
Abstract
Analogue in-memory computing (AIMC) is an emerging computational paradigm that can efficiently accelerate the key operations in deep learning (DL) inference workloads. Heterogeneous architectures, which integrate both AIMC tiles and digital processing units, have been proposed to enable the end-to-end execution of various deep neural network models. However, developing a software stack for these architectures is challenging, owing to their distinct characteristics — such as the need for extensive or complete weight stationarity and pipelined execution across layers, if maximum performance is to be achieved. Moreover, AIMC tiles are inherently stochastic and hence introduce a combination of stochastic and deterministic noise, which adversely affects accuracy. As a result, existing tools for software stack development are not directly applicable. In this Perspective, we give an overview of the key attributes of DL software stacks and AIMC-based accelerators, outline the challenges associated with designing DL software stacks for AIMC-based accelerators and present opportunities for future research.
Key points
-
Analogue in-memory computing (AIMC)-based accelerators, comprising AIMC tiles and digital processing units (DPUs), can be used to perform end-to-end execution of deep learning (DL) inference workloads, with low latency and high energy efficiency.
-
The large-scale adoption of AIMC-based accelerators demands efficient techniques and tools for the co-design of software and hardware, in addition to sophisticated software stacks, which abstract the deployment of diverse deep neural network (DNN) models.
-
AIMC-based accelerators based on non-volatile memory have unique attributes, such as fixed weight stationarity and noise arising from analogue computation, and these have a substantial impact on how software stacks are developed for them.
-
In most work on memory devices for AIMC or the design of AIMC-based accelerators, the complexity of DL software stack development and, consequently, the amount of time required are given insufficient consideration.
This is a preview of subscription content, access via your institution
Access options
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout



Similar content being viewed by others
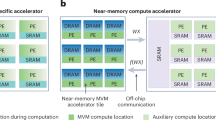

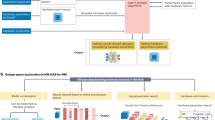
References
Wu, C.-J. et al. Sustainable AI: environmental implications, challenges and opportunities. In Proc. Machine Learning and Systems 4 (eds Marculescu, D. et al.) 795–813 (2022).
Chen, Y., Xie, Y., Song, L., Chen, F. & Tang, T. A survey of accelerator architectures for deep neural networks. Engineering 6, 264–274 (2020).
Sebastian, A., Gallo, M. L., Khaddam-Aljameh, R. & Eleftheriou, E. Memory devices and applications for in-memory computing. Nat. Nanotechnol. 15, 529–544 (2020).
Jouppi, N. P. et al. In-datacenter performance analysis of a tensor processing unit. In 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA) https://doi.org/10.1145/3079856.3080246 (IEEE, 2017).
Ambrogio, S. et al. An analog-AI chip for energy-efficient speech recognition and transcription. Nature 620, 768–775 (2023).
Guo, A. et al. 4.3 A 22nm 64kb Lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog-storage quantizers for transformer and CNNs. In IEEE International Solid-State Circuits Conference (ISSCC) Vol. 67 570–572 (IEEE, 2024).
Aguirre, F. et al. Hardware implementation of memristor-based artificial neural networks. Nat. Commun. 15, 1974 (2024).
Huang, Y. et al. Memristor-based hardware accelerators for artificial intelligence. Nat. Rev. Electr. Eng. 1, 286–299 (2024). This review covers the latest progress in memristive crossbar arrays, peripheral circuits, architectures, hardware–software co-designs and system implementations for memristor-based hardware accelerators.
Jain, S. et al. A heterogeneous and programmable compute-in-memory accelerator architecture for analog-AI using dense 2-D mesh. IEEE Trans. Very Large Scale Integr. VLSI Syst. 31, 114–127 (2023).
Burr, G. W. et al. Design of analog-AI hardware accelerators for transformer-based language models. In 2023 International Electron Devices Meeting (IEDM) https://doi.org/10.1109/IEDM45741.2023.10413767 (2023).
Krestinskaya, O. et al. Neural architecture search for in-memory computing-based deep learning accelerators. Nat. Rev. Electr. Eng. 1, 374–390 (2024). This review presents applications of hardware neural architecture search to the specific features of IMC hardware and compares existing optimization frameworks.
Gallo, M. L. et al. A 64-core mixed-signal in-memory compute chip based on phase-change memory for deep neural network inference. Nat. Electron. 6, 680–693 (2023).
Boybat, I. et al. Heterogeneous embedded neural processing units utilizing PCM-based analog in-memory computing. In 2024 IEEE International Electron Devices Meeting (IEDM) https://doi.org/10.1109/IEDM50854.2024.10873479 (IEEE, 2024).
Paszke, A. et al. Automatic differentiation in PyTorch. In NIPS 2017 Workshop on Autodiff (2017).
Li, M. et al. The deep learning compiler: a comprehensive survey. IEEE Trans. Parallel Distrib. Syst. 32, 708–727 (2021). This paper presents a comprehensive survey of deep learning compilation.
