
Abstract
Comprehensively studying modifiable risk factors to understand their contributions to dementia mechanisms is imperative. This study used natural language processing (NLP) models to pre-select candidate risk factors for dementia from 5505 baseline variables in the UK Biobank. We then applied causal discovery approaches to examine the relationships among the selected variables and their links to dementia in later life, presenting these connections in a causal network. We identified eight risk factors that directly or indirectly influence dementia, with mental disorders due to brain dysfunction (ICD-10 F06) acting as direct causes and mediators in pathways from other neurological disorders to dementia. Although evidence for the direct link between biological age and dementia was less pronounced, its potential value in dementia management remains non-negligible. This study advances our understanding of dementia mechanisms and highlights the potential of NLP and machine learning for the causal discovery of complex diseases from high-dimensional data.
Similar content being viewed by others
Introduction
Dementia is an increasing global health threat, currently affecting over 55 million people worldwide1. The number is expected to triple by 2025, posing significant challenges to healthcare1. Identification of modifiable causal risk factors that could be the basis for the prevention of dementia is of increasing scientific interest.
Age is the known strongest risk factor for dementia2, which is however, non-modifiable. The concept of biological age has been introduced as a biomarker designed to capture the aging processes at the biological level more accurately than chronological age3. Phenotypic age, calculated from 10 biomarkers, is not only associated with chronological age but also closely linked to various bodily functions and disease risks4,5, These biological age measurements have demonstrated their potential to effectively predict both overall mortality and specific health outcomes like dementia, surpassing the predictive power of chronological age3.
The Lancet Commission has reported 14 modifiable risk factors for dementia6. In a comprehensive meta-analysis of over 800 reviews, Anstey et al. identified 39 dementia-associated risk factors, spanning lifestyle factors such as physical activity and diet, as well as medical conditions like stroke and renal disease7. However, the underlying causal mechanisms linking these risk factors to dementia remain unclear. To inform effective disease intervention, it is essential to systematically and objectively examine the potential pathways and interactions through which these factors may contribute to dementia.
Causality inference generally contain two aspects: 1) causal discovery exploring causal relationships by integrating prior knowledge with data structure, 2) causal estimation quantifying the strength and significance of causal relationships8. While prior knowledge is valuable, it is often inadequate for high-dimensional data where complex relationships and unmeasured confounders may exist. This study has focused on the causal discovery aspect.
In the era of big data9, causal discovery from high-dimensional observational data can be particularly challenging. It involves identifying causal connections among numerous variables while accounting for many potential confounders. To address this, advanced machine learning techniques have been developed, such as Double Machine Learning10 and frameworks based on Structural Causal Models11. However, these approaches primarily focus on causal estimation, assuming that all relevant confounders are observed—a strong assumption that cannot be verified using only observed data.
To overcome this limitation, causal discovery methods have emerged as powerful tools for uncovering causal structures when unmeasured confounders may be present. Fast Causal Inference (FCI)12 is a machine learning causal discovery approach designed to overcome the limitations of assuming that all confounders are observed. FCI operates by conducting a series of conditional independence tests. By identifying patterns of dependency and independence, FCI infers potential causal structures that account for hidden confounders, resulting in a Partial Ancestral Graph (PAG) that represents plausible causal connections consistent with the data13. These methods are emerging as powerful tools for efficiently identifying complex data structures, offering new evidence and insights into biological processes and disease etiology14.
Here, we exploited graphical and machine learning approaches to systematically examine how modifiable risk factors contribute to pathways to dementia collectively and map them out into a network. Additionally, two pre-trained information retrieval (IR) models15,16 were employed to select dementia-related factors from a large pool of variables in the UK Biobank, with the aim to evaluate whether natural language processing (NLP) models have the potential to help variable selection from extensive databases.
Results
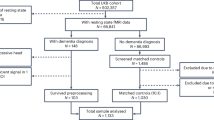
The workflow of the study is represented in Fig. 1. After pre-processing, we included 5505 variables as candidates for NLP model selection (Supplementary Table S1).

