
Abstract
Acute Lymphoblastic Leukemia (ALL), a kind of blood cancer, more frequently observed in the pediatric population, causes rapid production of immature White Blood Cells. Most of the diagnostic techniques like bone marrow aspiration, imaging techniques, etc. are time consuming, error-prone, costly and depend on the skill set of experts. The ultimate goal of this work is to develop a computer aided automatic classification system to classify Benign, Early, Pro-B and Pre-B classes of ALL. Images from the publicly available dataset were subjected to pre-processing and Region of Interest is obtained by adapting the proposed Multilevel Hierarchical Marker-Based Watershed Algorithm (MHMW). A subset of most vital features were selected by utilizing nature inspired metaheuristic Enhanced Glowworm Swarm Optimization (EGSO) algorithm. Popular classifiers -Decision tree, Random Forest, Multi-Layer Perceptron, Naive Bayes and Linear, Polynomial, Radial basis function, sigmoid kernels of Support Vector Machine were used for multiclass classification. Performance of the proposed system has been compared with three other popular optimization algorithms- Particle Swarm Optimization, Artificial Bee Colony Optimization and Elephant Herd Optimization. Random Forest fed with the optimized features obtained from the proposed integration of MHMW and EGSO algorithms outperformed other classifiers with 98.23%, 98.25%, 98.23% of accuracy, precision and F1 score respectively.
Similar content being viewed by others


