacher model and the student model is optimized to achieve the acceleration of the sampling process of the diffusion model.
-
(3)
For the temporal sequence of airborne target intention data, we construct a temporal module based on dilated causal convolution. The temporal module introduces the idea of Inception, which can fully explore the correlation of time series. At the same time, the graph attention mechanism is introduced to mine and analyze the relationship between different intention features. Combining the two further improves the feature extraction ability of the model.
To verify the quality and diversity of the generated data, this paper visualizes the generated data by the t-SNE algorithm and compares it with GAN and VAE. To validate the performance of IDERDL, this paper conducts comparative experiments with a variety of existing intention recognition methods, such as DBP16, Attention-TCN-BiGRU17, STABC-IR23, Decision Tree27, BiGRU-Attention28, PCLSTM29, etc.
The rest of the paper is organized as follows. Section "Related work" focuses on existing intention recognition methods. Section "Air target intention recognition task description and transformation" describes in detail the air target operational intention recognition problem and the process of constructing the air target intention space and intention feature set. Section "IDERDL model for air target intention recognition" details the proposed IDERDL model. Section "Experiments and discussions" describes the relevant experiments and analyzes the experimental results in detail. Section "Conclusions" summarizes the whole paper and points out the next research direction.
Related work
Intention recognition research was initially applied in the fields of natural language understanding, story comprehension, and speech translation. As technology has evolved continuously, it has gradually extended to a broader spectrum of areas, including multi—intelligence body monitoring and collaboration, dynamic traffic surveillance, adventure gaming, network intrusion detection, robotics, and the military, among others. In natural semantic understanding, intention recognition predominantly processes textual data, resulting in a relatively singular data modality. Its essence lies in deciphering the intent underlying human language expressions by leveraging established language rules and semantic logic. This application is typically found in stable and predictable scenarios, such as daily conversations and intelligent customer service systems.
In contrast, air target intention recognition confronts a more intricate situation. The data sources for this type of recognition are extensive and complex, incorporating multiple modalities like the target’s motion state and physical attributes, along with battlefield environment information. Moreover, it operates within a highly adversarial and uncertain environment. Given this, the recognition results need to provide immediate support for decision-making, and inaccurate recognition could lead to severe consequences. Existing NLP methods, for instance, attention mechanisms30, do provide valuable inspiration. Nevertheless, they necessitate adaptation to cope with the unique complexities of military applications.
Regarding existing approaches to air target intention recognition, they can be categorized into statistical theory-based methods (Evidence theory5,6,7,8, Bayesian networks9,10,11,12,13), cognitive model-based methods (Template matching14, Expert systems15), and Artificial intelligence-based methods16,17,18,19,20,21,22,23,24,25,26. In this section, we analyze their characteristics, limitations, and unsolved challenges.
Statistical theory-based methods
Statistical theory-based methods utilize probabilistic frameworks to infer intentions from uncertain observations. Typical approaches include evidence theory and Bayesian networks. Xia et al.5 used a gray Markov chain to analyze and predict the speed, angle, attack, and detection of enemy UAVs and inferred the intentions in a short time by combining the predictors with the rules provided by rough sets. Bao et al.6 used high-dimensional spatial similarity to measure the degree of support of target states for their intentions, and combined evidence theory to sequentially identify the tactical intentions of targets. Zhao et al.7 combined the confidence rule base and evidence theory to recognize the intentions of air targets. Zhang et al. proposed an information fusion method for target intention recognition based on deep learning and fuzzy discount-weighting, where the probability distribution of the deep learning output is converted into uncertain information and the original evidence is modified by combining internal and external information through fuzzy weighting operations, which improved the reliability of the fusion results8. Xu et al.9 applied the dynamic sequential Bayesian network to the problem of target intention recognition and optimized the algorithm through the information entropy theory, which achieved better results. Yang et al.10 proposed an improved algorithm based on a semi-supervised plain Bayesian classifier to achieve effective recognition of air combat target intention. Jin et al. used network nodes and conditional probability tables to build an initial Bayesian network model with high model identification accuracy11. Aiming at data uncertainty and potential causal mechanisms, Zhang et al. proposed a target intention causal analysis paradigm by combining an Intervention Retrieval model and a Hybrid Intention Recognition model, which improved the interpretability of intention recognition12. Facing the highly variable situation and the uncertainty of the opponent’s information, Ren et al. proposed an incomplete information dynamic game model to model the dynamic process of air combat and designed a dynamic Bayesian network to infer the tactical intention of the opponent13.
Although methods based on statistical theory have certain advantages in dealing with uncertainty and fusing multi-source information, they still face many challenges in practical applications. Taking the evidence theory as an example, it has limited capability in dealing with conflict evidence, and the construction of the basic probability distribution function is more difficult, which often leads to the reliability of the intention recognition results being affected. In the complex and changing air combat environment, evidence from different sources may be in great conflict, and at this time, it is difficult for evidence theory to accurately integrate this information, which in turn affects the judgment of the target’s intention. The Bayesian network has difficulties in parameter estimation and has poor adaptability to the dynamically changing battlefield environment. The battlefield situation changes rapidly, and the target’s behavioral patterns and intentions may change at any time, and the Bayesian network is difficult to adapt to such changes quickly and update the parameters accurately in time, thus reducing the accuracy and timeliness of intention recognition.
Cognitive model-based methods
Cognitive models mimic human reasoning processes through template matching and expert systems. Chen et al.14 first constructed a posture template based on expert experience and used D-S evidence theory to construct an inference model for intention recognition. Yin et al.15 used a statistical approach to the prior knowledge to obtain the target combat intention knowledge and rule base, and proposed an intention recognition method based on discriminant analysis.
Although cognitive model-based methods have the advantages of being easy to understand and conforming to human cognition, they also have obvious limitations. Template matching methods face greater difficulties in constructing and updating template libraries, and with the increasing complexity of the battlefield environment and the diversity of target behaviors, it is difficult to cover all possible scenarios and has limited ability to process complex battlefield information. In modern air combat, enemy aircraft may employ a variety of new types of tactics, and these new situations may not be able to find matches in the existing template library, leading to bias in intention recognition. Expert systems, on the other hand, have the problem of difficult knowledge acquisition, which mainly relies on expert experience, and the acquisition process is time-consuming and labor-intensive, with limited real-time and practicality. When new combat modes or technologies emerge on the battlefield, expert systems are difficult to update their knowledge in a timely manner, affecting the accurate identification of target intention.
Artificial intelligence-based methods
Intention recognition methods based on artificial intelligence leverage data-driven models to learn intention patterns. These mainly include neural networks, deep learning, and so on. From the perspective of the problem solved, it can be divided into three categories.
The first is for the problem of insufficient feature extraction. Zhou et al.16 proposed an air target intention recognition method based on deep neural network, which optimized the backpropagation algorithm using the Rectified Linear Unit (ReLU) function and Adaptive Moment Estimation (Adam) algorithm. It improved the model recognition effect. To address the temporal properties of target intention features, Teng et al.17 combined Temporal Convolutional Network (TCN) and Bidirectional Gated Recurrent Unit (BiGRU) to extract the temporal properties of the features, while introducing an attention mechanism to assign different weights to the features. The proposed model has a good effect on recognizing the target intention. Aiming at the limitations of existing algorithms such as relying on empirical knowledge, being difficult to extract full temporal features, and not being able to meet the requirements of real combat, Yang et al. proposed a target tactical intention recognition algorithm based on bi-directional long and short-term memory (BiLSTM), with a recognition accuracy of up to 92%18. Qu et al.19 proposed an air target intention recognition method based on fully connected neural networks, convolutional neural networks, and recurrent neural networks to realize the target intention recognition function based on real-time situational information, and the proposed method has good robustness. Zhang et al.20 proposed a spatial non-cooperative target intention inference method based on BiGRU-Self Attention, which was able to achieve 97.1% accuracy on the test set. To realize enemy aircraft intention recognition in an uncertain and incomplete air combat information environment, Xia et al.21 proposed an airborne target intention recognition model based on decision tree and GRU. Sun et al.22 proposed an intention recognition method based on deep neural network for spatial non-cooperative targets, and the proposed method calculated the probability of different potential intentions in real time using the instantaneous single relative motion position and velocity of the non-cooperative targets as inputs.
The second is for the problem of interpretable deficiencies. Aiming at the shortcomings of existing methods in terms of temporal properties and interpretability, Wang et al.23 designed an air target intention recognition model based on BiGRU and Conditional Random Field (CRF), which achieved a high recognition accuracy. Li et al.24 proposed a hierarchical aggregated perception pipeline to recognize target tactical intention, which improved intention recognition performance by sensing and aggregating hierarchical information in a tactical context.
The third is for the problem of data distribution bias. Considering that the deviation of the training data distribution can lead to the degradation of the recognition accuracy, Zhang et al.25 proposed an airborne target intention recognition method based on BiGRU and Sampling Reweighting (SR). It applied the SR model to eliminate the statistical correlation between correlated and uncorrelated features, thus avoiding the nonlinear dependence between features, and the proposed method was more effective. Aiming at the long-tailed distribution of battlefield data and the neglect of spatial dimension information of multivariate time series leading to model performance degradation, Wang et al.26 proposed a class balanced spatio-temporal self-attention model (CBSTSA), which introduced a spatial and temporal attention mechanism, and a reweighted class-balanced loss function. The accuracy was up to 95.67%.
Artificial intelligence-based methods perform well in learning data features, but there are some urgent problems to be solved. In terms of insufficient feature extraction, some methods are difficult to fully mine the temporal features and complex relationships in the intention data, which affects the recognition accuracy. When dealing with air combat target intention recognition, the behavior of the target has complex dynamic changes in the time series, and some models are unable to effectively capture these patterns of change, leading to inaccurate judgments of target intention. In terms of interpretability, many deep learning models have complex structures that make it difficult to explain their decision-making process, which is a major obstacle for battlefield decisions that require a clear basis for judgment. Commanders, when referring to the model identification results, have difficulty understanding why the model made the judgment it did, increasing the decision-making risk. In addition, the problem of data distribution bias can also lead to degradation of model performance. Battlefield data often has a long-tailed distribution, sample imbalance, etc., which makes it easy for the model to be biased toward the majority class of samples during training, with insufficient ability to recognize the minority class of samples, reducing the generalization performance of the model.
Summary of challenges
The advantages and disadvantages of the different methods are shown in Table 1. As we can see, existing methods face three critical challenges: data scarcity, temporal modeling and feature interaction. To address these issues, we propose IDERDL, which integrates denoising diffusion models for data augmentation, dilated causal convolution for temporal modeling, and graph attention networks for feature interaction mining.
Air target intention recognition task description and transformation
Intention recognition task description and transformation
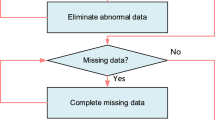
The recognition of combat intention of air targets in air defense operations specifically refers to the process of extracting corresponding battlefield information, static and real-time dynamic attributes of air targets from the real-time confrontation air defense battlefield environment, analyzing these elements, and then discerning and reasoning the combat intention of enemy’s air targets. The specific process is shown in Fig. 1.