Lattner, C. & Pienaar, J. MLIR primer: a compiler infrastructure for the end of Moore’s Law. Preprint at https://arxiv.org/abs/2002.11054 (2019). This paper introduces the MLIR project, which is a novel approach to building reusable and extensible compiler infrastructure.
Pichler, C., Li, P., Schatz, R. & Mössenböck, H. Hybrid execution: combining ahead-of-time and just-in-time compilation. In Proc. 15th ACM SIGPLAN International Workshop on Virtual Machines and Intermediate Languages 39–49 (Association for Computing Machinery, 2023).
He, K., Chakraborty, I., Wang, C. & Roy, K. Design space and memory technology co-exploration for in-memory computing based machine learning accelerators. In ICCAD ‘22: Proc. 41st IEEE/ACM International Conference on Computer-Aided Design https://doi.org/10.1145/3508352.3549453 (Association for Computing Machinery, 2022).
Sharma, S. & Kumar, V. A comprehensive review on multi-objective optimization techniques: past, present and future. Arch. Comput. Methods Eng. 29, 5605–5633 (2022).
Abadi, M. TensorFlow: learning functions at scale. In ICFP 2016: Proc. 21st ACM SIGPLAN International Conference on Functional Programming https://doi.org/10.1145/2951913.2976746 (Association for Computing Machinery, 2016).
Roesch, J. et al. Relay: a new IR for machine learning frameworks. In MAPL 2018: Proceedings of the 2nd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages 58–68 (Association for Computing Machinery, 2018).
Cyphers, S. et al. Intel nGraph: an intermediate representation, compiler, and executor for deep learning. Preprint at http://arxiv.org/abs/1801.08058 (2018).
Chen, T. et al. TVM: an automated end-to-end optimizing compiler for deep learning. In OSDI’18: Proc. 13th USENIX conference on Operating Systems Design and Implementation 579–594 (USENIX Association, 2018).
Lattner, C. & Adve, V. LLVM: a compilation framework for lifelong program analysis & transformation. In International Symposium on Code Generation and Optimization, 2004 75–86 (IEEE, 2004).
Rotem, N. et al. Glow: Graph lowering compiler techniques for neural networks. Preprint at http://arxiv.org/abs/1805.00907 (2018).
Jeong, E., Kim, J. & Ha, S. TensorRT-based framework and optimization methodology for deep learning inference on Jetson boards. ACM Trans. Embedded Computer Systems https://doi.org/10.1145/3508391 (2022).
Demidovskij, A. et al. OpenVINO Deep Learning Workbench: a platform for model optimization, analysis and deployment. In 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI) 661–668 (IEEE, 2020).
Lammie, C. et al. LIONHEART: a layer-based mapping framework for heterogeneous systems with analog in-memory computing tiles. IEEE Transactions on Emerging Topics in Computing https://ieeexplore.ieee.org/document/10910024 (IEEE, 2025).
Khaddam-Aljameh, R. et al. HERMES core – a 14 nm CMOS and PCM-based in-memory compute core using an array of 300ps/LSB linearized CCO-based ADCs and local digital processing. In 2021 Symposium on VLSI Technology https://ieeexplore.ieee.org/document/9508706 (IEEE, 2021).
Lammie, C., Büchel, J., Vasilopoulos, A., Le Gallo, M. & Sebastian, A. The inherent adversarial robustness of analog in-memory computing. Nat. Commun. 16, 1756 (2025).
Rasch, M. J. et al. Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators. Nat. Commun. 14, 5282 (2023).
Si, M., Cheng, H.-Y., Ando, T., Hu, G. & Ye, P. D. Overview and outlook of emerging non-volatile memories. MRS Bull. 46, 946–958 (2021).
Ferro, E. et al. A precision-optimized fixed-point near-memory digital processing unit for analog in-memory computing. In IEEE International Symposium on Circuits and Systems (ISCAS) https://ieeexplore.ieee.org/document/10558286 (IEEE, 2024).
Benmeziane, H. et al. Multi-task neural network mapping onto analog-digital heterogeneous accelerators. In 38th Second Workshop on Machine Learning with New Compute Paradigms (2024).
Andrulis, T., Emer, J. S. & Sze, V. CiMLoop: a flexible, accurate, and fast compute-in-memory modeling tool. In IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) 10–23 (IEEE, 2024).
Roux, B., Gautier, M., Sentieys, O. & Delahaye, J.-P. Energy-driven design space exploration of tiling-based accelerators for heterogeneous multiprocessor architectures. MICPRO or Microprocess. 77, 103138 (2020).
Wang, I., Tarnawski, J., Phanishayee, A. & Mahajan, D. Integrated hardware architecture and device placement search. In ICML’24: Proc. 41st International Conference on Machine Learning (eds Salakhutdinov, R. et al.) 51523–51545 (JMLR.org, 2024).
Cong, J., Fang, Z., Gill, M. & Reinman, G. PARADE: a cycle-accurate full-system simulation platform for accelerator-rich architectural design and exploration. In 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD) 380–387 (IEEE, 2015).