Introduction
Cancer, a major cause for the non-accidental mortality in recent years, is a condition that results in the abnormal growth of cells hindering the functionality of normal cells. There are many types of cancer based on the part of the body that has been affected. Leukemia, one of the most common types of cancer that affects bone marrow and blood1, resulting in the abnormal production i.e. excessive or immature production of White Blood Cells (WBC) disturbing the proper functionality of the immune system. Leukemia has been classified into two types-Acute and chronic, based on the growth rate of the affected cells. Acute leukemia exhibits a faster growth rate whereas chronic leukemia has a comparatively slower growth rate. Based on the type of cells that has been affected leukemia has been categorized into two different types, Lymphocytic leukemia where lymphocytes are affected, and myeloid leukemia if monocytes and granulocytes are infected. Thus four major categories of leukemia are Acute Lymphocytic Leukemia (ALL), Acute Myeloid Leukemia (AML), Chronic Lymphocytic Leukemia (CLL), Chronic Myeloid Leukemia (CML)2.ALL is further categorized into Early Pre-B, Pre-B, and Pro-B ALL based in the presence of precursor. There are many causes for the occurrence of the disease including genetic factors, radiation exposure, transmitted diseases etc.
A major pediatric cancer ALL, due to its rapid proliferation nature, affecting not only blood but also other vital organs becomes dreadful, if left untreated. According to World Health Organization (WHO), 487,294 leukemia cases have been reported in the year 2022 in which 227,206 cases from Asia and 107,748 cases from Europe3. The worldwide mortality rate for the specified year was 305,405 cases with 158,144 cases in Asia and 63,839 cases in Europe4. Early diagnosis of ALL and its subtypes is paramount in the effective treatment planning leading to the increase in survival rate. Among the available detection tests such as flow cytometry, cytogenetic analysis, fluorescence in situ hybridization, immunophenotyping, the microscopic examination of Peripheral Blood Smear (PBS) images is considered as the standard initial screening technique5 due to its minimum invasive nature and cost efficiency. Manual examination of PBS, though done by skilled experts, includes many challenges, availability of experts across the globe, opinion variations among different experts leading to inconsistent results, time consuming, labor intensive and error prone6. Further experts’ opinion is highly influenced by the initial staining techniques and smear preparation methods leading to misclassification. In order to overcome these drawbacks, An Automated detection system that is capable of providing more accurate, faster and consistent classification results even in case of noisy input data, utilizing comparatively less expensive hardware and computational complexity, is thus required for the early diagnosis of ALL leading to effective treatment planning.
The key contributions of this work are listed as follows,
-
A Novel segmentation algorithm, Multilevel Hierarchical Marker-Based Watershed Algorithm, is proposed to obtain the desired ROI from preprocessed PBS images containing overlapping cells.
-
Handcrafted features are extracted from the segmented ALL images to enhance system performance.
-
A novel meta heuristic, nature inspired Enhanced Glowworm swarm optimization algorithm, is introduced to select optimal features, ensuring the removal of redundant and irrelevant features, to elevate model’s efficiency.
-
A Comparative analysis of selected popular machine learning classifiers through the important evaluation metrics to access their performance
-
The developed system is benchmarked against other nature-inspired optimization algorithms-ABC, PSO and EHO to validate its effectiveness.
-
Machine learning (ML) based approach, designed to handle limited quantities of medical dataset effectively, while maintaining a perfect balance between the classification accuracy and computational complexity, deployable in a light weight devices, assisting medical practitioner across the globe.
The Manuscript is organised into five sections. Review of the existing literature is presented in section two, proposed methodology and its underlying processes are detailed in section three. Results of the proposed model & its relevant analysis are exhibited in section four. Conclusion along with future scope is presented in section five.
Literature review
In literature, a wide variety of methodologies have been proposed for the detection of Leukemia. An automatic approach to classify leukemia proposed in7 utilized Expectation maximization for segmentation, Principal component selection for significant feature selection and sparse representation for classification of leukemia in Acute Lymphoblastic Leukemia Image Database version 2 (ALL-IDB2) dataset. The proposed system achieved an accuracy of 94% but utilized only a limited dataset focusing on binary classification. Automatic optical image analysis system put forward in8 has employed a dataset from the department of hematology-Jimma medical center. The preprocessed images are segmented using k-means clustering, watershed & morphological operations and classified by Support Vector Machine(SVM). Analysis of the developed system using publicly available dataset is missing.
An integrated system for leukemia detection developed in9 employed adaptive neuro fuzzy, Principal Component Analysis(PCA), Genetic Algorithm, Particle Swarm Optimization(PSO) and Group Method Data Handling. Adaptive Neuro-Fuzzy Inference System classified ALL and AML after a lot of preprocessing steps. Major limitation of this model is its dependency on Complete Blood Count (CBC) values which is prone to outliers affecting the models accuracy. Sorayya Rezayi et al.10 used novel Convolutional Neural Networks(CNN) to classify leukemia and got 82% of test accuracy on the dataset obtained from Codalab competition. Performance of the proposed binary class classification system has been compared with two other deep learning models-Visual Geometry Group -VGG16 and ResNet-50 and it is concluded that increased dataset volume can lead to increase in system performance.
Immature leukocytes detection and classification system proposed in11 employed image format conversion, multi Otsu thresholding, morphological operations for segmentation, Random forest (RF) for classification, yielded an accuracy of 92.99% and 93.45% for detection and classification respectively. The developed system focused on AML classification, failed to segment the overlapping cells. The Leukemia detection system developed in12 utilized the Alexnet model to detect AML outperformed LeNet-5 with the accuracy of 88.9%. Zeinab et al.13 followed traditional Machine Learning (ML) procedures, preprocessing, segmentation using marker controlled watershed & global local contrast enhancement and k-means clustering. SVM uses the most relevant fifty features from a diverse dataset to obtain an accuracy of 91.025%.ALL detection system suggested in14 explored eight variants of EfficientNet to extract features and classified ALL by the ensemble of logistic regression, random forest, and SVM to obtain the accuracy of 98.5%.ALL prediction system15 used Resnet and VGG16 to obtain features from the preprocessed images of Chinese National Medical Centre (C-NMC) leukemia dataset. Ensemble soft voting classifier yielded an accuracy of 87.4% whereas SVM outperformed it with an accuracy of 90% but failed to classify ALL subtypes. A System with three major phases16, preprocessing, feature extraction and classification is explored to classify normal and abnormal images of C-NMC leukemia dataset. Hyperparameters of CNN have been optimized by the fuzzy to obtain the accuracy of 99.99%. Time required by the system to provide accurate results has not been explicitly provided. Automated system with DenseNet20117 and DenseNet169 with flipped attention block18 utilized for the classification of ALL_-IDB2 images yielded an accuracy of 94.6% and 97.94% respectively.
DL based feature engineering process put forward in19 compares the performance of Bayesian optimized SVM and subspace discriminant ensemble learning classifiers with the features from PSO, PCA and hybrid PSO-PCA and found the Bayesian optimized SVM trained by the features from hybrid PSO-PCA outperformed with the accuracy of 97.4%. Web based platform20 employed Resnet 152 as base learner for the weighted ensemble learning algorithm. Despite consuming more time for training and increased computational overhead, the model achieved an accuracy of 99.95% in the classification of types of ALL. Diagnostic model21 utilized traditional image processing techniques to detect leukemia and Resnet50 with SVM- hybrid model to classify the types of ALL. The model obtained an accuracy of 99% on the availability of sufficient quantity and quality of images in the dataset.
Algorithms proposed for optimization has been inspired from different sources such as social behavior, physics, biology, chemistry, music, sports etc., Bilal Alatas et al.22 proposed two intelligent optimization algorithms inspired by the law of reflection and refraction, Ray Optimization(RO) and Optics Inspired Optimization(OIO). Evaluation of these methods on real world engineering problems and benchmark functions bestowed evidence that RO method outperformed the latter. Sports based optimization algorithm, League Championship Algorithm23 proposed to elevate the performance of teams, competing over multiple weeks, by enhancing their tactics over time. Physics inspired optimization algorithm, OIO24 put forward to model the wavy mirror as the search space, where concave and convex mirrors are considered as valleys and peaks, handles the local optimal tracking and slow convergence speed thereby enhancing the system performance. Three optimization algorithms25 Grey Wolf Optimization (GWO), OIO, Chaos Based Optics Inspired Optimization (CBOIO) were compared on deception detection problems and CBOIO showed higher efficacy than the remaining two algorithms. El-Sayed M et al.26 proposed Greylag Goose Optimization algorithm inspired by the V shape formation of geese during migration, to reduce air resistance experienced by the following ones. Model provided better results on different cases including pressure vessel design, tension spring design etc., Mona Ahmed Yassen et al.27 developed a renewable energy sources prediction system with the aid of ML and DL algorithms. A review on ML algorithms28 provided the feasibility of improved public health forecasting and Zika virus monitoring.
Most of the Machine learning based automated systems proposed in the literature focused on the binary classification of leukemia and failed to classify its types. Many of them have not used the publicly available dataset for classification. Segmentation of overlapping cells has to be addressed in order to obtain the proper ROI and increase in the accuracy of the classification process. Although it is found that some of the deep learning models are capable of yielding a higher accuracy, it requires a large amount of data, less feasible in case of medical image dataset such as leukemia. Further deep learning methods are computationally expensive, requiring more resources, making it less deployable in the resource limited environment. Effectiveness of the optimization algorithms inspired from different phenomena is highly problem dependent, slow in high dimensional search space like leukemia, reduced search efficiency due to the lack of adaptive step size. Hence the work focused on development of a ML model that works on the publicly available dataset to have a high accuracy multiclass classification by considering segmentation of overlapping cells and selection of optimal features by enhanced swarm-based algorithm.
Proposed methodology
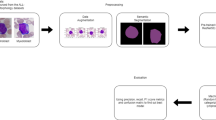
Development of a system for the automatic detection of leukemia involves the sequence of process such as dataset acquisition, preprocessing of acquired dataset, followed by segmentation, extracting features from the segmented data, selection of the most important and relevant feature, classification of the disease and finally the evaluation of the developed system. Pictorial representation of the process involved in the proposed system is presented in Fig. 1.

Steps involved in the development of an automatic system for the classification of leukemia present in the blood microscopic images.
Dataset acquisition
Among the different methods available to determine the presence of Leukemia, the microscopic view of PBS is chosen as the modality due to its minimal invasive nature, comparatively less requirement of cost and time. Publicly available dataset employed for the proposed model contains 3256 PBS images obtained from 89 patients, in which 25 patients are healthy and the remaining 64 patients are malignant. It is collected from the bone marrow laboratory of Taleqani Hospital situated in Tehran, Iran. The skilled laboratory staff members of the hospital categorized benign by the presence of hematogones, normal B-lymphocyte precursors. This does not demand any therapeutic intervention to sort it out. The malignant images are further grouped into Early Pre-B, Pre-B, and Pro-B ALL images. The images of 224 × 224 dimensions are obtained with the help of a Zeiss camera present in the microscope29. Table 1 outlines the dataset details.
Pre-processing
Images present in the dataset may contain noise due to a variety of reasons such as poor illumination, vibration, changes that occur during the initial staining of slides and other environmental factors. It is handled by different preprocessing techniques. Among those methods, median filtering and Contrast Limited Adaptive Histogram Equalization (CLAHE)techniques are deployed to elevate the image quality for obtaining effective results in the subsequent stages. Median Filter will reduce noise present in the dataset and at the same time does not blur the edges of the image. Filtered image is then subjected to a special variant of Adaptive Histogram Equalization- Contrast Limited AHE to increase the local contrast, enhancing visibility of important features of the image. Over amplification of noise artifacts are overcome by the use of the above sequence of preprocessing. Effectiveness of the preprocessing steps is evident from the increase in the PSNR-Peak Signal to Noise Ratio. Figure 2 represents the results of the preprocessing module.

