
Abstract
Medical artificial intelligence (AI) systems hold promise for transforming healthcare by supporting clinical decision-making in diagnostics and treatment. The effective deployment of medical AI requires trust among key stakeholders — including patients, providers, developers and regulators — which can be built by ensuring transparency in medical AI, including in its design, operation and outcomes. However, many AI systems function as ‘black boxes’, making it challenging for users to interpret and verify their inner workings. In this Review, we examine the current state of transparency in medical AI, from training data to model development and model deployment, identifying key challenges, risks and opportunities. We then explore a range of techniques that promote explainability, highlighting the importance of continual monitoring and system updates to ensure that AI systems remain reliable over time. Finally, we address the need to overcome barriers that inhibit the integration of transparency tools into clinical settings and review regulatory frameworks that prioritize transparency in emerging AI systems.
Key points
-
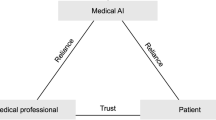
As AI systems are used more often in clinical decision-making, ensuring transparency in their design, operation and outcomes is essential for their safe and effective deployment and for building trust among stakeholders.
-
Achieving transparency requires a holistic approach that spans the entire development pipeline: from data collection and model development to clinical deployment.
-
Explainable AI techniques, including feature attributions, concept-based explanations and counterfactual explanations, elucidate how medical AI models process data and make clinical predictions.
-
Transparent deployment of medical AI systems demands rigorous real-world evaluation, continuous performance monitoring and evolving regulatory frameworks to maintain long-term safety, reliability and clinical impact.
-
Further advancing transparency requires democratizing access to large language models, integrating transparency tools into clinical workflows, and systematically evaluating their clinical utility.
This is a preview of subscription content, access via your institution
Access options
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout




Similar content being viewed by others

References
Rajpurkar, P. & Lungren, M. P. The current and future state of AI interpretation of medical images. N. Engl. J. Med. 388, 1981–1990 (2023).
Song, A. H. et al. Artificial intelligence for digital and computational pathology. Nat. Rev. Bioeng. 1, 930–949 (2023).
Jones, O. T. et al. Artificial intelligence and machine learning algorithms for early detection of skin cancer in community and primary care settings: a systematic review. Lancet Digit. Health 4, e466–e476 (2022).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017).
Ouyang, D. et al. Video-based AI for beat-to-beat assessment of cardiac function. Nature 580, 252–256 (2020).
Christensen, M., Vukadinovic, M., Yuan, N. & Ouyang, D. Vision–language foundation model for echocardiogram interpretation. Nat. Med. 30, 1481–1488 (2024).
Arnold, C. Inside the nascent industry of AI-designed drugs. Nat. Med. 29, 1292–1295 (2023).
Rakers, M. M. et al. Availability of evidence for predictive machine learning algorithms in primary care: a systematic review. JAMA Netw. Open 7, e2432990–e2432990 (2024).
Wu, E. et al. How medical AI devices are evaluated: limitations and recommendations from an analysis of FDA approvals. Nat. Med. 27, 582–584 (2021).
Dorr, D. A., Adams, L. & Embí, P. Harnessing the promise of artificial intelligence responsibly. JAMA 329, 1347–1348 (2023).
Muehlematter, U. J., Daniore, P. & Vokinger, K. N. Approval of artificial intelligence and machine learning-based medical devices in the USA and Europe (2015–20): a comparative analysis. Lancet Digit. Health 3, e195–e203 (2021).
US Food and Drug Administration. Artificial Intelligence and Machine learning (AI/ML)-Enabled Medical Devices (2024).
Smak Gregoor, A. M. et al. An artificial intelligence based app for skin cancer detection evaluated in a population based setting. npj Digit. Med. 6, 90 (2023).
Chen, W. et al. Early detection of visual impairment in young children using a smartphone-based deep learning system. Nat. Med. 29, 493–503 (2023).
Temple, S. W. P. & Rowbottom, C. G. Gross failure rates and failure modes for a commercial AI-based auto-segmentation algorithm in head and neck cancer patients. J. Appl. Clin. Med. Phys. 25, e14273 (2024).
Daneshjou, R. et al. Disparities in dermatology AI performance on a diverse, curated clinical image set. Sci. Adv. 8, eabq6147 (2022).
Chen, R. J. et al. Algorithmic fairness in artificial intelligence for medicine and healthcare. Nat. Biomed. Eng. 7, 719–742 (2023).
Maleki, F. et al. Generalizability of machine learning models: quantitative evaluation of three methodological pitfalls. Radiol. Artif. Intell. 5, e220028 (2023).
Yang, J. et al. Generalizability assessment of AI models across hospitals in a low–middle and high income country. Nat. Commun. 15, 8270 (2024).
Ong Ly, C. et al. Shortcut learning in medical AI hinders generalization: method for estimating AI model generalization without external data. npj Digit. Med. 7, 124 (2024).
DeGrave, A. J., Janizek, J. D. & Lee, S.-I. AI for radiographic COVID-19 detection selects shortcuts over signal. Nat. Mach. Intell. 3, 610–619 (2021). This article reports that deep-learning models for COVID-19 detection from radiographs rely on confounding shortcuts rather than pathology, and emphasizes the importance of explainable AI for model auditing.
Laghi, A. Cautions about radiologic diagnosis of COVID-19 infection driven by artificial intelligence. Lancet Digit. Health 2, e225 (2020).
Wang, L., Lin, Z. Q. & Wong, A. COVID-Net: a tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 10, 19549 (2020).
Marey, A. et al. Explainability, transparency and black box challenges of AI in radiology: impact on patient care in cardiovascular radiology. Egypt J. Radiol. Nucl. Med. 55, 183 (2024).
Poon, A. I. F. & Sung, J. J. Y. Opening the black box of AI-medicine. J. Gastroenterol. Hepatol. 36, 581–584 (2021).
Saw, S. N. & Ng, K. H. Current challenges of implementing artificial intelligence in medical imaging. Phys. Med. 100, 12–17 (2022).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172–180 (2023).
Jiang, L. Y. et al. Health system-scale language models are all-purpose prediction engines. Nature 619, 357–362 (2023).
Tiu, E. et al. Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning. Nat. Biomed. Eng. 6, 1399–1406 (2022).
