
Abstract
It is well-understood that the network structure of complex systems affects their robustness; the role played by the shape of spatially embedded networks, however, is less explored. Here, we study the robustness of networks where links are physical objects or physically transfer some quantity, hence the links can be disrupted at any point along their trajectory. To model physical damage, we tile each network with boxes and we sequentially damage these boxes, removing any link from the network that intersects a damaged tile. Using model and empirical networks, we systematically explore how the layout and the structure of networks jointly affect the resulting percolation transition. For example, we analytically and numerically show that randomly damaging a vanishing fraction of tiles is enough to destroy large-scale connectivity in randomly embedded networks. This demonstrates that the presence of long-range links makes networks extremely vulnerable to physical damage. Our work contributes to the emergent theory of physical networks.
Similar content being viewed by others


Introduction
From the earliest days of complex network research, percolation processes were used to study the robustness of networks against external perturbations1,2,3. Since then, various strategies of damages were introduced, including percolation on spatially embedded networks4,5,6,7, interdependent8,9,10,11,12 and triadic percolation13,14, explosive percolation15,16, and many others17,18,19,20,21,22. Here, we explore the robustness of spatial networks against physical damage. By physical damage, we mean the random or targeted removal of entire regions of the space, such that all nodes inside and links passing through are disrupted. Hence, we focus on spatial networks where the links represent physical objects or the physical transfer of some quantity, such that the link can be disrupted at any point along its trajectory. Note that recent literature defined physical networks as networks built from physical objects where volume exclusion plays an important role, i.e., the network is composed of tightly packed nodes and links23,24,25. Here, we model a broader class of systems that include networks such as the air traffic network, where volume exclusion may not be a significant factor, yet links can be disrupted along their path by physical perturbations such as storms, volcanic eruptions, or military conflicts.
Physically embedded systems are vulnerable to spatially correlated disruption, where damage does not happen to single elements of the network, but to entire regions of the embedding space. Examples include permanent damage of the brain or other biological tissues due to injury or diseases26,27, or natural disasters like floods, earthquakes, storms and other localized attacks that disrupt entire regions of socio-technological infrastructure28,29,30,31, or even the effect of targeted cyberattacks and military strikes that may render entire areas of a communication network inoperable. When disruption happens to entire regions, any link that passes through the region is removed. As a result, links that are distant in the network but adjacent in the embedding space may be removed together, introducing non-trivial correlations to the loss of network connectivity. Hence, to understand the robustness of physically embedded networks, we must take into account the detailed trajectory and shape of the links connecting the elements of the system.
To formally set up the problem, we represent a physically embedded network by a combinatorial network, \({{{\mathcal{G}}}}\), and a physical layout, \({{{\mathcal{P}}}}\), which provides the location and shape of the nodes and links. We focus on physical nodes represented by a point in space connected by straight or curved lines; however, our framework easily extends to alternative physical network representations, including nodes and links that occupy volume23,24 or network-of-networks representations25,32,33. To capture the effects of physical damage, we first tile the D-dimensional space occupied by a physical network \({{{\mathcal{P}}}}\) with D-dimensional cubes of side length b (Fig. 1a). We then damage tiles sequentially and, when a tile t is damaged, we remove from \({{{\mathcal{G}}}}\) each link e intersected by t. As tiles are removed, the combinatorial network \({{{\mathcal{G}}}}\) undergoes a continuous percolation transition that is a mixture of site and bond percolation: if a node is inside a damaged tile, then its links are removed simultaneously, in effect removing the node. On the other hand, if a link is traversing a damaged tile, then the link is removed but the nodes at its endpoints are not. Our overarching goal is to understand how the physical layout \({{{\mathcal{P}}}}\) and the structure of the combinatorial network, \({{{\mathcal{G}}}}\), jointly affect this critical transition. In the following, we introduce a set of mathematical tools for this and apply them to model networks and empirical data sets.

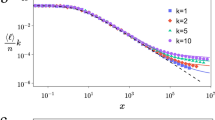
a We tile a physical network with D-dimensional square tiles. Damaging a tile t removes all links e intersecting t, for example, damaging tile (3, 3) (light blue) removes all links from \({{{\mathcal{G}}}}\). b The bipartite intersection graph, \({{{\mathcal{I}}}}\), captures how tile damage of \({{{\mathcal{P}}}}\) translates to link removal in \({{{\mathcal{G}}}}\). Vertices on the left represent tiles and vertices on the right represent links; a tile and a link are connected if they intersect in the layout. c The tile-side and link-side degree distribution of \({{{\mathcal{I}}}}\) for a single randomly embedded Erdős-Rényi (ER) network (N = 105, c = 4, ρ = 4). In random embeddings, links typically span the entire system, hence \({{{\mathcal{I}}}}\) becomes dense. d We increase the network size N while keeping constant the expected number of nodes per tile, ρ. Both the tile-side average degree ct and link-side average degree cl scale as ~ N−1/D. Networks are generated using parameters c = 4 and ρ = 4; each marker represents an average of 20 independent runs and the error bars representing the standard error of the mean are smaller than the marker size.
Methods
Intersection graph
We start by introducing the intersection graph, \({{{\mathcal{I}}}}\), to concisely represent how tile damage translates to link removal. First, we identify which physical link, e, intersects which tile, t, and we summarize these intersections as a bipartite graph, \({{{\mathcal{I}}}}\): on one side of \({{{\mathcal{I}}}}\) each vertex represents a tile t, on the other side each vertex represents a physical link e; a tile t and a link e is connected in \({{{\mathcal{I}}}}\) if they intersect in the physical space (Fig. 1b).
The intersection graph, \({{{\mathcal{I}}}}\), encodes potential sources of heterogeneity and correlations of the physical layout that affect link removal: (i) long links intersect more tiles than short links, captured by the degree distribution Pl(k) of the vertices that represent physical links in \({{{\mathcal{I}}}}\) (Fig. 1c); (ii) in absence of periodic boundary conditions, centrally located tiles are expected to intersect more links than peripheral tiles, captured by the degree distribution Pt(k) of the vertices that represent tiles (Fig. 1c); (iii) the spatial organization of \({{{\mathcal{P}}}}\) is captured by structural correlations of \({{{\mathcal{I}}}}\), for example, two physical links running approximately parallel to each other tend to intersect the same tiles, leading to an abundance of length-4 cycles in \({{{\mathcal{I}}}}\).
Beyond its structure, an additional way \({{{\mathcal{I}}}}\) carries information relevant to the percolation process is through its link-side vertex labels which connect \({{{\mathcal{I}}}}\) and \({{{\mathcal{G}}}}\). For example, links attached to the same node v must all intersect the tile t that contains v; therefore, if t is damaged, all links incident on v are removed together from \({{{\mathcal{G}}}}\). Furthermore, because long links intersect many tiles, they become vulnerable to tile damage, and if such links tend to be important in \({{{\mathcal{G}}}}\), the combinatorial network inherits their vulnerability.