Preprocessed images (a) Original (b) Median filter (c) CLAHE.
Segmentation
The proposed novel segmentation method, Multilevel Hierarchical Marker-Based Watershed Algorithm (MHMW) combines the aspects of multilevel Otsu’s thresholding, morphological operations, contour detection and watershed algorithm to get the desired region of interest. The sequence of steps involved in the proposed MHMW is detailed as follows.
Step 1: Multilevel thresholding.
It is needed to process the leukemia images as the peripheral blood smear has different constituent elements30. Otsu’s method is employed to separate the given input image into classes based on the pixel’s intensity level. The classes are separated based on the optimal value of the threshold(T) that focuses on the maximization of the intra class variance.
Multilevel threshold is carried out by combining the effects of various binary level thresholding.
Image resulting from the above thresholding process contains few factors, noise that need not to be processed further.
Step 2: Morphological closing and contour detection.
From the studies it is found that the particles with area less than 80 pixels are non-WBC and hence can be eliminated from the following processing steps31. The image is subjected to cleaning by the morphological operations32. Used to fill the small gaps and smoothen the obtained image, Morphological closing creates a uniform representation of the cells. The individual cells in the images are detected with the help of contours. It represents the boundaries of the connected regions.
Step 3: Hierarchical marker selection watershed algorithm.
The image is then subjected to watershed segmentation. This topology based segmentation has the ability to handle the overlapping cells present in the PBS images. It uses markers as the seed points to start flooding the basins until the basins corresponding to different markers reach the watershed. The position of the markers is very much important for the effective extraction of ROI 33. Traditional watershed algorithm suffer from the problem of over segmentation and hence it has been addressed by employing modified watershed algorithm. Hierarchical marker selection has been incorporated in the traditional watershed algorithm where background and foreground markers are defined explicitly to enhance the segmentation quality. Distance transform computes the distance internally through the Euclidean metrics.
Desired region of interest is extracted by the MHMW algorithm involving a novel sequence of steps generating a cleaned binary image by multilevel thresholding followed by morphological operation. Watershed algorithm is applied by hierarchical marker selection where the markers are defined with respect to the foreground and background likelihoods using distance transform and thresholding. Figure 3 indicates outcomes of the proposed segmentation module. Input image is converted into binary image, where different regions of PBS have been separated based on intensity levels. Segmented images, final result of the proposed MHMW algorithm, shows the ROI isolated from the background.

Results of the proposed segmentation algorithm.
Feature extraction
Characteristics of the blast cells is pivotal in the effective detection of the classes of leukemia. Extraction of the vital features improves the accuracy of the system by avoiding the utilization of redundant data 34. Among the different categories of features considered in medical image processing, the unique features possessed by the blast cells such as morphological features, HSV (Hue, Saturation, Value) histogram, Correlogram, geometrical features, frequency based features and Gray Level Co-occurrence Matrix (GLCM) features are extracted from the segmented images. Figure 4 presents a detailed overview of the extracted features, where the number of features under each category is represented in brackets, reaching a total of 320 features.

Feature set extracted from PBS images.
Feature selection
Effectiveness of the proposed multiclass classification model can be improved by reducing the irrelevant and the redundant features. Enhanced Glowworm Swarm Optimization has been utilized for feature selection due to its ability to adapt to the dynamic environment and its decentralized behavior enhances the robustness, scalability of the model. Images of ALL exhibit a high degree of variability in the features due to cell irregularities, staining variations etc. Further the high dimensional dataset shows variation in the importance of features among various images. The proposed optimization algorithm strives to maintain balance between exploration and exploitation.
Enhanced glowworm swarm optimization
A nature inspired Meta heuristic algorithm Glowworm swarm optimization—GSO relies on the bioluminescence behavior of glow worms 35. Glow worms are an adherent of Lampyridae- a family of beetles that have the ability to emit light naturally. This luciferin characteristic takes advantage of attracting mates and prey. Intensity of the glow changes from normal to high in accordance with the state of glow worms. Local resolution range is the region where the agents- Glow worms have its view. In the search space, agents aim at occupying a region with larger objective value. Local decision domains will be established if a neighbor with high luciferin is detected and the domains will extend on the increase in the number of high luciferin neighbors. Agent’s position is subjected to change at each iteration and fitness is proportional to the luciferin intensity level. The process will progress through three different phases-Luciferin Update Phase (LUP), Motion Phase (MP) & Decision Threshold Phase (DTP)36. At the beginning of the process the glow worms are dispersed randomly.
Luciferin Update Phase (LUP): The agents of optimization algorithm have been put on with the same level of luciferin value lcgw at the starting level even though it varies based on the environmental factors. gw represents the number of agents in the search space. Agents tend to move towards the neighbors with higher lcgw. Delay in the glow is visualized by withdrawing a portion of it. At each iteration luciferin value of glowworm \({lc}_{gw}\), is updated following the below rule.
Luciferin level \({lc}_{gw}\) measures the quality of the output over the time \(x\). It depends on \(\rho\), \(\gamma\) & \({j}_{gw}\) values, that represents glowworm’s ability to forget the old information, scaling terms for the fitness function and index term of the best neighbor respectively. The agents then progress to the adjacent phase.
Motion Phase (MP): The pattern of motion of agents in the glowworm swarm will be disturbed at each iteration by the behavior of different neighbors. Each individual glow worm in the swarm exploits the probabilistic means in determining the migration towards the neighbor exhibiting brighter glow. Greater the luciferin value greater the attraction. Probability of glow worm \({P}_{gwn}\) propagating towards the neighbor n is attributed by the Eq. 6.
n ∈ kgw (d) represents the set of glowworm neighborhoods. Preference of glow worm \({P}_{gwn}\) moving towards its neighbour is influenced by luciferin value of itself \({L}_{gw}\left(x\right)\), its neighbor \({L}_{n}\left(x\right)\) and highest \({L}_{h}\left(x\right)\) among the neighbors.
Decision threshold phase(DTP): The decision radius and the sensory radius associated with the agents is represented in Fig. 5. At each iterative stage the radius changes enabling the reach towards the global optimum rather than the local optimum. Function with the multiple peaks can be effectively handled with the glowworm swarm optimization. The radius range can be adaptively modified in accordance with Eq. 7.