This workflow diagram illustrates the pre-processing and analysis steps of the study. Green box 1 details the variable selection step using natural language processing models. The variables initially filtered from the UK Biobank data dictionary are further selected using natural language processing models based on cosine similarity scores. Green Box 2 outlines the causal network analysis steps - Mixed Graphical Models and Fast Causal Inference are used to construct networks of dementia from each imputed dataset. The results are then pooled into a single comprehensive network of dementia.
Identified causal networks of dementia and risk factors
In total, 120 variables were included in the network analysis. Our analysis identified eight variables potentially closely contributing to dementia onset (Fig. 2). Among these, other mental disorders due to brain damage, dysfunctions, and to physical disease (ICD10-F06) consistently appeared to be direct contributor to dementia risks. These disorders also mediated the impact of other disorders of the brain, facial nerve disorders, and personality and behavioural disorders due to brain damage and dysfunction on dementia, with the possibility that these mediation associations might confounded by unobserved factors.

A With chronological age included. B With phenotypic age included instead of chronological age, using different agreement rate (pooling threshold) of 50 imputed datasets. A pooling threshold is, for each connected pair of variables, the percentage of the 50 datasets which identified the same relationships (100% -top, 50%-middle and 30%-bottom). Higher pooling threshold demonstrate more robust evidence of the associations. In each panel, the presence of an arrow “->” suggests a non-null relationship and its direction. The symbol “⟜ >” depicts three possible relationships between a pair of variables. For example, in a relationship denoted by A ⟜ > B, it is possible that 1) A directly causes B; or 2) the observed relationship between A and B is purely due to unmeasured confounding; or 3) A directly causes B, and there is unmeasured confounding between A and B.
In the network analysis including chronological age, we found strong evidence that chronological age directly affects dementia in all imputed datasets (pooling threshold = 100%). However, this relationship may be confounded by latent factors (Fig. 2A, top panel). Additionally, there was weaker evidence (present in more than 30% but less than 50% of the imputed datasets) suggesting that mental and behaviour disorders due to opioid use may contribute to dementia risk (Fig. 2A, bottom panel). When chronological age was replaced with phenotypic age, we found suggestive evidence that phenotypic age was directly associated with dementia, and acted as a mediator on the pathway from ever having had bowel cancer screening to dementia (Fig. 2B, bottom panel).
Besides the pathways directly linked to dementia, consistent associations across 57 variables that might reveal interesting pathways among the diseases or risk factors related to dementia were observed. A comprehensive list of the inferred pairwise relationships from each dataset is provided in Supplementary Tables S2 and S3, with an explanation of variable indices in Supplementary Table S4.
Performance of variable selection using language model
The IR models selected 344 candidate variables (Supplementary Table S5, Supplementary Fig. S1), which were mapped into 24 dementia risk factor categories based on their literal meaning7 (Table 1). Of the initial 40 dementia risk factor-related phrases (Supplementary Table S6), 10 were either not present in the UK Biobank variable list (e.g., bilingualism) or were only applicable to certain groups (e.g., hormone replacement therapy (HRT), relevant only to females) and were therefore removed from quality control (QC). Therefore, the IR model failed to identify variables related to 6 risk factors, that were “Education”, “BMI”, “Carotid atherosclerosis”, “TBI”, “hypotension” and “Anti-inflammatories”. Overall, the IR models successfully selected variables linked to 24 out of 30 manually identifiable dementia risk factors (accuracy = 0.80) from an initial pool of 5505 variables.
Discussion
We identified diseases classified under ICD10-F60, which specifically designates mental disorders resulting from brain damage and dysfunction17, as direct contributors to dementia risk. As expected, disorders under the category may directly progress to dementia, directly increase dementia risks or share the common causal pathways with dementia. For example, mild cognitive disorder under ICD10-F60 category can progress to dementia18. Additionally, vascular degeneration or brain illnesses can lead to both mental disorders19,20 and the development of dementia21,22,23 while mental disorders could also increase the risk of dementia24.
