
Abstract
Large language models (LLMs) show promising diagnostic and triage performance, yet direct comparisons with healthcare professionals (HCPs) and collaborative effects remain limited. We conducted a systematic review and meta-analysis of studies (January 2020 to September 2025) comparing the diagnostic or triage accuracy of LLMs, HCPs, or their collaboration across seven databases. Studies using multiple-choice formats rather than open diagnostic generation were excluded. We extracted top-1, top-3, top-5, and top-10 diagnostic and triage accuracies and pooled results using multilevel random-effects models to account for nested observations. Of 10,398 studies screened, 50 met criteria, evaluating 25 different LLMs across diverse medical specialties. The relative diagnostic accuracy of LLMs versus HCPs progressively improved from 0.89 (95% CI, 0.79–1.00) for top-1 to 0.91 (0.83–1.00) for top-3, 1.04 (0.89–1.22) for top-5, and 1.17 (0.87–1.57) for top-10 diagnoses, with significant model variability. LLM-assisted HCPs outperformed HCPs alone, with relative diagnostic accuracy of 1.13 (1.00–1.27) for top-1, 1.11 (1.01–1.23) for top-3, 1.42 (1.16–1.73) for top-5, and 1.33 (0.94–1.87) for top-10 diagnoses. Triage accuracy was similar between LLMs and HCPs (1.01 [0.94–1.09]). These findings show potential for LLM integration but methodological flaws in studies necessitate rigorous real-world evaluation before clinical implementation.
Similar content being viewed by others
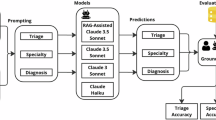

Data availability
The datasets used during the current study are available from the corresponding author on reasonable request.
Code availability
The codes used in the analysis of this study will be made available from the corresponding author upon reasonable request.
References
FDA. FDA Issues Comprehensive Draft Guidance for Developers of Artificial Intelligence-Enabled Medical Devices. https://www.fda.gov/news-events/press-announcements/fda-issues-comprehensive-draft-guidance-developers-artificial-intelligence-enabled-medical-devices (2025).
Levine, D. M. et al. The diagnostic and triage accuracy of the GPT-3 artificial intelligence model: an observational study. Lancet Digit. Health 6, e555–e561 (2024).
Graber, M. L. The incidence of diagnostic error in medicine. BMJ Qual. Saf. 22(Suppl 2), ii21–ii27 (2013).
Nguyen, H., Meczner, A., Burslam-Dawe, K. & Hayhoe, B. Triage errors in primary and pre-primary care. J. Med. Internet Res. 24, e37209 (2022).
Bedi, S. et al. Testing and evaluation of health care applications of large language models: a systematic review. JAMA 333, 319–328 (2024).
Kulkarni, P. A. & Singh, H. Artificial intelligence in clinical diagnosis: opportunities, challenges, and hype. JAMA 330, 317–318 (2023).
Liu, M. et al. Performance of ChatGPT across different versions in medical licensing examinations worldwide: systematic review and meta-analysis. J. Med. Internet Res. 26, e60807 (2024).
Kanjee, Z., Crowe, B. & Rodman, A. Accuracy of a generative artificial intelligence model in a complex diagnostic challenge. JAMA 330, 78–80 (2023).
Kim, S. H. et al. Benchmarking the diagnostic performance of open source LLMs in 1933 Eurorad case reports. NPJ Digit. Med. 8, 97 (2025).
Takita, H. et al. A systematic review and meta-analysis of diagnostic performance comparison between generative AI and physicians. NPJ Digit. Med. 8, 175 (2025).
Mendel, T., Singh, N., Mann, D. M., Wiesenfeld, B. & Nov, O. Laypeople’s use of and attitudes toward large language models and search engines for health queries: survey study. J. Med. Internet Res. 27, e64290 (2025).
Abdullahi, T., Singh, R. & Eickhoff, C. Learning to make rare and complex diagnoses with generative AI assistance: qualitative study of popular large language models. JMIR Med. Educ. 10, e51391 (2024).
