
Abstract
Autonomous robot navigation within a dynamic environment is a complicated issue since environmental factors keep on changing, safety remains a factor, and issues of data privacy concern are also on the increase. The existing reinforcement learning (RL) navigation systems mainly focus on path performance and avoidance of collisions but do not focus on privacy protection, adaptation learning stability, and real deployment. This research aims to overcome these constraints by suggesting a novel framework Secure and Privacy-Preserving Hyperparameter-Tuned RL Model (SPHTRLM) to the efficient generation of path plans in grid ecosystems with dynamic environments. The framework incorporates adjusted Q-learning with federated learning (FL) based distributed updates, refined differentiated privacy, minimal encrypted parameter exchange, adaptive reward shaping and automatic hyperparameter optimization. In a further attempt to enhance practicability, the proposed architecture also embraces mobility conscious aggregation and heterogeneous model support of resource-limited robotic platforms. The suggested SPHTRLM has a success rate of (95% ± 2%), and it is better than the comparable one Q-learning (87% ± 4%) and Deep RL (DRL) baselines (88%) when these methods were evaluated under the same condition. The framework minimizes distances to the average path with a reduction of 20–25% and convergence is speeded up by around 35% compared to normal Q-learning. When the obstacles are very thick then the collision rate becomes and the obstacle reduces to 0.08, and the safety of the navigation process improves. Although there are additional privatization mechanisms, the computational costs are minimal (8–12%), and the average decision time is 110–125 ms, which meets the real-time operational capabilities. Privacy analysis with formally stated membership inference and reconstruction attacks provide status of attack rate less than 5% attack success with both white and black box adversary. These findings underscore that SPHTRLM is a feasible way of achieving the goals of ensuring navigation, learning consistency, safety as well as privacy protection to give credible acceptance to using autonomous robotic systems in dynamic and data-sensitive environment.
Similar content being viewed by others

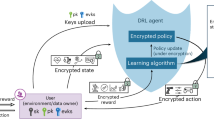
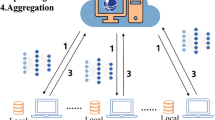
Data availability
All data relevant to this study are included within the article itself. Any additional data and materials can be obtained from the corresponding author upon reasonable request.
References
Makoviychuk, V. et al. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning. arXiv. (2021).
Carta, T., Oudeyer, P. Y., Sigaud, O., Lamprier, S. & Eager Asking and answering questions for automatic reward shaping in language-guided rl. Adv. Neural Inf. Process. Syst. 35, 12478–12490 (2022).
Frank, H., Kotthoff, L. & Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges (Springer Nature, 2019).
Meng, J. et al. Deep reinforcement learning for robust robot navigation in complex and crowded environments. J. King Saud Univ. Comput. Inf. Sci. 37, 333. https://doi.org/10.1007/s44443-025-00357-z (2025).
Ramalingam, V. et al. A hybrid federated learning framework with generative AI for privacy-preserving and sustainable security in IOT-enabled smart environments. Sci. Rep. 16, 3071. https://doi.org/10.1038/s41598-025-31769-6 (2026).
Alqazzaz, A. Federated Learning with Homomorphic Encryption: A Privacy-Preserving Solution for Smart Cities. Int. J. Comput. Intell. Syst. 18, 304. https://doi.org/10.1007/s44196-025-00829-0 (2025).
Bockrath, K., Ernst, L., Nadeem, R., Pedraza, B. & Dera, D. Trustworthy navigation with variational policy in deep reinforcement learning. Front. Robot AI. 12, 1652050. https://doi.org/10.3389/frobt.2025.1652050 (2025).
Denesh Babu, M., Maheswari, C. & Priya, B. M. Dynamic robot navigation in confined indoor environment: unleashing the perceptron-Q learning fusion. Sensors, 25, 6384. https://doi.org/10.3390/s25206384 (2025).
Tiwari, R., Srinivaas, A. & Velamati, R. K. Adaptive Navigation in Collaborative Robots: A Reinforcement Learning and Sensor Fusion Approach. Appl. Syst. Innov. 8, 9. https://doi.org/10.3390/asi8010009 (2025).
Li, L. et al. Coordinated multi-robot planning while preserving individual privacy. 2019 International Conference on Robotics and Automation (ICRA), 2188. (2019).
