
Abstract
Spatially resolved transcriptomics enables mapping of multiplexed gene expression within tissue contexts. While existing methods prioritize spatially variable genes within a single slice, few address identifying genes with differential spatial expression patterns (DSEPs) across multiple conditions—an critical need for complex experimental designs. Challenges include modeling cross-slice spatial variation, scalability to large datasets, and disentangling inter-slice heterogeneity. We introduce DSEP gene prioritization as a new analytical task and present River, an interpretable deep learning framework that identifies genes exhibiting condition-relevant spatial changes. River features a two-branch predictive architecture and a post hoc attribution strategy to rank genes (or other features) by their contribution to condition differences. Its spatially-informed modeling ensures scalability to large spatial datasets, and we further decouple spatial and non-spatial components to enhance interpretability. We evaluate River on simulations and apply it to diverse biological contexts, including embryogenesis, diabetes-affected spermatogenesis, and lupus-associated splenic changes. In triple-negative breast cancer, River prioritizes survival-associated spatial patterns that generalize across patients. River is distribution-agnostic and compatible with diverse spatial data types, offering a flexible and scalable solution for analyzing tissue-wide expression dynamics across multiple biological conditions.
Similar content being viewed by others
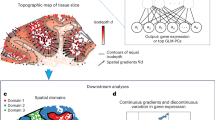

Introduction
The advent of spatially resolved transcriptomics technologies has revolutionized our understanding of tissue architectures by enabling gene expression profiling while preserving spatial context1,2. As these technologies become increasingly accessible, the scale of experimental data has expanded from hundreds of cells collected from a single slice or a few slices to millions of cells collected from dozens of slices across conditions or temporal stages3,4,5,6,7.
This explosion of data has created a pressing need for computational methods that can effectively analyze complex spatial expression patterns of genes at scale8. In spatial transcriptomics, a key aspect of spatial data analysis is the identification of spatially variable genes (SVGs), which exhibit significant spatial dependencies in their expression levels9,10. SVGs play critical roles in establishing and maintaining tissue organization, and their dysregulation has been implicated in various pathological conditions11,12. Several computational methods have been developed to identify SVGs, including early methods like SpatialDE13 and Trendsceek14, which utilize statistical tests to assess gene spatial variability. Later and recent methods, such as SPARK15, SPARKX16, SpatialDM17, SOMDE18, Sepal19, and others20,21,22,23, have improved the accuracy and/or scalability of SVG identification by introducing various spatial kernels, identifying spatially co-expressed ligand-receptor pairs, employing self-organizing maps, and using diffusion-based processes. Despite these computational advancements, existing methods primarily focus on identifying gene patterns within a single slice. However, with the increase of large-scale and multi-condition perturbation studies, comparing spatial expression patterns across multiple slices from various conditions has become critical for understanding tissue organization and function.
To address this challenge, we propose a significant task that has not been well addressed before: prioritizing gene spatial patterns most responsive to biological perturbations, aka., identifying genes with differential spatial expression patterns (DSEPs) in multi-condition spatial omics data. DSEP genes exhibit changes in spatial expression patterns across different slices, encompassing both gene expression level changes and spatial pattern changes. Existing methods, such as SVG methods and non-spatial methods24,25, cannot identify DSEP genes, as they focus on single-slice analysis or gene expression abundance without considering spatial information. To overcome these limitations, we developed River, an interpretable deep learning-based method specifically designed to identify genes exhibiting DSEPs among multiple slices and multiple conditions in spatial omics data. River is based on the assumption that only genes with significant DSEPs across slices can contribute to the prediction of slice/condition labels.
In this work, we establish the versatility and robustness of our proposed method, River, demonstrating its superior performance on simulation benchmarks and its ability to generate biologically grounded results across diverse real-world applications. Specifically, we demonstrate River’s performance on carefully designed simulated datasets. We show that River-identified DSEP signal can be decoupled into non-spatial and spatial components. Using a mouse E15.5 embryo dataset, we demonstrate the non-spatial variations of River-identified DSEP genes and validate its generalizability in E16.5 embryos. We also developed a strategy to only pinpoint spatial variation along eight development stages based on gene expression binarization. In mouse models, River identified diabetes-induced DSEPs in spermatogenesis and lupus-induced DSEPs in the spleen. In human cancer, River identified DSEPs related to triple-negative breast cancer subtypes, which was validated generalizable across the unseen patient groups. River is also compatible with other spatial omics data other than spatial transcriptomics, for example Multiplexed ion beam imaging by time-of-flight (MIBI-TOF)26 and Co-Detection by Indexing (CODEX)27. Additionally, River’s special design for modeling spatial-informed gene expression makes it scalable to large-scale spatial omics datasets, making it well-suited for the rapidly accumulating spatial omics data. Our studies demonstrate River’s potential to uncover novel insights into the molecular mechanisms driving spatial heterogeneity and its alterations in different biological contexts.
Results
River overview
River (Fig. 1A) is designed to identify genes exhibiting differential spatial expression patterns (DSEPs) among multiple slices in spatial omics data. Each “slice” can be associated with labels such as conditions, developmental stages, disease states, or treatment groups (Fig. 1B). River is based on interpretable deep learning and the main idea can be summarized as follows: In a multi-slice dataset, DSEPs contribute to differentiate among different slices/conditions, thereby enabling a prediction model to utilize spatially resolved gene expression to distinguish between these slices/conditions. Only genes that show significant changes (spatial and/or non-spatial) between different slices/conditions provide useful information for the prediction model. River’s process can be broken down into the following steps: (1) designing the prediction model to fully utilize the spatial-aware gene expression features in a multi-slice and multi-condition dataset, (2) quantifying contributions of each gene to the prediction model, and (3) integrating different deep learning attribution methods to prioritize gene patterns.

A Workflow of the River process for identifying the differential spatial expression pattern (DSEP) genes in multi-slice and multi-condition spatial omics data, where each slice is annotated with a slice-level label, e.g., development stage or disease. River is composed of two main modules: prediction model and post-hoc attribution. River first fits the prediction model by inputting spatial omics and then utilizes the post-hoc attribution to quantify each gene’s contribution to the prediction. The input spatial omics data for River contains each cell’s expression vector and spatial location, and River utilizes each individual cell’s gene expression incorporated with spatial coordinates as prediction model input. For multi-slice data within different coordinate systems, River applies heterogeneous alignment to ensure a consistent coordinate system for each input cell. River assigns the cell-level input label based on the slice annotation to which it belongs, which is used as supervised information for prediction model training. (i) River utilizes each individual cell as model input instead of using the entire slice as in previous work. River adapts the spatial information by incorporating gene expression with spatial location coordinates in the original slices. (ii) Slices from different spatial coordinates are aligned into the same coordinate space to ensure comparable input spatial coordinates. (iii) The prediction model in River is composed of three parts: position encoder, gene expression encoder, and classifier. The position encoder and gene expression encoder individually encode the input gene expression and spatial coordinates for each cell, obtaining spatial and gene expression latent embeddings, which are concatenated as classifier input spatial-aware gene expression latent. (iv) River utilizes three attribution methods to score the contribution of each gene in the prediction of the target cell-level label based on the fitted prediction model. The outcome of this tentative attribution process is three independent gene score vectors. River utilizes rank aggregation to combine the multiple attribution results to form a final gene rank list. B River can be utilized in diverse multi-slice scenarios, including consecutive slices, development stages, and disease conditions.
To aggregate spatial position and gene expression data (Fig. 1A-i) and obtain spatial-aware gene expression latent representations for each input cell, River utilizes a joint two-branch architecture. This architecture includes a position encoder (to extract features from spatial information) and a gene expression encoder (to extract features from gene expression), which independently extract features and then fuse them in the latent space (Fig. 1A-iii). Before input into position encoder, cells from different slices are spatially aligned using heterogeneous spatial alignment to harmonize spatial information (Fig. 1A-ii). Above approach ensures that gene expression features in the latent space are spatial information-aware, which are then sent to subsequent modules to predict slice-level labels. The position encoder is motivated by its efficiency and scalability compared to previous graph neural network based spatial embedding methods, while maintaining information integrity, as demonstrated in previous spatial omics studies28. After the training phase, River employs multiple deep learning attribution strategies to obtain cell-level gene contribution scores, which are then aggregated to derive the final global scores (Fig. 1A-iv). Compared with direct and global-level selection methods like Lasso29, the instance-level scores reflect the high cell-wise heterogeneity in spatial omics slices. A rank aggregation method synthesizes the contribution rankings provided by multiple interpretation attribution techniques. This aggregation process is critical, as it combines insights from multiple analytical perspectives and obtains a robust and reliable measure of each gene’s contribution on the prediction of slice labels. More details can be found in Methods.
Both the training of the prediction network and the attribution module can be conducted in mini-batch distributed computation on GPUs. Moreover, the use of non-graph spatial information embedding techniques ensures the scalability and efficiency of River on large-scale multi-slice data, which is critically important in modern large-scale biological studies. We benchmarked River’s performance and demonstrated its ability with various biological applications (Fig. 1B).
Notably, the key differences between SVG, DEG, and DSEP methodologies are fundamental to understanding River’s unique contribution. Spatially Variable Genes (SVGs) identify genes with spatial heterogeneity but are typically limited to analyzing single slices independently, making them unable to compare across different conditions. Differentially Expressed Genes (DEGs) detect significant expression changes between conditions but overlook the spatial distribution patterns that are critical in tissue biology. In contrast, Differential Spatial Expression Patterns (DSEPs) focus on genes whose spatial distribution patterns—not just expression levels—change significantly between conditions. This distinction is crucial because the biological importance in spatial omics often depends on where genes are expressed within the tissue architecture.
While there can be overlap (some DSEPs may also be SVGs or DEGs), these categories represent distinct biological phenomena. For example, a gene might show spatial variability without changing patterns across conditions (SVG but not DSEP), or it might be differentially expressed while preserving a similar spatial distribution (DEG but not DSEP). Meanwhile, a DSEP gene can also be an SVG, a DEG, or both, since DSEPs are not an exclusive property. River specifically targets DSEPs to identify genes whose spatial organization shifts between conditions, revealing changes in cell type localization and niche composition that traditional methods might miss.
Benchmarking analysis
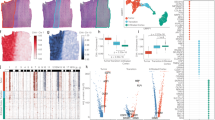
To evaluate the performance of River, we generated simulated datasets (Fig. 2A, see Methods). The control slice (slice 0) contained four different spatial domains. Condition slices (Slices 1–6) were generated based on slice 0, each with a carefully designed and distinct perturbation to control gene expression variability (Fig. 2A). This setup provided a ground truth where perturbed genes were known and labeled as positive (DSEP genes) and the remaining genes as negative (background or non-DSEP genes), which allowed us to evaluate the performance of various methods. We compared slice 0 with each of slices 1 – 6 (resulting in datasets 1 to 6) using different gene prioritization methods (Fig. 2B).

