
Abstract
We aimed to develop a machine-learning model to predict all-cause mortality among Brazilians aged 50 and over, incorporating demographic, health, and lifestyle characteristics as predictors. We analyzed data from the Brazilian Longitudinal Study of Aging (ELSI-Brazil), waves 1 and 2 (2015–2021), a nationally representative sample from 70 municipalities across Brazil’s five regions. Nine algorithms, including Random Forest, Gradient Boosting, XGBOOST, and Logistic Regression, were tested on 9412 participants (54.6% female), with 970 deaths recorded over approximately five years. Using 59 predictor variables, we assessed performance with metrics like AUC, accuracy, precision, and F1-Score. Random Forest excelled with an AUC of 0.92 (95% CI: 0.90–0.94). SHAP analysis highlighted age, sex, BMI, medication use, and physical activity as top predictors. Integrating these models into healthcare systems can improve policy planning and enable targeted interventions, ultimately fostering better health outcomes for aging populations.
Similar content being viewed by others

Introduction
The impact of population aging on society, particularly in the increasing prevalence of chronic non-communicable diseases, demands focused attention from public health policymakers. Globally, there is a steady rise in chronic disease incidence and the associated healthcare costs1. The World Health Organization (WHO), together with partners at the United Nations, has launched a report on the Decade of Healthy Ageing, which aims to improve the quality of life of older people1. Despite this, the prevalence of multiple chronic diseases in the same individual, called multimorbidity, is high and can reach around 40% in adult women and almost 33% in adult men around the world2, reaching more than half of the population above 60 years2.
The occurrence of chronic diseases leads to poor health and even mortality3. However, premature mortality is not only due to chronic diseases but also related to other factors such as poor diet, physical inactivity, and deprived social determinants of health4,5,6. Mortality, especially all-cause mortality, is difficult to predict as it can be influenced by numerous predictors that may interact with each other and vary across countries. However, with advances in technology, especially in computational capacity and new algorithms capable of leading better than traditional approaches with the interaction of predictors, it is now possible to perform more complex predictive analyses, combining different types of predictor variables to create a model that achieves optimal performance based on the available data.
Machine learning (ML) is an area within artificial intelligence in which computers can learn from data without manual programming to perform certain activities and has shown potential in predicting different health outcomes7. Currently, several health problems are being identified in less time using ML, such as reducing queuing times and identifying diseases earlier7.
In Brazil, a study evaluated older adults in São Paulo and created a predictive model with a good performance for predicting mortality, with all models showing an AUC ROC value greater than 0.708. However, as far as we know, there are no studies that have evaluated ML’s performance in predicting mortality among the entire Brazilian aging population. In other countries, such as United States and United Kingdom, studies have already created models in population-based studies with good results in predicting mortality from all causes9,10. The Brazilian Longitudinal Study of Aging (ELSI-Brazil) is the only population-based longitudinal study of aging populations in Brazil and allows for this evaluation. We aimed to create a machine-learning model for predicting all-cause mortality among Brazilians aged 50 and over, considering demographic, health, and lifestyle characteristics as predictors.
Results
Sample characteristics
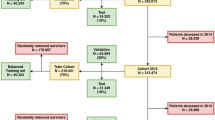
In total, the sample included 9.412 participants (Table 1). The positive class (death) (n = 970) was older (mean 70.0, 95% CI 68.7–71.3 vs. 61.7, 95% CI 60.9–62.5), with more males (52.9%, 95% CI 48.8–57.0 vs. 45.4%, 95% CI 42.3–48.4) and fewer females (47.1%, 95% CI 43.0–51.2 vs. 54.6%, 95% CI 51.6–57.7) than the negative class (no death) (n = 8442). The positive class has fewer married/stable union individuals (48.0%, 95% CI 62.1–67.9 vs. 65.0%, 95% CI 62.1–67.9), more widowed (26.2%, 95% CI 23.3–29.4 vs. 13.6%, 95% CI 11.7–15.6), more with less than 8 years of education (75.5%, 95% CI 71.5–79.2 vs. 60.2%, 95% CI 57.0–63.3), and fewer with 11+ years (13.6%, 95% CI 10.9–16.8 vs. 26.8%, 95% CI 24.4–29.2).