Chen, H., Laine, K. & Player, R. Simple encrypted arithmetic library-seal v2. 1, In: Proceedings of the International Conference on Financial Cryptography and Data Security, 3–18, (Springer, 2017).
Prorok, A. & Kumar, V. A macroscopic privacy model for heterogeneous robot swarms, In: International Conference on Swarm Intelligence, 15–27, (Springer, 2016).
Wang, B., Liu, Z., Li, Q. & Prorok, A. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robotics and Automation Lett., 5, 4, 6932–6939, (2020). https://doi.org/10.1109/LRA.2020.3026638
Cohen, L. et al. The fastmap algorithm for shortest path computations, In: International Joint Conference on Artificial Intelligence, 1427–1433. (2018).
Riviere, B., Hoenig, W., Yue, Y. & Chung, S. J. GLAS: Global-to-local safe autonomy synthesis for multi-robot motion planning with end-to-end learning. IEEE Robotics and Automation Lett., 5, 3, 4249–4256, (2020). https://doi.org/10.1109/LRA.2020.2994035
Barer, M., Sharon, G., Stern, R. & Felner, A. Sub-optimal variants of the conflict-based search algorithm for the multi-agent path-finding problem, In: European Conference on Artificial Intelligence, 961–962. (2014).
Liu, Z., Yang, Y., Miller, T. & Masters, P. Deceptive reinforcement learning for privacy-preserving planning. In: Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS ‘21). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 818–826, (2021). https://doi.org/10.5555/3463952.3464050
Mor Vered, Gal, A. & Kaminka Heuristic online goal recognition in continuous domains. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI’17). 4447–4454, (AAAI Press, 2017). https://doi.org/10.5555/3171837.3171908
Peta masters and sebastian sardina. goal recognition for rational and irrational agents. In: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS. ‘19). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 440–448., (2019). https://doi.org/10.5555/3306127.3331725
Goldsztejn, E., Feiner, T. & Brafman, R. PTDRL: Parameter tuning using deep reinforcement learning. In: International Conference on Intelligent Robots and Systems, IROS, United States, 11356–11362, (2023). https://doi.org/10.1109/IROS55552.2023.10342140
Chiang, H. T. L., Faust, A., Fiser, M. & Francis, A. Learning navigation behaviors end-to-end with autorl. IEEE Rob. Autom. Lett. 4 (2), 2007–2014 (2019).
Szegedy, C. et al. Intriguing properties of neural networks, In: 2nd International Conference on Learning Representations, ICLR, Banff, AB, April 14–16, (2014). https://doi.org/10.48550/arXiv.1312.6199
Perille, D., Truong, A., Xiao, X. & Stone, P. Benchmarking metric ground navigation, In: 2020 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR). IEEE Press, 116–121. https://doi.org/10.1109/SSRR50563.2020.9292572
Kim, M., Kim, J. S. & Park, J. H. Automated Hyperparameter Tuning in Reinforcement Learning for Quadrupedal Robot Locomotion. Electronics 13 (1), 116. https://doi.org/10.3390/electronics13010116 (2024).
Han, S., Ma, H., Taherkordi, A., Lan, D. & Chen, Y. Privacy-preserving data integration scheme in industrial robot system based on fog computing and edge computing. IET Commun. 18 (7), 461–476. https://doi.org/10.1049/cmu2.12749 (2024).
Vulin, N., Christen, S., Stevši´c, S. & Hilliges, O. Improved learning of robot manipulation tasks via tactile intrinsic motivation. IEEE Robot Autom. Lett. 6, 2194–2201 (2021).
Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518 (7540), 529–533. https://doi.org/10.1038/nature14236 (2015).
Liu, Z. et al. MAPPER: Multi-agent path planning with evolutionary reinforcement learning in mixed dynamic environments. Preprint at https://arxiv.org/abs/2007.15724 (2020).
Dewangan, R. R., Soni, S. & Mishal, A. An approach of privacy preservation and data security in cloud computing for secured data sharing. Recent. Adv. Electr. Electron. Eng., 17. https://doi.org/10.2174/0123520965280683240112085521 (2024).
Liu, Z., Yang, Y., Miller, T. & Masters, P. Deceptive reinforcement learning for privacy-preserving planning. Preprint at https://arxiv.org/abs/2102.03022 (2021).
