
Abstract
Precise identification of T cell antigens in silico is crucial for the development of cancer mRNA vaccines. However, current computational methods only utilize sequence-level rather than atomic level features to identify T cell antigens, which results in poor representation of those that activate immune responses. Here we propose deepAntigen, a graph convolutional network-based framework, to identify T cell antigens at the atomic level. deepAntigen achieves excellent performance both in the prediction of antigen-human leukocyte antigen (HLA) binding and antigen-T cell receptor (TCR) interactions, which can provide comprehensive guidance for identification of T cell antigens. The tumor neoantigens predicted by deepAntigen in lung, breast and pancreatic cancer patients are experimentally validated through ELISPOT assays, which detect successful activation of CD8+ T cells to release IFN-γ. Overall, deepAntigen can accurately identify T cell antigens at the atomic level, which could accelerate the development of personalized neoantigen targeted immunotherapies for cancer patients.
Similar content being viewed by others

Introduction
T cell antigens refer to short peptide epitopes presented on Major Histocompatibility Complex (MHC) molecules, also known as Human Leukocyte Antigens (HLA) in humans, and recognized by the T cell receptor (TCR). T cell antigens primarily consist of two crucial sources: HLA class I (HLA I)-restricted antigens that are produced via the cytosolic pathway and recognized by CD8+ T cells, and HLA class II (HLA II)-restricted antigens that are generated through the endocytic pathway and recognized by CD4+ T cells1. Recently, T cell antigens have been exploited in immunotherapies such as cancer mRNA vaccines2,3,4,5. These vaccines leverage the ability of T cell antigens to provoke immune responses against tumor cells, making them a promising approach in cancer treatments. Traditional experimental methods for identifying T cell antigens, such as tetramer-associated T-cell receptor sequencing6, yeast display7, T-Scan8 and TScan-II9, are not only time-consuming but also costly, given that antigens and TCRs are both huge diversity and only a limited fraction of antigens can trigger T cell immune responses10. Thus, identifying T cell antigens with artificial intelligence is crucial for accelerating the development of mRNA vaccine. However, the overall accuracy of T cell antigen identification remains far from satisfactory. Most of the identified antigens did not activate T cell immune responses in previous clinical validations11,12,13.
Two crucial elements of T cell antigen identification in silico are the prediction of both antigen-HLA binding and antigen-TCR interactions. Early computational methods for antigen-HLA binding prediction relied on antigen sequence similarity and amino acid position-specific scoring matrices to develop scoring functions for estimating antigen-HLA binding affinity, including SYFPEITHI14, MixMHCpred15, SMM-align16 and MixMHC2pred17. Alternatively, other computational approaches for antigen-TCR interaction prediction grouped TCRs based on TCR sequence similarity to determine antigen specificity, with notable methods such as GLIPH18, TCRdist19, GIANA20 and DeepTCR21. These methods are generally tailored to specific HLA alleles or antigens and they cannot efficiently capture the non-linear relations and complicated patterns, resulting in limited generalizability. In recent years, with the advancement of artificial intelligence (AI), AI-driven general antigen-HLA binding prediction methods (e.g., NetMHCPan22, TransPHLA23, NetMHCIIPan24 and HLAIIPred25) and antigen-TCR binding prediction methods (e.g., ERGO226, ImRex27, pMTnet28, PanPep29 and TEIM30) have been developed to extend predictions to all antigens and HLA alleles. Most of AI-driven methods utilize text embedding architectures such as transformers to independently encode antigens, HLAs and TCRs, which regard them as text sequences with amino acids as tokens, then design attention mechanism to characterize antigen-HLA binding23,25 or antigen-TCR interactions31,32.
The latest researches on HLA-antigen-TCR complex crystal structures indicated that atomic level contacts between antigen and TCR, especially for the non-covalent interactions, are crucial for the activation of T cell immune responses33,34,35,36,37,38. Sibener et al33. discovered that newly formed hydrogen bonds or salt bridges during dissociation prolong the contact time between the immunogenic antigen and TCR (catch bond), while non-immunogenic antigens do not show the formation of new atomic level non-covalent interactions with the TCR. Catch bonds have been employed to precisely regulate TCR activity and have shown promise in cancer immunotherapy39,40. Incorporating information about the HLA-antigen-TCR complex structure could provide new insights into T cell specificity41,42,43,44,45,46. Recently, revolutionary AI tools like RosettaFold All-Atom47 and AlphaFold348 have provided atomic level insights into studying general molecular interactions. RosettaFold All-Atom47 utilizes SE(3)-Transformers to generate 3D backbone from homologous structure templates and performs all-atom expansion according physicochemical principles. AlphaFold348 leverages a diffusion network to transform an atomic cloud into the accurate molecular structure through iterative refinement. But they still struggle to capture the relative contributions of details such as hydrogen bonding, electrostatic forces, and hydrophobic effects to the overall stability and specificity of interactions49,50.
Despite these progresses, challenges remain in accurately identifying T cell antigens for several reasons. First, except for pMTnet, most tools consider either antigen-HLA binding or antigen-TCR interactions when identifying T cell antigens, without comprehensively modeling both sides of the HLA-antigen-TCR complex. Second, sequence-based methods are insufficient to characterize the refined atomic level interactions between antigen and TCR41. Third, the scarcity of high-quality HLA-antigen-TCR complex crystal structures limits the effectiveness of template-based structure prediction tools in accurately modeling the diverse range of HLA-antigen-TCR interactions50. Fourth, the independent encoders separately encode the antigen and HLA, which limits the powerful representation ability of AI. In other words, a specific HLA allele can usually present thousands of different antigens, but the embedding of HLA cannot be adaptively adjusted according to the antigen by current methods, leading to a lack of flexibility51.
To address these challenges, we propose deepAntigen, a deep learning framework based on graph convolutional networks (GCN), to predict not only antigen-HLA binding but also antigen-TCR interactions at the atomic level. Our framework transforms the amino acid sequences of antigens, HLAs and TCRs into graphs, in which nodes correspond to atoms and edges correspond to chemical bonds. deepAntigen utilizes GCN and cross-attention to characterize crucial atomic level contacts between antigens and HLAs/TCRs. Comprehensive validations and analyzes demonstrate that deepAntigen outperforms state-of-the-art methods in identifying T cell antigens. In addition, deepAntigen is capable of discovering antigen-specific TCR motifs and capturing the impact of antigen mutations on T cell immune responses. The successful application of deepAntigen in clinical cancer patients further highlights its utility in neoantigen discovery. Together, these advancements indicate that deepAntigen holds the potential to drive the development of personalized neoantigen-targeted immunotherapies for cancer patients.
Results
Overview of deepAntigen
deepAntigen takes the sequence of an antigen and HLA/TCR as input. The HLA is encoded in terms of a pseudo sequence consisting of 34 polymorphic amino acid residues in contact with antigens52,53. TCRs are heterodimers composed of one α and one β chain, where the complementarity-determining region 3 (CDR3) is primarily involved in antigen recognition, while the other two CDRs (CDR1 and CDR2) mediate contact primarily with the HLA31. In this study, we only considerate the CDR3 of TCR β chain due to the importance of the CDR3β in antigen-TCR interactions18 and the number of antigen-TCRαβ pairs is much smaller than the antigen-TCRβ pairs29,54. deepAntigen_Seq, a sequence-level binding predictor, outputs a sequence-level interaction probability between antigen and HLA/TCR, while deepAntigen_Atom, an atomic level contact predictor, outputs the atomic level contact probabilities between antigen and HLA/TCR (Fig.1 and Methods).

a–c deepAntigen workflow. a, deepAntigen takes the residue sequences of antigen, TCR β chain complementary determine region 3 (CDR3) and HLA as input. The input residue sequences are transformed into topological graphs, in which each node corresponds to an atom and each edge corresponds to chemical bond, through the atomic graph representation module (Fig. 1b). Next, crucial atoms for the interaction process can be identified through GCN layer and Scoring layer. Finally, multi-head attention module extends respective top-k atoms to form a k×k interaction map. deepAntigen_Seq aggregates interaction features of pairwise atoms from antigen and HLA/TCR to predict the interaction probability through a multilayer perceptron (MLP). b The generation process of atomic graph representation for a given residue sequence. c Fine-tuning deepAntigen_Atom using structural data after pretraining deepAntigen_Seq on the sequence-level binding data. Parameters of GCN in light blue region were frozen, while those in light pink region were fine-tuned. deepAntigen_Atom directly predicts the contact probability of each atom pairs through an MLP according the interaction map. d General comparison between deepAntigen and other state-of-the-art methods on diverse independent test dataset. #, the number of unique objects. The schematic diagram of the TCR-antigen-HLA complex in (a) was created in BioRender. Que, J. (2025) https://BioRender.com/hbixhe0.
Sequence-to-graph transformation, atomic level feature extractor and interacting feature map generator are three main components of deepAntigen (Fig.1a). Firstly, each sequence is transformed into a graph, in which nodes correspond to atoms and edges correspond to chemical bonds (Fig.1b and Methods). In the training stage, randomly masking a few atoms and relevant chemical bonds is designed to augment the graph. Secondly, the atomic level feature extractor updates atom representations by utilizing GCN to aggregate neighborhood information. In each graph convolution layer, we developed an atomic level communication mechanism (Supplementary Fig. 1) between the antigen and the HLA that adaptively adjusts the embedding of the HLA according to the antigen (Methods). The results of the ablation experiments show that the communication mechanism indeed improves the performance of deepAntigen in predicting antigen-HLA binding (Supplementary Fig. 2). Thirdly, top-k atoms pooling and multi-head attention block generate crucial atomic level contacting feature map. Finally, deepAntigen_Seq aggregates atomic level contacting features to predict the sequence-level binding probability (Fig.1a), while deepAntigen_Atom directly predicts atomic level contact probabilities (Fig.1c). We evaluated the robustness of deepAntigen with different key hyperparameters through ten-fold cross-validation (Supplementary Fig. 3 and Methods): (1) the number of the top-k atoms; (2) the size of hidden units in GCN; and (3) the number of GCN layers. All assessments were conducted using corresponding antigen-HLA I, antigen-HLA II and antigen-TCR training dataset (Training Dataset 1,2,3). The results indicated that deepAntigen maintained relatively stable performance across different hyperparameters.
Due to the scarcity of antigen-HLA and antigen-TCR complex crystal structures for training deepAntigen_Atom, we applied a few-shot learning strategy by incorporating sequence-level interaction information into atomic level contact prediction, which benefited from the transformation of sequences into atomic graphs. Specifically, we first pre-trained deepAntigen_Seq using abundant sequence-level antigen-HLA/TCR binding data (Fig.1a). During the pre-training stage, GCN can implicitly capture atomic level information from sequence-level binding data. Next, we frozen the parameters of GCN and fine-tuned other components of deepAntigen_Atom with structural data from Protein Data Bank (PDB) (Fig.1c and Methods). The pairwise distances between atoms of the antigen and HLA/TCR guide the scoring of each atom, ensuring that the overall score is linearly correlated with the distance. Through this strategy, we can extend the training data beyond structural databases for atomic level contact prediction.
