
Abstract
Glaucoma is a progressive disease that can lead to permanent vision loss, making progression prediction vital for guiding effective treatment. Deep learning aids progression prediction but may yield unequal outcomes across demographic groups. We proposed a model called FairDist, which utilized baseline optical coherence tomography scans to predict glaucoma progression. An equity-aware EfficientNet was trained for glaucoma detection, which was then adapted for progression prediction with knowledge distillation. Model accuracy was measured by the AUC, Sensitivity, Specificity, and equity was assessed using equity-scaled AUC, which adjusts AUC by accounting for subgroup disparities. The mean deviation, fast progression, and total deviation pointwise progression were explored in this work. For both progression types, FairDist achieved the highest AUC and equity-scaled AUC for gender and racial groups, compared to methods with and without unfairness mitigation strategies. FairDist can be generalized to other disease progression prediction tasks to potentially achieve improved performance and fairness.
Similar content being viewed by others
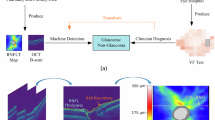

Introduction
Glaucoma is the second-leading cause of blindness worldwide, characterized by progressive vision loss (Fig. 1a)1. It impacts over 3 million patients in the US, and projections indicate that by 2050, this number will escalate to 6.3 million due to an aging population, with African Americans and Hispanics being disproportionately affected2. The irreversible nature of visual impairment from glaucoma progression underscores the importance of detecting visual dysfunction in its early stages3. Glaucoma progression has traditionally been assessed by tracking the decline in visual function sensitivity over time using standard automated perimetry, though this approach is susceptible to substantial test-retest variability and confounding effects of age-related changes4. Current standard clinical care for glaucoma also includes optical coherence tomography (OCT) imaging, which allows for the detection of progressive morphological changes, such as retinal nerve fiber layer (RNFL) thinning, closely associated with vision loss5. Recent studies have developed deep learning-based methods to detect visual field (VF) deterioration from longitudinal OCT scans and RNFL thickness, achieving promising area under the ROC curve (AUC) scores6,7. However, OCT measurements over an extended period, often spanning several years, are typically needed to identify progression status8, which makes it challenging to collect sufficient data for training a generalizable progression prediction model. In addition, methods that rely on RNFL thickness may be affected by OCT layer segmentation artifacts9,10. Hence, we develop a deep learning model that uses the baseline OCT scans to predict glaucoma progression status. The glaucoma progression was defined by longitudinal VF data from at least five consecutive visits over a six-year period (Fig. 1b).

a Illustration of progressive vision loss in a glaucoma patient. b Examples of glaucoma progression identified from longitudinal visual field tests. c The proposed equity-aware EfficientNet, called EqEffNet, for training a glaucoma detection model. d The proposed framework, called FairDist, generalizes the pretrained glaucoma detection model to enhance the demographic equity in glaucoma progression prediction through knowledge distillation.
On the other hand, while deep learning has the potential to improve the efficiency and accessibility of glaucoma diagnosis for a broader population11,12,13,14, their performance across different demographic groups is underexplored. A growing body of research indicates that deep learning algorithms can reinforce and amplify biases present in the data15,16,17,18, raising significant fairness concerns, particularly for certain racial and ethnic minorities. For example, a recent study found that Black individuals experience significantly lower performance outcomes compared to Whites and Asians when using RNFL thickness and OCT scans for glaucoma detection18. Two other studies offered a comprehensive analysis of inequity concerns in artificial intelligence (AI) across various healthcare applications17,19, especially impacting the underrepresented communities. The unfairness of AI models can stem from several factors. First, skewed data distributions in diagnosis labels and sensitive attributes may result in inadequate feature representation for specific groups. Second, anatomical differences between subgroups can create varying levels of difficulty for AI models to provide accurate diagnoses. Third, annotation inconsistencies arising from clinicians’ varying preferences based on patient attributes can confuse AI models and contribute to bias. Last, the AI model itself can perpetuate unfairness. Conventional AI training processes prioritize maximizing overall performance, which may inadvertently widen performance gaps between subgroups. Regardless of different reasons, it is of paramount importance to explicitly address the potential unfairness of AI models for equitable medical diagnosis.
