
Abstract
Far more attention has been paid to attitudes toward Standard Arabic than colloquial varieties, especially Jazani Arabic. This study aimed to identify Saudis’ stereotypes, beliefs, and attitudes toward Jazani, as well as salient sociophonetic features that might have an impact on those attitudes. An additional goal was to determine whether Saudi speakers of other dialects could identify Jazani. The study asked the following questions. Can speakers of different Saudi dialects identify Jazani speakers from sociophonetic input alone? What are Saudi speakers’ attitudes toward Jazani Arabic? What are the salient sociophonetic features of Jazani Arabic? A total of 183 Saudi Arabic speakers participated in an online attitudinal survey. Qualitative and quantitative analyses were conducted on the collected data. Findings showed that respondents could identify the speakers as Jazanis based solely on sociophonetic characteristics. Non-emphatic /r/ and word-initial consonant clusters were pointed out as salient features of Jazani Arabic. In addition, participants’ responses included general impressions, cultural associations, and social status. Overall, speakers of other Saudi dialects had more positive attitudes than Najdi speakers, who held more negative attitudes toward Jazani speakers. The results reflected the social stratification in Saudi Arabia and confirmed beliefs, stereotypical views, and misrepresentations of Jazani speakers’ social status.
Similar content being viewed by others

Introduction
Arabic is spoken by about 300 million people in the Middle East and North Africa (Albirini 2016; Bale 2010), with different varieties spoken in different countries and regions (Theodoropoulou and Tyler 2014). Some dialects, such as Moroccan Arabic (Boudlal 2001; Chakrani 2013), Jordanian Arabic (Al-Masri and Jongman, 2004; Khattab et al. 2006), Baghdadi Arabic (Abu-Haidar 1989; Youssef 2013), and Egyptian Arabic (Broselow 1976; Watson 2002), have received more attention in research than others. Within Saudi Arabic (SA), the most extensively studied dialects include Najdi Arabic (Al-Rojaie 2013; Ingham 1994) and Hijazi Arabic (Abu-Mansour 1987; Al-Mozainy 1981). Conversely, southern Saudi dialects including those of Rijal Alma (Asiri 2009) and Abha have received less attention (Al-Azraqi 1998). A few studies (e.g., Al-Hakami 2023; Bosli and Cahill 2022; Durvasula et al. 2021; Essa 2022; Hamdi 2015; Shamakhi 2016) have focused on the folklore, ethnographic, syntactic, and phonological aspects of Jazani Arabic (JA), and most recently, Al-Hakami (2023) and Ruthan (2020) examined this dialect through a sociolinguistic and folk linguistic perspective.
Jazan and Jazani Arabic
JA is a dialect spoken in and around the southwestern region and the city of Jizan in Saudi Arabia (see Fig. 1). The region of Jazan, shown in red, is situated on Yemen’s northern border and extends along the Red Sea. Jizan City, one of Saudi Arabia’s most significant maritime cities, serves as the region’s capital. Jazan has a population of 1.4 million people, including 1.1 million Saudis and 260,000 non-Saudis, according to the General Authority for Statistics (2019).

This figure shows 13 administrative regions of Saudi Arabia. This figure is covered by the Creative Commons Attribution 4.0 International License.
Prior to the formation of modern Saudi Arabia, Jazan was ruled by the Idrisi State from 1906 to 1934, a rebellion movement against the Ottoman Empire led by its monarch, Muhammad Ibn Ali Al Idrisi (Bang 1996; Vassiliev 1999). Geographically, the Idrisi State spanned from Asir in the north to Midi (today in Yemen) in the south, with its geographic center being Jazan. The state had extended its influence to Al Hudaydah (present-day Yemen), which Imam Yahya, the Yemeni monarch, had retaken and annexed, along with a portion of Tihamah (an Arabian Peninsula coastal region). Fearing the Yemenis planned to incorporate Asir and Jazan into Yemen, the Idrisi State’s monarch entered into a deal with the Saudis in 1926, establishing a protectorate over the Idrisi State and granting the Saudis permission to annex Asir and Jazan. The Yemenis claimed that Asir belonged to Yemen, leading to a Saudi-Yemeni confrontation. On March 20, 1934, Ibn Saud and Imam Yahya signed the Al Taif Treaty, which placed Jazan, Asir, and Najran under Saudi rule, after two years of warfare along the southern frontier. In recognition of their independence and as a sign of amicable relations, the treaty declared that the peoples of Saudi Arabia and Yemen would be regarded as a single nation. Nevertheless, some tribal rulers escaped to Saudi Arabia (Vassiliev 1999; Wynbrandt 2010). It is therefore plausible to conclude that tribes of Yemenis that migrated to Saudi Arabia during that period and up to the present day had close interactions with Saudis, most likely with Jazanis. Thus, JA speakers are influenced by and thought of as sounding like Yemeni Arabic speakers due to the latter’s influence.
Other SA dialect speakers hold a negative view of JA. Part of this stigma appears to be related to how JA differs from other SA dialects and Classical Arabic. For example, unlike Najdi Arabic, which has two allophones of /r/—emphatic [r], which occurs before or after the vowel /u/, and non-emphatic [r], which occurs with /i/—JA has an unusual realization or distribution of /r/, which seems to contribute to its negative social evaluation.
Furthermore, contrary to Classical Arabic—which normally only includes one consonant in word-initial position, as in [ʔʊk.tʊb] “write!”—JA permits word-initial consonant sequences, as in [ktʊb] “write!” This raises the question of whether it is a salient feature of Jazani Arabic.
Such features may carry negative connotations among other speakers; thus, this paper examined the social aspects of these features, focusing on the following:
-
1.
Salient linguistic features of JA.
-
2.
Saudi speakers’ attitudes toward JA.
Saudi dialects
Alghamdi (2003) divided the 13 administrative regions of Saudi Arabia into five regional dialects (see Fig. 2):
-
1.
Najdi dialect (spoken in the central region).
-
2.
Hijazi dialect (spoken in the western region).
-
3.
Gulf Arabic dialect (spoken in the eastern region).
-
4.
Southern dialect (JA is a subregional dialect of this group).
-
5.
Northern dialect.

This figure shows the five main Saudi dialects.
Social stratification and dialect evaluation of SA
Regional dialects in Saudi Arabia are socially stratified. For instance, Najdi Arabic is a prominent and prestigious variety because it is spoken by the royal family and due to its linguistic conservatism and similarity to Classical Arabic (Aldosaree 2016; Omar 1975). Other scholars, such as Alqahtani (2014), have asserted that Najdi is the standard SA dialect. Hijazi Arabic is used for official government and business matters and is hence widely known in the Arabian Peninsula (Omar 1975). Hijazi Arabic, however, was referred to by Omar (1975) as a less “pure” Saudi dialect than Najdi because it incorporates linguistic elements, most notably consonants, from Palestinian, Egyptian, and Sudanese dialects. For instance, Hijazi Arabic, like Egyptian and Palestinian dialects, reflects Classical Arabic [θ] as [t] and [s], while [θ] is maintained in Najdi, eastern, southern, and northern dialects. Yet whereas the social standing of Najdi and Hijazi has been established, the social standing of northern and eastern SA dialects is less certain. Najdis have described the northern dialect of SA as hilarious yet monotonous, while comparing the eastern dialect to Bahraini Arabic and calling it a “heavy accent” with “big throats” to suggest sounding like a drawl (Alrumaih 2002). On the other hand, due to linguistic similarity to or influence from the nearby country, Yemen, southern SA dialects in general are socially stigmatized (Alrumaih 2002). In research on linguistic attitudes by Alrumaih (2002), the Najdi respondents noted similarities between Yemeni and southern SA dialects. The southern region was referred to by several responders as “Yemen” and “Sana’a” (the capital city of Yemen). Alrumaih did not address the issue of which characteristics of Yemen the participants were thinking of or whether they contained any of the characteristics listed below. Najdi participants also offered straightforward derogatory terms for southern dialects, such as “bad” and “unbearable.” These negative labels, according to Alrumaih, stemmed from Saudis’ negative views of Yemen and Yemeni immigrants.
