
Abstract
Bacterial vaginosis (BV) is a prevalent vaginal syndrome, affecting millions of women globally. The complexity of the vaginal microbiome can challenge conventional diagnostic approaches, particularly for populations of women with healthy, yet diverse vaginal microbiomes. Advanced sequencing technologies coupled with machine learning (ML) offer promise in elucidating these complexities; however, ML models have been shown to be vulnerable to existing health disparities. To determine the ability of ML models to perform equitably, this study evaluates the performance of ML algorithms in predicting symptomatic BV across different ethnic groups using 16S rRNA sequencing data. Results indicate differential predictive performance across ethnicities, with models exhibiting lower accuracy for Black women. Moreover, we found variation in significant bacterial taxa for predicting BV by ethnicity. Future research aims to explore these factors and validate findings in larger, more diverse cohorts, with the goal of improving BV diagnosis and mitigating health disparities across ethnic groups.
Similar content being viewed by others


Introduction
Bacterial vaginosis (BV) is a common vaginal syndrome among women of reproductive age, affecting millions of women globally. Mediated by a non-optimal vaginal microbiome, BV is associated with several adverse obstetric and gynecological outcomes. Among these are an increased risk of sexually transmitted infections (STI), human immunodeficiency virus (HIV), a positive correlation with cervical cancer, and pre-term birth1,2,3,4,5. BV can be diagnosed clinically using Amsel’s criteria which requires the display of three of the following symptoms: malodor, pH above 4.5, the presence of clue cells, and/or vaginal discharge6. Alternatively, BV can be diagnosed using Nugent scoring, a microbiological method that quantitatively measures the amount of aerobic and anaerobic bacteria within the vagina. A Nugent score is assigned by using the morphology of gram-positive and gram-variable rods7, with a designated score for BV negative (0–3), indeterminate (4–6), and BV positive (>7). Traditionally, a positive Nugent score with accompanying clinical symptoms is diagnosed as symptomatic BV8,9.
Sequencing technologies using 16S ribosomal RNA allow for identification of the relative abundances of individual bacterial species in a microbiome, making it possible to characterize the vaginal microbiota in healthy and diseased states. The vaginal microbiota can be further grouped by dominant bacteria into community state types (CSTs)10. CST I is dominated by L. crispatus, CST II by L. gasseri, CST III by L. iners, and CST V by L. jensenii11. CSTs I, II, III, and V are low diversity state types that are lactobacilli dominated. Within CST IV there is usually not a singularly dominant bacterial species, and several different species make significant contributions to the microbiota10. Generally, low diversity lactobacilli-dominated vaginal microbiomes (CSTs I, II, and V) are considered optimal12,13. Other work has shown that microbial compositions vary within the healthy vaginal microbiome, with some ethnic groups, such as Black and Hispanic women, trending towards a larger range of microbiota10,14. However, a diverse vaginal microbiota has traditionally been associated with a positive BV outcome15.
Artificial intelligence (AI) and machine learning (ML) provide an opportunity for the development of predictive models using sequencing data. The expansion of advanced computational methods using AI shows promise in highlighting the differences in important vaginal microbiota that may vary across individuals. Metagenomic community state types (mgCSTs) are one example. This expansion of CSTs uses ML to cluster metagenomic sequencing data and categorizes vaginal microbiomes based on both composition and functional potential16. Further, feature selection methods highlight understudied bacterial combinations important to consider for accurate diagnosis17,18.
Several studies have used ML and sequencing data to predict BV in women. Baker et al. use various ML models to predict BV using 16S rRNA sequencing data from 25 women generated over 10 weeks19. Beck and Foster use both Logistic Regression and Random Forest models to predict BV using 16S rRNA sequencing data from datasets generated by Ravel and Srinivasan20. In a subsequent study, Beck and Foster evaluated important features determined by their models17. These studies use ML to diagnose BV with high accuracy, but few have investigated the effect of variations across race and ethnicity on ML performance.
It is important to understand if these variations in the vaginal microbiome lead to misdiagnosis when using ML. Existing health disparities are often the byproduct of inadequate access to health care, cultural biases, socioeconomic status, and, at times, discriminatory medical practices, whether intentional or not21,22,23,24,25. These disparities can be further exacerbated with the application of AI and machine learning due to biased data and/or algorithms and inadequate evaluation and auditing practices26,27,28,29,30,31,32. For example, recent work showed ethnic disparity in BV diagnosis in an asymptomatic BV cohort and highlighted bacteria, such as Lactobacilli crispatus, Lactobacilli iners, Gardnerella, and Prevotella, that were significant to accurate BV diagnosis between ethnic groups18.
