
Abstract
Intrusion detection in the Internet of Thing (IoT) faces several challenges, including scalability, attack diversity, and the need for components to cooperate in the threat detection process. Current approaches have failed to simultaneously address these challenges. In this regard, our research presents a collaborative solution for intrusion detection in the IoT that relies on a combination of fuzzy logic techniques and Convolutional Neural Network (CNN) ensemble. Our goal is to solve the challenges in intrusion detection by using this combination and provide better performance in threat detection. Our proposed method consists of two main phases. In the first phase, the network decomposition and deployment of intrusion detection models are performed. In this phase, first the neighbor identification and weighting of the communication links between nodes are performed. Then, based on these weighted connections, the network clustering and decomposition operations are performed. After clustering, an observer node is assigned to each subnet, in which a separate detection model is deployed, so that intrusion detection can be performed in the second phase. In the second phase, which is performed locally in each subnet, the data is first preprocessed and the feature selection operation is performed using a combination of feature ranking methods and a fuzzy logic model. In this phase, the Backward Elimination Feature Selection model is used to identify the most relevant indicators with the type of attacks, and finally, a CNN model is used to identify intrusions in each subnet. In the detection process, when each of the participating observer nodes performs its local detection using this algorithm, they exchange the obtained information with each other to determine the final result of intrusion detection based on a voting method. It should also be noted that our proposed method was tested on two datasets, NSLKDD and NSW-NB15, and the results obtained show a significant improvement in the intrusion detection performance compared to previous methods. So that the average accuracy obtained was 99.72% in the NSLKDD dataset and 98.36% in the NSW-NB15 dataset.
Similar content being viewed by others
Introduction
Today, many electronic devices are floating around our planet, changing human life. In this respect, IoT is emerging as a revolutionary technology, making industries and life smarter by changing the way of smart peripherals which have enhanced connectivity, for example, smart homes, smart agriculture, water management, environment monitoring, and health monitoring. More specifically, the Internet of Things allows a huge number of diverse physical devices to collaborate and communicate with each other in order to move data across several networks without being hampered by interfaces between humans or devices1,2,3,4. About 41.6 billions IoT devices are predicted to be linked by 2025, posing a number of difficulties for the real-world implementation of IoT5. In particular, large IoT networks exhibit several problems with respect to data integrity and confidentiality. Security issues have grown higher, including zero-day attacks against internet users. Due to the wide usage of the Internet in many countries like Australia and the USA, the zero-day attacks hit hard6.
Utilizing cryptographic approaches in IoT security7 leads in significant transmission and computational overhead because IoT devices are resource-constrained. This problem is resolved by the development and implementation of intrusion detection systems (IDS). Therefore, in order to provide effective security in IoT interactions, IDS have been widely utilized for monitoring and identifying impostors in internet of things8,9. IDS is software that runs on Internet of Things devices. The intrusion detection system (IDS) keeps an eye on how the gadgets in the network behave and detects any malicious activity that the devices may be engaging in. When an assault or intrusion is discovered10, the device administrator is notified and takes the appropriate steps to prevent such incursions by isolating hostile devices. IDSs aid in preserving the safety of devices in the framework of the Internet of Things in this manner11. According to the kind of intrusion, intrusion detection systems are generally divided into two kinds12: fraud-based intrusions and overtly anomaly-based invasions. External intruders are responsible for the anomalous incursions. On the other hand, internal IoT system members who have been given authentication credentials by the system manager are the ones who carry out abuse intrusions13. Therefore, in order to identify and stop intrusions in the Internet of Things, machine learning and deep learning approaches are crucial. These techniques help to identify cyberattacks and automatically respond to systems by analyzing data and identifying abnormal patterns. However, challenges such as scalability in implementation and diversity of attacks still exist that require further research. As a large network, the IoT requires scalable methods for detecting attacks, because previous methods usually rely on single observers to detect intrusions. In this context, our proposed method seeks to improve intrusion detection in large-scale networks with high traffic through network decomposition and the use of multiple models to more effectively respond to these challenges. In addition, the second challenge is the diversity of attacks; the wide range of attack patterns and different methods of intrusion into networks have caused many previous methods to be unable to detect attacks that have not been previously trained. Therefore, our proposed method, by employing the cooperative strategy, attempts to increase the chances of detecting and resisting these attacks, thus helping to improve the security of IoT networks.
Research innovations in the field of IoT intrusion detection include new and effective approaches that can help improve the accuracy and efficiency of security systems. The first innovation is collaborative intrusion detection; in this approach, several learning models work together to increase the detection accuracy and provide greater effectiveness in detecting cyberattacks. The second innovation is the presentation of a new feature selection method based on the combination of Analysis of Variance (ANOVA), Relief, and Information Gain (IG) techniques, as well as feature ranking based on fuzzy logic. This method helps to form a more suitable feature selection system for solving IoT intrusion detection problems and provides a significant improvement in system performance. The contributions of the paper include the following:
-
1.
The proposed method, using a network decomposition approach, helps manage large-scale IoT networks and can effectively solve the scalability problem of IDS.
-
2.
The accuracy of attack detection is improved by combining the collaborative approach and feature selection techniques by the proposed method.
-
3.
Improving the overall network security through the network partitioning strategy in the IoT structure is possible by applying the proposed method, which increases the network resistance to cyber-attacks.
The paper follows this progression: Similar publications are examined in Section "Related work". Section "Proposed method" provides detailed descriptions of the proposed method. Section "Research finding" presents the implementation results, and section "Conclusion" concludes with the recommended approach described.
Related work
This section evaluates and analyzes recent studies. Bougueroua et al.14 proposed a taxonomy for Collaborative Intrusion Detection Systems (CIDS) using Multi-Agent Systems for designing Collaborative IDS. This taxonomy contained information on general architecture, agent technology, decision methods; past, present and future threats. Alshahrani15 proposed a detection system to determine the presence of malicious behavior in IoT devices through a machine learning-based methodology known as CoLLaborative (CoLL)-IoT with up to 98% accuracy on the UNSW-NB15 dataset.
Alsoufi et al.16 analised 26 papers that presented anomaly-based intrusion detection with focus on deep learning methods in IoT security. In their study, they compared the results from supervised methods with both unsupervised and semi-supervised ones, as well as the data types and the learning methods used. Yadav et al.17 designed a deep learning-based ID for IoT networks and produced high accuracy 99.76%. This system effectively solved the rising problem of IoT cybercrimes, thus improving trustworthy user-oriented cybersecurity models.