In addition, we identified three variables --‘other disorders of the brain’ (ICD10-G93), ‘facial nerve disorders’ (ICD10-G51), and ‘personality and behavioural disorders due to brain disease, damage, and dysfunctions’ (ICD10-F07), may directly affect disorders in ICD10-F60, and subsequently affect dementia, though the relationships might be confounded by unobserved factors. Each of the variable, represents a broad spectrum of disease conditions, of which many are rare. This rarity has resulted in limited literature support for some of the specific links observed in our analysis. Moreover, brain damage related to opioid use emerged as a potential, albeit weaker, contributor to dementia risk. Opioid use has been previously associated with an increased risk of dementia25,26, though our findings do not rule out the possibility of unobserved confounding influencing this relationship.
Nevertheless, all these variables are related to nerve or brain damage disorders, which showed the most direct connections to dementia. This suggested that neurological disorders may play a more immediate role in dementia onset compared to other risk factors and could be prioritized for targeted interventions. Furthermore, the clustering of various mental and neurological disorders indicates that these conditions may be linked to dementia through multiple pathways (e.g., Frontetemporal dementia27. Additionally, interactions among these disorders may collectively contribute to the development of dementia.
Besides disorders of the nervous system, our study identified chronological age as another direct cause to dementia, with a possible presence of unobserved confounding. This is concordant with existing research findings which acknowledge that age is the known strongest risk factor for dementia2 but not an absolute cause28. When age was replaced by phenotypic age —a biomarker that accounts for both chronological age and other physiological conditions, the association between dementia and phenotypic age, although less pronounced, was not confounded. Previous studies showed that clinical biomarker-based biological age was associated with the risk of dementia as well as other neurological disorders29. Recently developed biological age metrics derived from other omics data have also demonstrated strong performance in predicting dementia risk30. Our findings suggested that while chronological age itself may not have a direct impact on dementia, an individual’s overall health status in combination with their age may directly influence the risk of dementia. Though this marker may contain more variability and potential noise compared to the absolute chronological age. More importantly, unlike chronological age, biological age is potentially modifiable through lifestyle changes, such as increased physical activity, offering valuable opportunities for dementia prevention and management. Consequently, biological ages may hold greater promise in predicting and mitigating dementia risk.
In addition, pathways identified that were not directly linked to dementia may still provide valuable biological insights. For example, one pathway traced the progression from feelings of depression to seeking treatment and consulting a doctor (V55- > V61- > V20- > V21) (Supplementary Figs. S2 and S3). This sequence is logical, as patients often start with experiencing symptoms, followed by receiving medication and consulting healthcare providers.
While most of our findings align with existing evidence in the literature, some relationships identified in this study warrant further investigation. For example, although several studies have linked changes in total cholesterol levels to the later development of diabetes31,32, it remained important to validate the specific association we found between blood cholesterol levels and diabetes (V5- > V40) in independent studies.
Notably, some well-established dementia risk factors33, such as high-density lipoprotein, hearing loss, physical activity, and diabetes, appeared in the pooled causal network but were linked to dementia only indirectly, through multiple other variables such as age, metabolic rate, and sex, and potential latent factors. This may suggest that, unlike direct contributors to dementia such as brain injury, these risk factors may influence dementia through more complex pathways, potentially making the effects of interventions on these factors less straightforward. Additionally, certain known risk factors (e.g., education33) did not appear in the network graph of dementia. This absence of direct paths could be due to the potential unobserved confounding and/or mediation, limited statistical power, or uncertainty introduced through data imputation.
The FCI algorithm was designed to explore directional causal relationships between variables, but not inherently estimate the magnitude of effects. Importantly, it has the capacity of detecting unmeasured confounding, represented by bidirected edges in the inferred causal graphs. The presence of unmeasured confounding may lead to biased relationships, making it difficult to accurately quantify causal effects.
To move beyond causal discovery, effect sizes can be estimated using various techniques once causal graphs are constructed. For example, G-methods and Double Machine Learning can be used to estimate average treatment effect while adjusting for confounders34, while Bayesian Networks and Structural Equation Models can be considered for complex causal relationships35. In future research, integrating these methods with causal discovery will provide more comprehensive understanding of disease mechanisms and guide more effective disease management strategies.