Within this work, we assess accuracy in BV prediction within a group of 220 women with symptomatic BV from multiple ethnicities. We evaluate four AI/ML algorithms (Random Forest, Logistic Regression, Support Vector Machine, and Multi-layer Perceptron) in predicting BV using vaginal microbiome sequencing data from women of diverse ethnicity. We identify disparities in BV diagnosis in this symptomatic group and utilize paired ethnicity datasets and statistical feature selection methods to reduce disparities in model performance. Through feature selection, we identify unique bacterial communities important for accurate prediction that vary between ethnic groups.
Results
The data used in this work was produced by Srinivasan et al. 33, which consists of 220 women with and without bacterial vaginosis (BV). BV was diagnosed based on Nugent scoring, indicated based on the Gram stain test of vaginal smears. Patients with a Nugent score of seven or greater are identified as BV positive, and those with a score below seven are identified as BV negative. Given the goal of predicting bacterial vaginosis (BV), we used four machine learning (ML) models: Random Forest (RF), Logistic Regression (LR), Support Vector Machine (SVM), and Multi-layer Perceptron (MLP). The hyperparameters used to optimize each classifier are provided in Supplementary Table 1. Four metrics, including balanced accuracy (BACC), area under the precision-recall curve (AUPRC), false positive rate (FPR), and false negative rate (FNR), were used to evaluate the performance of the ML models in predicting BV.
Descriptive statistics
Within the dataset, there were 220 women, of which 97 (44%) were White, 75 (34%) were Black, and 48 (22%) were of other ethnicities (i.e., Asian, Native Hawaiian/Pacific Islander, American Indian/Alaska Native, mixed, chose not to disclose their ethnicity, or did not know their race). All ethnic categories were self-described. Figure 1 displays the percentage of BV diagnosis based on Nugent scoring, including by ethnicity. 53% of the women had a positive BV diagnosis with Black women and women of Other ethnicities having a higher prevalence of BV compared to White women (Fig. 1). Upon conducting a chi-square test, we found that there is a significant association between ethnicity and BV outcome (p = 0.0001 < 0.05). In this work, we examine the impact of this association between ethnicity and BV outcome on machine learning performance for predicting BV outcomes across ethnic groups.

BV diagnosis was based on Nugent score. Patients with a Nugent score of 7 or above are diagnosed as BV positive; patients with a Nugent score below 7 are diagnosed as BV negative.
Figure 2a displays a two-dimensional t-distributed stochastic neighbor embedding (t-SNE) projection of the operational taxonomic unit (OTU) variables mapped to BV diagnosis based on Nugent scoring. From examining the t-SNE projection, most of the data is separable by BV diagnosis. However, some samples are not well-separated in the t-SNE project, potentiating challenges in diagnosis using AI/ML models. To further explore the impact of dominant bacterial species on BV diagnosis, a t-SNE projection mapped to community state type (CST) classification is shown (Fig. 2b). The plot separates well by CST, with the majority of CST I in the BV negative cluster, and the majority of CST IV in the BV positive cluster. The cluster of mixed BV diagnosis is heavily comprised of CST III, indicating an L. iners dominant microbiome for mixed diagnosis.

t-SNE plot of 16S rRNA bacterial variables by (a) BV diagnosis based on Nugent scoring and by (b) community state type.
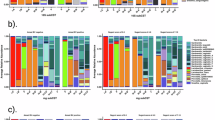
Figure 3 displays the percentage and count of women in each CST across ethnicity. CST IV is the predominant CST for Black (56%) and Other (50%) women. CST III, which is L. iners dominated, is the second most common state type for women in these two groups (34.7% of Black women and 25% of Other women). CST I, the L. crispatus dominated microbiome, is the third most common CST among Black women (8%) and women labeled as Other (22.9%). In contrast, CST III is the most common state type among White women (39.2%) in this cohort, followed by CST IV (33%) and CST I (26.8%). All three ethnic groups had only one patient with CST V (L. jensenii dominated). Neither group had patients categorized as CST II (L. gasseri dominated).

Community state type (CST) distribution within the (a) White, (b) Black, and (c) Other ethnicities. CST I is dominated by L. crispatus, CST II by L. gasseri, CST III by L. iners, and CST V by L. jensenii. CST IV consists of diverse bacteria with no Lactobacillus dominance.
