
Abstract
Timely care in a specialised neuro-intensive therapy unit (ITU) reduces mortality and hospital stays. Planned admissions to ITU following surgery are safer than unplanned ones. However, post-operative care decisions remain subjective. This study used artificial intelligence (AI), specifically natural language processing (NLP) to analyse electronic health records (EHRs) of elective neurosurgery patients from University College London Hospital (UCLH) and predict ITU admissions. Using a refined CogStack-MedCAT NLP model, we extracted clinical concepts from 2268 patient records and trained AI models to classify admissions into ward and ITU. The Random Forest model achieved a recall of 0.87 (CI 0.82–0.91) for ITU admissions, reducing the proportion of unplanned ITU cases missed by human experts from 36% to 4%. Interpretability analysis confirmed the use of clinically relevant concepts. The study highlights the opportunity for AI to aid in allocating resources for neurosurgical patients but requires further research and integration into practice.
Similar content being viewed by others

Introduction
Intensive therapy units (ITU) have been developed to provide more detailed observations and invasive treatments for patients who typically require single or multiple organ support1,2. National guidelines in the USA, UK and elsewhere recommend that routine critical care admissions be common practice for surgical patients with a significant 30-day mortality, or who are deemed to be at a higher risk due to their age and / or comorbidities1,3,4, to improve patient outcomes. Critical care has been defined in the literature as those requiring level 2 or 3 care, with level 3 corresponding to ITU care where, either advanced respiratory or multi-organ support is required; and level 2 care corresponding to High Dependency Unit (HDU) care reserved for more detailed observations or single organ support1. Critical care admission is prevalent in neurosurgery due to the high morbidity and mortality that exists. In addition, neurosurgical interventions have significant complications with a 22.2% complication rate following cranial surgery and 11.1% following spinal surgery; 4.8% mortality rate following cranial surgery and 0.5% following spinal surgery5.
It is well-recognised that critically ill neurological and neurosurgical patients benefit from timely care in a specialised neuro-ITU in the form of reduced mortality and length of hospital stay6,7. Furthermore, there is evidence that outcomes are better for planned ITU admissions following surgery1,4,8. Conversely, unplanned intensive care admissions, when patients are triaged pre-operatively as not requiring ITU, but later do, are more costly and have an increased risk of longer hospital stays, morbidity and mortality9,10,11,12. Additionally, due to the aging neurosurgical patient population, the consequences of getting the decision wrong are greater13,14,15.
However, there is great variability across centres in how patients are selected for intensive care post-operatively following elective craniotomy16. It used to be common practice that all patients required intensive care management or monitoring following elective craniotomy17. However, with the development of post-anaesthesia care units (PACU), the adequacy of HDU, and routine post-operative extubation in the operating room enabling direct ward discharges, there has been a push towards discouraging ITU admission as routine practice16,17. It remains the case that decisions on the post-operative destination for elective neurosurgical patients are based on expert opinion rather than on robust objective data17,18. Due to factors such as recency bias and other human factor error, this decision-making process is far more prone to error with 14–28% of ITU admissions being unplanned12,19,20.
The widespread adoption of electronic health records (EHRs) has led to a significant increase in the exploration of artificial intelligence (AI) to streamline healthcare processes. Among the most pertinent AI subfields in this context are machine learning (ML) and natural language processing (NLP)6. ML empowers computers to learn autonomously and make predictions by recognising patterns in new data, without the need for explicit programming. This capability is especially crucial for the large-scale analysis of narrative data found in EHRs, where NLP enables computers to extract meaningful information from unstructured text entries.
While the prediction of unplanned ITU admissions was previously explored using structured data alone (e.g., see ref. 21), our study is the first to demonstrate that an NLP-driven approach (in particular, CogStack-MedCAT22,23) can accurately identify these events using unstructured free-text from EHRs. This represents a novel application of NLP in the post-neurosurgical context.
This study aims to evaluate the application of established NLP and machine learning techniques for predicting unplanned ITU admissions among elective neurosurgical patients, using concept mentions extracted from EHR clinical notes. The intended users of this AI assistant are healthcare professionals, including doctors and nurses, who aim to enhance their clinical decisions with data-driven insights.
Our objectives are:
-
1.
Build a reliable NLP model using well-studied techniques in the literature to accurately extract concepts from the free-text notes of patients undergoing elective surgery.
-
2.
Demonstrate the utility of concept extraction by NLP to support human experts in enhancing decision-making for intensive care settings. This includes a proof of concept evaluating the importance of these extracted features for predicting ITU admissions, particularly unplanned cases.
-
3.
Conduct a thorough interpretability study to confirm the clinical intuition behind the importance scores of the extracted features.
Results
The following section presents the key findings from our study, highlighting the performance metrics of our models and the insights gained from the data.
Table 1 provides a detailed summary of the baseline statistics and demographics for ITU admissions and ward stays. Given the small sample size for ITU admissions, we averaged the results across subtypes to ensure a more reliable analysis. The data indicate that the median age for both ITU and ward patients is similar, at 56 and 57 years, respectively, with ward patients exhibiting a slightly broader age range (16-95 years). The sex distribution is balanced, with an equal percentage of females in both ITU admissions and ward stays (51%). Ethnicity data shows a slightly higher proportion of White patients in ward stays (62%) compared to ITU admissions (57%).
Note that the notes for 58 patients were unavailable from Epic at the time of extraction.
57,433 documents (47,048 level 1/ ward; 8687 planned HDU or ITU; 1698 unplanned HDU or ITU) were extracted from the 2210 patients. All documents contained codable SNOMED-CT concepts and were predominantly either progress notes, plan of care notes or nursing notes.
Overall, 8300 unique SNOMED-CT concepts were extracted from the medical records. Of these, 6462 concepts appeared more than once, with 2980 unique concepts in planned admissions, 1369 unique concepts in unplanned admissions, and 5879 unique concepts in level 1 or ward-level care.
Before applying ML to the concepts extracted by NLP, we first analysed the statistical differences in concept frequency counts between ITU and ward patients. Due to the limited sample size of unplanned ITU admissions, we did not separate the data into planned and unplanned categories. To address the significant imbalance in patient counts between groups, we analysed normalized frequency counts using the Chi-squared test to determine whether there were significant differences between ITU and ward patients. To address the issue of multiple hypothesis testing and reduce the likelihood of false positives, we applied the Benjamini–Hochberg False Discovery Rate (FDR) correction using tools available in the Scikit toolkit24. A significance threshold of α = 0.05 was used to control the expected proportion of false discoveries among the rejected hypotheses. Among those that passed the significance test, we selected the top 50 concepts based on their highest and lowest frequency ratios between ward and ITU patients. This selection allowed us to investigate the concepts that are more frequent among ward patients and those that are more common among ITU patients, respectively (see Supplementary Table 1 and Supplementary Table 2).
