
Fig. 1: Chip architecture.
From: An analog-AI chip for energy-efficient speech recognition and transcription
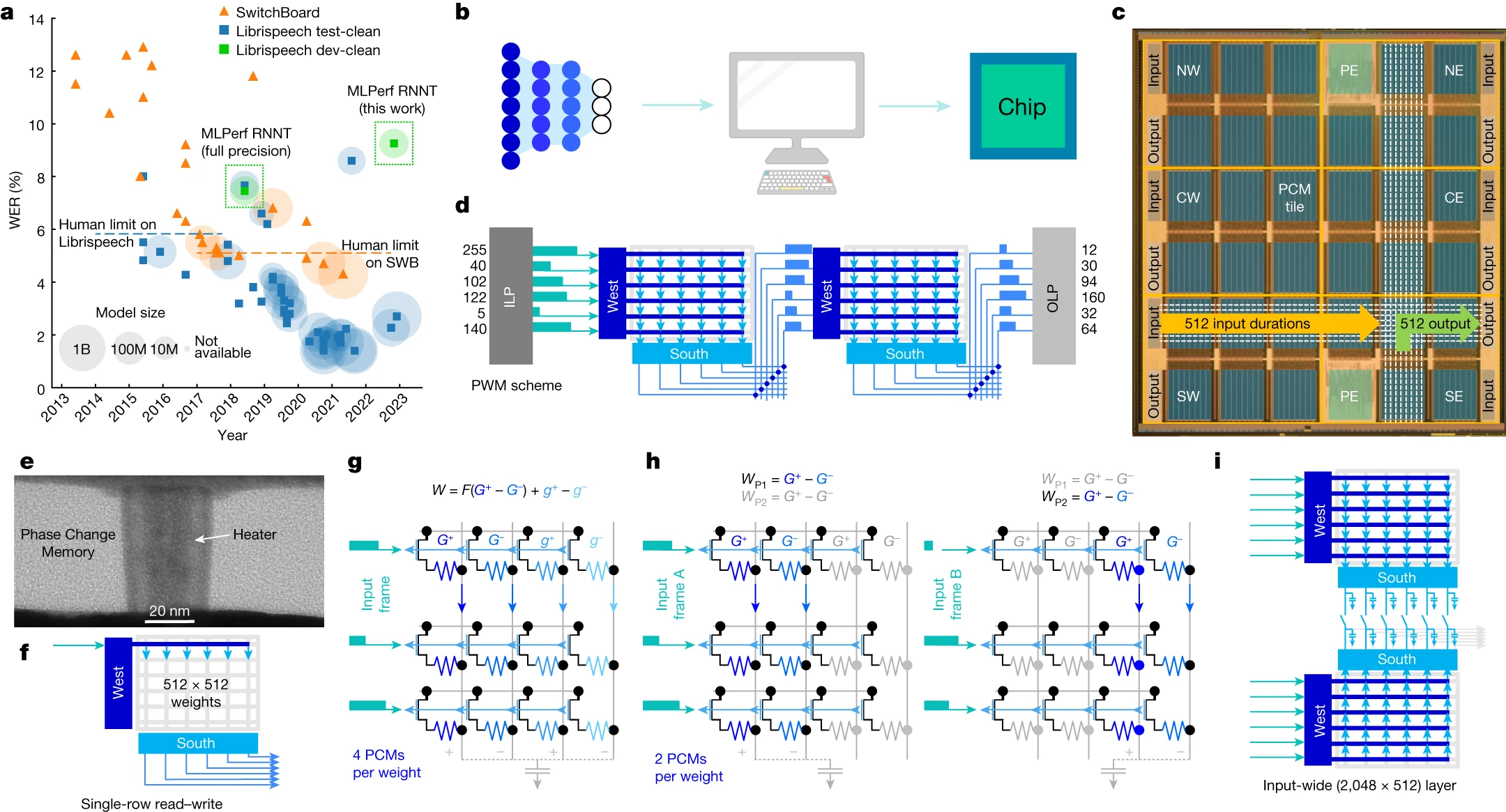
a, Speech recognition has improved markedly over the past 10 years, driving down the WER for both the Librispeech and SwitchBoard (SWB) datasets, thanks to substantial increases in model size and improved networks, such as RNNT or transformer. For comparison with our results, the MLPerf RNNT full-precision WER is shown for two Librispeech datasets (‘test-clean’ and ‘dev-clean’)8, along with this work’s WER, which was computed on Librispeech dev-clean. For model size: B, 1 billion; M, 1 million. b, Inference models are trained using popular frameworks such as PyTorch or TensorFlow. Further optimization for analog AI can be achieved with the IBM analog HW acceleration kit (https://aihwkit.readthedocs.io/en/latest/). c, Trained model weights are then used on a 14-nm chip with 34 analog tiles, two processing elements (PE, not used for this work) and six ILP–OLP pairs. Tiles are labelled as north (N), centre (C) or south (S) followed by west (W) or east (E). d, Each ILP converts 512 8-bit inputs into 512 element vectors of pulse-modulated durations, which are then routed to the analog tiles for integration using a fully parallel 2D mesh that allows multi-casting to multiple tiles. After MAC, the charge on the peripheral capacitors is converted into durations4 and sent either to other tiles, leading to new MACs, or to the OLP, where durations are reconverted into 8-bit representations for off-chip data-processing. e, Transmission Electron Microscopy (TEM) image of one PCM. f, Each tile contains a crossbar array with 512 × 2,048 PCMs, programmed using a parallel row-wise algorithm4. g, PCMs can be organized in a 4-PCM-per-weight configuration, with G+, g+ adding and G−, g− subtracting charge from the peripheral capacitor, with a significance factor F (which is 1 in this paper). h, Alternatively, they can have a 2-PCM-per-weight configuration, which achieves a higher density. By reading different input frames through weights WP1 or WP2, a single tile can map 1,024 × 512 weight layers. i, Finally, two adjacent tiles can share their banks of 512 peripheral capacitors, enabling integration in the analog domain across 2,048 input rows.