Air target intention reasoning process.
The air combat intention recognition problem is a specific mapping of target intention recognition features to target intent recognition types. Target intention recognition in air combat occurs in real-time complex, high-confrontation battlefield environments, and there are certain limitations in the ability to obtain and analyze information, which usually makes it difficult for our commanders to accurately obtain the combat intention of enemy targets. Therefore, in this paper, we use the probability that an intention may occur to represent the outcome of intention recognition at that moment. In the actual combat environment, the enemy target may conceal its tactical intention through a variety of means, so there is a certain degree of one-sidedness and falsity in judging the target’s tactical intention based only on the battlefield data of a single moment. Therefore, in this paper, we choose to extract target features from battlefield data obtained at consecutive moments and thus recognize their tactical intentions. Define \(I_{t} = \{ I_{t1} ,I_{t2} ,...,I_{tn} \}\) as the set of time-series features of the target, where It consists of consecutive air combat real-time features from moment t1 to moment tn. Defining Yt as the tactical intention space of a target, the air combat target intention recognition problem can be described as a mapping process from It to Yt.
In this paper, we train the IDERDL model by the data obtained from the battlefield simulation system, so as to implicitly establish the mapping relationship between features and intentions, and transform the intention recognition task into the concrete model shown in Fig. 2.

Concretized intent recognition model.
Air target intention data selection
For different battlefield environments, different combat styles, and different combat objectives, the intention space has large differences, so it needs to be defined in conjunction with the specific combat context. This paper focuses on air targets in air defense operations, such as reconnaissance planes, fighter planes, early warning planes, etc. Referring to the common intentions in the current domestic and international intention recognition models, we determine that the intention space of enemy air targets is {Attack, Penetrate, Interference, Feint, Surveillance, Reconnaissance, Retreat} seven kinds of intention17. The details of the different intentions are shown in Table 2.
The intention recognition problem is also a multi-classification problem. This paper establishes a coding and decoding mechanism as shown in Fig. 3, which facilitates the training of the model by coding the intention of the enemy target.

