
Abstract
While multi-object tracking is critical for autonomous driving systems, traditional algorithms exhibit three fundamental limitations in complex scenarios: (1) blurred feature representation under occlusion and re-identification scenarios causing identity switches, (2) insufficient sensitivity to scale-variant targets due to fixed geometric constraints in conventional IoU-based loss functions, and (3) gradient degradation in deep convolutional layers hindering discriminative feature learning. To address these challenges, we propose AE-StrongSORT (Attention-Enhanced StrongSORT), an attention-enhanced tracking framework featuring three systematic innovations: first, the GAM-YOLO (global attention mechanism-YOLO)hybrid architecture integrates multi-scale feature fusion with a global attention mechanism (GC2f structure). This design enhances cross-dimensional feature interaction through localized channel-spatial attention gates, significantly improving occlusion-resistant feature representation (IDF1 \(\uparrow\) 9.99%, IDsw \(\downarrow\) 9.85%). Second, the F-EIoU loss function introduces dynamic size-dependent penalty terms and difficulty-adaptive weighting factors, effectively balancing learning priorities between small targets and normal instances. Third, the optimized CBH-Conv module employs Hardswish activation and depthwise separable convolution to mitigate gradient vanishing while maintaining real-time efficiency (achieving a 17% MOTA improvement at 213 FPS).Evaluated on the MOT-16 dataset, AE-StrongSORT demonstrates substantial improvements over the baseline StrongSORT, with 17%, 2.78%, and 9.99% gains in MOTA, HOTA, and IDF1 metrics respectively, alongside significant reductions in false/missed detections. These advances establish a novel technical pathway for robust vehicle tracking in real-world traffic scenarios characterized by coexisting challenges of scale variation, motion blur, and dense occlusion.
Similar content being viewed by others
Introduction
Multiple Object Tracking (MOT), as a crucial task in scene understanding and video analysis, aims to identify, locate, and consistently track targets across video frames. This technology finds extensive applications in fields such as intelligent transportation and urban security. Nevertheless, MOT encounters several challenges in practical applications, including target occlusion, re-identification after disappearance, and significant scale variations of targets1. With the rapid advancement of autonomous driving technology, researchers have accelerated the development of multi-target tracking systems, establishing them as a core component of autonomous driving. This progress has driven the creation of a Tracking-by-Detection (TBD) based MOT algorithm2. The algorithm workflow involves: detecting potential targets in each frame through an object detector, which generates bounding boxes and category labels. Subsequently, the detected targets undergo data association with tracked targets from previous frames to maintain motion trajectories. It is noteworthy that the performance of the target detector directly dictates the effectiveness of multi-target tracking systems. The schematic diagram of the multi-target detection task is shown in Fig. 1.