A 6 different perturbations were applied on the control slice (slice 0) in silico, obtaining 6 new slices (details in Methods). B The control slice (slice 0) was compared with each of slice 1 to slice 6 using River. C Benchmarking outcome for each method on six datasets. The performance of different methods is evaluated by F1-scores. River achieves the highest F1 score across six experiments with statistical significance (p-value < 0.05) Box plots display the median (center lines), inter-quartile range (hinges) and 1.5 × IQR (whiskers). One-sided Wilcoxon rank-sum tests were applied to F1-scores (n = 6 slices per method). P-values = 2.42 × 10⁻³, 2.16 × 10⁻³, 1.34 × 10⁻³, 1.34 × 10⁻³, 2.46 × 10⁻³, 2.46 × 10⁻³, 1.34 × 10⁻³, 2.46 × 10⁻³, 1.34 × 10⁻³, 1.34 × 10⁻³, 1.34 × 10⁻³, 1.34 × 10⁻³, 1.34 × 10⁻³, 1.34 × 10⁻³, respectively. D Benchmarking results summary for top-k parameter dependency methods among different k values in F1 scores. X-axis: different k choices. Y-axis: F1-score. E Comparison of score distribution between River and Sepal. River’s attribution method is IG for this figure, other two methods are also compared with Sepal in Supplementary Fig. 2. For each dataset, the left line chart indicates the score value for each gene, where positive genes (Ground truth DSEP genes) are expected to obtain larger scores compared with remaining negative genes. Violin plots on the right show the score distributions for DSEP (positive) and non-DSEP (negative) genes across two methods, River and Sepal. Each violin includes 200 DSEP genes and 900 non-DSEP genes per dataset (n = 200 for River(pos) and Sepal(pos); n = 900 for River(neg) and Sepal(neg); each point represents the score of a single gene). Violin plots display the full distribution, with internal box plots indicating the median (center lines), interquartile range (hinges), and 1.5× interquartile range (whiskers). One-sided Wilcoxon rank-sum tests were used to assess group differences. Exact p-values for River(pos) vs. River(neg) across datasets 1–6 are: 2.28 × 10⁻⁵⁶, 1.17 × 10⁻⁶⁰, 1.00 × 10⁻⁶⁷, 9.11 × 10⁻⁶³, 3.18 × 10⁻⁵⁷, and 3.98 × 10⁻⁶⁴. Corresponding p-values for Sepal(pos) vs. Sepal(neg) are: 0.380, 0.693, 0.261, 0.506, 0.579, and 0.711.
Since there are currently no methods for identifying differential spatial expression pattern (DSEP) genes across slices, we adapted existing methods to be compatible with the multi-slice context. Specifically, our competing methods included adapted highly variable gene (HVG) selection methods (SeuratV330, Seurat31, CellRanger (10x Genomics)) and adapted spatially variable gene (SVG) selection methods (SPARKX16, SpatialDE13, Sepal19, Moran’s I32, Geary’s C32, and BSP33). Note that the original purposes of these methods are not for identifying DSEP genes across conditions, so they cannot be directly applied to multi-condition cases. We carefully checked each of their codes and made modifications to make them compatible with multi-condition cases. We believe such efforts are necessary to test the power of existing methods and to demonstrate the necessity of our new method. We explained how these methods were adapted to multi-slice analysis (see Methods).
The performance of River and 16 competing methods (including one ablation version of River) was summarized across six datasets (Fig. 2C). River significantly outperformed all other methods in terms of F1-score (p-value < 0.05). River ranked first with a median F1-score of around 0.59, while the second- and third-best methods, Sepal and SpatialDE, had median scores of ~0.41 and 0.32, respectively (Fig. 2C). The other methods had F1-scores close to zero, highlighting their inadequacy for this challenging task (Fig. 2C).
Additionally, since River, Sepal, SeuratV3, Seurat, and CellRanger can output gene-wise ranks, we compared the F1-scores under different top-k choices (Fig. 2D). Regardless of the selected k, River outperformed the other methods in almost all cases (Fig. 2D). Furthermore, the “River no spatial” method showed a significant performance decrease due to the lack of spatial information, demonstrating the importance of considering spatial context in our benchmarking datasets.
River’s attribution module (see Methods) can output meaningful scores for each gene, prioritizing those with differential spatial expression patterns. To further validate River’s attribution scoring capability, we analyzed whether River’s attribution score could differentiate true DSEP genes from background genes (Fig. 2E). We compared one of the attribution methods (see Methods), Integrated Gradient (IG) score of River with Sepal (second best method that can output gene-wise scores as shown in Fig. 2C-D). For each dataset, we plotted the gene-wise scores provided by River and Sepal (Fig. 2E). Across the six datasets, River (represented by the red curve) consistently assigned higher scores to DSEP genes compared to background genes (red dashed lines always higher than orange dashed lines across 6 datasets), with the scores exhibiting significant differences between true DSEP genes (denoted as River (pos)) and background genes (denoted as River (neg)) (p-value < 0.05) as shown in the violin plots (Fig. 2E). In contrast, Sepal (represented by the green curve) failed to differentiate DSEP genes from background genes (red solid line always overlap with orange solid line), as Sepal-computed scores did not show significant differences between the two groups, i.e., Sepal (pos) and Sepal (neg), as shown in the violin plots (Fig. 2E). Additional comparisons of other attribution methods can be found in Supplementary Fig. 2.
River detects non-biological spatial expression patterns across slices
When comparing slices, differential spatial expression patterns (DSEPs) identified by River can arise from both spatial and non-spatial variations. Non-spatial variations may originate from gene expression level differences between slices, either due to biological or non-biological factors (e.g., batch effects). We used a mouse embryo dataset34 to demonstrate River’s capability to identify genes with non-spatial variations among slices. Specifically, this dataset contains four replicate slices of E15.5 mouse embryos and another four replicate slices of E16.5 mouse embryos (Fig. 3A).

A Dataset: Stereo-seq mouse embryo dataset in E15.5 and E16.5 development time, each with four continuous depth slices. River utilizes the depth as the slice level label and fits the model on the E15.5 dataset. B 3D visualization of the spatial gene expression pattern of River-selected top-3 genes at the E15.5 timepoint: Trim30a, Cdk8, and Tlk1. C 3D UMAP visualization of River-selected top-20 genes, 2000 HVG genes, and River-selected bottom genes (two versions (DE and SVG)) (see Methods) on E15.5 timepoint data for each cell. Points in the figure are colored by each cell’s slices id. D 3D UMAP visualization of River-selected top-20 genes (fitted in E15.5), 2000 HVG genes, and River-selected bottom genes (two versions) on E15.5 timepoint data for each cell. Points in the figure are colored by each cell’s slice id. E 2D UMAP visualization of Harmony integrated datasets (development stage as batch key) used in Fig. 3A, using River-selected top genes (left) and 2000 HVG genes (right). F Batch integration metrics comparison among different River-selected top-k (k = [5,10,15,20]). River-selected genes with River-selected bottom genes (two versions) and 2000 HVG genes. The metrics include ARI, NMI, Graph Connectivity (GC) and iLISI.
We applied River to detects genes that can differentiate the four slices of the E15.5 dataset. Since these slices were consecutive from the same embryo, any differential genes among them were likely attributed to non-biological factors (e.g., caused by different experimental batches or sectioning positions) (Supplementary Fig. 3A). Visualizations of the top-3 River-identified genes (Trim30a, Cdk8, and Tlk1) in a stacked 3D space confirmed their distinct expression patterns across the slices (Fig. 3B). Specific regions, including liver (Fig. 3B-i), brain (Fig. 3B-ii), and heart (Fig. 3B-iii), highlighted the different expression levels evidently.
To validate that River-prioritized genes can be attributed to non-biological factors, we performed Uniform Manifold Approximation and Projection (UMAP) on all cells from the four slices using different gene sets (2000 HVG genes, River-selected top-20 genes, and two versions of River-selected bottom genes (SVG and DE) (see Methods)) as input features. This allowed us to assess the information contained in River-selected genes and their negative controls. When using the top-20 genes prioritized by River, cells from each slice clustered together and were clearly separated in the 3D UMAP space (Fig. 3C-i), indicating that these genes effectively captured the most prominent differences of the consecutive slices. Using all genes as features resulted in a less distinct separation of the slices (Fig. 3C-ii). On the negative control, using the River-selected bottom genes as features completely failed to distinguish the slices (Fig. 3C-iii, iv), confirming that these genes had the lowest inter-slice differences.
We hypothesize that these top-ranked genes are also most affected by non-biological factors like batch effects in another embryo. To test the generalizability of the River-selected gene sets, we applied the top-20 genes identified in the E15.5 slices to four slices from the E16.5 embryo. Strikingly, the 3D UMAP using these genes effectively separated the E16.5 slices, demonstrating the generalizability of River-identified genes on different animal, and the bottom genes (negative control) from E15.5 failed to distinguish the E16.5 slices (Fig. 3D).
We hypothesize that these genes can be used to improve data integration. By applying Harmony35 to the top River genes, we observed a superior mixing of cells from E15.5 and E16.5 in the UMAP space compared to using all genes (Fig. 3E). We used the well-known integration benchmarking framework, scib36, to evaluate the integration performance using different gene sets (see Methods). The results confirmed that the top genes identified by River can substantially improve the data integration (Fig. 3F).
In the above analyses, we did not try to avoid batch effects but used these signals as a sanity check to demonstrate that River can identify different gene signals across slices. We also showed that such batch effect genes exhibit similar behaviors in other samples and demonstrated the improvement in downstream data integration analyses.
River uncovers DSEP genes along developmental stages
To demonstrate the diverse and generalized utility of River in identifying DSEP genes across different conditions in multi-slice datasets, we focus on another spatial omics application of interest to the research community: temporal changes37. Existing studies often focus on gene spatial patterns within the same slice, overlooking changes in spatial gene expression patterns over time. Here, we applied River to the Stereo-seq dataset of mouse embryos spanning eight development stages34 (same sectioning position in respective animals) (Fig. 4A). In this case, River-identified differential genes may be attributed to both spatial and non-spatial variations caused by development.

A Dataset: Stereo-seq mouse embryo dataset across eight development stages ([E9.5, E10.5, E11.5, E12.5, E13.5, E14.5, E15.5, E16.5]). B Visualization of River-identified top-5 genes using count expression values. C Visualization of different gene set inputs (2000 HVG genes, River-selected top-20 genes, and two versions of River-selected bottom genes (DE and SVG) (see Methods)). Notably, the SVG bottom genes’ embedding is collapsed in the embedding space due to the lack of information, providing a negative control for River-selected genes. D Unsupervised clustering results comparison between different input gene sets (top-5 genes, 2000 HVG genes, and River-selected bottom genes (two versions)) using NMI, ARI, and cLISI metrics. E Pairwise silhouette score across eight development stages for different input gene sets. The pairwise silhouette score reflects the distance between two clusters in the UMAP space in Fig. 4C. F Principal Component Analysis for River-selected top-5 genes colored by development stages. The right panel shows the principal components’ distribution change tendency along with developmental changes. Box plots display the principal component values of individual cells across developmental stages (n = 5000 point per development stage; each point represents one cell’s principal component score). Box plots indicate the median (center lines), interquartile range (hinges), and 1.5× interquartile range (whiskers). G Visualization of River-identified top genes using binary expression values (unique to the gene set of River-count). H Significant enriched (FDR adjusted p-value < 0.05) gene sets uniquely identified by River-binary in GO biological process reference.
