
Abstract
Foundation models for medical imaging are a prominent research topic, but risks associated with the imaging features they can capture have not been explored. We aimed to assess whether imaging features from foundation models enable patient re-identification and to relate re-identification to demographic features prediction. Our data included Colour Fundus Photos (CFP), Optical Coherence Tomography (OCT) b-scans, and chest x-rays and we reported re-identification rates of 40.3%, 46.3%, and 25.9%, respectively. We reported varying performance on demographic features prediction depending on re-identification status (e.g., AUC-ROC for gender from CFP is 82.1% for re-identified images vs. 76.8% for non-re-identified ones). When training a deep learning model on the re-identification task, we reported performance of 82.3%, 93.9%, and 63.7% at image level on our internal CFP, OCT, and chest x-ray data. We showed that imaging features extracted from foundation models in ophthalmology and radiology include information that can lead to patient re-identification.
Similar content being viewed by others
Introduction
Deep Learning (DL) is the current state-of-the-art class of methods for medical image analysis, with applications in various branches of medical imaging, including radiology1,2,3, pathology4,5,6, and ophthalmology7,8,9. Within DL, the transformer architecture10 (and its adaptation to images11) has proven itself as the current model of choice11. This architecture has led to the introduction of a novel concept: foundation models. Such models are trained on large quantity of data12 and are general purpose and task-agnostic: they capture a foundational understanding of a given data modality so that task-specific models can then be trained starting from the foundation model13,14. While such models were first introduced for text15,16, they were later adapted to images17,18, videos19,20, and combinations of modalities21,22. In addition, the medical imaging research community developed foundation models specific to radiology23,24,25, histopathology26,27,28, ophthalmology29,30,31, or across specialties32,33. Such models have shown remarkable performance on a variety of clinical tasks like disease diagnosis25,29, risk prediction29, medical question-answering30,33, and segmentation26,32.
Previous work has started investigating the limitations of DL models. For instance, they can learn biases inherent in their training data (e.g., racial bias, where a model performs differently depending on a patient’s race34). This observation suggests that DL models that can convert images into highly specific feature vectors, might “learn” features associated with an individual’s demographic characteristics. This concern has been extensively corroborated, with DL models introduced to predict age, gender, race, and ethnicity from both radiological35,36,37 and ophthalmic images38,39,40.
In this work, we combined the observation that foundation models are general-purpose and task-agnostic with the fact that DL models can predict demographic characteristics. We reasoned that foundation models may exhibit good re-identification abilities due to the large amount of data they were trained on, as well as to the learned features being general. In fact, the large training dataset may increase the likelihood that, given a query image, a very similar image has been seen during training. In addition, the lack of a specific training task could lead to features that are descriptive of general patient features (e.g., their demographics), aiding patient re-identification.
Patient re-identification represents a privacy concern that was recently addressed by the American Academy of Ophthalmology41. With this work, we contribute to the discussion by evaluating the novel risks that could be associated with an emerging class of methods: foundation models. These models are often made publicly available, allowing researchers to extract features from any imaging database (private or public). Understanding the risks to patient re-identification linked to the use and sharing of such features is an important part of that conversation, although a thorough discussion of the tradeoff between the potential societal benefit of making datasets more widely available and the potential harm from these risks is beyond the scope of this work.
Previous work on re-identification has mainly focused on radiological images (chest x-rays42,43 and trunk CT scans44), reaching almost-perfect performance. While this study is similar in intent, we focus on the re-identification potential of features from frozen foundation models, not solely on the ability to train a model on the re-identification task. We are also the first, to the best of our knowledge, to study re-identification in ophthalmology, where the lack of a large, public dataset makes carrying out such experiments challenging. Finally, the foundation models we analyzed employ the state-of-the-art transformer architecture10, while previous work used convolutional neural networks45,46, which predate transformers.