In this work, we propose an equity-aware deep learning model to address these limitations. From the analyses above, two obstacles may hinder the development of a responsible progression prediction model: (1) the limited availability of longitudinal data with annotations and (2) potential disparities in prediction performance across different demographic groups. To address the challenge of limited data, we proposed training a glaucoma detection model (Fig. 1c) using a large dataset and subsequently generalizing it for progression prediction through a knowledge distillation process (Fig. 1d). Additionally, we introduced an equity-aware feature learning mechanism that adjusts the importance of OCT scan features based on patient identity information. The proposed integration of knowledge distillation and equitable feature learning aims to enhance both the performance and fairness of deep learning models for glaucoma progression prediction. The terms equity and fairness are used interchangeably in this paper.
Results
Dataset collection
In this study, we utilized a glaucoma detection dataset (Table 1). It is a large-scale glaucoma detection dataset to develop a glaucoma detection model. The dataset contains 10,000 reliable (signal strength is greater than 6) spectral-domain OCT (Cirrus, Carl Zeiss Meditec, Dublin, California) samples of 10,000 patients from the Massachusetts Eye and Ear glaucoma service between 2010 and 2022. The average age of patients was 60.7 ± 6.3 years. Each 3D OCT data sample contains 200 B-scans, each with a dimension of 200 × 200. The self-reported patient demographic information was as follows (Fig. 2a): 57.0% of the patients are female and 43.0% are male; racially, 8.5% are Asian, 14.9% are Black, and 76.6% are White. 51.3% of the patients are categorized as non-glaucoma and 48.7% as glaucoma.

a The distributions of demographics and glaucomatous status of 10,000 patients in the glaucoma detection dataset. b The distributions of demographics, glaucomatous and progression status of 500 patients in the progression prediction dataset.
Additionally, we used a glaucoma detection and progression prediction dataset (Table 1). It is a public dataset for both glaucoma detection and progression prediction tasks. It includes 500 spectral-domain Cirrus OCT samples of 500 glaucoma patients from the Massachusetts Eye and Ear. The average age of patients was 62.9 ± 6.4 years. Each OCT sample contains 200 B-scans, accompanying both glaucoma detection and progression prediction labels. Demographic information was as follows: Gender distribution is 54.0% female and 46.0% male; racial composition includes 9.4% Asian, 15.6% Black, and 75.0% White. The patients were divided into non-glaucoma and glaucoma categories, making up 55.2% and 44.8% of the dataset, respectively. Two types of glaucoma progression, including Mean Deviation (MD) fast progression and Total Deviation (TD) pointwise progression, were explored in this work. For MD fast progression, 91.2% are categorized as non-progression and 8.8% as progression20. For TD progression, the percentages are 90.6% for non-progression and 9.4% for progression.
Glaucoma detection results
We integrated an equity-aware feature attention learning layer into EfficientNet to develop the EqEffNet model. For gender groups, EqEffNet improved the overall AUC by 0.01 (p < 0.05), with the Male group improved from 0.83 to 0.85 (Fig. 3). For racial groups, both overall AUC and ES-AUC of EqEffNet had an improvement of 0.02 (p < 0.01) compared with EfficientNet, which was contributed by a significant improvement of 0.04 in AUC for the White group, although Asians and Blacks had no improvements (Fig. 3).

a Gender. b Race.