Vishwakarma and Kesswani18 proposed a deep neural network-based IDS that utilizes benchmark Netflow datasets and packet capture algorithms to address the issue of IoT devices being vulnerable to attacks. Saba et al.19 represented an IDS based on CNN using iot’s power, discovering security threats in IoT devices with the accuracy of 99.51% and, ensuring 92.85% of IoT devices secure.
Khan20 proposed a deep learning-based hybrid IDS that used convolutional recurrent neural networks (CRNNs) for motivating and categorizing cyberattacks surpassing existing techniques with a malicious attack detection rate accuracy of 97.75%. Luo21 described an IDS for distributed systems using the SDN technology, segmenting the networks and using a decision tree enhanced by the Black-Hole based Optimization (BHO) algorithm. This approach was therefore more effective than the previous methods which had accuracies of 99.2% and 97.2%.
Otoum et al.22 presented the Deep Learning-based IDS, which generally detects different types of anomalies associated with the denial of service, User-to-Root (U2R), probe, and Remote-to-Local (R2L) attacks in the fields of IoT that are growing very fast. Nasir et al.23 proposed the use of the DF-IDS model to detect intrusions in IoT traffic by using SpiderMonkey, Principal Component Analysis (PCA), IG, and Correlation Attribute Evaluation (CAE). This model yielded an accuracy of 99.23% and an F1 score of 99.27% and showed enhancement when compared to other models.
Alani and Awad24 proposed a two-layer Investigations and machine learning based-identification system for IoT with an accuracy rate of 99.15% for packet-based characteristic and 99.66% for the flow-based classifier making it an efficient and transparent system. Ge et al.25 had presented a new intrusion detection methodology for IoT utilizing deep learning approaches using the latest dataset and a feed-forward neural network model that performs multi-class classification.
Ullah et al.26 developed an enhanced IoT-IDS based on multimodal big data representation and transfer learning. While the model was able to achieve an accuracy of 98.2% on three datasets, the model was found highly vulnerable to flood attacks. Choudhary et al.27 proposed an IDS for IoT environments using the deep learning model with Aquila optimization. This hybrid model has consisted of a CNN and Aquila optimization algorithm that provided efficient anomaly detection and control.
Kaushik and Raweshidy28 proposed a Teaching–Learning-Based Optimization-enabled IDS (TLBO-IDS) which successfully defended IoT networks against intrusion attacks and exceeded other algorithms in its class, being 22.2% and 40% more efficient.
Hanafi et al.29 have proposed a new HTTP-IDS model based on IoT for detecting and preventing intrusions using the Improved Binary Golden Jackal Optimization algorithm and the Long Short-Term Memory network. The proposed model obtained 98.21% accuracy on the NSL-KDD and CICIDS2017 datasets outperforming other models. A summarization about the goal, employed methods, and potential limitations of the reviewed works is presented in Table 1.
Proposed method
Detecting intrusions in large networks such as IoT is a challenging process due to factors such as high traffic load, diversity of traffic patterns and intrusion methods, the presence of unknown attacks, and more. In this research, a new collaborative approach based on independent learning models is presented to address these challenges, which will be discussed after outlining the characteristics of the data used.
Dataset
The current study employed NSLKDD and NSW-NB15 datasets to simulate object behavior data whereas both datasets are widely recognized in intrusion detection research. The selected datasets provided full-range traffic pattern representations and numerous attack conditions which made them appropriate evaluation sources for our proposed intrusion detection procedure. Our method utilized several metrics to determine its ability to identify attack-related flows in these datasets.
The NSLKDD dataset emerged as a response to fix the reliability issues in the KDD’99 dataset through addressing its redundancy and bias problems. The database contains 1.074 million samples which capture network traffic communication between pairs of network nodes. The network connection data consists of 41 distinct features which explain different aspects of the connections. The NSL-KDD features organize into four categories: basic features (e.g., protocol type, service, flag) and content features (e.g., failed logins, file creations) as well as time-based traffic features (e.g., same host connection counts) and host-based traffic features (e.g., service from host counts). The full feature list along with descriptions can be found in the33. Our experiments used a 20% subset from the large dataset which included 25,192 data records. The subset contains 13,413 normal samples alongside other attack indicators that make up the rest of the records.
The NSW-NB15 dataset was chosen because it overcomes the deficiencies of older datasets KDD’99 and NSLKDD by including modern network attack patterns. The dataset includes 2,540,044 samples which are described through 49 different features. The collection of network features contains four main groups which include content features (payload characteristics) and temporal features (time-related flow attributes) alongside header-based features (packet header information) and flow-based features (statistical flow properties). A comprehensive list of these features exists in34 together with their detailed explanation. The database delivers an authentic depiction of contemporary network traffic by containing different attack variants. We applied sampling to balance the dataset distribution by decreasing the number of normal samples while keeping the attack instances at 508,000 data points because the original data contained 87.35% normal points. The dataset becomes more representative and challenging for training our model by implementing this method.
The NSLKDD and NSW-NB15 feature sets include characteristics which align with IoT network features. These datasets serve as an excellent base for studying IoT network traffic patterns and attack behaviors even though they originate from outside actual IoT deployments. The network-related features together with protocol features and traffic patterns and packet characteristics demonstrate direct similarities to those found in IoT network systems. These datasets contain different attack categories including denial-of-service, probing and remote-to-local attacks which demonstrate the security threats that IoT devices encounter. The evaluation of our proposed method on these datasets enables us to measure its intrusion detection capabilities across multiple network situations for IoT security assessments.
Proposed method
In this research, intrusion detection is approached collaboratively within the IoT structure, where the detection process is carried out with the cooperation of learning models deployed in a number of monitoring nodes. This collaborative detection process will lead to the formation of an aggregated learning system, where the effect of each learning model on the final detection result is determined based on its performance history and expressed as a weight value. The establishment of this intrusion detection model requires the preparation of the network’s communication infrastructure by breaking it down into a set of subnetworks. After the network decomposition, a set of monitoring nodes will be selected to deploy independent detection models, which will subsequently collaborate throughout the detection process. Given this explanation, the proposed method can be broken down into the following two main phases:
-
1.
Network decomposition and deployment of the intrusion detection model
-
2.
Collaborative intrusion detection
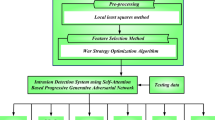
Figure 1 illustrates the details of collaborative intrusion detection using the proposed method. The first phase of the proposed method begins with preparing communications and identifying active neighbors for each node, followed by weighting each network connection based on criteria such as delay and energy. In this phase, the network structure is decomposed into a set of clusters based on the weighted connections, with each cluster considered as a subnetwork. At the conclusion of this phase, the monitoring nodes for each subnetwork are identified based on the connectivity degree criteria. The result of this phase will be a set of subnetworks, each equipped with a learning model for detecting attacks at its respective monitoring node. This process is carried out locally in each subnetwork during the second phase of the proposed method, as depicted in the lower section of Fig. 1.