Target detection diagram.
As a detection-based MOT algorithm, StrongSORT’s performance is inherently constrained by target detection accuracy. It remains particularly susceptible to performance degradation under challenging conditions such as illumination variations and motion blur, where detector inaccuracies directly propagate to tracking failures. Real-world deployment further introduces critical challenges including multi-target interference, occlusion, target re-identification, and extreme scale variations. Specifically: Degraded feature discriminability in occlusion and re-identification scenarios, where blurred appearance representations exacerbate identity switches; Geometric sensitivity imbalance in conventional IoU-based matching mechanisms, which struggle to reconcile scale-disproportionate targets (e.g., distant vehicles vs. nearby pedestrians); Progressive feature attenuation across convolutional layers, severely compromising long-term tracking robustness under motion blur. These limitations manifest through two primary failure modes: (1) Detection drift induced by illumination fluctuations and abrupt scale variations; (2) Disrupted motion-appearance correlations caused by multi-target interference and dense occlusion.
To tackle these challenges, this paper proposes a multi-object tracking framework that integrates an optimized YOLOv8 architecture (You Only Look Once, Version 8) with the StrongSORT tracking paradigm. As an advanced object detection algorithm, YOLOv8 has demonstrated remarkable performance in real-time applications. However, our analysis reveals persistent limitations in complex scenarios, particularly regarding degraded detection accuracy under occlusion and high-density traffic conditions.
We propose multi-level enhancements to YOLOv8, including architectural modifications and training strategy improvements, to elevate detection robustness. These optimizations subsequently enhance the multi-object tracking performance within the StrongSORT framework.
The paper is organized as follows: “Introduction” section establishes the research context by analyzing the significance and challenges of MOT systems in intelligent transportation, while defining the objective of optimizing StrongSORT through detection enhancements. “Related work” section conducts a critical review of current MOT research, systematically evaluating strengths and limitations of mainstream algorithms, thereby formulating the theoretical basis for our methodology. “Methods” section elaborates on the proposed algorithmic improvements to StrongSORT, focusing on detection accuracy enhancement and tracking stability optimization. “Experiments and results” section provides a comprehensive evaluation comparing our AE-StrongSORT model with state-of-the-art tracking models. Finally, “Conclusion” section summarizes the key innovations, validates the proposed method’s effectiveness in advancing MOT performance, and discusses current limitations along with potential future research directions.
Related work
Most MOT methods typically involve applying a detector to each video frame, followed by associating detected objects across frames using spatial or appearance features1. This detection-driven paradigm establishes the detector as the foundation of MOT, where its performance critically determines the tracking accuracy. We survey recent advances in object detection and MOT methods within deep learning frameworks.
Object detection
In 2012, Krizhevsky et al.3 revolutionized image classification through convolutional neural networks (CNNs), achieving unprecedented accuracy in ILSVRC. This breakthrough catalyzed the evolution of object detection into two dominant paradigms: single-stage and two-stage algorithms.
The two-stage detection paradigm originated from R-CNN. Girshick et al.4 pioneered region proposal networks with CNNs in 4, substantially advancing detection accuracy. Subsequent improvements through Fast R-CNN5 and Faster R-CNN6 achieved enhanced speed and precision. Nevertheless, the two-stage process’ inherent computational complexity from region proposal generation and feature resampling hindered real-time applications7, motivating the development of single-stage detectors.
Single-stage methods enable real-time performance through single-pass feature extraction, albeit with slightly lower accuracy. Redmon et al.8 revolutionized the field in 2016 with YOLO, framing detection as a regression problem for direct bounding box and class prediction. Despite setting speed records, YOLO exhibited limitations in small object detection. Liu et al.9 addressed this through multi-scale feature map predictions in SSD, improving accuracy at speed costs. Concurrently, Lin et al.10 introduced RetinaNet with Focal Loss, overcoming class imbalance to surpass two-stage model accuracy, though computational demands remained high.
The YOLO series evolved significantly through YOLOv211 and v312, achieving speed-accuracy breakthroughs. The recent YOLOv8 incorporates previous strengths with architectural optimizations, yet still requires task-specific enhancements for optimal performance.
As object detection tasks evolve towards complex dynamic scenarios, performance optimization of detectors has gradually shifted from individual module enhancements to multi-component collaborative design, aiming to break through the inherent balance bottleneck among feature discriminability, localization accuracy, and computational efficiency. Recent research reveals strong coupling relationships among three critical aspects: the feature focusing capability of attention mechanisms, scale-sensitive compensation in loss functions, and dynamic nonlinear modeling through activation functions. Their synergistic optimization can significantly improve model performance.
Attention Mechanism: While Li et al.13. proposed a hybrid attention mechanism that enhances single-stage detector performance through multi-module collaboration (spatial-channel-alignment), the stacked modules introduce redundant computational operations, resulting in less efficient cross-dimensional information fusion compared to the parallel interaction paradigm of our Global Attention Mechanism (GAM)14.Woo et al.15developed Convolutional Block Attention Module (CBAM), a lightweight dual-path attention mechanism, which improves detection performance through channel-spatial cooperative feature refinement. Nevertheless, CBAM’s sequential computation of channel and spatial attention overlooks cross-dimensional interactions, leading to information loss and accumulated computational costs in deep networks. Its reliance on local convolutional kernels also limits global context modeling for large-scale targets. In contrast, GAM’s channel attention module amplifies cross-dimensional interactions (channel, spatial width, and height) while preserving spatial information, demonstrating superior global dynamic modeling and efficient cross-dimensional interaction capabilities.
Loss function: Traditional loss functions apply equal weighting to all samples’ loss contributions, causing insufficient optimization for low-IoU samples (e.g., occluded targets). While CIoU introduces an aspect ratio penalty term, its fixed-weighting mechanism creates imbalanced gradient updates for small and large targets1617. F-EIoU18 addresses this by dynamically adjusting regression weights across different scales, assigning higher weights to low-confidence samples (hard samples) to enhance learning capability for edge cases.
Activation functions: Handling complex scenarios (occlusion, multi-scale variations, deformations) requires moving beyond the limited expressiveness of linear convolutional operations. Layer-wise nonlinear transformations (e.g., HardSwish19) progressively decouple low-level textures (edges, corners) from high-level semantic features (vehicle components, pedestrian postures), enabling finer fitting of target-background decision boundaries.
Target tracking
Early object tracking methods primarily relied on handcrafted features, which inherently lacked adaptability to dynamic appearance variations20,21. The introduction of SORT (2016)22 marked a breakthrough by integrating Kalman filtering with the Hungarian algorithm, enabling lightweight real-time multi-object tracking, though it suffered from limited target re-identification capabilities. With the advent of deep learning, DeepSORT (2017) significantly enhanced tracking robustness through deep feature extraction, achieving notable improvements in long-term identity preservation23. The recently proposed StrongSORT (2023) further optimizes association strategies and adaptive updating mechanisms, yet still faces challenges in computational resource demands and parameter tuning bottlenecks24. This evolutionary progression demonstrates continuous advancements in balancing tracking precision with practical deployment requirements.
(1) Adaptability in Dynamic Environments: The Gomaa team (2020–2022)25,26 optimized vehicle tracking using morphological operations and keypoint motion analysis, achieving efficient counting in fixed-camera scenarios. However, their approach demonstrated limited robustness to moving viewpoints and complex occlusions. Hao et al.27 proposed lightweight Fast-PP-LCNet and OSNet networks to reduce identity switches in maritime tracking, but struggles with complex background interference. The Xue team28 innovatively integrated wavelet domain analysis and sparse attention mechanisms, enhancing small-target tracking stability in UAV scenarios, though cross-frame association efficacy for high-speed dynamic targets remains unverified. In 2023, Meimetis et al.29 refined DeepSORT’s initialization logic with YOLO for real-time tracking, yet performance degrades under dense occlusion. Du et al.30 fused Slim-Nick and CBAM attention mechanisms to improve feature extraction, but severe occlusions still lead to missed detections. Addressing heterogeneity challenges in multi-UAV tracking, Xue et al.31 introduced sparse attention mechanisms into collaborative tracking, effectively mitigating cross-heterogeneous interference, with validated precision and robustness on the MDOT dataset. However, tracking robustness for high-speed dynamic targets remains untested. Tian et al.32 provided a practical solution for real-time traffic tracking via lightweight feature fusion improvements, yet robustness in extreme congestion scenarios requires further validation. These advancements highlight persistent trade-offs between adaptability and environmental complexity in dynamic tracking systems.
(2) Multi-Scale and Heterogeneous Target Handling: Zhou et al.33 enhanced detection of occluded targets through their MultiMap algorithm, though sensitivity to drastic scale variations remains a limitation. Separately, Xue et al.34 proposed the lightweight siamese tracker MobileTrack, refining MobileNetV2’s dilation rates and stride configurations to strengthen feature representation for small targets, thereby achieving a speed-accuracy balance. However, the method underperforms in scenarios involving occlusions or significant scale variations. These works underscore the persistent challenges in harmonizing multi-scale adaptability with real-world deployment constraints.
(3) Sensor Collaboration and Real-Time Optimization:Fang et al.35 advanced a multi-vehicle LiDAR collaboration framework to overcome single-view occlusion limitations, yet unresolved data consistency issues arising from communication delays persist. The Gomaa team36 adopted low-rank decomposition for model compression, reducing annotation costs, though their background subtraction methods remain vulnerable to sudden illumination changes. Xue et al.37 introduced a dynamic query updating mechanism to mitigate occlusion challenges, but error accumulation in Kalman filtering under abrupt motion persists, while computational efficiency in multi-object occlusion scenarios may degrade due to cross-fusion layer complexity. In parallel, Xue et al.38 proposed frequency-domain feature enhancement and a dual-branch interaction mechanism, significantly improving target discriminability in UAV scenarios. However, computational efficiency in multi-object tracking could be compromised by stacked attention modules. These efforts highlight the delicate balance required between real-time performance and algorithmic sophistication in sensor-aided tracking systems.
This section reviews recent advancements in MOT and object detection. Algorithms like DeepSORT and HybridSORT have advanced target re-identification but still face limitations. DeepSORT exhibits reduced real-time performance, particularly with small targets, occlusions, and rapid motion. While HybridSORT enhances detection accuracy using YOLO or SSD detectors, it remains susceptible to identity confusion and target loss under occlusions and dynamic backgrounds.
To address these challenges, AE-StrongSORT integrates three key components: 1) GAM attention mechanism, 2) F-EIoU loss function, and 3) HardSwish activation. The GAM mechanism enhances focus on critical features, improving tracking of small and occluded targets. The F-EIoU optimizes performance in complex environments through effective handling of difficult samples, while HardSwish improves computational efficiency and nonlinear representation. Collectively, these innovations enable AE-StrongSORT to achieve superior detection accuracy and robustness, especially for challenging scenarios involving small targets, complex occlusions, and dynamic backgrounds.
The core contributions of this work include: First, integration of GAM into YOLOv8’s C2f layer backend, which minimizes speed degradation through localized feature selection, thereby enhancing cross-dimensional feature interactions. Second, incorporation of Focal-EIoU (F-EIoU) strengthens focus on hard sampleswhile reducing computational costs. Third, the enhanced CBH-Conv (Convolution-BatchNorm-HardSwish) structure mitigates gradient vanishing, improves feature representation, and boosts target discrimination accuracy. Experimental results validate AE-StrongSORT’s superior performance in complex scenes, particularly excelling in handling small targets, multi-object occlusions, and dynamic environments.
Methods
Detector
GC2f structure
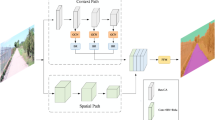
This paper proposes the integration of the GAM into YOLOv8’s architecture14. The GAM framework operates through sequential processing of channel attention and spatial attention submodules, as illustrated in Fig. 2. This mechanism computes position-wise attention weights, adaptively enhancing salient features while suppressing background interference39.