In approximately five years between baseline and the first wave, 970 deaths (mortality rate of 18.6 per 1000 person-years) were identified up to follow-up, ~10% of the total sample, which was considered as an independent variable (target). Of these, 707 deaths were confirmed by a proxy during the second-wave interview. Loss to follow-up rate was 24%.
Models results
Table 2 shows the algorithms that were used and the results of the tests of the predictive models. The model with the best predictive performance was chosen based on the Area Under the Roc Curve (AUC). The Random Forest model showed the best overall result, with an AUC of 0.92 (95%CI: 0.90–0.94), and AUC-PR of 0.75, being chosen as the best predictive model. The KNN and XGBoost models were also satisfactory, with confidence intervals similar to those of Random Forest, but with other metrics showing lower results. Figure 1 shows the Roc curve graphic with all models. Figure 2 presents the confusion matrix for the Random Forest model, showing the rates of true positives (TP), with 1894 cases, false positives (FP) with 32 cases, false negatives (FN), with 642 cases, and true negatives (TP), with 256 cases. In addition, the Random Forest model showed an accuracy of 0.76, precision of 0.29, Recall of 0.89, F1-Score of 0.43, and specificity of 0.75.

Roc curve showing the AUC value for the nine models on the test dataset.

Confusion matrix for Random Forest model on the test dataset.
Figure 3 illustrates the main predictor variables and their influence on the results using the SHAP technique. It was identified that age was the most impactful factor, showing a positive influence on the probability of all-cause mortality. In addition, BMI and the use of medications also had an important impact on the model, as well as physical activity, life satisfaction, and education. On the other hand, the presence of hypertension, stroke, and cataract were some of the variables with less importance in the model.

The graph illustrates the impact and relative contribution of each variable to the model's output, with higher SHAP values indicating stronger influence on mortality predictions.
The result Cross-validation F1 score (0.8426 ± 0.0066) indicates that the model obtained an average F1-score of 0.8426 in the cross-validation iterations, with a variation of ±0.0066 between the different iterations. Finally, Boruta identified two variables age and BMI.
Discussion
We aimed to create a machine learning model for the prediction of all-cause mortality among Brazilians aged 50 and over. The models showed satisfactory results, with AUC values ranging from 0.71 (Decision Tree) to 0.92 (Random Forest). However, the models had difficulty predicting the positive class (death). The challenge of creating a model for predicting mortality by all classes in a study that represents all individuals in Brazil aged 50 and over is great and shaped by the outcome that occurs less frequently, around 10% in this study. This challenge is further compounded by Brazil’s vast territorial size and the significant regional disparities in socioeconomic conditions, healthcare access, cultural habits, and population health profiles, which demand highly stratified analyses and robust models to account for such heterogeneity. However, the results were significant and showed that some characteristics of the individual, such as age, BMI, medication use, and physical activity can be good predictors of mortality in this population. On the other hand, variables that are known to be predictors of mortality in epidemiological studies using traditional analyses were not robust predictors in this study, such as meat consumption11 and life satisfaction12.
The Random Forest model demonstrated the highest effectiveness in predicting all-cause mortality, achieving an AUC of 0.92, highlighting its ability to handle complex, heterogeneous data typical of diverse populations like Brazil’s. Its strength lies in constructing multiple independent decision trees and aggregating their predictions, minimizing the risk of overfitting while effectively capturing non-linear variable interactions—a crucial advantage in public health analyses. The model showed notably higher discriminative power in the test set (AUC = 0.919) compared to training (AUC = 0.759), which may be attributed to the data resampling techniques applied during training. This performance difference, rather than indicating overfitting, suggests the model effectively learned generalizable patterns despite the class imbalance challenges. The increase in AUC on the test set likely reflects the benefits of the sampling strategy used. Additionally, its high precision and specificity reinforce its robustness in identifying high-mortality-risk individuals, optimizing resource allocation, and guiding preventive interventions. As a sensitivity analysis, we recreated the same model by removing the main predictor variable, which was age. The AUC value was 0.86, maintaining a similar robustness to the main model.