General structure of the proposed method.
In the second phase of the proposed method, the traffic features are first preprocessed, and then a fuzzy model is used to rank the features based on their importance in the attack detection process. To accomplish this, three different strategies are initially utilized: IG, ANOVA, and Relief, to assign weights to the traffic features. The mentioned fuzzy model then determines the importance of each feature by combining the weights assigned by these three strategies. Subsequently, the appropriate number of features for selection is determined using the BEFS technique. The selected features are then used to train a CNN model. After training the CNN model deployed at each monitoring node, the intrusion detection process can be performed locally. In the proposed method, a collaborative strategy is employed for intrusion detection to enhance the performance of the detection system and improve the reliability of the model. In this technique, the participating monitoring nodes initially perform local intrusion detection on each traffic stream using their CNN models and then share their local detection results with other participating monitors of the stream. Finally, a weighted voting strategy is used to determine the final detection outcome.
Network decomposition and deployment of the intrusion detection model
The proposed approach works by decomposing network structure in the initial phase into a set of subnetworks through a fast and inexpensive mechanism in order to enable efficient security management of network communications. This process begins with identifying the active neighbors of each node. To this end, each node broadcasts a control packet to its neighboring nodes. Upon receiving this packet, each node adds the identifier of the sending node to its neighbor list and waits for a specific period to receive all control packets from neighboring nodes. Subsequently, each node responds to each of the received control packets. In this process, each node sends information about its remaining energy, the number of identified neighbors, and the communication link delay back to the sending node through a response packet. To store this information in the response packet, each node first normalizes it. The normalization of energy for node i uses the formula \(E{nergy}_{i}=\frac{{\text{e}}_{\text{i}}}{{\text{P}}_{\text{i}}}\). \({P}_{i}\) is the node i’s initial power in joules, and \({e}_{i}\) is its current power in this formula. The time from when data is transmitted and when it is successfully delivered and acknowledged as delivered is known as the delay for terminal i. As a result, by averaging the time between packet transmission and acknowledgment, each active node can determine how long it takes to communicate with its neighbors. To put it another way, the delay criteria is determined by looking at the communication histories of the devices. It is calculated as follows: \(Dela{y}_{i}=\frac{{\sum }_{j=1}^{N}{t}_{j}}{N}\), wherein N is the total amount of packets that have been sent to node i in the past and \({t}_{j}\) is the latency of the jth sent message. After getting this data from its neighbors, each node is able to weigh the communication connection with the item and evaluate it. In this case, node j weights a nearby item, such as i, in the manner described below:
The value of \({P}_{i}\) in the above equation indicates the value of the connection with the neighboring node i and \({C}_{i}\) is the number of active neighbors declared by node i. Next, node j calculates its weight as follows:
Subsequently, each node evaluates its own likelihood of being a monitor by comparing its weight value (Eq. 2) with the weights calculated for its neighbors (Eq. 1). In this scenario, if a node, such as j, has a weight greater than all of its neighbors, it sends a multicast message containing \({W}_{jj}\) to its neighbor list, signaling its readiness to form a subnetwork. This process is carried out by all nodes in the network, so that eventually each active node in the network receives one or more messages announcing the formation of a subnetwork. In this case, each node will join the subnetwork whose forming node has the highest weight value. Through implementing this process, the entire network structure will be divided into a number of subnetworks, which can be thought of as a clustering structure, and each forming node of the subnetwork is regarded as the monitor of this subnetwork. A subnetwork’s objects are able to interact with one another via their monitor in this configuration. This characteristic can provide more security to the network and can increase the chances of identifying Trojan attacks.
The network decomposition robustness receives additional enhancement through the implementation of link stability estimation. The goal of this step involves predicting how long a communication link between two nodes can stay operational by analyzing both their relative positions and velocities and communication ranges. Consider two nodes, \(a\) and \(b\), located in \(\left({x}_{a}, {y}_{a}\right)\) and \(\left({x}_{b}, {y}_{b}\right)\), respectively. Each node such as \(a\) has the velocity \({v}_{a}\) in direction \({\theta }_{a}\). Also, the communication range for this node is \({r}_{a}\). The initial distance between nodes \(a\) and \(b\) uses the Euclidean metric as \({d}_{ab}\). The decomposition process obtains the two nodes’ relative velocity vector through \(x\) and \(y\) component analysis of their velocity vectors. The formula to calculate \({v}_{rel}\) defines the relative velocity as:
where,
We proceed to determine the breakage time of the link. The time \({t}_{break}\) can be determined when nodes move directly away from each other with constant relative velocity according to the following equation:
The expression features the minimum communication range of nodes a and b measured by \({r}_{min}\). The link stability duration is determined by \({t}_{break}\) value. Nodes moving closer to each other produce a negative \({t}_{break}\) which indicates link stability during the specified time interval. The network re-decomposition period depends on the shortest stable link duration (positive \({t}_{break}\) values) and occurs every \({t}_{break}\) time interval.
Collaborative intrusion detection
Following subnetwork creation, each subnetwork’s surveillance is attributed to a specific observer. In this instance, the surveillance device detects attacks within its subdomain using a CNN-based learner, which is covered in more detail in the following paragraphs. Generally, the attack detection phase for each monitor can be broken down into the following detailed steps:
-
Data preprocessing
-
Feature selection
-
Local CNN-based detection
-
Ensemble of local results and collaborative detection
The traffic flow’s properties are first converted into a format that could be processed in the following stages. The attributes pertinent to the attack are then identified in the subsequent step using a novel hybrid approach. This method uses a mixture of IG, ANOVA, and Relief criteria for feature weighting, followed by the final ranking of features conducted by a fuzzy model to ultimately determine the appropriate number of features for selection using the BEFS strategy. After selecting the attack-related features, in the third step, a CNN model is used for attack detection in each subnetwork. This learning model is deployed in the memory of the monitor node and performs local detection. At the end of the intrusion detection process, the monitoring nodes participating in the traffic stream share their local decision results with each other in order to determine the existence of a security threat in the traffic stream using a weighted voting strategy.
Pre-processing
The set of features that describe the connection between devices is preprocessed as the first stage in the suggested intrusion identification procedure. All categorical characteristics are initially transformed into numerical values during the preprocessing stage. During this procedure, all False/No values are changed to 0 s and all True/Yes values to 1 s. The dataset is then cleared of any records that have missing values. Every input numeric characteristic is normalized at the conclusion of the preprocessing stage. For this purpose, each numeric feature vector is mapped to the range of 0 to 1 using the following equation:
In the above equation, \(x\) represents the feature vector before normalization and \({X}_{n}\) represents the values of this vector after normalization. Also, \({x}_{min}\) and \({x}_{max}\) describe the minimum and maximum numerical values in the feature vector x, respectively. The preprocessed feature set is used as the input of the proposed feature selection algorithm.