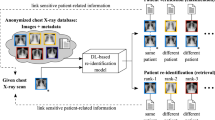
Since we want to study the patient re-identification potential of imaging features from a frozen, off-the-shelf foundation model, we started by extracting such features for all images in our datasets. To evaluate re-identification, we considered each image as a query image and computed the feature similarity between the query and every other image. If the most similar image belonged to the same patient as the query image, the query image was considered re-identified. To avoid comparing multiple images taken during the same encounter, we did not compare a query image with images for the same patient taken on the same day. Figure 1 depicts this pipeline.

In our experiments: (a) we extracted features from a frozen foundation model, (b) we compared features for a query image with features for the remaining images, (c) we fine-tuned the model on the re-identification task.
The main goal of this study was to evaluate how well image re-identification can be performed based on features extracted from frozen, off-the-shelf foundation models. We also compared the performance of such frozen features with a baseline that was trained on the re-identification task in a supervised way (Fig. 1c). Such a supervised approach represents an upper bound for re-identification performance and allowed us to quantify the amount of additional information the foundation model features need to learn to capture.
Our datasets include Colour Fundus Photos (CFP), Optical Coherence Tomography (OCT) B-scans, and chest x-ray images. For ophthalmology, we used two internal datasets and a public one: we collected 33,697 Topcon CFPs from 2796 patients (CORIS-CFP) and 332,794 Spectralis OCT B-scans from 1000 patients (CORIS-OCT), and we used the GRAPE dataset47 consisting of 631 CFP taken with Topcon and Canon cameras from 144 patients. For radiology, we used one internal dataset including 106,563 chest x-ray images from 60,020 patients (MGH), and data from the publicly available MIDRC dataset. Specifically, we selected a total of 106,473 PA or AP images for 39,749 patients. Table 1 shows summary statistics for all the datasets, as well as for the subsets of patients with at least two time points, which we use to report re-identification performance. In Table 1, we report how both CORIS datasets and the MIDRC dataset are homogeneous in terms of race and ethnicity (with most patients being Caucasian and non-Hispanic). All datasets were retrospectively collected from different institutions, and, as such, they reflect the same characteristics of the populations those institutions serve. We highlight the geographical diversity of the included datasets: the CORIS datasets are collected from patients in the Denver, CO area, GRAPE includes data from Hangzhou, Zhejiang, China, MGH from the Boston, MA area, and MIDRC includes public data from the chestX-ray848 dataset (from NIH in Bethesda, MD) and cheXpert49 (from Stanford, CA).
Results
Patient re-identification
Table 2 shows the re-identification rate at 1 and 10 (R@1, R@10) and the Average Precision (AP) at image and patient level for images and patients with at least two time points in our datasets. We report corresponding Precision-Recall curves in Supplementary Fig. 1.
We noticed re-identification rate R@10 above 85% at patient level in our internal datasets (86.5% and 89.9% for CORIS-CFP and CORIS-OCT, respectively) and above 50% at image level across all three ophthalmology datasets. In general, performance was lower for GRAPE than for CORIS-CFP; this can be explained by the lower average number of time points per patient for GRAPE (Table 1), as well as by the lower number of patients with longitudinal data (100 vs. almost 1000 in our internal datasets). Supplementary Fig. 2 shows examples of correctly and incorrectly re-identified CFPs from the GRAPE dataset.
For radiology results, we noticed how patient level re-identification did not reach the same performance as in ophthalmology. In addition, image level re-identification rate was lower for MGH than for MIDRC, likely due to the different average number of time points per patient in the two datasets (2.9 and 5.1, respectively).
Table 3 shows R@1 and R@10 at image and patient level and AP values, stratified by number of time points per patient. We selected a subset of patients in the MGH and MIDRC datasets with a fixed minimum number of time points (5 and 7, respectively), and randomly sampled a lower number of time points per patient from this subset (e.g., 2, 3) before repeating our re-identification experiments.
From Table 3, we noticed how re-identification performance depended on number of time points per patient, with R@1 increasing from 16.9% to 53.8% and from 18.7% to 70.3% for MGH and MIDRC, when increasing the number of time points from 2 to 5+ (7+ for MIDRC). At patient level, when requiring at least 5 time points in both radiology datasets, we observed R@1 similar to that for ophthalmology datasets (Table 2): 78.1% and 86.1% for CORIS-CFP and CORIS-OCT, respectively.