We can find that River selected top-ranked gene in mouse embryo development shares a highly overlap with Hbb gene family and the previous studies have already found that Hbb gene family, responsible for encoding beta-globin proteins, exhibits dynamic spatial and temporal expression patterns during mouse embryonic development. These patterns shift significantly over time due to the developmental regulation of different globin genes to meet the oxygen transport needs at various embryonic stages. Initially, embryonic globin genes are expressed, followed by fetal and adult globin genes as development progresses. This sequential activation ensures that hemoglobin composition is optimized for the changing oxygen requirements of the developing embryo38,39,40.
Visualization of the prioritized genes identified by River confirmed their spatiotemporal variation along the developmental axis (Fig. 4B). To assess the effectiveness of the top genes in distinguishing different developmental stages, we visualized these genes in low dimension embedding space (Fig. 4C). We found that the embedding space effectively separated cells from different stages (Fig. 4C left), with visually better separation compared to using 2000 HVG genes (Fig. 4C middle). In contrast, using River-selected bottom genes (two versions (SVG and DE)) (see Methods) completely failed to distinguish the stages (Fig. 4C right). This provides a strong negative control example for River-selected gene set. These findings were further supported by three quantitative metrics (NMI, ARI, and Cell-type LISI (cLISI) score, see Methods) on different gene set-constructed embedding spaces, confirming that genes prioritized by River contain the non-spatial (gene expression level, Supplementary Fig. 3B) variations to discriminate across stages (Fig. 4D).
Furthermore, we used the pairwise silhouette score to measure the distance for each development stage in the expression values obtained using different input gene sets as in Fig. 4C. Figure 4E shows that in the River-prioritized gene set, the closer time points share more similar pairwise silhouette score patterns and show better clustering compared to the entire input gene set, indicating that the non-spatial variation captured by River contains biological signals related to development. Moreover, it has been reported that non-linear dimension reduction methods typically retain local data structure better than global data structure41,42, meaning that the cell group distance (global structure) in the embedding recorded in the silhouette score may be blurred. To more strictly test the biological relevance of River-prioritized genes, we performed Principal component analysis (PCA), which retains global data structures. PCA using only the top-5 genes identified by River showed clear separation of cells from different stages, indicating that these top genes successfully captured non-spatial gene expression variations related to development (Fig. 4F left). Interestingly, we observed that the slices arranged in a consistent order along the developmental timeline in the PCA space (Fig. 4F left), and PC1 alone significantly separated the different stages in the correct order (Fig. 4F right), indicating that these non-spatial gene expression variations are not solely due to non-biological factors such as batch effects and indeed contain biological signals related to development.
Above analysis has demonstrated River’s ability to capture non-spatial differences along development, to demonstrate River’s capability to capture spatial pattern differences (Supplementary Fig. 3C), we decoupled the spatial and non-spatial variations using a gene expression binarization approach (see Methods). This process transforms all gene expression in the input slices into 0/1 values (0 for off and 1 for on), and we used this binarized expression as input for River. The benefits of this procedure are that (1) binarized gene expression is reported to be robust to batch effects in both single cell43,44 and spatial transcriptomics45,46, and (2) binarized gene expression removes gene expression level signals and only retains spatial signals. River with binary input (River-binary) identified the top-10 ranked pure spatial pattern shift genes, and six of these were the same as those identified using the count expression value-informed River (River-count) outcome (Hbb family genes, Fig. 4B). This demonstrated River’s ability to capture spatial variations. We present the remaining four uniquely selected genes from River-binary results, all of which show significant spatial pattern shifts across the developmental stages (Fig. 4G). We further conducted gene set enrichment analysis for the gene set identified by River-binary (pure spatial pattern shift) uniquely to River-count. The results showed that these unique genes are highly enriched in two main biological processes occurring during embryo development: chemotaxis and skin morphogenesis. Chemotaxis and skin morphogenesis play crucial roles in mouse embryonic development by guiding cell migration and differentiation to form tissues and organs. Chemotaxis directs neural crest cells and other progenitor populations via signaling pathways like SDF-1/CXCR4, ensuring proper tissue positioning and preventing congenital anomalies47,48. Similarly, skin morphogenesis involves complex signaling interactions, such as Wnt10b activation before hair follicle formation, and Rho GTPase-mediated cytoskeletal remodeling, both essential for epidermal patterning and development49,50. These tightly regulated processes highlight the intricate molecular coordination necessary for embryonic tissue organization and indicating that River can capture development-related spatial pattern changes (Fig. 4H).
River identified diabetes-induced DSEP genes in spermatogenesis
Apart from applications in multi-slice developmental studies, River can also be used to analyze spatial properties in tissue samples from both normal and diseased states. This capability is crucial for uncovering complex cellular interactions and gene expression patterns associated with disease perturbations. To illustrate this, we applied River to study the impact of diabetes on spermatogenesis in mice. The input dataset comprised testis sections from three wild-type (WT) and three leptin-deficient diabetic mice51 (Fig. 5A). River utilized the slice-level label (i.e., WT and diabetic) during model fitting. The top-ranked genes selected by River are displayed in Fig. 5B. Notably, Prm1 and Prm2, previously associated with ES/spermatozoa loss in diabetic testes52, were identified by River.

A Slide-seq Dataset: 6 mouse testis Slide-seq slices (3 Diabetes and 3 WT). River utilized the Diabetes/WT condition label to select the diabetes-induced pathological changes related genes. B The visualization of cell type, spatial expression gene pattern of River-selected top-ranked genes (Prm1, Prm2). C Significantly enriched gene sets (FDR adjusted p-value < 0.05) in gene set enrichment results for River-selected top-50 genes on three reference gene sets: KEGG, Jensen TISSUE, and Elsevier Pathway Collection.
We performed gene set enrichment analysis on the top-50 genes prioritized by River using three databases: KEGG, Jensen TISSUE, and Elsevier Pathway Collection (https://maayanlab.cloud/Enrichr/) (Fig. 5C). The enrichment results indicated that, from both pathway and tissue composition perspectives, the River-prioritized genes were significantly enriched in diabetes-induced pathological changes in spermatogenesis. Specifically, the Elsevier pathway analysis showed enrichment in the male infertility pathway, while KEGG analysis revealed enrichment in the Glycolysis/Gluconeogenesis pathway, aligning with previously reported disturbances in the male reproductive system associated with diabetes53. In terms of tissue composition, the Jensen enrichment results demonstrated significant enrichment of River-selected genes in spermatogenesis-related tissue components in the testis, such as spermatids, germ cells, and seminiferous tubules. This supports that River can capture genes pertinent to spermatogenesis-related cells and tissue composition.
Applications on spatial proteomics datasets
We applied River to two spatial proteomics datasets to test its generalization potential on platforms other than spatial transcriptomics. First, we used a triple-negative breast cancer (TNBC) spatial proteomics dataset54 measured by MIBI-TOF. The dataset featured three patient groups associated with significantly different survivals: Mixed (high immune infiltration), Compartmentalized (distinct tumor and immune cell regions), and Cold (low immune cell presence) (Fig. 6A, Supplementary Fig. 4A). For each patient group, we selected one patient to input to River and used the River-score to prioritize the protein set. We visualized the top-ranked proteins—Vimentin, Beta-catenin, and CD45—on each patient in Fig. 6B. Each of these proteins exhibited distinctive spatial patterns across patients. For instance, CD45, a marker of immune cells, showed denser expression patterns in both Mixed and Compartmentalized conditions. Meanwhile, Beta-catenin and Vimentin, markers of TNBC tumor cells, displayed a more scattered distribution in Mixed conditions and a dense, centralized distribution in Compartmentalized conditions, reflecting the characteristics of immune infiltration and separation54.

A MIBI-TOF dataset: MIBI data from 41 patients with 19 Mixed (high immune infiltration), 15 Compartmentalized (distinct tumor and immune cell regions), and 6 Cold (low immune cell presence). We randomly chose one sample per category to fit River. Remaining hold-out slices were utilized for the validation of River-selected biomarker panel generalization. B Visualization of cell types and River-selected proteins on MIBI-TOF dataset. C CODEX dataset: CODEX data from 9 mice with 3 WT and 6 lupus spleens. We randomly chose one sample per category to fit River. Remaining hold-out slices were utilized for the validation of the River-selected protein panel generalization. D Visualization of cell types and the River-selected proteins on CODEX dataset. E-F The validation results of the River-selected panel generalization on hold-out samples on the MIBI-TOF patient dataset (E) and the CODEX mouse dataset (F). Feature vector for each sample (i.e., patient for MIBI-TOF data and mouse for CODEX data) was the mean expression levels of all cells from the sample. We conducted 5-fold cross validation on the hold-out samples using three classifiers (Support Vector Classifier, Random Forest, and Logistic Regression). For these classifiers, each instance is a patient (for MIBI-TOF data) or a mouse (for CODEX data), and the input feature are full protein panel or selected top-k (using either random selection or River prioritization) protein panels. The line chart shows the 5-fold accuracy on the validation set with mean and shaded area represents the confidence interval (± standard deviation) for different k ([2, 4, 6, 8, 10]).
To validate the biological significance of the signals captured by River, we tested whether River-identified DSEPs contain biological variations applicable to unseen patients. We employed the genes ranked in the different top-k (k = [2, 4, 6, 8, 10]) identified on one patient and tested on unseen patients. This selected protein set was used to compute the mean expression value as a patient-level feature. We then analyzed this feature using three classifiers (Support Vector Classifier (SVC), Logistic Regression (LR), and Random Forest (RF)) with 5-fold validation. The results, shown in Fig. 6E, indicate that the selected genes maintained comparable predictive power to the original full gene set and remained robust to the selection of k parameter, with consistent improvements compared to the random selection.
Next, we tested River on a second dataset. This dataset contains spatial proteomics (CODEX) data measured on lupus spleen mouse model with two condition labels: WT and lupus27 (Fig. 6C, Supplementary Fig. 4B). We followed the same setup as the previous TNBC dataset, choosing one slice from each condition to apply River and select top proteins. The visualizations of the River-selected top-ranked proteins (CD44, MHC class II, CD90) abundance on the chosen slice are shown in Fig. 6D. Previous studies have identified MHC class II as associated with lupus susceptibility55. Specifically, in mice, the MHC class II locus directly contributes to lupus disease susceptibility, similar to observations in humans. Additionally, CD44, a surface marker of T-cell activation and memory, was overexpressed in T cells of lupus spleen56. CD90, a marker of T cells, also showed significant changes in the T cell niche between lupus and WT conditions57. These proteins reflect the properties of lupus at both molecular and cell niche interaction levels. To further validate the predictive power of the River-selected panel on hold-out unseen slices, we conducted quantitative prediction tasks. Following the same settings as the TNBC experiment, we trained SVC, LR, and RF using the mean value of the chosen panel for different top-k (k = [2, 4, 6, 8, 10]) in the hold-out unseen slices with five-fold validation. The results showed that River-prioritized proteins obtained comparable accuracy with the full protein panel (Fig. 6F). Additional application on a colorectal cancer (CRC) CODEX dataset also supported River’s performance (see Methods and Supplementary Fig. 5).
