
Abstract
The transition of SARS-CoV-2 into a recurrent, seasonal pathogen has underscored the need for the induction of durable immune protection. The nucleocapsid (N) protein is regarded as a promising complementary target for therapeutic and vaccine strategies, owing to its structural robustness, clinical relevance, and ability to elicit critical immune response. Within the N protein, the C-terminal domain (N-CTD) plays a pivotal role in assembly of viral RNA (vRNA)-N protein complexes, and in facilitating liquid-liquid phase separation (LLPS) through specific interactions with RNA on its dimerization surface. Despite its functional importance, the molecular mechanisms by which the RNA-binding surface of this domain can be selectively targeted by inhibitors remain poorly defined. Herein, we report a 2.06 Å crystal structure of the SARS-CoV-2 N-CTD in complex with nCoV400Fab, a human monoclonal antibody derived from single B-cell screening. The structure reveals that nCoV400Fab engages multiple basic residues on the RNA-binding surface, forming a steric blockade that hinders vRNA binding. Functional assays demonstrate that nCoV400Fab disrupts both viral ribonucleoprotein (vRNP) assembly and RNA-induced condensate formation. Together, these findings define a structural mechanism by which a human antibody disrupts the RNA-binding surface of N-CTD, laying the foundation for the development of macromolecular inhibitors.

Similar content being viewed by others


Introduction
The majority of current Coronavirus Disease 2019 (COVID-19) therapeutic strategies target the spike (S) protein of SARS-CoV-2, which facilitates viral entry into host cells. However, the emergence of mutations in the S protein across variants has diminished the effectiveness of many spike-specific antibodies1,2. The virus’s capacity for immune evasion highlights the urgent need for targeting a broader spectrum of conserved viral components. Among these, the viral nucleocapsid (N) protein has emerged as a promising auxiliary target for therapeutic interventions. As a fundamental and highly conserved component of Sarbecoviruses3,4, the N protein is essential for viral RNA recognizing and packaging into ribonucleoprotein complex (RNP), contributing to multiple stages of the coronavirus life cycle5,6,7,8. Additionally, the N protein has roles in viral genomic RNA transcription, replication and immune regulation9,10,11. Notably, its RNA-binding activity enables the N protein to antagonize host antiviral responses, thereby contributing to virulence and pathogenesis12.
Beyond its intracellular functions, the N protein is highly immunogenic and has become a promising vaccine target capable of inducing strong post-infection adaptive immune responses13,14,15,16,17. For instance, antibodies against the N protein can contribute to protective immunity14,18,19. Moreover, T cell responses targeting conserved viral epitopes within the N protein appear crucial for long-term protection20. It is reported that a universal SARS-CoV-2 DNA vaccine encoding spike receptor-binding domain alongside M and N proteins elicited broad neutralizing antibodies and T cell responses. Of note, the N protein-specific T cell alone induced by this vaccine was 60% protective21. Additional investigations concur that such cross-reactive T cell immunity could provide broad coverage against emerging variants22,23,24.
In addition to its vaccine potential, the N protein is abundantly present as a circulating antigen in the serum of COVID-19 patients, often detectable within 2 days of symptom onset, preceding the production of anti-N antibodies25. This high immunogenicity not only makes N protein a highly sensitive early biomarker compared to spike-based assays26,27,28, but also implicates it as an active contributor to COVID-19 pathogenesis. Specifically, circulating N antigen has been shown to activate NF-κB signaling pathways and MASP-2-mediated complement cascades, driving inflammation and dysregulated innate immune responses29,30. These attributes position the N protein as a potentially variant-resilient antiviral target, broadening therapeutic options beyond spike-based antibodies. However, in contrast to the extensively characterized S protein, how the N protein is recognized by the adaptive immune system remains comparatively underexplored31.
Typically, the N protein forms structurally heterogeneous complexes with viral RNA in vitro or in vivo. Structurally, it consists of a folded N-terminal domain (NTD), a folded C-terminal dimerization domain (CTD), and three intrinsically disordered regions (IDRs), all of which contribute to RNA binding7,32. Upon RNA engagement, the N protein adopts a more organized conformation that promotes CTD dimer-dimer interactions33. This structural coordination subsequently facilitates the ordered assembly of the N protein onto the viral RNA scaffold, yielding compact vRNP architectures3,34,35,36,37. Among these domains, the N-CTD is especially critical due to its ability to mediate oligomerization, RNA binding and higher-order vRNP assembly. Notably, the N-CTD drives RNA-induced liquid-liquid phase separation (LLPS), enabling the formation of viral replication condensates that protect viral components from innate immune surveillance38,39. This functional versatility reflects the N-CTD’s capacity to bridge viral RNA handling and host regulatory engagement through dynamic multivalent protein–RNA and protein–protein interactions38,40,41,42. These interactions allow the N-CTD to suppress innate antiviral immunity by inhibiting dsRNA-induced interferon-β (IFN-β) expression10,43,44,45, and to interfere with host cell proliferation via binding to the host translation elongation factor 1α (EF1α)46. Besides, the CTD is the most immunogenic region of the N protein, harboring dominant antigenic sites and exhibiting strong reactivity with convalescent antibodies, supporting its potential to elicit protective immunity against SARS-CoV and SARS-CoV-247,48,49. Despite its essential functional roles, the N-CTD remains remarkably conserved and structurally stable, sharing over 90% sequence identity across SARS-CoV-2 variants of concern (VOCs), with no reported mutations throughout viral evolution50,51. Of note, the SARS-CoV-2 N-CTD shares 96% sequence identity with other Sarbecoviruses3, rendering it a promising target for broad-spectrum antiviral therapies aimed at disrupting viral genomic encapsulation, transcription, replication, and modulation of the host immune response52,53. However, most inhibitor development efforts have focused on the N-NTD, leaving the functionally crucial N-CTD pharmacologically underexplored. The α-helical surface of the N-CTD contains a cluster of basic residues, suggesting a functionally essential RNA-binding interface38. Yet, available small-molecule inhibitors engage only limited surface areas and fail to sufficiently block these essential residues, resulting in incomplete inhibition of RNA binding activity54,55. Together, these limitations underscore the therapeutic urgency of developing inhibitors that specifically target N-CTD functions.
Building on our previous research, we identified a human monoclonal antibody (mAb) named nCoV400, obtained through single B-cell screening, which binds specifically to the N-CTD18. To elucidate how this antibody interacts with the N-CTD, we determined the crystal structure of the complex formed between the antigen-binding fragment of mAb nCoV400 (nCoV400Fab) and the N-CTD. The structure reveals that nCoV400Fab engages multiple basic residues on the RNA-binding surface, inducing local conformational rearrangements and generating extensive steric hindrance that may underlie its RNA-blocking capability. Functional assays confirmed that nCoV400Fab hinders N-CTD binding to viral genomic RNA segments, thereby interfering with vRNP-complexes assembly and RNA-driven condensate formation. To the best of our knowledge, this represents the first detailed structural characterization of a human monoclonal antibody targeting the RNA-binding interface of the N-CTD. These findings serve as a fundamental framework for comprehending the mechanisms that could potentially promote the development of macromolecular inhibitors.
Results
Specific binding of N-CTD protein with human monoclonal antibody nCoV400Fab
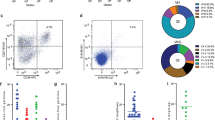
In our previous research, we successfully isolated 32 mAbs that bind the recombinant N protein of SARS-CoV-218. Among these, one mAb, designated nCoV400, exhibited selective reactivity toward the N-CTD antigen, as determined through single B-cell human antibody screening methodologies (Fig. 1a). To evaluate the evolutionary conservation of these epitopes, we performed a comparative analysis of N-CTD sequences across circulating SARS-CoV-2 variants, including VOCs, variants of interest (VOIs), and variants under monitoring (VUMs). Our analysis revealed that the N-CTD is remarkably conserved (Fig. 1b), with no mutations detected across the examined variants (within 6,141,022 viral genomic sequences56,57). Furthermore, the N-CTD of SARS-CoV-2, shares high sequence homology with that of SARS-CoV and other Sarbecoviruses (Supplementary Fig. S1). This exceptional degree of conservation, combined with the domain’s central role in the virus life cycle, highlights the N-CTD as a compelling broad-spectrum therapeutic target.

a Workflow of isolation of the specific human monoclonal antibody from a COVID-19 convalescent patient, created by Figdraw. b SARS-CoV-2 variants mutation prevalence across lineages and the mutated amino acids within the N protein are shown (gray or black). The statistics were generated by outbreak.info. All SARS-CoV-2 sequences are received via direct provision from the GISAID Initiative. The VOCs, VOIs, and VUMs are defined by the World Health Organization (WHO). c The binding affinity of SARS-CoV-2 N-FL with nCoV400Fab measured by BLI. The nCoV400Fab at different concentrations was exposed to 5 μg/mL biotinylated N-FL. d The binding assay between SARS-CoV-2 N-NTD and N-CTD domains with nCoV400Fab, measured by BLI. nCoV400Fab at three different concentrations was exposed to 5 μg/mL biotinylated N-NTD or N-CTD. e The binding affinity of SARS-CoV-2 N-CTD with nCoV400Fab measured by BLI. The nCoV400Fab at different concentrations was exposed to 5 μg/mL biotinylated N-CTD.