MD fast progression prediction results
Among the five comparative methods (VGG, DenseNet, ResNet, ViT, and EfficientNet) without unfairness mitigation strategies (Fig. 4a), ResNet achieved the highest overall AUC of 0.69 and ES-AUC of 0.67 (p < 0.05) for the gender attribute, outperforming VGG (0.65 and 0.63), DenseNet (0.68 and 0.65), ViT (0.65 and 0.61), and EfficientNet (0.66 and 0.63). EfficientNet achieved the highest sensitivity of 0.67 (p < 0.01), while both VGG and ResNet demonstrated the highest specificity of 0.66 (p < 0.05) among the five methods (Fig. 4a). For gender groups, FairDist outperformed all five methods without unfairness mitigation strategies, achieving the highest overall AUC of 0.74 and ES-AUC of 0.69 (p < 0.01). The group AUCs for Females (0.75) and Males (0.79) were consistently higher than those of other methods. Additionally, FairDist matched EfficientNet with the highest sensitivity of 0.67 (Fig. 4a). While comparing with the two methods with unfairness mitigation on gender groups (Fig. 4b), FairDist improved the overall AUC, ES-AUC, and sensitivity by 0.06, 0.11, and 0.20 over EfficientNet + Adversarial (p < 0.01), and 0.05, 0.15, and 0.27 over EqEffNet (p < 0.01), respectively.

a Comparison of baseline methods and the proposed FairDist model for gender groups. b Comparison of methods with unfairness mitigation strategies for gender groups. c Comparison of baseline methods and the proposed FairDist model for racial groups. d Comparison of methods with unfairness mitigation strategies for racial groups. MD visual field mean deviation, Adversarial with adversarial training.
For racial groups, ResNet remained the highest AUC of 0.69 among the five baseline methods without fairness considerations. However, its ES-AUC (0.49) and sensitivity (0.53) were lower than those of EfficientNet, which achieved an ES-AUC of 0.56 and sensitivity of 0.67 (Fig. 4c). FairDist achieved the highest AUC of 0.78, ES-AUC of 0.68, and sensitivity of 0.73 when compared with other methods with and without applying unfairness mitigation strategies (Fig. 4c). Compared with EqEffNet, FairDist improved the AUCs for Asians and Blacks by 0.20 and 0.14 (p < 0.01), respectively. While comparing with EfficientNet + Adversarial, FairDist improved the AUC in the Black group by 0.14 (p < 0.01), although the corresponding AUCs for Asians and Whites had slight drops (Fig. 4d).
TD pointwise progression prediction results
On the gender attribute, EfficientNet achieved an overall AUC of 0.72, ES-AUC of 0.70 and sensitivity of 0.71, which outperformed (p < 0.05) other four methods including VGG, DenseNet (except for sensitivity), ResNet and ViT without designing fairness learning components (Fig. 5a). FairDist achieved the highest AUC (0.74) and ES-AUC (0.72) compared with all five methods without fairness considerations (Fig. 5a), and meanwhile outperformed EfficientNet + Adversarial (0.71 and 0.62) and EqEffNet (0.72 and 0.66) with fairness considerations (Fig. 5b). In addition, FairDist achieved the highest average sensitivity and specificity which was 0.67 (Fig. 5a and Fig. 5b), compared with VGG (0.60), ResNet (0.60), ViT (0.56), EfficientNet (0.65), EfficientNet + Adversarial (0.66) and EqEffNet (0.62), respectively. FairDist achieved the same specificity of 0.70 as DenseNet, but lower sensitivity (0.64) than DenseNet (0.71).

a Comparison of baseline methods and the proposed FairDist model for gender groups. b Comparison of methods with unfairness mitigation strategies for gender groups. c Comparison of baseline methods and the proposed FairDist model for racial groups. d Comparison of methods with unfairness mitigation strategies for racial groups. MD visual field mean deviation, Adversarial with adversarial training.
On the race attribute, FairDist achieved the highest AUC (0.75), ES-AUC (0.65), and specificity (0.76) compared with all other methods (p < 0.05, Fig. 5c, d). Although EqEffNet achieved a perfect AUC of 1.0 for Blacks and a better AUC than FairDist in the White group (Fig. 5d), its AUC in Asian groups is significantly lower than FairDist, which had caused much lower ES-AUC (0.51) than that of FairDist (0.65). FairDist also improved the sensitivity and specificity by 0.07 and 0.09 (p < 0.01), respectively, compared with EqEffNet (Fig. 5d).
