
Abstract
Background
This study presents a comprehensive evaluation of the performance of various large language models in generating responses for ophthalmology emergencies and compares their accuracy with the established United Kingdom’s National Health Service 111 online system.
Methods
We included 21 ophthalmology-related emergency scenario questions from the NHS 111 triaging algorithm. These questions were based on four different ophthalmology emergency themes as laid out in the NHS 111 algorithm. Responses generated from NHS 111 online, were compared to different LLM-chatbots responses to determine the accuracy of LLM responses. We included a range of models including ChatGPT-3.5, Google Bard, Bing Chat, and ChatGPT-4.0. The accuracy of each LLM-chatbot response was compared against the NHS 111 Triage using a two-prompt strategy. Answers were graded as following: −2 graded as “Very poor”, −1 as “Poor”, O as “No response”, 1 as “Good”, 2 as “Very good” and 3 graded as “Excellent”.
Results
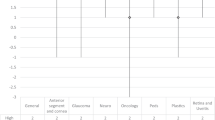
Overall LLMs’ attained a good accuracy in this study compared against the NHS 111 responses. The score of ≥1 graded as “Good” was achieved by 93% responses of all LLMs. This refers to at least part of this answer having correct information as well as absence of any wrong information. There was no marked difference and very similar results seen overall on both prompts.
Conclusions
The high accuracy and safety observed in LLM responses support their potential as effective tools for providing timely information and guidance to patients. LLMs hold promise in enhancing patient care and healthcare accessibility in digital age.
This is a preview of subscription content, access via your institution
Access options
Subscribe to this journal
Receive 18 print issues and online access
$259.00 per year
only $14.39 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout



Similar content being viewed by others

Data availability
Data supporting the findings of this study are available upon written request to the corresponding author.
References
Bates DW, Levine D, Syrowatka A, Kuznetsova M, Craig KJT, Rui A, et al. The potential of artificial intelligence to improve patient safety: a scoping review. NPJ Digit Med. 2021;4:54 https://doi.org/10.1038/s41746-021-00423-6.
Matheny ME, Whicher D, Thadaney Israni S. Artificial intelligence in health care: a report from the national academy of medicine. JAMA. 2020;323:509–10. https://doi.org/10.1001/jama.2019.21579.
Jiang X, Xie M, Ma L, Dong L, Li D. International publication trends in the application of artificial intelligence in ophthalmology research: an updated bibliometric analysis. Ann Transl Med. 2023;11:219.
OpenAI ChatGPT (Mar 13 version) [Large language model] Available at: https://openai.com/blog/chatgpt [Accessed Aug 13, 2023].
Bard, an experiment by Google (Mar 21 version). Available at: https://bard.google.com/. [Accessed August 13, 2023].
Microsoft Bing Chat (Feb 7 version). Available at: https://www.bing.com/new. [Accessed Aug 13, 2023].
[Internet]. NHS; [cited 2023 Aug 13]. Available from: https://www.nhs.uk/nhs-services/urgent-and-emergency-care-services/when-to-use-111/how-nhs-111-online-works/?_id=111Website.
[Internet]. NHS; [cited 2023 Aug 15]. Available from: https://digital.nhs.uk/services/nhs-111-online/nhs-111-online-is-a-class-1-medical-device.
Levine DM, Tuwani R, Kompa B, Varma A, Finlayson SG, Mehrotra A, et al. The diagnostic and triage accuracy of the GPT-3 artificial intelligence model: an observational study. Lancet Digit Health. 2024;6:e555–e561.
Moor M, Banerjee O, Abad ZSH, Krumholz HM, Leskovec J, Topol EJ, et al. Foundation models for generalist medical artificial intelligence. Nature. 2023;616:259–65.
Kung TH, Cheatham M, Medenilla A, Sillos C, De Leon L, Elepaño C, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digit Heal. 2023;2:e0000198.
Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, Chung HW. et al. Large language models encode clinical knowledge [published correction appears in Nature.Nature.2023;620:172–80.
Raimondi R, Tzoumas N, Salisbury T, Simplicio SD, Romano MR, et al. Comparative analysis of large language models in the Royal College of Ophthalmologists fellowship exams. Eye (2023). https://doi.org/10.1038/s41433-023-02563-3.
Singhal K, Tu T, Gottweis J, Sayres R, Wulczyn E, Amin M, et al. Towards expert-level medical question answering with large language models. Nat Med. (2025). https://doi.org/10.1038/s41591-024-03423-7.
Cappellani F, Card KR, Shields CL, Pulido JS, Haller JA Reliability and accuracy of artificial intelligence ChatGPT in providing information on ophthalmic diseases and management to patients. Eye (2024). https://doi.org/10.1038/s41433-023-02906-0.
Bsharat SM, Myrzakhan A, Shen Z Principled instructions are all you need for questioning LLaMA-1/2, GPT-3.5/4, principled instructions are all you need for questioning llama-1/2, GPT-3.5/4. Available at: https://arxiv.org/html/2312.16171v2 (Accessed: 19 April 2024).
Sallam M.ChatGPT utility in healthcare education, research, and practice: Systematic review on the promising perspectives and valid concerns.Healthcare.2023;11:887.
Author information
Authors and Affiliations
Contributions
Chrishan Gunasekera (CG) was responsible for the study conception and design. Shaheryar Ahmed Khan (SAK) was involved with the study design, data collection, and literature review. CG and SAK were responsible for data analysis and interpretation of results. Both the authors contributed to draft manuscript preparation, reviewed the results, and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Khan, S.A., Gunasekera, C. “Comparative analysis of large language models against the NHS 111 online triaging for emergency ophthalmology”. Eye 39, 1301–1308 (2025). https://doi.org/10.1038/s41433-025-03605-8
Received:
Revised:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41433-025-03605-8
