
Abstract
Phenotypic information for cancer research is embedded in unstructured electronic health records (EHR), requiring effort to extract. Deep learning models can automate this but face scalability issues due to privacy concerns. We evaluated techniques for applying a teacher-student framework to extract longitudinal clinical outcomes from EHRs. We focused on the challenging task of ascertaining two cancer outcomes—overall response and progression according to Response Evaluation Criteria in Solid Tumors (RECIST)—from free-text radiology reports. Teacher models with hierarchical Transformer architecture were trained on data from Dana-Farber Cancer Institute (DFCI). These models labeled public datasets (MIMIC-IV, Wiki-text) and GPT-4-generated synthetic data. “Student” models were then trained to mimic the teachers’ predictions. DFCI “teacher” models achieved high performance, and student models trained on MIMIC-IV data showed comparable results, demonstrating effective knowledge transfer. However, student models trained on Wiki-text and synthetic data performed worse, emphasizing the need for in-domain public datasets for model distillation.
Similar content being viewed by others

Introduction
Modern precision oncology research requires an understanding of associations between clinical or molecular features and clinical outcomes. However, datasets containing detailed clinical outcomes for linking to molecular data are limited. The challenge arises from the collection of data on key clinical outcomes (phenotypes) for cancer patients undergoing treatment in real-world clinical settings. Relevant phenotypic information is typically embedded in unstructured electronic health records (EHR), historically necessitating considerable manual effort and time to abstract.
Artificial intelligence methods, such as deep neural networks, provide a means to extract phenotypes from unstructured EHR data. Several studies have demonstrated the feasibility of using conventional natural language processing (NLP) and large language models (LLMs)-based approaches to extract outcomes such as disease progression and response to cancer therapy from individual radiology reports and medical oncologist notes1,2,3,4,5. However, many clinical variables of interest in cancer research and care delivery, such as traditional Response Evaluation Criteria in Solid Tumors (RECIST) annotations6,7, can only be defined in the longitudinal context of a patient’s disease trajectory. Neural network architectures that can implicitly process longitudinal inputs may therefore be better suited to extract such data.
A key challenge that limits scalability of models trained using highly sensitive longitudinal EHR data8,9 is their theoretical ability to implicitly memorize sensitive details during training and inadvertently expose them during inference10,11. Federated learning, in which private training data are housed within individual silos and only model weight updates are shared centrally, has been proposed as one solution to generalizable model training12. However, federated learning may not necessarily eliminate the privacy concern related to encoding private data into those model weights. Model distillation within a teacher-student paradigm is another possible approach13. This method involves training a “teacher” model on the sensitive patient data, which is then used to generate synthetic labels for a publicly available dataset. A “student” model is subsequently trained on this labeled public dataset, effectively transferring the learned knowledge from the teacher while mitigating the risk of privacy leaks. This can be extended formally using Private Aggregation of Teacher Ensembles, in which labels are generated on public data by multiple teacher models trained independently on private datasets and aggregated prior to training of the student model14.
Previously, we successfully applied teacher-student distillation framework to annotate real-world cancer outcomes from EHRs15. However, optimal strategies for applying model distillation to longitudinal clinical phenotyping using unstructured EHR data are still not well-defined. Therefore, in this study, we extend the teacher-student distillation framework to ascertain RECIST-based clinical outcomes such as overall response and progression of disease, from free-text radiology reports, specifically investigating how variations in training data composition and distillation strategies impact model performance.
Results
This study included 5153 patients treated on clinical trials at Dana-Farber Cancer Institute (DFCI). The median age at the time of trial enrollment was 60 (interquartile range: 52–67). Approximately 3133 (60.8%) were female. Most of the patients were white (90.2%, n = 4653), followed by Asian (2.9%, n = 149), and black (2.8%, n = 145). The most common cancer types represented were breast cancer (n = 1006; 19.5%); lung cancer (n = 573; 11.1%); and ovarian cancer (n = 539; 10.5%). The detailed distribution of different cancers is outlined in Supplementary Table 1. The full cohort had 99,318 radiological reports with manually curated RECIST labels at a total of 38,727 timepoints (Table 1). On a per-timepoint basis in the validation set, the prevalence of overall response and progressive disease was 36% and 21%, respectively. Within the held-out test set, the prevalence of overall response and progressive disease was 33% and 21%, respectively.
