
Abstract
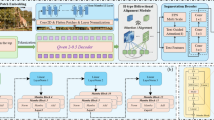
Video Moment Retrieval (VMR) serves as a fundamental task in video understanding, bridging vision and language by localizing the most relevant temporal segments in untrimmed videos according to a textual query. However, existing approaches excel at fine-grained alignment but often fail to capture global temporal context effectively, particularly in long-form videos. To address this challenge, we propose Hybrid Mamba Network (HM-Net), a two-level fusion architecture which unifying the strengths of attention and sequence modeling. Especially, its core lies in the Hybrid Modulated Bi-Mamba (HMB) Block, which integrates the powerful temporal modeling capability of Mamba into the VMR framework to achieve effective long-range temporal reasoning. Extensive experiments on the challenging TACoS and QVHighlights benchmarks show that HM-Net consistently outperforms existing approaches, achieving 3.84% improvement in R1@0.5 (TACoS) and 1.65% in mAP (QVHighlights), demonstrating notable gains in localization accuracy, particularly on long-form videos.
Similar content being viewed by others


Data availability
The datasets used and analysed during the current study are available in the following repositories: The TACoS dataset is available at https://zenodo.org/records/15379789. The QVHighlights dataset is available at https://github.com/jayleicn/moment_detr.
References
Liu, M., Nie, L., Wang, Y., Wang, M. & Rui, Y. A survey on video moment localization. ACM Comput. Surv. 55, 1–37. https://doi.org/10.1145/3556537 (2023).
Carion, N. et al. End-to-end object detection with transformers. In Computer Vision—ECCV 2020: 16th European Conference 213–229 https://doi.org/10.1007/978-3-030-58452-8_13 (2020).
Moon, W., Hyun, S., Park, S., Park, D. & Heo, J.-P. Query-dependent video representation for moment retrieval and highlight detection. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 23023–23033 https://doi.org/10.1109/cvpr52729.2023.02205 (2023).
Liu, Y. et al. Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 3042–3051 https://doi.org/10.1109/cvpr52688.2022.00305 (2022).
Jang, J., Park, J., Kim, J., Kwon, H. & Sohn, K. Knowing where to focus: Event-aware transformer for video grounding. In Proc. of the IEEE/CVF International Conference on Computer Vision (ICCV) 13846–13856 https://doi.org/10.1109/iccv51070.2023.01273 (2023).
Gao, J., Sun, C., Yang, Z. & Nevatia, R. Tall: Temporal activity localization via language query. In Proc. of the IEEE International Conference on Computer Vision (ICCV) https://doi.org/10.1109/iccv.2017.563 (2017).
Xu, H., Das, A. & Saenko, K. R-c3d: Region convolutional 3d network for temporal activity detection. In Proc. of the IEEE International Conference on Computer Vision (ICCV) https://doi.org/10.1109/iccv.2017.617 (2017).
Xu, H. et al. Multilevel language and vision integration for text-to-clip retrieval. In Proc. of the Thirty-Third AAAI Conference on Artificial Intelligence https://doi.org/10.1609/aaai.v33i01.33019062 (2019).
Rossi, E. et al. Temporal graph networks for deep learning on dynamic graphs. In ICML 2020 Workshop on Graph Representation Learning (2020).
Xiao, S., Chen, L., Shao, J., Zhuang, Y. & Xiao, J. Natural language video localization with learnable moment proposals. In Proc. of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) 4008–4017 https://doi.org/10.18653/v1/2021.emnlp-main.327 (2021).
Nan, G. et al. Interventional video grounding with dual contrastive learning. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2765–2775 https://doi.org/10.1109/cvpr46437.2021.00279 (2021).
Lei, J., Berg, T. L. & Bansal, M. Qvhighlights: Detecting moments and highlights in videos via natural language queries. In Proc. of the 35th International Conference on Neural Information Processing Systems(NeurIPS) https://doi.org/10.5555/3540261.3541167 (2021).
Xu, Y. et al. Mh-detr: Video moment and highlight detection with cross-modal transformer. 2024 International Joint Conference on Neural Networks (IJCNN) 1–8.https://doi.org/10.1109/IJCNN60899.2024.10650814 (2024).
Ma, H., Wang, G., Yu, F., Jia, Q. & Ding, S. Ms-detr: Towards effective video moment retrieval and highlight detection by joint motion-semantic learning. In Proc. of the 33rd ACM International Conference on Multimedia 4514–4523 https://doi.org/10.1145/3746027.3755484 (2025).
Zhang, H. et al. Video corpus moment retrieval with contrastive learning. In Proc. of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval 685–695 https://doi.org/10.1145/3404835.3462874 (2021).