Similar conclusions can be drawn from AP values, with MGH reaching an image level AP value comparable to those obtained in Ophthalmology (i.e., 79.3% vs. 72.6%, 73.8%, and 83.5% for CORIS-CFP, CORIS-OCT, and GRAPE, respectively).
Demographic features prediction
To verify that frozen features from foundation models contain information useful for demographic feature prediction, we trained linear models on top of such features. Supplementary Table 1 shows performance for gender, age, race, and ethnicity prediction. We reported gender AUC-ROC of 76.9% on CORIS-CFP, 69.3% on CORIS-OCT, and 95.4% on MGH; R2 for age prediction 0.7 across datasets; AUC-ROC > 95% for race prediction; and AUC-ROC of 79.0% on CORIS-CFP, 82.4% on CORIS-OCT, and 67.5% on MGH.
To show the relationship between re-identification performance and demographic features prediction performance, we stratified demographic features performance based on whether an image was correctly identified (Table 4).
For ophthalmology, we noticed the expected pattern: higher performance on patients correctly re-identified, with accuracy on race prediction from CORIS-CFP being the sole exception (with virtually same performance regardless of re-identification status). This indicated that our hypothesis that demographic features prediction and re-identification are related was correct. At the same time, we noted that the differences in performance between the two re-identification statuses were modest, suggesting there is likely more information contributing to re-identification than each of the four analyzed features. Interestingly, we did not observe the same pattern for MIDRC, which may indicate that re-identification from radiological images does not rely on the considered demographic features.
Training a model for re-identification
Table 5 compares results for our model fine-tuned on re-identification with those for features from a frozen model. Results were computed on a held-out test set the supervised model was not trained on. Supplementary Fig. 3 shows the corresponding image level Precision-Recall curves.
The trained re-identification models reached training accuracy of 84%, 79%, 87%, and 61% for CORIS-CFP, CORIS-OCT, MGH, and MIDRC, respectively.
For our ophthalmology datasets, we reported high re-identification performance achieved by the supervised approach, with re-identification rate reaching 99% at patient level for OCT and above 90% in general (only exception being R@1 = 82.3% for CFP at image level). Similarly, image level AP values are generally above 90% with MGH being the only exception (AP = 85.8%) We highlight how re-identification rate at patient level from frozen features was close to its supervised counterpart (R@1 = 81.8% vs. 95.0% for CFP and 87.0% vs. 99.5% for OCT), while the gap remained wide for re-identification rate at image level (R@1 = 53.0% vs. 82.3% for CFP and 59.7% vs. 94.0% for OCT). This further showed that having multiple images for a given patient was crucial for successful re-identification, and that there still was a noticeable amount of information that the imaging features needed to capture for best-performing re-identification.
Similar conclusions could be drawn from the radiology experiments: re-identification rate improved after training, with the most noticeable gains in performance being observed for the MGH dataset, which also had the lowest re-identification baseline performance (due to low average number of time points per patient).
Discussion
In this work, we analyzed the ability of imaging features extracted from frozen, off-the-shelf foundation models to re-identify ophthalmic and radiological images. We showed how re-identifying a patient was easier when multiple images are available, and how performance was comparable across different imaging modalities (specifically CFP, OCT, and x-rays), indicating that re-identification signals exist across modalities. We also reported lower re-identification performance on radiology than ophthalmology (Table 2); this could be due to the nature of the images themselves, with radiological images capturing less biometric information, or to higher variability in acquisition, with, for instance, patient positioning having a greater impact on image appearance for chest x-ray. This consideration may be linked to our analysis in Table 3: re-identification performance from chest x-rays was comparable with that from retinal imaging when more images per patient are available since it may be more likely to find similar images despite the variability in acquisition.