General attitudes about JA
Due to social stratification, like other southern SA dialects, JA is socially stigmatized. The most common way that laypeople describe JA or southern SA speakers is by saying that they sound Yemeni. The researcher has personally noticed and attributed these attitudes to the phonetic characteristics, proximity, and quantity of migrants in the southern region, as Alrumaih (2002) attested as well. Given that Yemeni Arabic and JA share several characteristics, these findings and observations suggested that the same attitudes might also be applicable to JA. Similar to other countries, SA dialects close to the national borders, like JA, are sensitive to external linguistic (areal) traits from neighboring areas (Alrumaih 2002; Chambers and Trudgill 1998). Some attested features in JA and other southern dialects that have been documented are shared with Yemeni Arabic, such as word-initial clusters (Hamdi 2015; Ruthan et al. 2019). Furthermore, the definite article /ʔam/ “the” is found in JA, the Rijal Alma dialect, and Yemeni Arabic (Asiri 2009; Hamdi 2015; Watson 2011). Finally, the sound /r/, which Watson (2002) described as non-pharyngealized in Yemeni Arabic, may have a comparable property in JA. Additionally, Jazan is located on the northern border of Yemen and is thus home to many Yemeni migrants. I attribute some of these negative attitudes towards Yemen to its relative lack of wealth compared to Saudi Arabia. For instance, Saudi Arabia’s GDP in 2022 was USD 1.11 trillion, compared to Yemen’s GDP of USD 21.06 billion (World Bank 2023). Yemen also has a lower standard of education compared to nearby countries like Saudi Arabia (Zakout 2014). Yemen’s unfavorable socioeconomic factors thus likely cast a pall over JA. These attitudes are the result of cumulative stereotypes that have been linked to Yemen over time and are not merely a result of Saudi Arabia’s involvement in the war in Yemen. In the media, when a Jazani character is portrayed in a TV show, that character usually reflects these stereotypes and negative attitudes. For example, Shabab Al-Bomb (“Youth Energy”), a popular Saudi TV show, featured a character with a JA accent who always appeared uncivilized and uneducated. Another example is the satirical comedy TV shows Wifi and Hyperloop, in which security guards are depicted with a Jazani accent. Such depictions reflect stereotypes that Jazani people come from a low socioeconomic background.
The significance of this study derives from JA, folk and sociolinguistically speaking, being an understudied variety of SA, with its sociophonetics completely unexplored. Furthermore, the negative attitudes toward JA have thus far only been described anecdotally, never from a sociolinguistic perspective. Therefore, this study’s main goal was to document and analyze Saudi people’s attitudes toward JA, thereby contributing to the burgeoning literature on JA and other SA dialects.
Literature review
Language attitudes and folk linguistics
Since Labov (1966), sociolinguists have sought to uncover beliefs, stereotypes, and attitudes regarding languages and their varieties, such as English (e.g., Garrett et al. 2005; Hartley 1996; Preston 1986, 1993a, 1993b), French (Evans 2002), German (Adler 2021), Spanish (Fernández and Fernández, 2002), Arabic (e.g., Abdel-Rahman 2016; Chakrani 2015; El-Dash and Tucker 1975), and SA (e.g., Alajmi 2022; Aldosaree, 2016; Alhazmi 2018; Alrumaih 2002).
This attitude-based research is closely related to folk linguistics. Since Hoenigswald (1966), numerous researchers have adopted folk linguistics, including Niedzielski and Preston (2010) and Preston (1993b). Folk linguistics is interested in the opinions and impressions of non-linguists. Perceptual dialectology is a branch of folk linguistics that “represents the dialectologist’s-sociolinguist’s-variationist’s interest in folk linguistics” (Preston 1999, p. xxv). It investigates how common people perceive differences in language or dialect. Folk linguistics and perceptual dialectology both seem to be interested in the perceptions, beliefs, and attitudes of laypeople, but their methods are different (Preston 1999, 2011). Folk linguistics studies use questionnaires and fieldwork interviews, whereas perceptual dialectology investigations use maps or the matched-guise test. Another key difference between the two is that folk linguistics is used to elicit overt stereotypes and attitudes from laypeople, whereas perceptual dialectology is used to obtain covert attitudes. Preston (1986) pioneered the perceptual map-drawing task to examine how laypeople understood regional variations in English. Respondents are asked to sketch boundaries on maps where they believe different forms of speech are spoken (Preston 2002).
Among others, studies on language attitudes in different communities have shown that respondents like Michiganders (Preston 1993b), Oregonians (Hartley 1996), Egyptians (Abdel-Rahman 2016), and Najdis (Alrumaih 2002) rated themselves highly for correctness and pleasantness, displaying good linguistic security and in-group loyalty, whereas southern Indiana respondents (Preston 1993b) rated themselves low, exhibiting linguistic insecurity. Such patterns are attributed to cultural prejudices about a specific variety of a language and how stereotypes have an impact on how one group is viewed by another.
Studies on attitude are either based on a “conceptual mode presentation” (Garrett et al. 2005) or “perceptual mode presentation” (Campbell-Kibler 2007; Preston 1999). Both are effective and have shown that respondents can identify some linguistic characteristics of American, British, Australian, New Zealand, Canadian, Scottish, Irish, and Welsh versions of English without listening to audio files (Garrett et al. 2005). Respondents have identified some linguistic characteristics they were aware of, such as non-rhotic pronunciation and the pronunciation of right as “roight” and six as “sux.” In addition, respondents have used social traits like “intelligent,” emotional expressions like “ugly” and “friendly,” and cultural associations like “Jerry Springer” (a well-known talk show host) for US English.
When Standard Arabic is compared with other languages, such as English and French, the purpose of its use and the context (television, radio, school, and formal and religious speeches) determines the attitudes (El-Dash and Tucker 1975). Classical Arabic is preferred and has more positive attitudes than colloquial Egyptian or Egyptian English. In a similar vein, Arabic is preferred for the same purposes, French is the language used in self-expressions and cultural activities, and English is preferred in technology, medicine, science, business, and higher education (Shaaban and Ghaith 2002). In such studies, French and English are associated with modernity and seen as a medium for technology and science in postcolonial countries like Morocco, whereas Standard Arabic, Moroccan Arabic, and Berber only represent Arabic identity and culture and are seen as ineffective in an educational context (Bentahila 1983; Chakrani and Huang 2014).