Krishnan, R., Rajpurkar, P. & Topol, E. J. Self-supervised learning in medicine and healthcare. Nat. Biomed. Eng. 6, 1346–1352 (2022).
Shick, A. A. et al. Transparency of artificial intelligence/machine learning-enabled medical devices. npj Digit. Med. 7, 21 (2024). This article presents key takeaways from an FDA-hosted workshop on the transparency of AI/ML-enabled medical devices, emphasizing the need for clear and accessible communication about device development, performance, intended use and potential limitations.
Chen, H., Gomez, C., Huang, C.-M. & Unberath, M. Explainable medical imaging AI needs human-centered design: guidelines and evidence from a systematic review. npj Digit. Med. 5, 156 (2022).
Cadario, R., Longoni, C. & Morewedge, C. K. Understanding, explaining, and utilizing medical artificial intelligence. Nat. Hum. Behav. 5, 1636–1642 (2021).
He, B. et al. Blinded, randomized trial of sonographer versus AI cardiac function assessment. Nature 616, 520–524 (2023).
Cruz Rivera, S. et al. Guidelines for clinical trial protocols for interventions involving artificial intelligence: the SPIRIT-AI extension. Nat. Med. 26, 1351–1363 (2020).
Zhou, Y., Shi, Y., Lu, W. & Wan, F. Did artificial intelligence invade humans? The study on the mechanism of patients’ willingness to accept artificial intelligence medical care: from the perspective of intergroup threat theory. Front. Psychol. 13, 866124 (2022).
Shevtsova, D. et al. Trust in and acceptance of artificial intelligence applications in medicine: mixed methods study. JMIR Hum. Factors 11, e47031 (2024).
Dean, T. B., Seecheran, R., Badgett, R. G., Zackula, R. & Symons, J. Perceptions and attitudes toward artificial intelligence among frontline physicians and physicians’ assistants in Kansas: a cross-sectional survey. JAMIA Open 7, ooae100 (2024).
Daneshjou, R., Smith, M. P., Sun, M. D., Rotemberg, V. & Zou, J. Lack of transparency and potential bias in artificial intelligence data sets and algorithms: a scoping review. JAMA Dermatol. 157, 1362–1369 (2021). This article discusses the widespread lack of dataset characterization, labelling quality and demographic reporting in diagnostic AI studies for skin disease.
Groh, M. et al. Evaluating deep neural networks trained on clinical images in dermatology with the Fitzpatrick 17k dataset. In IEEE Conference on Computer Vision and Pattern Recognition Workshop (eds Forsyth, D. et al.) 1820–1828 (IEEE, 2021).
Saenz, A., Chen, E., Marklund, H. & Rajpurkar, P. The MAIDA initiative: establishing a framework for global medical-imaging data sharing. Lancet Digit. Health 6, e6–e8 (2024). This article introduces the MAIDA initiative, a global collaborative framework for assembling and sharing diverse medical imaging datasets to improve the generalizability and evaluation of AI models.
Bak, M., Madai, V. I., Fritzsche, M.-C., Mayrhofer, M. T. & McLennan, S. You can’t have AI both ways: balancing health data privacy and access fairly. Front. Genet. 13, 929453 (2022).
Koetzier, L. R. et al. Generating synthetic data for medical imaging. Radiology 312, e232471 (2024).
Groh, M., Harris, C., Daneshjou, R., Badri, O. & Koochek, A. Towards transparency in dermatology image datasets with skin tone annotations by experts, crowds, and an algorithm. In Proc. ACM on Human–Computer Interaction (ed. Nichols, J.) 6, 521 (ACM, 2022).
Goldberg, C. B. et al. To do no harm — and the most good — with AI in health care. Nat. Med. 30, 623–627 (2024).
Liu, X. et al. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. Nat. Med. 26, 1364–1374 (2020).
Bluemke, D. A. et al. Assessing radiology research on artificial intelligence: a brief guide for authors, reviewers, and readers — from the radiology editorial board. Radiology 294, 487–489 (2020).
US Centers for Disease Control and Prevention. Health Insurance Portability and Accountability Act of 1996 (1996).
Carvalho, T., Antunes, L., Costa Santos, C. & Moniz, N. Empowering open data sharing for social good: a privacy-aware approach. Sci. Data 12, 248 (2025).
Andrus, M. & Villeneuve, S. Demographic-reliant algorithmic fairness: characterizing the risks of demographic data collection in the pursuit of fairness. In Proc. ACM Conference on Fairness Accountability and Transparency (eds Isbell, C. et al.) 1709–1721 (ACM, 2022).
Wang, A., Ramaswamy, V. V. & Russakovsky, O. Towards intersectionality in machine learning: including more identities, handling underrepresentation, and performing evaluation. In Proc. ACM Conference on Fairness, Accountability and Transparency (eds Isbell, C. et al.) 336–349 (ACM, 2022).
Tomasev, N., McKee, K. R., Kay, J. & Mohamed, S. Fairness for unobserved characteristics: insights from technological impacts on queer communities. In Proc. AAAI/ACM Conference on AI, Ethics and Society (eds Das, S. et al.) 254–265 (ACM, 2021).
Bowker, G. C. & Star, S. L. Sorting Things Out: Classification and its Consequences (MIT Press, 2000).
Hanna, A., Denton, R., Smart, A. & Smith-Loud, J. Towards a critical race methodology in algorithmic fairness. In Proc. ACM Conference on Fairness, Accountability and Transparency (eds Hildebrandt, M. et al.) 501–512 (ACM, 2020).
Muntner, P. et al. Potential US population impact of the 2017 ACC/AHA high blood pressure guideline. Circulation 137, 109–118 (2018).
Davatchi, F. et al. The saga of diagnostic/classification criteria in Behcet’s disease. Int. J. Rheum. Dis. 18, 594–605 (2015).
Winkler, J. K. et al. Association between surgical skin markings in dermoscopic images and diagnostic performance of a deep learning convolutional neural network for melanoma recognition. JAMA Dermatol. 155, 1135–1141 (2019).
Bissoto, A., Fornaciali, M., Valle, E. & Avila, S. (De)constructing bias on skin lesion datasets. In Conference on Computer Vision and Pattern Recognition Workshop (eds Gupta, A. et al.) 2766–2774 (IEEE, 2019).