In addition, we linked re-identification with demographic features prediction by first showing that features extracted from frozen foundation models can be used to train simple linear models to predict age, gender, race, and ethnicity. These results were in line with previously reported demographic features prediction performance, especially for CFP, where most of the efforts in the literature have focused. Specifically, previous work reported R2 = 0.74 on age prediction50, AUC-ROC = 90% for age >7038, AUC-ROC for gender is male from 70% to above 95%39,50,51, AUC-ROC = 93% for ethnicity is Hispanic38, and AUC-ROC > 90% for race40. Some of these results are higher than the ones we reported, likely because we trained simple linear models as opposed to DL methods. At the same time, performance for age is very similar to previous results (R2 = 0.71 vs. 0.74), as well as AUC-ROC on race (higher than 90%), showcasing the amount of information relevant to demographic features that foundation models can learn. In radiology, we predicted gender with AUC-ROC = 95.4%, race with AUC-ROC = 86.4% and ethnicity with AUC-ROC = 67.5%. Age was predicted with MAE less than 8 years, like for the ophthalmology datasets. These results are in line with previous studies: gender AUC-ROC > 99%52,53, race AUC-ROC > 98%35,53, and age AUC-ROC > 88%52.
Furthermore, we showed how, in ophthalmology, such predictions are more accurate for patients that were correctly re-identified as opposed to patients not re-identified, indicating a relationship between the two tasks. For radiology, we did not observe the same pattern, which may suggest different content in terms of biometric information between chest x-rays and retinal images. We leave further analysis of such differences to future work.
Finally, we fine-tuned the foundation models to learn the patient re-identification task in a supervised way, and we showed how the patient level performance of re-identification from frozen features was close to that of the fine-tuned features, while image level re-identification from frozen features lagged behind its supervised counterpart. This indicates that foundation features can be improved to successfully re-identify images. Similar findings have been reported in the literature, where supervised classifiers (based on convolutional neural networks) have shown high re-identification performance42,43,44.
Our work has some limitations: first, our re-identification experiments relied on at least one image for the same patient as the query image’s being present in the dataset; this limited the number of patients we could use to evaluate re-identification (Table 1). Second, when linking re-identification with demographic features prediction, we only considered age, gender, race, and ethnicity; additional features could be included. Third, our analyses focused on retrospectively collected cohorts, using our methods in real world scenarios may face additional challenges like data drift due to changing features of the underlying patient population. Also related to the cohorts, while within each dataset, demographic features such as race and ethnicity are homogeneous (see Table 1), the geographic locations of the institutions they were collected from vary from different parts of the US to Zhejiang, China (GRAPE). While increasing heterogeneity of such features within datasets would increase the generalizability of our results, we highlight how the re-identification task could be more challenging in a more homogeneous dataset. As we have shown, demographic features are linked to re-identification, so a homogeneous dataset would make re-identification more challenging since fewer of such features could be leveraged (as most patients share them). Finally, we note that our ophthalmology datasets only included patients with at least one eye condition (i.e., we do not have access to screening images for normal subjects). The presence of such diseases may hinder the re-identification process, with the pathological area disrupting useful signal, but it may also aid it, with a patient with, say, glaucoma being more easily identified by discarding all images for patients without it. Results in Supplementary Fig. 2 seem to support this dual, opposite effect eye conditions may have, with specific retinal presentations like tessellated fundus or peripapillary atrophy areas appearing to be used to match images both correctly and incorrectly.
Our study revealed the ability of foundation models to extract image features that are descriptive enough that they may be used for reidentification when matched with image features from a dataset containing the same patients. In a recent American Academy of Ophthalmology41 editorial discussing the risks and benefits of data sharing, the authors pointed out that such a comprehensive dataset currently does not exist. Nonetheless, these results are relevant for the larger discussion of societal benefit vs. harm of data sharing vs. privacy risk. Additionally, it would be worth investigating ways to counter the re-identification properties of features extracted from foundation models to mitigate this risk, especially as this ability of foundation models to learn identifying features is likely going to improve in the future. An interesting research direction toward this goal is feature disentanglement, which aims to learn separate sets of features, each related to a different aspect of the image (e.g., device characteristics, patient demographics, pathology related features)54,55. Mostly used in generative approaches to allow for a more fine-grained image generation process (e.g., to generate two synthetic images from the same theoretical patient taken at the same time by two devices)55,56, such techniques could help reduce re-identification risks by not sharing the part of the model responsible for learning demographic information. Such countermeasures need not be technological only (i.e., algorithmic approaches), but could also include patient consent strategies tailored toward imaging, like the All of Us project (https://allofus.nih.gov/about/protocol/all-us-consent-process).