Model performance varies by ethnicity in BV diagnosis
Table 1 shows the average balanced accuracy (BACC), area under the precision recall curve (AUPRC), false positive rate (FPR), and false negative rate (FNR) of the four ML models in predicting BV. Overall, the ML models performed well (BACC: 0.90–0.92; AUPRC: 0.93–0.96; FPR: 0.07–0.10; FNR: 0.10–0.10). Random Forest (RF) and Logistic Regression (LR) had higher BV predictive performances compared to other models, depending on the metric; however, there were no statistically significant differences in performance metrics (Table 1).
Upon examining the performance of ML models by ethnic group, we found differences in predictive outcomes (Fig. 4, Supplementary Table 2). Overall, Black women had the lowest balanced accuracy (BACC) (Fig. 4a) and highest FPRs (Fig. 4c) across all models. In contrast, FNR tended to be lower for White women, except when using the Multi-layer Perceptron (MLP) model (Fig. 4d).

a Boxplots showing the median, upper quartile, lower quartile, and outliers of balanced accuracy, (b) Area under precision-recall curve (AUPRC), (c) false positive rate (FPR), and d false negative rate (FNR). Asterisk (*) indicates group pairs with statistically significant difference in model performance.
In summary, most models, except for MLP, tended to perform worse for Black women compared to White women and women of Other ethnicities. However, MLP tended to perform the most comparably across all ethnic groups.
Using paired-ethnicity training to improve model performance
In this subsequent analysis, we sought to determine whether training and testing using data of the same ethnicity (i.e., paired-ethnicity training) would reduce ethnic disparities in model performance. We only show results for Logistic Regression (LR) since it had the highest overall balanced accuracy (Table 1).
Paired-ethnicity training (Fig. 5, Supplementary Table 3) for White and Black women resulted in either increased or comparable performance with training on samples from all ethnic groups. However, these improvements did not result in statistical significance. In contrast, all performance measures degraded, except for FNR, for women of Other ethnicities with statistical significance (balanced accuracy: p = 0.002; AUPRC: p = 0.037; FPR: p = 0.004).

Conducted 10 stratified train-test runs (with nested grid search cross validation in each run). a Boxplots showing the median, upper quartile, lower quartile, and outliers of balanced accuracy, (b) Area under precision-recall curve (AUPRC), (c) false positive rate (FPR), and d false negative rate (FNR). Asterisk (*) indicates group pairs with statistically significant differences in model performance.
We also examined whether these models could be generalizable to ethnic groups not used in the training process (i.e., cross-training). Overall, cross-training tended to only result in improved predictive performance for women of Other ethnicities (Fig. 5, Supplementary Table 3), particularly regarding balanced accuracy (White: p = 0.048), FPR (White: p = 0.005; Black: p = 0.012), and FNR (White: p = 0.046; Black: p = 0.039). In contrast, we found that paired-ethnicity training tended to result in better predictive outcomes for Black women compared to cross-training with data of women of Other ethnicities (BACC: p = 0.003; FPR: p = 0.004; FNR: p = 0.01). Similarly, paired-ethnicity training frequently resulted in higher predictive performance for White women than cross-training with data of women of Other ethnic groups (balanced accuracy: p = 0.006; AUPRC: p = 0.006; FPR: p = 0.006).
Bacterial taxa highlighted as significant for predicting BV
Using feature selection methods, we identified bacterial taxa that contributed to accurate BV diagnosis. The following feature selection methods were used to extract significant bacterial taxa: Gini Index, T-test, F-test, and Point Biserial (PB) Correlation. Both the p-value (PBsig) and correlation coefficient (PBcorr) of the PB Correlation were used to determine important features from this method. Results are only shown for the LR classifier since it was the best-performing model overall (Table 1).
Overall, the Gini Index method performed the best compared to other feature selection methods (Table 2). When examining model performance by ethnicity (Fig. 6, Supplementary Table 4), improvement in model performance varied for each ethnic group. For White and Black women, feature selection improved most predictive measures, although not statistically significant for most methods. In contrast, performance measures, specifically balanced accuracy and FNR, tended to degrade for women of Other ethnicities across all feature selection approaches. Overall, the PBcorr method tended to degrade most performance measures for each ethnic group.

Conducted 10 stratified train-test runs (with nested grid search cross validation in each run). a–d Boxplots showing the median, upper quartile, lower quartile, and outliers of balanced accuracy, area under precision-recall curve (AUPRC), false positive rate (FPR), and false negative rate (FNR).