By pooling results from multiple imputed datasets and setting different pooling thresholds for each pair of associations, we took into account the variation across imputed datasets and looked at the generalized overview of the networks. Here we assumed each imputed dataset contributes consistently and equally to the inference of pairwise relationships, which is difficult to test but serves as a pragmatic approach given the lack of explicit variance information or weighting criteria graphical models in the imputed datasets. Future research could benefit from enhanced pooling strategies that address both inter- and intra-group variations.
The NLP models provided a novel, effective, and efficient approach for selecting candidate variables from a large pool for downstream analysis. Unlike traditional methods that rely on background knowledge36, or standard data-driven feature selection techniques37, we provided a new data-driven strategy that does not depend directly on the original dataset. This helps avoid common issues such as overfitting, limited power, lack of generalizability and subjective bias, allowing us to expand our exploration into previously uncharted variables and potential unknowns.
However, the application is still in its early stages, with substantial room for improvement in the future. The IR model selection accurately identified 24 out of 30 manually recognizable dementia risk factors from an initial pool of 5505 variables. For risk factors not identified by the model, one possible reason could be variations in phrase abbreviations or formats that introduced ambiguity. While some of the selected IR models (such as Word2Vec and GloVe) store uppercase and lowercase terms separately15,16 they primarily operate in a case-insensitive manner, having been trained on mostly lowercase corpora. As a result, we applied standard preprocessing steps, including lowercasing all text, removing punctuation, and filtering out stopwords, as shown in Supplementary Figure S4. However, lowercasing can introduce ambiguity—for example, “US” and “us” carry different meanings yet become indistinguishable after lowercasing. Therefore, future work could explore case-sensitive models (e.g., BERT38) or alternative tokenization techniques to better preserve the semantic integrity of medical terms and improve text representation.
Furthermore, the IR model occasionally introduced noise. For example, it selected phrases like ‘Carotid ultrasound authorization,’ interpreting them as similar to cardiovascular disease, reflecting limitations in contextual understanding and semantic relevance. Approximately 16.8% of the selected variables could not be classified as dementia risk factors, suggesting potential inaccuracies in the IR model. However, this discrepancy might also suggest that our understanding of dementia risk factors is incomplete; variables initially considered irrelevant could be associated with dementia through latent, unknown factors.
Finally, the accuracy of pre-trained models is significantly affected by the databases they are trained on. Some variables received very low similarity scores, likely due to their infrequent occurrence in the source databases (e.g., “avMSE”, Supplementary Tables S7 and S8). Our models were trained on general-purpose databases like Google News and Wikipedia, which understandably differ from the specialized language used in medical research journals. By incorporating general-purpose language models trained on real-world text, we aimed to explore whether daily discourse and public discussions might highlight overlooked or emerging dementia risk factors that have yet to be systematically investigated. Future development of models trained specifically on electronic health records39, as well as further exploration of these approaches, could greatly enhance accuracy and relevance for medical research applications.
Due to a low prevalence of dementia in the UK Biobank, the term ‘dementia’ in our study is not subcategorised to its subtypes40. While subtypes like Alzheimer’s disease, vascular dementia, and Lewy body dementia share certain characteristics, they are believed to have distinct pathways41. Combining these conditions into the umbrella term ‘dementia’ could bring risks of overlooking the heterogeneity between subtypes, potentially leading to biases in the findings. When data collected from more dementia cases become available, it will be important to perform stratified analysis for the subtypes.
In conclusion, the identified causal network found several risk factors may closely contribute to dementia onset, offering valuable insights into the disease’s mechanisms. Beyond direct connections to brain illness, the potential direct link with biological age highlighted its possible value in dementia management. Moreover, the use of NLP models for variable selection introduced an innovative application in medical research, highlighting a promising future for advanced tools in large-scale data analyse.
Methods
Data
The UK Biobank comprises a large cohort of over 500,000 participants aged between 40 and 6942. The database contains 9079 variables collected from 2006 to June 2023 (https://biobank.ndph.ox.ac.uk/showcase/exinfo.cgi?src=AccessingData). We utilized the ‘algorithm defined all-cause dementia’ to identify dementia cases. This definition incorporated data from baseline assessments, as well as linked data from hospital admissions and death registries43. The cohort was accessed in July 2023.