In contrast, attitude research on colloquial Arabic varieties has not exhibited a stable preference for one dialect over others. Instead, there are differing attitudes toward colloquial Arabic dialects. This is attributed to the presence of different Arabic varieties belonging to different nationalities, such as Saudis, Moroccans, and Egyptians. Due to the geographic association with the birthplace of Islam and Arabic, SA is generally regarded as a prestigious variety. Due to its historical influence over Arab media, Egyptian Arabic is also considered a prestigious variety. Furthermore, 82.5 million people, the largest national population in the Arab world, speak Egyptian Arabic (Chakrani 2015; Sawe 2018). On the other hand, due to their contact and association with French, Berber, and African languages, Sudanese and Moroccan Arabic are considered low varieties with low prestige (Chakrani 2015).
In research on perceptual dialectology in the Arab world, respondents have classified Arabic dialects into five major groups: Egypt and Sudan, the Maghreb, Somalia, the Levant, and the Gulf (Abdel-Rahman 2016; Theodoropoulou and Tyler 2014). As a whole, respondents presented and concurred on a few labels connected to particular dialects. For example, the dialects of the Maghreb were described as “strange and difficult to understand,” the dialect of Qatar as “classy,” the dialect of Egypt as “brag,” the dialects of the Gulf—except Yemeni—as “similar,” and Sudanese as “lazy” (Theodoropoulou and Tyler 2014). Rating five different dialects—Kuwaiti, Iraqi, Egyptian, Syrian, and Tunisian—Egyptian respondents rated themselves and Egyptian Arabic highly on correctness, similarity to the respondents’ dialects, similarity to Modern Standard Arabic, and pleasantness, demonstrating that respondents were displaying linguistic security and in-group loyalty (Abdel-Rahman 2016).
Despite the social stratification of Saudi regional dialects, few studies have examined attitudes about them. In one, Alrumaih (2002) examined how Najdis perceived other dialects of SA. Alrumaih asked participants to mark boundaries on a blank map of Saudi Arabia where they believed different dialects were spoken, emulating Preston (1986). The respondents defined the same five regional dialect boundaries in Saudi Arabia. Najdis gave themselves high marks for correctness and pleasantness, indicating they felt linguistically secure. They rated the southern dialect poorly for correctness and pleasantness, below all other dialect averages, but gave it high marks for degree of difference.
Aldosaree (2016) conducted a study to investigate perceptions of the Najdi, Hijazi, and southern dialects of SA, or what he called “Janoubi” (the Arabic word for southern). Results showed that positive traits, such as “bravery,” “humility,” and “kindness,” were more frequently used by the respondents to describe their attitudes toward the southern speaker than were negative traits. Participants in the interviews, however, expressed unfavorable opinions about the socioeconomic standing of southern speakers. For instance, one interviewee claimed, “I have not seen a southern speaker hired as a minister in Saudi Arabia,” under the assumption that occupations are connected to dialect or social status. Thus, the study demonstrated that people who had a negative opinion of southern dialects were not limited to Najdi speakers, as in Alrumaih (2002). Speakers of other varieties of SA concurred with this view.
Such results beg the following questions. Why did Najdi respondents to Alrumaih’s (2002) survey regard southern dialects so negatively? Why did respondents to Aldosaree’s (2016) survey think southerners have a low socioeconomic status? Were these opinions influenced by a dialect’s linguistic and social characteristics from the South as a whole?
Alahmadi (2016) surveyed the opinions of urban Meccan Hijazi Arabic speakers regarding their own dialect. All respondents, regardless of sex, age, or education, generally had a positive opinion of their dialect and wanted to keep using it because it represented their identity and sense of community. As a result, Meccan respondents thought they should speak their dialect inside and outside of Mecca. The participants believed their dialect was an accurate representation of Hijazi culture. As an indication of affiliation, most preferred to be identified as speakers of the Hijazi dialect rather than speakers of any other dialect. In addition, they felt TV shows should feature their dialect. Alahmadi thus provided evidence of in-group loyalty, a social group’s positive attitudes toward its own dialect. The study, however, focused only on attitudes toward urban Meccan Hijazi Arabic.
In a broader study, Alhazmi (2018) asked participants to evaluate speakers of urban Bedouin Hijazi and Hadari Hijazi on a 5-point semantic differential scale divided into four evaluative scales: traditional, modern, serious, and similar to other Arabic dialects. The Hadari Hijazi speakers were seen as contemporary and similar to other Arabic dialects, whereas speakers of the urban Bedouin Hijazi were seen as traditional and serious. The respondents gave their own dialects higher ratings on scales that best described them, demonstrating strong in-group loyalty. In other words, while Hadari Hijazi speakers gave themselves high marks on the modernity scale, urban Bedouin Hijazi speakers gave themselves high marks on the traditional scale. Alhazmi concluded that the observed pattern was proof of a dialect dichotomy. That is, Hadari Hijazi was stereotypically associated with resemblance to other Arabic dialects and modernity, whereas urban Bedouin Hijazi was stereotypically associated with seriousness and tradition. Therefore, it was assumed that respondents in the current study would be able to compare Saudi and Yemeni dialects.
Perception of speech and sociophonetic variation
Numerous studies have found that phonetic variations in speech can convey social information and that non-experts can recognize a speaker’s regional dialect origin (Bush 1967; Preston 1999), ethnicity (Buck 1968; Purnell et al. 1999), and other personal characteristics (Campbell-Kibler 2007; Preston 1999). Concentrating on dialect identification, lay listeners use a range of grammar-related phenomena, including lexicon, morphology, and prosody, to recognize regional dialects (Barkat et al. 1999; Foreman 1999; Gooskens and Heeringa 2006). Nevertheless, the question remains whether non-linguistic experts can distinguish regional dialects of a language solely from its phonetics and phonology.
Dialect identification, in which participants are asked to identify the regional dialect of a speaker in the audio sample, is a common method in sociolinguistic research (e.g., Bush 1967; Preston 1999) that has proved successful in some studies because it shows that listeners can extract social cues and the source of regional dialects from audio files (e.g., Bush 1967; Campbell-Kibler 2007; Clopper and Pisoni 2004). However, this technique has not produced accurate results in dialect identification tasks in other studies (such as Boughton, 2006), as discussed later. Pertinent research on perceptions of languages and dialects is reviewed below.
One of the first studies to look at naïve listeners’ ability to distinguish between the countries of origin of various speakers based on actual speech samples was Bush (1967). Respondents were asked to identify the nationalities of speakers from the US, UK, and India based on recordings of them reading real and nonsense words and sentences. Listeners accurately identified national origin up to 90% of the time.
Recent research on the dialect origins of six American English speakers by Clopper and Pisoni (2004) confirmed that certain phonetic cues were connected to regional dialects. For example, in a perceptual categorization task, respondents were able to categorize speakers and rely on characteristics of the presented dialect, such as the non-rhotic accent from New England, the offglide centralization of the Northern /oʊ/ sound, and the backness of Northern /u/. Respondents also listed words such as “greasy” vs. “greazy” and “wash” vs. “warsh.” Other studies showed that respondents relied on and specifically mentioned some linguistic cues, such as monophthongization of /aj/ as a marked feature of southern speakers (Campbell-Kibler 2007).
Naïve listeners can recognize a speaker’s region of origin, according to the studies on dialect identification or categorization reviewed above. Regardless of accuracy rates, these results demonstrate that laypeople are aware of phonological variations in dialects and can assess the speech presented to them.