GAM attention mechanism.
As illustrated in Fig. 3, the original feature map initially undergoes processing through the Channel Attention Module (CAM). Through dimensional permutation, the tensor shape transforms from C \(\times\) W \(\times\) H to W \(\times\) H \(\times\) C for subsequent channel-wise analysis. Subsequently, two cascaded MLP layers implement nonlinear transformations to model inter-channel correlations, enabling dynamic weight redistribution across channels to suppress less informative or redundant features. Following feature vector compression along the channel dimension, an inverse permutation operation reconstructs the original tensor arrangement. The final output is normalized through a Sigmoid activation function, effectively amplifying cross-dimensional channel-space interactions. This computational process is formally expressed in Eqs. (1) and (2).

CAM channel attention submodule.
The processed feature map subsequently enters the Spatial Attention Module (SAM) for spatial refinement. As illustrated in Fig. 4, a \(7\times 7\) convolutional operator first aggregates spatial context while compressing the channel dimension from C to C/r. A complementary \(7\times 7\) convolution subsequently recovers the original channel count (C), followed by spatial feature recalibration through a Sigmoid activation function. The corresponding formula is shown in Eq. (3).

SAM spatial attention submodule.
This paper incorporates the GAM attention mechanism into the network architecture and proposes the GC2f module to replace the original C2f component, thereby enhancing the network’s feature extraction and multi-scale fusion capabilities. For high-speed vehicle detection tasks, the algorithm imposes strict constraints on inference latency. While conventional approaches typically position attention mechanisms before the C2f layer to emphasize critical features prior to complex processing, this strategy requires direct computation on high-resolution raw feature maps, substantially increasing computational demands. To address this, our solution repositions the attention mechanism after the C2f layer, allowing it to refine already processed features that have undergone extraction and fusion. This architectural adjustment enables the attention mechanism to leverage the C2f layer’s feature abstraction capabilities while avoiding computation-intensive operations on high-dimensional data, thereby achieving improved model performance with reduced computational overhead and lower inference latency.
Furthermore, as network depth increases, feature map dimensions exhibit an exponential growth in channel numbers while maintaining spatial resolution. Specifically, the feature map dimensions at the 6th and 8th layers measure \(40\times 40\times 512\) and \(20\times 20\times 1024\) respectively. Although spatial resolution decreases at deeper layers, the channel count doubles at each progression. The GAM mechanism’s requirement for channel-wise global weighting operations introduces significant computational and memory burdens. To maintain an optimal balance between model performance and resource efficiency, we preserve the original C2f module configurations at the 6th and 8th network layers. The architecture of our improved GC2f module is illustrated in Fig. 5.

GC2f module structure (the upper part is the overall structure of the GC2f module, and the lower part is the detailed structure of the corresponding module in the network structure).
Focal-EIoU loss
The CIoU loss employed in YOLOv8 evaluates bounding box regression through three components: the overlapping area between predicted and ground truth boxes, the Euclidean distance between their centroids, and the discrepancy in aspect ratios. However, CIoU’s formulation of aspect ratio discrepancy remains conceptually ambiguous—while it measures differences in width-height proportions, it fails to establish direct correlations between the predicted dimensions(w, h) and their ground truth counterparts(wgt, hgt). This imprecise characterization impedes the loss function’s convergence efficiency during training.
To address these limitations, we propose the F-EIoU loss, an enhanced version of CIoU that introduces two critical improvements. First, it incorporates a dimensional consistency term that directly penalizes discrepancies in width and height measurements, enabling more precise geometric alignment between predicted and target boxes18. Second, we implement a dynamic focusing mechanism that adaptively modulates the loss contribution based on sample difficulty: reducing weights for easily classified examples while emphasizing challenging cases. This dual enhancement not only improves scale adaptability across various object sizes but also significantly boosts performance in complex MOT scenarios featuring small objects, heavy occlusions, and severe overlaps. The mathematical formulation of F-EIoU is defined by Equations (4) and (5).
Among them, \(\gamma\) represents a parameter that controls the consistency of outliers.
As shown in Table 1, F-EIoU outperforms other loss functions in terms of \(^{A P^{v a l}}\) and \(A P_{75}^{v a l}\).
CBH-Conv structure
As a bounded variant of the ReLU activation function, ReLU6 constrains positive activations to the [0,6] range through output clipping, preventing numerical instability in deep learning systems. While effective for mitigating overflow risks in quantized networks, this design completely suppresses negative inputs through its abrupt saturation mechanism. Such hard zero-mapping induces neuron deactivation in convolutional layers, potentially leading to gradient dissipation and representational capacity loss. Furthermore, its piecewise-linear nature imposes limitations when handling sophisticated feature relationships in complex computer vision tasks.
In contrast, the Hardswish activation introduces a differentiable nonlinear transition within the critical [-3, 3] interval while maintaining ReLU-like linearity beyond this range19. By preserving moderate gradient signals in negative regions through its sigmoidal curve, it achieves three key advantages: (1) enhanced gradient propagation stability during backpropagation, (2) improved feature representation through continuous activation mapping, and (3) mitigation of abrupt boundary effects inherent in ReLU6. Our architectural modification replaces conventional activations with Hardswish in the CBH-Conv module, resulting in smoother feature transitions and reduced gradient vanishing risks. The activation’s mathematical formulation appears in Equation (6), while Fig. 6 illustrates the modified CBH-Conv architecture.

