
Abstract
Smart devices can easily capture changes in voice, movements, and gait in people with Parkinson’s disease (PD). We investigated whether smartphone-derived multimodal features combined with machine learning algorithms can aid in early PD identification. We recruited 496 participants, split into a training cohort (127 PD patients during “on” phase and 198 age-matched controls) and a test dataset (86 patients during “off” phase and 85 age-matched controls). Multidomain features from smartphone recordings were analyzed using machine learning classifiers with integration of a hyperparameter grid. Single-modality models for voice, hand movements, and gait showed diagnostic values of 0.88, 0.74, and 0.81, respectively, with test dataset values of 0.80, 0.74, and 0.76. An integrated multimodal model using a support vector machine improved performance to 0.86 and achieved 0.82 for identifying early-stage PD during the “off” phase. A smartphone-based integrated multimodality model combining voice, hand movement, and gait shows promise for early PD identification.
Similar content being viewed by others

Introduction
Parkinson’s disease (PD) is among the most common neurodegenerative disorders, predicted to affect almost 9 million people in 20301. The phenotypes of PD involve progressive motor disabilities, including bradykinesia, rigidity, rest tremor, and gait abnormalities such as shuffling gait, freezing, turn en-bloc, festination, and loss of posture reflex2. Current treatments for PD are symptomatic and there is no cure available yet. Given the likely entry of mechanism-targeted therapies into clinical trials3,4, detection of PD in the early stage is crucial. Significant efforts have focused on developing versatile imaging and biofluid markers for assisting early identification of patients with PD5, especially in the prodromal stage, but none have been widely used in the routine clinical practice.
Digital biomarkers analyzed by machine learning algorithms enable real-time, noninvasive diagnosis and monitoring of treatment effects in various disorders, including PD6. With advances in machine learning, prediction models that incorporate finger-tapping7, speech8, and arm-swing movements6 have been developed to assist in PD diagnosis. However, models using voice capture or movement-based tasks have mostly relied on single feature of PD and their output requires cautious evaluation because potential confounding effects may be overlooked, especially imbalances in age distribution between cohorts6,7,8. Furthermore, a single-domain modality may not be PD-specific, given that patients with stroke or arthritis also can experience gait disturbance or decreased arm swinging. As PD is a multi-faceted disorder with varying initial presentations, models focused on a single clinical feature alone may fall short in accurately identifying early-stage PD among elderly populations. In fact, criteria developed by the Movement Disorder Society to guide clinicians in diagnosing PD encompass multiple key manifestations of PD, including facial expression, voice change, hand and leg movement, and gait9. A model employing several of these features would likely yield greater diagnostic accuracy for identifying early-stage PD compared with models that rely on a single feature alone.
A previous study has incorporated speech, handwriting, and gait to build a multimodal deep-learning model and tested its discrimination of 43 patients with PD from 39 unaffected controls, showing an accuracy of 97.6%10. Another study group combining accelerometer information and silhouette images from home videos of 5 patients with PD and 5 unaffected control participants reported an acceptable accuracy for discriminating between groups11. Most studies incorporating multimodal features have been based on a limited number of participants and lacked a validation cohort. Overfitting is a risk for generalizing such models, and multifaceted models developed and verified in a large study population are needed. Furthermore, the stage of disease for participants in most previous studies has not been addressed10,11, and the ability to identify early-stage PD is largely unknown. To address this issue, we recruited a large cohort of PD patients with variable disease severity and neurologically normal elderly controls to establish and validate a deep-learning multimodality model. The model incorporates multiple core features of PD obtained from smartphone recordings, including speech, finger-tapping movements, and gait, to identify individuals with early-stage PD in the elderly population.
Results
Demographic characteristics
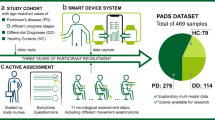
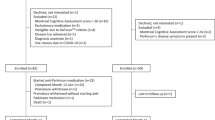
A total of 496 participants were recruited from the movement disorder clinics and geriatric clinics of a tertiary medical center (Table 1). The age was comparable between groups, while the proportion of men was higher among patients with PD compared with controls in both training and test data (Supplementary Table 1 and 2). Figure 1 shows the workflows in this study, and the assessment steps are publicly available at https://pd-demo-page.vercel.app/result.html.

The training cohort consisted of 127 patients with PD in the “on” phase and 198 age-/sex-matched controls. Multiple features were extracted based on smartphone-recorded data for model training to generate single-modality models with voice, finger-tapping movement, and gait. An integrated, multi-feature model combining features from these three modalities was established via a hyperparameters grid search among the single-modality models. Each single domain model and integrative model was further validated with another independent test data, consisting of 86 patients in the “off” phase and 85 age-/sex-matched controls. The hunched figure represents individuals with PD. Written informed consent was obtained from this participant for publication of the photograph.
Voice analysis
In the voice analysis, patients with PD took longer to read the provided article aloud, paused more during reading, and had reduced pitch and volume variability compared with control participants (Table 1). The voice pause percentage increased with disease severity and differed significantly between early PD or advanced PD and controls (all p < 0.001). Voice features were worse in patients with advanced compared with early-stage PD (Fig. 2A).

A The voice pause percentage increased while voice pitch variability decreased in patients with PD compared with unaffected controls. Voice features were worse in patients with advanced-stage PD compared to those in the early stage. B The mean index-to-thumb distance decreased in patients compared with controls, especially in patients with advanced-stage PD. The finger-tapping frequency tended to increase as finger-tapping distance declined. C The mean step length was shorter and turn duration longer in patients compared with controls, especially in patients with advanced-stage PD (all p < 0.001).
Finger-tapping analysis
On the finger-tapping test, the average frequency on both sides differed significantly between patients with PD and unaffected controls (all p < 0.001, Table 1). Of note, the index-to-thumb distance decreased with increasing PD severity and differed significantly between patients with advanced PD and controls (p < 0.001, Fig. 2B, left panel, Table 1). With increasing PD severity, the reduction of figure tapping distance was compensated by increased figure tapping frequency after repeated tapping movements (Fig. 2B, right panel, Table 1).
Gait analysis
Among the gait features, average step length was shorter and average turning duration per round was longer in patients with PD compared to controls. This difference was more prominent in alignment with disease severity, especially those in patients with advanced PD (all p < 0.001, Fig. 2C, Table 1).
