
Abstract
Low-cost air quality sensors (LCS) are increasingly used to complement traditional air quality monitoring yet concerns about their accuracy and fitness-for-purpose persist. This scoping review investigates topics, methods, and technologies in the application of LCS networks in recent years that are gaining momentum, focusing on LCS networks (LCSN) operation, drone-based and mobile monitoring, data fusion/assimilation, and community engagement. We identify several key challenges remaining. A major limitation is the absence of unified performance metrics and cross-validation methods to compare different LCSN calibration and imputation techniques and meta-analyses. LCSN still face challenges in effectively sharing and interpreting data due to a lack of common protocols and standardized definitions, which can hinder collaboration and data integration across different systems. In mobile monitoring, LCS siting, orientation, and platform speed are challenges to data consistency of different LCS types and limit the transferability of static calibration models to mobile settings. For drone-based monitoring, rotor downwash, LCS placement, flight pattern, and environmental variability complicate accurate measurements. In integrating LCS data with air quality models or data assimilation, realistic uncertainty quantification, ideally at the individual measurement level, remains a major obstacle. Finally, citizen science initiatives often encounter motivational, technological, economic, societal, and regulatory barriers that hinder their scalability and long-term impact.
Similar content being viewed by others
Introduction
Air pollution is a global environmental challenge with negative impacts on human health, ecosystems, and quality of life1,2,3. The conventional approach for air quality monitoring relies on networks of expensive, high-quality, fixed-reference monitoring stations. Reference monitoring networks are sparse due to the high cost, complexity of the equipment, and need for trained operators4. However, for more than a decade, researchers have investigated the potential of low-cost sensors (LCS) to fill in the gaps and expand participation in air quality monitoring5. The widespread deployment of LCS, characterized by their affordability (<USD 2,500 as defined by the US EPA Sensor Toolbox6), portability, and ease of use, has resulted in a new era in air quality monitoring and management.
The adoption of LCS, has empowered a range of actors, including citizens, researchers, and policy-makers, to actively engage in data collection and analysis, even in low- and middle-income countries7,8. The cost of LCS can vary depending on the pollutant species and the manufacturing process, as well as the features included (i.e., inlet drier, solar panels, software, etc.). Existing LCS deployments have made it possible to gather real-time-high-resolution data9, improving our understanding of air pollution patterns at local scales. At street, city, regional, and even global scales, LCS measurements can have benefits for validating atmospheric composition models10.
Individuals and communities have deployed LCS in various environments, both indoors and outdoors, to collect data on air pollutants such as particulate matter (PM)11, volatile organic compounds, and gases such as O3 (Ozone) and NO2 (Nitrogen dioxide)12,13. LCS have also been integrated into smart city initiatives14,15, environmental monitoring networks16,17, and public health systems5,18,19. The data obtained from these LCS can inform evidence-based decision-making, policy formulation, and the development of targeted interventions to improve air quality14.
However, despite the many advancements, uncertainties and limitations of LCS remain15. These include concerns relating to data accuracy, cross-sensitivity to ambient pollutants, sensor drift, data standardization, and interoperability between different LCS providers20. The most important LCS limitation that is extensively highlighted in literature is their lower accuracy compared to reference instruments. LCS must be calibrated for their data to be used robustly. Field calibration, or the correction of LCS, occurs by co-locating one or more sensors with a reference monitor for an extended time period which can range from ~ weeks to months, and then developing a model to correct the LCS so that the measurements closely represent those from the reference monitor. The logistics of deploying and calibrating large LCS networks (LCSN) can be challenging. Finally, the short operating lifetimes of these instruments (typically between 2 months to 2 years) require them to be replaced often18.
An additional, equally important but often overlooked aspect is the absence (at least until recently in the European Union) of a standardized framework for evaluating LCS performance. In Europe, CEN (European Committee for Standardization) has published standards for gases, CEN/TC 264/WG 42, and for particles, CEN/TS 17660-2:2024, which aim at simplifying the use of LCS as part of the regulatory framework resulting from the Clean Air for Europe Directive 2008/50/EC21, and its sub-directives. However, a new updated directive was recently put in place (2024/2881) that specifies that LCS measurements can act as indicative. Indicative measurements can supply sufficiently reliable data for assessing compliance with limit values, target values, critical levels, and alert or information thresholds. They can also provide the public with relevant information, potentially helping to reduce the number of reference mointoring stations needed.
Due to the rapid advancements and increasing interest in the application of LCS, numerous review papers have been published on different aspects of LCS technology. These papers cover field and laboratory sensor applications and development4,5,7,19,22,23,24,25,26,27,28,29, field calibration30,31,32,33 techniques, data quality, and validation8,15,34,20, protocols, and enabling technologies35, air quality data crowd-sourcing14,29,36, and drone-based measurements37,38.
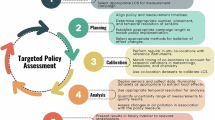
In this paper, we focus on reviewing some of the most emergent LCS applications found in the literature and use our domain knowledge and expertise to identify and explore the “evolving trends” in the application and operation of LCS. We identify key challenges that need to be overcome to guide future LCS research. By “evolving trends” in the application of LCS, we refer to new developments, methodologies, or shifts in how these sensors are used or perceived in environmental monitoring (Fig. 1). We selected the following trends that are currently evolving: (1) LCS operational data quality evaluations via advanced computing technologies (Industry 4.0), (2) LCS in mobile air quality monitoring (ground and aerial), (3) LCS data integration with air quality models and remote sensing datasets, and (4) LCS in citizen science.

On the left: available methods and technologies for monitoring and estimating air quality. On the right: established and evolving trends in the application of LCS, in combination with the methods and technologies presented on the left side.
Fixed LCSN data integration with regulatory environmental monitoring networks
Direct field calibration
Typically, the deployment of an LCSN begins with co-locating some sensors (one or more), or all if the fleet is small, alongside a high-precision reference instrument for a specific period, often 1–4 weeks39, depending on the measurement frequency, to develop field calibration functions. The co-location can involve either circulating a mobile reference station between sites or positioning sensors near a fixed reference station before relocating them to their final monitoring locations, where ongoing access to reference data is generally unavailable. Such direct, site-specific calibration forms the foundation of improving the accuracy of LCS, as demonstrated by Barcelo-Ordinas et al.40, De Vito et al.41, Ferrer-Cid et al.42, and Bisignano et al.43. However, reliance on initial baseline calibration alone has inherent limitations, including vulnerability to sensor drift or changing local conditions that could render the initial calibration insufficient. As networks expand, and/or become mobile44, maintaining performance often necessitates integrating direct co-location with proxy-based, transfer, or network-wide calibration strategies.
Proxy-based field calibration
When access to fixed reference stations is limited or infeasible, proxy-based calibration provides an adaptable alternative for extending calibration coverage. This semi-blind approach31 relies on using one or more mobile LCS as temporary proxies: first, co-locating the proxy sensor with a reference station to obtain a valid calibration function, then relocating it sequentially to other uncalibrated units to transfer the calibration indirectly. This chain or node-to-node method can be repeated across multiple sites, forming a practical solution for sparse reference networks or challenging terrain. Studies by Kizel et al.45, Maag et al.46, Sá et al.47, and Vajs et al.48 demonstrate the feasibility and operational benefits of proxy-based strategies under real-world conditions. However, these methods can be sensitive to cumulative error propagation if the chain is extended too far without periodic re-anchoring to a high-quality reference. Consequently, proxy-based calibration is best applied in combination with direct or periodic co-location to maintain accuracy across the network.
Transfer-based field calibration
Transfer-based calibration extends the use of an initial site-specific calibration function to other sensors of the same type deployed under comparable conditions. For the successful deployment of this strategy, similar climatological and source contexts49,50,51, and low intra-sensor variability52 are important in enabling a model trained at one location to be applied elsewhere with minimal additional reference data. Studies by Cheng et al.53, Laref et al.54, Liu et al.55, Cui et al.56, Villanueva et al.57, and DeSouza et al.58 illustrate this approach and show its efficiency when full co-location is impractical or prohibitively costly. Transfer calibration can reduce operational effort and costs; however, its performance depends strongly on the similarity between training and deployment environments52. Mismatches in pollutant mix, weather patterns, or local sources can degrade model accuracy, requiring periodic adaptation or supplemental local correction49,51.
A more generalized variant, global or multi-site transfer calibration (Fig. 2), aims to develop calibration models that remain robust across diverse geographic contexts and temporal conditions59. Instead of relying on a single reference site, this strategy combines data from multiple co-location pairs to build an aggregated model capable of capturing wider spatio-temporal variability. For example, Miquel-Ibarz et al.60, Chu et al.61, Vikram et al.62, De Vito et al.63, Solórzano et al.64, Bagkis et al.65, and Villanueva et al.57 demonstrate how global calibration frameworks can extend the validity of local LCSN, and at the same time, reduce the frequency of site-specific recalibration. Despite their scalability, these approaches require sufficiently diverse and representative training datasets to minimize location-specific biases. In practice, global models are most effective when paired with adaptive updates to account for emerging concept drift or unexpected local deviations.

Given N co-located pairs and six distributed air quality low-cost sensors (LCS), the data are retrieved into a central server. There, a global calibration function is learned with machine learning, trained on the combined dataset from all the co-located pairs, and the function is then applied to the six LCS. We give the credit to223 and the following: https://www.wunderground.com/sensors, from those, some images are used and modified to generate this figure.
Connectivity-based field calibration
Connectivity-based approaches integrate the physical and functional relationships between sensor nodes into the calibration process, often using graph theory to represent how pollutant concentrations disperse spatially and temporally across a network. By modeling each sensor as a node and its relationship with neighboring sensors as edges, graph-based methods can propagate local corrections, detect anomalies, and help stabilize measurements against drift or unexpected local variation. Studies by Zhang et al.66, Wu et al.67, Jin et al.68, Iyer et al.69, Li et al.70, and Ferrer-Cid et al.71 illustrate how connectivity-based models can enhance calibration performance in dense urban deployments and complex environments. Although these methods are promising for using the spatial structure of large LCSN, they require careful design of graph topology, sufficient data for training, and computational resources to operate in near real time.
Deep Learning as a cross-cutting layer
Deep learning methods increasingly complement traditional calibration by capturing non-linear relationships, managing domain adaptation, and improving performance accuracy (Supplementary Table 1). Architectures such as multi-layer perceptrons, recurrent neural networks, and graph neural networks have been deployed for both calibration and gap-filling tasks. They offer improved accuracy under changing ambient conditions. Recent studies, including Dey et al.72, Schlund et al.73, Zhang et al.66, Chen et al.74, and Okafor and Delaney75, demonstrate how deep learning can improve the stability and transferability of LCSN calibration and imputation pipelines. Combined with connectivity-based frameworks, deep learning can further strengthen adaptive calibration by exploiting both local network structure and spatiotemporal dynamics.
Graph-based modeling of LCSN
Graph-based modeling is increasingly recognized as a framework for capturing the spatial and temporal dependencies inherent in LCSN76. By representing each sensor as a node and linking them with edges that encode physical distances, wind flows, or other dispersion relationships, graph-based approaches align naturally with how pollutants propagate in urban and regional settings. Graph Neural Networks have emerged as tools for anomaly detection, data imputation, and spatiotemporal prediction within these networks. Recent studies show this momentum: Wu et al.67 applied Graph WaveNet and spatiotemporal graph convolutional networks to identify faulty sensors in Taiwan’s extensive LCSN, outperforming rule-based and conventional ML baselines. Xu et al.77 used dynamic, wind-informed graphs for short-term PM2.5 forecasting, and Jin et al.68 advanced this further using a spatio-temporal multi-attention multi-graph framework to improve long-term predictions. Iyer et al.69 combined message-passing recurrent networks with geostatistical techniques to generate fine-grained air quality maps for Delhi, robustly handling sparse or intermittent measurements. Li et al.70 proposed the GCN-Informer based on the informer78 architecture, integrating graph convolutional networks with transformer-based architectures for air quality prediction. Ferrer-Cid et al.71 focused on outlier detection, introducing the Volterra Graph-based Outlier Detection (VGOD) mechanism to identify and correct erroneous sensor data. Together, these studies highlight how graph-based methods can strengthen calibration, anomaly detection, and prediction pipelines by embedding domain knowledge of pollutant transport and inter-sensor relationships within LCSN.