In public health and epidemiology studies, mortality prediction is fundamental for the development of health policies and preventive strategies. While most studies focus on mortality from specific causes - such as cardiovascular diseases13,14, cancer15,16, and respiratory diseases17, benefiting from well-established and directly associated predictors - our study innovates by developing a model to predict all-cause mortality in adults aged 50 and over in Brazil. This comprehensive approach represents a significant challenge, given the diversity of factors that influence mortality in a heterogeneous population, but also offers a unique opportunity for more widespread preventive interventions.
Although the model demonstrated a good AUC value, indicating satisfactory discrimination performance, we faced the challenge of class imbalance, which could be common in mortality studies, with unbalanced classes, among the general population. Although AUC is an important metric, our results reinforce the need to test different metrics in machine learning studies18, especially when the outcome class is unbalanced. This study stands out for its universal applicability, providing valuable insights for the early identification of individuals at high risk of premature mortality, regardless of the specific cause. Such an approach is important for targeting resources and intervention strategies effectively, reinforcing the role of preventive medicine and public health policies in improving quality of life and reducing premature mortality in vulnerable populations.
In a cohort with a longer follow-up time, the problem could be minimized since there would be more cases of the outcome and the classes would be more balanced. However, in Brazil there is no study of this kind with the ageing population. Another important and necessary fact is that the sample size should be large enough to divide the dataset into training and testing. Nevertheless, in Brazil, most studies with large samples are cross-sectional and may infer reverse causality and lack important outcomes, such as mortality. ELSI is one of the few longitudinal studies in Brazil that has a considerable sample size and has measured mortality.
Some of the main predictors found in this study are already known risk factors for all-cause mortality, such as age and BMI19,20. With advancing age, the risk of mortality increases, as this is to be expected, especially in older adults with chronic problems. Studies have shown that advanced age is a risk factor for mortality in different populations21,22,23,24. On the other hand, a meta-analysis of cohort studies showed that healthy ageing reduces the risk of all-cause mortality by 50%25, demonstrating the importance of building healthy habits throughout life. While our results showed BMI as an important predictor of mortality, interestingly, in older populations, a meta-analysis showed that overweight was not a risk factor for mortality19, which may be related to survival bias in this population.
In order to build reliable and generalizable models, a diversity of data is essential. This study provides a representative sample of a large population, helping to ensure that the conclusions and interventions proposed accurately reflect the population as a whole. The variability in sociodemographic and clinical characteristics, such as age, gender, ethnicity, socioeconomic conditions, and health history, enriches the model, allowing it to recognize more complex and subtle patterns that affect health. It is therefore essential to create models trained on studies with robust populations or samples so that their results can be beneficial to everyone and not biased.
Compared to traditional models, some studies have shown that machine learning offers improvements26. For other outcomes, machine learning also performed better than traditional methods, as was the case with the classification of glaucoma published in 200227. Almost 20 years later, for acute coronary syndrome, machine learning proved to be highly calibrated and produced higher statistics compared to traditional methods28. With this, it can be inferred that over the years, machine learning has shown that it has the potential to help classify different health problems, and its use should be encouraged given the potential it offers to health.
The results of this study highlight the potential of applying algorithms to predict mortality in older adults’ populations, opening up new avenues for clinical practice and public health policy planning. In clinical practice, the early identification of individuals at high risk of mortality allows for targeted and personalized interventions, improving the management and quality of life of older adults. This proactive approach can contribute to the optimization of health resources, directing preventive and therapeutic efforts more effectively.