Target intention coding and decoding process.
Once the target intention space has been determined, the feature information needed for the model can be determined based on the relationship between the target attribute features and the intention. From the perspective of the combat mission attempted by the enemy, there are certain differences in the characteristic information displayed by enemy airplanes when they perform different combat missions.
-
i.
The flight speed of the target
The flight speed of fighter jets is generally 735 ~ 1470 km/h when it is engaged in air combat fighting. Bombers and transport planes generally fly at speeds of 600-850 km/h during their missions. The flight speed of the early warning aircraft is generally 750 ~ 950 km/h when attempting surveillance missions.
-
ii.
The flight altitude of the target
When enemy aircraft perform penetration missions, the low-altitude penetration altitude is 50–200 m, and the high-altitude penetration altitude is 10,000–11000 m. The altitude of fighter jets in air combat is generally 1000 ~ 6000 m. When enemy aircraft carry out reconnaissance missions, it flies at an altitude of 100 to 1000 m for low-altitude reconnaissance and at an altitude of more than 15,000 m for ultra-high-altitude reconnaissance.
-
iii.
The flight acceleration of the target
There is some possibility of maneuvering before the enemy aircraft performs its attack mission, so its acceleration will have a large variation. When performing reconnaissance and surveillance intentions, the acceleration does not change much. When performing penetrate missions, the acceleration of the enemy aircraft will vary considerably to avoid our defensive fire. When performing retreat missions, the acceleration of the enemy aircraft will vary considerably to increase the efficiency of the retreat.
-
iv
The heading angle, azimuth of target
When enemy aircraft carry out attack, surprise and feint missions, their heading and azimuth angles are always pointing towards our air defense strongholds. When carrying out reconnaissance and surveillance missions, its heading angle and azimuth will be adjusted according to the different reconnaissance areas. When retreating, its heading angle and azimuth are opposite to the direction of our air defense strongholds.
-
v.
The distance of the target.
When enemy aircraft carry out attack and surprise defense missions, their distance from our air defense strongholds is gradually reduced. When carrying out reconnaissance and surveillance missions, the distance will be adjusted according to the needs of the mission. When retreating, distance from our air defense strongholds is gradually increased.
-
vi.
The radar status of the target.
Fighter jets usually keep their radar on when engaging in air combat. The radar is generally silenced when the transport aircraft is on transportation missions. Bombers keep their air-to-air or sea-to-sea radars on only during bombing missions. The aircraft was on reconnaissance missions with both the air-to-air and sea-to-sea radars switched on.
-
vii.
The Jamming status of the target.
Enemy aircraft will be strongly switched on during jamming missions to achieve interference with our communications and radar. When performing other missions, it may be turned on.
-
viii.
The enemy recognition response.
Enemy aircraft do not normally answer when performing attack and penetrate missions. When performing tasks with several other intentions, enemy aircraft may make deceptive responses to interfere with our commander’s judgment.
In addition, considering the limitations of information technology, there are target features that cannot be directly acquired, such as target type, shape, etc., this paper chooses to use radar one-dimensional distance image and radar reflection cross-sectional area instead.
-
ix.
The radar 1D distance image of the target
When enemy aircraft carry out attack missions, the closer it gets to our air defense sites, the more obvious its radar one-dimensional distance image becomes. When performing tasks with other intentions, the radar one-dimensional distance image is not obvious.
-
x.
The RCS of the target.
The RCS varies considerably for aircraft of different purposes. The RCS of fighter jet is usually around 0.01 square meters. Bombers usually have an RCS of about 0.1 square meters. Transport aircraft typically have an RCS of 100 square meters or more.
In summary, the air defense target intention recognition feature set constructed in this paper is {altitude, speed, acceleration, heading angle, azimuth angle, distance, radar 1D distance image, radar cross-section, air-to-air radar status, air-to-ground radar status, jamming status, and enemy recognition response}. The first eight are numerical features and the last four are non-numerical features. The specific descriptions of the features are shown in Table 3.
For the eight numerical types of data in the table, the Min–Max normalization method is used to map them to the interval [0,1]. The specific calculation is as Eq. (2).
where x represents the eigenvalue of a certain numerical feature, \(x^{\prime}\) represents the normalized result of the numerical feature, min and max correspond to the minimum and maximum values of the eigenvalue in the set. The specific calculation is as Eq. (3).
where j represents the size of the classification space, and y is the value after mapping the original i-th non-numeric feature to the interval [0,1].
IDERDL model for air target intention recognition
Model framework
The deep learning-based air target intention recognition model framework proposed in this paper is shown in Fig. 4, which mainly includes an input module, a storage module, a data extension module, an intention recognition module, and an output module.

The framework of IDERDL model.
-
(1)
Storage module.
It is mainly used to store historical intention data, expert knowledge, domain knowledge, and rule knowledge. Historical intention data can be either labeled or unlabeled data and can provide a training dataset for deep learning models. Expert knowledge, domain knowledge, and rule knowledge are information extracted from battlefield intelligence, historical information, expert experience, etc., providing relevant knowledge information and constraint rules for the intention recognition module.
-
(2)
Input module.
It is mainly used to collect battlefield situational data acquired through underlying sensors, radars, etc., such as the target’s motion status, physical attributes, and other multimodal data. Afterwards, the data is input to the intention recognition module after performing operations such as uniform coding and normalization.
-
(3)
Data extension module.
It is mainly used to expand historical intention data so as to provide sufficient training datasets for deep learning models.
-
(4)
Intention recognition module.
It is mainly used to train the model based on the historical intention data and the knowledge information in the storage module, and the generated data in the data extension module, adjust the hyperparameters of the model to obtain the optimal effect, and then process the data entered in the input module to obtain the tactical intention of the target in the current state.
-
(5)
Output module.
It is mainly used to output the result of recognizing the tactical intention of the target at the current moment.
Intention data extension model structure
The intention data generation model is shown in Fig. 5, diffusion model is used to characterize data in latent space and thus learn the structure within the dataset. The forward process is a process of adding noise. The reverse process is a process of denoising and generating data. The inputs to U-Net are time t, latent variable xt at time t, and sample feature xc, respectively. Sections "Denoising diffusion probabilistic model" to "Training and sampling process" present the specific details of generating models.