Feature selection
In the second phase of the proposed method, irrelevant indicators that may cause errors in the prediction process are removed. In addition to increasing the accuracy of the prediction model, this process also improves processing speed. The proposed method for selecting relevant features aims to combine the capabilities of three ranking strategies: Relief, ANOVA, and IG to develop a more efficient feature selection mechanism. To this end, the normalized features are first weighted using the three mentioned strategies, and then a fuzzy model is utilized to combine the feature rankings and determine the importance of each. After establishing the final rankings of the features, the BEFS algorithm is employed to select the optimal number of features.
a. Feature ranking
At the beginning of the feature selection step, the set of characteristics from the database is ranked simultaneously by three different algorithms. The first ranking strategy used is Relief. The Relief algorithm is a filter-based algorithm that identifies important features based on the information available in the training data and ranks them according to their significance. In the Relief method, the distance of each sample from other samples is calculated, and then the weight of each feature is determined based on the distances between the samples. In this case, features that have a smaller distance to other samples receive a higher weight, and based on this weight, the importance of each feature is determined. The Relief algorithm is an iterative strategy in which all features are examined and the importance of the features is identified. The computational details of this algorithm are given in30.
The second strategy for ranking the features is ANOVA. The impact of every independent factor (input characteristics) on the one that is dependent (attack kind) can be investigated using One-way ANOVA31. Each input feature is subjected to this analysis in the suggested approach in order to calculate its impact on the variable of interest in the form of an F-score. Each feature’s F-score shows the proportion of variability within the group compared to between-group variation. When F > 1, the between-group variance ratio is greater than the within-group variation ratio, suggesting that the feature’s impact on the variable of interest may be greater than coincidence. Furthermore, this effect gets more evident as the numerical value of F rises. Therefore, the second ranking factor for the attributes in the suggested technique is the calculated F-statistic for any given input characteristic. The third technique used to estimate the importance of features in intrusion detection is IG. Each feature’s information entropy decrease within the target variable’s circumstances is quantified using the IG criterion. Consequently, the following formulation of this criterion can be made32:
The input and target characteristics are denoted by x and T, accordingly, in the equation above, while the entropy of characteristic x is denoted by E[x]. According to the formula above, a feature’s IG might fall between 0 and + ∞. A higher IG value denotes a feature of greater relevance, whereas a lower value denotes a feature of lesser importance and less powerful relationship with the target parameter.
After the ranking of features by each of the strategies Relief, IG, and ANOVA a fuzzy model is employed to combine these rankings and determine the importance of each feature more accurately. This fuzzy model aims to cover the weaknesses of each strategy by integrating the rankings from the aforementioned algorithms to achieve a more robust model for feature ranking. The structure of the proposed fuzzy model for determining the importance of database features is illustrated in Fig. 2.

Proposed fuzzy model for evaluating the level of resource renewal needs of each vendor.
According to Fig. 2, the proposed method utilizes a Mamdani fuzzy inference system. The ranking values determined by Relief, IG, and ANOVA constitute the three inputs to this model. Different states of the relationship between these three inputs for each feature are evaluated based on 27 rules to describe the importance of the corresponding feature input in the form of a fuzzy variable. Additionally, the membership functions for each of the input and output variables in the proposed fuzzy model for feature ranking are illustrated in Fig. 3.

Membership functions of fuzzy variables in the proposed method.
According to the membership functions illustrated in Fig. 3, the three input variables of the proposed fuzzy model have similar membership functions. Each input variable corresponds to the ranking values determined by the Relief, IG, and ANOVA strategies, and each feature’s ranking is mapped as a fuzzy number with three membership functions: low, medium, and high. It is important to note that the rankings determined by each of the three described strategies are mapped to the range [0,1] using Eq. (3) before being applied in the proposed fuzzy model. Based on the input fuzzy variables, the output of the fuzzy system will be determined, indicating the importance of the feature. In the proposed fuzzy model, this output variable is determined using the rules specified in Table 2.
The rules mentioned in Table 2 determine the importance of each feature in the form of a fuzzy variable with 5 membership functions: very low, low, medium, high, and very high.
b. Determining the optimal number of features
At the end of the feature selection step, the ranked features from the fuzzy model are sorted in descending order based on the fuzzy values obtained from the output of this model, and then the BEFS algorithm is used to determine the optimal feature set. The BEFS is an efficient ranking feature selector that enables the derivation of an optimal number of features that are most predictive of a target variable. The algorithm works in the following form: first, a learning model is trained based on all available features and validation error is calculated based on them. At each successive step, the lowest-ranked feature is removed from the available feature set, and the process of calculation of training and validation error is repeated. This process continues until removing a feature does not lead to a reduction in the validation error. At this point, the algorithm concludes, and the set of features that achieved the lowest error is considered as the selected set. This set is then used as input for the third stage of the proposed method.
Local CNN-based detection
After identifying the most relevant features related to the types of attacks, a CNN is used to predict attacks at each monitoring node in the subnetworks. CNNs demonstrate their traditional image processing excellence but can process numeric data after suitable conversion. The selected feature set which starts as numeric values between [0, 1] gets converted to a binary matrix format in our approach. This data conversion enables CNNs to utilize their spatial feature extraction algorithm because they can detect intricate patterns which regular machine learning algorithms typically miss.
In order to convert the selected features into a matrix format, the range of values for each feature is first divided into intervals as [0,0.01), …, [0.99,1]. Then, for each interval in each variable, one bit is assigned, and for each record, the corresponding bit for that feature is set to 1. For example, if the value of a feature for a given record is 0.025, then that feature will be described as a binary string where only the third bit is set to 1. If the number of selected features from the previous step is N, this process results in each data record being described as a binary matrix with dimensions N × 101. The resulting matrices are used to train the CNN and for local attack prediction. Through its matrix structure the CNN efficiently uncovers spatial relationships between elements and complicated feature connections thus improving its ability to detect delicate intrusion patterns.
The solution addresses computational constraints for IoT nodes by creating an efficient system design. The observer nodes specifically host CNN models since they possess suitable storage capacity and processing performance to execute deep learning operations. The processing tasks are split equally between observer nodes through network decomposition so individual devices handle reduced computing responsibilities. Each subnetwork in the network structure contains an assigned observer node which performs parallel processing to detect intrusions in its assigned region minimizing resource needs on any individual device. The structure of the proposed neural network is illustrated in Fig. 4.