Our study has a few limitations. The relatively short follow-up for the mortality outcome implied an unbalanced sample, and a cohort with a longer follow-up could result in a more balanced sample. Despite the techniques applied, the results need to be interpreted with caution, and it may be possible to obtain more robust results in the next ELSI-Brazil follow-ups. Furthermore, the representativeness of the sample, although comprehensive, may not capture all the nuances of specific subpopulations within the Brazilian context, limiting the generalization of the results to other cultural or demographic contexts. Moreover, the selection of predictor variables, although extensive, excluded potentially relevant health determinants, such as genetic factors or family medical histories, which could enrich the accuracy and clinical relevance of the model. Finally, potential biases due to self-reported data and regional disparities in healthcare access should be considered. Self-reported variables may introduce recall and reporting bias, affecting data accuracy. Furthermore, Brazil’s regional inequalities in healthcare availability and quality could influence mortality rates, potentially limiting the generalizability of our findings. These limitations underline the need for future research to broaden the understanding of mortality risk factors among older adults, thus improving the ability of predictive models to effectively contribute to clinical practice and public health policy planning.
Future research should explore the intersection of genetic, environmental, and socioeconomic variables to build more comprehensive and personalized predictive models. The integration of longitudinal data with a longer follow-up duration is also crucial to balance the sample and improve the robustness of machine learning models. In addition, it is necessary to carry out external validation of the models in different cohorts and population contexts to confirm their applicability and adaptability to different contexts. Another fertile field for research is the analysis of interventions based on predictive models, evaluating their effectiveness in reducing early mortality and promoting healthy ageing.
Finally, critical questions of ethics and privacy need to be raised. It is essential to guarantee the confidentiality of patient data, especially in models used in day-to-day life, ensuring transparency about the use of data. Informed consent must be obtained whenever necessary, and data anonymization must be guaranteed in the real world in order to protect the identity of individuals. Another important fact is to ensure that models are built that do not perpetuate existing biases, which could lead to health inequalities. Therefore, access to health services must be equal for everyone so that the models are used in the real world and do not create discrimination. For this to happen, public policies need to be informed about the results of the models and consider the broader social and economic context in which health and mortality are embedded. In this way, it is possible to use a model, in a fair way that preserves equity, to help prevent mortality in ageing populations.
In conclusion, the results showed that ML had a good AUC for predicting all-cause mortality but had difficulty predicting the positive class. Class imbalance was a challenge for the model to learn to predict mortality. In order for the results to be effective for drawing up public policies and prevention strategies, large longitudinal databases assessing mortality are needed.
Despite challenges related to class imbalance, our findings support the integration of machine learning in public health strategies to identify high-risk individuals, enabling targeted interventions and improving preventative care. This approach paves the way for more effective management of health outcomes in aging populations, reinforcing the importance of technological innovations in enhancing the quality of life for older adults. However, for this to happen, we need more robust data, longer follow-up times and greater acceptance of machine learning in healthcare, enabling its application to effectively support life-saving interventions across the general population.
Methods
Study design and participants
We analyzed longitudinal data from the Brazilian Longitudinal Study of Aging (ELSI-Brazil). The ELSI-Brazil sample was designed to represent the non-institutionalized Brazilian population aged 50 and older. Due to the absence of a centralized household registry, the study used IBGE’s geographic operational base for stratification and area selection. Municipalities were classified into four strata based on population size using the Lavallée and Hidiroglou method. Sampling followed a multi-stage design: three-stage selection for municipalities with up to 750,000 inhabitants and two-stage selection for larger cities. Eligible participants were all residents aged 50 and older in the selected households.