Glow worm position with decision and sensory radius.
Current position of the glowworm \({t}_{gw}\left(x\right)\) ie the starting point is updated to \({t}_{gw}\left(x+1\right)\) based on the calculated Euclidean distance between the current position of it with its neighbor \({t}_{n}\left(x\right)\) and the step size \(s\left(i\right)\)
After the random initialization of the agent with a random number lying in 0–1 range, the fitness function of agents is computed. The best value is determined. The glowworms in the swarm are moved and the fitness position corresponding to the latest change is evaluated and compared with the previous best fitness value and the location. Replacement of the values will be carried out if the new value is more effective than the previous state. The performance of GSO is enhanced by adaptively varying the step size,\(s\left(i\right)\) in accordance with Eq. 8.
Iterations continue until the termination condition is achieved resulting in the best solution. Hyperparameters of EGSO such as number of agents, maximum iterations, luciferin decay and enhancement values are tuned in the range of 20–40, 50–150, 0.3–0.5 and 0.5–0.7 respectively. Perfect tuning of the number of agents and iterations maintains a balance between finding better features and execution time. Dynamic search is facilitated by the precisely tuned value. Step size and radius range are made adaptive, promoting exploration at the initial stages and exploitation at the later stages. The flow diagram involved in the implementation of EGSO is represented in Fig. 6.

Flow diagram of enhanced glowworm swarm optimization.
Performance comparison
Effectiveness of the proposed model has been compared with the other three most popular nature inspired optimization algorithms- Particle Swarm Optimization, Artificial Bee Colony Optimization and Elephant Herd Optimization.
Particle swarm optimization
One of the most widely used evolutionary computation methodology -particle swarm optimization algorithm is based on the flocking behavior of birds to identify food without the presence of a leader. At first, birds in the swarm represented as particles in the population are randomly initialized. Each particle is associated with a velocity and position. The particles aim to find the best solution in the search space and register that as their own best position PBest. Global best (GBest) is the best solution with respect to the swarm 37.
Artificial bee colony optimization
Honey bees foraging behavior for nectar has been exploited for the determination of optimum solution in the search space. Self-organizing and intelligent behavior of three different kinds of bee population—scout, onlooker and employed bees were inspired for solving the optimization problem. Food source count and its abandonment corresponds to the solution count and limit whereas maximum generation count, position and quantity of food source corresponds to the maximum cycle count and fitness respectively38. In the employed bee phase nearby food sources having high quality and quantity of nectar is determined The solution with highest probability is considered as best in the onlooker bee phase and once the food source becomes exhausted it moves into scout bee phase repeating the searching process. ABC algorithms perform well only in exploration not in exploitation.
Elephant Herd optimization algorithm
The huge social creature -Elephants live in groups containing many clans (groups of females and their calves) headed by the matriarch. Global optimization can be achieved based on the herding nature of the elephants through clan updating and separating operators. Position of the elephant in the clan other than the fittest one is determined 39. Individuals with poor fitness will be removed by the separating operator influenced by the departure of male elephant from the clan once it attains puberty.
Classification
To categorize the given leukemia images, classifiers play a vital role. The potency of the classifier lies in its caliber to provide high accurate results with reduced computational cost and error. The relevant features are given to most popular machine learning classifiers—Decision Tree (DT), RF, Multi-Layer Perceptron(MLP), kernels of SVM & Naive Bayes (NB) to categorize them into benign, early, pro and pre types of acute lymphocytic leukemia.
Decision Tree
Classification by the Decision Tree is put forward by the recursive fractionating the available data and building a predictive model in each and every fraction 40. The final decision of the algorithm is captured by tracing a guided path in the hierarchical structure represented in a graphical manner 41. The most vital features are bestowed to the nodes of the tree and it bifurcates making a decision focusing on the maximization of accuracy in classification.
Random Forest
An ensemble learning algorithm, Random forest, relies on the majority voting of the findings of the decision trees. It can accomplish exemplary performance on the multiclass classification problems 42. The problem of overfitting can be effectively handled by this algorithm in addition to the capability of handling high dimensional datasets. Generalization capability and accuracy of the classification has been boosted by bringing in randomness in the selection of samples and the subsequent features 43.
Multilayer perceptron
Neural network containing input layer, few hidden layers and the output layer -Multilayer perceptron establishes connection between them in the feed forward fashion. Each node receives needed information from the preceding layer and guides the nodes in the forthcoming layers. The correlation in the given dataset can be effectively processed by the hidden layers. Classification accuracy relies mainly on the network structure and training methodologies 44. The networks computation is carried out by the Eq. 9
Support vector machine
The non-parametric and non-linear classifier, support vector machine classifiers the given dataset by settling the hyperplane, an optimal line that strives to maximize the margin between the different classes of the data 45. The classification process involves the use of various types of kernels—linear, polynomial, Radial Basis Function (RBF) and sigmoid kernels for the projection of nonlinear data into the high dimensional space. A wide range of hyperplanes can be created to segregate the designated data but SVM intended to select one that will impart maximum margin 46. The verdict on the class separation is based on the Eq. 10
Naive bayes
Classification by Naive Bayes relies on the Bayes theorem to estimate the probability of each outcome 47. This Simple yet powerful algorithm performs classification with the assumption that the features are independent of each other. Existence or nonexistence of a particular feature does not have an impact on the probability determination in the specified statistical algorithm 48. Classification accuracy of the algorithm will not shrink even in the presence of irrelevant features. Estimation is based on Eq. 11. Table 2 represents the hyper parameter values of the selected classifiers.
Result and discussion
The evaluation of the proposed automated system has been carried out with the aid of various benchmark metrics. For the multiclass classification of ALL, the dataset has been splitted into two parts, 80% of data for training the proposed model and the remaining 20% for testing. Dataset is found to be imbalanced. In case of an imbalanced dataset, the model may get trained to learn by ignoring the minority class due to data scarcity, leading to biased results. It is handled by oversampling, enabling the model to generalize among all the classes. Increase in the volume of data, results in elevated computation time, generating a tradeoff but it is effectively reduced EGSO’s vital feature selection ability. Early B class having 788 training images is identified as majority class and minority classes are oversampled to improve model learning. 652 images are used for testing the proposed model. Most popular ML algorithms-Decision tree, Random forest, Multilayer perceptron, Naive Bayes and four different kernels- Linear, polynomial, radial basis function and sigmoid kernels of SVM are employed for classification. Confusion matrix and Receiver Operating characteristic (ROC) curve of the classifiers before the optimum feature selection by EGSO are given in the Fig. 7