Norgeot, B. et al. Minimum information about clinical artificial intelligence modeling: the MI-CLAIM checklist. Nat. Med. 26, 1320–1324 (2020).
Hernandez-Boussard, T., Bozkurt, S., Ioannidis, J. P. A. & Shah, N. H. MINIMAR (MINimum Information for Medical AI Reporting): developing reporting standards for artificial intelligence in health care. J. Am. Med. Inform. Assoc. 27, 2011–2015 (2020).
Ganapathi, S. et al. Tackling bias in AI health datasets through the STANDING Together initiative. Nat. Med. 28, 2232–2233 (2022).
Collins, G. S. et al. TRIPOD+ AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ 385, q902 (2024).
Pushkarna, M., Zaldivar, A. & Kjartansson, O. Data cards: purposeful and transparent dataset documentation for responsible AI. In Proc. ACM Conference on Fairness, Accountability and Transparency (eds Isbell, C. et al.) 1776–1826 (ACM, 2022).
Gebru, T. et al. Datasheets for datasets. Commun. ACM 64, 86–92 (2021).
Mitchell, M. et al. Model cards for model reporting. In Proc. ACM Conference on Fairness, Accountability and Transparency (eds Chouldechovam, A. et al.) 220–229 (ACM, 2019).
Janizek, J. D., Erion, G. G., DeGrave, A. J. & Lee, S.-I. An adversarial approach for the robust classification of pneumonia from chest radiographs. In Proc. ACM Conference on Health, Inference and Learning (ed. Ghassemi, M.) 69–79 (ACM, 2020).
Chen, F., Wang, L., Hong, J., Jiang, J. & Zhou, L. Unmasking bias in artificial intelligence: a systematic review of bias detection and mitigation strategies in electronic health record-based models. J. Am. Med. Inform. Assoc. 31, 1172–1183 (2024).
Wu, J. et al. Clinical text datasets for medical artificial intelligence and large language models — a systematic review. NEJM AI 1, AIra2400012 (2024).
US White House. Blueprint for an AI Bill of Rights; https://bidenwhitehouse.archives.gov/ostp/ai-bill-of-rights/ (2022)
US Government Accountability Office. Artificial intelligence in health care: benefits and challenges of machine learning technologies for medical diagnostics; https://www.gao.gov/products/gao-22-104629 (2022).
Raab, R. et al. Federated electronic health records for the European health data space. Lancet Digit. Health 5, e840–e847 (2023).
Gutman, D. et al. Skin lesion analysis toward melanoma detection: a challenge at the International Symposium on Biomedical Imaging (ISBI) 2016, hosted by the International Skin Imaging Collaboration (ISIC). Preprint at https://doi.org/10.48550/arXiv.1605.01397 (2016).
Codella, N. C. F. et al. Skin lesion analysis toward melanoma detection: a challenge at the 2017 International symposium on Biomedical Imaging (ISBI), hosted by the International Skin Imaging Collaboration (ISIC). In Proc. 15th International Symposium on Biomedical Imaging (eds Erik, M. et al.) 168–172 (IEEE, 2018).
Codella, N. et al. Skin lesion analysis toward melanoma detection 2018: a challenge hosted by the International Skin Imaging Collaboration (ISIC). Preprint at https://doi.org/10.48550/arXiv.1902.03368 (2019).
Gonzales, S., Carson, M. B. & Holmes, K. Ten simple rules for maximizing the recommendations of the NIH data management and sharing plan. PLoS Comput. Biol. 18, e1010397 (2022).
Bianchi, D. W. et al. The All Of Us research program is an opportunity to enhance the diversity of US biomedical research. Nat. Med. 30, 330–333 (2024).
Hope Watson et al. Delivering on NIH data sharing requirements: avoiding open data in appearance only. BMJ Health Care Inf. 30, e100771 (2023).
van der Haak, M. et al. Data security and protection in cross-institutional electronic patient records. Int. J. Med. Inf. 70, 117–130 (2003).
Price, W. N. & Cohen, I. G. Privacy in the age of medical big data. Nat. Med. 25, 37–43 (2019).
Johnson, A. E. W. et al. MIMIC-III, a freely accessible critical care database. Sci. Data 3, 160035 (2016).
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 10, 1 (2023).
Labkoff, S. E., Quintana, Y. & Rozenblit, L. Identifying the capabilities for creating next-generation registries: a guide for data leaders and a case for “registry science”. J. Am. Med. Inform. Assoc. 31, 1001–1008 (2024).
Rieke, N. et al. The future of digital health with federated learning. npj Digit. Med. 3, 119 (2020).
Kushida, C. A. et al. Strategies for de-identification and anonymization of electronic health record data for use in multicenter research studies. Med. Care 50, S82–S101 (2012).
Sadilek, A. et al. Privacy-first health research with federated learning. npj Digit. Med. 4, 132 (2021).
Sheller, M. J. et al. Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 10, 12598 (2020).
Sarma, K. V. et al. Federated learning improves site performance in multicenter deep learning without data sharing. J. Am. Med. Inform. Assoc. 28, 1259–1264 (2021).
Lu, M. Y. et al. Federated learning for computational pathology on gigapixel whole slide images. Med. Image Anal. 76, 102298 (2022).
van Breugel, B., Liu, T., Oglic, D. & van der Schaar, M. Synthetic data in biomedicine via generative artificial intelligence. Nat. Rev. Bioeng. 2, 991–1004 (2024). This article provides an overview of generative AI methods for biomedical synthetic data generation and highlights their applications, including privacy preservation and data augmentation.
D’Amico, S. et al. Synthetic data generation by artificial intelligence to accelerate research and precision medicine in hematology. JCO Clin. Cancer Inform. 7, e2300021 (2023).
Dahan, C., Christodoulidis, S., Vakalopoulou, M. & Boyd, J. Artifact removal in histopathology images. Preprint at https://doi.org/10.48550/arXiv.2211.16161 (2022).
Jiménez-Sánchez, A., Juodelyte, D., Chamberlain, B. & Cheplygina, V. Detecting shortcuts in medical images — a case study in chest X-rays. In Proc. 20th International Symposium on Biomedical Imaging (eds Salvado, O. et al.) (IEEE, 2023).
Bluethgen, C. et al. A vision–language foundation model for the generation of realistic chest X-ray images. Nat. Biomed. Eng. 9, 494–506 (2025).
