
Abstract
Reconfigurable Intelligent Surfaces (RIS) are emerging technology to enhance the 6G wireless communication systems by intelligently reconfiguring the propagation environment. This paper propose a Modified Prioritized Deep Deterministic Policy Gradient (MP-DDPG) algorithm for jointly optimizing beamforming at the Base Station (BS) and RIS phases in a Multiple Input Single Output (MISO) downlink communication system. The primary objective is to minimize transmitted powers while adhering to critical constraints such as maximum power limits and Quality of Service (QoS) requirements of the User’s Equipment (UE). The simulation results show that the MP-DDPG algorithm offers a robust and adaptive framework for addressing the inherent non-convexity and dynamic nature of such an optimization problem. Key findings highlight the remarkable resilience to imperfect Channel State Information (CSI), and the crucial trade-offs between performance, computational complexity, and signaling overhead.
Similar content being viewed by others
Introduction
Some innovative applications, such as data-driven, instantaneous, ultra-massive, and ubiquitous wireless connectivity applications are expected to be supported by 6G-and beyond communications1.
A data-driven application is characterized by the real-time collection and analysis of large volume of network data, which are used as the basis for intelligent decision-making processes. Such applications enable advanced functionalities to improve the efficiency of wireless communication systems. Instantaneous applications refer to highly reliable services that require very-fast response times. Examples of instantaneous applications including autonomous driving, remote robotic control, which require high performance and safety. Ultra-massive connectivity, is driven by the rapid growth of IoT and smart industry. ultra-massive connectivity requires a very large numbers of heterogeneous device connected, coordinated, and managed efficiently.
These applications require high data rates. High reliability and low latency. Innovative technologies are needed to support such high QoS requirements with lower cost, energy consumption, and hardware complexity2,3.
Reconfigurable Intelligent Surfaces (RISs), also known as Intelligent Reflecting Surfaces (IRSs), are one of the most promising technologies to enable 6G and beyond wireless communications. RISs are envisioned to enhance the spectrum and energy efficiency of wireless systems by reconfiguring the wireless propagation environment. Unlike traditional active components like relays, RISs are typically composed of numerous passive, low-power reflecting elements4. These elements can precisely adjust the phase and amplitude of incident electromagnetic waves, thereby re-directing signals towards desired receivers or mitigating detrimental interference5,6. By precisely controlling the reflection coefficients of its elements, an RIS can steer electromagnetic waves towards intended receivers, effectively mitigating signal propagation impairments, overcoming blockages, and transforming otherwise unfavorable propagation paths into beneficial ones6,7. The core functionality of an RIS is governed by the configurable phase shifts of its elements, which must be jointly optimized with the BS’s beamforming weights to maximize the received signal power.8,9. This capability allows RIS to maximize the total number of served devices, improve the signal-to-noise ratio (SNR) value, and increase the network sum rate, furthermore, RIS can contribute to increasing the covered area and enhancing energy collection capacity in hybrid communication-and-energy-harvesting scenarios6.
During the past years, many works have studied RIS-assisted wireless communication. In Ref.10, the authors investigate the characteristic of the downlink sum rate of an RIS-assisted wireless communication. The authors of Ref.11 study the achievable rate in a downlink RIS system. The authors of Ref.12 propose a low-complexity algorithm to maximize the weighted sum-rate of all users in a multiuser multiple-input single-output (MISO) downlink RIS-aided communication system; they also validate the proposed algorithm by numerical results.
The authors of Ref.13 consider RIS assisted (mmWave) non-orthogonal multiple access (NOMA) communication system. In their work users are partitioned into clusters of users. Different users’ clusters are served by subsets of RIS. To maximize the sum achievable rate, the authors propose a machine learning (ML) based three-stage algorithm that jointly optimizes user clustering, RIS partitioning, active beamforming, passive beamforming, and power allocation, taking into consideration the quality-of-service (QoS) requirements of each user and the maximum transmit power constraint of the base station (BS). Simulation results show that the proposed algorithm improves system throughput and achieve higher sum rates than conventional optimization algorithm.
Due to the growing demands for next-generation wireless networks, CELL-FREE (CF) system is proposed. In CF system to reduce the communication distance, there are a large number of access points (Aps) are distributed over the large service area. Reducing the communication distance between Aps reduces the shadow fading negative effects. The authors of Refs.14,15 consider RIS-aided cell free (CF) system. To maximizing the weighted sum-rate of all users the authors of Ref.14 propose a distributed beamforming algorithm. The proposed algorithm designs active and passive beamforming with the constraints of transmit power of Aps, and unit-modulus of RIS elements. Numerical results demonstrates that the proposed algorithm improves the performance compared with conventional local beamforming methods. To maximize the worst-case sum rate of the CF system the authors of Ref.15 propose a new algorithm. The proposed algorithm divides the problem into two subproblems. The subproblems are the RIS phase shifts optimization subproblem, and a precoding optimization subproblem. Numerical results shows that the proposed algorithm improves the performance with low complexity.
To maximize the user-achievable rate in Ref.16, the authors propose a new two-phase algorithm to optimize beamforming at the BS and the phase shifts at the RIS. The proposed algorithm is based on genetic algorithms. They used statistical channel information to reduce channel estimation overheads.
The work in Ref.17 represents a derivation of an analytical closed-form expression for the effective rate, taking into consideration some impairments such as location uncertainty and imperfect phase estimation. A Monte Carlo simulation validates the results and shows high accuracy.