Confusion matrix and ROC curve of classifiers without EGSO.
One of the powerful accessing tool- confusion matrix and the qualities calculated from its entries are fruitfully exploited in judging the efficiency of the proposed automated detection and classification system. True Positive (TP), True Negative (TN), False Positive (FP) and False Negative (FN) of multiclass classifier values of chosen ML classifiers are exhibited in Table 3. Each entry corresponds to one of the classes of ALL. For instance, in the decision tree classifier, TP value of 101 indicates that 101 benign images are perfectly predicted as benign. Large values in case of true prediction and small values in false predictions indicate the classifier is more accurate in classifying the different classes of ALL. RF performs better than the other classifiers whereas sigmoid kernel SVM performs least.
Confusion matrix and ROC curve of the proposed model where the most vital features are selected with the aid of EGSO is presented in Fig. 8. Entries of the confusion matrix provided evidence that there has been a greater increase in the correct prediction of benign and malignant classes and decrease in false predictions. One vs Rest approach is used to obtain the receiver operating characteristics curve of multiclass classifiers with Area Under Curve (AUC) ranges from 0.75 to 1.

Confusion matrix and ROC curve of classifiers with EGSO.
TP, TN, FP and FN values of the proposed model using MHMW algorithm and EGSO represented in Table 4. A few instances of misclassification error of type 1 and type 2 has occurred during classification, where the model has produced a minimum number of False Positive and False Negative. In case of multi-class classification, a class of image incorrectly classified as any of other classes is marked as FP and the model’s inability to classify the image belonging to a particular class is represented as FN. The proposed model has effectively handled the root causes, noisy input data, presence of redundant or irrelevant features, resulting in significant error reduction. All the algorithms bestowed an increase in true predictions and decrease in false predictions with Random forest providing the highest number of true and least number of false predictions leading to effective treatment planning.
The exhaustive comparison of the classifiers with and without the use of EGSO for the evaluation parameter of accuracy, precision, is represented in Fig. 9. F1 score & kappa value comparison of classifiers with and without utilization of EGSO is exhibited in Fig. 10. Figure 11 presents the comparative analysis of Matthews correlation coefficient (MCC) and AUC ROC for the selected classifiers. Random forest exhibited the highest performance in comparison with other classifiers with the accuracy, precision and F1 score of 98.23%, 98.25%, 98.22% and 97.58%, 97.59%, 0.99 of Kappa, MCC and AUC ROC values respectively.

Comparison of classifiers with and without EGSO with respect to accuracy and precision.

Comparative analysis of F1 score and kappa values of classifiers with and without EGSO.

Comparison of MCC and ROC AUC for classifiers with and without EGSO.
Based on the performance, classifiers with the accuracy are arranged from the best to least as Random forest (98.23%) > MLP (97.43%) > SVM with linear kernel (97.35%) > SVM with RBF kernel (95.24%) > SVM with polynomial kernel (94.97%) > Decision tree (93.55%) > Naive Bayes (90.21%) > SVM with sigmoid kernel (67.97%). Even though the sigmoid kernel of SVM performs the least, all its performance parameters were increased reflecting the impact of EGSO in choosing the features.
Increase in accuracy is the evidence for the correctness of the model in multiclass classification. Higher precision (0.9825) proved that the positive cases classified by the model are really positive facilitating proper treatment planning. Existence of harmonic balance between precision and recall in the proposed model is demonstrated by the higher value of F1-score (0.9822). Higher value of MCC (0.9759) and Kappa (0.9758) validates models’ high performance in considering false cases avoiding unnecessary panic among the healthy individuals and proper treatment for the leukemia patients according to the affected class. AUC ROC metric ranging from 0.86 to 0.99 showed that all the classifiers had greater discrimination power in identifying the positive and negative classes. From the comparison graph, it is inferred that all chosen classifiers showed improved performance on the usage of EGSO for feature selection demonstrating its ability in selecting the most vital features. Solutions of the fitness function of the metaheuristic algorithm have been evaluated based on the classification accuracy of the support vector machine. Hence decision tree and random forest classifiers exhibited slight variation in the results with and without feature selection. The developed model exhibited slight under-performance, leading to misclassification, when the SVM sigmoid kernel is used to classify the high dimensional leukemia data. It is proposed to stack the different SVM kernels for further error reduction.
Specificity, Jaccard index and error rate comparison of selected classifiers in the task of classifying four different classes of ALL with and without EGSO is represented in Fig. 12. All classifiers showed increase in specificity and jaccard index after the involvement of EGSO proves the ability of the classifiers in identifying correct ALL classes. Enhancement in the model’s performance has been further confirmed by the reduction in the error rate of the classifiers.

Specificity, Jaccard Index and Error Rate Comparison of Classifiers with and without EGSO.
Game theory based approach, SHapley Additive exPlanations (SHAP) 49, is explored to ensure fairness in model’s interpretability and consistency. It assigns importance score for each feature facilitating both global and local view, ensuring transparency and trust in the diagnostic results. Figure 13 exhibits top 20 features, arranged in the increasing order of its impact on the model’s performance. High and low feature values are represented by red and blue color respectively and its spread indicates the model’s predicted probability. Feature 6 with wide spread, has the highest importance followed by feature 151.