Chen, R. J., Lu, M. Y., Chen, T. Y., Williamson, D. F. K. & Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 5, 493–497 (2021).
Shaban, M. T., Baur, C., Navab, N. & Albarqouni, S. Staingan: stain style transfer for digital histological images. In Proc. 16th International Symposium on Biomedical Imaging (eds Carbayo, M. et al.) 953–956 (IEEE, 2019).
Ktena, I. et al. Generative models improve fairness of medical classifiers under distribution shifts. Nat. Med. 30, 1166–1173 (2024).
Sagers, L. W. et al. Augmenting medical image classifiers with synthetic data from latent diffusion models. Preprint at https://doi.org/10.48550/arXiv.2308.12453 (2023).
Salimans, T. et al. Improved techniques for training GANs. In Advances in Neural Information Processing Systems (eds Lee, D. et al.) Vol. 29, 2234–2242 (Curran Associates, 2016).
Naeem, M. F., Oh, S. J., Uh, Y., Choi, Y. & Yoo, J. Reliable fidelity and diversity metrics for generative models. In Proc. 37th International Conference on Machine Learning (eds Daume, H. et al.) Vol. 119, 7176–7185 (PMLR, 2020).
Jordon, J. et al. Synthetic data — what, why and how? Preprint at https://doi.org/10.48550/arXiv.2205.03257 (2022).
Lee, J. & Clifton, C. in Information Security (eds Lai, X. et al.) 325–340 (Springer, 2011).
Esteban, C., Hyland, S. L. & Rätsch, G. Real-valued (medical) time series generation with recurrent conditional GANs. Preprint at https://doi.org/10.48550/arXiv.1706.02633 (2017).
Chefer, H. et al. The hidden language of diffusion models. In Proc. 12th International Conference on Learning Representations (eds Kim, B. et al.) 52637–52669 (ICLR, 2024).
Shen, Y., Gu, J., Tang, X. & Zhou, B. Interpreting the latent space of GANs for semantic face editing. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (eds Liu, C. et al.) 9243–9252 (IEEE, 2020).
Lu, M., Lin, C., Kim, C. & Lee, S.-I. An efficient framework for crediting data contributors of diffusion models. In Proc. 13th International Conference on Learning Representations (eds Yue, Y. et al.) 10072–10105 (ICLR, 2025).
Zheng, X., Pang, T., Du, C., Jiang, J. & Lin, M. Intriguing properties of data attribution on diffusion models. In Proc 12th International Conference Learning Representations (eds Kim, B. et al.) 18417–18452 (ICLR, 2024).
Kim, E., Kim, S., Park, M., Entezari, R. & Yoon, S. Rethinking training for de-biasing text-to-image generation: unlocking the potential of stable diffusion. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Conference 13361–13370 (IEEE, 2025).
Shrikumar, A., Greenside, P. & Kundaje, A. Learning important features through propagating activation differences. In Proc. 34th International Conference on Machine Learning Vol. 70, 3145–3153 (ACM, 2017).
Selvaraju, R. R. et al. Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 128, 336–359 (2020).
Wang, H. et al. Score-CAM: score-weighted visual explanations for convolutional neural networks. In Proc. IEEE/CVF Conference Computer Vision and Pattern Recognition Workshops (eds Liu, C. et al.) 24–25 (IEEE, 2020).
Sundararajan, M., Taly, A. & Yan, Q. Axiomatic attribution for deep networks. In International Conference on Machine Learning 3319–3328 (PMLR, 2017).
Covert, I., Lundberg, S. M. & Lee, S.-I. Explaining by removing: a unified framework for model explanation. J. Mach. Learn. Res. 22, 1–90 (2021).
Petsiuk, V., Das, A. & Saenko, K. RISE: randomized input sampling for explanation of black-box models. In British Machine Vision Conference (eds Shum, H. et al.) 151 (BMVA Press, 2018).
Fong, R. C. & Vedaldi, A. Interpretable explanations of black boxes by meaningful perturbation. In Proc. IEEE International Conference Computer Vision (Cucchiara, R. et al.) 3449–3457 (IEEE, 2017).
Ribeiro, M. T., Singh, S. & Guestrin, C. ‘ Why should I trust you?’ Explaining the predictions of any classifier. In Proc. 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (eds Krishnapuram, B. et al.) 1135–1144 (ACM, 2016).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems (eds Guyon, I. et al.) Vol. 30, 4765–4774 (Curran Associates, 2017). This article introduces SHAP, a unified framework that leverages game theory to provide accurate and theoretically grounded feature attributions for interpreting predictions of any machine learning model.
Loh, H. W. et al. Application of explainable artificial intelligence for healthcare: a systematic review of the last decade (2011–2022). Comput. Methods Prog. Biomed. 226, 107161 (2022).
Jahmunah, V., Ng, E. Y., Tan, R.-S., Oh, S. L. & Acharya, U. R. Explainable detection of myocardial infarction using deep learning models with Grad-CAM technique on ECG signals. Comput. Biol. Med. 146, 105550 (2022).
Wu, Y., Zhang, L., Bhatti, U. A. & Huang, M. Interpretable machine learning for personalized medical recommendations: a LIME-based approach. Diagnostics 13, 2681 (2023).
Vimbi, V., Shaffi, N. & Mahmud, M. Interpreting artificial intelligence models: a systematic review on the application of LIME and SHAP in Alzheimer’s disease detection. Brain Inf. 11, 10 (2024).
Aldughayfiq, B., Ashfaq, F., Jhanjhi, N. & Humayun, M. Explainable AI for retinoblastoma diagnosis: interpreting deep learning models with LIME and SHAP. Diagnostics 13, 1932 (2023).
Wang, X. et al. A radiomics model combined with XGBoost may improve the accuracy of distinguishing between mediastinal cysts and tumors: a multicenter validation analysis. Ann. Transl. Med. 9, 1737 (2021).
Lundberg, S. M. et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2, 749–760 (2018).
Beebe-Wang, N. et al. Unified AI framework to uncover deep interrelationships between gene expression and Alzheimer’s disease neuropathologies. Nat. Commun. 12, 5369 (2021).
Qiu, W., Chen, H., Kaeberlein, M. & Lee, S.-I. ExplaiNAble BioLogical Age (ENABL Age): an artificial intelligence framework for interpretable biological age. Lancet Healthy Longev. 4, e711–e723 (2023).