To understand how the above heterogeneities and correlations of \({{{\mathcal{I}}}}\) affect the robustness of physical networks, we introduce a set of randomizations of \({{{\mathcal{I}}}}\) that, similarly to the role played by the configurational model in revealing non-trivial correlations in abstract networks, provide us with benchmarks to highlight properties of the layout which influence physical robustness. In fact, different randomizations of the intersection graph, \({{{{\mathcal{I}}}}}_{{{{\rm{r}}}}}\), allow us to probe the role of different features of the physical embedding. For instance, substituting \({{{\mathcal{I}}}}\) with a bipartite configuration model having the same degree distributions Pl(k) and Pt(k), preserves link and tile heterogeneity but removes any additional structure (e.g., originating from parallel links or links sharing an endpoint) from \({{{\mathcal{I}}}}\). To remove link heterogeneity, we homogenize \({{{\mathcal{I}}}}\) by setting the vertices representing links to have approximately the same degree equal to the average cl. In practice, this means that in the randomized \({{{{\mathcal{I}}}}}_{{{{\rm{r}}}}}\) the link-side vertices are a mixture of vertices with degree ⌈cl⌉ and ⌊cl⌋ in a way that ensures that the overall average degree remains cl. Applying the same degree-homogenization to the tile vertices leads to four possible degree-preserving (DP) or homogenized (H) randomization protocols of \({{{\mathcal{I}}}}\): (i) tile and link degree-preserved (tDP-lDP), (ii) tile degree-preserved and link homogenized (tDP-lH), (iii) tile homogenized and link degree-preserved (tH-lDP), and (iv) tile and link homogenized (tH-lH). We stress that, while the randomized intersection graphs do not necessarily correspond to physically valid layouts —since a link in \({{{{\mathcal{I}}}}}_{{{{\rm{r}}}}}\) would generally intersect non-adjacent tiles— they still carry an intuitive meaning with respect to the physical percolation process. In particular, lDP randomization leaves invariant for each link the removal probability due to a single random tile damage (because this only depends on the length of a link) but ignores that links are not independently removed (as captured by correlations of \({{{\mathcal{I}}}}\)), and tDP randomization for each tile preserves the number of links that are removed together. Furthermore, lH and tH randomizations preserve, respectively, the average probability that a link is removed and the average number of links that are removed together.
The randomizations that preserve link-side degree in \({{{\mathcal{I}}}}\) (tDP-lDP and tH-lDP) do not remove correlations between \({{{\mathcal{G}}}}\) and \({{{\mathcal{I}}}}\): if long links are important in \({{{\mathcal{G}}}}\), then important links in \({{{\mathcal{G}}}}\) tend to have high degree in \({{{\mathcal{I}}}}\). To study the effect of this correlation we introduce an additional randomization procedure called “label shuffle” (LS): we shuffle the vertex labels in \({{{\mathcal{I}}}}\) and create a randomized intersection graph, \({{{{\mathcal{I}}}}}_{{{{\rm{LS}}}}}\), that is uncorrelated with \({{{\mathcal{G}}}}\) but otherwise has the same structure as \({{{\mathcal{I}}}}\). This means that dismantling \({{{\mathcal{G}}}}\) using \({{{{\mathcal{I}}}}}_{{{{\rm{LS}}}}}\) removes, on average, the same number of links as \({{{\mathcal{I}}}}\), but the links are chosen randomly in \({{{\mathcal{G}}}}\) independent of the original layout.
Table 1 summarizes the main features of the randomization protocols introduced above, whose relevance for the characterization of physical percolation under random and targeted damage is demonstrated through the model systems and empirical examples discussed in the following sections.
Link-side degree
The degree k(e) of a link e in the intersection graph \({{{\mathcal{I}}}}\) determines the vulnerability of e to tile damage: the more tiles e intersects, the more likely e is removed. In this section, we describe the relation between the length of e and k(e). We consider a physical network with N nodes and M links embedded in the unit D-dimensional cube such that the links are straight segments. We tile the network with cubes of side length b, hence the intersection graph \({{{\mathcal{I}}}}\) contains nt = b−D vertices representing tiles and nl = M vertices representing links. A link e with endpoints r = (r1, r2, …, rD) and s = (s1, s2, …, sD) following a straight trajectory intersects a sequence of tiles (t1, t2…, tk(e)). Whenever e crosses from a tile ti to the next ti+1, it punctures the shared face of ti and ti+1, the probability of crossing at an edge or a corner is zero. Therefore, link e must cross at least ∣si − ri∣/b tiles along each axis i, hence the approximate number of tiles intersected by e, i.e., its degree in \({{{\mathcal{I}}}}\), is
where the plus one corresponds to the starting tile. Note that it is not the Euclidean but the Manhattan distance of the endpoints of e that determines k(e). For example, in a randomly embedded network, the typical link length ℓ is on the order of the system size, ℓ ~ 1, meaning that a typical link intersects cl ~ Db−1 tiles and a typical tile is intersected by ct ~ MDbD−1 links. Therefore, in the N → ∞ large network limit, if we fix the average degree of \({{{\mathcal{G}}}}\) as 〈d〉 = 2M/N and the tile density as ρ = N/b−D, the intersection graph has diverging average degrees cl ~ N1/D and ct ~ N1/D (Fig. 1d). On the other extreme, if the physical network is lattice-like, i.e., nodes connect to their immediate spatial neighborhood and ℓ ~ b, the average degrees cl and ct remain constant. The diverging average degree ct indicates that randomly embedded networks are more susceptible to physical damage than lattice-like networks. In the following, we systematically investigate the role of physicality in random and targeted damage by relying on \({{{\mathcal{I}}}}\) both numerically and analytically.
Results
Random damage
In this section, we explore the effect of the combinatorial network \({{{\mathcal{G}}}}\) and the layout \({{{\mathcal{P}}}}\) on the physical percolation of randomly embedded networks. Figure 2 shows the relative size S of the largest component during random tile removal for randomly embedded Erdős-Rényi (ER) networks and scale-free (SF) networks generated by the static model34,35. We recall that the static model generates networks by fixing the expected degree of each node and allows controlling both the degree exponent γ and the average degree of the network c. We compare S of the original \({{{\mathcal{I}}}}\) to the five randomized null-models: protocols tDP-lDP, tH-lDP and LS that preserve Pl(k) follow the original percolation transition (S ≈ StDP − lDP = StH − lDP = SLS), while link-homogenized randomizations tDP-lH and tH-lH accelerate the transition, shifting \({f}_{{{{\rm{t}}}}}^{* }\) to the left (StDP − lH = StH − lH < S).

Relative size, S, of the largest connected component as a function of the fraction of tiles removed for randomly embedded a Erdős-Rényi (ER) networks in D = 2, b ER networks in D = 3, c scale-free (SF) networks in D = 2, and (d) SF networks in D = 3 dimensions. The dashed line represents the theoretical prediction obtained by solving Eqs. (6) and (7). Networks were generated with N = 105 nodes and average degree c = 4; for SF networks the degree exponent is γ = 2.5, and the tile density is set to ρ = 4. Each curve is an average of 10 independent realizations.
This means that, when tiles are damaged independently, only the heterogeneity of the link lengths affects robustness, while tile heterogeneity and correlations between adjacent tiles have negligible effects. To explain these observations and to systematically investigate random damage, we first develop an analytical solution for the relative size of the giant component. Then we use this analytical characterization together with the numerical randomizations of the intersection graph to explore the role of the degree distribution in randomly embedded networks.