Correlations among features of the three biometric modalities
Several selected features correlated with one another, especially as disease severity increased (Fig. 3A). Average duration per round of gait correlated moderately with finger-tapping frequency, especially with early PD (r = 0.05, p = 0.06, Fig. 3B). Average duration per round of gait displayed a significantly positive correlation with voice pause percentage in those with advanced PD (r = 0.13, p = 0.02, Fig. 3C), while the finger-tapping average frequency and voice pause percentage did not show a significant correlation (r = 0.05, p = 0.17, Fig. 3D).

A The key features retrieved from three biometric modalities – voice, finger-tapping, and gait – tended to correlate with each other in patients with PD but not in controls. These associations were more prominent in patients with advanced-stage PD than in those with early-stage PD. B The correlations between average duration per round of gait and finger-tapping frequency. C The correlations between average duration per round of gait and voice pause percentage. D The correlations between finger-tapping average frequency and voice pause percentage.
Diagnostic performance of single-modality models with different classifiers
With the training dataset, we first examined the diagnostic performance of a single-modality model using each of the three biometric markers to identify patients with PD, especially early-stage PD, in the training and test data. With voice features alone applied to differentiate the entire cohort of all patients with PD, including both early-stage and advanced-stage PD, from unaffected controls, the diagnostic values of AUROC were 0.88 in the training cohort and 0.80 in the test data using the RF classifier (Fig. 4A). With the AdaBoost or support vector machine (SVM) classifiers, AUROC values were 0.87 for both in the training cohort and respectively 0.79 and 0.80 in the test data (confusion matrix in Supplementary Fig. 2A). Compared with voice features alone, the finger-tapping test alone showed a lower performance in differentiating patients from unaffected controls with AUROC 0.74 in the training set and 0.74 in the test data using RF classifier (Fig. 4B; confusion matrix in Supplementary Fig. 2B). Gait features alone showed a diagnostic accuracy of 0.81 using AdaBoost in the training set and 0.76 in the test data (Fig. 4C; confusion matrix in Supplementary Fig. 2C). We compiled a detailed list of grid search parameters and the optimal model configurations for each algorithm (Supplementary Table 3).

Models were established based on single biometric modalities, including voice features (A), finger-tapping (B), or gait (C) in the training cohort, using different machine learning classifier models. The area under the curve indicates the ability to differentiate patients with PD in the overall cohort from unaffected controls in the training dataset. The diagnostic performance of each single-modality model in an independent test data. RF random forest, SVM support vector machine.
For distinguishing patients with early-stage PD from unaffected controls, the AUROC values for voice features alone were 0.83 in the training set and 0.74 in the test data using the SVM classifier, which was the best performance among the three classifiers (Fig. 5A). The finger-tapping test alone showed moderate diagnostic performance with the RF classifier in discriminating patients with early-stage PD from controls, yielding AUROC values of 0.75 in the training set and 0.73 in the test data (Fig. 5B). For gait features alone, with the RF classifier, AUROC values were 0.75 in the training set and 0.64 in the test data (Fig. 5C). The confusion matrices for all three single-modality models for distinguishing patients with early-stage from unaffected participants are shown in Supplementary Fig. 3.

Models were established based on single biometric modalities, including voice features (A), finger-tapping (B), or gait (C) in the training cohort, using different machine learning classifier models. The area under the curve indicates the ability to distinguish patients with early-stage PD from unaffected controls in the training dataset. The diagnostic performance of the single-modality models in an independent test data. RF random forest, SVM support vector machine.
To further validate these results, we included per-fold average performance metrics for differentiating all PD patients from unaffected controls using the SVM (Table 2), random forest and AdaBoost classifiers (Supplementary Tables 4,5). The voice-based model achieved an F1-score of 0.7393 ± 0.0151 and accuracy of 0.7368 ± 0.0148. The finger-tapping model showed an F1-score of 0.6725 ± 0.0055 and accuracy of 0.6708 ± 0.0048, while gait model had an F1-score of 0.6229 ± 0.1206 with an accuracy of 0.6295 ± 0.1239.
Diagnostic performance of the integrated multimodality model
Next, we integrated voice features, finger-tapping movement, and gait characteristics as an integrated model. We used the sequential forward selection method to select the best features for each classifier. The AUROC analyses with the SVM classifier provided the best diagnostic value of 0.86 for distinguishing patients with PD from unaffected controls in the test data. This performance was better than results for combinations of any two modalities among these three biometric markers (Fig. 6A; confusion matrix in Supplementary Fig. 4A).

The diagnostic performance of the integrated model combining all three modality features outweighed the performance of models combining any two modality features in distinguishing patients with PD (A), patients with early-stage PD (B), and patients with advanced-stage PD (C) from unaffected controls. SVM, support vector machine; ROC, receiver operating characteristic curve; PD, Parkinson’s disease.
For identification of patients with early-stage PD, the integrated model combining all three modalities displayed better performance compared with models derived from single modalities, with an AUROC value of 0.82 (Fig. 6B; confusion matrix in Supplementary Fig. 4B). The performance was more robust in identifying patients with advanced-stage PD in the test data, with an AUROC of 0.95 (Fig. 6C; confusion matrix in Supplementary Fig. 4C).
To further validate these results, we compared the performance of the integrated three-modality model with the single-modality models using the SVM (Table 2), as well as the random forest and AdaBoost classifiers (Supplementary Tables 4 and 5). Per-fold evaluation results showed that the three-modality model achieved an F1-score of 0.8056 ± 0.0086 and accuracy of 0.8047 ± 0.0079, significantly outperforming any of the single-modality models for differentiating all PD patients from unaffected controls (P < 0.001 for all comparisons) (Table 2). For early-stage PD detection from elderly controls, the integrated three-modality model had an F1-score of 0.6619 ± 0.0139 and accuracy of 0.7423 ± 0.0104, showing significant improvement over single-modality models (Table 2). In addition to the average per-fold performance approach, we also assessed and compared the model performance using aggregated cross-validation evaluation and ensemble test predictions (Supplementary Tables 6, 7). This alternative evaluation method provides a broader perspective on model stability by aggregating predictions across all folds rather than averaging per-fold results. Consistent with the results using the average per-fold performance approach (Table 2), the three-modality model demonstrated superior performance over single-modality models across all evaluation metrics, reinforcing its robustness in PD classification (Supplementary Tables 6, 7). Further error analysis demonstrates the advantages of this multimodal approach in reducing both false negatives and false positives across individual single modalities (Supplementary Table 8). For example, in patients across all stages of PD, the three-modality model correctly identified 28 out of 37 false negatives in the finger-tapping modality. The model also corrected 24 out of 36 false positives in the gait modality. For patients with early-stage PD, combining all three modalities improved accuracy, correcting 5 out of 10 false negatives in finger tapping and 26 out of 38 in gait (Supplementary Table 8). These findings demonstrate how each modality compensates for the others, creating a more robust diagnostic framework, particularly for early PD detection.