Scalability and reproducibility
River’s non-graph design greatly enhances its scalability for handling large-scale spatial datasets. Contrary to most existing methods that rely on graph structures to model cell-cell spatial relationships and suffer from scalability issues with large graphs (e.g., when a slice contains a vast number of cells). When we refer to River’s scalability, we mean that it can calculate scores using mini-batch processing with GPU acceleration in parallelized manner and thus can be runnable in extremely large dataset with adjustment of batch size parameter. River efficiently manages such challenges. We demonstrated this using a brain spatial transcriptomics dataset measured by MERSCOPE, which contains three replicates (Supplementary Fig. 1A). Each slice comprises more than 70,000 cells, posing significant computational hurdles for many existing methods, as previously highlighted58,59,60. However, River processes each replicate in ~7 min (machine information in Methods), showcasing its efficiency. Furthermore, the three replicates allowed us to test River’s reproducibility, and we observed that River consistently assigned gene-wise scores across the replicates (Supplementary Fig. 1B).
To verify River’s scalability and examine the relationship between input cell numbers and running time, we generated multiple simulated datasets. These datasets ranged from 32,000 cells (with 2766 genes) to 3,200,000 cells. The results, illustrated in Supplementary Fig. 1C, demonstrate that River’s running time shows a near-linear correlation with the number of input cells and can successfully handling 3 M cells within 5 h. This means the method can effectively scale to process large datasets. This performance is particularly significant for modern single-cell research. As atlas-level datasets continue to grow in size and complexity, River proves capable of managing millions of cells efficiently, offering researchers a powerful computational tool for large-scale analyses.
Discussions
Scalable spatial omics technologies have enabled the generation of large-scale multi-slice and multi-condition datasets. One key insight from such datasets is the identification of differences in spatial gene expression patterns across different conditions, which had previously been overlooked. We propose a new concept: Differential Spatial Expression Patterns (DSEPs). DSEPs refer to changes in a gene’s spatial expression pattern across different slices or conditions, encompassing changes in spatial arrangement, gene expression level, or both. This concept is more suitable for characterizing gene spatial properties in large-scale multi-slice studies than previous concepts, such as Differential Gene Expression (DEG) analysis and Spatially Variable Genes (SVGs) analysis.
We developed River, a method that uses interpretable deep learning to identify DSEPs across slices. Our results demonstrate that River is a scalable method capable of effectively identifying DSEPs genes across extensive multi-slice and multi-condition spatial omics datasets. River is not simply another differential gene expression or SVG identification method but is specifically designed to identify DSEPs without being limited by single-slice and cell-independent hypotheses. Furthermore, we have demonstrated River’s biomedical significance using various biological cases such as development and disease, which cannot be done with previous methods.
River’s novel point, which transforms the differential spatial expression pattern identification problem into a solvable computational task with interpretable deep learning, holds potential for future studies, especially those aiming to uncover factors significantly contributing to certain condition labels. This includes identifying cell states responding to certain perturbations and pinpointing microenvironments exclusive to certain diseases61,62,63. Additionally, River’s use of non-graph data structures to model cell-cell spatial relationships offers valuable insights for future spatial omics data modeling.
Several areas for future improvement remain. One major concern in comparing different slices and conditions is the batch effect. In this study, we eliminated this using two approaches: (1) a gene expression binarization method and (2) utilizing batch-effect-free datasets pre-processed by the original studies. Future research could enhance this framework by incorporating contrastive modules to create an end-to-end solution. Another potential enhancement involves using single-cell foundation models64,65,66,67,68 to replace River’s gene expression encoder, known for their robustness against batch effects. In cases where different slices and conditions originate from various spatial platforms and resolutions, employing recently proposed rasterization techniques69,70 could be beneficial. This would allow the direct comparison of data from different resolutions within the same spatial framework and make the analysis scalable to very large-scale datasets. Another important concern that may arise is that River outcome may be influenced by the external alignment algorithm, but luckily, most situations where River is applied do not have such an issue and River can be incorporated with advanced alignment methods seamlessly, and the performance can be improved by better methods. Moreover, most cases when alignment fails occur when the input slices have substantial batch effect, which is still a challenging open problem in the current single cell spatial omics domain.
Methods
Overview of River
River can be considered as a combination of two main functional modules. The first module is the prediction model, which utilizes spatial omics (transcriptomics/proteomics and other modalities; for simplicity, we refer to the input feature as gene expression in the following content) features and spatial location (represented by spatial coordinates) for each single cell as input. This module is made up of a Multi-Layer Perceptron (MLP) due to its representative capability. The training target of the model is predicting the condition label for each input cell, defined by the corresponding original slice-level condition label for each cell. River requires users to provide spatial omics data (which can be transcriptomics, proteomics, etc.) including each cell’s feature values and spatial coordinates, along with labels (e.g., phenotypes or conditions of interest). As a result, River cannot perform unsupervised gene panel selection. Specifically, River needs multiple distinct biological conditions for comparison and is not suitable for cases involving only a single condition or merely technical replicates within a single condition.
After training the prediction model, River applies multiple attribution methods to determine the genes contributing to the model’s prediction behavior for the corresponding label in each input cell. After cell-level normalization, River provides multiple cell-wise gene scores to measure the relevance of each cell to its corresponding label in different aspects. River then combines the multiple cell-wise gene score to obtain a global summary statistic for each gene in the input cell population, resulting in a final rank for the input gene list for each attribution method. Finally, River adopts rank aggregation methods to combine the different ranks obtained by various attribution methods to produce a final gene rank.
Alignment for multiple input slices
River requires spatial location coordinates as the predictive model input. When handling input slices from different spatial coordinate systems where the spatial locations have not been previously registered, any methods for heterogeneous spatial alignment can be applied. We chose the Spatial-Linked Alignment Tool (SLAT)71 for its flexibility and scalability, and this can be replaced with others with minimal adjustments.
For experiments with more than two slices, one slice is designated as the base slice, and SLAT alignment is then conducted for each of the remaining slices relative to this base slice. The outcome of the SLAT algorithm is a matching list, which identifies the corresponding cells of the remaining slices concerning the base slice. Regarding the SLAT parameters, we utilized the default settings recommended in official tutorial. This matching list enables the projection of the remaining slices’ coordinates into the same spatial coordinate system as the base slice. Formally, given the input slice K with nk cell/spots, and the corresponding spatial coordinate matrix Ck, we choose slice 0 as the base slice. Thus, we will have the matching list obtained from SLAT for the remaining slice mk, and we have the new aligned coordinates for each input slice k as the input for River:
Input data preprocess
Before using River, spatial omics data should undergo proper preprocessing to meet River’s input requirements and ensure training stability. For raw-count spatial transcriptomics datasets, we recommend applying scanpy.pp.normalize_total and scanpy.pp.log1p to each cell, thereby generating normalized gene expression inputs and enhancing River’s training stability.
For spatial proteomics data (e.g., CODEX), which is typically normalized during data generation, we do not apply specific preprocessing here. However, if users encounter raw spatial proteomics data, we recommend L2 normalization. When multiple samples or replicates per condition exist, we treat them equally by assigning the same group label and including all cells as River inputs.
In multi-replicate alignment—also applicable to temporal or 3D experiments—we randomly select one slice as the reference and align all remaining slices to the same coordinate system. For the consensus label condition, each condition is treated as a discrete category. Specifically, each time point or depth is encoded by its original order and then used as a discrete group label.
Prediction model architecture
Given the multi-slice annotated dataset, the input of River prediction model is composed of gene expression vector \({{{{\bf{x}}}}}_{{{{\bf{i}}}}}\) with dimension m (input feature (e.g., gene/panel) number) for each cell and the corresponding label \({{{{\bf{y}}}}}_{{{{\bf{i}}}}}\) as a one-hot vector with dimension n (slice label number) for the cell of its belonging slice label, the aligned coordinates \({{{{\bf{c}}}}}_{{{{\bf{i}}}}}^{{{{\bf{new}}}}}\) with dimension 2. The prediction model encoder is composed of two parts: the gene expression encoder, which extracts the feature from \({{{{\bf{x}}}}}_{{{{\bf{i}}}}}\), and the position encoder, which extracts the spatial information from \({{{{\bf{c}}}}}_{{{{\bf{i}}}}}^{{{{\bf{new}}}}}\). Furthermore, considering substantial batch effect input condition, we also provide additional learnable batch removal function: Add additional one-hot batch indictor variable \({{{{\bf{b}}}}}_{{{{\bf{i}}}}}\) with dimension b (input batch number) (Optionally) with input gene expression \({{{{\bf{x}}}}}_{{{{\bf{i}}}}}\) :
We utilize two MLPs as the position encoder \({{{{\rm{f}}}}}_{{{{\rm{pos}}}}}\) and expression encoder \({{{{\rm{f}}}}}_{\exp }\) separately. River adopts the double-branch architecture to encode the position information and the expression information separately and then combines them in the latent space to obtain the spatial-aware gene expression latent. We have the position latent vector \({{{{\bf{z}}}}}_{{{{\bf{i}}}}}^{{{{\bf{pos}}}}}\) with dimension k (position/expression encoder hidden dimension):
And the gene expression latent vector \({{{{\bf{z}}}}}_{{{{\bf{i}}}}}^{{{{\bf{exp }}}}}\) with dimension k (position/expression encoder hidden dimension):
River then concatenates the two latent vectors to get the spatial-aware gene expression latent vector \({{{{\bf{z}}}}}_{{{{\bf{i}}}}}\) with dimension 2*k (position/expression encoder hidden dimension) for the input cell:
This latent vector is then sent into a following MLP classifier to get prediction logits \({{{{\bf{y}}}}}_{{{{\bf{i}}}}}^{{{{\bf{pred}}}}}\):
And the model is trained using the cross-entropy objective \({{{{\bf{L}}}}}_{{{{\bf{ce}}}}}\) with the provided cell-level label \({{{{\bf{y}}}}}_{{{{\bf{i}}}}}\):
Attribution methods
As aforementioned in River framework composition, apart from the prediction model part, another important component of River is the attribution module. River’s ability to identify DSEP genes is based on the assumption that only genes with significant spatial expression pattern shifts across multiple slices can contribute to the prediction model’s ability to classify different slices. Thus, the attribution module aims to select the genes that contribute the most to the model’s decision process. In other words, River ranks each gene using the aggregation of multiply post-hoc attribution methods’ outcome based on each gene’s spatial expression pattern.