The authors of Ref.18 propose a new protocol to maximize the achievable sum rate for both the single-user and multiuser cases. To overcome the difficulty of obtaining instantaneous CSI in RIS-assisted wireless communication systems, they propose a two-timescale transmission protocol. The authors study the effect of channel correlations in the BS-RIS and RIS-user links on the performance of the proposed algorithm for different values of SNR.
In Ref.19, the authors study the impact of CSI errors on the outage performance in RIS-aided wireless systems. They propose two algorithms, considering both multiuser and single-user cases. The simulation results show that the proposed algorithm significantly reduces the transmitted power at the BS with guaranteed outage performance.
Research efforts in RIS-assisted systems frequently focus on transmit power minimization as a key optimization area, as this directly contributes to reducing operational costs and environmental impact8,9. In the context of the transmit power optimization, the authors of Ref.20 develop an iterative mean-square error minimization approach in an RIS-aided MIMO network. The authors investigate the bit-per-Joule Energy Efficiency (EE) which is defined as the ratio of the information rate to the total power consumption and the Spectral Efficiency (SE) tradeoff.
Some studies aim to minimize transmit power while satisfying a minimum SNR at the receiver, which is a direct QoS constraint9. In Ref.21, the authors consider the case of a single RIS-sided wireless communication system, They study how to maximize the energy efficiency of a multi-user multiple-input single-output (MISO) system by optimizing the transmitted power at the BS and the phase shifts of the RIS, taking into consideration the constraints of maximum power and minimum QoS requirements. To formulate the optimization problem a realistic RIS power consumption model is developed.
In Ref.22, the authors study the resource allocation problem for a distributed RIS-aided wireless communication system where a number of RIS are spatially distributed. The authors consider the optimization problem of maximizing the energy efficiency for the single- and multiple-user scenarios and propose two suboptimal iterative algorithms with low complexity.
The authors of Ref.23 consider secure transmission for RIS-based downlink multiuser MISO systems. The authors study the limitations of acquiring CSI and to solve the optimization problem of minimizing the transmit power with the minimum SNR constraints, they propose particle swarm optimisation based technique.
Some Deep Reinforcement Learning (DRL) approaches might prioritize maximizing the weighted sum rate, they inherently treat transmit power as an optimization variable, subject to maximum power constraints, implying that efficient power usage is a core component of their design24. The authors of Ref.25 study the power minimization problem under the constraints of SNR requirements and RIS power budget. They present an optimisation-driven DDPG approach, which is a variation of DRL-based algorithms. In the paper, the DDPG algorithm generates only one part of the action, which is the passive beamforming. The active beamforming is generated using a model-based convex approximation optimization.
This paper introduces a DRL solution for optimizing beamforming and phase shifts in RIS-assisted MISO wireless systems. The solution targets the downlink of an outdoor cellular network where a multi-antenna BS, communicates with single-antenna mobile users through a direct link and a RIS. A key advantage of this proposal is that it does not require CSI acquisition, which is typically a complex challenge in RIS-assisted systems. The main objective is to minimize the power consumed by the BS for data transmission, aiming for energy-efficient wireless communication. This power minimization is constrained by a maximum transmit power at the BS and minimum QoS requirements at the User’s Equipment (UE), specifically in terms of Signal-to-Interference-Noise Ratio (SINR). The key contributions of this work are outlined as follows:
-
1.
We propose the modification of the prioritized experience replay mechanism within DDPG. In our MP-DDPG, we introduce a novel priority metric that combines the distance in time between sample and its K nearest neighbor (KNN samples) and the reward of the sample.
-
2.
Since conventional DDPG suffers from slow convergence and high-power consumption due to inefficient learning from past experiences, our MP-DDPG directly improves sample efficiency and convergence stability. This improvement leads to the faster convergence and superior performance as demonstrated in our results.
-
3.
We study the performance in terms of total transmitted power, scalability, and the convergence speed. The simulation results show that our proposed MP-DDPG algorithm is more effective and practical for larger-scale systems compared to conventional DDPG.
In the following section, a literature review is presented for the DRL-based algorithms, their core principles and how they are used in the context of RIS, especially in the power minimization problem. In Sections 3 and 4, the system model under consideration and the problem formulation are detailed; then Section 5 is dedicated to the proposed deep reinforcement learning solution (MP-DDPG). Section 6 presents the simulation environment and results, while Section 7 discusses the complexity analysis. Finally, Section 8 concludes the paper.
Literature review
A consistent observation across the literature is that joint optimization problems involving RIS and beamforming, especially with QoS and power constraints, are inherently non-convex and often classified as NP-hard, this poses a significant challenge for traditional optimization methods, leading to extremely high computational complexity. Deep Reinforcement Learning (DRL) algorithms ability to handle such complex, non-linear, and non-convex problems without relying on explicit mathematical models makes it a highly viable, and often superior, approach for achieving real-time optimization in dynamic wireless scenarios26
DRL represents a powerful paradigm in artificial intelligence that integrates deep neural networks with reinforcement learning, allowing DRL agents to learn optimal policies through interaction with complex, dynamic environments and receive feedback in the form of rewards or penalties, ultimately maximizing long-term cumulative returns27,28. Neural networks in DRL act as robust function approximators, enabling efficient processing of high-dimensional state spaces and discerning intricate relationships in raw input data27.