The biological intuition behind deepAntigen is that non-covalent interactions among the few crucial atoms play a key role in the activation of T cell immune response, which is overlooked by existing state-of-the-art computational methods. Thus, deepAntigen could overcome the trouble encountered by sequence-based methods, such as the limitation on sequence length or the bias resulting from sequence similarity, which outperforms current state-of-the-art computational methods across multiple tasks on various independent datasets (Fig.1d and Supplementary Table 1,2,3).
deepAntigen improved prediction of antigen-HLA binding
Only the antigen that can bind to specific regions of the HLA and form a stable complex can be recognized by T cells. Therefore, we evaluated the performance of deepAntigen in predicting antigen-HLA binding. We compared deepAntigen with other state-of-the-art antigen-HLA I binding prediction methods, including MixMHCpred2.215, NetMHCpan4.122 and TransPHLA23, using the benchmark test dataset for antigen-HLA I binding (Dataset 1). This dataset consists of 72,936 antigen-HLA I pairs covering 67,951 unique antigens and 95 HLA I alleles. The results indicated that deepAntigen achieved the best overall performance in terms of area under the Receiver Operating Characteristic curve (AUROC) and area under the Precision-Recall curve (AUPR), reaching 0.98 and 0.97 respectively (Fig.2a). By visualizing the attention map of deepAntigen in predicting antigen-HLA I binding, we found that the attention map strongly highlighted the second and last positions of the antigen (Supplementary Fig. 7). These positions are referred to as anchor positions, which are supported by previous studies55,56. The varying lengths of antigens and types of HLA alleles typically correspond to different binding rules, which are key factors influencing the performance of antigen-HLA binding prediction. We further stratify Dataset 1 by both antigen length and HLA I allele type to analyze their impact on the performance. We found that the performance and the stability of deepAntigen are better than all the antigen-HLA I binding prediction methods mentioned above, with variations in antigen length (Fig.2b). In addition, deepAntigen outperformed current methods on the majority of the 95 alleles (above the diagonal). Other methods perform poorly on certain HLA I alleles (e.g., C*03:03, A*23:01 and C*16:01), but deepAntigen consistently maintained good performance (Fig.2c).

a The ROC curves, PR curves of deepAntigen and state-of-the-art methods on the antigen-HLA I benchmark test dataset (Dataset 1). b The AUROC of deepAntigen and state-of-the-art methods on individual subsets grouped by length of antigens from Dataset 1. c The AUROC of deepAntigen and state-of-the-art methods on individual subsets grouped by HLA I allele type from Dataset 1. Circles represent different alleles, and the size of each circle indicates the number of antigens. Magenta circles indicate deepAntigen outperforms others, while dark blue circles signify inferiority. d The ROC curves, PR curves of deepAntigen and state-of-the-art methods on the antigen-HLA II benchmark test dataset (Dataset 5). e The AUROC of deepAntigen and state-of-the-art methods on individual subsets grouped by length of antigens from Dataset 5. f The AUROC of deepAntigen and state-of-the-art methods on individual subsets grouped by HLA II allele type from Dataset 5. Circles represent different alleles, and the size of each circle indicates the number of antigens. Magenta circles indicate deepAntigen outperforms others, while dark blue circles signify inferiority.
Compared to HLA I molecules, HLA II-binding antigens are more promiscuous in terms of length and binding sequence motifs, and the polymorphism of the α and β chains in HLA II also considerably expands the diversity of antigen binding specificity10. Therefore, the antigen-HLA II binding prediction is currently less precise. We evaluated the performance of deepAntigen in predicting antigen-HLA II binding on the benchmark test dataset for antigen-HLA II binding (Dataset 5), which consists of 50,956 antigen-HLA II pairs covering 46,182 unique antigens and 83 HLA II allele types. We compared deepAntigen with other state-of-the-art methods, including NetMHCIIpan4.224 and MixMHC2pred2.017. The results indicated that deepAntigen achieved the highest AUROC of 0.87 and AUPR of 0.87, with improvements of 0.14 and 0.10 compared to NetMHCIIPan4.2, and 0.20 and 0.13 compared to MixMHC2pred2.0 (Fig.2d). As expected, deepAntigen was more stable than current state-of-the-art methods with variations in length of antigens and HLA II allele types (Fig.2e,f), which demonstrated that its effectiveness in achieving pan-allele and pan-length antigen-HLA II binding prediction. The 9-mer binding core of the antigen is uncertain due to the opening of the HLA II antigen-binding groove57. To explore potential antigen-HLA II binding rules, we collected 85,756 HLA-DR401-binding antigens from previous study57. Each antigen in this library is 9-mer flanked by constant residues (two residues at N-terminal, four residues at C-terminal) to favor HLA II binding in a determined core57. We identified motifs at positions 1, 4, 6, and 9, which are accommodated by the pockets on the surface of HLA II molecules58,59 (Supplementary Fig. 10a, b). Then, we utilized deepAntigen to analyzed this antigen library and found that it not only recognized the binding core region but also focused on motifs at positions 4 and 6 of the antigens (Supplementary Fig. 10c,d).
The ability to generalize to antigens and HLAs not seen in the training datasets is crucial for the utility of deepAntigen. We evaluated its performance in predicting antigen-HLA I binding on Training Dataset 1 (Supplementary Table 1) and antigen-HLA II binding on Training Dataset 2 (Supplementary Table 2) using leave-one allele-out cross-validation. Our results showed that deepAntigen achieved a median AUROC of 0.97 in predicting antigen-HLA I binding and a median AUROC of 0.87 in predicting antigen-HLA II binding (Supplementary Fig. 11a, b). In addition, we evaluated the performance of deepAntigen and current state-of-the-art methods on the unseen antigens (Dataset 2 and Dataset 6), where all antigens were not present in the training datasets of any methods mentioned above (Methods). As shown in Supplementary Fig. 11c,d, deepAntigen had the highest AUROC in both prediction of unseen antigen-HLA binding, demonstrating the powerful predictive performance of deepAntigen. Moreover, we further analyzed the sequence similarity between unseen antigens and all antigens in our training datasets and found that the decrease of sequence similarity did not lead to a collapse in the performance of deepAntigen (Supplementary Fig. 12a,b).
deepAntigen achieved accurate prediction of antigen-TCR interactions
TCRs recognize antigens presented by HLA to trigger T cell immune responses. Predicting antigen-TCR interactions is of great importance for identifying immunogenic antigens. Because the number of known interacting TCRs for each antigen exhibits long-tail distribution29 (Supplementary Fig. 13), most antigen-TCR interaction prediction methods cannot be extended to unknown antigen. To evaluate the performance of deepAntigen in predicting antigen-TCR interactions, we collected antigen-TCR interaction dataset complied by Gao et al29. (Supplementary Table 3 and Methods), which corresponding three different settings (zero-shot, few-shot and majority learning). Firstly, we compared deepAntigen with other methods including TEIM30, PanPep29, ImRex27 and ERGO226 on 20 zero-shot datasets with different negative antigen-TCR pairs, which were reconstructed based on Dataset 8 by randomly sampling non-interacting TCRs 20 times from control TCRs (Methods). All antigens that were present in training datasets of any methods involved in testing were excluded from reconstructed zero-shot datasets. deepAntigen outperformed current state-of-the-art methods in terms of AUROC and AUPR in the zero-shot setting (Fig.3a). PanPep did not achieve the expected performance, which demonstrated that it is sensitive for non-interacting TCRs. TEIM achieved an AUROC and AUPR over 0.8, perhaps benefiting from aggregating fine-grained residue-level interaction features. As pMTnet28 requires HLA types as input, we cannot directly evaluate it on benchmark test dataset for antigen-TCR interactions (Dataset 8). Instead, we evaluated the performance of deepAntigen on the test dataset provided by pMTnet. We obtained 322 TCR-antigen-HLA positive samples after excluding antigens that appeared in training datasets, and then generated 10 times negative samples through randomly mismatching the TCRs and antigen-HLAs. On this independent dataset, deepAntigen achieved an AUROC of 0.95 and an AUPR of 0.84, whereas pMTnet with an AUROC of 0.82 and an AUPR of 0.56 (Fig.3b). To eliminate the doubt that data redundancy problem caused by similar antigen sequences between the training dataset and test dataset may result in ‘easy predictions’, we calculated pairwise antigen sequence similarities (Methods) between Training Dataset 3 and Dataset 8, ensuring that no sequences in the Training Dataset 3 and subsets of the Dataset 8 shared similarities greater than a threshold. Then we conducted a more rigorous performance evaluation of deepAntigen under different thresholds of sequence similarity. Our results showed that the performance of deepAntigen remained relatively stable even as the antigen sequence similarity threshold decreased (Supplementary Fig. 12c). Thus, we can infer that deepAntigen is capable of accurately identifying tumor neoantigens or exogenous antigens that have not been previously encountered by the immune system.

a Box plots of AUROC and AUPR for deepAntigen and state-of-the-art methods on the Dataset 8, evaluated over 20 independently generated negative sample sets. The boxplots display data distribution where the box spans the interquartile range (IQR, 25th to 75th percentile), the line inside the box indicates the median. The whiskers extend to the minimum and maximum values within 1.5×IQR from the quartiles. b The ROC curves and PR curves of deepAntigen and pMTnet on the test datasets provided by pMTnet. Shaded area labeled the 95% confidence interval of the ROC curves, which were estimated from 2000 stratified bootstraps. c The average AUROC and AUPR for deepAntigen (0.71 and 0.75), TEIM (0.67 and 0.67), PanPep (0.51 and 0.51), ImRex (0.49 and 0.49) and ERGO2 (0.49 and 0.49) on the large independent COVID−19 test dataset (Dataset 9) covering 1,129,028 SARS-CoV-2 antigen-TCR pairs. The averages were calculated using reconstructed datasets with 20 groups of independently generated negative samples. d The ROC curves and PR curves of deepAntigen and PanPep on the zero-shot, few-shot, and majority antigen-TCR test datasets. P-values were computed using two-side DeLong test.
To validate deepAntigen can identify immunogenic exogenous antigens, we collected a large independent SARS-CoV-2 antigen-TCR dataset (Dataset 10) from COVID-19 cohort provided by the ImmuneCODE project60 (Supplementary Table 3). The dataset consisted of 564,514 antigen-TCR interaction pairs after removing antigens present in Training Dataset 3. In order to ensure a reliable evaluation, we generated twenty groups of non-interacting TCRs to balance the interacting TCRs by randomly sampling from control TCRs twenty times. Using these 20 datasets that incorporate positive pairs and each group of negative pairs, we found that deepAntigen achieved higher average AUROC and AUPR in identifying SARS-CoV-2 T cell antigens at the sequence level, compared to the second-best predictor TEIM (an average AUROC of 0.71 and an average AUPR of 0.75 for deepAntigen; an average AUROC of 0.67 and an average AUPR of 0.67 for TEIM) (Fig.3c). We further filtered Dataset 10 by excluding TCRs present in Training Dataset 3, generating a dataset where both antigens and TCRs are unseen. The test results indicate that deepAntigen still outperforms current state-of-the-art methods (Supplementary Fig. 14). It must be acknowledged that deepAntigen consumes more time due to the need to transform sequences into graphs. However, deepAntigen supported multiprocessing to accelerate this process (Supplementary Table 4), which can be scaled to handle large-scale data (Supplementary Table 5).