River uses multiple attribution methods to enhance its robustness, especially in corner cases. By combining various mechanisms in an ensemble fashion, River mitigates the risk of relying on a single method’s assumptions and achieves a more stable, reliable outcome. This principle is well-established in machine learning, as seen in ensemble learning and Mixture of Experts (MoE)72 approaches.
In the context of deep learning model attribution, methods generally fall into two categories: gradient-based and non-gradient-based. Non-gradient methods like SHAP73 rely on permutation tests and other model-agnostic techniques to estimate the importance of input features based on Shapley Value concept in game theory; however, these approaches can be inefficient for larger models with substantial training and inference times. Therefore, River adopts gradient-based attribution methods for greater efficiency and scalability.
River employs three state-of-the-art gradient-based attribution methods: Integrated Gradients74, DeepLift75, and GradientShap73. River applies these three attribution methods to attribute the model’s prediction logits on ground-truth class \({s}_{i}({x}_{i})\) back to the input features \({{{{\bf{x}}}}}_{{{{\bf{i}}}}}\), yielding a weight vector \({{{{\bf{w}}}}}_{{{{\bf{i}}}}}^{{{{\bf{method}}}}}\) with dimension m (input feature (e.g., gene/panel) number) for each gene in each input cell that signifies the importance of each input gene.
One of the simplest attribution methods for deep learning is the Gradient * Input technique, initially proposed to enhance the clarity of attribution maps75. This method calculates attribution by partial derivatives of the output corresponds to the input and then multiplying these derivatives by the input. However, Gradient * Input is insufficient for handling complex scenarios. Therefore, we utilize three tailored attribution methods from modern deep learning to address these complexities.
For Integrated Gradient, we utilize \(\bar{{{{\bf{x}}}}}\) represents the baseline input. we chose all zero gene expression input vector as the baseline in all the following methods, in cell i we have
Integrated Gradient similarly to Gradient * Input, computes the partial derivatives of the output with respect to each input feature. However, while Gradient * Input computes a single derivative, Integrated Gradients computes the average gradient while the input varies along a linear path from a baseline \(\bar{{{{\bf{x}}}}}\) to \({{{{\bf{x}}}}}_{{{{\bf{i}}}}}\).
As for GradientShap, it approximates SHAP values by computing the expectations of gradients by randomly sampling gradients since the exact SHAP value calculation is too expensive and cannot scale to large-scale cell datasets. In River, we apply the GradientShap method by adding white noise to each input gene expression n (n = 5 in River default parameters) times,
And then construct a random point \({q}_{i}\) along the path between the baseline and the noisy input with scale parameter \(\lambda\):
Then we compute the gradient of outputs with respect to those selected random points and get the final attribution score \({{{{\bf{w}}}}}_{{{{\bf{i}}}}}^{{{{\bf{GS}}}}}\):
DeepLIFT is an attribution recursive prediction explanation method for neural networks that proceeds in a backward fashion. The importance for DeepLIFT is based on propagating activation differences on each neural unit in the neural network. Thus, compared with the previous two methods, DeepLIFT is proposed only for neural network attribution. For the sake of convenience, we utilize the modified chain rule notation introduced in Given two neural units (\(a\), \(b\)) in the multi-layer perceptron, there must exist a path set \(P\) from \(a\) to \(b\) in the neural network due to the fully-connected property of the MLP. We can define a modified chain rule based on this path set \({P}_{{ab}}\):
Where \({{{\bf{z}}}}\) indicates the linear transformation for each neural unit. For the neural input unit \(j\) and the output unit \(i\), we have the output \({{{{\bf{z}}}}}_{{{{\bf{j}}}}}\):
And g can be any other nonlinear transformation function. When g is the original non-linear activation function in the model, this modified chain rule will be equal to the partial differential.
With this notation, given the baseline and input gene expression, we have \({{{{\bf{w}}}}}_{{{{\bf{i}}}}}^{{{{\bf{DL}}}}}\):
Where
And f is the prediction model’s original activation function, (ReLU76 in our default setting), and \(\bar{{{{\bf{z}}}}}\) indicates the baseline corresponding \({{{\bf{z}}}}\).
After multiple attributions, we can have the cell-level attribution score vector for each method. River normalizes them per cell-wise. The motivation here is to follow per-cell gene expression normalization preprocess, which can normalize different cells’ score on the same scale while maintaining heterogeneity. River normalizes each cell’s absolute weight vector using L2 normalization:
Then, River computes the global attribution vector for each method by averaging the normalized vectors:
Finally, River ranks the genes based on their global attribution scores to determine their relative importance:
River further tries to aggregate these three different methods ranks into one final rank.
Rank aggregation for multiple-attribution
Given the global weight vector for each gene derived from three state-of-the-art attribution methods (Integrated Gradient, DeepLIFT, and GradientShap), River aims to aggregate the attribution results for each method to obtain robust and stable attribution results since the three attributions indicate three different attribution perspectives (average gradient, estimated SHAP value, and neural unit activation). Here, each method provides a rank of genes based on their contribution to the prediction model’s predictions. To aggregate these rankings into a final comprehensive ranking, we employ the Borda count method77.
The procedure for applying the Borda count method to our context is as follows: for each attribution method, assign a score to each gene based on its rank. If a gene is ranked first, it receives a score equal to the total number of genes N; the second-ranked gene receives N − 1, and so on, with the lowest-ranked gene receiving a score of 1. We then aggregate the scores for each gene across all attribution methods:
where \({{{{\rm{Score}}}}}_{{{{\rm{method}}}}\left({{{\rm{g}}}}\right)}\) is the score assigned to gene g by the ranking from a particular method. Finally, the final rank of the genes can be obtained based on aggregated Borda scores:
This Borda count aggregation method ensures that the final ranking reflects a balanced consensus across the different attribution methods, taking into account the unique perspectives each method offers on gene importance.
Outcome gene set selection
Compared with hypothesis test-based methods, River cannot generate significance p-values but instead will provide priority rank for each gene and users can choose gene set based on top-k ranks. Additionally, if users attempt to select priority gene set automatically, we implement the Elbow point method to the sorted and smoothed River score curve (which can be either IG score or other scores from River’s output), which can choose a k cutoff threshold automatically based on the gradient of the score curve.
Simulation dataset
Data generation
To generate the simulated dataset, we first created a control slice consisting of a square region with four distinct spatial domains using SRTsim78: domain A, domain B, domain C, and domain D. The gene expression in this slice was simulated using the SRTsim reference-free simulation procedure. Specifically, the simulated slice was composed of 980 randomly placed cells in a square shape. We initially divided the slice into domains A, B, C, and D with square shapes. SRTsim generated gene expression counts for 1100 genes by sampling from a ZINB distribution with the following parameters: zero percentage 0.05, dispersion 0.5, and mean value 2, and then randomly assigned them to 980 generated spatial locations in the square slice.
Furthermore, to mimic the true distribution on a real slice, SRTsim was applied to generate domain-specific differential genes for each given domain. After this procedure, the 1100 genes were split into three groups: higher signal genes (100 genes), lower signal genes (100 genes), and background genes (900 genes). Higher signal genes showed higher fold-changes in each domain with the domain-specific fold-change ratios (1.0 for domain A, 2.0 for domain B, 1.5 for domain C, and 3.0 for domain D). Meanwhile, the lower signal genes exhibited lower fold-changes in each domain with the same predefined domain-specific fold-change ratios. Finally, background genes maintained the same expression pattern as the original generation distribution.
We regarded this simulated slice as the control slice for our subsequent condition-perturbed slice generation. Here, we aimed to perturb the background genes to generate differential spatial expression patterns across the condition and control slices. The reason for not utilizing the signal genes was that the Spatially Variable Gene (SVG) property on the original slice would influence the perturbation efficiency. The signal genes acted as distractors to improve the benchmarking difficulty, as we did not modify the signal genes across the condition and control slices.
More specifically, instead of designating all non-spatial genes as positive, a selected subset is used, while the negative class includes both non-spatial and spatial genes. This design increases task complexity, making it more realistic by introducing spatial genes as distractors. If spatial genes were set as positive, the method would simply identify spatially variable genes (SVGs), reducing the challenge to a basic comparison between spatial and non-spatial genes. By selecting a subset of non-spatial genes as positive, the task shifts to identifying spatially perturbed genes across conditions, aligning more closely with real-world scenarios. The goal is not to differentiate between spatial and non-spatial genes but to assess the method’s ability to detect genes with differential spatial expression patterns.
For the perturbation process, we first randomly chose 200 target genes from the background genes for each perturbation. The perturbation process consisted of two main parts. The first part involved the random permutation of the spatial locations for the chosen target gene expression values for each cell. For each pair of spatial location and target gene expression in each cell, we randomly permuted the corresponding relation. Each cell was assigned a new target gene expression value that originally belonged to another cell in the slice. This procedure ensured that only the spatial pattern of the chosen target genes was influenced, while the expression levels of other genes remained unchanged. In the second step, we altered the fold-change ratio for the chosen target genes only in specifically chosen domains by applying a twofold change on the permuted slice. We obtained the final version of the condition slice after this step. The two perturbation steps ensured that the spatial gene expression pattern of the chosen target genes in the condition slice differed from the control slice in both spatial distribution and gene expression value.
We generated our benchmarking dataset using two target gene sets and three chosen domains (domain B, domain C, domain D), resulting in a total of six simulated benchmarking datasets.
Implementation details of River
We introduce the implementation details of River for benchmark experiments and subsequent real data experiments.
For the benchmark dataset, because the condition slice is simulated based on the control slice, their spatial coordinates are located in the same space. Thus, pre-alignment of the two input slices is not needed. The prediction model part of River comprises a gene expression encoder, a position encoder, and the final classifier, forming three main parts. All of them are two-layer MLPs with the ReLU function as the activation function. The two encoders have the same hidden dimension of 64, while the classifier has a hidden dimension of 32. Dropout regularization is added during model training to avoid overfitting, with a dropout ratio of 0.3. For model training, the Adam optimizer is utilized with a commonly-used learning rate of 0.001 and a weight decay rate of 0.0001. The model is trained for 100 epochs, and the last epoch model is used as the attributed model. The batch size is set to 4096 to ensure efficiency and fast convergence. For the attribution part, the captum package is adopted to implement the three attribution methods, utilizing the default parameters of the official package to obtain stable attribution results. River selects the top-200 ranked genes, corresponding to the predefined target gene number in the benchmark experiment.
For other real data experiments requiring pre-alignment, SLAT is utilized as the pre-alignment tool. For spatial transcriptomics data, the PCA value of the gene expression is used as the input for SLAT, and the raw profiled expression value of the spatial proteomics is used as input due to its relatively lower dimension (<100). After choosing a base slice for each experiment, every slice is subsampled to the same cell number as the base slice to ensure each cell has a corresponding aligned coordinate in the base slice. The neighborhood graph is then constructed using the K-nearest cells (K = 20), and the preprocessed data is sent into SLAT to get the aligned coordinates for non-base slices. Apart from the alignment procedure, real data experiments use the same model parameters as mentioned in the benchmark dataset section.