To further investigate the functional and structural properties of this mAb targeting the conserved N-CTD region, we expressed a recombinant fragment antigen-binding (Fab) antibody, termed nCoV400Fab. Using BLI, we evaluated the binding kinetics of nCoV400Fab with N-FL protein as well as its truncated domains (N-NTD, N-CTD). nCoV400Fab exhibited strong binding to N-FL, with a KD value of ~56.67 nM (Fig. 1c and Supplementary Table S1). Competitive BLI assays further demonstrated that nCoV400Fab specifically recognizes the N-CTD, showing negligible affinity for the N-NTD (Fig. 1d). Moreover, direct binding assays confirmed that nCoV400Fab binds tightly to N-CTD with a KD of around 96.31 nM (Fig. 1e and Supplementary Table S1).
For comparative evaluation, we next benchmarked nCoV400 against RM3165-00, a commercial diagnostic antibody. In plate-based ELISA, nCoV400 displayed a markedly lower EC50 than RM3165 (8.66 vs. 130.6 ng/mL; Supplementary Fig. S2a). However, BLI assay revealed that RM3165 exhibited faster association and slower dissociation rates, resulting in a tighter binding profile in solution-phase measurements (Supplementary Fig. S2b, c and Supplementary Table S1). These differences likely reflect distinct epitope orientations in solid-phase versus solution-phase settings.
To further assess epitope specificity, we measured binding of nCoV400Fab to the N-CTDs of two non-sarbecovirus betacoronaviruses, MERS-CoV and HCoV-OC43, via BLI. While the full-length antibody nCoV400 showed high affinity for the SARS-CoV-2 N-CTD (KD = 0.393 nM), its bindings to the MERS-CoV and HCoV-OC43 homologs were markedly weaker (Supplementary Fig. S2d, e), consistent with the limited sequence conservation of the nCoV400 epitope beyond the Sarbecovirus lineage (Supplementary Fig. S2f).
Together, these findings establish nCoV400 as a human monoclonal antibody that binds the SARS-CoV-2 N-CTD with high affinity and specificity, recognizing a conserved epitope restricted to Sarbecovirus.
Crystal structure of the nCoV400Fab–N-CTD complex reveals a novel binding mode
To comprehensively investigate the molecular mechanism underlying the interaction between nCoV400Fab and the N-CTD antigen, we determined the crystal structure of the SARS-CoV-2 N-CTD in complex with nCoV400Fab at 2.06 Å resolution using X-ray crystallography. Briefly, the complex structure was solved by molecular replacement using the N-CTD structure (PDB ID: 7DE1) and monoclonal antibody omalizumab Fab (PDB ID: 6TCN) as search models. The final model includes electron density for residues 249–364 (SARS-CoV-2 N-CTD), 1–235 (nCoV400Fab, the heavy chain of the Fab), and 1–215 (nCoV400Fab, the light chain of the Fab, except for the linker residues ranging from 136 to 141). The asymmetric unit contains one dimeric N-CTD complexed with two nCoV400Fab molecules. The comprehensive details regarding data collection, phasing, and refinement can be accessed in Supplementary Table S2. The coordinates have been deposited in the Protein Data Bank under accession code 9KUR.
With the aid of the high-resolution structure, we identified the complementarity-determining regions (CDRs) in nCoV400Fab: light chain CDR1, residues 26–31 (L-CDR1), light chain CDR2, residues 49–51 (L-CDR2), light chain CDR3, residues 88–99 (L-CDR3), heavy chain CDR1, residues 26–33 (H-CDR1), heavy chain CDR2, residues 51–58 (H-CDR2), and heavy chain CDR3, residues 97–119 (H-CDR3), as annotated in Supplementary Fig. S3. The nCoV400Fab adopts a unique binding configuration when compared with other reported N-CTD inhibitors54,58,59,60. As shown in Fig. 2a, the stable dimeric N-CTD provides a scaffold that accommodates dual nCoV400Fab molecules. The N-CTD dimer presents two distinct surfaces: an alpha-helical face enriched with basic residues, and a beta-sheet-rich facade with primarily neutral polar amino acids. Most previously reported inhibitors engage either the beta-sheet face or the cleft on the side of the dimeric N-CTD structure54,61,62,63, with only limited recognition of the alpha-helix-dominated face. In contrast, our determined structure reveals that two nCoV400Fab molecules simultaneously bind to the positively charged helical surface of the N-CTD dimer in a cooperative manner, likely stabilized by inter-Fab interactions, thereby defining a previously uncharacterized mode of antibody engagement (Fig. 2b, c).

a Overall crystal structure of two nCoV400Fab bound to the α-helix side of the dimerized N-CTD. The color scheme for the different structural elements is consistent throughout the paper. Three boxed regions mark the binding epitopes (Epitope 1–3). b The top view of the crystal structure. c The bottom view of the crystal structure showed that the nCoV400Fab interacted with the α-helix side of the N-CTD dimer.
Binding interface and conformational adaptations of the N-CTD dimer upon recognition by a nature-inspired mAb
A key structural feature of the nCoV400Fab–N-CTD complex is the simultaneous occupancy of two nCoV400Fab molecules on the same α-helical facet of the dimeric N-CTD. This results in extensive buried surface areas (BSA) of ~1083 Å2 for the light chain and 716 Å2 for the heavy chain (Fig. 3a and Supplementary Table S3). Based on a BSA threshold of >10 Å2, PISA analysis identified 24 residues of the N-CTD involved in nCoV400Fab binding. This interaction creates a defined cavity between the VH1-CDR3 and VL1-CDR3, which forms a 51.98° angle and a 15.93 Å opening that envelops the positively charged N-terminal α-helix of one N-CTD monomer (Fig. 3b–d, epitope 1, Supplementary Fig. S4a). A similar pocket exists on the opposite monomer between VH2-CDR3 and VL2-CDR3, forming a 49.25° angle and an opening of 16.46 Å (Supplementary Fig. S4b). These positively charged N-terminal α-helices have previously been identified as crucial regions for RNA binding7,35, suggesting that nCoV400Fab sterically occludes this functionally essential surface.

a The overlook of three main epitopes of N-CTD recognized by nCoV400Fab in the crystal structure. The nCoV400Fab is shown in a ribbon representation while the N-CTD dimer is shown in an electrostatic surface representation. b, c The first epitope (250–257) of N-CTD (cornflower blue) is recognized by nCoV400Fab VL1-CDR1,3 (medium purple) and VH1-CDR2-3 (dark magenta) via numerous hydrogen bond interactions and π-stacking interactions in the left panel. The interacting residues of N-CTD and nCoV400Fab are highlighted with the stick representation (left panel). The hydrogen bonds are shown as dashed lines. The VL1-CDR1,3 and VH1-CDR2-3 of nCoV400Fab are shown in an electrostatic surface representation in which blue denotes a positive charge potential while red indicates a negative charge potential (right panel). d Recognition of K257 in N-CTD by VL1-CDR1-2 of nCoV400Fab with the stick representation (left panel), and the interacting residues of nCoV400Fab are illustrated in an electrostatic surface representation (right panel). e The second epitope of N-CTD is recognized by nCoV400Fab VL2-CDR2 (light pink) via hydrogen bond interactions and hydrophilic interactions. f The third epitope of N-CTD recognized by nCoV400Fab VH2-CDR3 via hydrogen bonds interactions and π-stacking interactions.
Specifically, a network of interactions from residues 255-257 of N-CTD to the light chain L-CDR1 and L-CDR2 highlights the critical contribution of conserved residue K257 of SARS-CoV-2 N-CTD to nCoV400Fab binding at epitope 1 (Fig. 3c, d). In epitope 2, residues K299, P302, Q303, and Q306 of N-CTD form multiple hydrophilic and hydrophobic interactions with residues Y48, K49, E52, and R53 of L-CDR2. The side chains of residues E52 and R53 of L-CDR2 establish hydrogen bond interactions with N-CTD residues K299 and Q303 (Fig. 3e). In epitope 3, N-CTD residues D340 and D343 form hydrogen bonds with Y113 and Y115 of H-CDR3, while residues D343 and P344 of N-CTD simultaneously stack with the π-aromatic of Y113 and Y115 of H-CDR3 (Fig. 3f). Additional stabilizing interactions are mediated by N-CTD residues at positions 251, 261–263, and 268, which engage L-CDR1/CDR3 residues at positions 28, 29, 90, 97, and 98 through hydrophobic and π-stacking contacts (Supplementary Fig. S5a).
To assess antibody-induced conformational changes, we aligned the apo N-CTD35 (PDB: 7DE1) with our nCoV400Fab-bound complex (Fig. 4a). The overall Cα root mean square deviation (RMSD) was modest (0.573 Å), but the three epitopes respond differently. Epitope 1 (residues 250–258) underwent the largest rearrangement (local RMSD = 10.12 Å; Fig. 4b). Specifically, S250 shifted outward by 20.89 Å; E253 and K256 rotated downward by 15.75 and 10.07 Å, respectively; and S255 pivoted upward 9.27 Å to engage VL-CDR1. K257 moved 1.5 Å, consolidating contacts with VL-CDR1/2 (Supplementary Fig. S5b). In contrast, epitope 2 (299–306) and epitope 3 (340–344) displayed moderate backbone shifts of 1.37 and 1.57 Å, respectively (Fig. 4c, d). In epitope 2, K299 and Q303 each adjusted ~1.2 Å to optimize hydrogen bonds with VL-CDR2, whereas in epitope 3, D340, D343 and P344 moved 2.5–3.0 Å downward to relieve steric strain and reinforce VH-CDR3 contacts. Collectively, these data support an induced-fit model in which nCoV400Fab remodels the highly basic N-terminal helix (epitope 1) while leaving the remaining RNA-binding surface largely intact.