Distillation dataset alignment
The Medical Information Mart for Intensive Care-IV (MIMIC-IV) and generative pre-trained transformer-4-turbo (GPT-4) synthetic datasets showed strong semantic alignment with the original PHI containing DFCI dataset (mean of max cosine similarities: 0.794 and 0.809, respectively). As expected, Wiki-text had lower semantic alignment, with mean of max cosine similarities of 0.197). The mean coefficients of variation across randomly selected batches of 16 documents from each of these datasets were calculated, and the GPT-4 synthetic dataset had the lowest variation (174%), while MIMIC-IV had the highest (307%); Supplementary Table 2.
Performance across training strategies
Performance across different training strategies is shown as Figs. 1, 2 and Supplementary Tables 3, 4. Confusion matrices are available in Supplementary Tables 5, 6. Performance curves are available in Supplementary Figs. 1–12. Performance is reported on the validation dataset (10% of the original protected health information [PHI]-containing DFCI dataset) and on the held-out test dataset (10% of the original dataset).

The validation set is sampled from the original PHI-containing DFCI dataset and is used during the training process to fine-tune hyperparameters and monitor model performance. The figure includes six panels representing experimental setups: a Teacher with temporal context, b Teacher without temporal context, c Teacher-Public Student (MIMIC-IV), d Teacher-Public Student (Wiki-text), e Teacher-GPT-4 Student, and f GPT-4 Student only. Metrics are shown with purple for AUROC, teal for AUPRC, and yellow for Best F1. Red dashed lines indicate 36% overall response prevalence, and blue dashed lines indicate 21% progressive disease prevalence. AUROC Area Under the Receiver Operating Characteristic Curve, AUPRC Area Under the Precision-Recall Curve, MIMIC-IV Medical Information Mart for Intensive Care IV, GPT-4 Generative Pre-trained Transformer 4.

The held-out test set is sampled from the original PHI-containing DFCI dataset but is separate from the training and validation sets. It is used exclusively for evaluating the final performance of trained models. The figure includes six panels representing experimental setups: a Teacher with temporal context, b Teacher without temporal context, c Teacher-Public Student (MIMIC-IV), d Teacher-Public Student (Wiki-text), e Teacher-GPT-4 Student, and f GPT-4 Student only. Metrics are shown with purple for AUROC, teal for AUPRC, and yellow for Best F1. Red dashed lines indicate 33% overall response prevalence, and blue dashed lines indicate 21% progressive disease prevalence. AUROC Area Under the Receiver Operating Characteristic Curve, AUPRC Area Under the Precision-Recall Curve, MIMIC-IV Medical Information Mart for Intensive Care IV, GPT-4 Generative Pre-trained Transformer 4.
Teacher models trained on PHI-containing DFCI data
For the teacher model trained on PHI-containing DFCI data, the area under the receiver operating characteristic (AUROC) curve for overall response was 0.89 in both the validation and held-out test sets, with area under the precision-recall curve (AUPRC) of 0.84 and 0.80, and best F1 scores of 0.76 and 0.74 within the two subsets respectively (Supplementary Fig. 1). The results were similar for progressive disease, with an AUROC of 0.90 and 0.89, AUPRC of 0.74 and 0.71, and best F1 scores of 0.70 and 0.66, within the validation and held-out test sets, respectively (Supplementary Fig. 2).
With the exclusion of longitudinal temporal context, a decrease in performance was observed. For overall response, the AUROC was 0.82 in both sets, with AUPRC of 0.72 in both, and best F1 scores of 0.68 and 0.65 within the validation and held-out test sets, respectively (Supplementary Fig. 3). For progressive disease, the AUROC decreased to 0.87 and 0.83, with AUPRC of 0.68 and 0.61, and best F1 scores of 0.64 and 0.59 within the validation and held-out test sets, respectively (Supplementary Fig. 4).
Student models trained on MIMIC-IV data
For the student models trained on MIMIC imaging reports to predict labels assigned by the teacher models trained on PHI-containing DFCI data, the AUROC for ascertaining overall response from the original DFCI data was 0.88 and 0.87, with AUPRC of 0.80 and 0.74, and best F1 scores of 0.75 and 0.73 within the validation and held-out test sets, respectively (Supplementary Fig. 5). The results were consistent for progressive disease, with an AUROC of 0.90 and 0.88, AUPRC of 0.72 and 0.67, and best F1 scores of 0.69 and 0.66, within the validation and held-out test DFCI sets, respectively (Supplementary Fig. 6).
