
Abstract
Blepharospasm is a focal dystonia characterized by involuntary eyelid contractions that impair vision and social function. The subtle clinical signs of blepharospasm make early and accurate diagnosis difficult, delaying timely intervention. In this study, we propose a dual cross-attention deep learning framework that integrates temporal video features and facial landmark dynamics to assess blepharospasm severity, frequency, and diagnosis from smartphone-recorded facial videos. A retrospective dataset of 847 patient videos collected from two hospitals (2016–2023) was used for model development. The model achieved high accuracy for severity (0.828) and frequency (0.82), and moderate performance for diagnosis (0.674).SHAP analysis identified case-specific video fragments contributing to predictions, enhancing interpretability. In a prospective evaluation on an independent dataset (N = 179), AI assistance improved junior ophthalmologist’s diagnostic accuracy by up to 18.5%. These findings demonstrate the potential of an explainable, smartphone-compatible video model to support early detection and assessment of blepharospasm.
Similar content being viewed by others

Introduction
Blepharospasm (BSP), the most common subtype of dystonia affecting up to 732 per 100,000 individuals1, is characterized by involuntary, repetitive blinking and eyelid closure caused by abnormal contraction of the orbicularis oculi muscles2. The condition significantly impairs visual function and diminishes the quality of life of the patients3. Patients often experience functional blindness, social embarrassment, and emotional distress, contributing to an overall reduction in life satisfaction and mental health4. BSP can be highly complex spatiotemporally heterogeneous5, such as facial muscle fibrillation, brief or prolonged spasms and a narrowing or closure of the eyelids occurring on variable time scales and exacerbated or alleviated by certain movements6. These manifestations are easily overlooked, and the narrowing or closure of the eyelids is often misdiagnosed as dry eye, ptosis, or myasthenia gravis (MG), which can lead to unnecessary treatments and exacerbation of symptoms. Considering that botulinum toxin may exacerbate muscle weakness in patients with MG, it is imperative to optimize the management of MG before administering botulinum toxin to those with concurrent MG and BSP7. Despite its profound impact, diagnosis remains challenging, predominantly due to its episodic nature. Symptoms may not manifest during clinical evaluations, complicating timely and accurate diagnosis. Observable symptoms, electromyography (EMG) and physical examination are often used for the diagnosis of BSP. However, the transient and unpredictable occurrence of symptoms often leads to negative EMG results and misdiagnosis.
Studies8,9 indicate that roughly 61% of BSP cases spread to neighboring and/or more distant body regions, primarily within the first 5 years after onset. Thus, there is an urgent need to develop accurate, non-invasive, and cost-efficient diagnostic tools for both clinical diagnosis and patient self-diagnosis. Since facial movements and expressions in patients with BSP are subtle and hardly perceptible, the objective assessment of BSP severity is such a difficult task that only experienced neurologists or ophthalmologists could rate accurately. AI technologies, especially those employing video analysis and facial recognition algorithms, have demonstrated potential in identifying subtle and transient symptoms of eyelids10. Peterson et al.11 employed the Computer Expression Recognition Toolbox (CERT) to compare clinical rating scales of BSP severity with involuntary eye closures by performing a frame-by-frame video analysis to evaluate eye closure duration. Trotta et al.12 proposed a neural network-based software capable of detecting the state of the eyes as well as recognizing and counting symptoms of BSP in video recordings. This software demonstrated high sensitivity in identifying both brief and prolonged spasms but was less effective in detecting blinks, highlighting the potential of AI to continuously and objectively analyze visual data, potentially identifying BSP episodes missed during standard clinical assessments.
Video classification has been widely studied over the years, with methods such as 3D convolutional network (3D CNN)13, optical flow14, graph convolutional network15 being proposed for various applications. One widely adopted model architecture combines spatial models to extract features from individual frames with temporal models to capture dependencies over time. Spatial models like VGG16, Resnet17 and Vision Transformer18 have shown excellent performance in 2D image classification dataset like ImageNet19 and Cifar1020. After spatial features are extracted for each frame, they are concatenated along the time dimension and fed into temporal model. Models like LSTM21 or Transformer22 are commonly used to extract temporal features and convert them to final classification result. Numerous studies have explored video classification architectures, achieving significant advancements across various domains23,24,25,26. However, this approach has not yet been explored in the diagnosis of BSP due to two primary challenges. Firstly, effective model training for BSP classification requires a relatively large dataset, as dataset size directly impacts model performance and generalization. However, no publicly available BSP dataset currently exists, and prior research12 has relied on small datasets containing videos from 9 patients, which significantly limits training outcome. Secondly, video classification tasks demand substantial computational resources, particularly in terms of GPU memory. Models such as Video Vision Transformer (ViViT) often mitigate this by sampling subframes from the original video. However, the complex and involuntary nature of facial spasms in BSP, characterized by considerable variability in movement patterns and duration, complicates this approach. Subframe sampling may result in the loss of critical information, further hindering accurate classification.