Methods
This study was approved by the Institutional Review Board at the University of Colorado Anschutz Medical centre and by the Institutional Review Board at Massachusetts General Hospital. Informed consent was waived as the project represented secondary research and posed minimal risk to subjects.
We quantified re-identification performance using re-identification rate at 1 (R@1) and re-identification rate at 10 (R@10): R@1 is the percentage of query images whose most similar image belonged to the same patient, R@10 is the percentage of query images for which at least another image from the same patient was in the top 10 most similar images. R@1 is a more restrictive metric than R@10, and is inspired by information retrieval, which also distinguishes our work from previous studies on re-identification42,43, which used classification-based metrics such as accuracy. We do not report such metrics since they require the creation of a set of “negative pairs” of non-matching images, which cannot be computed due to its number. Previous work has thus chosen them randomly, making the analysis dependent on the selected negative pair set.
We also computed re-identification rates at patient level: a patient was considered re-identified if any query image belonging to that patient was correctly re-identified. Patient level rates evaluate the scenario where multiple images for the same patient are available as queries, and results can be aggregated.
In addition, we computed Average Precision (AP) by using the top 1 similarity score for each query image and we drew Precision-Recall (PR) curves. Both AP and the PR curves were computed at image level and at patient level. Similarly to what we did for re-identification rate, to compute patient level AP and PR curves, we aggregated matches for each query patient by looking at the closest match from the same patient; if no matched image was from the same patient, we considered the closest match.
Number of time points
We also investigated whether re-identification performance can be affected by the number of time points available per patient (specifically in radiology, where we noticed lower re-identification performance). To verify this hypothesis, we selected a subset of patients with a fixed minimum number of time points. We then randomly selected a lower number of time points per patient from this subset (e.g., 2, 3) and repeated our re-identification experiments. We expected performance to increase with the number of time points per patient.
Demographic features prediction
After showing the ability of features extracted from a frozen foundation model to re-identify patients, we aimed to interpret these results. Specifically, we hypothesized that re-identification may happen (at least partially) through prediction of demographic features.
We started by verifying that features extracted from foundation models can be used to predict demographic characteristics. Subsequently, we analyzed the relationship between re-identification and demographic features prediction by stratifying demographic features prediction performance based on whether an image was correctly re-identified or not. We expected demographic features prediction to perform better for re-identified images (i.e., if an image is re-identified, its corresponding demographics should be more accurately predicted).
Training a model for re-identification
To train a model for re-identification, we used contrastive learning, where the foundation model was fine-tuned on recognizing if an input pair of images belong to the same patient. Figure 1c depicts this approach.
Implementation
As foundation models, we used RETFound29 for ophthalmology and the CXR Foundation model23 for radiology. For RETFound, we extracted features from the layer before the classification head in the vision transformer architecture11, while for CXR Foundation, we extracted imaging embeddings using the API for the v1 model. We refer the reader to previous work for further details on the architecture of RETFound11,29,57 and CXR Foundation23,25.
For our re-identification experiments, we stored the features extracted from foundation models in a vector database using chromadb (https://www.trychroma.com/) for efficient comparison of feature vectors. For each query image, we queried the vector database to return the most similar images (based on the L2 vector distance).
To predict demographic features, we used our full CORIS-CFP, CORIS-OCT, and MGH cohorts, and we split our data into train/validation/test at patient level with a 60/20/20 proportion. We trained logistic regression models for gender, race, and ethnicity prediction and linear regression models for age, and we evaluated the former using accuracy and Area Under the Receiver Operating Characteristics Curve (AUC-ROC), and the latter using R2 and mean absolute error (MAE). To train these linear models, we used the sklearn python package (https://scikit-learn.org/stable/index.html), and we selected hyperparameters for logistic regression using a grid search over the validation split to choose between L1 and L2 penalty and between C values of 1 and 10. Selection was based on AUC-ROC on the validation set.
