
Abstract
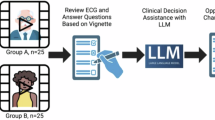
For novice medical learners, do the benefits of correct AI explanations outweigh the risks of plausible misinformation? In a randomized trial with 111 students, we found they do not. Our results reveal a significant and problematic asymmetry: misleading AI explanations significantly degraded diagnostic accuracy, while correct explanations offered no significant improvement over a no-explanation control. Misleading explanations reduced diagnostic accuracy and showed no evidence of confidence calibration, such that confidence did not reliably distinguish correct from incorrect responses. This study provides crucial empirical evidence that, without proper safeguards, the harm caused by AI-generated falsehoods in this population and task is more potent and robust than the benefit derived from correct guidance. This finding highlights a fundamental safety challenge for AI in medical education, demanding a strategic pivot towards building learners’ critical appraisal skills. Trial registration: Chinese Clinical Trial Registry (ChiCTR), ChiCTR2500111932, registered on 7 November 2025.
Similar content being viewed by others
Data availability
De-identified participant data will be made available following publication, upon reasonable request to the corresponding author (email). Access will be granted after the signing of a data use agreement and approval from the institutional ethics committee of the National Cancer Center.
Code availability
The code is available upon request to the corresponding author (email: zhaodan@cicams.ac.cn).
References
Kung, T. H. et al. Performance of chatgpt on usmle: potential for ai-assisted medical education using large language models. PLoS Digit. Health 2, e0000198 (2023).
Lazarus, M. D., Truong, M., Douglas, P. & Selwyn, N. Artificial intelligence and clinical anatomical education: promises and perils. Anat. Sci. Educ. 17, 249–262 (2024).
Chan, K. S. & Zary, N. Applications and challenges of implementing artificial intelligence in medical education: integrative review. JMIR Med. Educ. 5, e13930 (2019).
Tolsgaard, M. G. et al. The fundamentals of artificial intelligence in medical education research: amee guide no. 156. Med. Teach. 45, 565–573 (2023).
Masters, K. Artificial intelligence in medical education. Med. Teach. 41, 976–980 (2019).
Emsley, R. Chatgpt: these are not hallucinations—they’re fabrications and falsifications. Schizophrenia 9, 52 (2023).
Roy, S. et al. Beyond accuracy: investigating error types in GPT-4 responses to USMLE questions. In Proc 47th International ACM SIGIR Conference on Research and Development in Information Retrieval 1073–1082 (ACM, 2024).
Davis, S. M. et al. Profound hypokalemia associated with severe diabetic ketoacidosis. Pediatr. Diab. 17, 61–65 (2016).
Kitabchi, A. E., Umpierrez, G. E., Miles, J. M. & Fisher, J. N. Hyperglycemic crises in adult patients with diabetes. Diab. Care 32, 1335 (2009).
Sampson, M., Jones, C. et al. Joint british diabetes societies for inpatient care: clinical guidelines and improving inpatient diabetes care. Diabet. Med. 35, 988–91 (2018).
Qiu, P. et al. Quantifying the reasoning abilities of llms on clinical cases. Nat. Commun. 16, 9799 (2025).
Maynez, J., Narayan, S., Bohnet, B. & McDonald, R. On faithfulness and factuality in abstractive summarization. In Proc. of the 58th Annual Meeting of the Association for Computational Linguistics 1906–1919 (2020).
Ji, Z. et al. Survey of hallucination in natural language generation. ACM Comput. Surv. 55, 1–38 (2023).
Messeri, L. & Crockett, M. Artificial intelligence and illusions of understanding in scientific research. Nature 627, 49–58 (2024).
Reber, R. & Schwarz, N. Effects of perceptual fluency on judgments of truth. Conscious. Cogn. 8, 338–342 (1999).
Rozenblit, L. & Keil, F. The misunderstood limits of folk science: an illusion of explanatory depth. Cogn. Sci. 26, 521–562 (2002).
Fazio, L. K., Brashier, N. M., Payne, B. K. & Marsh, E. J. Knowledge does not protect against illusory truth. J. Exp. Psychol. Gen. 144, 993 (2015).
Westbrook, J. I., Gosling, A. S. & Coiera, E. W. The impact of an online evidence system on confidence in decision making in a controlled setting. Med. Decis. Mak. 25, 178–185 (2005).
Skitka, L. J., Mosier, K. L. & Burdick, M. Does automation bias decision-making? Int. J. Hum. Comput. Stud. 51, 991–1006 (1999).
Parasuraman, R. & Riley, V. Humans and automation: use, misuse, disuse, abuse. Hum. factors 39, 230–253 (1997).
Parasuraman, R. & Manzey, D. H. Complacency and bias in human use of automation: an attentional integration. Hum. factors 52, 381–410 (2010).