Analytical characterization
We start by calculating S for the case when \({{{\mathcal{G}}}}\) is generated using the configuration model and tiles are removed in random order. We rely on the standard generating function formalism with the addition that link removal depends on the intersection graph \({{{\mathcal{I}}}}\), leading to an analytical characterization similar to the so-called feature-enriched percolation36. In our solution, we assume no correlations between the removed links, an assumption that is generally valid only for the randomized versions of the intersection graph. We focus on the sparse large network limit N → ∞, where the average degree of the combinatorial network c remains constant, and we also fix the tile density ρ = N/b−D, i.e., the expected number of physical nodes contained in a tile. This means that the total number of tiles scales as
and the size of tiles scales as
Link e is removed if we damage any of its neighbors in \({{{\mathcal{I}}}}\); therefore, the probability that e is removed after independently damaging K random tiles is
where ft = K/nt is the fraction of tiles removed, and the exponential approximation assumes large k(e). For straight links, Eq. (1) connects the degree of links with its length as k(e) = 1 + b−1l, which means that the survival probability of a link drops exponentially with l, making long links extremely vulnerable to random tile damage.
Let s(k) denote the probability that a random link with link-side degree k leads to the giant component in \({{{\mathcal{G}}}}\). Assuming no correlation between the degree of a link in \({{{\mathcal{I}}}}\) and its position in \({{{\mathcal{G}}}}\), we write the self-consistent equation for s(k)
where q(d) = (d + 1)/cp(d + 1) is the excess degree distribution of \({{{\mathcal{G}}}}\). Averaging Eq. (5) over k, we obtain
where H(z) = ∑dq(d)zd is the generating function of q(d), and Gl(z) = ∑kPl(k)zk is the moment generating function of the link-side degree distribution of \({{{\mathcal{I}}}}\). Similarly, we can obtain the relative size of the giant component S as
where G(z) = ∑dp(d)zd is the generating function of the degree distribution p(d) of \({{{\mathcal{G}}}}\).
A crucial quantity in Eq. (6) is \(1-{G}_{l}\left(1-{f}_{{{{\rm{t}}}}}\right)\equiv f\) providing the probability that a random link is removed, which we calculate by averaging Eq. (4) over Pl(k). Equivalently, for straight links, we can leverage Eq. (1) connecting the degree of a link in \({{{\mathcal{I}}}}\) to its length to obtain f by averaging over the link lengths, i.e.,
where l is the link length measured by its Manhattan distance and p(l) is the link length distribution. Equation (8) is valid for the original \({{{\mathcal{I}}}}\) and the randomizations that do not modify the link-side degree (tDP-lDP and tH-lDP). On the other hand, randomizations tDP-lH and tH-lH homogenize the link degree in \({{{\mathcal{I}}}}\), i.e., k = 1 + b−1〈l〉 for all links in \({{{{\mathcal{I}}}}}_{{{{\rm{r}}}}}\), where 〈l〉 is the average Manhattan link length. Therefore, tDP-lH and tH-lH also modify the link removal probability as
Invoking Jensen’s inequality, we find that
for any p(l), meaning that link length heterogeneity always decreases the number of links removed for a given ft (for example, see Fig. 2).
Note that Eqs. (6) and (7) are exactly the equations describing bond percolation in the configuration model with link removal probability \(f=1-{G}_{l}\left(1-{f}_{{{{\rm{t}}}}}\right)\). That is, when Eqs. (6) and (7) hold, the only relevant feature of the layout is the link-side degree distribution Pl(k) of \({{{\mathcal{I}}}}\), which affects the percolation transition only through the number of links removed. The main assumptions we made when deriving these equations is that (i) \({{{\mathcal{G}}}}\) is generated by the configuration model, (ii) the links removed from \({{{\mathcal{G}}}}\) are uncorrelated, and (iii) there are no correlations between a link’s degree in \({{{\mathcal{I}}}}\) and it’s importance in \({{{\mathcal{G}}}}\).
Effect of degree distribution
To investigate the role of the degree distribution of the combinatorial network \({{{\mathcal{G}}}}\), we focus on purely random embeddings. We select the position of physical nodes uniformly at random from the D-dimensional unit cube, \({{{{\mathcal{B}}}}}_{D}={[0,1]}^{\times D}\), and connect pairs of nodes with straight links. The Manhattan length of a link e is l(e) = ∑∣ri − si∣, where \({{{\bf{r}}}}\in {{{{\mathcal{B}}}}}_{D}\) and \({{{\bf{s}}}}\in {{{{\mathcal{B}}}}}_{D}\) are the endpoints of e, since ri and si are chosen uniformly from the unit interval, their difference x = ∣ri − si∣ follows the distribution p(x) = 2(1 − x). Hence, following Eq. (8), we get that the average link removal probability is
which is valid for the original \({{{\mathcal{I}}}}\) and the randomizations that do not modify the link-side degree (tDP-lDP and tH-lDP). For randomizations tDP-lH and tH-lH that homogenize the link degree, the link removal probability is obtained using Eq. (9), providing that
In the N → ∞ large network limit, keeping the tile density ρ = N/b−D constant makes the side length of the tiles to scale as \(b \sim {n}_{{{{\rm{t}}}}}^{-1/D}\to 0\). Hence the majority of links are removed after damaging only a vanishing fraction of the tiles for both the original and the homogenized distributions Pl(k). Notice, in fact, that the second term of both Eqs. (11) and (12) indicate that almost all links are removed on the scale of \({f}_{{{{\rm{t}}}}} \sim {n}_{{{{\rm{t}}}}}^{-1/D}\), while the first term for vanishing ft is \({e}^{-{f}_{{{{\rm{t}}}}}}\approx 1\). This means that the number of tiles to destroy a positive fraction of links in a randomly embedded network scales as \(\sim {n}_{{{{\rm{t}}}}}^{(D-1)/D}\), i.e., it is on the order of the number of tiles needed to be damaged to cut the network into two parts.
Figure 2 compares numerical simulations with the analytical estimate of S obtained by inserting Eqs. (11) and (12) into Eq. (6). We find that the analytical solutions align perfectly with the randomizations and closely follow the simulations using the original \({{{\mathcal{I}}}}\). We observe small deviations between the predicted S and original simulated S, particularly for ER networks in D = 2. To explain this, recall that our calculations assumed that the links are removed from \({{{\mathcal{G}}}}\) in an uncorrelated fashion. This assumption only holds approximately for the original \({{{\mathcal{I}}}}\): links connected to the same node v tend to intersect the same tiles in the vicinity of v, thus having a higher chance of getting removed together. The effect of such correlations depends on the typical link length ℓ and tile size b, if ℓ ≫ b the likelihood of removing a link near its endpoint diminishes. In the limit N → ∞, with fixed tile density ρ, the relevant length scales are ℓ ~ 1 and b ~ N−1/D; therefore we expect that the above analytical solution correctly captures S for large networks.