The first baseline of the ELSI-Brazil was carried out between 2015 and 2016 and involved a representative sample of 9412 participants aged 50 and over living in different regions of Brazil. This initial phase focused on collecting comprehensive information on physical and mental health, functional capacity, lifestyle, social support, and use of health services. The first follow-up took place between 2019 and 2021 and aimed to reevaluate the participants of the initial wave to monitor the changes that occurred over the period. In this phase, 9949 participants were interviewed, including replacement of the lost sample. More methodological details of the ELSI-Brazil baseline and wave one wave can be found in the methodological studies published by the coordinators21,29,30. ELSI-Brazil was approved by the Research Ethics Committee of the Oswaldo Cruz Foundation, Minas Gerais (protocol 34649814.3.0000.5091). All participants signed an informed consent form. For this study, baseline variables were used as predictors for model building, while deaths that occurred between the baseline and the first follow-up were used as the outcome (target).
Algorithms
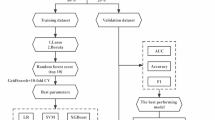
Based on research in a systematic review on the potential of ML for different health problems7, we tested nine Machine Learning algorithms (Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, Support Vector Machine (SVM), K-Nearest Neighbors (KNN), XGBoost, LightGBM, and CatBoost), each with its own particularities and unique approaches to processing data and building predictive models.
Outcome
The main outcome (target), 0 (no) 1 (death), was all-cause mortality cases in the period between baseline and follow-up, ~five years. The information was collected during the follow-up interview and reported by a third party, with subsequent confirmation by linking the data collected by the study with that from the National Mortality Information System (SIM in Portuguese)29. There was also additional confirmation of deaths, which made it possible to identify more deaths among the participants initially considered lost to follow-up29.
Predictors
Fifty-nine predictor variables were selected, encompassing demographic characteristics, health conditions, and lifestyle habits. The choice of predictor variables was based on the availability of the database and epidemiological, including the ELSI-Brazil, studies that evaluated factors associated with mortality21,31,32.
The continuous variables included age, Body Mass Index (BMI), the daily time in minutes that the individual spends sitting during the week and on the weekend, the level of life satisfaction assessed on a scale of 1 to 10, life satisfaction in comparison to others of the same age, and the number of medications consumed. Among the categorical variables, gender, marital status, level of education, and income range were used for the demographic characteristics. Health conditions, including a wide range of chronic diseases, multimorbidity, and individual diseases such as diabetes, hypertension, heart attacks, and cancer, among others, were used. In addition, lifestyle aspects such as consumption of vegetables, fruit, red meat, fish, and physical activity were included in the model. Self-assessment of health and sleep quality, weekly use of sleeping pills, oral health, and memory classification complement the set of predictor variables in order to understand whether these characteristics can predict mortality among Brazilians aged 50 and over. Table 3 shows the complete list of variables, their type, and the code used to construct the models in our study.
Performance metrics
The mortality prediction models were evaluated using various performance metrics. The Area Under the ROC Curve (AUC) measures the model’s ability to distinguish between classes, with values above 0.70 indicating good performance33. The AUC-PR was evaluated taking into account the unbalanced sample. Accuracy assesses the overall effectiveness of the model, while Precision measures the reliability of positive predictions. Recall quantifies the ability to capture all real positive cases, which is crucial in health contexts. F1-Score balances precision and recall, especially useful in situations of class imbalance. Specificity evaluates the ability to correctly identify negative cases, which is important to avoid overestimating mortality rates. Together, these metrics provide a comprehensive assessment of the model’s performance in predicting all-cause mortality. A cross-validation was performed using k-fold cross-validation with k = X folds to evaluate model performance. The F1-score was computed for each fold, and the result was reported as the mean ± standard deviation across all iterations.
Statistical analysis
The analyses were carried out in Python and included various processes to optimize operations. The first step was to install and load the essential packages, such as dfply, scikit-plot, graphviz, dtreeviz, random forest, xgboost, lightgbm, catboost, and shap. The data set was then loaded, and the pre-processing stage was carried out. For categorical variables with more than two categories, dummies were created for one-hot encoding. After this, the continuous variables were standardized, and the dataset was randomly split into training and testing sets using stratified sampling to maintain the class distribution. The train_test_split function from scikit-learn was applied with 30% of the data allocated for testing and a fixed random seed (42) to ensure reproducibility.