Intention Data Intention Model.
Denoising diffusion probabilistic model
The Denoising Diffusion Probabilistic Model (DDPM) consists of two main processes, a forward process that perturbs the data into noise and a reverse process that converts the noise into data. Suppose that a total of T diffusion steps is performed, producing a series of noisy samples x. The noise parameter of the diffusion process is determined by the incremental sequence \(\beta_{1:T} \in (0,1]^{T}\). The forward diffusion process gradually transforms the original data distribution \(q(x{}_{0})\) into the latent variable distribution \(q(x_{T} )\), as in Eq. (4).
where \(q(x_{t} |x_{t - 1} ) = {\rm N}(x_{t} ;\sqrt {\alpha_{t} } x_{t - 1} ,(1 - \alpha_{t} ){\rm I})\).
For ease of computation and formula representation, let \(\alpha_{t} = 1 - \beta_{t}\) and \(\overline{\alpha }_{t} = \prod\limits_{n = 1}^{t} {\alpha_{n} }\).
The derivation of Eq. (5) can be used to calculate the data distribution at any instant in time.
where \(\varepsilon \in {\rm N}(0,{\rm I})\).
As t increases, the proportion of noise becomes larger, and the proportion of raw data becomes smaller. When \(\overline{\alpha }_{t} \approx 0\), \(x_{T}\) is almost Gaussian distributed, at which point the diffusion process of the model can be considered complete.
The noise-adding method in the above-mentioned forward process is only applicable to numerical features. The air target intention data in the article also contains non-numerical features, such as Air-to-air radar status, Air-to-ground radar status, Jamming status, and Enemy recognition response. Before adding noise, one-hot encoding is first performed on non-numerical features. Taking the radar status as an example, it has two states, “on” and “off”. After encoding, the encoded value for the “on” state is [1,0], and the encoded value for the “off” state is [0,1]. In the forward diffusion process, Gaussian noise is added to the encoded vectors. Considering that the values of vector elements may exceed the range of [0,1] after adding noise, truncation processing is required to make them return to [0,1] interval to ensure the rationality of the data31.
The reverse process of DDPM utilizes the Markov chain to transform the distribution \(p_{\theta } (x_{T} )\) of latent variables into the data distribution \(p_{\theta } (x_{0} )\). Considering that the noise added at each step of the forward process is small, it is assumed that \(p_{\theta } (x_{t - 1} |x_{t} )\) is also a Gaussian distribution. \(p_{\theta } (x_{t - 1} |x_{t} )\) is an unknown probability distribution that can be fitted with a neural network and \(\theta\) denotes the parameters of the neural network.
When \(\beta_{t}\) is sufficiently close to 1, for all \(x_{0}\) there is \(q(x_{t} |x_{0} )\) converging to the standard normal distribution. Therefore, \(q(x_{t} |x_{0} )\) is set as a standard normal distribution and the joint probability distribution of the reverse diffusion process is shown in Eq. (8).
where \(p_{\theta } (x_{t - 1} |x_{t} ): = {\rm N}(x_{t - 1} ;\mu_{\theta } (x_{t} ,t),\sigma_{\theta } (x_{t} ,t)^{2} {\rm I})\).
Decompose \(\mu_{\theta }\) into noise and \(x_{t}\) to obtain an approximate value of the mean as follows.
Setting the constant \(\beta_{t}\) associated with \(\tilde{\beta }_{t}\) to be the variance and the trainable parameters are only present in the mean, the generation process can be expressed as Eq. (10).
where \(\varepsilon_{\theta }\) denotes a neural network with the same inputs and outputs, and the noise predicted at each step of \(\varepsilon_{\theta }\) is used in the reverse process.
The goal of the DDPM is to find the parameter \(\theta\) that maximizes the bi-objective data distribution \(p_{\theta } (x_{0} )\). A KL scatter is added to the negative log-likelihood function \(- \log p_{\theta } (x_{0} )\) of the target data, which constitutes an upper bound on the negative log-likelihood. The denoising loss function of DDPM can be expressed as Eq. (11).
where \(\mu_{\theta } (x_{t} ,t) = \frac{1}{{\sqrt {\alpha_{t} } }}(x_{t} , - \frac{{\beta_{t} }}{{\sqrt {1 - \overline{\alpha }_{t} } }}\varepsilon_{\theta } (x_{t} ,t))\).
To further simplify the representation, the following loss function is minimized during training.
In the inference process, the latent variable \(x_{T} \sim N(x_{T} ;0,{\rm I})\) is first sampled from the standard normal distribution, after which \(x_{t - 1}\) is again sampled from it using the above equation. The reverse process ends when \(p_{\theta } (x_{0} )\) is computed.
Knowledge distillation
In order to optimize the quality of the generated sample of battlefield data, the diffusion model often requires thousands of computational steps to obtain a new sample, and their sampling efficiency still needs to be improved. Therefore, a key challenge in generating battlefield data samples using diffusion modeling is how to address the time cost consumption associated with multiple sampling. Existing methods to accelerate the sampling of diffusion models include noise prediction model compression, optimization of SDE discretization methods, and deterministic diffusion inverse mapping. Knowledge distillation is now widely used in diffusion modeling as a high-performance model compression method.
In the future information-based intelligent war, combat units will be more miniaturized and intelligent to improve their mobility and concealment, and thus they will not be able to provide huge arithmetic power to support the training of models. In this paper, we introduce the knowledge distillation method to accelerate the sampling process of the diffusion model, as shown in Fig. 6. Deploy the teacher model in the cloud to generate high-quality samples by utilizing the powerful arithmetic resources and running speed in the cloud, and then train an intention recognition model with high recognition accuracy. And deploy student models in each operational unit. The application of knowledge distillation has three main advantages. First, low cost, it can realize to spend less time and cost to solve the problem of scarcity of battlefield samples in actual combat. Second, high security, it can realize effective protection of data security, once the combat unit is destroyed or captured, the enemy gets only a more general performance of the student model, and can not be directly applied. Third, low power consumption, the terminal deployment of the student model is relatively simple and can be applied to different scenarios of the environment and power requirements.

Application of knowledge distillation method.
Training and sampling process
Algorithm 1 gives the specific training procedure. First, the model is prepared, and its parameters are randomly initialized. The dataset used during training is the air target operational intention data, described in detail in Section "Model framework". The original input is subjected to feature extraction to obtain the feature \(x_{c}\) . After that, during the training process, we randomly sample a sample from the dataset, randomly sample time t from the uniformly distributed \(\{ 1,...,T\}\) , and compute the latent variable \(x_{t}\) at time t according to Eq. (7). Finally, input \(x_{c}\), \(x_{t}\), and t into the U-Net model and optimize them using gradient descent algorithm.

Training Process
Algorithm 2 gives the specific sampling procedure. The sampling process takes a total of T steps and starts at t = T. First, sample \(x_{T}\) from a standard normal distribution and output samples with different noise levels at each iteration. When t > 1, we sample z from the standard normal distribution; when t = 1, set z to zero. Finally, \(x_{t - 1}\) is computed by a noise predictor with \(x_{c}\), \(x_{t}\), and t as inputs, and \(x_{0}\) is used as the final output.

Sampling Process
Considering that the reverse process of DDPM often requires hundreds or thousands of steps, it greatly slows down the sampling speed. In order to speed up the model sampling speed, this paper introduces the knowledge distillation method, as shown in Fig. 7. In order to adapt to the needs of future informatized and intelligent warfare, the paper deploys multiple teacher models and a single student model in the cloud computing center and combat terminal, respectively. The design details of the knowledge distillation method used in this paper are as follows.