Feature importance by SHAP Value.
Comparison of proposed model with three chosen nature inspired algorithms are represented in Table 5 All the meta-heuristic methods specified in the manuscript run up to 100 iterations, on the identical fitness function, with 30 candidate solutions in each iteration. Solutions of the fitness function of all the optimization algorithms have been evaluated based on the classification accuracy of SVM. Around 320 extracted features, EGSO selected the most vital 153 features consuming considerably less optimization time (511 s). RF bestowed better performance among the selected classifiers in all the chosen optimization algorithms with EGSO providing highest accuracy.
In a large scale application, computational cost becomes a vital parameter. In case of our proposed model, it depends on various factors such as number of iterations, population size and dimensionality of data. Other Optimization algorithms, ABC & EHO incorporates elaborate search process, requiring more iterations, whereas the proposed EGSO uses adaptive tuning reducing the iteration count. Even though it increases the per iteration cost compared with PSO, it is compensated by the faster convergence. Optimisation algorithms exhibit a tradeoff between accuracy and optimization time. ABC and EHO needs increased iterations to produce more accurate results. PSO facilitates faster convergence at the risk of premature convergence. The proposed model strives to balance the optimization time and quality feature selection. Comparative performance of the metaheuristic algorithms & ROC curve is represented in Fig. 14 and Fig. 15 respectively., where the proposed method selected the minimum number of optimal features in comparatively less time.

Comparison of Metaheuristics algorithms.