To fine-tune the RETFound foundation models for re-identification, we adopted SimCLR58: given an input image pair, we extracted features for both images, passed them through an additional fully connected layer, and computed the InfoNCE loss to teach the model to recognize whether the two input images belong to the same patient. The choice of adding a layer was borrowed from the SimCLR paper, where the authors argued it helps performance. We used the fine-tuned foundation model features to re-run our re-identification experiments. For the CXR Foundation model, we could not fine-tune the whole model since we extracted features using APIs (https://github.com/Google-Health/imaging-research/tree/master/cxr-foundation). For this reason, we trained a linear layer on top of the extracted features, and we used the linear layer’s output as the new imaging features to re-run our re-identification experiments. To fine-tune these models, we only considered patients with images from more than one time point and we split them with a 60/20/20 ratio into train/validation/test.
We fine-tuned RETFound using batch size 10 images per GPU (using 4 NVIDIA RTX A4000 GPUs), base learning rate of 0.001, and 1 warmup epoch. We trained for 35 epochs for CFP and 70 epochs for OCT given the difference in dataset size. Model selection was done based on validation loss. We trained our contrastive model for both MGH and MIDRC data for 1000 epochs, batch size 40 and learning rate 0.01.
Data availability
The CORIS-CFP, CORIS-OCT, and MGH datasets are private and cannot be made available. The datasets generated and/or analyzed during the current study are available in the GRAPE and MIDRC repository, https://springernature.figshare.com/collections/GRAPE_A_multi-modal_glaucoma_dataset_of_follow-up_visual_field_and_fundus_images_for_glaucoma_management/6406319/1 and https://www.midrc.org/xai-challenge-2024.
Code availability
The underlying code for this study is available on GitHub at https://github.com/QTIM-Lab/re_identification/tree/main.
References
Saba, L. et al. The present and future of deep learning in radiology. Eur. J. Radiol. 114, 14–24 (2019).
Yu, A. C., Mohajer, B. & Eng, J. External validation of deep learning algorithms for radiologic diagnosis: a systematic review. Radiol. Artif. Intell. 4, e210064 (2022).
Monshi, M. M. A., Poon, J. & Chung, V. Deep learning in generating radiology reports: a survey. Artif. Intell. Med. 106, 101878 (2020).
Srinidhi, C. L., Ciga, O. & Martel, A. L. Deep neural network models for computational histopathology: a survey. Med. Image Anal. 67, 101813 (2021).
Echle, A. et al. Deep learning in cancer pathology: a new generation of clinical biomarkers. Br. J. Cancer 124, 686–696 (2021).
Van der Laak, J., Litjens, G. & Ciompi, F. Deep learning in histopathology: the path to the clinic. Nat. Med. 27, 775–784 (2021).
Ramanathan, A., Athikarisamy, S. E. & Lam, G. C. Artificial intelligence for the diagnosis of retinopathy of prematurity: a systematic review of current algorithms. Eye 37, 2518–2526 (2023).
Li, T. et al. Applications of deep learning in fundus images: a review. Med. Image Anal. 69, 101971 (2021).
Muchuchuti, S. & Viriri, S. Retinal disease detection using deep learning techniques: a comprehensive review. J. Imaging 9, 84 (2023).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5998–6008 (2017).
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for image recognition at scale. In International Conference on Learning Representations (2021).
Schuhmann, C. et al. Laion-5b: an open large-scale dataset for training next generation image-text models. Adv. Neural Inf. Process. Syst. 35, 25278–25294 (2022).
Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at arXiv https://doi.org/10.48550/arXiv.2108.07258 (2021).
Azizi, S. et al. Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging. Nat. Biomed. Eng. 7, 756–779 (2023).
Kenton, J. D. M.-W. C. & Toutanova, L. K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proc. NAACL-HLT. 4171–4186 (Association for Computational Linguistics, 2019).
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I. & others. Improving language understanding by generative pre-training (2018)
Zhang, H. et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection. In The Eleventh International Conference on Learning Representations (2023).
Oquab, M. et al. DINOv2: learning robust visual features without supervision. Trans. Mach. Learn. Res. J. 1, 31 (2024).