To further investigate how to improve equity in model performance, features identified as significant for BV diagnosis for each ethnic group were used to train ML models, independently, using the Gini Index method. Unique bacterial taxa were found in each ethnicity-specific subset for BV diagnosis (Fig. 7). Eggerthella sp. type 1 and Atopobium vaginae (Fannyhessea vaginae) were identified as most significant for BV diagnosis for White women in this cohort, corresponding to significant bacterial taxa identified for the entire cohort. In contrast, Gardnerella vaginalis and L. crispatus were found to be important predictors of BV for women of Other ethnicities. Dialister sp. Type 2 and Gardnerella vaginalis were highlighted as important bacterial taxa for BV diagnosis among Black women. Upon training the Logistic Regression (LR) model with feature sets corresponding to each ethnic group, we found that model performance degraded, except for FNR (Supplementary Fig. 1 and Supplementary Table 5). Using paired-ethnicity training or simplistic training (i.e., no feature selection nor ethnicity-specific training) tended to perform better for each ethnic group.

The shared, top bacterial taxa indicative of BV identified using the Gini Index are provided overall and across each ethnic group.
Discussion
Accurate diagnosis of bacterial vaginosis (BV) involves an understanding of the complex interplay of microbial communities that exist in a dysbiotic state. Variations in the vaginal microbiome can complicate diagnostic accuracy; however, machine learning and AI-based tools offer innovative methodologies to analyze bacterial compositions in healthy and diseased states. Incorporating population-specific data enables the identification of weaknesses in the AI/ML pipeline (e.g., data generation, model development, model evaluation) by assessing predictive outcomes and key predictors for BV across varying demographic groups. Identification of understudied vaginal microbial communities, which have been shown to vary by race and ethnicity, provides a framework to gain mechanistic insights to answer these questions.
In this study, we evaluate four machine learning classifiers for BV prediction in a cohort of women tested for symptomatic BV. Model performance was comparable to prior analyses that used ML to diagnose women with asymptomatic BV using 16S rRNA sequencing data18,20,34,35. A recent study found disparity in accurate BV classification across ethnic groups within an asymptomatic cohort with predictive accuracy being the highest for White women and the lowest for Asian women18. Differences in model performances were attributed in part to the large variety of community state types seen across Asian women in the dataset10. In this cohort, we found that model performance was highest for White women and lowest for Black women (Fig. 4). This could be a result of the data not being separable by BV diagnosis for these groups or high CST III and IV types, resulting in model difficulty in discriminating between positive and negative samples.
Within this dataset, the CST IV, which has high microbe diversity, is prevalent in 56% of Black women and 33% of White women (Fig. 3). There was also a marked difference in Lactobacillus species profiles by subpopulation group. For instance, when examining Lactobacillus dominant microbiota for Black women, L. crispatus accounts for 8%, L. iners for 34.7%, and L. jensenii for 1.3%. For white women, L. crispatus accounts for 26.8%, L. iners for 39.2%, and L. jensenii for 1%. The lack of Lactobacilli dominant microbiomes for Black women in this cohort and the dominance of CST IV could both contribute to lower algorithm performance.
Generally, women with L. crispatus-dominated microbiotas were predicted to be BV negative, while L. iners-dominant (CST III) microbiotas had mixed BV outcomes33. Within the context of BV diagnoses, L. iners can be dominant in both healthy and BV states, which can complicate BV diagnosis using ML36. This can be seen in Fig. 2b, where the BV negative cluster is dominated by CST I (L. crispatus) samples, the BV positive cluster is dominated by CST IV (high microbe diversity) samples, and the mixed cluster by CST III (L. iners dominant) samples. These results highlight the need for advanced development of ML algorithms to accurately diagnose BV even when presented with a complexity of microbiome profiles.
To address the ethnic disparity found in model performance, paired-ethnicity training, cross-training, and feature selection were implemented. When using paired ethnicity, model performance consistently improved for White and Black women, while cross training improved predictive accuracy of BV diagnosis for women of Other ethnicities. The improved accuracy with cross-training for this group could be due to the difference in sample size between ethnicities, as women of Other ethnicities had a smaller sample size than Black and White groups. Feature selection tended not to lead to significant improvement in predictive accuracy of BV for all ethnic groups (Fig. 6 and Supplementary Fig. 1, Supplementary Table 4, and Supplementary Table 5). These results emphasize the need for further research in developing ML models for improving the predictive accuracy of BV across all ethnic groups.