Discussion
In this study, we developed a multimodality model derived from smartphone-based recordings of PD cardinal features, including voice, finger-tapping, and gait, and applied machine learning classifiers to discriminate patients with PD from elderly unaffected controls. A model using the SVM classifier showed the best diagnostic performance for distinguishing patients with early-stage PD from age-matched controls, which finding was validated in another cohort of PD patients during the “off” phase and another group of elderly controls, representing real-world scenarios.
Voice impairment, an early soft sign of PD, has been viewed as an important digital biometric feature in identifying people with PD. The typical characteristics of PD speech include loss of loudness, restricted pitch variability, imprecise articulation, and altered pause ratio12,13. Previous studies have incorporated this clinical presentation to develop several models for recognizing PD, including instructed vowel phonation14, syllabus repetition15, repetitive sentences16, or a short paragraph17. These models have involved either traditional machine-learning classifiers or neural network methods, with reported diagnostic accuracy values ranging from 83% to 98%. In our study, using a voice recording taken as participants read a script, we found a diagnostic accuracy of 87% with the AdaBoost classifier, demonstrating a non-inferior performance compared with previous reports that had identified the voice feature as potentially distinguishing patients with PD from unaffected controls. Speech production is a complicated process with multiple dimensions, including speech respiration, phonation, articulation, and prosody. Models trained with single vowel sounds may oversimplify the features of speech. Several studies have indicated that a model trained with voice samples retrieved from reading sentences shows a superior performance in discriminating patients with PD compared to a model trained with simple vowel sound recordings18,19. Our results in a large PD cohort further support the ability of such voice samples to discriminate people with PD from controls, even in the on stage. In keeping with our findings, a study enrolling 48 participants with PD found that patients displayed voice features that differed not only from unaffected controls but also between those with early-onset versus late-onset PD, especially in inspiration, voice quality, and consonant articulation15. Another study of 115 people with PD also demonstrated acceptable performance in classifying the early- or mid-advanced stage of disease20,21. Our results support the feasibility of voice recording via readily available smartphones to distinguish patients with PD from unaffected controls in an elderly population and also demonstrate the generalizability of a voice model in real-world scenarios. However, because our recordings were scripted and of fixed length, they lack the capacity for language-based analyses of spontaneous speech, such as lexical diversity and syntactic complexity, which may provide additional diagnostic insights for PD. Future studies incorporating open-ended speech tasks could explore these dimensions further, enhancing our model’s diagnostic power for language and cognitive changes in PD.
Bradykinesia is the main cardinal feature of PD. Finger-tapping is a movement task widely used for clinical assessment of bradykinesia severity and is proposed in the Movement Disorder Society criteria for PD9. Most studies assessing bradykinesia or movement have applied special sensors19 or wearable devices22,23,24,25, including accelerometers, gyrometers, and inertial measurement units (IMUs). In one recent study employing accelerometers to extract movement features derived from 49 patients with PD and 29 unaffected controls for model training, accuracy in discriminating patients with PD from controls was 95%26. Despite a satisfactory performance in identifying PD, however, the specific wearable device from that study is not accessible to a general population and not feasible for large population screening. Recently, several studies have demonstrated that models developed based on movement data recorded by smart devices, including smartwatches and smartphones, show variable performance in predicting Unified Parkinson’s Disease Rating Scale motor scores, with AUROC values of 62%–90%27,28,29. Our results, derived in a large cohort, demonstrated only a moderate diagnostic performance using finger-tapping movement data alone. The diagnostic performance was even lower in discriminating patients with early-stage PD from controls. Our results nevertheless are in line with previous findings, highlighting a potential limitation of using smartphone video–based movement features as the sole modality for identifying PD, especially in the early disease stage.
Gait disturbance is caused by the combination of bradykinesia, rigidity, and reduced amplitude and automaticity of movement in the PD process30. Gait pattern changes detected by IMU31,32,33, ground pressure sensors34, or special cameras35,36 have differentiated patients with PD from unaffected controls with an accuracy >80%. However, as with some accelerometer studies, the cost of the devices hampers broad community screening for early identification of PD in an aging society. Recently, a study comparing smartphone-based accelerometry data to IMU data for 20 participants showed a high consistency of 94%37, suggesting the feasibility of using inertial device–embedded smartphones in gait assessment. Similar results were obtained in a later study of 152 patients with PD and another independent dataset38,39. Model performance based on mobile phone–recorded two-dimensional (2D) gait video features in that study was comparable to performance based on IMU data, but this single-modality feature showed only moderate performance in distinguishing PD participants from controls, with AUROC values of 0.65–0.7840,41. In the current study, in addition to applying the 2D gait features, we developed three-dimensional (3D) landmarks to enrich the multidomain gait features of PD, including turning and associated arm and leg movements. We acknowledge that 3D human pose estimation from monocular images faces challenges, such as depth ambiguity and camera angle dependency42,43. In our controlled setup, the camera was positioned 1 meter from each participant at an approximate height of 1.2 meters, directly facing participants to ensure consistent data collection. To mitigate angle-dependent inaccuracies, we calculated normalized relative distances rather than relying on absolute coordinates. This approach aligns with methods used in previous studies, where temporal consistency and invariant bone lengths were employed to enhance pose estimation robustness despite perspective variability42,43. Using normalized distances effectively reduces the impact of inconsistent spatial configurations, helping to address known issues in monocular 3D pose estimation, such as occlusion and depth ambiguity. Our 3D gait model thus provides satisfactory diagnostic performance, expanding on smartphone-based gait analysis as a viable source of digital biomarkers for PD. The 3D gait model derived from a variety of features showed satisfactory diagnostic performance in discriminating patients with PD from unaffected controls, extending current understanding of smartphone-based video recording for gait analysis and as a potential source of digital biomarkers of PD other than wearable sensor–based information. However, the performance in discriminating early-stage PD was moderate in our model using only gait features, re-emphasizing the insufficiency of a single modality for distinguishing people with early-stage PD from unaffected controls in an elderly population.