Tong, Z., Song, Y., Wang, J. & Wang, L. Videomae: masked autoencoders are data-efficient learners for self-supervised video pre-training. Adv. Neural Inf. Process. Syst. 35, 10078–10093 (2022).
Wang, L. et al. Videomae v2: scaling video masked autoencoders with dual masking. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14549–14560 (IEEE, 2023).
Bai, J. et al. Qwen-vl: a versatile vision-language model for understanding, localization, text reading, and beyond. Preprint at arXiv https://doi.org/10.48550/arXiv.2308.12966 (2023).
Zhu, D., Chen, J., Shen, X., Li, X. & Elhoseiny, M. MiniGPT-4: enhancing vision-language understanding with advanced large language models. The Twelfth International Conference on Learning Representation (2024).
Sellergren, A. B. et al. Simplified transfer learning for chest radiography models using less data. Radiology 305, 454–465 (2022).
Yao, J. et al. EVA-X: a foundation model for general chest X-ray analysis with self-supervised learning. CoRR abs/2405.05237 (2024).
Xu, S. et al. ELIXR: towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders. CoRR abs/2308.01317 (2023).
Dippel, J. et al. RudolfV: a foundation model by pathologists for pathologists. CoRR abs/2401.04079 (2024).
Vorontsov, E. et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nat. Med. https://doi.org/10.1038/s41591-024-03141-0 (2024).
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical Twitter. Nat. Med. 29, 2307–2316 (2023).
Zhou, Y. et al. A foundation model for generalizable disease detection from retinal images. Nature 622, 156–163 (2023).
Haghighi, T. et al. EYE-Llama, an in-domain large language model for ophthalmology. iScience 112984 (2025).
Chia, M. A. et al. Foundation models in ophthalmology. Br. J. Ophthalmol. bjo-2024-325459 https://doi.org/10.1136/bjo-2024-325459 (2024).
Ma, J. et al. Segment anything in medical images and videos: benchmark and deployment. Preprint at http://arxiv.org/abs/2408.03322 (2024).
Li, C. et al. LLaVA-Med: training a large language-and-vision assistant for biomedicine in one day. in Advances in Neural Information Processing Systems (eds Oh, A. et al.) 36 28541–28564 (Curran Associates, Inc., 2023).
Pierson, E., Cutler, D. M., Leskovec, J., Mullainathan, S. & Obermeyer, Z. An algorithmic approach to reducing unexplained pain disparities in underserved populations. Nat. Med. 27, 136–140 (2021).
Gichoya, J. W. et al. AI recognition of patient race in medical imaging: a modelling study. Lancet Digit. Health 4, e406–e414 (2022).
Banerjee, I. et al. Reading race: AI recognises patient’s racial identity in medical images. Preprint at arXiv https://doi.org/10.48550/arXiv.2107.10356 (2021).
Wang, R. et al. Drop the shortcuts: image augmentation improves fairness and decreases AI detection of race and other demographics from medical images. eBioMedicine 102, 105047 (2024).
Khan, N. C. et al. Predicting systemic health features from retinal fundus images using transfer-learning-based artificial intelligence models. Diagnostics 12, 1714 (2022).
Rim, T. H. et al. Prediction of systemic biomarkers from retinal photographs: development and validation of deep-learning algorithms. Lancet Digit. Health 2, e526–e536 (2020).
Coyner, A. S. et al. Association of biomarker-based artificial intelligence with risk of racial bias in retinal images. JAMA Ophthalmol. 141, 543 (2023).
American Academy of Ophthalmology Board of Trustees. Special Commentary: Balancing benefits and risks: the case for retinal images to be considered as nonprotected health information for research purposes. Ophthalmology 132, 115–118 (2025).
Ueda, Y. & Morishita, J. Patient identification based on deep metric learning for preventing human errors in follow-up X-ray examinations. J. Digit. Imaging 36, 1941–1953 (2023).
Packhäuser, K. et al. Deep learning-based patient re-identification is able to exploit the biometric nature of medical chest X-ray data. Sci. Rep. 12, 14851 (2022).