Arslan, B., Nuhoglu, C., Satici, M. O. & Altinbilek, E. Evaluating LLM-based generative AI tools in emergency triage: a comparative study of ChatGPT Plus, Copilot Pro, and triage nurses. Am. J. Emerg. Med. 89, 174–181 (2024).
Delsoz, M. et al. Performance of ChatGPT in diagnosis of corneal eye diseases. Cornea 43, 640–670 (2024).
Delsoz, M. et al. The use of ChatGPT to assist in diagnosing glaucoma based on clinical case reports. Ophthalmol. Ther. 12, 3121–3132 (2023).
Eraybar, S., Dal, E., Aydin, M. O. & Begenen, M. Transforming emergency triage: a preliminary, scenario-based cross-sectional study comparing artificial intelligence models and clinical expertise for enhanced accuracy. Bratisl. Lek. Listy 125, 738–743 (2024).
Fraser, H. et al. Comparison of diagnostic and triage accuracy of Ada health and WebMD symptom checkers, ChatGPT, and physicians for patients in an emergency department: clinical data analysis study. JMIR Mhealth Uhealth 11, e49995 (2023).
Gan, R. K., Ogbodo, J. C., Wee, Y. Z., Gan, A. Z. & González, P. A. Performance of Google Bard and ChatGPT in mass casualty incidents triage. Am. J. Emerg. Med. 75, 72–78 (2024).
Gan, R. K., Uddin, H., Gan, A. Z., Yew, Y. Y. & González, P. A. ChatGPT’s performance before and after teaching in mass casualty incident triage. Sci. Rep. 13, 20350 (2023).
Hirosawa, T. et al. Diagnostic accuracy of differential-diagnosis lists generated by generative pretrained transformer 3 chatbot for clinical vignettes with common chief complaints: a pilot study. Int. J. Environ. Res. Public Health 20, 3378 (2023).
Hirosawa, T. et al. ChatGPT-generated differential diagnosis lists for complex case-derived clinical vignettes: diagnostic accuracy evaluation. JMIR Med. Inf. 11, e48808 (2023).
Hirosawa, T., Mizuta, K., Harada, Y. & Shimizu, T. Comparative evaluation of diagnostic accuracy between Google Bard and physicians. Am. J. Med. 136, 1119–1123.e1118 (2023).
Horiuchi, D. et al. Comparing the diagnostic performance of GPT-4-based ChatGPT, GPT-4V-based ChatGPT, and radiologists in challenging neuroradiology cases. Clin. Neuroradiol. 34, 779–787 (2024).
Horiuchi, D. et al. ChatGPT’s diagnostic performance based on textual vs. visual information compared to radiologists’ diagnostic performance in musculoskeletal radiology. Eur. Radiol. 35, 506–516 (2025).
Ilić, N. et al. The artificial intelligence-assisted diagnosis of skeletal dysplasias in pediatric patients: a comparative benchmark study of large language models and a clinical expert group. Genes 16, 762 (2025).
Ito, N. et al. The accuracy and potential racial and ethnic biases of GPT-4 in the diagnosis and triage of health conditions: evaluation study. JMIR Med. Educ. 9, e47532 (2023).
Jiao, C. et al. Diagnostic performance of publicly available large language models in corneal diseases: a comparison with human specialists. Diagnostics 15, 1221 (2025).
Kim, S. H. et al. Human-AI collaboration in large language model-assisted brain MRI differential diagnosis: a usability study. Eur. Radiol. 35, 5252–5263 (2025).
Krusche, M., Callhoff, J., Knitza, J. & Ruffer, N. Diagnostic accuracy of a large language model in rheumatology: comparison of physician and ChatGPT-4. Rheumatol. Int. 44, 303–306 (2024).
Le Guellec, B. et al. Comparison between multimodal foundation models and radiologists for the diagnosis of challenging neuroradiology cases with text and images. Diagn. Interv. Imaging 106, 345–352 (2025).