Few studies in the Arabic context have examined the perception of the dialect as a whole or the perception of particular linguistic features of some dialects. In a broader scope, Abdel-Rahman (2016) investigated how Arabic speakers perceived and whether they could distinguish between five Arabic varieties. Twenty Arab nationalities were represented by the respondents, who were asked to identify their country/region of origin after listening to five audio clips, one for each speaker from Egypt, Syria, Iraq, Tunisia, and Kuwait. These audio clips each had a different script and neither the linguistic (such as lexis) nor the metalinguistic (such as proper names) information was controlled. Among the varieties, Egyptian Arabic was the most accurately recognized (98.99%), while Tunisian Arabic was the least identified (38.65%).
Aldosaree (2016) asked participants to guess the speakers’ dialects based on what they heard in a dialect identification task. Overall, 78% of respondents were able to identify the southern speaker, 73% identified him as suburban, 80% identified him as working class, and 6% identified him as upper-class.
Alhazmi (2018) played recordings of five female and male readers of a script about the weather who were either urban Bedouin or Hadari Hijazi speakers, with either real or made-up surnames (since some names are stereotypically connected with various social groups). For urban Bedouin Hijazi, these voice samples had distinct sets of prominent phonological features, such as /ð/, /r/, /θ/, whereas /z/, /ɾ/, and /s/ are variants of the same three phonemes in Hadari Hijazi. Because of this, respondents were compelled to base their perceptions of the Hijazi speakers more on linguistic than metalinguistic data. In other words, the manipulation of the dialects had a greater impact on respondents’ responses in identifying the social category of the speaker than did the manipulation of the surnames. Thus, respondents used /z/, /ɾ/, and /s/ as linguistic cues to identify Hadari Hijazi speakers and /ð/, /r/, and /θ/ to identify urban Bedouin Hijazi speakers.
Methodology
The study employed an online survey designed by the researcher using Qualtrics (Qualtrics, 2005). The survey incorporated three tasks: an identification task, scaled attitude questions, and open-ended questions. The study also used four common approaches in the field. The first approach was a verbal guise test, which was used to present the voice samples in the identification task. This approach has proved effective and has thus been used extensively in this type of research (see Campbell-Kibler 2007; Preston 1999). The second approach was a dialect identification map task, which was used to identify the speakers’ regional dialect (see Bush 1967; Campbell-Kibler 2007; Clopper and Pisoni 2004). The third approach was a semantic differential scale, which was used to rate the speakers on a 6-point scale based on five traits to elicit participant attitudes. The fourth approach was the use of open-ended questions, eliciting implicit attitudes from indirect questions and explicit attitudes from direct questions. This approach has been effective at demonstrating respondent beliefs and attitudes (see Garrett et al. 2005).
Script and audio stimuli
I wrote the script about watching a soccer match. To avoid variation within the dialect and recordings, three educated male Jazani speakers from the same region, Samtah in Jazan, were intentionally selected to read the script. The readers, aged 32–34, were selected because they had similar voice registers. They were provided with the script and asked to read it in 15 sec in the Jazani dialect and record it in a quiet room to avoid background noise.
Procedures
The survey was distributed online using Qualtrics. Facebook was used to find respondents, who were recruited with help from the organizers of the Saudis in the USA Facebook page (253,753 followers in 2018), an essential social platform providing access to a large prospective sample. Data collection was carried out from October 2017 to January 2018. To guarantee that the respondents would be conversant in the dialect of interest, participation was restricted to Saudi nationals. I requested that each respondent take the survey on their own to prevent information sharing or outside influence. Respondents were not compensated for their voluntary participation.
Respondent sample
Out of the 382 respondents, 195 did not complete the survey, two opted not to take part after reading the consent page, and two identified themselves as not Saudis and were therefore eliminated. As a result, the data examined were based on responses from 183 Saudis, whose demographic information is shown in Table 1.
Survey tasks
Based on Preston (1986) with slight changes, I used a coded blank map of Saudi Arabia to reveal where the respondents thought speakers were from. However, instead of drawing boundaries, respondents were asked to click on a map. I used Qualtrics’ heatmap tool, which captured the location of each click/answer by respondents and identified them as belonging to one of the five regions (see Fig. 3). These divisions, however, were only visible to the researcher and not to the respondents. The tool automatically generated heatmaps from their clicks/answers. Unaltered audio recordings of three Jazani speakers were used, which the respondents listened to one at a time before identifying the speaker’s regional dialect. Since the study targeted explicit attitudes about JA, I used a vocally presented approach (in which audio recordings were presented to the respondents) rather than a conceptually presented approach (in which no audio recordings would be presented to the respondents, thus relying on respondents’ prior knowledge of a target language/dialect) (Alhazmi 2018).

This figure shows the divisions of the five main Saudi dialects.
Following Campbell-Kibler (2007), the respondents were asked to listen to each speaker and rate them on a 6-point semantic differential scale with features like slow vs. fast and educated vs. uneducated in order to find out how they felt about JA and what social traits they identified with JA speakers.
To uncover both implicit and explicit opinions about JA, I adopted a strategy akin to Garrett et al.’s (2005) method; the survey asked respondents open-ended questions to obtain more detailed information. Respondents were given an entry box with no word limit to write their answers freely. The researcher alone categorized responses into groups, such as “cultural association” and “comparison,” in order to quantify the qualitative responses.
Results and discussion
Dialect identification task
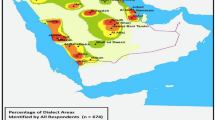
The heatmap in Fig. 4 demonstrates that Jazan and southwestern Saudi Arabia received the bulk of the replies (red), indicating that people were able to recognize the local dialect (Jazan) of the speakers regardless of identification varying among speakers. The heatmaps indicated that Speaker 3 was more frequently viewed as a Jazani than Speakers 1 and 2 despite the fact that all three speakers were mostly perceived as Jazanis. This variation in perception could be attributed to one sociophonetic characteristic (non-emphatic /r/) being more noticeable in the speech of Speaker 3 than the other two.

This figure shows that participants mainly chose Jazan to indicate Speaker 3’s dialect.
Following the presentation of the audio stimuli and the map, participants were instructed to enter their responses in a text entry box to verify whether they could recognize the speakers’ regional dialect. Responses were categorized as “Jazan” if the speaker’s city (Jazan) was mentioned and “southern” if the southern area or other southern cities were mentioned. Responses for the central, eastern, northern, and western areas followed the same methodology (see Fig. 5).

This figure shows how participants perceived Jazani speakers’ regional dialect.
Overall, Saudi speakers were able to identify the three speakers as being from Jazan, as seen by the distribution in Fig. 5. Unsurprisingly, the southern area had the second-highest number of replies, while the remaining responses were dispersed across the other regions.
Attitudinal rating task
Respondents were required to rate the speakers on a semantic differential scale ranging from 1 (the most negative) to 6 (the most positive) based on five traits: friendly, intelligent, fast, pleasant, and educated. These traits were chosen because they would be easy for laypeople to grasp and make judgments on, as they often come up in daily conversation to describe someone’s speech.
Table 2 shows a descriptive analysis with means and standard deviations of the differences between these traits. A lower mean denotes a more negative attitude, whereas a higher mean denotes a more positive attitude. Table 2 shows that Saudi speakers predominantly regarded Jazani speakers as friendly, while educated received the lowest rating. Friendly received the most positive attitudes, followed by smart, fast, and finally pleasant.