LCS in mobile monitoring
Ground measurements
Mobile monitoring has been used to complement stationary measurements of air pollution to capture hyperlocal (street-by-street) variations in pollutants. Although some pollutants like PM2.5 display more variation at the regional scale, concentrations of other traffic-related pollutants like NO2 and CO can vary over a few meters79,80,81. LCS are increasingly being adopted for mobile monitoring purposes. Although there have been several reviews of mobile air pollution monitoring using higher-quality instruments82,83,84, none of these reviews have focused on the application of LCS.
Mobile monitoring using high-quality instruments often requires specialized vehicles operated by trained staff. A key advantage of using LCS for mobile applications is the possibility of using non-specialized vehicles, such as bicycles85,86, trains87, trash trucks88, people89, and taxi cabs90 as monitoring platforms. LCS can be deployed for pedestrian-based air quality monitoring as well9,91. The use of these routine vehicles for sampling purposes can increase the spatial areas and time of sampling cost-effectively. O’Keeffe et al.92 and Anjomshoaa et al.93, for example, demonstrated a methodology to evaluate the number of routine vehicles needed to be outfitted with sensors to cover a given space-time sampling cross-section of a city. The portability of LCS has also enabled the development of personal exposure assessments for epidemiologic and awareness-raising applications94,95,96. Kappelt et al.97 and Russell et al.98 employed LCS to determine the PM levels inside the metro system (i.e., onboard trains) of Copenhagen and showed that the PM concentration levels increased when compared with the ambient measurements out of the metro system. Mobile measurements from LCS have also been successfully integrated into models to develop high-resolution exposure assessments for different cities99,100,101 as well as with measurements from other sources (stationary monitors, satellite instruments, and models)102.
Aerial-based measurements
An increasingly important development in atmospheric science is monitoring the vertical distribution of air pollutants103, from ground level to several hundred meters104. The use of LCS on-board drones (or Unmanned Aerial Vehicle) has emerged for three-dimensional measuring of key pollutants such as PM₁, PM2.5, PM₁₀, NO₂, CO, and O₃ at altitudes (from ground level to several hundred meters) and is currently evolving as a promising technology to collect data at different altitudes105,106,107,108 (see Supplementary Note 1).
Conventional ground-based monitoring networks cannot resolve the vertical gradients in pollutant concentrations that shape local exposure, urban heat islands, and near-source pollution dynamics. Recent research shows that copter drone-based LCS monitoring can deliver high-resolution datasets when combined with data analytics106,108,109,110,111. Hemamalini et al.112, for example, integrated drone-mounted LCS data with deep learning to forecast air pollution levels near open dumpsites in India. Or Villa et al.38 evaluated the utility of using small drones for ambient mobile monitoring.
Recent studies have also demonstrated the use of fixed-wing drones for vertical profiling of air pollutants, particularly in peri-urban or special event contexts113,114,115. Although fixed-wing drones provide greater flight endurance and spatial reach, regulatory constraints and safety concerns make them less suitable for urban environments. They have been successfully used to monitor pollutants near airports, assess Saharan dust events, and measure PM1, PM2.5, and PM10 profiles in rural India. However, their application in dense urban environments remains limited compared to copter-based drones. In addition to air quality monitoring, the recent deployment of drone-based LCS systems has shown promise in validating numerical models such as Weather research forecasting coupled with chemistry (WRF-Chem), Community Multiscale Air Quality (CMAQ), or EURopean Air pollution Dispersion – Inverse Model (EURAD-IM) models116,117,118,119.
LCS data integration with air quality models and remote sensing datasets
Integrating LCS systems with models via data assimilation120 and data fusion121 techniques has the potential to enhance the accuracy and resolution of air quality122 mapping at local and regional scales and is thus a promising application of LCSN. Although individual LCS accuracy is typically limited, their fusion with model data (e.g., local-scale dispersion or chemical transport models) using these techniques can offer valuable complementary insights, provided the sensors are carefully calibrated, quality-controlled, and uncertainties are properly assessed. This integration adds value to the LCSN by robustly and objectively interpolating point observations in space and simultaneously enhances models by constraining simulations with real observations102,123.
We distinguish here two main approaches for combining LCS observations with models or auxiliary data: (1) Data fusion, which relies on geostatistics124 or similar traditional statistical methods, typically applied offline as post-processing and (2) data assimilation, stemming from the field of numerical weather prediction, which is typically conducted online and actively updates the model state during runtime125.
Data fusion techniques
Data fusion techniques traditionally refer to combining multiple observations, but here we use the term to also include integrating observations with models to clearly distinguish from data assimilation methods (e.g., Shetty et al.126). Data fusion, which in our context typically refers to approaches such as geostatistics, land-use regression, or machine learning (ML), allows for merging data from various air quality sources to create an improved overall mapping result. These techniques typically use statistical approaches applied as post-processing rather than directly assimilating data into running models. (1) Spatial Interpolation: Includes simpler methods like nearest neighbor resampling or Inverse Distance Weighting (IDW), as shown, for example, by Chu et al.61 in mapping PM2.5 with LCS. (2) Geostatistics: These methods use spatial correlations among measurements to estimate pollutant levels at unsampled locations. Kriging techniques commonly interpolate pollutant concentrations, potentially incorporating auxiliary data from dispersion or chemical transport models. Such approaches generate high-resolution air quality maps accounting for spatial variability. Examples include studies by Li et al.127, Castell et al.128, Schneider et al.102, Schneider et al.129, and Gressent et al.130. (3) Land-Use Regression (LUR): LUR models correlate air quality data with land-use and emission-related variables (e.g., traffic density, population density). Using statistical regression incorporating spatial and temporal predictors, LUR estimates pollutant levels at unmonitored sites. Studies using this method include Adams et al.131, Coker et al.132, Jain et al.133, Lim et al.134, and Weissert et al.135. (4) Machine Learning (ML): ML is widely employed for calibrating LCS, yet its use in combining sensor data with models remains less explored. Demonstrations of ML methods integrating simulated LCS observations with models are provided by Coker et al.132, Guo et al.136, Jain et al.133, Liang et al.137, Lim et al.134, and Lopez-Ferber et al.138.
Data assimilation techniques
Data assimilation techniques for atmospheric composition integrate observations from multiple sources, such as LCS, traditional monitoring stations, and satellites, with mathematical models to improve air pollutant concentration estimates139. These methods assimilate observed data directly into the model’s internal state estimation process, typically represented by a vector of model variables. (1) Optimal Interpolation (OI): OI minimizes differences between model predictions and observations using statistical interpolation to weight observations by proximity. It can function offline without directly updating the model’s internal state vector. Examples using OI with LCS data include Mijling140, Schneider et al.122, and Hassani et al.141 (see Fig. 3 as an example). (2) Ensemble Kalman Filter (EnKF): EnKF iteratively updates an ensemble of model states by integrating observations with model predictions. The observations adjust ensemble members, enhancing the predictions. Lopez-Restrepo et al.142 demonstrated EnKF use with LCS. (3) 3D-Var, 4D-Var, and 4D-EnVar: These variational methods minimize a cost function143,144 to assimilate observations into models, often employing adjoint models to efficiently calculate gradients. 3D-Var updates at single time points, while 4D-Var assimilates data across a temporal window. Although primarily designed for surface observations or satellites, these systems can be adapted for LCS data, despite limited applications to date. Lopez-Ferber et al.138 used 3D-Var with simulated sensor observations.

This is the example of average PM2.5 concentrations from December 1, 2020, to February 28, 2021, for the city of Kristiansand, Norway. Top left panel: Model a priori dataset (background) together with sensor observations (symbols); top right panel: depiction of innovation, showing disparities between model predictions and sensor data at deployment sites; bottom left panel: the resultant concentration field from data assimilation (the “Analysis”); bottom right panel: visualization of differences between analysis and the model, highlighting spatial corrections made during assimilation. Base map copyright OpenStreetMap contributors, map tiles by Stamen Design under CC BY 3.0. Modified from a similar figure in Hassani et al.141.
Distinctions between these techniques can overlap; for example, OI shares similarities with geostatistical methods, and many studies combine techniques like land-use regression with ML. Each approach has strengths and limitations, but all are valuable for urban air quality mapping using LCSN, depending on specific requirements and data availability.
Low-cost sensors data integration with satellite observations
Due to the growing interest in integrating LCS data with satellite observations, we have focused more on this topic. Earth observation satellites have become key tools in air quality monitoring145. They overcome the spatial limitations and uneven distribution of ground monitors by providing daily, global data on air pollutants145. Instruments like TROPOMI on Sentinel 5-Precursor (S5-P), Moderate Resolution Imaging Spectroradiometer (MODIS) on Terra and Aqua, the Ozone Monitoring Instrument on Aura, and VIIRS on the Suomi NPP/NOAA satellites retrieve key atmospheric components such as NO2, O3, CO, Methane (CH4), SO2, formaldehyde, as well as Aerosol Optical Depth/Thickness (AOD/AOT) and other aerosol properties through spectral radiance measurements146.
Satellites provide columnar measurements of atmospheric constituents, representing total atmospheric content147. However, these measurements cannot be directly used for urban-scale health exposure assessments, which require information specifically about surface-level concentrations148. Many studies convert satellite-derived columnar measurements into spatially continuous surface concentration estimates by integrating them with ground-based air quality observations (such as reference stations, LCS, etc.) and/or outputs from chemical transport models through data fusion or assimilation techniques149,150. Supplementary Table 2 summarizes a selection of recent studies that combine LCS and satellite observations to estimate or analyze surface air pollutant levels. These studies can broadly be categorized based on the methodology used for LCS integration: (1) Spatial Interpolation-Based Approaches. LCS data are used in conjunction with satellite-derived variables (e.g., AOD or tropospheric NO2 columns) in spatial interpolation models to estimate surface concentrations across a region. (2) Regression and ML-Based Approaches. LCS data are integrated as either independent or dependent variables, or serve in both roles, alongside satellite inputs and auxiliary parameters (e.g., meteorology, land use), to enhance spatial mapping and predictive accuracy of surface pollution levels.
Fewer studies have adopted interpolation-based approaches for integrating LCS and satellite data (e.g., Li et al.127, Chao et al.151, and Gupta et al.152). Most LCS networks are concentrated in urban areas, where spatial interpolation alone may not be optimal, as it tends to smooth out localized pollution peaks, leading to underestimation. This highlights the need for data integrations and alternative approaches, with ML being the most adopted approach due to its robustness and ability to model complex, non-linear relationships. Tree-based ML algorithms, particularly the Random Forest, are among the most widely used. For example, Huang et al.153 found that Random Forest models outperformed or matched other ML methods such as Support Vector Machines, Gradient Boosting, and neural networks, citing superior predictive accuracy and greater computational efficiency, along with ease of training and interpretability.
Neural networks, particularly Convolutional Neural Networks (CNNs), can capture spatial and temporal dependencies through their layered structure but are often computationally intensive and require large, well-curated datasets for training. As a result, their application in this context has been limited. Nevertheless, Liang et al.137 demonstrated the potential of CNNs by integrating LCS data, AOD, and traffic indicators to estimate PM2.5 at a high spatial resolution of 30 m over Denton County, Texas, ideal for capturing intra-urban pollution variability.
In ML applications, LCS data have been used as targets, predictors, or both. When used as targets, LCS data offer higher spatial density, improving model performance, especially in residential areas, compared to using only reference-grade data153,154,155. However, differences in data accuracy can introduce bias154. Weighted approaches, like Bi et al.155’s Random Forest model, reduce this bias by giving more weight to reference data. As predictors, LCS help enhance spatial detail. For example, Fu et al.156 integrated LCS and satellite NO₂ data to improve high-resolution pollution mapping. Some studies use LCS both as inputs and targets by incorporating interpolated LCS layers (e.g., via kriging) to capture fine-scale variability137,157. In addition, LCS data have also been used to derive correction factors for satellite-based PM2.5 estimates158.