The location of the critical point where the giant component is destroyed is often used to quantify the robustness of networks. To determine the critical point \({f}_{{{{\rm{t}}}}}^{* }\) in our setup, we insert Eq. (11) into the Molloy-Reed criterion
where the left-hand side only depends on the physical layout, while the right-hand side only depends on the abstract network structure. For combinatorial networks with finite second moment, 〈d2〉, the right-hand side does not depend on N and hence on b, while the left-hand side only depends on b−1ft = Nt1/Dft. Therefore the critical point vanishes as
in the large network limit.
Scale-free combinatorial networks with γ < 3 have diverging second moments; hence, almost all links need to be removed to destroy the giant component in random fashion in the N → ∞ large network limit, i.e., f* ≈ 1. For traditional random percolation, the finite size scaling of the critical point is characterized by the finite-size scaling 1 − f* ~ N−τ, where the exact value of the critical exponent τ depends on the subtleties of how the scale-free networks are generated37,38,39. Inserting the latter into Eq. (13) and keeping only leading terms in b−1ft yields
which, in turn, leads to the finite-size scaling
for 2 < γ < 3. To test the above relation, we first numerically estimate the critical exponent τ by simulating traditional bond percolation on SF combinatorial networks and insert these numerical estimates into Eq. (16). Figure 3 compares the predicted scaling relation to numerical simulations of \({f}_{{{{\rm{t}}}}}^{* }\) for physically embedded SF networks, finding a good agreement for sufficiently large N.

We simulate random tile damage on randomly embedded scale-free (SF) networks with increasing size N and fixed tile density ρ, and we measure the location of the critical point, \({f}_{{{{\rm{t}}}}}^{* }\), by finding the maximum of the second largest component. We show the scaling of \({f}_{{{{\rm{t}}}}}^{* }\) with N for (a) D = 2 and (b) D = 3 dimensions: markers represent numerical simulations, dashed lines represent the scaling ~ N−(τ−1)/D predicted by Eq. (16) for networks with diverging 〈d2〉, and the dotted lines represent the scaling N−1/D predicted for networks with finite 〈d2〉. We generated networks using c = 4 and ρ = 4, the markers represent the average of 50 independent runs, and the error bars represent their standard deviation.
Overall, we demonstrated that randomly removing a vanishingly small fraction of tiles is sufficient to dismantle randomly embedded networks and that higher dimensional embeddings increase their vulnerability. This is because of the presence of links whose length scales with the linear size of the unit cube, i.e. ℓ ~ 1, even in the N → ∞ limit. Therefore, the number of tiles the links intersect diverges as ~ b−1 ~ N1/D, making them extremely vulnerable to physical damage. We also found that the analytical solution, which in general is valid for the randomized versions of the intersection graph, well describes the percolation transition for the original \({{{\mathcal{I}}}}\) in large networks, revealing that random tile damage is equivalent to a random bond percolation, where the number of links we remove is determined by the layout \({{{\mathcal{P}}}}\).
Targeted damage
We now turn our attention to targeted physical attacks, where we iteratively damage a fraction ft of the tiles having the highest degree in \({{{\mathcal{I}}}}\). More formally, given a tiling described by the intersection graph \({{{\mathcal{I}}}}\):
-
1.
we find tile t with the highest degree in \({{{\mathcal{I}}}}\);
-
2.
we remove t from \({{{\mathcal{I}}}}\) together with each of its neighbors, i.e., with each link e that intersects t;
-
3.
we repeat steps 1 and 2 until all links are removed.
As before, we investigate the role of the degree distribution of \({{{\mathcal{G}}}}\) and explore the simpler case of randomly embedded networks. Figure 4a, b show the size of the largest component of a randomly embedded Erdős-Rényi (ER) network in D = 2 and D = 3 dimensions under targeted physical attacks.

We show the relative size S of the largest connected component as a function of the fraction of tiles removed for randomly embedded a Erdős-Rényi (ER) networks in D = 2, b ER networks in D = 3, c scale-free (SF) networks in D = 2, and d SF networks in D = 3 dimensions. Networks were generated with N = 105 and c = 4, for SF networks the degree exponent is γ = 2.5, and the tile density is set to ρ = 4. Each curve is an average of 10 independent realizations.
When analyzing random damage, we found that the only relevant property affecting S during random tile removal is the link-side degree distribution of \({{{\mathcal{I}}}}\). In the case of targeted physical damage, a richer picture emerges. By comparing the original \({{{\mathcal{I}}}}\) with its randomized versions, we find that StDP − lH < StDP − lDP < S ≈ SLS < StH − lH < StH − lDP for the entire range of ft. This means that (i) tile heterogeneity increases the vulnerability of the network, (ii) correlations in \({{{\mathcal{I}}}}\) (such as short loops caused by neighboring links intersecting the same tiles), and link heterogeneity makes the network more robust against targeted attacks. Finally, we find that S for the original \({{{\mathcal{I}}}}\) is identical to the case where we randomly remove the same number of links (LS randomization), meaning that for the ER network, targeted attacks dismantle the network faster than random tile removal, because it damages more links per tile, but not remove links that are important for network cohesion.
Figure 4 c, d show instead the relative size of the giant component, S, for SF networks with degree exponent γ = 2.5, thus having a divergent second moment. The situation, in this case, is analogous to the one observed in ER networks, with one key exception: while initially S ≈ SLS, near the critical point the original network falls apart faster than the LS and even the tDP-lDP version, i.e., \({f}_{{{{\rm{t}}}}}^{* } < {f}_{{{{\rm{t}}}},{{{\rm{tDP}}}}-{{{\rm{lDP}}}}}^{* } < {f}_{{{{\rm{t}}}},{{{\rm{LS}}}}}^{* }\). This means that correlations between \({{{\mathcal{I}}}}\) and \({{{\mathcal{G}}}}\) accelerate the targeted disruption of the network.
To further clarify the role of degree heterogeneity in \({{{\mathcal{G}}}}\), we plot the location of the initial 50 tiles removed for a D = 2 SF network with γ = 5 and with γ = 2.1, for both the original network (Fig. 5a and d) and the tDP-lDP randomization (Fig. 5b and e). For the original homogeneous network (γ = 5), the initial removal of the tiles concentrates in the center of the embedding square, forming a spatial structure that cuts through the network along a straight line (for D = 3 such a structure is less apparent). In contrast, for the heterogeneous network (γ = 2.1), the removed tiles are randomly scattered in space.

a The location of the first 50 tiles removed from a scale-free (SF) network with degree exponent γ = 5. b The tile-degree-preserving and link-degree-preserving (tDP-lDP) randomization of the network removes the overlap between the links intersected by neighboring tiles, therefore, the attack targets the center tiles. c The spatial distribution of the tile-degree shows that the center tiles intersect the most links, and monotonically drops towards the edges of the square. d The first 50 tiles removed from a SF network with degree exponent γ = 2.1 target the hubs in \({{{\mathcal{G}}}}\). e In the case of the tDP-lDP randomization, tile removal targets the tiles surrounding the highest degree nodes. f The spatial distribution of the tile-degree has peaks at tiles that contain hubs of \({{{\mathcal{G}}}}\). The figure shows single networks with N = 5 × 104, c = 4, and ρ = 4, the color of the tiles in (a), (b), (d), and (e) indicates the order at which the files are removed.