PD is a multifaceted neurodegenerative disorder involving variable initial presentations, and clinical assessment for identifying PD, especially in the early stage, calls for multimodal approaches. Models relying on a single modality to support a PD diagnosis should be evaluated with caution because many lack sufficient numbers of age-matched controls or are based on a limited number of participants, which can lead to overfitting model performance. Furthermore, PD is a highly heterogeneous disorder with varying early-stage presentations. Some individuals may experience subtle tremors, while others may primarily present with bradykinesia, postural instability, or speech changes. As such, models based on a single clinical feature are likely to miss the full spectrum of PD manifestations, particularly in its early stages. These limitations are especially relevant in elderly populations, where the disease often presents with atypical symptoms that overlap with other age-related conditions.
Many other conditions, such as stroke, arthritis, or even normal aging, can cause similar motor or speech impairments. For instance, gait disturbances are common in patients with stroke44 or arthritis45, and these patients may also exhibit reduced arm swinging or abnormal gait patterns, which could be misinterpreted as signs of PD. Therefore, a model that uses a single feature may not effectively differentiate PD from these other conditions, reducing its clinical utility. However, it is important to note that our dataset does not include individuals with these potentially confounding conditions, and future studies incorporating such cases will be necessary to further validate the model’s specificity for PD. Models that focus solely on one clinical domain may therefore struggle to accurately identify PD in these populations, potentially leading to misdiagnosis or delayed diagnosis. To improve diagnostic accuracy, multi-domain models that integrate multiple features—such as voice, gait, and other motor or non-motor symptoms—are essential. Combining these modalities can help provide a more comprehensive assessment of PD, account for its heterogeneous presentation, and reduce the influence of confounding factors like age-related changes. Recent advancements in machine learning and multi-modal analysis offer promising solutions to enhance the sensitivity and specificity of PD detection, and integrating data from multiple sources can help differentiate PD from other similar conditions28,46,47,48. Compared to these previous studies, our integrated model with both a large training and test data based on smartphone-derived recordings of digital markers showed satisfactory performance in discriminating people with PD and especially with early-stage PD from elderly controls. Furthermore, our integrated three-modality model significantly improved classification accuracy, especially in early-stage PD, compared to single-modality approaches. Our study demonstrates the feasibility of using smartphone video samples for model training and highlights the value of a multimodal framework in capturing PD’s diverse manifestations, with potential for population-level screening in aging societies.
An advantage of our approach is the smartphone-based acquisition of multiple digital markers, including voice, hand movement, and gait, in a large dataset involving patients with PD of varying severity and age-matched controls. This approach holds potential for future low-cost screening in large populations and for monitoring treatment response remotely and objectively. The evolution of smartphones along with widely accessible machine learning algorithms could facilitate objective measurements of emerging subtle motor dysfunction in individuals at risk for PD. Our study had some limitations. First, the voice dataset was based primarily on local language, and diagnostic performance with other languages is uncertain. A future model incorporating a multi-language training cohort is needed to support different language needs. Second, although we had a test data in the current study, outside validation in a community-based population is needed to confirm the diagnostic performance of this multimodality model. Third, our study focuses exclusively on acoustic-based features, without incorporating language-based features, such as the correctness of spoken content or syntax from the reading test. Our voice recordings were scripted and of fixed length, limiting the scope of certain language-based analyses, especially those that benefit from spontaneous speech. Since the recordings followed a predetermined script, our analysis could not explore language-based metrics, such as word choice, syntactic complexity, discourse coherence, or thematic content, which typically require open-ended responses or narrative tasks. A future study incorporating unscripted, open-ended speech tasks is needed to assess features like lexical diversity, sentence complexity, narrative coherence, and fluency, providing deeper insights into cognitive and linguistic functions. This will complement our current acoustic features and enhance the diagnostic power of our model for detecting PD-related language and cognitive changes. Fourth, the distance-based features for finger tapping were calculated using 2D data, which may not fully capture the effects of hand rotation, potentially introducing slight inaccuracies in the calculated distances. While we controlled for hand positioning as much as possible, future work could explore the use of 3D lifting techniques to improve robustness by capturing depth-related information. Incorporating 3D data would provide a more comprehensive view of hand dynamics and further enhance the accuracy of finger-tapping features. Additionally, while our study used a controlled background to ensure consistent feature extraction, real-world environments may introduce background noise that could impact model accuracy. Future work should assess the impact of background variability on performance and explore preprocessing techniques to improve robustness in uncontrolled settings. In practical applications, preprocessing techniques such as background segmentation, adaptive thresholding, or depth estimation may be necessary to enhance robustness in cluttered environments. Future studies should assess the impact of dynamic and visually complex backgrounds on model performance and explore strategies to improve MediaPipe’s adaptability in real-world scenarios to enhance generalizability.
In conclusion, we demonstrated the capability of a smartphone-based integrated multimodality model for early identification of patients with PD. Our results also emphasize the superiority of a model that combines multiple digital biomarkers over models based on a single modality. A multi-language–based biometric assessment implemented in a longitudinal prospective study is needed to validate our model for identifying patients with early-stage PD.
Methods
Study participants and data collection
We recruited 496 participants, including 213 patients with PD and 283 unaffected controls, from National Taiwan University Hospital. The diagnosis of PD was following the United Kingdom PD Society Brain Bank Clinical Diagnostic Criteria49. Neurologically normal participants who were spouses or friends accompanying the patients with PD were enrolled as controls. Participants with voice disturbance from a non-neurologic etiology and otolaryngologic disease were excluded. Those who could not read, had a Montreal Cognitive Assessment score <20, or had depressive disorders were excluded. Motor severity in patients with PD was evaluated using the Movement Disorder Society Unified Parkinson’s Disease Rating Scale part III scores and Hoehn–Yahr staging. PD was classified further as either early-stage (Hoehn–Yahr stage < 3) or advanced-stage (Hoehn–Yahr stage ≥3). This study was approved by the institute of ethics board committee of the National Taiwan University Hospital (201912112RIND and 202301013RINA), and all participants provided written informed consent before joining the study.