Discussion
Deep learning approaches have been increasingly adopted to analyze clinical data such as VF, fundus images, and OCT scans for automated glaucoma detection21,22. However, glaucoma progression prediction remains underexplored compared to glaucoma detection with deep learning, primarily due to the scarcity of available data23. This challenge is further complicated by deep learning models, which have raised significant concerns regarding fairness17. Unlike existing progression prediction methods that often require large datasets and overlook demographic biases, we propose a novel approach that addresses both data scarcity and group disparities in progression prediction.
Compared to the baseline methods, the advantages of the proposed approach stem from two key factors. First, the EqEffNet model with an equity-aware feature attention layer enhances both performance and equity, as demonstrated in glaucoma detection (Fig. 3) across gender and racial attributes. The equity-aware attention layer enables the model to adjust feature importance in OCT scans according to the demographic attributes (Fig. 6a), thus allowing the model to have improved capacity to balance the feature learning of various groups. Additionally, EqEffNet generally outperformed methods without considering group disparities in progression prediction, with notable improvements for race in MD Fast progression (Fig. 4c, d) and for both gender and race in TD Pointwise progression (Fig. 5). Second, the pretrained detection model is beneficial to enhance the glaucoma progression prediction model through knowledge distillation which can be observed by the comparison between FairDist and EqEffNet (Figs. 4 and 5). This allows an equity-enhanced and well-performing glaucoma detection model to guide the feature learning of a progression prediction model, which is beneficial especially when data scarcity is a challenge to train a good model. The averaged gradient-weighted class activation map of FairDist (Fig. 6b), which closely resembles that of EqEffNet (Fig. 6a), also demonstrates that knowledge distillation has effectively reshaped the progression model to extract meaningful features from OCT scans for enhanced model performance and equity. This is also meaningful that features around OCT retinal layers were more important, which were better captured by FairDist than the baseline EfficientNet model (Fig. 6c). Although FairDist did not consistently outperform baseline models on all metrics, it achieved improved overall model performance and equity across different demographic groups, which are key factors for reliable and trustworthy clinical deployment. For example, while FairDist may not always achieve the highest sensitivity, it often achieves a better balance between sensitivity and specificity, which is crucial for clinical applications that require minimizing both false negatives and false positives.

a EfficientNet versus EqEffNet on glaucoma classification. b EfficientNet versus FairDist on MD Fast progression prediction. c EfficientNet versus FairDist on TD Pointwise progression prediction.
It is interesting to note that EqEffNet improved overall AUC and model fairness on the race attribute with compromised group AUCs in Asians and Blacks (Fig. 3b). This contradictory trend can be explained by two major factors. First, EfficientNet inherently tends to favor the Asian group in the studied dataset, whereas EqEffNet prioritizes overall performance and fairness through an optimized balance across groups globally without intentionally biasing specific groups. Second, patients according to different identity attributes (i.e., gender and race) could fall into the same or different groups, which can hinder a unified model from achieving consistent improvements across various identity attributes and groups. Additionally, although FairDist consistently achieved the highest AUC and ES-AUC scores compared with other methods, including VGG, DenseNet, ResNet, ViT, EfficientNet, and EqEffNet with and without integrating fairness learning, it did not always improve the AUCs across different groups. For example, FairDist achieved the best performance of 0.75 (p < 0.05) in Female group among all methods but its AUC (0.79) was worse than that (0.90) of EqEffNet Male group in the prediction of MD Fast progression (Fig. 4b). For TD Pointwise progression, FairDist did not excel in both Female (AUC: 0.77) and Male (AUC: 0.73) groups, where EfficientNet + Adversarial led the Female (AUC: 0.79) and EqEffNet led the Male (AUC: 0.76) groups, respectively (Fig. 5b). Once again, this is because mitigating the unfairness of deep learning models involves a multi-objective optimization process that seeks to reduce group disparities without sacrificing overall model performance24,25. This process will inevitably rebalance different groups, leading to performance increase or decrease in certain groups.