a Overall structure of the nCoV400Fab–N-CTD complex aligned with the apo N-CTD (PDB: 7DE1). nCoV400Fab is shown as ribbons, the N-CTD dimer in the complex is shown in blue (Complex-N-CTD), and the apo N-CTD is shown in yellow (Apo N-CTD). b Superposition of the N-CTD structures in the nCoV400Fab–N-CTD complex (blue) and the apo state (yellow, PDB: 7DE1). Red arrows indicate regions of conformational shift in N-CTD upon antibody binding. c Close-up view of epitope 2 (residues 299–306), showing local conformational changes in response to nCoV400Fab binding. Key residues of N-CTD in the complex (blue) and apo N-CTD (yellow), as well as nCoV400Fab VL2-CDR2 (light pink), are depicted as sticks. Dashed lines indicate the direction of displacement, with the corresponding distances labeled. d Close-up view of epitope 3 (residues 340–344), showing local conformational changes in response to nCoV400Fab binding. Key residues of N-CTD in the complex (blue) and apo N-CTD (yellow), as well as nCoV400Fab VH2-CDR3 (magenta), are depicted as sticks. Dashed lines indicate the direction of displacement, with the corresponding distances labeled.
Despite these localized changes, the β-sheet–mediated interface that stabilizes the N-CTD dimer remains intact upon nCoV400Fab binding. In line with its uncomplexed state, the two monomers are stabilized through three key interfacial regions, with a BSA of 2587 Å2 out of a total N-CTD monomer surface area of 8892 Å2 (Supplementary Fig. S6a–d and Supplementary Table S3). First, β2 strands from both monomers are stabilized by a network of hydrogen bonds in the β-sheet-rich region (Supplementary Fig. S6a). Second, the η1 region forms strong hydrogen bond interactions with the α3 and α4 helices of neighboring monomers, creating a grip that secures them firmly in place (Supplementary Fig. S6b). The third critical stabilization factor for the N-CTD dimer involves residues R277 and N285 interacting with the main chain of G316, S318, and I320 within the α4 helix of the adjacent monomer (Supplementary Fig. S6c). The last feature is that residue R319 further stabilizes this interface by contacting G278, E280, and Q283 via three hydrogen bonds (Supplementary Fig. S6d). The close positioning of the two Fabs bound to the dimerized N-CTD reinforces this configuration, enabling extensive inter-Fab hydrogen bonding, with a BSA of 355 Å2 (Supplementary Fig. S6e, f and Supplementary Table S3).
nCoV400Fab interferes with viral RNA binding and disrupts higher-order vRNP assembly
Given the structural details of the antibody–antigen interaction, we hypothesized that nCoV400Fab may inhibit the binding of N-CTD to viral genomic RNA not only through steric hindrance, but also by engaging key basic residues critical for electrostatic interactions with RNA. To test this, we evaluated the ability of nCoV400Fab to suppress N-CTD binding to viral genomic RNA, using a defined viral packaging signal as a model substrate. In coronaviruses, the initial step of viral RNA packaging involves recognition of a packaging signal—often a stable stem-loop structure—located near the 3′ end of the ORF1b region. This has been documented in mouse hepatitis virus (MHV), MERS-CoV, SARS-CoV, and SARS-CoV-264,65,66,67. Based on secondary structural predictions, we selected a 157-nucleotide segment (vRNA157, encompassing coordinates 19951-20107) from the 3’-end of the ORF1b region of the SARS-CoV-2 genomic RNA, which forms a stem-loop structure (Supplementary Fig. S7a). Sequence alignment confirmed that vRNA157 is relatively conserved across SARS-CoV-2, SARS-CoV, and other Sarbecoviruses (Fig. 5a). To assess whether the nCoV400Fab affects the interaction between N-CTD and viral RNA, we synthesized vRNA157 for in vitro binding assays. Primarily, upon titration with increasing concentrations of N-CTD, vRNA157 shifts towards the negative electrode, consistent with formation of RNP complexes in native gel shift assay (Fig. 5b). Moreover, the addition of equimolar nCoV400Fab disrupted this shift, resulting in the release of vRNA157, suggesting disassembly of the RNP complex. We also tested the ability of nCoV400Fab to inhibit the formation of RNP between N-FL and vRNA157. As the concentration of N-FL increased, vRNA157 bound to N-FL, forming higher-order RNP structures with different aggregation states. When N-FL was added at a fourfold molar excess, vRNA157 was completely sequestered into RNP complexes. However, co-incubation with equimolar nCoV400Fab moderately impaired this binding at high concentrations, partially releasing vRNA157 (Supplementary Fig. S7b).

a Sequence alignment of SARS-CoV-2 genomic RNA (20910-21079) between BatCoV-RaTG13, SARS-CoV, BatCoV-HKU3, HCoV-OC43, and MERS-CoV. b Native PAGE of vRNA157 with varying molar ratios of N-CTD, in the absence or presence of nCoV400Fab at an equimolar ratio to N-CTD. Lane 1 contains no protein, and lane 2 contains only nCoV400Fab, while the subsequent lanes contain increasing amounts of N-CTD protein with molar ratios of 1, 2, 4, and 8 to vRNA157. The electrophoretic result was stained with ethidium bromide for nucleic acid detection (left panel), and then the same gel was stained with Coomassie Blue for protein visualization (right panel). c Competitive binding of nCoV400Fab to vRNA157 based on SARS-CoV-2 N-CTD. The biotinylated N-CTD was captured onto the streptavidin biosensors. The nCoV400Fab (upper panel) or vRNA157 (lower panel) as the first analyte, followed by nCoV400Fab mixed with vRNA157 as the second analyte. The competitive binding model was created with BioRender.com. d BLI analysis of the interaction between nCoV400 and the K257E mutant N-CTD of SARS-CoV-2. nCoV400 (5 μg/mL) was immobilized onto AHC2 biosensors and incubated with serial concentrations (3.125–100 nM) of the N-CTD K257E mutant protein. e BLI analysis of the interaction between nCoV400Fab and the N-terminally truncated N-CTD (ΔN-CTD, residues 264–364) under the same conditions as in panel (a). f Native PAGE analysis of the RNA-binding capacities of three N-CTD variants: N-terminally truncated N-CTD (ΔN-CTD, residues 264–364), K257E mutant, and wild-type N-CTD. In each assay, 2 μg of 55-nt vRNA was used as a fixed amount (defined as 1× for molar ratio calculations). Lane 1 contains vRNA only and lane 6 contains ΔN-CTD (264–364) only, while lanes 2–5 show increasing amounts of ΔN-CTD (264–364) (0.5, 1, 2, 4, and 8× relative to vRNA). In lanes 7–10, a fixed amount of vRNA was incubated with increasing amounts of K257E N-CTD mutant (1, 2, 4, and 8× relative to vRNA), while lane 11 contains only the K257E mutant. Lanes 12–15 show wild-type N-CTD incubated with vRNA at increasing protein-to-RNA molar ratios (1, 2, 4, and 8× relative to vRNA). Gels were stained with ethidium bromide for nucleic acid detection (left panels), followed by Coomassie Blue for protein visualization (right panels). The positions of free vRNA, free N-CTD variants, and bound complexes are indicated.
To further validate these findings, we conducted in-tandem BLI binding assays. Pre-loading N-CTD with nCoV400Fab marginally reduced the subsequent binding of vRNA157 (Fig. 5c, the upper panel). Conversely, pre-binding of N-CTD with vRNA157 did not prevent subsequent binding of nCoV400Fab (Fig. 5c, the lower panel). Such outcomes denote that nCoV400Fab can partially compete with vRNA157 for binding to the N-CTD, likely by occupying critical RNA-binding residues.
To further clarify whether this disruptive effect extends to additional genomic elements, we synthesized two shorter vRNA fragments: a 55-nt segment from the 5′-UTR (positions 1–55) and a 60-nt segment from the Nsp1 coding region (positions 335–394) (Supplementary Fig. S8). Native gel assays confirmed that both vRNAs formed higher-order complexes with N-CTD in a protein concentration-dependent manner. Upon titration of nCoV400Fab into the preformed complexes, the shifted vRNP bands progressively diminished, and were nearly abolished at an equimolar ratio of Fab to N-CTD. These results indicate that nCoV400Fab effectively impedes N-CTD binding to multiple viral RNA segments.