We grouped data derived from 496 participants into a training set (127 patients during “on” phase and 198 age-matched controls) and a test set (86 patients during “off” phase and another independent group of 85 age-matched controls). The “on” and “off” phases were respectively defined as within 3 h and more than 12 h after the last dose of dopaminergic medication individually. The test group assignment was based on whether an anti-parkinsonism medication effect was evident in patients with PD when they underwent smartphone-based biometric feature recordings. We hypothesized that a model capable of discriminating patients in the “on” phase in this way would demonstrate optimal diagnostic performance in distinguishing drug-naïve patients with PD or patients in the off phase from unaffected controls in real-world scenarios with an elderly population.
All participants received an active movement–based assessment using a laboratory-customized app on the smartphone, as instructed by the smartphone app and guided by a study nurse (Fig. 1). The assessment steps were designed to establish a simple, easy-to-follow examination, and the assessment process is publicly available at https://pd-demo-page.vercel.app/result.html.
Voice data acquisition and processing
Participants were asked to read a ~500-word script displayed on the smartphone and were recorded by the device’s voice recorder at a distance of 35 cm from the participant. Voice samples were recorded in linear PCM format (.wav) at a sampling rate of 44.1 kHz with a 24-bit sample size. The signal was subsequently converted to 44.1 kHz and 16-bit in a linear PCM format.
We focused on volume and pitch features that discriminated patients with PD from unaffected controls as described before50. Volume represented the loudness of the audio signal, and pitch represented the vibration rate of the audio signal. We selected six voice-related features for further voice analysis and model development, defined as follows:
-
1.
Reading time: the time between starting and finishing reading the paragraph.
-
2.
Phonetic score: given for every participant based on reading the paragraph and calculated (https://ss.mirlab.org) with the acoustic model, with articulatory scores calculated with the articulatory model.
-
3.
Pause percentage: the percentage of time a participant paused when reading the paragraph. We performed frame blocking first, converting a stream of audio signals to a set of frames, each with a duration set at 25 ms. When a frame volume was lower than the threshold, the frame was counted as a pause. The threshold was set lower than the average volume of all audio signals, i.e., to 30 if the average volume was over 100 and otherwise to 20.
-
4.
Volume variability: the difference between the average volume of the first half of the audio signals and the second half of the audio signals for each participant, computed as follows:
A negative value indicated increased volume, and small absolute values suggested little change in volume.
Average pitch: Pitch is a musical tone based on the perception of vibration frequency. We set the frame size to 10 ms for each participant. We adopted the detection algorithm computing the number of zero-crossings during each frame; zero-crossing is the point at which the sign of a mathematical function changes and is commonly used in electronics, mathematics, and acoustic processing.
We computed the average time spent on each audio signal over the total number of frames as follows:
For items in the function, n is the total number of frames for an audio signal. CZ(t) is the number of times the signal crossed the 0 level reference during the time (t) of the frame.
Pitch variability: the average difference between frames, determined as follows:
Google MediaPipe
Google MediaPipe is compatible with operating systems such as Windows, macOS, Linux, and Raspberry Pi OS 64-bit. It requires Python versions 3.9 to 3.12, and MediaPipe can be installed via pip using the command python -m pip install mediapipe. For GPU acceleration, OpenGL ES 3.1+ is required, and additional packages may be necessary for Linux systems. For some functions in the Hand solution, OpenCV is also needed to read the video recording. While our study was conducted in a clinical environment, where patients were asked to walk in a fixed area against a white wall to ensure consistency, real-world applications may involve more complex and uncontrolled settings. MediaPipe is designed to function under varying lighting and background conditions; however, its accuracy can be affected by visual noise, poor lighting, or occlusions commonly encountered in everyday environments.
Finger-tapping movement data acquisition and processing
The participants were instructed to perform the finger-tapping task with each hand in front of the smartphone camera. We applied Google MediaPipe (https://github.com/google/mediapipe) to detect finger gestures by capturing 2D coordinates of hand landmarks (Supplementary Fig. 1A, B for an example of hand landmark prediction)51, which were then normalized to account for variations in hand size. This normalization ensures that the extracted features are relatively consistent across different hand sizes, reducing the potential influence of individual anatomical differences. A total of 21 hand gesture features were detected by MediaPipe. For further analysis, we selected index-to-thumb duration, index-to-thumb duration change, and index-to-thumb distance as the main features, defined as follows:
-
1.
Index-to-thumb duration: With finger-tapping movement as an oscillatory movement, the average period of each movement cycle was counted with autocorrelation. The duration of each open-to-close movement was further measured using the peak-finding algorithm from the Scipy package52.
-
2.
Index-to-thumb duration change: To signify changes in tapping duration, the change in duration was defined as the difference between the average duration of the first three and last three cycles of the tapping movement.
-
3.
Index-to-thumb distance: The “Index-to-thumb distance” is calculated by measuring the Euclidean distance between the landmarks of the index finger and thumb in each video frame. Specifically, we measure the distance between the tip of the index finger (landmark 8) and the tip of the thumb (landmark 4) across all frames in the video (Supplementary Fig. 1A, B). The average distance across these frames is then used as a feature representing the overall index-to-thumb separation during the finger-tapping task.
-
4.
Index-to-thumb frequency: extracted from the oscillatory movement by short-time Fourier transform.
-
5.
Index-to-thumb intensity: calculated by taking the mean of all “open” distances (maximum distance between index finger and thumb) as measured during the finger-tapping test.
-
6.
Index-to-thumb frequency intensity: The dot products of index-to-thumb frequency and index-to-thumb intensity.
Gait data acquisition and processing
Participants were asked to stand in front of the study-specific smartphone at a distance of 1 m and walk to and from in a straight line ahead of the camera, covering a distance of 4 m back and forth while the recording was in progress (Supplementary Fig. 1C). The whole process of gait recording for each participant lasted around 1 min 30 s. The body pose was estimated with a human pose estimation model, which was pre-trained and served for both pose analysis and 2D-to-3D landmark prediction53, to generate the Microsoft Common Objects in Context (COCO) whole-body landmarks (https://paperswithcode.com/dataset/coco-wholebody (Supplementary Fig. 1D–F). A sample gait landmark prediction is shown in Supplementary Fig. 1C. We applied the estimation model to generate COCO whole-body markers. The 2D COCO landmarks were yielded first. A plot of y-coordinate change against time, referred to as a “walking wavelet,” was generated. The walking wavelet could provide information about the depth of walking steps. The 2D landmarks were further reconstructed to 3D landmarks, and the process was completed using PoseFormer53. PoseFormer adopted sequences of 2D landmarks to predict 3D poses (Supplementary Fig. 1C). The estimation finally yielded 22 gait features, four of them extracted from 2D COCO landmarks and the others from 3D landmarks. The detailed 2D and 3D landmark features are listed below.