In this study, we introduce a novel deep learning model, the Dual Cross-Attention Video Vision Transformer (DCA-ViViT), specifically designed for BSP diagnosis. Our approach leverages multimodal input sources, including video frames and face mesh detection, without the need for subframe sampling, thereby preserving the full temporal dynamics of facial spasms. This innovation facilitates reliable classification of BSP diagnosis, severity and frequency, overcoming challenges associated with limited data and computational constraints. Furthermore, our investigation into model visualization provides valuable insights that may inform future research in treatment strategies and AI-assisted diagnostic systems.
Results
Data characteristics
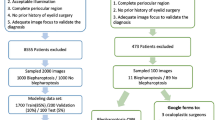
The overall workflow of our study is shown in Fig. 1. After excluding videos with insufficient quality, a total of 847 facial videos were included for the model construction: 109 videos (12.9%) were labeled as “No BSP”, 238 (28.1%) as “Monocular BSP,” and 500 (59.0%) as “Binocular BSP” (Table 1). Among the 847 patients included in the retrospective dataset, 218 (25.7%) were male, and the average age was 57.9 years (SD 11.7; range 15–88). All patients younger than 20 years belonged to the non-BSP group, and no juvenile-onset BSP cases were included in the dataset. The prospective set (N = 179) was collected separately to assess the model’s generalizability and to evaluate its potential to assist clinicians by comparing human–AI diagnostic performance. For the prospective set, 44 (24.6%) were male, with a higher average age of 61.4 years (SD 10.0; range 31–86). Detailed patient demographics across the retrospective and prospective datasets are summarized in Table 2. According to Table 1, 282 videos (33.3%) were classified as mild severity, and 565 (66.7%) as severe. Regarding frequency, 227 videos (26.8%) showed mild frequency, while 620 videos (73.2%) demonstrated severe frequency (Table 1).

This study comprises four main components: Dataset Establishment, Model Training, Evaluation and Explanation, and Clinical Validation.
Model performance
The architecture of our AI model is shown in Fig. 2. The results presented in Table 3 demonstrate the performance of variations in spatial and temporal architectures of DCA-ViViT (SA-RNViT, CA-RNViT, DCA-RNViT, SA-ViViT, CA-ViViT, and DCA-ViViT) and two benchmark video classification models (ViViT and VideoMAE) in predicting the severity, frequency, and diagnosis of BSP. Based on our evaluation, DCA-ViViT outperformed the other models in 10 out of the 15 assessed metrics. In the severity and frequency categories, it achieved the highest accuracy, recall, and F1 scores. Notably, its recall exceeded 93%, indicating a strong ability to identify positive cases effectively. Although overall performance on the diagnosis task was relatively low across all models, DCA-ViViT still attained the highest scores among them.

The architecture consists of four modules: a Pretrained FaceMesh detector for facial landmark extraction, b ViViT model for spatial feature extraction, c Dual cross attention model, d Dual cross attention layer. PE positional embedding, DCAL dual cross attention layer, MLP multilayer perceptron, SA self attention, LN layer norm, CA cross attention, FF feed-forward layer.
The t-test results in Fig. 3b, d, f indicate that among benchmark methods and the six spatial temporal variations of DCA-ViViT, our model consistently excels in frequency. Notably, the model demonstrates competitive advantages in severity and diagnosis, outperforming 5 out of 7 alternative models.

Confusion matrices of DCA-ViViT for diagnosis (a), severity (c), and frequency (e) classification. Accuracy distributions across different splits for each model on three model tasks: diagnosis (b), severity (d), and frequency (f). *: statistically significant differences between models (p < 0.05, t-test).