Dombrowski, A.-K. et al. Explanations can be manipulated and geometry is to blame. In Advances in Neural Information Processing Systems (eds Larochelle, H. et al.) Vol. 32 (Curran Associates, 2019).
Adebayo, J. et al. Sanity checks for saliency maps. In Advances in Neural Information Processing Systems (eds Bengio, S. et al.) Vol. 31, 9525–9536 (Curran Associates, 2018).
Jethani, N., Sudarshan, M., Covert, I. C., Lee, S.-I. & Ranganath, R. FastShap: real-time Shapley value estimation. In Proc. International Conference on Learning Representations (ICLR, 2021).
Covert, I. & Lee, S.-I. Improving KernelShap: practical Shapley value estimation using linear regression. In International Conference on Artificial Intelligence and Statistics (eds Banerjee, A. et al.) 3457–3465 (PMLR, 2021).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2, 56–67 (2020).
Covert, I. C., Kim, C. & Lee, S.-I. Learning to estimate Shapley values with vision transformers. In Proc. 11th International Conference on Learning Representations (eds Wang, M. et al.) (ICLR, 2023).
Lipton, Z. C. The mythos of model interpretability: in machine learning, the concept of interpretability is both important and slippery. Queue 16, 31–57 (2018).
Ghassemi, M., Oakden-Rayner, L. & Beam, A. L. The false hope of current approaches to explainable artificial intelligence in health care. Lancet Digit. Health 3, e745–e750 (2021).
Daneshjou, R., Yuksekgonul, M., Cai, Z. R., Novoa, R. A. & Zou, J. SkinCon: a skin disease dataset densely annotated by domain experts for fine-grained debugging and analysis. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35, 18157–18167 (Curran Associates, 2022).
Tsao, H. et al. Early detection of melanoma: reviewing the ABCDEs. J. Am. Acad. Dermatol. 72, 717–723 (2015).
Chen, Z., Bei, Y. & Rudin, C. Concept whitening for interpretable image recognition. Nat. Mach. Intell. 2, 772–782 (2020).
Crabbé, J. & van der Schaar, M. Concept activation regions: a generalized framework for concept-based explanations. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35 (Curran Associates, 2022).
Kim, B. et al. Interpretability beyond feature attribution: quantitative testing with concept activation vectors (TCAV). In Proc. 35th International Conference on Machine Learning (Dy, J. et al.) 2668–2677 (PMLR, 2018). This article introduces the TCAV method to interpret an AI model’s behaviour in terms of high-level, human-friendly concepts using directional derivatives.
Janik, A., Dodd, J., Ifrim, G., Sankaran, K. & Curran, K. Interpretability of a deep learning model in the application of cardiac MRI segmentation with an ACDC challenge dataset. In Medical Imaging 2021: Image Processing (eds Isgum, I. & Landman, B.) Vol. 11596, 861–872 (SPIE, 2021).
Mincu, D. et al. Concept-based model explanations for electronic health records. In Proc. Conference on Health, Inference and Learning (eds Naumann, T. & Pierson, E.) 36–46 (PMLR, 2021).
Ghorbani, A., Wexler, J., Zou, J. Y. & Kim, B. Towards automatic concept-based explanations. In Advances in Neural Information Processing Systems (ed. Larochelle, H.) Vol. 32 (Curran Associates, 2019).
Radford, A. et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (eds Meila, M. & Zhang T.) 8748–8763 (PMLR, 2021).
Kim, C. et al. Transparent medical image AI via an image–text foundation model grounded in medical literature. Nat. Med. 30, 1154–1165 (2024).
Lu, M. Y. et al. A visual-language foundation model for computational pathology. Nat. Med. 30, 863–874 (2024).
Zhang Sheng et al. A multimodal biomedical foundation model trained from fifteen million image–text pairs. NEJM AI 2, AIoa2400640 (2025).
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical twitter. Nat. Med. 29, 2307–2316 (2023).
Ikezogwo, W. et al. Quilt-1m: One million image-text pairs for histopathology. In Advances in Neural Information Processing Systems (eds Fan, A. et al.) Vol. 36 (Curran Associates, 2023).
Dunlap, L. et al. Describing differences in image sets with natural language. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (eds Akata, Z. et al.) 24199–24208 (IEEE, 2024).
Li, J., Li, D., Savarese, S. & Hoi, S. Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning (eds Brunskill, E. et al.) 19730–19742 (PMLR, 2023).
Verma, S., Dickerson, J. & Hines, K. Counterfactual explanations for machine learning: a review. In ACM Computing Surveys (eds Atienza, D & Milano M.) Vol. 56 (2024). This article reviews counterfactual explanation methods, highlighting their utility and key challenges.
Lang, O. et al. Explaining in style: training a GAN to explain a classifier in stylespace. In Proc. IEEE/CVF International Conference on Computer Vision (eds Hassner, T. et al.) 693–702 (IEEE, 2021).
Singla, S., Pollack, B., Chen, J. & Batmanghelich, K. Explanation by progressive exaggeration. In Proc. International Conference on Learning Representations (eds Song, D. et al.) (PMLR,2020).
DeGrave, A. J., Cai, Z. R., Janizek, J. D., Daneshjou, R. & Lee, S.-I. Auditing the inference processes of medical-image classifiers by leveraging generative AI and the expertise of physicians. Nat. Biomed. Eng. 9, 294–306 (2023).
Gadgil, S. U., DeGrave, A. J., Daneshjou, R. & Lee, S.-I. Discovering mechanisms underlying medical AI prediction of protected attributes. Preprint at medRxiv https://doi.org/10.1101/2024.04.09.24305289 (2024).
Lang, O. et al. Using generative AI to investigate medical imagery models and datasets. eBioMedicine 102, 105075 (2024).
Molnar, C. A guide for making black box models explainable. Github https://christophm.github.io/interpretable-ml-book/ (2018).
Quinlan, J. R. Induction of decision trees. Mach. Learn. 1, 81–106 (1986).
Bennett, K. P. & Blue, J. A. Optimal decision trees. Rensselaer Polytech. Inst. Math. Rep. 214, 128 (1996).
Hastie, T. J. Generalized additive models. In Statistical Models in S 249–307 (Routledge. 2017).