The 2D landmark features used in the current study included
-
1.
Average walking duration per turn: We proposed that a full walking cycle, encompassing both the approach towards and the return from the camera, could be ascertained by enumerating the peaks within the walking wavelet, as shown in Supplementary Fig. 1C. To compute the mean duration of a complete walking cycle (referred to as the period of the wavelet), we employed a find peak algorithm52. This algorithm comprises two main components: an auto-correlation function and a peak detection function. The auto-correlation function estimated the average periods of the wavelet. Despite the auto-correlation function’s capacity to directly furnish the mean walking duration per cycle, it remained necessary to subsequently identify each peak within the wavelet. This step was pivotal for measuring additional attributes. Each peak signified the zenith within the average period of the wavelet. Consequently, our approach integrated the principles of wavelet analysis and peak detection to discern distinctive features of the walking pattern, thus offering comprehensive insights into each participant’s gait and movement characteristics.
-
2.
Average number of steps per turn (left and right): We separated the entire wavelet into different sections based on the peak and valley coordinates (Supplementary Fig. 1C, D). Each participant’s foot movement could be further analyzed during walking cycles. Because of normal walking gait patterns, the foot remained in contact with the ground momentarily, resulting in a delay in the wave. Each step could be further calculated by searching for the peaks after detrending the wave. The average number of steps was then determined by counting the entire walking wavelet and dividing it by the number of turns.
-
3.
Walking duration change: The peak-finding algorithm supported depiction of the line graph of the whole walking process. Each peak represented the foot landmark closest to the camera, and each valley (local minimum) represented points further away from the camera. We further separated the whole walking process into single sections of turning via the line graph. The value was defined as the difference between the mean walking duration of the first three cycles of back-and-forth walking and the mean duration of the last three cycles of walking (Supplementary Fig. 1D).
The 3D landmark features used in the current study included
-
1.
Estimated maximum and average step length: We calculated the pixel distances between the left foot landmark and the right foot landmark within a single frame as a relative measurement of step length. Furthermore, we determined the average step length by aggregating step lengths from all frames and subsequently dividing by the total frame count.
-
2.
Average turning duration (left and right): We evaluated alterations in the x-axis displacement between pelvis landmarks to assess each participant’s turning duration. The variation in pelvis landmark distances alternates between a positive magnitude (d) and its corresponding negative value (-d) within a stable 2D plane. The average duration could be calculated by determining each turning episode subsequently. We have expanded our visualization to include displacement versus frame curves for the x-axis, y-axis, and z-axis coordinates. These curves illustrate how each axis evolves over time during gait analysis, providing a more comprehensive view of the participant’s movement patterns. While the x-axis displacement shows stable and clear oscillations, the y-axis and z-axis provide additional context on vertical and depth-related changes, respectively, enhancing our analysis of turning duration and slope (Supplementary Fig. 1E). The three-axis approach to pelvis landmarks helps clarify the evolution of gait features across all three planes during the turning phase.
-
3.
Turning duration slope (left and right): The slope was defined as the gradient of the transition of pelvis landmark x-axis displacement between d to -d or -d to d. The value was indicative of the turning speed.
-
4.
Percentage of foot on ground (left and right): We measured the percentage of the foot remaining in contact with the ground by leveraging the 3D landmarks. We set the threshold on the z-axis of the 3D landmarks to estimate the percentage. The Z-axis provides insights into vertical movement relative to the floor plane, which is essential for tracking foot contact. Conversely, the Y-axis mainly records movement along the body’s vertical axis and is less informative for assessing ground contact. To support this choice, we have added supplementary illustration (Supplementary Fig. 1F) visualizations showing both Y-axis and Z-axis changes over time.” A threshold on the Z-axis was established to determine ground contact, calculated based on the mean Z-axis value from the first 30 frames (approximately the first second), during which the participant was instructed to stand with both feet firmly on the ground. This threshold allowed us to estimate the percentage of time each foot-maintained ground contact throughout the gait cycle.
Machine learning model training
For each modality of biometric features, we first trained the model separately. We employed the sequential forward selection (SFS) algorithm to identify the most relevant features for distinguishing patients with PD from controls54. SFS is a stepwise feature selection method that starts with an empty set and iteratively adds features to improve model performance, based on recall in our study. In each iteration, the algorithm selects the feature that most enhances performance and permanently adds it to the set. This process continues until no additional features significantly improve performance or a pre-defined number of features is reached. By focusing on feature relevance, SFS efficiently reduces the feature set to those most important for predictive accuracy, while minimizing computational complexity54. Three classifiers, including Support Vector Machine (SVM), Random Forest (RF), and AdaBoost, were applied as base models in sequential forward selection. The percentage of feature coverage selected by each classifier was calculated and ranked. The performance of each classifier was evaluated for accuracy, precision, recall, F1 score, and area under receiver operating characteristic curve (AUROC) for binary classification. To obtain an objective estimate of performance, we conducted 10-fold cross-validation in each model training process. To assess classifier performance, we employed two evaluation approaches in cross-validation: aggregated cross-validation evaluation and averaged per-fold performance. In the average per-fold performance approach, performance metrics were calculated separately for each fold on both the validation and test sets, then averaged across all 10 folds, with standard deviations reported to capture variability. In the aggregated approach, predictions from all validation folds were combined, and overall performance metrics (e.g., accuracy, F1-score, AUROC) were computed on the pooled set. The test data were evaluated using all 10-fold models, and an ensemble method was applied by averaging the predicted probabilities to obtain a final classification score. While the aggregated approach provides a stable overall performance estimate, the average per-fold approach accounts for variability across folds and allows for statistical significance testing.
After evaluation and comparison of these three (Voice, Finger tapping, and Gait) models, a weighted average of the predicted probability was calculated for each modality using the same classifier. The best weights were determined through a grid search method applied exclusively to the training data, ensuring that no information from the test data influenced model optimization (Fig. 1).