Additionally, we tested deepAntigen and PanPep29 at different settings (zero-shot, few-shot and majority learning). In the zero-shot setting, all antigens in zero-shot dataset have not appeared in Training Dataset 3. deepAntigen exhibited significant better performance (AUROC of 0.80 and AUPR of 0.80) compared with PanPep (AUROC of 0.71 and AUPR of 0.71) in the zero-shot setting (Fig.3d left; DeLong test P = 5.3×10−10). In the few-shot setting, we fine-tuned deepAntigen (10 epochs) and PanPep (3 loops, default) using a few interacting TCRs for each antigen that were absent from Training Dataset 3 and tested their ability to predicting whether these antigens can be recognized by other TCRs. The AUROC and AUPR of deepAntigen (0.84 and 0.85, respectively) showed significant improvement over those of PanPep (0.76 and 0.75, respectively) in the few-shot setting (Fig.3d middle; DeLong test P = 2.4×10−25). The results of zero-shot and few-shot setting indicated that deepAntigen was not biased towards antigens with large known interacting TCRs. The majority setting is a relatively simple task, because models can learn the binding patterns easily for each antigen with a large number of known interacting TCRs. We retrained and then evaluated deepAntigen and PanPep on the majority dataset which contained 25 antigen-specific TCR repertoires. In the majority setting, deepAntigen achieved a higher AUROC of 0.82 and an AUPR of 0.84, compared to 0.79 for both AUROC and AUPR for PanPep (Fig.3d right; DeLong test P = 6.8×10−10).
deepAntigen deciphered atomic level contacts between antigen and HLA/TCR
Atomic level contact prediction is a distinctive capability of deepAntigen, which facilitates revealing the underlying binding or interaction mechanism at the atomic level. We froze the parameters of the graph convolutional layers in deepAntigen_Seq. Then we fine-tuned the scoring layer for atoms and the atomic level contact prediction classifier using limited structural data to obtain deepAntigen_Atom (Methods). We evaluate the performance of deepAntigen in predicting atomic level contacts between antigen and HLA/TCR through leave-one-out cross-validation strategies, because of the scarcity of available structural data (Dataset 4, 7, 11). The negative Pearson correlation coefficient (NPCC) between joint scores and true distances serves as an indicator of the effectiveness in identifying crucial atoms from the antigen and HLA/TCR (Methods). deepAntigen achieved a median NPCC of 0.57 and a median AUROC above 0.94 in predicting atomic level contacts between antigen and HLA I; a median NPCC of 0.57 and a median AUROC above 0.88 in predicting atomic level contacts between antigen and HLA II; and a median NPCC of 0.92 with a median AUROC exceeding 0.81 in predicting atomic level contacts between antigen and TCR (Fig.4a). These results demonstrated that deepAntigen can identify the few crucial atom pairs that exert a dominant effect on antigen-HLA binding or antigen-TCR interactions. Additionally, the pre-training strategy significantly improved the effectiveness of deepAntigen in identifying crucial atoms (t-test P = 1.0×10-20 for antigen-HLA I binding; P = 1.3×10-21 for antigen-HLA II binding; P = 1.7×10-11 for antigen-TCR interactions) and their contact (t-test P = 2.8×10-5 for antigen-HLA I binding; P = 0.002 for antigen-HLA II binding; P = 5.5×10-5 for antigen-TCR interactions). In other words, deepAntigen can incorporate useful sequence-level binding information into the atomic level contact prediction.

a Boxplots of NPCC and AUROC for deepAntigen through leave-one-out cross validation on the antigen-HLA I (left, n = 130), antigen-HLA II (middle, n = 73) and antigen-TCR (right, n = 134) structural dataset (Dataset 4,7,11, respectively), with or without pre-training. The boxplots display data distribution where the box spans the interquartile range (IQR, 25th to 75th percentile), the line inside the box indicates the median. The whiskers extend to the minimum and maximum values within 1.5×IQR from the quartiles. Outliers beyond this range are plotted as diamond-shaped blocks. P-values were computed using a one-sided paired t-test. ‘w/’ is the abbreviation for ‘with’, and ‘w/o’ is the abbreviation for ‘without’. b The crystal structure of C259-NYESO complex and the hydrogen bonds between the antigen and the TCR β chain (PDB:2BNQ). The α and β chains of NY-ESOc259 TCR are colored in green and purple, respectively. The HLA is colored in gray and the antigen is colored in orange. The hydrogen bonds between atoms are plotted by ChimeraX61 as dotted lines. c The pairwise true distance and contact probability of crucial atoms that were identified by deepAntigen. The first line of tick labels indicates the atom name from PDB and the second line is the residue type and position. I6 and T7 in the antigen are the core of contacting with CDR3. d The correlation between experimental binding, activation and killing score change and predicted interaction probability change before and after mutation. The experimental data is derived from T cell immune responses stimulated by 133 mutated antigens generated by single residue substitution of NY-ESO−1. Each point in the scatter plots represents a mutaion, and the bands represent the 95% confidence intervals for the linear fitting. P-values were calculated by a two-side Pearson correlation test. e The average of contact probability change between the core of antigen and each crucial atom of CDR3 after the two mutations (W5V and Q8S). f, The contact scores of motif sites and ‘non-motif’ sites in the LLLDRLNQL-specific TCR pools. The motifs were identified by GLIPH18. The contact score is the average probability of k-mer residues contacting the antigen. For each residue, the contact probability is the sum of all pairwise atom contact probabilities involved in that residue. The contact scores are significantly higher for motif sites than ‘non-motif’ sites, shown as mean values with 1.5 times standard errors. The total number of CDR3s is 192. The number of CDR3s associated with each motif is provided in Supplementary Table 9. P-values were computed using a one-sided paired t-test (n = 192).
Atomic level contact prediction enables deepAntigen to capture the effect of subtle mutation on T cell immune responses. We obtained the experimental crystal structure (PDB:2BNQ) of an antigen-TCR sample, NY-ESOc259 TCR and NY-ESO-1 antigen presented by HLA-A*02:01 (referred to as C259-NYESO thereafter). NY-ESO-1 is a cancer testis antigen with the sequence SLLMWITQV, which exhibits limited expression in normal adult tissues but frequently presence in various tumors. NY-ESOc259 is a human-derived TCR with enhanced affinity that recognizes NY-ESO-1, whose CDR3β is CASSYVGNTGELFF. We analyzed the hydrogen bonds between the antigen and the TCR β chain using ChimeraX61 software. There were only two hydrogen bonds observed: one formed between the carboxyl oxygen atom of TCR-V95 and the amino nitrogen atom of the antigen-I6, and the other between the amino nitrogen atom of TCR-N97 and the side chain oxygen atom of the antigen-T7 (Fig.4b). Thus, I6 and T7 in the antigen are the core residues in contact with TCRβ CDR3. According to the atomic level contact prediction, deepAntigen identified some close atoms, and the closer they are, the higher the predicted contact probability (Fig.4c). Importantly, the predicted contact probability is highest for the two pairs of atoms involved in forming hydrogen bonds described above (Fig.4c right). Karapetyan A. R. et al62. investigated which amino acids at each position of the antigen enable specific TCR interactions by sequentially replacing every amino acid position outside of anchor positions 2 and 9 with all 19 possible alternative amino acids, resulting in 134 antigens (133 altered antigens and a wild-type antigen). Each antigen was individually evaluated using three different ex vivo assays: binding of the NY-ESOc259 TCR to the antigen, antigen-dependent activation of TCR-expressing cells, and the killing of antigen-presenting target cells. We applied deepAntigen to predict interaction probabilities and found that changes in the interaction probabilities of mutant samples correlated with changes in experimental binding scores, activation scores, and killing scores (Fig.4d), which demonstrated the ability of deepAntigen in capturing the effect of subtle mutation on T cell immune responses. Interestingly, the experiment results of Karapetyan, A. R. et al62. indicated that the mutation of amino acids at positions 5 and 8 lead to the most significant decrease in the intensity of T cell immune responses. We analyzed the atomic level contact map of two mutation (W5V and Q8S), and found that the predicted contact probabilities between the core (I6 and T7 in the antigen) and nearly all crucial atoms of the CDR3 experienced a decrease (Fig.4e), which may be the direct reason for the weakened T cell immune responses. Such subtleties and nuances of these interactions captured by deepAntigen can provide valuable biological insights not only for identifying immunogenic neoantigen but also for engineering TCR-T cells. More importantly, the capacity for atomic level contacts prediction can yield a broader understanding of the physical principles underlying molecular interactions, such as small molecule drug discovery, protein-ligand docking and antibody-antigen binding affinity.
We also seek to explore whether AlphaFold3 and RosettaFold All-Atom possess similar capabilities. First, we input the wild-type antigen, HLAαβ, and TCRαβ sequences into the AlphaFold3 web server and the local RosettaFold All-Atom model, using default parameters to predict the structure of the complex. We found AlphaFold3 is able to predict the complex structure very well and correctly identified the hydrogen bonds between the TCR and I6, T7 of the antigen (Supplementary Fig. 15a left). However, there are some issues with the details. For example, there is no hydrogen bond between Q8 and the TCR β chain, but AlphaFold3 predicts this as a false positive contact. The performance of RosettaFold All-Atom was disappointing, as it seems incapable of predicting the structure of complexes effectively (Supplementary Fig. 15b left). In addition, we used AlphaFold3 and RosettaFold All-Atom to analyze the interactions between TCR and two mutant antigens (W5V and Q8S). In the structure of W5V predicted by AlphaFold3, the hydrogen bond between TCR and I6 was disrupted (Supplementary Fig. 15a middle), weakening the interaction and leading to a reduced immune response. However, in the case of the Q8S mutation, AlphaFold3 predicted positive hydrogen bonds between TCR and both I6 and T7 (Supplementary Fig. 15a right), which contradicts the experimental results and the predictions of deepAntigen. The structures of W5V and Q8S predicted by RosettaFold All-Atom are still unexpected (Supplementary Fig. 15b middle and right).
Atomic level contact prediction enables deepAntigen to discover antigen-specific TCR motifs. we validated deepAntigen by comparing the predicted contact scores of the CDR3β motif sites revealed by GLIPH18 with the remaining non-motif sites. We collected a set of TCRs targeting the antigen LLLDRLNQL (referred to as LLL thereafter), which was a dominant nucleocapsid antigen of SARS-CoV-2 and elicited the greatest proliferative response from both convalescent and uninfected donors63. As shown in Fig.4f, the predicted contact scores of the motif sites were significantly higher than those of the non-motif sites (t-test P = 2.8×10-36). Another notable instance is the structural characterization of the TCR-LLL-HLA-A2 complex (PDB:8DNT) (Supplementary Fig. 16a). Key contact sites are observed at position 5-8 of the antigen and position 96-100 of the TCRβ. The prediction results perfectly matched the true contact region (Supplementary Fig. 16b). The contact scores of two elevated domains at L6 and Q8 are higher than those of other positions. These results indicated that deepAntigen can assist understanding the underlying interaction mechanisms between antigens and TCRs. We also tested the effectiveness of AlphaFold3 and RosettaFold All-Atom in identifying antigen-specific TCR motifs. Using the antigen and specific CDR3 sequences (whole sequences and other chains were not available) as input, we predicted the structures by AlphaFold3 and RosettaFold All-Atom. The reciprocal average of interatomic distances was used as the contact score between residues, and we analyzed the difference in contact scores between motif sites and non-motif sites. The results showed that AlphaFold3 could not distinguish the motif and non-motif sites. Although RosettaFold All-Atom was able to capture this difference, the magnitude of the difference was very small (Supplementary Fig. 15c,d).
