
Abstract
Three-dimensional voxel reconstruction based on stereo vision is essential for environmental perception in autonomous robots. Existing pseudo-LiDAR methods recover voxel grids by estimating depth maps and projecting them pixel by pixel, leading to high computational cost and boundary over-smoothing. To overcome these issues, we model the inverse relationship between 2D pixels and 3D voxel grids and propose a Self-supervised 3D Voxel Reconstruction network from Stereo vision (SVRS). Specifically, we represent a given 3D scene as multi-scale uniform cubic voxel grids and introduce a novel Pixel-Voxel Projecting Module (PVPM). PVPM projects the 3D position of each voxel grid into index coordinates, which establishes implicit stereo–voxel correspondences and converts dense pixel features into sparse voxel representations. Furthermore, we explore an Octree-based Encoder-Decoder Architecture (OEDA) to reconstruct multi-scale voxel grids via hierarchical spatial partitioning, avoiding the influence of dense empty grids on sparse occupied grids via a coarse-to-fine manner. Finally, SVRS leverages off-the-shelf stereo matching methods within a self-supervised training framework. Experiments on the DrivingStereo dataset show that SVRS achieves competitive reconstruction accuracy while improving inference speed by up to 14\(\times\) over advanced pseudo-LiDAR approaches and 3\(\times\) over real-time approaches.
Similar content being viewed by others


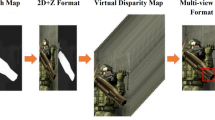
Data availability
The data supporting the findings of this study are available within the paper. The associated pre-processed raw data is available and can be shared with interested parties upon reasonable request. Please contact the corresponding author for more information.
Code availability
Our code is avaliable on https://github.com/zzy729425207/SVRS. Please contact the corresponding author for more information.
References
Menze, M., Heipke, C. & Geiger, A. Joint 3d estimation of vehicles and scene flow (ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2015).
Guo, Y. et al. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 43, 4338–4364 (2020).
You, Y. et al. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv preprint arXiv:1906.06310 (2019).
Wang, Y. et al. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8445–8453 (2019).
Roldao, L., De Charette, R. & Verroust-Blondet, A. 3d semantic scene completion: A survey. Int. J. Comput. Vision 130, 1978–2005 (2022).
Zhang, Z., Peng, R., Hu, Y. & Wang, R. Geomvsnet: Learning multi-view stereo with geometry perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21508–21518 (2023).
Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 30, 328–341 (2007).
Guo, X., Yang, K., Yang, W., Wang, X. & Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3273–3282 (2019).
Wu, Z. et al. Real-time stereo matching with high accuracy via spatial attention-guided upsampling. Appl. Intell. 53, 24253–24274 (2023).
Xu, G., Wang, Y., Cheng, J., Tang, J. & Yang, X. Accurate and efficient stereo matching via attention concatenation volume. IEEE Trans. Pattern Anal. Mach. Intell. (2023).
Xu, H. & Zhang, J. Aanet: Adaptive aggregation network for efficient stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1959–1968 (2020).
Lipson, L., Teed, Z. & Deng, J. Raft-stereo: Multilevel recurrent field transforms for stereo matching. In 2021 International Conference on 3D Vision (3DV), 218–227 (IEEE, 2021).
Guo, C., Peng, H. & Wang, J. Recurrent convolutional model based on gated spiking neural p system for stereo matching networks. Appl. Intell. 53, 29570–29584 (2023).
Tosi, F., Liao, Y., Schmitt, C. & Geiger, A. Smd-nets: Stereo mixture density networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8942–8952 (2021).
Li, Z. et al. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers. IEEE Trans. Pattern Anal. Mach. Intell. (2024).
Li, Y. et al. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo. In Proc. AAAI Conf. Artif. Intell. 37, 1486–1494 (2023).
Huang, Y., Zheng, W., Zhang, Y., Zhou, J. & Lu, J. Tri-perspective view for vision-based 3d semantic occupancy prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9223–9232 (2023).
Li, Y. et al. Voxformer: Sparse voxel transformer for camera-based 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9087–9098 (2023).
Rukhovich, D., Vorontsova, A. & Konushin, A. Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection. In 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 1265–1274, https://doi.org/10.1109/WACV51458.2022.00133 (2022).
Li, H. et al. Stereovoxelnet: Real-time obstacle detection based on occupancy voxels from a stereo camera using deep neural networks. In 2023 IEEE International Conference on Robotics and Automation (ICRA), 4826–4833 (IEEE, 2023).