Statistical analysis
All continuous variables are presented as means and standard deviations, and nominal variables as numbers and percentages. The continuous variables were compared with two-sample t-test or analysis of variance. The Mann–Whitney U test was applied for non-normally distributed continuous variables. We applied the Chi-square test for comparison of categorical variables. The diagnostic performance of the models was quantified using the AUROC. All statistical analyses were executed using SAS (version 9.4, Cary, NC, USA) and GraphPad Prism (version 9.0.0, San Diego, CA, USA). A significance threshold of p < 0.05 was adopted to determine statistical significance.
Data availability
The datasets generated and analyzed during the current study are available at the following repository: Parkinson’s Disease Voice, Hand, and Gait Model (https://github.com/LeoLim3092/Parkinsons-Disease-Voice-Hand-Gait-Model).
Code availability
The underlying code for this study is available in AUTO-AI and can be accessed via this link (https://github.com/LeoLim3092/AUTO-AI). The feature extraction and pose estimation code are available on GitHub to ensure transparency and reproducibility. GitHub Link: https://github.com/LeoLim3092/Parkinsons-Disease-Voice-Hand-Gait-Model.
References
Poewe, W. et al. Parkinson disease. Nat. Rev. Dis. Prim. 3, 17013 (2017).
Jankovic, J. & Tan, E. K. Parkinson’s disease: etiopathogenesis and treatment. J. Neurol. Neurosurg. Psychiatry 91, 795–808 (2020).
Pagano, G. et al. Prasinezumab slows motor progression in rapidly progressing early-stage Parkinson’s disease. Nat. Med. 30, 1096–1103 (2024).
McFarthing, K. et al. Parkinson’s disease drug therapies in the clinical trial pipeline: 2023 update. J. Parkinsons Dis. 13, 427–439 (2023).
Mollenhauer, B. Status of current biofluid biomarkers in parkinson’s disease. Mov. Disord. Clin. Pr. 10, S18–S20 (2023).
Varghese, J. et al. Machine Learning in the Parkinson’s disease smartwatch (PADS) dataset. NPJ Parkinsons Dis. 10, 9 (2024).
Islam, M. S. et al. Using AI to measure Parkinson’s disease severity at home. njp Digit. Med. 6, 156 (2023).
Hossain, M. A. & Amenta, F. Machine learning-based classification of parkinson’s disease patients using speech biomarkers. J. Parkinsons Dis. 14, 95–109 (2024).
Postuma, R. B. et al. MDS clinical diagnostic criteria for Parkinson’s disease. Mov. Disord. 30, 1591–1601 (2015).
Vasquez-Correa, J. C. et al. Multimodal assessment of parkinson’s disease: a deep learning approach. IEEE J. Biomed. Health Inf. 23, 1618–1630 (2019).
Heidarivincheh, F. et al. Multimodal classification of parkinson’s disease in home environments with resiliency to missing modalities. Sensors (Basel) 21, 4133 (2021).
Gibb, W. & Lees, A. The relevance of the Lewy body to the pathogenesis of idiopathic Parkinson’s disease. J. Neurol., Neurosurg. Psychiatry 51, 745–752 (1988).
Lim, W. S. et al. An integrated biometric voice and facial features for early detection of Parkinson’s disease. NPJ Parkinsons Dis. 8, 145 (2022).
Lugaresi, C. et al. Mediapipe: a framework for building perception pipelines.arXiv https://doi.org/10.48550/arXiv.1906.08172 (2019).
Virtanen, P. et al. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat. Methods 17, 261–272 (2020).
Zheng, C. et al. 3D Human pose estimation with spatial and temporal transformers. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 11636–11645 (IEEE, 2021).
Khalid, S., Khalil, T. & Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. 2014 Science and Information Conference, London, UK, 372–378 (2014).
Skodda, S., Gronheit, W., Mancinelli, N. & Schlegel, U. Progression of voice and speech impairment in the course of Parkinson’s disease: a longitudinal study. Parkinsons Dis. 2013, 389195 (2013).
Canter, G. J. Speech characteristics of patients with parkinson’s disease. 3. articulation, diadochokinesis, and over-all speech adequacy. J. Speech Hear Disord. 30, 217–224 (1965).
Iyer, A. et al. A machine learning method to process voice samples for identification of Parkinson’s disease. Sci. Rep. 13, 20615 (2023).
Rusz, J., Tykalova, T., Novotny, M., Ruzicka, E. & Dusek, P. Distinct patterns of speech disorder in early-onset and late-onset de-novo Parkinson’s disease. NPJ Parkinsons Dis. 7, 98 (2021).
Wiesman, A. I. et al. Aberrant neurophysiological signaling associated with speech impairments in Parkinson’s disease. NPJ Parkinsons Dis. 9, 61 (2023).
Rahman, S., Hasan, M., Sarkar, A. K. & Khan, F. Classification of parkinson’s disease using speech signal with machine learning and deep learning approaches. Eur. J. Electr. Eng. Comput. Sci. 7, 20–27 (2023).
Cesarini, V. et al. Voice disorder multi-class classification for the distinction of parkinson’s disease and adductor spasmodic dysphonia. Appl. Sci. 13, 8562 (2023).
Abedinzadeh Torghabeh, F., Hosseini, S. A. & Ahmadi Moghadam, E. Enhancing Parkinson’s disease severity assessment through voice-based wavelet scattering, optimized model selection, and weighted majority voting. Med. Novel Technol. Devices 20, 100266 (2023).
Suppa, A. et al. Voice in Parkinson’s disease: a machine learning study. Front Neurol. 13, 831428 (2022).
Buongiorno, D. et al. A low-cost vision system based on the analysis of motor features for recognition and severity rating of Parkinson’s Disease. BMC Med. Inf. Decis. Mak. 19, 243 (2019).
Kang, P., Li, J., Fan, B., Jiang, S. & Shull, P. B. Wrist-worn hand gesture recognition while walking via transfer learning. IEEE J. Biomed. Health Inform. 26, 952–961 (2022).
Salarian, A. et al. Quantification of tremor and bradykinesia in Parkinson’s disease using a novel ambulatory monitoring system. IEEE Trans. Biomed. Eng. 54, 313–322 (2007).
