
Abstract
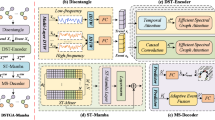
Night-time image quality assessment (NTIQA) requires jointly modeling global illumination consistency and spatially localized distortions, such as noise, glare, and halo artifacts. Existing CNN-based methods are effective at capturing local degradations but are limited in modeling long-range contextual dependencies, whereas Transformer-based approaches improve global perception at the cost of higher computational complexity. To address this challenge, we propose HCA-Mamba, a hybrid framework that combines Vision Mamba (ViM)-based global context modeling with CNN-based local distortion perception for NTIQA. Specifically, a ViM backbone is employed to capture long-range dependencies and global luminance structure, while a parallel CNN branch extracts multi-scale local degradation cues and compacts them into distortion-aware tokens through a multi-scale distortion extractor (MSDE). These tokens are then progressively injected into successive ViM layers via a local distortion injection module (LDIM), which performs gated cross-attention to enable stable interaction between global and local representations across network depths. The fused representation is finally mapped to a perceptual quality score by a regression head. Experiments on the NNID and EHNQ benchmarks, together with additional cross-dataset evaluation on NPHD, including both intra-dataset evaluation and cross-dataset generalization settings, demonstrate the effectiveness and generalization potential of the proposed method. A controlled synthetic distortion severity study further evaluates the model response to progressively intensified night-time degradations. Extensive ablation studies further verify the effectiveness of MSDE and LDIM in enhancing sensitivity to night-time distortions.
Similar content being viewed by others


Acknowledgements
This work was supported by the Special Project for the Construction of Disciplines and Postgraduate Education of the Beijing Institute of Graphic Communication (No. 21090126017, 21090126005), the Key Laboratory Project of Signal and Information Processing for High-End Printing Equipment of Beijing (No.20190226003), the research project of Beijing Institute of Graphic Communication (No.E6202405), and the Beijing Institute of Graphic Communication Scientific Research Platform Construction Project (No.KYCPT202509).
Funding
This work was funded by the Special Project for the Construction of Disciplines and Postgraduate Education of the Beijing Institute of Graphic Communication (No. 21090126017, 21090126005), the Key Laboratory Project of Signal and Information Processing for High-End Printing Equipment of Beijing (No.20190226003), the research project of Beijing Institute of Graphic Communication (No.E6202405), and the Beijing Institute of Graphic Communication Scientific Research Platform Construction Project (No.KYCPT202509).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, T., Dong, W., Lu, L. et al. HCA-Mamba: a hierarchical cross-attention framework combining Vision Mamba and CNN for night-time image quality assessment. Sci Rep (2026). https://doi.org/10.1038/s41598-026-54065-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-026-54065-3