Ueda, Y., Ogawa, D. & Ishida, T. Patient re-identification based on deep metric learning in trunk computed tomography images acquired from devices from different vendors. J. Imaging Inform. Med. 37, 1124–1136 (2024).
Tan, M. & Le, Q. Efficientnetv2: smaller models and faster training. In International Conference on Machine Learning 10096–10106 (PMLR, 2021).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. IEEE Conference on Computer Vision and Pattern Recognition. 770–778 (IEEE Computer Society, 2016).
Huang, X. et al. GRAPE: a multi-modal dataset of longitudinal follow-up visual field and fundus images for glaucoma management. Sci. Data 10, 520 (2023).
Wang, X. et al. ChestX-ray8: hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 3462–3471 (IEEE Computer Society, 2017).
Irvin, J. et al. CheXpert: a large chest radiograph dataset with uncertainty labels and expert comparison. Proc. AAAI Conf. Artif. Intell. 33, 590–597 (2019).
Poplin, R. et al. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2, 158–164 (2018).
Zhang, L. et al. Prediction of hypertension, hyperglycemia and dyslipidemia from retinal fundus photographs via deep learning: a cross-sectional study of chronic diseases in central China. PLoS ONE 15, e0233166 (2020).
Adleberg, J. et al. Predicting patient demographics from chest radiographs with deep learning. J. Am. Coll. Radiol. 19, 1151–1161 (2022).
Jabbour, S., Fouhey, D., Kazerooni, E., Sjoding, M. W. & Wiens, J. Deep learning applied to chest X-rays: exploiting and preventing shortcuts. In Machine Learning for Healthcare Conference 750–782 (PMLR, 2020).
Müller, S., Koch, L. M., Lensch, H. P. A. & Berens, P. Disentangling representations of retinal images with generative models. Med. Image Anal. 103628 (2025).
Liu, X., Sanchez, P., Thermos, S., O’Neil, A. Q. & Tsaftaris, S. A. Learning disentangled representations in the imaging domain. Med. Image Anal. 80, 102516 (2022).
Fei, Y. et al. Deep learning-based multi-modal computing with feature disentanglement for MRI image synthesis. Med. Phys. 48, 3778–3789 (2021).
He, K. et al. Masked autoencoders are scalable vision learners. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16000–16009 (IEEE, 2022).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proc. 37th International Conference on Machine Learning (eds III, H. D. & Singh, A.) 119 1597–1607 (PMLR, 2020).
Acknowledgements
This study was funded by the European Union’s Horizon Europe research and innovation programme under grant agreement No. GA 101137074 (Hereditary project), an Unrestricted Research grant to the Department of Ophthalmology from Research to Prevent Blindness, and the NIH/NCATS Colorado CTSA Grant (UM1 TR004399). The funders played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
G.N. designed/conceptualized the study, ran the experiments, interpreted results, and drafted the paper, S.K. ran the experiments, S.M. designed/conceptualized the study, C.B. and N.M. provided data, J.P.C., M.C. and P.S. interpreted results, J.K.C. designed/conceptualized the study, provided data, and interpreted results. All authors reviewed and approved the manuscript. P.S. and J.K.C. contributed equally to the work and should be considered co-senior authors.
Corresponding author
Ethics declarations
Competing interests
Author S.M. has previously acted as a paid consultant for Evolution Optiks but declares no non-financial competing interests. Author J.P.C. has received financial support from Genentech and Boston AI Lab and is the owner of Siloam Vision but declares no non-financial competing interests. Author N.M. has previously acted as a paid consultant for Soma Logic and ONL Therapeutics but declares no non-financial competing interests. Author J.K.C. has previously acted as a paid consultant for Siloam Vision and has received financial support from Genentech and Boston AI Lab but declares no non-financial competing interests. All other authors declare no financial or non-financial competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Nebbia, G., Kumar, S., McNamara, S.M. et al. Re-identification of patients from imaging features extracted by foundation models. npj Digit. Med. 8, 469 (2025). https://doi.org/10.1038/s41746-025-01801-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01801-0