To get an intuition about the emergence of this pattern, consider that the spatial distribution of links in homogeneous networks is approximately the same as picking uniformly random segments from the unit square. As a result, we expect tile degree k(t) to be the highest in the center of the embedding square and monotonically decreasing toward the edges (Fig. 5c), explaining why the center tiles are picked initially. However, the highest-degree center tiles are redundant: they are intersected by the same links, i.e., they share many neighbors in the intersection graph \({{{\mathcal{I}}}}\). The one-dimensional structure of the removed tiles emerges as a result of the targeted attack greedily minimizing the redundancy between the removed tiles. Indeed, the tDP-lDP randomization keeps the degree of the tiles but removes correlations between them, hence the initial removed tiles concentrate at the center of the embedding square forming a two-dimensional patch (Fig. 5b). This also means that the total number of links removed by the tDP-lDP randomization increases compared to the number of links removed by the original \({{{\mathcal{I}}}}\), explaining the observation StDP − lDP < S.
For heterogeneous networks, on the other hand, links are not uniformly distributed: tiles that contain the hubs of \({{{\mathcal{G}}}}\) intersect an out-sized number of links, resulting in an uneven spatial distribution of the tile-degree (Fig. 5f). The random distribution of the initially removed tiles is a result of the targeted attack selecting tiles that contain the hubs of \({{{\mathcal{G}}}}\). The tDP-lDP randomization removes redundancy between the tiles surrounding the hubs; hence, tile removal is concentrated on the few largest hubs of the network, explaining why StDP − lDP < S in the early stages of the process. The LS and tDP-lDP randomizations remove links in an uncorrelated way from \({{{\mathcal{G}}}}\), meaning that hubs are not removed in a single step but lose instead links in a continuous fashion. The fact that tile removal for LS and tDP-lDP does not eliminate hubs entirely, thus delaying the critical point of the transition, explains the observed \({f}_{{{{\rm{t}}}}}^{* } < {f}_{{{{\rm{t}}}},{{{\rm{tDP}}}}-{{{\rm{lDP}}}}}^{* } < {f}_{{{{\rm{t}}}},{{{\rm{LS}}}}}^{* }\).
In the above, we have shown that, for homogeneous networks, tiles with the most links passing through get targeted first, while, for heterogeneous networks, the location of the hubs of \({{{\mathcal{G}}}}\) determines which tiles get removed. To explore when node degree dominates tile removal, we divide degree k(t) of tile t in \({{{\mathcal{I}}}}\) into two contributions:
where kpass(t) is the number of links that pass through t, i.e., links that intersect t, but have endpoints outside t, and knodes(t) is the number of links that have at least one endpoint in t. We estimate the maximum of the two contributions in the N → ∞ limit with fixed tile density ρ = NbD. First, note that the tile t0 at the center of the unit square or cube has the highest expected number of links passing through, i.e., links that intersect t0 but have endpoints outside of t0. The probability that a randomly placed segment s intersects t0 is proportional to the cross section of t0 perpendicular to s, which is \(\sim {b}^{D-1} \sim {N}^{-\frac{D-1}{D}}\). The number of links in the network is ~ N; therefore, the total number of links passing through t0 scales as
The scaling of the maximum contribution of kpass(t) is provided by scaling the largest degree node in \({{{\mathcal{G}}}}\), hence it depends on the topology of the network. For heterogeneous networks generated in the static model40, this is given by \({k}_{\max }\propto {N}^{\theta }\) with θ = 1/(γ − 1), so that
The above two scaling relations determine whether the center tile or the tile containing the largest hub of the network gets removed in the first step of the targeted tile removal: for γ < D + 1, the value of \(\max \left[{k}_{{{{\rm{nodes}}}}}\right]\) outgrows \(\max \left[{k}_{{{{\rm{pass}}}}}\right]\) and initially the hubs get removed, otherwise the targeted attack removes the tiles close to the center. Figure 6 illustrates the scaling of the maximum tile degree. For γ = 2.1, the contribution of hubs \(\max \left[{k}_{{{{\rm{nodes}}}}}\right]\) dominates both in D = 2 and D = 3 dimensions. In contrast, for γ = 3.5, the contribution \(\max \left[{k}_{{{{\rm{pass}}}}}\right]\) dominates for D = 2, while for D = 3, hubs eventually outgrow the effect of links passing through. Note, however, that the latter only happens for very large networks outside of the regime of most real networks.

We measured the maximum tile degree (circles) for increasing size N for scale-free (SF) networks embedded in D = 2 and D = 3 dimensions and with γ = 2.1 and γ = 3.5 degree exponents and average degree c = 4. We randomly placed cN/2 segments in the unit square and measured the maximum number of segments intersecting a tile (circles), and we also measured the maximum degree of the combinatorial networks (triangles). The dashed lines represent the scaling predicted by Eqs. (18) and (19). a, b For γ = 2.1, the contribution of the hubs dominates the maximum tile degree for both D = 2 and D = 3. c For γ = 3.5 and D = 2 dimensions, γ > D + 1, hence the contribution of \(\max {k}_{{{{\rm{pass}}}}}\) dominates. d In contrast, for γ = 3.5 and D = 3, we predict that \(\max {k}_{{{{\rm{nodes}}}}}\) dominate. However, extrapolating the simulations shows that \(\max {k}_{{{{\rm{nodes}}}}}\) only outgrows \(\max {k}_{{{{\rm{pass}}}}}\) for extremely large networks. Circle markers represent the average of 20 independent physically embedded networks, while triangles and squares represent the average of 100 runs. Error bars represent the standard deviation and are typically smaller than the marker size.
Overall, in this section, we found that the degree distributions of the intersection graph are not enough to fully explain the patterns observed during targeted attacks, in contrast to random damage, meaning that spatial correlations do play a role. Nonetheless, careful investigation of the tile-side degrees allows us identify the parameter range where network dismantling is driven by the hubs of the combinatorial network or by the links traversing central tiles (Fig. 6).
Before exploring the effect of physical damage in real datasets, let us stress that the geometric effects detailed above can depend on the subtleties of how the networks are generated. In the static model for scale-free networks, for example, one has the natural degree cut-off \({k}_{\max }\propto {N}^{\theta }\), where θ = 1/(γ − 1), above which degree correlations start to appear. Similarly, for randomly growing SF networks, one has θ = 1/(γ − 1), while in the uncorrelated configurational model38, θ generally depends on multi-degree or single-edges constraints and it is, respectively, given by θ = 1/(γ − 1) and θ = 1/239. The latter scaling, in particular, suggests that in the targeted removal of tiles, hubs and center tiles are removed with equal likelihood in the early stages only for D = 2, while hubs are always the first ones to be removed for embedding dimensions D≥3.
Empirical networks
In this section, we analyze the robustness of three empirical networks using the intersection graph: an airline network, a vascular network and a neural network. We perform both random and targeted tile removal, and compare the percolation transition obtained for the original layout against the randomized null models. Finally, we test the robustness of our results by systematically changing the size of the tiles.
A difference between model networks and empirical data is that we embedded model networks in the unit square or cube. Real networks, on the other hand, typically have a less regular shape, hence their bounding box may contain large empty regions. Therefore, to tile an empirical network, we identify its axis-aligned bounding box, we tile this bounding box with cubic boxes, and, crucially, we leave out the empty tiles from our analysis. In other words, we remove isolated vertices from the intersection graph \({{{\mathcal{I}}}}\) before simulating tile removal. In the following, we discuss each case separately.