To assess the impact of nCoV400Fab on vRNP assembly, we analyzed the vRNA157–N-CTD complex by SEC (Supplementary Fig. S9a). In the absence of nCoV400Fab, a high-molecular-weight peak eluting at 1.60–1.75 mL yielded only a uniform free RNA band without mobility shift, suggesting that the potential complexes were either oversized or insufficiently stable to enter the gel (Supplementary Fig. S9b, the upper panel). Upon addition of nCoV400Fab, these same fractions produced distinct shifted RNA bands that entered the gel matrix, indicating a reduction in complex size and altered assembly state (Supplementary Fig. S9b, the lower panel). Consistently, negative-stain electron microscopy revealed that the large, amorphous aggregates observed in Fab-free samples were replaced by more filamentous and dispersed particles upon nCoV400Fab treatment (Supplementary Fig. S9c).
In agreement with SEC and EM results, dynamic light scattering (DLS) analysis showed that N-CTD assembled into large particles with 60-nt vRNA, exhibiting a dominant hydrodynamic diameter of ~800 nm (Supplementary Fig. S9d). Upon the addition of nCoV400Fab, the average particle size was markedly decreased to ~200 nm, indicating disassembly of higher-order vRNPs. A similar but less pronounced reduction was observed for the 55-nt vRNA complex, suggesting moderate disruption of vRNP assembly (Supplementary Fig. S9d).
Collectively, these data demonstrate that nCoV400Fab targets a conserved, lysine-rich RNA-binding surface on the N-CTD dimer, competitively blocks RNA binding, and destabilizes the formation of higher-order vRNP structures.
Conserved N-terminal residues within the Fab-binding epitope are essential for RNA interaction
Guided by the crystal structure, we next investigated whether key residues within the antibody-binding epitope also contribute to RNA recognition. Prior studies have shown that the N-terminal region of N-CTD, enriched in basic lysines, forms a prominent electropositive surface essential for RNA binding38. To test this, we introduced a point mutation (K257E) and generated an N-terminal truncation mutant (ΔN-CTD, residues 264–364). As measured by BLI, both mutants exhibited severely reduced binding to nCoV400Fab (Fig. 5d, e), and failed to form detectable vRNP complexes with 55-nt RNA in native gel assays, even at elevated protein concentrations (Fig. 5f). These findings confirm that the basic N-terminal region, particularly K257, is indispensable for both recognition by nCoV400Fab and RNA binding.
To further evaluate the mechanistic specificity of this inhibition, we compared nCoV400Fab with L-chicoric acid, a previously reported small-molecule ligand that binds the lateral cleft of N-CTD54. Structural modeling suggested that L-chicoric acid engages N-CTD at a distant site from the nCoV400Fab epitope, interacting primarily with residues T271, R276, and R277 through electrostatic and hydrogen bond contacts (Supplementary Fig. S10a–c). While both ligands bind the N-CTD, only nCoV400Fab—which directly targets the highly conserved, electropositive α-helical surface—was able to disrupt vRNP formation in native gel assays. In contrast, L-chicoric acid showed no inhibitory activity, even at the highest tested concentration (Supplementary Fig. S10d). Together, these results emphasize that effective inhibition of RNA binding requires direct engagement of the structurally conserved, functionally essential epitope on the α-helical face of N-CTD.
The nCoV400Fab attenuates N protein–RNA condensate formation in vitro and in cells
The formation of membraneless condensates by the N protein in coordination with host factors is known to facilitate viral replication machinery assembly while shielding viral components from host immune surveillance. These condensates are stabilized by dynamic and multivalent protein–RNA interactions. Given the potent RNA-binding inhibition exhibited by nCoV400Fab, we sought to determine whether nCoV400Fab could undermine the condensate formation capability of N-CTD.
To test this, we performed a fluorescence microscopy experiment using AF488-labeled N-CTD protein (20 μM) mixed with vRNA157 (1 μM), followed by the addition of various concentrations of the crowding polymer PEG8000 (Fig. 6a and Supplementary Fig. S11). Condensate formation occurred only when both N-CTD and vRNA157 were present, indicating their interaction was necessary to nucleate these assemblies (Supplementary Fig. S12a). Importantly, equimolar addition of nCoV400Fab significantly reduced both the average fluorescence intensity and the number of observed droplets (Fig. 6a and Supplementary Fig. S12). These results suggest that nCoV400Fab interferes with the multivalent interactions required for condensate formation, which could affect viral genome-associated biological processes. We next assessed the specificity of this inhibition using a 55-nt Cy5-labeled vRNA fragment and AF488-labeled N-CTD, along with various controls (Supplementary Fig. S13). Robust colocalized liquid-like droplets formed in samples containing both components (Fig. 6b, c), and this condensate formation was abolished by the N-terminally truncated mutant (ΔN-CTD 264–364) (Fig. 6b, d), reinforcing the essential role of the N-terminal RNA-binding epitope. Similarly, the addition of nCoV400Fab markedly impaired condensate formation, as indicated by decreases in fluorescence intensity, condensate number, and area occupied, whereas nCoV396Fab, which targets the N-NTD, had no detectable effect (Fig. 6b, d). We further compared the inhibitory potency of nCoV400Fab to small molecules, including L-chicoric acid and ampicillin. Both small-molecule inhibitors exhibited only minor effects on condensate formation (Fig. 6b, d). Structural analysis indicates that, unlike nCoV400Fab, these compounds do not bind the highly basic α-helical surface of N-CTD but instead interact with regions distinct from the primary RNA-binding site (Supplementary Fig. S10a, b and Supplementary Fig. S14), which likely accounts for their limited effect.

a Representative fluorescence images of AF488-labeled N-CTD protein (20 μM) mixed with vRNA157 (1 μM) to form condensate liquid droplets in vitro, in the absence or presence of nCoV400Fab at an equimolar ratio to N-CTD. Lanes 1 and 2 with the addition of 10% PEG8000 while lane 3 and 4 contained 20% PEG8000. Scale bars, 50 μm. b Fluorescence microscopy images showing condensate droplets formed by incubation of AF488-labeled full-length N-CTD (green, 20 μM) or AF488-labeled truncated N-CTD (Δ264–364) (green, 20 μM) with Cy5-labeled 55-nt vRNA (red, 20 μM) in the presence or absence of different inhibitors. Conditions included full-length N-CTD with vRNA (lane 1), truncated N-CTD (Δ264–364) with vRNA (lane 2), and N-CTD with vRNA incubated separately with nCoV400Fab (lane 3), L-chicoric acid (lane 4), ampicillin (lane 5), or the non-N-CTD-specific antibody nCoV396Fab (lane 6). Merged images (yellow) illustrate colocalization of N-CTD and RNA. Scale bar, 10 μm. c Representative line profile analysis demonstrating the colocalization pattern between AF488-N-CTD and Cy5-55-nt vRNA signals. d Quantitative analysis of condensate formation, including integrated fluorescence intensity, droplet counts, and area occupied by droplets, calculated from four randomly selected fields for each condition. Data represent mean ± SD. Statistical significance was analyzed by one-way ANOVA (Exact p values are indicated; ns, not significant). e Confocal fluorescence microscopy images of HEK293T cells under four conditions, corresponding to lanes 1–4 from left to right: Lane 1: transfected with N-FL-mCherry alone; Lane 2: transfected with N-FL-mCherry and treated with poly(I:C); Lane 3: co-transfected with N-FL-mCherry and plasmids encoding nCoV400-GFP, then treated with poly(I:C); Lane 4: transfected with nCoV400-GFP alone. N-FL-mCherry is shown in red, nCoV400-GFP in green, and merged images (yellow) indicate colocalization. White arrows indicate representative N protein condensates. Scale bar, 10 μm. f Representative fluorescence intensity profiles showing colocalization of N-FL-mCherry (red) and nCoV400-GFP (green) signals. g Quantification of N protein condensates per cell under each condition. Data were collected from three independent experiments, with 17 randomly selected cells analyzed per group. Data represent mean ± SD. Statistical significance was determined by one-way ANOVA (Exact p values are indicated; ns not significant).
To evaluate whether this inhibitory effect extends to cellular settings, we co-transfected HEK293T cells with mCherry-tagged N-FL and plasmids encoding nCoV400 heavy chain-GFP fusion and light chain. Following poly(I:C) stimulation, confocal imaging showed cytoplasmic puncta formation in cells expressing N alone (Fig. 6e), whereas co-expression of nCoV400 markedly reduced their abundance (Fig. 6e, g). Line-scan analysis further confirmed cytoplasmic colocalization between nCoV400 and N protein (Fig. 6f), supporting its activity in live cells.
Together, these results demonstrate that nCoV400Fab impairs the ability of N-CTD to form RNA-driven condensate both in vitro and in cells, reinforcing its potential as a targeted antiviral agent.
Discussion
Coronaviruses have long posed a threat to global health, with their pandemic potential recognized well before the emergence of COVID-19. These RNA viruses span a broad spectrum of pathogenicity—from mild respiratory illness to more severe diseases, such as Middle East Respiratory Syndrome (MERS), severe acute respiratory syndrome (SARS), and the ongoing COVID-19 pandemic. Within this family, the Sarbecovirus subgenus of betacoronaviruses has raised particular concern, as it includes some of the most pathogenic viruses known to infect humans, such as SARS-CoV and SARS-CoV-2. Their emergence is frequently attributed to zoonotic spillover events, where viruses circulating in animal reservoirs cross into humans—often through intermediate hosts—setting the stage for outbreaks and global transmission.