Model visualization by SHAP value
Visualization of model attention is instrumental for evaluating both performance and interpretability in spasm video classification. Ultimately, these visualizations not only validate the model’s accuracy but also facilitate clear communication of results to medical professionals and other stakeholders, ensuring that the research translates effectively into practical diagnostic tools and treatments. As shown in Fig. 4a, we used one-sided critical z-score and case-specific significance level to calculate a threshold value, as shown in the red dash line. For each task, we found consecutive fragments with SHAP value above threshold. The SHAP time series was aligned to video frames at 30 frames per second (fps), enabling identification of temporally localized intervals considered critical by the model. Figure 4b presents selected video frames corresponding to the matched segments, demonstrating clinical relevance. For the diagnosis task, the model primarily focused on brief sequences of abnormal blinking events; for severity classification, it emphasized frames capturing contractions of multiple facial muscle groups; and for frequency prediction, it identified extended abnormal blinking episodes exceeding 1 s. Figure 4c illustrates an example of the consistency assessment from a single video in which SHAP-derived segments are compared with expert annotations. In the consistency analysis across 20 videos, match rates were 95% for all three tasks (Fig. 4d). These findings indicate substantial alignment between the model’s attention and expert clinical judgment.

a Example SHAP value curves for a representative video. Red dashed lines indicate the SHAP threshold; consecutive frames exceeding the threshold were grouped as decision-support intervals with start/end times labeled and shown as light blue grids on the video time bar (each grid = 1 s). b Representative frames from matched segments: frequency segments exceeded 1 s, and severity segments exhibited visible facial muscle spasms (red regions on the face). c AI (SHAP-identified) vs. expert-labeled time segments in one representative case out of 20 comparison videos. Match: defined as a temporal overlap of at least 1 s between the AI and expert-labeled segments. d AI-expert match rates for three model tasks. Orange, green, and blue indicate diagnosis, severity, and frequency model task, respectively.
Evaluation of DCA-ViViT assisted diagnostic accuracy
The experimental design is shown in Fig. 5a. Figure 5b summarizes the diagnostic performance of the DCA-ViViT, junior and senior ophthalmologist across three tasks (diagnosis, JRS-severity, and JRS-frequency). DCAViViT outperformed junior physicians in JRS-frequency and JRS-severity tasks, achieving accuracy comparable to that of senior physicians. AI assistance improved the accuracy of both junior and senior physicians in all tasks (Fig. 5c). The confusion matrices (Fig. 5d) illustrate the distribution of predictions, revealing a reduction in misclassifications when AI support was incorporated, especially for junior physicians. The examples of the doctor-AI comparison were presented in Supplementary Fig. 1.

a Experiment design. b Accuracy of each class. c The accuracy of ophthalmologists was effectively improved with the assistance of DCA-ViViT. d Confusion matrix on each task (DCA-ViViT v.s. ophthalmologist).
Discussion
Our study underscores the potential value of advanced and precise diagnostic tools for BSP through the DCA-ViViT model. The DCA-ViViT model enables a comprehensive evaluation by diagnosing BSP and assessing its severity and frequency simultaneously. This multifaceted approach is essential for effective clinical practice.
As illustrated in Table 3 and Fig. 3, DCA-ViViT outperforms other models in 10/15 evaluation metrics. Notably, it achieves high recall (over 93%) in both severity and frequency classification, which is particularly valuable for treatment decisions. Although all models demonstrated lower performance in diagnosis classification compared to severity and frequency, further analysis revealed a notable disparity between binocular and monocular cases. Specifically, the model achieved high accuracy in diagnosing binocular BSP (~90%) but performed poorly in monocular cases (~25%). One likely reason is that the unaffected eye in monocular cases may still display subtle involuntary movements or blinking, introducing ambiguous cues that complicate classification. Unlike severity or frequency assessments, which rely on more distinct spatiotemporal patterns, distinguishing unilateral from bilateral symptoms may lack sufficiently discriminative visual features. This result underscores the inherent difficulty in identifying subtle unilateral signs and highlights current model limitations in capturing fine-grained, long-range temporal dynamics. Despite employing horizontal mirroring during training, monocular diagnosis remains challenging. Future work should address this limitation by expanding the monocular case dataset and incorporating improved model architectures—such as hierarchical attention or auxiliary feature fusion—to enhance robustness in complex diagnostic tasks. In addition to laterality-based subgroup analysis, we also explored model performance across age and sex subgroups. No significant differences were observed between male and female patients. However, stratification by age revealed distinct patterns (Supplementary Table 1). While the model achieved higher accuracy in predicting severity and frequency in the 70–79 age group, its diagnostic accuracy declined in this cohort. One possible explanation is that age-related weakening of periorbital muscles may enhance the visual expression of severity and frequency, facilitating classification. In contrast, features important for accurate diagnosis (such as eyelid movements and inter-eye asymmetry) may be masked by dermatochalasis or age-related periorbital muscle dysfunction, making it more difficult for the model to differentiate between monocular and binocular spasms.