Improved CBH-Conv module structure diagram.
The above improvements are applied to the target detection network, and its network structure is shown in Fig. 7.

Improved CBH-Conv module structure diagram. (The upper part illustrates the overall structure of the algorithm, while the lower part details the specific structure of some individual modules.).
Summarize
As depicted in Fig. 8, the GAM attention mechanism enhances the feature representation of key areas (e.g., red regions) by weighting the input feature map. Simultaneously, it suppresses non-essential information, such as background interference, thereby improving the specificity and precision of feature extraction. The F-EIoU loss function introduces a weighting factor to the traditional IoU loss. It reduces the influence of simple samples on the loss function while increasing the weight of challenging samples, such as small targets and occluded targets. This approach significantly enhances the model’s detection performance in complex scenarios. Furthermore, the introduction of the Hardswish activation function effectively enhances the model’s nonlinear representational capacity. This improvement optimizes classification and regression performance, thereby boosting the accuracy and robustness of the detection task.

Schematic diagram of the effect of GAM and F-EIoU.
Tracker
Our proposed AE-StrongSORT algorithm achieves robust multi-target tracking through novel integration of motion dynamics and appearance representations. The detector first constructs a multi-scale feature pyramid from input frames, where the GAM selectively enhances discriminative features through spatial-channel attention weighting. This multi-resolution feature fusion framework, empowered by attention mechanisms, significantly improves scale-adaptive feature extraction capabilities.
The training process employs two key enhancements: (1) F-EIoU loss implementation with dynamic sample weighting mechanism that prioritizes hard examples through quality-aware focal adjustment, and (2) Hardswish activation integration in convolutional blocks to enable smoother gradient propagation while preserving negative-range information. These modifications collectively enhance model resilience in complex MOT scenarios characterized by occlusion and dense overlaps.
In the tracking phase, high-confidence detections undergo appearance embedding extraction via BoT architecture, followed by state estimation using the Novelty-Sensitive Adaptive (NSA) Kalman filter. A comprehensive similarity metric combines: (1) cosine distance between appearance embeddings for visual discrimination, and (2) Mahalanobis distance of motion states for kinematic consistency. The resulting association matrix undergoes optimal bipartite matching through Hungarian algorithm, yielding final tracking trajectories with improved identity preservation.
Improved multi-target tracking process:
(1) This algorithm is trained on the MOT-16 dataset to determine the optimal parameter settings. The maximum cosine distance for features \(\left( max \_dist\right)\) is set to 0.2 to measure feature similarity; the maximum intersection-over-union distance \(\left( max\_iou\_distance\right)\) is set to 0.7 to determine the accuracy of target detection; the maximum number of target losses \(\left( max \_age\right)\) is set to 30 to ensure the stability and robustness of the algorithm; and the number of consecutive matching frames \(\left( n \_init\right)\) is set to 3 to ensure the accuracy and continuity of target tracking.
(2) Visible light cameras acquire real-time traffic video data.
(3)The target detector performs real-time detection on each frame of the collected video, generating feature maps of different resolutions through multi-scale feature extraction. The GAM attention mechanism is then applied to weight the feature map, highlighting the target and key features. Bounding box predictions are made on the multi-scale feature map, and the output detection results include the coordinates of the upper left point (x, y), the center point(cx, cy), height, width, category label, confidence score, and unique ID.
(4)Data filtering: Detection results with low confidence are filtered out based on a preset threshold to reduce false detections. For cases where the same target is detected multiple times, the best detection result is retained by suppressing bounding boxes with high overlap.
(5)The Kalman filter is used to extract the motion features of the target. For each newly detected target, a Kalman filter is initialized to estimate the target’s motion state, including information such as position, velocity, and acceleration.
(6)To compensate for camera motion errors, the Appearance Consistency Calibration (ECC) technology is introduced. ECC is responsible for matching and calibrating the extracted appearance features to address instability caused by perspective changes, illumination variations, or occlusion. It continuously compares feature vectors across frames to ensure that the same target maintains similar appearance features, thereby reducing mismatches and target drift, as shown in Eq. (7).
(7) After matching the image, the Kalman filter predicts the target’s position in the current frame based on the previous motion state. The predicted state includes the target’s next position and velocity, forming the predicted value of the motion feature. When the number of consecutive matching frames is set to 3, the NSA Kalman filter’s prediction in the first two frames will be considered unconfirmed. Only from the third frame onward may the NSA Kalman filter’s prediction enter a confirmed state.
(8) A global matching strategy is employed to match the predicted bounding boxes with the detected boxes. Adaptive noise covariance calculation is introduced to adjust the noise model according to the target’s motion changes or environmental uncertainty. This adjustment improves the accuracy and stability of the matching process and reduces drift and error accumulation during tracking, as shown in Eq. (8).
(9) Using the BoT feature extractor, a high-dimensional feature vector is generated for each target detected by YOLOv8. This vector is extracted from the target’s bounding box to represent its appearance information, as illustrated in Eq. (9).
(10) Match YOLOv8’s detection results with the tracking trajectories from the previous frame. Generate a set of matching candidates using the Kalman filter’s predicted position and the BoT feature vector. Apply the Hungarian algorithm to associate targets by combining motion feature distances (Mahalanobis distance) with appearance feature distances (cosine distance). Identify the closest tracking trajectory for each detected target and update the trajectory status accordingly. The Mahalanobis distance is defined in Eqs. (10) and (11), and the cosine distance is defined in Eqs. (12) and (13).
Among them, \(d^{(1)}(i,j)\) represents the matching degree between the j-th predicted bounding box and the i-th track; \(d_{j}\) denotes the position of the j-th detection box; \(y_{i}\) represents the position of the i-th predicted bounding box; \(S_{i}^{-1}\) is the covariance matrix between the detection position and the predicted position of the i-th target; and \(b_{i, j}^{(1)}\) is the threshold function that compares the Mahalanobis distance with the threshold derived from the chi-square distribution. Here, \(b_{i, j}^{(1)}\) is determined by the probability P and the degrees of freedom m in the chi-square distribution. If the Mahalanobis distance is less than this threshold, the match is considered successful.
Among them, \(d^{(2)}(i,j)\) represents the appearance matching score, while \(r_{j}\) denotes the appearance feature descriptor computed for each detection box \(d_{j}\). \(R_{i}\) refers to the set of feature vectors corresponding to the i-th tracking box. The term \(r_{j}^{T} r_{k}^{(i)}\) calculates the cosine similarity between the appearance features. \(b_{i,j}^{(2)}\) serves as a threshold function, with \(t^{(2)}\) representing the threshold value, which is set to 0.2 in the code (controlled by the parameter \(\left( max \_dist\right)\)) and can be adjusted based on the specific characteristics of the detected targets. Finally, the comprehensive matching score \(c_{i,j}\) is derived by combining the motion feature distance and the appearance feature distance, as shown in Eqs. (14) and (15).
Where \(\lambda\) is the weight coefficient.
(11) After completing the IOU matching and evaluation, successfully matched targets are sent back to the NSA Kalman filter for variable updates in the next frame of data. Targets that failed to match are marked as unconfirmed new targets and are reintroduced into the NSA Kalman filter. Meanwhile, tracking continues for those targets that were not successfully matched. Finally, any target that still fails to match is processed in the subsequent steps.
(12) After confirmation status evaluation, if a target that failed to match remains in an unconfirmed state, it is deleted immediately; if the target is in a confirmed state, it proceeds to the next processing stage.
(13) When processing target tracking data, if the maximum number of target losses exceeds 30, the target is considered abnormal and is deleted. If the number of target losses is below 30, the data is considered valid and returned to the Kalman filter for variable updates in the next frame. This strategy ensures the accuracy and stability of the target tracking data.
(14) For successfully matched targets, their bounding boxes, categories, IDs, and other related information (such as speed, confidence, etc.) are output. The tracking information for the current frame is saved to continue tracking in subsequent frames. The improved flowchart is shown in Fig. 9.