DRL’s model-free nature is crucial for its application in dynamic wireless environments. Unlike traditional model-based optimization techniques that struggle with unknown channel models and rapidly changing network conditions29,30, DRL can learn about radio channels without requiring explicit prior knowledge of the channel model or mobility patterns6,31,32. It achieves this by autonomously observing rewards and iteratively finding solutions to optimization problems6, directly addressing the limitations of traditional approaches and leading to robust performance and real-time adaptability in unpredictable wireless scenarios29,32. Furthermore, DRL algorithms have demonstrated significant efficiency in resolving the complexity of non-convex optimization problems in wireless communication systems33.
Developing a DRL solution for jointly optimizing BS beamforming and RIS phase shifts requires careful design of the Markov Decision Process (MDP) components: the state space, action space, and reward function.
The state space provides the DRL agent with comprehensive information about the wireless environment at each time step. For example, in sum-rate maximization problems, the state might include the current rate of each UE and cascaded channel information from each BS26. In more complex full-duplex systems, the state can encompass SINRs at both the BS and downlink UE from the previous time step, previously predicted RIS phase shifts and beamforming vectors, and the transmit powers of the BS and uplink UE24. For delay optimization problems, the state can be augmented with factors like the number of backlogged packets in buffers and current packet arrival rates34.
The action space defines all possible decisions the DRL agent can make, including the BS’s active beamforming vector and the RIS’s passive phase shifts9. Given the continuous nature of these variables, actions can be defined as optimal variables encompassing azimuth and elevation angles for beamforming, along with parameters for RIS and UEs, which may include both continuous angles and discrete association decisions components26. In some DRL frameworks, the actor network directly outputs predicted RIS phase shifts, the real and imaginary parts of transmit and receive beamforming vectors, and transmit powers. These outputs are often normalized (using \(\tanh\) activation) and scaled to their valid ranges (\([0, 2\pi ]\) for RIS phases, unit norm for beamformers)24. To facilitate exploration and accelerate convergence during training, Gaussian noise is often added to the action space. For practical implementation and to reduce signaling overhead, the framework can be extended to handle quantized RIS phase shifts, where the neural network might predict probabilities for selecting specific quantized phase values, or passive elements can be grouped24.
The reward function is crucial for guiding the DRL agent’s learning by providing immediate feedback on its actions. For power minimization under QoS constraints, the reward function must incentivize lower transmit power while penalizing QoS violations. In scenarios focused on maximizing sum-rate, the reward function is often directly equivalent to the objective equation, such as the sum of logarithmic rates26. For maximizing a weighted sum rate, the reward can be calculated as a weighted sum of uplink and downlink data rates, with weights balancing different traffic types24. This type of reward implicitly incorporates channel CSI, guiding the agent towards satisfying underlying QoS requirements related to signal quality.
Table 1 provides an overview of prominent DRL model-free algorithms and their typical applications within the context of RIS-aided wireless systems. Various DRL algorithms adapted for RIS-based wireless communication systems include Deep Q-Network (DQN), Deep Deterministic Policy Gradient (DDPG), Proximal Policy Optimization (PPO), and Soft Actor-Critic (SAC) each offering distinct advantages depending on the characteristics of the problem. DQN is foundational for discrete action spaces6,28. However, the continuous nature of beamforming weights and RIS phase shifts often necessitates algorithms capable of handling continuous action spaces, leading to the use of DDPG, PPO, and SAC6,26,36. DDPG is effective for dynamic beamforming design involving continuous state and action spaces due to its double-network architecture24,36. PPO is a robust model-free, on-policy, actor-critic method often used for optimizing gathered energy and sum rate33. SAC DRL is frequently proposed for complex joint optimization problems, such as joint beamforming and BS-RIS-UE association in mmWave networks, particularly for intractable non-convex problems with continuous action spaces, by incorporating a maximum entropy framework in the reward function26. The newer algorithms are more sophisticated and can be precisely tailored to allow for more detailed control and better overall performance.
Specifically, many papers suggested various DRL approaches for joint beamforming and RIS phase optimization, these papers are summarized in Table 2 highlighting their system models, objectives, and key features.
Various DRL algorithms, including DDPG, PPO, and SAC, have been successfully employed, showcasing their adaptability to continuous action spaces inherent in beamforming and phase shift control.
Specifically, there is a significant amount of research in the area of using DDPG algorithms to solve this problem. DDPG is a deep reinforcement learning algorithm that uses an actor-critic approach to learn deterministic policies in continuous action spaces. It involves two neural networks: an actor network that outputs actions and a critic network that evaluates the value of those actions. The DDPG is well-suited and widely researched solution for this problem due to the following factors:
-
Continuous Action Space: The active beamforming vector at the BS and the passive phase shifts at the RIS are continuous variables. DDPG is specifically designed for environments with continuous action spaces, making it a natural fit for this type of optimization problem. This is highlighted in the literature, where DDPG is noted for its “effectiveness in dynamic beamforming design involving continuous state and action spaces”.
-
Joint Optimization Capability: Numerous studies leverage DDPG to jointly optimize both the transmit beamforming at the BS and the RIS phase shifts. For instance,24 uses DDPG (specifically, MSF-DRL) to maximize weighted sum rates in RIS-assisted Full-Duplex systems, which involves optimizing transmit powers and RIS phase shifts.6 uses the Twin Delayed DDPG (TD3) method, a DDPG variant, for optimizing RIS phase shifts to minimize the transmission power in RIS-aided MISO-OFDM systems.
-
Handling Non-Convexity: The problem you described (power minimization under QoS constraints with joint beamforming and RIS phases) is inherently non-convex and often NP-hard. DRL algorithms, including DDPG, are well-suited to handle such complex, non-linear, and non-convex problems without relying on explicit mathematical models, which makes them a viable and often superior approach for real-time optimization.