Liu, X. et al. A generalist medical language model for disease diagnosis assistance. Nat. Med. 31, 932–942 (2025).
Lyons, R. J., Arepalli, S. R., Fromal, O., Choi, J. D. & Jain, N. Artificial intelligence chatbot performance in triage of ophthalmic conditions. Can. J. Ophthalmol. 59, e301–e308 (2024).
Makhoul, M., Melkane, A. E., Khoury, P. E., Hadi, C. E. & Matar, N. A cross-sectional comparative study: ChatGPT 3.5 versus diverse levels of medical experts in the diagnosis of ENT diseases. Eur. Arch. Otorhinolaryngol. 281, 2717–2721 (2024).
Mao, X. et al. A phenotype-based AI pipeline outperforms human experts in differentially diagnosing rare diseases using EHRs. NPJ Digit. Med. 8, 68 (2025).
McDuff, D. et al. Towards accurate differential diagnosis with large language models. Nature 642, 451–457 (2025).
Meral, G., Ateş, S., Günay, S., Öztürk, A. & Kuşdoğan, M. Comparative analysis of ChatGPT, Gemini and emergency medicine specialist in ESI triage assessment. Am. J. Emerg. Med. 81, 146–150 (2024).
Milad, D. et al. Assessing the medical reasoning skills of GPT-4 in complex ophthalmology cases. Br. J. Ophthalmol. 108, 1398–1405 (2024).
Ming, S. et al. Performance of ChatGPT in ophthalmic registration and clinical diagnosis: cross-sectional study. J. Med. Internet Res. 26, e60226 (2024).
Mitsuyama, Y. et al. Comparative analysis of GPT-4-based ChatGPT’s diagnostic performance with radiologists using real-world radiology reports of brain tumors. Eur. Radiol. 35, 1938–1947 (2025).
Naeem, A. et al. Language artificial intelligence models as pioneers in diagnostic medicine? A retrospective analysis on real-time patients. J. Clin. Med. 14, 1131 (2025).
Nógrádi, B. et al. ChatGPT M.D: is there any room for generative AI in neurology? PLoS ONE 19, e0310028 (2024).
Pan, Y. et al. Clinical feasibility of AI Doctors: evaluating the replacement potential of large language models in outpatient settings for central nervous system tumors. Int. J. Med. Inf. 203, 106013 (2025).
Pasli, S. et al. ChatGPT-supported patient triage with voice commands in the emergency department: a prospective multicenter study. Am. J. Emerg. Med. 94, 63–70 (2025).
Paslı, S. et al. Assessing the precision of artificial intelligence in emergency department triage decisions: Insights from a study with ChatGPT. Am. J. Emerg. Med. 78, 170–175 (2024).
Rojas-Carabali, W. et al. Evaluating the diagnostic accuracy and management recommendations of ChatGPT in Uveitis. Ocul. Immunol. Inflamm. 32, 1526–1531 (2024).
Rutledge, G. W. Diagnostic accuracy of GPT-4 on common clinical scenarios and challenging cases. Learn. Health Syst. 8, e10438 (2024).
Shemer, A. et al. Diagnostic capabilities of ChatGPT in ophthalmology. Graefes Arch. Clin. Exp. Ophthalmol. 262, 2345–2352 (2024).
Sheng, L. et al. Large language models for diagnosing focal liver lesions from CT/MRI reports: a comparative study with radiologists. Liver Int. 45, e70115 (2025).
Siepmann, R. et al. The virtual reference radiologist: comprehensive AI assistance for clinical image reading and interpretation. Eur. Radio. 34, 6652–6666 (2024).
Singh, J. et al. Diagnostic accuracy of a large language model (ChatGPT-4) for patients admitted to a community hospital medical intensive care unit: a retrospective case study. J. Intensive Care Med. https://doi.org/10.1177/08850666251368270 (2025). online ahead of print.
Sorin, V. et al. Integrated visual and text-based analysis of ophthalmology clinical cases using a large language model. Sci. Rep. 15, 4999 (2025).