Competing methods
In this study, we compared three main categories of methods to identify the differential spatial expression patterns between condition and control slices in six different simulation benchmark datasets.
The first category of methods includes the previously highly variable genes (HVGs) selection methods. We adopted the most commonly used HVGs selection methods - Seurat, Seurat v3, and CellRanger as the baseline methods. In each experiment, given the condition and control slice gene expression as input, we defined the selected gene number as 200 (equal to the target gene number). The implementation of these three methods utilized the scanpy24 package with the default parameters.
The second category includes the conventional Spatially Variable Genes (SVGs) selection methods. However, as mentioned previously, these SVGs methods cannot handle multi-slice input. Therefore, modifications were made to these methods to enable them to perform the same task. For the significance-based methods, due to the difficulty in comparing the output significant statistics among slices, we utilized the absolute difference value (to ensure non-negative input) of the same position cells in two slices as the input for the following test-based SVGs methods. The motivation here is that the spatial variance of the difference value can reflect the spatial expression pattern to an extent. We utilized four commonly used methods: SPARKX, SpatialDE, Moran’s I, and Geary’s C as the test-based SVGs method baseline. Default parameters were utilized for both methods, and significant genes (p-value < 0.05) were regarded as detected positive genes, with the remaining as negative.
Apart from the test-based SVGs methods, there is another type of SVGs method: score-based SVGs detection. This method provides a score for each gene as output, indicating the spatially related situation for each gene, making comparison between slices possible. Here, we utilized Sepal as the baseline method in the score-based SVGs methods. The original code in the Sepal package was used. Transformation was applied to convert our input slice into spot-level data like Visium, since Sepal only accepts such format input. The official transformation function provided in Sepal was used to convert the slice into a spot-like arrangement, and Sepal was then applied to the two control and condition slices independently. The output scores were normalized into the range [0,1], making the scores among the two slices comparable. The absolute difference value for each gene was then calculated, and the spatial pattern change was ranked by this absolute difference score, with a higher value indicating a larger difference. As with the previous HVGs methods, a selected gene number k was set to select the top-k highest score genes, using k = 200 as with HVG methods.
The final category comparison method is the 3D SVGs identification methods. These methods aim to find the genes which show significant spatial expression patterns considering 3-dimensional spatial information. We utilized the recently proposed BSP as our 3D SVGs baseline. The control and condition slices were stacked to obtain a pseudo-3D slice dataset, setting the z-coordinate for all control slices as 0 and condition slices as 1. The official version of BSP was then applied to this pseudo-3D input slice with its predefined 3D format. The output of BSP is also the significant statistics. Thus, significant genes (p-value < 0.05) were regarded as positive genes, with the remaining as negative genes.
Furthermore, we also include comparison methods utilized in traditional differential expression analysis for single-cell transcriptomics data, as well as differential expression methods that consider spatial variation in samples. Specifically, we use the commonly-utilized MAST79, EdgeR80, muscat81, rank-sum test, and the newly proposed SpatialDiff82 as baselines. We apply condition/control labels for each slice as the group condition and treat each slice as an individual sample. Because our benchmark only contains two slices in each experiment (i.e., one replicate for each group condition), for methods requiring replicates (MAST, EdgeR, rank-sum test, muscat), we manually duplicate each slice twice to enable their operation. Since all these methods rely on hypothesis tests to acquire p-values for significant gene set selection, we cannot adopt the top-k selection approach. Thus, we use an adjusted p-value threshold of 0.05 to select gene sets (i.e., p-values below 0.05).
Moreover, to provide a more comprehensive comparison, we also evaluate PERSIST45, a recently proposed deep-learning-based method for gene selection in single-cell transcriptomics. PERSIST follows a pipeline similar to River by selecting input gene features based on a fitted deep learning model. However, since PERSIST does not incorporate spatial modeling, it differs significantly from River. Here, we use PERSIST’s default parameters for supervised gene selection with condition/control labels for the input slices, and we apply the same k value used in other top-k methods for selecting gene sets. Additionally, we conduct an ablation study within our baseline comparison to verify the necessity of spatial information input. Specifically, we force all input coordinates for each location to be the same (0, 0) and run River pipeline without further modifications (River no spatial version).
Evaluation metrics
We utilized the F1-score as the metric to measure each model’s performance in identifying Differential Spatial Expression Pattern (DSEP) genes. The reason for not adopting recall and precision as additional metrics is that, for the k selected methods (e.g., River, Sepal, and HVGs methods), the F1-scores are the same as recall and precision. Regarding the perturbed target genes as the positively labeled genes and the method selecting positive genes, we have the F1-score:
Furthermore, to evaluate the robustness of the k selected methods, the performance among k selected methods is compared by the F1 score on different k values.
Analysis of the Stereo-seq mouse embryo dataset on batch-related genes
Dataset overview
We utilized the Stereo-seq mouse embryo multi-slice dataset, which is composed of eight different development stages at near single-cell resolution. Each development stage consists of different depth 3D slices from the same replicates. We utilized the E15.5 development stage as the input multi-slice dataset for River. This developmental time point slice is composed of four continuous depth slices along the z-axis, similar to the E16.5 development stage. We used the depth for each slice as the slice-level label and selected the slice with the lowest depth as the base slice, with 10,000 subsampled cells for each slice for alignment. River then applied fitting and selection on the input depth-informed cells dataset.
Slice integration and evaluation
In the visualization of the River-selected top-ranked genes, we observed that the top-ranked genes are highly related to the depth for input cells. In other words, it is possible to integrate the input cells from different batches to the same depth by using such depth information-preserved genes as input features. We used only the River selected top-20 genes as input to conduct the integration across two development stages (E15.5 and E16.5). It is worth noting that River did not see any E16.5 cells during training. Therefore, this integration not only supports that depth information-preserved genes can help integrate cells at the same depth but also provides evidence of the River-selected genes’ generalization. We utilized Harmony as our integration method due to its efficiency and accuracy and then evaluated the integration results using the scib package. This package first conducts a fine-grained search for the best clustering resolution of Leiden clustering and then utilizes the best cluster outcome to evaluate both biological-preserved metrics (Normalized Mutual Information (NMI), Adjusted Rand Index (ARI)) and batch-removal metrics (Graph Connectivity (GC), Integration LISI (iLISI) graph score). Specifically, we utilized depth as the biological information variable and the different development stages (E15.5, E16.5) as the batch variable.
NMI compares the overlap of two clustering:
Where \(P\) and \(T\) are categorical distributions for the predicted and real clustering, \(I\) is the mutual entropy, and \(H\) is the Shannon entropy.
As for ARI, it considers both correct clustering overlaps while also counting correct disagreements between two clustering:
Where Rand Index (RI) computes a similarity score between two clustering assignments by considering matched and unmatched assignment pairs. Both of them evaluate whether the integrated embedding can capture biological information properly.
As for the batch-removal metrics, iLISI and cLISI are adopted from the Local Inverse Simpson’s Index (LISI) for the batch-related and biological preservation metrics. Here, we utilize the iLISI modified version in scib.
LISI scores are computed from neighborhood lists per node from integrated kNN graphs. Specifically, the inverse Simpson’s index is used to determine the number of cells that can be drawn from a neighbor list before one batch is observed twice. Thus, LISI scores range from 1 to B, where B is the total number of batches in the dataset, indicating perfect separation and perfect mixing, respectively, and scib rescales them to the range of 0 to 1. Given the total batch label-based LISI score set X, we have:
Where x indicates the previous LISI score for each batch label, we have
With higher iLISI indicating a better batch mix situation.
For cLISI, we need to modify the \(f(x)\) into \(g(x)\):
Where B here indicates the total cell type number and x indicates the LISI score for each cell type, and X is the total cell type-based LISI score set. We have:
The GC metric quantifies the connectivity of the subgraph per cell type label. The final score is the average for all cell type labels C according to the equation:
Where \(\left|{LCC}\left({subgrap}{h}_{c}\right)\right|\) stands for all cells in the largest connected component in the dataset, and \(\left|c\right|\) stands for all cell numbers of cell type c.
These metrics examine the integrated embedding’s batch information mixture situation. Higher values indicate better batch removal performance.
We compared River selected genes with commonly utilized Highly Variable Genes (HVG) baseline, we here utilize 2000 as selected gene number. For negative control, we propose to utilize the bottom genes selected by River as baseline to conduct evaluation. Nevertheless, most of River selected bottom genes tend to be sparsely expressed genes in the dataset.
To make the negative control more biologically meaningful, we created two advanced negative controls instead of relying solely on the bottom genes identified by River. We first calculated each slice’s SVGs based on Moran I scores and DE genes (with DE genes derived from a rank-sum test comparing each slice to all other slices), then selected the overlap between these two sets and River’s bottom-3000 genes separately to generate two version bottom gene sets: DE bottom and SVG bottom. This ensures that the negative control gene set retains a meaningful biological signal. We also add an external independent housekeeping sets to do further negative control test (see Supplementary Fig. 8)
Analysis of the Stereo-seq mouse embryo dataset on development-related genes
Dataset overview
We utilized the Stereo-seq mouse embryo multi-slice dataset, which is composed of eight different development stages at near single-cell resolution. Each development stage is composed of different depth 3D slices on the same replicates. We utilized the eight development stages at the same depth as the input multi-slice dataset for River. The input multi-slice dataset is composed of [E9.5, E10.5, E11.5, E12.5, E13.5, E14.5, E15.5, E16.5] eight slices in the first layer for each time point 3D slice. We used the time point for each slice as the slice level label and selected the slice with the E9.5 as the base slice with 5000 subsampled cells for each slice for alignment. River then applied fitting and selection on the input development-informed cells dataset.
Pairwise silhouette score
To measure whether distance biological information preserves the condition in different input gene panel situations, i.e., whether the cell’s distance in the development timeline can be reflected in the latent space distance acquired from different input genes, we calculated the silhouette score pairwise for each cell pair of development stages.
Given any two development stage \(p\) and \(q\) pair, we have pairwise silhouette score \(S(p,q)\):
Where \(\left|p\right|\) indicates the cell number in p development stage and \({d}_{p}\left(i\right)\) denotes the mean L1 distance of cell i to all cell in distance p of input gene expression:
A smaller silhouette score indicates a shorter distance between two groups of cells in the gene expression space. After calculating the silhouette score for each development pair combination, hierarchical clustering can be conducted on the silhouette score vector for each development stage to determine the similarity situation for the development stage in the gene expression space.
Embedding evaluation based clustering
To quantitatively evaluate the latent space embeddings, we used the scib38 pipeline to perform Leiden clustering with an optimal resolution search for each input gene set. The resolution parameter ranged from 0.0 to 1.0 in increments of 0.1. We then compared each gene set’s embedding based on the best NMI, ARI, and Cell-type LISI (cLISI) scores found during the search. Higher NMI and ARI values indicate better preservation of developmental stage information and lower noise, and we applied the same baseline comparisons used in the previous 3D Stereo-seq analysis, namely the 2000 HVGs and the overlap of per-slice DEGs and SVGs with the 3000 bottom-ranked genes selected by River.