-
Addressing Practical Challenges: DDPG-based solutions have also been shown to be robust to practical challenges such as imperfect CSI and hardware impairments, further increasing their applicability in real-world wireless systems. Studies discuss how DDPG can operate with minimal signaling feedback, which is crucial for practical deployments.
Traditional DDPG uses a random sampling of experiences for training, which can be inefficient. Prioritized experience replay focuses on sampling more important experiences (e.g., those with higher errors) to improve learning speed and sample utilization. Modifications to DDPG typically involve incorporating techniques like prioritized experience replay to improve efficiency and convergence, or using fractional-order learning to accelerate training. In this work, a Modified Prioritized Deep Deterministic Policy Gradient (MP-DDPG) which is an enhanced version of the standard DDPG algorithm, is explored to solve the problem under consideration.
System model
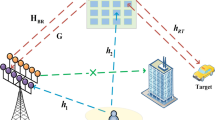
The system under consideration,as shown in Fig. 1, involves a BS, in the context of 4G/5G mobile networks, referred to as an Evolved Node B (eNB), equipped with multiple transmit antennas (\(N_t\) transmit antennas), serving K single-antenna UEs in the downlink. This configuration defines a Multiple users Multiple Input Single Output (MU-MISO) communication system. A Reconfigurable Intelligent Surface (RIS) is strategically deployed to assist this communication, particularly in scenarios where direct links between the BS and UE are weak or obstructed due to blockages9,24 The RIS functions as a passive reflector, intelligently altering the propagation path to enhance signal reception at the UE9.

System Model.
The reflectors of the RIS are M passive elements so the RIS does not consume any transmit power. The amplification gain of the RIS comes from the adjustment of the reflecting elements’ phase21. For simplicity, we consider the maximum signal reflection, hence we set the amplitude reflection coefficient to unity.
Let \(X \in \mathbb {C}^{K \times 1}\) represent the transmitted vector from eNB to the K UEs where every element \(x_k\) is the transmitted data to the \(k^{th}\) UE where \(k=1,2, \cdots K\), and \(\textbf{W} \in \mathbb {C}^{N_t \times K}\) denote the active transmit beamforming matrix applied at the BS. Let \(\textbf{H}_d \in \mathbb {C}^{K \times N_t}\) represents the direct channel matrix from the eNB to the K UEs, while \(\textbf{G} \in \mathbb {C}^{M \times N_t}\) represents the channel matrix from the eNB to the RIS.
The RIS introduces phase shifts to incident signals. This is represented by a diagonal matrix \({{\Phi }} \in \mathbb {C}^{M \times M}\), where \({{\Phi }} = \text {diag}(\phi _1, \phi _2, \dots , \phi _M)\). Each element \(\phi _m\) corresponds to the phase shift induced by the \(m-{th}\) reflecting element. For passive RIS elements, the magnitude of each phase shift is unity, typically expressed as \(\phi _m = e^{j\theta _m}\), where \(\theta _m \in [0, 2\pi )\) is the phase shift angle. Let the \(\textbf{H}_r \in \mathbb {C}^{K \times M}\) represents the channel vector from the RIS to the K UEs. Finally, let N be the additive white Gaussian noise (AWGN) vector at the K UEs receivers, where each element \(n_k \sim \mathcal{C}\mathcal{N}(0, \sigma ^2)\).
The Received Signal vector at the UEs, \(Y \in \mathbb {C}^{K \times 1}\) is the superposition of the signal traveling through the direct path and the signal reflected by the RIS and can be given as
The SINR, \(\gamma _{k}(\Phi , W)\), at the \(k^{th}\) UE is given by:
where \(h_{kd}\) is the \(k^{th}\) row of the matrix \(\mathbf {H_{d}}\) and \(h_{kr}\) is the \(k^{th}\) row of the matrix \(\mathbf {H_{r}}\) corresponding to the UE k.
Optimization problem formulation
The core problem addressed in this context is formulated as a nonconvex optimization challenge. The objective is to minimize the total transmit power at the eNB by jointly optimizing the active beamforming vector at the eNB and the passive phase shifts at the RIS. This minimization must adhere to crucial constraints, including a maximum allowable transmit power at the eNB and minimum QoS requirements for the User Equipment. This problem is inherently nonconvex.
Objective function
The core objective is to jointly optimize the active beamforming matrix \(\textbf{W}\) at the eNB and the passive phase shifts \({{\Phi }}\) at the RIS to minimize the total transmitted power, which is represented by the the squared Frobenius norm of the beamforming vector \(\textbf{W}\) (i.e. \(\min _{\textbf{W}, {{\Phi }}} \vert |\textbf{W} \Vert ^2\))
Constraints
To ensure practical feasibility and user satisfaction, the power minimization objective must adhere to specific constraints. The maximum transmit power constraint limits the power consumption of the eNB that must not exceed a predefined maximum allowable power, \(\vert |\textbf{W}|\vert ^2 \le P_{\max }\), preventing excessive interference to other users and respecting hardware limitations24. The QoS constraint guarantees a minimum level of service for the UE, typically expressed as a minimum achievable data rate or SINR8,9,26. For example, a minimum communication rate for each UE is a common QoS requirement, \(\gamma _{k}({{\Phi }}, \textbf{W}) \ge \gamma _{\min }, \quad \text {for } k = 1, \dots , K\)26. Additionally, the constant-modulus constraint for RIS phase shifts, where the magnitude of each element is constrained to 1, is another fundamental physical limitation that must be satisfied, \(\vert \phi _m\vert = 1, \text {for } m = 1, \dots , M\)8,24.