Important bacterial features vary between ethnic groups and offer insight into key mediators of BV that can be considered on a population level. The features shared between White women and the entire training cohort were Eggerthella sp. type 1 and Atopobium vaginae (Fannyhessea vaginae). For Black women within this cohort, Dialister sp. Type 2 and G. vaginalis were indicated as important predictors of BV, also found to be associated with positive BV outcomes by Srinivasan et al. 33. Among the training samples for grouped ethnicities (i.e., Asian, Native Hawaiian/Pacific Islander, American Indian/Alaska Native, mixed, chose not to disclose their ethnicity, or did not know their race), G. vaginalis and L. crispatus were indicated as the most significant features for predicting BV. G. vaginalis was the one important bacterial feature shared across all ethnic groups and has been widely studied as an etiological agent of BV37,38,39,40,41.
A limitation of our work is that women whose ethnicity was not Black nor White were grouped, as the sample sizes of those ethnicities were too small to evaluate individually. This impacted our ability to assess model performance on sub-populations (Asian, Native Hawaiian/Pacific Islander, American Indian/Alaska Native) within this study. Furthermore, we also understand that there are several factors that contribute to variance in results by ethnicity, including environmental and sociocultural factors, which were not included in this study. Although the results of this work cannot be generalized given the low number of women represented in this cohort, the findings of this work coincide with prior findings, which found ethnic disparity in BV predictive analysis18.
Overall, these results highlight the need for the development of improved methods for addressing ethnic disparity, including larger and more diverse training sets. Future studies would include developing Fair AI models for accurate BV diagnosis and building larger cohorts for accurate training across groups.
Methods
Data source
The data used in this work were produced by Srinivasan et al. 33, which consisted of 220 women with and without bacterial vaginosis (BV). BV was diagnosed based on Nugent scoring, which is indicated based on the Gram stain test of vaginal smears7. Participants with BV were treated with intravaginal metronidazole gel used each night for 5 days. The women were recruited from the Public Health, Seattle, and King County Sexually Transmitted Diseases Clinic. The protocol was approved by the Institutional Review Board at the Fred Hutchinson Cancer Research Center (IORG0000017) and complied with all relevant ethical regulations, including the Declaration of Helsinki. All study participants provided written informed consent. Women were categorized into the following racial groups: Black, White, Asian, Native Hawaiian/Pacific Islander, American Indian/Alaska Native, mixed, or selected Don’t Know/Does not wish to answer.
ML/AI algorithms
Due to the high dimensionality of the data, we used the following supervised machine learning algorithms to conduct these experiments: Support Vector Machine (SVM), Random Forest (RF), and Multi-layer Perceptron (MLP). Logistic Regression (LR) was also chosen given its implementation in prior research for predicting BV diagnosis19,20 and examining ethnic disparities in BV predictions18. All classifiers were implemented with the scikit-learn Python library package.
The outcome predicted was BV diagnosis based on Nugent scoring. A Nugent score of seven or higher was indicated as BV positive, while a Nugent score below seven was indicated as BV negative.
BV diagnosis was predicted using the 155 bacterial taxa sequenced using 16S rRNA from the V3-V4 hypervariable regions. Srinivasan et al. provide a list of the bacterial taxa for this dataset33.
Evaluation measures
The models were evaluated using the following metrics: balanced accuracy, area under the precision-recall curve (AUPRC), false positive rate (FPR), and false negative rate (FNR). Although the class label (i.e., BV positive and negative) used in this work was balanced overall, the class label was imbalanced when examined by ethnicity (Fig. 1). Therefore, balanced accuracy was chosen as the metric to measure the accuracy of the models since it is robust to imbalanced datasets, therefore providing a fair representation of model performance. In addition, the area under the precision-recall curve (AUPRC) was used instead of the area under the receiver operating characteristic curve (AUROC) to better capture model performance across ethnicities, due to class imbalance by ethnicity. AUPRC is also indicative of average precision. Balanced accuracy and AUPRC were computed using the metric functions found in the Python sklearn.metrics package. False positive rate (FPR) and false negative rate (FNR) were measured to easily examine differences in model performance by ethnicity. Below are the equations for calculating balanced accuracy, AUPRC, FPR, and FNR, where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, and FN is the number of false negatives.