We introduced SHAP value to enhance model interpretability, enabling visualization of how temporal and spatial features influence classification outcomes. This method not only aids in identifying critical diagnostic features but also uncovers potential data anomalies, guiding model refinement and feature selection. As illustrated in Fig. 4, SHAP analysis revealed that the model attends to physiologically plausible regions: spasm-specific periocular activity in the diagnosis task, multi-muscle contractions for severity assessment, and sustained involuntary blinks for frequency estimation. The expert consistency assessment showed high alignment between SHAP-highlighted segments and clinician-identified key intervals, with match rates of 95% for diagnosis, severity, and frequency. The results indicate that the DCA-ViViT model identified brief positive moments of BSP and related abnormal facial muscle, and predominantly relies on video features that clinicians also consider essential, supporting the model’s transparency and potential clinical acceptance. Looking forward, future work could explore whether the model identifies features beyond human perception and investigate finer-grained spatial correspondence between SHAP-highlighted facial areas and standard Botox injection sites. Such alignment could further improve the clinical interpretability of the model’s outputs and inform treatment planning.
The results of the human-AI comparison demonstrate that the DCA-ViViT achieves high accuracy in the Severity and Frequency tasks, comparable to senior clinicians. This is likely due to its ability to consistently identify subtle patterns, such as spasm-related muscle activity and prolonged blinking events. To further evaluate the clinical utility of the model, we conducted non-inferiority statistical testing across three performance metrics (accuracy, precision, and recall) using a predefined margin of 10% based on clinician performance. The model passed all non-inferiority tests for severity classification and two out of three for frequency, but failed to meet the non-inferiority threshold in all three metrics for diagnosis (Supplementary Table 2). These results reinforce the model’s strength in severity and frequency prediction, while highlighting its current limitations in the diagnostic task. Notably, the AI significantly enhances junior clinicians’ diagnostic accuracy, particularly in the Frequency task. This improvement stems from its efficiency in extracting key features, objective and consistent performance, and ability to reliably detect eyelid fluttering exceeding 1 s, which are often challenging for human observation. These findings align with SHAP analysis, validating the model’s focus on critical diagnostic features. These results underscore the potential of AI to improve diagnostic accuracy across different tasks, particularly for less experienced clinicians, thereby contributing to more consistent and objective clinical evaluations. However, we acknowledge a potential source of bias in the human-AI comparison design. Despite implementing a 10-day washout period, the evaluation order was fixed—clinicians first assessed without AI assistance, followed by an assessment with AI support. This fixed sequence may introduce order effects or learning biases that could partially inflate the observed benefit of AI assistance. In future studies, we plan to counterbalance the order of conditions across participants to better isolate the true effect of AI augmentation.
Early identification and assessment of BSP is critical to prevent disease progression, improve quality of life, and reduce healthcare costs. However, symptoms such as intermittent eyelid spasms are often missed during brief clinical visits. Our model, capable of analyzing patient-recorded smartphone videos, addresses this challenge and may reduce the need for in-person assessments. This aligns with prior evidence suggesting the feasibility of remote video-based assessments for oculoplastic disorders27. By supporting remote self-diagnosis and automated analysis, our model facilitates earlier detection, minimizes in-person visits, and improves access to care, particularly in underserved areas. Moreover, recent studies have highlighted altered facial dynamics in neurological disorders such as Parkinson’s disease28, further underscoring the clinical value of automated video analysis in detecting subtle motor anomalies.
Compared with previous studies11,12 in the diagnosis and assessment of BSP, our study presents several significant advantages. One notable strength is the utilization of a relatively larger dataset, comprising 847 videos, compared to the limited datasets of 9 and 49 patients used in prior studies. This substantial increase in data volume enhances the robustness and reliability of our findings, allowing for a more comprehensive analysis and contributing to the improved performance of our model. Additionally, our approach leverages a detailed Facemesh with 468 points, in contrast to the 68-point facial landmark detection. This high-resolution facial mapping, when combined with video-based analysis, enables fine-grained tracking of subtle movements, aligning with recent advances in pose estimation techniques for studying motor disorders such as dystonia29. Furthermore, our method avoids the common problem of information loss by maintaining the integrity of raw video data, unlike previous studies that may have filtered out significant details from images or videos during processing. This comprehensive approach results in a model with superior generalization capabilities, making it more applicable to diverse clinical scenarios.
