
Abstract
Computer vision is an important field of artificial intelligence that enables machines to interpret and understand visual information from images. It is the basis of automated visual understanding in smart systems. Monitoring of streets, recognizing different vehicles and pedestrians, and comprehending the ever-changing traffic conditions for making right decisions are some of the features of modern intelligent traffic systems. It is indispensable for a computer to visually recognize the semantic segmentation (SS) of a scene, as it maps each and every pixel of the image to the categories like roads, vehicles, pedestrians, traffic lights, etc. However, existing traffic scene segmentation models often perform poorly under challenging conditions such as low lighting, blur, noise, and low resolution. These limitations limit the robustness of these methods. They can be a major obstacle to the development of autonomous vehicle technologies because they reduce the ability of perception systems to recognize a wide range of situations. This work proposes a new method for processing poor quality traffic images by sequentially applying super-resolution (SR), semantic segmentation (SS), and object detection with YOLOv8x. The SR module transforms degraded inputs, while U-Net and DeepLabV3+ are exploited for accurate pixel-level segmentation mask generation. Besides, YOLOv8x provides the precise object detection, which is really one of the critical steps for the avoidance of the errors in the crowded and complicated TSs. YOLOv8x uses bounding boxes to check segmentation and raise mAP. U-Net delivers PSNR of 41.93 dB, SSIM of 0.997, mIoU of 0. 750, and mAP of 0.950, whereas DeepLabV3+ yields PSNR of 46.03 dB, SSIM of 0.938, mIoU of 0.819, and mAP of 0.937.
Similar content being viewed by others
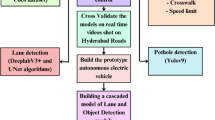
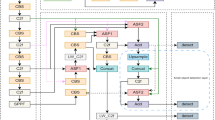
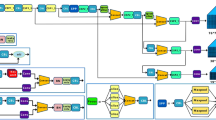
Data availability
The data sets analyzed during the current study are available in curated subset of the Microsoft COCO dataset \(\phantom{0}^{16}\).
References
Zhu, J., Zhou, Y., Xu, N. & Huo, C. Collaborative learning network for change detection and semantic segmentation of remote sensing images. IEEE Geosci. Remote Sens. Lett. 20, 1–5. https://doi.org/10.1109/LGRS.2023.3329058 (2023).
Das, P. K., Sahu, A., Xavy, D. V. & Meher, S. A deforestation detection network using deep learning-based semantic segmentation. IEEE Sensors Lett. 8(1), 1–4. https://doi.org/10.1109/LSENS.2023.3340562 (2024).
Zhang, Z., Wang, L., Chen, Y. & Zheng, C. Crop identification of UAV images based on an unsupervised semantic segmentation method. IEEE Geosci. Remote Sens. Lett. 21, 1–5. https://doi.org/10.1109/LGRS.2024.3365468 (2024).
Wu, J., Qin, C., Ren, Y. & Feng, G. EPFNet: Edge-prototype fusion network toward few-shot semantic segmentation for aerial remote-sensing images. IEEE Geosci. Remote Sens. Lett. 20, 1–5. https://doi.org/10.1109/LGRS.2023.3292832 (2023).
Wu, Z. et al. Diff-HRNet: A diffusion model-based high-resolution network for remote sensing semantic segmentation. IEEE Geosci. Remote Sens. Lett. 22, 1–5. https://doi.org/10.1109/LGRS.2024.3505552 (2025).
Kim, Y. W. & Kim, W. Clustering-based adaptive query generation for semantic segmentation. IEEE Signal Process. Lett. 32, 1580–1584. https://doi.org/10.1109/LSP.2025.3558160 (2025).
Wang, Y., Li, G. & Liu, Z. SGFNet: Semantic-guided fusion network for RGB-thermal semantic segmentation. IEEE Trans. Circuits Syst. Video Technol. 33(12), 7737–7748. https://doi.org/10.1109/TCSVT.2023.3281419 (2023).