(a), (b) & (c) represents ROC curves of classifiers with PSO, ABC and EHO algorithms for feature selection respectively.
Performance of the proposed system is validated with the additional dataset ALL-IDB2, consisting of 260 images with 257 X 257 resolution , 24 bit color depth, out of which 130 images are normal and the remaining 130 images are malignant 50. Evaluation metric values of binary classification presented in Table 6, show that there is an enhancement in the model’s behavior with the utilization of EGSO. RF and SVM with RBF kernel produced highest classification accuracy followed by DT & SVM with polynomial kernel.
Table 7 presents comparative analysis of proposed systems with the models presented in literature. To maintain fairness, literature that uses the same dataset has been selected for comparison. In Case of binary and multiclass classification, the proposed model bestows higher accuracy than most of the other models due to effective feature selection. Few DL models 20,21 exhibited slightly higher accuracy at the expense of increased computational complexity, expensive hardware requirement and focused on a single dataset, lacking validation of results on other dataset. Further, usage of color grouping method 21 exhibits the potential limitation, requiring sufficient number high quality RGB image. It is also mentioned that the model’s efficiency will be lowered, if the requirement is not satisfied. Proposed system tested on two different dataset strives to maintain the balance between accuracy and computational complexity, even on the limited amount of data.
For the real world deployment, the proposed model should be generalized. Even though there are data sharing constraints in many hospitals across the globe, results of the developed system have been validated on two different publicly available datasets. Further the quality of input image given to it, differs owing to a variety of factors such as setting of microscope, staining variations and deviation in imaging devices parameters but the proposed model has the ability to handle it through pre-processing techniques. In order to facilitate the integration of the proposed system with the existing diagnostic tools, ML techniques are preferred since it does not require expensive hardware and comparatively less computational complex. One potential limitation of the model is the utilisation of single modality for diagnosis. Performance of it can be further enhanced by multimodal data fusion techniques where data from different modalities like CBC, Next Generation Sequencing, chromosomal abnormalities, Gene expression data etc., can be combined to have more discriminative features as well as increasing model’s accuracy and robustness to noise. Fusion can be either early or late depending whether the raw data from different modalities or their results of classification were combined.
Conclusion
Early and effective detection of appropriate classes of Acute Lymphocytic Leukemia will lead to proper treatment planning and speedy recovery. The proposed model utilized 3256 peripheral blood smear images acquired from 89 patients. Image enhancement has been carried out with the sequence of preprocessing steps of applying median filter and contrast limited adaptive histogram equalization. Then the images are segmented using a MHMW algorithm facilitating the extraction of ROI even in the presence of overlapping cells and most robust features form the pool of 320 extracted features are selected by the Enhanced Glowworm swarm optimization algorithm. Proposed model aimed at multiclass classification of Benign, Early, Pro-B, Pre-B classes by the most popular machine learning classifiers. Ability of the classifiers analyzed with various benchmark performance metrics such as Accuracy, precision, F1 score, kappa, MCC, AUC-ROC, specificity, Jaccard index and error rate proved that Random Forest yields better performance with 98.23% of accuracy compared to other selected algorithms. Enhanced ability of multiclass classification has been achieved by most of the classifiers with the involvement of EGSO. Comparison with three popular nature inspired optimization algorithms-PSO, ABC and EHO proved that the proposed model having high performance can be effectively used in the early screening of types of ALL.
Future scope
In future, the developed system can be further extended to classify other types of leukemia- AML, CLL, CML and its subtypes by performing Multi Task Learning, enabling the model to learn common features among the types and optimizing classification tasks independently. Further the model has to be trained to learn invariant features, making it robust to variations in multi institutional datasets. It is planned to improve the system performance by having multimodal data analysis.
Data availability
Data sets employed in the current study are available from the corresponding author on reasonable request.
References
Hegde, R. B., Prasad, K., Hebbar, H., Singh, B. M. K. & Sandhya, I. Automated decision support system for detection of leukemia from Peripheral Blood Smear images. J. Digit. Imaging 33(2), 361–374. https://doi.org/10.1007/s10278-019-00288-y (2020).
Patel, N. & Mishra, A. Automated leukaemia detection using microscopic images. Procedia Comput. Sci. 58, 635–642. https://doi.org/10.1016/j.procs.2015.08.082 (2015).
https://gco.iarc.fr/today/en/dataviz/tables?mode=population&cancers=36 [accessed on 28.2.2025]
https://gco.iarc.fr/today/en/dataviz/tables?mode=population&cancers=36&types=1 [accessed on 28.2.2025]
Kazemi, F., Najafabadi, T. & Araabi, B. Automatic recognition of acute myelogenous leukemia in blood microscopic images using K-means clustering and support vector machine. J. Med. Sign. Sens. 6(3), 183. https://doi.org/10.4103/2228-7477.186885 (2016).
Das, P. K., Pradhan, A., & Meher, S. Detection of Acute Lymphoblastic Leukemia Using Machine Learning Techniques. In (ed. Gopi, E.S.) Machine Learning, Deep Learning and Computational Intelligence for Wireless Communication. Lecture Notes in Electrical Engineering, 749, 425–437. https://doi.org/10.1007/978-981-16-0289-4_32 (Springer, Singapore, 2021).
Sukhia, K. N., Ghafoor, A., Riaz, M. M. & Iltaf, N. Automated acute lymphoblastic leukaemia detection system using microscopic images. IET Image Proc. 13(13), 2548–2553. https://doi.org/10.1049/iet-ipr.2018.5471 (2019).
Dese, K. et al. Accurate Machine-Learning-Based classification of Leukemia from Blood Smear Images. Clin. Lymphoma Myeloma Leuk. 21(11), e903–e914. https://doi.org/10.1016/j.clml.2021.06.025 (2021).
Fathi, E., Rezaee, M. J., Tavakkoli-Moghaddam, R., Alizadeh, A. & Montazer, A. Design of an integrated model for diagnosis and classification of pediatric acute leukemia using machine learning. Proc. Inst. Mech. Eng. [H] 234(10), 1051–1069. https://doi.org/10.1177/0954411920938567 (2020).
Rezayi, S., Mohammadzadeh, N., Bouraghi, H., Saeedi, S. & Mohammadpour, A. Timely Diagnosis of acute lymphoblastic leukemia using artificial intelligence-oriented deep learning methods. Comput. Intell. Neurosci. 2021, 1–12. https://doi.org/10.1155/2021/5478157 (2021).
Dasariraju, S., Huo, M. & McCalla, S. Detection and classification of immature leukocytes for diagnosis of acute myeloid leukemia using random forest algorithm. Bioengineering 7(4), 120. https://doi.org/10.3390/bioengineering7040120 (2020).
Shaheen, M. et al. Acute Myeloid Leukemia (AML) detection using alexnet model. Complexity 2021, 1–8. https://doi.org/10.1155/2021/6658192 (2021).
Bin Aof, A. M., Awad, E. A., Omer, S. R., Ibraheem, B. A. & Mustafa, Z. A. A Computer-Aided Diagnoses Program for Leukemia Detection Using Blood Samples. J. Clini. Eng. 47(1), 44–49. https://doi.org/10.1097/JCE.0000000000000508 (2022).
Baby, D., Juliet, S. & Anishin Raj, M. M. An efficient lymphocytic leukemia detection based on EfficientNets and ensemble voting classifier. Int. J. Imaging Syst. Technol. 33(1), 419–426. https://doi.org/10.1002/ima.22787 (2023).
Almadhor, A. et al. An efficient computer vision-based approach for acute lymphoblastic leukemia prediction. Front. Comput. Neurosci. https://doi.org/10.3389/fncom.2022.1083649 (2022).
Talaat, F. M. & Gamel, S. A. Machine learning in detection and classification of leukemia using C-NMC_Leukemia. Multimedia Tools Appl. 83(3), 8063–8076. https://doi.org/10.1007/s11042-023-15923-8 (2024).