Predicted neoantigens from clinical cancer patients successfully activated T cell immune responses
Neoantigens can trigger immune responses that are not subject to central and peripheral tolerance, which are promising targets for cancer immunotherapies10. Nevertheless, the high degree of heterogeneity in tumors poses a significant hurdle for identifying neoantigens as each tumor contains numerous unique putative neoantigens10,64. We collected 608 antigens (Dataset 3) screened by the research from tumor neoantigen selection alliance (TESLA) global consortium12, of which 37 antigens were shown to activate immune responses, as validated by biological experiments. We carefully checked that none of these 608 antigens overlapped with any antigens in the training dataset of deepAntigen. We then used deepAntigen with different threshold to predict the binding of these 608 antigen-HLA I pairs. Because the number of negative antigens far exceeds that of positive antigens in practical clinical settings, we increased the threshold for predicting positive antigens beyond the default value of 0.5. Our results indicated that deepAntigen achieve an average true discovery rate (TDR) of 8% (34/421), which is over the 6% (37/608) reported by TESLA (Supplementary Fig. 17a). deepAntigen successfully recalled 34 out of 37 neoantigens, while achieving a lower false positive rate compared to TESLA (Supplementary Fig. 17b). Antigen presentation by HLA is only the first element in the initiation of an immune response. The interaction between antigen and TCR, which is crucial for predicting immune responses, has been overlooked in the research conducted by TESLA. To evaluate the capacity of deepAntigen to recall immunogenic neoantigens, we collected 384 tumor neoantigens generated by single residue mutation and known to activate T cell immune responses from the NeoTCR65 database. The result showed that deepAntigen achieved the highest true positive rate (61%) compared with other state-of-the-art methods (Supplementary Fig. 18).
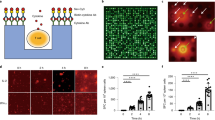
We further validated deepAntigen’s ability to identify tumor neoantigens of clinical cancer patients (Fig.5a). We collected fresh tumor tissues, adjacent normal tissues, and peripheral blood from five patients (2 lung cancer patients, 2 breast cancer patients and 1 pancreatic cancer patient, Supplementary Table 8), and performed whole-exome sequencing (WES) on both tumor and adjacent tissues, RNA-seq on the tumor tissues, and TCR-seq on the peripheral blood. A portion of the peripheral blood was preserved for subsequent Enzyme-linked Immunospot (ELISPOT) assays. The mapping results show high depth and coverage in tumor and matched normal tissues for all cancers. The mean sequencing depth of targeted regions is 153.6×, 176.4× and 157.7× in lung cancer, breast cancer, and pancreatic cancer respectively. At the same time, the average percentage of reads with at least 50× coverage was 88.9%, 91.7%, and 95.3% respectively. After mutation calling and filtering (Methods), we identified variants that could result in amino acid substitutions, insertions, deletions, or stop-gain mutations. Specifically, we identified 53 variants for #P980589, 63 variants for #P1017343, 305 variants for #P9280216, 442 variants for #P1057556, and 16 variants for #P1060513, respectively. Finally, we generated all possible 8-11mer variant peptides as candidate neoantigens using a sliding-window approach.

All panels show immunogenicity results for neoantigens tested in triplicate, with bar plots displaying mean values with 1.5 standard errors. Statistical significance was determined by one-side distribution-free resampling (DFR) test. P-values were adjusted using the step-down max T procedure. In the bar plot, the purple bars represent significant immunogenic responses. ‘NC’ denotes negative control. a Neoantigen immunogenicity validation via ex vivo ELISPOT assays. b Among the top 20 neoantigens with the highest predicted immunogenicity scores in the lung cancer patient #P1017343, five neoantigens activated strong immune responses in vitro. c Among the top 20 neoantigens with the highest predicted immunogenicity scores in the breast cancer patient #P980589, three neoantigens activated strong immune responses in vitro. d Among the top 20 neoantigens with the highest predicted immunogenicity scores in the pancreatic cancer patient #P9280216, two neoantigens activated strong immune responses in vitro. The panel (a) was created in BioRender. Que, J. (https://BioRender.com/hbixhe0).
Then deepAntigen was applied to identify candidate neoantigens with the potential to activate T cell immune responses. We ranked the neoantigens based on their immunogenicity scores and selected the top 20 neoantigens to stimulate peripheral blood mononuclear cells (Fig.5c,d left and Methods). To identify the T cell immune responses induced by the neoantigens, we performed ex vivo IFN-γ ELISPOT assays (Supplementary Figs. 19,20,21). The number of spot-forming units (SFU) reflects the number of activated T cells that recognize and respond to the presented peptides and the strength of immune responses. We detected that 15 of 100 neoantigens predicted by deepAntigen across five cancer patients successfully activate strong CD8+ T cell immune responses (Fig.5b,c,d and Supplementary Fig. 22). These results demonstrated that deepAntigen has great potential for discovering mRNA vaccine targets and will accelerate the development of tumor mRNA vaccines.
Discussion
Precise identification of T cell antigens is crucial for the development of a cancer mRNA vaccine. However, current computational methods identify T cell antigens only at the sequence or residue level and cannot explicitly deal with atom attributes. In this study, we present deepAntigen, the first method for identifying T cell antigens at the atomic level, inspired by the biological fact that catch-bonds33,38,39,40 play a crucial role in the activation of T cell immune responses. More specifically, deepAntigen transforms each residue sequence of the antigen, HLA and TCR into an atomic graph, and utilizes GCN to extract crucial atom features for predicting antigen-HLA binding and antigen-TCR interactions, as well as identifying the atomic level contacts. As the number of solved antigen-HLA and antigen-TCR complex crystal structures is limited, we applied a few-shot learning strategy to train deepAntigen for atomic level contact prediction. Pre-training can assist deepAntigen to learn latent atomic level information from the abundant sequence-level binding data and thus provided appropriate model initialization for atomic level contact prediction. Fine-tuning deepAntigen with limited structural data enhanced the accuracy of atomic level contact prediction.
DeepAntigen has excelled in various prediction tasks within T cell antigen identification, including antigen-HLA binding and antigen-TCR interactions, particularly in scenarios such as tumor neoantigen identification. Neoantigens predicted by deepAntigen from clinical patients successfully activated the T cell immune responses in vitro. We believe that the success of deepAntigen is attributed to its capability to capture the atomic level differences between immunogenic antigens and non-immunogenic antigens. With minimum modifications, deepAntigen can be used to predict interactions between nucleic acids, proteins, and other molecules at the atomic level. Additionally, its applications in antigen-specific TCR motif discovery and mutation effects prediction not only enhance our understanding of the atomic level interaction details but also provide valuable biological insights for clinical applications, such as optimizing TCR sequences for T cell receptor-engineered T cell therapy.
Sequence-to-graph transformation requires more time, so deepAntigen is less efficient in terms of computational speed compared to sequence-based methods (Supplementary Table 4,6,7). However, we can accelerate this process through multiprocessing (Supplementary Table 4), enabling deepAntigen to be scaled for large-scale data in clinical applications (Supplementary Note 4). To identify the small subset of crucial atoms that play key roles in binding or interactions66 and reduce the computational workload, we specially designed a top-k pooling layer to select potential contact atoms, but it can lead to information loss. We compared the impact of the top-k pooling with the commonly used global max pooling methods on model performance. Our results indicate that top-k pooling results in slightly lower overall prediction accuracy, approximately 0.01 less, compared to global max pooling (Supplementary Fig. 23). Additionally, we analyzed how varying k-values influence the performance. In general, as the k-value increases, the accuracy gradually improves. Due to the limited availability of mono-allelic HLA II restricted antigens for training, the performance of antigen-HLA II binding prediction is expected to improve as the amount of mono-allelic HLA II binding data increases (Supplementary Fig. 24). Other studies have employed deconvolution algorithms, such as NNAlign_MA67 and MoDec68, to simultaneously determine both the binding core and allele assignment of each antigen from the multi-allelic HLA II ligandome. While these methods can increase the number of identified antigen-HLA II pairs, it is crucial to rigorously assess the data quality to avoid bias that are not consistent with actual data distribution69. Another limitation of deepAntigen is that it only considers the sequence of TCRβ CDR3. Due to the stringent technical requirement of single-cell TCR sequencing, the availability of paired TCRα and TCRβ data is limited and uneven data quality54. When more information on TCRα chains or other regions, the performance of deepAntigen is expected to improve (Supplementary Fig. 25). In the validation of neoantigens identified by deepAntigen, our main goal was to validate their immunogenicity using ELISPOT assays. However, we did not explore the TCRs specific to these neoantigens, which would require antigen-specific T cell sequencing (such as BEAM-T sequencing reported by 10x Genomics70) or TCR sequencing before and after antigen stimulation to detect neoantigen-expanded T cell clones2. The accumulation of neoantigen-specific TCRs enables iterative algorithm optimization, while the optimized algorithm enhances the efficiency of biological experimental validation, further accelerating immunogenic neoantigen discovery.
In summary, deepAntigen is a powerful and scalable method for identifying T cell antigens at the atomic level. We provide the proof of principle for clinical application of deepAntigen for the identification of neoantigens to facilitate personalized neoantigen-targeted immunotherapies and propose its utility for designing cancer mRNA vaccines in the future.
Methods
The study was carried out with approval by the independent ethics committee (Medical Ethics Committee of Harbin Institute of Technology and Ethics Committee of Harbin Medical University Cancer Hospital) and the competent regulatory authorities. All clinical investigations were conducted according to the principles expressed in the Declaration of Helsinki and good clinical practice guidelines. All patients provided written informed consent.
Data curation
Antigen-HLA I binding data
We collected antigen-HLA I binding data from IEDB71 and peer-reviewed papers72,73. Starting from the IEDB homepage, the following filters were applied: For Epitope, “Linear Epitopes”; for Assay, “Positive Assays Only” and “MHC Ligand Assays”; for Epitope Source, no filters for Organism or Antigen Name; for MHC Restriction, “Class I”; for Host, “Human”; and for Disease, “Any Disease”. The antigen-HLA I binding data in IEDB are primarily determined through ex vivo binding affinity assays, overlooking antigen processing and presentation processes. Therefore, we also retrieved natural eluted ligands from previous studies72,73. These studies utilized mass spectrometry to profile high-throughput antigens eluted from cell lines with mono-allelic HLA I. We included only HLA I with known four-digit alleles and antigens that did not contain non-standard residues. For each positive pair, a non-binding antigen was generated as a negative pair by cleaving a segment of equal length from the protein where the binding antigen is located. We ensured that negative peptides were not redundant with positive peptides for a specific HLA by conducting thorough checks during the generation of negative peptides. Although false negative peptides may be generated, the possibility and proportion of such peptides are very low74. Even if unexpected false negatives did occur, they would not affect the differences in data distribution between positive and negative peptides (Supplementary Figs. 5,6). After preprocessed, the dataset comprises a total of 364,664 samples with a balanced ratio of positive to negative pairs. We randomly selected 20% as the test dataset (Dataset 1), while the remaining 80% was used for training and validating the model (Training Dataset 1). The Training Dataset 1 comprises 232,163 unique antigens, while the Dataset 1 consists of 67,591 unique antigens, collectively covering 95 HLA I alleles. Additionally, we collected an external dataset from Xu et al75., which contains 26,974 antigens not seen in training dataset of any methods (deepAntigen, NetMHCPan, MixMHCpred and TransPHLA) and 85 HLA I alleles with 27,902 related antigen-HLA I pairs (Dataset 2). We also collected 608 neoantigen-HLA I pairs (Dataset 3) from TESLA12, which contains 37 experimentally validated positive pairs and 571 experimentally validated negative pairs.