Given the ongoing threat posed by Sarbecoviruses, there is a pressing need to develop effective functional inhibitors that can disrupt the virus’s ability to replicate or cause disease. A central challenge in this effort lies in identifying conserved viral elements that can serve as broadly effective therapeutic targets—ideally, those preserved across current and emerging Sarbecovirus lineages. One such target is the conserved N-CTD protein, which plays a crucial role in viral pathogenesis and replication via its RNA-binding ability. In particular, a basic α-helical region near the N-terminus of the domain facilitates vRNA capture, initiates vRNP assembly, and drives RNA-mediated condensate formation. Despite its functional importance, only a handful of studies have reported inhibitors that engage this surface54,59,60,61,62,63, and none to date match the breadth or potency achieved by our antibody lead. Our research identifies a unique human monoclonal antibody, nCoV400Fab, that specifically recognizes the RNA-binding surface of SARS-CoV-2 N-CTD and disrupts multiple downstream functions. Sequence alignment reveals that the epitope targeted by nCoV400Fab—a basic α-helical patch—is virtually invariant across all known Sarbecoviruses but diverges sharply in MERS-CoV and HCoV-OC43, consistent with our BLI data showing dramatically reduced cross-clade binding (Supplementary Fig. S2d–f). By selectively recognizing this structurally conserved and functionally indispensable hotspot, nCoV400Fab provides a promising foundation for the development of a pan-Sarbecovirus inhibitor, potentially reducing the impact of future outbreaks from this viral subgenus.
As macromolecular therapeutics, human antibodies offer key advantages over small molecules. Firstly, they are derived from naturally paired heavy and light chain genes in single B cells and are thus evolutionarily optimized to recognize exposed, accessible epitopes. In our structure analysis, nCoV400Fab binds the N-CTD dimer in a 2:2 stoichiometry, contacting 24 residues across three conserved epitope clusters. These sites are not only functionally critical but also evolutionarily stable, reducing the likelihood of escape mutations in emerging variants. Secondly, antibodies utilize their CDRs to form highly specific and multivalent contacts, achieving a stronger and more sustained blocking effect than small molecules. These hypervariable loops within the CDRs regions of antibodies directly contact the epitope, forming a shape-complementary pocket that ensures a tight and selective engagement of epitope surfaces. Structural comparison further revealed that nCoV400Fab buries 1799 Å2 of surface area upon binding and induces subtle conformational changes in the α-helical RNA-binding surface, supporting an induced-fit mechanism. In contrast, small-molecule ligands such as L-chicoric acid engage six residues on a peripheral face while ampicillin binds a neutral α-helical flank, and consequently exhibit limited inhibition of RNA binding or condensate formation. Thus, the multivalent and shape-complementary interaction pattern of nCoV400Fab enables high avidity and steric blockade that small molecules are structurally unable to replicate. Our structural and functional findings reveal that the adaptive immune system can generate antibodies that not only recognize but also disrupt the function of the SARS-CoV-2 N protein. This extends the current immunological focus beyond the S protein and highlights the translational potential of N-targeting antibodies as a complementary broad-spectrum antiviral strategy.
While our structural data suggest an induced-fit mechanism, our current analysis is limited to a static comparison. We did not perform molecular dynamics (MD) simulations or other computational approaches to directly investigate the dynamic features of antibody–antigen recognition, which remains a limitation of the present study. Recent studies68,69 have demonstrated that multiscale and machine learning-based approaches can uncover conformational features beyond static structural analysis, and may guide future extensions of our work.
Beyond these structural and mechanistic insights, our biochemical and cellular findings now also open clear translational avenues. As a diagnostic reagent, nCoV400 exhibits markedly higher ELISA sensitivity than the commercial antibody RM3165, while retaining sub-nanomolar affinity in solution. Coupled with its strict Sarbecovirus selectivity, nCoV400 is an excellent candidate for a next-generation probe for high-throughput diagnostic platforms or multiplex serological assays. As a therapeutic scaffold, nCoV400 abolishes RNA–induced N-protein condensates in living cells without perturbing basal cellular physiology, confirming that its epitope remains accessible within the crowded cytoplasm. This property, along with the atomic-level definition of its interaction surface, enables structure-guided engineering of optimized Fab or nanobody formats. Ongoing advances in intracellular antibody delivery—including mRNA or lipid nanoparticles (LNPs) formulations70,71,72, cell-penetrating peptides (CPPs)-mediated transport73,74, and viral-vector technologies—are rapidly expanding the feasibility of such strategies75,76,77,78. Our high-resolution structural data of nCoV400 provide a precise framework for engineering affinity-matured Fab or nanobody derivatives optimized for such platforms. Importantly, because the targeted α-helical patch is essential for RNA binding and functionally indispensable, any potential escape mutation would likely impair viral replication fitness, creating a high genetic barrier to resistance.
In sum, nCoV400 combines structural precision with functional potency, targeting a conserved and essential RNA-binding epitope on the N-CTD that underpins multiple stages of the Sarbecovirus life cycle. Its dual utility as both a sensitive diagnostic tool and a structurally guided, variant-resilient antiviral scaffold positions it as a valuable asset in pandemic preparedness and countermeasure development.
Materials and methods
Cloning, expression and purification
The SARS-CoV-2 N-FL (UniProtKB: P0DTC9) plasmid was kindly provided by the Guangdong Medical Laboratory Animal Center. HCoV-OC43-N-FL (UniProtKB: P33469) and Middle East Respiratory Syndrome coronavirus (MERS-CoV)-N-FL (UniProtKB: K9N4V7) plasmids were purchased from RuiBiotech. Based on secondary structure predictions and sequence conservation, we designed a series of SARS-CoV-2 N constructs, including full-length N (residues 1–419), the N-terminal domain (N-NTD, residues 41–174), the C-terminal domain (N-CTD, residues 250–365), a truncation mutant (ΔN-CTD, residues 264–364), and a point mutant N-CTD (K257E). Homologous N-CTD constructs from HCoV-OC43 and MERS-CoV were also cloned for expression. Gene fragments were amplified by polymerase chain reaction (PCR) and subsequently inserted into the pRSF-Duet-1 vector with an N-terminal 6xHis-SUMO tag using BamHI and XhoI restriction sites. DNA primers used in this study are listed in Supplementary Table S4. Protein expression was induced in E. coli Rosetta (DE3) cells grown in terrific broth (TB) at OD600 = 0.8–1.0 using 0.1 mM isopropyl-β-D-1-thiogalactopyranoside (IPTG), followed by overnight incubation at 16 °C.
Following nickel affinity chromatography, the fusion tag was removed via Ulp1 protease digestion. The N-CTD and N-NTD proteins were further purified via size-exclusion chromatography (SEC) (Superdex® 75 Increase 16/600, GE Healthcare) in buffer containing 20 mM Tris-HCl (pH 8.0), 150 mM sodium chloride, 1 mM dithiothreitol, and concentrated using a 3 kDa MWCO Amicon Ultra 15 mL centrifugation filter (Milipore) to a final concentration of 36 mg/ mL. The N-FL protein was purified in the form of inclusion bodies. The inclusion bodies were solubilized in 6 M Urea, 50 mM HEPES (pH 8.0), and 150 mM sodium chloride, followed by nickel column chromatography and ion exchange column chromatography (Q and SP-Sepharose, Cytiva). After refolding, SUMO tags were cleaved by Ulp1, and proteins were further purified with a Superdex® 200 Increase 16/600 column (GE Healthcare) with a buffer consisting of 20 mM HEPES (pH 8.0), 150 mM sodium chloride, then concentrated through a 10 kDa Amicon Ultra 15 mL centrifugation filter (Milipore). Purification data are shown in Supplementary Figs. S15–18.
Expression and purification of nCoV400Fab
The variable regions of the nCoV400 heavy and light chains were cloned into the pCDNA3.1+ (Invitrogen) mammalian expression vector for Fab-format expression. The heavy chain construct comprised the VH and CH1 domains, while the light chain included the full-length human lambda constant region. Expression plasmids were co-transfected into HEK293F cells cultured in serum-free medium using polyethylenimine (PEI). After 7–8 days of culture, supernatants were collected and the Fab fragments were purified by affinity chromatography using Lambda FabSelect resin (GE Healthcare), according to the manufacturer’s instructions.
Crystallization and data collection
Prior to crystallization, the SARS-CoV-2 N-CTD sample and nCoV400Fab were incubated at a 1.5:1 molar ratio for approximately half an hour and then further purified via SEC (Superdex® 200 Increase 10/300 column, GE Healthcare) (Supplementary Fig. S15b). Crystals were grown by the sitting drop method using a mosquito crystallization robot with 0.3 μL of protein (8 mg/mL) mixed with an equal volume of well solution at 16 °C. After 3 days of initial crystallization, optimized crystals were obtained in 0.2 M sodium formate, 16% PEG3350 conditions. Crystals were frozen in liquid nitrogen in a reservoir solution supplemented with 25% glycerol as a cryoprotectant. X-ray diffraction data were collected at Shanghai Synchrotron Radiation Facility BL10U2. The complex structure of N-CTD with the nCoV400Fab was determined by Phenix-1.20.1-4487 molecular replacement using the SARS-CoV-2 N-CTD structure (PDB ID: 7DE1) and the monoclonal antibody omalizumab Fab (PDB ID: 6TCN) as the search models. Structural figures were generated by ChimeraX-1.8. The X-ray diffraction and structure refinement statistics are summarized in Supplementary Table S2. The final Ramachandran statistics are 97.87% favored, 2.13% allowed, and 0% outliers.