Air traffic network
Our first case study is a network representing air traffic in the contiguous US, which we constructed using data available from the Bureau of Transportation Statistics for the year 202341. The network contains N = 419 nodes representing cities, and we added a link between two cities if the total number of passengers on direct flights between the pair exceeded 1000, resulting in an average degree of c ≈ 16.7. We obtained the coordinates of the cities from OpenStreetMap and we transformed the longitude and latitude pairs to Euclidean space using the Albers equal area projection42,43. For simplicity, we considered flight paths to be straight lines between cities.
Figure 7 a shows the degree distribution p(d) of the combinatorial network \({{{\mathcal{G}}}}\). We find that p(d) is highly heterogeneous: the median degree is 4, while the largest hub is connected to 194 nodes, representing close to half of the cities. To construct the intersection graph \({{{\mathcal{I}}}}\), we tiled the network such that we place 40 square tiles along the longest axis of its bounding box, resulting in nt = 743 non-empty square tiles and tile density ρ ≈ 0.56. Flights often traverse the US, hence the longest links in the network are comparable to the size of the bounding box. As a consequence, the tile-side degree distribution Pt(k) and the link-side degree distribution Pl(k) of \({{{\mathcal{I}}}}\) resemble the degree distributions observed in randomly embedded networks (Fig. 7b), where there is also no constraint on the maximum link length.

a The degree distribution p(d) of the combinatorial network. The largest hub is connected to 194 of the N = 419 nodes of the network. b The tile-side degree distribution, Pt(k), and the link-side degree distribution, Pe(k), of the intersection graph \({{{\mathcal{I}}}}\). c, d The size of the largest component, S, during random and targeted tile removal. e, f The fraction of tiles ft,10% needed to be removed to reduce the largest component to S = 0.1 for random and targeted tile removal as a function of the number of non-empty tiles, nt, used to cover the network. The order of the randomized variants is insensitive to the choice of tile size. In (c–f), lines and markers represent an average of 20 independent randomizations, and the error bars indicate the standard deviation.
Figure 7 c shows the size of the largest component, S, as a function of the tiles removed. Due to the high average degree c ≈ 16.7, a large fraction of the links are needed to be removed to dismantle the network: for traditional bond percolation, we must remove approximately f ≈ 0.97 fraction of the links from \({{{\mathcal{G}}}}\) to reduce its largest component to S = 0.1. In stark contrast, the same reduction in S is achieved by randomly removing only ft ≈ 0.24 fraction of the tiles. Comparing the original intersection graph \({{{\mathcal{I}}}}\) to its randomizations, we find that tile-degree heterogeneity by itself has little effect and that the link-side degree heterogeneity delays the percolation (StDP − lH ≈ StH − lH < StDP − lDP ≈ StH − lDP), similarly to randomly embedded model networks (Fig. 2). However, in contrast to randomly embedded networks, we find that the LS randomization initially reduces S faster than the original \({{{\mathcal{I}}}}\) (S > SLS) but eventually LS delays the percolation transition (S < SLS). Recall that LS randomization removes the same number of links from \({{{\mathcal{G}}}}\), but it does so randomly; therefore, the above observations suggest that there is a correlation between a link’s degree in \({{{\mathcal{I}}}}\) and its importance in \({{{\mathcal{G}}}}\). Indeed, calculating the Pearson correlation between link-degree and the product of the degree of a link’s endpoints in \({{{\mathcal{G}}}}\), we find a positive correlation of r ≈ 0.26. This means that the original tile removal tends to remove links connecting hubs faster than the LS randomization, which explains the observed pattern: removing links between hubs in the network with high c initially does not reduce S, but in the long run accelerates the destruction of the largest component.
For targeted tile removal, we found that tiles containing the largest hubs are removed first from degree heterogeneous networks; hence we expect a similar pattern for the airline network. Indeed, the first five tiles removed, for example, all contain major airline hubs, such as Denver, Dallas, or Atlanta. Figure 7d compares the original S to its randomized counterparts, and we find a similar pattern to randomly embedded networks: S ≈ SLS < StDP − lH < StDP − lDP < StH − lH < StH − lDP, meaning that tile-degree heterogeneity accelerates, while link-degree heterogeneity slows down the percolation process. A key difference compared to model networks is that the original removal decays even faster than the tDP-lH and tDP-lDP randomizations. To explain this observation, note that the links intersecting tiles that contain hubs in \({{{\mathcal{I}}}}\) have less overlap than in the randomized versions. For example, in our network Dallas has 194 and Denver has 182 connections, but only one of these connections, namely flights between Dallas and Denver, overlap. The expected overlap between random sets of links of the same size is 194 ⋅ 182/3500 ≈ 10, hence when removing the tiles containing Dallas and Denver, more unique links are damaged by the original process than by the randomized variants.
Finally, to test the effect of tile size, we measure the fraction of tiles ft,10% needed to be removed to reduce the largest component to S = 0.1 for tilings of various sizes. Figure 7e and f show that the order of the randomizations does not change in the entire range of tiles that we tested both for random and targeted percolation.
Vascular network
Our second case study is a network representing the vasculature in a sample of the brain of a mouse44. In the network, nodes represent branching points of the vessels or terminal points at the edge of the sample, while links represent vessels in between branching point, overall resulting in N = 1558 nodes and M = 2359 links. Note that links are not straight lines, but follow a winding trajectory. Figure 8a shows that the degree distribution p(d) highly homogeneous, largely concentrated on d = 3, which indicates that most branching points split vessels into two new branches. For more details about the properties of the network see ref. 45.

a The degree distribution, p(d), of the combinatorial network. The majority of nodes are bifurcation points with degree d = 3. b The tile-side degree distribution, Pt(k), and the link-side degree distribution, Pe(k), of the intersection graph \({{{\mathcal{I}}}}\). c, d The size of the largest component, S, during random and targeted tile removal. e, f The fraction of tiles ft,10%, needed to be removed to reduce the largest component to S = 0.1 for random and targeted tile removal as a function of the number of non-empty tiles, nt, used to cover the network. The order of the randomized variants is insensitive to the choice of tile size. In (c–f), lines and markers represent an average of 20 independent randomizations, the error bars indicate the standard deviation.
We tile the network with cubes such that 20 tiles are placed along the longest axis of the network’s bounding box. After dropping the empty tiles, the network is covered by nt = 3276 boxes, resulting in a tile density of ρ ≈ 0.48. In contrast to the airline network, Fig. 8b shows that the link-side degree distribution Pl(k) is peaked at k = 1, meaning that typical links are short compared to tile size b. As a consequence, the average tile-side degree is also much lower compared to the airline network. The low link-side degrees of \({{{\mathcal{I}}}}\) together with the homogeneous degree distribution of \({{{\mathcal{G}}}}\) makes the vascular network lattice-like, in contrast with the airline network and the randomly embedded model networks.