Thus, the optimization problem can be formulated as follows:
Proposed MP-DDPG algorithm
To solve the non-convex optimization problem in (3a), we propose the use of DRL which combines Reinforcement Learning (RL) and Deep Neural Network (DNN). RL is used to solve Markov Decision Problem (MDP) where the agent decides to take actions based on what it learns. DRL can be used to solve optimization problems when the states of MDP are of very high dimension. In our work, we propose to use a modifier prioritized Deep Deterministic policy Gradient (MP-DDPG). The traditional DDPG is a model free deep reinforcement learning algorithm which is effective in solving high dimension continuous optimization problems. DDPG is an actor-critic RL algorithm. In DDPG agent interact with the environment to generate experience data. Experience data is stored in finite size memory called experience replay buffer. Each iteration, data in experience replay buffer are sampled randomly to update the network. A fixed size of samples is randomly selected. Experience replay removes the correlation between observations samples which may result in instability in reinforcement learning process. Other limitations of DDPG is occurrence of local minimum. To increase the convergence speed and reduce the limitations in DDPG method, we propose an enhanced algorithm.
Conventional DDPG is actor-critics framework in which the workflow can be described as follow: First, the agent interacts with the environment to collect data and store it in experience replay buffer. Secondly, the sampled data from the replay buffer is used to update the actor- critics networks.
The basic components of a single agent DDPG learning architecture are as follows:
-
State Space S : In our work, the action space consists of the eNB beamform vector, and RIS elements phase shift. The system status which is represented by the state space consists of the previous phases of all the RIS elements, previous beamforming ,received power, and the received SINR. For each learning iteration t, we define the state vector \(S_t\) that represents a vector of the previous phases of all the RIS elements (\(\Phi\)), the previous active beamforming at eNB (W), received power, and SINR values.
-
Action Space A : for each learning iteration t, the action vector \(a_t\) represents the continues change in the RIS element phases for each element, and eNB active beamforming. The action determines the next state \(S_{t+1}\).
-
Reward: we consider Weighted Multi-Objective Reward where
$$\begin{aligned} r(t)= - \left( \zeta _1 \frac{P_t}{P_{max}}+ \zeta _2 \gamma _c + \zeta _3 P_c \right) \end{aligned}$$(4)where \(\gamma _c\) is an indication of the satisfaction of the SINR constraint of (3b), \(\gamma _c =1\) if the constraint is satisfied, and \(\gamma _c = 0\) otherwisee, \(P_c\) is an indication of the satisfaction of the maximum power constraint of (3c), where \(P_c =1\) if the constraint is satisfied and \(P_c = 0\) otherwise, \(P_t\) is the transmitted power, finally \(\zeta _1\), \(\zeta _2\) and \(\zeta _3\) are the adjustable weights. In our work, we assume equal weights (\(\zeta _1= \zeta _2 = \zeta _3 = 1\)).
DDPG incorporates two deep neural networks, single actor network, and single critic network. The input to the actor network is the state vector. For each state \(s_t \in S\), the actor generates the continues action \(a_t \in A\) which is optimized for the environment applying the policy \(\pi\). The action \(a_t\) is generated based on the policy of the actor \(\pi\), and the current state \(s_t\)
Where \(N_t\) is the exploration noise that generated randomly, and \(\theta _\pi\) is the parameters of the actor network. The critic takes the state vector and the action taken as inputs. For each state action pairs, the critic estimates the Q value. The target value \(y_t\) is given by
where \(r_{t+1}\) is the reward, \(\gamma\) is the discount factor. \(Q'\),and \({\pi '}\) are the target critic and actor networks with parameters \(\theta ^{Q'}\) and \(\theta ^{\pi '}\) respectively.
Let \(L(\theta ^Q)\) be the loss function of the critic network. During network training, the network is updated by minimizing the loss function. If the batch size is B, then the loss function is given by
In Conventional DDPG, random selection of samples from replay buffer breaks the correlation between samples. To improve the convergence time, the prioritized replay buffer is applied3839.
In our work, we assign a weight for each sample in the replay buffer. The weight reflects the importance of the sample. The selection of samples from the replay buffer depends on the successful performance of the sample while training, which is reflected in the sample weight.
The selected samples from the replay buffer should be diverse in states over time, and at the same time could improve policy and value function.
Let us define the distance in time between the sample i and j, \(d(t_i,t_j )=\Vert s_{ti}- s_{tj} \Vert\), which represents the Euclidean distance in state space between the samples. To reduce computation overhead, instead of getting the distance between each sample and all other samples in the replay buffer we get the distance between each sample and its K nearest neighbor (KNN samples). If the reward of sample i is \(r_i\). then we can calculate the priority of sample i as

Modified Priority-DDPG.
Simulation and results
In this section, we evaluate the performance of the proposed algorithm using MATLAB-based Monte Carlo simulations. We assume the channels are Rician fading with log-distance path loss40,41,42,43, consider one reflection only by the RIS and neglect any signals reflected more than once, we have:
where \(G^{LOS}\) and \(G^{NLOS}\) denot the Line of Sight (LoS), and Non Line of Sight (LNoS) components respectively and \(\beta _{AR}\) denotes the Rician factor. For modeling BS-UE channel and the RIS-UE channel, we use the same model. In our work we assume \(\beta _{AR}\) =0, \(\beta _{AU}=0\), and \(\beta _{RU}=1\)42.