Student models trained on Wiki-text data
The performance of student models trained on Wiki-text data was modestly lower than performance of student models trained with MIMIC data. For overall response, the AUROC of the Wiki-text student model was 0.85 in the DFCI validation and test sets, with AUPRC of 0.75 and 0.72, and best F1 scores of 0.72 and 0.70 within the DFCI validation and held-out test sets respectively (Supplementary Fig. 7). For progressive disease, the AUROC was 0.87 and 0.86, with AUPRC of 0.68 and 0.63, and best F1 scores of 0.65 and 0.63 within the DFCI validation and held-out test sets, respectively (Supplementary Fig. 8).
Student models trained on matched-synthetic data from GPT-4
For student models trained on matched synthetic data from GPT-4 to predict labels assigned by the teacher model trained on PHI-containing DFCI data, the performance at extracting outcomes from DFCI data was comparable to training on Wiki-text data (Figs. 1, 2 and Supplementary Figs. 9, 10).
However, “student-only” models, exclusively trained on data generated by GPT-4 based only on sequences of true labels from our DFCI training data, exhibited the lowest performance. The AUROCs were 0.64 and 0.69, with AUPRC of 0.46 and 0.47, and best F1 scores of 0.72 for overall response within the DFCI validation and held-out test sets, respectively (Supplementary Fig. 11). For progressive disease, the AUROC was 0.82 and 0.81, with AUPRC of 0.59 and 0.51, and best F1-scores of 0.57 and 0.59 within the DFCI validation and held-out test sets, respectively (Supplementary Fig. 12).
The lower performance of the “student-only” model for overall response prompted a post-hoc error analysis, where the teacher model labeled the GPT-4 generated synthetic dataset, and its predictions were compared to the original seed labels. This yielded an AUROC of 0.94, AUPRC of 0.79, and a best F1 score of 0.84, indicating strong concordance between teacher model predictions and the labels used to prompt GPT-4 to generate text. However, the calibration curve deviated from the diagonal, with teacher-assigned predictions of response generally lower than the “true” seed labels in the mid-range of predicted probabilities (Supplementary Fig. 13). This suggests that GPT-4 sometimes generated imaging reports that did not meet the teacher model’s response criteria. Further analysis revealed that GPT-4 hallucinated missing sequences, occasionally producing unrealistic sequence of events, such as complete response following progressive disease. Still, even when the “student-only” model was re-trained on synthetic data restricted to observations with complete outcome sequences, performance remained consistent, with AUROC values of 0.68 and 0.69, AUPRC values of 0.51 and 0.47, and best F1 scores of 0.58 and 0.57 for the validation and held-out test sets, respectively. These findings, along with Wiki-text distillation results, highlight how model distillation can mitigate performance gaps caused by distribution mismatches between clinical inference datasets and synthetic or public training datasets.
Sensitivity analyses by demographics and cancer type
Overall, the pattern of results for demographic subgroups were consistent with the results for the overall population. Results for the held-out DFCI test set are reported here; detailed results for the DFCI validation and held-out tests are available in Supplementary Tables 7, 8. In the test set, teacher models trained on PHI-containing DFCI data demonstrated an AUROC ranging from 0.82 (non-White patients) to 0.95 (Hispanic patients) for overall response, and 0.83 (non-White patients) to 0.91 (Hispanic patients) for progressive disease. Teacher-informed student models trained on MIMIC-IV data performed similarly, with AUROC ranging from 0.81 (non-White patients) to 0.95 (Hispanic patients) for overall response, and 0.82 (non-White patients) to 0.91 (Hispanic patients) for progressive disease. For Wiki-text-trained models, performance was slightly lower, with AUROC ranging from 0.81 (non-White patients) to 0.93 (Hispanic patients) for overall response, and 0.79 (non-White patients) to 0.92 (Hispanic patients) for progressive disease. Models trained on GPT-4 synthetic data only exhibited the lowest performance, consistent with the full denominator in our study, with AUROC ranging from 0.67 (male patients) to 0.77 (Hispanic patients) for overall response, and 0.81 (non-White, male or female patients) to 0.90 (Hispanic patients) for progressive disease.
Likewise, the pattern of results for the five most common cancer types in dataset (breast, ovarian, non-small cell lung cancer, chronic lymphocytic leukemia, renal cell carcinoma) were consistent with the results for the overall population. Detailed results for the DFCI validation and held-out tests are available in Supplementary Tables 9, 10.
Differential privacy—stochastic gradient descent and the teacher model
Computational constraints restricted our training and inference on these longitudinal data to a batch size of 1, preventing ready implementation of off the shelf differential privacy—stochastic gradient descent (DP-SGD) methods16. However, we did confirm that injection of normally distributed noise into gradients during training of the progressive disease teacher model impaired model performance (Supplementary Figs. 14–16).