Antigen-HLA II binding data
We acquired antigen-HLA II binding data from previously published literature76, with all antigens derived from eluted ligands from cell lines with mono-allelic HLA II. This dataset including 175,291 antigen-HLA II pairs after removing redundant antigens. Then, we generated negative antigens cleaved from the protein where the binding antigen is located to balance the dataset. We carefully controlled for potential false negative risks (Supplementary Figs. 8,9) in this dataset and split it into a training dataset and a test dataset with an 8:2 ratio. The portions of the test dataset that overlap with the training dataset of other methods17,24 were extracted and added to our training dataset. Finally, our training dataset contains 299,324 pairs (Training Dataset 2), and the test dataset (Dataset 5) contains 50,956 pairs. Training Dataset 2 contains 242,851 unique antigens and 83 unique HLA II alleles. Dataset 5 contains 46,182 unique antigens and 83 unique HLA II alleles. We filtered antigens from Dataset 5 that were not present in the training dataset of any methods (deepAntigen, NetMHCIIPan, MixMHC2pred) to compile an unseen antigen-HLA II binding dataset (Dataset 6). Dataset 6 contains 19,091 unique antigens and 83 unique HLA II alleles with related 19,322 antigen-HLA II pairs.
Antigen-TCR interaction data
We collected antigen-TCR interaction pairs to train and test our model following the settings outlined by Gao et al.29. It is worth noting that they designed three settings: zero-shot, few-shot, and majority learning, corresponding to without known interacting TCRs, with few known interacting TCRs, and with numerous known interacting TCRs in the training dataset for each unique antigen, respectively. We collected antigen-TCR interaction data from IEDB71, VDJdb77, PIRD78, and McPas-TCR79 databases, retaining only high-confidence interacting TCRs from Homo sapiens. Furthermore, due to the limited available TCR alpha chain, only the CDR3 region of the TCR beta chain was considered, which was the primary contact area with the antigen. The dataset comprised 32,080 related antigen-TCR interaction pairs, consisting of 699 unique antigens and 29,467 unique TCRs. We selected antigens with at least five interacting TCRs to construct training dataset (Training Dataset 3), which consist of 208 different antigens with 31,233 antigen-TCR interaction pairs. For zero-shot setting, the remaining 491 unique antigens with 857 known interacting TCR pairs were directly used to test model (Dataset 8). For few-shot setting, two interacting TCR pairs of each antigen in zero-shot dataset were included in fine-tuning process, other pairs are used to test fine-tuned model. For majority setting, we merged the dataset from pMTnet28, ERGO226 and DLpTCR80 and selected antigens whose known number of interacting TCRs is more than 100 in the training datasets of these tools. The majority dataset consisting of 25 antigens with 23,232 known antigen-TCR interaction pairs used for training and 5,320 antigen-TCR pairs used for testing. The non-interacting TCRs in the negative samples were randomly sampled from 60,333,379 non-activated TCRs derived from peripheral blood of 587 healthy donors81, with an extremely low probability of binding to a given antigen (control TCR). For the SARS-CoV-2 antigen-TCR dataset collected from ImmuneCODE project60, we retained the TCRs with multiple specific antigens and excluded the antigens available in the Training Dataset 3. Non-interacting TCRs for each antigen were randomly sampled from the control TCRs, resulting in a total of 1,129,028 antigen-TCR pairs associated with 518 unique antigens (Dataset 9). To evaluate the capacity of deepAntigen to recall immunogenic neoantigens, we also collected 384 tumor neoantigens (Dataset 10) generated by single residue mutation and known to activate T cell immune responses from the NeoTCR65 database.
Structural data
To fine-tune the model for identifying atomic level contacts, we collected PDB identifies of 166 TCR-antigen-HLA I complexes from the STCRDab82 database and 123 PDB identifies of antigen-HLA II complexes from the MHC Motif Atlas83. We downloaded the corresponding structural data from the PDB database. After removing redundancy, there were 130 antigen-HLA I (Dataset 4), 73 antigen-HLA II (Dataset 7), and 133 antigen-TCR (Dataset 11) complexes remaining. Initially, atoms in CDR3 of TCR β chain and polymorphic residues of HLA are extracted from PDB files. Then the distances of pairwise atoms from antigen and HLA/TCR are calculated according to the atom coordinates. If the distance between atoms is less than 5 Å, the atom pair is labeled as a contact site.
Sequence-to-graph transformation
deepAntigen takes amino acid sequences of antigen, HLA and TCR as inputs. Initially, using structural formulas of 20 common amino acids and assembling them through a process similar to dehydration synthesis, an undirected molecular graph is constructed with atoms as nodes and chemical bonds as edges. Then, a graph representation \(G=\{V,{E}\}\) can be embedded through attributes of atoms and chemical bonds. Specifically, each node (i.e., atom) \({v}_{i}\in V\) is represented by an attribute vector \({{\bf{v}}}_{i}^{{init}}\) of length 25, which is the concatenation of one-hot encodings representing the atom type, formal charge, hybridization type, hydrogen bond, aromaticity, degree and other properties of the corresponding atom.
Each edge (i.e., chemical bond) \({e}_{i,j}\in E\) is represented by an attribute vector \({{\bf{e}}}_{i,j}\) of length 11, which is the concatenation of one-hot encodings representing the bond type, stereo configuration, and other properties, e.g., whether the bond is conjugated and whether it is in a ring.
Graph data augmentation
In the training process, some nodes and their connected edges are randomly dropped out with a 5% probability for data augmentation. On one hand, graph augmentation expands the dataset, while on the other hand, dropping out crucial nodes helps the model identify atoms playing a key role in binding processes through feedback from the loss function. Our results showed that data augmentation in the training stage can effectively alleviate overfitting and slightly improve performance on validation dataset (Supplementary Fig. 4).
Detailed implementation of deepAntigen_Seq
deepAntigen_Seq takes the node embeddings \({\bf{v}}\), edge embeddings \({\bf{e}}\), and adjacency matrix \({\bf{A}}\) as inputs. Initially, the atom initial features are transformed to \({{\mathbb{R}}}^{h}\) through a single-layer neural network, as shown in formula (1). \(h\) is the number of hidden units.
\({{\bf{W}}}_{{init}}\in {{\mathbb{R}}}^{h\times 25}\), is a learnable weight matrix. \({\rm{Leaky}}\_{\rm{Relu}}(x)=\max (0,x)+0.1*\min (0,x)\) is a nonlinear activation function. Specially, we introduce a virtual super node \(s\) for a graph and design a communication mechanism to exchange information between the super node \({s}_{{antigen}}\) of the antigen graph and the super node \({s}_{h{la}}\) of the HLA graph. The super node embedding \({{\bf{s}}}^{0}\) is initialized with as the summation of all the atom features, that is,
Next, the atom features are processed by \(L\) layers of graph convolutional networks to generate updated atom features \({{\bf{v}}}^{L}\in {{\mathbb{R}}}^{N\times h}\). During this process, the features of each edge are not updated. At each iteration of graph convolution, the atom features are processed sequentially by message passing units and gated recurrent units (GRU). The message passing units extract graph features through two steps: message aggregation and information update. The first step involves aggregating features \({{\bf{a}}}_{i}^{l}\) from neighboring atoms and chemical bonds for each atom \({v}_{i}\), as shown in formula (3).
\({\mathscr{N}}({v}_{i})\) is the set of neighboring atoms for \({v}_{i}\). \({{\bf{v}}}_{k}^{l-1}\) is the feature representation of the kth atom in the previous layer. \([\cdot,\cdot ]\) stands for the concatenation operation. \({{\bf{W}}}_{{\rm{gather}}}^{l}\in {{\mathbb{R}}}^{h\times (h+11)}\). The second step involves updating atom features based on the aggregated information \({{\bf{a}}}_{i}^{l}\) and atom features \({{\bf{v}}}_{i}^{l-1}\) of in the previous layer, as shown in formula (4).
To adoptively adjust the embedding of the HLA according the antigen, we utilize gating-based attention to exchange information between the super node \({s}_{{antigen}}\) of the antigen graph and the super node \({s}_{h{la}}\) of the HLA graph. However, before proceeding, it is essential to first exchange information between the super node and the atomic nodes. The embedding of the super node \(s\) is updated through a single-layer neural network to obtain \({{\bf{u}}}_{s}^{l}\) and the information passed from the super node to atomic nodes is computed by another neural network, as shown in formula (5)(6).
When extracting the information to be passed to the super node from the atomic nodes, a multi-head attention mechanism is used to weight the contribution of each atom, as shown in formula (7)(8)(9).
K is the number of attention heads. \({{\bf{W}}}_{{vatt}}^{k,l},{{\bf{W}}}_{{satt}}^{k,l}\in {{\mathbb{R}}}^{h\times h}\), \({{\bf{W}}}_{{att}}^{k,l}\in {{\mathbb{R}}}^{1\times h}\) and \({{\bf{W}}}_{v\to s}^{l}\in {{\mathbb{R}}}^{h\times Kh}\). Then, we utilize the gating unit to fuse the information to be passed with the information from the super node or atomic node itself, as shown in formula (10)(11)(12)(13).
\({{\bf{W}}}_{{\rm{gate}}1}^{{\rm{l}}},{{\bf{W}}}_{{\rm{gate}}2}^{{\rm{l}}},{{\bf{W}}}_{{\rm{gate}}3}^{{\rm{l}}},{{\bf{W}}}_{{\rm{gate}}4}^{{\rm{l}}}\in {{\rm{R}}}^{{\rm{h}}\times {\rm{h}}}\). \({{\bf{f}}}_{s}^{l}\) and \({{\bf{f}}}_{i}^{l}\) represent the features after the information exchange between the super node and atomic nodes, respectively. Next, the super node \({s}_{{antigen}}\) and the super node \({s}_{h{la}}\) exchange information as shown in formula (14)(15)(16)(17)(18)(19).
\({{\bf{W}}}_{{gate}5}^{l},{{\bf{W}}}_{{gate}6}^{l},{{\bf{W}}}_{{gate}7}^{l},{{\bf{W}}}_{{gate}8}^{l}\in {{\mathbb{R}}}^{h\times h}\). \({{\bf{q}}}_{h{la}}^{l}\) and \({{\bf{q}}}_{{antigen}}^{l}\) represent the features after the information exchange between the super node \({s}_{h{la}}\) and the super node \({s}_{{antigen}}\), respectively.
In GCN, the kth layer aggregates features make up of k-hop neighbors. To preserve multi-scale features across layers, we have introduced Gated Recurrent Unit (GRU) cells to reset and update the features from the previous layer, as shown in formula (20)(21).
Top-k pooling aims to select crucial nodes with updated features through graph convolutional layers, which can represent the entire graph. Gao et al84., Knyazev et al85. and Cangea et al86. utilized neural networks to score each node and select the top-k atoms with the highest scores. In this study, we adopted a similar strategy, as shown in formula (22).
\({{\bf{W}}}_{\text{score}}\in {{\mathbb{R}}}^{1\times h}\), \(\tanh (\cdot )\) is the hyperbolic tangent activation function.
After obtaining the top-k atom features, the interaction map generator is used to characterize pairwise atom interactions. Taking the antigen-TCR interactions as an example, the interaction features \({\bf{F}}\) are calculated through the multi-head attention module, as shown in formulas(23)(24).
\({{\bf{W}}}_{{att\_a}}^{m},{{\bf{W}}}_{{att\_t}}^{m}\in {{\mathbb{R}}}^{d\times d}\), \(M\) is the number of attention heads. \(i\) and \(j\) represent the atom indices in the top-k scored atoms for antigen and TCR, respectively. \({\alpha }_{{ij}}\) is the average of weights in multi-head attention. Then, a multilayer perceptron (MLP) predicts the probability of interaction between antigen and TCR based on the interaction features \({\bf{F}}\), as shown in formula (25).
The cross-entropy loss function is utilized to update the model parameters, as shown in formula (26).
\({p}_{t}\) represents the binding probability of the tth antigen-TCR pair and \({y}_{t}\) represents its label.