For random tile removal, Fig. 8c shows that the randomizations overlap, especially in the later stages of the percolation process (StDP − lDP ≈ StDP − lH ≈ StH − lDP ≈ StH − lH). This is explained by the fact that Pl(k) follows an exponential distribution; therefore, further homogenizing it has little affect on random removal. A curious pattern is that the original process is slower at dismantling the largest component than randomly removing the same number of links (S < SLS). To understand this, notice that the majority of links intersect only a few tiles; therefore a link e is likely to be removed at its endpoint node v, together with other links adjacent to v. Links connected to the same node v play a redundant role in the connectivity of the network, hence removing them together reduces S slower than removing the same number of random links.
For targeted removal, Fig. 8d shows that tile-side degree heterogeneity matters (StDP − lDP ≈ SLS ≈ StDP − lH < S < StH − lDP < StH − lH), meaning that although Pt(k) is exponentially distributed, targeting its tail still gives an advantage. Similarly to random removal, we observe that S < SLS, which is again explained by removing links at their endpoint and the fact that p(d) lacks hubs that would need to be removed.
Overall, tH null models are more robust than the original layout, which would make sense as for homogenized tiles, each one would be equally likely, thus resembling the random attack scenario. On the other hand, all other null models are less robust and break down quicker than the original layout. One potential explanation is that even though some regions contain many dense tiles, which might cause redundant removals that effectively just prune the network, instead of severing it into larger disconnected components.
Finally, to test the effect of tile size, we measure the fraction of tiles ft,10% needed to be removed to reduce S to 0.1. Similarly to the airline network, Fig. 8e and f show that the order of the randomizations does not change in the entire range of tiles that we tested both for random and targeted percolation.
Neural network
As the final case study, we analyze a network of neurons comprising a region of the central nervous systems of a fruit fly46. The network is composed of 96 neurons and 6249 synaptic connections. Each neuron in the data set is represented as a spatially embedded tree and these embedded trees are bound together through synapses. Here, we focus on a microscopic representation of this network: we treat branching points and terminal points of the linked trees as nodes, and we treat the connections between them as links. This way our network contains N = 97, 588 nodes and M = 100, 388 links, making it our largest example. Fig. 9a shows that the degree distribution, p(d), of \({{{\mathcal{G}}}}\) is concentrated on d = 1 and d = 3, indicating that most nodes are terminal or bifurcation points of the neurons. For more details about the properties of this network, see ref. 45.

a The degree distribution, p(d), of the combinatorial network. Majority of nodes are terminal or bifurcation points with degree d = 1 or d = 3, respectively. The average degree of the network c ≈ 2.06 is close to two, which would correspond to a tree. b The tile-side degree distribution, Pt(k), and the link-side degree distribution, Pe(k), of the intersection graph \({{{\mathcal{I}}}}\). c, d The size of the largest component, S, during random and targeted tile removal. e, f The fraction of tiles, ft,10%, needed to be removed to reduce the largest component to S = 0.1 for random and targeted tile removal as a function of the number of non-empty tiles, nt, used to cover the network. The order of the randomized variants is insensitive to the choice of tile size. In (c–f), lines and markers represent an average of 20 independent randomizations, and the error bars indicate the standard deviation.
We tile the network with cubes such that 40 tiles are placed along the longest axis of the network’s bounding box. After dropping the empty tiles, the network is covered by nt = 11, 389 boxes, resulting in a tile density of ρ ≈ 8.6. Figure 9b shows that the link-side degree distribution, Pl(k), is sharply peaked at k = 1, meaning that typical links are shorter than b and are contained inside a single tile. Note, however, that despite the peak at k = 1 there are still a few links that span the bounding box. We observe a high maximum tile-side degree, this is due to tiles that contain many nodes. Although there are some key differences, the high peak of Pl(k) at k = 1 and the homogeneous p(d) make the fruit fly neural network similar to the vascular network.
For random tile removal, Fig. 9c shows a very similar pattern to the vascular network, with the difference that link-degree does have an effect. For targeted removal, shown in Fig. 9d, the ordering of the randomizations is identical to that of the vascular network.
Finally, as in both cases before, Fig. 9e and f show that the order of the randomizations is not sensitive to the choice of tile size in the ranges that we tested.
Discussion
In this article, we have proposed a framework to explore the vulnerability of complex networks against physical damage. The setup aims to model spatially localized attacks and it takes into account the routing of the links. One key observation is that long links are necessarily susceptible to physical damage; hence, their presence makes networks extremely vulnerable. Traditional network science focuses solely on combinatorial networks, while spatial network theory also takes into account the coordinates of nodes but in most cases ignores link routing. Our results highlight that incorporating the physical shape of links and nodes can reveal properties of networks that are otherwise missed by more traditional approaches.
The central tool of our analysis is the intersection graph, \({{{\mathcal{I}}}}\), which provides a concise representation of how the physical layout of a network influences its robustness to physical damages. By capturing the essential morphological features of spatially embedded and physical networks, the intersection graph enables a systematic characterization of layout-dependent phenomena using established analytical and numerical tools of network science. Similar constructs—such as the meta-graph introduced in ref. 24 or the contactome of ref. 47—illustrate the potential of such representations to bridge the complexity of physical networks with the analytical clarity of abstract models. Furthermore, the randomization techniques of the intersection graph play here a role analogous to the use of the configurational model in traditional network science, offering null benchmarks to reveal morphological or structural correlations of the physical layout.
Our work raises several questions. For example, we studied randomly embedded model networks, which allowed simple analytical characterization. Future work may extend this to more realistic models which take into account distance when creating links48 or other physical constraints24,25, or may explore the role of the spatial organization of links, such as bundling49 and entanglement50,51. Also, throughout this paper, we focused on network embeddings where nodes are point-like and links are extended objects connecting them. Many physically embedded networks, however, are better characterized by extended nodes with point-like connections between them, e.g., neurons are extended objects with complex shapes which connect to each other via point-like synapses. Such physical networks are better represented as spatially embedded network-of-networks and future work may extend the tile removal percolation to such representations25,32,33.
Data availability
All empirical data used in this study are available from the cited public repositories.
Code availability
The source code supporting our analysis is available at https://github.com/posfaim/PhysNetRobustness.
References
Albert, R., Jeong, H. & Barabási, A.-L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000).
Callaway, D. S., Newman, M. E., Strogatz, S. H. & Watts, D. J. Network robustness and fragility: percolation on random graphs. Phys. Rev. Lett. 85, 5468 (2000).
Cohen, R. & Havlin, S.Complex networks: structure, robustness and function (Cambridge University Press, 2010).
Moukarzel, C. F. Percolation in networks with long-range connections. Phys. A Stat. Mech. Appl. 372, 340–345 (2006).
Li, D. et al. Percolation of spatially constraint networks. Europhys. Lett. 93, 68004 (2011).
Vaknin, D., Gross, B., Buldyrev, S. V. & Havlin, S. Spreading of localized attacks on spatial multiplex networks with a community structure. Phys. Rev. Res. 2, 043005 (2020).
Amit, G., Ben Porath, D., Buldyrev, S. V. & Bashan, A. Percolation in fractal spatial networks with long-range interactions. Phys. Rev. Res. 5, 023129 (2023).
Leicht, E. & D’Souza, R. M. Percolation on interacting networks. arXiv preprint arXiv:0907.0894 (2009).