Shao, Y. S., Xi, S. L., Srinivasan, V., Wei, G.-Y. & Brooks, D. Co-designing accelerators and SoC interfaces using gem5-Aladdin. In 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) https://ieeexplore.ieee.org/document/7783751 (IEEE, 2016).
Klein, J. et al. ALPINE: analog in-memory acceleration with tight processor integration for deep learning. IEEE Trans. Comput. 72, 1985–1998 (2023).
Büchel, J. et al. AIHWKIT-Lightning: a scalable HW-aware training toolkit for analog in-memory computing. In NeurIPS Workshop Machine Learning with new Compute Paradigms https://neurips.cc/virtual/2024/101271 (NeurIPS, 2024).
Lammie, C. et al. Improving the accuracy of analog-based in-memory computing accelerators post-training. In 2024 IEEE International Symposium on Circuits and Systems (ISCAS) https://ieeexplore.ieee.org/document/10558540 (IEEE, 2024).
Yao, P. et al. Fully hardware-implemented memristor convolutional neural network. Nature 577, 641–646 (2020).
Wan, W. et al. A compute-in-memory chip based on resistive random-access memory. Nature 608, 504–512 (2022).
Yu, J., Hogervorst, T. & Nane, R. A domain-specific language and compiler for computation-in-memory skeletons. In GLSVLSI ‘17: Proc. Great Lakes Symposium on VLSI 2017 71–76 (Association for Computing Machinery, 2017). This paper introduces the first compiler for IMC hardware.
Chakraborty, D., Raj, S., Gutierrez, J. C., Thomas, T. & Jha, S. K. In-memory execution of compute kernels using flow-based memristive crossbar computing. In 2017 IEEE International Conference on Rebooting Computing (ICRC) https://ieeexplore.ieee.org/document/8123643 (IEEE, 2017).
Fujiki, D., Mahlke, S. & Das, R. In-memory data parallel processor. In ASPLOS ‘18: Proc. Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems https://doi.org/10.1145/3173162.3173171 (Association for Computing Machinery, 2018).
Vadivel, K. et al. TDO-CIM: transparent detection and offloading for computation in-memory. In 2020 Design, Automation Test in Europe Conference & Exhibition (DATE) 1602–1605 (IEEE, 2020).
Siemieniuk, A. et al. OCC: an automated end-to-end machine learning optimizing compiler for computing-in-memory. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 41, 1674–1686 (2022).
Ambrosi, J. et al. Hardware–software co-design for an analog-digital accelerator for machine learning. In 2018 IEEE International Conference on Rebooting Computing (ICRC) https://ieeexplore.ieee.org/document/8638612 (2018).
Peng, X., Huang, S., Jiang, H., Lu, A. & Yu, S. DNN + NeuroSim V2.0: an end-to-end benchmarking framework for compute-in-memory accelerators for on-chip training. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 40, 2306–2319 (2020).
Ankit, A. et al. PUMA: A programmable ultra-efficient memristor-based accelerator for machine learning inference. In Proc. 24th International Conference on Architectural Support for Programming Languages and Operating Systems 715–731 (Association for Computing Machinery, 2019).
Drebes, A. et al. TC-CIM: empowering tensor comprehensions for computing-in-memory. In IMPACT 2020 10th International Workshop on Polyhedral Compilation Techniques (2020).
Park, J. & Sung, H. XLA-NDP: efficient scheduling and code generation for deep learning model training on near-data processing memory. IEEE Computer Architecture Letters 22, 61–64 (2023).
Jin, H. et al. A compilation tool for computation offloading in ReRAM-based CIM architectures. ACM Trans. Architecture and Code Optimization 20, 1–25 (2023).
Delm, J. V. et al. HTVM: efficient neural network deployment on heterogeneous TinyML platforms. In 2023 60th ACM/IEEE Design Automation Conference (DAC) https://ieeexplore.ieee.org/document/10247664 (IEEE, 2023).
Sun, X., Wang, X., Li, W., Han, Y. & Chen, X. PIMCOMP: an end-to-end DNN compiler for processing-in-memory accelerators. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 44, 1745–1759 (2024).
Bai, Y. et al. A compilation framework for SRAM computing-in-memory systems with optimized weight mapping and error correction. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 43, 2379–2392 (2024).
Qu, S. et al. CIM-MLC: a multi-level compilation stack for computing-in-memory accelerators. In Proc. 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems Vol. 2 185–200 (ACM, 2024).
Acknowledgements
This work was supported by the IBM Research AI Hardware Center.
Author information
Authors and Affiliations
Contributions
C.L. conceptualized the article. C.L., with the help of H.B. and A.S., drafted the manuscript. W.S., E.F., A.V., J.B., M.L.G. and I.B. contributed to discussions and assisted in editing the manuscript. All authors reviewed and approved the final version of the article.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Reviews Electrical Engineering thanks Huaqiang Wu and Jianhua Yang for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lammie, C., Benmeziane, H., Simon, W. et al. Deep learning software stacks for analogue in-memory computing-based accelerators. Nat Rev Electr Eng 2, 621–633 (2025). https://doi.org/10.1038/s44287-025-00187-1
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s44287-025-00187-1