Vulnerability to membership inference attacks
In an unrealistic scenario in which an attacker has full access to private training and validation data, then trains an “attacker model” to predict whether a specific observation was in the training dataset, it was possible to derive moderately performant attack models (with AUROC scores of 0.61 for the teacher model and 0.60 for the teacher-trained-MIMIC-IV student model). However, in the more realistic scenario in which an attacker has access only to a teacher model and to in-domain data not included in training, using those data to train “shadow” attack models (Supplementary Fig. 17) yielded AUROC scores of 0.52 for the teacher model and 0.53 for the teacher-trained-MIMIC-IV student model.
Discussion
This study explored strategies for using deep NLP models trained to extract clinical outcomes from unstructured, private EHR data to label intermediary public datasets to derive secondary “student” models to predict RECIST annotations of a given longitudinal series of imaging reports for patients being treated for cancer. Our intention was not to derive models that can formally replace RECIST annotations, which are based on data such as individual tumor dimension changes that are not always included in clinical imaging reports. Instead, we leveraged this dataset to evaluate variations of a “teacher-student” artificial intelligence distillation approach17 for developing longitudinal clinical deep learning models that can be shared without direct exposure to protected health information. We found that surprisingly good student model performance could be achieved even if the intermediary datasets were completely out-of-domain, but in-domain intermediary data that were as realistic as possible yielded optimal performance. Furthermore, applying a hierarchical neural network architecture, which facilitated “interpretation” of a given document in the context of prior clinical data for each patient, also improved performance. These results will inform future efforts to develop shareable AI models to extract data from electronic health records.
Our findings underscore the importance of the choice of public dataset for training a student model in the teacher-student framework. The lower performance of the student model trained on the general Wiki-text data, compared to the model trained on the domain-specific MIMIC-IV dataset, highlights the necessity of utilizing public datasets with relevant medical context for effective knowledge transfer from the teacher model. These findings indicate that training student models on datasets more closely resembling the target domain, such as MIMIC-IV for clinical text, may yield better performance than training on more general-purpose datasets like Wiki-text. Moreover, we investigated an alternative approach wherein we used matched synthetic data generated by GPT-4, coupled with the outcome labels predicted by the teacher model, to train the student model. While the performance was lower than the student model trained on real clinical data, these results suggest the potential of using large LLMs to generate synthetic data for training student models, especially in instances where access to real clinical data is limited. However, the findings of this study also highlight the limitations associated with solely relying on synthetic data for model training; student models trained solely on synthetic data without the guidance of a teacher model exhibited the lowest performance. This suggests that while LLMs can generate synthetic data useful for student model training, their effectiveness in developing accurate clinical phenotyping models may be limited without knowledge transfer from teacher models trained on real clinical data. The model trained on GPT-4-generated synthetic data only—without a teacher model—performed worse than the one trained on WikiText, which is completely out-of-domain, to predict teacher model labels. This counterintuitive result may be attributed to the high quantity of data, diversity and natural linguistic variation in WikiText, which enables the model to learn generalizable language features. In contrast, GPT-4-generated synthetic data, while fluent and domain-specific, may suffer from over-simplified or overly repetitive patterns—as well as smaller size given computational constraints—that fail to capture the complexity and variability required for robust annotation tasks.
While the results from this study demonstrate the promise of the teacher-student framework for developing shareable models, there is still room for improvement. One potential avenue for enhancing model performance is through the incorporation of curriculum learning strategies18. This involves training the student model on a carefully curated sequence of data, progressing from simpler samples to more complex ones as the model’s capabilities improve. This strategy has the potential to not only enhance performance but also improve generalizability in complex phenotyping tasks, which require integration of information from various data sources. Moreover, the teacher-student framework does not necessarily have to be limited to a single cycle. A multi-stage distillation process is another approach, in which a series of teacher and student models are iteratively trained, with each subsequent student model benefiting from the knowledge distilled from the preceding teacher model19. This iterative refinement process could potentially yield increasingly robust, accurate, and generalizable student models.