RNA synthesis and purification
The 157-nt viral RNA (vRNA157) was transcribed in vitro using a PCR-amplified DNA template derived from the SARS-CoV-2 genomic cDNA. The RNA product was resolved by denaturing PAGE (8 M urea and 10% acrylamide), and the target band was excised and eluted using the Elutrap electroelution system overnight at 4 °C in 0.5× TBE buffer, followed by ethanol precipitation. The 55-nt and 60-nt vRNA fragments were chemically synthesized and HPLC-purified by GENEWIZ (Suzhou, China). Sequences of all DNA primers and RNA products used in this study are listed in Supplementary Table S4.
Affinity and kinetic measurements by BLI
The biolayer interferometry (BLI) assay was performed using an eight-channel OctetRED biolayer interferometry system (FortéBio) at room temperature (25 °C). SARS-CoV-2 N-CTD, N-NTD and N-FL proteins were biotinylated using the Biotinylation Kit (Thermo Scientific™) for 60 min at 4 °C. To characterize nCoV400Fab binding kinetics, biotinylated SARS-CoV-2 N-FL, N-NTD, and N-CTD (5 μg/mL) were loaded onto the Streptavidin-coated (SA) biosensor (Sartorius) tips pre-equilibrated in the kinetics buffer containing PBS, 0.1% BSA, and 0.02% Tween-20 for 300 s. The kinetic buffer without the loading sample was set to correct the non-specific signals. Following 60 s of baseline in the kinetics buffer, the loaded biosensors were dipped into serially diluted nCoV400Fab protein for 180 s for association. The sensors were then dipped into a kinetic buffer for 180 s to record dissociation. The kinetic buffer without analytes was set to correct the background. This configuration was also used for comparative analysis of RM3165, a commercially available diagnostic antibody, with binding to biotin-N-FL assessed in parallel under identical conditions79. To assess epitope specificity and cross-reactivity, full-length nCoV400 antibody (10 μg/mL) was immobilized on anti-Human IgG Fc Capture (AHC2) biosensors (Sartorius). Analytes included N-CTD (residues 250–365), a truncated variant ΔN-CTD (residues 264–364), a point mutant N-CTD (K257E), and homologs from MERS-CoV and HCoV-OC43. ForteBio’s data analysis software was used to fit the dissociation constant (KD) data using the global fitting method, and the binding profile was processed by GraphPad Prism 8 Software.
An in-tandem BLI-based binding assay was performed on the OctetRED biolayer interferometry system (FortéBio) at room temperature (25 °C). The biotin-N-CTD (5 μg/mL) was loaded onto the SA biosensor tips for 300 s. The loaded sensors were dipped into the first analyte (2 μM 157-nt-viral RNA (vRNA157) or 10 nM nCoV400Fab) for 600 s. The sensors were then dipped into the second analyte (10 nM nCoV400Fab, 2 μM vRNA157 or a mixture) for 300 s for competitive binding, followed by a 300 s dissociation phase with kinetics buffer. ForteBio’s data analysis software was used to export data, and the binding profile was processed by GraphPad Prism 8 Software.
Enzyme-linked immunosorbent assay (ELISA)
To evaluate the binding affinity of nCoV400 relative to the diagnostic monoclonal antibody RM3165, ELISA assays were performed using recombinant SARS-CoV-2 N-FL protein. High-binding 96-well ELISA plates (Corning, USA) were coated with 100 μL per well of 5 μg/mL N-FL protein diluted in PBS and incubated overnight at 4 °C. The plates were blocked with 4% BSA in 0.5% Tween-20 PBS (PBST) for 1 h at 37 °C. Serial dilutions of nCoV400 or RM3165 (ranging from 0.064 to 5000 ng/mL) were then added and incubated for 1 h at 37 °C. After three washes with PBST, wells were incubated with HRP-conjugated goat anti-human IgG secondary antibody (1:5000, EarthOx) for 1 h at 37 °C. Following the additional three washes, 3,3′,5,5′-tetramethylbenzidine (TMB) substrate solution (JinKangLong, China) was added, and the colorimetric reaction was stopped with 2 M sulfuric acid. Absorbance at 450 nm was measured using an EnVision multimode plate reader (PerkinElmer). All measurements were performed in six independent replicates. Binding curves were fitted using a four-parameter logistic (4PL) regression model in GraphPad Prism 8 Software, and EC50 values were calculated accordingly.
Native PAGE assays
To investigate the effect of nCoV400Fab on the formation of RNP complexes involving the N protein and viral RNA, native polyacrylamide gel electrophoresis (native PAGE) was performed in 8% separating gel (pH 8.8). The purified proteins without nucleic acids (estimated by OD260/OD280) were prepared in protein buffer (20 mM HEPES (pH 8.0), 150 mM sodium chloride). Viral RNA substrates included vRNA157, as well as shorter 55-nt (5′-UTR-derived) and 60-nt (Nsp1-derived) segments. In each reaction, 2 μg RNA (defined as 1×) was mixed with increasing molar ratios of N protein, including wild-type N-CTD, truncation mutant ΔN-CTD (264–364), and point mutant N-CTD (K257E). Where indicated, nCoV400Fab was added at an equimolar concentration to the N-CTD protein. These mixtures were incubated at 4 °C for 30 min before analysis by native PAGE. The samples were electrophoresed at 80 V for 3 h at 4 °C. After electrophoresis, the gel was stained with Ethidium Bromide and used a short-wavelength UV transilluminator for nucleic acid detection. Then the same gel was stained with Coomassie Blue R-250 for protein visualization.
Condensate formation assays
In vitro condensate formation assays were performed at room temperature to evaluate the condensate-forming ability of wild-type and truncated N-CTD proteins in the presence of viral RNA. Purified N-CTD protein and its truncated variant (residues 264–364) (in 20 mM HEPES (pH 7.5), 75 mM Potassium chloride) were labeled by incubation with a 10:1 ratio of fluorescent dye Alexa Fluor® 488 succinimidyl ester (NHS ester, Thermo Fisher) (termed AF488 in this study) at 4 °C for 1 h. Unreacted dye was removed using a Hitrap Desalting column (5 mL, Cytiva). Condensate formation was induced by mixing 20 μM N-CTD (wild-type or Δ264–364) with 1 μM viral RNA (vRNA157 or Cy5-labeled 55-nt vRNA) in 5 mM HEPES (pH 7.5), 150 mM potassium chloride. Samples were mixed immediately and then added to individual wells in the pretreated 96-well plate. All reactions at room temperature, unless otherwise indicated, before being imaged on an Olympus IX73 inverted microscope with a 40× objective. For quantification, condensates were identified using particle analysis in ImageJ analysis software, and then the mean gray values of fluorescence inside condensates and the total count of condensates were calculated.
Cell culture and transfection
HEK293T cells were obtained from the ATCC (CRL-3216) and maintained in DMEM (Gibco) supplemented with 10% fetal bovine serum (FBS, Gibco) and 100 U/mL penicillin-streptomycin at 37 °C with 5% CO2. All cell lines were routinely tested and confirmed to be mycoplasma-free.
To visualize expression and intracellular localization, we constructed expression plasmids encoding SARS-CoV-2 N-FL fused to C-terminal mCherry, and full-length nCoV400 antibody comprising heavy and light chain expression vectors. The heavy chain vector included a CMV promoter, a Kozak sequence (GCCACCATGG), and a fusion GFP tag. The light chain gene was cloned into a separate CMV-driven vector. Poly(I:C) (tlrl-pic) was obtained from InvivoGen. Plasmid transfection was performed using Lipofectamine 3000 (Thermo Fisher Scientific) according to the manufacturer’s protocol. For nCoV400 expression, equimolar amounts of paired heavy and light chain plasmids were co-transfected. Poly(I:C) transfection was used to simulate intracellular viral dsRNA signaling.
Confocal microscopy
HEK293T cells were seeded into glass-bottom dishes (NEST) and co-transfected with plasmids encoding N-mCherry and nCoV400-GFP for 6 h. At 24 h post-transfection, cells were further stimulated with poly(I:C). Live-cell imaging was performed 24–72 h after transfection on a Zeiss LSM 880 confocal microscope using a 63× oil immersion objective. Images were acquired using Zen software.
Dynamic light scattering (DLS)
DLS measurements were performed using a Zetasizer Nano ZS instrument (Malvern Instruments) at 25 °C. For each condition, 5 μg of synthetic vRNA (either 55-nt or 60-nt) was mixed with a fourfold molar excess of purified SARS-CoV-2 N-CTD, in the presence or absence of a fivefold molar excess of nCoV400Fab. All samples were prepared in PBS buffer with a final volume of 1 mL and incubated at room temperature for 30 min before measurement. The hydrodynamic diameter corresponding to the predominant peak was used for comparative evaluation. Each condition was independently measured in triplicate, and average values were plotted with standard deviation.