Ramyashree, R., Venugopala, P. S., Raghavendra, S. & Sarojadevi, S. Optimal information hiding: Advanced bitstream-based watermarking for secure and efficient integration of image data in digital videos. J. Eng. 2024(1), 8860475. https://doi.org/10.1155/2024/8860475 (2024).
Ni, P., Li, X., Kong, D. & Yin, X. Scene-adaptive 3D semantic segmentation based on multi-level boundary-semantic-enhancement for intelligent vehicles. IEEE Trans. Intell. Veh. 9(1), 1722–1732. https://doi.org/10.1109/TIV.2023.3274949 (2024).
Jiang, Z., Yuan, Y. & Yuan, Y. Prototypical metric segment anything model for data-free few-shot semantic segmentation. IEEE Signal Process. Lett. 31, 2800–2804. https://doi.org/10.1109/LSP.2024.3476208 (2024).
Natha, S., Siraj, M., Ahmed, F., Altamimi, M. & Syed, M. An integrated CNN-BiLSTM-transformer framework for improved anomaly detection using surveillance videos. IEEE Access 13, 95341–95357. https://doi.org/10.1109/ACCESS.2025.3574835 (2025).
Natha, S. et al. A fusion approach of YOLOv8 and CNN-transformer for end-to-end road anomaly detection. Sci. Rep. https://doi.org/10.1038/s41598-025-29718-4 (2025).
Zhou, W., Jiao, J., Xu, H., Wei, M. & Zhao, X. PointBiMssc: Bidirectional multiscale attention-based point cloud semantic segmentation for water conservancy environment. IEEE Geosci. Remote Sens. Lett. 21, 1–5. https://doi.org/10.1109/LGRS.2024.3432671 (2024).
Zheng, Y. et al. A novel semantic segmentation algorithm for RGB-D images based on non-symmetry and anti-packing pattern representation model. IEEE Access 11, 36290–36299. https://doi.org/10.1109/ACCESS.2023.3266251 (2023).
Huang, Z., Chen, Z. & Liu, Y. FBINet: Few-shot semantic segmentation with foreground and background iteration. IEEE Trans. Instrum. Meas. 74, 1–10. https://doi.org/10.1109/TIM.2025.3550211 (2025).
Zhang, A., Li, S., Wu, J., Li, S. & Zhang, B. Exploring semantic information extraction from different data forms in 3D point cloud semantic segmentation. IEEE Access 11, 61929–61949. https://doi.org/10.1109/ACCESS.2023.3287940 (2023).
Wu, L. et al. Querying labeled for unlabeled: Cross-image semantic consistency guided semi-supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 45(7), 8827–8844. https://doi.org/10.1109/TPAMI.2022.3233584 (2023).
Ma, Y., Wang, Y., Liu, X. & Wang, H. SWINT-RESNet: An improved remote sensing image segmentation model based on transformer. IEEE Geosci. Remote Sens. Lett. 21, 1–5. https://doi.org/10.1109/LGRS.2024.3433034 (2024).
Ni, X., Zhang, Y. & Li, Z. A boundary-sensitive boosting strategy for improving semantic segmentation accuracy in 3D scenes. IEEE Trans. Image Process. 32, 64 (2023).
Das, A., Kumar, P. & Singh, R. Deep learning-based semantic segmentation for environmental monitoring applications. IEEE Access 9, 12345–12356 (2021).
Wang, H., Zhang, L. & Chen, Y. RGB-thermal fusion for semantic segmentation in low-light environments. IEEE Trans. Intell. Transp. Syst. 23(4), 5678–5687 (2022).
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P. & Zitnick, C. L. Microsoft COCO: Common objects in context. In European Conference on Computer Vision, 740–755 (2014).