Goddard, K., Roudsari, A. & Wyatt, J. C. Automation bias: a systematic review of frequency, effect mediators, and mitigators. J. Am. Med. Inform. Assoc. 19, 121–127 (2012).
Lyell, D. & Coiera, E. Automation bias and verification complexity: a systematic review. J. Am. Med. Inform. Assoc. 24, 423–431 (2017).
Dzindolet, M. T., Peterson, S. A., Pomranky, R. A., Pierce, L. G. & Beck, H. P. The role of trust in automation reliance. Int. J. Hum. Comput. Stud. 58, 697–718 (2003).
Li, Y. & Li, J. Generative artificial intelligence in medical education: way to solve the problems. Postgrad. Med. J. 100, 203–204 (2024).
Buçinca, Z., Malaya, M. B. & Gajos, K. Z. To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making. Proc. ACM Hum. Comput. Interact. 5, 1–21 (2021).
Organization, W. H. Ethics and Governance of Artificial Intelligence for Health: Large Multi-Modal Models. WHO Guidance (World Health Organization, 2024).
Singhal, K. et al. Toward expert-level medical question answering with large language models. Nat. Med. 31, 943–950 (2025).
Thirunavukarasu, A. J. et al. Large language models in medicine. Nat. Med. 29, 1930–1940 (2023).
Hopewell, S. et al. Consort 2025 statement: updated guideline for reporting randomised trials. Lancet 405, 1633–1640 (2025).
Eysenbach, G. & Group, C.-E. CONSORT-EHEALTH: improving and standardizing evaluation reports of web-based and mobile health interventions. J. Med. Internet Res. 13, e126 (2011).
OpenAI et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
Nori, H., King, N., McKinney, S. M., Carignan, D. & Horvitz, E. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:2303.13375 (2023).
Faul, F., Erdfelder, E., Lang, A.-G. & Buchner, A. G* power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods 39, 175–191 (2007).
Wittwer, J. & Renkl, A. How effective are instructional explanations in example-based learning? A meta-analytic review. Educ. Psychol. Rev. 22, 393–409 (2010).
Bates, D., M"achler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48 (2015).
Kuznetsova, A., Brockhoff, P. B. & Christensen, R. H. lmertest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26 (2017).
Lenth, R. V. emmeans: Estimated marginal means, aka least-squares means. R package https://rvlenth.github.io/emmeans/ (2025).
Barr, D. J., Levy, R., Scheepers, C. & Tily, H. J. Random effects structure for confirmatory hypothesis testing: keep it maximal. J. Mem. Lang. 68, 255–278 (2013).
Lenth, R. V. & Piaskowski, J. emmeans: Estimated Marginal Means, aka Least-Squares Means https://rvlenth.github.io/emmeans/ (2025).
Tukey, J. W. Comparing individual means in the analysis of variance. Biometrics 5, 99–114 (1949).
Nakagawa, S. & Schielzeth, H. A general and simple method for obtaining r2 from generalized linear mixed-effects models. Methods Ecol. Evol. 4, 133–142 (2013).
Acknowledgements
We gratefully acknowledge the colleagues who provided technical and administrative support during the revision of this manuscript. We also thank all medical educators and clinical experts who assisted in the multi-stage medical accuracy check of the correct and misleading explanations used in the experiment. This research work is supported by the National Natural Science Foundation of China (no. 62176267&82302788), the Capital’s Funds for Health Improvement and Research (no. 2022-2-4026), the Beijing Natural Science Foundation (no. 7252116), the CAMS Innovation Fund for Medical Sciences (no. 2024-I2M-C&T-A-003), the Qinghai Province Key Research and Development and Transformation Plan (no. 2025-QY-220), and the Zhiyuan Scientific Research Fund Project by BIPT (no. 2026005).
Author information
Authors and Affiliations
Contributions
D.T. (Da Teng) designed the study, developed the system, conducted the experiment, analyzed the data, wrote, and revised the manuscript. L.T. (Lihua Tan) led in system development and data collection with the assistance of Q.C. (Qiyuan Cao). N.Z. (Na Zhang) contributed to the project supervision and manuscript revision. D.Z. (Dan Zhao) supervised the project, secured funding, and revised the manuscript. Y.X. (Yanwei Xia) and J.L. (Jiantao Li) made critical contributions to the revision of this manuscript. Specifically, Y.X. conducted the complete statistical re-analysis using mixed-effects models. J.L. contributed to the fundamental restructuring of the theoretical framework. All authors critically reviewed and edited the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Teng, D., Tan, L., Cao, Q. et al. Impact of AI misinformation on diagnostic accuracy and confidence calibration in novice medical students. npj Digit. Med. (2026). https://doi.org/10.1038/s41746-026-02547-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-026-02547-z