Statistical testing
For statistical analysis, a one-tailed t-test (scipy.stats.ttest_rel) or a one-tailed Wilcoxon signed rank test (scipy.stats. Wilcoxon) was used, depending on the normality of the data. Normality was determined based on the Shapiro-Wilks test (scipy.stats. Shapiro). For comparing model performance between ethnic groups, pairwise comparisons using a one-tailed Mann-Whitney U rank test were performed.
General preprocessing procedures
For all experiments, only the 16S rRNA sequence data (i.e., bacterial taxa) from the dataset were used as predictor variables, and the Nugent score was used to indicate BV diagnosis (score >= 7 is BV positive, < 7 is BV negative) as the target variable. Given the bacterial composition of the vaginal microbiome for each subject was presented in the form of relative abundance, the data was normalized by dividing by 100 to ensure all predictor variables were between 0 and 1. The ethnicity of women was specified as White, Black, or Other. The Other category consisted of women who identified as Asian, Native Hawaiian/Pacific Islander, American Indian/Alaska Native, mixed, or selected Don’t Know/Does not wish to answer.
ML performance for predicting BV: overall and by ethnicity
The general preprocessing procedures, indicated previously, were followed. No other preprocessing procedures were needed to complete this experiment.
For each model, an 80–20 train-test split stratified by BV outcome and ethnicity was performed. The sklearn.model_selection GridSearchCV function was employed to perform a grid search on the training data to select the optimal hyperparameters for each classifier—LR, SVM, RF, and MLP. Table S1 provides the hyperparameter search space for each classifier for determining the optimal models. The optimized model was then used on the test set. The model predictions were evaluated by overall performance as well as by ethnicity in the test set. The process was performed 10 times by iterating the train-test split random state from 10 to 19.
ML performance with ethnicity-specific cohorts
First, all general preprocessing procedures indicated previously were followed. Data was grouped into three independent subsets based on ethnicity (i.e., White, Black, Other) to generate three ethnicity-specific datasets.
For each ethnicity-specific dataset, an 80–20 train-test split stratified by BV outcome was performed. For all three training sets, the sklearn.model_selection GridSearchCV function was employed to perform a grid search on the training data to select the optimal hyperparameters for the Logistic Regression (LR). Table S1 indicates hyperparameters search space of the LR classifier for determining the optimal model. The optimized model was used to make predictions on the test set (i.e., paired-ethnicity training) and externally validated with the other two ethnicity-specific datasets to assess model transferability (i.e., cross training).
ML performance with feature selection
General preprocessing procedures were followed to address whether feature selection improves overall model performance. Data was grouped into three independent subsets based on ethnicity (i.e., White, Black, Other) to generate three ethnicity-specific datasets.
F-test, T-test, Gini Index, and Point Biserial test were the feature selection methods used to identify significant bacterial taxa. For the Point Biserial test, two feature sets were obtained, using both p-value (p < 0.2) and correlation value (correlation value > 0.5). F-test and T-test were implemented through the stats Python library. For Gini Index, the DecisionTreeClassifier function in the sci-kit learn Python package sklearn.tree was implemented to find optimal features. Significant features were found for the entire dataset and for each ethnicity subset.
An 80–20 train-test split, stratified by BV outcome and ethnicity, was performed on the dataset using selected features. A grid search was performed using sklearn.model_selection. GridSearchCV function to select the optimal model for the Logistic Regression (LR) classifier. Table S1 provides the hyperparameter search space of the LR classifier. Model predictions were evaluated by overall performance and by ethnicity. The process was performed 10 times by iterating the train-test split random state from 10 to 19. These steps were executed for each feature selection method. The ML model and corresponding feature selection method that resulted in the highest overall balanced accuracy were selected as the optimal pair. The best-performing feature selection method was used to select features for each ethnicity-specific dataset. The same steps indicated previously were followed to assess the effect of feature selection on model performance for each ethnic group.
Data availability
The bacterial 16S rRNA gene sequence dataset33 analyzed during the current study is available in the National Center for Biotechnology Information Short Read Archive (SRA051298), [https://www.ncbi.nlm.nih.gov/sra/?term=SRA051298]. Data on race and ethnicity [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0037818#s5].
Code availability
The underlying code for this study is available on GitHub and can be accessed via this link: https://github.com/ikenn04/Fair-AI-Symptomatic-BV.
References
Ness, R. B. et al. A cluster analysis of bacterial vaginosis–associated microflora and pelvic inflammatory disease. Am. J. Epidemiol. 162, 585–590 (2005).
Sweet, R. L. Role of bacterial vaginosis in pelvic inflammatory disease. Clin. Infect. Dis. 20, S271–S275 (1995).