However, the proposed equitable model and its evaluation have several limitations. First, we studied a critical task of glaucoma progression prediction and evaluated the model for the glaucoma detection task. However, we have not evaluated the model performance and equity for other disease progression tasks due to a lack of public datasets with demographic attributes. Additionally, we focused on the OCT scans in this work, while there is a need to integrate other modalities, such as fundus images, to study a multimodal fairness learning problem, especially when different data modalities may unevenly cause group disparities. Second, we primarily used the equity-scaled AUC to assess the model equity, while other metrics such as demographic parity and equalized odds can also be used26,27. However, it is impossible to satisfy different metrics due to varying definitions and constraints, especially in situations of highly imbalanced distributions of demographics and labels, which could be an interesting future direction28. Third, we primarily focused on the EfficientNet model to design the equitable deep learning model since it generally outperformed other baseline models for progression predictions in this work. However, it is meaningful to explore more powerful model architectures and training paradigms, such as adapting pretrained foundation models to boost the model performance with low-rank based model adaptation techniques29. Fourth, we designed an equity-aware attention layer, which was helpful to differentiate image feature importance for improved model performance and equity. However, future work necessitates a comprehensive comparison of different unfairness mitigation strategies and comparing their generalizability to various demographic groups15. Last, the progression prediction dataset included in this evaluation is not substantial, which is a critical challenge that hinders the advancement of developing equitable deep learning models. Further work will test the generality of the proposed model using an increased scale of the dataset.
In conclusion, we proposed an equity-aware deep learning model with knowledge distillation to enhance the model performance and equity of glaucoma progression prediction. The model has been tested on MD Fast and TD Pointwise progressions, achieving improved performance compared with methods with and without fairness learning components. Our approach has the potential to improve demographic equity in glaucoma progression, and it can also be generalized to other disease progression prediction tasks.
Methods
Two datasets were used to develop deep learning models for glaucoma progression prediction. This study complied with the guidelines outlined in the Declaration of Helsinki. In light of the study’s retrospective design, the requirement for informed consent was waived.
Dataset description
In both glaucoma detection and progression prediction datasets, glaucomatous status was defined based on a reliable Humphrey VF test, which included a fixation loss of ≤33%, false-positive rate of ≤20%, and false-negative rate of ≤ 20%. A VF test conducted within 30 days of OCT was utilized to identify glaucoma patients. Criteria for the presence of glaucoma include a VF mean deviation less than −3 dB, coupled with abnormal results on both the glaucoma hemifield test and the pattern standard deviation20. In the progression prediction, two criteria were used to assess glaucoma progression based on VF maps collected over a minimum of five visits within a six-year period30, with each map represented by a vector of 52 TD values ranging from −38 dB to 26 dB. The criteria are: (1) MD Fast Progression: eyes with an MD slope ≤ −1 dB. (2) TD Progression: eyes with at least three locations exhibiting a TD slope ≤ −1 dB; Note that the 500 samples included are baseline OCT scans, and the VF data used to define the labels are private.
The proposed equity-aware deep learning model with knowledge distillation
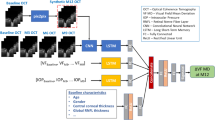
The proposed approach includes two phases. First, we developed an equity-aware deep learning model called EqEffNet for glaucoma detection using a large dataset (Fig. 1c). Then, the pretrained EqEffNet was generalized to a glaucoma progression prediction model called FairDist through knowledge distillation (Fig. 1d). Specifically, EqEffNet used EfficientNet as the backbone model and integrated a fair attention mechanism to extract features from the OCT scans. The EfficientNet architecture is organized into seven blocks, each distinguished by a different color. Each block contains multiple MBConv layers, where an MBConv layer is a mobile inverted bottleneck convolution that incorporates squeeze-and-excitation optimization. These blocks differ in filter depth and size, as reflected by their kernel dimensions and the number of layers within each block. Starting with the initial standard convolution layer, the network progresses through