Detailed implementation of deepAntigen_Atom
To further identify atomic level contacts in the binding process, we utilize structural information of antigen-HLA/TCR complexes from the PDB to fine-tune deepAntigen_Atom. The core idea of the fine-tuning process is to score atoms guided by the distances of pairwise atoms. It is worth noting that we added positional information to atom features through positional encoding before scoring, as shown in formula (27)(28)(29).
\({\bf{PE}}\) is positional encoding matrix. \(i\) is the position index of atoms in the graph. \(h\) is the dimension of positional encoding, which is equal to the number of hidden units in the GCN. \(d\) is the index used to traverse the dimension of each positional encoding vector. Although graph convolutional layers aggregate information from neighbors, similar neighborhood structures could lead to similar features in different nodes if ignoring the inherent positional biases of atoms. The sinusoidal positional encoding provides a smooth, continuous, and unique encoding for each atom in the graph. In cases where the number of atoms differs across graphs, the relative positions of atoms in different graphs can still remain consistent. Additionally, this encoding can also represent atom counts that the model has never encountered during training.
The fine-tuning process involves two steps: firstly, to ensure that two atoms involved in a contacting are simultaneously selected, we calculate joint scores of pairwise atoms from antigen and TCR, and design a loss function based on the Pearson correlation coefficient that allows joint scores to be negative correlated with the real distances, as shown in formula (30)(31)(32).
\(\text{COV}\) \((\bullet )\) is covariance. \(\sigma\) is standard deviation. \({\rm{scor}}{{\rm{e}}}_{i}\) is the score of the ith atom of the antigen. \({\rm{scor}}{{\rm{e}}}_{j}\) is the score of the jth atom of the TCR. \({\bf{S}}\) and \({\bf{D}}\) respectively represent the joint scores and real distances of pairwise atoms from the antigen and TCR. \((x,y,z)\) is the coordinate of the atom in space. In the first step, the parameters of GCN were frozen. Due to the non-covalent interactions occurring between oxygen and nitrogen atoms, deepAntigen_Atom focuses on the top-k highest scoring oxygen and nitrogen atoms. Secondly, while ensuring our model can identify key atoms, further fine-tuning is performed using the cross-entropy loss function to predict the contact probabilities of pairwise atoms. In the second step, the parameters of GCN and scoring module were frozen.
Cross-validation and hyperparameter setting
For deepAntigen_Seq, we used a 10-fold cross-validation strategy to evaluate its performance with different hyperparameters on our collected training datasets. More specifically, we randomly partitioned the whole training dataset into 10 subsets and validated on one subset when trained on the other 9 subsets. We did not actually perform an explicit hyperparameter search, as a comprehensive hyperparameter search is resource-intensive and may offer limited performance improvement. We experimented with different combinations of hyperparameters (top k-value, the number of hidden units, and the number of graph convolutional layers) across various tasks. We observed that hyperparameters had a relatively minor influence on the performance of deepAntigen. However, increasing the number of hidden units and graph convolutional layers led to greater model complexity. Balancing performance and complexity, we selected appropriate hyperparameters tailored to each task: for antigen-HLA I and antigen HLA II binding, a top k-value of 20, 64 hidden units and 5 graph convolutional layers; for antigen-TCR interaction, a top k-value of 20, 128 hidden units and 5 graph convolutional layers. A stochastic gradient descent (SGD) optimizer with a learning rate of 1.0×10-4 was used to optimized deepAntigen_Seq.
For deepAntigen_Atom, we used a leave-one-out cross-validation strategy to evaluate its performance because of the scarcity of antigen-HLA/TCR complexes. This strategy involves iteratively training a model on all but one complex, using the omitted complex for validation. This process is repeated for each complex in the dataset. Batch effects arising from different structural approaches could lead to variations in distance distribution across different complexes and further influence the Pearson correlation between joint scores and true distances. Therefore, we set the mini-batch size to 1 when fine-tuning the deepAntigen_Atom. An Adam optimizer with a learning rate 1.0×10-3 was used to optimize deepAntigen_Atom.
Sequence similarity calculation
The similarity between two antigen sequences \({p}_{i}\) and \({p}_{j}\) is defined as:
which had successfully been used by TEIM30 for performance evaluation. \(\text{SW}(\cdot,\cdot )\) stands for the Smith-Waterman (SW) alignment score between two sequences. The SW alignment score was calculated by PaSWAS87, which is a parallel SW alignment software accelerated by the CUDA toolkit.
Evaluation metrics
In this study, whether sequence-level binding prediction or atomic level contact prediction, they are binary tasks. We utilized the binding probability or contact probability to generate a fusion matrix including true positive (TP), true negative (TN), false positive (FP) and false negative (FN), then Sensitivity and Specificity can be formulated as follows:
The receiver operating characteristic (ROC) curve can be drawn with 1-Specificity as the horizontal axis and Sensitivity as the vertical axis. Then we can get the area of under ROC curve, which is used to quantitatively evaluate the overall performance.
Additionally, Precision can be formulated as follows:
Recall is also calculated using the same formula (34). The Precision-Recall (PR) curve can be drawn with Recall as the horizontal axis and Precision as the vertical axis. Then we can get the area of under PR curve, which is used to quantitatively evaluate the performance in identifying positive samples. Above all metrics are calculated using the Python package scikit-learn (1.3.0).
The Negative Pearson correlation coefficient (NPCC) between joint scores and true distances is used to measure the effectiveness of deepAntigen_Atom in identifying the few crucial atoms for antigen-HLA/TCR binding. NPCC can be calculated as follows:
\({\bf{S}},{\bf{D}}\) are shown in formula (31)(32). The range of NPCC values is from −1 to 1. A NPCC closer to 1 indicates a stronger negative correlation between joint scores and true distances. In other words, the closer the distance, the higher the scores of corresponding atoms, making them more likely to be regarded as top-k atoms by deepAntigen_Atom.
Running of published methods
We compared the performance of deepAntigen with ten other state-of-the-art methods, including three antigen-HLA I binding prediction methods, NetMHCPan (v.4.1), MixMHCpred (v.2.2), TransPHLA (v.1.0), two antigen-HLA II binding prediction methods, NetMHCIIPan (v.4.2), MixMHC2pred (v.2.0), and five antigen-TCR interaction prediction methods, TEIM (v.1.0), PanPep (v.1.0), ImRex (v.1.0), ERGO2 (v.2.0), pMTnet (v.1.0). All methods were tested using default parameters. For identifying neoantigens from NeoTCR, antigen with scores above 0.5 in PanPep, ImRex, and ERGO as positive predictions. However, because TEIM tends to bias towards negative predictions without an explicit threshold recommended by its authors, we determined the optimal threshold (scores>0.15) based on the Youden’s Index calculated from the benchmark test dataset for antigen-TCR interactions.
Patient samples and PBMC isolation
Peripheral blood, tumor samples and tumor-adjacent samples were obtained from study participants. The inclusion criteria for participants are: aged 18 to 80 years; histologically confirmed solid tumors (breast cancer, lung cancer or pancreatic cancer) eligible for surgical resection; an expected survival of more than 12 weeks. The exclusion criteria are: any systemic anti-tumor therapy prior to surgery, including experimental drugs; prior radiotherapy; long-term use (≥14 days continuously) of immunosuppressive or other immunomodulatory drugs within 6 months before surgery; active autoimmune or inflammatory diseases; HIV, HBV, HCV, acute EBV, CMV, or syphilis infection; other malignant tumors within the past 5 years; documented primary immunodeficiency or organ transplantation.
Patients’ peripheral blood mononuclear cells (PBMC) were isolated from peripheral blood by density gradient centrifugation using Ficoll Plus (Solarbio, P4350). Fresh PBMCs were then cryopreserved with 10% DMSO in FBS. Peripheral blood used for TCR-seq analysis was stored in PAXgene Blood RNA tubes (Qiagen, 762165), followed by total RNA extraction. Tumor samples and normal samples from patients were obtained in RNAlater solution (Invitrogen, AM7024) immediately after surgery.
WES sequencing
DNA was extracted from tumor and tumor-adjacent tissue using a commercial kit (TIANGEN Biotech (Beijing) Co., China, DP341) according to the manufacturer’s instructions. DNA quality was determined by examining the A260/A280 ratio using a Nanodrop™ OneC spectrophotometer (Thermo Fisher Scientific Inc.). Genomic DNA integrity was checked by 0.5% agarose gel electrophoresis. Qualified DNA was finally quantified using a Qubit 3.0 fluorometer with the Qubit™ RNA Broad Range Assay kit (Life Technologies, Q10210).
DNA libraries were prepared using 50–200 ng of DNA and captured using the xGen™ Exome Hyb Panel v2 (Integrated DNA Technologies) following the manufacturer’s instructions. PCR products corresponding to 200–500 bp were enriched, quantified, and finally sequenced on a DNBSEQ-T7 sequencer (MGI Tech Co., Ltd., China) in PE150 mode.
RNA sequencing
Total RNA was extracted from tumor tissue using TRIzol™ Reagent (Invitrogen, cat. no. 15596026) following the methods described by Chomczynski et al.88. DNA digestion was carried out after RNA extraction using DNase I. RNA quality was determined by examining the A260/A280 ratio using a Nanodrop™ OneC spectrophotometer (Thermo Fisher Scientific Inc.). RNA integrity was confirmed by 1.5% agarose gel electrophoresis. Qualified RNA was finally quantified using a Qubit 3.0 fluorometer with the Qubit™ RNA Broad Range Assay kit (Life Technologies, Q10210).
A total of 2 μg RNA was used for stranded RNA sequencing library preparation using the KC-Digital™ Stranded mRNA Library Prep Kit for Illumina® (catalog no. DR08502, Wuhan Seqhealth Co., Ltd., China) following the manufacturer’s instructions. The kit eliminates duplication bias during PCR and sequencing steps by using unique molecular identifiers consisting of 8 random bases to label pre-amplified cDNA molecules. Library products corresponding to 200-500 bp were enriched, quantified, and finally sequenced on a DNBSEQ-T7 sequencer (MGI Tech Co., Ltd., China) in PE150 mode.
TCR sequencing
Total RNA was extracted from blood samples using the PAXgene Blood RNA Kit (Qiagen, Cat. No. 762174) following the manufacturer’s instructions. DNA digestion was carried out after RNA extraction using DNase I (Thermo Scientific™, Cat. No. EN0521). RNA quality was determined by examining the A260/A280 ratio using a Nanodrop™ OneC spectrophotometer (Thermo Scientific™, Cat. No. ND-ONEC-W). RNA integrity was confirmed by 1.5% agarose gel electrophoresis. Qualified RNA was finally quantified using a Qubit™ 3 fluorometer (Invitrogen™, Cat. No. Q33216) with the Qubit™ RNA HS Assay Kit (Invitrogen™, Cat. No. Q32855).
Approximately 2 μg RNA from each sample was used for TCR sequencing library preparation using the KC-Digital™ Stranded TCR-seq Library Prep Kit for Illumina® 150 (Seqhealth Technology Co., Ltd., Wuhan, China, Cat. No. DT0813-02) following the manufacturer’s instructions. The kit eliminates duplication bias during PCR and sequencing steps by using unique molecular identifiers consisting of 8 random bases to label pre-amplified cDNA molecules. Library products corresponding to 250-500 bp were enriched, quantified, and finally sequenced on a NovaSeq system (Illumina®).