The analysis presents differences in clinical presentation between ward and ITU populations, particularly in the prevalence of rare neurological, vascular, and musculoskeletal conditions. Ward patients were significantly more likely to present with rare neurological conditions such as moyamoya disease, pinealoma, corneal anesthesia, neurofibromatosis type 2, and thoracic myelopathy, with frequency ratios ranging from 82 to over 290. Moyamoya disease was absent in ITU patients. Similarly, vascular abnormalities like aneurysms of the posterior and anterior communicating arteries, internal carotid, and middle cerebral arteries were almost exclusively observed in ward patients, with frequency ratios of around 100. Musculoskeletal and soft tissue conditions, including compartment syndrome, swollen calf, inguinal pain, and groin hematoma, were also more common in ward patients.
In contrast, ITU patients presented more frequently with infectious diseases, which were observed at a rate 20% higher than in ward patients. ITU patients were more likely to present with musculoskeletal findings (17% more frequent), including osteoporosis, which was 14% more common compared to ward patients, and wounds (4% more frequent). Postoperative nausea and vomiting were also notably common in the ITU group, occurring 7% more often in the ITU cohort.
These trends capture both chronic and acute comorbidities, with a greater representation of dynamic comorbidities in the ITU cohort. This may reflect the stability/instability divide, where ITU patients are more likely to be frailer and have a lower physiological reserve following an intracranial neurovascular event, making them more susceptible to nausea and infections.
For our predictive models in the binary classification scenario, we first filtered the patient notes in the original dataset to include only those within the 30-day window before the operation. This filtering reduced the dataset by 33 patients who did not have any notes in that period (see Table 2). After a manual inspection, no specific reason was identified for the absence of these notes. For training, most samples came from the ward category, resulting in a heavily imbalanced training set with a 10:1 patient ratio for ward patients versus ITU admissions. In contrast, we designed a balanced test set with an equal ratio of ward patients to ITU admissions (1:1) via random sampling. It is important to note that all 75 cases of unplanned admissions were excluded from the training data and included in the test set. Clinicians miss those 36% of actual HDU or ITU cases (i.e., the unplanned cases). The primary goal is to evaluate the effectiveness of automated assistance in minimising decision errors and reducing ITU admission costs.
In the cross-validation setting, our predictive models demonstrated stable performance with relatively low standard deviation across different training folds (see Supplementary Table 3). This stability ensures reliable and consistent prediction outcomes.
Results of our experiments are presented in Table 3. Both Random Forests (RFs25) and time-series Long Short-Term Memory (LSTM26) networks enhanced with BERT embeddings27 (BERT + LSTM) achieve high precision (0.93 on average), recall (0.92 on average), and F1-scores (0.92 on average) across classes. In terms of performance per class, we observe notable variations: higher precision (1.0) and lower recall (0.85) is characteristic for the ITU patients but higher recall (1.0) and lower precision (0.86) for the ward patients. This is because ward patients are overrepresented in our training data leading to the models that better capture patterns related to this group.
The table indicates that RFs perform better than BERT + LSTM. The RF model achieves perfect precision and a recall of 0.87 for ITU admissions, 0.85 for planned ITU admissions, and 0.89 for unplanned ITU admissions. The area under the curve (AUC) is 0.99, confirming very good classification performance (see Supplementary Fig. 1). This highlights the model’s potential to identify cases that clinicians might otherwise overlook. These metrics are, on average, 3 points higher than those for the BERT + LSTM model. The FN rates are 0.13 for ITU, 0.15 for planned, and 0.11 for unplanned admissions, averaging 0.04 lower than for the BERT + LSTM model. Notably, only 11% of unplanned ITU cases remain undetected, significantly reducing the total proportion of ITU cases missed by human experts from 36% to just 4%.
It is important to note that the RF model does not consider the temporal aspect of patient data; it simply aggregates the concept counts from each patient’s notes. As described in the Methods section, before inputting concept counts into the RF models, we identified the most important concepts using a feature selection algorithm based on the Chi-squared statistic. We selected the 20 most significant features to build our RF models. The number of features was a hyperparameter we fine-tuned manually (see Fig. 1). These selected features align with the outcomes of our previous statistical analysis of concept distributions. In our previous analysis, we observed that neurological conditions, musculoskeletal issues including osteoporosis, pain, and gastrointestinal conditions were important in distinguishing between ward and ITU patients. Our feature selection process identifies neurovascular, neuro-oncological, and infection concepts (e.g., “Intracranial Meningioma,” “Intracranial Aneurysm,” and “Fungal Infection of Central Nervous System”). It also highlights musculoskeletal concepts such as “Blister of Skin and/or Mucosa” and “Osteoporosis,” gastrointestinal concepts like “Carcinoma of Esophagus,” and pain-related concepts such as “Inguinal Pain”.

The selected features align with our statistical analysis, emphasising the significance of neurovascular, neuro-oncological, infection and musculoskeletal concepts for ITU / ward patients. Note that Battery stands for VNS (vagus nerve stimulation) battery, and EVD refers to the external ventricular drain.
Additionally, the external ventricular drain (EVD) is an important concept in ITU. It is essential for managing acute conditions that require immediate intervention to control intracranial pressure. In this context, “battery” specifically refers to the VNS (Vagus Nerve Stimulator) battery. The proper functioning of this device is vital for patients with epilepsy or depression, as it plays a crucial role in managing these chronic conditions. “Dry skin” primarily indicates the state of post-operative wounds that heal.
In contrast, BERT + LSTM processes each patient note individually and examines the sequential dependencies of those notes. This approach might explain the increase in missed ITU cases (0.04 higher FN rates than for RFs), as the model’s complexity may hinder its ability to learn effectively from the limited data.
We attempted to investigate whether RFs and the BERT + LSTM model identify different cases. To do so, we averaged the output probabilities of both models and applied a decision rule with a threshold of 0.5 to predict ITU admissions. However, we observed that the detected ITU cases overlapped, and this ensembling approach did not provide any improvement over using RFs alone (see Supplementary Table 4).
We further evaluated our best RF model by measuring its calibration and fairness. Among the three models, RFs demonstrated better calibration, remaining closest to the ideal line, especially in mid-range probability values. In contrast, the BERT + LSTM and Ensembling models exhibited stronger miscalibration, underestimating the probability of ITU due to imbalanced data (see Fig. 2 below).