There are several limitations of the current study. First, our intent was to evaluate methods for model distillation on longitudinal healthcare data, not to deploy a task-specific model for wide use. Therefore, we have not performed external validation on an independent dataset from a separate center. Variations in reporting styles, terminologies, and data distributions across different institutions would likely influence model performance. Second, we did not formally explore or assess explainability20, potentially limiting the interpretability of the model’s predictions. Third, the synthetic data generated using GPT-4, while domain-specific, was highly dependent on the quality of the prompts used. Hence, additional optimization through systematic prompt engineering might improve model performance. Fourth, it is possible that utilization of ensemble “teachers”—as in the PATE framework, which involves training multiple teacher models on disjoint subsets of the sensitive data and aggregating their outputs to generate labels for a public dataset14—could yield better performance. Fifth, this study did not focus on implementing formal differential privacy guarantees within the teacher-student framework. While the distillation paradigm inherently provides some privacy-preserving benefits, the lack of differential privacy mechanisms limits its robustness in scenarios requiring strict privacy standards17. Future research could compare this framework to alternative privacy-preserving approaches such as homomorphic encryption or GAN-based synthetic data generation21,22. Sixth, most patients included in the original dataset belonged to White/Caucasian and Non-Hispanic/Non-Latino racial and ethnic backgrounds. However, we evaluated performance by minority racial/ethnic subgroups and gender. Performance metrics were comparable across different demographics, with consistent patterns of results compared to the overall population. F1-score variations are likely due to differing disease progression distributions and small sample sizes for some subpopulations. Datasets like MIMIC-IV or synthetic data may not fully capture subgroup characteristics, and the limited sample size of certain demographic subgroups in the DFCI cohort could potentially skew performance. Moreover, while we did not manually annotate the intermediary datasets, our final evaluation was conducted on the original private labeled DFCI dataset. Finally, it could be argued that direct de-identification of training data is a more straightforward approach than distillation; however, given the scale of the dataset used in this study—99,318 radiological reports—its effectiveness is limited by substantial manual-resource demands, high costs, and risks of inter-reviewer variability. Artificial intelligence-based de-identification also carries reliability concerns23, as even minor oversights in identifying PHI could have serious consequences.
In conclusion, a teacher-student distillation approach to developing shareable AI models to extract longitudinal phenotypes for patients with cancer is feasible. The best performance was obtained using temporal context-aware architectures, in-domain public student training data, and labels assigned by a teacher model trained for supervised tasks on real clinical data rather than relying on a large language model to generate synthetic data and labels.
Methods
This observational study was reported in accordance with the Strengthening the Reporting of Observational Studies in Epidemiology guidelines24.
Primary patient cohort
This retrospective study included patients treated at DFCI for solid tumors that underwent next generation sequencing (NGS) from 2013 to 2022. The subset that was treated on therapeutic clinical trials from 2004 to 2022 and had radiology reports available in the EHR linked to RECIST labels available from the Dana-Farber/Harvard Cancer Center Tumor Imaging Metrics Core (https://www.dfhcc.harvard.edu/research/core-facilities/tumor-imaging-metrics) was used to train and evaluate neural network models to predict RECIST labels from radiology report text (RECIST dataset).
RECIST labels (complete and partial response, stable disease, progressive disease, baseline) using RECIST version 1.17 generated on a timepoint-specific basis during clinical trial treatments were considered the gold standard. For model training purposes, two binary labels were created for each timepoint after treatment initiation: (1) overall response (complete or partial); and (2) progressive disease.
Core model architecture
Independent binary categorical models were trained for the two outcomes of (1) overall response and (2) progressive disease at each timepoint. The architecture treated each patient-treatment combination as a single unit of analysis, ascertaining outcomes following initiation of a given clinical trial treatment for a given patient. Each linked document was tokenized into a sequence of tokens. The model architecture consisted of a hierarchical Transformer25. Each imaging report for a given patient was first processed using a ClinicalBERT architecture26. The final hidden state vector for the [CLS] token for each document was then extracted as a document embedding, and when multiple reports were present at an individual timepoint, a max-pooling operation was applied to the [CLS] token embeddings for that timepoint to derive a timepoint-level embedding. These timepoint vectors were then extracted and processed using a small custom Transformer layer to make label predictions from individual timepoints context-sensitive; in other words, predictions of RECIST labels at each timepoint could be based on radiology reports from that timepoint as well as reports from prior timepoints for each patient-treatment combination. Linear layers then transformed vectors from each timepoint into a single numeric output representing the prediction of the RECIST label (response for the response model, and progression for the progression model) for that timepoint. The models were constructed within the PyTorch framework27. The core model architecture is outlined in Supplementary Fig. 18. We were unable to share even deidentified versions of the RECIST-annotated radiology reports due to intellectual property considerations related to clinical trial sponsorship agreements, but our code for training and evaluating models is provided at https://github.com/kenlkehl/recist_nlp_teacher_student.