The distance dependent pathloss PL(d) is also taken into consideration. Our simulation scenario is shown in Fig. 2, where \(d_1= 51 \ m\) and \(d_3 =2 \ m\). The distance between the eNB and the UE is then given by \(d_{BU}=\sqrt{d_2^2+d_3^2}\), the distance between the RIS and the UE is given by \(d_{RU}=\sqrt{(d_2-d_1)^2+d_3^2}\).

Simulation Scenario.
We also consider the replay buffer of size 10000, while the batch size B is 100 samples. The neural networks architectures and hyperparameters of the MP-DDPG under consideration are summarized in Table 3.
To evaluate the performance of the proposed scheme, we compare the performance of the proposed MP-DDPG scheme with two well-known schemes. The first one is the Particle Swarm Optimization (PSO)23, and the second is Deep Deterministic Policy Gradient (DDPG)24,33,36. PSO is a canonical and well-understood classical optimization approach, while DDPG is a reinforcement learning-based technique, which is effective for continuous action space.
Figure 3 investigates the transmitted power from eNB for different numbers of episodes/iterations. It compares the transmitted power for PSO, DDPG and MP-DDPG with the number of iterations /episodes.

The transmitter power at eNB vs number of episodes/iterations.
Figure 3 demonstrates that applying DRL to solve the optimization problem improves the performance in terms of reducing the transmitted power from BS. The convergence of the optimization algorithm is very critical. It is clear from the figure that DRL (DDPG, and MP-DDPG) converges to the minimum transmitted power faster than PSO. The performance of DDPG is further improved when applying priority RB. The improvement results from a better training process due to the selection of good sample sets for training.

The transmitter power at eNB vs number of RIS elements.
Figure 4 investigates the effect of increasing the number of RIS elements on the transmission power in BS. The figure shows the transmitted power at eNB for different numbers of RIS elements. The figure also shows that DRL based solution reach the minimum for a smaller number of RIS elements than the PSO. It is also clear that the proposed MP-DDPG algorithm reaches to the minimum transmitted power for a smaller number of RIS elements that DDPG. Applying the proposed MP-DDPG algorithm and increasing the number of RIS elements from 20 to 30 elements reduces the transmitted power by \(35\%\), while achieving the same percentage of improvement in performance (same reduction of transmitted power) the number of RIS elements must increases from 20 to 40 elements when applying DDPG and from 20 to 80 elements when applying PSO.
Figure 5 illustrates the transmitted power at eNB with the increasing number of antennas at BS. It is shown in the figure that increasing the number of antennas at eNB improves the performance for all algorithm due to increasing the special diversity. When applying the DDPG and MPDDG, the transmitted power is saturated at certain minimum value at certain number of antennas at eNB. MP-DDPG results in lower minimum saturated value of transmitted power at a smaller number of eNB antennas.

The transmitted power at eNB versus the number of antennas at eNB (Number of RIS elements =20).
Form Figs. 4 and 5, we can see that applying MP-DDPG algorithm results in improving the performance with less increasing in system complexity in terms of number of RIS elements, and number of eNB antennas.
From Figs. 3, 4 and 5, it is clear that applying MP-DDPG improves the performance than applying DDPG. This improves comes from the selection of most effective samples in the training of the DRL model instead of selecting them randomly.
Complexity analysis
In the conventional DDPG algorithm, the computational complexity per update iteration is dominated by the forward and backward propagation through the actor and critic networks. If each network has L layers with N neurons per layer, the complexity is approximately \(O(B.L.N^2)\) where B is the batch size used during training. Replay buffer sampling is random, with complexity O(B). Thus, the overall per-iteration complexity of the DDPG is \(O(B.L.N^2)\)
The proposed MP-DDPG algorithm introduces the following additional steps: Priority Assignment, Priority-Based Sampling, and then Neural Network Training. The total computational complexity of MP-DDPG arises from the complexity of all these stages. If the buffer size is R, B is the batch size, and K is the number of the number of nearest neighbors used for distance-based priority calculation, the complexity of the priority assignments for each sample based on the distance to KNN is O(R.K.d) where d is the state-space dimension.
For the Priority-Based Sampling, instead of the uniform random sampling, samples are drawn according to their assigned priority. Using a tree-based data structure, this operation has a complexity of \(O(B.\log {R})\).
Finally, in the Neural Network Training step, the actor and critic networks updates remain identical to conventional DDPG, with complexity and it is of order \(O(B.L.N^2)\).
The overall complexity of MP-DDPG is then of order \(O(R.K.d) + O(B.\log {R})+ O(B.L.N^2)\).
Although MP-DDPG adds extra overhead due to to the priority assignment and structured sampling, this increase is justified by the significant improvement in performance. As indicated by Fig. 3, MP-DDPG converges to the optimal policy in significantly fewer episodes than DDPG. The prioritization mechanism ensures that each update is performed on a more informative and diverse set of experiences, leading to more efficient learning.