Buldyrev, S. V., Parshani, R., Paul, G., Stanley, H. E. & Havlin, S. Catastrophic cascade of failures in interdependent networks. Nature 464, 1025–1028 (2010).
Brummitt, C. D., D’Souza, R. M. & Leicht, E. A. Suppressing cascades of load in interdependent networks. Proc. Natl Acad. Sci. USA 109, E680–E689 (2012).
Gross, B., Bonamassa, I. & Havlin, S. Dynamics of cascades in spatial interdependent networks. Chaos Interdiscip. J. Nonlinear Sci. 33 (2023).
Pan, X., Zhou, J., Zhou, Y., Boccaletti, S. & Bonamassa, I. Robustness of interdependent hypergraphs: a bipartite network framework. Phys. Rev. Res. 6, 013049 (2024).
Sun, H., Radicchi, F., Kurths, J. & Bianconi, G. The dynamic nature of percolation on networks with triadic interactions. Nat. Commun. 14, 1308 (2023).
Millán, A. P., Sun, H., Torres, J. J. & Bianconi, G. Triadic percolation induces dynamical topological patterns in higher-order networks. PNAS nexus 3, pgae270 (2024).
Achlioptas, D., D’souza, R. M. & Spencer, J. Explosive percolation in random networks. Science 323, 1453–1455 (2009).
D’Souza, R. M., Gómez-Gardenes, J., Nagler, J. & Arenas, A. Explosive phenomena in complex networks. Adv. Phys. 68, 123–223 (2019).
Lee, D., Kahng, B., Cho, Y., Goh, K.-I. & Lee, D.-S. Recent advances of percolation theory in complex networks. J. Korean Phys. Soc. 73, 152–164 (2018).
Shekhtman, L. M. et al. Critical field-exponents for secure message-passing in modular networks. N. J. Phys. 20, 053001 (2018).
Bianconi, G. & Ziff, R. M. Topological percolation on hyperbolic simplicial complexes. Phys. Rev. E 98, 052308 (2018).
Li, M. et al. Percolation on complex networks: theory and application. Phys. Rep. 907, 1–68 (2021).
Schwarze, A. C., Jiang, J., Wray, J. & Porter, M. A. Structural robustness and vulnerability of networks. arXiv preprint arXiv:2409.07498 (2024).
Artime, O. et al. Robustness and resilience of complex networks. Nat. Rev. Phys. 6, 114–131 (2024).
Dehmamy, N., Milanlouei, S. & Barabási, A.-L. A structural transition in physical networks. Nature 563, 676–680 (2018).
Pósfai, M. et al. Impact of physicality on network structure. Nat. Phys. 20, 142–149 (2024).
Pete, G., Timár, Á., Stefánsson, S. Ö., Bonamassa, I. & Pósfai, M. Physical networks as network-of-networks. Nat. Commun. 15, 4882 (2024).
Aktas, O., Ullrich, O., Infante-Duarte, C., Nitsch, R. & Zipp, F. Neuronal damage in brain inflammation. Arch. Neurol. 64, 185–189 (2007).
Taoufik, E. & Probert, L. Ischemic neuronal damage. Curr. Pharm. Des. 14, 3565–3573 (2008).
Dueñas-Osorio, L., Craig, J. I. & Goodno, B. J. Seismic response of critical interdependent networks. Earthq. Eng. Struct. Dyn. 36, 285–306 (2007).
Ouyang, M. & Duenas-Osorio, L. Multi-dimensional hurricane resilience assessment of electric power systems. Struct. Saf. 48, 15–24 (2014).
Argyroudis, S., Selva, J., Gehl, P. & Pitilakis, K. Systemic seismic risk assessment of road networks considering interactions with the built environment. Comput. Aided Civ. Infrastruct. Eng. 30, 524–540 (2015).
Wang, W., Yang, S., Stanley, H. E. & Gao, J. Local floods induce large-scale abrupt failures of road networks. Nat. Commun. 10, 2114 (2019).
Bianconi, G. Superconductor-insulator transition in a network of 2d percolation clusters. Europhys. Lett. 101, 26003 (2013).
Chepuri, R. T. & Kovács, I. A. Complex quantum network models from spin clusters. Commun. Phys. 6, 271 (2023).
Goh, K.-I., Kahng, B. & Kim, D. Universal behavior of load distribution in scale-free networks. Phys. Rev. Lett. 87, 278701 (2001).
Chung, F. & Lu, L. Connected components in random graphs with given expected degree sequences. Ann. Combinatorics 6, 125–145 (2002).
Artime, O. & De Domenico, M. Percolation on feature-enriched interconnected systems. Nat. Commun. 12, 2478 (2021).
Cohen, R., Ben-Avraham, D. & Havlin, S. Percolation critical exponents in scale-free networks. Phys. Rev. E 66, 036113 (2002).
Dorogovtsev, S. N., Goltsev, A. V. & Mendes, J. F. Critical phenomena in complex networks. Rev. Mod. Phys. 80, 1275–1335 (2008).
Bhamidi, S., Dhara, S. & van der Hofstad, R. Multiscale genesis of a tiny giant for percolation on scale-free random graphs. The Annals of Probability 53, 1331–1381 (2025).
Lee, J.-S., Goh, K.-I., Kahng, B. & Kim, D. Intrinsic degree-correlations in the static model of scale-free networks. Eur. Phys. J. B-Condens. Matter Complex Syst. 49, 231–238 (2006).
Bureau of Transportation Statistics https://www.transtats.bts.gov.
OpenStreetMap.Accessed: 2024-06-14 https://www.openstreetmap.org.
pyproj 3.0.1 https://pyproj4.github.io.
Gagnon, L. et al. Quantifying the microvascular origin of bold-fmri from first principles with two-photon microscopy and an oxygen-sensitive nanoprobe. J. Neurosci. 35, 3663–3675 (2015).
Blagojević, L. & Pósfai, M. Three-dimensional shape and connectivity of physical networks. Sci. Rep. 14, 16874 (2024).
Clements, J. et al. neuprint: Analysis tools for em connectomics. biorxiv (2020).
Salova, A. & Kovács, I. A. Combined topological and spatial constraints are required to capture the structure of neural connectomes. Network Neuroscience 9, 181–206 (2025).
Barthélemy, M. Spatial networks. Phys. Rep. 499, 1–101 (2011).
Bonamassa, I. et al. Logarithmic kinetics and bundling in random packings of elongated 3D physical links. Proc. Natl. Acad. Sci. U.S.A. 122, e2427145122 (2025).
Liu, Y., Dehmamy, N. & Barabási, A.-L. Isotopy and energy of physical networks. Nat. Phys. 17, 216–222 (2021).
Glover, C. & Barabási, A.-L. Measuring entanglement in physical networks. Phys. Rev. Lett. 133, 077401 (2024).
Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. 810115-DYNASNET).
Author information
Authors and Affiliations
Contributions
L.B., I.B., and M.P. derived the analytical results and performed the numerical simulations. L.B. analyzed the empirical data. L.B., I.B., and M.P. designed the study and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Communications Physics thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Blagojević, L., Bonamassa, I. & Pósfai, M. Network dismantling by physical damage. Commun Phys 8, 333 (2025). https://doi.org/10.1038/s42005-025-02228-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s42005-025-02228-5