Sorin, V. et al. Generative pre-trained transformer (GPT)-4 support for differential diagnosis in neuroradiology. Quant. Imaging Med. Surg. 14, 7551–7560 (2024).
Suh, P. S. et al. Comparing diagnostic accuracy of radiologists versus GPT-4V and Gemini Pro Vision using image inputs from diagnosis please cases. Radiology 312, e240273 (2024).
Tu, T. et al. Towards conversational diagnostic artificial intelligence. Nature 642, 442–450 (2025).
Ward, M. et al. A Quantitative Assessment of ChatGPT as a Neurosurgical Triaging Tool. Neurosurgery 95, 487–495 (2024).
Wu, X., Huang, Y. & He, Q. A large language model improves clinicians’ diagnostic performance in complex critical illness cases. Crit. Care 29, 230 (2025).
Yang, X. et al. Multiple large language models versus experienced physicians in diagnosing challenging cases with gastrointestinal symptoms. npj Digit. Med. 8, 85 (2025).
Yazaki, M. et al. Emergency patient triage improvement through a retrieval-augmented generation enhanced large-scale language model. Prehosp. Emerg. Care 29, 203–209 (2025).
Zaboli, A. et al. Chat-GPT in triage: still far from surpassing human expertise - An observational study. Am. J. Emerg. Med. 92, 165–171 (2025).
Zheng, C. et al. Development and evaluation of a large language model of ophthalmology in Chinese. Br. J. Ophthalmol. 108, 1390–1397 (2024).
Barnett, G. O., Cimino, J. J., Hupp, J. A. & Hoffer, E. P. DXplain. An evolving diagnostic decision-support system. JAMA 258, 67–74 (1987).
Fraser, H., Coiera, E. & Wong, D. Safety of patient-facing digital symptom checkers. Lancet 392, 2263–2264 (2018).
Bond, W. F. et al. Differential diagnosis generators: an evaluation of currently available computer programs. J. Gen. Intern. Med. 27, 213–219 (2012).
Hautz, W. E. et al. Diagnoses supported by a computerised diagnostic decision support system versus conventional diagnoses in emergency patients (DDX-BRO): a multicentre, multiple-period, double-blind, cluster-randomised, crossover superiority trial. Lancet Digit. Health 7, e136–e144 (2025).
Schmieding, M. L. et al. Triage accuracy of symptom checker apps: 5-year follow-up evaluation. J. Med. Internet Res. 24, e31810 (2022).
Harada, Y., Sakamoto, T., Sugimoto, S. & Shimizu, T. Longitudinal changes in diagnostic accuracy of a differential diagnosis list developed by an AI-based symptom checker: retrospective observational study. JMIR Form. Res. 8, e53985 (2024).
Semigran, H. L., Linder, J. A., Gidengil, C. & Mehrotra, A. Evaluation of symptom checkers for self diagnosis and triage: audit study. BMJ 351, h3480 (2015).
Wallace, W. et al. The diagnostic and triage accuracy of digital and online symptom checker tools: a systematic review. NPJ Digit. Med. 5, 118 (2022).
Zhou, S. et al. Large language models for disease diagnosis: a scoping review. NPJ Artif Intell 1, 9 https://doi.org/10.1038/s44387-025-00011-z (2025).
Naveed, H. et al. A comprehensive overview of large language models. ACM Transactions on Intelligent Systems and Technology 16, 1–72 (2025).
Goh, E. et al. Large language model influence on diagnostic reasoning: a randomized clinical trial. JAMA Netw. Open 7, e2440969 (2024).
Goh, E. et al. GPT-4 assistance for improvement of physician performance on patient care tasks: a randomized controlled trial. Nat. Med. 31, 1233–1238 (2025).
Duan, L. et al. Application of large language models to natural language processing and image analysis tasks in dermatology: a systematic review. Intell. Med. 1, 100089 (2025).
Bhasuran, B. et al. Preliminary analysis of the impact of lab results on large language model generated differential diagnoses. npj Digit. Med. 8, 166 (2025).