Conclusion
This research proposes a Modified Prioritized Deep Deterministic Policy Gradient (MP-DDPG) algorithm for robust beamforming optimization in Reconfigurable Intelligent Surface (RIS)-assisted wireless communication systems. The primary objective of this algorithm is to minimize transmitted power at the eNB by jointly optimizing beamforming at the eNB and the phase shifts of the RIS, while satisfying constraints such as maximum transmit power and QoS requirements of the User Equipment (UE). A key advantage of the proposed DRL solution is its ability to operate without requiring instantaneous CSI acquisition, which is typically complex in RIS-assisted systems. The simulation results consistently demonstrate the superior performance of the MP-DDPG algorithm. Compared to Particle Swarm Optimization (PSO) and conventional DDPG, the MP-DDPG algorithm achieves faster convergence to the minimum transmitted power. Furthermore, it attains a lower minimum saturated transmitted power with a smaller number of RIS elements and eNB antennas, indicating improved performance with reduced system complexity. This performance improvement is attributed to the prioritized experience replay mechanism within MP-DDPG, which selects more effective samples to train the DRL model instead of random selection, leading to a better training process. The findings highlight the potential of MP-DDPG as an efficient and robust solution to optimize resource allocation in future 6G and beyond wireless communication networks.
Data availability
The simulated data, used in this study, was generated using Matlab code which can be provided from the corresponding author upon reasonable request.
References
Tariq, F. et al. A speculative study on 6G. IEEE Wirel. Commun. 27(4), 118–125 (2020).
Letaief, K. B., Chen, W., Shi, Y., Zhang, J. & Zhang, Y.-J.A. The roadmap to 6G: AI empowered wireless networks. IEEE Commun. Mag. 57(8), 84–90 (2019).
Saad, W., Bennis, M. & Chen, M. A vision of 6G wireless systems: Applications, trends, technologies, and open research problems. IEEE Network 34(3), 134–142 (2020).
Wu, Q. & Zhang, R. Towards smart and reconfigurable environment: Intelligent reflecting surface aided wireless network. IEEE Commun. Mag. 58(1), 106–112 (2020).
H. Choi, L. V. Nguyen, J. Choi, & A. L. Swindlehurst, “A Deep Reinforcement Learning Approach for Autonomous Reconfigurable Intelligent Surfaces,” arXiv preprint arXiv:2403.09270 (2024). Available: arxiv:2403.09270
Puspitasari, A. A. & Lee, B. M. A survey on reinforcement learning for reconfigurable intelligent surfaces in wireless communications. Sensors 23(5), 2554 (2023).
H. Tang, J. Zhang, Z. Zhao, H. Wu, H. Sun, & P. Jiao, “Joint Optimization based on Two-phase GNN in RIS- and DF-assisted MISO Systems with Fine-grained Rate Demands,” arXiv preprint arXiv:2506.02642, (2025).
Y. Liu, R. Wang, & Z. Han, “Passive Beamforming For Practical RIS-Assisted Communication Systems With Non-Ideal Hardware,” arXiv preprint arXiv:2401.07754, (2024).
B. Saglam, D. Gurgunoglu, and S. S. Kozat, “Deep Reinforcement Learning Based Joint Downlink Beamforming and RIS Configuration in RIS-aided MU-MISO Systems Under Hardware Impairments and Imperfect CSI,” KTH Royal Institute of Technology, 2022. Available: http://kth.diva-portal.org/smash/get/diva2:1709520/FULLTEXT01.pdf
C. Huang, A. Zappone, M. Debbah, and C. Yuen, “Achievable rate maximization by passive intelligent mirrors,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, pp. 3714–3718, April 2018.
M. Jung, W. Saad, M. Debbah, and C. S. Hong, “On the optimality of reconfigurable intelligent surfaces (RISs): Passive beamforming, modulation, and resource allocation,” arXiv preprint arXiv:1910.00968, 2019.
H. Guo, Y.-C. Liang, J. Chen, & E. G. Larsson, Weighted sum-rate maximization for reconfigurable intelligent Surface aided wireless networks. IEEE Trans. Wirel. Commun. 19(5), (2020).
Wei, T. et al. Machine learning-enabled RIS-assisted mmWave NOMA systems: RIS partitioning, beamforming design, and power allocation. IEEE Trans. Commun. 73(9), 7617–7632 (2025).
Ni, P., Li, M., Liu, R. & Liu, Q. Partially distributed beamforming design for RIS-aided cell-free networks. IEEE Trans. Veh. Technol. 71(12), 13377–13381 (2022).
Yao, J. et al. Robust beamforming design for RIS-aided cell-free systems with CSI uncertainties and capacity-limited Backhaul. IEEE Trans. Commun. 71(8), 4666–4680 (2023).
Souto, V. D. P., Souza, R. D., Uchôa-Filho, B. F. & Li, Y. Intelligent reflecting surfaces beamforming optimization with statistical channel knowledge. Sensors 22(6), 2390 (2020).
Kong, L., Kisseleff, S., Chatzinotas, S., Ottersten, B. & Erol-Kantarci, M. “Effective Rate of RIS-aided Networks with Location and Phase Estimation Uncertainty,” IEEE Wireless Communications and Networking Conference (WCNC) 2071–2075 (Austin, TX, USA, 2022).
Zhao, M.-M., Wu, Q., Zhao, M.-J. & Zhang, R. Intelligent reflecting surface enhanced wireless networks: Two-timescale beamforming optimization. IEEE Trans. Wireless Commun. 20(1), 2–17 (2021).
Zhao, M.-M., Liu, A. & Zhang, R. Outage-constrained robust beamforming for intelligent reflecting surface aided wireless communication. IEEE Trans. Signal Process. 69, 1301–1316 (2021).
You, L. et al. Energy efficiency and spectral efficiency tradeoff in RIS-aided multiuser MIMO uplink transmission. IEEE Trans. Signal Process. 69, 1407–1421 (2021).