To address the class imbalance issue in our dataset, we applied the RandomUnderSampler technique, which randomly removes samples from the majority class to balance the dataset. This method was chosen after testing various approaches, and it performed the best in improving model performance. Additionally, we used the best_threshold function to determine the optimal decision threshold for maximizing specific performance metrics, such as F1-Score, rather than relying on the default threshold of 0.5. This allowed us to fine-tune the balance between precision and recall.
Furthermore, during model training, we applied RandomizedSearchCV to optimize the hyperparameters of our model. In each model, specific combinations defined in the model’s dictionary were tested, such as C for logistic regression or max_depth for decision trees. Validation was carried out internally by GridSearchCV with cross-validation (cv = 5), eliminating the need for a separate validation set.
To explain the results and identify the variables that contributed most to the results, the SHAP technique was applied34,35. This technique calculates the contribution value of each predictor variable to the model’s decision, considering all possible combinations of variables. By assigning a SHAP value to each variable, it becomes possible to identify the relative importance of each one in predicting mortality. In addition to facilitating the interpretation of the model, it is possible to promote transparency and understanding of the algorithm’s decisions.
To identify the possibility of excluding less relevant predictors, we applied the Boruta algorithm. Boruta selects important features by iteratively comparing each predictor’s importance to a set of shadow variables, which are created by randomizing the original data. If variables consistently show greater importance than the shadow variables, the algorithm retains them; otherwise, it discards less relevant features. By using Boruta, we ensured that the model focused on the most significant predictors for mortality, enhancing both efficiency and interpretability while avoiding overfitting or the inclusion of irrelevant features.
Data availability
The longitudinal data used in this study are from the Elsi-Brasil database and are not available for download, only upon consultation and approval by the research coordinators.
Code availability
The codes used in this manuscript can be requested by contacting the corresponding author of the study.
References
United Nations agencies launch first report on the Decade of Healthy Ageing, 2021-2030. accessed 4 Feb 2024; https://www.who.int/news/item/22-11-2023-united-nations-agencies-launch-first-report-on-the-decade-of-healthy-ageing--2021-2030.
Chowdhury, S. R., Chandra, Das D., Sunna, T. C., Beyene, J. & Hossain, A. Global and regional prevalence of multimorbidity in the adult population in community settings: a systematic review and meta-analysis. EClinicalMedicine 57, https://doi.org/10.1016/j.eclinm.2023.101860 (2023).
Nunes, B. P., Flores, T. R., Mielke, G. I., Thumé, E. & Facchini, L. A. Multimorbidity and mortality in older adults: a systematic review and meta-analysis. Arch Gerontol. Geriatr. 67, 130–138 (2016).
Taneri, P. E. et al. Association between ultra-processed food intake and All-Cause mortality: a systematic review and meta-analysis. Am. J. Epidemiol. 191, 1323–1335 (2022).
Blond, K., Brinkløv, C. F., Ried-Larsen, M., Crippa, A. & Grøntved, A. Association of high amounts of physical activity with mortality risk: a systematic review and meta-analysis. Br. J. Sports Med. 54, https://doi.org/10.1136/bjsports-2018-100393 (2020).
Silva Vde, L., Cesse, EÂ. & de Albuquerque Mde, F. Social determinants of death among the elderly: a systematic literature review. Revista Brasileira de Epidemiol. 17, 178–193 (2014).
Delpino, F. M. et al. Machine learning for predicting chronic diseases: a systematic review. Public Health 205, 14–25 (2022).
Santos, H. G. D., Nascimento, C. F. D., Izbicki, R., Duarte, Y. A. O. & Porto Chiavegatto Filho, A. D. ADPC. Machine learning for predictive analyses in health: an example of an application to predict death in the elderly in São Paulo, Brazil. Cad Saude Publica 35, e00050818 (2019).