Ravel, J., Moreno, I. & Simón, C. Bacterial vaginosis and its association with infertility, endometritis, and pelvic inflammatory disease. Am. J. Obstet. Gynecol. 224, 251–257 (2021).
Wiesenfeld, H. C., Hillier, S. L., Krohn, M. A., Landers, D. V. & Sweet, R. L. Bacterial vaginosis is a strong predictor of Neisseria gonorrhoeae and Chlamydia trachomatis infection. Clin. Infect. Dis. 36, 663–668 (2003).
Atashili, J., Poole, C., Ndumbe, P. M., Adimora, A. A. & Smith, J. S. Bacterial vaginosis and HIV acquisition: a meta-analysis of published studies. AIDS 22, 1493–1501 (2008).
Amsel, R. et al. Nonspecific vaginitis. Diagnostic criteria and microbial and epidemiologic associations. Am. J. Med. 74, 14–22 (1983).
Nugent, R. P., Krohn, M. A. & Hillier, S. L. Reliability of diagnosing bacterial vaginosis is improved by a standardized method of gram stain interpretation. J. Clin. Microbiol. 29, 297–301 (1991).
Muzny, C. A. & Schwebke, J. R. Asymptomatic bacterial vaginosis: to treat or not to treat?. Curr. Infect. Dis. Rep. 22, 32 (2020).
Klebanoff, M. A. et al. Vulvovaginal symptoms in women with bacterial vaginosis. Obstet. Gynecol. 104, 267–272 (2004).
Ravel, J. et al. Vaginal microbiome of reproductive-age women. Proc. Natl. Acad. Sci. USA108, 4680–4687 (2011).
Abou Chacra, L., Fenollar, F. & Diop, K. Bacterial vaginosis: What do we currently know?. Front. Cell. Infect. Microbiol. 11, 672429 (2021).
Africa, C. W. J., Nel, J. & Stemmet, M. Anaerobes and bacterial vaginosis in pregnancy: virulence factors contributing to vaginal colonisation. Int. J. Environ. Res. Public. Health 11, 6979–7000 (2014).
Marrazzo, J. M. & Hillier, S. L. Chapter 18—Bacterial Vaginosis. in Sexually Transmitted Diseases (Second Edition) (eds. Stanberry, L. R. & Rosenthal, S. L.) 463–498 (Academic Press, 2013). https://doi.org/10.1016/B978-0-12-391059-2.00018-8.
Hickey, R. J., Zhou, X., Pierson, J. D., Ravel, J. & Forney, L. J. Understanding vaginal microbiome complexity from an ecological perspective. Transl. Res. 160, 267–282 (2012).
Fettweis, J. M. et al. Differences in vaginal microbiome in African American women versus women of European ancestry. Microbiology 160, 2272–2282 (2014).
Holm, J. B. et al. Integrating compositional and functional content to describe vaginal microbiomes in health and disease. Microbiome 11, 259 (2023).
Beck, D. & Foster, J. A. Machine learning classifiers provide insight into the relationship between microbial communities and bacterial vaginosis. BioData Min. 8, 23 (2015).
Celeste, C. et al. Ethnic disparity in diagnosing asymptomatic bacterial vaginosis using machine learning. Npj Digit. Med. 6, 1–10 (2023).
Baker, Y. S., Agrawal, R., Foster, J. A., Beck, D. & Dozier, G. Detecting bacterial vaginosis using machine learning. in Proceedings of the 2014 ACM Southeast Regional Conference 1–4 (ACM, Kennesaw Georgia, 2014). https://doi.org/10.1145/2638404.2638521.
Beck, D. & Foster, J. A. Machine learning techniques accurately classify microbial communities by bacterial vaginosis characteristics. PLoS ONE 9, e87830 (2014).
Vela, M. B. et al. Eliminating explicit and implicit biases in health care: evidence and research needs. Annu. Rev. Public Health 43, 477–501 (2022).
Mackenbach, J. P. et al. Socioeconomic inequalities in health in 22 European countries. N. Engl. J. Med. 358, 2468–2481 (2008).
Phimphasone-Brady, P., Page, C. E., Ali, D. A., Haller, H. C. & Duffy, K. A. Racial and ethnic disparities in women’s mental health: a narrative synthesis of systematic reviews and meta-analyses of the US-based samples. Fertil. Steril. 119, 364–374 (2023).
Crear-Perry, J. et al. Social and structural determinants of health inequities in maternal health. J. Women’s. Health 2002 30, 230–235 (2021).