Satellite data functions as an independent covariate in all reviewed studies (Supplementary Table 2). MODIS MAIAC (Multi-Angle Implementation of Atmospheric Correction) AOD159 retrieved from the Terra and Aqua satellites is mostly used in PM2.5 studies, mainly due to its fine 1 km spatial resolution, while TROPOMI is preferred for NO₂ monitoring due to its high spatial resolution of trace gas retrievals. The importance and predictive value of satellite variables can vary across studies and pollutants. For example, Huang et al.153 and Yu et al.154 identified satellite AOD as highly important for PM2.5 estimation, while Liang et al.137 and Bi et al.157 observed lower importance, likely due to the complex spatio-temporal AOD-PM2.5 relationship. The effectiveness of satellite AOD as a predictor can depend on atmospheric conditions, aerosol type, vertical distribution, and the presence of meteorological covariates in the model160. In contrast, for pollutants like NO₂, where columnar measurements are more directly related to surface concentrations, satellite products such as TROPOMI NO2 may provide better predictive power.
Across studies, RMSE values range from 1.15 – 21 µg m-3 and R2 values from 0.7 and 0.86, mostly based on K-fold cross-validation. Particularly, the RMSEs for ML-based studies were lower at 1.15−9.3 µg m-3. Most studies focus on urban-scale PM2.5 mapping, especially in the United States and China, with limited work at regional scales. This emphasis reflects the dense availability of PM2.5 LCSN. The most common spatial-temporal resolution across studies is daily averages at a 1 km spatial scale, though some studies reach finer spatial resolutions of 30−100 m.
Low-cost sensors application in citizen science and community engagement projects
Citizen science projects using LCS technology have proliferated globally, raising greater public engagement and awareness of environmental issues. This part of our review aims to provide an overview of the current state of LCS air quality monitoring within citizen science projects, including both the successes and obstacles encountered in these initiatives.
Kruger and Shannon161 define citizen science as the involvement of citizens in science as active researchers. In the literature, “citizen science” is also referred to by several equivalent terms, including participatory science, community science, crowdsourced science, public science, and amateur science. In some cases, depending on the context and the specific focus of the research, open science, volunteer science, distributed science, and Do It Yourself (DIY) science can also be relevant. The emergence of LCS has opened new possibilities for citizen science and community engagement in the air quality field, allowing individuals to actively participate in monitoring and addressing air pollution-related issues162,163. The evolving application of LCS in citizen science projects in air quality monitoring has brought numerous benefits and opportunities. LCS have improved air quality data collection by spreading independent community-based networks for air quality monitoring25. Through citizen science projects, individuals can install sensors in their homes, workplaces, or public spaces, providing a vast amount of real-time data5,164. This crowd-sourced approach enhances spatial coverage4,165, enables the identification of pollution hotspots141,166, and helps prioritize the required interventions. Additionally, engaging citizens in air quality monitoring raises awareness about the effects of air pollution on human health and the environment167,168. This awareness motivates behavioral changes regarding indoor and outdoor air pollution, such as reducing vehicle emissions, adopting sustainable transportation modes, or modifying personal habits (e.g., Park et al.169, leading to a collective effort to mitigate pollution). Engaging citizens in air quality monitoring projects empowers them to actively participate in environmental decision-making processes14,170. Through collecting and analyzing personalized air quality data, citizens become stakeholders and contributors to scientific research, policy-making, and environmental management20. This empowerment raises a sense of ownership and responsibility for environmental issues.
LCS bridge the gap between citizen scientists and the scientific community. Involving citizens in data collection facilitates knowledge exchange, collaboration, and co-creation of solutions171. The data produced by citizen science projects is made decision-ready through user-friendly formats such as real-time data streams, interactive maps, and reports (e.g., Longo et al.172 or Barros et al.173). Scientists can benefit from datasets provided by citizen scientists, while citizens and communities gain access to scientific expertise, validation of their findings, and a deeper understanding of the scientific process (see e.g., Hassani et al.86, Hassani et al.141, Hassani et al.166, and Connolly et al.174). Citizen science projects using LCS can establish connections between communities and various institutions, including governmental bodies, academic institutions, and environmental organizations.
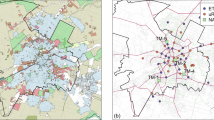
Tracking and reporting all citizen science projects, initiative stories, and community-based networks on air quality (Fig. 4) can be a challenging task due to the overwhelming number of projects in existence (uRADMonitor164, AirQo175, PRAISE-HK176, CAIRSENSE177, CanAirIO [https://canair.io/, accessed 07.04.2025] are just a few). However, some inventories and databases provide information and resources related to citizen science activities and initiatives (see Supplementary Note 2).

Only sensors with at least 30 days of data availability (not necessarily continuous) are displayed on the map. PurpleAir was initially founded with a strong emphasis on citizen science and community engagement, allowing individuals to contribute air quality data through crowdsourcing. Over time, the network has expanded, and not all sensors are necessarily owned by individual citizens, some are operated by institutions, research projects, or local authorities. However, it remains one of the largest networks with significant community participation, and its public data availability continues to support local engagement in air quality monitoring.
Remaining challenges and future research directions
Enhancing operational efficiency of low-cost sensor networks/graphs
In the reviewed studies (Supplementary Table 3 to Supplementary Table 7), typically simple train–test splits are used to evaluate calibration models; however, near-real-time LCSN require careful choice of cross-validation to ensure performance under operational conditions. Random cross-validation (RCV) remains common in ML but is poorly suited for LCSN, which collects sequential, strongly auto-correlated data. To maintain accuracy when models are applied in real time, training and validation must respect temporal order and spatial deployment (Supplementary Fig. 1). Practitioners should therefore combine spatial cross-validation (SCV), such as leaving out stations or areas without co-location, with temporal cross-validation (TCV) to test model transfer over time. Forward cross-validation (FCV), which progressively expands the test set, is especially effective for detecting abrupt performance drops due to drift. Together, using SCV, TCV, and FCV helps ensure that calibration models for LCSN remain reliable when new data streams in, including for LCS never directly co-located with a reference instrument.
Across the core themes of field calibration, imputation, concept drift, and graph-based modeling, nearly every major class of ML algorithm, from simple linear regression to advanced spatio-temporal multi-attention graph networks, has now been tested. However, comparing LCS studies remains challenging due to the lack of standardized performance metrics. Studies often report results using varied indicators, from correlation coefficients and error statistics to custom measures, making it difficult to compare models directly or evaluate compliance with regulatory targets. To address this, the adoption of a unified metric such as relative expanded uncertainty could help standardize performance reporting by expressing total measurement uncertainty as a percentage of the true value, aligning with air quality guidelines. Normalizing uncertainty to pollutant concentrations also makes results easier to interpret across contexts. More broadly, combining several metrics and monitoring performance continuously is essential to detect unexpected drifts and ensure reliable sensor data over time. Ideally, a combination of (1) linearity, (2) error, (3) uncertainty, (4) bias, and (5) distribution-based metrics should be considered for a thorough understanding of the calibration behavior.
Although several field calibration approaches exist (e.g., baseline, global), their application depends on the availability of reference stations. The description of a LCSN or, more generally, of a monitoring network as a graph is gaining attraction due to the versatility of graphs to describe relationships between nodes. Based on the reviewed studies in this section, treatment of LCSN as a graph can include spatiotemporal relationships and increase modeling accuracy (e.g., during imputation, outlier elimination, calibration, forecasting). Through adopting the graph approach, researchers can investigate the influence of several parameters represented as connectivity (e.g., edges derived from wind fields, traffic congestion data, dispersion models, land use, altitude, etc.) and make use of the graph computation tools (PyTorch Geometric, networkX, etc.) that are readily available. Therefore, a more suitable term for LCSN that includes connectivity should be LCS graphs.
At least two major operational challenges, missing data imputation and concept drift, should still be addressed for a successful LCSN field calibration design. LCSN data often have missing values due to (1) abrupt malfunctions, (2) power shortages, (3) maintenance, (4) data transmission issues, and (5) removed outliers (see Supplementary Fig. 2)178. In parallel, concept drift179, where sensor behaviors shift over time, is a risk to calibration accuracy and transferability (Fig. 5). These issues can be addressed by incorporating an incremental data treatment into the air quality datasets to increase trust in predictions. Many studies implement gap-filling methods to maintain continuous time series, ranging from simple linear interpolation and moving averages to more sophisticated statistical imputation or even ML-based interpolation using neighboring sensors’ data. Such preprocessing steps, though sometimes under-reported, critically influence model reliability. A well-designed preprocessing pipeline ensures that the calibration model learns from representative, reliable data and that real-world deployment of the model is not skewed by transient anomalies. In large networks, automated quality control and data cleaning become essential, as manually vetting data from hundreds of sensors is impractical.

On the top panel, the daily time series of the PM2.5 concentrations of a reference instrument is shown, while on the lower panel, the daily time series of the NO2 concentrations is presented. The red verticals indicate a change in the concept of the series as identified by the adaptive windowing (ADWIN) algorithm224. The statistical properties of each segment are presented above the time series to demonstrate the effect of the concept drifts.
Therefore, the minimal requirements to successfully operate a static LCSN is to (1) keep one sensor collocated with every reference instrument continuously, (2) calibrate the LCSN as accurately as possible, (3) monitor the performance of calibration models, (4) adapt the calibration models as needed based on triggers, (5) perform a combination of SCV, TCV, and FCV for robust evaluation, and (6) address missing data and concept drift. Finally, the description of LCSN via graphs is an evolving trend in air quality and in LCSN calibration specifically. Seeking new and better connectivity schemes for the description of irregularly distributed monitoring networks, as well as combining meteorological, traffic, and air quality graphs to inform one another, can be two novel research directions.
Challenges with ground-based monitoring using mobile low-cost sensors
A key research question relates to how sensor siting, orientation, and vehicle velocity can impact mobile LCS measurements. So far, there have only been a handful of studies that have systematically addressed this concern. Mui et al.180 for example, piloted such an evaluation technique for PM2.5 and gas LCS in California. They found that the PM2.5 LCS overestimated PM2.5 concentrations under high wind-speed conditions, suggesting that a flow-directing device was likely necessary to use such sensors reliably for mobile monitoring. Their work also showed that PM loading on the LCS gas inlet resulted in significant noise. Hassani et al.86 conducted a study in an urban environment in Norway, using Sinfferbike sensors equipped with Sensirion SPS30 to measure PM2.5 levels. They found that for every 1 km h-1 increase in the speed of the bicycles, the standard deviation of the PM2.5 measurements increased by ~0.03 to 0.04 μg m−3 (Fig. 6). This suggests that higher cycling speeds can introduce variability in the air quality data collected by these mobile sensors.

Change in the Standard Deviation of the factory-calibrated PM2.5 measurements of 11 Snifferbikes (Sensirion SPS30) compared to the bike speed during the on-bike tests conducted on May 31, 2021, and June 10, 2021, in Kristiansand, Norway (after Hassani et al.86).
deSouza et al.181 found that the orientation of PM2.5 LCS for mobile monitoring impacted device performance (deviation of PM2.5 measurements from those of a higher-quality instrument) in an experiment in Boston; however, device age and choice of calibration approach also proved to be extremely important factors in determining the performance of LCS in a mobile setting. Russell et al.182 found that the rate of change of pollutant concentrations in different environments, and not vehicle speed, impacted the performance of low-cost PM2.5 and NO2 sensors, relative to reference instrumentation, in a mobile sensor deployment in London. Russell et al.182 also reported that the time resolution of the electrochemical NO2 sensor they used in their experiment could not capture gradients of NO2 concentrations in highly variable environments. We note, however, that some research groups have begun to develop strategies to mitigate the slow dynamics of LCS for gaseous species for mobile sensing183, although more research is needed.