Qiu, W. et al. Interpretable machine learning prediction of all-cause mortality. Commun. Med. 2, https://doi.org/10.1038/s43856-022-00180-x (2022).
Zhang, T. et al. Machine learning and statistical models to predict all-cause mortality in type 2 diabetes: results from the UK Biobank study. Diab. Metab. Syndr. 18, https://doi.org/10.1016/J.DSX.2024.103135 (2024).
Larsson, S. C. & Orsini, N. Red meat and processed meat consumption and all-cause mortality: a meta-analysis. Am. J. Epidemiol. 179, 282–289 (2014).
Lin, T. F. et al. Life satisfaction components and all-cause and cause-specific mortality: a large prospective cohort study. J. Affect Disord. 350, 916–925 (2024).
Tsarapatsani, K. et al. Prediction of all-cause mortality in cardiovascular patients by using machine learning models. Eur. Heart J. 43, https://doi.org/10.1093/eurheartj/ehac544.1185 (2022).
de Souza e Silva, C. G. et al. Prediction of mortality in coronary artery disease: role of machine learning and maximal exercise capacity. Mayo Clin. Proc. 97, 1472–1482 (2022).
Bozkurt, C. & Aşuroğlu, T. Mortality prediction of various cancer patients via relevant feature analysis and machine learning. SN Comput. Sci. 4, https://doi.org/10.1007/s42979-023-01720-5 (2023).
Oyama, S. et al. In-Hospital cancer mortality prediction by multimodal learning of non-english clinical texts. In: Studies in Health Technology and Informatics. https://doi.org/10.3233/SHTI230276 (2023).
Yan, P. et al. A new risk model based on the machine learning approach for prediction of mortality in the respiratory intensive care unit. Curr. Pharm. Biotechnol. 24, 1673–1681 (2023).
Hicks, S. A. et al. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 12, 5979 (2022).
Winter, J. E., MacInnis, R. J., Wattanapenpaiboon, N. & Nowson, C. A. BMI and all-cause mortality in older adults: a meta-analysis. Am. J. Clin. Nutr. 99, 875–890 (2014).
Ebeling, M., Rau, R., Malmström, H., Ahlbom, A. & Modig, K. The rate by which mortality increase with age is the same for those who experienced chronic disease as for the general population. Age Ageing 50, 1633–1640 (2021).
Macinko, J., Beltrán-Sánchez, H., Mambrini, J. V. de M. & Lima-Costa, M. F. Socioeconomic, disease burden, physical functioning, psychosocial, and environmental factors associated with mortality among older adults: the Brazilian Longitudinal Study of Ageing (ELSI-Brazil). J. Aging Health 36, https://doi.org/10.1177/08982643231171184 (2024).
Bakshi, A. S., Sharma, N., Singh, J., Batish, S. & Sehgal, V. To study demographics as risk factor for mortality associated with COVID-19: a retrospective cohort study. Biomed. Pharmacol. J. 14, https://doi.org/10.13005/bpj/2253 (2021).
Veiga, V. C. & Cavalcanti, A. B. Age, host response, and mortality in COVID-19. Eur. Respir. J. 62, 2300796 (2023).
Kobayashi, M. et al. Risk factors for early mortality in older patients with traumatic cervical spine injuries—a multicenter retrospective study of 1512 Cases. J. Clin. Med. 12, 708 (2023).
Mao, L. et al. The relationship between successful aging and all-cause mortality risk in older adults: a systematic review and meta-analysis of cohort studies. Front. Med. 8, https://doi.org/10.3389/fmed.2021.740559 (2022).
Desai, R. J., Wang, S. V., Vaduganathan, M., Evers, T. & Schneeweiss, S. Comparison of machine learning methods with traditional models for use of administrative claims with electronic medical records to predict heart failure outcomes. JAMA Netw. Open 3, e1918962 (2020).