Wheeler, S. M. & Bryant, A. S. Racial and ethnic disparities in health and health care. Obstet. Gynecol. Clin. North Am. 44, 1–11 (2017).
Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447–453 (2019).
Giovanola, B. & Tiribelli, S. Beyond bias and discrimination: redefining the AI ethics principle of fairness in healthcare machine-learning algorithms. AI Soc. 38, 549–563 (2023).
Ferrara, E. Fairness and bias in artificial intelligence: a brief survey of sources, impacts, and mitigation strategies. Sci 6, 3 (2023).
Ferryman, K. Addressing health disparities in the Food and Drug Administration’s artificial intelligence and machine learning regulatory framework. J. Am. Med. Inform. Assoc. JAMIA 27, 2016–2019 (2020).
Fletcher, R. R., Nakeshimana, A. & Olubeko, O. Addressing fairness, bias, and appropriate use of artificial intelligence and machine learning in global health. Front. Artif. Intell. 3, 561802 (2021).
Paulus, J. K. & Kent, D. M. Predictably unequal: understanding and addressing concerns that algorithmic clinical prediction may increase health disparities. Npj Digit. Med. 3, 1–8 (2020).
Smith, M. J., Axler, R., Bean, S., Rudzicz, F. & Shaw, J. Four equity considerations for the use of artificial intelligence in public health. Bull. World Health Organ 98, 290–292 (2020).
Srinivasan, S. et al. Bacterial communities in women with bacterial vaginosis: high resolution phylogenetic analyses reveal relationships of microbiota to clinical criteria. PLoS One 7, e37818 (2012).
Baker, Y. S., Agrawal, R., Foster, J. A., Beck, D. & Dozier, G. Applying machine learning techniques in detecting bacterial vaginosis. Proc. Int. Conf. Mach. Learn. Cybern. Int. Conf. Mach. Learn. Cybern. 2014, 241–246 (2014).
Pérez-Gómez, J. F., Canul-Reich, J., Hernández-Torruco, J. & Hernández-Ocaña, B. Predictor selection for bacterial vaginosis diagnosis using decision tree and relief algorithms. Appl. Sci. 10, 3291 (2020).
Zheng, N., Guo, R., Wang, J., Zhou, W. & Ling, Z. Contribution of Lactobacillus iners to vaginal health and diseases: a systematic review. Front. Cell. Infect. Microbiol. 11, 792787 (2021).
Gardner, H. L. & Dukes, C. D. Haemophilus vaginalis vaginitis: a newly defined specific infection previously classified non-specific vaginitis. Am. J. Obstet. Gynecol. 69, 962–976 (1955).
Fredricks, D. N., Fiedler, T. L., Thomas, K. K., Oakley, B. B. & Marrazzo, J. M. Targeted PCR for detection of vaginal bacteria associated with bacterial vaginosis. J. Clin. Microbiol. 45, 3270–3276 (2007).
Zozaya-Hinchliffe, M., Lillis, R., Martin, D. H. & Ferris, M. J. Quantitative PCR assessments of bacterial species in women with and without bacterial vaginosis. J. Clin. Microbiol. 48, 1812–1819 (2010).
Aviles, A. G. P., Zaragoza, M. O. & Coria, A. I. Bacterial vaginosis a” broad overview”. Rev. Latinoam. Microbiol. -Mex. - 41, 25–34 (1999).
Khan, K. J., Shah, R., Gautam, M. & Patil, S. Clue cells. Indian J. Sex. Transm. Dis. AIDS 28, 108–109 (2007).
Acknowledgements
This publication was supported by the National Institute of General Medical Sciences, National Institutes of Health, through Grant Number R25GM143298. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH/NIGMS. The funder had no role in study design, data collection, data analysis, data interpretation, or writing of the manuscript.
Author information
Authors and Affiliations
Contributions
I.K.P. designed the study. R.F. and D.P.O. designed machine learning analysis and experimental setup. D.P.O., C.C., and D.M. prepared figures. D.P.O., C.C., and D.M. conducted the statistical analysis. I.K.P. and R.F. supervised the project. All authors contributed to the initial draft of the manuscript. All authors contributed critical revisions to the manuscript and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ojo, D.P., Celeste, C., Ming, D. et al. Population-level predictive variation in machine learning diagnosis of symptomatic bacterial vaginosis. npj Womens Health 3, 45 (2025). https://doi.org/10.1038/s44294-025-00092-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s44294-025-00092-w