To ensure a temporal order for causal inference in this prospective study design, we excluded individuals diagnosed with dementia prior to recruitment (N = 177). Dementia outcomes were categorized based on the timing of diagnosis: within two years post-recruitment, more than two years post-recruitment, or none. All other variables were collected at baseline, with other disease variables only considered if they were diagnosed or reported before baseline. Our goal is to focus on modifiable risk factors for both genders. Thus, we filtered out variables related to genomics, imaging, dementia-associated health outcomes, and gender-specific health outcomes (examples of the field can be found in Supplementary Note S1). This left 5505 variables for further filtering.
Variable selection
Typically, pre-selection of dementia risk factors were either based on clinical knowledge/experience36, or through data-driven methods like LASSO regression37. The first approach, while grounded in expert knowledge, can be subjective and may overlook unknown features, especially in large datasets with numerous variables, such as the UK Biobank. In contrast, the traditional data-driven methods offer more objectivity but can result in variable selection influenced by confounders or highly correlated variables, which can lead to overfitting and reduce generalizability due to dataset-specific biases44.
Here, we novelly used pre-trained NLP models to select variable names that appeared ‘similar to’ dementia and its known risk factors7. Specifically, ‘similarity’ in this context refers to the semantic and contextual likeness that NLP models can identify between different words or phrases. Two IR models Word2Vec15 and Doc2Vec16 were used to understand and quantify the relationships between ‘terms’. Forty dementia-related phrases from literature7 were used as input phrases (Supplementary Table S6). We used cosine similarity score to determine the similarity between the potential variable names and the target dementia-related phrases (Supplementary Figs. S5 and S6).
Four word2vec models (‘word2vec-google-news-300’, ‘glove-wiki-gigaword-300’, ‘glove-twitter-200’ and ‘fasttext-wiki-news-subwords-300’) and two doc2vec models (‘English Wikipedia DBOW’ and ‘Associated Press News DBOW’) were trained from sources such as Google News, Wikipedia and Twitter. Details of the model information can be found at https://github.com/RaRe-Technologies/gensim-data and https://github.com/jhlau/doc2vec#pre-trained-doc2vec-models. The IR models were implemented with the Genism library in Python (v 3.9). Illustration and examples of the IR model selection can be found in Supplementary Note S2.
Data pre-processing and quality control
For the variables selected by IR models, we further proceeded pre-processing and multi-stage QC, including adding key variables, processing ICD-10 coded health-related traits, removing non-analysable variables, addressing variables with multiple arrays, low-frequency categories and high missing rate. Examples of the QC step can be found in Supplementary Note S3 and S4. We manually reviewed these variables to assess the IR model’s performance, ensuring that any dementia risk factors not selected by IR models were added. Additionally, gender and age were included to enhance robustness. Considering chronological age is an important but non-modifiable risk factor of dementia, we also used phenotypic age as a proxy of biological age4,5, in parallel analysis. Unlike chronological age, phenotypic age reflects both age and disease risk45, and importantly, is modifiable, making it more suitable for an interventional causal framework46. Continuous variables were standardised by mean and standard deviation. The phenotypic age was calculated by 10 biomarkers from UK Biobanks using R package ‘BioAge’. Details of the variables and weight can be found in Supplementary Table S9.
The sample QC filtered out individuals with mismatched gender, and related individuals, as well as the individuals with dementia diagnosis before recruitment. After these filtering steps, 406,837 participants were included in our analysis, among which 6057 were dementia cases and 400,780 were controls (Table 2). Missing data in the cohort were imputed using multivariate imputation by chained equations (MICE) with random forest47. We set the missing rate threshold at 0.75, to ensure the retained variables exhibit a consistent pattern of missingness (Supplementary Fig. S7). As we allowed a relatively high missing rate, the number of imputed datasets was set to 50 to well capture the original distribution of those variables with incomplete data. Data imputation was performed using MICE package in R (v 4.1.0).
Statistical analyses
As FCI is computationally intensive48, we firstly applied Mixed Graphical Models (MGM)49 to rapidly infer the data structure among all selected variables. This process resulted in a skeleton structure with undirected edges between variables that represent associations without implying any directions. The skeleton structure was used as prior knowledge to inform the initial structure in the FCI algorithm50. Detailed illustration of FCI and MGM was in Supplementary Note S5.