these MBConv blocks, which increase in complexity and depth. Note that each block represents a stage in feature extraction where similar operations are applied to the input features. This hierarchical structure allows EfficientNet to efficiently manage computational resources while maximizing learning and representational capacity, making it highly effective for tasks requiring detailed image analysis and classification. However, EfficientNet may exhibit biases towards certain demographic groups (e.g., Asians and Blacks) and lead to notable group disparities. To address this, we introduced a fairness-aware attention layer that adjusts feature learning based on demographic attributes. Specifically, we utilized a multilayer perceptron (MLP) encoder to process the binary-encoded demographic attributes associated with the input scans. Afterwards, the learned attribute and image features were used to calculate the importance weights for each of the image features. Assuming \({{\bf{X}}}_{\mathrm{pred}}\) and \({{\bf{A}}}_{\mathrm{pred}}\) are the raw image and demographic attribute features, the fairness-aware attention layer can be defined as:
where \({{\bf{h}}}_{\mathrm{pred}}\) and \({{\bf{h}}}_{\mathrm{attr}}^{\mathrm{pred}}\) represent the image and attribute features learned by the EfficientNet and MLP, respectively. \(d\) is the dimension of the latent image and attribute features. \({{\bf{W}}}^{{\bf{1}}}\), \({{\bf{W}}}^{{\bf{2}}}\), and \({{\bf{W}}}^{{\bf{1}}}\) are learnable weight parameters. With the fairness-aware attention layer, image features could adjust their importances for identity attributes to obtain balanced attentions and contributions for the final glaucoma detection and progression prediction outcomes. The glaucoma detection model EqEffNet was trained using the Glaucoma Detection Dataset including 10,000 OCT samples. 60%, 10% and 30% of the samples were used for model training, evaluation and testing, respectively.
Next, the pretrained glaucoma detection model was used to initialize a glaucoma detection model which guided the training of a glaucoma progression prediction model termed FairDist (Fig. 1d). Both glaucoma detection and progression prediction models used EqEffNet to learn features, and these two EqEffNet models took the same OCT scans as inputs but performing glaucoma detection and progression prediction tasks, respectively. At the same time, the pretrained glaucoma detection model (as a teacher) empowered the progression prediction model (as a student) through a knowledge distillation process which minimizes the attribute and image feature distances based on the Kullback–Leibler (KL) divergence31:
where \({D}_{\mathrm{KL}}^{\mathrm{img}}\) and \({D}_{\mathrm{KL}}^{\mathrm{attr}}\) represent the KL similarities of images and attributes, respectively. \(\alpha\) and \(\beta\) are hyperparameters used to control the image and attribute feature similarities between the two EqEffNet models in FairDist. FairDist was trained using the Progression Prediction Dataset, which contains OCT scans with glaucomatous status and progression outcomes. 70% and 30% of samples were used for model training and testing, respectively.
Comparative methods, evaluation metrics, and statistical analysis
We evaluated the progression prediction performance and demographic equity of five popular deep learning models for processing medical images, including VGG32, DenseNet33, ResNet34, Vision Transformer (ViT)35, and EfficientNet36. In addition, we also compared with the adversarial training approach to mitigate model biases37. All deep learning modeling and statistical analyses were performed in Python 3.8 (available at http://www.python.org) on a Linux system. Model performance was assessed using the area under the receiver operating characteristic curve (AUC), Sensitivity, and Specificity. To assess demographic equity, we adopted the equity-scaled AUC (ES-AUC)18, defined as: \({\mathrm{AUC}}_{\mathrm{ES}}\,=\,{\mathrm{AUC}}_{\mathrm{overall}}/(1\,+\,\Sigma |{\mathrm{AUC}}_{\mathrm{overall}}\,-\,{\mathrm{AUC}}_{\mathrm{group}}|)\). This metric balances overall AUC with performance disparities among different groups. Statistical significance was evaluated using t-tests and bootstrapping to compare AUC and ES-AUC values between models with and without FAS. Bootstrapping provided confidence intervals and standard error estimates. Results with p < 0.05 were considered statistically significant.
Parameter settings
The CNN models, including VGG, DenseNet, ResNet, and EfficientNet, were trained using a learning rate of 1e−4 for 10 epochs with a batch size of 6. For the ViT, we followed settings from the literature38: training for 50 epochs with a layer decay of 0.55, weight decay of 0.01, dropout rate of 0.1, batch size of 64, and a base learning rate of 5e−4. All models were optimized using AdamW39. In FairDist, the default values for α and β were set to 1.0 and 0.05, respectively.