To obtain reliable patterns of air pollution in a study area, mobile monitoring routes need to be selected such that specific routes are sampled multiple times. Messier et al.184 found that in San Francisco, for example, 10-20 mobile monitoring runs/road segment were sufficient to obtain robust long-term spatial patterns of traffic-related pollutants in their study area. Hassani et al.86, in their Snifferbike study, showed that at least 27 PM2.5 measurements per 50 m road segment are required to have reliable averages. Opportunistic sampling with routine vehicles may or may not be able to achieve such a desired repeatability. Studies have used simulations to evaluate how many of these vehicles are needed to achieve this sampling strategy185.
Pedestrian-based LCS deployments have key limitations. Pedestrians often transition rapidly between diverse environments, e.g., between indoor and outdoor spaces11, where environmental conditions such as temperature and humidity can vary significantly. LCS performance is sensitive to these changes, potentially affecting measurement accuracy unless sensors are deployed for monitoring in a specific and controlled environment (e.g., only within a park or defined area). Other concerns about LCS for mobile monitoring are similar to those of stationary sensors: field calibration, drift, and degradation181. Although a wide variety of field calibration models have been used to calibrate LCS for mobile monitoring, research has shown that considering the transferability of calibration approaches from the stationary to the mobile setting is important, specifically because the micro-environments experienced by the sensors during sampling may not represent stationary calibration conditions86. As a rule of thumb, deSouza et al.181 found that for short calibration periods, simpler field calibration models were more transferable to the mobile setting. They found that short calibration periods relative to the length of the mobile campaign do not transfer well to the mobile setting because of seasonal changes in aerosol sources. Moreover, deSouza et al.181 also determined that using minute-level co-located data, instead of hourly-averaged data, led to a better-performing calibration model. Other researchers have also successfully adopted on-the-fly or drive-by calibration models for mobile LCS when the sensors drive within a given distance from a fixed reference monitor (for example, Hasenfratz et al.186).
Challenges associated with low-cost sensor monitoring using drones
Earlier overviews187,188 summarized the emergence of drone-based chemical monitoring as a complement to stationary networks and manned aircraft. They highlighted applications ranging from volcanic plume sampling to methane leak detection189,190. However, early studies mostly demonstrated technical feasibility under controlled or low-complexity conditions and did not address the operational, calibration, or regulatory barriers to large-scale, routine drone-based monitoring with LCS, which we cover below.
Influence of environmental variables on the performance of LCS: PM LCS can overestimate concentrations under high humidity. Studies by Savvakis et al.189 and Bretschneider et al.107 showed that silica gel-based diffusion dryers placed upstream of the LCS can reduce relative humidity from ambient levels down to about 40% for durations that match typical drone endurance (20–30 min). Masic et al.191 demonstrated that these simple dryers are effective for short flights but may saturate over time and require replacement.
Rotor downwash effects on measurement stability: Hedworth et al.108 quantified the impact of rotor-induced flow on PM2.5 readings using wind tunnel and field experiments, showing fluctuation in particle number concentration when sensors are mounted directly beneath propellers. Wu et al.104 and Liang and Shen190 recommend extending sampling inlets 50–60 cm vertically above the drone to reduce downwash turbulence. Moormann et al.192, proposed an alternative approach that the LCS could be fixed 100 cm above the drone frame using two elongated fixed connecting rods, further stabilizing measurements. However, the optimal inlet length depends on rotor design, flight pattern, and local conditions. Another solution to mitigate this issue could be the miniaturization of drones. This includes the development of nano-drones, which may help mitigate environmental and noise concerns and also enable gas-sensing operations within closed spaces. However, as the size of drones decreases, conventional motors become less efficient, necessitating the development of alternative propulsion methods needed for vehicles weighing just a few grams187.
Sampling flow stability issues in LCS on-board drone: Another consideration for using the PM LCS onboard drones is to improve the flow stability of the LCS. The LCS typically uses a small fan or blower to achieve nominal flow rates under ideal conditions with no upstream tubing or equipment. However, it is recommended that the initial flow configuration of the LCS be modified (by replacing the fan with a miniature pump) to accommodate pressure drops caused by upstream sampling lines (e.g., to facilitate the use of aerosol dryers) and to increase stability against abrupt changes in airspeed typical of drone operations192.
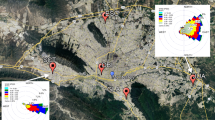
Limited endurance time of drones (short operating time): Copter drones may be limited to short flights (e.g., 15–20 min), which restrict vertical profiling depth and horizontal coverage189. Some applications, such as monitoring large industrial sites, necessitate the use of drones that are capable of both prolonged endurance and agile maneuverability. This could be achieved through the deployment of drones equipped with high-power lithium-polymer batteries, fixed-wing platforms, or the use of multiple drones working together in a swarm configuration110,113 (see e.g., Supplementary Fig. 3). Tethered drones can provide longer hover durations for repeated vertical profiling, although they have reduced flexibility for horizontal transects187. These drones are well-suited for point-based observations for longer sampling durations, particularly when the field campaign is carefully planned, considering their limitations.
Optimal sampling altitude and mission planning: Different operational and research needs will dictate the optimal height. As an example, Pochwała et al.109 used decision tree models to optimize drone flight altitude for different PM fractions, identifying that PM10 is best measured around 30 m, and PM1 and PM2.5 are best measured between 40–50 m in their Polish case study. However, typically, drone research requires measurements at elevations much higher than 30 m.
Lack of in-flight inter-comparison experiments between co-located instruments and LCS on-board drones: Savvakis et al.189 and Pochwała et al.106 emphasize the value of in-flight intercomparison (Supplementary Figure 4): drones can hover near reference stations at 10–15 m above ground before sampling to validate sensor accuracy under operational conditions.
Obstacles and challenges of data fusion and assimilation of low-cost sensors
Beyond ensuring robust, high-quality LCS measurements193 and transparent processing79,194,195, accurate uncertainty estimates for both models and sensors are crucial, ideally assessed for each measurement individually. Realistic uncertainty estimates are essential for effective data fusion or assimilation, enabling optimal integration of sensor data and model predictions123,125,196. However, detailed uncertainty assessment for large-scale LCSN can be prohibitively expensive and time-consuming197, especially with diverse sensor types. For models, the main challenge is representing error covariance realistically, capturing spatial and temporal propagation of observational signals, rather than overall performance metrics.
Offline data fusion methods, such as geostatistical approaches124,143, are widely used but only post-process model results, limiting real-time bias correction and forecasting improvements. Standard geostatistical tools often struggle with complex error covariance structures like those related to urban or road-network features198. Simpler assimilation methods like Optimal Interpolation offer flexibility, but constructing the necessary background error covariance matrix remains challenging125,143, especially in complex high-resolution urban contexts with dense LCSN. Ensemble methods such as EnKF effectively build this unsupervised matrix but require substantial computational resources, making their use difficult for real-time operational use199. Variational data assimilation methods present additional challenges, notably in developing and maintaining accurate adjoint models144,200 required for calculating gradients. Errors in adjoint models can impact assimilation reliability, emphasizing the need for careful validation and expertise.
Overcoming these challenges and moving forward, continued work on innovative algorithms, advancement in algorithmic efficiency, and computational capabilities will be necessary for improved real-time operational integration of LCS data with air quality models. Work on automated and ideally scalable methods for uncertainty quantification and validation should be prioritized. This will improve the reliability of sensor networks and assimilation techniques. New opportunities could include exploring ML techniques for characterizing covariance structures with a potential improvement in assimilation performance. Research on and implementation of standardized LCS data protocols and open-source LCS platforms could further enhance the reproducibility, accessibility, and wider adoption of data fusion and assimilation techniques for better exploiting LCS observations.
Challenges in integration of low-cost sensors with satellite observation data
A comparison of various LCS-satellite integration strategies within ML frameworks is necessary to identify robust/scalable modeling approaches. Standardized metrics such as relative error or normalized RMSE are essential to help inter-study comparisons. A key research direction involves assessing the spatial generalizability of models. Most current studies develop localized models tailored to specific cities or regions. However, building generalized models applicable over larger geospatial domains would enhance their practicality for air pollution monitoring and policymaking.
Although LCS offer high temporal resolution, this potential often remains underutilized due to data discontinuities caused by sensor drift, aging, calibration, or maintenance issues. Additionally, coarse temporal resolution of low-earth polar-orbiting satellites (1–2 observations per day) limits their synergy with LCS. The advent of geostationary satellite (e.g., from Geostationary Environment Monitoring Spectrometer (GEMS), Tropospheric Emissions: Monitoring of Pollution (TEMPO) or the recently launched Sentinel-4), which offer hourly observations of NO2, O3, AOD, formaldehyde, SO2, presents a promising solution to enhance temporal continuity in air quality monitoring, though their integration remains largely unexplored and calls for further research.
A persistent challenge is the spatial mismatch between satellite pixel-based data (several km resolution) and point-based LCS readings. Multiple LCS units can fall within a single satellite pixel, creating a spatial resolution mismatch, as it requires reconciling detailed local measurements with broader, average satellite observations. One solution is to integrate or assimilate the LCS and satellite observations into a numerical model where their unique properties and representativity can be accounted for mathematically through detailed specification of their uncertainty and error propagation.
Another potential research direction is the use of satellite remote sensing products for LCS quality control. For example, products such as NO₂ and O₃ from TROPOMI, AOD from MODIS, and even land surface temperature or vegetation indices (e.g., NDVI) can provide contextual information to flag outliers or validate trends, especially in areas with limited ground-truth reference stations. For instance, if multiple LCS units in a region report unusually high NO₂ values, satellite data can be used to verify whether a regional pollution event is occurring or if sensor malfunction is likely. However, the utility of such comparisons depends on aligning spatial and temporal resolutions; as higher-resolution satellites continue to be launched (e.g., TEMPO), the integration of satellite data into LCS quality assurance workflows will become feasible. Future work could focus on developing frameworks or automated tools for real-time or retrospective LCS validation using satellite inputs.
To make impact, citizen science projects focused on air quality often encounter various barriers, also called obstacles, and bottlenecks201. These obstacles include motivational, technological, economic, competition, individual/societal, legal, and regulatory aspects. These obstacles are not peculiar to air-quality citizen science projects, and other community engagements for environmental monitoring also suffer from them.
The “local needs and motivations to monitor” barrier in citizen science projects highlights the importance of clearly defining the research question or the purpose behind gathering data and engaging citizens177,201. Stakeholders ranging from citizens to scientists and data collectors, along with decision-makers and policymakers at diverse levels, need a thorough comprehension of what motivates, incentivizes, and hinders their engagement202. In some cases, data collection may occur without a specific focus or a clear objective, leading to limited alignment with local needs and engagement from policymakers.
Technological barriers can manifest in the form of limited access to or unfamiliarity with required technologies163. For instance, citizens may lack the necessary equipment or software to participate effectively in data collection and analysis203. This can be particularly challenging for individuals with limited technical expertise or resources. Additionally, establishing a common language between citizens and the project team, which includes developers and data scientists, can be challenging23,202. This arises due to the differing backgrounds, expertise, and technical knowledge of the involved parties204.
Lack of trust in sensor performance, limited metadata, and absence of quality standards raise concerns about accuracy, reliability, and bias, hindering policy acceptance and limiting integration of citizen science data with official air quality networks and other sources18,166,174,201,205. In some citizen science projects, commercial sensor systems process LCS data before providing it to analysts. Although convenient, this limits long-term quality control and calibration, as manufacturers may alter proprietary processing algorithms without disclosure, hindering full understanding and control.
Economic barriers arise when citizen science projects face challenges related to funding and resource availability2. High costs associated with purchasing or maintaining equipment and technologies can restrict participation. Limited financial resources can hinder the scalability and sustainability of initiatives, preventing them from reaching a broader audience206.