Chan, K. et al. Comparison of machine learning and traditional classifiers in glaucoma diagnosis. IEEE Trans. Biomed. Eng. 49, 963–974 (2002).
Gibson, W. J. et al. Machine learning versus traditional risk stratification methods in acute coronary syndrome: a pooled randomized clinical trial analysis. J. Thromb Thrombolysis 49, https://doi.org/10.1007/s11239-019-01940-8 (2020).
Lima-Costa, M. F. et al. Cohort Profile: The Brazilian Longitudinal Study of Ageing (ELSI-Brazil). Int. J. Epidemiol. 2022, 1–9 (2022).
Lima-Costa, M. F. et al. The Brazilian Longitudinal Study of Aging (ELSI-Brazil): Objectives and Design. Am. J. Epidemiol. 187, 1345–1353 (2018).
Zhang, Y. B. et al. Combined lifestyle factors, all-cause mortality and cardiovascular disease: a systematic review and meta-analysis of prospective cohort studies. J. Epidemiol. Community Health. 75, https://doi.org/10.1136/jech-2020-214050 (2021).
Rezende, L. F. M. et al. Lifestyle risk factors and all-cause and cause-specific mortality: assessing the influence of reverse causation in a prospective cohort of 457,021 US adults. Eur. J. Epidemiol. 37, 11–23 (2022).
Meurer, W. J. & Tolles, J. Logistic regression diagnostics understanding how well a model predicts outcomes. JAMA - J. Am. Med. Assoc. 317, 1068–1069 (2017).
Nohara, Y., Matsumoto, K., Soejima, H. & Nakashima, N. Explanation of machine learning models using shapley additive explanation and application for real data in hospital. Comput. Methods Programs Biomed. 214, 106584 (2022).
Rodríguez-Pérez, R. & Bajorath, J. Interpretation of machine learning models using shapley values: application to compound potency and multi-target activity predictions. J. Comput. Aided Mol. Des. 34, 1013–1026 (2020).
Acknowledgements
F.M.D. received a postdoctoral fellowship from the National Council for Scientific and Technological Development. B.P.N. received a Research Productivity Fellow (process number: 308772/2022-9) - Level 2 from the National Council for Scientific and Technological Development. ELSI-Brazil was supported by the Brazilian Ministry of Health: DECIT/SCTIE – Department of Science and Technology from the Secretariat of Science, Technology and Strategic Inputs (Grants: 404965/2012-1 and TED 28/2017); COPID/DECIV/SAPS – Health Coordination of the Older Person in Primary Care, Department of Life Course from the Secretariat of Primary Health Care (Grants: 20836, 22566, 23700, 25560, 25552, and 27510). This study was also supported by the Conselho Nacional de Desenvolvimento Cientifico e Tecnologico – CNPq” “National Council for Scientific and Technological Development – CNPq and Fundação de Amparo à Pesquisa do Estado do Rio Grande do Sul - FAPERGS.
Author information
Authors and Affiliations
Contributions
F.M. Delpino contributed to the conception, analysis, writing, and organization of the article. B.P. Nunes contributed to conception, critical review of the analysis, writing, and critical review of the manuscript. A.D.P. Chiavegatto Filho, J.L. Torres, and M.F.L. Costa critically reviewed the manuscript and contributed to the writing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
ELSI-Brazil was approved by the Research Ethics Committee of the Oswaldo Cruz Foundation, Minas Gerais (protocol 34649814.3.0000.5091). All participants signed an informed consent form.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Delpino, F.M., Chiavegatto Filho, A.D.P., Torres, J.L. et al. Predicting all-cause mortality with machine learning among Brazilians aged 50 and over: results from The Brazilian Longitudinal Study of Ageing (ELSI-Brazil). npj Aging 11, 22 (2025). https://doi.org/10.1038/s41514-025-00210-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41514-025-00210-7