Data availability
The dataset for glaucoma detection can be accessed at https://github.com/Harvard-Ophthalmology-AI-Lab/FairVision, while the dataset for glaucoma progression detection is available at https://github.com/Harvard-Ophthalmology-AI-Lab/Harvard-GDP.
Code availability
The codes for the proposed model are available at https://github.com/shiminxst/FairDist.
References
Quigley, H. A. The number of people with glaucoma worldwide in 2010 and 2020. Br. J. Ophthalmol. 90, 262–267 (2006).
Friedman, D. S. et al. Prevalence of open-angle glaucoma among adults in the United States. Arch. Ophthalmol. 122, 532–538 (2004).
Jayaram, H., Kolko, M., Friedman, D. S. & Gazzard, G. Glaucoma: now and beyond. Lancet 402, 1788–1801 (2023).
Thompson, A. C., Jammal, A. A. & Medeiros, F. A. A Review of Deep Learning for Screening, Diagnosis, and Detection of Glaucoma Progression. Transl. Vis. Sci. Technol. 9, 42 (2020).
Zhang, X. et al. Comparison of Glaucoma Progression Detection by Optical Coherence Tomography and Visual Field. Am. J. Ophthalmol. 184, 63–74 (2017).
Hou, K. et al. Predicting Visual Field Worsening with Longitudinal OCT Data Using a Gated Transformer Network. Ophthalmology 130, 854–862 (2023).
Mohammadzadeh, V. et al. Prediction of visual field progression with baseline and longitudinal structural measurements using deep learning. Am. J. Ophthalmol. 262, 141–152 (2024).
Mariottoni, E. B. et al. Deep learning–assisted detection of glaucoma progression in spectral-domain OCT. Ophthalmol. Glaucoma 6, 228–238 (2023).
Shi, M., Tian, Y., Luo, Y., Elze, T. & Wang, M. RNFLT2Vec: artifact-corrected representation learning for retinal nerve fiber layer thickness maps. Med Image Anal. 94, 103110 (2024).
Shi, M. et al. Artifact correction in retinal nerve fiber layer thickness maps using deep learning and its clinical utility in glaucoma. Transl. Vis. Sci. Technol. 12, 1–12 (2023).
Li, F. et al. The AI revolution in glaucoma: bridging challenges with opportunities. Prog. Retin Eye Res. 103, 101291 (2024).
Huang, X. et al. Artificial intelligence in glaucoma: opportunities, challenges, and future directions. Biomed. Eng. Online 22, 126 (2023).
Shon, K., Sung, K. R. & Shin, J. W. Can artificial intelligence predict glaucomatous visual field progression? A spatial–ordinal convolutional neural network model. Am. J. Ophthalmol. 233, 124–134 (2022).
Thakur, A., Goldbaum, M. & Yousefi, S. Predicting glaucoma before onset using deep learning. Ophthalmol. Glaucoma 3, 262–268 (2020).
Caton, S. & Haas, C. Fairness in machine learning: a survey. ACM Comput Surv. 56, 1–38 (2024).
Jin, R. et al. FairMedFM: fairness benchmarking for medical imaging foundation models. Adv. Neural. Inf. Process. Syst. 37, 111318–111357 (2024).
Chen, R. J. et al. Algorithmic fairness in artificial intelligence for medicine and healthcare. Nat. Biomed. Eng. 7, 719–742 (2023).
Luo, Y. et al. Harvard glaucoma fairness: a retinal nerve disease dataset for fairness learning and fair identity normalization. IEEE Trans. Med. Imaging 43, 2623–2633 (2024).
Xu, Z. et al. Addressing fairness issues in deep learning-based medical image analysis: a systematic review. NPJ Digit Med. 7, 286 (2024).
Wang, M. et al. Characterization of central visual field loss in end-stage glaucoma by unsupervised artificial intelligence. JAMA Ophthalmol. 138, 190 (2020).