Lou, Y., Caruana, R., Gehrke, J. & Hooker, G. Accurate intelligible models with pairwise interactions. In Proc. 19th ACM SIGKDD International Conference Knowledge Discovery and Data Mining 623–631 (ACM, 2013).
Semenova, L., Rudin, C. & Parr, R. On the existence of simpler machine learning models. In Proc. ACM Conference on Fairness, Accountability and Transparency (eds Borgesius, F. et al.) 1827–1858 (ACM, 2022).
Mohammadjafari, S., Cevik, M., Thanabalasingam, M., Basar, A. & Alzheimer’s Disease Neuroimaging Initiative. Using ProtoPNet for interpretable Alzheimer’s disease classification. In Proc. 34th Canadian Conference on Artificial Intelligence (CAIAC, 2021).
Barnett, A. J. et al. A case-based interpretable deep learning model for classification of mass lesions in digital mammography. Nat. Mach. Intell. 3, 1061–1070 (2021).
Koh, P. W. et al. Concept bottleneck models. In International Conference on Machine Learning (eds Daume, H. & Singh, A.) 5338–5348 (PMLR, 2020). This article introduces a class of interpretable models that first predict human-understandable concepts before making final predictions, allowing users to inspect, intervene on and debug model output through these intermediate concepts.
Lanchantin, J., Wang, T., Ordonez, V. & Qi, Y. General multi-label image classification with transformers. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (eds Forsyth, D. et al.) 16478–16488 (IEEE, 2021).
Jeyakumar, J. V. et al. Automatic concept extraction for concept bottleneck-based video classification. Preprint at https://doi.org/10.48550/arXiv.2206.10129 (2022).
Sun, X. et al. Interpreting deep learning models in natural language processing: a review. Preprint at https://doi.org/10.48550/arXiv.2110.10470 (2021).
Klimiene, U. et al. Multiview concept bottleneck models applied to diagnosing pediatric appendicitis. In 2nd Workshop on Interpretable Machine Learning in Healthcare (eds Jin, W. et al.) (ICML, 2022).
Wu, C., Parbhoo, S., Havasi, M. & Doshi-Velez, F. Learning optimal summaries of clinical time-series with concept bottleneck models. In Machine Learning for Healthcare Conference 648–672 (PMLR, 2022).
Yüksekgönül, M., Wang, M. & Zou, J. Post-hoc concept bottleneck models. In Proc. 11th International Conference on Learning Representations (eds Nickel, M. et al.) (PMLR, 2023).
Yang, X. et al. A large language model for electronic health records. npj Digit. Med. 5, 194 (2022).
Li, C. et al. LLaVA-med: training a large language-and-vision assistant for biomedicine in one day. In Advances in Neural Information Processing Systems (Fan, A. et al.) Vol. 37 (Curran Associates, 2024).
Jin, D. et al. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Appl. Sci. 11, 6421 (2021).
Singhal, K. et al. Toward expert-level medical question answering with large language models. Nat. Med. 31, 943–950 (2025).
Gilbert, S., Harvey, H., Melvin, T., Vollebregt, E. & Wicks, P. Large language model AI chatbots require approval as medical devices. Nat. Med. 29, 2396–2398 (2023).
Moor, M. et al. Foundation models for generalist medical artificial intelligence. Nature 616, 259–265 (2023). This article introduces a paradigm for medical AI, referred to as generalist medical AI, which encompasses models trained using self-supervision that can carry out a diverse set of tasks using little or no task-specific labelled data.
Chowdhery, A. et al. PaLM: scaling language modeling with pathways. J. Mach. Learn. Res. 24, 1–113 (2023).
Huang, S., Mamidanna, S., Jangam, S., Zhou, Y. & Gilpin, L. H. Can large language models explain themselves? A study of LLM-generated self-explanations. Preprint at https://doi.org/10.48550/arXiv.2310.11207 (2023).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35, 24824–24837 (Curran Associates, 2022).
Madsen, A., Chandar, S. & Reddy, S. Are self-explanations from large language models faithful? In Findings of the Association for Computational Linguistics (eds Ku, L.-W. et al.) 295–337 (ACL, 2024).
Turpin, M., Michael, J., Perez, E. & Bowman, S. R. Language models don’t always say what they think: unfaithful explanations in chain-of-thought prompting. In Advances in Neural Information Processing Systems (eds Oh, A. et al.) Vol. 36, 74952–74965 (Curran Associates, 2023).
Agarwal, C., Tanneru, S. H. & Lakkaraju, H. Faithfulness vs. plausibility: on the (un)reliability of explanations from large language models. Preprint at https://doi.org/10.48550/arXiv.2402.04614 (2024).
Madsen, A., Lakkaraju, H., Reddy, S. & Chandar, S. Interpretability needs a new paradigm. Preprint at https://doi.org/10.48550/arXiv.2405.05386 (2024).
Peng, Z. et al. Grounding multimodal large language models to the world. In International Conference on Representation Learning (eds Kim, B. et al.) 51575–51598 (ICLR, 2024).
Huben, R., Cunningham, H., Smith, L., Ewart, A. & Sharkey, L. Sparse autoencoders find highly interpretable features ln Language models. In International Conference on Representation Learning (eds Kim, B. et al.) 7827–7845 (ICLR, 2024).
Bills, S. et al. Language models can explain neurons in language models. OpenAI https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html (2023).
Templeton, A. et al. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Transformer Circuit, 2024).
Conmy, A., Mavor-Parker, A. N., Lynch, A., Heimersheim, S. & Garriga-Alonso, A. Towards automated circuit discovery for mechanistic interpretability. In Proc. 37th International Conference on Neural Information Processing Systems (eds Globerson, A. et al.) 16318–16352 (Curran Associates, 2023).
Simon, E. & Zou, J. InterPLM: discovering interpretable features in protein language models via sparse autoencoders. Preprint at bioRxiv https://doi.org/10.1101/2024.11.14.623630 (2024).
Zhong, H. et al. Copyright protection and accountability of generative AI: attack, watermarking and attribution. In Companion Proc. ACM Web Conference (eds Aroyo, L. et al.) 94–98 (ACM, 2023).
Liu, Y. et al. Trustworthy LLMs: a survey and guideline for evaluating large language models’ alignment. Preprint at https://doi.org/10.48550/arXiv.2308.05374 (2024).