Kostopoulou, O., Sirota, M., Round, T., Samaranayaka, S. & Delaney, B. C. The role of physicians’ first impressions in the diagnosis of possible cancers without alarm symptoms. Med. Decis. Mak. 37, 9–16 (2017).
Leblanc, V. R., Brooks, L. R. & Norman, G. R. Believing is seeing: the influence of a diagnostic hypothesis on the interpretation of clinical features. Acad. Med. 77, S67–S69 (2002).
Liberati, E. G. et al. What hinders the uptake of computerized decision support systems in hospitals? A qualitative study and framework for implementation. Implement. Sci. 12, 113 (2017).
Chen, M. et al. Acceptance of clinical artificial intelligence among physicians and medical students: a systematic review with cross-sectional survey. Front. Med. 9, 990604 (2022).
Hassan, N. et al. Systematic review to understand users perspectives on AI-enabled decision aids to inform shared decision making. NPJ Digit. Med. 7, 332 (2024).
See, K. E., Morrison, E. W., Rothman, N. B. & Soll, J. B. The detrimental effects of power on confidence, advice taking, and accuracy. Organ. Behav. Hum. Decis. Process. 116, 272–285 (2011).
Kaboudi, N. et al. Diagnostic accuracy of ChatGPT for patients’ triage; a systematic review and meta-analysis. Arch. Acad. Emerg. Med. 12, e60 (2024).
Kopka, M., von Kalckreuth, N. & Feufel, M. A. Accuracy of online symptom assessment applications, large language models, and laypeople for self–triage decisions. npj Digit. Med. 8, 178 (2025).
Alber, D. A. et al. Medical large language models are vulnerable to data-poisoning attacks. Nat. Med. 31, 618–626 (2025).
Han, T. et al. Medical large language models are susceptible to targeted misinformation attacks. NPJ Digit. Med. 7, 288 (2024).
Reddy, S. Explainability and artificial intelligence in medicine. Lancet Digit. Health 4, e214–e215 (2022).
Huang, L. et al. A survey on hallucination in large language models: principles, taxonomy, challenges, and open questions. ACM T Inf. Syst 43, 1–55 (2024).
Towhidul Islam Tonmoy, S. M. et al. A comprehensive survey of hallucination mitigation techniques in large language models. Preprint at https://arXiv.org/abs/2401.01313 (2024).
Zhao, H. et al. Explainability for large language models: a survey. ACM T Intel. Syst. Tech. 15, 20 (2024).
Ennab, M. & McHeick, H. Enhancing interpretability and accuracy of AI models in healthcare: a comprehensive review on challenges and future directions. Front. Robot. AI 11, 1444763 (2024).
Sounderajah, V. et al. The STARD-AI reporting guideline for diagnostic accuracy studies using artificial intelligence. Nat. Med. 31, 3283–3289 (2025).
Johri, S. et al. An evaluation framework for clinical use of large language models in patient interaction tasks. Nat. Med. 31, 77–86 (2025).
Tam, T. Y. C. et al. A framework for human evaluation of large language models in healthcare derived from literature review. NPJ Digit. Med. 7, 258 (2024).
Conduah, A. K., Ofoe, S. & Siaw-Marfo, D. Data privacy in healthcare: global challenges and solutions. Digit. Health 11, 20552076251343959 (2025).
Ong, J. C. L. et al. Ethical and regulatory challenges of large language models in medicine. Lancet Digit. Health 6, e428–e432 (2024).
Comeau, D. S., Bitterman, D. S. & Celi, L. A. Preventing unrestricted and unmonitored AI experimentation in healthcare through transparency and accountability. npj Digit. Med. 8, 42 (2025).
Zack, T. et al. Assessing the potential of GPT-4 to perpetuate racial and gender biases in health care: a model evaluation study. Lancet Digit. Health 6, e12–e22 (2024).
Menz, B. D. et al. Gender representation of health care professionals in large language model–generated stories. JAMA Netw. Open 7, e2434997 (2024).