Despite the above advantages, our study has limitations. The dataset, while larger than previous studies, is still relatively small and imbalanced, potentially biasing the model’s performance. These constraints also influenced our decision to adopt a binary classification approach for severity and frequency, rather than formulating a more granular multi-class or regression model based on the original JRS scores. In contrast, standard video classification datasets such as Kinetics-700 provide at least 600 training and 100 testing samples per label, highlighting the relative scarcity of our data. Additionally, the dataset used for our model development was collected from two independent medical centers and included prospectively gathered samples for human–AI comparison, external datasets from independent institutions were not included in the current evaluation. Therefore, the model’s generalizability to broader populations and unseen clinical environments remains to be further validated. We acknowledge this as an important limitation and are actively expanding our data collection efforts and establishing collaborations with other institutions to support future multi-center validation. Besides, using raw video data reduces information loss but increases the risk of overfitting by capturing noise or irrelevant details. To address these issues, future work should focus on expanding the dataset to include more diverse patient populations and a more balanced representation across symptom levels. Exploring multi-class classification or regression frameworks to support finer-grained and longitudinal symptom monitoring would be of great value in both research and clinical settings. Additionally, incorporating strategies such as regularization, data augmentation, and robust cross-validation will be important to enhance model generalizability and stability.
Our study proposes DCA-ViViT which significantly improves the diagnosis and assessment of BSP by evaluating severity and frequency simultaneously. DCA-ViViT outperforms other models, showing higher accuracy and robustness in all tasks. SHAP visualizations further support model interpretability and clinical utility. The model shows significant potential for clinical applications, offering a foundation for telemedicine by enabling early diagnosis from patient submitted videos.
Methods
This study was approved by the ethics committee of the Second Affiliated Hospital, Zhejiang University School of Medicine, Hangzhou, China (approval number: Y2024-0678). Informed consent was obtained from patients in accordance with the Declaration of Helsinki.
Dataset
Facial videos were collected during routine outpatient visits at the Eye Center of the Second Affiliated Hospital, Zhejiang University School of Medicine and Ningbo Eye Hospital between January 2016 and December 2023. Patients were included in this study based on the following criteria: (1) For BSP patients: Diagnosis of BSP was confirmed by at least two experienced specialists (ophthalmologists or movement disorder neurologists), and facial videos were recorded during episodes with clinically evident dystonic eyelid activity. (2) For non-BSP controls: Subjects were included only if no abnormal blink frequency or other involuntary eyelid movements were observed during video recording, as determined by clinicians. Written informed consent for video acquisition, analysis, and publication was obtained from all participants or their legal guardians (for participants under the age of 18). All patient facial images presented in the manuscript were cropped or blurred to protect personal identity and ensure anonymity. To ensure consistency across recordings, all patients were seated in a standardized position facing the camera under ambient clinical lighting. Each recording lasted 15–30 s and was captured using an iPhone at 30 fps with an original resolution of 1080 × 1920 pixels. To ensure usable input for model training, all recordings maintained full facial visibility. Videos with insufficient quality (inadequate lighting, overexposure, or motion blur) were excluded.
Two senior ophthalmologists and a senior neurologist, reviewing the video recordings, identified diagnosis of BSP and evaluated severity and frequency of the recruited patients by applying the Jankovic Rating Scale (JRS) scale30. In cases where discrepancies occurred among the three experts, a consensus meeting was conducted to discuss and resolve the differences, and the final label was determined by mutual agreement. A detailed annotation description was shown in Table I.
The dataset was partitioned into three subsets: training, validation, and testing. Specifically, 70% of the data was allocated for training purposes, 15% was reserved for validation, and the remaining 15% was designated for testing.