The analysis in Table 2 shows that all features had comparable means and nearly equal standard deviations, indicating that respondents’ perceptions of Jazani speakers on the measured scales were consistent. The study’s primary focus was on how respondents’ social profiles may have influenced their perceptions of Jazani speakers. Thus, each of the five traits are explored individually below in relation to the social variables and how they could have an impact on respondents’ attitudes.
Fifteen linear mixed effects regression models were performed to investigate the impact of three social factors—respondents’ dialect, age, and gender—on the ratings of the five dependent traits (educated, pleasant, fast, intelligent, and friendly).
The mixed effects regression analysis (see Table 3) revealed a statistically significant relationship between the respondents’ regional dialect and attitude toward Jazani speakers on the educated rating scale, displaying an estimate decrease from southern to Najdi speakers. This result supported the notion that Najdi speakers, who had the lowest mean and estimate, thought more negatively of Jazani speakers than southern speakers did. Negative attitudes by Najdi speakers were anticipated because Najdis are speakers of a more prestigious variety and were thus expected to feel more linguistically secure.
On the fast scale, among the three main (fixed) factors and models with interactions, age was the best predictor, as shown in Table 4. This shows that only respondent age appeared to influence the ratings. That is, older respondents were more likely than younger ones to perceive Jazani speakers as talking more quickly. In other words, attitudes toward Jazani speakers increased from the younger group to the older group on the fast scale. The regression analysis in Table 4 shows a statistically significant difference between the age groups with the fast rating values. The perception that younger speakers talk more quickly than older ones, however, makes this discovery predictable and interpretable (Jacewicz et al. 2009). As a result, I contend that younger speakers did not perceive JA speakers as talking as fast as older speakers did.
On the smart scale, out of the three fixed effects, regional dialect was the strongest indicator, as shown in Table 5. Southern speakers more frequently considered Jazani speakers as smart, whereas Najdi speakers were less likely to do so. Table 5 presents the best fit model after fitting various models to the data.
The best fit model comprised the smart scale rating values as the dependent variable and the respondents’ dialects as fixed effects, with a random intercept of respondent. The mixed effects regression analysis revealed that respondent regional dialect from all dialect groups had a statistically significant impact on attitudes about Jazani speakers on the smart rating scale. The impact, however, differed from group to group. The model revealed a slight increase from southern and other speakers to Najdi speakers, indicating a greater impact by Najdis. This indicated that Najdi speakers, who had the lowest mean and estimate, thought that Jazani speakers were less smart than southern speakers did. This also confirmed my prediction that Najdi speakers would evaluate JA speakers poorly due to their linguistic security. In contrast, southerners demonstrated in-group loyalty, evaluating JA speakers as much smarter than Najdi respondents did.
Again, regional dialect was the strongest indicator of the friendly scale. Results revealed that speakers of different dialects and southern speakers rated Jazani speakers as more friendly, whereas Najdi speakers were less inclined to do so. Speakers of other dialects had a somewhat more positive attitude than southern speakers. It was not surprising that southerners rated themselves as less friendly than others, indicating linguistic insecurity, because a similar pattern, but with correctness, has been observed in previous studies, such as with residents of southern Indiana who rated other states as more correct than themselves (Preston, 1993b). Table 6 reveals that respondent regional dialect had a significant effect on the friendly rating scale for Najdi speakers, a less significant effect for other dialect speakers, and no effect for southern speakers.
Overall, respondents’ dialects had a more significant effect on attitudes toward Jazani speakers with several traits than any other social factors. Southerners were more tolerant, as observed by their more favorable attitudes toward JA, whereas Najdi respondents were harsher, as evidenced by their more unfavorable attitudes. On the educated, smart, and friendly scales, Najdi respondents ranked Jazani speakers lower than southern dialects and speakers of other dialects. These findings supported the assumption that the dialect situation is socially stratified, which is represented in the various attitudes associated with different dialects that represent distinct social groupings. Some of these findings, particularly those pertaining to Najdi respondents, were consistent with Alrumaih (2002). Regarding the other social factors, the only effect from age was on the fast scale, indicating that older respondents slightly more frequently than younger respondents considered Jazani speakers to have faster speech. In contrast, gender had no influence on opinions about JA. Furthermore, there was no two-way or three-way interaction of social factors in any of the full models. These findings suggested that gender and, to a lesser extent, age had little to no effect on attitudes regarding JA.
With the influence of social variables on attitudes in scaled and quantitative questions presented above, the next section looks at non-scaled qualitative questions to learn more about Saudi speakers’ attitudes toward JA.
Qualitative attitude responses
I followed a content analytic approach to organize the responses. To quantify the qualitative data, I assigned responses to one of eight categories, modeled after Garrett et al. (2005): linguistic features, affective (positive or negative), status and social norms (cultured or uncultured), cultural association, comparison, and domestic comparison. Each of these categories is described below.
Table 7 provides a summary of the categorized responses. Responses were divided into two main categories, implicit and explicit attitudes. Answers to the survey questions that directly asked respondents to evaluate JA (e.g., “What impression comes to mind when you think of JA speakers?”) revealed respondents’ explicit attitudes. In accordance with these two groups, percentages went up or down.
To generate the percentages shown in Table 7, I calculated the number of comments for each category and summed the total number of comments for each encompassing category. For example, 26% of the 1078 terms provided by respondents indicated linguistic features, while only 1% denoted association.
Linguistic features
Most of the comments were categorized under linguistic features. As seen in Table 7, these comments formed 26% of all implicit replies, far more than any other category, and 48% of explicit replies, again far more than any other category. This result showed that respondents relied primarily on linguistic (in this case, phonetic) factors to identify and evaluate Jazani speakers. As previously stated, linguistic feature responses ranged from broad observations about pronunciation to more specific observations regarding segments, lexis, and speech rate.
Beginning with comments related to implicit attitudes, it was not surprising that word-initial consonant patterns in the stimuli attracted a lot of attention. The respondents did not directly address this issue but rather made an indirect reference to it by stating a vowel or consonant was missing, such as in [smaʕ] and [bkar]. According to respondents, Jazani speakers spoke more quickly than speakers of other dialects because of the presence of such linguistic features in JA.
The variable /r/ was also a significant salient feature for all three speakers in the implicit attitude category. The letter/sound /r/ was called “moraqqaqah,” or non-emphatic [r]. It is interesting to note that Speaker 3 was connected to non-emphatic [r] 88% of the time, Speaker 1 8% of the time, and Speaker 2 4% of the time. This demonstrated that Speaker 3 had a salient /r/ production, supporting the claim that /r/ would be a strong predictor of speaker dialect and illuminating why Speaker 3 was thought to sound the most Jazani. Instead of providing options for respondents to pick from, I relied on open-ended responses. In an exploratory investigation, this approach is appropriate to avoid limiting the possible answers and to collect as much data as feasible. However, it does not ensure that participants will comment on something. As a result, it was uncertain whether there was true heterogeneity in the production of /r/ in Jazani speech or if respondents decided to mention it once and the comments just happened to pertain to Speaker 3.