Huang, Y. et al. Position: TRUSTLLM: trustworthiness in large language models. In Proc. 41st International Conference on Machine Learning (eds Heller, K. et al.) 20166–20270 (PMLR, 2024).
Li, D. et al. A survey of large language models attribution. Preprint at https://doi.org/10.48550/arXiv.2311.03731 (2023).
Gao, L. et al. RARR: researching and revising what language models say, using language models. In Proc. 61st Annual Meeting of the Association for Computational Linguistics Vol. 1, 16477–16508 (ACL, 2023).
Guu, K. et al. Simfluence: modeling the influence of individual training examples by simulating training runs. Preprint at https://doi.org/10.48550/arXiv.2303.08114 (2023).
Gao, Y. et al. Retrieval-augmented generation for large language models: a survey. Preprint at https://doi.org/10.48550/arXiv.2312.10997 (2024).
Lewis, P. et al. Retrieval-augmented generation for knowledge-intensive NLP 1144 tasks. In Advances in Neural Information Processing Systems (ed Ranzato, M.) Vol. 33, 9459–9474 (Curran Associates, 2020).
Ancona, M., Ceolini, E., Öztireli, C. & Gross, M. Towards better understanding of gradient-based attribution methods for deep neural networks. In Proc. 6th International Conference on Learning Representations (eds Murray, I. et al.) (PMLR, 2018).
Hooker, S., Erhan, D., Kindermans, P.-J. & Kim, B. A benchmark for interpretability methods in deep neural networks. In Proc. 33rd International Conference on Neural Information Processing Systems (ed. Larochelle, H.) 9737–9748 (Curran Associates, 2019).
Zhang, J., Lin, Z., Brandt, J., Shen, X. & Sclaroff, S. Top-down neural attention by excitation backprop. In Computer Vision 14th European Conference Proc. IV (eds Leibe, B. et al.) 543–559 (Springer, 2016).
Beede, E. et al. A human-centered evaluation of a deep learning system deployed in clinics for the detection of diabetic retinopathy. In Proc. 2020 CHI Conference on Human Factors in Computing Systems (eds Bernhaupt, R. et al.) (ACM, 2020).
Wang, B. et al. AI-assisted CT imaging analysis for COVID-19 screening: Building and deploying a medical AI system. Appl. Soft. Comput. 98, 106897 (2021).
Jotterand, F. & Bosco, C. Keeping the “human in the loop” in the age of artificial intelligence: accompanying commentary for “correcting the brain?” by Rainey and Erden. Sci. Eng. Ethics 26, 2455–2460 (2020).
Bakken, S. AI in health: keeping the human in the loop. J. Am. Med. Inform. Assoc. 30, 1225–1226 (2023).
Kostick-Quenet, K. M. & Gerke, S. AI in the hands of imperfect users. npj Digit. Med. 5, 197 (2022).
Wu, J. T. et al. AI accelerated human-in-the-loop structuring of radiology reports. In AMIA Annual Symposium Proc. (eds Wilcox, A. et al.) 1305–1314 (AMIA, 2021).
US Food and Drug Administration. Transparency for Machine Learning-Enabled Medical Devices: Guiding Principles (2021). These guidelines outline principles jointly developed by multiple regulatory agencies to promote transparency, explainability and human-centred design in machine-learning-enabled medical devices.
Marchetti, M. A. et al. Prospective validation of dermoscopy-based open-source artificial intelligence for melanoma diagnosis (PROVE-AI study). npj Digit. Med. 6, 127 (2023).
Dembrower, K., Crippa, A., Colón, E., Eklund, M. & Strand, F. Artificial intelligence for breast cancer detection in screening mammography in Sweden: a prospective, population-based, paired-reader, non-inferiority study. Lancet Digit. Health 5, e703–e711 (2023).
Elhakim, M. T. et al. AI-integrated screening to replace double reading of mammograms: a population-wide accuracy and feasibility study. Radiol. Artif. Intell. 6, e230529 (2024).
Sridharan, S. et al. Real-world evaluation of an AI triaging system for chest X-rays: a prospective clinical study. Eur. J. Radiol. 181, 111783 (2024).
Patel, M. R., Balu, S. & Pencina, M. J. Translating AI for the clinician. JAMA 332, 1701–1702 (2024).
Steidl, M., Felderer, M. & Ramler, R. The pipeline for the continuous development of artificial intelligence models — current state of research and practice. J. Syst. Softw. 199, 111615 (2023).
Feng, J. et al. Clinical artificial intelligence quality improvement: towards continual monitoring and updating of AI algorithms in healthcare. npj Digit. Med. 5, 66 (2022).
Shah, N. H., Pfeffer, M. A. & Ghassemi, M. The need for continuous evaluation of artificial intelligence prediction algorithms. JAMA Netw. Open. 7, e2433009 (2024).
Vokinger, K. N., Feuerriegel, S. & Kesselheim, A. S. Continual learning in medical devices: FDA’s action plan and beyond. Lancet Digit. Health 3, e337–e338 (2021).
Bouderhem, R. Shaping the future of AI in healthcare through ethics and governance. Human. Soc. Sci. Commun. 11, 416 (2024).
Joshi, G. et al. FDA-approved artificial intelligence and machine learning (AI/ML)-enabled medical devices: an updated landscape. Electronics 13, 498 (2024).
US Food and Drug Administration. Artificial Intelligence and Machine Learning in Software as a Medical Device (2021).
US Food and Drug Administration. Total Product Life Cycle for Medical Device (2023).
US Food and Drug Administration. Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-based Software as a Medical Device (SaMD) — Discussion Paper and Request for Feedback (2019).
US Food and Drug Administration. Good Machine Learning Practice for Medical Device Development: Guiding Principles (2025).
Meskó, B. & Topol, E. J. The imperative for regulatory oversight of large language models (or generative AI) in healthcare. npj Digit. Med. 6, 120 (2023).
Minssen, T., Vayena, E. & Cohen, I. G. The challenges for regulating medical use of ChatGPT and other large language models. JAMA 330, 315–316 (2023).
Groeneveld, D. et al. OLMo: accelerating the science of language models. In Proc. 62nd Annual Meeting Association for Computational Linguistics (eds Ku, L.-W. et al.) 15789–15809 (ACL, 2024).