Training and inference experiments
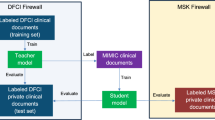
Training of teacher PHI-containing DFCI data (Fig. 3). The dataset from the primary patient cohort at DFCI containing PHI was utilized for the training and development of the teacher models using the core model architecture. An ablation study was then performed with the exclusion of the hierarchical Transformer component, which confers longitudinal temporal context upon the core model architecture, to assess the robustness of the models’ performance without temporal contextual awareness. The dataset was randomly sampled at the individual patient level to generate training (80%), validation (10%), and test (10%) data subsets.

This figure illustrates the training, development, and evaluation strategies for different model configurations. The teacher model (green diamond) is trained on a PHI-containing DFCI dataset, producing predictions and outcomes. Three student models (purple diamonds) are trained using different datasets: (1) MIMIC-IV (blue), (2) Wiki-text (pink), and (3) matched synthetic data generated by a GPT-4 model (yellow and purple). The synthetic data model is further divided into a teacher-informed student (trained on labels assigned by the teacher model to the synthetic text data) a fully synthetic student (trained exclusively on GPT-4-generated synthetic data). All trained models are evaluated using a held-out test set, generating predictions and outcomes. Solid arrows represent direct training and inference, while dashed arrows denote applications of trained models. DFCI Dana-Farber Cancer Institute, MIMIC-IV Medical Information Mart for Intensive Care IV, GPT-4 Generative Pre-trained Transformer 4.
Training of student on MIMIC-IV data: The deidentified Medical Information Mart for Intensive Care-IV (MIMIC-IV)28 was utilized for the training and development of the first student models. A selected subset of clinical radiology reports from MIMIC was extracted for this study. MIMIC data are drawn from a denominator of patients hospitalized in an intensive care unit, so to identify reports most relevant to oncology, documents that included the terms “cancer” or “malignan*“ were deemed eligible for inclusion. The teacher models trained on the DFCI PHI dataset were then applied to the eligible subset of the MIMIC-IV imaging reports to predict “overall response” and “progressive disease” for each timepoint. Serial imaging reports for individual MIMIC patients were collected to simulate the sequences of reports at separate timepoints generated during a treatment trajectory. Student models for each outcome with the same architecture as the teachers but with weights re-initialized were then trained on the eligible subset of the MIMIC-IV dataset linked to the corresponding predicted labels for overall response and progression.
Training of student on Wiki-text data: To evaluate the benefit of using in-domain public data to train student models, additional student models were trained on the Wiki-text dataset29,30 to predict response and progression labels assigned by the DFCI teacher models. This dataset is a collection of textual data extracted from Wikipedia articles. It has been widely used for natural language processing tasks, including language modeling and text generation. It is a general domain corpus, without restriction to healthcare topics or radiology reports. WikiText was intentionally selected as an out-of-domain dataset to test the hypothesis that the choice of intermediary data impacts knowledge transfer. By treating WikiText articles as if they were imaging reports, we evaluated whether meaningful student model performance could be achieved even with irrelevant public training data, as long as it was labeled by the teacher model.
To facilitate alignment with the DFCI teacher model task of predicting RECIST annotations based on current and prior imaging reports, sequences of Wikipedia articles were randomly defined to simulate a cancer treatment trajectory. A sample dataset is described in Supplementary Table 11.
Training on student matched-synthetic data from GPT-4: To evaluate the utility of in-domain but synthetic intermediary training data for deriving student models, a synthetic dataset of imaging report trajectories, based on the trajectory of RECIST annotations from the real patients in our cohort, was generated using GPT-4-turbo. GPT-4-turbo was prompted using a structured prompt as shown in Supplementary Table 12. A sample dataset is provided in Supplementary Table 13.
Next, “student” models were trained based on the GPT-4-generated datasets. The DFCI teacher models were used to label each synthetic imaging report timepoint with predicted log odds of any response (CR/PR) or progression (PD). Freshly initialized student models were then trained to predict the log odds assigned by the teacher.
Finally, a naïve, reinitialized “student only” model was trained to use the synthetic imaging report text to predict the RECIST timepoint annotations originally used to prompt GPT-4 to generate the text. The DFCI teacher model was not used in this process.