Proposed CNN model for local intrusion detection in each subnet.
This CNN model receives input features in matrix format and extracts feature maps through two consecutive two-dimensional convolutional layers. The first convolution layer extracts high-level features of the data, while the second convolution layer extracts more detailed features. It is noteworthy that the depth of this CNN model and the tuning of its hyperparameters are performed empirically based on a grid search strategy. In this search process, various combinations for the hyperparameters of the convolutional layer dimensions (with a search space of \(\left\{\text{3,4},\dots ,9\right\}\)), the number of convolutional filters (with a search space of \(\left\{\text{8,16},\dots ,64\right\}\)), the type of pooling function (with the evaluated cases of max, average, and global), and the training optimizer (with the evaluated cases of SGDM and Adam) were tested. The findings indicated that considering a depth greater than 2 for both target variables increase the risk of overfitting, while relying solely on a single convolutional layer may lead to a reduction in detection accuracy. This is because a single convolutional layer cannot effectively extract the patterns relevant to each classification target. After each convolution layer in the proposed CNN model, a ReLU layer is responsible for activating the output of the convolution layer, based on which only positive values are passed to the next layer. Next, a max pooling layer is used to reduce the dimensionality of the feature maps. This layer has dimensions of 2 × 2 in both convolutional components, with a stride size set to 2.
At the end of this CNN model, two fully connected layers and a classification layer are utilized to predict the target variable. The first fully connected layer in both proposed CNN models has a dimension of 30, while the size of the second fully connected layer is determined based on the number of target categories. The training of each CNN model used in the monitoring nodes is conducted using the Adam optimizer with a minimum batch size of 32. In the final step of the proposed method, the participating monitoring nodes exchange information with each other to identify the presence of an attack through the sharing of their local decisions.
By adopting this approach, we effectively leverage the powerful feature extraction capabilities of CNNs for numeric intrusion detection data, while also mitigating the computational challenges associated with IoT deployments. This strategic combination of data transformation and distributed processing allows for robust and efficient intrusion detection in resource-constrained IoT environments.
Ensemble of local results and collaborative detection
Each monitor uses the CNN model that is stored in its memory to identify attacks at the conclusion of the detection stage of the suggested technique. This study looks at individual as well as collaborative identification of attacks techniques. The monitoring node in the individual strategy continually monitors the traffic that passes by and uses the CNN to evaluate every new connection before approving and passing it. In this instance, the monitor will permit the connection to keep going if the CNN deems the traffic flow to be normal. Conversely, if the CNN attributes the traffic flow to one of the attack categories, the monitor will reject that traffic flow. In the collaborative detection approach, the monitoring nodes located along a path first exchange features of the traffic stream instead of forwarding the stream. Then, each node classifies the traffic using the CNN model stored in its memory. These classification results will be sent to the source controller, which will allow setting up a connection only if the majority vote of the collaborating monitors gives evidence of no attack.
Research finding
In this study, MATLAB 2020a software was used to simulate the experiments. The experiments were performed using the cross-validation technique with 10 replications, and the tests were conducted separately for each of the NSLKDD and NSW-NB15 datasets. The proposed method is investigated in three different modes. The first mode, Proposed (Coop.), refers to the situation in which the network is decomposed and intrusion detection is proposed through a cooperative strategy. The second mode, Proposed (Indv.), refers to the situation in which the detection is performed only based on a single model, so that the network decomposition is not performed and a single model is used for detection. Finally, in the third mode, Proposed (no FS), the feature selection operation is ignored and the detection is performed based on all input features. Additionally, in this scenario the detection is done in a cooperative manner. These three modes help us to accurately evaluate the performance of the proposed method in different conditions. In addition, to compare the performance of the proposed method, the results are also compared with three references19,20,21.
This proposed approach considers four standard metrics for the effectiveness of the method, which are Accuracy, Precision, Recall, and F-Measure. Now, we have to define these aforementioned evaluation metrics, for which the definition of the following needs to be defined: True Positive, False Positive, True Negative, and False Negative.
-
True Positive (TP) refers to an example that belongs to the positive class and is correctly identified by the model.
-
False Positive (FP) refers to an example that belongs to the negative class but is incorrectly classified as an example of the positive class.
-
True Negative (TN) refers to an example that belongs to the negative class and is correctly identified by the model.
-
False Negative (FN) refers to an example that belongs to the positive class but is incorrectly classified as an example of the negative class.
The following is a description of the four evaluation criteria:
The accuracy rate gives an indication about the model, giving a Fig. 5 of how many correct predictions were made. However, a high trueness does not guarantee the high ability to classify different classes in the case of a highly imbalanced dataset. Having a model that works with all classes is useful, in particular for medical image feature classification. In such cases, precision and recall values give insight into how this model works. Precision refers to the extent to which items in the positive label predicted by the model are relevant. It gives the proportion of correct predictions out of all those predicted by the model. On the contrary, recall computes the percentage of ground truth positive that is correctly classified by the model. These two-evaluation metrics will tell us whether the model can minimize the number of times it made FP and FN predictions. Again, the approach to analyze the f-measure also incorporates False Positives and False Negatives unlike just Precision or Recall alone. It penalizes extreme values of one of the most important measures, ‘precision’, and ‘recall’; both of which are obtained at the cost of the other.

Evaluation of the average accuracy for (a) NSLKDD and (b) UNSW-NB15 datasets.
Figure 5 shows the average accuracy of the proposed method and the comparative methods on the NSLKDD and NSW-NB15 datasets. The results of this show that our proposed method has achieved an accuracy of over 99% on the NSLKDD dataset and an accuracy of over 98% on the NSW-NB15 dataset. These observations emphasize that the proposed method performs very well in timely and correct intrusion detection. The high accuracy of this system not only helps in preventing cyber-attacks, but also is effective in maintaining data security. Therefore, continuous evaluation of its accuracy plays an important role in optimizing the system performance.
Figure 6 shows the confusion matrix for the NSLKDD and NSW-NB15 datasets. According to this matrix, our proposed method has been successful in detecting normal samples and attacks with an accuracy of 99.73% on the NSLKDD dataset, and has performed well compared to other methods. Furthermore, on the NSW-NB15 dataset, the proposed method has been successful in detecting attacks with an accuracy of 98.36%, demonstrating its superiority in this regard.

Evaluation of the Confusion matrix for (a) NSLKDD and (b) UNSW-NB15 datasets.