Improved knowledge distillation method.
First, design teacher models. Seven teacher models (\(N_{Te}^{1} ,...,N_{Te}^{7}\)) are designed based on the seven operational intentions of air targets. The difference between different teacher models is that their inputs are different, and the input is only a single intention data. For example, the input of \(N_{Te}^{1}\) is retreat intention data.
Second, design student models. The data of the seven intentions are simultaneously input into the teacher models, and the best model which is denoted as \(N_{Te}^{best}\) is selected through multiple experiments. At this point, the student model \(N_{S}\) replaces the U-Net network of the model \(N_{Te}^{best}\) with a relatively small U-Net network. The number of channels in the input layer of the U-Net network used in the student model is kept the same, and the number of channels of the convolutional neural network in the rest of the positions is halved, while a neural network with a convolutional kernel of 1 is added to solve the problem of matching the feature sizes of the reduced U-Net network.
Third, design the loss function. The seven combat intentions data is simultaneously input into the seven teacher models and the student model, where the original input dataset is \(D: = \{ (x_{i} ,y_{i} )\}_{i = 1}^{7}\), the student model parameterized by \(\theta_{S}\) is \(N_{S}\) and the teacher model parameterized by \(\theta_{Te}^{k}\) is \(\{ N_{Te}^{k} \}_{k = 1}^{7}\). The loss function designed in this paper for use in the knowledge distillation method consists of three main parts, one is to calculate the cross entropy \(L_{label}\) between the real labels and the student model; the second is to calculate the average value \(L_{TeS}\) of the cross entropy between the output of the teacher model and the output of the student model; and the third is to calculate the loss value \(L_{{{\text{inter}}}}\) of the intermediate layer.
where \(N_{Te}^{k\tau }\) and \(N_{S}^{\tau }\) denote the soft outputs of \(N_{Te}^{k}\) and \(N_{S}\), \(\tau > 1\) indicates the temperature parameter for the softening operation, \(F_{Te}^{k} ( \cdot )\) denotes the output feature map of an intermediate layer of the k-th teacher model, \(F_{S} ( \cdot )\) denotes the output feature map of an intermediate layer of the student model, \(MSE( \cdot )\) denotes the mean square error between different feature maps, \(\alpha\), \(\beta\) and \(\gamma\) indicate the weights of the three loss values and sum to 1, \(H( \cdot , \cdot )\) denotes the cross entropy.
Intention Recognition Model Structure
The intention recognition model is shown in Fig. 8 and the main steps are as follows.
-
(1)
Data preprocessing. In this paper, non-numerical features are transformed into numerical features by the method mentioned in Section "Air target intention data selection", after which the features are normalized to form a standard data set.
-
(2)
Feature extraction. Dilated causal convolution is introduced to model the links between inputs at different moments and mine the information embedded in the intention data.
-
(3)
Enhanced feature representation capability. The graph attention mechanism is introduced to capture the connection between multiple features and dynamically adjust the attention weights of different nodes.
-
(4)
Intention recognition. The output of the graph attention mechanism will be channeled to the softmax layer for classification, and finally get the result of target intention recognition at the current moment.

Intention Recognition Model Structure.
Temporal block
Dilated Causal Convolution (DCC) is a network structure that can handle time series data as proposed by Shaojie Bai et al. in Temporal Convolution Neural Network (TCN) in 201821. Compared to CNN, DCC is able to predict yt based on \(\{ x_{1} ,x_{2} ,...,x_{t} \}\) and \(\{ y_{1} ,y_{2} ,...,y_{t - 1} \}\), making yt close to the true value. When processing air combat intention data, due to its unique convolutional approach, it can expand the sensory field of the convolutional kernel without losing the time series information, so as to more effectively capture the long-distance dependency between the target’s movements at different moments. Taking the state class data of enemy aircraft as an example, it can analyze the change patterns of enemy aircraft flight speed, heading angle and other features over multiple time steps more accurately by adjusting the expansion factor, providing strong support for accurate identification of intentions. In order to fully extract the temporal features of the situational data, this paper introduces the idea of Inception to construct the Temporal Block as shown in Fig. 9. The Temporal Block consists of 4 parts, each with the same size of the dilated causal convolution kernel and a different dilatation factor.

Specific framework of Temporal Block.
Given the processed input data \(V = \{ V_{1} ,V_{2} ,...,V_{m} \}\), activated by the sigmoid function and tanh function respectively after Temporal Block, the output features Sa and Sb are obtained.
Graph attention network
Graph Attention Network (GAT) is a node classification network based on attention proposed by Petar Velickovic et al. The basic idea is to update the node representation based on each node’s attention on its neighboring nodes. At the input layer, GAT receives the node characteristics of the graph data and the topology of the graph. For the IDERDL model constructed in this paper, the node features of the graph are the feature vectors extracted by fusing Temporal Block and Conv1d, and the topology is the adjacency matrix constructed from the similarity between the feature vectors. Specifically, the feature vectors are firstly normalized to avoid affecting the similarity calculation results due to feature scale differences. After that the cosine similarity between the feature vectors is calculated. If the cosine similarity between two feature vectors is greater than the pre-set threshold 0.5, it means there is an association between the two corresponding nodes in the graph. In this case, the element Aij in the adjacency matrix A is assigned a value of 1. Conversely, if it is less than or equal to the threshold, Aij is 0. The graph structure constructed in this way can assist GAT in calculating the node attention weights and pertinently performing weighted aggregation on the features of adjacent nodes. The calculation process of the relative importance between nodes is described as follows.
The input is the node feature \(H = \left\{ {\vec{h}_{1} ,\vec{h}_{2} ,...,\vec{h}_{N} } \right\},\vec{h}_{i} \in {\text{R}}^{F}\), where N represents the number of nodes and F represents the feature dimension of the node. In order to obtain sufficient expressive power, GAT uses a shared linear transform implementation parameterized by a weight matrix to transform the input features into higher-level features. Also, shared attention mechanism a is introduced to compute the importance eij of node j's features with respect to node i.
where the shared attention mechanism \(a:{\kern 1pt} {\kern 1pt} {\text{R}}^{{{\text{F}}^{\prime }}} \times {\text{R}}^{{\text{F}}} \to {\text{R}}\) is a single-layer feed-forward neural network and \({\text{W}} \in {\text{R}}^{{F^{\prime} \times F}}\) denotes the weights applied to each node of the graph.
In order to make the coefficients between different nodes easy to compare, the paper is normalized using the softmax function to obtain the normalized attention coefficients.
where \({\vec{\text{a}}} \in {\text{R}}^{{2F^{\prime}}}\) is the initialized weight vector of the attention mechanism a, LeakyReLU is used to perform the nonlinear operation, Ni is one of the domains of node i in the graph, and || represents the splicing operation.
In order to stabilize the learning process of the self-attention mechanism, the paper extends the attention mechanism to a multi-attention mechanism, where K attention mechanisms run independently, and the obtained output features are spliced to obtain the final feature.
Experiments and discussions
Experimental setup
Experimental datasets
Experimental data were obtained from the Air Combat Maneuvering Generator (ACMG). During the data collection process, a variety of air combat scenarios are set up, such as air defense operations in different terrains such as plains and mountains. The temporal characterization data of the target and the initially set intention data are output through the system interface, after which the target intention is revised by experts in the field of air warfare. The data from different scenarios are fused to get a total of 3520 samples, where the time step is 6 sampling cycles. Considering the limited number of samples and the large amount of training data required for model training, we did not set a separate validation set. The different categories of testing and training are categorized as shown in Table 4, where training samples account for 80% and testing samples account for 20%.
However, such a dataset division strategy will have a certain impact on the model training process. During the training process, the lack of validation sets will make it impossible to dynamically adjust and optimize the hyperparameters, which will easily lead to overfitting phenomenon and weaken the generalization ability of the model. It also leads to the difficulty of accurately determining whether the model converges during the training process, increasing the uncertainty of the training process.
To solve these problems, we use a fivefold cross-validation method to train and evaluate the model several times during the experiment, and strictly monitor the two evaluation indexes, namely, the accuracy and the loss value. During the training process, if it is found that the test loss is not reduced by 10 epochs in a row, or the model’s performance difference between the training set and the test set is large, the training is stopped, and the hyper-parameter settings are adjusted. Through these measures, the deficiencies caused by not setting the validation set are compensated to a certain extent, ensuring the reliability of the model performance evaluation and the generalization ability of the model.
Evaluation indicators
In order to verify the effectiveness of the proposed model, this paper mainly chooses accuracy, recall, precision, and F1-score as the evaluation indicators. Air target tactical intention recognition is essentially a multi-classification problem, and these evaluation metrics can respond to the effectiveness of the model’s classification.
where TP is the true class, FN is the false negative class, FP is the false positive class, and TN is the true negative class.
Experimental details
In this paper, an air target intention recognition model based on deep learning is proposed, and the model mainly consists of data generation and intention recognition. In the data extension module, Adam is used to update U-Net parameters, the number of steps in the forward and backward diffusion processes of the DDPM are set to 1000. In the intention recognition module, the model parameters mainly contain the optimizer, batch size, training epoch, learning rate, convolution kernel size, and dilated factor for dilated causal convolution in the Temporal Block, and the number of nodes for graph attention mechanism. For the optimizer, this paper compares five algorithms, stochastic gradient descent (SGD), root mean square propagation (RMSprop), adaptive moment estimation (Adam), NAdam, and Adamax. The accuracy of the test set is shown in Table 5. In addition, this paper compares the accuracy of the model on the test set under different batch sizes and learning rates, and the experimental results are shown in Table 6. The optimizer, batch size, and learning rate corresponding to the maximum accuracy are chosen as the parameters of this paper. TemporalNet module comparison experiments are also added in this paper, and the results are shown in Table 7, comparing the experimental accuracy and model parameters for different numbers of modules, and finally setting the TemporalNet module to 2. The model hyperparameters of IDERDL are set as shown in Table 8. The experiments conducted in the paper were performed using Python 3.8 and Pytorch 1.12.1, accelerated by NVIDIA GeForce RTX2080 Ti GPUs and CUDA 12.2.
To verify the performance of the proposed IDERDL model, this paper sets up multiple sets of experiments around the following three questions.
-
(1)
Can the intention data extension module generate high-quality time series data?
-
(2)
Can the generated intention data be applied to the intention recognition module and achieve more accurate recognition results?
-
(3)
Can the intention recognition model effectively extract temporal features of the intention data, and can the recognition process be convincing to the commander?
Analysis of intention recognition results
In this paper, intention recognition experiments are conducted based on original and generated data respectively. During experiments, we used the same test intention data. The results are shown in Table 9. We can find that the data generated by the improved DDPM (IDDPM) has the best evaluation indicators in the experimental results achieved by the intention recognition model.
Figure 10 gives the accuracy and loss value variation curves of DIDDPM during the training process of the intention recognition model. We can find that the model has converged after 30 Epochs and there is no significant change in the accuracy and loss values. The accuracy varies around 98%, with a maximum of 98.61% and the loss value is about 0.05.