In the FCI analysis, we added an additional constraint based on the cohort’s temporal order, ensuring that dementia was not considered a cause of any other variable. Additionally, we specified that no variable could be treated as a cause of age or gender, using a ‘forbidden’ list within the FCI algorithm. False discovery rate was used to correct for multiple testing51. For computational efficiency, we utilized a streamlined version of FCI, known as Fast Causal Inference-Max (FCI-MAX), to deduce the final network48. The implementation of the analysis was performed using the ‘rCausalMGM’ package in R.
Results pooling from imputed datasets
In the output Partial Ancestral Graph (PAG), nodes represent variables (e.g., smoking), while edges indicate potential directional associations between them48. From FCI algorithm, four types of relationships between variables can be inferred from the observational data. Illustration of each association/edge type inferred from the FCI algorithm can be found in Supplementary Note S6. To aggregate the output from each imputed dataset, we pooled results by assigning equal weights to pairwise relationships identified across datasets. Specifically, we retained associations that the FCI algorithm consistently identified, including only those present in at least 30%, 50%, or all datasets in our final model. To further refine the results, the detected structure was concentrated to highlight variables that have a direct or indirect influence on dementia onset.
Data availability
Publicly available data from the UK Biobank study was analysed in this study. The datasets are available to researchers through an open application via https://www.ukbiobank.ac.uk/enable-your-research/register.
References
Nichols, E. et al. Estimation of the global prevalence of dementia in 2019 and forecasted prevalence in 2050: an analysis for the Global Burden of Disease Study 2019. Lancet Public Health 7, e105–e125 (2022).
Abbott, A. Dementia: A problem for our age. Nature, 475, 7355, (2011).
Wu, J.W. et al. Biological age in healthy elderly predicts aging-related diseases including dementia. Sci. Rep. 11, 15929 (2021).
Levine, M.E. et al. An epigenetic biomarker of aging for lifespan and healthspan. Aging 10, 573–591 (2018).
Liu, Z. et al. A new aging measure captures morbidity and mortality risk across diverse subpopulations from NHANES IV: A cohort study. PLOS Med. 15, e1002718 (2018).
Livingston, G. et al. Dementia prevention, intervention, and care: 2024 report of the Lancet standing Commission. Lancet 404, 572–628 (2024).
Anstey, K.J., Ee, N., Eramudugolla, R., Jagger, C. & Peters, R. A Systematic Review of Meta-Analyses that Evaluate Risk Factors for Dementia to Evaluate the Quantity, Quality, and Global Representativeness of Evidence. J. Alzheimers Dis. 70, S165–S186 (2019).
Lin, S.-H. & Ikram, M.A. On the relationship of machine learning with causal inference. Eur. J. Epidemiol. 35, 183–185 (2020).
Beam, A.L. & Kohane, I.S. Big Data and Machine Learning in Health Care. JAMA 319, 1317–1318 (2018).
Chernozhukov, V. et al. Double/debiased machine learning for treatment and structural parameters. Econ. J. 21, C1–C68 (2018).
Bongers, S., Forré, P., Peters, J. & Mooij, J.M. Foundations of structural causal models with cycles and latent variables. Ann. Stat. 49, 2885–2915 (2021).
Spirtes, P. Glymour, C. N. & Scheines, R. Causation, Prediction, and Search (MIT Press, 2000).
Shen, X., Ma, S., Vemuri, P. & Simon, G. Challenges and Opportunities with Causal Discovery Algorithms: Application to Alzheimer’s Pathophysiology. Sci. Rep. 10, 1, (2020).
Kelly, J., Berzuini, C., Keavney, B., Tomaszewski, M. & Guo, H. A review of causal discovery methods for molecular network analysis. Mol. Genet. Genom. Med. 10, e2055 (2022).
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, https://doi.org/10.48550/arXiv.1301.3781 (2013).
Lau, J. H. & Baldwin, T. An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation. arXiv 18, https://doi.org/10.48550/arXiv.1607.05368 (2016).