Figure 7 shows the precision, recall and f-measure metrics of the NSLKDD and NSW-NB15 datasets. Precision represents the percentage of correct positive predictions and helps reduce false alarms, while recall measures the ability to detect real attacks and avoids neglecting threats. F-measure is the ratio that combines the quantitative measure of the efficiency of the final classification and measures the relation between efficiency and investigated indicators to define the model’s effectiveness with greater accuracy. By these metrics, the proposed method can detect the cyber threats on IoT environment and helps in maintain the security of data.

Evaluation of the classification quality for (a) NSLKDD and (b) UNSW-NB15 datasets.
Figure 8 shows the ROC curve for the NSLKDD and NSW-NB15 datasets. This curve uses the True Positive Rate (TPR) and False Positive Rate (FPR) to evaluate the performance of our joint IDS, which uses fuzzy logic and a set of CNN. The ROC curve clearly shows the relationship between the false positive rate and the true positive rate, and measures the performance of the model in identifying threats and detecting intrusions in a timely manner.

Evaluation of the ROC curve for (a) NSLKDD and (b) UNSW-NB15 datasets.
Table 3 compares the performance of different methods in terms of Precision, Recall, F-Measure, and Accuracy in NSLKDD dataset. The results show that our proposed method with the cooperative approach has achieved the best performance; its accuracy is 99.7268, recall is 99.7231, and F-Measure is 99.7249. While the individual (Indv.) and no feature selection (no FS) methods show lower accuracies, respectively. Other comparative methods, such as Saba et al. and HCRNNIDS, also perform worse than the proposed method. Overall, these results indicate the superior ability of our system to accurately identify threats in IoT environments.
Table 4 displays the results for the Precision, Recall, F-Measure and Accuracy of different methods in NSW-NB15 dataset. The most effective proposed method to use with the cooperative approach is our method with the precision of 0.98,1282, the recall of 0.983585 and F-Measure of 0.98, 2412. In contrast, the individual (Indv.) and no feature selection (no FS) methods show accuracies of 96.3639 and 94.4245, respectively. Other comparative methods also perform poorly, with accuracies of less than 97%. Overall, these results indicate the superiority of the proposed method in detecting threats in IoT environments.
Feature selection analysis
This section explores the efficiency of the proposed feature selection algorithm and compares its performance with the previous feature reduction algorithms. In this regard, the performance of various feature reduction methods such as Minimum Redundancy Maximum Relevance (mRMR)35, Relief30, Singular Value Decomposition (SVD)36, and Sine Cosine hybrid optimization algorithm with Modified Whale Optimization Algorithm (SCMWOA)37 have been compared with the proposed algorithm. In this experiment, same instances were fed to each algorithm and then, the selected/extracted features were obtained and the proposed prediction model was trained based on each set. Finally, the performance measures obtained for each set of features were compared. To ensure validity of the results, the experiment was repeated 10 times and the average of the results was considered. Table 5 represents the results obtained through applying various feature reduction methods on NSLKDD data.
It should be noted that for mRMR and Relief algorithms, after ranking features based on them, the conventional sequential feature selection approach was used for determining the appropriate number of features. Also, in SVD case the threshold for sum of squares of the diagonal matrix was considered as 98%.
The suggested combination of IG, F1-Score, Relief and FIS produced a feature selection algorithm with 99.7261% accuracy and F1-score, precision, and recall exceeding 99.72%. The feature selection method demonstrates its ability to identify important features which results in a trustworthy intrusion detection model with high accuracy. The computation times of mRMR35 and Relief30 are smaller than the proposed approach (60.352 s and 55.902 s); but, produced accuracy rates of 98.1% and 97.9% which were lower than the proposed method. The process reveals that choosing faster operations requires sacrificing detection precision. Our proposed method reaches a detection performance improvement while demanding a computation time of 127.55 s.
The SVD36 method achieved only 96.2567% accuracy while remaining the fastest computational method with a time of 19.383 s. The algorithm performed fastest with 19.383 s of computation time but achieved lower accuracy levels during intrusion detection. Network intrusion patterns tend to exist at multiple dimensions so reducing them is not enough to detect their complex operational characteristics. The hybrid optimization algorithm SCMWOA37 demonstrated 99.0235% accuracy in its performance. The performance of our proposed method surpasses the results obtained through this method. The computation time of SCMWOA matched our method at 130.964 s.
The proposed feature selection algorithm demonstrates its effectiveness in uncovering the most important features for intrusion detection according to these research findings. The feature importance assessment becomes more precise through the integration of IG and ANOVA and Relief with the FIS. The longer computation period is acceptable because the system achieves superior detection precision which makes it suitable for critical applications. The analysis confirms that our feature selection method effectively improves the efficiency of the proposed intrusion detection system.
Memory Considerations for CNN Deployment on Observer Nodes
The distributed implementation of our intrusion detection system utilizes CNN models which run on observer nodes that are specifically placed throughout subnetworks as explained in section "Proposed method". The observer nodes are chosen specifically from the network nodes which fulfill the memory requirements needed to execute the trained CNN model. The chosen nodes must have sufficient resources to deploy and execute the detection model because of this selection requirement.
The CNN model’s memory usage depends mainly on the number of trainable parameters which exist as weights and biases in its various layers. Our CNN architecture includes two convolutional layers named convolution1 and convolution2 while its fully connected layers are referred to as FC1 and FC2 as per Fig. 4. The total number of trainable parameters reached approximately 1,749,258 based on the architecture and the worst-case scenario of feature selection (N ≤ 24). The memory requirement for this system comes out to about 6.67 MB when each parameter needs 4 bytes for its single-precision floating-point representation. A sufficient memory requirement exists for observer node choice because it emphasizes the need to account for RAM capacity. The selection procedure guarantees proper accommodation of the trained CNN model by nodes. The detection model requires 6.67 MB of RAM but some IoT devices with Raspberry Pi-like capabilities have enough memory while resource-constrained IoT nodes might not have enough available RAM.
Quantization proves to be one of the most successful methods to decrease the memory footprint size. Converting weights and biases from 32-bit single-precision floating-point numbers to 8-bit integer formats allows memory usage to decrease by 4 times. The conversion process dramatically reduces memory needs to about 1.66 MB which enhances model compatibility with devices that have restricted RAM. The quantization process results in minor accuracy loss where NSLKDD decreased by 0.8922 points and NSW-NB15 dropped by 1.0560 points.
The memory and computational requirements can be minimized further through additional optimization techniques in addition to quantization methods. The process of model pruning enables researchers to eliminate unimportant network connections in fully connected layers which results in reduced parameter numbers. Knowledge distillation serves as a beneficial technique by training a smaller efficient model to replicate the performance of a larger CNN. Deep learning model deployment on resource-limited IoT devices becomes more feasible through these implementation techniques that need proper evaluation.