Accuracy and loss value change curves.
The accuracy only reflects the overall recognition effectiveness of the model for the seven different intention data. Therefore, the recognition accuracy of each intention is further analyzed in this paper, and the confusion matrix of the test set is shown in Fig. 11. The depth of the colors in the figure represents the magnitude of the accuracy, the darker the color the higher the accuracy, and the diagonal line indicates the recognition accuracy for intentions. From the confusion matrix, it can be found that the IDERDL model proposed in this paper has high recognition accuracy for all seven different intentions, especially for the retreat intention, which is up to 100%. Retreat intention is easier to recognize than the other six intentions because of the distinct differences in distance, azimuth, heading angle, and other characteristics. In addition, we find that there is a certain misclassification probability for the three intentions of interference, reconnaissance, and surveillance, as well as a certain misclassification probability for the two intentions of attack and feint, which is in line with actual operations. Targets executing feint usually take a variety of tactical maneuvers to confuse the enemy and provide cover for targets executing attack, and the characteristics of the two are relatively similar, thus making it easy for misjudgments to occur. Targets performing surveillance intention and reconnaissance intention have certain similarities in characteristics such as altitude, speed, acceleration, heading angle, azimuth, distance, etc., and thus are also susceptible to misjudgment.

Confusion matrix.
Analysis of generated data
To compare and analyze the quality of the generated data, this paper introduces the T-SNE algorithm to visualize the original data and the generated data separately, and the sample size of the generated data is the same as that of the original data. The visualized results are shown in Fig. 12.

Visualized results of different dataset.
In addition, we also introduce Maximum Mean Discrepancy (MMD) to measure the difference between two sample distributions. The basic idea of MMD is to compare two distributions by means of mean embedding in the Reproducing Kernel Hilbert Space (RKHS). Given the original sample set \(P = \{ x_{i} \}_{i = 1}^{m}\) and the generated sample set \(Q = \{ y_{j} \}_{j = 1}^{n}\), the MMD is calculated as follows:
where m denotes the number of samples in the original sample set P and \(x_{i}\) is the sample point in P. n denotes the number of samples in the original sample set Q and \(y_{j}\) is the sample point in Q. And \(k( \cdot , \cdot )\) denotes the Gaussian kernel function. The smaller the MMD, the smaller the difference between the generated sample set Q and the original sample set P, and the more similar the two are. The results are shown in Table 10.
From Table 10 and Fig. 12, it can be seen that the MMD value of the proposed model in this paper is only 0.0838, indicating that its generated samples highly overlap with the original data in the feature space. It is further demonstrated that the model proposed in this paper significantly outperforms GAN and VAE in terms of the quality of the generated data, suggesting that it is suitable for the task of generating high-fidelity air target intention data.
Ablation experiment
To further validate the effectiveness of the IDERDL model for the intention recognition task, this paper designs an ablation experiment for the dataset and an ablation experiment for the model, respectively.
-
(1)
Ablation experiment for the dataset.
The experiments were conducted on the original data set, the generated data set, and the data set after merging the original data with the generated data. The results of the experiments are shown in Table 11, and the change curves of the accuracy rate and loss value are shown in Fig. 13.