Huang, C., Zappone, A., Alexandropoulos, G. C., Debbah, M. & Yuen, C. Reconfigurable intelligent surfaces for energy efficiency in wireless communication. IEEE Trans. Wireless Commun. 18(8), 4157–4170 (2019).
Yang, Z. et al. Energy-efficient wireless communications with distributed reconfigurable intelligent surfaces. IEEE Trans. Wireless Commun. 21(1), 665–679 (2022).
Pegorara Souto, V. D., Souza, R. D., Uchôa-Filho, B. F., Li, A. & Li, Y. Beamforming optimization for intelligent reflecting surfaces without CSI. IEEE Wirel. Commun. Lett. 9(9), 1476–1480 (2020).
N. Nayak, S. Kalyani, & H. A. Suraweera, “A DRL Approach for RIS-Assisted Full-Duplex UL and DL Transmission: Beamforming, Phase Shift and Power Optimization,” arXiv preprint arXiv:2212.13854, (2022).
J. Lin, Y. Zou, X. Dong, S. Gong, D. T. Hoang, & D. Niyato, Optimization-driven Deep Reinforcement Learning for Robust Beamforming in IRS-assisted Wireless Communications. In: Proc. IEEE Global Communications Conference (GLOBECOM), (2020).
Y. Zhu et al., “DRL-based Joint Beamforming and BS-RIS-UE Association Design for RIS-Assisted mmWave Networks,” ResearchGate, (2022). Available: https://www.researchgate.net/publication/358763517
A. Sharma, & R. Mehta, Deep Reinforcement Learning: Bridging the Gap with Neural Networks. Int. J. Intell. Syst. Appl. Eng. (IJISAE) 11(2), (2023).
Terven, J. Deep reinforcement learning: A chronological overview and methods. AI 6(3), 46 (2025).
A. A. Puspitasari et al., “DeepSeek-Inspired Exploration of RL-based LLMs and Synergy with Wireless Networks: A Survey,” ResearchGate, (2025). Available: https://www.researchgate.net/publication/391376441
Sun, Y., Lee, H. & Simpson, O. Machine learning in communication systems and networks. Sensors 24(6), 1925 (2024).
Y. Liu, X. Zhang, & M. Zhao, “Joint Beamforming Design for RIS-Assisted Integrated Satellite-HAP-Terrestrial Networks Using Deep Reinforcement Learning,” PubMed Central, (2023). Available: https://pmc.ncbi.nlm.nih.gov/articles/PMC10051352/
J. V. Saraiva et al., “Deep Reinforcement Learning for QoS-Constrained Resource Allocation in Multiservice Networks,” arXiv preprint arXiv:2003.02643, (Mar. 2020). Available: arxiv:2003.02643
H. Peng, & L.-C. Wang, “Energy Harvesting Reconfigurable Intelligent Surface for UAV Based on Robust Deep Reinforcement Learning,” ResearchGate, (2023). Available: https://www.researchgate.net/publication/368762340
S. Gong et al., “Beamforming Optimization for Intelligent Reflecting Surfaces without CSI,” ResearchGate, 2020. Available: https://www.researchgate.net/publication/341333766
Y. Ma, C. Guo, L. Liang, X. Li, & S. Jin, “Joint Beamforming and Resource Allocation for Delay Optimization in RIS-Assisted OFDM Systems: A DRL Approach,” arXiv preprint arXiv:2506.03586, (Jun. 2025). Available: arxiv:2506.03586
W. Li, W. Ni, H. Tian, & M. Hua, “Deep Reinforcement Learning for Energy-Efficient Beamforming Design in Cell-Free Networks,” arXiv preprint arXiv:2102.03077, (Feb. 2021). Available: arxiv:2102.03077
D. Pereira-Ruisanchez, O. Fresnedo, D. Perez-Adan, & L. Castedo, “Joint Optimization of IRS-assisted MU-MIMO Communication Systems through a DRL-based Twin Delayed DDPG Approach,” Proceedings of the 2022 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Bilbao, Spain, pp. 1–6, 15–17 (June 2022).
T. Schaul, J. Quan, I. Antonoglou, & D. Silver, “Prioritized experience replay,” In: Proceedings of the International Conference on Learning Representations (ICLR), San Juan, PUR, USA, pp. 1–23, (2016).
Y. Hou, L. Liu, Q. Wei, X. Xu, & C. Chen, “A novel DDPG method with prioritized experience replay,” In Proc. International Conference on Systems, Man, and Cybernetics (SMC), Oct. 2017, pp. 316–321.
Wu, Q. & Zhang, R. Intelligent reflecting surface enhanced wireless network via joint active and passive beamforming. IEEE Trans. Wireless Commun. 18(11), 5394–409 (2019).
Özdogan, Ö., Björnson, E. & Larsson, E. G. Intelligent reflecting surfaces: Physics, propagation, and pathloss modeling. IEEE Wirel. Commun. Lett. 9(5), 581–585 (2020).
Zhang, Z. & Dai, L. A joint precoding framework for wideband reconfigurable intelligent surface-aided cell-free network. IEEE Trans. Signal Process. 69, 4085–4101 (2021).
Su, R., Dai, L., Tan, J., Hao, M. & MacKenzie, R. Capacity Enhancement for Reconfigurable Intelligent Surface-Aided Wireless Network: From Regular Array to Irregular Array. IEEE Trans. Vehic. Technol. 72(5), (2023).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). Open access funding provided by the Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank(EKB).
Author information
Authors and Affiliations
Contributions
S.S. conceived and conducted the experiment(s), Y.F. suggested the research and revised the literature. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-36179-w