Akalin, N. & Loutfi, A. Reinforcement Learning Approaches in Social Robotics. Sensors 21, 1292. https://doi.org/10.3390/s21041292 (2021).
Rahman, M. M., Rashid, S. M. H. & Hossain, M. M. Implementation of Q learning and deep Q network for controlling a self balancing robot model. Robot Biomim. 5, 8. https://doi.org/10.1186/s40638-018-0091-9 (2018).
Dong, C. et al. BDFL: A blockchain-enabled FL framework for edge-based smart UAV delivery systems. In: Proceedings of the Third International Symposium on Advanced Security on Software and Systems (ASSS ‘23). Association for Computing Machinery, New York, NY, USA, Article 4, 1–11. (2023). https://doi.org/10.1145/3591365.3592948
Dong, C. et al. Securing smart UAV delivery systems using zero trust principle-driven blockchain architecture. In: IEEE International Conference on Blockchain (Blockchain), Danzhou, China, 2023, pp. 315–322, (2023). https://doi.org/10.1109/Blockchain60715.2023.00056
Dong, C. et al. Revolutionizing virtual shopping experiences: A blockchain-based metaverse UAV delivery solution. In: IEEE International Conference on Metaverse Computing, Networking and Applications (MetaCom), 658–661, (2023). https://doi.org/10.1109/MetaCom57706.2023.00116
Miki, T. et al. Learning robust perceptive locomotion for quadrupedal robots in the wild. Sci. Robot. 7 eabk 2822. (2022).
Bodong, T. & Jae-Hoon, K. Deep reinforcement learning-based local path planning in dynamic environments for mobile robot. J. King Saud Univ. Comput. Inform. Sci., 36, 10, 102254, 1319–1578, (2024). https://doi.org/10.1016/j.jksuci.2024.102254
Yang, H. et al. An efficient personalized federated learning approach in heterogeneous environments: a reinforcement learning perspective. Sci. Rep. 14, 28877. https://doi.org/10.1038/s41598-024-80048-3 (2024).
Petitcolas, F. A. P. in in Kerckhoffs’ principle Encyclopedia of Cryptography and Security. 2nd edn, Vol. 675 (eds van Tilborg, H. C. A. & Jajodia, S.) (Springer, 2011).
Dewangan, R. R., Soni, S. & Mishal, A. Optimized Homomorphic Encryption (OHE) algorithms for protecting sensitive image data in the cloud computing environment. Int. J. Inform. Technol. https://doi.org/10.1007/s41870-024-01921-y (2024). E- ISSN:2511 – 2112.
Jeong, E., Gwak, J., Kim, T. & Kang, D. O. Distributed Deep Learning for Real-World Implicit Mapping in Multi-Robot Systems. In Proceedings of the 2024 24th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 29 October–1 November ; pp. 1619–1624. (2024).
Zhu, Y. et al. Deep Reinforcement Learning of Mobile Robot Navigation in Dynamic Environment. Rev. Sens. 25 (11), 3394. https://doi.org/10.3390/s25113394 (2025).
Martinez-Baselga, D., Riazuelo, L., Montano, L. & RUMOR. Reinforcement learning for understanding a model of the real world for navigation in dynamic environments. Robot. Auton. Syst. 191, 105020. https://doi.org/10.1016/j.robot.2025.105020 (2025).
Funding
Open access funding provided by Symbiosis International (Deemed University).
Author information
Authors and Affiliations
Contributions
Conceptualization, **RRD** , **VP; ** Formal Analysis, **DT, BKD; ** Investigation, **VP, MV; ** Methodology, **RRD** , **MV; ** Software, **DT** , **MV; ** Writing – Original Draft Preparation, **BKD, VP; ** Writing – Review & Editing, **AP, NS; ** Validation, **DT, BKD; ** Visualization, **MV** , **AP; ** Supervision, **BKD, NS; ** Project Administration, **BKD, NS.** All authors have read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Dewangan, R.R., Thombre, D., Parganiha, V. et al. SPHTRLM: secure and privacy-preserving hyperparameter-tuned reinforcement learning method for robot path finding in dynamic environments. Sci Rep (2026). https://doi.org/10.1038/s41598-026-48141-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-48141-x