Panta, L. et al. Cross-modal contrastive learning with asymmetric co-attention network for video moment retrieval. In 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), 617–624, https://doi.org/10.1109/wacvw60836.2024.00071 (2024).
Gao, J. & Xu, C. Fast video moment retrieval. In Proc. of the IEEE/CVF International Conference on Computer Vision (ICCV), 1523–1532, https://doi.org/10.1109/iccv48922.2021.00155 (2021).
Zeng, Y., Zhang, X. & Li, H. Multi-grained vision language pre-training: Aligning texts with visual concepts. In Proc. of the 38th International Conference on Machine Learning (ICML) (2021).
Xue, Y. et al. Fmtrack: Frequency-aware interaction and multi-expert fusion for rgb-t tracking. IEEE Trans. Circuits Syst. Video Technol. https://doi.org/10.1109/TCSVT.2025.3601598 (2026).
Xue, Y. et al. Target-distractor aware uav tracking via global agent. IEEE Trans. Intell. Transp. Syst. https://doi.org/10.1109/TITS.2025.3581391 (2025).
Wu, W. et al. Adaptive patch contrast for weakly supervised semantic segmentation. Eng. Appl. Artif. Intell. https://doi.org/10.1016/j.engappai.2024.109626 (2025).
Wu, W. et al. Image fusion for cross-domain sequential recommendation. In Companion Proceedings of the ACM on Web Conference 2025, https://doi.org/10.1145/3701716.3717566 (2025).
Wu, W. et al. Tag-enriched multi-attention with large language models for cross-domain sequential recommendation. IEEE Trans. Consum. Electron. https://doi.org/10.1109/TCE.2025.3620527 (2025).
Wu, W. et al. Llm-enhanced multimodal fusion for cross-domain sequential recommendation. ArXiv arXiv:2506.17966, https://doi.org/10.48550/arXiv.2506.17966 (2025).
Fang, X. et al. Fewer steps, better performance: efficient cross-modal clip trimming for video moment retrieval using language. In Proc. of the Thirty-Eighth AAAI Conference on Artificial Intelligence https://doi.org/10.1609/aaai.v38i2.27941 (2024).
Hou, D., Pang, L., Shen, H. & Cheng, X. Event-aware video corpus moment retrieval. arXiv preprint arXiv:2402.13566https://doi.org/10.48550/ARXIV.2402.13566 (2024).
Liu, W. et al. Context-enhanced video moment retrieval with large language models. IEEE Transactions on Multimedia 6296–6306 https://doi.org/10.1109/TMM.2025.3581797 (2025).
Jiang, Y. et al. Prior knowledge integration via LLM encoding and pseudo event regulation for video moment retrieval. In Proc. of the 32nd ACM International Conference on Multimedia (ACM MM), https://doi.org/10.1145/3664647.3681115 (2024).
Gu, A., Goel, K. & Re, C. Efficiently modeling long sequences with structured state spaces. In International Conference on Learning Representations (ICLR) (2022).
Gu, A. & Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023).
Dao, T. & Gu, A. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. In International Conference on Machine Learning (ICML) https://doi.org/10.5555/3692070.3692469 (2024).
Zhu, L. et al. Vision mamba: Efficient visual representation learning with bidirectional state space model. In Forty-first International Conference on Machine Learning (ICML) https://doi.org/10.5555/3692070.3694654 (2024).
Liu, Y. et al. VMamba: Visual state space model. In The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS), https://doi.org/10.52202/079017-3273 (2024).
Wang, Z., Li, C., Xu, H., Zhu, X. & Li, H. Mamba yolo: a simple baseline for object detection with state space model. In Proc. of the Thirty-Ninth AAAI Conference on Artificial Intelligence https://doi.org/10.1609/aaai.v39i8.32885 (2025).
Li, H. et al. Cfmw: Cross-modality fusion mamba for robust object detection under adverse weather. IEEE Trans. Circuits Syst. Video Technol. https://doi.org/10.1109/tcsvt.2025.3587918 (2025).
Lan, P., Xian, Y., Shen, T., Lee, Y. & Zhao, Q. Semantic-guided mamba fusion for robust object detection of tibetan plateau wildlife. Electronics https://doi.org/10.3390/electronics14224549 (2025).
Li, K. et al. Videomamba: State space model for efficient video understanding. In Computer Vision—ECCV 2024: 18th European Conference, 237–255, https://doi.org/10.1007/978-3-031-73347-5_14 (2024).