Omiye, J. A., Lester, J. C., Spichak, S., Rotemberg, V. & Daneshjou, R. Large language models propagate race-based medicine. NPJ Digit. Med. 6, 195 (2023).
Hasanzadeh, F. et al. Bias recognition and mitigation strategies in artificial intelligence healthcare applications. NPJ Digit. Med. 8, 154 (2025).
Schuitmaker, L., Drogt, J., Benders, M. & Jongsma, K. Physicians’ required competencies in AI-assisted clinical settings: a systematic review. Br. Med. Bull. 153 (2025).
FDA. Clinical Decision Support Software Guidance for Industry and Food and Drug Administration Staff https://www.fda.gov/regulatory-information/search-fda-guidance-documents/clinical-decision-support-software (2022).
European Parliament, E. C. Consolidated text: Regulation (EU) 2017/745 of the European Parliament and of the Council of 5 April 2017 on medical devices, amending Directive 2001/83/EC, Regulation (EC) No 178/2002 and Regulation (EC) No 1223/2009 and repealing Council Directives 90/385/EEC and 93/42/EEC (Text with EEA relevance) https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02017R0745-20250110 (2017).
WHO. Ethics and Governance of Artificial Intelligence for Health: Guidance on Large Multi-Modal Models https://www.who.int/publications/i/item/9789240084759 (2024).
WHO. Ethics and Governance of Artificial Intelligence for Health: WHO Guidance Executive Summary https://www.who.int/publications/i/item/9789240037403 (2021).
Warraich, H. J., Tazbaz, T. & Califf, R. M. FDA perspective on the regulation of artificial intelligence in health care and biomedicine. JAMA 333, 241–247 (2025).
Parliament, E. Artificial Intelligence Act: MEPs Adopt Landmark Law https://www.europarl.europa.eu/news/en/press-room/20240308IPR19015/artificial-intelligence-act-meps-adopt-landmark-law (2024).
Sounderajah, V. et al. A quality assessment tool for artificial intelligence-centered diagnostic test accuracy studies: QUADAS-AI. Nat. Med. 27, 1663–1665 (2021).
Whiting, P. F. et al. QUADAS-2: a revised tool for the quality assessment of diagnostic accuracy studies. Ann. Intern. Med. 155, 529–536 (2011).
Fernández-Castilla, B. et al. The application of meta-analytic (multi-level) models with multiple random effects: a systematic review. Behav. Res. Methods 52, 2031–2052 (2020).
Higgins, J. P., Thompson, S. G., Deeks, J. J. & Altman, D. G. Measuring inconsistency in meta-analyses. BMJ 327, 557–560 (2003).
Sun, X., Ioannidis, J. P., Agoritsas, T., Alba, A. C. & Guyatt, G. How to use a subgroup analysis: users’ guide to the medical literature. JAMA 311, 405–411 (2014).
Egger, M., Davey Smith, G., Schneider, M. & Minder, C. Bias in meta-analysis detected by a simple, graphical test. BMJ 315, 629–634 (1997).
Acknowledgements
This study was supported by the Tencent Sustainable Social Value Inclusive Health Lab and through the Chongqing Tencent Sustainable Development Foundation “Comprehensive Prevention and Control Demonstration Project for Eliminating Cervical Cancer and Breast Cancer in Low Health Resource Areas of China” (SD20240904145730) and the CAMS Innovation Fund for Medical Sciences (CIFMS 2021-I2M-1-004).
Author information
Authors and Affiliations
Contributions
M.C. contributed to the study design, conceptualization, and literature search. M.C., Y.W., J.M., and X.J. screened the literature, extracted data, and evaluated the quality of included studies. M.C. and Y.W. conducted the analysis and wrote the initial manuscript. C.G., F.Z. and Y.Q. revised the manuscript. All authors approved the final version of the manuscript and take accountability for all aspects of the work.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, M., Wu, Y., Ma, J. et al. Independent and collaborative performance of large language models and healthcare professionals in diagnosis and triage. npj Digit. Med. (2026). https://doi.org/10.1038/s41746-026-02409-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-026-02409-8