Surprisingly, other comments in the implicit attitudes brought up the segments /ħ/ and /dʒ/. Some perceived Saudi speakers of southern dialects to produce /ħ/ and /dʒ/ differently from other Saudi dialects. Two words from the audio stimuli, [rɪħna] “we went” and [madʒnunah] “crazy,” were mentioned by one respondent as being pronounced with what he called “southerners’ /ħ/ and /dʒ/.” The same respondent explained this by referring to the Arabic grammatical term “kasrah,” which is a high short vowel that comes before or after the consonant /ħ/. This justification supports the assertion in the next paragraph regarding the “sharpness of /ɡ/.” I could deduce that vowels were a trigger for these segments to be perceived as salient in JA. It was not clear if /dʒ/ fell under this attribution. Another possibility is that /dʒ/ was subject to change and hence realized as /ʒ/, as in Hijazi Arabic (Omar, 1975). However, this is simply a supposition and would demand additional phonetic research, which was outside the scope of this study.
Additionally, for several respondents, the [o] in the word [ʕɪndoh] “at his/he has” was another indication of JA in the implicit attitude data. However, it led several respondents to believe the speakers were Najdi, specifically Qassimis. This was understandable given that Qassimi Arabic employs the same vowel and hence Qassimi speakers pronounce the word in the same way Jazani speakers do, as opposed to other Saudi dialects in which the word [ʕɪndoh] is realized as [ʕɪndah] with [a].
In the explicit attitudes, other linguistic features, notably the segment /ɡ/, were mentioned in the comments. “Jazani speakers have their own way of pronouncing /ɡ/,” one respondent observed, and another clarified that /ɡ/ in Jazani speech was spoken with “sharpness.” There were no occurrences of /ɡ/ in the stimuli. Rather, respondents mentioned this point in light of their prior knowledge of JA. Only in answer to the explicit attitudes question “What are some salient linguistic features pronounced differently in JA?” did these comments appear. The vowel that comes after the letter “g” may be responsible for what respondents described as a sharpness of /ɡ/. I assume that the [ɪ] makes /ɡ/ “sharp” in words like [ɡɪdim] “old.” Other respondents made inaccurate generalizations about Yemeni Arabic’s use of /ɡ/ rather than /dʒ/ in JA. For instance, in JA, “camel” is pronounced [dʒamal], whereas in Taizi Yemeni Arabic, it is [ɡamal].
With respect to lexis and morphemes, the word [maho] “how about?” and the definite article [ʔam] “the” were purposefully left out of the audio stimuli. Nonetheless, [maho] was mentioned in both the implicit and explicit attitude categories, while [ʔam] was mentioned only in the explicit attitude category, suggesting they are well-known linguistic elements linked with JA.
Regarding phonetic cues, a few respondents thought nasality was a characteristic of JA. Some commented that Jazani speakers had “thin voices,” most likely referring to high-pitched voices, while others noted that the rhythm of the language was different, maybe in an effort to indicate different stress patterns and intonation. These comments appeared in both implicit and explicit attitude categories.
Affective categories
Table 7 demonstrates a consistent pattern of more affective comments being positive (15%) and negative (9%) in the implicit attitude category than positive (8%) and negative (5%) affective comments related to explicit attitudes. This showed that when respondents were not aware of the dialect they were judging, they felt freer to voice their opinions, and when they were aware of the dialect, they were more sensitive. This would account for why there are generally more comments in Table 7’s implicit attitude column (over 1000) than in the explicit attitude column (only 284). Some responses confirmed this, such as “I think it’s a shame to criticize people’s dialects” and “All dialects on the eye and head,” meaning all dialects are appreciated.
Numerous other comments were given by respondents to assess Jazani speakers favorably and unfavorably. For instance, positive affective comments included “simplicity,” “pleasant,” “friendly,” and “calm,” whereas negative affective comments included “harsh,” “weird,” “annoying,” and “underestimated.”
Culture
In the implicit attitude category, positive culture comments attracted the second-largest proportion (23%), but in the explicit attitude category, this proportion sharply dropped to 5%, as seen in Table 7. This was in line with the pattern in affective comments, which showed a decrease in comments with explicit attitudes. The assumption that respondents were sensitive when judging certain dialects, especially when they were named, was borne out once more by this pattern. Examples of positive comments in the culture category were “smart,” “social,” “comprehensible,” and “confident.” In a similar vein, negative comments in the culture category were higher (11%) in the implicit attitude category, whereas they were lower (6%) in the explicit attitude category. Negative comments comprised the words “uneducated,” “careless,” “stupid,” and “influent.”
Cultural associations
In terms of implicit attitudes, cultural associations obtained the lowest percentage (1%) of any category. Contrary to affective and culture comments, however, explicit attitudes in cultural association comments rose to 6%. This was unsurprising because respondents would be more likely to make cultural comments if they were made aware of the speakers’ cultural context. In this category, responses centered around symbols or icons of Jazani culture and nature, such as the “jasmine,” “mountains,” and “mango” for which Jazan is famous, or the typical Jazani attire, which consists of a blouse, wizrah (similar to a skirt), and a floral and basil headpiece. Other comments were related to names like Abdu, which is a common name among Jazanis. Mohammed Abdu, a well-known Jazani singer, was brought up in this context to highlight how emblematic of Jazan he is and how he immediately springs to mind when considering Jazani speakers.
Comparison
Comparisons were consistently made in response to the qualitative questions. Although “Emirati” and “Omani” comparisons were made, they were only mentioned a few times (once or twice), with the primary emphasis being on “Yemeni.” Examples of some comments related to Yemeni Arabic were “He seemed to have a Yemeni accent,” “He sounded like a Yemeni speaker,” “He is influenced by the Yemeni dialect,” and “He pronounced X word in a Yemeni way.” Yemeni Arabic was mentioned 106 times, with “Yemen” appearing 60 times in the implicit attitude category and 46 comments in the explicit attitude category responding to direct questions concerning JA.
Socioeconomic and occupational status
It was expected that Jazani speakers would be associated with low-paying occupations, including security, the military, and cashiers. For each speaker, a single question was posed, asking what respondents thought of the speaker’s socioeconomic status, level of education, and occupation. Most of the time, respondents just responded to one section of the question and overlooked the others. As a result, the socioeconomic status and level of education of the speakers were rarely addressed in the responses.
In terms of the speaker’s occupation, most of the respondents guessed “student.” This might be attributable to the topic, which suggested that the speakers were youthful and engaged in watching soccer matches, leading respondents to picture speakers as students. While some respondents specifically stated the occupation of the speakers, others just stated “employee.” Such general comments on occupation were useless as they did not provide specific details that could be used to produce quantitative data. Important comments are highlighted below, particularly jobs associated with misconceptions about Jazani people as coming from a low socioeconomic background.
Although stereotypes about Jazanis seem to be changing, some expected low-income jobs associated with Jazani people still appeared in the responses, such as salesman, cashier, security guard, soldier, mechanic, and animal breeder. In other words, the old misconception depicts Jazanis as uneducated, whereas the new stereotype depicts them as hardworking, strict, and educated. This perception was evident in two comments: “To my knowledge, Jazanis are known for their keenness to get the highest degrees” and “What comes to my mind is that Jazan is a city of culture and knowledge.” Nevertheless, the old stereotypes co-exist with the new ones and were evident in the following comments: “a job has nothing to do with speaking or delivering a speech” and “I can’t know his job from this recording; however, I can exclude some jobs. Therefore, I think he is not an educated or specialized person, and so I don’t think he is an academic or a teacher or relating to jobs that require education.” These comments suggested that some respondents held negative attitudes toward the speakers’ dialect, which influenced their views on the kinds of jobs that should be appropriate for them.