Mutation discovery
To reduce the false positives, both DNA and RNA sequencing data were used for the somatic mutation calling: (1) Adapter trimming and low-quality reads filtering were performed on raw DNA sequencing data to generate using trim_galore (v4.7). (2) The clean DNA data were mapped to the reference genome (hg19) using BWA-MEM(v0.7.17-r1188). In this process, picard (v1.119) was used to remove duplicate reads from the BAM files, GATK(v4.1.9.0) was used for local realignment around indels and base quality score recalibration. (3) The somatic mutation calling and filtering were performed using GATK Mutect2 and FilterMutectCalls. (4) The somatic mutations were further filtered according to its transcription level. In this process, the RNA-seq raw reads were also processed with default parameters by trim_galore (v4.7). Then, the clean RNA data were aligned to the hg19 reference genome using STAR (v2.5.2b), After that, the SplitNCigarReads and Base Quality Score Recalibration were applied with GATK. Finally, the mutations which were not presented at the refined BAM files in tumor sample were excluded from the following analysis. (5) All the remaining somatic mutations (including the SNV and InDel) were translated into amino acid sequences, and only the mutations resulting in amino acid sequence change were used for following analysis.
Immunogenicity score
We used deepAntigen to predict the binding probabilities between neoantigens and HLA molecules, then selected neoantigens with a binding probability greater than 0.5 as candidate neoantigens. We assessed the interaction probabilities between candidate neoantigens and the top 10,000 TCR clonotypes with the highest clonal frequencies in the TCR repertoire using deepAntigen, and calculated the average as the immunogenicity score for the candidate neoantigens. Candidate neoantigens were ranked based on their immunogenicity scores.
Generation of neoantigen peptides
Fmoc-Pro-Wang Resin was swelled in dimethylformamide (DMF) (20 ml) for 1 h. The Suspension was filtered. Twenty percent piperidine in DMF (20 ml) was added to the resin to remove Fmoc. The suspension was kept at room temperature for 0.5 h, while a stream of nitrogen was bubbled through it. The mixture was filtered, and the resin was washed with DMF (6*20 ml). Fmoc-Thr (tBu)-OH (0.3 mM) was pre-activated with N, N’-diisopropylcarbodiimide (DIC) (0.3 mM) and hydroxybenzotriazole (HOBt) (0.3 mM) in 10 ml DMF, and then the mixture was added into the resin. The reaction was carried out in a nitrogen atmosphere. The Kaiser ninhydrin test was used to indicate reaction completion. After the reaction was completed, the suspension was filtered, and the resin was washed with DMF (3*20 ml). After that, all sequences of amino acids were coupled and completed using the same method.
Cleavage solution (90% TFA:5% Tis:5% H2O) was added into the peptidyl resin, and the suspension was shaken for 3.5 h followed by filtration. Ether (2000 ml) was added into the filtrate, and the peptide was precipitated. The mixture was centrifuged, and the ether layer was decanted. The peptide was washed three times with ether and dried under vacuum overnight to give the crude peptide.
IFN-γ ELISPOT assay
PBMCs were obtained using Ficoll Plus (Solarbio). IFN-γ ELISPOT assay were performed using human IFN-γ single-color enzymatic ELISPOT assay kit (Cellular Technology Limited) according to manufacturer’s instructions. 1 × 105 PBMCs were plated with 10 μg/ml candidate neoantigen peptides and incubated 24 hours at 37°C in a 5% CO2 incubator. Plates were rinsed two times with PBS containing 0.05% Tween-20 and then anti-human IFN-γ detection solution was added. After incubation at room temperature for 2 hours, the plates were rinsed three times with 0.05% Tween-PBS and then tertiary solution was added for 30 minutes at room temperature. After rinsing two times with PBS containing 0.05% Tween-20 and two times with distilled water, blue developer solution was added, incubating at room temperature for 15 minutes. The reactions were stopped by gently rinsing membrane with tap water for three times. After the plates were air-dried, the spots were scanned and counted using an ImmunoSpot plate reader and associated software (Cellular Technology Limited). All tests were performed in triplicate wells per peptide, including DMSO as negative control and CEF Antigen Pool as positive control. Ex vivo responses were scored positive if SFUs per 1×105 PBMCs were significantly higher than those in the negative control. Statistical significance was determined based on distribution-free resampling (DFR) test.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All datasets used in this study have been summarized in Supplementary Table 1, 2, 3. We provided the processed data for our model training and evaluation at the Zenodo (https://doi.org/10.5281/zenodo.14769241). The raw data were all downloaded from public websites or peer-reviewed literatures. The sequence-level antigen-HLA I binding datasets were downloaded from IEDB and two public literatures72,73. The sequence-level antigen-HLA II binding datasets were downloaded from two public literatures57,76. Proteins corresponding to genes where antigens are located were downloaded from UniProt (https://www.uniprot.org/), which are cleaved to generate negative antigen-HLA pairs. The sequence-level antigen-TCR interaction datasets were download from IEDB, VDJdb (https://vdjdb.cdr3.net/), PIRD, McPas-TCR (http://friedmanlab.weizmann.ac.il/McPAS-TCR/), ImmuneCODE (https://clients.adaptivebiotech.com/pub/covid-2020) and NeoTCR (http://neotcrdb.bioaimed.com/home). The control TCRs from 587 healthy individuals can be obtained from original study (https://genomemedicine.biomedcentral.com/articles/10.1186/s13073-015-0238-z). The atomic level TCR-antigen-HLA I structural data were download from STCRDab (https://opig.stats.ox.ac.uk/webapps/stcrdab-stcrpred/Browser?all=true) and PDB (https://www.rcsb.org/). The atomic level antigen-HLA II structural data were download from (http://mhcmotifatlas.org/home) and PDB. The sequencing raw data of clinical cancer patients in this study have been deposited in the Sequence Read Archive database under accession code PRJNA1253793. Source data are provided with this paper.
Code availability
The source code of deepAntigen and a detailed tutorial are freely available via GitHub at https://github.com/JiangBioLab/deepAntigen and via Code Ocean at https://codeocean.com/capsule/6907488/tree/v1.
References
Joglekar, A. V. & Li, G. T cell antigen discovery. Nat. Methods 18, 873–880 (2021).
Rojas, L. A. et al. Personalized RNA neoantigen vaccines stimulate T cells in pancreatic cancer. Nature 618, 144–150 (2023).
Zacharakis, N. et al. Immune recognition of somatic mutations leading to complete durable regression in metastatic breast cancer. Nat. Med 24, 724–730 (2018).
Hilf, N. et al. Actively personalized vaccination trial for newly diagnosed glioblastoma. Nature 565, 240–245 (2019).
Sahin, U. et al. Personalized RNA mutanome vaccines mobilize poly-specific therapeutic immunity against cancer. Nature 547, 222–226 (2017).
Zhang, S.-Q. et al. High-throughput determination of the antigen specificities of T cell receptors in single cells. Nat. Biotechnol. 36, 1156–1159 (2018).
Wang, L. & Lan, X. Rapid screening of TCR-pMHC interactions by the YAMTAD system. Cell Discov. 8, 30 (2022).
Kula, T. et al. T-Scan: a genome-wide method for the systematic discovery of T cell epitopes. Cell 178, 1016–1028.e13 (2019).
Dezfulian, M. H. et al. TScan-II: A genome-scale platform for the de novo identification of CD4+ T cell epitopes. Cell 186, 5569–5586 (2023).
Xie, N. et al. Neoantigens: promising targets for cancer therapy. Sig Transduct. Target Ther. 8, 9 (2023).
Katsikis, P. D., Ishii, K. J. & Schliehe, C. Challenges in developing personalized neoantigen cancer vaccines. Nat. Rev. Immunol. 24, 213–227 (2024).
Wells, D. K. et al. Key parameters of tumor epitope immunogenicity revealed through a consortium approach improve neoantigen prediction. Cell 183, 818–834 (2020).
Buckley, P. R. et al. Evaluating performance of existing computational models in predicting CD8+ T cell pathogenic epitopes and cancer neoantigens. Brief. Bioinforma. 23, bbac141 (2022).
Rammensee, H.-G., Bachmann, J., Emmerich, N. P. N., Bachor, O. A. & Stevanović, S. SYFPEITHI: database for MHC ligands and peptide motifs. Immunogenetics 50, 213–219 (1999).
Gfeller, D. et al. Improved predictions of antigen presentation and TCR recognition with MixMHCpred2.2 and PRIME2.0 reveal potent SARS-CoV-2 CD8+ T-cell epitopes. Cell Syst. 14, 72–83 (2023).
Nielsen, M., Lundegaard, C. & Lund, O. Prediction of MHC class II binding affinity using SMM-align, a novel stabilization matrix alignment method. BMC Bioinforma. 8, 238 (2007).
Racle, J. et al. Machine learning predictions of MHC-II specificities reveal alternative binding mode of class II epitopes. Immunity 56, 1359–1375 (2023).
Glanville, J. et al. Identifying specificity groups in the T cell receptor repertoire. Nature 547, 94–98 (2017).
Dash, P. et al. Quantifiable predictive features define epitope-specific T cell receptor repertoires. Nature 547, 89–93 (2017).
Zhang, H., Zhan, X. & Li, B. GIANA allows computationally-efficient TCR clustering and multi-disease repertoire classification by isometric transformation. Nat. Commun. 12, 4699 (2021).
Sidhom, J.-W. et al. DeepTCR is a deep learning framework for revealing sequence concepts within T-cell repertoires. 12, 1605 (2021).
Reynisson, B., Alvarez, B., Paul, S., Peters, B. & Nielsen, M. NetMHCpan-4.1 and NetMHCIIpan-4.0: improved predictions of MHC antigen presentation by concurrent motif deconvolution and integration of MS MHC eluted ligand data. Nucleic Acids Res. 48, W449–W454 (2020).
Chu, Y. et al. A transformer-based model to predict peptide–HLA class I binding and optimize mutated peptides for vaccine design. Nat. Mach. Intell. 4, 300–311 (2022).
Nilsson, J. B. et al. Machine learning reveals limited contribution of trans-only encoded variants to the HLA-DQ immunopeptidome. Commun. Biol. 6, 442 (2023).
Haghighatlari, M. et al. HLAIIPred: cross-attention mechanism for modeling the interaction of HLA class Ii molecules with peptides. Preprint at https://doi.org/10.1101/2024.10.01.616078 (2024).
Springer, I., Tickotsky, N. & Louzoun, Y. Contribution of T Cell receptor alpha and beta CDR3, MHC typing, V and J genes to peptide binding prediction. Front. Immunol. 12, 664514 (2021).
Moris, P. et al. Current challenges for unseen-epitope TCR interaction prediction and a new perspective derived from image classification. Brief. Bioinforma. 22, bbaa318 (2021).
Lu, T. et al. Deep learning-based prediction of the T cell receptor–antigen binding specificity. Nat. Mach. Intell. 3, 864–875 (2021).
Gao, Y. et al. Pan-peptide meta learning for T-cell receptor–antigen binding recognition. Nat. Mach. Intell. 5, 236–249 (2023).
Peng, X. et al. Characterizing the interaction conformation between T-cell receptors and epitopes with deep learning. Nat. Mach. Intell. 5, 395–407 (2023).
Croce, G. et al. Deep learning predictions of TCR-epitope interactions reveal epitope-specific chains in dual alpha T cells. Nat. Commun. 15, 3211 (2024).
Yang, J. et al. De novo generation of T-cell receptors with desired epitope-binding property by leveraging a pre-trained large language model. Preprint at https://doi.org/10.1101/2023.10.18.562845 (2023).
Sibener, L. V. et al. Isolation of a structural mechanism for uncoupling T cell receptor signaling from peptide-MHC binding. Cell 174, 672–687.e27 (2018).
Das, D. K. et al. Force-dependent transition in the T-cell receptor β-subunit allosterically regulates peptide discrimination and pMHC bond lifetime. Proc. Natl. Acad. Sci. USA 112, 1517–1522 (2015).