This plot compares the predicted probabilities with the actual outcome probabilities for three models: Ensembling (blue), BERT + LSTM (orange), and RFs (green). The red dashed line represents perfect calibration, where a predicted probability of 70% corresponds to an outcome that occurs 70% of the times. RFs (green) exhibit the best calibration, as their curve remains closest to the perfect line across probability levels.
Our RF model demonstrated classification parity across sex and ethnicity groups (0.99 ratio across metrics for both Male/Female and White/Non-white subgroups). The only notable difference was a slightly lower FN rate for Female and Non-white patients (1.42 ratio on average across demographic groups), suggesting better recall for these subgroups (see Supplementary Table 5 and Supplementary Table 6).
Finally, to demonstrate the model’s ability to generalise to unplanned ITU admissions, we conducted two additional experiments. First, we trained the RF model on all 75 unplanned ITU admissions (excluding planned cases), matched with a 10:1 sample of ward patients. Using 5-fold cross-validation, the model achieved an average F1 score of 0.95 and an ROC-AUC of 1.00 when evaluated on the test folds, demonstrating good performance in identifying unplanned admissions. To further validate this and mitigate concerns about data sparsity, we performed a second experiment where half of the unplanned ITU cases (n = 38) were included in the training set, with the remaining unplanned cases, along with 173 planned ITU and 210 ward patients, forming the test set (this test set is of comparable size to that used in the main experiment). This setup yielded similar performance (F1 = 0.99, ROC-AUC = 1.00). In these two experiments we used the same hyperparameters as in the main experiment. Our findings confirm that the model is not merely distinguishing between known ward / planned ITU cases and unknown unplanned ITU, but can learn to detect unplanned ITU admissions (see Supplementary Tables 7 and 8, Supplementary Figs. 2 and 3).
Our models demonstrate very good predictive capabilities. However, these numerical values alone do not provide any insights on whether the model decision-making procedure is correct. Hence, we conduct a thorough explainability analysis. We use the two popular interpretability techniques: SHAP (Shapley Additive Explanations28) and Local Interpretable Model-agnostic Explanations (LIME29) to understand how individual concepts contribute to model predictions and whether those contributions could be justified from the clinical perspective. In our interpretability analysis we focus on the RF model for simplicity. Spurious correlations are possible when using unstructured text data, as certain features may reflect documentation practices or contextual artifacts rather than true underlying clinical signals. Hence, our interpretability results generated by SHAP and LIME were reviewed by the expert clinical authors of this study. They confirmed the clinical relevance and validity of the highlighted features and model explanations, providing a validation of the model’s interpretability. Our future work will incorporate systematic feature filtering strategies and expert review pipelines to further reduce such risks.
SHAP values provide feature importances across all model predictions. This approach directly links back to our feature selection process, enabling us to understand how changes in each concept count influence the predicted probability of ITU admission (see Fig. 3 for predictions over the training data). Positive values on the x-axis indicate an increased chance of ITU admission, while negative values reduce this chance. The colour on the y-axis represents concept counts, with red indicating high values and blue indicating low values. From Fig. 3, we can see that frequent mentions of osteoporosis and dry skin decrease the chance of ITU admission, while conditions such as intracranial meningioma and aneurysm increase those chances.

The top features for ITU admission are sorted by their mean absolute SHAP importance values. Each row indicates the impact of each concept on predictions, with each data sample represented as a dot. The colour of the dots ranges from blue (lower concept frequency values) to red (higher frequency values). The horizontal position of a dot (SHAP value) shows the concept’s contribution to the prediction, with right indicating ITU admission and left indicating ward. For example, in the top row, less frequent mentions of osteoporosis increase the chances of ward stay, while frequent mentions of intracranial meningioma increase the probability of ITU admission.
Note that the Chi-squared feature importance plot (Fig. 1) and the SHAP feature importance plot highlight different aspects of the feature selection process. The Chi-squared test measures the statistical dependence between each feature and the target variable. Features with the highest Chi-squared scores, such as “EVD,“ “Hemangioma,“ and “Intracranial meningioma,“ indicate a significant association with the target label. On the other hand, Shapley values measure the contribution of each feature to a model’s prediction, showing how individual features interact with each other and contribute to the model’s decision-making process. Here, features like “Osteoporosis“ and “Dry skin“ appear at the top. Although statistical analysis showed that “Osteoporosis “ and “Dry skin“ are more frequent for ITU patients (see Supplementary Table 2), their presence in combination with other features steers the model towards predicting a ward stay. All these differences suggest that some features with high statistical correlation may not influence prediction outcomes in the expected way, while others with lower Chi-squared scores can have a higher contribution in combination with other features. Additionally, features with higher Chi-squared scores may influence the model in unexpected ways when considered in complex interactions with other features.
In contrast, the LIME technique offers localised explanations for each individual example (see Fig. 4). By applying LIME to ITU admission classification, we can examine why the model classified one patient as requiring ITU admission while another was not flagged. We have thoroughly investigated our LIME explanations and discovered that correct classification decisions of unplanned admissions rely on infections, pain, and musculoskeletal conditions. False negatives, or missed unplanned cases, are frequently associated with mentions of osteoporosis and dry skin.

The x-axis represents concept importance, where positive values (orange) indicate features that contribute to ITU admission, while negative values (blue) indicate concepts that contribute to ward stay. The y-axis lists the contributing concepts and their importance scores. In this example, the neurological disorders “Congenital arteriovenous malformation” and “Intracranial meningioma” contribute to the correct classification of admission with highest importance scores. The scores of other concepts fall below the threshold of floating-point precision.
To conclude, we observe high coherence between model explainability outcomes and statistical observations, confirming clinical validity of our high prediction performance.
Discussion
This exploratory study serves as a proof of concept and demonstrates the ability of an artificial intelligence (AI) natural language processing (NLP) model to analyse the electronic health records (EHRs) of post-operative elective neurosurgical patients and effectively characterise their post-operative destinations.
This is exciting given the novelty and the potential scope of its application. AI has already demonstrated its utility within neurosurgery in various ways, such as in automatic tumour segmentation; the prediction of symptomatic vasospasm following subarachnoid haemorrhage; and in the prediction of survival in patients with Glioma30,31. Similarly, NLP has been utilised in the field of spinal surgery to analyse operative notes, radiology reports, and social media to detect outcomes such as post-operative infections, venous thromboembolism, and patient satisfaction32.