Assessment of proxy datasets
The data distribution of proxy datasets (MIMIC-IV, Wiki-text, GPT-4 generated synthetic data) were evaluated by assessing their semantic alignment with the dataset from the primary patient cohort at DFCI containing PHI. Embeddings of textual data from each dataset were generated using a pre-trained SentenceTransformer model (all-MiniLM-L6-v2)31. Cosine similarity scores were computed between embeddings from the original PHI containing DFCI dataset and each proxy dataset. For each document in a proxy dataset, the maximum cosine similarity (highest similarity to any DFCI text) and mean cosine similarity (average similarity across all DFCI texts) were calculated.
Model evaluation
Performance of teacher and all student models were evaluated on the held-out test subset of the original dataset containing PHI from the primary patient cohort at DFCI. The test subset was held out and not analyzed until the models were finalized. The baseline timepoint (imaging at treatment start) for all patients was excluded from evaluation of the test subset to prevent overestimation of the model’s performance, since predicting whether a given timepoint is the first timepoint in a longitudinal model is a trivial task.
The performance of each model was assessed using the area under the receiver operating characteristic (AUROC) curve, area under the precision-recall curve (AUPRC), and the F1 score at the best F1 threshold.
Additional sensitivity analyses were conducted to evaluate performance by the minority racial/ethnic subgroups (non-White, Hispanic), gender, and the 5 most common cancer types.
Differential privacy—stochastic gradient descent and the teacher model
To evaluate the impact of DP-SGD techniques16 on teacher model training, we implemented two specific mechanisms: gradient clipping and noise injection into gradients.
Vulnerability to membership inference attacks (MIAs)
Post-hoc exploratory experiments were conducted to assess vulnerability of developed models for progressive disease to MIAs using both direct and shadow model-based approaches. Specifically, we performed likelihood ratio MIA32 against the progressive disease ascertainment models to evaluate their practical vulnerability to attacks aimed at predicting whether a given observation was included in the teacher model’s training data.
Data availability
The datasets generated and/or analyzed during the current study are not publicly available because they contain protected health information. They are housed at Dana-Farber Cancer Institute.
Code availability
The underlying code for this study is available in GitHub repository and can be accessed via this link: https://github.com/kenlkehl/recist_nlp_teacher_student.
References
Kehl, K. L. et al. Artificial intelligence-aided clinical annotation of a large multi-cancer genomic dataset. Nat. Commun. 12, 7304 (2021).
Kehl, K. L. et al. Natural language processing to ascertain cancer outcomes from medical oncologist notes. JCO Clin. Cancer Inf. 4, 680–690 (2020).
Kehl, K. L. et al. Assessment of deep natural language processing in ascertaining oncologic outcomes from radiology reports. JAMA Oncol. 5, 1421–1429 (2019).
Casey, A. et al. A systematic review of natural language processing applied to radiology reports. BMC Med. Inform. Decis. Mak. 21, 179 (2021).
Tan, R. S. Y. C. et al. Inferring cancer disease response from radiology reports using large language models with data augmentation and prompting. J. Am. Med. Inform. Assoc. 30, 1657–1664 (2023).
Arbour, K. C. et al. Deep learning to estimate RECIST in patients with NSCLC treated with PD-1 blockade. Cancer Discov. 11, 59–67 (2021).
Eisenhauer, E. A. et al. New response evaluation criteria in solid tumours: revised RECIST guideline (version 1.1). Eur. J. Cancer 45, 228–247 (2009).
Office for Civil Right, H. Std. for privacy of individually identifiable health information. Final rule. Federal Register (2002).
Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule. https://www.hhs.gov/hipaa/index.html.
Hartley, J., Sanchez, P. P., Haider, F. & Tsaftaris, S. A. Neural networks memorise personal information from one sample. Sci. Rep. 13, 21366 (2023).
Neel, S. & Chang, P. Privacy issues in large language models: a survey. arXiv preprint arXiv:2312.06717 (2023).
Antunes, R. S., André da Costa, C., Küderle, A., Yari, I. A. & Eskofier, B. Federated learning for healthcare: systematic review and architecture proposal. ACM Trans. Intell. Syst. Technol. (TIST) 13, 1–23 (2022).
Wang, L. & Yoon, K.-J. Knowledge distillation and student-teacher learning for visual intelligence: a review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 44, 3048–3068 (2021).
Papernot, N. et al. Scalable private learning with pate. arXiv preprint arXiv:1802.08908 (2018).
Kehl, K. L. et al. Shareable artificial intelligence to extract cancer outcomes from electronic health records for precision oncology research. Nat. Commun. 15, 9787 (2024).
Abadi, M. et al. Deep learning with differential privacy. In Proc. ACM SIGSAC Conference on Computer and Communications Security (ACM, 2016).