AI model construction
The complex and involuntary nature of facial spasms in BSP, characterized by considerable variability in movement patterns and duration, complicates the AI model architecture design. To accurately capture these transient features, it is essential to consider all frames instead of subframes. This requirement imposes a significant memory burden on the network architecture. Additionally, the scarcity of training data often results in overfitting, where the model performs well on the training data but poorly on new data. Using two or more input sources has been shown to improve performance compared to relying on a single input source31,32. To address these challenges, we employed a spatial-temporal architecture with a multimodal input approach (Fig. 2).
We extract features from each video frame using two distinct modalities to ensure a comprehensive representation of spasm characteristics. The first modality involves spatial feature extraction using a pretrained Vision Transformer (ViT), with the original classification head replaced by a Multi-Layer Perceptron (MLP) layer, producing the raw video feature sequence XR. The second modality focuses on extracting facial landmark location features using FaceMesh33. The outputs coordinates are normalized to the range [−1, 1], then processed by a separate MLP, resulting in the normalized face mesh coordinate sequence XF. These diverse features are subsequently concatenated along the temporal dimension, forming the input to the temporal model.
In our temporal model, we employ a dual-cross attention transformer encoder architecture with two input sequences XR and XF. A dual-cross attention layer consists of two multi-head cross-attention layers. Each cross-attention layer comprises a self-attention module, a cross-attention module, layer normalizations, and a feed-forward module (Fig. 2). Compared to the standard cross-attention ViViT, our Dual Cross-Attention ViViT (DCA-ViViT) introduces bidirectional cross-modal interaction. In the conventional setup, spatial features serve as the primary sequence, and facial mesh coordinates as the secondary sequence, with only the primary sequence updated at each layer. In contrast, DCA-ViViT employs two parallel branches in which each modality alternately acts as primary and secondary, enabling both sequences to be dynamically updated via mutual cross-attention. This design facilitates richer spatial-temporal feature fusion between raw video and facial geometry.
We ran our models on an NVIDIA A40 GPU for 50 epochs with a batch size of 4. We utilized the Adam optimizer with a learning rate of 10−6 and learning rate decay of 0.95. The original video was cropped to center the patient’s face and resized to 256 × 256 pixels. During training, the input video batch was randomly resized between 256 × 256 pixels and 320 × 320 pixels, and then a random 224 × 224 pixels subset was cropped. The MLP after ViT is set with input dimension of 768 and output dimension of 512. The MLP after facemesh is set with input dimension of 936 and output dimension of 512. We set the input sequence length to 900, applying zero-padding to videos shorter than this and truncating videos that exceed it. Additionally, random horizontal flipping was applied. For all transformer encoders of different architectures, we set embedding space dimension \({D}_{k}=512\), multi-head attention number \(n=8\), Feed-Forward layer hidden space dimension \({D}_{m}=2048\), attention layers \({num\_layers}=3\) and a dropout rate of 0.1.
AI model evaluation
We evaluated our DCA-ViViT model against various ViViT architectures, including self-attention and cross-attention models. To further extend the comparison, we replaced the ViT spatial feature extractor with ResNet, resulting in five variants: Self-Attention ResNet Video Transformer (SA-RNViT), Cross- Attention ResNet Video Transformer (CA-RNViT), Dual Cross-Attention ResNet Video Transformer (DCA-RNViT), Self-Attention Video Vision Transformer (SA-ViViT) and Cross-Attention Video Vision Transformer (CA-ViViT). We evaluated our model across four independent runs using different splits of the dataset. Additionally, we compared the results with two transformer-based video classification models (ViViT and VideoMAE) that utilize subframe sampling as benchmark. Final evaluation on the test set employed metrics including accuracy, precision, recall, F1-score, and area under the curve (AUC). For evaluation metrics, we performed a t-test between our model and other alternative models. We set p value equal 0.05 to assess whether our model’s performance metrics were statistically significantly better than those of the alternatives.
To quantify the contribution of each feature to the model’s decision-making process, we applied the SHapley Additive exPlanations (SHAP) methodology34. This methodology allows us to visualize the influence of individual frames and facial attributes on the classification outcome, thereby enhancing interpretability and model transparency. Moreover, SHAP values help identify critical features and potential data anomalies, guiding the iterative process of model refinement and feature selection.