The CogStack NLP model was twice-refined, first using the data of patients with Normal Pressure Hydrocephalus (NPH) and then with the data of Vestibular Schwannoma patients. The model was proven, following these rounds of refinement, to be both accurate (substantial or high inter-annotator agreement) and precise (F1-score 0.93 on average)33,34,35. Our investigations of the extracted concepts revealed significant differences in the prevalence of infections, pain and musculoskeletal conditions which were much more common in ITU patients. In contrast, rare neurological disorders and vascular disorders were more prevalent in ward patients. This distinction may reflect the greater frailty and lower physiological reserve of ITU patients, making them more susceptible to infections.
We integrated the extracted concepts into two AI predictive models: RFs and LSTM + BERT. The simpler and more intuitive RF model was the clear winner, with a recall of 0.89 (CI 0.82–0.96) for unplanned ITU, reducing the total proportion of ITU cases missed by human experts from 36% to just 4%. Our thorough interpretability analysis of the RF model, both at the algorithm level and for individual examples, confirmed the importance of neurovascular, neuro-oncological, and musculoskeletal concepts in the model’s decisions, thereby validating the clinical relevance of the predictions. Our RF model demonstrated satisfactory calibration and very good classification parity across sex and ethnicity groups.
Our findings provide promising evidence that using similar AI predictive models in clinical practice could improve decision-making, reduce medical errors, and lower hospital admission costs.
Intensive care units account for around 22%–33% of the total costs within a hospital and are on average three to five times greater than the cost of ward level care; as such, there has been a greater emphasis on ensuring that care within such units is reserved for those who truly need it. There is, however, currently no standardised criteria for post-operative ITU allocations, with the decision being based on expert opinion and with the current model, unplanned ITU admissions remain as high as 14–28%17,18,19,20,36.
Given the above, there has been recognition of the need to characterise these patients, and to do so in a timely manner to improve healthcare outcomes and reduce ITU emergency costs. One such study, by Hanak et al identified that age and diabetes are predictive of the ITU admission on multivariate analysis36. Similarly, Memtsoudis et al. characterised critical care requirements in patients undergoing lumbar spine fusion and identified that comorbidities such as myocardial infarction, peripheral vascular disease, COPD, uncompleted and complicated diabetes, cancer, and sleep apnoea as well as older age were all significant predictors of the need for ITU level care, with complicated diabetes and sleep apnoea carrying the highest risk37.
One of the advantages of AI and machine learning (ML) is the ability to learn without direct programming and to recognise patterns in vast quantities of data than can be amassed by a single person30. There has been a growing awareness of the utility of AI in healthcare: AI has been used to automatically classify epilepsy with 60% accuracy (62% clinician accuracy); predict tumour type, including glioma, with an 86% accuracy; and diagnose cerebral aneurysms with >90% accuracy31.
Recent developments in AI and NLP advance the digital transformation of healthcare, with Clinical Decision Support Systems (CDSS) offering potential to enhance patient care. While challenges such as clinical validation and adoption remain, they present valuable opportunities to build trust and support the safe integration of these tools into clinical workflows38,39.
In emergency and intensive care settings, AI applications have progressed from traditional ML approaches, for example, for forecasting emergency department (ED) volumes40, optimising patient flow41, or reducing wait times42, to the successful deployment of large language models (LLMs). These models have shown particular promise in communication and documentation tasks, including admission communication43 and drafting discharge summaries44, and are now demonstrating performance on par with traditional ML in analytical tasks with minimal supervision, such as predicting ED admissions45, triaging patients46, and scheduling surgeries47.
Despite these advancements, the prediction of unplanned critical care admissions remains relatively underexplored and often relies on ad-hoc scoring systems or traditional ML applied to structured data: for example, predicting unplanned readmissions in trauma48, in-hospital deterioration49, or mortality in cancer patients50.
A related study by Yao et al. (2022) developed a logistic regression model for unplanned ITU admissions in neurosurgical patients, identifying several perioperative predictors and achieving strong performance (c-statistic 0.811; Hosmer-Lemeshow P = 0.141), though the model was limited to structured tabular data21.
Recent work demonstrated that incorporating free-text data, such as triage notes, can significantly improve model sensitivity for identifying critical conditions51,52,53. LLMs now represent the state of the art in free-text analysis, and while tools like GPT showed early promise in simulated clinical environments45,46, their real-world application remains limited due to concerns around cost, data privacy, explainability, and lack of clinical validation54,55,56. In contrast, more established NLP tools based on ontologies and discriminative models, such as MedCAT, offer a more practical and cost-effective alternative for current clinical use.
Our study is the first of its kind to demonstrate the ability of an NLP-driven algorithm to accurately detect unplanned ITU admissions using unstructured text for post-operative elective neurosurgical patients.
A key gap in the existing literature on predicting unplanned ITU admissions is the failure to include free-text. Prior studies relied solely on structured data. Our study addressed this limitation by incorporating unstructured text. Our approach aligns with current trends towards hybrid data integration in clinical AI57.
We demonstrated that our NLP model22 effectively and accurately extracts clinical concepts and generalises well to new hospital settings, including neurosurgical patients. AI-based clinical management systems face several well-documented challenges, including limited generalisability, lack of clinician trust, insufficient economic evaluation, and difficulties integrating structured and unstructured data58. Our study addressed those by incorporating free-text data using scalable NLP tools and emphasising the need for external validation. As a first step to promote clinician trust, we integrated explainable AI techniques like SHAP and LIME and validated their outcomes with clinical expertise.
One of the major strengths of this study is the robust final model, which was trained on a large dataset and further refined for optimal performance using data from patients with normal pressure hydrocephalus and subsequently vestibular schwannoma, increasing its applicability to a broad range of such patients. We demonstrated the potential utility of the extracted medical concepts for the AI-based prediction of ITU admission within the context of our dataset. Further validation across institutions and time periods is necessary to confirm generalisability.
The large dataset is a strength, but the fact that it was obtained retrospectively and from a single centre increases the risk of potential overfitting, despite the demonstrated generalisation capacity.
A further limitation is that, with post-operative destination triage being based on expert opinion, a few patients may have been selected for a planned post-operative HDU or ITU admission who may not have truly needed HDU or ITU level support or intervention whilst there. This might skew the interpretation of the data as the planned HDU or ITU group of patients might be functionally similar to the level 1 or ward category of patients. For this reason, future research should aim to define a true HDU or ITU, whether planned or unplanned, based on whether ITU or HDU intervention was required.