Mayer, N. et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4040–4048 (2016).
Durou, J.-D., Falcone, M. & Sagona, M. Numerical methods for shape-from-shading: A new survey with benchmarks. Comput Vision Image Understanding 109, 22–43 (2008).
Schonberger, J. L. & Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4104–4113 (2016).
Kaya, B., Kumar, S., Oliveira, C., Ferrari, V. & Van Gool, L. Multi-view photometric stereo revisited. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 3126–3135 (2023).
Su, W. & Tao, W. Efficient edge-preserving multi-view stereo network for depth estimation. Proc. AAAI Conf. Artif. Intell. 37, 2348–2356 (2023).
Müller, T., Evans, A., Schied, C. & Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (TOG) 41, 1–15 (2022).
Tosi, F., Tonioni, A., De Gregorio, D. & Poggi, M. Nerf-supervised deep stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 855–866 (2023).
Fei, B. et al. 3d gaussian splatting as new era: A survey. IEEE Transactions on Visualization and Computer Graphics (2024).
Peng, Z. et al. Rtg-slam: Real-time 3d reconstruction at scale using gaussian splatting. In ACM SIGGRAPH 2024 Conference Papers, 1–11 (2024).
Zhou, X. et al. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21634–21643 (2024).
Xue, Y. et al. Bi-ssc: Geometric-semantic bidirectional fusion for camera-based 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 20124–20134 (2024).
Xiao, H., Xu, H., Kang, W. & Li, Y. Instance-aware monocular 3d semantic scene completion. IEEE Trans. Intell. Transportation Syst. (2024).
Behley, J. et al. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 9297–9307 (2019).
Cao, A.-Q. & De Charette, R. Monoscene: Monocular 3d semantic scene completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3991–4001 (2022).
Shamsafar, F., Woerz, S., Rahim, R. & Zell, A. Mobilestereonet: Towards lightweight deep networks for stereo matching. In Proceedings of the ieee/cvf Winter Conference on Applications of Computer Vision, 2417–2426 (2022).
Duan, Y., Guo, X. & Zhu, Z. Diffusiondepth: Diffusion denoising approach for monocular depth estimation. arXiv preprint arXiv:2303.05021 (2023).
Miao, R. et al. Occdepth: A depth-aware method for 3d semantic scene completion. arXiv preprint arXiv:2302.13540 (2023).
Li, B. et al. Bridging stereo geometry and bev representation with reliable mutual interaction for semantic scene completion. arXiv preprint arXiv:2303.13959 (2023).
Mei, X. et al. On building an accurate stereo matching system on graphics hardware. In 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), 467–474 (IEEE, 2011).
Zbontar, J. & LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1592–1599 (2015).
Kendall, A. et al. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, 66–75 (2017).
Xu, B., Xu, Y., Yang, X., Jia, W. & Guo, Y. Bilateral grid learning for stereo matching networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12497–12506 (2021).
Xu, G., Wang, X., Ding, X. & Yang, X. Iterative geometry encoding volume for stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 21919–21928 (2023).
Shi, X. et al. Convolutional lstm network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Proc. Syst. 28 (2015).
Howard, A. G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4510–4520 (2018).
Cheng, J. et al. Monster: Marry monodepth to stereo unleashes power. In Proceedings of the Computer Vision and Pattern Recognition Conference, 6273–6282 (2025).
Koneputugodage, C. H., Ben-Shabat, Y. & Gould, S. Octree guided unoriented surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16717–16726 (2023).
Kanopoulos, N., Vasanthavada, N. & Baker, R. Design of an image edge detection filter using the sobel operator. IEEE J. Solid-State Circuits 23, 358–367. https://doi.org/10.1109/4.996 (1988).
Yang, G. et al. Drivingstereo: A large-scale dataset for stereo matching in autonomous driving scenarios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 899–908 (2019).
Funding
This publication has emanated from research supported by The National Natural Science Foundation of China (Grant No. 52374165).
Author information
Authors and Affiliations
Contributions
Zou.Z and Wu.Y wrote the main manuscript text and conducted the experiments, Zhang.H and Xu.Q checked the manuscript text, Wang.R collected experimental data. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zou, Z., Wu, Y., Zhang, H. et al. SVRS: self-supervised 3D voxel reconstruction network from stereo vision. Sci Rep (2026). https://doi.org/10.1038/s41598-026-45924-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-45924-0