The memory needs of our CNN model create difficulties for deployment on IoT nodes with limited resources but proper observer selection and model optimization approaches can successfully resolve this problem. Future evaluations will study the optimization methods to determine their effect on model efficiency and the amount of memory required when running in actual IoT networks.
Limitations and future directions
Our proposed cooperative intrusion detection system shows good performance in accurate threat detection but it requires more development to improve its effectiveness.
Expansion of the attack detection mechanism
Our present system execution handles binary classification by detecting intrusions but it does not identify specific attack types. Our system employes a majority voting technique for the fusion of predictions made by individual learners (CNNs); but in future developments, will plan to replace this strategy with a machine learning-based meta-learner to enable multi-class classification across several attack categories. The approach will reveal detailed information about the threats detected.
Communication overhead
Our collaborative intrusion detection system requires the reduction of communication overhead as a fundamental necessity. Several possible optimization methods can be explored to achieve this:
-
The system may utilize a method of selective information exchange that depends on confidence thresholds. In this case, the observer nodes will communicate only when their detection confidence reaches or surpasses a specific threshold value such as 85%. The selected approach cuts down unnecessary communication especially when nodes repeatedly confirm normal traffic behavior.
-
The LZ4 algorithm could serve as the basis for lightweight compression assessment. In this case, the LZ4 compression technique will be implemented to reduce data transmission size because of its fast compression speed and high efficiency. The observer nodes will apply this compression technique to data before transmission in order to reduce bandwidth usage.
-
The system may use local detection results aggregation techniques as part of its operation. In this approach, the observer nodes will combine their local detection findings throughout a ten-second time span before delivering them to the source controller. The aggregation process will decrease the number of individual messages and reduce both communication frequency and overhead.
-
The next plan includes the implementation of MQTT for efficient communication. We could deploy MQTT as our messaging protocol because it functions with constrained devices and low-bandwidth high-latency networks to lower information exchange overhead. The new protocol will function instead of the existing lengthy HTTP protocol.
The optimized strategies will help decrease network traffic while simultaneously saving substantial energy usage on IoT devices with limited resources. Our research includes future work sections with experimental results demonstrating effective communication reduction methods to boost energy efficiency and decrease overhead.
Dynamic network adaptability
Although the suggested network reconstruction system with dynamic time intervals based on predicted link stability deals with dynamic network adaptability; but additional improvements need to be developed for complex and fast-changing network structures. Future research may consider combining adaptive clustering algorithms with dynamic node assignment approaches for maintaining robust performance against highly dynamic environments.
Light-weight feature selection
The fourth limitation originates from the suggested feature selection model. The fuzzy-logic based feature selection technique faces computational complexity as a main drawback even though we have performed method comparisons with other techniques. In future research we plan to study combination methods of feature selection with dimension reduction strategies to attain higher efficiency in detection accuracy.
Energy efficiency and practicality
Energy efficiency stands as a primary factor that must be addressed during IoT deployment implementation. The distributed processing system across observer nodes needs additional optimization to reduce power consumption in resource-limited IoT devices. Energy-saving routing protocols along with adjustable sampling rates combined with lightweight CNN architecture designs remain study subjects for advancing energy efficiency in upcoming research.
The deployment of deep learning models on resource-limited IoT nodes creates built-in operational barriers. To achieve practicality on resource-constrained devices it is necessary to enhance the design of lightweight CNN models while additionally optimizing their performance capabilities.
Real-world application
It must be acknowledged that the present assessment relies on simulated results obtained from NSLKDD and NSW-NB15 datasets, through MATLAB tools. These datasets that researchers frequently use in intrusion detection analyses fail to capture authentic characteristics of IoT environments according to38. Real-world IoT deployments show dissimilarities between their traffic patterns and device behaviors and attack vectors and what is present in these datasets. The performance results from benchmark datasets would not necessarily predict the effectiveness of our proposed method when applied to IoT deployment environments. Our system needs real-world IoT deployment testing as part of future research so its performance in practical applications can be evaluated by implementing it in testbeds and network simulators. The system’s operational effectiveness across various network conditions will become possible because of this assessment process. Our future research will focus on studying the development processes for datasets specific to IoT systems which help assess intrusion detection capability in IoT networks.
Our cooperative intrusion detection system will gain better effectiveness and applicability in securing IoT environments through addressing identified limitations and implementing future directions.
Conclusion
In this paper, we present an innovative method for intrusion detection in the IoT, which is based on the combination of fuzzy logic techniques and CNN ensemble. Considering the complex challenges such as scalability, attack diversity, and the necessity of cooperation between different components in the threat detection process, our proposed method is able to respond to these challenges simultaneously by providing a collaborative solution. Proposed method consists of two main phases: in the first phase, the analysis network and intrusion detection models are deployed, and in the second phase, this detection is performed locally in each subnet. The results obtained from testing the proposed method on two datasets NSLKDD and NSW-NB15 show a significant improvement in the intrusion detection performance; such that an average accuracy of 99.72% is obtained in the NSLKDD dataset and 98.36% in the NSW-NB15 dataset. These results confirm that the combination of fuzzy logic techniques and CNN can be used as an effective solution to strengthen intrusion detection systems in IoT environments and help improve security in this area.
Data availability
All data generated or analysed during this study are included in this published article.
References
Jan, S. U., Ahmed, S., Shakhov, V. & Koo, I. Toward a lightweight intrusion detection system for the internet of things. IEEE Access 7, 42450–42471 (2019).
Nivaashini, M., & Thangaraj, P. (2018). A framework of novel feature set extraction based intrusion detection system for internet of things using hybrid machine learning algorithms. In 2018 International Conference on Computing, Power and Communication Technologies (GUCON) (pp. 44–49). IEEE.
Tait, K. A., Khan, J. S., Alqahtani, F., Shah, A. A., Khan, F. A., Rehman, M. U., & Ahmad, J. (2021). Intrusion detection using machine learning techniques: an experimental comparison. In 2021 International Congress of Advanced Technology and Engineering (ICOTEN) (pp. 1–10). IEEE.
Khan, M. A., Khan Khattk, M. A., Latif, S., Shah, A. A., Ur Rehman, M., Boulila, W., & Ahmad, J. (2022). Voting classifier-based intrusion detection for iot networks. In Advances on Smart and Soft Computing: Proceedings of ICACIn 2021 (pp. 313–328). Springer, Singapore.
Abiodun, O. I., Abiodun, E. O., Alawida, M., Alkhawaldeh, R. S. & Arshad, H. A review on the security of the internet of things: Challenges and solutions. Wirel. Pers. Commun. 119, 2603–2637 (2021).
Khraisat, A., Gondal, I., Vamplew, P. & Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2(1), 1–22 (2019).