Competition barriers arise when multiple citizen science projects with similar themes or geographic focus compete to attract participants, secure resources, and capture attention207. For example, if several initiatives are seeking to monitor air quality within a specific city, citizens may be overwhelmed with options, leading to reduced engagement and fewer data contributions. Additionally, despite the vast amount of data being generated, the siloed operations of stakeholders impede its effective utilization208.
Individual and societal barriers include factors such as limited awareness, motivation, and time constraints209,210. Lack of awareness about citizen science opportunities may discourage potential participants from engaging in projects207. Additionally, time constraints and competing priorities can limit the level of involvement from citizens. For example, neighborhoods characterized by a high turnover of residents, such as areas with many short-term rental houses or flats (typically for durations of 1–3 years), may show decreased interest in policy co-creation and air quality monitoring initiatives.
Socio-economic disparities may also influence participation rates and the representation of diverse communities, creating challenges in achieving broad inclusivity211. Neighborhoods with a high concentration of immigrants and refugees may also exhibit lower levels of interest in air quality citizen engagement projects212. Citizen science projects are predominantly established in Western, educated, industrialized, rich, and democratic (WEIRD) societies, often overlooking Indigenous and non-Western perspectives213. These initiatives tend to attract participants with formal education, economic stability, and access to technology and infrastructure, typically in politically stable regions212,214. As a result, marginalized and Indigenous communities, both in the Global South and the Global North, are often excluded or unaware of such opportunities, limiting their engagement in citizen science efforts212. We explicitly note that some of the insights presented here are informed by our direct involvement in several citizen engagement initiatives, particularly in the context of air quality monitoring. We acknowledge that a more rigorous, quantitative documentation of such participatory efforts remains an important direction for future research.
Similarly, in a neighborhood characterized by socio-economic disparities, residents from lower-income backgrounds may face financial constraints that limit their ability to actively participate in citizen science initiatives215. deSouza and Kinney216 analyzed deployment patterns of a commonly used LCS (PurpleAir) based on demographics and pollutant concentrations. They found census tracts with LCS were wealthier, more predominantly white, and better educated than the US average. The costs associated with acquiring sensor equipment, attending meetings or workshops, or even accessing reliable internet connections for data submission may pose barriers for individuals with limited financial resources.
Environmental priorities can also influence participation rates and the representation of diverse communities in citizen science projects207. In Nordic countries, for example, the priorities regarding environmental issues may differ from regions where air quality is considered a critical concern. The Nordic countries are known for their emphasis on sustainability, clean energy, and environmental stewardship. However, air quality concerns may not be at the forefront of environmental consciousness (see e.g., Sääksjärvi217) due to factors such as strict environmental regulations, relatively low levels of air pollution compared to other regions, and a strong focus on other environmental issues such as climate change and biodiversity.
Lastly, legal and regulatory barriers add complexities to citizen science projects. Issues related to privacy, confidentiality, fairness, transparency, data ownership, and ethical considerations can impede progress205,218,219. Compliance with relevant laws and regulations, obtaining permits or approvals, and ensuring data protection can be time-consuming and challenging. For example, a project involving the use of drones for vertical distribution of pollutants monitoring may face restrictions due to aviation regulations or privacy concerns related to aerial imagery. Furthermore, the collection of personal data represents a common concern and barrier to citizen engagement. Fairness in data collection and analysis is another legal and regulatory consideration. It is important to ensure that the data collected from citizen science projects is representative and unbiased, without favoring specific demographics or locations220. This requires implementing appropriate sampling strategies, considering potential biases in participant recruitment, and applying rigorous data validation and quality control measures. Transparency in data management and reporting is essential for establishing trust and credibility in citizen science projects218,221,222. Moreover, making project results and findings openly accessible to the public promotes transparency and allows for scrutiny and further analysis. As citizen science projects increasingly use advanced technologies like ML, new ethical considerations emerge that need to be addressed. It is important to address concerns such as algorithmic bias, transparency of decision-making processes, and potential unintended consequences of relying solely on automated systems. Training ML algorithms on diverse and representative datasets and implementing interpretability and explainability techniques are essential to maintain fairness, accountability, and transparency.
Data Availability
No datasets were generated or analysed during the current study.
References
Kampa, M. & Castanas, E. Human health effects of air pollution. Environ. Pollut. 151, 362–367 (2008).
Lovett, G. M. et al. Effects of air pollution on ecosystems and biological diversity in the eastern United States. Ann. N. Y. Acad. Sci. 1162, 99–135 (2009).
Manisalidis, I., Stavropoulou, E., Stavropoulos, A. & Bezirtzoglou, E. Environmental and health impacts of air pollution: a review. Front. Public health 8, 14 (2020).
Snyder, E. G. et al. The changing paradigm of air pollution monitoring. Environ. Sci. Technol. 47, 11369–11377 (2013).
Kumar, P. et al. The rise of low-cost sensing for managing air pollution in cities. Environ. Int. 75, 199–205 (2015).
Williams, R. et al. Air Sensor Guidebook, US Environmental Protection Agency. https://www.epa.gov/sites/default/files/2015-09/documents/nacept_background_material_2.pdf (2014).
Lewis, A., Peltier, W. R. & von Schneidemesser, E. Low-Cost Sensors For The Measurement Of Atmospheric Composition: Overview Of Topic And Future Applications. https://www.ccacoalition.org/resources/low-cost-sensors-measurement-atmospheric-composition-overview-topic-and-future-applications (2018).
Rai, A. C. et al. End-user perspective of low-cost sensors for outdoor air pollution monitoring. Sci. Total Environ. 607, 691–705 (2017).
Considine, E. M., Braun, D., Kamareddine, L., Nethery, R. C. & deSouza, P. Investigating use of low-cost sensors to increase accuracy and equity of real-time air quality information. Environ. Sci. Technol. 57, 1391–1402 (2023).
Motlagh, N. H. et al. Toward massive scale air quality monitoring. IEEE Commun. Mag. 58, 54–59 (2020).
Salamalikis, V., Amirhossein, H., Paweł, Z., Sebastian, B. & Núria, C. Citizen-operated low-cost sensors for estimating outdoor particulate matter infiltration. Air Quality, Atmosphere & Health 1–16 (2025).
European Environment Agency. Assessing Air Quality Through Citizen Science. https://www.eea.europa.eu/en/analysis/publications/assessing-air-quality-through-citizen-science (2019).
White, R. M. et al. Sensors and ‘apps’ for community-based atmospheric monitoring. EM Air Waste Manag. Assoc. Mag. Environ. Manag. 5, 36–40 (2012).
Mahajan, S. et al. Translating citizen-generated air quality data into evidence for shaping policy. Hum. Soc. Sci. Commun. 9, 1–18 (2022).
Castell, N. et al. Can commercial low-cost sensor platforms contribute to air quality monitoring and exposure estimates?. Environ. Int. 99, 293–302 (2017).
Brienza, S., Galli, A., Anastasi, G. & Bruschi, P. A low-cost sensing system for cooperative air quality monitoring in urban areas. Sensors 15, 12242–12259 (2015).
Munir, S., Mayfield, M., Coca, D., Jubb, S. A. & Osammor, O. Analysing the performance of low-cost air quality sensors, their drivers, relative benefits and calibration in cities—a case study in sheffield. Environ. Monit. Assess. 191, 1–22 (2019).
Levy Zamora, M., Buehler, C., Datta, A., Gentner, D. R. & Koehler, K. Identifying optimal co-location calibration periods for low-cost sensors. Atmos. Meas. Tech. 16, 169–179 (2023).
Alfano, B. et al. A review of low-cost particulate matter sensors from the developers’ perspectives. Sensors 20, 6819 (2020).
Karagulian, F. et al. Review of the performance of low-cost sensors for air quality monitoring. Atmosphere 10, 506 (2019).
European Union. Directive 2008/50/EC of the European Parliament and of the Council of 21 May 2008 on ambient airquality and cleaner air for Europe. Official Journal of the European Union (2008).
Baron, R. & Saffell, J. Amperometric gas sensors as a low cost emerging technology platform for air quality monitoring applications: a review. ACS Sens. 2, 1553–1566 (2017).
Clements, A. L. et al. Low-cost air quality monitoring tools: from research to practice (a workshop summary). Sensors 17, 2478 (2017).
McKercher, G. R., Salmond, J. A. & Vanos, J. K. Characteristics and applications of small, portable gaseous air pollution monitors. Environ. Pollut. 223, 102–110 (2017).
Morawska, L. et al. Applications of low-cost sensing technologies for air quality monitoring and exposure assessment: How far have they gone?. Environ. Int. 116, 286–299 (2018).
Omidvarborna, H., Kumar, P., Hayward, J., Gupta, M. & Nascimento, E. G. S. Low-cost air quality sensing towards smart homes. Atmosphere 12, 453 (2021).
Peltier, R. E. et al. An Update on Low-Cost Sensors for the Measurement of Atmospheric Composition, December 2020. https://library.wmo.int/records/item/37465-an-update-on-low-cost-sensors-for-the-measurement-of-atmospheric-composition?offset=29 (2021).
Ródenas García, M. et al. Review of low-cost sensors for indoor air quality: features and applications. Appl. Spectrosc. Rev. 57, 747–779 (2022).
Thompson, J. E. Crowd-sourced air quality studies: a review of the literature & portable sensors. Trends Environ. Anal. Chem. 11, 23–34 (2016).
Delaine, F., Lebental, B. & Rivano, H. In situ calibration algorithms for environmental sensor networks: a review. IEEE Sens. J. 19, 5968–5978 (2019).
Maag, B., Zhou, Z. & Thiele, L. A survey on sensor calibration in air pollution monitoring deployments. IEEE Int. Things J. 5, 4857–4870 (2018).
Giordano, M. R. et al. From low-cost sensors to high-quality data: a summary of challenges and best practices for effectively calibrating low-cost particulate matter mass sensors. J. Aerosol Sci. 158, 105833 (2021).
Venkatraman Jagatha, J. et al. Calibration method for particulate matter low-cost sensors used in ambient air quality monitoring and research. Sensors 21, 3960 (2021).
Kang, Y., Aye, L., Ngo, T. D. & Zhou, J. Performance evaluation of low-cost air quality sensors: a review. Sci. Total Environ. 818, 151769 (2022).
Idrees, Z. & Zheng, L. Low cost air pollution monitoring systems: a review of protocols and enabling technologies. J. Ind. Inf. Integr. 17, 100123 (2020).
Oyola, P., Carbone, S., Timonen, H., Torkmahalleh, M. & Lindén, J. Editorial: Rise of low-cost sensors and citizen science in air quality studies. Front. Environ. Sci. https://doi.org/10.3389/fenvs.2022.868543 (2022).
Kokate, P., Middey, A., Sadistap, S., Sarode, G. & Narayan, A. Review on drone-assisted air-quality monitoring systems. Drones Autonomous Veh. 1, 10005 (2023).
Villa, T. F., Gonzalez, F., Miljievic, B., Ristovski, Z. D. & Morawska, L. An overview of small unmanned aerial vehicles for air quality measurements: present applications and future prospectives. Sensors 16, 1072 (2016).
Clements, A., Duvall, R., Greene, D. & Dye, T. The Enhanced Air Sensor Guidebook. US Environmental Protection Agency. https://cfpub.epa.gov/si/si_public_record_report.cfm?Lab=CEMM&dirEntryId=356426 (2022).
Barcelo-Ordinas, J. M., Garcia-Vidal, J., Doudou, M., Rodrigo-Muñoz, S. & Cerezo-Llavero, A. Calibrating low-cost air quality sensors using multiple arrays of sensors. In 2018 IEEE Wireless Communications and Networking Conference (WCNC), 1-6 (IEEE, 2018).
De Vito, S., Esposito, E., Castell, N., Schneider, P. & Bartonova, A. On the robustness of field calibration for smart air quality monitors. Sens. Actuators B: Chem. 310, 127869 (2020).
Ferrer-Cid, P., Barcelo-Ordinas, J. M., Garcia-Vidal, J., Ripoll, A. & Viana, M. Multisensor data fusion calibration in IoT air pollution platforms. IEEE Internet Things J. 7, 3124–3132 (2020).