Negative-staining transmission electron microscopy
Samples were collected from SEC fractions and diluted to an appropriate concentration for visualization. For each grid, 3 μL of sample was applied to glow-discharged carbon-coated copper grids (Zhongjingkeyi) and incubated for 30 s at room temperature. Excess liquid was removed by blotting with filter paper. Negative staining was performed by sequential application of 20 μL 0.75% uranyl acetate three times: 10 s, 10 s, and 1 min, respectively, with blotting after each step. Grids were air-dried and imaged on a Tundra cryo-transmission electron microscope (Thermo Fisher Scientific) operated at 100 kV. Images were acquired using EPU software (Thermo Fisher) at a nominal magnification of 87,000×.
Statistics and reproducibility
For comparisons between two groups, the parametric Student’s t-test was used. For multi-group comparisons, one-way ANOVA was applied. The statistical analyses were performed using GraphPad Prism v8.0.2. Data from at least three independent biological replicates were included in the figures. Differences were considered statistically significant when *p < 0.05, **p < 0.01, and ***p < 0.001.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
References
Harvey, W. T. et al. SARS-CoV-2 variants, spike mutations and immune escape. Nat. Rev. Microbiol. 19, 409–424 (2021).
Singh, D. D., Sharma, A., Lee, H. J. & Yadav, D. K. SARS-CoV-2: recent variants and clinical efficacy of antibody-based therapy. Front. Cell Infect. Microbiol. 12, 839170 (2022).
Ye, Q., West, A. M. V., Silletti, S. & Corbett, K. D. Architecture and self-assembly of the SARS-CoV-2 nucleocapsid protein. Protein Sci. 29, 1890–1901 (2020).
Royster, A. et al. SARS-CoV-2 nucleocapsid protein is a potential therapeutic target for anticoronavirus drug discovery. Microbiol. Spectr. 11, e0118623 (2023).
Chang, C. K., Hou, M. H., Chang, C. F., Hsiao, C. D. & Huang, T. H. The SARS coronavirus nucleocapsid protein-forms and functions. Antivir. Res. 103, 39–50 (2014).
Kang, S. et al. Crystal structure of SARS-CoV-2 nucleocapsid protein RNA binding domain reveals potential unique drug targeting sites. Acta Pharm. Sin. B 10, 1228–1238 (2020).
Peng, Y. et al. Structures of the SARS-CoV-2 nucleocapsid and their perspectives for drug design. EMBO J.39, e105938 (2020).
Zhao, D. et al. Understanding the phase separation characteristics of nucleocapsid protein provides a new therapeutic opportunity against SARS-CoV-2. Protein Cell 12, 734–740 (2021).
Cong, Y. et al. Nucleocapsid protein recruitment to replication-transcription complexes plays a crucial role in coronaviral life cycle. J. Virol. https://doi.org/10.1128/jvi.01925-19 (2020).
Lu, X., Pan, J., Tao, J. & Guo, D. SARS-CoV nucleocapsid protein antagonizes IFN-β response by targeting initial step of IFN-β induction pathway, and its C-terminal region is critical for the antagonism. Virus Genes 42, 37–45 (2011).
Surjit, M., Liu, B., Chow, V. T. & Lal, S. K. The nucleocapsid protein of severe acute respiratory syndrome-coronavirus inhibits the activity of cyclin-cyclin-dependent kinase complex and blocks S phase progression in mammalian cells. J. Biol. Chem. 281, 10669–10681 (2006).
Mu, J. et al. SARS-CoV-2-encoded nucleocapsid protein acts as a viral suppressor of RNA interference in cells. Sci. China Life Sci. 63, 1413–1416 (2020).
Gao, W. et al. Effects of a SARS-associated coronavirus vaccine in monkeys. Lancet 362, 1895–1896 (2003).
Dangi, T., Class, J., Palacio, N., Richner, J. M. & Penaloza MacMaster, P. Combining spike- and nucleocapsid-based vaccines improves distal control of SARS-CoV-2. Cell Rep. 36, 109664 (2021).
Hajnik, R. L. et al. Dual spike and nucleocapsid mRNA vaccination confer protection against SARS-CoV-2 Omicron and Delta variants in preclinical models. Sci. Transl. Med. 14, eabq1945 (2022).
Arieta, C. M. et al. The T-cell-directed vaccine BNT162b4 encoding conserved non-spike antigens protects animals from severe SARS-CoV-2 infection. Cell 186, 2392–2409.e2321 (2023).
Nesamari, R. et al. Post-pandemic memory T cell response to SARS-CoV-2 is durable, broadly targeted, and cross-reactive to the hypermutated BA.2.86 variant. Cell Host Microbe 32, 162–169.e163 (2024).
Kang, S. et al. A SARS-CoV-2 antibody curbs viral nucleocapsid protein-induced complement hyperactivation. Nat. Commun. 12, 2697 (2021).
Dangi, T. et al. Improved control of SARS-CoV-2 by treatment with a nucleocapsid-specific monoclonal antibody. J. Clin. Invest. https://doi.org/10.1172/jci162282 (2022).
Braun, A. et al. Mapping the immunopeptidome of seven SARS-CoV-2 antigens across common HLA haplotypes. Nat. Commun. 15, 7547 (2024).
Appelberg, S. et al. A universal SARS-CoV DNA vaccine inducing highly cross-reactive neutralizing antibodies and T cells. EMBO Mol. Med. 14, e15821 (2022).
Low, J. S. et al. Clonal analysis of immunodominance and cross-reactivity of the CD4 T cell response to SARS-CoV-2. Science 372, 1336–1341 (2021).
Mallajosyula, V. et al. CD8(+) T cells specific for conserved coronavirus epitopes correlate with milder disease in COVID-19 patients. Sci. Immunol. https://doi.org/10.1126/sciimmunol.abg5669 (2021).
Augusto, D. G. et al. A common allele of HLA is associated with asymptomatic SARS-CoV-2 infection. Nature 620, 128–136 (2023).
Yokoyama, R. et al. Association of the serum levels of the nucleocapsid antigen of SARS-CoV-2 with the diagnosis, disease severity, and antibody titers in patients with COVID-19: a retrospective cross-sectional study. Front. Microbiol. 12, 791489 (2021).
Burbelo, P. D. et al. Sensitivity in detection of antibodies to nucleocapsid and spike proteins of severe acute respiratory syndrome coronavirus 2 in patients with coronavirus disease 2019. J. Infect. Dis. 222, 206–213 (2020).
Thudium, R. F. et al. Early laboratory diagnosis of COVID-19 by antigen detection in blood samples of the SARS-CoV-2 nucleocapsid protein. J. Clin. Microbiol. 59, e0100121 (2021).
Zhang, Y. et al. Diagnostic value of nucleocapsid protein in blood for SARS-CoV-2 infection. Clin. Chem. 68, 240–248 (2021).
Xia, J. et al. SARS-CoV-2 N protein induces acute lung injury in mice via NF-ĸB activation. Front. Immunol. 12, 791753 (2021).
Gao, T. et al. Highly pathogenic coronavirus N protein aggravates inflammation by MASP-2-mediated lectin complement pathway overactivation. Signal Transduct. Target Ther. 7, 318 (2022).
Yuan, M. & Wilson, I. A. Structural immunology of SARS-CoV-2. Immunol. Rev. 329, e13431 (2025).
Pontoriero, L. et al. NMR reveals specific tracts within the intrinsically disordered regions of the SARS-CoV-2 nucleocapsid protein involved in RNA encountering. Biomolecules https://doi.org/10.3390/biom12070929 (2022).
Zhao, H. et al. Assembly of SARS-CoV-2 nucleocapsid protein with nucleic acid. Nucleic Acids Res. 52, 6647–6661 (2024).
Zhao, H. et al. Plasticity in structure and assembly of SARS-CoV-2 nucleocapsid protein. PNAS Nexus 1, pgac049 (2022).
Yang, M. et al. Structural insight into the SARS-CoV-2 nucleocapsid protein C-terminal domain reveals a novel recognition mechanism for viral transcriptional regulatory sequences. Front. Chem. 8, 624765 (2020).
He, R. et al. Characterization of protein-protein interactions between the nucleocapsid protein and membrane protein of the SARS coronavirus. Virus Res. 105, 121–125 (2004).
Yu, I. M., Oldham, M. L., Zhang, J. & Chen, J. Crystal structure of the severe acute respiratory syndrome (SARS) coronavirus nucleocapsid protein dimerization domain reveals evolutionary linkage between corona- and arteriviridae. J. Biol. Chem. 281, 17134–17139 (2006).
Lu, S. et al. The SARS-CoV-2 nucleocapsid phosphoprotein forms mutually exclusive condensates with RNA and the membrane-associated M protein. Nat. Commun. 12, 502 (2021).
Savastano, A., Ibáñez de Opakua, A., Rankovic, M. & Zweckstetter, M. Nucleocapsid protein of SARS-CoV-2 phase separates into RNA-rich polymerase-containing condensates. Nat. Commun. 11, 6041 (2020).
Chen, H. et al. Liquid-liquid phase separation by SARS-CoV-2 nucleocapsid protein and RNA. Cell Res. 30, 1143–1145 (2020).
Perdikari, T. M. et al. SARS-CoV-2 nucleocapsid protein phase-separates with RNA and with human hnRNPs. EMBO J.39, e106478 (2020).
Masters, P. S. Coronavirus genomic RNA packaging. Virology 537, 198–207 (2019).