Improved multi-target tracking process.
Experiments and results
Experimental conditions and datasets
(1) Experimental Configuration: The experiments were conducted on a system with an AMD Ryzen 7 5800H processor, NVIDIA GeForce RTX 3060 graphics card, and 16GB RAM, running Windows 11 OS with Python 3.8 and PyTorch 2.0.1 (CUDA-enabled).
(2) Dataset Description: We evaluate our enhanced AE-StrongSORT model against baseline methods using two benchmark datasets: BDD100K40 for detection tasks and MOT-1641 for tracking evaluation. The experimental dataset includes a total of 63,010 images, categorized into three classes and partitioned into training (70%), testing (20%), and validation (10%) subsets.
For tracking evaluation, MOT-16 provides 7 training sequences (5,316 frames) and 7 test sequences (5,919 frames), while our custom dataset contains 8 training sequences (5,760 frames), 5 test sequences (3,750 frames), and 3 validation sequences (2,160 frames). Ablation studies adopt temporal split validation, using MOT-16’s first half for training and second half for validation.
(3) Custom Dataset Collection: Our proprietary dataset captures real-world driving scenarios in Jimo District, Qingdao, using vehicle-mounted cameras across diverse environments (rural roads, provincial highways) and lighting conditions. It features five critical object categories: pedestrians, vehicles, traffic signals, lane markings, and road infrastructure, with sample illustrations shown in Fig. 10.

Homemade dataset.
(4) Benchmark Analysis: BDD100K stands as the largest driving dataset with 100K videos and 10 annotated tasks, providing unparalleled diversity in weather conditions, illumination variations, and urban/rural environments. Its complex traffic scenarios make it ideal for evaluating detection robustness in autonomous driving applications.
MOT-16 remains the gold standard for MOT evaluation, emphasizing pedestrian and vehicle tracking under challenging conditions: heavy occlusions, abrupt motion patterns, and transient object disappearances. These characteristics mirror real-world tracking complexities, making it essential for assessing algorithm resilience in practical scenarios.
Collectively, BDD100K and MOT-16 provide complementary challenges spanning detection accuracy, tracking consistency, and environmental adaptability, establishing comprehensive evaluation grounds for intelligent transportation systems.
Evaluation indicators
This paper uses Precision, Recall, Average Precision (AP), Frames Per Second (FPS), F1-score, and mean Average Precision (mAP) as evaluation metrics for the object detection experiments. The F1-score and AP are influenced by Precision and Recall, making them useful for evaluating the network model.
For the tracking experiments, metrics such as MOTA, MOTP, IDF1, HOTA, AssA, DetA, and ID switches (IDsw) are used to assess tracking performance. MOTA considers false positives, missed detections, and ID switches to measure the algorithm’s overall performance. MOTP evaluates the accuracy of correctly tracked target locations. IDF1 assesses the consistency of identity matching between the correctly detected targets and their corresponding tracks. HOTA evaluates tracking performance by measuring the higher-order accuracy of detection (DetA) and association (AssA). IDsw counts the number of incorrect ID switches during tracking.
Multi-target detection experiment
Ablation experiment
(1) Experimental results and analysis:
To validate the efficacy of our loss function optimization, we conducted controlled experiments comparing F-EIoU against the baseline CIoU. As evidenced in Table 2, F-EIoU achieves consistent improvements across all critical detection metrics:
Precision: + 2.13% (reduced false positives) Recall: + 2.09% (mitigated missed detections) mAP50: + 0.94% (enhanced localization accuracy) These gains demonstrate F-EIoU’s dual advantages: (1) Superior hard sample mining through its focal weighting mechanism, and (2) geometric-aware optimization via comprehensive size penalties. The precision-recall synergy confirms improved robustness in complex scenes with occluded targets and dense overlaps.
While F-EIoU introduces marginal computational overhead (FPS decrease), this trade-off is justified by its significant error reduction. The results substantiate that our loss function reformulation effectively addresses CIoU’s limitations in aspect ratio modeling and sample balancing, establishing F-EIoU as a superior choice for MOT-optimized detection frameworks.
As demonstrated in Table 3, replacing conventional activations with Hardswish significantly boosts the model’s performance. Compared to LeakyReLU and ReLU6 baselines, Hardswish achieves substantial gains:
Classification accuracy: + 13.14% (vs LeakyReLU) and + 9.68% (vs ReLU6) Localization precision: mAP50 improves by 4.27% and 1.90% respectively These improvements stem from Hardswish’s dual advantages: (1) Smooth gradient transitions in the critical [-3, 3] input range prevent neuron saturation, and (2) selective retention of negative activations enhances feature discriminability. The combined effects reduce localization errors and false negatives, validating its superiority in multi-scale object detection tasks.
The GAM addresses feature redundancy through cross-dimensional interaction, as quantified in Table 4. By simultaneously refining spatial and channel-wise feature responses, GAM delivers:
+ 6.2% detection accuracy (suppressed background noise) + 1.3% recall (improved small object recovery) + 7.7% mAP (enhanced multi-class discrimination) GAM’s spatial-channel co-attention mechanism redistributes feature energy toward critical regions, reducing redundant computations while increasing feature distinctiveness.
(2) Analysis of the synergistic impact of various improvements:
The GAM enhances feature discriminability through spatial-channel reweighting, amplifying critical regions while suppressing background interference. As shown in Table 4, this mechanism improves detection accuracy by 6.20% at the cost of reduced inference speed due to architectural complexity.
To optimize this trade-off, we integrate the F-EIoU module that recalibrates sample contributions via dynamic weighting-suppressing easy samples while emphasizing hard cases. This integration enables GAM to prioritize challenging regions (e.g., occluded/small targets), boosting environmental adaptability by 1.2%. The synergy between GAM and F-EIoU streamlines computations, restoring 6.37% FPS while maintaining accuracy gains.
Further enhancements derive from Hardswish activation, which enriches nonlinear feature transformations across diverse object categories. This modification strengthens classification robustness and regression precision, particularly for low-contrast targets and ambiguous class boundaries.
In summary, our phased integration strategy delivers:
GAM-driven feature refinement F-EIoU-enabled sample rebalancing Hardswish-augmented nonlinear modeling While individual components introduce marginal trade-offs (e.g., recall fluctuations), the holistic framework demonstrates unequivocal effectiveness in multi-object detection, achieving balanced improvements in accuracy (6.2%), speed (6.37% FPS recovery), and environmental adaptability (1.2%).
Comparative experiment
We conduct comprehensive comparisons between our optimized YOLOv8-based algorithm (OUR) and mainstream detectors on the BDD100K test set. As shown in Table 5 and Fig. 11, OUR demonstrates superior performance metrics:

Changes in accuracy, recall rate, and mAP50 indicators.
Precision: 8.74% higher than YOLOv8 (second-ranked) mAP50: 1.88% improvement over DETR mAP50-95: 1.70% advantage against SSD Analysis reveals that while YOLOv11 introduces novel architectural components, its performance remains insufficiently optimized for complex BDD100K scenarios compared to standardized benchmarks like COCO/VOC. In contrast, YOLOv8’s extensive validation across diverse datasets and lightweight architecture makes it particularly suitable for driving scene applications, explaining its stronger baseline performance.
Our enhancements build upon YOLOv8’s validated foundation, achieving simultaneous improvements across all key metrics:
Precision gains from reduced false positives mAP50/mAP50-95 boosts through precise localization Maintained real-time capability
To validate real-world applicability, we rigorously evaluate our model on a custom-collected dataset capturing challenging road scenarios. This dataset encompasses critical MOT challenges:
Temporal variations (daytime/nighttime transitions) Target re-identification after occlusion Severe multi-object overlaps (> 80% IOU) Extreme scale variations (10\(\times\) size differences) As demonstrated in Fig. 12, our enhanced algorithm achieves superior detection consistency across multi-target scenarios compared to baseline methods. Figure 13 further reveals enhanced robustness against occlusion and scale variations, empirically validating our architectural improvements.

Improved multi-target tracking process.

Comparison of actual detection results of three algorithms (from left to right: YOLOv5, YOLOv8, improved OUR).
These visual comparisons confirm our method’s strengthened capability to handle real-world complexities without dataset-specific tuning, maintaining stable performance under conditions that typically degrade conventional detectors.
Multi-target tracking experiment
Longitudinal comparative experiment
In the model testing section of this paper, two key experiments were designed to comprehensively evaluate the impact of different detectors on the performance of the StrongSORT algorithm. We conducted experiments on the effects of various detectors on StrongSORT’s performance using the MOT-16 dataset, and the experimental results are presented in Table 6.
he optimized algorithm achieves state-of-the-art performance in MOTA (\(\uparrow\) 3.86%), IDF1, HOTA, AssA, and DetA (\(\uparrow\) 1.22%), while securing the second-highest rankings in MOTP and IDsw metrics. Compared to baseline YOLOv8, the architectural refinements yield the following performance improvements: The substantial enhancements in MOTA and DetA metrics validate that our improvements to the StrongSORT detector significantly boost overall algorithmic effectiveness, particularly regarding feature extraction precision. By incorporating GAM’s global context modeling and cross-dimensional interaction mechanisms alongside the C2f layer’s multi-scale feature aggregation capability, our approach prioritizes critical features through optimized architectural design, effectively reducing both false positives and missed detections. Furthermore, adopting the Focal Loss framework enables adaptive adjustment of attention weights for challenging samples within the EIoU paradigm, thereby enhancing detection robustness for small and occluded targets while maintaining precision-recall balance.
Notable gains in HOTA (\(\uparrow\) 2.78%), IDF1 (\(\uparrow\) 0.89%), and AssA (\(\uparrow\) 4.42%) demonstrate our architectural modifications substantially improve target association fidelity. The synergistic integration of the GC2f module’s hierarchical feature fusion capacity with GAM’s discriminative feature enhancement elevates StrongSORT’s representational power, enabling superior inter-target differentiation that minimizes both mismatches and tracking fragmentation. Complementing these advancements, F-EIoU’s adaptive sample weighting mechanism strengthens challenging sample processing to improve matching reliability. The strategic adoption of Hardswish activation further optimizes convolutional layer expressiveness, collectively elevating association precision across diverse scenarios.
The drastic 25.90% reduction in ID switches, coupled with improved AssA and IDF1 metrics, underscore enhanced feature discriminability and identity preservation capabilities in our enhanced StrongSORT framework. Concurrently, the MOTP improvement (\(\uparrow\) 1.80%) quantifies advancements in localization accuracy, validating our architectural refinements’ effectiveness in precision-critical detection tasks.
Horizontal comparison experiment
Secondly, this paper also conducts horizontal comparison experiments among different tracking algorithms. The performance of this algorithm is compared with other advanced algorithms on the MOT-16 dataset. The experimental results are shown in Table 7. The data visualization is shown in Fig. 14.