Bisignano, A., Carotenuto, F., Zaldei, A. & Giovannini, L. Field calibration of a low-cost sensors network to assess traffic-related air pollution along the Brenner highway. Atmos. Environ. 275, 119008 (2022).
DeSouza, P. et al. Estimating PM 2.5 in Fort Collins, Colorado Using a Robust Drive-By Calibration of Low-Cost Air Quality Monitors Deployed on School Buses. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5215372 (2025).
Kizel, F. et al. Node-to-node field calibration of wireless distributed air pollution sensor network. Environ. Pollut. 233, 900–909 (2018).
Maag, B., Zhou, Z., Saukh, O. & Thiele, L. SCAN: Multi-hop calibration for mobile sensor arrays. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 1, 1–21 (2017).
Sá, J. et al. Two step calibration method for ozone low-cost sensor: field experiences with the UrbanSense DCUs. J. Environ. Manag. 328, 116910 (2023).
Vajs, I., Drajic, D. & Cica, Z. Data-driven machine learning calibration propagation in a hybrid sensor network for air quality monitoring. Sensors 23, 2815 (2023).
Ouimette, J. et al. Fundamentals of low-cost aerosol sensor design and operation. Aerosol Sci. Technol. 58, 1–15 (2024).
Ouimette, J. R. et al. Evaluating the PurpleAir monitor as an aerosol light scattering instrument. Atmos. Meas. Tech. 15, 655–676 (2022).
Jaffe, D. et al. An evaluation of the US EPA’s correction equation for purple air sensor data in smoke, dust and wintertime urban pollution events. Atmos. Meas. Tech. Discuss. 2022, 1–20 (2022).
Raheja, G. et al. Low-cost sensor performance intercomparison, correction factor development, and 2+ years of ambient pm2. 5 monitoring in Accra, Ghana. Environ. Sci. Technol. 57, 10708–10720 (2023).
Cheng, Y., He, X., Zhou, Z. & Thiele, L. Ict: In-field calibration transfer for air quality sensor deployments. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 3, 1–19 (2019).
Laref, R., Losson, E., Sava, A. & Siadat, M. In 2021 International Conference on Control, Automation and Diagnosis (ICCAD). 1-6 (IEEE, 2021).
Liu, N. et al. MAIC: metalearning-based adaptive in-field calibration for IoT air quality monitoring system. IEEE Internet Things J. 9, 15928–15941 (2022).
Cui, H. et al. A new calibration system for low-cost sensor network in air pollution monitoring. Atmos. Pollut. Res. 12, 101049 (2021).
Villanueva, E., Espezua, S., Castelar, G., Diaz, K. & Ingaroca, E. Smart multi-sensor calibration of low-cost particulate matter monitors. Sensors 23, 3776 (2023).
DeSouza, P. et al. Calibrating networks of low-cost air quality sensors. Atmos. Meas. Tech. 15, 6309–6328 (2022).
Abu-Hani, A., Chen, J., Balamurugan, V., Wenzel, A. & Bigi, A. Transferability of ML-based global calibration models for NO 2 and NO low-cost sensors. Atmos. Meas. Tech. Discuss. 2024, 1–23 (2024).
Miquel-Ibarz, A., Burgués, J. & Marco, S. Global calibration models for temperature-modulated metal oxide gas sensors: a strategy to reduce calibration costs. Sens. Actuators B. Chem. 350, 130769 (2022).
Chu, H.-J., Ali, M. Z. & He, Y.-C. Spatial calibration and PM2. 5 mapping of low-cost air quality sensors. Sci. Rep. 10, 22079 (2020).
Vikram, S. et al. Evaluating and improving the reliability of gas-phase sensor system calibrations across new locations for ambient measurements and personal exposure monitoring. Atmos. Meas. Tech. 12, 4211–4239 (2019).
De Vito, S., D’Elia, G. & Di Francia, G. In IEEE International Symposium on Olfaction and Electronic Nose (ISOEN). 1-4 (IEEE, 2022).
Solórzano, A. et al. Multi-unit calibration rejects inherent device variability of chemical sensor arrays. Sens. Actuators B: Chem. 265, 142–154 (2018).
Bagkis, E., Kassandros, T. & Karatzas, K. Learning calibration functions on the fly: hybrid batch online stacking ensembles for the calibration of low-cost air quality sensor networks in the presence of concept drift. Atmosphere 13, 416 (2022).
Zhang, Y. et al. STCM: A spatio-temporal calibration model for low-cost air monitoring sensors. Inf. Sci. 644, 119307 (2023).
Wu, D. Y. et al. Detecting inaccurate sensors on a large-scale sensor network using centralized and localized graph neural networks. IEEE Sens. J. 23, 16446–16455 (2023).
Jin, Z., Xu, J., Huang, R., Shao, W. & Xiao, X. In International Joint Conference on Neural Networks (IJCNN). 01-08 (IEEE, 2022).
Iyer, S. R. et al. Modeling fine-grained spatio-temporal pollution maps with low-cost sensors. npj Clim. Atmos. Sci. 5, 76 (2022).
Li, P., Zhang, T. & Jin, Y. A spatio-temporal graph convolutional network for air quality prediction. Sustainability 15, 7624 (2023).
Ferrer-Cid, P., Barcelo-Ordinas, J. M. & Garcia-Vidal, J. Volterra graph-based outlier detection for air pollution sensor networks. IEEE Trans. Netw. Sci. Eng. 9, 2759–2771 (2022).
Dey, S., Arora, V. & Tripathi, S. N. Leveraging unsupervised data and domain adaptation for deep regression in low-cost sensor calibration. In IEEE Transactions on Neural Networks and Learning Systems (IEEE, 2024).
Schlund, R. et al. International Summit Smart City 360. https://link.springer.com/conference/sc (2020).
Chen, F. et al. Adaptive graph convolutional imputation network for environmental sensor data recovery. Front. Environ. Sci. 10, 1025268 (2022).
Okafor, N. U. & Delaney, D. T. Missing data imputation on IoT sensor networks: implications for on-site sensor calibration. IEEE Sens. J. 21, 22833–22845 (2021).
Dong, G. et al. Graph neural networks in IoT: a survey. ACM Trans. Sens. Netw. 19, 1–50 (2023).
Xu, J. et al. Dynamic graph neural network with adaptive edge attributes for air quality prediction: a case study in China. Heliyon 9, e17746 (2023).
Zhou, H. et al. Informer: Beyond efficient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 35, 11106–11115 (2021).
Hassani, A., Salamalikis, V., Schneider, P., Stebel, K. & Castell, N. A scalable framework for harmonizing, standardization, and correcting crowd-sourced low-cost sensor PM2. 5 data across Europe. J. Environ. Manag. 380, 125100 (2025).
Jion, M. M. M. F. et al. A critical review and prospect of NO2 and SO2 pollution over Asia: hotspots, trends, and sources. Sci. Total Environ. 876, 162851 (2023).
Kilpatrick, D. J. et al. Geographic variations in urban-rural particulate matter (PM2. 5) concentrations in the United States, 2010–2019. GeoHealth 8, e2023GH000920 (2024).
Wang, A. et al. Key themes, trends, and drivers of mobile ambient air quality monitoring: a systematic review and meta-analysis. Environ. Sci. Technol. 57, 9427–9444 (2023).
Sladojevic, S., Arsenovic, M., Nikolic, D., Anderla, A. & Stefanovic, D. Advancements in mobile-based air pollution detection: from literature review to practical implementation. J. Sens. 2024, 4895068 (2024).
Gozzi, F., Della Ventura, G. & Marcelli, A. Mobile monitoring of particulate matter: state of art and perspectives. Atmos. Pollut. Res. 7, 228–234 (2016).
Elen, B. et al. The Aeroflex: a bicycle for mobile air quality measurements. Sensors 13, 221–240 (2012).
Hassani, A., Castell, N., Watne, ÅK. & Schneider, P. Citizen-operated mobile low-cost sensors for urban PM2. 5 monitoring: field calibration, uncertainty estimation, and application. Sustain. Cities Soc. 95, 104607 (2023).
Mendoza, D. L. et al. The TRAX light-rail train air quality observation project. Urban Sci. 3, 108 (2019).
deSouza, P. Air Quality Monitoring Case Study Using Mobile Low-cost Sensors mounted on Trash-Trucks: Methods Development and Lessons Learned. Sustain. Cities Soc 60, 102239 (2020).
Bales, E. et al. Personal pollution monitoring: mobile real-time air quality in daily life. Personal. Ubiquitous Comput. 23, 309–328 (2019).
An, S., Hu, X. & Wang, J. Urban taxis and air pollution: a case study in Harbin, China. J. Transp. Geogr. 19, 960–967 (2011).
Krüger, E., Ihlenfeld, W., Callejas, I. & Leder, S. Introducing PLEMS: the application of a low-cost, portable monitoring system in environmental walks. Int. J. Biometeorol. 68, 2357–2371 (2024).
O’Keeffe, K. P., Anjomshoaa, A., Strogatz, S. H., Santi, P. & Ratti, C. Quantifying the sensing power of vehicle fleets. Proc. Natl Acad. Sci. 116, 12752–12757 (2019).
Anjomshoaa, A., Santi, P., Duarte, F. & Ratti, C. Quantifying the spatio-temporal potential of drive-by sensing in smart cities. J. Urban Technol. 28, 199–216 (2021).
Kim, S.-Y., Blanco, M. N., Bi, J., Larson, T. V. & Sheppard, L. Exposure assessment for air pollution epidemiology: a scoping review of emerging monitoring platforms and designs. Environ. Res. 223, 115451 (2023).
Mahajan, S. & Kumar, P. Evaluation of low-cost sensors for quantitative personal exposure monitoring. Sustain. Cities Soc. 57, 102076 (2020).
West, S. E. et al. Particulate matter pollution in an informal settlement in Nairobi: using citizen science to make the invisible visible. Appl. Geogr. 114, 102133 (2020).
Kappelt, N. et al. Particulate air pollution in the Copenhagen metro part 1: mass concentrations and ventilation. Environ. Int. 171, 107621 (2023).
Russell, H. S. et al. Particulate air pollution in the Copenhagen metro part 2: low-cost sensors and micro-environment classification. Environ. Int. 170, 107645 (2022).
Priyanka, N. D. et al. Spatial variation of fine particulate matter levels in Nairobi before and during the COVID-19 curfew: implications for environmental justice. Environ. Res. Commun. 3, 071003 (2021).
Tian, Y. et al. Evaluating the meteorological effects on the urban form–air quality relationship using mobile monitoring. Environ. Sci. Technol. 56, 7328–7336 (2022).
Tian, Y. et al. Improving NO2 prediction by integrating tree diversity, urban form, and scale sensitivity through mobile monitoring. Appl. Geogr. 154, 102943 (2023).
Schneider, P. et al. Mapping urban air quality in near real-time using observations from low-cost sensors and model information. Environ. Int. 106, 234–247 (2017).
Dubey, R., Patra, A. K., Joshi, J. & Blankenberg, D. Evaluation of vertical and horizontal distribution of particulate matter near an urban roadway using an unmanned aerial vehicle. Sci. Total Environ. 836, 155600 (2022).
Wu, C. et al. Vertical profiling of black carbon and ozone using a multicopter unmanned aerial vehicle (UAV) in urban Shenzhen of South China. Sci. Total Environ. 801, 149689 (2021).
Dubey, R. et al. Vertical distribution of particulate matter near a national highway and influence of roadside tree canopy: a drone/UAV based study. Atmos. Environ. 336, 120761 (2024).
Pochwała, S., Gardecki, A., Lewandowski, P., Somogyi, V. & Anweiler, S. Developing of low-cost air pollution sensor—measurements with the unmanned aerial vehicles in Poland. Sensors 20, 3582 (2020).
Bretschneider, L. et al. MesSBAR—multicopter and instrumentation for air quality research. Atmosphere 13, 629 (2022).