Russakoff, D. B. et al. A 3D deep learning system for detecting referable glaucoma using full OCT macular cube scans. Transl. Vis. Sci. Technol. 9, 12 (2020).
Christopher, M. et al. Deep learning approaches predict glaucomatous visual field damage from OCT optic nerve head en face images and retinal nerve fiber layer thickness maps. Ophthalmology 127, 346–356 (2020).
Li, J., Cairns, B. J., Li, J. & Zhu, T. Generating synthetic mixed-type longitudinal electronic health records for artificial intelligent applications. NPJ Digit. Med. 6, 98 (2023).
Luo, Y. et al. FairCLIP: harnessing fairness in vision-language learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) pp 12289–12301.
Tian, Y. et al. FairDomain: achieving fairness in cross-domain medical image segmentation and classification. In: European Conference on Computer Vision (ECCV) (2024) pp 251–271.
Hardt, M., Price, E. & Srebro, N. Equality of opportunity in supervised learning. Adv. Neural Inf. Process. Syst. 29, 1–9 (2016).
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. & Galstyan, A. A Survey on bias and fairness in machine learning. ACM Comput. Surv. 54, 1–35 (2022).
Kleinberg, J., Mullainathan, S. & Raghavan, M. Inherent trade-offs in the fair determination of risk scores. Proceedings of the 8th Conference on Innovations in Theoretical Computer Science (ITCS) (2017) pp 1–43.
Zanella, M. & Ben Ayed, I. Low-rank few-shot adaptation of vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (2024) pp 1593–1603.
Vesti, E., Johnson, C. A. & Chauhan, B. C. Comparison of different methods for detecting glaucomatous visual field progression. Investig. Opthalmol. Vis. Sci. 44, 3873 (2003).
Zhang, Y. et al. On the properties of Kullback-Leibler divergence between multivariate Gaussian distributions. Adv. Neural Inf. Process. Syst. 36, 58152–58165 (2024).
Simonyan, K. & Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Published online September 4, 2014.
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (IEEE, 2017) pp 2261–2269. https://doi.org/10.1109/CVPR.2017.243.
He, K., Zhang, X., Ren, S. & Jian, S. Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition. (2016) pp 770–778.
Dosovitskiy, A. et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. Published online October 22, 2020.
Tan M., Le Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Published online May 28, 2019.
Yang, J., Soltan, A. A. S., Eyre, D. W., Yang, Y. & Clifton, D. A. An adversarial training framework for mitigating algorithmic biases in clinical machine learning. NPJ Digit. Med. 6, 55 (2023).
He, K. et al. Masked autoencoders are scalable vision learners. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (IEEE; 2022) pp 15979–15988. https://doi.org/10.1109/CVPR52688.2022.01553.
Zhou, P., Xie, X., Lin, Z. & Yan, S. Towards understanding convergence and generalization of AdamW. IEEE Trans. Pattern Anal. Mach. Intell. 46, 6486–6493 (2024).
Acknowledgements
This work was partially supported by Louisiana Board of Regents under Contract LEQSF(2025-28)-RD-A-19 (M.S.), NIH R01 EY036222 (M.W.), NIH R21 EY035298 (M.W.), NIH P30 EY003790 (M.W.), FireCyte Therapeutics Inc. (L.S.), Tianqiao and Chrissy Chen Institute Scholar (J.S.), All May See and Think Forward Foundation (J.S.), and UCSF Perstein Award (J.S.).
Author information
Authors and Affiliations
Contributions
M.S. and S.O.A. conceived the study. S.O.A. and M.S. developed the deep learning model. M.S., L.Q.S. and M.W. collected the data. S.O.A., L.G., and M.S. performed data processing, experiment, and analysis. M.S., M.W., J.S. and L.Q.S. contributed materials and clinical expertise. M.S. supervised the work. All authors wrote and revised the paper. All authors have read and approved the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Afolabi, S.O., Gheisi, L., Shan, J. et al. Equity-enhanced glaucoma progression prediction from OCT with knowledge distillation. npj Digit. Med. 8, 477 (2025). https://doi.org/10.1038/s41746-025-01884-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01884-9