Karati, A., Fan, C. I. & Hsu, R. H. Provably secure and generalized signcryption with public verifiability for secure data transmission between resource-constrained IoT devices. IEEE Internet Things J. 6(6), 10431–10440 (2019).
Fang, D., Qian, Y. & Hu, R. Q. A flexible and efficient authentication and secure data transmission scheme for IoT applications. IEEE Internet Things J. 7(4), 3474–3484 (2020).
Chaabouni, N., Mosbah, M., Zemmari, A., Sauvignac, C. & Faruki, P. Network intrusion detection for IoT security based on learning techniques. IEEE Commun. Surv. Tutor. 21(3), 2671–2701 (2019).
Kang, I., Jeong, M. K. & Kong, D. A differentiated one-class classification method with applications to intrusion detection. Expert Syst. Appl. 39(4), 3899–3905 (2012).
Eskandari, M., Janjua, Z. H., Vecchio, M. & Antonelli, F. Passban IDS: An intelligent anomaly-based intrusion detection system for IoT edge devices. IEEE Internet Things J. 7(8), 6882–6897 (2020).
Anthi, E., Williams, L., Słowińska, M., Theodorakopoulos, G. & Burnap, P. A supervised intrusion detection system for smart home IoT devices. IEEE Internet Things J. 6(5), 9042–9053 (2019).
Santhosh Kumar, S. V. N., Selvi, M. & Kannan, A. A comprehensive survey on machine learning-based intrusion detection systems for secure communication in Internet of Things. Comput. Intell. Neurosci. 2023(1), 8981988 (2023).
Bougueroua, N. et al. A survey on multi-agent based collaborative intrusion detection systems. J. Artif. Intell. Soft Comput. Res. 11(2), 111–142 (2021).
Alshahrani, H. M. Coll-iot: A collaborative intruder detection system for internet of things devices. Electronics 10(7), 848 (2021).
Alsoufi, M. A. et al. Anomaly-based intrusion detection systems in iot using deep learning: A systematic literature review. Appl. Sci. 11(18), 8383 (2021).
Yadav, N., Pande, S., Khamparia, A. & Gupta, D. Intrusion detection system on IoT with 5G network using deep learning. Wirel. Commun. Mob. Comput. 2022(1), 9304689 (2022).
Vishwakarma, M. & Kesswani, N. DIDS: A Deep Neural Network based real-time Intrusion detection system for IoT. Decis. Anal. J. 5, 100142 (2022).
Saba, T., Rehman, A., Sadad, T., Kolivand, H. & Bahaj, S. A. Anomaly-based intrusion detection system for IoT networks through deep learning model. Comput. Electr. Eng. 99, 107810 (2022).
Khan, M. A. HCRNNIDS: Hybrid convolutional recurrent neural network-based network intrusion detection system. Processes 9(5), 834 (2021).
Luo, K. A distributed SDN-based intrusion detection system for IoT using optimized forests. PLoS ONE 18(8), e0290694 (2023).
Otoum, Y., Liu, D. & Nayak, A. DL-IDS: a deep learning–based intrusion detection framework for securing IoT. Trans. Emerg. Telecommun. Technol. 33(3), e3803 (2022).
Nasir, M., Javed, A. R., Tariq, M. A., Asim, M., & Baker, T. (2022). Feature engineering and deep learning-based intrusion detection framework for securing edge IoT. J. Supercomput., 1–15.
Alani, M. M. & Awad, A. I. An intelligent two-layer intrusion detection system for the internet of things. IEEE Trans. Ind. Inf. 19(1), 683–692 (2022).
Ge, M., Syed, N. F., Fu, X., Baig, Z. & Robles-Kelly, A. Towards a deep learning-driven intrusion detection approach for Internet of Things. Comput. Netw. 186, 107784 (2021).
Ullah, F., Turab, A., Ullah, S., Cacciagrano, D. & Zhao, Y. Enhanced network intrusion detection system for internet of things security using multimodal big data representation with transfer learning and game theory. Sensors 24(13), 4152 (2024).
Choudhary, V., Tanwar, S. & Choudhury, T. Evaluation of contemporary intrusion detection systems for internet of things environment. Multimedia Tools Appl. 83(3), 7541–7581 (2024).
Kaushik, A. & Al-Raweshidy, H. A novel intrusion detection system for internet of things devices and data. Wirel. Netw. 30(1), 285–294 (2024).
Hanafi, A. V., Ghaffari, A., Rezaei, H., Valipour, A. & Arasteh, B. Intrusion detection in Internet of things using improved binary golden jackal optimization algorithm and LSTM. Clust. Comput. 27(3), 2673–2690 (2024).
Urbanowicz, R. J., Meeker, M., La Cava, W., Olson, R. S. & Moore, J. H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 85, 189–203 (2018).
Sharma, Y., Sharma, S., & Arora, A. (2022). Feature ranking using statistical techniques for computer networks intrusion detection. In 2022 7th International Conference on Communication and Electronics Systems (ICCES) (pp. 761–765). IEEE.
Azhagusundari, B. & Thanamani, A. S. Feature selection based on information gain. Int. J. Innov. Technol. Explor. Eng. 2(2), 18–21 (2013).
Tavallaee, M., Bagheri, E., Lu, W., & Ghorbani, A. A. (2009). A detailed analysis of the KDD CUP 99 data set. In 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications (pp. 1–6). IEEE.
Moustafa, N., & Slay, J. (2015). UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In 2015 military communications and information systems conference (MilCIS) (pp. 1–6). IEEE.
Wang, G., Lauri, F. & El Hassani, A. H. Feature selection by mRMR method for heart disease diagnosis. IEEE Access 10, 100786–100796 (2022).
Wall, M. E., Rechtsteiner, A., & Rocha, L. M. (2003). Singular value decomposition and principal component analysis. In A practical approach to microarray data analysis (pp. 91–109). Boston, MA: Springer US.
El-Kenawy, E. S. M. et al. Novel meta-heuristic algorithm for feature selection, unconstrained functions and engineering problems. IEEE Access 10, 40536–40555 (2022).
Prasad, M., Pal, P., Tripathi, S. & Dahal, K. AI/ML driven intrusion detection framework for IoT enabled cold storage monitoring system. Secur. Privacy 7(5), e400 (2024).
Author information
Authors and Affiliations
Contributions
All authors wrote the main manuscript text. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qiu, X., Shi, L. & Fan, P. A cooperative intrusion detection system for internet of things using fuzzy logic and ensemble of convolutional neural networks. Sci Rep 15, 15934 (2025). https://doi.org/10.1038/s41598-025-99938-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-99938-1