A final limitation is the paucity of clinical records prior to the operation date. Analysis of primary care data could similarly be a focus of future research.
When implementing our ITU prediction model, poor quality or missing features should be identified and addressed through data imputation techniques (e.g., k-nearest neighbours).
Our findings demonstrate the feasibility of developing a natural language processing (NLP) model capable of accurately extracting clinical features from unstructured electronic health records (EHRs) for post-operative neurosurgical patients. In our study, we evaluated the importance of these extracted features and discovered that they are clinically useful, helping to create systems that achieve very high performance in predicting ITU admissions, particularly unplanned cases.
Our future research will work towards integrating an AI-assisted “high-risk for HDU or ITU” alert system into the local EHR using CogStack59.
Our work opens new avenues for understanding patient trajectories. The distinct prevalence of infectious, pain-related, and musculoskeletal conditions among ITU patients as compared to the higher incidence of rare neurological and vascular disorders in ward patients highlights the potential for developing phenotype-driven risk stratification tools that account for patient vulnerability. Future research could explore how these condition patterns interact with other clinical variables to improve early identification of patients at risk.
We adhered to the TRIPOD + AI guidance for reporting clinical prediction models that use regression or machine learning methods60. The completed checklist is available in the Supplementary Material.
Methods
Study design
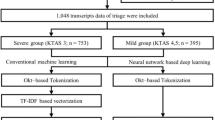
This study analyses the clinical records of elective neurosurgical patients at UCLH using NLP. Written EHRs, including clinical notes, correspondence, and radiology reports, were collected for patients undergoing neurosurgery from April 2019 to September 2021 (see Fig. 5). Patients were categorised into three groups: planned HDU or ITU admissions, unplanned HDU or ITU admissions, and all others.

This diagram outlines the full pipeline used for model development and evaluation. The process began with 2268 neurosurgical patients treated between April 2019 and September 2021. After applying exclusion criteria, patients were categorized into three groups: ward, planned ITU, and unplanned ITU admissions. For unplanned cases, clinical concepts were extracted from free-text clinical notes using MedCAT within a 30-day preoperative window. The resulting dataset was split into a training set (n = 1766) and a test set (n = 411). The training set was used for model development and hyperparameter tuning via 5-fold cross-validation.
Planned admissions were defined as post-operative destinations that were pre-booked and agreed upon before the surgery. Unplanned admissions were defined as either: a) a decision to admit to neurocritical care after the commencement of surgery, or b) admission to ITU or HDU up to 14 days post-surgery due to complications61.
Patients were identified from a prospectively maintained clinical database. According to the consensus statement released by the Intensive Care Society62, ITU corresponds to level 3 care, HDU to level 2 care, and “everyone else” to level 1 or ward-level care.
Eligibility criteria
We included all patients who underwent elective neurosurgical procedures at our hospital between April 2019 and September 2021. Exclusions were made for patients undergoing interventional radiological procedures and those whose electronic health records were unavailable.
We also excluded patients undergoing carpal tunnel or ulnar nerve decompression, nerve and muscle biopsies, and sacral nerve modulator insertions because these procedures are typically minor, low-risk surgeries that are rarely associated with unplanned ITU admissions. Most biopsies and carpal tunnel decompressions are performed under local anaesthesia and sacral nerve modulators are a uro-gynaecological procedure performed as day case surgery at this hospital. Including these cases could have introduced bias by disproportionately lowering the proportion of ITU admissions.
Patients whose pre-operative urgency of surgical interventions could not be determined according to the NCEPOD (National Confidential Enquiry into Patient Outcome and Death)63 classification or prior post-operative decisions were excluded. To ensure unique entries across the cohorts, only the first operation for each patient was included.
Cohort characteristics
From the UCLH databases, 2268 patients met the eligibility criteria for inclusion. Among these, 349 were admitted to HDU or ITU in a planned manner, 87 were admitted in an unplanned manner, and 1832 required either level 1 or ward-level care post-operatively.
Demographic information, including age, sex, and ethnicity, was extracted from structured data elements within the EHR. SNOMED concepts related to diagnoses, signs, symptoms, and co-morbidities were extracted from free-text part of EHRs using NLP techniques.
The overall median age at the time of operation was 56 years (ranging from 16 to 95 years), with a male to female ratio of 1:1.05 (49% males, 51% females). Most patients identified ethnically as White (60%).
Natural language processing (NLP) model: training and evaluation
We used the CogStack information retrieval platform to extract written clinical information for eligible patients from the EHR system (Epic Systems, Verona, USA). This extracted information was then processed through the CogStack Natural Language Processing platform, enabling analysis with the Medical Concept Annotation Tool (MedCAT), a named-entity-recognition (NER) machine learning model, which identified Systematized Nomenclature of Medicine Clinical Terms (SNOMED-CT) concepts within the clinical notes.
The MedCAT model was trained in two distinct phases. The first phase involved unsupervised learning to develop a base model using non-specific medical records. During this phase, we pre-trained the model on 1 million randomly sampled EHRs from the hospital-wide database. Following this, the model was fine-tuned using 500 randomly sampled documents annotated with SNOMED-CT concepts by two independent assessors, creating a versatile base model.
In the second phase, this base model underwent further fine-tuning for specific conditions. Initially, it was fine-tuned for NPH, and subsequently for Vestibular Schwannoma (VS). The base model was fine-tuned for NPH and VS because these two conditions represent clinically significant subgroups within the population of patients undergoing elective neurosurgery. The decision to develop models for these conditions was guided by clinical relevance and need. This two-step fine-tuning process resulted in a final model with enhanced applicability to elective neurosurgical patients.
During this second stage the base model pre-annotated 300 documents from NPH patients. These annotations were then validated in a blinded manner by two independent assessors using the MedCATTrainer interface35. The assessors reviewed the model’s annotations to label terms as correct or incorrect or selected a different concept that best represented the written information. Discrepancies between the assessors were resolved through discussion or adjudication by a third assessor if necessary (see ref.33 for details).
This first refinement phase achieved a high inter-annotator agreement of 97%. The validated dataset was then used to train the ML model, utilising 80% of the eligible documents. The remaining 20% of the documents were reserved for testing, and model accuracy was assessed using cross-validation on the test set. Cross-validation on the test set involves dividing the test set into k subsets and evaluating the model k times. This approach provides a more reliable estimate of model performance, reducing the impact of any one test split that might be unusually easy or difficult.