Liu, B., Chen, W., Evavold, B. D. & Zhu, C. Accumulation of dynamic catch bonds between TCR and agonist peptide-MHC triggers T cell signaling. Cell 157, 357–368 (2014).
Rushdi, M. N. et al. Cooperative binding of T cell receptor and CD4 to peptide-MHC enhances antigen sensitivity. Nat. Commun. 13, 7055 (2022).
Hong, J. et al. A TCR mechanotransduction signaling loop induces negative selection in the thymus. Nat. Immunol. 19, 1379–1390 (2018).
Wu, P. et al. Mechano-regulation of Peptide-MHC class i conformations determines TCR antigen recognition. Mol. Cell 73, 1015–1027.e7 (2019).
Zhao, X. et al. Tuning T cell receptor sensitivity through catch bond engineering. Science 376, eabl5282 (2022).
Choi, H.-K. et al. Catch bond models may explain how force amplifies TCR signaling and antigen discrimination. Nat. Commun. 14, 2616 (2023).
McMaster, B., Thorpe, C., Ogg, G., Deane, C. M. & Koohy, H. Can AlphaFold’s breakthrough in protein structure help decode the fundamental principles of adaptive cellular immunity?. Nat. Methods 21, 766–776 (2024).
Parizi, F. M., Marzella, D. F., Ramakrishnan, G., Karimi-Jafari, M. H. & Xue, L. C. PANDORA v2.0: Benchmarking peptide-MHC II models and software improvements. Front. Immunol. 14, 1285899(2023).
Fasoulis, R., Rigo, M. M., Lizée, G., Antunes, D. A. & Kavraki, L. E. APE-Gen2.0: expanding rapid class i peptide–major histocompatibility complex modeling to post-translational modifications and noncanonical peptide geometries. J. Chem. Inf. Model. 64, 1730–1750 (2024).
Zhao, Y. et al. DeepAIR: a deep learning framework for effective integration of sequence and 3D structure to enable adaptive immune receptor analysis. Sci. Adv. 9, eabo5128 (2023).
Jiang, D. et al. NeoaPred: a deep-learning framework for predicting immunogenic neoantigen based on surface and structural features of peptide–human leukocyte antigen complexes. 40, btae547 (2024).
Riley, T. P. et al. Structure based prediction of neoantigen immunogenicity. Front. Immunol. 10, 2047 (2019).
Krishna, R. et al. Generalized biomolecular modeling and design with RoseTTAFold All-Atom. Science 384, eadl2528 (2024).
Abramson, J. et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature 630, 493–500 (2024).
Baek, M. Towards the prediction of general biomolecular interactions with AI. Nat. Methods 21, 1382–1383 (2024).
Mason, D. M. & Reddy, S. T. Predicting adaptive immune receptor specificities by machine learning is a data generation problem. Cell Syst. 15, 1190–1197 (2024).
Wang, X. et al. RPEMHC: improved prediction of MHC–peptide binding affinity by a deep learning approach based on residue–residue pair encoding. Bioinformatics 40, btad785 (2024).
Nielsen, M. et al. NetMHCpan, a method for quantitative predictions of peptide binding to any HLA-A and -B locus protein of known sequence. PLoS ONE 2, e796 (2007).
Karosiene, E. et al. NetMHCIIpan-3.0, a common pan-specific MHC class II prediction method including all three human MHC class II isotypes, HLA-DR, HLA-DP and HLA-DQ. Immunogenetics 65, 711–724 (2013).
Zhang, W. et al. A framework for highly multiplexed dextramer mapping and prediction of T cell receptor sequences to antigen specificity. Sci. Adv. 7, eabf5835 (2021).
Matsumura, M., Fremont, D. H., Peterson, P. A. & Wilson, L. A. Emerging principles for the recognition of peptide antigens by MHC class i molecules. Science 257, 927–934 (1992).
Falk, K., Rötzschke, O., Stevanović, S., Jung, G. & Rammensee, H. G. Allele-specific motifs revealed by sequencing of self-peptides eluted from MHC molecules. Nature 351, 290–296 (1991).
Rappazzo, C. G., Huisman, B. D. & Birnbaum, M. E. Repertoire-scale determination of class II MHC peptide binding via yeast display improves antigen prediction. Nat. Commun. 11, 4414 (2020).
Jones, E. Y., Fugger, L., Strominger, J. L. & Siebold, C. MHC class II proteins and disease: a structural perspective. Nat. Rev. Immunol. 6, 271–282 (2006).
Dessen, A., Lawrence, C. M., Cupo, S., Zaller, D. M. & Wiley, D. C. X-Ray crystal structure of HLA-DR4 (DRA*0101, DRB1*0401) complexed with a peptide from human collagen II. Immunity 7, 473–481 (1997).
Nolan, S. et al. A Large-Scale Database of T-cell receptor beta (TCRβ) sequences and binding associations from natural and synthetic exposure to SARS-CoV-2. https://www.researchsquare.com/article/rs-51964/v1 (2020).
Goddard, T. D. et al. UCSF ChimeraX: meeting modern challenges in visualization and analysis. Protein Sci. 27, 14–25 (2018).
Karapetyan, A. R. et al. TCR Fingerprinting and Off-Target Peptide Identification. Front. Immunol. 10, 2501 (2019).
Choy, C. et al. SARS-CoV-2 infection establishes a stable and age-independent CD8+ T cell response against a dominant nucleocapsid epitope using restricted T cell receptors. Nat. Commun. 14, 6725 (2023).
Pounraj, S. et al. Targeting tumor heterogeneity with neoantigen-based cancer vaccines. Cancer Res 84, 353–363 (2024).
Zhou, W. et al. NeoTCR: an immunoinformatic database of experimentally-supported functional neoantigen-specific TCR sequences. Genomics, Proteomics & Bioinformatics qzae010 (2024) https://doi.org/10.1093/gpbjnl/qzae010.
Hennecke, J. & Wiley, D. C. T cell receptor–MHC interactions up close. Cell 104, 1–4 (2001).
Alvarez, B. et al. NNAlign_MA; MHC peptidome deconvolution for accurate MHC binding motif characterization and improved T-cell epitope predictions. Mol. Cell Proteom. 18, 2459–2477 (2019).
Racle, J. et al. Robust prediction of HLA class II epitopes by deep motif deconvolution of immunopeptidomes. Nat. Biotechnol. 37, 1283–1286 (2019).
Nilsson, J. B. et al. Accurate prediction of HLA class II antigen presentation across all loci using tailored data acquisition and refined machine learning. Sci. Adv. 9, eadj6367 (2023).
10X Genomics. A New Way of Exploring Immunity–Linking Highly Multiplexed Antigen Recognition to Immune Repertoire and Phenotype. https://pages.10xgenomics.com/rs/446-PBO-704/images/10x_AN047_IP_A_New_Way_of_Exploring_Immunity_Digital.pdf (2022).
Vita, R. et al. The immune epitope database (IEDB): 2018 update. Nucleic Acids Res. 47, D339–D343 (2019).
Abelin, J. G. et al. Mass spectrometry profiling of HLA-associated peptidomes in mono-allelic cells enables more accurate epitope prediction. Immunity 46, 315–326 (2017).
Sarkizova, S. et al. A large peptidome dataset improves HLA class I epitope prediction across most of the human population. Nat. Biotechnol. 38, 199–209 (2020).
Yewdell, J. W. & Bennink, J. R. Immunodominance in major histocompatibility complex class I-restricted T lymphocyte responses. Annu Rev. Immunol. 17, 51–88 (1999).
Xu, H. et al. ImmuneApp for HLA-I epitope prediction and immunopeptidome analysis. Nat. Commun. 15, 8926 (2024).
Stražar, M. et al. HLA-II immunopeptidome profiling and deep learning reveal features of antigenicity to inform antigen discovery. Immunity 56, 1681–1698.e13 (2023).
Shugay, M. et al. VDJdb: a curated database of T-cell receptor sequences with known antigen specificity. Nucleic Acids Res. 46, D419–D427 (2018).
Zhang, W. et al. PIRD: pan immune repertoire database. Bioinformatics 36, 897–903 (2020).
Tickotsky, N., Sagiv, T., Prilusky, J., Shifrut, E. & Friedman, N. McPAS-TCR: a manually curated catalogue of pathology-associated T cell receptor sequences. Bioinformatics 33, 2924–2929 (2017).
Xu, Z. et al. DLpTCR: an ensemble deep learning framework for predicting immunogenic peptide recognized by T cell receptor. Brief. Bioinforma. 22, bbab335 (2021).
Dean, J. et al. Annotation of pseudogenic gene segments by massively parallel sequencing of rearranged lymphocyte receptor loci. Genome Med 7, 123 (2015).
Leem, J., de Oliveira, S. H. P., Krawczyk, K. & Deane, C. M. STCRDab: the structural T-cell receptor database. Nucleic Acids Res. 46, D406–D412 (2018).
Tadros, D. M., Eggenschwiler, S., Racle, J. & Gfeller, D. The MHC Motif Atlas: a database of MHC binding specificities and ligands. Nucleic Acids Res. 51, D428–D437 (2023).
Gao, H. & Ji, S. Graph U-Nets. IEEE Trans. Pattern Anal. Mach. Intell. 1–1 https://doi.org/10.1109/TPAMI.2021.3081010 (2021).
Knyazev, B., Taylor, G. W. & Amer, M. Understanding Attention and Generalization in Graph Neural Networks. in Advances in Neural Information Processing Systems vol. 32 (2019).
Cangea, C., Veličković, P., Jovanović, N., Kipf, T. & Liò, P. Towards sparse hierarchical graph classifiers. Preprint at http://arxiv.org/abs/1811.01287 (2018).
Warris, S., Yalcin, F., Jackson, K. J. L. & Nap, J. P. Flexible, fast and accurate sequence alignment profiling on GPGPU with PaSWAS. PLoS ONE 10, e0122524 (2015).
Chomczynski, P. & Sacchi, N. Single-step method of RNA isolation by acid guanidinium thiocyanate-phenol-chloroform extraction. Anal. Biochem. 162, 156–159 (1987).
Acknowledgements
This study was supported by the National Natural Science Foundation of China (Nos. T2325009, 62032007, U24A20370, T2495273, 32270789, 32470689 and 32400643) and the National Science and Technology Major Project of China (2022ZD0117702).
Author information
Authors and Affiliations
Contributions
Q.J., Z.X., P.W. and H.S. conceived and designed the study; Q.J., J.Q., G.X., T.W., H.S., P.W. and X.J. performed the research; Z.Wang, Y.Y., F.P., Y.H., Z.Wei and J.X. collected and constructed the benchmark datasets; J.Q., G.X., T.W., W.Y., Y.C., Y.L., M.L., and Y.W. designed and implemented the computational framework with guidance from Q.J. and Z.X.; Q.D., Y.L., Y.Y., F.P., J.Z., X.J. and Y.W. completed downstream analysis work. H.S., S.X., J.Q. and G.X. performed the ex vivo assays; Y.C., W.Y., Y.H., Z.Wang and J.X. released the source code on Github; Q.J., Z.X., P.W., H.S., J.Q. and G.X. wrote the paper with input from all other authors. All authors read and approved the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Dinler Antunes, who co-reviewed with Martiela Vaz de Freitas, Max Little and Adithya Polasa for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Que, J., Xue, G., Wang, T. et al. Identifying T cell antigen at the atomic level with graph convolutional network. Nat Commun 16, 5171 (2025). https://doi.org/10.1038/s41467-025-60461-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-60461-6