Riedemann, L., Labonne, M. & Gilbert, S. The path forward for large language models in medicine is open. npj Digit. Med. 7, 339 (2024).
Kanter, G. P. & Packel, E. A. Health care privacy risks of AI chatbots. JAMA 330, 311–312 (2023).
Hsieh, C.-Y. et al. Distilling step-by-step! Outperforming larger language models with less training data and smaller model sizes. In Findings of the Association for Computational Linguistics (eds Rogers, A. et al.) 8003–8017 (ACL, 2023).
Kim, S. et al. SqueezeLLM: dense-and-sparse quantization. In Proc. 41st International Conference on Machine Learning (PMLR, 2024).
Dettmers, T., Lewis, M., Belkada, Y. & Zettlemoyer, L. GPT3.int8(): 8-bit matrix multiplication for transformers at scale. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35, 30318–30332 (Curran Associates, 2022).
Blumenthal D. & Patel B. The regulation of clinical artificial intelligence. NEJM AI 1, aIpc2400545 (2024).
Covert, I. C., Kim, C., Lee, S.-I., Zou, J. & Hashimoto, T. Stochastic amortization: a unified approach to accelerate feature and data attribution. In Advances in Neural Information Processing Systems (eds Globerson, A. et al.) Vol. 37, 4374–4423 (Curran Associates, 2024).
Li, W. & Yu, Y. Faster approximation of probabilistic and distributional values via least squares. In International Conference on Representation Learning (eds Kim, B. et al.) 51182–51216 (ICLR,2024).
Park, S. M., Georgiev, K., Ilyas, A., Leclerc, G. & Madry, A. TRAK: attributing model behavior at scale. In Proc. 40th International Conference on Machine Learning (eds Krause, A. et al.) Vol. 202, 27074–27113 (PMLR, 2023).
Mekki, Y. M. & Zughaier, S. M. Teaching artificial intelligence in medicine. Nat. Rev. Bioeng. 2, 450–451 (2024).
Mohamed, M. M., Mahesh, T. R., Vinoth, K. V. & Suresh, G. Enhancing brain tumor detection in MRI images through explainable AI using Grad-CAM with Resnet 50. BMC Med. Imaging 24, 107 (2024).
Panwar, H. et al. A deep learning and grad-CAM based color visualization approach for fast detection of COVID-19 cases using chest X-ray and CT-Scan images. Chaos Solitons Fractals 140, 110190 (2020).
Gildenblat, J. et al. PyTorch Library for CAM Methods. Github https://github.com/jacobgil/pytorch-grad-cam (2021).
Erion, G., Janizek, J. D., Sturmfels, P., Lundberg, S. M. & Lee, S.-I. Improving performance of deep learning models with axiomatic attribution priors and expected gradients. Nat. Mach. Intell. 3, 620–631 (2021).
Chen, C. et al. This looks like that: deep learning for interpretable image recognition. In Advances in Neural Information Processing Systems (eds Wallach, H. et al.) Vol. 32, 8928–8939 (Curran Associates, 2019).
Kim, Y., Wu, J., Abdulle, Y. & Wu, H. MedExQA: medical question answering benchmark with multiple explanations. In Proc. 23rd Workshop on Biomedical Natural Language Processing (eds Demner-Fushman, D. et al.) 167–181 (ACL, 2024).
Lindsey, J. et al. On the Biology of a Large Language Model (Transformer Circuits, 2025).
Meng, K., Bau, D., Andonian, A. & Belinkov, Y. Locating and editing factual associations in GPT. In Advances in Neural Information Processing Systems (eds Koyejo, S. et al.) Vol. 35, 17359–17372 (Curran Associates, 2022).
Zakka, C. et al. Almanac — retrieval-augmented language models for clinical medicine. NEJM AI 1, AIoa2300068 (2024).
Kim, J., Hur, M. & Min, M. From RAG to QA-RAG: integrating generative AI for pharmaceutical regulatory compliance process. In Proc. 40th ACM/SIGAPP Symposium on Applied Computing 1293–1295 (ACM, 2025).
Fleckenstein, M. et al. Age-related macular degeneration. Nat. Rev. Dis. Prim.7, 31 (2021).
Ai, L., Usman, M. & Lu, H. Experimental study of cerebral edema and expression of VEGF and AQP4 in the penumbra area of rat brain trauma. Sci. Rep. 15, 17040 (2025).
Gerke, S., Babic, B., Evgeniou, T. & Cohen, I. G. The need for a system view to regulate artificial intelligence/machine learning-based software as medical device. npj Digit. Med. 3, 53 (2020).
116th Congress (2019-2020). H.R.6216 — National Artificial Intelligence Initiative Act of 2020; https://www.congress.gov/bill/116th-congress/house-bill/6216 (2020).
World Health Organization. Ethics and Governance of Artificial Intelligence for Health (2021).
European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (2016).
European Commission. European Health Data Space Regulation (EHDS) (2025).
van Smeden, M. et al. Guideline for High-Quality Diagnostic and Prognostic Applications of AI in Healthcare (Ministry of Health, Welfare and Sport, 2021).
European Commission. Ethics Guidelines for Trustworthy AI (2019).
Acknowledgements
C.K., S.U.G. and S.-I.L. received support from the National Institutes of Health (grants R01 AG061132, R01 EB035934 and RF1 AG088824).
Author information
Authors and Affiliations
Contributions
All authors contributed equally to the preparation of this manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Citation diversity statement
The authors acknowledge that research authored by scholars from historically excluded groups are systematically under-cited. Every attempt has been made to reference relevant research in a manner that is equitable in terms of racial, ethnic, gender and geographical representation.
Peer review
Peer review information
Nature Reviews Bioengineering thanks Hayden Mctavish, Eric Karl Oerman and Chris McIntosh for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kim, C., Gadgil, S.U. & Lee, SI. Transparency of medical artificial intelligence systems. Nat Rev Bioeng 4, 11–29 (2026). https://doi.org/10.1038/s44222-025-00363-w
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s44222-025-00363-w
This article is cited by
-
A swarm intelligence-driven hybrid framework for brain tumor classification with enhanced deep features
Scientific Reports (2025)
-
Diagnostic and interpretive gains from reasoning over conclusions with a large reasoning model in radiology
npj Digital Medicine (2025)