Hedworth, H. A., Sayahi, T., Kelly, K. E. & Saad, T. The effectiveness of drones in measuring particulate matter. J. Aerosol Sci. 152, 105702 (2021).
Pochwała, S. et al. Optimization of air pollution measurements with unmanned aerial vehicle low-cost sensor based on an inductive knowledge management method. Optim. Eng. 22, 1783–1805 (2021).
Motlagh, N. H. et al. Unmanned aerial vehicles for air pollution monitoring: a survey. In IEEE Internet of Things Journal 21687−21704 (IEEE, 2023).
Sharma, M. & Jain, S. Unmanned aerial vehicles and low-cost sensors for air quality monitoring: a comprehensive review of applications across diverse emission sources. Sustain Cities Soc 127, 106409 (2025).
Hemamalini, R. R. et al. Air quality monitoring and forecasting using smart drones and recurrent neural network for sustainable development in Chennai city. Sustain. Cities Soc. 85, 104077 (2022).
Padmakumari, B., Kalgutkar, S., Nikam, M. & Mukherjee, S. Lower atmospheric profiling for climate studies pertaining to aerosols, radiation and turbulence using unmanned aerial system in India: initial results. Atmos. Environ 351, 121211 (2025).
Harm-Altstädter, B. et al. First study using a fixed-wing drone for systematic measurements of aerosol vertical distribution close to a civil airport. Front. Environ. Sci. 12, 1376980 (2024).
Schön, M., Savvakis, V., Kezoudi, M., Platis, A. & Bange, J. OPC-Pod: A new sensor payload to measure aerosol particles for small uncrewed aircraft systems. J. Atmos. Ocean. Technol. 41, 499–513 (2024).
Liu, C. et al. Evaluation of WRF-Chem simulations on vertical profiles of PM2. 5 with UAV observations during a haze pollution event. Atmos. Environ. 252, 118332 (2021).
Zhu, Z., Do, K., Ivey, C. E. & Collins, D. R. Assessing CMAQ model discrepancies in a heavily polluted air basin using UAV vertical profiles and sensitivity analyses. Environ. Sci. Atmos.4, 1051–1063 (2024).
Lee, S.-H. & Kwak, K.-H. Assessing 3-D spatial extent of near-road air pollution around a signalized intersection using drone monitoring and WRF-CFD modeling. Int. J. Environ. Res. Public Health 17, 6915 (2020).
Erraji, H. et al. The potential of drone observations to improve air quality predictions by 4D-var. Atmos. Chem. Phys. 24, 13913–13934 (2024).
Carrassi, A., Bocquet, M., Bertino, L. & Evensen, G. Data assimilation in the geosciences: An overview of methods, issues, and perspectives. Wiley Interdiscip. Rev.: Clim. Change 9, e535 (2018).
Lepioufle, J.-M. et al. Data fusion of sparse, heterogeneous, and mobile sensor devices using adaptive distance attention. Environ. Data Sci. 3, e19 (2024).
Schneider, P. et al. Deployment and evaluation of a network of open low-cost air quality sensor systems. Atmosphere 14, 540 (2023).
Lahoz, W. A. & Schneider, P. Data assimilation: making sense of Earth observation. Front. Environ. Sci. 2, 16 (2014).
Goovaerts, P. Geostatistics for Natural Resources Evaluation Online edn (Oxford University Press, USA, 1997).
Kalnay, E. Atmospheric Modeling, Data Assimilation and Predictability, Vol. 368 (Cambridge university press, 2003).
Shetty, S. et al. Daily high-resolution surface PM2. 5 estimation over Europe by ML-based downscaling of the CAMS regional forecast. Environ. Res. 264, 120363 (2025).
Li, J. et al. Integrating low-cost air quality sensor networks with fixed and satellite monitoring systems to study ground-level PM2. 5. Atmos. Environ. 223, 117293 (2020).
Castell, N. et al. Localized real-time information on outdoor air quality at kindergartens in Oslo, Norway using low-cost sensor nodes. Environ. Res. 165, 410–419 (2018).
Schneider, P. et al. A network of low-cost air quality sensors and its use for mapping urban air quality.In Mobile Information Systems Leveraging Volunteered Geographic Information For Earth Observation, (eds. Bordogna, G., Carrara, P.) 93−110 (Springer, 2018).
Gressent, A., Malherbe, L., Colette, A., Rollin, H. & Scimia, R. Data fusion for air quality mapping using low-cost sensor observations: feasibility and added-value. Environ. Int. 143, 105965 (2020).
Adams, M. D., Massey, F., Chastko, K. & Cupini, C. Spatial modelling of particulate matter air pollution sensor measurements collected by community scientists while cycling, land use regression with spatial cross-validation, and applications of machine learning for data correction. Atmos. Environ. 230, 117479 (2020).
Coker, E. S., Amegah, A. K., Mwebaze, E., Ssematimba, J. & Bainomugisha, E. A land use regression model using machine learning and locally developed low cost particulate matter sensors in Uganda. Environ. Res. 199, 111352 (2021).
Jain, S., Presto, A. A. & Zimmerman, N. Spatial modeling of daily PM2. 5, NO2, and CO concentrations measured by a low-cost sensor network: comparison of linear, machine learning, and hybrid land use models. Environ. Sci. Technol. 55, 8631–8641 (2021).
Lim, C. C. et al. Mapping urban air quality using mobile sampling with low-cost sensors and machine learning in Seoul, South Korea. Environ. Int. 131, 105022 (2019).
Weissert, L. et al. Low-cost sensor networks and land-use regression: Interpolating nitrogen dioxide concentration at high temporal and spatial resolution in Southern California. Atmos. Environ. 223, 117287 (2020).
Guo, R. et al. High-resolution urban air quality mapping for multiple pollutants based on dense monitoring data and machine learning. Int. J. Environ. Res. public health 19, 8005 (2022).
Liang, L. et al. Integrating low-cost sensor monitoring, satellite mapping, and geospatial artificial intelligence for intra-urban air pollution predictions. Environ. Pollut. 331, 121832 (2023).
Lopez-Ferber, R., Leirens, S. & Georges, D. Source estimation: variational method versus machine learning applied to urban air pollution. IFAC PapersOnLine 55, 78–83 (2022).
Bocquet, M. et al. Data assimilation in atmospheric chemistry models: current status and future prospects for coupled chemistry meteorology models. Atmos. Chem. Phys. 15, 5325–5358 (2015).
Mijling, B. High-resolution mapping of urban air quality with heterogeneous observations: a new methodology and its application to Amsterdam. Atmos. Meas. Tech. 13, 4601–4617 (2020).
Hassani, A., Schneider, P., Vogt, M. & Castell, N. Low-cost particulate matter sensors for monitoring residential wood burning. Environ. Sci. Technol. 57, 15162–15172 (2023).
Lopez-Restrepo, S. et al. Urban air quality modeling using low-cost sensor network and data assimilation in the aburrá valley, colombia. Atmosphere 12, 91 (2021).
Fletcher, S. J. Data Assimilation for the Geosciences: From Theory to Application. (Elsevier, 2017).
Bannister, R. N. A review of operational methods of variational and ensemble-variational data assimilation. Q. J. R. Meteorol. Soc. 143, 607–633 (2017).
Martin, R. V. Satellite remote sensing of surface air quality. Atmos. Environ. 42, 7823–7843 (2008).
Kuttippurath, J. & Patel, V. K. in Sustainable Development Perspectives in Earth Observation 1st edn (Elsevier, 2025).
Engel-Cox, J. A., Hoff, R. M. & Haymet, A. Recommendations on the use of satellite remote-sensing data for urban air quality. J. Air Waste Manag. Assoc. 54, 1360–1371 (2004).
Wang, Y., Cai, G., Yang, L., Zhang, N. & Du, M. Monitoring of urban ecological environment including air quality using satellite imagery. PLoS ONE17, e0266759 (2022).
Friberg, M. D., Kahn, R. A., Limbacher, J. A., Appel, K. W. & Mulholland, J. A. Constraining chemical transport pm 2.5 modeling outputs using surface monitor measurements and satellite retrievals: application over the san joaquin valley. Atmos. Chem. Phys. 18, 12891–12913 (2018).
East, J. D. et al. Inferring and evaluating satellite-based constraints on NOx emissions estimates in air quality simulations. Atmos. Chem. Phys. Discuss. 2022, 1–31 (2022).
Chao, C.-Y. et al. Integrating fixed monitoring systems with low-cost sensors to create high-resolution air quality maps for the Northern China plain region. ACS Earth Space Chem. 5, 3022–3035 (2021).
Gupta, P. et al. Impact of California fires on local and regional air quality: the role of a low-cost sensor network and satellite observations. GeoHealth 2, 172–181 (2018).
Huang, K. et al. Estimating daily PM2. 5 concentrations in New York City at the neighborhood-scale: implications for integrating non-regulatory measurements. Sci. Total Environ. 697, 134094 (2019).
Yu, M. et al. Developing high-resolution PM2. 5 exposure models by integrating low-cost sensors, automated machine learning, and big human mobility data. Front. Environ. Sci. 11, 1223160 (2023).
Bi, J., Wildani, A., Chang, H. H. & Liu, Y. Incorporating low-cost sensor measurements into high-resolution PM2. 5 modeling at a large spatial scale. Environ. Sci. Technol. 54, 2152–2162 (2020).
Fu, J. et al. A machine learning-based approach for fusing measurements from standard sites, low-cost sensors, and satellite retrievals: application to NO2 pollution hotspot identification. Atmos. Environ. 302, 119756 (2023).
Bi, J. et al. Contribution of low-cost sensor measurements to the prediction of PM2. 5 levels: a case study in Imperial County, California, USA. Environ. Res. 180, 108810 (2020).
Lin, C. et al. Observation of PM2. 5 using a combination of satellite remote sensing and low-cost sensor network in Siberian urban areas with limited reference monitoring. Atmos. Environ. 227, 117410 (2020).
Lyapustin, A., Wang, Y. MCD19A2 MODIS/Terra+Aqua Land Aerosol Optical Depth Daily L2G Global 1km SIN Grid. https://ladsweb.modaps.eosdis.nasa.gov/missions-and-measurements/products/MCD19A2 (2025).
Seinfeld, J. H. & Pandis, S. N. Atmospheric Chemistry And Physics: From Air Pollution To Climate Change 3rd edn, Vol. 1152 (John Wiley & Sons, 2016).
Kruger, L. E. & Shannon, M. A. Getting to know ourselves and our places through participation in civic social assessment. Soc. Nat. Resour. 13, 461–478 (2000).
Singh, D., Dahiya, M., Kumar, R. & Nanda, C. Sensors and systems for air quality assessment monitoring and management: a review. J. Environ. Manag. 289, 112510 (2021).
Watne, ÅK. et al. Tackling data quality when using low-cost air quality sensors in citizen science projects. Front. Environ. Sci. 9, 733634 (2021).
Velea, L., Udriștioiu, M. T., Puiu, S., Motișan, R. & Amarie, D. A community-based sensor network for monitoring the air quality in Urban Romania. Atmosphere 14, 840 (2023).
Alfonso, L., Gharesifard, M. & Wehn, U. Analysing the value of environmental citizen-generated data: Complementarity and cost per observation. J. Environ. Manag. 303, 114157 (2022).
Hassani, A. et al. Low-cost sensors and Machine Learning aid in identifying environmental factors affecting particulate matter emitted by household heating. Atmos. Environ. 314, 120108 (2023).
Hubbell, B. J. et al. Understanding social and behavioral drivers and impacts of air quality sensor use. Sci. Total Environ. 621, 886–894 (2018).
Mahajan, S. et al. A citizen science approach for enhancing public understanding of air pollution. Sustain. Cities Soc. 52, 101800 (2020).
Park, Y. M. et al. Personal exposure monitoring using GPS-enabled portable air pollution sensors: a strategy to promote citizen awareness and behavioral changes regarding indoor and outdoor air pollution. J. Exposure Sci. Environ. Epidemiol. 33, 347–357 (2023).