ICD-10 Version:2019. Available: https://icd.who.int/browse10/2019/en#/F06.9 (2024).
Knopman, D.S. & Petersen, R.C. Mild Cognitive Impairment and Mild Dementia: A Clinical Perspective. Mayo Clin. Proc. 89, 1452–1459, (2014).
Stangeland, H., Orgeta, V. & Bell, V. Poststroke psychosis: a systematic review. J. Neurol. Neurosurg. Psychiatry 89, 879–885 (2018).
Skajaa, N. et al. Stroke and Risk of Mental Disorders Compared With Matched General Population and Myocardial Infarction Comparators. Stroke 53, 2287–2298 (2022).
Vascular dementia - Symptoms and causes. Mayo Clinic. Available: https://www.mayoclinic.org/diseases-conditions/vascular-dementia/symptoms-causes/syc-20378793 (Accessed 2024).
Howlett, J.R., Nelson, L.D. & Stein, M.B. Mental health consequences of traumatic brain injury. Biol. Psychiatry 91, 413–420 (2022).
Graham, N.S. & Sharp, D.J. Understanding neurodegeneration after traumatic brain injury: from mechanisms to clinical trials in dementia. J. Neurol. Neurosurg. Psychiatry 90, 1221–1233 (2019).
Richmond-Rakerd, L.S., D’Souza, S., Milne, B.J., Caspi, A. & Moffitt, T.E. Longitudinal Associations of Mental Disorders With Dementia: 30-Year Analysis of 1.7 Million New Zealand Citizens. JAMA Psychiatry 79, 333–340 (2022).
Dublin, S. et al. Prescription Opioids and Risk of Dementia or Cognitive Decline: A Prospective Cohort Study. J. Am. Geriatrics Soc. 63, 1519–1526 (2015).
Levine, S.Z., Rotstein, A., Goldberg, Y., Reichenberg, A. & Kodesh, A. Opioid Exposure and the Risk of Dementia: A National Cohort Study. Am. J. Geriatr. Psychiatry 31, 315–323 (2023). no. 5.
Frontotemporal dementia - Symptoms and causes. Mayo Clinic. Available: https://www.mayoclinic.org/diseases-conditions/frontotemporal-dementia/symptoms-causes/syc-20354737 (Accessed 2024).
WHO. Dementia. ttps://www.who.int/news-room/fact-sheets/detail/dementia (2023).
Mak, J. K. L., McMurran, C.E. & Hägg, S. Clinical biomarker-based biological ageing and future risk of neurological disorders in the UK Biobank. J. Neurol Neurosurg. Psychiatry, https://doi.org/10.1136/jnnp-2023-331917 (2023).
Argentieri, M.A. et al. Proteomic aging clock predicts mortality and risk of common age-related diseases in diverse populations. Nat. Med. 30, 2450–2460 (2024).
Rhee, E.-J., Han, K., Ko, S.-H., Ko, K.-S. & Lee, W.-Y. Increased risk for diabetes development in subjects with large variation in total cholesterol levels in 2,827,950 Koreans: A nationwide population-based study. PLOS ONE 12, e0176615 (2017).
Seo, M.H. et al. Association of Lipid and Lipoprotein Profiles with Future Development of Type 2 Diabetes in Nondiabetic Korean Subjects: A 4-Year Retrospective, Longitudinal Study. J. Clin. Endocrinol. Metab. 96, E2050–E2054 (2011).
Livingston, G. et al. Dementia prevention, intervention, and care: 2020 report of the Lancet Commission. Lancet 396, 413–446 (2020).
Moccia, C. et al. Machine learning in causal inference for epidemiology. Eur. J. Epidemiol. 39, 1097–1108 (2024).
Gupta, S. & Kim, H.W. Linking structural equation modeling to Bayesian networks: Decision support for customer retention in virtual communities. Eur. J. Operational Res. 190, 818–833 (2008). no. 3.
You, J. et al. Development of a novel dementia risk prediction model in the general population: A large, longitudinal, population-based machine-learning study. eClinicalMedicine, 53, https://doi.org/10.1016/j.eclinm.2022.101665 (2022).