The IDF1-MOTA-HOTA graph compares the comprehensive performance of the proposed AE-StrongSORT with other advanced trackers on the MOT16 test set. The horizontal axis is MOTA, the vertical axis is IDF1, and the radius of the circle is HOTA. The proposed algorithm shows superior performance in IDF1, HOTA, and MOTA.
Experimental results demonstrate superior performance across multiple metrics:
-
MOTA: Our approach achieves 36.511 MOTA, significantly outperforming existing methods including BotSORT (31.513), StrongSORT (31.205), and ByteTrack (33.886). This represents a 3.87% increase over the second-best performer DeepOCSORT and 17.00% enhancement compared to the baseline StrongSORT implementation. The improvements primarily stem from enhanced detection of challenging samples and reduced false positives and miss rates.
-
MOTP: With an average positioning accuracy of 80.74, our method surpasses all compared trackers, showing 2.40% improvement over BotSORT (78.847) and 0.76% gain versus the original StrongSORT. This confirms the algorithm’s precision in spatial localization.
-
HOTA: The proposed method achieves state-of-the-art performance with 38.146 HOTA, demonstrating 9.14% and 5.83% improvements over baseline StrongSORT and second-ranked BotSORT respectively. These gains validate the effectiveness of our joint detection-association enhancements.
-
AssA: Our method obtains the highest association accuracy (46.042 AssA), outperforming DeepOCSORT (39.191) by 17.48% and exceeding second-ranked StrongSORT by 5.02%. This reflects optimized feature discrimination and reduced cross-frame matching errors.
-
DetA: The detection accuracy reaches 31.853, showing 13.56% improvement over the baseline StrongSORT (28.051), indicating enhanced recall-precision balance.
-
IDsw: Our approach achieves the fewest identity switches, reducing IDsw by 9.85% compared to second-best StrongSORT, demonstrating superior temporal consistency in target tracking.
To validate real-world performance, we conducted evaluations on a custom urban traffic dataset containing challenging scenarios liketarget re-identification, heavy occlusion, and high-density traffic flow. Figure 16 illustrates tracking performance across five representative frames: 529, 655, 1694, 2037, and 2524.
Our analysis reveals three key failure patterns in baseline methods:In frames 529 and 2037, StrongSORT, DeepOCSORT, and BoTSORT all failed to detect small vehicles. Frame 655 exposed false positive detections across all baseline methods, while frames 1694 and 2524 demonstrated missed detections of occluded targets in these algorithms.
The comprehensive enhancements in AE-StrongSORT address these limitations through three key innovations:
Enhanced multi-scale perception via YOLOv8’s feature fusion combined with GAM’s GC2f structure for global context modeling Optimized training dynamics through F-EIoU’s size-aware penalty and computational-efficient attention mechanisms Strengthened feature learning via CBH-Conv’s gradient-preserving architecture that better distinguishes motion and appearance features These technical improvements translate to absolute metric gains of 17%, 2.78%, and 9.99% in MOTA, HOTA, and IDF1 respectively. As visualized in Fig. 15, our method demonstrates superior robustness in dynamic environments, small object tracking, and complex occlusion handling, achieving both higher precision and more stable identity maintenance.

FS score area chart.
Cost-benefit analysis
As the cornerstone metric, MOTA serves as a composite indicator integrating false positives, miss rates, and identity switches to quantitatively evaluate tracking system efficacy. Given its comprehensive nature, MOTA serves as the primary optimization target during algorithmic enhancements. HOTA establishes a multi-dimensional assessment framework by jointly optimizing detection precision and association consistency, making it particularly advantageous in complex scenarios and thus claiming secondary but critical priority. IDF1 occupies a subordinate yet vital role in quantifying identity preservation accuracy, becoming indispensable for applications demanding strict multi-target tracking continuity. FPS represents a system-level performance constraint, attaining paramount importance in autonomous driving contexts where real-time processing acts as a non-negotiable constraint. This hierarchical metric selection—prioritizing MOTA and HOTA for algorithmic refinement while contextually weighting IDF1 and FPS—constitutes our evaluation framework, with the performance-speed balance score mathematically formalized in Eq. (16).
Here, parameter A quantifies the performance difference between baseline and enhanced models, while B denotes the pre-optimization performance. Weighting coefficients C, D, E, and F are dynamically calibrated according to scenario-specific priorities. Three distinct operational environments are analyzed: Ordinary road scenarios typically involve complex traffic patterns that prioritize accuracy and stability with moderate real-time requirements. Highway environments, characterized by simpler target distributions and high-speed vehicles, emphasize real-time processing capabilities while sustaining adequate detection precision. Complex urban scenarios encompass heterogeneous targets (pedestrians, vehicles, traffic signals) in cluttered environments, imposing stringent joint requirements on accuracy, stability, and speed. These operational demands are mathematically encoded through differential metric weighting, as systematized in Table 8.
As visualized in Fig. 15, the enhanced algorithm demonstrates overwhelmingly favorable performance-speed tradeoffs across all three scenarios. The quantified advantage (positive area) substantially exceeds disadvantages (negative area), with balance scores (FS) of 0.0623 (ordinary roads), 0.0002 (highways), and 0.0857 (complex roads). Notably, the highway scenario achieves 213 FPS—substantially exceeding the 30-60 FPS benchmark for autonomous driving systems—while maintaining detection robustness, thereby validating its suitability for high-velocity applications. This comprehensive evaluation confirms the algorithm’s scenario-adaptive superiority in balancing computational efficiency with tracking fidelity.
Conclusion
To address tracking challenges in complex traffic environments, this paper proposes an enhanced StrongSORT detector with systematic improvements that substantially elevate both detection robustness and tracking reliability. The three-stage optimization framework operates as follows: First, the GAM attention mechanism is strategically integrated into YOLOv8’s C2f feature processing backbone. This position-sensitive design achieves enhanced global feature awareness and cross-dimensional interaction with minimal computational speed penalty. Second, the proposed F-EIoU loss function synergistically strengthens sample difficulty weighting, prioritizing challenging instances while maintaining computational efficiency. Furthermore, the redesigned CBH-Conv structure mitigates gradient vanishing during backpropagation and amplifies discriminative feature representation, particularly for low-resolution and partially occluded targets.
These innovations collectively yield dual improvements in detection precision and tracking continuity. The enhanced AE-StrongSORT demonstrates superior motion-appearance feature discrimination, enabling more reliable target association amidst complex interactions like high-speed motion and dense occlusions. Benchmarked on the MOT-16 dataset, the solution outperforms state-of-the-art trackers across key metrics: Notably, it achieves a 17% absolute improvement in MOTA while maintaining top-tier IDF1 and HOTA scores. Remarkably, these gains are accomplished while sustaining real-time processing at 213 FPS, demonstrating practical viability for traffic surveillance applications.
While the current implementation experiences moderate FPS reduction compared to baseline models, its computational efficiency remains sufficient for deployment. Future directions include computational graph optimization for faster inference and cross-dataset validation to strengthen scenario generalization. The empirical success in handling intricate traffic patterns positions this method as a promising foundation for intelligent transportation systems (Fig. 16).