SHAP values were computed across three classification tasks—diagnosis, severity, and frequency—to localize temporally informative regions within each input video. To further validate the clinical relevance of these SHAP-derived segments, we conducted an expert consistency assessment. Two experts (ophthalmologists with extensive clinical experience in the diagnosis and treatment of blepharospasm) independently reviewed 20 randomly selected videos in which all three tasks had been correctly predicted by the model. For each task, the experts manually annotated the time periods they considered most relevant for each task. Any discrepancies between the two experts were resolved through discussion to reach consensus annotations. These expert-defined key intervals were then compared to the corresponding SHAP-highlighted video segments. A segment-level match was defined as an overlap of at least 1 s between expert and SHAP-identified intervals. Match rates were computed as the proportion of videos exhibiting at least one matched segment.
To evaluate the effectiveness of AI model (DCA-ViViT) in improving clinical accuracy, a follow-up diagnostic test was conducted on 179 facial videos of BSP patients collected between January and September 2024. Two ophthalmologists from the Second Affiliated Hospital, Zhejiang University School of Medicine participated: one senior with 6 years of experience and one junior with 2 years. Initially, all videos were independently classified by DCA-ViViT and 2 ophthalmologists. To minimize recall bias, a 10-day washout period was implemented35. Following this period, the senior and junior ophthalmologist reevaluated the videos, this time with access to the AI model’s diagnostic results for reference. The reclassification process allowed us to assess the impact of incorporating AI assistance on physician diagnostic performance.
Statistical analysis
A demographic table was generated to describe the distribution of the videos in the dataset. We summarized the number of patients regarding their gender, age, BSP severity and frequency. Data analysis was performed using Python version 3.12 (Python Software Foundation). All metrics were calculated through Python sklearn, Numpy, and Pandas packages.
Data availability
The datasets generated and analyzed during the current study are not publicly available due to patient privacy concerns.
Code availability
The code for this study could be available to qualified researchers on reasonable request from the corresponding authors (J.Y., yejuan@zju.edu.cn, and Q.G., gaoqi8977@zju.edu.cn).
References
Balint, B. et al. Dystonia. Nat Rev Dis Primers 4, 25 (2018).
Defazio, G., Hallett, M., Jinnah, H. A., Conte, A. & Berardelli, A. Blepharospasm 40 years later. Mov. Disord. 32, 498–509 (2017).
Hirunwiwatkul, P. et al. Health-related quality of life of daily-life-affected benign essential blepharospasm: multi-center observational study. PLoS ONE 18, e0283111 (2023).
Bedarf, J. R., Kebir, S., Michelis, J. P., Wabbels, B. & Paus, S. Depression in blepharospasm: a question of facial feedback?. Neuropsychiatr. Dis. Treat. 13, 1861–1865 (2017).
Albanese, A. et al. Phenomenology and classification of dystonia: a consensus update. Mov. Disord. 28, 863–873 (2013).
Ferrazzano, G. et al. Disease progression in blepharospasm: a 5-year longitudinal study. Eur. J. Neurol. 26, 268–273 (2019).
Huang, X.-F., Wang, K.-Y., Liang, Z.-H., Du, R.-R. & Zhou, L.-N. Clinical Analysis of patients with primary blepharospasm: a report of 100 cases in China. Eur. Neurol. 73, 337–341 (2015).
Martino, D. et al. Age at onset and symptom spread in primary adult-onset blepharospasm and cervical dystonia. Mov. Disord. 27, 1447–1450 (2012).
Berman, B. D. et al. Risk of spread in adult-onset isolated focal dystonia: a prospective international cohort study. J. Neurol. Neurosurg. Psychiatry 91, 314–320 (2020).
Schulz, C. B., Clarke, H., Makuloluwe, S., Thomas, P. B. & Kang, S. Automated extraction of clinical measures from videos of oculofacial disorders using machine learning: feasibility, validity and reliability. Eye 37, 2810–2816 (2023).
Peterson, D. A. et al. Objective, computerized video-based rating of blepharospasm severity. Neurology 87, 2146–2153 (2016).
Trotta, G. F. et al. A neural network-based software to recognise blepharospasm symptoms and to measure eye closure time. Comput. Biol. Med. 112, 103376 (2019).
Hara, K., Kataoka, H. & Satoh, Y. Learning spatio-temporal features with 3D residual networks for action recognition. in 2017 IEEE International Conference on Computer Vision Workshops (ICCVW 2017) 3154–3160 (IEEE, 2017).
Sun, S., Kuang, Z., Ouyang, W., Sheng, L. & Zhang, W. Optical flow guided feature: a fast and robust motion representation for video action recognition. in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 1390–1399 (IEEE, 2018).