The refined model demonstrated high precision and recall, achieving a macro F1-score of 0.92 across identified SNOMED-CT concepts. Precision measures the proportion of examples that the model correctly identifies as relevant out of all the cases it predicts as relevant. Recall measures the proportion of actual relevant examples that the model identifies. The F1-score combines precision and recall into their harmonic mean, providing a balanced measure of the model’s performance.
The second refinement followed a similar process using records from VS patients. The model annotated 300 documents from the VS patient dataset, which were validated by two independent assessors using the MedCATTrainer interface. The model achieved an inter-annotator agreement of 72%, indicating substantial agreement. 80% of the validated dataset was used to train the model, while the remaining 20% served as the test set. The model achieved a macro F1-score of 0.93 on the test set in a cross-validation setup34.
This twice refined and validated base model was then applied to documents from ITU patients meeting the eligibility criteria. Due to time constraints, validation of the model’s performance on these records was not possible. However, given the overlap in patient groups, we expect assessment results to be similar to the ones reported above.
Meta-annotations were employed to enhance the accuracy and relevance of the extracted information for our ITU cohort. These annotations are particularly valuable in cases where, despite accurately capturing a term’s intended meaning, contextual qualifiers render it irrelevant to the patient. For instance, a documented diagnosis might be negated, as in “COVID-negative”; it might pertain to another individual, as in “family history”; or it might indicate a suspected diagnosis. Terms marked with meta-annotations such as “Negation = Yes,” “Experiencer = Other,” and “Certainty = Suspected” were excluded from further analysis, as they were deemed not directly relevant to the patient.
Predictive models: training and evaluation
In our study, we distinguish between patients who require ITU admission (both planned and unplanned) and those who are admitted to the ward. The goal is to train the model to generalise over both planned and unplanned ITU admissions, whilst only being trained on planned ITU and ward cases. This setup allows us to evaluate how well the model can identify patients who were later admitted to the ITU unplanned, based on the same information available to clinicians at the time of decision-making. Essentially, assessing missed cases to evaluate the model’s potential to support human experts in early identification of patients at risk.
We considered the task of predicting ITU admissions or ward stays a binary classification problem. We explored the potential of concepts extracted by CogStack using both time-unaware RFs and time-series LSTM networks. We investigated both time-series and non-time-series approaches to effectively capture the intricacies of patient data. Both RFs and LSTM networks are well-established techniques within the AI community, particularly in healthcare applications.
The RF algorithm constructs multiple decision trees using random subsets of the data and combines their results to enhance accuracy. Each decision tree classifies data by forming a tree-like structure where internal nodes represent decision rules, branches represent outcomes, and leaf nodes represent final predictions. This algorithm does not account for patient timelines and uses the counts of concepts from each patient’s notes as inputs. We employed the K-Best feature selection method, based on the Chi-squared statistic, to identify the most relevant features for RFs. This method selects the top k features that have the highest Chi-squared scores, indicating their importance in distinguishing between different classes. To further control for false positives, we applied the Benjamini–Hochberg False Discovery Rate (FDR) correction to the obtained p-values with the significance threshold set at α = 0.05. This correction controls the expected proportion of false positives among the rejected hypotheses. It is less conservative than Bonferroni Correction making it more suitable for exploratory studies like ours64.
In contrast, LSTM networks are designed to handle sequential data, processing patient notes one at a time. Following best NLP practices, we encoded patient notes using the BERT (Bidirectional Encoder Representations from Transformers) algorithm. BERT, based on transformer models, processes words in relation to all other words in a text span, providing a deep understanding of context and encoding the interdependencies of concepts in clinical notes.
To ensure the robustness of our outcomes, we trained multiple models with different random seeds and employed the cross-validation technique. This technique involves partitioning the dataset into k “folds” or subsets (we used k = 5 in our case). Each model is trained on a combination of these folds and tested on the remaining fold, rotating through all folds to ensure each is used for both training and testing.
We used Scikit-learn24 and Pytorch65. In our study, we performed a limited grid hyperparameter search, selecting the best configurations based on the F1 score obtained through 5-fold cross-validation over the training data. For the Random Forest (RF) classifier, we experimented with the number of decision trees in the ensemble (n_estimators) by testing values of 50, 100, and 200 trees. We also varied the maximum depth of each tree (max_depth): we tested models with no depth limit, as well as with maximum depths of 10 and 20. In the case of the LSTM model, we experimented with hidden layer sizes of 64, 128, and 256. The implementation details and final hyperparameters are detailed in Table 4.
We used the standard threshold of 0.5 as a decision rule to convert model probabilities into classification ITU vs. ward outcomes. This means that if the predicted probability of an ITU was 0.5 or higher, the model classified it as a positive case. Probabilities below 0.5 were classified as ward admissions. We did not explicitly address the class imbalance problem during training or testing.
To assess the quality of ITU admission predictions, we calculated the F1-score, precision, recall and False Negative (FN) ratio at the patient level. A true positive (TP) is defined as a case where the model predicts ITU admission and the patient was indeed admitted to the ITU (either planned or unplanned). An FN, in this context, would be a patient who was admitted to the ITU but was predicted to go to the ward. The FN ratio refers to the proportion of times a model fails to identify an admission when it is present. We also include a ROC (Receiver Operating Characteristic) curve to evaluate and visualise the model’s performance across a range of decision thresholds, rather than relying on the fixed threshold of 0.5, which may not always be optimal in clinical settings. The ROC curve illustrates the trade-off between sensitivity (true positive rate) and specificity (false positive rate) to identify the appropriate thresholds for different clinical priorities. AUC-ROC (Area Under the ROC Curve) is a single scalar value that summarises this overall performance of the model across all possible thresholds.
We assessed calibration curves to evaluate how well the predicted probabilities matched actual outcomes. Calibration curves are computed by dividing predicted probabilities into bins and comparing the average predicted probability and actual ITU rate for each bin. Accurate probabilities could help healthcare professionals to adequately assess risk levels. Additionally, we assessed fairness by evaluating classification parity across sex and ethnicity demographic subgroups. We measured the ratios of our performance metrics (precision, recall, etc.) for these subgroups66. For example, we calculated the ratio of each performance metric for the Male group divided by the Female group, and similarly, we did the same for the White group divided by the Non-white group.
To gain deeper insights into how our models make predictions, we employed SHAP (SHapley Additive exPlanations) values and LIME (Local Interpretable Model-agnostic Explanations) interpretability techniques. SHAP values quantify the overall contribution of each feature to the prediction, indicating whether it positively or negatively impacts the outcome for any given input. This helps us understand the global behaviour of the model. On the other hand, LIME focuses on individual predictions by highlighting the most influential features for a specific patient, thereby elucidating the model’s decision-making process for that particular case.