Jagielski, M. et al. Students parrot their teachers: membership inference on model distillation. In Proc. 37th International Conference on Neural Information Processing Systems (NIPS ‘23). 44382–44397 (Curran Associates Inc., Red Hook, NY, USA, 2023).
Matiisen, T., Oliver, A., Cohen, T. & Schulman, J. Teacher–student curriculum learning. IEEE Trans. Neural Netw. Learn. Syst. 31, 3732–3740 (2019).
Zhao, J. et al. Multistage collaborative knowledge distillation from a large language model for semi-supervised sequence generation. In Proc. 62nd Annual Meeting of the Association for Computational Linguistics. Vol. 1, Long Papers (eds Ku, L. W., Martins, A. & Srikumar, V.) 14201–14214 (Association for Computational Linguistics, 2024). https://doi.org/10.18653/v1/2024.acl-long.766.
Ribeiro, M. T., Singh, S. & Guestrin, C. In Proc. 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1135–1144 (ACM, 2016).
Khalid, N., Qayyum, A., Bilal, M., Al-Fuqaha, A. & Qadir, J. Privacy-preserving artificial intelligence in healthcare: techniques and applications. Comput. Biol. Med. 158, 106848 (2023).
Venugopal, R. et al. Privacy preserving generative adversarial networks to model electronic health records. Neural Netw. 153, 339–348 (2022).
Yogarajan, V., Pfahringer, B. & Mayo, M. A review of automatic end-to-end de-identification: is high accuracy the only metric? Appl. Artif. Intell. 34, 251–269 (2020).
Cuschieri, S. The STROBE guidelines. Saudi J. Anaesth. 13, S31–s34 (2019).
Nawrot, P. et al. Hierarchical transformers are more efficient language models. In Findings of the Association for Computational Linguistics: NAACL 2022 (eds Carpuat, M., de Marneffe M. C. & Ruiz, M. IV) 1559–1571 (Association for Computational Linguistics, 2022). https://doi.org/10.18653/v1/2022.findings-naacl.117.
Alsentzer, E. et al. Publicly available clinical BERT embeddings. In Proc. 2nd Clinical Natural Language Processing Workshop (eds Rumshisky, A., Roberts, K., Bethard, S. & Naumann, T.). 72–78 (Association for Computational Linguistics, 2019). https://doi.org/10.18653/v1/W19-1909.
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. In Proc. 33rd International Conference on Neural Information Processing Systems, 8026–8037 (Red Hook, NY, USA, Curran Associates Inc, 2019).
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 10, 1 (2023).
Merity, S., Xiong, C., Bradbury, J. & Socher, R. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843 (2016).
Wiki-text-103, Hugging Face. https://huggingface.co/datasets/Salesforce/wikitext.
Reimers, N., Freire, P., Becquin, G., Espejel, O. & Gante, J. Sentence-Transformers/All-MiniLM-L6-v2 Hugging Face. Available online: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 (accessed on 8 February, 2025).
Carlini, N. et al. Membership inference attacks from first principles. In Proc. IEEE Symposium on Security and Privacy (SP), 1897–1914 (IEEE, 2021).
Author information
Authors and Affiliations
Contributions
I.B.R. and K.L.K. conceptualized the idea and developed the study design. K.L.K. and N.A. trained and validated the models and analyzed the results. S.A.A.N. visualized the results. I.B.R., S.A.A.N., and K.L.K. prepared the original draft. I.B.R., S.A.A.N., N.A., G.J.H., and K.L.K. critically reviewed and revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
I.B.R., S.A.A.N., N.A., K.L.K. do not report any disclosures relevant to this work. G.J.H. serves as the co-founder, chief science officer, and board member, Yunu, Inc and serves on the scientific advisory board, Fovia, Inc.
Ethical approval
This study was approved by the Institutional Review Board at Dana-Farber/Harvard Cancer Center (IRB protocol #16-360; Strategic and Analytic Approach to Collecting Clinical and Outcomes Data and Derived Molecular Features for Annotating Profile Results). There was a waiver of informed consent given the minimal risk to patients of the medical record review and the large cohort size, which would have precluded re-approaching each patient individually for this specific study.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Riaz, I.B., Naqvi, S.A.A., Ashraf, N. et al. Empirical evaluation of artificial intelligence distillation techniques for ascertaining cancer outcomes from electronic health records. npj Digit. Med. 8, 347 (2025). https://doi.org/10.1038/s41746-025-01646-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01646-7