Liu, D., Zhang, H. & Zhou, P. Video-based facial expression recognition using graph convolutional networks. in 2020 25th International Conference on Pattern Recognition (ICPR) 607–614 (IEEE, 2021).
Simonyan, K. & Zisserman, A. very deep convolutional networks for large-scale image recognition. Preprint at https://doi.org/10.48550/arXiv.1409.1556 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 770–778 (IEEE, 2016).
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for image recognition at scale. Preprint at https://doi.org/10.48550/arXiv.2010.11929 (2021).
Deng, J. et al. ImageNet: a large-scale hierarchical image database. in 2009 IEEE Conference on Computer Vision and Pattern Recognition 248–255. https://doi.org/10.1109/CVPR.2009.5206848 (2009).
Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images.
Hochreiter, S. & Schmidhuber, J. Long Short-Term Memory. Neural Comput 9, 1735–1780 (1997).
Vaswani, A. et al. Attention is all you need. Advances in Neural Information Processing Systems 30 (NIPS, 2017).
Liu, Z. et al. Video swin transformer. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022) 3192–3201 (IEEE, 2022).
Tong, Z., Song, Y., Wang, J. & Wang, L. VideoMAE: masked autoencoders are data-efficient learners for self-supervised video pre-training. Advances in Neural Information Processing Systems 30 (NIPS, 2022).
Fan, H. et al. Multiscale vision transformers. in 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) 6804–6815 (IEEE, 2021).
Arnab, A. et al. ViViT: a video vision transformer. in 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) 6816–6826 (IEEE, 2021).
Jamison, A. et al. Telemedicine in oculoplastics: the real-life application of video consultation clinics. Ophthal. Plast. Reconstr. Surg. 37, S104–S108 (2021).
Rodríguez-Antigüedad, J. et al. Facial emotion recognition deficits are associated with hypomimia and related brain correlates in Parkinson’s disease. J. Neural Transm. 131, 1463–1469 (2024).
Peach, R. et al. Head movement dynamics in dystonia: a multi-centre retrospective study using visual perceptive deep learning. NPJ Digit. Med. 7, 160 (2024).
Jankovic, J., Kenney, C., Grafe, S., Goertelmeyer, R. & Comes, G. Relationship between various clinical outcome assessments in patients with blepharospasm. Mov. Disord. 24, 407–413 (2009).
Lin, H. et al. CAT: cross attention in vision transformer. in 2022 IEEE International Conference on Multimedia and Expo (ICME)1-6 (IEEE, 2022).
Chen, C.-F., Fan, Q. & Panda, R. CrossViT: cross-attention multi-scale vision transformer for image classification. in 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) 347–356 (IEEE, 2021).
Kartynnik, Y., Ablavatski, A., Grishchenko, I. & Grundmann, M. Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs. Preprint at https://doi.org/10.48550/arXiv.1907.06724 (2019).
Lundberg, S. & Lee, S.-I. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems 30 (NIPS, 2017).
Xue, Y. et al. A multi-feature deep learning system to enhance glaucoma severity diagnosis with high accuracy and fast speed. J. Biomed. Inform. 136, 104233 (2022).
Acknowledgements
This study was supported by grant No. 82330032 from Key Program of the National Natural Science Foundation of China, grant No. U20A20386 from National Natural Science Foundation Regional Innovation and Development Joint Fund, grant No. 2024C03204 from Key Research and Development Program of Zhejiang Province, grant No. 82301208 from the National Natural Science Foundation of China, grant No. KLY25H180311 from the Natural Science Foundation of Zhejiang Province.
Author information
Authors and Affiliations
Contributions
S.H. and B.Y. contributed equally as co–first authors to this work, S.H. conceived and designed the study and was responsible for drafting the manuscript, S.H. and B.Y. performed the statistical analysis. X.H., H.Z., D.L., G.T., Y.W., Y. S. and M.C. contributed to data acquisition, analysis, and interpretation. M.C., Q.G. and J.Y. provided fundings. Q.G. and J.Y. had full access to all of the data in the study, provided critical revisions, supervised the study and take responsibility for the integrity of the data and the accuracy of the data analysis. All authors have reviewed and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huang, S., Yang, B., Huang, X. et al. Smartphone video-based early diagnosis of blepharospasm using dual cross-attention modeling enhanced by facial pose estimation. npj Digit. Med. 8, 505 (2025). https://doi.org/10.1038/s41746-025-01904-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01904-8