Commodore, A., Wilson, S., Muhammad, O., Svendsen, E. & Pearce, J. Community-based participatory research for the study of air pollution: a review of motivations, approaches, and outcomes. Environ. Monit. Assess. 189, 1–30 (2017).
Ekman, K. & Weilenmann, A. Behind the scenes of planning for public participation: planning for air-quality monitoring with low-cost sensors. J. Environ. Plan. Manag. 64, 865–882 (2021).
Longo, A., Zappatore, M. & Bochicchio, M. A. Apollon: Towards a citizen science methodology for urban environmental monitoring. Future Gener. Comput. Syst. 112, 899–912 (2020).
Barros, N. et al. SchoolAIR: A citizen science IoT framework using low-cost sensing for indoor air quality management. Sensors 24, 148 (2023).
Connolly, R. E. et al. Long-term evaluation of a low-cost air sensor network for monitoring indoor and outdoor air quality at the community scale. Sci. Total Environ. 807, 150797 (2022).
Bainomugisha, E., Ssematimba, J. & Okure, D. Design considerations for a distributed low-cost air quality sensing system for urban environments in low-resource settings. Atmosphere 14, 354 (2023).
Che, W. et al. PRAISE-HK: A personalized real-time air quality informatics system for citizen participation in exposure and health risk management. Sustain. Cities Soc. 54, 101986 (2020).
Jiao, W. et al. Community Air Sensor Network (CAIRSENSE) project: evaluation of low-cost sensor performance in a suburban environment in the southeastern United States. Atmos. Meas. Tech. 9, 5281–5292 (2016).
Libasin, Z., Ul-Saufie, A. Z., Ahmat, H. & Shaziayani, W. N. Single and multiple imputation method to replace missing values in air pollution datasets: a review. IOP Conf. Ser. Earth Environ. Sci. 616, 012002 (2020).
Xiang, Q., Zi, L., Cong, X. & Wang, Y. Concept drift adaptation methods under the deep learning framework: a literature review. Appl. Sci. 13, 6515 (2023).
Mui, W. et al. Development of a performance evaluation protocol for air sensors deployed on a google street view car. Environ. Sci. Technol. 55, 1477–1486 (2021).
deSouza, P. et al. Evaluating the performance of low-cost PM2.5 sensors in mobile settings. Environ. Sci. Technol. 57, 15401–15411 (2023).
Russell, H. S. et al. Hyperlocal air pollution in london: validating low-cost sensors for mobile measurements from vehicles. ACS EST Air 1, 438–450 (2024).
Arfire, A., Marjovi, A. & Martinoli, A. In EWSN'16: Proceedings of the 2016 International Conference on Embedded Wireless Systems and Networks, 159–167 (Junction Publishing, 2016).
Messier, K. P. et al. Mapping air pollution with google street view cars: efficient approaches with mobile monitoring and land use regression. Environ. Sci. Technol. 52, 12563–12572 (2018).
Anjomshoaa, A. et al. City scanner: building and scheduling a mobile sensing platform for smart city services. IEEE Int. Things J. 5, 4567–4579 (2018).
Hasenfratz, D., Saukh, O. & Thiele, L. European Conference on Wireless Sensor Networks. https://www.ewsn.org/ (2025).
Burgués, J. & Marco, S. Environmental chemical sensing using small drones: a review. Sci. total Environ. 748, 141172 (2020).
Lambey, V. & Prasad, A. A review on air quality measurement using an unmanned aerial vehicle. Water, Air, Soil Pollut. 232, 1–32 (2021).
Savvakis, V., Schön, M., Bramati, M., Bange, J. & Platis, A. Small-scale diffusion dryer on an optical particle counter for high-humidity aerosol measurements with an uncrewed aircraft system. J. Atmos. Ocean. Technol. 41, 205–219 (2024).
Liang, C.-W. & Shen, C.-H. Integrated unmanned aerial vehicle platform with sensing and sampling systems for the measurement of air pollutant concentrations. Atmos. Meas. Tech. Discuss. 2023, 1–21 (2023).
Masic, A. et al. Evaluation of optical particulate matter sensors under realistic conditions of strong and mild urban pollution. Atmos. Meas. Tech. 13, 6427–6443 (2020).
Moormann, L. et al. The Flying Laboratory FLab: Development and application of a UAS to measure aerosol particles and trace gases in the lower troposphere. EGUsphere 2024, 1–30 (2024).
Diez, S. et al. Air pollution measurement errors: is your data fit for purpose?. Atmos. Meas. Tech. 15, 4091–4105 (2022).
Hagler, G. S. W., Williams, R., Papapostolou, V. & Polidori, A. Air quality sensors and data adjustment algorithms: when is it no longer a measurement?. Environ. Sci. Technol 52, 5530–5531 (2018).
Schneider, P. et al. Toward a unified terminology of processing levels for low-cost air-quality sensors. Environ. Sci. Technol. 53, 8485–8487 (2019).
Evensen, G., Vossepoel, F. C. & Van Leeuwen, P. J. Data Assimilation Fundamentals: A Unified Formulation Of The State And Parameter Estimation Problem 1st edn, Vol. 245 (Springer Nature, 2022).
Peters, D. R. et al. Evaluating uncertainty in sensor networks for urban air pollution insights. Atmos. Meas. Tech. Discuss. 2021, 1–23 (2021).
Tilloy, A., Mallet, V., Poulet, D., Pesin, C. & Brocheton, F. BLUE-based NO 2 data assimilation at urban scale. J. Geophys. Res. Atmos. 118, 2031–2040 (2013).
Evensen, G. The ensemble Kalman filter: theoretical formulation and practical implementation. Ocean Dyn. 53, 343–367 (2003).
Wang, K. Y., Lary, D. J., Shallcross, D. E., Hall, S. M. & Pyle, J. A. A review on the use of the adjoint method in four-dimensional atmospheric-chemistry data assimilation. Q. J. R. Meteorol. Soc. 127, 2181–2204 (2001).
Conrad, C. C. & Hilchey, K. G. A review of citizen science and community-based environmental monitoring: issues and opportunities. Environ. Monit. Assess. 176, 273–291 (2011).
Wehn, U. & Almomani, A. Incentives and barriers for participation in community-based environmental monitoring and information systems: a critical analysis and integration of the literature. Environ. Sci. Policy 101, 341–357 (2019).
Hassani, A., Santos, G. S., Schneider, P. & Castell, N. Interpolation, satellite-based machine learning, or meteorological simulation? a comparison analysis for spatio-temporal mapping of mesoscale urban air temperature. Environ. Model. Assess. 29, 291–306 (2024).
Sorensen, A. E. et al. Reflecting on efforts to design an inclusive citizen science project in West Baltimore. Citiz. Sci. Theory Pract. 4, 1 (2019).
Lee, K. A., Lee, J. R. & Bell, P. A review of citizen science within the Earth sciences: potential benefits and obstacles. Proc. Geologists’ Assoc. 131, 605–617 (2020).
Maccani, G., Goossensen, M., Righi, V., Creus, J. & Balestrini, M. Scaling Up Citizen Science: What Are The Factors Associated With Increased Reach And How To Lever Them To Achieve Impact. https://publications.jrc.ec.europa.eu (2020).
Geoghegan, H., Dyke, A., Pateman, R., West, S. & Everett, G. Understanding Motivations for Citizen Science. Fhttps://www.sei.org/publications/understanding-motivations-for-citizen-science/ (2016).
Kaginalkar, A., Kumar, S., Gargava, P. & Niyogi, D. Stakeholder analysis for designing an urban air quality data governance ecosystem in smart cities. Urban Clim. 48, 101403 (2023).
Muñoz-Pizza, D. M. et al. Barriers and opportunities to incorporate scientific evidence into air quality management in Mexico: a stakeholders’ perspective. Environ. Sci. Policy 129, 87–95 (2022).
West, S. E., Pateman, R. M. & Dyke, A. Variations in the motivations of environmental citizen scientists. Citiz. Sci. Theory Pract. 6, 1 (2021).
Grineski, S. E., Collins, T. W. & Mullen, C. J. When not implemented communally, citizen science efforts may reflect, reinforce, and potentially exacerbate environmental injustice. Am. J. Public Health 112, 348–350 (2022).
Benyei, P. et al. Challenges, strategies, and impacts of doing citizen science with marginalised and indigenous communities: reflections from project coordinators. Citiz. Sci. Theory Pract. 8, 21 (2023).
Tengö, M., Austin, B. J., Danielsen, F. & Fernández-Llamazares, Á Creating synergies between citizen science and Indigenous and local knowledge. BioScience 71, 503–518 (2021).
Pateman, R. M., Dyke, A. & West, S. E. The diversity of participants in environmental citizen science. Citiz. Sci. Theory Pract. 6, 9 (2021).
Tubridy, F., Mölter, A., Lennon, M. & Pilla, F. Citizen science and environmental justice: exploring contradictory outcomes through a case study of air quality monitoring in Dublin. Local Environ. 27, 622–638 (2022).
deSouza, P. & Kinney, P. L. On the distribution of low-cost PM2. 5 sensors in the US: demographic and air quality associations. J. Exposure Sci. Environ. Epidemiol. 31, 514–524 (2021).
Sääksjärvi, S. C. Positioning the Nordic countries in European Union environmental policy. J. Environ. Dev. 29, 393–419 (2020).
de Sherbinin, A. et al. The critical importance of citizen science data. Front. Clim. 3, 650760 (2021).
Fraisl, D. et al. Citizen science in environmental and ecological sciences. Nat. Rev. Methods Prim. 2, 64 (2022).
Christine, D. I. & Thinyane, M. Citizen science as a data-based practice: a consideration of data justice. Patterns 2, 100224 (2021).
Bowser, A. et al. Still in need of norms: the state of the data in citizen science. Citiz Sci. Theory Pract 5, 18 (2020).
Heigl, F. et al. Co-creating and implementing quality criteria for citizen science. Citiz. Sci. Theory Pract. 5, 23 (2020).
Van Poppel, M., Schneider, P., Peters, J., Yatkin, S., Gerboles, M., Matheeussen, C., & Haugen, R. (2023). SensEURCity: A multi-city air quality dataset collectedfor 2020/2021 using open low-cost sensor systems. Scientific data, 10(1), 322.
Bifet, A. & Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings Of The 2007 SIAM International Conference On Data Mining. 443−448 (Society for Industrial and Applied Mathematics (SIAM), 2027).
Acknowledgements
We acknowledge funding for CitiObs project funded by the European Union, under grant agreement No.101086421. Further partial funding through the projects CitySatAir (European Space Agency, 4000131513/20/I-DT) and URBANITY (Norwegian Research Council, Project 321118) is gratefully acknowledged.
Funding
Open access funding provided by NILU - Norwegian Institute For Air Research.
Author information
Authors and Affiliations
Contributions
Conceptualization: E.B., A.H., A.A., and J.K. Methodology: E.B., A.H., A.A., and J.K. Writing — Abstract and Introduction: A.H. and E.B. Fixed LCSN Data Integration with Regulatory Environmental Monitoring Networks: E.B., A.H., K.K., and T.K., Mobile Monitoring: P.D. and A.H. Application of Sensors in Vertical Monitoring of Pollutants using Drones: A.A. and A.H. Using Sensor LCS Data for Data Fusion and Data Assimilation: P.S. Recent Applications in Remote Sensing Studies and data Fusion with Satellite Data: S.S., J.K., and A.H. Sensors Application in Citizen Science Projects: A.H. and N.C. Visualization: E.B., A.H., and P.S. Final Review and Editing: A.H. and E.B.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bagkis, E., Hassani, A., Schneider, P. et al. Evolving trends in application of low-cost air quality sensor networks: challenges and future directions. npj Clim Atmos Sci 8, 335 (2025). https://doi.org/10.1038/s41612-025-01216-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41612-025-01216-4
This article is cited by
-
Drone measurements reveal high near-surface urban haze
npj Clean Air (2026)