Li, X., Zhang, Z., Zhang, X., Li, J. & Sun, J. Mask DINO: Towards a unified transformer-based framework for object detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
Preetha, R., Priyadarsini, M. J. P. & Nisha, J. S. Brain tumor segmentation using multi-scale attention U-Net with EfficientNetB4 encoder for enhanced MRI analysis. Sci. Rep. 15(9914), 1–20. https://doi.org/10.1038/s41598-025-94267-9 (2025).
Cammarasana, S. & Patanè, G. Learning-based and quality preserving super-resolution of noisy images. Multimed. Tools Appl. 84, 6007–6023. https://doi.org/10.1007/s11042-024-19202-y (2025).
Jiang, Y. et al. Deep learning-based super-resolution reconstruction and segmentation of photoacoustic images. Appl. Sci. 14(12), 5331. https://doi.org/10.3390/app14125331 (2024).
Ramyashree, R., Venugopala, P. S., Raghavendra, S. & Kubihal, V. S. Enhancing secure medical data communication through integration of LSB and DCT for robust analysis in image steganography. IEEE Access 13, 1566–1580. https://doi.org/10.1109/ACCESS.2024.3522957 (2025).
Ming, Q. & Xiao, X. Towards accurate medical image segmentation with gradient-optimized dice loss. IEEE Signal Process. Lett. 31, 191–195. https://doi.org/10.1109/LSP.2023.3329437 (2024).
Fernandez, J. B., Venkatesh, G. M., Zhang, D., Little, S. & O’Connor, N. E. Semi-automatic multi-object video annotation based on tracking, prediction and semantic segmentation. In 2019 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2019). https://doi.org/10.1109/CVPRW.2019.00000
Xu, X., Meng, F., Li, H., Wu, Q., Ngan, K. N. & Chen, S. A new bounding box based pseudo annotation generation method for semantic segmentation. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), 1–4 (2020). https://doi.org/10.1109/VCIP49842.2020.9301745
Shao, Y., Zhang, Z., Wang, X., Zhao, C., Zheng, Y., Ma, X., Deng, W. & Huang, Y. Research on image segmentation methods of highway pavement distress based on semantic segmentation convolutional neural network. In 2024 9th International Conference on Signal and Image Processing (ICSIP), 801–805 (2024). https://doi.org/10.1109/ICSIP61881.2024.10671560
Chen, R., Zhang, X., Lin, T. & Yu, S. EMSSD: Two-stage model enhancing medical image segmentation based on stable diffusion. In IEEE 22nd International Symposium on Biomedical Imaging (ISBI). (To appear) (2025). https://doi.org/10.1109/ISBI60581.2025.10981045
Vobecký, P. et al. Unsupervised semantic segmentation of urban scenes via cross-modal distillation. Int. J. Comput. Vis. 133, 3519–3541 (2024).
Chen, W., Miao, Z., Qu, Y. & Shi, G. HRDLNet: A semantic segmentation network with high resolution representation for urban street view images. Complex Intell. Syst. 10, 7825–7844. https://doi.org/10.1007/s40747-024-01582-1 (2024).
Anonymous. Real-time semantic segmentation network with an enhanced backbone based on Atrous spatial pyramid pooling module. Eng. Appl. Artif. Intell. (2024). https://doi.org/10.1016/j.engappai.2024.107988
Mi, X., et al., Semantics recalibration and detail enhancement network for real-time semantic segmentation. In IET Computer Vision (2023).
Funding
Open access funding provided by Manipal Academy of Higher Education, Manipal. No funding was received to assist with the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
R.M contributed to the conceptualization, methodology design, and drafting of the manuscript. U.T carried out data preprocessing, experimental analysis with U-Net, and preparation of results. R.S guided the study design, interpreted the findings, and refined the manuscript for coherence. A.B.N implemented DeepLabV3+, validated the results, and assisted in manuscript editing. V.P.S supervised the project and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ramyashree, Utsavi, S.R., Raghavendra, S. et al. Comparative performance analysis of U-Net and DeepLabV3+ for semantic segmentation in traffic environments. Sci Rep (2026). https://doi.org/10.1038/s41598-026-46740-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-46740-2