Ethical considerations
The study was conducted as part of a service evaluation within University College London Hospitals NHS Foundation Trust (UCLH) and was approved by the UCLH Clinical Governance Committee. As this was a service evaluation, the requirement for informed consent was waived by the UCLH Clinical Governance Committee on the grounds that the study involved analysis of routinely collected, anonymised clinical data and posed no additional risk to participants.
Data availability
The data are derived from electronic health records (EHRs) at University College London Hospital (UCLH). These data are not publicly available. However, de-identified data that support the findings of this study can be made available through collaboration. This is subject to institutional approvals and compliance with applicable data protection regulations. The authors affirm that all necessary permissions for data use were obtained prior to conducting the study.
Code availability
Code could not be publicly shared due to its confidentiality requirement but can be made available through collaboration. The code was implemented in Python 3.10.
References
Onwochei, D. N., Fabes, J., Walker, D., Kumar, G. & Moonesinghe, S. R. Critical care after major surgery: a systematic review of risk factors for unplanned admission. Anaesthesia 75, 62–74 (2020).
Smith, G. & Nielsen, M. Criteria for admission. BMJ 318, 1544–1547 (1999).
National Confidential Enquiry into Patient Outcome and Death Themes and recommendations common to all hospital specialities. [online] Available at: https://www.ncepod.org.uk/CommonThemes.pdf [Accessed 16 February 2025]. (2018).
Pearse, R. M. et al. Identification and characterisation of the high-risk surgical population in the United Kingdom. Crit. Care 10, 81 (2006).
Rock, A. K., Opalak, C. F., Workman, K. G. & Broaddus, W. C. Safety outcomes following spine and cranial neurosurgery: evidence from the National Surgical Quality Improvement Program. J. Neurosurg. Anesthesiol. 30, 328–336 (2018).
Chen, Y. et al. Machine learning model identification and prediction of patients’ need for ICU admission: a systematic review. Am. J. Emerg. Med. 73, 166–170 (2023).
Varelas, P. N. et al. Impact of a neurointensivist on outcomes in patients with head trauma treated in a neurosciences intensive care unit. J. Neurosurg. 104, 713–719 (2006).
Jhanji, S. et al. Mortality and utilisation of critical care resources amongst high-risk surgical patients in a large NHS trust. Anaesthesia 63, 695–700 (2008).
Lefrant, J. Y. et al. The daily cost of ICU patients: a micro-costing study in 23 French Intensive Care Units. Anaesth. Crit. Care Pain. Med 34, 151–157 (2015).
McLaughlin, A. M., Hardt, J., Canavan, J. B. & Donnelly, M. B. Determining the economic cost of ICU treatment: a prospective “micro-costing” study. Intensive Care Med 35, 2135–2140 (2009).
Gold, C. A., Mayer, S. A., Lennihan, L., Claassen, J. & Willey, J. Z. Unplanned transfers from hospital wards to the neurological intensive care unit. Neurocrit. Care 23, 159–165 (2015).
Angus, D. C. et al. Critical care delivery in the United States: distribution of services and compliance with Leapfrog recommendations. Crit. Care Med. 34, 1016–1024 (2006).
Edlmann, E. & Whitfield, P. C. The changing face of neurosurgery for the older person. J. Neurol. 267, 2469–2474 (2020).
Chibbaro, S. et al. Neurosurgery and elderly: analysis through the years. Neurosurg. Rev. 34, 229–234 (2010).
Whitehouse, K. J., Jeyaretna, D. S., Wright, A. & Whitfield, P. C. Neurosurgical care in the elderly: increasing demands necessitate future healthcare planning. World Neurosurg 87, 446–454 (2016).
Badenes, R., Prisco, L., Maruenda, A. & Taccone, F. S. Criteria for intensive care admission and monitoring after elective craniotomy. Curr. Opin. Anaesthesiol. 30, 540–545 (2017).
Rhondali, O. et al. Do patients still require admission to an intensive care unit after elective craniotomy for brain surgery. J. Neurosurg. Anesthesiol. 23, 118–123 (2011).
Williamson, C. A. Shedding a little light on the need for scheduled ICU admission following endovascular treatment of unruptured intracranial aneurysm. Neurocrit. Care 36, 16–17 (2022).
Groeger, J. S. et al. Descriptive analysis of critical care units in the United States: patient characteristics and intensive care unit utilization. Crit. Care Med. 21, 279–291 (1993).
Escobar, G. J. et al. Intra-hospital transfers to a higher level of care: contribution to total hospital and intensive care unit (ICU) mortality and length of stay (LOS). J. Hosp. Med. 6, 74–80 (2011).
Yao, H. J. et al. Perioperative risk factors associated with unplanned neurological intensive care unit events following elective infratentorial brain tumor resection. World Neurosurg 165, 206–215 (2022).
Kraljevic, Z. et al. Multi-domain clinical natural language processing with MedCAT: the medical concept annotation toolkit. Artif. Intell. Med. 117, 102083 (2021).
Noor, K. et al. Deployment of a free-text analytics platform at a UK national health service research hospital: CogStack at University College London Hospitals. JMIR Med. Inf. 10, e38122 (2022).
Pedregosa, F. et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Breiman, L. Random forests. Mach. Learn 45, 5–32 (2001).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput 9, 1735–1780 (1997).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proc NACL. Stroudsburg, PA, USA, pp.4171–4186. (2019).
Shapley, L. A Value for n-Person Games. In: Kuhn, H. and Tucker, A., eds. Contributions to the Theory of Games, Volume I. I. Princeton: Princeton University Press, pp.307–318. (1953).
Ribeiro, M., Singh, S. and Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In: Proc NACL, pp.97–101. (2016).
Tangsrivimol, J. A. et al. Artificial intelligence in neurosurgery: a state-of-the-art review from past to future. Diagnostics 13, 24–29 (2023).
Mofatteh, M. Neurosurgery and artificial intelligence. AIMS Neurosci 8, 477–495 (2021).
Huang, B. B., Huang, J. & Swong, K. N. Natural language processing in spine surgery: a systematic review of applications, bias, and reporting transparency. World Neurosurg 167, 156–164 (2022).
Funnell, J. P. et al. Characterization of patients with idiopathic normal pressure hydrocephalus using natural language processing within an electronic healthcare record system. J. Neurosurg. 138, 1731–1739 (2022).
Williams, S. C. et al. Concept recognition and characterization of patients undergoing resection of vestibular schwannoma using natural language processing. J. Neurol. Surg. B Skull Base 86, 332–341 (2024).