Test result chart.
Data availability
The data used in this study can be obtained from MOT-16 at https://motchallenge.net/data/MOT16/#download. The data is provided in video and image formats and follows the usage restriction of for academic research and educational purposes only, requiring citation of the original paper, and not to be modified or republished. To access the data, please follow the instructions on the official website to download it. The data used in this study can be obtained from BDD100K at http://bdd-data.berkeley.edu/. The data is provided in video and image formats and follows the usage restriction of for academic research and non-commercial use only, requiring citation of the related papers, and not to modify the dataset contents. To access the data, please follow the instructions on the official website to download it.
References
Yuan, Y., Wu, Y., Zhao, L., Chen, H. & Zhang, Y. Multiple object detection and tracking from drone videos based on gm-yolo and multi-tracker. Image Vis. Comput. 143, 104951 (2024).
Huang, X. & Zhan, Y. Multi-object tracking with adaptive measurement noise and information fusion. Image Vis. Comput. 144, 104964 (2024).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25, 66 (2012).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 580–587 (2014).
Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 1440–1448 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
Huang, Z. et al. Dc-spp-yolo: Dense connection and spatial pyramid pooling based yolo for object detection. Inf. Sci. 522, 241–258 (2020).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 779–788 (2016).
Liu, W. et al. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14 21–37 (Springer, 2016).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision 2980–2988 (2017).
Redmon, J. & Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 7263–7271 (2017).
Redmon, J. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Li, Y.-L. & Wang, S. Har-net: Joint learning of hybrid attention for single-stage object detection. arXiv preprint arXiv:1904.11141 (2019).
Liu, Y., Shao, Z. & Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv preprint arXiv:2112.05561 (2021).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 3–19 (2018).
Rezatofighi, H. et al. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 658–666 (2019).
Zheng, Z. et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 52, 8574–8586 (2021).
Zhang, Y.-F. et al. Focal and efficient iou loss for accurate bounding box regression. Neurocomputing 506, 146–157 (2022).
Howard, A. et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision 1314–1324 (2019).
Comaniciu, D., Ramesh, V. & Meer, P. Real-time tracking of non-rigid objects using mean shift. In Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662) vol. 2, 142–149 (IEEE, 2000).
Isard, M. & Blake, A. Condensation-conditional density propagation for visual tracking. Int. J. Comput. Vis. 29, 5–28 (1998).
Bewley, A., Ge, Z., Ott, L., Ramos, F. & Upcroft, B. Simple online and realtime tracking. In 2016 IEEE International Conference on Image Processing (ICIP) 3464–3468 (IEEE, 2016).
Wojke, N., Bewley, A. & Paulus, D. Simple online and realtime tracking with a deep association metric. In 2017 IEEE International Conference on Image Processing (ICIP) 3645–3649 (IEEE, 2017).
Du, Y. et al. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 25, 8725–8737 (2023).
Gomaa, A., Abdelwahab, M. M. & Abo-Zahhad, M. Efficient vehicle detection and tracking strategy in aerial videos by employing morphological operations and feature points motion analysis. Multimed. Tools Appl. 79, 26023–26043 (2020).
Gomaa, A., Minematsu, T., Abdelwahab, M. M., Abo-Zahhad, M. & Taniguchi, R.-I. Faster cnn-based vehicle detection and counting strategy for fixed camera scenes. Multimed. Tools Appl. 81, 25443–25471 (2022).
Hao, K. et al. Lightweight multiobject ship tracking algorithm based on trajectory association and improved yolov7tiny. Expert Syst. Appl. 66, 125129 (2024).
Xue, Y. et al. Smalltrack: Wavelet pooling and graph enhanced classification for uav small object tracking. IEEE Trans. Geosci. Remote Sens. 61, 1–15 (2023).
Meimetis, D., Daramouskas, I., Perikos, I. & Hatzilygeroudis, I. Real-time multiple object tracking using deep learning methods. Neural Comput. Appl. 35, 89–118 (2023).
Du, P. et al. Green pepper fruits counting based on improved deepsort and optimized yolov5s. Front. Plant Sci. 15, 1417682 (2024).
Xue, Y. et al. Consistent representation mining for multi-drone single object tracking. IEEE Trans. Circuits Syst. Video Technol. 6, 66 (2024).
Zhonglin, T. et al. Sffsort multi-object tracking by shallow feature fusion for vehicle counting. IEEE Access 11, 76827–76841 (2023).
Zhou, X. et al. Advancing tracking-by-detection with multimap: Towards occlusion-resilient online multiclass strawberry counting. Expert Syst. Appl. 255, 124587 (2024).
Xue, Y. et al. Mobiletrack: Siamese efficient mobile network for high-speed uav tracking. IET Image Process. 16, 3300–3313 (2022).
Fang, S. & Li, H. Multi-vehicle cooperative simultaneous lidar slam and object tracking in dynamic environments. IEEE Trans. Intell. Transp. Syst. 25, 11411–11421 (2024).
Gomaa, A. & Abdalrazik, A. Novel deep learning domain adaptation approach for object detection using semi-self building dataset and modified yolov4. World Electr. Veh. J. 15, 255 (2024).
Xue, Y. et al. Handling occlusion in uav visual tracking with query-guided redetection. IEEE Trans. Instrum. Meas. 6, 66 (2024).
Yuanliang, X., Guodong, J., Tao, S., Lining, T. & Lianfeng, W. Template-guided frequency attention and adaptive cross-entropy loss for uav visual tracking. Chin. J. Aeronaut. 36, 299–312 (2023).
Dalal, N. & Triggs, B. Histograms of oriented gradients for human detection. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05) vol. 1 886–893 (IEEE, 2005).
Xu, H., Gao, Y., Yu, F. & Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2174–2182 (2017).
Milan, A., Leal-Taixé, L., Reid, I., Roth, S. & Schindler, K. Mot16: A benchmark fors multi-object tracking. arXiv preprint arXiv:1603.00831 (2016).
Cai, Z., Chen, R., Wu, Z. & Xue, W. Yolov8n-fawl: Object detection for autonomous driving using yolov8 network on edge devices. IEEE Access 6, 66 (2024).
Hu, X., Jeon, Y. & Gwak, J. Fftransmot: Feature-fused transformer for enhanced multi-object tracking. IEEE Access 11, 130060–130071 (2023).
Bashar, M., Islam, S. & Hussain, K. K. Real-Time Multiple Object Tracking with Hierarchical Attention. Ph.D. thesis, Department of Computer Science and Engineering (CSE), Islamic University of ... (2023).
Author information
Authors and Affiliations
Contributions
W.X. provided critical guidance on the study design and methods and played a key role in analyzing the data and reviewing the manuscript. X.D.D. conceived the study, designed the experiments, developed the methods, and conducted the experiments. X.D.D. also performed the data analysis and significantly contributed to writing and revising the manuscript. R.C.L., B.J.L., and Y.H.J. participated in the experiments, collected data, and conducted preliminary analyses. L.X. offered overall guidance and reviewed the final manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, W., Du, X., Li, R. et al. Attention-enhanced StrongSORT for robust vehicle tracking in complex environments. Sci Rep 15, 17472 (2025). https://doi.org/10.1038/s41598-025-99524-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-99524-5