Anatürk, M. et al. Development and validation of a dementia risk score in the UK Biobank and Whitehall II cohorts. BMJ Ment. Health, 26, e300719 (2023).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv, https://doi.org/10.48550/arXiv.1810.04805, (2019)
Li, Y. et al. BEHRT: Transformer for Electronic Health Records. Sci. Rep. 10, 7155 (2020).
Goodman, R.A. et al. Prevalence of dementia subtypes in United States Medicare fee-for-service beneficiaries, 2011–2013. Alzheimers Dement. 13, 28–37 (2017).
Maclin, J.M.A., Wang, T. & Xiao, S. Biomarkers for the diagnosis of Alzheimer’s disease, dementia Lewy body, frontotemporal dementia and vascular dementia. Gen. Psychiatr. 32, e100054 (2019).
Sudlow, C. et al. UK Biobank: An Open Access Resource for Identifying the Causes of a Wide Range of Complex Diseases of Middle and Old Age. PLOS Med. 12, e1001779 (2015).
alg_outcome_dementia.pdf. Available: https://biobank.ndph.ox.ac.uk/ukb/ukb/docs/alg_outcome_dementia.pdf. Accessed: Aug. 06, 2024.
Bleeker, S.E. et al. External validation is necessary in prediction research: A clinical example. J. Clin. Epidemiol. 56, 826–832 (2003).
Mak, J. K. L. et al. Clinical biomarker-based biological aging and risk of cancer in the UK Biobank. Br J Cancer, 129, 1, (2023).
Imbens, G.W. & Rubin, D. B. Rubin Causal Model. In Microeconometrics (eds, Durlauf, S. N. & Blume, L. E.) 229–241 (Palgrave Macmillan UK, 2010), https://doi.org/10.1057/9780230280816_28.
Shah, A. D., Bartlett, J. W., Carpenter, J., Nicholas, O. & Hemingway, H. Comparison of Random Forest and Parametric Imputation Models for Imputing Missing Data Using MICE: A CALIBER Study. Am. J. Epidemiol. 179, 764–774 (2014).
Raghu, V.K. et al. Comparison of strategies for scalable causal discovery of latent variable models from mixed data. Int. J. Data Sci. Anal. 6, 33–45 (2018).
Sedgewick, A.J., Shi, I., Donovan, R. M. & Benos, P. V. Learning mixed graphical models with separate sparsity parameters and stability-based model selection. BMC Bioinformatics, 17, S175 (2016)
Glymour, C., Zhang, K. & Spirtes, P. Review of Causal Discovery Methods Based on Graphical Models. Front. Genet. 10, https://doi.org/10.3389/fgene.2019.00524 (2019).
Benjamini, Y. & Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B 57, 289–300 (1995).
Acknowledgements
This study used the UK Biobank application number 94719. We would like to thank the UK Biobank participants and staff for data access. The research leading to the results presented in this paper has received funding from the UKRI -Project 10103541: Prediction, Monitoring and Personalized Recommendations for Prevention and Relief of Dementia and Frailty and is conducted in the context of COMFORTage project that is funded by the European Union's Horizon Europe research and innovation programme under grant agreement no. 101137301. The COMFORTage project is funded from the European Union’s Horizon Europe research and innovation programme under the grant agreement No 101137301. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the Health and Digital Executive Agency. Neither the European Union nor the granting authority can be held responsible for them. Hui Guo acknowledges support of the UKRI AI programme, and the Engineering and Physical Sciences Research Council, for CHAI - Causality in Healthcare AI Hub [grant number EP/Y028856/1].
Author information
Authors and Affiliations
Contributions
X.Y. and H.G. designed the study. X.Y. and V.H. performed the analyses and wrote the first draft. H.G., K.M. and A.L. supervised the project. H.G. supervised the statistical analysis. All authors contributed to the interpretation of the results and reviewed and edited the manuscript. All authors have read and approved the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, X., Lophatananon, A., Holmes, V. et al. Investigating causal networks of dementia using causal discovery and natural language processing models. npj Dement. 1, 4 (2025). https://doi.org/10.1038/s44400-025-00006-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s44400-025-00006-2