Searle, T., Kraljevic, Z., Bendayan, R., Bean, D. & Dobson, R. MedCATTrainer: A Biomedical Free Text Annotation Interface with Active Learning and Research Use Case Specific Customisation. In: Proc EMNLP-IJCNLP: System Demonstrations. Hong Kong, China: pp.139–144. (2019).
Hanak, B. W. et al. Post-operative intensive care unit requirements following elective craniotomy. World Neurosurg 81, 165–172 (2014).
Memtsoudis, S. G. et al. Critical care in patients undergoing lumbar spine fusion: a population-based study. J. Intensive Care Med 29, 275–284 (2014).
Schütze, D. et al. Requirements analysis for an AI-based clinical decision support system for general practitioners: a user-centered design process. BMC Med. Inform. Decis. Mak. 23, 144 (2023).
Abdulazeem, H. M. et al. Knowledge, attitude, and practice of primary care physicians toward clinical AI-assisted digital health technologies: Systematic review and meta-analysis. Int. J. Med. Inform. 201, 105945 (2025).
Jilani, T. et al. Short and Long term predictions of Hospital emergency department attendances. Int J. Med. Inf. 129, 167–174 (2019).
Lee, S. & Lee, Y. H. Improving emergency department efficiency by patient scheduling using deep reinforcement learning. Healthcare 8, 77 (2020).
Pak, A., Gannon, B. & Staib, A. Predicting waiting time to treatment for emergency department patients. Int. J. Med. Inform. 145, 104303 (2021).
Wan, P. et al. Outpatient reception via collaboration between nurses and a large language model: a randomized controlled trial. Nat. Med. 30, 2878–2885 (2024).
Williams, C. Y. K. et al. Physician- and large language model-generated hospital discharge summaries. JAMA Intern. Med. https://doi.org/10.1001/jamainternmed.2025.0821 (2025).
Glicksberg, B. S. et al. Evaluating the accuracy of a state-of-the-art large language model for prediction of admissions from the emergency room. J. Am. Med. Inf. Assoc. 31, 1921–1928 (2024).
Colakca, C. et al. Emergency department triaging using ChatGPT based on emergency severity index principles: a cross-sectional study. Sci. Rep. 14, 22106 (2024).
Wan, F. et al. Surgery scheduling based on large language models. Artif. Intell. 166, 10 (2025).
O’Quinn, P. C. et al. Predicting unplanned readmissions to the intensive care unit in the trauma population. Am. Surg. 90, 2285–2293 (2024).
Torvik, M. A. et al. Unplanned transfers from wards to intensive care units: how well does NEWS identify patients in need of urgent escalation of care? Scand. J. Trauma Resusc. Emerg. Med. 33, 105 (2025).
Uyar, G. C. et al. Prediction of 90-day mortality among cancer patients with unplanned hospitalisation: a retrospective validation study of three prognostic scores. Lancet Reg. Health Eur. 54, 101317 (2025).
Fernandes, M. et al. Predicting intensive care unit admission among patients presenting to the emergency department using machine learning and natural language processing. PloS one 15, e022 (2020).
Joseph, J. W. et al. Deep-learning approaches to identify critically Ill patients at emergency department triage using limited information. J. Am. Coll. Emerg. Physicians Open 1, 773–781 (2020).
Klang, E. et al. Predicting adult neuroscience intensive care unit admission from emergency department triage using a retrospective, tabular-free text machine learning approach. Sci. Rep. 11, 1381 (2021).
Balta, K. Y. et al. Evaluating the appropriateness, consistency, and readability of ChatGPT in critical care recommendations. J. Intensive Care Med 40, 184–190 (2025).
Workum, J. D. et al. Comparative evaluation and performance of large language models on expert level critical care questions: a benchmark study. Crit. Care 29, 72 (2025).
Haltaufderheide, J. & Ranisch, R. The ethics of ChatGPT in medicine and healthcare: a systematic review on Large Language Models (LLMs). npj Digit. Med. 7, 183 (2024).
Abualnaja, S. Y. et al. Machine learning for predicting post-operative outcomes in meningiomas: a systematic review and meta-analysis. Acta Neurochir 166, 505 (2024).
El Arab, R. A. & Al Moosa, O. A. The role of AI in emergency department triage: an integrative systematic review. Crit. Care Nurs. 89, 104058 (2025).
Noor, K. et al. Detecting clinical intent in electronic healthcare records in a UK national healthcare hospital. In: 2024 IEEE 12th International Conference on Healthcare Informatics (ICHI). 3 June IEEE. pp.484–489. (2024).
Collins, G. S. et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. B. M. J. (Clin. Res. ed.) 385, e078378 (2024).
Haller, G. et al. Systematic review and consensus definitions for the Standardised Endpoints in Perioperative Medicine initiative: clinical indicators. Br. J. Anaesth. 123, 228–237 (2019).
Intensive Care Society Levels of Care. [online] Available at: https://ics.ac.uk/resource/levels-of-care.html [Accessed 22 August 2025]. (2022).
National Confidential Enquiry into Patient Outcome and Death Classification of Intervention. [online] Available at: https://www.ncepod.org.uk/classification.html [Accessed 16 February 2025]. (2023).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Stat. Method. 57, 289–300 (1995).
Paszke, A. et al. PyTorch: An imperative style, high-performance deep learning library. In: Proc NIPS. pp. 8026–8037 (2019).
Caton, S. & Haas, C. Fairness in machine learning: a survey. ACM Comput. Surv. 56, 1–38 (2024).
Acknowledgements
HJM is supported by the National Institute for Health and Care Research, University College London Hospitals Biomedical Research Centre. No other funding was granted for the study.
Author information
Authors and Affiliations
Contributions
J.I.: Conceptualisation, Methodology, Software, Validation, Formal analysis, Investigation, Writing—Final draft preparation, Writing—Reviewing and Editing. O.O.: Conceptualisation, Methodology, Formal Analysis, Investigation, Writing—Early draft preparation, Writing—Reviewing and Editing. K.N.: Resources, Data Curation. R.D., A.L., H.M.: Conceptualisation, Methodology, Writing—Reviewing and Editing. J.F., J.B., S.L., U.R.: Conceptualisation, Writing—Reviewing and Editing. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ive, J., Olukoya, O., Funnell, J.P. et al. AI assisted prediction of unplanned intensive care admissions using natural language processing in elective neurosurgery. npj Digit. Med. 8, 549 (2025). https://doi.org/10.1038/s41746-025-01952-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-025-01952-0