Binarize spatial gene expression
To evaluate River’s capability to identify pure spatial pattern shift genes across slices, we binarized the input gene expression data when fitting the prediction model (after the pre-alignment process). Specifically, for all input gene expressions, values >0 were transformed into 1, while 0 values remained unchanged. This binarization process removes the influence of gene expression values and preserves only the spatial expression patterns, which we refer to as the pure spatial pattern. Apart from this binarization process, other parameters and settings remained the same as in the normal format.
After identifying the top-k binarized pure spatial pattern shift genes, we compared them with the previous top-k expression value-informed selected genes. We then selected the genes found only in the pure spatial pattern shift list as the unique pure spatial pattern shift genes for downstream analysis.
While binarizing gene expression (i.e., distinguishing “on/off” states) can reduce technical batch effects originating from expression magnitude differences (e.g., sequencing depth, mRNA capture efficiency), our analysis reveals critical scenarios where this approach is safe versus unsafe:
For cases where binarization is safe: When comparing datasets generated using identical spatial platforms (e.g., two Stereo-seq experiments). Binarization mitigates batch effects caused by differences in library size or global scaling (count-depth variation). Cases where binarization is unsafe: When integrating datasets from different platforms (e.g., MERFISH vs. Visium), binarization fails to resolve systematic differences in gene detection thresholds (sensitivity/specificity) inherent to the technologies. Nevertheless, for dropout ratio, in image-based platforms (MERFISH, STARmap), the capture ratio is high, and comparing slices across image-based techniques will not show significant dropout ratio differences, allowing relatively safe application of binarization. However, when comparing slices from image-based methods with sequencing-based methods (Visium), binarization should be applied carefully. Furthermore, if you are comparing slices from the same protocol, you can apply the binarization process directly. The influence can also be gene property dependent, for example: genes with robust expression (median ≥10 counts, high detection rate) are minimally affected by zero-inflation artifacts, as their “on” state (nonzero vs. zero) is reliably captured even across batches, and it will be relatively safe to binarize them. Meanwhile, genes expressed near the detection limit (median <5 counts) risk false zeros due to stochastic technical dropout.
Nevertheless, we need to clarify here that removing batch effects across spatial omics slices is still a challenging open problem in the current research community; most current methods can only resolve cross-dataset integration within platforms or only across platforms without substantial batch effects (such as CAST73), and River is one of the pioneering works trying to address and propose feasible solution.
Gene set enrichment analysis
We conducted gene set enrichment analysis for the top-50 unique pure spatial pattern shift genes using the Enrichr API in the gseapy Python package, with GO Biological Process 2023 as the reference gene set. The cutoff for significantly enriched gene sets was an FDR-adjusted p-value of <0.05.
Analysis of diabetes-induced and WT mouse testis
Dataset Overview
We applied River to disease-related spatial transcriptomics multi-slice datasets to demonstrate the application diversity of River. The dataset is composed of six Slide-seq slices from three leptin-deficient diabetic mice (Diabetes) and three matching wild-type (WT) mice. The WT−1 sample was selected as the base slice, and each slice was subsampled into 10,000 cells for alignment. The Diabetes and WT phenotypes for each slice were used as the corresponding slice labels.
Gene set enrichment analysis
We conducted gene set enrichment analysis for the top-50 DSEP genes using the Enrichr API in the gseapy Python package, with KEGG, Jensen TISSUES, and Elsevier Pathway Collection as reference gene sets. The cutoff for significantly enriched gene sets was an FDR-adjusted p-value of <0.05.
Analysis of MIBI and CODEX disease-related spatial proteomics data
Dataset Overview
We applied River on two disease-related spatial proteomics multi-slice datasets to show the modality-agnostic property of River and its further potential in clinical applications. The first disease spatial proteomics dataset is the human Triple Negative Breast Cancer (TNBC) MIBI dataset. The dataset is composed of 41 slices with three different TNBC subtypes featured by the immune cell infiltration condition: 15 Mixed (high immune infiltration) slices, 19 Compartmentalized (distinct tumor and immune cell regions) slices, and 5 Cold (low immune cell presence) slices. We randomly chose one slice from each subtype as the fitting multi-slice dataset for River and the remaining 38 slices as the hold-out slices. The chosen Mixed slice was regarded as the base slice, and every slice was subsampled into 2000 cells to conduct alignment. The second spatial proteomics multi-slice dataset is composed of nine CODEX mouse lupus spleen samples (3 WT and 6 lupus mouse samples). We selected one slice in each condition randomly and preserved the remaining 6 slices as the hold-out slices. The WT slice was regarded as the base slice and subsampled into 20,000 cells in each slice for alignment.
To further assess River’s performance, we conducted an experiment using the Colorectal Cancer (CRC) CODEX dataset with a larger sample size83. This dataset consists of CODEX data from 17 patients with CLR and 18 with DII, totaling 140 tissue regions across 35 patients, with four slices per patient analyzed using 56 biomarkers. For training, we assigned subtype labels at the patient level and randomly selected 20 samples per condition, subsampling each slice into 2000 cells to ensure alignment in River training.
Panel generalization evaluation
In the disease-related proteomics multi-slice dataset, to evaluate the River-selected panel generalization and clinic application potential, it is assumed that the River selected top panel can be utilized in the unseen slice phenotype identification. The mean value of the selected panel expression on the slice is utilized as the input feature, and the predictive power of the panel feature is evaluated by conducting 5-fold cross-validation on hold-out slices in the original dataset with different baseline classifiers. We utilized the default parameters for three commonly used models (Support Vector Classifier (SVC), Logistic Regression (LR), and Random Forest (RF)) as classifiers. The 5-fold accuracy is compared for different panel selected situations (different top-k [2, 4, 6, 8, 10]) of River selected panel, randomly selected panel, and full panel.
Computational resources
All experiments were performed on a server running Ubuntu 22.04 with a 32-core Intel(R) Xeon(R) Gold 6338 CPU @ 2.00 GHz and an Nvidia A800 (80 G) GPU.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The Stereo-seq mouse embryo development dataset used in this study is available from the CNGB database under accession code CNP0001543. The Slide-seq mouse diabetes dataset can be downloaded from Dropbox (https://www.dropbox.com/s/ygzpj0d0oh67br0/Testis_Slideseq_Data.zip?dl=0). The CODEX mouse lupus dataset is accessible via Mendeley Data (https://data.mendeley.com/datasets/zjnpwh8m5b/1). The MIBI human TNBC dataset is available from MIBI Share under restricted access due to patient privacy considerations; access can be requested through the platform (https://mibi-share.ionpath.com). The MERSCOPE mouse brain dataset is publicly available at Vizgen (https://vizgen.com/resources/using-merscope-to-generate-a-cell-atlas-of-the-mouse-brain-that-includes-lowly-expressed-genes/). The simulation benchmark dataset generated in this study is available in the River GitHub repository (https://github.com/C0nc/River).
Code availability
The Python implementation and tutorial of River is available at https://github.com/C0nc/River.
References
Zormpas, E., Queen, R., Comber, A. & Cockell, S. J. Mapping the transcriptome: realizing the full potential of spatial data analysis. Cell 186, 5677−5689 (2023).
Bressan, D., Battistoni, G. & Hannon, G. J. The dawn of spatial omics. Science 381, eabq4964 (2023).
Xu, J. et al. A spatiotemporal atlas of mouse liver homeostasis and regeneration. Nat. Genet. 56, 953−969 (2024).
Wu, B. et al. A spatiotemporal atlas of cholestatic injury and repair in mice. Nat. Genet. 56, 938–952 (2024).
Lucas, C. G. et al. Spatial genomic, biochemical and cellular mechanisms underlying meningioma heterogeneity and evolution. Nat. Genet. 56, 1121−1133 (2024).
Chen, X. et al. Whole-cortex in situ sequencing reveals input-dependent area identity. Nature https://doi.org/10.1038/s41586-024-07221-6 (2024).
Greenwald, A. C. et al. Integrative spatial analysis reveals a multi-layered organization of glioblastoma. Cell 187, 2485–2501 e2426 (2024).
Yuan, X. et al. HEARTSVG: a fast and accurate method for identifying spatially variable genes in large-scale spatial transcriptomics. Nat. Commun. 15, 5700 (2024).
Chen, C., Kim, H. J. & Yang, P. Evaluating spatially variable gene detection methods for spatial transcriptomics data. Genome. Biol. 25, 18 (2024).
Li, Z. et al. Benchmarking computational methods to identify spatially variable genes and peaks. bioRxiv 3, 2023.12.02.56971 (2023).
Wu, L. et al. An invasive zone in human liver cancer identified by Stereo-seq promotes hepatocyte-tumor cell crosstalk, local immunosuppression and tumor progression. Cell Res. 33, 585–603 (2023).
Sziraki, A. et al. A global view of aging and Alzheimer’s pathogenesis-associated cell population dynamics and molecular signatures in human and mouse brains. Nat. Genet. 55, 2104–2116 (2023).
Svensson, V., Teichmann, S. A. & Stegle, O. SpatialDE: identification of spatially variable genes. Nat. Methods 15, 343–346 (2018).
Edsgard, D., Johnsson, P. & Sandberg, R. Identification of spatial expression trends in single-cell gene expression data. Nat. Methods 15, 339–342 (2018).
Sun, S., Zhu, J. & Zhou, X. Statistical analysis of spatial expression patterns for spatially resolved transcriptomic studies. Nat. Methods 17, 193–200 (2020).
Zhu, J., Sun, S. & Zhou, X. SPARK-X: non-parametric modeling enables scalable and robust detection of spatial expression patterns for large spatial transcriptomic studies. Genome. Biol. 22, 184 (2021).
Li, Z., Wang, T., Liu, P. & Huang, Y. SpatialDM for rapid identification of spatially co-expressed ligand-receptor and revealing cell-cell communication patterns. Nat. Commun. 14, 3995 (2023).
Hao, M., Hua, K. & Zhang, X. SOMDE: A scalable method for identifying spatially variable genes with self-organizing map. Bioinformatics 37, 4392−4398 (2021).
Anderson, A. & Lundeberg, J. sepal: identifying transcript profiles with spatial patterns by diffusion-based modeling. Bioinformatics 37, 2644−2650 (2021).
Yu, S. & Li, W. V. spVC for the detection and interpretation of spatial gene expression variation. Genome. Biol. 25, 103 (2024).
Weber, L. M., Saha, A., Datta, A., Hansen, K. D. & Hicks, S. C. nnSVG for the scalable identification of spatially variable genes using nearest-neighbor Gaussian processes. Nat. Commun. 14, 4059 (2023).