Cascarina, S. M. & Ross, E. D. Phase separation by the SARS-CoV-2 nucleocapsid protein: consensus and open questions. J. Biol. Chem. 298, 101677 (2022).
Wu, Y. et al. RNA-induced liquid phase separation of SARS-CoV-2 nucleocapsid protein facilitates NF-κB hyper-activation and inflammation. Signal Transduct. Target Ther. 6, 167 (2021).
Wang, S. et al. Targeting liquid-liquid phase separation of SARS-CoV-2 nucleocapsid protein promotes innate antiviral immunity by elevating MAVS activity. Nat. Cell Biol. 23, 718–732 (2021).
Zhou, B. et al. The nucleocapsid protein of severe acute respiratory syndrome coronavirus inhibits cell cytokinesis and proliferation by interacting with translation elongation factor 1alpha. J. Virol. 82, 6962–6971 (2008).
Shang, B. et al. Characterization and application of monoclonal antibodies against N protein of SARS-coronavirus. Biochem. Biophys. Res. Commun. 336, 110–117 (2005).
Lutomski, C. A., El-Baba, T. J., Bolla, J. R. & Robinson, C. V. Multiple roles of SARS-CoV-2 N protein facilitated by proteoform-specific interactions with RNA, host proteins, and convalescent antibodies. JACS Au 1, 1147–1157 (2021).
Wu, C. et al. Characterization of SARS-CoV-2 nucleocapsid protein reveals multiple functional consequences of the C-terminal domain. iScience 24, 102681 (2021).
Nguyen, A. et al. Modulation of biophysical properties of nucleocapsid protein in the mutant spectrum of SARS-CoV-2. Elife https://doi.org/10.7554/eLife.94836 (2024).
Gupta, R. et al. SARS-CoV-2 (COVID-19) structural and evolutionary dynamicome: insights into functional evolution and human genomics. J. Biol. Chem. 295, 11742–11753 (2020).
Monod, A. et al. Learning from structure-based drug design and new antivirals targeting the ribonucleoprotein complex for the treatment of influenza. Expert Opin. Drug Discov. 10, 345–371 (2015).
Ahamad, S., Gupta, D. & Kumar, V. Targeting SARS-CoV-2 nucleocapsid oligomerization: insights from molecular docking and molecular dynamics simulations. J. Biomol. Struct. Dyn. 40, 2430–2443 (2022).
Mercaldi, G. F. et al. Discovery and structural characterization of chicoric acid as a SARS-CoV-2 nucleocapsid protein ligand and RNA binding disruptor. Sci. Rep. 12, 18500 (2022).
Dhaka, P., Mahto, J. K., Singh, A., Kumar, P. & Tomar, S. Structural insights into the RNA binding inhibitors of the C-terminal domain of the SARS-CoV-2 nucleocapsid. J. Struct. Biol. 217, 108197 (2025).
Gangavarapu, K. et al. Outbreak.info genomic reports: scalable and dynamic surveillance of SARS-CoV-2 variants and mutations. Nat. Methods 20, 512–522 (2023).
Tsueng, G. et al. Outbreak.info Research Library: a standardized, searchable platform to discover and explore COVID-19 resources. Nat. Methods 20, 536–540 (2023).
Chauhan, A. et al. Structural and conformational analysis of SARS CoV 2 N-CTD revealing monomeric and dimeric active sites during the RNA-binding and stabilization: insights towards potential inhibitors for N-CTD. Comput. Biol. Med. 134, 104495 (2021).
Hu, X. et al. The study of antiviral drugs targeting SARS-CoV-2 nucleocapsid and spike proteins through large-scale compound repurposing. Heliyon 7, e06387 (2021).
Chauhan, A. et al. An insight into the simulation directed understanding of the mechanism in SARS CoV-2 N-CTD, dimer integrity, and RNA-binding: Identifying potential antiviral inhibitors. J. Biomol. Struct. Dyn. 40, 13912–13924 (2022).
Márquez-Moñino, M. et al. The ALS drug riluzole binds to the C-terminal domain of SARS-CoV-2 nucleocapsid protein and has antiviral activity. Structure https://doi.org/10.1016/j.str.2024.10.025 (2024).
Dang, M. & Song, J. Structural basis of anti-SARS-CoV-2 activity of HCQ: specific binding to N protein to disrupt its interaction with nucleic acids and LLPS. QRB Discov. 2, e13 (2021).
Ye, Q., Lu, S. & Corbett, K. D. Structural basis for SARS-CoV-2 nucleocapsid protein recognition by single-domain antibodies. Front. Immunol. 12, 719037 (2021).
Narayanan, K. & Makino, S. Cooperation of an RNA packaging signal and a viral envelope protein in coronavirus RNA packaging. J. Virol. 75, 9059–9067 (2001).
Hsieh, P. K. et al. Assembly of severe acute respiratory syndrome coronavirus RNA packaging signal into virus-like particles is nucleocapsid dependent. J. Virol. 79, 13848–13855 (2005).
Hsin, W. C. et al. Nucleocapsid protein-dependent assembly of the RNA packaging signal of Middle East respiratory syndrome coronavirus. J. Biomed. Sci. 25, 47 (2018).
Skittrall, J. P., Irigoyen, N., Brierley, I. & Gog, J. R. A novel approach to finding conserved features in low-variability gene alignments characterises RNA motifs in SARS-CoV and SARS-CoV-2. Sci. Rep. 13, 12079 (2023).
Yadav, A. J., Kumar, S., Maurya, S., Bhagat, K. & Padhi, A. K. Interface design of SARS-CoV-2 symmetrical nsp7 dimer and machine learning-guided nsp7 sequence prediction reveals physicochemical properties and hotspots for nsp7 stability, adaptation, and therapeutic design. Phys. Chem. Chem. Phys. 26, 14046–14061 (2024).
Sharma, A. et al. An integrated multiscale computational framework deciphers SARS-CoV-2 resistance to sotrovimab. Biophys. J. https://doi.org/10.1016/j.bpj.2025.05.015 (2025).
Pardi, N. et al. Nucleoside-modified mRNA immunization elicits influenza virus hemagglutinin stalk-specific antibodies. Nat. Commun. 9, 3361 (2018).
Jackson, L. A. et al. An mRNA vaccine against SARS-CoV-2 - preliminary report. N. Engl. J. Med. 383, 1920–1931 (2020).
Polack, F. P. et al. Safety and efficacy of the BNT162b2 mRNA Covid-19 vaccine. N. Engl. J. Med. 383, 2603–2615 (2020).
Yang, J., Luo, Y., Shibu, M. A., Toth, I. & Skwarczynskia, M. Cell-penetrating peptides: efficient vectors for vaccine delivery. Curr. Drug Deliv. 16, 430–443 (2019).
Xie, C. et al. A cell-penetrating bispecific antibody suppresses hepatitis B virus replication and secretion. Virus Res. 353, 199531 (2025).
Khanefard, N. et al. Influenza neuraminidase virus-like particle-based nanocarriers as a new platform for the delivery of small-peptide antigens. Mol. Biotechnol. https://doi.org/10.1007/s12033-025-01403-x (2025).
Böldicke, T. Therapeutic potential of intrabodies for cancer immunotherapy: current dtatus and future directions. Antibodies https://doi.org/10.3390/antib11030049 (2022).
Hanke, L. et al. Vesicular stomatitis virus N protein-specific single-domain antibody fragments inhibit replication. EMBO Rep. 18, 1027–1037 (2017).
Wongsodirdjo, P. et al. Messenger RNA-encoded antibody approach for targeting extracellular and intracellular tau. Brain Commun. 6, fcae100 (2024).
Ding, H. et al. A semi-quantitative upconversion nanoparticle-based immunochromatographic assay for SARS-CoV-2 antigen detection. Front. Microbiol. 14, 1289682 (2023).
Acknowledgements
This work is supported by the National Key R&D Program of China (2022YFC2304200), National Natural Science Foundation of China (92269106 and 32171192), Sun Yat-sen University supporting grant (2024_89000_B25886). We thank Guangdong Medical Laboratory Animal Center for providing the N-protein encoding gene plasmids. We thank the staff members of BL10U2/BL17B1/BL18U1/BL19U1 beamlines at the National Facility for Protein Science in Shanghai, for technical support in X-ray diffraction data collection and analysis.
Author information
Authors and Affiliations
Contributions
S.C. contributed to the conception of the study, established the construction of the article, designed the experiments, and wrote the manuscript. S.H., Z.H., G.H., and M.Y. contributed to protein purification and crystallization. S.X., S.H., Z.H., and M.Y. performed structural determination and validation. S.X., S.H., X.C., and G.H. contributed to in vitro protein–protein interaction analysis. S.X., G.H., and Q.C. contributed to in vitro condensate formation analysis. S.X. and S.H. drew figures. W.Z. and S.L. contributed to the interpretation of data. S.X. and S.H. contributed equally to this work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Biology thanks the anonymous reviewers for their contribution to the peer review of this work. Primary Handling Editors: Janesh Kumar and Mengtan Xing. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xue, S., He, S., Huang, Z. et al. Structural basis of a human antibody targeting SARS-CoV-2 nucleocapsid protein dimerization domain and interfering with RNA-binding. Commun Biol 8, 1248 (2025). https://doi.org/10.1038/s42003-025-08648-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42003-025-08648-x