Prasath, N., Jasthi, M., Saikia, R., Loganathan, M. & Devi, S. S. Acute Lymphoblastic Leukemia Detection Using DenseNet Model from Microscopic Blood Smear Images. In (eds. Namasudra, S., Trivedi, M.C., Crespo, R.G. & Lorenz, P.) Data Science and Network Engineering. ICDSNE 2023. Lecture Notes in Networks and Systems, 791, 261–270. https://doi.org/10.1007/978-981-99-6755-1_20 (Springer, Singapore, 2024).
Al-Zubaidi, A. S., Al-Mukhtar, M. & Baghdadi, A. A. A. ALL-FABNET: Acute Lymphocytic Leukemia Segmentation Using a Flipping Attention Block Decoder-Encoder Network. J. Image Graphics 12(3), 239–249. https://doi.org/10.18178/joig.12.3.239-249 (2024).
Atteia, G., Alnashwan, R. & Hassan, M. Hybrid feature-learning-based PSO-PCA feature engineering approach for Blood Cancer Classification. Diagnostics 13(16), 2672. https://doi.org/10.3390/diagnostics13162672 (2023).
Perveen, S., Alourani, A., Shahbaz, M., Ashraf, M. U. & Hamid, I. A Framework for early detection of acute lymphoblastic leukemia and its subtypes from Peripheral Blood smear images using deep ensemble learning technique. IEEE Access 12, 29252–29268. https://doi.org/10.1109/ACCESS.2024.3368031 (2024).
Bose, P. & Bandyopadhyay, S. A Comprehensive Assessment and Classification of Acute Lymphocytic Leukemia. Math. Comput. Appl. 29(3), 45. https://doi.org/10.3390/mca29030045 (2024).
Alatas, B. & Bingol, H. Comparative Assessment Of Light-based Intelligent Search And Optimization Algorithms. Light Eng. 03–2020, 51–59. https://doi.org/10.33383/2019-029 (2020).
Bingol, H. & Alatas, B. Chaotic League Championship Algorithms. Arab. J. Sci. Eng. 41(12), 5123–5147. https://doi.org/10.1007/s13369-016-2200-9 (2016).
Bingol, H. & Alatas, B. Chaos based optics inspired optimization algorithms as global solution search approach. Chaos, Solitons Fractals 141, 110434. https://doi.org/10.1016/j.chaos.2020.110434 (2020).
Bingol, H. & Alatas, B. Chaos enhanced intelligent optimization-based novel deception detection system. Chaos, Solitons Fractals 166, 112896. https://doi.org/10.1016/j.chaos.2022.112896 (2023).
El-kenawy, E.-S.M. et al. Greylag Goose Optimization: Nature-inspired optimization algorithm. Expert Syst. Appl. 238, 122147. https://doi.org/10.1016/j.eswa.2023.122147 (2024).
Abdel-Fattah, M. G. A., Ismail, I., Kenawy, E.-S.M. & El Moustafa, H.E.-D. An AI-Based System for Predicting Renewable Energy Power Output Using Advanced Optimization Algorithms. J. Artif. Intell. Metaheuristics 8(1), 01–08. https://doi.org/10.54216/JAIM.080101 (2024).
El-Sayed, E., Eid, M. M. & Abualigah, L. Machine Learning in Public Health Forecasting and Monitoring the Zika Virus. Metaheuristic Optimization Rev. 1(2), 01–11. https://doi.org/10.54216/MOR.010201 (2024).
Aria, M. et al. Acute Lymphoblastic Leukemia (ALL) image dataset. Kaggle https://doi.org/10.34740/KAGGLE/DSV/2175623 (2021).
Deshpande, N. M., Gite, S., Pradhan, B., Kotecha, K. & Alamri, A. Improved Otsu and Kapur approach for white blood cells segmentation based on LebTLBO optimization for the detection of Leukemia. Math. Biosci. Eng. 19(2), 1970–2001. https://doi.org/10.3934/mbe.2022093 (2021).
Aris, T. A., Nasir, A. S. A., & Mustafa, W. A. (n.d.). Analysis of Distance Transforms for Watershed Segmentation on Chronic Leukaemia Images.
Abrol, V., Dhalla, S., Gupta, S., Singh, S. & Mittal, A. An Automated Segmentation of Leukocytes Using Modified Watershed Algorithm on Peripheral Blood Smear Images. Wireless Pers. Commun. 131(1), 197–215. https://doi.org/10.1007/s11277-023-10424-1 (2023).
Gamarra, M., Zurek, E., Escalante, H. J., Hurtado, L. & San-Juan-Vergara, H. Split and merge watershed: A two-step method for cell segmentation in fluorescence microscopy images. Biomed. Signal Process. Control 53, 101575. https://doi.org/10.1016/j.bspc.2019.101575 (2019).
Das, B. K. & Dutta, H. S. Infection level identification for leukemia detection using optimized Support Vector Neural Network. Imaging Sci. J. 67(8), 417–433. https://doi.org/10.1080/13682199.2019.1701172 (2019).
Chavan, R. & Pete, D. Automatic multi-disease classification on retinal images using multilevel glowworm swarm convolutional neural network. J. Eng. Appl. Sci. 71(1), 26. https://doi.org/10.1186/s44147-023-00335-0 (2024).
Krishnanand, K. N. & Ghose, D. Glowworm swarm optimisation: a new method for optimising multi-modal functions. Int. J. Comput. Intell. Stud. 1(1), 93–119. https://doi.org/10.1504/IJCIStudies.2009.02534 (2009).
Gao, L., Ye, M. & Wu, C. Cancer classification based on support vector machine optimized by particle swarm optimization and artificial bee colony. Molecules 22(12), 2086. https://doi.org/10.3390/molecules22122086 (2017).
Öztürk, Ş, Ahmad, R. & Akhtar, N. Variants of Artificial Bee Colony algorithm and its applications in medical image processing. Appl. Soft Comput. 97, 106799. https://doi.org/10.1016/j.asoc.2020.106799 (2020).
Wang, G.-G., Deb, S. & Coelho, L. d. S. Elephant Herding Optimization. 2015 3rd International Symposium on Computational and Business Intelligence (ISCBI). In Proceedings of the IEEE symposium, 1–5. https://doi.org/10.1109/ISCBI.2015.8 (Bali, Indonesia, 2015).
Loh, W. Classification and regression trees. WIREs Data Min. Knowl. Discovery 1(1), 14–23. https://doi.org/10.1002/widm.8 (2011).
Moraes, L. O., Pedreira, C. E., Barrena, S., Lopez, A. & Orfao, A. A decision-tree approach for the differential diagnosis of chronic lymphoid leukemias and peripheral B-cell lymphomas. Comput. Methods Programs Biomed. 178, 85–90. https://doi.org/10.1016/j.cmpb.2019.06.014 (2019).
Mirmohammadi, P., Ameri, M. & Shalbaf, A. Recognition of acute lymphoblastic leukemia and lymphocytes cell subtypes in microscopic images using random forest classifier. Phys. Eng. Sci. Med. 44(2), 433–441. https://doi.org/10.1007/s13246-021-00993-5 (2021).
Parmar, A., Katariya, R., & Patel, V. A Review on Random Forest: An Ensemble Classifier 758–763. https://doi.org/10.1007/978-3-030-03146-6_86 (2019).
Salihah Abdul Nasir, A., Yusoff Mashor, M., Hassan, R., & Abdul Nasir, A. Classification of acute leukaemia cells using multilayer perceptron and simplified fuzzy ARTMAP neural networks. In The International Arab Journal of Information Technology 10(4): https://www.researchgate.net/publication/233483832 (2013).
Bodzas, A., Kodytek, P. & Zidek, J. Automated Detection of Acute Lymphoblastic Leukemia From Microscopic Images Based on Human Visual Perception. Front. Bioeng. Biotechnol. 8. https://doi.org/10.3389/fbioe.2020.01005 (2020).
Thanmayi A, V. L., Reddy, S. D. & Kochuvila, S. Detection of Leukemia Using K-Means Clustering and Machine Learning. In (eds. Kumar, N., Vinodhini, M. & Venkatesha Prasad, R.R.) Ubiquitous Communications and Network Computing. UBICNET 2021. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, 383, 198–209. https://doi.org/10.1007/978-3-030-79276-3_15 (Springer, Cham, 2021).
Suryani, E. W., Putra, A. P. & Widiarto, W. Detection of Acute Myeloid Leukemia based on White Blood Cell Morphological Imaging using Naïve Bayesian Algorithm. Int. J. Adv. Comput. Sci. Appl. 12(10). https://doi.org/10.14569/IJACSA.2021.01210273 (2021).
Gautam, A., Singh, P., Raman, B., & Bhadauria, H. Automatic classification of leukocytes using morphological features and Naïve Bayes classifier. 2016 IEEE Region 10 Conference (TENCON), 1023–1027. https://doi.org/10.1109/TENCON.2016.7848161 (2016).
Choi, J.-H., Choi, Y., Lee, K.-S., Ahn, K.-H. & Jang, W. Y. Explainable Model Using Shapley Additive Explanations Approach on Wound Infection after Wide Soft Tissue Sarcoma Resection: “Big Data” Analysis Based on Health Insurance Review and Assessment Service Hub. Medicina 60(2), 327. https://doi.org/10.3390/medicina60020327 (2024).
Labati, R. D., Piuri, V., & Scotti, F. All-IDB: The acute lymphoblastic leukemia image database for image processing. 2011 18th IEEE International Conference on Image Processing, 2045–2048. https://doi.org/10.1109/ICIP.2011.6115881 (2011).
Author information
Authors and Affiliations
Contributions
N.S- Conceptualisation, Data collection, Methodology, Investigation, Formal analysis, Writing – original draft, review & editing. M.K- Supervision, reviewing and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
N, S., M, K. An improved multiclass classification of acute lymphocytic leukemia using enhanced glowworm swarm optimization. Sci Rep 15, 13985 (2025). https://doi.org/10.1038/s41598-025-98823-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-98823-1