Kats, I., Vento-Tormo, R. & Stegle, O. SpatialDE2: Fast and localized variance component analysis of spatial transcriptomics. bioRxiv https://doi.org/10.1101/2021.10.27.466045 (2021).
Zhang, K., Feng, W. & Wang, P. Identification of spatially variable genes with graph cuts. Nat. Commun. 13, 5488 (2022).
Wolf, F. A., Angerer, P. & Theis, F. J. SCANPY: large-scale single-cell gene expression data analysis. Genome Biol 19, 15 (2018).
Bunne, C. et al. Learning single-cell perturbation responses using neural optimal transport. Nat. Methods 20, 1759–1768 (2023).
Keren, L. et al. MIBI-TOF: A multiplexed imaging platform relates cellular phenotypes and tissue structure. Sci. Adv. https://doi.org/10.1126/sciadv.aax5851 (2019).
Goltsev, Y. et al. Deep profiling of mouse splenic architecture with CODEX multiplexed imaging. Cell 174, 968–981 e915 (2018).
Varrone, M., Tavernari, D., Santamaria-Martinez, A., Walsh, L. A. & Ciriello, G. CellCharter reveals spatial cell niches associated with tissue remodeling and cell plasticity. Nat. Genet. 56, 74–84 (2024).
Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Series B 58, 267–288 (1996).
Stuart, T. et al. Comprehensive integration of single-cell data. Cell 177, 1888−1902.e21 (2019).
Satija, R., Farrell, J. A., Gennert, D., Schier, A. F. & Regev, A. Spatial reconstruction of single-cell gene expression data. Nat. Biotechnol 33, 495–U206 (2015).
Palla, G. et al. Squidpy: a scalable framework for spatial omics analysis. Nat. Methods 19, 171–178 (2022).
Wang, J. et al. Dimension-agnostic and granularity-based spatially variable gene identification using BSP. Nat. Commun. 14, 7367 (2023).
Chen, A. et al. Spatiotemporal transcriptomic atlas of mouse organogenesis using DNA nanoball-patterned arrays. Cell 185, 1777−1792.e21 (2022).
Korsunsky, I. et al. Fast, sensitive and accurate integration of single-cell data with harmony. Nat. Methods 16, 1289–1296 (2019).
Luecken, M. D. et al. Benchmarking atlas-level data integration in single-cell genomics. Nat. Methods 19, 41–50 (2022).
Velten, B. & Stegle, O. Principles and challenges of modeling temporal and spatial omics data. Nat. Methods 20, 1462–1474 (2023).
Stamatoyannopoulos, G. Control of globin gene expression during development and erythroid differentiation. Exp. Hematol. 33, 259–271 (2005).
Dzierzak, E. & Philipsen, S. Erythropoiesis: development and differentiation. Cold Spring Harbor Perspect. Med. 3, a011601 (2013).
Chada, K., Magram, J. & Costantini, F. An embryonic pattern of expression of a human fetal globin gene in transgenic mice. Nature 319, 685–689 (1986).
Kobak, D. & Linderman, G. C. Initialization is critical for preserving global data structure in both t-SNE and UMAP. Nat. Biotechnol. 39, 156–157 (2021).
Maaten, L. V. D. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Qiu, P. Embracing the dropouts in single-cell RNA-seq analysis. Nat. Commun. 11, 1169 (2020).
Bouland, G. A., Mahfouz, A. & Reinders, M. J. T. Consequences and opportunities arising due to sparser single-cell RNA-seq datasets. Genome. Biol. 24, 86 (2023).
Covert, I. et al. Predictive and robust gene selection for spatial transcriptomics. Nat. Commun. 14, 2091 (2023).
Lin, S. et al. Complete spatially resolved gene expression is not necessary for identifying spatial domains. Cell Genom. 4, 100565 (2024).
Southgate, T. D. et al. CXCR4 mediated chemotaxis is regulated by 5T4 oncofetal glycoprotein in mouse embryonic cells. PLoS ONE 5, e9982 (2010).
Sadri, F., Rezaei, Z. & Fereidouni, M. The significance of the SDF-1/CXCR4 signaling pathway in the normal development. Mol. Biol. Rep. 49, 3307–3320 (2022).
Laurin, M. et al. An RNAi screen unravels the complexities of Rho GTPase networks in skin morphogenesis. Elife 8, e50226 (2019).
Reddy, S. et al. Characterization of Wnt gene expression in developing and postnatal hair follicles and identification of Wnt5a as a target of Sonic hedgehog in hair follicle morphogenesis. Mech. Dev. 107, 69–82 (2001).
Chen, H. et al. Dissecting mammalian spermatogenesis using spatial transcriptomics. Cell Rep. 37, 109915 (2021).
Bhat, G. K. et al. Influence of a leptin deficiency on testicular morphology, germ cell apoptosis, and expression levels of apoptosis‐related genes in the mouse. J. Androl. 27, 302–310 (2006).
Maresch, C. C. et al. Hyperglycemia induces spermatogenic disruption via major pathways of diabetes pathogenesis. Sci/ Rep. 9, 13074 (2019).
Keren, L. et al. A structured tumor-immune microenvironment in triple negative breast cancer revealed by multiplexed ion beam imaging. Cell 174, 1373 (2018).
Relle, M. & Schwarting, A. Role of MHC‐linked susceptibility genes in the pathogenesis of human and murine lupus. J. Immunol. Res. 2012, 584374 (2012).
Yi, P. et al. Overexpressed CD44 is associated with B-cell activation via the HA-CD44-AIM2 pathway in lupus B cells. Clin. Immunol. 255, 109710 (2023).
Suárez-Fueyo, A., Bradley, S. J. & Tsokos, G. C. T cells in systemic lupus erythematosus. Curr. Opin. Immunol. 43, 32–38 (2016).
Birk, S. et al. Large-scale characterization of cell niches in spatial atlases using bio-inspired graph learning. bioRxiv https://doi.org/10.1101/2024.02.21.581428 (2024).
Singhal, V. et al. BANKSY unifies cell typing and tissue domain segmentation for scalable spatial omics data analysis. Nat. Genet. 56, 431−441 (2024).
Yuan, Z. et al. Benchmarking spatial clustering methods with spatially resolved transcriptomics data. Nat. Methods 21, 712−722 (2024).
Dann, E., Henderson, N. C., Teichmann, S. A., Morgan, M. D. & Marioni, J. C. Differential abundance testing on single-cell data using k-nearest neighbor graphs. Nat. Biotechnol. 40, 245–253 (2021).
Burkhardt, D. B. et al. Quantifying the effect of experimental perturbations at single-cell resolution. Nat Biotechnol. 39, 619−629 (2021).
Litinetskaya, A. et al. Multimodal weakly supervised learning to identify disease-specific changes in single-cell atlases. bioRxiv https://doi.org/10.1101/2024.07.29.605625 (2024).
Theodoris, C. V. et al. Transfer learning enables predictions in network biology. Nature 618, 616–624 (2023).
Cui, H. et al. scGPT: toward building a foundation model for single-cell multi-omics using generative AI. Nat. Methods 21, 1470−1480 (2024).
Hao, M., Gong, J. & Zeng, X. et al. Large-scale foundation model on single-cell transcriptomics. Nat. Method 21, 1481–1491 (2024).
He, Y. et al. Towards a universal spatial molecular atlas of the mouse brain. bioRxiv https://doi.org/10.1101/2024.05.27.594872 (2024).
Schaar, A. C. et al. Nicheformer: a foundation model for single-cell and spatial omics. bioRxiv https://doi.org/10.1101/2024.04.15.589472 (2024).
Aihara, G. et al. SEraster: a rasterization preprocessing framework for scalable spatial omics data analysis. Bioinformatics 40, btae412 (2024).
Kover, B. & Vigilante, A. Rapid and memory-efficient analysis and quality control of large spatial transcriptomics datasets. bioRxiv https://doi.org/10.1101/2024.07.23.604776 (2024).
Xia, C. R., Cao, Z. J., Tu, X. M. & Gao, G. Spatial-linked alignment tool (SLAT) for aligning heterogenous slices. Nat Commun 14, 7236 (2023).
Cai, W. et al. A survey on mixture of experts in large language models. IEEE Trans. Knowl. Data Eng. (2025).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inform. Proc. Syst. 30, 4768−4777 (2017).
Sundararajan, M., Taly, A. & Yan, Q. Axiomatic Attribution for Deep Networks. In International Conference on Machine Learning. 3319−3328 (PMLR, 2017).
Shrikumar, A., Greenside, P. & Kundaje, A. Learning important features through propagating activation differences. In International conference on machine learning. 3145−3153 (PMlR, 2017).
Glorot, X., Bordes, A. & Bengio, Y. Deep sparse rectifier neural networks. In Proc. Fourteenth International Conference on Artificial Intelligence and Statistics, 315−323 (PMLR, 2011).
Ludwin, W. G. Strategic voting and the Borda method. Public Choice 33, 85–90 (1978).
Zhu, J., Shang, L. & Zhou, X. SRTsim: spatial pattern preserving simulations for spatially resolved transcriptomics. Genome. Biol. 24, 39 (2023).
Finak, G. et al. MAST: a flexible statistical framework for assessing transcriptional changes and characterizing heterogeneity in single-cell RNA sequencing data. Genome. Biol. 16, 1–13 (2015).
Robinson, M. D., McCarthy, D. J. & Smyth, G. K. edgeR: a bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 26, 139–140 (2010).
Crowell, H. L. et al. Muscat detects subpopulation-specific state transitions from multi-sample multi-condition single-cell transcriptomics data. Nat. Commun. 11, 6077 (2020).
Ospina, O. E. et al. Differential gene expression analysis of spatial transcriptomic experiments using spatial mixed models. Sci. Rep. 14, 10967 (2024).
Schürch, C. M. et al. Coordinated cellular neighborhoods orchestrate antitumoral immunity at the colorectal cancer invasive front. Cell 182, 1341−1359.e19 (2020).
Acknowledgements
Z.Y. acknowledges the support by National Nature Science Foundation of China (62303119 (Z.Y.), 32470706 (Z.Y.)), National Key R&D Program of China (2023YFF1204800 (Z.Y.)), Shanghai Science and Technology Development Funds (23YF1403000 (Z.Y.)), Chenguang Program of Shanghai Education Development Foundation and Shanghai Municipal Education Commission (22CGA02 (Z.Y.)), Fund of Fudan University and Cao’ejiang Basic Research (24FCA10 (Z.Y.)), and Shanghai Science and Technology Commission Program (23JS1410100 (Z.Y.)).
Author information
Authors and Affiliations
Contributions
Z.Y. and Y.C. conceived and designed the study, developed the computational methods, performed the analysis, and wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Cui, Y., Yuan, Z. Prioritizing perturbation-responsive gene patterns using interpretable deep learning. Nat Commun 16, 6095 (2025). https://doi.org/10.1038/s41467-025-61476-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-61476-9
This article is cited by
-
Interpretation, extrapolation and perturbation of single cells
Nature Reviews Genetics (2026)