Conclusion
This study’s main goals were finding socially significant sociophonetic characteristics of JA and examining Saudis’ views of JA. The findings demonstrated that word-initial consonant sequences and /r/ were important sociophonetic characteristics, while respondents’ age and dialect had an impact on their attitudes. I conducted an online survey using an identification task, attitudinal scales, and open-ended questions. To design this survey, I first wrote a Jazani script that three Jazani speakers recorded. These recordings were played to the 183 respondents, who came from different regions of Saudi Arabia. Notable lexical, morphological, and syntactic JA features were absent from all of the recordings. Respondents listened to each speaker once and determined their region of origin. Then, each speaker was scored on a 6-point semantic differential scale for five social traits, such as smart and pleasant (to listen to). To gather additional useful information, respondents were then asked a few open-ended questions about the speakers and JA.
In the identification task, respondents were able to identify the speakers’ region of origin (Jazan) based solely on sociophonetic input. Respondents’ dialects significantly influenced their attitudes toward Jazani speakers on the smart, educated, and friendly scales. Najdis had more unfavorable attitudes toward JA than southerners did. These findings corresponded with the notion that Saudi society is socially stratified, with opinions toward other social groups’ dialects and speech varying across social groups. The respondents’ age also had an impact on their perception of the speaking rate of Jazani speakers, as older respondents were more likely than younger respondents to assume that Jazani speakers spoke quickly. The respondents’ gender had no impact on their opinions about JA. An examination of the qualitative data revealed that respondents were able to identify linguistic and, more significantly, sociophonetic characteristics of JA. The high frequency of comments on linguistic characteristics showed that respondents largely depended on phonetic characteristics to recognize and rate Jazani speakers. Many linguistic traits were noted in the comments, especially /r/, word-initial consonant sequences, and [ʔam] (which was not in the script but is a well-known characteristic of JA). Although they appeared to feel free to express their implicit attitudes but not their explicit attitudes, respondents appeared to be sensitive in how they expressed their attitudes. Symbolic and iconic representations of Jazani culture and popular individuals like Mohammed Abdu were used in the cultural association comments. Open-ended survey responses validated earlier anecdotal observations, including comments such as the speakers sounding like Yemenis. Furthermore, the comparison with Yemeni speakers was obtained from respondents’ interpretation of the phonetics of the audio stimuli, not just from their prior knowledge of Yemen’s proximity to southern Saudi Arabia, contradicting previous studies (e.g., Aldosaree 2016; Alrumaih 2002). Finally, Jazani speakers tended to be associated with low-paying occupations.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Abdel-Rahman M (2016) I speak better arabic: Arabic native speakers’ perception of Arabic dialects. PhD Dissertation, University of Mississippi
Abu-Haidar F (1989) Are Iraqi women more prestige conscious than men? Sex differentiation in Baghdadi Arabic. Lang Soc 18:471–481
Abu-Mansour MH (1987) A nonlinear analysis of Arabic syllabic phonology, with special reference to Makkan. Unpublished PhD Thesis, University of Florida
Adler A (2021) Language, or dialect, that is the question. How attitudes affect language statistics using the example of Low German. Languages. https://doi.org/10.3390/languages6010040
Al-Azraqi M (1998) Aspects of the syntax of the dialect of Abha (South-West Saudi Arabia). Doctoral Thesis, Durham University
Al-Hakami AY (2023) A mixed-methods investigation of saudis’ attitudes towards and experiences with contemporary Saudi Arabic. Dissertation, University of Leicester
Al-Masri M, Jongman A (2004) Acoustic correlates of emphasis in Jordanian Arabic: preliminary results. Society 4:96–106
Al-Mozainy HQ (1981) Vowel alternations in a Bedouin Hiiazi Arabic dialect: abstractness and stress. Ph.D. Thesis, University of Texas
Al-Rojaie Y (2013) Regional dialect leveling in Najdi Arabic: the case of the deaffrication of [k] in the Qaṣīmī dialect. Lang Var Change 25:43–63
Alahmadi SD (2016) Insight into the attitudes of speakers of urban Meccan Hijazi Arabic towards their dialect. Adv Lang Lit Stud 7:249–256
Alajmi NM (2022) Social attitudes towards bedouin and sedentary dialects in Central Najd. World J Engl Lang 12:343–351
Albirini A (2016) Modern Arabic sociolinguistics: diglossia, variation, codeswitching, attitudes and identity. Routledge, New York
Aldosaree O (2016) Language attitudes toward Saudi dialects. California State University, Long Beach
Alghamdi M (2003) Saudi main dialects. http://www.mghamdi.com/SaudiD.jpg. Accessed 13 Mar 2017
Alhazmi L (2018) Perceptions of Hijazi Arabic dialects: an attitudinal approach. Unpublished Doctoral Thesis, University of Sheffield
Alqahtani MSM (2014) Syllable structure and related processes in optimality theory: an examination of Najdi Arabic. Unpublished Doctoral Thesis, Newcastle University
Alrumaih AA (2002) Najdi perceptions of Saudi regional speech. Thesis, Michigan State University
Asiri YM (2009) Remarks on the dialect of Rijal Alma’(South-west Saudi Arabia). Wien Z Kunde Morgen 99:9–21
Bale J (2010) Arabic as a Heritage language in the United States. Int Multiling Res J 4:125–151
Bang A (1996) The Idrisi State of Asir 1906-1934: Politics, religion and personal prestige as state-building factors in early twentieth century Arabia. Hurst & Company, London
Barkat M, Ohala J, Pellegrino F (1999) Prosody as a distinctive feature for the discrimination of arabic dialects. Paper presented at the 6th European conference on speech communication and technology, Eötvös Loránd University, Budapest, 5-9 September 1999
Bentahila A (1983) Language attitudes among Arabic-French Bilinguals in Morocco. Multilingual Matters, Exeter, England
Bosli R, Cahill L (2022) The analysis of coda clusters in Jizani Arabic: an OT perspective. Int J Engl Linguist 12:89
Boudlal A (2001) Constraint interaction in the phonology and morphology of Casablanca Moroccan Arabic. Doctorat d’Etat Thesis, Mohammed V University, Rabat, Morocco
Boughton Z (2006) When perception isn’t reality: accent identification and perceptual dialectology in French. J Fr Lang Stud 16:277–304
Broselow EI (1976) The phonology of Egyptian Arabic. Ph.D. Dissertation, University of Massachusetts
Buck JF (1968) The effects of Negro and White dialectal variations upon attitudes of college students. Speech Monogr 35:181–186
Bush CN (1967) Some acoustic parameters of speech and their relationships to the perception of dialect differences. TESOL Q 1:20–36
Campbell-Kibler K (2007) Accent, (Ing), and the social logic of listener perceptions. Am Speech 82:32–64
Chakrani B (2013) The impact of the ideology of modernity on language attitudes in Morocco. J North Afr Stud 18:431–442