Accuracy and loss value change curves of different datasets.
From Table 11 and Fig. 13, combining the original dataset D and the generated data DIDDPM gives the best results, with an increase of 0.12% in accuracy compared to DIDDPM, and an increase of 1.85% compared to D accuracy. The experimental results show that the intention recognition model has a good feature extraction ability for the generated data, and the accuracy rate is significantly improved, and the loss value is significantly reduced with the increase of the number of trainings. There is not much improvement in the accuracy of the merged dataset, which is affected by the feature extraction capability of the model. Combined with the analysis of the experimental results in Section "Analysis of intention recognition results" and Section "Analysis of generated data", the generated intention data is more consistent with the original intention data in terms of feature distribution, indicating that the generated samples are of high quality and can meet the needs of the intention recognition task.
-
(2)
Ablation experiment for the model.
The experimental results of training different models on the same dataset are shown in Table 12, and the variation curves of accuracy and loss values are shown in Fig. 14. In the table, IDERDL w/o KD denotes the removal of the Knowledge Distillation module. IDERDL w/o GAT denotes the removal of the Graph Attention Mechanism module. IDERDL w/o TB denotes the removal of the Temporal Block, and it is replaced by a normal 1D convolution.

Accuracy and loss value change curves of different models.
From Table 12 and Fig. 14, the accuracy, precision, recall and F1_score values of IDERDL are higher than the other three models. After removing GAT, the accuracy of the model decreased by 0.83%, which indicates that GAT is effective in capturing the association between features. Comparing the number of parameters between the two, it can be found that the number of parameters in IDERDL w/o GAT is ten times higher than that of IDERDL, which is due to the fact that GAT models complex relationships between features in a more efficient way through the dynamic attention mechanism and parameter sharing, thus compressing the parameters of the model while maintaining performance. This design has important applications in resource-constrained battlefield environments. After removing Temporal Block, there is a significant decrease of 1.5% in accuracy, which indicates that time-series feature extraction plays a key role for the intention recognition task. The generation time of the un-accelerated diffusion model increases by nearly 20 times, but the accuracy only decreases by 0.2%, which shows that the knowledge distillation method can accelerate the sample generation while maintaining the data quality. To further compare the recognition performance of the models, we use the recall and F1_score to reflect the recognition accuracy of different models for the seven intentions, and the results are shown in Table 13.
As can be seen from Table 13, IDERDL has the highest recall and F1_score among the seven different intents. For the three types of intents that rely on multi-feature correlation, such as interference, reconnaissance, and surveillance, the significant advantage of IDERDL further validates that GAT can dynamically capture the nonlinear relationships among features. For attack, penetrate, and other intentions that rely on temporal variations, IDERDL’s higher recall reflects Temporal Block’s ability to model time-series data.
Comparative experiments with other methods
IDERDL was compared with seven existing air target intention recognition models, LSTM-Attention, DBP, Attention-TCN-BiGRU, STABC-IR, BiGRU-Attention, PCLSTM, and SVM, to compare the models’ intention recognition accuracy, precision, recall, F1_score, and loss values under the same dataset. The results are shown in Table 14.
From Table 14, the IDERDL model not only achieves the highest accuracy (98.73%) but also outperforms other models in precision (98.70%), recall (98.71%), and F1 score (98.71%). This indicates that the IDERDL model is not only able to accurately recognize the target’s intention, but also has a better ability to recognize positive samples with a lower false positive rate. In contrast, other models have certain shortcomings in different indicators. For example, traditional models like SVM exhibit significant performance degradation in precision and recall due to their inability to handle temporal dependencies and feature relationships in complex intention data. Although the Attention-TCN-BiGRU model has a certain performance in accuracy, the recall and precision rate still have a gap relative to the IDERDL model, which indicates that there is still room for improvement of the model in recognizing positive samples and ensuring recognition accuracy.
It can be found through comparative experiments that in the case of data scarcity, the data extension module of IDERDL model based on denoising diffusion model can generate high-quality supplementary data and effectively alleviate the impact of insufficient data on model training. When dealing with complex air combat scenarios, IDERDL is able to extract the temporal features of the target’s intention and the relationship between the features more efficiently and identify the target’s true intention more accurately through a combination of DCC and GAT. When confronted with confusing intentions such as attacks and feints, GAT allows dynamic modeling of feature relationships with significantly lower misclassification rates.
Analysis of model transferability
Considering that air combat missions may involve a wider range of operational scenarios, it is difficult to validate the transferability of models by training and testing them only on specific datasets. Based on this, we conducted experiments on the publicly available human behavioral intent dataset (AReM). The AReM dataset is the same multivariate time-series dataset as the intention recognition dataset, which contains seven activities, such as bending1, bending2, cycling, flying, sitting, standing, and walking. Each activity contains six timing features, such as avg_rss12, var_rss12, avg_rss13, var_rss13, avg_rss23 and var_rss23. The sampling frequency is 20 Hz, the clock is 250 ms, and the total duration is 120 s. The specific experimental results on the AreM dataset are shown in Table 15, and the variation curves of accuracy and loss values are shown in Fig. 15.