Shima, K., Tsuji, T., Kandori, A., Yokoe, M. & Sakoda, S. Quantitative evaluation of human finger tapping movements through magnetic measurements. IEEE/ASME Trans. Mechatron. 24, 186–196 (2019).
Djurić-Jovičić, M. et al. Quantification of finger-tapping angle based on wearable sensors. Sensors (Basel) 17, 203 (2017).
Li, J. et al. A three-dimensional finger-tapping framework for recognition of patients with mild Parkinson’s disease. IEEE Trans. Neural Syst. Rehabil. Eng. 31, 3331–3340 (2023).
Yang, Y. Y. et al. FastEval Parkinsonism: an instant deep learning-assisted video-based online system for Parkinsonian motor symptom evaluation. NPJ Digit. Med. 7, 31 (2024).
Zhan, A. et al. Using smartphones and machine learning to quantify parkinson disease severity: the mobile parkinson disease score. JAMA Neurol. 75, 876–880 (2018).
Jha, A. et al. The CloudUPDRS smartphone software in Parkinson’s study: cross-validation against blinded human raters. NPJ Parkinsons Dis. 6, 36 (2020).
Mirelman, A. et al. Gait impairments in Parkinson’s disease. Lancet Neurol. 18, 697–708 (2019).
Uchitomi, H., Ming, X., Zhao, C., Ogata, T. & Miyake, Y. Classification of mild Parkinson’s disease: data augmentation of time-series gait data obtained via inertial measurement units. Sci. Rep. 13, 12638 (2023).
Liuzzi, P. et al. Machine learning based estimation of dynamic balance and gait adaptability in persons with neurological diseases using inertial sensors. Sci. Rep. 13, 8640 (2023).
Moon, S. et al. Classification of Parkinson’s disease and essential tremor based on balance and gait characteristics from wearable motion sensors via machine learning techniques: a data-driven approach. J. Neuroeng. Rehabil. 17, 125 (2020).
Sharma, N. P., Junaid, I. & Ari, S. In 2023 2nd International Conference on Smart Technologies and Systems for Next Generation Computing (ICSTSN). 1–6 (IEEE, 2023).
Ferreira, M., Barbieri, F. A., Moreno, V. C., Penedo, T. & Tavares, J. Machine learning models for Parkinson’s disease detection and stage classification based on spatial-temporal gait parameters. Gait Posture 98, 49–55 (2022).
Munoz-Ospina, B. et al. Machine learning classifiers to evaluate data from gait analysis with depth cameras in patients with Parkinson’s disease. Front. Hum. Neurosci. 16, 826376 (2022).
Tang, S.-T., Tai, C.-H., Yang, C.-Y. & Lin, J.-H. Feasibility of smartphone-based gait assessment for Parkinson’s disease. J. Med. Biol. Eng. 40, 582–591 (2020).
Abujrida, H., Agu, E. & Pahlavan, K. In 2017 IEEE Healthcare Innovations and Point of Care Technologies (HI-POCT). 6–8 (IEEE, 2017).
Abujrida, H., Agu, E. & Pahlavan, K. DeepaMed: Deep learning-based medication adherence of Parkinson’s disease using smartphone gait analysis. Smart Health 30, 100430 (2023).
Liu, P. et al. Quantitative assessment of gait characteristics in patients with Parkinson’s disease using 2D video. Parkinsonism Relat. Disord. 101, 49–56 (2022).
Zeng, Q. et al. Video-based quantification of gait impairments in Parkinson’s disease using skeleton-silhouette fusion convolution network. IEEE Trans. Neural Syst. Rehabil. Eng. 31, 2912–2922 (2023).
Dill, S. et al. Accuracy evaluation of 3D pose estimation with mediapipe pose for physical exercises. Curr. Direct. Biomed. Eng. 9, 563–566 (2023).
El Kaid, A. & Baïna, K. A systematic review of recent deep learning approaches for 3D human pose estimation. J. Imag.9, 275 (2023).
Jiao, Y. et al. Systematic review of automatic post-stroke gait classification systems. Gait Posture 109, 259–270 (2024).
Jansen, M. P. et al. Can gait patterns be explained by joint structure in people with and without radiographic knee osteoarthritis? Data from the IMI-APPROACH cohort. Skelet. Radio. 53, 2409–2416 (2024).
Deng, K. et al. Heterogeneous digital biomarker integration out-performs patient self-reports in predicting Parkinson’s disease. Commun. Biol. 5, 58 (2022).
Schwab, P. & Karlen, W. In Proceedings of the AAAI conference on artificial intelligence, 1118–1125 (AAAI, 2025).
Anudeep, P., Mourya, P. & Anandhi, T. In Advances in Electronics, Communication and Computing. (eds Pradeep Kumar Mallick, Akash Kumar Bhoi, Gyoo-Soo Chae, & Kanak Kalita) 483–493 (Springer Nature Singapore).
Acknowledgements
We thank all of the participants who joined this study. We are grateful for funding support from the Ministry of Science and Technology (MOST 109-2221-E-002 -163 -MY3) and Academia Sinica (Healthy Longevity Global Grand Challenge Catalyst Award AS-HLGC-110-03).
Author information
Authors and Affiliations
Contributions
Study concept and design: C.H.L. Acquisition of data: W.S.L., S.I.C., M.C.W., S.F.T., P.H.W., K.P.L., Y.M.C., P.L.P., JSR Jang, C.H.L. Analysis and interpretation of data: W.S.L., S.I.C., M.C.W., S.F.T., P.H.W., J.S.R.J., C.H.L. Drafting of the manuscript: W.S.L., S.I.C., C.H.L. Critical revision of the manuscript for important intellectual content: C.H.L. Statistical analysis: W.S.L., S.I.C., C.H.L. Obtained funding: JSR Jang, C.H.L. Study supervision: C.H.L. W.S.L. and S.I.C. are considered “co-first authors” as they contributed equally to the study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lim, WS., Fan, SP., Chiu, SI. et al. Smartphone-derived multidomain features including voice, finger-tapping movement and gait aid early identification of Parkinson’s disease. npj Parkinsons Dis. 11, 111 (2025). https://doi.org/10.1038/s41531-025-00953-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41531-025-00953-w
This article is cited by
-
What are you looking at? Modality contribution in multimodal medical deep learning
International Journal of Computer Assisted Radiology and Surgery (2025)