Moon, W., Hyun, S., Lee, S. & Heo, J.-P. Correlation-guided query-dependency calibration in video representation learning for temporal grounding. arXiv preprint arXiv:2311.08835 (2023).
Liu, Z. et al. Towards balanced alignment: Modal-enhanced semantic modeling for video moment retrieval. In Proc. of the AAAI Conference on Artificial Intelligence 38, 3855–3863. https://doi.org/10.1609/aaai.v38i4.28177 (2024).
Gu, A. et al. Combining recurrent, convolutional, and continuous-time models with linear state-space layers. In Proc. of the 35th International Conference on Neural Information Processing Systems (NeurIPS) https://doi.org/10.5555/3540261.3540305 (2021).
Gu, A., Dao, T., Ermon, S., Rudra, A. & Ré, C. Hippo: recurrent memory with optimal polynomial projections. In Proc. of the 34th International Conference on Neural Information Processing Systems (NeurIPS), https://doi.org/10.5555/3495724.3495849 (2020).
Liu, S. et al. DAB-DETR: Dynamic anchor boxes are better queries for DETR. In International Conference on Learning Representations (ICLR) (2022).
Rezatofighi, H. et al. Generalized intersection over union: A metric and a loss for bounding box regression. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) https://doi.org/10.1109/cvpr.2019.00075 (2019).
Wu, W., Luo, H., Fang, B., Wang, J. & Ouyang, W. Cap4video: What can auxiliary captions do for text-video retrieval? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 10704–10713 https://doi.org/10.1109/CVPR52729.2023.01031 (2023).
Primus, P., Schmid, F. & Widmer, G. Tacos: Temporally-aligned audio captions for language-audio pretraining. In 2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) https://doi.org/10.1109/waspaa66052.2025.11230997 (2025).
Feichtenhofer, C., Fan, H., Malik, J. & He, K. Slowfast networks for video recognition. In Proc. of the IEEE/CVF International Conference on Computer Vision (ICCV) https://doi.org/10.1109/iccv.2019.00630 (2019).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Proc. of the 38th International Conference on Machine Learning (ICML) (2021).
Tran, D., Bourdev, L., Fergus, R., Torresani, L. & Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In 2015 IEEE International Conference on Computer Vision (ICCV), 4489–4497, https://doi.org/10.1109/iccv.2015.510 (2015).
Pennington, J., Socher, R. & Manning, C. D. Glove: Global vectors for word representation. In Proc. of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532–1543, https://doi.org/10.3115/v1/d14-1162 (2014).
Wang, Z., Wang, L., Wu, T., Li, T. & Wu, G. Negative sample matters: A renaissance of metric learning for temporal grounding. In Proc. of the AAAI Conference on Artificial Intelligence 2613–2623 https://doi.org/10.1109/cvpr52729.2023.01031 (2022).
Lin, K. Q. et al. Univtg: Towards unified video-language temporal grounding. In Proc. of the IEEE/CVF International Conference on Computer Vision (ICCV) 2794–2804 https://doi.org/10.1109/iccv51070.2023.00262 (2023).
Tang, K., He, L., Dang, J. & Gao, X. Boosting temporal sentence grounding via causal inference. In Proc. of the 33rd ACM International Conference on Multimedia https://doi.org/10.1145/3746027.3755624 (2025).
Hu, J. et al. Maskable retentive network for video moment retrieval. In Proc. of the 32nd ACM International Conference on Multimedia (ACM MM), https://doi.org/10.1145/3664647.3680746 (2024).
Jang, J., Park, J., Kim, J., Kwon, H. & Sohn, K. Knowing where to focus: Event-aware transformer for video grounding. In Proc. of the IEEE/CVF International Conference on Computer Vision (ICCV) https://doi.org/10.1109/iccv51070.2023.01273 (2023).
Xiao, Y. et al. Bridging the gap: A unified video comprehension framework for moment retrieval and highlight detection. arXiv preprint arXiv:2311.16464https://doi.org/10.1109/cvpr52733.2024.01770 (2023).
Chen, B. et al. From global to granular: Revealing iqa model performance via correlation surface, https://doi.org/10.48550/arXiv.2601.21738 (2026)
Acknowledgements
This work was supported by the Shanghai Municipal Fund for Promoting the Development of the Cultural and Creative Industries (2025020022) and the Shanghai Natural Science Foundation (25ZR1401130).
Author information
Authors and Affiliations
Contributions
Bing Yu and Jingyu Li wrote the main manuscript text. Bing Yu and Jingyu Li did experients of the manuscript. Youxian Di and Yingran Liu preparesd all figures. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep (2026). https://doi.org/10.1038/s41598-026-44804-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-44804-x