Accuracy and loss value change curves of different models.
From Table 15 and Fig. 15, the model has a high recognition accuracy for the AreM dataset, which can reach 93.61% after the same preprocessing operations on the data. The experimental results show that the IDERDL model proposed in the paper is transferable and still has good recognition results for different time-series datasets.
Conclusions
Aiming at the problems of data scarcity and insufficient temporal feature extraction in the process of air target intention recognition, an air target intention recognition model based on deep learning (IDERDL) is proposed. First, the air target intention recognition problem is analyzed in detail, the air target intention space and intention feature set are constructed and coded uniformly, and the decision maker’s empirical knowledge is encapsulated into intention labels. Second, the intention data generation model is constructed based on the denoising diffusion model, where Gaussian noise is added to the intention data in the forward process and denoised in the reverse process to generate the air target intention data. The improved knowledge distillation method is applied to the denoising diffusion model to accelerate the sampling process of the model. Finally, the temporal module based on dilated causal convolution is constructed to solve the problem of temporal feature extraction of intention data; meanwhile, the graph attention mechanism is introduced to mine and analyze the relationship between different intention features. By combining the two, the feature extraction capability of the model is greatly improved. The visualized intention data indicate that the model generates high-quality samples. Comparison experiments with other state-of-the-art intention recognition methods show that IDERDL has higher intention recognition accuracy and performance. Ablation experiments also validate the effectiveness of the model.
Our proposed intention recognition model can both compensate for the lack of intention data and effectively improve temporal feature extraction. However, there are still some limitations. First, deep learning-based intention recognition methods are more dependent on intention labels labeled by experts during the training process, while intent ambiguity may exist in real battlefield environments, affecting model training. Second, although we introduce knowledge distillation methods to improve the sampling efficiency of diffusion models, they are still limited by the number of teacher models. The following five areas will be focused on in the upcoming research.
-
(1)
To address the limitations of IDERDL, semi-supervised learning methods are introduced into the intention recognition task to fully utilize unlabeled data, while exploring lightweight diffusion model architectures to reduce the computational cost.
-
(2)
Although the existing intention recognition model has achieved a high recognition accuracy rate, the cost of war brought about by intention misjudgment in actual combat cannot be borne by both warring parties, and the performance and interpretability of the model still need to be improved.
-
(3)
Existing intentions are labeled by experts based on empirical knowledge, while in actual combat, there is a large similarity between intentions, and it is difficult to achieve a strict distinction between different intentions.
-
(4)
The battlefield data collected in actual combat is less, the existing model is more dependent on the support of data, and how to obtain more high-quality intention data is also a future research direction.
-
(5)
Analyzed from the perspective of the OODA ring, if the combat intention of the enemy target can be predicted in advance, it can lay the foundation for accelerating the closure of the OODA ring, and then it can be a prerequisite for the victory of the war.
Data availability
The data presented in this study are available on request from the corresponding author.
References
Fusano, A., Sato, H. & Namatame, A. Multi-agent based combat simulation from OODA and network perspective. in 2011 UkSim 13th International Conference on Computer Modelling and Simulation 249–254 (2011).
Krichen, M. Generative Adversarial Networks. in 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT) 1–7 (2023).
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models. in Advances in Neural Information Processing Systems vol. 33 6840–6851 (Curran Associates, Inc., 2020).
Kingma, D. P. & Welling, M. Auto-encoding variational bayes. arXiv.org https://arxiv.org/abs/1312.6114v11 (2013).
Xia, P., Chen, M., Zou, J. & Feng, X. Prediction of air target intention utilizing incomplete information. in Proceedings of 2016 Chinese Intelligent Systems Conference (eds. Jia, Y., Du, J., Zhang, W. & Li, H.) 395–403 (Springer, Singapore, 2016).
Lei, B. Study on recognition technique of targets’ tactical intentions in sea battlefield based on D-S evidence theory. in (2012).
Fu-jun, Z., Zhi-jie, Z., Chang-hua, H. U., Li, W. & Tao-yuan, L. I. U. Aerial target intention recognition approach based on belief-rule-base and evidential reasoning. dgykz 24, 15 (2017).
Zhang, Z. et al. An information fusion method based on deep learning and fuzzy discount-weighting for target intention recognition. Eng. Appl. Artif. Intell. 109, 104610 (2022).
Xu, Y., Cheng, S., Zhang, H. & Chen, Z. Air Target Combat Intention Identification Based on IE-DSBN. in 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI) 36–40 (2020).
Ximeng, X., Rennong, Y. & Ying, F. Situation assessment for air combat based on novel semi-supervised naive Bayes. J. Syst. Eng. Electron. 29, 768–779 (2018).
Qing, J., Xiantai, G., Weidong, J. & Nanfang, W. Intention recognition of aerial targets based on Bayesian optimization algorithm. in 2017 2nd IEEE International Conference on Intelligent Transportation Engineering (ICITE) 356–359 (2017).
Zhang, Y., Huang, F., Deng, X., Li, M. & Jiang, W. Air target intention recognition and causal effect analysis combining uncertainty information reasoning and potential outcome framework. Chin. J. Aeronaut. 37, 287–299 (2024).
Ren, Z., Zhang, D., Tang, S., Xiong, W. & Yang, S. Cooperative maneuver decision making for multi-UAV air combat based on incomplete information dynamic game. Defence Technology 27, 308–317 (2023).
Chen, Y. & Li, C. Simulation of Target tactical intent recognition based on knowledge graph. Comput. Simul. 36, 1–4 (2019) ((in Chinese)).
Yin, X., Zhang, M. & Chen, M. Operational intent recognition of airborne targets based on discriminant analysis. J. Project., Rockets, Missiles Guid. 38, 46–50 (2018) ((in Chinese)).
Zhou, W. et al. Combat intention recognition for aerial target based on deep neural network. Acta Aeronautica et Astronautica Sinica 39, 200–208 (2018) ((in Chinese)).
Teng, F., Song, Y. & Guo, X. Attention-TCN-BiGRU: an air target combat intention recognition model. Mathematics 9, 2412 (2021).
Wang, X. et al. Tactical Intention Recognition Method of Air Combat Target Based on BiLSTM network. in 2022 IEEE International Conference on Unmanned Systems (ICUS) 63–67 (2022).
Qu, C., Guo, Z., Xia, S. & Zhu, L. Intention recognition of aerial target based on deep learning. Evol. Intel. 17, 303–311 (2022).
Zhang, H., Luo, J., Gao, Y. & Ma, W. An intention inference method for the space non-cooperative target based on BiGRU-Self Attention. Adv. Space Res. 72, 1815–1828 (2023).
Xia, J., Chen, M. & Fang, W. Air combat intention recognition with incomplete information based on decision tree and GRU network. Entropy 25, 671 (2023).
Sun, Q. & Dang, Z. Deep neural network for non-cooperative space target intention recognition. Aerosp. Sci. Technol. 142, 108681 (2023).
Wang, S. et al. STABC-IR: An air target intention recognition method based on bidirectional gated recurrent unit and conditional random field with space-time attention mechanism. Chin. J. Aeronaut. 36, 316–334 (2023).
Li, Y., Wu, J., Li, W., Dong, W. & Fang, A. Hierarchical aggregation perceptual pipeline for tactical intention recognition. Multimed Tools Appl 83, 58245–58265 (2024).
Zhang, Y., Ma, W., Huang, F., Deng, X. & Jiang, W. A novel air target intention recognition method based on sample reweighting and attention-Bi-GRU. IEEE Syst. J. 18, 501–504 (2024).
Wang, X., Jin, B., Jia, M., Wu, G. & Zhang, X. A class balanced spatio-temporal self-attention model for combat intention recognition. IEEE Access 12, 112074–112084 (2024).
Zhou, T., Chen, M., Wang, Y., He, J. & Yang, C. Information entropy-based intention prediction of aerial targets under uncertain and incomplete information. Entropy 22, 279 (2020).
Teng, F., Guo, X., Song, Y. & Wang, G. An air target tactical intention recognition model based on bidirectional GRU with attention mechanism. IEEE Access 9, 169122–169134 (2021).
Xue, J., Zhu, J., Xiao, J., Tong, S. & Huang, L. Panoramic convolutional long short-term memory networks for combat intension recognition of aerial targets. IEEE Access 8, 183312–183323 (2020).
Huang, X. et al. An effective multimodal representation and fusion method for multimodal intent recognition. Neurocomputing 548, 126373 (2023).
Kotelnikov, A., Baranchuk, D., Rubachev, I. & Babenko, A. TabDDPM: modelling tabular data with diffusion models. in Proceedings of the 40th International Conference on Machine Learning 202, 17564–17579 (JMLR.org, Honolulu, Hawaii, USA, 2023).
Acknowledgements
The work is supported in part by National Natural Science Foundation of China, Grant Number: 72071209.
Author information
Authors and Affiliations
Contributions
B.C wrote the main manuscript text, Q.X and L.L provided technical support and financial guarantee for the article, W.L checked the formulas and pictures. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Cao, B., Xing, Q., Li, L. et al. An air target intention data extension and recognition model based on deep learning. Sci Rep 15, 13894 (2025). https://doi.org/10.1038/s41598-025-98438-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-98438-6