Chakrani B (2015) Arabic interdialectal encounters: investigating the influence of attitudes on language accommodation. Lang Commun 41:17–27
Chakrani B, Huang JL (2014) The work of ideology: examining class, language use, and attitudes among Moroccan university students. Int J Biling Educ Biling 17:1–14
Chambers JK, Trudgill P (1998) Dialectology. Cambridge University Press, Cambridge
Clopper CG, Pisoni DB (2004) Some acoustic cues for the perceptual categorization of American English regional dialects. J Phon 32:111–140
Durvasula K, Ruthan MQ, Heidenreich S, Lin YH (2021) Probing syllable structure through acoustic measurements: case studies on American English and Jazani Arabic. Phonology 38:173–202
El-Dash L, Tucker GR (1975) Subjective reactions to various speech styles in Egypt. Int J Socio Lang 1975:33–54
Essa A (2022) Left dislocation in Arabic dialects: new evidence from Jizani Arabic. Degree of Master, California State University
Evans BE (2002) Attitudes of Montreal students towards varieties of French. In: Long D, Preston DR (eds) Handbook of perceptual dialectology. John Benjamins Publishing Company, Amsterdam & Philadelphia, p 71–93
Fernández JM, Fernández FM (2002) Madrid perceptions of regional varieties in Spain. In: Long D, Preston DR (eds) Handbook of Perceptual Dialectology. John Benjamins Publishing Company, Amsterdam & Philadelphia, p 295–320
Foreman CG (1999) Dialect identification from prosodic cues. In: Ohala J, Hasegawa Y, Ohala M, Granville, Bailey A (eds) ICPhS’99: Proceedings of The XIVth International Congress of Phonetic Sciences. 14th International Congress of Phonetic Sciences, San Francisco, August, 1999. Congress organizers at the Linguistics Department, Berkeley, p 1237
Garrett P, Williams A, Evans B (2005) Attitudinal data from New Zealand, Australia, the USA and UK about each other’s Englishes: recent changes or consequences of methodologies? Multilingua 24:211–235
General Authority for Statistics (2019) Residents distribution in administrative regions according to sex and nationality, Riyadh. https://www.stats.gov.sa/en. Accessed 24 Dec 2019
Gooskens C, Heeringa W (2006) The relative contribution of pronunciational, lexical, and prosodic differences to the perceived distances between Norwegian dialects. Lit Linguist Comput 21:477–492
Hamdi S (2015) Phonological aspects of Jizani Arabic. Int J Lang Linguist 2:91–94
Hartley L (1996) Oregonian perceptions of american regional speech. M.A. Thesis, Michigan State University
Hoenigswald HM (1966) A proposal for the study of folk-linguistics sociolinguistics. Sociolinguistics 16:16–26
Ingham B (1994) Najdi Arabic: central Arabian. John Benjamins Publishing Co, Amsterdam
Jacewicz E, Fox RA, O’Neill C, Salmons J (2009) Articulation rate across dialect, age, and gender. Lang Var Change 21:233–256
Khattab G, Al-Tamimi F, Heselwood B (2006) Acoustic and auditory differences in the/t/-/T/opposition in male and female speakers of Jordanian Arabic. In: Boudelaa S (ed.) ASAL’16: Perspectives on arabic linguistics XVI. 16th annual symposium on Arabic Linguistics, Cambridge, March, 2002. Vol 16. John Benjamins Publishing Company, Cambridge, p 131
Labov W (1966) The social stratification of English in New York city. Center for Applied Linguistics, Washington DC
Niedzielski NA, Preston DR (2010) Folk linguistics. Walter de Gruyter, Berlin
Omar MK (1975) Saudi Arabic–urban Hijazi dialect: basic course. Foreign Service Institute, Michigan
Preston DR (1986) Five visions of America. Lang Soc 15:221–240
Preston DR (1993a) Folk dialectology. In: Preston DR (ed) American dialect research. John Benjamins Publishing Company, Amsterdam/Philadelphia, p 333–377
Preston DR (1993b) Two heartland perceptions of language variety. In: Frazer TC (ed) ‘Heartland’ english: variation and transition in the American midwest. University of Alabama Press, Tuscaloosa, p 23–47
Preston DR (1999) Handbook of perceptual dialectology. John Benjamins Publishing Company, Amsterdam
Preston DR (2002) Language with an attitude. In: Chambers JK, Trudgill P, Schilling-Estes N (ed) The handbook of language variation and change. Blackwell, Malden, p 40–66
Preston DR (2011) Perceptual dialectology: nonlinguists’ views of areal linguistics. Walter de Gruyter, Berlin
Purnell T, Idsardi W, Baugh J (1999) Perceptual and phonetic experiments on American English dialect identification. J Lang Soc Psychol 18:10–30
Qualtrics (2005) Provo, Utah. https://www.qualtrics.com
Ruthan M (2020) Aspects of Jazani Arabic. PhD Dissertation, Michigan State University
Ruthan MQ, Durvasula K, Lin YH (2019) Temporal coordination and sonority of Jazani Arabic word-initial clusters. Proc Annu Meet Phonol 7:1–7
Sawe BE (2018) Arabic speaking countries. In: Society. WorldAtlas. Available via https://www.worldatlas.com/articles/arabic-speaking-countries.html. Accessed 29 Sep 2023
Shaaban K, Ghaith G (2002) University students’ perceptions of the ethnolinguistic vitality of Arabic, French and English in Lebanon. J Socioling 6:557–574
Shamakhi M (2016) Scopal relationship of negation and quantifiers in jizani arabic. California State University, California
Theodoropoulou I, Tyler J (2014) Perceptual dialectology of the Arab world: a principal analysis. Al-ʿArabiyya 47:21–39
Vassiliev A (1999) The history of Saudi Arabia. Choice Rev Online 36(7):4062–4062. https://doi.org/10.5860/choice.36-4062
Watson JC (2002) The phonology and morphology of Arabic. Oxford University Press, Oxford
Watson JC (2011) South Arabian and Yemeni dialects. Salford working papers in linguistics and applied linguistics, pp 27–40
World Bank (2023) Saudi Arabia GDP, Washington. https://data.worldbank.org. Accessed 29 Sep 2023
Wynbrandt J (2010) A brief history of Saudi Arabia (2nd ed.). Infobase Publishing, New York
Youssef I (2013) Place assimilation in Arabic: contrasts, features, and constraints. Thesis for PhD, University of Tromsø
Zakout W (2014) Raising the quality of education in Yemen. World Bank Blogs. https://blogs.worldbank.org/arabvoices/raising-the-quality-of-education-in-yemen. Accessed 28 Sep 2023
Acknowledgements
This study was supported via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2024/R/1445).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Ethical approval
The study was approved by the Human Research Protection Program (HRPP) and Institutional Review Board (IRB) at Michigan State University. The HRPP and IRB made sure that all ethical standards were met (Approval No. IRB# x17-984eD).
Informed consent
Online consent was obtained from the participants to use their responses for research purposes. The participants agreed, by clicking the “Agree” button, on the following endorsement: “I have read and understood the provided information (i.e., research purpose) and have had the opportunity to ask questions. I understand that my participation is voluntary and that I am free to withdraw at any time, without giving a reason and without cost.”
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ruthan, M.Q. Salient sociophonetic features, stereotypes, and attitudes toward Jazani Arabic. Humanit Soc Sci Commun 11, 330 (2024). https://doi.org/10.1057/s41599-024-02832-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1057/s41599-024-02832-w

{kind=link}